
Forwarded from Denis Sexy IT 🤖
В выходные игрался с генерацией видео из текста на библейские мотивы и нагенерировал семь смертных грехов, можете попробовать угадать где какой:
✨ Зависть
✨ Гнев
✨ Уныние
✨ Жадность
✨ Чревоугодие
✨ Похоть
✨ Гордыня
P.S. Пусть вас не смущает там внезапный ленивец 🦥 – CLIP обучен на английском языке, где «Ленивец» (Sloth) и Уныние (Ленность) как грех (Sloth) одинаково пишутся ¯\_(ツ)_/¯
✨ Зависть
✨ Гнев
✨ Уныние
✨ Жадность
✨ Чревоугодие
✨ Похоть
✨ Гордыня
P.S. Пусть вас не смущает там внезапный ленивец 🦥 – CLIP обучен на английском языке, где «Ленивец» (Sloth) и Уныние (Ленность) как грех (Sloth) одинаково пишутся ¯\_(ツ)_/¯
❤1
Forwarded from DL in NLP (nlpcontroller_bot)
What is Automatic Differentiation?
youtube.com/watch?v=wG_nF1awSSY
Наверное самая хитрая и непонятная тема для тех, кто только погружается в DL — это бэкпроп. Для меня в своё время совершенно знаковой была задачка написания бэкпропа для BatchNorm на нумпае (кстати рекомендую). Но если вместо жёсткого погружения в код вы хотите посмотреть хороший видос по автоматическому дифференцированию, который лежит в основе бэкпропа, я очень рекомендую вот этот видос. В нём рассказывают об отличии численного дифференцирования от аналитического от автоматического. В том числе рассказывают про разницу между forward-mode и backward-mode дифференцированием. А также как их можно комбинировать для эффективного рассчёта hessian-vector product, который вам например нужен в MAML. В общем рекомендую к просмотру.
youtube.com/watch?v=wG_nF1awSSY
Наверное самая хитрая и непонятная тема для тех, кто только погружается в DL — это бэкпроп. Для меня в своё время совершенно знаковой была задачка написания бэкпропа для BatchNorm на нумпае (кстати рекомендую). Но если вместо жёсткого погружения в код вы хотите посмотреть хороший видос по автоматическому дифференцированию, который лежит в основе бэкпропа, я очень рекомендую вот этот видос. В нём рассказывают об отличии численного дифференцирования от аналитического от автоматического. В том числе рассказывают про разницу между forward-mode и backward-mode дифференцированием. А также как их можно комбинировать для эффективного рассчёта hessian-vector product, который вам например нужен в MAML. В общем рекомендую к просмотру.
YouTube
What is Automatic Differentiation?
This short tutorial covers the basics of automatic differentiation, a set of techniques that allow us to efficiently compute derivatives of functions implemented as programs. It is based in part on Baydin et al., 2018: Automatic Differentiation in Machine…
👍1
Forwarded from я обучала одну модель
DABS: A Domain-Agnostic Benchmark for Self-Supervised Learning
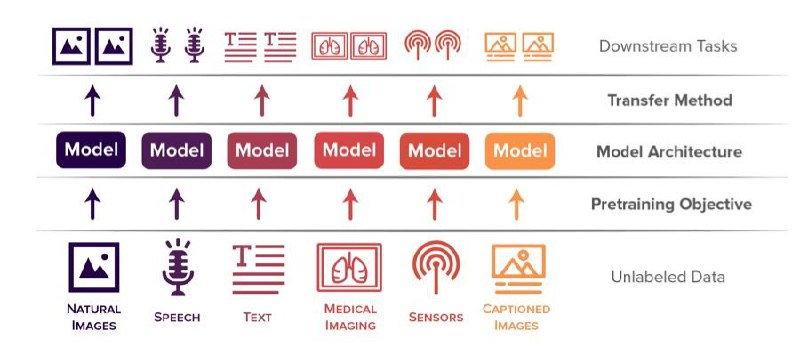
Ресерчеры из Стенфорда выложили бенчмарк для мультмодальных моделей – в их датасете есть изображения, изображения + текст, просто текст, аудио, medical data и сенсоры. В целом они не особо делают что-то новое, скорее комбинируют существующие подходы:
1. Сначала для каждого типа данных тренируется отдельный энкодер, потом он замораживается. После него эмбеддинги подаются в обычную архитектуру Трансформера, общую для всех типов данных.
