
cdebug — нож швейцарской армии для отладки работы контейнеров
С помощью этого инструмента вы можете:
⚡️Устранять неполадки в контейнерах, для которых нет системной оболочки и/или инструментов отладки
⚡️Перенаправлять неопубликованные или даже локальные порты на хост-систему
⚡️Открывать конечные точки из хост-системы для контейнеров и сетей Kubernetes
⚡️Удобно экспортировать файловую систему образа и/или контейнера в локальные папки
⚡️и многое другое
Репыч на Гитхабе
С помощью этого инструмента вы можете:
⚡️Устранять неполадки в контейнерах, для которых нет системной оболочки и/или инструментов отладки
⚡️Перенаправлять неопубликованные или даже локальные порты на хост-систему
⚡️Открывать конечные точки из хост-системы для контейнеров и сетей Kubernetes
⚡️Удобно экспортировать файловую систему образа и/или контейнера в локальные папки
⚡️и многое другое
Репыч на Гитхабе
{kind=link}
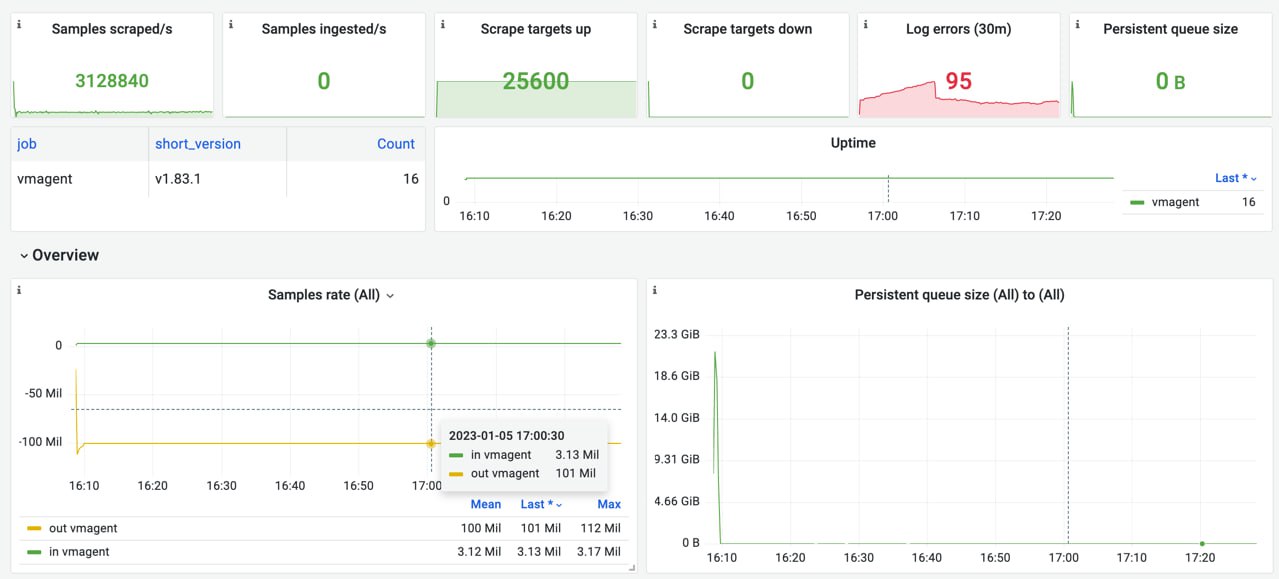
Monitoring benchmark: how to generate 100 million samples/s of production-like data (статья из блога Victoria Metrics)
Не смотря на то, что VictoriaMetrics может обрабатывать данные со скоростью 100 миллионов событий в секунду для одного миллиарда активных временных рядов, эталонный инструмент, используемый для создания такой нагрузки, обычно упускается из виду. В этой статье рассказывается о проблемах масштабирования инструмента prometheus-benchmark для создания такой нагрузки. Читать дальше.
