
Мониторинг: измеряем потери пакетов с помощью C++
Всем хорош Zabbix, за исключением маленьких таймаутов для встроенных и внешних проверок. В файле конфигурации сервера указан максимальный таймаут 30 секунд, чего совершенно недостаточно, например, для пинга с использованием 10 000 пакетов, даже если мы установим интервал в 100 мс. Как мы знаем, по российским нормативам потери пакетов в сетях связи не должны превышать один пакет на тысячу. Особо требовательные заказчики трактуют эту цифру по-своему: всё что больше или равно 0,05% можно округлить до тех самых 0,1% или одного пакета на тысячу. Поэтому автор этой статьи решил для самых критичных узлов, особенно при поступлении заявки, использовать внешнюю программу (назовём её losshd), которая будет в несколько потоков измерять потери пакетов и записывать результаты в базу, а для Zabbix использовать простую утилиту (назовём её getloss), которая быстро вытащит из базы необходимое значение. Читать дальше.
Всем хорош Zabbix, за исключением маленьких таймаутов для встроенных и внешних проверок. В файле конфигурации сервера указан максимальный таймаут 30 секунд, чего совершенно недостаточно, например, для пинга с использованием 10 000 пакетов, даже если мы установим интервал в 100 мс. Как мы знаем, по российским нормативам потери пакетов в сетях связи не должны превышать один пакет на тысячу. Особо требовательные заказчики трактуют эту цифру по-своему: всё что больше или равно 0,05% можно округлить до тех самых 0,1% или одного пакета на тысячу. Поэтому автор этой статьи решил для самых критичных узлов, особенно при поступлении заявки, использовать внешнюю программу (назовём её losshd), которая будет в несколько потоков измерять потери пакетов и записывать результаты в базу, а для Zabbix использовать простую утилиту (назовём её getloss), которая быстро вытащит из базы необходимое значение. Читать дальше.
{kind=link}
Jaeger для трассировки в микросервисной архитектуре
Рассмотрим, как работает Jaeger, один из популярных инструментов, который помогает расследовать инциденты и находить узкие места в производительности в микросервисной архитектуре. Разберём, как правильно настроить трассировку и с какими проблемами можно столкнуться в процессе. Эта статья не для джунов: от должности джуна до состояния, когда можно осознанно подойти к пониманию observability, к OpenTelemetry-стандарту и Jaeger, может пройти несколько лет. До этого нужно дорасти. Читать дальше.
Рассмотрим, как работает Jaeger, один из популярных инструментов, который помогает расследовать инциденты и находить узкие места в производительности в микросервисной архитектуре. Разберём, как правильно настроить трассировку и с какими проблемами можно столкнуться в процессе. Эта статья не для джунов: от должности джуна до состояния, когда можно осознанно подойти к пониманию observability, к OpenTelemetry-стандарту и Jaeger, может пройти несколько лет. До этого нужно дорасти. Читать дальше.
{kind=link}
Symfony + Filebeat + Elasticsearch
Observability (и, как следствие, сбор логов) — это важная составляющая материальных средств, без которой было бы очень трудно исследовать баги или обнаруживать брутфорс-атаки. Обычно приложение выводит логи в специальный файл журнала или стандартный вывод системы (stdout). Это, конечно, уже что-то, но отсюда вытекает несколько проблем:
⚡️Работа с логами в текстовой форме и в зачастую огромных файлах сложна и не очень удобна.
⚡️Необходимо иметь доступа к машине с логами (в случае, если логи хранятся в файлах журналов).
⚡️Коррелирование таких логов не представляется возможным.
К счастью, существуют решения, облегчающие централизацию и работу с логами приложений (Elastic, Grafana Loki и т.д.). Читать дальше.
Observability (и, как следствие, сбор логов) — это важная составляющая материальных средств, без которой было бы очень трудно исследовать баги или обнаруживать брутфорс-атаки. Обычно приложение выводит логи в специальный файл журнала или стандартный вывод системы (stdout). Это, конечно, уже что-то, но отсюда вытекает несколько проблем:
⚡️Работа с логами в текстовой форме и в зачастую огромных файлах сложна и не очень удобна.
⚡️Необходимо иметь доступа к машине с логами (в случае, если логи хранятся в файлах журналов).
⚡️Коррелирование таких логов не представляется возможным.
К счастью, существуют решения, облегчающие централизацию и работу с логами приложений (Elastic, Grafana Loki и т.д.). Читать дальше.
{kind=link}
Как сделать мониторинг инженерной инфраструктуры ЦОД на примере DataLine
В этой статье рассмотрены основные задачи системы мониторинга ЦОД и подводные камни, которые помогут создать или улучшить собственную систему мониторинга, опираясь на опыт специалистов DataLine. Читать дальше.