2. Дальше авторы предлагают два бейзлайна:
2.1. SHED: Shuffled Embedding Prediction Objective – в эбеддингах перемешивается часть позиций, и сеть должна предсказать, какие именно элементы стоят не на своих местах (как в сетке ELECTRA)
2.2. e-Mix: A Contrastive Embedding-Mixup Objective – эмбеддинги нескольких объектов перемешиваются друг с другом с какими-то коэффициентами, и тогда энкодер должен продуцировать эмбеддинг в латентном пространстве удаленный от взятых объектов пропорционально этим коэффициентам
Имхо, важен сам по себе тот факт, что для мультимодальных моделей может появиться уже устоявшийся бенчмарк, как GLUE в NLP
📝 arxiv
🖥 git
Ресерчеры из Стенфорда выложили бенчмарк для мультмодальных моделей – в их датасете есть изображения, изображения + текст, просто текст, аудио, medical data и сенсоры. В целом они не особо делают что-то новое, скорее комбинируют существующие подходы:
1. Сначала для каждого типа данных тренируется отдельный энкодер, потом он замораживается. После него эмбеддинги подаются в обычную архитектуру Трансформера, общую для всех типов данных.
2. Дальше авторы предлагают два бейзлайна:
2.1. SHED: Shuffled Embedding Prediction Objective – в эбеддингах перемешивается часть позиций, и сеть должна предсказать, какие именно элементы стоят не на своих местах (как в сетке ELECTRA)
2.2. e-Mix: A Contrastive Embedding-Mixup Objective – эмбеддинги нескольких объектов перемешиваются друг с другом с какими-то коэффициентами, и тогда энкодер должен продуцировать эмбеддинг в латентном пространстве удаленный от взятых объектов пропорционально этим коэффициентам
Имхо, важен сам по себе тот факт, что для мультимодальных моделей может появиться уже устоявшийся бенчмарк, как GLUE в NLP
📝 arxiv
🖥 git
{kind=link}
Forwarded from эйай ньюз
Датасеты для Vision-and-Language моделей
Поговорим немного о text-image датасетах, которые содержат картинки и текстовые описания к ним. Зачем они нам нужны? Например, для обучения таких моделей как DALL-E (генерит картинку по текстовому описанию), либо CLIP (умеет вычислять похожесть текста и фотографий за счет проецирования текстовых строк и картинок в одно и то же многомерное пространство). Тот же Google Image Search вполне может использовать что-то вроде CLIP для ранжирования картинок исходя из текстового запроса пользователя.
Чтобы натренировать text-to-image модель вроде CLIP, разумеется, нужен дохерильон размеченных данных. Например, OpenAI тренировали CLIP на 400M пар текст-фото, но датасет свой так никому и не показали. Хорошо, что хоть веса моделей выложили на гитхабе. В похожем стиле была натренирована модель DALL-E, выбрали подмножество из 250M пар текст-фото и также никому не показали датасет. Есть подозрение, что боятся копирайта.