Не смотря на то, что VictoriaMetrics может обрабатывать данные со скоростью 100 миллионов событий в секунду для одного миллиарда активных временных рядов, эталонный инструмент, используемый для создания такой нагрузки, обычно упускается из виду. В этой статье рассказывается о проблемах масштабирования инструмента prometheus-benchmark для создания такой нагрузки. Читать дальше.
{kind=link}
How to Monitor the Kubelet
Мониторинг Kubelet необходим при работе Kubernetes в проде. Kubelet—- это важная служба в кластере Kubernetes.
Этот компонент Kubernetes отвечает за обеспечение работоспособности и здоровья контейнеров, определенных в Pods. Как только планировщик назначает узел для запуска Pod, Kubelet принимает это назначение и запускает Pod. В этой статье рассказывается о том, как контролировать Kubelet и каковы наиболее важные метрики Kubelet. Читать дальше.
Мониторинг Kubelet необходим при работе Kubernetes в проде. Kubelet—- это важная служба в кластере Kubernetes.
Этот компонент Kubernetes отвечает за обеспечение работоспособности и здоровья контейнеров, определенных в Pods. Как только планировщик назначает узел для запуска Pod, Kubelet принимает это назначение и запускает Pod. В этой статье рассказывается о том, как контролировать Kubelet и каковы наиболее важные метрики Kubelet. Читать дальше.
{kind=link}
How to monitor Istio, the Kubernetes service mesh
Istio service mesh добавляет такие ключевые возможности, как наблюдаемость, безопасность и управление трафиком, в приложения без необходимости вносить изменения в код или конфигурацию. В этой статье рассказывается об основных концепциях Istio. Вы узнаете, какие метрики наиболее интересны для мониторинга Istio. Кроме того, узнаете о наборе инструментов, необходимых для управления Istio и проверки того, что находится под капотом.
В статье рассматриваются следующие темы:
⚡️Что такое Istio?
⚡️Обзор Istio
⚡️Как контролировать Istio с помощью Prometheus
⚡️Дашборды Grafana для Istio
⚡️Что такое Kiali?
⚡️Что такое Jaeger?
Читать дальше.
Istio service mesh добавляет такие ключевые возможности, как наблюдаемость, безопасность и управление трафиком, в приложения без необходимости вносить изменения в код или конфигурацию. В этой статье рассказывается об основных концепциях Istio. Вы узнаете, какие метрики наиболее интересны для мониторинга Istio. Кроме того, узнаете о наборе инструментов, необходимых для управления Istio и проверки того, что находится под капотом.
В статье рассматриваются следующие темы:
⚡️Что такое Istio?
⚡️Обзор Istio
⚡️Как контролировать Istio с помощью Prometheus
⚡️Дашборды Grafana для Istio
⚡️Что такое Kiali?
⚡️Что такое Jaeger?
Читать дальше.
{kind=link}
json_exporter
Экспортер Prometheus, который забирает JSON в формате JSONPath.
Проверка конфигурации JSONPath, поддерживаемой экспортером
Каталог примеров для примера конфигурации экспортера, конфигурации prometheus и ожидаемого формата данных.
Репыч на Гитхабе
Экспортер Prometheus, который забирает JSON в формате JSONPath.
Проверка конфигурации JSONPath, поддерживаемой экспортером
Каталог примеров для примера конфигурации экспортера, конфигурации prometheus и ожидаемого формата данных.
Репыч на Гитхабе
Что должен знать каждый SRE о внутреннем устройстве оболочки GNU/Linux: файловые дескрипторы, каналы, терминалы, пользовательские сессии, группы процессов и демоны
Несмотря на эру контейнеров, виртуализации и растущего числа пользовательских интерфейсов всех видов, SRE часто проводят значительную часть своего времени в оболочках GNU/Linux. Это может быть отладка, тестирование, разработка или подготовка новой инфраструктуры. Это может быть старый добрый bash, более новый и модный
В этой статье показаны примеры пайплайнов, файловых дескрипторов, оболочек, терминалов, процессов, заданий и сигналов, как все они взаимодействуют друг с другом для создания простой и надежной среды. И все это будет показано в контексте ядра Linux, его внутренних компонентов, а также различных инструментов и подходов к отладке. Читать дальше.