В этой статье рассмотрены основные задачи системы мониторинга ЦОД и подводные камни, которые помогут создать или улучшить собственную систему мониторинга, опираясь на опыт специалистов DataLine. Читать дальше.
{kind=link}
«Карманный синоптик за час». Пишем Telegram-бота для мониторинга погоды на Python
Мониторинг погоды — тоже мониторинг. Из этой статьи вы узнаете, как написать своего Telegram-бота для получения данных о погоде в любом городе нашей планеты. Детально рассмотрена работа с API, парсинг JSON и показано как написать бота на асинхронной библиотеке aiogram. А после — загрузка его на виртуальный сервер и запуск. Читать дальше.
Мониторинг погоды — тоже мониторинг. Из этой статьи вы узнаете, как написать своего Telegram-бота для получения данных о погоде в любом городе нашей планеты. Детально рассмотрена работа с API, парсинг JSON и показано как написать бота на асинхронной библиотеке aiogram. А после — загрузка его на виртуальный сервер и запуск. Читать дальше.
{kind=link}
👎1
SLOs should be easy, say hi to Sloth
Sloth генерирует понятные, единообразные и надежные SLO для Prometheus.
Статья с описанием
Репыч на Гитхабе
Sloth генерирует понятные, единообразные и надежные SLO для Prometheus.
Статья с описанием
Репыч на Гитхабе
{kind=link}
Как в Yandex Cloud сделали незаметную капчу?
Как сделать так, чтобы капча работала и отсеивала ботов, а пользователям не приходилось вводить текст с картинки? На этот вопрос отвечают разработчики Yandex SmartCaptcha — в статье они делятся историей создания сервиса, рассказывают про изменение кода, рефакторинг архитектуры, невидимую для пользователя проверку и заботу о людях.
Читайте статью в новом блоге Yandex Cloud и Yandex Infrastructure на Хабре, и не забудьте подписаться, чтобы не пропустить истории о том, как строится инфраструктура Яндекса и делается публичная облачная платформа.
Как сделать так, чтобы капча работала и отсеивала ботов, а пользователям не приходилось вводить текст с картинки? На этот вопрос отвечают разработчики Yandex SmartCaptcha — в статье они делятся историей создания сервиса, рассказывают про изменение кода, рефакторинг архитектуры, невидимую для пользователя проверку и заботу о людях.
Читайте статью в новом блоге Yandex Cloud и Yandex Infrastructure на Хабре, и не забудьте подписаться, чтобы не пропустить истории о том, как строится инфраструктура Яндекса и делается публичная облачная платформа.
Why You Shouldn’t Fear to Adopt Opentelemetry for Observability
В этой статье автор делится своим опытом внедрения Otel в очень сложную архитектуру с нулевым временем простоя для конечных пользователей. Читать дальше.
В этой статье автор делится своим опытом внедрения Otel в очень сложную архитектуру с нулевым временем простоя для конечных пользователей. Читать дальше.
{kind=link}
Grafana Mimir — бесконечное хранилище для Prometheus
Grafana Mimir — продукт Grafana Labs, построенный на основе проекта Cortex, был анонсирован и запущен в 2022 году. По нему практически нет подробных разборов и гайдов от пользователей. В статье расскажут, как он устроен и в чём его плюсы и минусы. А также попробуем сравнить его с известными инструментами Thanos и VictoriaMetrics. Читать дальше.
Grafana Mimir — продукт Grafana Labs, построенный на основе проекта Cortex, был анонсирован и запущен в 2022 году. По нему практически нет подробных разборов и гайдов от пользователей. В статье расскажут, как он устроен и в чём его плюсы и минусы. А также попробуем сравнить его с известными инструментами Thanos и VictoriaMetrics. Читать дальше.
{kind=link}
Логи из Linux в Zabbix. Подробнейшая инструкция
В этой статье вы узнаете про мониторинг линуксовых логов в Zabbix 6.4. Читать дальше.
В этой статье вы узнаете про мониторинг линуксовых логов в Zabbix 6.4. Читать дальше.
Monitoring CPU/RAM/disk metrics with OpenTelemetry and Uptrace
Небольшой гайд по сбору метрик сервера при помощи Opentelemetry. Читать дальше.
Небольшой гайд по сбору метрик сервера при помощи Opentelemetry. Читать дальше.
{kind=link}
Как специалисту по безопасности повысить свою квалификацию?