Недавно нашумевшая ru-DALL-E (о ней я писал тут) от Сбера был тренировалась на более 120M пар, что приближается к 250M от OpenAI. Сбер использовал всевозможные публичные датасеты. Сначала взяли Сonceptual Captions, YFCC100m, данные русской Википедии, ImageNet. Затем добавили датасеты OpenImages, LAION-400m, WIT, Web2M, HowTo и щепотку кроулинга интернета, как я понимаю. Все это отфильтровали, чтобы уменьшить шум в данных, а все английские описания были решительно переведены на русский язык. Но, к сожалению, датасет тоже не выложили. Зато опубликовали свою натренированную модельку, в отличие от OpenAI
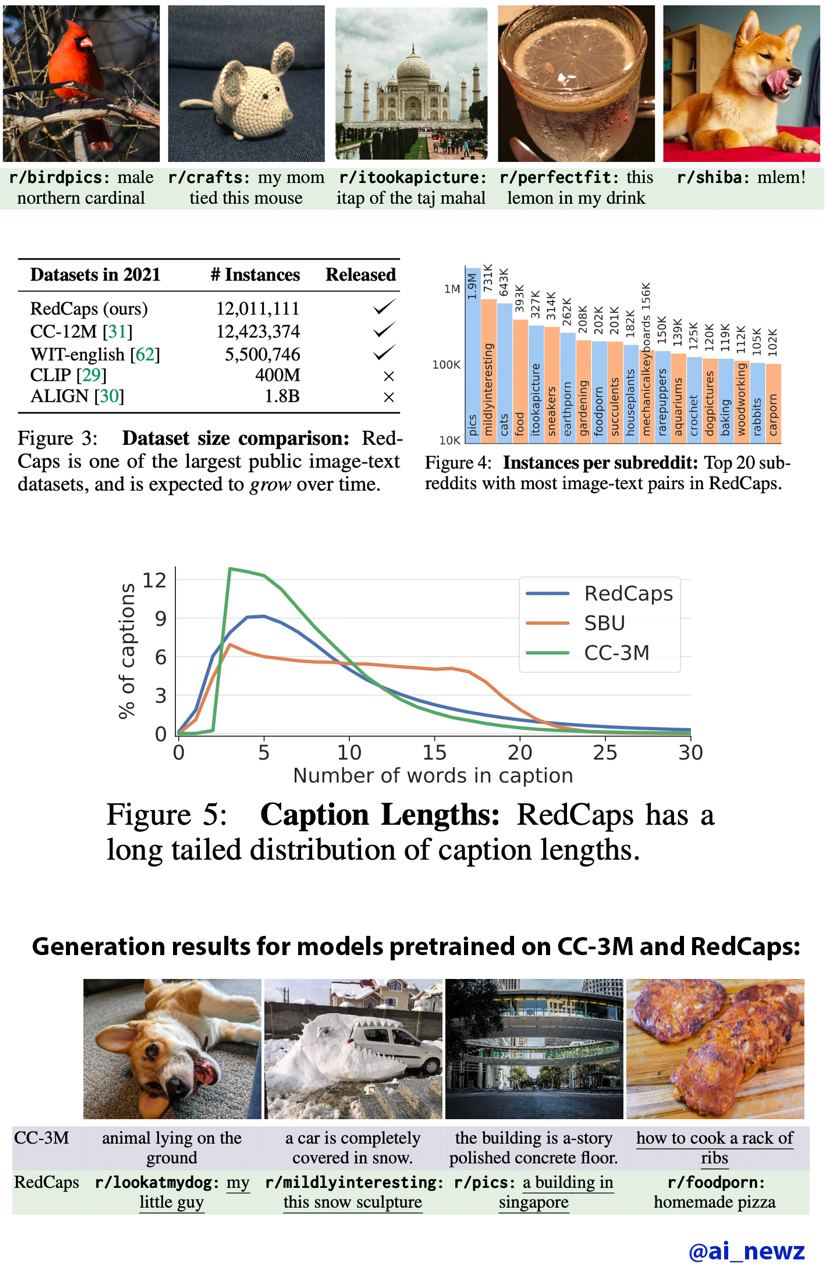
Ещё расскажу о новом датасете RedCaps от Justin Johnson (это имя нужно знать, он крутой молодой профессор) и его студетов из университета Мичигана. Парни попытались найти в интернете новый источник бесплатных аннотаций вида "текст-картинка", который содержал бы меньше мусора по сравнению со скачиванием всего интернета в лоб. Решено было выкачать посты с картинками с Reddit-a, и в качестве аннотаций использовать подпись к картинке и название сабреддита. Названия сабреддитов обычно говорящие и уже сами по себе несут много информации, например, "r/cats", "r/higing", "r/foodporn". После выбора подмножетсва из 350 сабреддитов и небольшой фильтрации вышло 12M пар фото-текст, которые покрывают 13 лет истории Reddit.
На примере этого датасета можно проследить, какакие меры принимаются для уменьшения риска получить повестку в суд после публикации такого огромного количества данных пользователей форума. Все фото с людьми были задетекчены с помощью RetinaNet и нарочито выброшены, а сам датасет опубликовали в виде списка ссылок с анонимизированными текстовыми описаниями (картинки на сайте не хранят). Кроме того, на сайте с датасетом есть форма, где несогласные могут запросить удалить любую ссылку.
В итоге, получился довольно качественный датасет, который превосходит существующие публичные датасеты (кроме LAION-400m, с которым забыли сравниться) для обучения модели генерировать описания по картинке. В качестве ксперимента, обучили Image Captioning модель на разныз датасетах и протестировали на задаче переноса выученной репрезентации на новые датасеты в Zero-Shot сценарии, а также с помощью обучений логистической регрессии поверх фичей (linear probing). Но, конечно обученная учеными из Мичигана модель существенно уступает CLIP по ряду причин: CLIP имеет слегка другую архитектуру (он не генерит текст, а учит эмбеддинги), он толще и жирнее, и тренировали его в 40 раз больше итераций на гигантском датасете, который превосходит в размере RedCaps в 35 раз.
