
Personalized, Health-Aware Recipe Recommendation: An Ensemble Topic
arxiv.org/abs/1908.0014
🔗 Personalized, Health-Aware Recipe Recommendation: An Ensemble Topic Modeling Based Approach
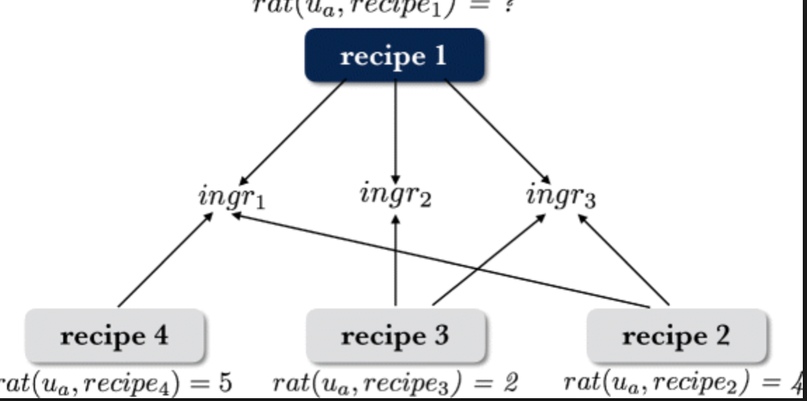
Food choices are personal and complex and have a significant impact on our long-term health and quality of life. By helping users to make informed and satisfying decisions, Recommender Systems (RS) have the potential to support users in making healthier food choices. Intelligent users-modeling is a key challenge in achieving this potential. This paper investigates Ensemble Topic Modelling (EnsTM) based Feature Identification techniques for efficient user-modeling and recipe recommendation. It builds on findings in EnsTM to propose a reduced data representation format and a smart user-modeling strategy that makes capturing user-preference fast, efficient and interactive. This approach enables personalization, even in a cold-start scenario. This paper proposes two different EnsTM based and one Hybrid EnsTM based recommenders. We compared all three EnsTM based variations through a user study with 48 participants, using a large-scale,real-world corpus of 230,876 recipes, and compare against a conventional Content
arxiv.org/abs/1908.0014
🔗 Personalized, Health-Aware Recipe Recommendation: An Ensemble Topic Modeling Based Approach
Food choices are personal and complex and have a significant impact on our long-term health and quality of life. By helping users to make informed and satisfying decisions, Recommender Systems (RS) have the potential to support users in making healthier food choices. Intelligent users-modeling is a key challenge in achieving this potential. This paper investigates Ensemble Topic Modelling (EnsTM) based Feature Identification techniques for efficient user-modeling and recipe recommendation. It builds on findings in EnsTM to propose a reduced data representation format and a smart user-modeling strategy that makes capturing user-preference fast, efficient and interactive. This approach enables personalization, even in a cold-start scenario. This paper proposes two different EnsTM based and one Hybrid EnsTM based recommenders. We compared all three EnsTM based variations through a user study with 48 participants, using a large-scale,real-world corpus of 230,876 recipes, and compare against a conventional Content
{kind=link}
Статистика на службе у бизнеса. Методология расчёта множественных экспериментов
Как и было обещано в предыдущей статье, сегодня мы продолжим разговор о методологиях, применяемых в A/B-тестировании и рассмотрим методы оценки результатов множественных экспериментов. Мы увидим, что методологии довольно просты, и математическая статистика не так страшна, а первооснова всего — аналитическое мышление и здравый смысл. Однако предварительно хотелось бы сказать пару слов о том, какие же бизнес-задачи помогают решать строгие математические методы, нужны ли они Вам на данном этапе развития Вашей компании и какие pros and cons существуют в Большой аналитике.
https://habr.com/ru/post/462345/
🔗 Статистика на службе у бизнеса. Методология расчёта множественных экспериментов
Добрый день! Как и было обещано в предыдущей статье, сегодня мы продолжим разговор о методологиях, применяемых в A/B-тестировании и рассмотрим методы оценки рез...