Несмотря на эру контейнеров, виртуализации и растущего числа пользовательских интерфейсов всех видов, SRE часто проводят значительную часть своего времени в оболочках GNU/Linux. Это может быть отладка, тестирование, разработка или подготовка новой инфраструктуры. Это может быть старый добрый bash, более новый и модный
zsh, или даже fish или tcsh с их интересными и уникальными возможностями.В этой статье показаны примеры пайплайнов, файловых дескрипторов, оболочек, терминалов, процессов, заданий и сигналов, как все они взаимодействуют друг с другом для создания простой и надежной среды. И все это будет показано в контексте ядра Linux, его внутренних компонентов, а также различных инструментов и подходов к отладке. Читать дальше.
{kind=link}
Мониторинг HTTP и SSL через Prometheus blackbox_exporter
Опыт наладки мониторинга статус-кодов ответов web-сервисов, а также сроков действия SSL-сертификатов. Читать дальше на Хабре.
Опыт наладки мониторинга статус-кодов ответов web-сервисов, а также сроков действия SSL-сертификатов. Читать дальше на Хабре.
{kind=link}
Экономный APM для backend или как использовать Loki+Grafana+логи приложения для APM
Решено было использовать логи приложения из nginx и сервера приложения (php-fpm в данном случае), отправляемые в loki, для складирования агрегированной информации по запросам-ответам, которые потому будут агрегированы grafana+loki и по которым будут построены графики. Читать дальше на Хабре.
Решено было использовать логи приложения из nginx и сервера приложения (php-fpm в данном случае), отправляемые в loki, для складирования агрегированной информации по запросам-ответам, которые потому будут агрегированы grafana+loki и по которым будут построены графики. Читать дальше на Хабре.
How We Improved Our Monitoring Stack With Only a Few Small Changes
В этом посте рассказ о процессе совершенствования системы мониторинга в компании Riskified (на примере улучшений в Prometheus). Читать дальше.
В этом посте рассказ о процессе совершенствования системы мониторинга в компании Riskified (на примере улучшений в Prometheus). Читать дальше.
OpenTelemetry — Understanding SLI and SLO with OpenTelemetry Demo
Даже если вы не предполагаете, что вам не нужны или даже не используете Service Level Objectives (SLO), вы так или иначе используете их. В этой статье на примере приложения электронной коммерции из OpenTelemetry Demo показан анализ и визуализация реального сценария с использованием SLIs и SLOs. Читать дальше.
Даже если вы не предполагаете, что вам не нужны или даже не используете Service Level Objectives (SLO), вы так или иначе используете их. В этой статье на примере приложения электронной коммерции из OpenTelemetry Demo показан анализ и визуализация реального сценария с использованием SLIs и SLOs. Читать дальше.
{kind=link}
Monitoring Kubernetes layers: Key metrics to know
Метрики Kubernetes можно извлекать из службы kube-state-metrics, которая слушает сервер Kubernetes control plane/API и генерирует метрики о задействованных ресурсах или объектах. Как и в случае с другими видами мониторинга, можно использовать собранную информацию для оповещения команды о том, что происходит внутри системы. Создание алертов по определенным метрикам также может предупредить о приближающихся сбоях, что поможет сократить время решения проблемы. В этой статье в блоге Grafana разобраны 5 типов метрик k8s, которые рекомендуется отслеживать. Читать дальше.
Метрики Kubernetes можно извлекать из службы kube-state-metrics, которая слушает сервер Kubernetes control plane/API и генерирует метрики о задействованных ресурсах или объектах. Как и в случае с другими видами мониторинга, можно использовать собранную информацию для оповещения команды о том, что происходит внутри системы. Создание алертов по определенным метрикам также может предупредить о приближающихся сбоях, что поможет сократить время решения проблемы. В этой статье в блоге Grafana разобраны 5 типов метрик k8s, которые рекомендуется отслеживать. Читать дальше.