Посмотреть на примеры из RedCaps можно на сайте https://redcaps.xyz/.
Поговорим немного о text-image датасетах, которые содержат картинки и текстовые описания к ним. Зачем они нам нужны? Например, для обучения таких моделей как DALL-E (генерит картинку по текстовому описанию), либо CLIP (умеет вычислять похожесть текста и фотографий за счет проецирования текстовых строк и картинок в одно и то же многомерное пространство). Тот же Google Image Search вполне может использовать что-то вроде CLIP для ранжирования картинок исходя из текстового запроса пользователя.
Чтобы натренировать text-to-image модель вроде CLIP, разумеется, нужен дохерильон размеченных данных. Например, OpenAI тренировали CLIP на 400M пар текст-фото, но датасет свой так никому и не показали. Хорошо, что хоть веса моделей выложили на гитхабе. В похожем стиле была натренирована модель DALL-E, выбрали подмножество из 250M пар текст-фото и также никому не показали датасет. Есть подозрение, что боятся копирайта.
Недавно нашумевшая ru-DALL-E (о ней я писал тут) от Сбера был тренировалась на более 120M пар, что приближается к 250M от OpenAI. Сбер использовал всевозможные публичные датасеты. Сначала взяли Сonceptual Captions, YFCC100m, данные русской Википедии, ImageNet. Затем добавили датасеты OpenImages, LAION-400m, WIT, Web2M, HowTo и щепотку кроулинга интернета, как я понимаю. Все это отфильтровали, чтобы уменьшить шум в данных, а все английские описания были решительно переведены на русский язык. Но, к сожалению, датасет тоже не выложили. Зато опубликовали свою натренированную модельку, в отличие от OpenAI
Ещё расскажу о новом датасете RedCaps от Justin Johnson (это имя нужно знать, он крутой молодой профессор) и его студетов из университета Мичигана. Парни попытались найти в интернете новый источник бесплатных аннотаций вида "текст-картинка", который содержал бы меньше мусора по сравнению со скачиванием всего интернета в лоб. Решено было выкачать посты с картинками с Reddit-a, и в качестве аннотаций использовать подпись к картинке и название сабреддита. Названия сабреддитов обычно говорящие и уже сами по себе несут много информации, например, "r/cats", "r/higing", "r/foodporn". После выбора подмножетсва из 350 сабреддитов и небольшой фильтрации вышло 12M пар фото-текст, которые покрывают 13 лет истории Reddit.
На примере этого датасета можно проследить, какакие меры принимаются для уменьшения риска получить повестку в суд после публикации такого огромного количества данных пользователей форума. Все фото с людьми были задетекчены с помощью RetinaNet и нарочито выброшены, а сам датасет опубликовали в виде списка ссылок с анонимизированными текстовыми описаниями (картинки на сайте не хранят). Кроме того, на сайте с датасетом есть форма, где несогласные могут запросить удалить любую ссылку.
В итоге, получился довольно качественный датасет, который превосходит существующие публичные датасеты (кроме LAION-400m, с которым забыли сравниться) для обучения модели генерировать описания по картинке. В качестве ксперимента, обучили Image Captioning модель на разныз датасетах и протестировали на задаче переноса выученной репрезентации на новые датасеты в Zero-Shot сценарии, а также с помощью обучений логистической регрессии поверх фичей (linear probing). Но, конечно обученная учеными из Мичигана модель существенно уступает CLIP по ряду причин: CLIP имеет слегка другую архитектуру (он не генерит текст, а учит эмбеддинги), он толще и жирнее, и тренировали его в 40 раз больше итераций на гигантском датасете, который превосходит в размере RedCaps в 35 раз.
Посмотреть на примеры из RedCaps можно на сайте https://redcaps.xyz/.
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
🦑 KAPAO | Новая сахарная SOTA на CrowdPose
KAPAO - это эффективный и точный single-stage метод детекции и оценки позы человека. Есть код и веса!