Как и было обещано в предыдущей статье, сегодня мы продолжим разговор о методологиях, применяемых в A/B-тестировании и рассмотрим методы оценки результатов множественных экспериментов. Мы увидим, что методологии довольно просты, и математическая статистика не так страшна, а первооснова всего — аналитическое мышление и здравый смысл. Однако предварительно хотелось бы сказать пару слов о том, какие же бизнес-задачи помогают решать строгие математические методы, нужны ли они Вам на данном этапе развития Вашей компании и какие pros and cons существуют в Большой аналитике.
https://habr.com/ru/post/462345/
🔗 Статистика на службе у бизнеса. Методология расчёта множественных экспериментов
Добрый день! Как и было обещано в предыдущей статье, сегодня мы продолжим разговор о методологиях, применяемых в A/B-тестировании и рассмотрим методы оценки рез...
Consider TPOT your Data Science Assistant. TPOT is a Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
https://github.com/EpistasisLab/tpot
🔗 EpistasisLab/tpot
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming. - EpistasisLab/tpot
https://github.com/EpistasisLab/tpot
🔗 EpistasisLab/tpot
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming. - EpistasisLab/tpot
GitHub
GitHub - EpistasisLab/tpot: A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming. - EpistasisLab/tpot
#ProgrammingKnowledge #ComputerVision #OpenCV
OpenCV Python Tutorial For Beginners 30 - Probabilistic Hough Transform using HoughLinesP in OpenCV
🎥 OpenCV Python Tutorial For Beginners 30 - Probabilistic Hough Transform using HoughLinesP in OpenCV
👁 1 раз ⏳ 648 сек.
OpenCV Python Tutorial For Beginners 30 - Probabilistic Hough Transform using HoughLinesP in OpenCV
🎥 OpenCV Python Tutorial For Beginners 30 - Probabilistic Hough Transform using HoughLinesP in OpenCV
👁 1 раз ⏳ 648 сек.
code - https://gist.github.com/pknowledge/baa1e9785d818e70be78f7ac5795ee51
In this video on OpenCV Python Tutorial For Beginners, we are going to see Probabilistic Hough Transform using HoughLinesP method in OpenCV.
OpenCV implements two kind of Hough Line Transforms
The Standard Hough Transform (HoughLines method)
The Probabilistic Hough Line Transform (HoughLinesP method)
lines=cv.HoughLinesP(image, rho, theta, threshold[, lines[, minLineLength[, maxLineGap]]])
rho : Distance resolution of the accumVk
OpenCV Python Tutorial For Beginners 30 - Probabilistic Hough Transform using HoughLinesP in OpenCV
code - https://gist.github.com/pknowledge/baa1e9785d818e70be78f7ac5795ee51
In this video on OpenCV Python Tutorial For Beginners, we are going to see Probabilistic Hough Transform using HoughLinesP method in OpenCV.
OpenCV implements two kind of Hough Line…
In this video on OpenCV Python Tutorial For Beginners, we are going to see Probabilistic Hough Transform using HoughLinesP method in OpenCV.
OpenCV implements two kind of Hough Line…
#Python #ArtificialIntelligence #AI
AI Teaches Itself to Play Flappy Bird - Using NEAT Python!
🎥 AI Teaches Itself to Play Flappy Bird - Using NEAT Python!
👁 1 раз ⏳ 617 сек.
AI Teaches Itself to Play Flappy Bird - Using NEAT Python!
🎥 AI Teaches Itself to Play Flappy Bird - Using NEAT Python!
👁 1 раз ⏳ 617 сек.
Watch an genetic/evolutionary algorithm slowly progress and teach itself to flappy bird. The AI that learns to play this game using an algorithm called NEAT. In this video I show how the AI works and go into some specific details about the concepts behind it.
