
Travis CI → GitHub Actions
В прошлом году я писал, как сделать классный Python-пакет. Там упоминаются полезные облачные сервисы: Travis CI для сборки, Coveralls для покрытия, Code Climate для качества кода.
Так вот, сдается мне, что Travis CI пора на покой. В 2020 году Гитхаб довел до ума свои Actions, и они просто бесподобны. Где еще вы настроите сборку и публикацию под Windows, Linux и macOS за десять минут?
Рекомендация этого года — GitHub Actions:
https://antonz.ru/github-actions/
#код
В прошлом году я писал, как сделать классный Python-пакет. Там упоминаются полезные облачные сервисы: Travis CI для сборки, Coveralls для покрытия, Code Climate для качества кода.
Так вот, сдается мне, что Travis CI пора на покой. В 2020 году Гитхаб довел до ума свои Actions, и они просто бесподобны. Где еще вы настроите сборку и публикацию под Windows, Linux и macOS за десять минут?
Рекомендация этого года — GitHub Actions:
https://antonz.ru/github-actions/
#код
Простое против легкого
9 лет назад в докладе «Simple Made Easy» Рич Хикки рассказал о разнице между простым (simple) и легким (easy) в разработке софта. Стремление к простым программам (в противоположность легким) — самый важный, наверное, принцип разработки. И при этом совершенно непопулярный.
Simple — это о внутреннем устройстве программы, ее архитектуре. У простых программ мало внутренних зависимостей, движущихся частей, настроек. Антипод простой программы — сложная. Простая программа или сложная — это объективная характеристика.
Easy — это о том, насколько человеку легко работать с программой. Это субъективная характеристика: что мне легко, другому сложно, и наоборот. Антипод легкой программы — тяжелая.
Например, SQLite — легкая, но не простая. Внутри там ад, особенно в системе типов и взаимовлиянии многочисленных параметров. А Redis — простой. Но для многих не такой легкий, как SQLite, потому что непривычный. Docker — «легкий», но сложный. Kubernetes — тяжелый и адово сложный.
JavaScript — легкий, но очень сложно устроен. Python — тоже легкий и сложный, хотя и попроще джаваскрипта. Go — простой.
Модули стандартной библиотеки bisect и heapq — простые. Но не легкие, если вы не знаете алгоритмов, которые они реализуют. dataclasses и namedtuple созданы, чтобы быть легкими, но при этом очень сложные.
Простые программы в долгой перспективе лучше легких. В простой программе оказывается легче разобраться, легче использовать на реальных сценариях, легче менять и дорабатывать. Легкую (но при этом сложную) программу можно быстро начать использовать, но дальше ждет стена.
Разработчики предпочитают писать «легкие» программы, а не простые — потому что простые делать тяжело. Придется продумывать архитектуру, работать с ограничениями, много раз переписывать. Намного легче слепить из палочек и веточек, а сверху приделать «легкий» интерфейс.
Я очень хочу, чтобы в мире софта появлялось больше простых, а не «легких» программ и библиотек. А у вас есть любимые простые штуки?
#код
9 лет назад в докладе «Simple Made Easy» Рич Хикки рассказал о разнице между простым (simple) и легким (easy) в разработке софта. Стремление к простым программам (в противоположность легким) — самый важный, наверное, принцип разработки. И при этом совершенно непопулярный.
Simple — это о внутреннем устройстве программы, ее архитектуре. У простых программ мало внутренних зависимостей, движущихся частей, настроек. Антипод простой программы — сложная. Простая программа или сложная — это объективная характеристика.
Easy — это о том, насколько человеку легко работать с программой. Это субъективная характеристика: что мне легко, другому сложно, и наоборот. Антипод легкой программы — тяжелая.
Например, SQLite — легкая, но не простая. Внутри там ад, особенно в системе типов и взаимовлиянии многочисленных параметров. А Redis — простой. Но для многих не такой легкий, как SQLite, потому что непривычный. Docker — «легкий», но сложный. Kubernetes — тяжелый и адово сложный.
JavaScript — легкий, но очень сложно устроен. Python — тоже легкий и сложный, хотя и попроще джаваскрипта. Go — простой.
Модули стандартной библиотеки bisect и heapq — простые. Но не легкие, если вы не знаете алгоритмов, которые они реализуют. dataclasses и namedtuple созданы, чтобы быть легкими, но при этом очень сложные.
Простые программы в долгой перспективе лучше легких. В простой программе оказывается легче разобраться, легче использовать на реальных сценариях, легче менять и дорабатывать. Легкую (но при этом сложную) программу можно быстро начать использовать, но дальше ждет стена.
Разработчики предпочитают писать «легкие» программы, а не простые — потому что простые делать тяжело. Придется продумывать архитектуру, работать с ограничениями, много раз переписывать. Намного легче слепить из палочек и веточек, а сверху приделать «легкий» интерфейс.
Я очень хочу, чтобы в мире софта появлялось больше простых, а не «легких» программ и библиотек. А у вас есть любимые простые штуки?
