
Как я и говорил, меня удивляет возможность DALL•E понимать не только стилистику, географию и времена дня и года (в данном случае «живопись, масло, лето, рассвет»), но и высокоуровневые концепции. Для этого примера, я сделал генерацию по запросу «кафе трамвай». При этом вся генерация смотрится целостной. И самое важное — эстетически прекрасной!
Forwarded from Denis Sexy IT 🤖
This media is not supported in your browser
VIEW IN TELEGRAM
Nvidia на днях показали бета-версию своего редактора который поможет добавить спойлер и наклейку Sparko к вашей девятке может высококачественно редактировать изображения с помощью GAN нейронки, еще один шаг в сторону GAN-пэинта.
Все еще нужна модель объекта который вы будете редактировать (в видео пример на модели с автомобилями, но можно экспериментировать и с лицами и тп) и пока непонятно, можно ли загрузить в такой редактор свое фото, но результаты уже очень классные. Такую маску редактировать намного проще и быстрее чем фотошопить все детали объекта, тем более думаю генерация такой же маски по фото задачи решенная.
В общем, в видео все видно как работает. Кода пока нет, но напишу как выложат.
Сайт проекта | Краткое техническое описание на русском
Все еще нужна модель объекта который вы будете редактировать (в видео пример на модели с автомобилями, но можно экспериментировать и с лицами и тп) и пока непонятно, можно ли загрузить в такой редактор свое фото, но результаты уже очень классные. Такую маску редактировать намного проще и быстрее чем фотошопить все детали объекта, тем более думаю генерация такой же маски по фото задачи решенная.
В общем, в видео все видно как работает. Кода пока нет, но напишу как выложат.
Сайт проекта | Краткое техническое описание на русском
Forwarded from DL in NLP (nlpcontroller_bot)
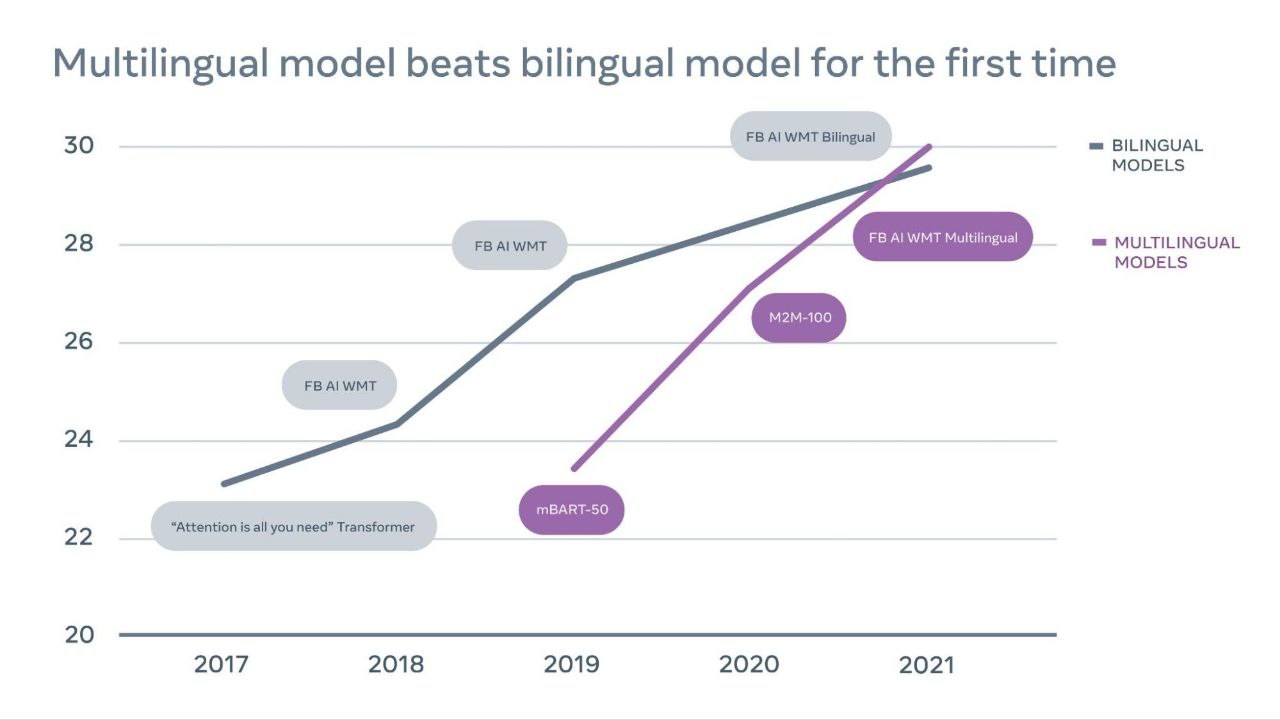
Мультиязычная модель машинного перевода от FAIR превзошла двуязычные модели на соревновании WMT-21.