Code: https://github.com/techwithtim/NEAT-Flappy-Bird
NEAT-Python Moduler: https://neat-python.readthedocs.io/en/latest/
Original NEAT Paper: http://nn.cs.utexas.edu/downloads/papers/stanley.cec02.pdf
Inspired By: https://www.youtube.com/watch?v=WSW-Vk
AI Teaches Itself to Play Flappy Bird - Using NEAT Python!
Watch an genetic/evolutionary algorithm slowly progress and teach itself to flappy bird. The AI that learns to play this game using an algorithm called NEAT. In this video I show how the AI works and go into some specific details about the concepts behind…
Differential Privacy Note 2: A Powerful Synopsis from the Bible of Privacy
“Tell me and I forget. Teach me and I remember. Involve me and I learn.” — Benjamin Franklin
https://towardsdatascience.com/differential-privacy-note-2-a-powerful-synopsis-from-the-bible-of-privacy-51e2f99d3900?source=collection_home---4------2-----------------------
🔗 Differential Privacy Note 2: A Powerful Synopsis from the Bible of Privacy
“Tell me and I forget. Teach me and I remember. Involve me and I learn.”
— Benjamin Franklin
“Tell me and I forget. Teach me and I remember. Involve me and I learn.” — Benjamin Franklin
https://towardsdatascience.com/differential-privacy-note-2-a-powerful-synopsis-from-the-bible-of-privacy-51e2f99d3900?source=collection_home---4------2-----------------------
🔗 Differential Privacy Note 2: A Powerful Synopsis from the Bible of Privacy
“Tell me and I forget. Teach me and I remember. Involve me and I learn.”
— Benjamin Franklin
Medium
Differential Privacy Note 2: A Powerful Synopsis from the Bible of Privacy
“Tell me and I forget. Teach me and I remember. Involve me and I learn.” — Benjamin Franklin
What is Decision Intelligence?
A new discipline for leadership in the AI era
https://towardsdatascience.com/introduction-to-decision-intelligence-5d147ddab767?source=collection_home---4------1-----------------------
🔗 Introduction to Decision Intelligence
A new discipline for leadership in the AI era
A new discipline for leadership in the AI era
https://towardsdatascience.com/introduction-to-decision-intelligence-5d147ddab767?source=collection_home---4------1-----------------------
🔗 Introduction to Decision Intelligence
A new discipline for leadership in the AI era
Medium
Introduction to Decision Intelligence
A new discipline for leadership in the AI era
Model predicts cognitive decline due to Alzheimer’s, up to two years out
Researchers hope the system can zero in on the right patients to enroll in clinical trials, to speed discovery of drug treatments.
http://news.mit.edu/2019/model-predicts-alzheimers-decline-0802
🔗 Model predicts cognitive decline due to Alzheimer’s, up to two years out
Researchers hope the system can zero in on the right patients to enroll in clinical trials, to speed discovery of drug treatments.
Researchers hope the system can zero in on the right patients to enroll in clinical trials, to speed discovery of drug treatments.
http://news.mit.edu/2019/model-predicts-alzheimers-decline-0802
🔗 Model predicts cognitive decline due to Alzheimer’s, up to two years out
Researchers hope the system can zero in on the right patients to enroll in clinical trials, to speed discovery of drug treatments.
MIT News
Model predicts cognitive decline due to Alzheimer’s, up to two years out
An artificial intelligence model developed at MIT predicts cognitive decline of patients at risk for Alzheimer’s disease by predicting their cognition test scores up to two years in the future. The model could be used to improve the selection of candidate…
Курс «Программирование на языке Python для сбора и анализа данных»
Наш телеграм канал - tglink.me/ai_machinelearning_big_data
1. Первое знакомство
2. Списки и цикл for
3. Ввод-вывод списков и проверка условий
4. Функции
5. Словари, списковые включения
6. Сортировка. Форматирование строк
7. Указатели. Множества. Строки. Файлы
8. Извлечение данных из веб-страниц
9. Работа с открытыми API с помощью XML
#python
🎥 Лекция №1: первое знакомство
👁 2 раз ⏳ 2902 сек.