#код
🎙️ Сегодня я узнал
Всегда хотел слушать короткий подкаст о разработке. Только не новостной, а практический. В итоге как-то так получилось, что сделал сам 🤷
Называется «Сегодня я узнал». Вот основные принципы:
1) Никакой пустой болтовни. Никаких рассуждений об очередном айфоне, цене биткойна или что там Маск написал в твитере.
2) Только практические штуки. В каждом выпуске — одна тема, которую можно взять и сразу применять на работе или в жизни.
3) Очень короткие эпизоды — пять минут или около того. Не хочу долго занимать эфир, да и вообще длинных подкастов уже достаточно.
Доступен в Apple и Google Podcasts. Если интересен такой формат — подписывайтесь!
https://we.fo/1556171504
#подкаст
Всегда хотел слушать короткий подкаст о разработке. Только не новостной, а практический. В итоге как-то так получилось, что сделал сам 🤷
Называется «Сегодня я узнал». Вот основные принципы:
1) Никакой пустой болтовни. Никаких рассуждений об очередном айфоне, цене биткойна или что там Маск написал в твитере.
2) Только практические штуки. В каждом выпуске — одна тема, которую можно взять и сразу применять на работе или в жизни.
3) Очень короткие эпизоды — пять минут или около того. Не хочу долго занимать эфир, да и вообще длинных подкастов уже достаточно.
Доступен в Apple и Google Podcasts. Если интересен такой формат — подписывайтесь!
https://we.fo/1556171504
#подкаст
we.fo
Сегодня я узнал | We.fo - Fast podcast sharing
Компактный практический подкаст о программировании и продуктах.
Python ❤️ SQLite
Создавать новые функции в SQLite через Python — одно удовольствие. Например, хотим привести заголовки новостей к Title Case:
Вот так просто ツ
#stdlib
Создавать новые функции в SQLite через Python — одно удовольствие. Например, хотим привести заголовки новостей к Title Case:
import sqlite3
def title(value):
return value.title()
query = "select title(headline) from news"
db = sqlite3.connect("news.db")
db.create_function("title", 1, title)
cursor = db.execute(query)
result = cursor.fetchall()
db.close()Вот так просто ツ
#stdlib
SQLite для аналитики
или как работать с данными без экселя и pandas
В январе я начал делать курс о том, как использовать SQLite для повседневной работы с данными. И наконец он готов! Вот чему научатся участники:
— Загружать и выгружать данные в разных форматах.
— Находить проблемы в данных и исправлять их.
— Соединять данные так и сяк, чтобы получить нужную информацию.
— Оценивать статистические показатели, которые характеризуют датасет.
— Выбирать данные из JSON-документов любой сложности.
— Быстро работать с большими наборами данных.
— Строить аналитические отчеты с помощью оконных функций.
Входные требования: базовое понимание SQL и любовь к командной строке. Навыки программирования не требуются.
Курс платный, стоит 3000₽. Специально для подписчиков канала до конца недели действует скидка 500₽ по промокоду OHMYPY.
Для всех, кто оставлял заявку на бета-тест — бессрочная скидка 50%, как обещал (пишите в личку @nalgeon).
Первый модуль курса (5 уроков и 13 практических заданий) доступен для всех бесплатно и без регистрации.
Перейти к курсу
#курс
или как работать с данными без экселя и pandas
В январе я начал делать курс о том, как использовать SQLite для повседневной работы с данными. И наконец он готов! Вот чему научатся участники:
— Загружать и выгружать данные в разных форматах.
— Находить проблемы в данных и исправлять их.
— Соединять данные так и сяк, чтобы получить нужную информацию.
— Оценивать статистические показатели, которые характеризуют датасет.
— Выбирать данные из JSON-документов любой сложности.
— Быстро работать с большими наборами данных.
— Строить аналитические отчеты с помощью оконных функций.
Входные требования: базовое понимание SQL и любовь к командной строке. Навыки программирования не требуются.
Курс платный, стоит 3000₽. Специально для подписчиков канала до конца недели действует скидка 500₽ по промокоду OHMYPY.
Для всех, кто оставлял заявку на бета-тест — бессрочная скидка 50%, как обещал (пишите в личку @nalgeon).
Первый модуль курса (5 уроков и 13 практических заданий) доступен для всех бесплатно и без регистрации.
Перейти к курсу
#курс
📦 Как сделать классный Python-пакет в 2021
В прошлом году я написал инструкцию, как сделать модный и современный питонячий пакет. Рекомендовал там использовать Travis CI.
А потом распробовал альтернативу — GitHub Actions. Это бесконечно крутой сервис, который использую теперь буквально для всего. Ну и для тестирования и публикации пакетов тоже, конечно.
Использовать Тревис больше нет никакого смысла. Поэтому вот новая версия руководства: https://antonz.ru/packaging/
#код
В прошлом году я написал инструкцию, как сделать модный и современный питонячий пакет. Рекомендовал там использовать Travis CI.
А потом распробовал альтернативу — GitHub Actions. Это бесконечно крутой сервис, который использую теперь буквально для всего. Ну и для тестирования и публикации пакетов тоже, конечно.