Каждый день появляется примерно 70 новых уязвимостей. Поэтому специалистам по безопасности важно постоянно развиваться и учиться новому. Специально для Middle и Senior ИТ-специалистов, которые отвечают за цифровую безопасность компании и продуктов, команда Yandex Cloud разработала курсы:
— «Защита облачной инфраструктуры» поможет настроить и поддерживать необходимый уровень безопасности;
— «DevSecOps в облачном CI/CD» научит обеспечивать безопасность приложений, познакомит с методологией DevSecOps, которая поможет автоматизировать проверки безопасности и экономить ресурсы;
— «Аутентификация и управление доступом» поможет подготовиться к росту инфраструктуры и команды, научит настраивать и регулировать доступ в облаке.
Также скоро появятся курсы «Погружение в сетевую безопасность» и «Compliance».
Обучение бесплатное — уроки откроются сразу после регистрации ➡️
Каждый день появляется примерно 70 новых уязвимостей. Поэтому специалистам по безопасности важно постоянно развиваться и учиться новому. Специально для Middle и Senior ИТ-специалистов, которые отвечают за цифровую безопасность компании и продуктов, команда Yandex Cloud разработала курсы:
— «Защита облачной инфраструктуры» поможет настроить и поддерживать необходимый уровень безопасности;
— «DevSecOps в облачном CI/CD» научит обеспечивать безопасность приложений, познакомит с методологией DevSecOps, которая поможет автоматизировать проверки безопасности и экономить ресурсы;
— «Аутентификация и управление доступом» поможет подготовиться к росту инфраструктуры и команды, научит настраивать и регулировать доступ в облаке.
Также скоро появятся курсы «Погружение в сетевую безопасность» и «Compliance».
Обучение бесплатное — уроки откроются сразу после регистрации ➡️
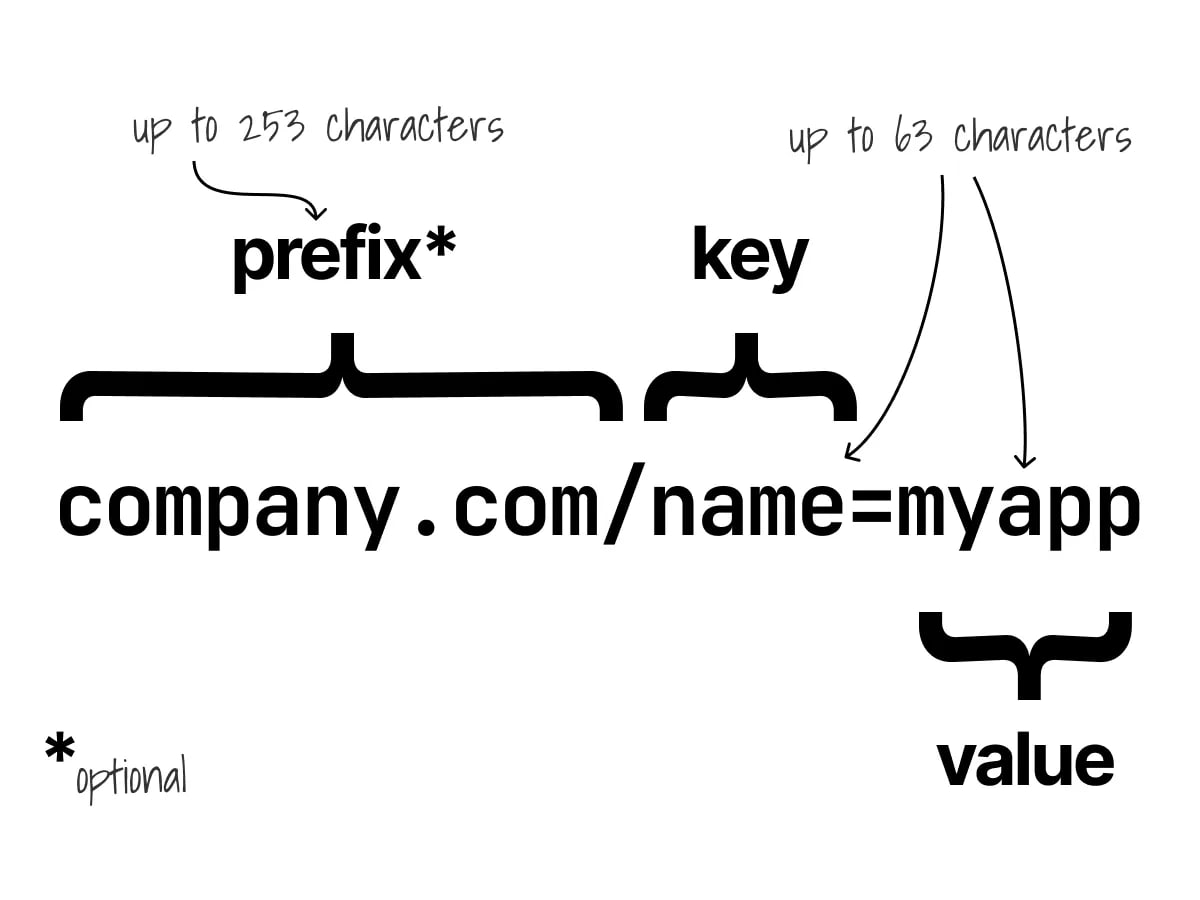
Label & Annotations in Kubernetes
Гайд о важности использования меток и аннотаций в Kubernetes. Читать дальше.