🎥 Лекция №2: Списки и цикл for
👁 1 раз ⏳ 4009 сек.
🎥 Лекция №3: ввод-вывод списков и проверка условий
👁 1 раз ⏳ 4227 сек.
🎥 Лекция №4: функции
👁 1 раз ⏳ 4247 сек.
🎥 Лекция №5: словари, списковые включения
👁 1 раз ⏳ 2632 сек.
🎥 Лекция №6. Сортировка. Форматирование строк
👁 1 раз ⏳ 3229 сек.
🎥 Лекция №7: Указатели. Множества. Строки. Файлы
👁 1 раз ⏳ 3848 сек.
🎥 Лекция 8. Извлечение данных из веб-страниц
👁 1 раз ⏳ 3044 сек.
🎥 Лекция №9: Работа с открытыми API с помощью XML
👁 1 раз ⏳ 1458 сек.
Наш телеграм канал - tglink.me/ai_machinelearning_big_data
1. Первое знакомство
2. Списки и цикл for
3. Ввод-вывод списков и проверка условий
4. Функции
5. Словари, списковые включения
6. Сортировка. Форматирование строк
7. Указатели. Множества. Строки. Файлы
8. Извлечение данных из веб-страниц
9. Работа с открытыми API с помощью XML
#python
🎥 Лекция №1: первое знакомство
👁 2 раз ⏳ 2902 сек.
Курс «Программирование на языке Python для сбора и анализа данных», НИУ ВШЭ, 2015-16 учебный год, лектор Илья Щуров. Лекция №1: первое знакомство.
...🎥 Лекция №2: Списки и цикл for
👁 1 раз ⏳ 4009 сек.
Курс «Программирование на языке Python для сбора и анализа данных», НИУ ВШЭ, 2015-16 учебный год, лектор Илья Щуров. Лекция №2: Списки и цикл for, ...🎥 Лекция №3: ввод-вывод списков и проверка условий
👁 1 раз ⏳ 4227 сек.
Курс «Программирование на языке Python для сбора и анализа данных», НИУ ВШЭ, 2015-16 учебный год, лектор Илья Щуров. Лекция №3: ввод-вывод списков ...🎥 Лекция №4: функции
👁 1 раз ⏳ 4247 сек.
Курс «Программирование на языке Python для сбора и анализа данных», НИУ ВШЭ, 2015-16 учебный год, лектор Илья Щуров. Лекция №4: функции, 24 октября...🎥 Лекция №5: словари, списковые включения
👁 1 раз ⏳ 2632 сек.
Курс «Программирование на языке Python для сбора и анализа данных», НИУ ВШЭ, 2015-16 учебный год, лектор Илья Щуров. Лекция №5: Словари. Списковые ...🎥 Лекция №6. Сортировка. Форматирование строк
👁 1 раз ⏳ 3229 сек.
Курс «Программирование на языке Python для сбора и анализа данных», НИУ ВШЭ, 2015-16 учебный год, лектор Илья Щуров. Лекция №6: Сортировка. Формати...🎥 Лекция №7: Указатели. Множества. Строки. Файлы
👁 1 раз ⏳ 3848 сек.
Курс «Программирование на языке Python для сбора и анализа данных», НИУ ВШЭ, 2015-16 учебный год, лектор Илья Щуров. Лекция №7: Указатели. Множест...🎥 Лекция 8. Извлечение данных из веб-страниц
👁 1 раз ⏳ 3044 сек.
Курс «Программирование на языке Python для сбора и анализа данных», НИУ ВШЭ, 2015-16 учебный год, лектор Илья Щуров. Лекция №8: Извлечение данных ...🎥 Лекция №9: Работа с открытыми API с помощью XML
👁 1 раз ⏳ 1458 сек.