Использовать Тревис больше нет никакого смысла. Поэтому вот новая версия руководства: https://antonz.ru/packaging/
#код
Утилиты для работы с данными на питоне
В последнее время думаю о таком курсе для прокачки навыков Python. Курс состоит из набора уроков, на каждом уроке воспроизводим на чистом питоне с нуля одну из линуксовых утилит: head, cut, tr, wc, split, paste, sort, uniq, grep, sed. Используем только модули стандартной библиотеки.
Плюсы:
— Одновременно осваиваешь сами утилиты и прокачиваешь питон.
— Учишься эффективно работать со структурами данных.
— Осваиваешь самые разные модули стандартной библиотеки.
— Результат можно использовать в повседневной работе.
— Уроки независимые, можно начинать с любого или выполнять выборочно.
Минусы:
— Курс по питону не сделал только ленивый, лезть в это неохота.
Что думаете?
#курс
В последнее время думаю о таком курсе для прокачки навыков Python. Курс состоит из набора уроков, на каждом уроке воспроизводим на чистом питоне с нуля одну из линуксовых утилит: head, cut, tr, wc, split, paste, sort, uniq, grep, sed. Используем только модули стандартной библиотеки.
Плюсы:
— Одновременно осваиваешь сами утилиты и прокачиваешь питон.
— Учишься эффективно работать со структурами данных.
— Осваиваешь самые разные модули стандартной библиотеки.
— Результат можно использовать в повседневной работе.
— Уроки независимые, можно начинать с любого или выполнять выборочно.
Минусы:
— Курс по питону не сделал только ленивый, лезть в это неохота.
Что думаете?
#курс
Что думаете о курсе?
Anonymous Poll
15%
Немедленно начну
52%
В целом интересно
20%
Скорее нет
13%
Точно не нужно
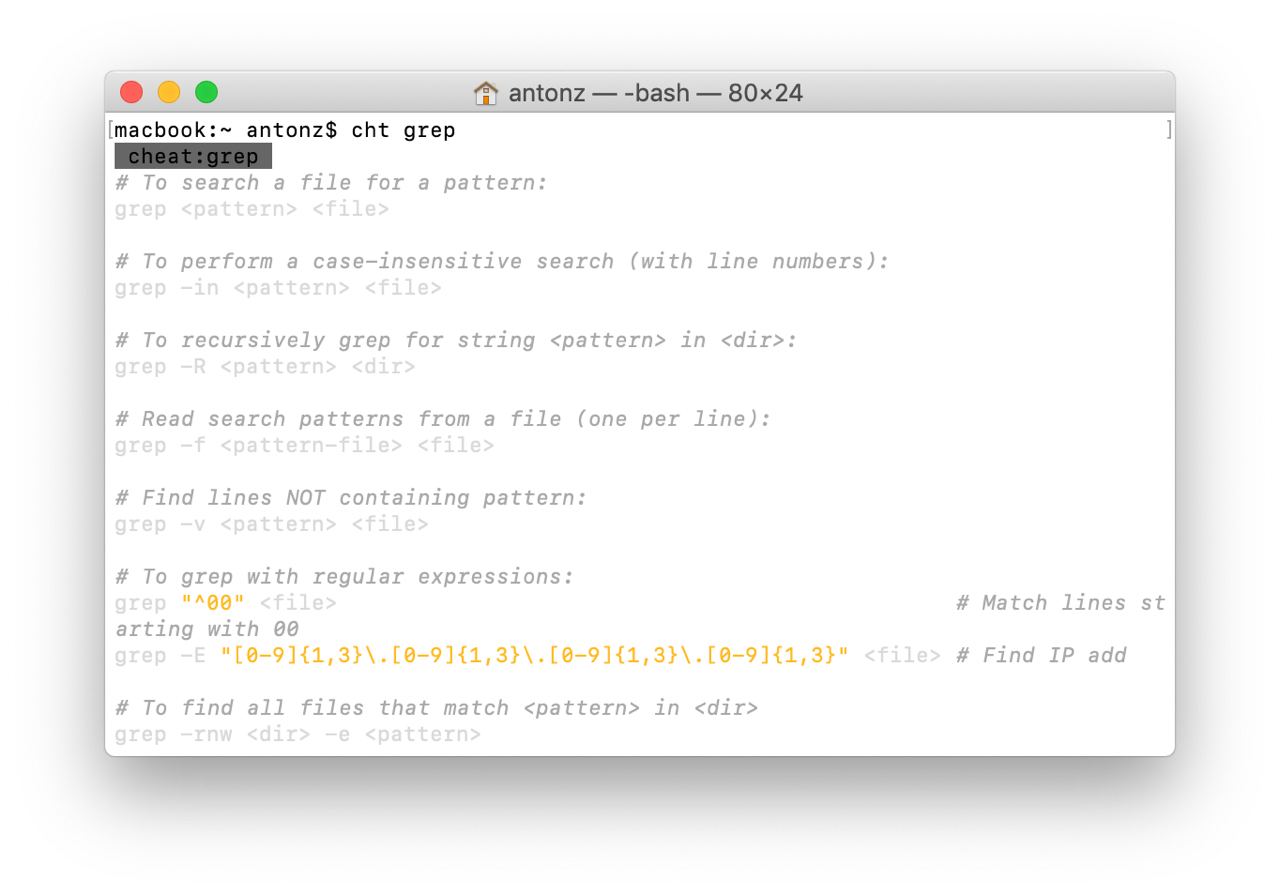
Шпаргалки как альтернатива man
Я вечно забываю синтаксис линуксовых утилит вроде
Поэтому я был бесконечно счастлив, когда на днях нашел приятную альтернативу от Игоря Чубина — «шпаргалки» с конкретными примерами. Чтобы их включить, достаточно добавить такую функцию в
И вызвать шпаргалку по конкретной команде:
Есть консольный клиент и много всяких наворотов, подробности в репозитории автора.