Ресерчеры представили 3 версии: KAPAO-S, KAPAO-M, KAPAO-L
- Эффективный (быстрый) и точный метод
- KAPAO-L(arge) бъет SOTA на CrowdPose
- Решение основано на yolov5 (s,m,l)
💻 Code 📰 Paper
p.s.: ребята шарят и умеют в demo!
KAPAO - это эффективный и точный single-stage метод детекции и оценки позы человека. Есть код и веса!
Ресерчеры представили 3 версии: KAPAO-S, KAPAO-M, KAPAO-L
- Эффективный (быстрый) и точный метод
- KAPAO-L(arge) бъет SOTA на CrowdPose
- Решение основано на yolov5 (s,m,l)
💻 Code 📰 Paper
p.s.: ребята шарят и умеют в demo!
Forwarded from DLStories
Смотрите-ка, после анонса создания Isomorphic Lab (нового подразделения DeepMind для разработок ИИ для биомедицины) применением ИИ для разработки лекарств хотят заняться и другие компании. Вот AstraZeneca открыла центр разработки препаратов с помощью ИИ. (на фото к посту — здание центра)
Новый "Центр научных открытий" (DISC) базируется в Кембридже (UK), компания потратила на его создание ~1.3 млрд $. Говорят, открыть центр решили после того, как в компании разработали новый антиковидный препарат AZD7442, который в два раза сократил риск тяжелой формы болезни и летального исхода. Препарат был получен на основе комбинации антител. В компании верят, что ИИ поможет находить более эффективные комбинации и ускорит разработки новых лекарств.
Ну что, ставим ставки: кто круче: Isomorphic Labs или DISC? =)
Новый "Центр научных открытий" (DISC) базируется в Кембридже (UK), компания потратила на его создание ~1.3 млрд $. Говорят, открыть центр решили после того, как в компании разработали новый антиковидный препарат AZD7442, который в два раза сократил риск тяжелой формы болезни и летального исхода. Препарат был получен на основе комбинации антител. В компании верят, что ИИ поможет находить более эффективные комбинации и ускорит разработки новых лекарств.
Ну что, ставим ставки: кто круче: Isomorphic Labs или DISC? =)
Forwarded from AbstractDL
This media is not supported in your browser
VIEW IN TELEGRAM
GradInit: перебор гиперпараметров оптимизатора и warmup больше не нужны (by Google)
В гугл предложили супер крутой универсальный architecture-agnostic метод инициализации весов моделей.
Идея очень простая: добавить множители перед каждым блоком параметров и запустить по ним несколько итераций оптимизации лосса. Дальше эти множители фиксируем и учим модель как обычно. Такая инициализация не зависит от глубины и типа архитектуры (работает и на резнетах и на трансформерах) и почти полностью решает проблему взрывающихся\затухающих градиентов.
В итоге отпадает необходимость в переборе гиперпараметров оптимизатора, а трансформер вообще получилось обучить без warmup’a, что считалось практически невозможным. Как бонус, такая инициализация даёт небольшой буст на многих бенчмарках (и картиночных и текстовых).
Статья, GitHub
В гугл предложили супер крутой универсальный architecture-agnostic метод инициализации весов моделей.
Идея очень простая: добавить множители перед каждым блоком параметров и запустить по ним несколько итераций оптимизации лосса. Дальше эти множители фиксируем и учим модель как обычно. Такая инициализация не зависит от глубины и типа архитектуры (работает и на резнетах и на трансформерах) и почти полностью решает проблему взрывающихся\затухающих градиентов.
В итоге отпадает необходимость в переборе гиперпараметров оптимизатора, а трансформер вообще получилось обучить без warmup’a, что считалось практически невозможным. Как бонус, такая инициализация даёт небольшой буст на многих бенчмарках (и картиночных и текстовых).
Статья, GitHub
Forwarded from эйай ньюз
This media is not supported in your browser
VIEW IN TELEGRAM
Отвал башки! Тут пацаны из гугла обучили NERF на RAW фотках. Получается просто башенного качества рендеринг HDR изображений. Можно менять экспозицию, фокус. Вы только посмотрите на получаемый эффект боке в ночных сценах!
Дополнительное преимущество этого метода перед обычным нерфом - это то, что он хорошо работает на шумных снимках с малым освещением. За счет того, что информация агрегируется с нескольких фотографий, метод хорошо справляется с шумом и недостатком освещения, превосходя специализированные single-photo denoising модели.