Курс «Программирование на языке Python для сбора и анализа данных», НИУ ВШЭ, 2015-16 учебный год, лектор Илья Щуров. Лекция №9: Работа с открытыми ...Vk
Лекция №1: первое знакомство
Курс «Программирование на языке Python для сбора и анализа данных», НИУ ВШЭ, 2015-16 учебный год, лектор Илья Щуров. Лекция №1: первое знакомство. ...
Deep Sensor Fusion for Real-Time Odometry Estimation
Authors: Michelle Valente, Cyril Joly, Arnaud de La Fortelle
Abstract: …consecutive frames. Results on a real road dataset show that the fusion network runs in real-time and is able to improve the odometry estimation of a single sensor alone by learning how to fuse two different types of data information.
https://arxiv.org/abs/1908.00524
🔗 Deep Sensor Fusion for Real-Time Odometry Estimation
Cameras and 2D laser scanners, in combination, are able to provide low-cost, light-weight and accurate solutions, which make their fusion well-suited for many robot navigation tasks. However, correct data fusion depends on precise calibration of the rigid body transform between the sensors. In this paper we present the first framework that makes use of Convolutional Neural Networks (CNNs) for odometry estimation fusing 2D laser scanners and mono-cameras. The use of CNNs provides the tools to not only extract the features from the two sensors, but also to fuse and match them without needing a calibration between the sensors. We transform the odometry estimation into an ordinal classification problem in order to find accurate rotation and translation values between consecutive frames. Results on a real road dataset show that the fusion network runs in real-time and is able to improve the odometry estimation of a single sensor alone by learning how to fuse two different types of data information.
Authors: Michelle Valente, Cyril Joly, Arnaud de La Fortelle
Abstract: …consecutive frames. Results on a real road dataset show that the fusion network runs in real-time and is able to improve the odometry estimation of a single sensor alone by learning how to fuse two different types of data information.
https://arxiv.org/abs/1908.00524
🔗 Deep Sensor Fusion for Real-Time Odometry Estimation
Cameras and 2D laser scanners, in combination, are able to provide low-cost, light-weight and accurate solutions, which make their fusion well-suited for many robot navigation tasks. However, correct data fusion depends on precise calibration of the rigid body transform between the sensors. In this paper we present the first framework that makes use of Convolutional Neural Networks (CNNs) for odometry estimation fusing 2D laser scanners and mono-cameras. The use of CNNs provides the tools to not only extract the features from the two sensors, but also to fuse and match them without needing a calibration between the sensors. We transform the odometry estimation into an ordinal classification problem in order to find accurate rotation and translation values between consecutive frames. Results on a real road dataset show that the fusion network runs in real-time and is able to improve the odometry estimation of a single sensor alone by learning how to fuse two different types of data information.
{kind=link}
"Songs to sing in the car" - recommender systems at Spotify (human vs machine) | AI Podcast Clips
🔗 "Songs to sing in the car" - recommender systems at Spotify (human vs machine) | AI Podcast Clips
This is a clip from a conversation with Gustav Soderstrom on the Artificial Intelligence podcast. You can watch the full conversation here: http://bit.ly/2yzx6hN or watch other AI clips here: http://bit.ly/2JYkbfZ Gustav Soderstrom is the Chief Research & Development Officer at Spotify, leading Product, Design, Data, Technology & Engineering teams. Full episode: http://bit.ly/2yzx6hN Clips playlist: http://bit.ly/2JYkbfZ Full episodes playlist: http://bit.ly/2EcbaKf Podcast website: https://lexfridman.com
🔗 "Songs to sing in the car" - recommender systems at Spotify (human vs machine) | AI Podcast Clips
This is a clip from a conversation with Gustav Soderstrom on the Artificial Intelligence podcast. You can watch the full conversation here: http://bit.ly/2yzx6hN or watch other AI clips here: http://bit.ly/2JYkbfZ Gustav Soderstrom is the Chief Research & Development Officer at Spotify, leading Product, Design, Data, Technology & Engineering teams. Full episode: http://bit.ly/2yzx6hN Clips playlist: http://bit.ly/2JYkbfZ Full episodes playlist: http://bit.ly/2EcbaKf Podcast website: https://lexfridman.com
YouTube
"Songs to sing in the car" - recommender systems at Spotify (human vs machine) | AI Podcast Clips
This is a clip from a conversation with Gustav Soderstrom on the Artificial Intelligence podcast. You can watch the full conversation here: http://bit.ly/2yz...