Я вечно забываю синтаксис линуксовых утилит вроде
grep, sed и find. Есть команда man, которая показывает документацию по утилите, но для меня она совершенно бесполезна — никогда не получается найти то, что нужно (возможно, это только я такой тупой).Поэтому я был бесконечно счастлив, когда на днях нашел приятную альтернативу от Игоря Чубина — «шпаргалки» с конкретными примерами. Чтобы их включить, достаточно добавить такую функцию в
.bashrc:function cht() { curl "cht.sh/$1"; }И вызвать шпаргалку по конкретной команде:
$ cht grep
$ cht sed
$ cht tr
Есть консольный клиент и много всяких наворотов, подробности в репозитории автора.
{kind=link}
Второй язык для питониста
Если вы давно и хорошо знаете питон, некоторые моменты в нем могут напрягать. Например, необходимость начинать каждый новый проект с создания виртуального окружения и установки пачки тулов вроде black, pylint и pytest. Или отсутствующий рефакторинг и частые ошибки из-за динамической типизации. Или убоговатая асинхронность и костыль в виде GIL.
Если у вас так — возможно, пора освоить второй язык. Логично выбрать вариант без питонячих недостатков: статически типизированный, с готовым тулингом, продуманной асинхронностью и параллелизмом.
Давайте посмотрим, кто из топа StackOverflow подходят на роль второго языка.
JavaScript. Динамический язык, который во всем хуже питона. Единственный плюс — только с ним нативно работают браузеры. Если мечтаете о фронтенде — хороший выбор, если нет — с негодованием отметаем.
Bash/Shell/PowerShell. Моя любимая тройка write-only языков! Легко написать что угодно, уже через неделю невозможно понять, что написал. Нет.
C#. Интересный вариант. Новее питона, отличная стандартная библиотека, статически типизирован, все в порядке с асинхронностью. Начинался как очень простой, но за 20 лет превратился в один из самых фичастых языков. Кросс-платформенный, несмотря на виндовые корни.
PHP. Динамический язык с тяжелым наследием, который в свежих версиях решили превратить в Java образца 2005 года. Я даже не знаю, что может быть хуже.
TypeScript. А это JavaScript, который решили превратить в современную Java. Классическая дырявая абстракция, джаваскрипт протекает из всех щелей. Статически типизирован, куча наворотов. Стандартная библиотека отсутствует. Фронтендеры на него молятся, но у питониста вряд ли вызовет что-то помимо отвращения.
C++. В рейтинге мозговыносящих языков точно занял бы первое место. Старый язык, в который запихнули все что только можно. Гарантирую, писать на C++ вам будет физически больно.
C. Самый старый, но относительно простой язык. Статические типы, очень низкоуровневый, скудная стандартная библиотека. В 1991 году был бы хорошим выбором. Зато быстрый, да.
Go. Интересный вариант. Новый, отличная стандартная библиотека, статически типизирован, классная асинхронность. Одним из основных принципов считает простоту, так что не превратился в фича-монстра, в отличие от C#. Можно делать как низкоуровневые штуки, так и бизнес-приложения.
Kotlin. Интересный вариант. Котлин — это Java, если бы ее изобрели в 2010 году. Статический, много фич. Работает поверх JVM (виртуальная машина джавы), можно использовать любые джава-либы.
И несколько нишевых языков с преданным сообществом:
Rust. Современная альтернатива C++. Отличный вариант для низкоуровневых штук, плохо подходит для остального. Много фич, тяжело освоить. Хорошая стандартная библиотека.
Clojure. Современный LISP. Язык, в котором простота возведена в абсолют — всё есть данные. Акцент на неизменяемых данных, продуманная стандартная библиотека. Работает поверх JVM.
Итого, из топ-10 мне кажутся интересными C#, Go и Kotlin. Лично я выбрал Go, потому что устал от фичастых языков и наслоений абстракций. Хочу простоты.
Если вам тоже интересно попробовать — присоединяйтесь ко мне на бесплатном курсе:
https://stepik.org/96832
Если вы давно и хорошо знаете питон, некоторые моменты в нем могут напрягать. Например, необходимость начинать каждый новый проект с создания виртуального окружения и установки пачки тулов вроде black, pylint и pytest. Или отсутствующий рефакторинг и частые ошибки из-за динамической типизации. Или убоговатая асинхронность и костыль в виде GIL.