Статья: arxiv.org/abs/2108.03265
Блог: ai.facebook.com/blog/the-first-ever-multilingual-model-to-win-wmt-beating-out-bilingual-models/
Мультиязычный перевод сложно делать. Несмотря на то, что за последние годы научились обучать большие модели, которые улучшают качество перевода на низкоресурсных языках, с высокоресурсными языками это долгое время не работало и двуязычные модели продолжали работать лучше мультиязычных.
FAIR (Meta AI?) в новой статье наконец-то преодолели этот порог. Их модель превосходит двуязычные, чего добились с помощью более умного (и объемного) майнинга обучающих данных - как параллельных так и непараллельных и использования mixture of experts (MoE) для скейлинга модели до 52B параметров.
Статья: arxiv.org/abs/2108.03265
Блог: ai.facebook.com/blog/the-first-ever-multilingual-model-to-win-wmt-beating-out-bilingual-models/
Мультиязычный перевод сложно делать. Несмотря на то, что за последние годы научились обучать большие модели, которые улучшают качество перевода на низкоресурсных языках, с высокоресурсными языками это долгое время не работало и двуязычные модели продолжали работать лучше мультиязычных.
FAIR (Meta AI?) в новой статье наконец-то преодолели этот порог. Их модель превосходит двуязычные, чего добились с помощью более умного (и объемного) майнинга обучающих данных - как параллельных так и непараллельных и использования mixture of experts (MoE) для скейлинга модели до 52B параметров.
{kind=link}
🕋 AI HOUSE CONFERENCE | Киев, 25 ноября
Помните Мишин Лернинг принимал участие в Pawa Chats 🔊 подкаст на ютубе, где мы в течение часа говорили про нейронную архитектуру трансформер? Кстати, если ещё не слушали, то очень рекомендую этот выпуск!
Так вот, их коллеги, ребята из AI HOUSE организовывают крутую конфу в Киеве (оффлайн, 25го ноября). Ребята смогли выцепить Kai-Fu Lee (автора известных бестселлеров по AI).
Если интересно, то для нас сделали промокод mishin_learning на 20%.
▪️AI HOUSE CONFERENCE
Помните Мишин Лернинг принимал участие в Pawa Chats 🔊 подкаст на ютубе, где мы в течение часа говорили про нейронную архитектуру трансформер? Кстати, если ещё не слушали, то очень рекомендую этот выпуск!
Так вот, их коллеги, ребята из AI HOUSE организовывают крутую конфу в Киеве (оффлайн, 25го ноября). Ребята смогли выцепить Kai-Fu Lee (автора известных бестселлеров по AI).
Если интересно, то для нас сделали промокод mishin_learning на 20%.
▪️AI HOUSE CONFERENCE
Forwarded from AI для Всех
This media is not supported in your browser
VIEW IN TELEGRAM
ProsePainter
Создавайте образы, рисуя словами.
ProsePainter сочетает в себе рисование руками с оптимизацией изображения в реальном времени с помощью машинного обучения. Просто скажите, что вы хотите, и выделите нужную область.
🖥 Код
#CLIP #images #multimodal
Создавайте образы, рисуя словами.
ProsePainter сочетает в себе рисование руками с оптимизацией изображения в реальном времени с помощью машинного обучения. Просто скажите, что вы хотите, и выделите нужную область.
🖥 Код
#CLIP #images #multimodal
Лекция Zero-Shot — Zero Problem прошла на “ура”! А тут астрологи объявили месяц DALL-E, и мне захотелось встретиться с вами еще раз! Сделаю событие 24го или 25го ноября. На чем сосредоточимся?