Treat Negation Stopwords Differently According to Your NLP Task
The negation words (not, nor, never) are considered to be stopwords in NLTK, spacy and sklearn, but we should pay different attention
https://towardsdatascience.com/treat-negation-stopwords-differently-according-to-your-nlp-task-e5a59ab7c91f?source=collection_home---4------1-----------------------
🔗 Treat Negation Stopwords Differently According to Your NLP Task
The negation words (not, nor, never) are considered to be stopwords in NLTK, spacy and sklearn, but we should pay different attention…
The negation words (not, nor, never) are considered to be stopwords in NLTK, spacy and sklearn, but we should pay different attention
https://towardsdatascience.com/treat-negation-stopwords-differently-according-to-your-nlp-task-e5a59ab7c91f?source=collection_home---4------1-----------------------
🔗 Treat Negation Stopwords Differently According to Your NLP Task
The negation words (not, nor, never) are considered to be stopwords in NLTK, spacy and sklearn, but we should pay different attention…
Medium
Treat Negation Stopwords Differently According to Your NLP Task
The negation words (not, nor, never) are considered to be stopwords in NLTK, spacy and sklearn, but we should pay different attention…
Shifts & Twists in Business Analytics: Reflections from Qlik Qonnections and Alteryx Inspire
Business Analytics evolves mostly upward, but with unexpected shifts in thinking and sudden twists in technology.
https://towardsdatascience.com/https-towardsdatascience-com-shifts-twists-in-business-analytics-bec8766091b9?source=topic_page---------2------------------1
🔗 Shifts & Twists in Business Analytics: Reflections from Qlik Qonnections and Alteryx Inspire
Business Analytics evolves mostly upward, but with unexpected shifts in thinking and sudden twists in technology.
Business Analytics evolves mostly upward, but with unexpected shifts in thinking and sudden twists in technology.
https://towardsdatascience.com/https-towardsdatascience-com-shifts-twists-in-business-analytics-bec8766091b9?source=topic_page---------2------------------1
🔗 Shifts & Twists in Business Analytics: Reflections from Qlik Qonnections and Alteryx Inspire
Business Analytics evolves mostly upward, but with unexpected shifts in thinking and sudden twists in technology.
Medium
Shifts & Twists in Business Analytics:Reflections from Qlik Qonnections and Alteryx Inspire
Business Analytics evolves mostly upward, but with unexpected shifts in thinking and sudden twists in technology.
LSTM-based African Language Classification
Tired of German-French dataset? Look at Yemba, and stand out. Mechanics of LSTM, GRU explained and applied, with powerful visuals and code.
https://towardsdatascience.com/lstm-based-african-language-classification-e4f644c0f29e?source=collection_home---4------0-----------------------
🔗 LSTM-based African Language Classification
Tired of German-French dataset? Look at Yemba, and stand out. Mechanics of LSTM, GRU explained and applied, with powerful visuals and code.
Tired of German-French dataset? Look at Yemba, and stand out. Mechanics of LSTM, GRU explained and applied, with powerful visuals and code.
https://towardsdatascience.com/lstm-based-african-language-classification-e4f644c0f29e?source=collection_home---4------0-----------------------
🔗 LSTM-based African Language Classification
Tired of German-French dataset? Look at Yemba, and stand out. Mechanics of LSTM, GRU explained and applied, with powerful visuals and code.
Medium
LSTM-based African Language Classification
Tired of German-French dataset? Look at Yemba, and stand out. Mechanics of LSTM, GRU explained and applied, with powerful visuals and code.