Если у вас так — возможно, пора освоить второй язык. Логично выбрать вариант без питонячих недостатков: статически типизированный, с готовым тулингом, продуманной асинхронностью и параллелизмом.
Давайте посмотрим, кто из топа StackOverflow подходят на роль второго языка.
JavaScript. Динамический язык, который во всем хуже питона. Единственный плюс — только с ним нативно работают браузеры. Если мечтаете о фронтенде — хороший выбор, если нет — с негодованием отметаем.
Bash/Shell/PowerShell. Моя любимая тройка write-only языков! Легко написать что угодно, уже через неделю невозможно понять, что написал. Нет.
C#. Интересный вариант. Новее питона, отличная стандартная библиотека, статически типизирован, все в порядке с асинхронностью. Начинался как очень простой, но за 20 лет превратился в один из самых фичастых языков. Кросс-платформенный, несмотря на виндовые корни.
PHP. Динамический язык с тяжелым наследием, который в свежих версиях решили превратить в Java образца 2005 года. Я даже не знаю, что может быть хуже.
TypeScript. А это JavaScript, который решили превратить в современную Java. Классическая дырявая абстракция, джаваскрипт протекает из всех щелей. Статически типизирован, куча наворотов. Стандартная библиотека отсутствует. Фронтендеры на него молятся, но у питониста вряд ли вызовет что-то помимо отвращения.
C++. В рейтинге мозговыносящих языков точно занял бы первое место. Старый язык, в который запихнули все что только можно. Гарантирую, писать на C++ вам будет физически больно.
C. Самый старый, но относительно простой язык. Статические типы, очень низкоуровневый, скудная стандартная библиотека. В 1991 году был бы хорошим выбором. Зато быстрый, да.
Go. Интересный вариант. Новый, отличная стандартная библиотека, статически типизирован, классная асинхронность. Одним из основных принципов считает простоту, так что не превратился в фича-монстра, в отличие от C#. Можно делать как низкоуровневые штуки, так и бизнес-приложения.
Kotlin. Интересный вариант. Котлин — это Java, если бы ее изобрели в 2010 году. Статический, много фич. Работает поверх JVM (виртуальная машина джавы), можно использовать любые джава-либы.
И несколько нишевых языков с преданным сообществом:
Rust. Современная альтернатива C++. Отличный вариант для низкоуровневых штук, плохо подходит для остального. Много фич, тяжело освоить. Хорошая стандартная библиотека.
Clojure. Современный LISP. Язык, в котором простота возведена в абсолют — всё есть данные. Акцент на неизменяемых данных, продуманная стандартная библиотека. Работает поверх JVM.
Итого, из топ-10 мне кажутся интересными C#, Go и Kotlin. Лично я выбрал Go, потому что устал от фичастых языков и наслоений абстракций. Хочу простоты.
Если вам тоже интересно попробовать — присоединяйтесь ко мне на бесплатном курсе:
https://stepik.org/96832
Stepik: online education
Thank Go! Golang на практике
Осваиваем Golang на практических задачах. Для опытных разработчиков, которые хотят быстро начать применять Go в работе.
Субботний пакет
Репозиторий питонячих пакетов (PyPI) включает аж 300 тысяч проектов. Среди них есть прикладные (requests) и инфраструктурные (pip), полезные (redis) и не очень (insultgenerator). Есть большие и маленькие, надежные и бажные, набирающие обороты и давно заброшенные. Всякие есть.
Я подумал, что было бы неплохо писать об одном из них раз в неделю, по субботам — в рубрике #пакетик. Так что если вы автор какого-нибудь классного пакета — дайте знать в личку (@nalgeon). Может, одна из суббот станет вашей ツ
Репозиторий питонячих пакетов (PyPI) включает аж 300 тысяч проектов. Среди них есть прикладные (requests) и инфраструктурные (pip), полезные (redis) и не очень (insultgenerator). Есть большие и маленькие, надежные и бажные, набирающие обороты и давно заброшенные. Всякие есть.
Я подумал, что было бы неплохо писать об одном из них раз в неделю, по субботам — в рубрике #пакетик. Так что если вы автор какого-нибудь классного пакета — дайте знать в личку (@nalgeon). Может, одна из суббот станет вашей ツ
Естественная сортировка
Мой сегодняшний выбор — пакет Сета Мортона natsort, который сортирует строки привычным для человека образом.
Допустим, у нас есть список важных гостей. Он в легком беспорядке:
Отсортируем:
Порядка не прибавилось ツ А вот как будет с
Другое дело!
#пакетик
Мой сегодняшний выбор — пакет Сета Мортона natsort, который сортирует строки привычным для человека образом.
Допустим, у нас есть список важных гостей. Он в легком беспорядке:
data = [
"4 - Дуглас",
"2 - Клер",
"11 - Зоя",
"1 - Френк",
"31 - Питер",
]
Отсортируем:
>>> sorted(data)
['1 - Френк', '11 - Зоя', '2 - Клер', '31 - Питер', '4 - Дуглас']
Порядка не прибавилось ツ А вот как будет с
natsort:>>> import natsort
>>> natsort.natsorted(data)
['1 - Френк', '2 - Клер', '4 - Дуглас', '11 - Зоя', '31 - Питер']
Другое дело!