{kind=link}
Analyzing Kubernetes Traffic with Kubeshark
Kubeshark — это веб-инструмент, который позволяет захватывать и анализировать сетевой трафик в кластере Kubernetes. Он интегрируется с Wireshark, фильтровать и анализировать сетевые пакеты в режиме реального времени. Kubeshark также предоставляет удобный интерфейс для визуализации сетевого трафика, облегчая понимание сетевых потоков и выявление потенциальных проблем.
Kubeshark построен на базе Cilium, Kubernetes-нативной сетевой платформы и платформы безопасности, которая обеспечивает расширенные возможности применения сетевых политик и наблюдения. Cilium использует технологию eBPF для перехвата сетевого трафика на уровне ядра, что обеспечивает низкоуровневую видимость сетевых потоков без значительных накладных расходов на кластер. Читать статью.
Репыч на Гитхабе.
Kubeshark — это веб-инструмент, который позволяет захватывать и анализировать сетевой трафик в кластере Kubernetes. Он интегрируется с Wireshark, фильтровать и анализировать сетевые пакеты в режиме реального времени. Kubeshark также предоставляет удобный интерфейс для визуализации сетевого трафика, облегчая понимание сетевых потоков и выявление потенциальных проблем.
Kubeshark построен на базе Cilium, Kubernetes-нативной сетевой платформы и платформы безопасности, которая обеспечивает расширенные возможности применения сетевых политик и наблюдения. Cilium использует технологию eBPF для перехвата сетевого трафика на уровне ядра, что обеспечивает низкоуровневую видимость сетевых потоков без значительных накладных расходов на кластер. Читать статью.
Репыч на Гитхабе.
{kind=link}
How to find unused Prometheus metrics using mimirtool
В этой статье рассказывается, как с помощью mimirtool определить, какие метрики используются Prometheus, а какие нет. Читать дальше.
В этой статье рассказывается, как с помощью mimirtool определить, какие метрики используются Prometheus, а какие нет. Читать дальше.
Medium
How to find unused Prometheus metrics using mimirtool
In this article, I will explain how I used mimirtool to identify which metrics were used on the platform, and which wasn’t.
В сервис добавили сканер уязвимостей в Yandex Container Registry
Платформа Yandex Cloud открыла общий доступ к сканеру, который до этого был доступен только в режиме превью.
С помощью него вы можете:
— проводить анализ контейнерных образов на предмет уязвимостей;
— использовать крупнейшую базу уязвимостей;
— сканировать образы при непрерывном развёртывании приложений;
— создавать CI-сценарии для проверки безопасности.
Из нового — теперь можно сканировать контейнерные образы автоматически при загрузке.
Сканер уязвимостей работает только с образами из Container Registry.
Подробнее о сканере уязвимостей ➡️
Платформа Yandex Cloud открыла общий доступ к сканеру, который до этого был доступен только в режиме превью.
С помощью него вы можете:
— проводить анализ контейнерных образов на предмет уязвимостей;
— использовать крупнейшую базу уязвимостей;
— сканировать образы при непрерывном развёртывании приложений;
— создавать CI-сценарии для проверки безопасности.
Из нового — теперь можно сканировать контейнерные образы автоматически при загрузке.
Сканер уязвимостей работает только с образами из Container Registry.
Подробнее о сканере уязвимостей ➡️
Prometheus’ performance and cardinality in practice
В этой статье рассказано, как я проанализировать и настроить Prometheus, чтобы значительно снизить использование ресурсов. Читать дальше.
В этой статье рассказано, как я проанализировать и настроить Prometheus, чтобы значительно снизить использование ресурсов. Читать дальше.