Final Results
55%
Отдельную лекции про нейросеть DALL-E: во всех деталях про архитектуру и нюансы различных реализаций
45%
Лекцию про мультимодальные модели и мультимодальные трансформеры вообще
This media is not supported in your browser
VIEW IN TELEGRAM
🗣 Многоязычный подход — это будущее машинного перевода!
Если вдруг пропустили этот важный шаг в NLP: впервые одна многоязычная модель превзошла лучшие двуязычные модели в 10 из 14 языковых пар побила SOTA в WMT.
Он не только проще и масштабируем, но и обеспечивает лучший перевод для всех языковых пар! Подход «одна модель — много языков» также упрощает разработку систем перевода в реальных приложениях: замена тысяч моделей только одной упростит создание новых приложений и услуг для всех во всем мире.
Действительно важный и большой шаг в правильном направлении!
И ребята выложили код и веса single best dense model’ей на гит!
📝FAIR MAIR blog 📄 paper 💻 code
Если вдруг пропустили этот важный шаг в NLP: впервые одна многоязычная модель превзошла лучшие двуязычные модели в 10 из 14 языковых пар побила SOTA в WMT.
Он не только проще и масштабируем, но и обеспечивает лучший перевод для всех языковых пар! Подход «одна модель — много языков» также упрощает разработку систем перевода в реальных приложениях: замена тысяч моделей только одной упростит создание новых приложений и услуг для всех во всем мире.
Действительно важный и большой шаг в правильном направлении!
И ребята выложили код и веса single best dense model’ей на гит!
📝
Forwarded from Derp Learning
Допилил колаб с RealESRGAN от Sбера. Добавил обработку загруженных файлов, скачивание архивом. Спрятал код :)
Напомню, сетка увеличивает фото х2 х4 х8, на выбор.
Идеально для улучшения результатов работы @face2comicsbot
Потыкать тут
Напомню, сетка увеличивает фото х2 х4 х8, на выбор.
Идеально для улучшения результатов работы @face2comicsbot
Потыкать тут
Forwarded from AI для Всех
Masked Autoencoders Are Scalable Vision Learners
Ещё одна идея, которая казалось бы была на поверхности, and yet… Берём картиночный автоэнкодер, делим картинку на патчи, прячем их в случайном порядке, и просим декодер восстановить изображение (в режиме self-supervised).
Авторы (Facebook/Meta AI), обнаружили, что скрытие большой части входного изображения, например, 75%, дает нетривиальную и осмысленную задачу для self-supervised обучения. Оказалось, что в такой формулировке, автоэнкодер обучается в ~3 раза быстрее (чем если бы мы учили на изображениях без масок).
Более того, оказалось, что если к такому обученному автоэнкодеру прикрутить голову на классификацию (например), то она будет показывать SOTA результаты. Так же, авторы показывают, что при масштабировании датасета, результаты только улучшаются.
📎 Статья
#selfSupervised #autoencoders #images
Ещё одна идея, которая казалось бы была на поверхности, and yet… Берём картиночный автоэнкодер, делим картинку на патчи, прячем их в случайном порядке, и просим декодер восстановить изображение (в режиме self-supervised).
Авторы (Facebook/Meta AI), обнаружили, что скрытие большой части входного изображения, например, 75%, дает нетривиальную и осмысленную задачу для self-supervised обучения. Оказалось, что в такой формулировке, автоэнкодер обучается в ~3 раза быстрее (чем если бы мы учили на изображениях без масок).
Более того, оказалось, что если к такому обученному автоэнкодеру прикрутить голову на классификацию (например), то она будет показывать SOTA результаты. Так же, авторы показывают, что при масштабировании датасета, результаты только улучшаются.
📎 Статья
#selfSupervised #autoencoders #images
This media is not supported in your browser
VIEW IN TELEGRAM
🧿 Meta AI Research выкатили Demucs v3 | Demucs Music Source Separation
Задача сведения музыки сложна, зато если трек сведен хорошо, то он становится шедевром. Что может быть сложнее? Все верно, разложить готовый трек на исходные дорожки, и выделить отдельно, как в примере (вкл звук 🔉):
- Барабаны
- Вокал и бэк-вокал
- Гитары и синты
- Бас гитару
Задача сепарирования оригинального микса на дорожки можно считать решенной. И все благодаря нейронной архитектуре Demucs 3, вдохновенной сверточным Wave-U-Net’ом.