Гайд о важности использования меток и аннотаций в Kubernetes. Читать дальше.
{kind=link}
Open-Source Tracing Tools: Jaeger Vs. Zipkin Vs. Grafana Tempo
В этой статье рассматриваются три популярных инструмента трассировки с открытым исходным кодом: Jaeger, Zipkin и Grafana Tempo. Есть из чего выбрать. Читать дальше.
В этой статье рассматриваются три популярных инструмента трассировки с открытым исходным кодом: Jaeger, Zipkin и Grafana Tempo. Есть из чего выбрать. Читать дальше.
{kind=link}
Kubernetes Logging Best Practices
В этой статье рассказывается о практиках ведения логов в среде Kubernetes. Читать дальше.
В этой статье рассказывается о практиках ведения логов в среде Kubernetes. Читать дальше.
Provision Grafana Dashboards and Alerts Using Helm and Sidecars
В этой статье рассказано, как представить в виде кода дашборды и алерты Grafana в кластере k8s, используя новую систему оповещения Grafana 9. Конфигурирование дашбордов и алертов таким образом имеет много преимуществ, главное из которых — управление ими через систему контроля версий, например GitHub. Читать дальше.
В этой статье рассказано, как представить в виде кода дашборды и алерты Grafana в кластере k8s, используя новую систему оповещения Grafana 9. Конфигурирование дашбордов и алертов таким образом имеет много преимуществ, главное из которых — управление ими через систему контроля версий, например GitHub. Читать дальше.
{kind=link}
👍1🔥1
OpenTelemetry: Sending Traces From Ingress-Nginx to Multi-Tenant Grafana Tempo
Автор статьи использует Grafana Tempo в качестве бэкенда для хранения трассировок вызовов. Это позволяет хранить информацию о трассировках в недорогом объектном хранилище вместо размещения их в ElasticSearch при использовании такого инструмента, как Jaeger.
Поскольку данные собираются с общих для команд разработчиков приложений кластеров Kubernetes, еще одной очень важной особенностью Grafana Tempo является многопользовательский доступ. Читать дальше.
Автор статьи использует Grafana Tempo в качестве бэкенда для хранения трассировок вызовов. Это позволяет хранить информацию о трассировках в недорогом объектном хранилище вместо размещения их в ElasticSearch при использовании такого инструмента, как Jaeger.
Поскольку данные собираются с общих для команд разработчиков приложений кластеров Kubernetes, еще одной очень важной особенностью Grafana Tempo является многопользовательский доступ. Читать дальше.
{kind=link}
OpenTelemetry Dynamic Integrations
В этой статье описано, как настроить OpenTelemetry в двух средах и показано, как OpenTelemetry может упростить переключение между этими двумя средами без необходимости изменения строк кода или конфигурации бэкендов систем наблюдаемости (источников данных и инструментов визуализации). Читать дальше.
В этой статье описано, как настроить OpenTelemetry в двух средах и показано, как OpenTelemetry может упростить переключение между этими двумя средами без необходимости изменения строк кода или конфигурации бэкендов систем наблюдаемости (источников данных и инструментов визуализации). Читать дальше.
{kind=link}
Integrating Prometheus and Grafana for Metrics Monitoring in a Spring Boot Application
В этой статье показано как интегрировать Prometheus и Grafana для мониторинга метрик приложения на Spring Boot. Читать дальше.
В этой статье показано как интегрировать Prometheus и Grafana для мониторинга метрик приложения на Spring Boot. Читать дальше.
{kind=link}
👍1🔥1
Deploying Grafana, Prometheus, and Alertmanager on Kubernetes: A Quick and Easy Guide
Эта статья — краткое руководство по настройке grafana, prometheus и alertmanger с помощью kube-prometheus-stack helm chart. Читать.
Эта статья — краткое руководство по настройке grafana, prometheus и alertmanger с помощью kube-prometheus-stack helm chart. Читать.
👍1