Deep Generative Model Driven Protein Folding Simulation
Authors: Heng Ma, Debsindhu Bhowmik, Hyungro Lee, Matteo Turilli, Michael T. Young, Shantenu Jha, Arvind Ramanathan
Abstract: …ensemble of MD runs, and (2) identifying novel states from which simulations can be initiated to sample rare events (e.g., sampling folding events).
https://arxiv.org/abs/1908.00496
🔗 Deep Generative Model Driven Protein Folding Simulation
Significant progress in computer hardware and software have enabled molecular dynamics (MD) simulations to model complex biological phenomena such as protein folding. However, enabling MD simulations to access biologically relevant timescales (e.g., beyond milliseconds) still remains challenging. These limitations include (1) quantifying which set of states have already been (sufficiently) sampled in an ensemble of MD runs, and (2) identifying novel states from which simulations can be initiated to sample rare events (e.g., sampling folding events). With the recent success of deep learning and artificial intelligence techniques in analyzing large datasets, we posit that these techniques can also be used to adaptively guide MD simulations to model such complex biological phenomena. Leveraging our recently developed unsupervised deep learning technique to cluster protein folding trajectories into partially folded intermediates, we build an iterative workflow that enables our generative model to be coupled with
Authors: Heng Ma, Debsindhu Bhowmik, Hyungro Lee, Matteo Turilli, Michael T. Young, Shantenu Jha, Arvind Ramanathan
Abstract: …ensemble of MD runs, and (2) identifying novel states from which simulations can be initiated to sample rare events (e.g., sampling folding events).
https://arxiv.org/abs/1908.00496
🔗 Deep Generative Model Driven Protein Folding Simulation
Significant progress in computer hardware and software have enabled molecular dynamics (MD) simulations to model complex biological phenomena such as protein folding. However, enabling MD simulations to access biologically relevant timescales (e.g., beyond milliseconds) still remains challenging. These limitations include (1) quantifying which set of states have already been (sufficiently) sampled in an ensemble of MD runs, and (2) identifying novel states from which simulations can be initiated to sample rare events (e.g., sampling folding events). With the recent success of deep learning and artificial intelligence techniques in analyzing large datasets, we posit that these techniques can also be used to adaptively guide MD simulations to model such complex biological phenomena. Leveraging our recently developed unsupervised deep learning technique to cluster protein folding trajectories into partially folded intermediates, we build an iterative workflow that enables our generative model to be coupled with
{kind=link}
Location-Based Recommendations
Create a location-based recommender with machine learning.
https://towardsdatascience.com/location-based-recommendations-bb70af7b1538?source=collection_home---4------2-----------------------
🔗 Location-Based Recommendations
Create a location-based recommender with machine learning.
Create a location-based recommender with machine learning.
https://towardsdatascience.com/location-based-recommendations-bb70af7b1538?source=collection_home---4------2-----------------------
🔗 Location-Based Recommendations
Create a location-based recommender with machine learning.
Medium
Location-Based Recommendations
Create a location-based recommender with machine learning.
Stanford University School of Engineering CS224N Natural Language Processing with Deep Learning
https://www.youtube.com/playlist?list=PLU40WL8Ol94IJzQtileLTqGZuXtGlLMP_
🔗 CS224N Natural Language Processing with Deep Learning - YouTube
http://web.stanford.edu/class/cs224n/syllabus.html
https://www.youtube.com/playlist?list=PLU40WL8Ol94IJzQtileLTqGZuXtGlLMP_
🔗 CS224N Natural Language Processing with Deep Learning - YouTube
http://web.stanford.edu/class/cs224n/syllabus.html
#data #mining #weka
Data mining with Weka | Data mining Tutorial for Beginners
🎥 Data mining with Weka | Data mining Tutorial for Beginners
👁 1 раз ⏳ 13741 сек.
Data mining with Weka | Data mining Tutorial for Beginners
🎥 Data mining with Weka | Data mining Tutorial for Beginners
👁 1 раз ⏳ 13741 сек.