Вообще очень советую посмотреть репозиторий этого проекта. Там и архитектура и веса, и модели работающие в спектральном и волновом домене. Кстати, сам Demucs 3 гибрид: работает и со спектром и с волной!
p.s.: Представьте себе не просто ремастеринг, а полноценное новое сведение старых треков, для которых не сохранились исходники! Да и создание ремиксов из них теперь станет куда более доступным.
💿 Code 🔮 Demucs Colab 🤗 Demo
Задача сведения музыки сложна, зато если трек сведен хорошо, то он становится шедевром. Что может быть сложнее? Все верно, разложить готовый трек на исходные дорожки, и выделить отдельно, как в примере (вкл звук 🔉):
- Барабаны
- Вокал и бэк-вокал
- Гитары и синты
- Бас гитару
Задача сепарирования оригинального микса на дорожки можно считать решенной. И все благодаря нейронной архитектуре Demucs 3, вдохновенной сверточным Wave-U-Net’ом.
Вообще очень советую посмотреть репозиторий этого проекта. Там и архитектура и веса, и модели работающие в спектральном и волновом домене. Кстати, сам Demucs 3 гибрид: работает и со спектром и с волной!
p.s.: Представьте себе не просто ремастеринг, а полноценное новое сведение старых треков, для которых не сохранились исходники! Да и создание ремиксов из них теперь станет куда более доступным.
💿 Code 🔮 Demucs Colab 🤗 Demo
Forwarded from эйай ньюз
О Нейронном Рендеринге
Что такое Нейронный Рендеринг? Если немного сумбурно, то нейронный рендеринг — это когда мы берем классические алгоритмы синтеза изображений из компьютерной графики и заменяем часть пайплайна нейронными сетями (тупо, но эффективно). Нейронный рендеринг учится рендерить и представлять сцену из одной или нескольких реальных фотографий, имитируя физический процесс камеры, которая фотографирует сцену. Ключевая особенность нейронного рендеринга — разделение процесса фотографирования (т.е. проекции и формирования изображения) и представления трехмерной сцены во время обучения. То есть мы учим отдельное представление трехмерное сцены в явном виде (воксели, облака точек, параметрически заданные поверхности) либо в неявном виде (signed distance function), из которого рендерятся наблюдаемые изображения. Чтобы всё это обучать, важно чтобы весь процесс рендеринга был дифференцируемым.
Может вы не заметили, но тема нейронного рендеринга, включая всякие нерфы-шмерфы, сейчас хайпует в компьютерном зрении. Вы скажете, что нейронный рендеринг — это очень медленно, и вы будете правы. Обычная тренировка на небольшой сцене с ~50 фотографиями занимает у самого быстрого метода около 5.5 часов на одной GPU, но прогресс не стоит на месте и методы очень активно развиваются. Чтобы охватить все недавние наработки в этом направлении, очень советую прочитать этот SOTA репорт "Advances in Neural Rendering".
Что такое Нейронный Рендеринг? Если немного сумбурно, то нейронный рендеринг — это когда мы берем классические алгоритмы синтеза изображений из компьютерной графики и заменяем часть пайплайна нейронными сетями (тупо, но эффективно). Нейронный рендеринг учится рендерить и представлять сцену из одной или нескольких реальных фотографий, имитируя физический процесс камеры, которая фотографирует сцену. Ключевая особенность нейронного рендеринга — разделение процесса фотографирования (т.е. проекции и формирования изображения) и представления трехмерной сцены во время обучения. То есть мы учим отдельное представление трехмерное сцены в явном виде (воксели, облака точек, параметрически заданные поверхности) либо в неявном виде (signed distance function), из которого рендерятся наблюдаемые изображения. Чтобы всё это обучать, важно чтобы весь процесс рендеринга был дифференцируемым.
Может вы не заметили, но тема нейронного рендеринга, включая всякие нерфы-шмерфы, сейчас хайпует в компьютерном зрении. Вы скажете, что нейронный рендеринг — это очень медленно, и вы будете правы. Обычная тренировка на небольшой сцене с ~50 фотографиями занимает у самого быстрого метода около 5.5 часов на одной GPU, но прогресс не стоит на месте и методы очень активно развиваются. Чтобы охватить все недавние наработки в этом направлении, очень советую прочитать этот SOTA репорт "Advances in Neural Rendering".