#пакетик
«Отнаследовать» функцию от существующей
Некоторые справедливо заметили, что если формат исходной строки заранее известен, то отсортировать список можно через стандартную
Чтобы добавить семантичности и не таскать везде дополнительный параметр
Есть и более лакончиный способ сделать это — через
Таким образом,
* Строго говоря, не функцию, а вызываемый объект, у которого определен дандер
#stdlib
Некоторые справедливо заметили, что если формат исходной строки заранее известен, то отсортировать список можно через стандартную
sorted():data = [
"4 - Дуглас",
"2 - Клер",
"11 - Зоя",
"1 - Френк",
"31 - Питер",
]
def _key(src):
parts = src.partition(" - ")
return int(parts[0])
>>> sorted(data, key=_key)
['1 - Френк', '2 - Клер', '4 - Дуглас', '11 - Зоя', '31 - Питер']
Чтобы добавить семантичности и не таскать везде дополнительный параметр
key, можно создать собственную функцию на основе sorted():def natsorted(iterable, reverse=False):
return sorted(iterable, key=_key, reverse=reverse)
>>> natsorted(data)
['1 - Френк', '2 - Клер', '4 - Дуглас', '11 - Зоя', '31 - Питер']
Есть и более лакончиный способ сделать это — через
functools.partial():import functools
natsorted = functools.partial(sorted, key=_key)
partial() создает новую функцию* на основе существующей. При этом можно «зафиксировать» один или несколько параметров (мы зафиксировали key), разрешив менять остальные (iterable и reverse в нашем случае).Таким образом,
partial() помогает создавать узкоспециализированные функции на базе более универсальных.* Строго говоря, не функцию, а вызываемый объект, у которого определен дандер
__call__ — его можно вызывать, как будто это функция.#stdlib
Планировщик задач
В стандартной библотеке есть встроенный планировщик задач (а чего вообще в ней нет?). Подробно расскажу в другой раз, но в целом он, скажем так, не слишком юзер-френдли.
Поэтому Дэн Бэйдер сделал schedule — «планировщик для людей». Смотрите, какой милый:
Ноль зависимостей, чистый и великолепно документированный код, примеры на все случаи жизни.
#пакетик
В стандартной библотеке есть встроенный планировщик задач (а чего вообще в ней нет?). Подробно расскажу в другой раз, но в целом он, скажем так, не слишком юзер-френдли.
Поэтому Дэн Бэйдер сделал schedule — «планировщик для людей». Смотрите, какой милый:
import schedule
import time
def job():
print("I'm working...")
schedule.every().hour.do(job)
schedule.every(5).to(10).minutes.do(job)
schedule.every().day.at("10:30").do(job)
while True:
schedule.run_pending()
time.sleep(1)
Ноль зависимостей, чистый и великолепно документированный код, примеры на все случаи жизни.
#пакетик
Задачка: неэффективный планировщик
Субботний пакет-планировщик вскрыл интересное искажение у некоторых подписчиков. Давайте проверим, есть ли оно у вас ツ
Пусть есть задача, которую мы хотим выполнять каждую минуту:
И есть планировщик. Он ужасно плохо написан, и тупит 0.2 секунды при каждом запуске:
Мы гоняем планировщик в бесконечном цикле каждую секунду:
И — о ужас — с каждым запуском планировщик все сильнее запаздывает:
Вопрос: насколько сильно будет опаздывать запуск задачи
Опрос следует.
#задачка
Субботний пакет-планировщик вскрыл интересное искажение у некоторых подписчиков. Давайте проверим, есть ли оно у вас ツ
Пусть есть задача, которую мы хотим выполнять каждую минуту:
def job():
print("Executing job")
И есть планировщик. Он ужасно плохо написан, и тупит 0.2 секунды при каждом запуске:
class Scheduler:
def run_pending(self):
time.sleep(0.2)
print(dt.datetime.now())
// запускает job(),
// если наступила новая минута
Мы гоняем планировщик в бесконечном цикле каждую секунду:
sched = Scheduler()
while True:
sched.run_pending()
time.sleep(1)
И — о ужас — с каждым запуском планировщик все сильнее запаздывает:
2021-05-24 15:19:01.9
2021-05-24 15:19:03.1
2021-05-24 15:19:04.3
2021-05-24 15:19:05.6
2021-05-24 15:19:06.8
2021-05-24 15:19:08.0
2021-05-24 15:19:09.2
2021-05-24 15:19:10.4
Вопрос: насколько сильно будет опаздывать запуск задачи
job()? Напомню, она должна запускаться каждую минуту.Опрос следует.
#задачка
Насколько сильно будет опаздывать запуск задачи?
Final Results
35%
Максимум на 1 секунду
16%
Максимум на 1 минуту
1%
Максимум на 1 час
48%
Все больше и больше, до бесконечности
Поэлементно сравнить коллекции
Однажды мы уже смотрели, как множества помогают быстро проверить, входит ли элемент в коллекцию.
Конечно, это не единственная возможность. Множества в питоне идеально подходят, чтобы поэлементно сравнивать коллекции.