Статью ознаменовали как NeRF in the Dark: High Dynamic Range View Synthesis from Noisy Raw Images. Ну, разве что кода еще нет.
Сайт проекта | Arxiv
Дополнительное преимущество этого метода перед обычным нерфом - это то, что он хорошо работает на шумных снимках с малым освещением. За счет того, что информация агрегируется с нескольких фотографий, метод хорошо справляется с шумом и недостатком освещения, превосходя специализированные single-photo denoising модели.
Статью ознаменовали как NeRF in the Dark: High Dynamic Range View Synthesis from Noisy Raw Images. Ну, разве что кода еще нет.
Сайт проекта | Arxiv
Forwarded from эйай ньюз
O проблеме GAN Inversion
Как манипулируют изображениями с помощью StyleGAN? Ну, для начала нужно получить latent code, который соответствует входному фото. Затем уже можно менять этот код, и получать изменённые картинки. Процесс получения latent code по фото называют GAN Inversion.
Базовый метод для нахождения кода по фото - это итеративный градиентый спуск, где веса сетки заморожены, и меняется только сам код, пока сгенеренная из кода картинка не станет похожей на исходную. Но вот зараза, медленно работает! Тогда народ стал применять дополнительную сеть-энкодер, которую учат мапить картинку в latent code за один прогон. Это быстро, но восстановленное из кода изображение все же теряет некоторые детали. Тут пхд студенты почесали репу и предложили немного файнтюнить веса StyleGAN под определенный latent code, чтобы получить картинку более близкую к исходной, и затем уже проводить с ней манипуляции в скрытом пространстве. Но это же тоже медленно!
Но и тут нашелся выход. В статье HyperStyle (есть код) авторы предложили использовать ещё одну "гиперсеть", которая получает на вход оригинальное фото и восстановленное из кода, который, скажем, был получен базовым методом с итеративной оптимизацией либо энкодером. Эта "гиперсеть" напрямую предсказывает, как обновить веса StyleGAN, чтобы изображение сгенерированное из данного кода было максимально похоже на исходное. Этакий "нейронный градиент" вместо честного градиента посчитанного по функции потерь.
Итого, файнтюнинг весов StyleGAN под конкретную входную картинку даёт очень хорошие результаты и позволяет менять, например, лица людей без потери идентичности. А с помощью HyperStyle это можно делать раз в 40 быстрее, заменяя честный файнтюнинг на трюк с гиперсетью.
Как манипулируют изображениями с помощью StyleGAN? Ну, для начала нужно получить latent code, который соответствует входному фото. Затем уже можно менять этот код, и получать изменённые картинки. Процесс получения latent code по фото называют GAN Inversion.
Базовый метод для нахождения кода по фото - это итеративный градиентый спуск, где веса сетки заморожены, и меняется только сам код, пока сгенеренная из кода картинка не станет похожей на исходную. Но вот зараза, медленно работает! Тогда народ стал применять дополнительную сеть-энкодер, которую учат мапить картинку в latent code за один прогон. Это быстро, но восстановленное из кода изображение все же теряет некоторые детали. Тут пхд студенты почесали репу и предложили немного файнтюнить веса StyleGAN под определенный latent code, чтобы получить картинку более близкую к исходной, и затем уже проводить с ней манипуляции в скрытом пространстве. Но это же тоже медленно!
Но и тут нашелся выход. В статье HyperStyle (есть код) авторы предложили использовать ещё одну "гиперсеть", которая получает на вход оригинальное фото и восстановленное из кода, который, скажем, был получен базовым методом с итеративной оптимизацией либо энкодером. Эта "гиперсеть" напрямую предсказывает, как обновить веса StyleGAN, чтобы изображение сгенерированное из данного кода было максимально похоже на исходное. Этакий "нейронный градиент" вместо честного градиента посчитанного по функции потерь.
Итого, файнтюнинг весов StyleGAN под конкретную входную картинку даёт очень хорошие результаты и позволяет менять, например, лица людей без потери идентичности. А с помощью HyperStyle это можно делать раз в 40 быстрее, заменяя честный файнтюнинг на трюк с гиперсетью.
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
🥴 HyperStyle: StyleGAN Inversion with HyperNetworks for Real Image Editing
Отображение (реконструкция) исходного изображения — большая и очень важная задача и проблема для StyleGAN.
Авторы решают это это не просто медленным файнтюном StyleGAN’а, а обучаемой (мета)оптимизацией, предсказываая синтетические градиенты для StyleGAN.