{kind=link}
Unpacking Observability: The Observability Stack
"Наш текущий стек Observability выглядит как набор различных продуктов с открытым исходным кодом, в результате того, что команда X хотела использовать инструмент A, а команда Y хотела использовать инструмент B. В итоге мы получили стек, включающий кучу различных инструментов, собранных вместе в надежде обеспечить Observability. В последний год или около того я внимательно следил за развитием Observability, и я был уверен, что мы можем уменьшить этот стек в разы."
В этой статье разбирается кейс уменьшения набора решений для Observability. Читать дальше.
"Наш текущий стек Observability выглядит как набор различных продуктов с открытым исходным кодом, в результате того, что команда X хотела использовать инструмент A, а команда Y хотела использовать инструмент B. В итоге мы получили стек, включающий кучу различных инструментов, собранных вместе в надежде обеспечить Observability. В последний год или около того я внимательно следил за развитием Observability, и я был уверен, что мы можем уменьшить этот стек в разы."
В этой статье разбирается кейс уменьшения набора решений для Observability. Читать дальше.
{kind=link}
An overview of metrics in Prometheus
В этой статье вы найдете обзор типов метрик, которые есть в Prometheus, включая назначение каждого типа метрик. Читать дальше.
В этой статье вы найдете обзор типов метрик, которые есть в Prometheus, включая назначение каждого типа метрик. Читать дальше.
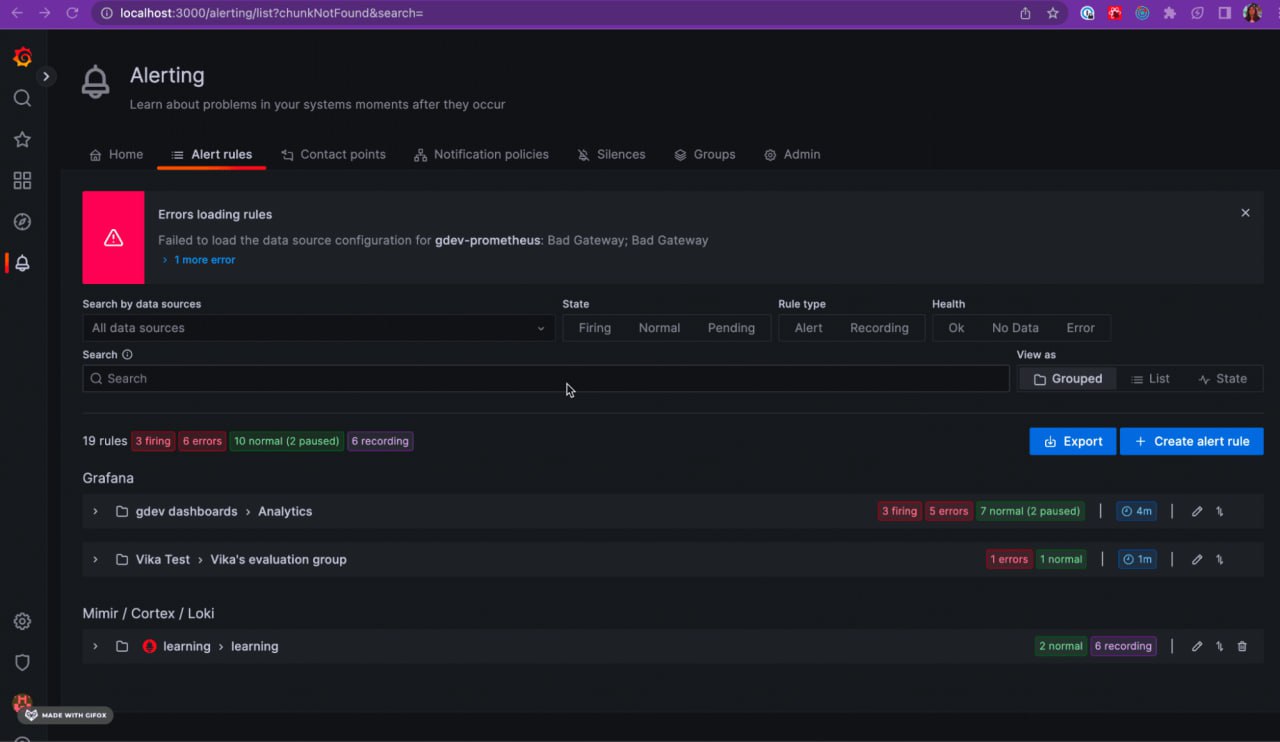
Grafana Alerting: Searching for Grafana alerts just got faster, easier, and more accurate
Управление сотнями, если не тысячами, правил оповещения в Grafana является обычным явлением и становится все более нетривиальным для пользователей.