Допустим, мы ведем учет посетителей:
И хотим узнать, кто приходил в январе и феврале. Нет ни малейшего желания писать вложенный цикл с перебором
Были в январе и феврале:
В январе или марте:
В феврале, но не в марте:
В январе или феврале, но не в оба месяца:
Все эти операции выполняются за линейное время
Кроме обычных множеств бывают замороженные (их нельзя менять):
Множество можно слепить из любого iterable-типа. Например, из строки:
Или даже из диапазона:
В общем, полезная штука.
#stdlib
Однажды мы уже смотрели, как множества помогают быстро проверить, входит ли элемент в коллекцию.
Конечно, это не единственная возможность. Множества в питоне идеально подходят, чтобы поэлементно сравнивать коллекции.
Допустим, мы ведем учет посетителей:
jan = ["Питер", "Клер", "Френк"]
feb = ["Френк", "Зоя", "Дуглас"]
mar = ["Клер", "Питер", "Зоя"]
И хотим узнать, кто приходил в январе и феврале. Нет ни малейшего желания писать вложенный цикл с перебором
jan и feb. Намного приятнее (и быстрее) использовать множества.jan = {"Питер", "Клер", "Френк"}
feb = {"Френк", "Зоя", "Дуглас"}
mar = {"Клер", "Питер", "Зоя"}Были в январе и феврале:
>>> jan & feb
{'Френк'}
В январе или марте:
>>> jan | mar
{'Питер', 'Клер', 'Зоя', 'Френк'}
В феврале, но не в марте:
>>> feb - mar
{'Френк', 'Дуглас'}
В январе или феврале, но не в оба месяца:
>>> jan ^ feb
{'Питер', 'Клер', 'Зоя', 'Дуглас'}
Все эти операции выполняются за линейное время
O(n) вместо квадратичного O(n²), как было бы на списках.Кроме обычных множеств бывают замороженные (их нельзя менять):
>>> visitors = frozenset().union(jan, feb, mar)
>>> visitors
frozenset({'Питер', 'Клер', 'Зоя', 'Френк', 'Дуглас'})
Множество можно слепить из любого iterable-типа. Например, из строки:
>>> frozenset('abcde')
frozenset({'b', 'd', 'e', 'c', 'a'})Или даже из диапазона:
>>> set(range(1, 10))
{1, 2, 3, 4, 5, 6, 7, 8, 9}
В общем, полезная штука.
#stdlib
Счетчик для огромных коллекций
В стандартной библиотеке есть класс Counter. Он отлично подходит, чтобы считать количество объектов разных типов. Но что делать, если объектов миллиарды, и счетчик просто не помещается в оперативную память?
Поможет bounter — это счетчик, который предоставляет схожий интерфейс, но внутри построен на вероятностных структурах данных. За счет этого он занимает в 30–250 раз меньше памяти, но может (слегка) привирать.
Ноль зависимостей, питон 3.3+
#пакетик
В стандартной библиотеке есть класс Counter. Он отлично подходит, чтобы считать количество объектов разных типов. Но что делать, если объектов миллиарды, и счетчик просто не помещается в оперативную память?
Поможет bounter — это счетчик, который предоставляет схожий интерфейс, но внутри построен на вероятностных структурах данных. За счет этого он занимает в 30–250 раз меньше памяти, но может (слегка) привирать.
from bounter import bounter
counts = bounter(size_mb=128)
counts.update(["a", "b", "c", "a", "b"])
>>> counts.total()
5
>>> counts["a"]
2
Ноль зависимостей, питон 3.3+
#пакетик
Главный критерий хорошего кода
Хороший код — понятный и непрожорливый до ресурсов. Давайте поговорим об этом.
Время на понимание
Главный критерий хорошего кода — это время T, которое требуется не-автору, чтобы разобраться в коде. Причем разобраться не на уровне «вроде понятно», а достаточно хорошо, чтобы внести изменения и ничего не сломать.
Чем меньше T, тем лучше код.
Допустим, Нина и Витя реализовали одну и ту же фичу, а вы хотите ее доработать. Если разберетесь в коде Нины за 10 минут, а в коде Вити за 30 минут — код Нины лучше. Неважно, насколько у Вити чистая архитектура, функциональный подход, современный фреймворк и всякое такое.
T-метрика для начинающего и опытного программиста отличается. Поэтому имеет смысл ориентироваться на средний уровень коллег, которые будут работать с кодом. Если у вас в коллективе люди трудятся 10+ лет, и каждый написал по компилятору — даже очень сложный код будет иметь низкое T. Если у вас огромная текучка, а нанимают вчерашних студентов — код должен быть совершенно дубовым, чтобы T не зашкаливало.
Напрямую T не очень-то померяешь, поэтому часто отслеживают вторичные метрики, которые влияют на T:
— соответствие код-стайлу (black для питона),
— «запашки» в коде (pylint, flake8),
— цикломатическую сложность (mccabe),
— зависимости между модулями (import-linter).
Плюс код-ревью.
Количество ресурсов
Второй критерий хорошего кода — количество ресурсов R, которое он потребляет (времени, процессора, памяти, диска). Чем меньше R, тем лучше код.