ResNet обучен принимать исходное фото и инверсию изображения и предсказывать поправки (синтетические градиенты) весов для StyleGAN!
Это работает быстрее, чем обычный файнтюн StyleGAN под конкретное изображение.
p.s.: результаты не супер, а вот подход..! ResNet обучен файнтюнить StyleGAN 🤯
📰 Paper 💻 Git
📝 Project 🔮 Colab
@mishin_learning
Отображение (реконструкция) исходного изображения — большая и очень важная задача и проблема для StyleGAN.
Авторы решают это это не просто медленным файнтюном StyleGAN’а, а обучаемой (мета)оптимизацией, предсказываая синтетические градиенты для StyleGAN.
ResNet обучен принимать исходное фото и инверсию изображения и предсказывать поправки (синтетические градиенты) весов для StyleGAN!
Это работает быстрее, чем обычный файнтюн StyleGAN под конкретное изображение.
p.s.: результаты не супер, а вот подход..! ResNet обучен файнтюнить StyleGAN 🤯
📰 Paper 💻 Git
📝 Project 🔮 Colab
@mishin_learning
🧠 Подборка полезных видео про NeRF: Neural Radiance Fields Forever
Нейронный 3D рендер — это уже настоящее. И NeRF и его производные захватывают наши сердца.
Хотели погрузиться в эту тему, но не знали с чего начать? Собрал крутую подборку самых полезных youtube видео про технологию:
💟 NeRF paper review от Яныка
🔍 NeRF лекция от Матью из Berkeley
⏳FastNeRF 200fps от Microsoft
🔻NeX + NeRF от Gradient Dude (от автора эйай ньюз)
🧸 Почему нейронный рендеринг это круто? от MIT
p.s.: каждый пиксель картинки к посту сделал при помощи далли Malevich
#всохраненки
Нейронный 3D рендер — это уже настоящее. И NeRF и его производные захватывают наши сердца.
Хотели погрузиться в эту тему, но не знали с чего начать? Собрал крутую подборку самых полезных youtube видео про технологию:
💟 NeRF paper review от Яныка
🔍 NeRF лекция от Матью из Berkeley
⏳FastNeRF 200fps от Microsoft
🔻NeX + NeRF от Gradient Dude (от автора эйай ньюз)
🧸 Почему нейронный рендеринг это круто? от MIT
p.s.: каждый пиксель картинки к посту сделал при помощи далли Malevich
#всохраненки
🥑 Нейросеть DALL•E: Искусство Искусственного Интеллекта | Лекция от «Мишин Лернинг»
Коллеги, жду вас всех в эту среду 8-го декабря в 19:30 (GMT+2).
🗺 YouTube, Free
🥷 Лектор: Миша Константинов
Что будет на лекции:
▪️ История генеративных моделей
▪️ GPT-3 для генерации текстов
▪️ DALL·E от OpenAI: разбор
▪️ CogView, DALL-E mini
▪️ VQ-GAN, ESRGAN, Real-ESRGAN
▪️ ruDALL-E Malevich: разбор
▪️ Примеры использования
▪️ DALL·E: Zero-Shot, Few-Shot, Fine-Tune
▪️ NÜWA: to Text-2-Video and beyond
👉 Регистрация на лекцию по DALL•E
Коллеги, жду вас всех в эту среду 8-го декабря в 19:30 (GMT+2).
🗺 YouTube, Free
🥷 Лектор: Миша Константинов
Что будет на лекции:
▪️ История генеративных моделей
▪️ GPT-3 для генерации текстов
▪️ DALL·E от OpenAI: разбор
▪️ CogView, DALL-E mini
▪️ VQ-GAN, ESRGAN, Real-ESRGAN
▪️ ruDALL-E Malevich: разбор
▪️ Примеры использования
▪️ DALL·E: Zero-Shot, Few-Shot, Fine-Tune
▪️ NÜWA: to Text-2-Video and beyond
👉 Регистрация на лекцию по DALL•E
Forwarded from Denis Sexy IT 🤖
Вчера наконец-то добрался поэкспериментировать над ruDall-E, о которой писал тут.
Модель ruDall-E можно ✨слегка✨ дообучить рядом картинок, ну, например чтобы она рисовала стилем какого-то художника или вроде того, процесс занимает минут ~10 (на A100).