Чтобы решить эту проблему, в Grafana внедрена поисковая система, призванная помочь пользователям быстро выполнять поиск по оповещениям и упростить управление большим количеством правил и сложными воркфлоу. Читать дальше.
Управление сотнями, если не тысячами, правил оповещения в Grafana является обычным явлением и становится все более нетривиальным для пользователей.
Чтобы решить эту проблему, в Grafana внедрена поисковая система, призванная помочь пользователям быстро выполнять поиск по оповещениям и упростить управление большим количеством правил и сложными воркфлоу. Читать дальше.
26 апреля вышла Grafana 9.5
В этом посте рассмотрим пару ключевых улучшений.
Обновление алертов
В Grafana Alerting появился поиск правил оповещения для нескольких источников данных, доступ к правилам оповещений непосредственно из дашбордов, а также переход к соответствующим дашбордам или панели управления правилами оповещения. Также внесены обновления в настройки правил оповещения и политики уведомлений, которые помогают уменьшить количество шумовых оповещений.
Появились саппорт бандлы
Теперь можно быстро собрать набор файлов с настройками Grafana для того, чтобы, например, поделиться ими с коллегами.
и несколько других улучшений. Читать в блоге Grafana.
В этом посте рассмотрим пару ключевых улучшений.
Обновление алертов
В Grafana Alerting появился поиск правил оповещения для нескольких источников данных, доступ к правилам оповещений непосредственно из дашбордов, а также переход к соответствующим дашбордам или панели управления правилами оповещения. Также внесены обновления в настройки правил оповещения и политики уведомлений, которые помогают уменьшить количество шумовых оповещений.
Появились саппорт бандлы
Теперь можно быстро собрать набор файлов с настройками Grafana для того, чтобы, например, поделиться ими с коллегами.
и несколько других улучшений. Читать в блоге Grafana.
{kind=link}
Integrate Zabbix with your data pipelines by configuring real-time metric and event streaming
До версии 6.4 метрики можно было экспортировать в файлы в формате JSON. С выходом Zabbix 6.4 метрики, собранные Zabbix, и события, сгенерированные на основе триггеров, могут быть переданы во внешние системы с помощью новой функции потоковой передачи метрик и событий в режиме реального времени. Чтобы передавать только необходимые метрики или события, их можно фильтровать по тегам. Данные передаются в формате JSON. Самый, наверное, популярный use case этой новой функции может заключаться в передаче исторических данных во внешние озера данных для целей аналитики, машинного обучения и прочих модных слов.
Читать статью в блоге Zabbix.
До версии 6.4 метрики можно было экспортировать в файлы в формате JSON. С выходом Zabbix 6.4 метрики, собранные Zabbix, и события, сгенерированные на основе триггеров, могут быть переданы во внешние системы с помощью новой функции потоковой передачи метрик и событий в режиме реального времени. Чтобы передавать только необходимые метрики или события, их можно фильтровать по тегам. Данные передаются в формате JSON. Самый, наверное, популярный use case этой новой функции может заключаться в передаче исторических данных во внешние озера данных для целей аналитики, машинного обучения и прочих модных слов.
Читать статью в блоге Zabbix.
{kind=link}
❤1