In this data mining course you will learn how to do data mining tasks with Weka. This #data #mining course has been designed for beginners. It will walk you through data mining process with #weka. Weka is very powerful and widely used for data mining.
Enjoy this data mining course and share with those who need it.
Topic Covered:
***************
Data Mining with Weka (1.1: Introduction)
Data Mining with Weka (1.2: Exploring the Explorer)
Data Mining with Weka (1Vk
Data mining with Weka | Data mining Tutorial for Beginners
In this data mining course you will learn how to do data mining tasks with Weka. This #data #mining course has been designed for beginners. It will walk you through data mining process with #weka. Weka is very powerful and widely used for data mining.
Enjoy…
Enjoy…
Dog Breed prediction using CNNs and transfer learning
In this article, I will demonstrate how to use keras and tensorflow to build, train, and test a Convolutiuonal Neural Network
https://towardsdatascience.com/dog-breed-prediction-using-cnns-and-transfer-learning-22d8ed0b16c5?source=collection_home---4------2-----------------------
🔗 Dog Breed prediction using CNNs and transfer learning
In this article, I will demonstrate how to use keras and tensorflow to build, train, and test a Convolutiuonal Neural Network capable of…
In this article, I will demonstrate how to use keras and tensorflow to build, train, and test a Convolutiuonal Neural Network
https://towardsdatascience.com/dog-breed-prediction-using-cnns-and-transfer-learning-22d8ed0b16c5?source=collection_home---4------2-----------------------
🔗 Dog Breed prediction using CNNs and transfer learning
In this article, I will demonstrate how to use keras and tensorflow to build, train, and test a Convolutiuonal Neural Network capable of…
Medium
Dog Breed prediction using CNNs and transfer learning
In this article, I will demonstrate how to use keras and tensorflow to build, train, and test a Convolutiuonal Neural Network capable of…
Несколько соображений по поводу параллельных вычислений в R применительно к «enterprise» задачам
#BigData
Параллельные или распределенные вычисления — вещь сама по себе весьма нетривиальная. И среда разработки должна поддерживать, и DS специалист должен обладать навыками проведения параллельных вычислений, да и задача должна быть приведена к разделяемому на части виду, если таковой существует. Но при грамотном подходе можно весьма ускорить решение задачи однопоточным R, если у вас под руками есть хотя бы многоядерный процессор (а он есть сейчас почти у всех), с поправкой на теоретическую границу ускорения, определяемую законом Амдала. Однако, в ряде случаев даже его можно обойти.
https://habr.com/ru/post/462469/
🔗 Несколько соображений по поводу параллельных вычислений в R применительно к «enterprise» задачам
Параллельные или распределенные вычисления — вещь сама по себе весьма нетривиальная. И среда разработки должна поддерживать, и DS специалист должен обладать навы...
#BigData
Параллельные или распределенные вычисления — вещь сама по себе весьма нетривиальная. И среда разработки должна поддерживать, и DS специалист должен обладать навыками проведения параллельных вычислений, да и задача должна быть приведена к разделяемому на части виду, если таковой существует. Но при грамотном подходе можно весьма ускорить решение задачи однопоточным R, если у вас под руками есть хотя бы многоядерный процессор (а он есть сейчас почти у всех), с поправкой на теоретическую границу ускорения, определяемую законом Амдала. Однако, в ряде случаев даже его можно обойти.
https://habr.com/ru/post/462469/
🔗 Несколько соображений по поводу параллельных вычислений в R применительно к «enterprise» задачам
Параллельные или распределенные вычисления — вещь сама по себе весьма нетривиальная. И среда разработки должна поддерживать, и DS специалист должен обладать навы...
Хабр
Несколько соображений по поводу параллельных вычислений в R применительно к «enterprise» задачам
Параллельные или распределенные вычисления — вещь сама по себе весьма нетривиальная. И среда разработки должна поддерживать, и DS специалист должен обладать навы...