Но как оказалось, не обязательно даже собирать кучу картинок, достаточно одной – скормил на 30 итераций картину Ивана Айвазовского «9 вал» и получил модельку которая умеет генерировать что угодно, в стиле этой картины – в галерее примеры по разным запросам.
В общем, поищу свою самую любимую картину или арт, и поэкспериментирую еще чуть позже.
Прошлые эксперименты:
🖼 Генерация Василия Кандинского тут.
🖼 Генерация Ивана Айвазовского тут.
🖼 Генерация Кузьмы Петрова-Водкина тут.
Модель ruDall-E можно ✨слегка✨ дообучить рядом картинок, ну, например чтобы она рисовала стилем какого-то художника или вроде того, процесс занимает минут ~10 (на A100).
Но как оказалось, не обязательно даже собирать кучу картинок, достаточно одной – скормил на 30 итераций картину Ивана Айвазовского «9 вал» и получил модельку которая умеет генерировать что угодно, в стиле этой картины – в галерее примеры по разным запросам.
В общем, поищу свою самую любимую картину или арт, и поэкспериментирую еще чуть позже.
Прошлые эксперименты:
🖼 Генерация Василия Кандинского тут.
🖼 Генерация Ивана Айвазовского тут.
🖼 Генерация Кузьмы Петрова-Водкина тут.
Сделал при помощи ruDALL-E Malevich pop-art обложку для GPT проекта Neural Pushkin от авторов каналов love death transformers и я обучала одну модель
📝 Генерировать стихи и прозу в Neural Pushkin
📝 Генерировать стихи и прозу в Neural Pushkin
🍄 Emojich или Ленин — гриб!
Сегодня вышел пейпер Emojich – zero-shot emoji generation using Russian language.
Авторы сделали файнтюн ruDALL-E Malevich (XL) 1.3B используя методы, позволяющие сохранять генерализацию.
Cгенерировал при помощи Эмодзича (законного отпрыска Малевича) стикер-пак Ленин — Гриб! <- Если вдруг не видели эту работу Курехина, то смотреть обязательно!
Модель помнит, кто такой Ленин, и способна совмещать формы, как и классический DALL-E, но при этом делает это в домене эмодзи (после файн-тюна).
Спасибо, Alex Shonenkov, за Kaggle ноутбук с файнтюном!
p.s.: Если интерсено, как работает DALL-E, история и детали генеративных моделей, и как делать файнтюн самому под Вашу задачу, то жду завтра (8.12 в 19-30 GMT+2) на моей лекции Нейросеть DALL-E: Искусство Искусственного Интеллекта.
🥑 YouTube лекция: Все про генеративные модели и DALL-E
🍄 СТИКЕР ПАК ЛЕНИН ГРИБ
🔮kaggle 📰 paper 🥑demo
Сегодня вышел пейпер Emojich – zero-shot emoji generation using Russian language.
Авторы сделали файнтюн ruDALL-E Malevich (XL) 1.3B используя методы, позволяющие сохранять генерализацию.
Cгенерировал при помощи Эмодзича (законного отпрыска Малевича) стикер-пак Ленин — Гриб! <- Если вдруг не видели эту работу Курехина, то смотреть обязательно!
Модель помнит, кто такой Ленин, и способна совмещать формы, как и классический DALL-E, но при этом делает это в домене эмодзи (после файн-тюна).
Спасибо, Alex Shonenkov, за Kaggle ноутбук с файнтюном!
p.s.: Если интерсено, как работает DALL-E, история и детали генеративных моделей, и как делать файнтюн самому под Вашу задачу, то жду завтра (8.12 в 19-30 GMT+2) на моей лекции Нейросеть DALL-E: Искусство Искусственного Интеллекта.
🥑 YouTube лекция: Все про генеративные модели и DALL-E
🍄 СТИКЕР ПАК ЛЕНИН ГРИБ
🔮kaggle 📰 paper 🥑demo
👍1
🤖 Телеграм-бот Эмодзич: Генерируй стикерпаки нейросетью DALL-E
🤖 бот для генерации 👈
📼 youtube разбор нейросети
📚 инструкция
p.s.: на картинке «профессиональный эмодзи робота в шапочке, машинное обучение»
🤖 бот для генерации 👈
📼 youtube разбор нейросети
📚 инструкция
p.s.: на картинке «профессиональный эмодзи робота в шапочке, машинное обучение»
👍1