Если Нина и Витя реализовали фичу с одинаковым T, но код Нины работает за O(n), а код Вити за O(n²) (при одинаковом потреблении прочих ресурсов) — код Нины лучше.
Насчет ситуации «пожертвовать понятностью ради скорости». Для каждой задачи есть порог потребления ресурсов R0, в который должно уложиться решение. Если R < R0, не надо ухудшать T ради дальнейшего сокращения R.
Если некритичный сервис обрабатывает запрос за 50мс — не надо переписывать его с питона на C, чтобы сократить время до 5мс. И так достаточно быстро.
Иногда, если ресурсы ограничены, или исходные данные большие — не получается достичь R < R0 без ухудшения T. Тогда действительно приходится жертвовать понятностью. Но:
1) Это последний вариант, когда все прочие уже испробованы.
2) Участки кода, где T↑ ради R↓, должны быть хорошо изолированы.
3) Таких участков должно быть мало.
4) Они должны быть подробно документированы.
Итого
Мнемоника хорошего кода:
Оптимизируйте T, следите за R. Коллеги скажут вам спасибо.
#код
Хороший код — понятный и непрожорливый до ресурсов. Давайте поговорим об этом.
Время на понимание
Главный критерий хорошего кода — это время T, которое требуется не-автору, чтобы разобраться в коде. Причем разобраться не на уровне «вроде понятно», а достаточно хорошо, чтобы внести изменения и ничего не сломать.
Чем меньше T, тем лучше код.
Допустим, Нина и Витя реализовали одну и ту же фичу, а вы хотите ее доработать. Если разберетесь в коде Нины за 10 минут, а в коде Вити за 30 минут — код Нины лучше. Неважно, насколько у Вити чистая архитектура, функциональный подход, современный фреймворк и всякое такое.
T-метрика для начинающего и опытного программиста отличается. Поэтому имеет смысл ориентироваться на средний уровень коллег, которые будут работать с кодом. Если у вас в коллективе люди трудятся 10+ лет, и каждый написал по компилятору — даже очень сложный код будет иметь низкое T. Если у вас огромная текучка, а нанимают вчерашних студентов — код должен быть совершенно дубовым, чтобы T не зашкаливало.
Напрямую T не очень-то померяешь, поэтому часто отслеживают вторичные метрики, которые влияют на T:
— соответствие код-стайлу (black для питона),
— «запашки» в коде (pylint, flake8),
— цикломатическую сложность (mccabe),
— зависимости между модулями (import-linter).
Плюс код-ревью.
Количество ресурсов
Второй критерий хорошего кода — количество ресурсов R, которое он потребляет (времени, процессора, памяти, диска). Чем меньше R, тем лучше код.
Если Нина и Витя реализовали фичу с одинаковым T, но код Нины работает за O(n), а код Вити за O(n²) (при одинаковом потреблении прочих ресурсов) — код Нины лучше.
Насчет ситуации «пожертвовать понятностью ради скорости». Для каждой задачи есть порог потребления ресурсов R0, в который должно уложиться решение. Если R < R0, не надо ухудшать T ради дальнейшего сокращения R.
Если некритичный сервис обрабатывает запрос за 50мс — не надо переписывать его с питона на C, чтобы сократить время до 5мс. И так достаточно быстро.
Иногда, если ресурсы ограничены, или исходные данные большие — не получается достичь R < R0 без ухудшения T. Тогда действительно приходится жертвовать понятностью. Но:
1) Это последний вариант, когда все прочие уже испробованы.
2) Участки кода, где T↑ ради R↓, должны быть хорошо изолированы.
3) Таких участков должно быть мало.
4) Они должны быть подробно документированы.
Итого
Мнемоника хорошего кода:
T↓ R<R0Оптимизируйте T, следите за R. Коллеги скажут вам спасибо.
#код
Универсальные оповещения
Есть куча способов отправлять уведомления — от проверенного SMTP и удобного Telegram до смс и специальных приложений для мобилок вроде Pushover.
Обычно для этого используют 3rd-party библиотеку соответствующего провайдера. Но есть более удобный способ — пакет notifiers от Ора Карми. Он предоставляет простой универсальный интерфейс для отправки сообщений через любой сервис.
Например, через телеграм:
Поддерживается аж 16 провайдеров, а интерфейс один — метод
Питон 3.6+
#пакетик
Есть куча способов отправлять уведомления — от проверенного SMTP и удобного Telegram до смс и специальных приложений для мобилок вроде Pushover.
Обычно для этого используют 3rd-party библиотеку соответствующего провайдера. Но есть более удобный способ — пакет notifiers от Ора Карми. Он предоставляет простой универсальный интерфейс для отправки сообщений через любой сервис.
Например, через телеграм:
import notifiers
token = "bot_token"
chat_id = 1234
tg = notifiers.get_notifier("telegram")
tg.notify(message="Привет!", token=token, chat_id=chat_id)
Поддерживается аж 16 провайдеров, а интерфейс один — метод
.notify(). И никаких дополнительных 3rd-party библиотек. Удобно!Питон 3.6+
#пакетик