Audio
Протестировал Demucs из предыдущего поста и разложил свою импровизацию на партии
Пару месяцев назад набросал loop: барабаны, бас и синт, чтобы поимпровизировть на telecaster’е. Исходных дорожек как раз не осталось.
🥁 Барабаны достались неплохо, хотя чуть страдают транзиенты. Присутствуют протечки с синта. Не критично
🔊 Бас был изначально записан на Moog так, что транзитов там не было. Стал мыльным. Слышны протечки.
🎸 Инструментал пострадал больше всего. Местами сильно убиты транзиенты, верхние частоты, слышны протечки.
Итого. Я бы поставил 5/10. Если другого варианта получить дорожки нет, то это лучше чем ничего. Но таком случае все еще лучше мастеринг, благо инструменты такие как izotope ozone способны на магию. Но направление супер перспективное + я тестил v2, а не v3. Потом сделаю сравнение с ней. Уверен, что через пару лет задачу можно будет считать решенной для коммерческих задач звукорежжиссуры.
p.s. Посетила идея добавить обложку с астронавтом, сгенерированным DALL-E, и запилить метарок альбом.
Пару месяцев назад набросал loop: барабаны, бас и синт, чтобы поимпровизировть на telecaster’е. Исходных дорожек как раз не осталось.
🥁 Барабаны достались неплохо, хотя чуть страдают транзиенты. Присутствуют протечки с синта. Не критично
🔊 Бас был изначально записан на Moog так, что транзитов там не было. Стал мыльным. Слышны протечки.
🎸 Инструментал пострадал больше всего. Местами сильно убиты транзиенты, верхние частоты, слышны протечки.
Итого. Я бы поставил 5/10. Если другого варианта получить дорожки нет, то это лучше чем ничего. Но таком случае все еще лучше мастеринг, благо инструменты такие как izotope ozone способны на магию. Но направление супер перспективное + я тестил v2, а не v3. Потом сделаю сравнение с ней. Уверен, что через пару лет задачу можно будет считать решенной для коммерческих задач звукорежжиссуры.
p.s. Посетила идея добавить обложку с астронавтом, сгенерированным DALL-E, и запилить метарок альбом.
🧿 Ресерчеры из Facebook Meta AI Research обучили три нейросети для распознавания речи на 4.5 миллионах часов записей голосов людей из 120 стан мира
Ресерчеры обучили три модели (100M, 1B, 10B параметров) для распознавания речи на огромном и супер-вариативном датасете.
Как можно ожидать из названия статьи “Scaling ASR Improves Zero and Few Shot Learning”, такие модели отлично показывают себя в новых условиях (доменах) даже в zero-shot.
🧠 После же few-shot learning c fine-tune модели становятся способны даже распознавать речь людей с нарушениями, вызванными повреждением мозга, на бенчмарке AphasiaBank.
📰 paper
Ресерчеры обучили три модели (100M, 1B, 10B параметров) для распознавания речи на огромном и супер-вариативном датасете.
Как можно ожидать из названия статьи “Scaling ASR Improves Zero and Few Shot Learning”, такие модели отлично показывают себя в новых условиях (доменах) даже в zero-shot.
🧠 После же few-shot learning c fine-tune модели становятся способны даже распознавать речь людей с нарушениями, вызванными повреждением мозга, на бенчмарке AphasiaBank.
📰 paper
LiT🔥: Zero-Shot Transfer with Locked-image Text Tuning | Новый подход contrastive-tuning от Google Research, Brain Team, Zurich обходит CLIP и ALIGN
Contrastive Language–Image Pre-training подход в CLIP подарил нам полноценный Zero-shot для классификации изображений. Теперь сеть не нужно дооубучать под новый домен, достаточно лишь удачно описать нужный класс на естественном языке.
🔓 В CLIP и текстовая и визуальная “башня” контрастив модели учились с нуля. u - unlocked from-scratch
🔐 Возникает вопрос: не будет ли лучше взять претрейны моделей (e.g.: ResNet, ViT, MLP-Mixer), и дальше файнтюнить их в режиме contrastive language–image? U - unlocked from a pre-trained model
🔒 Авторы показали, что лучше всего работает подход с полностью замороженной визуальной “башней”!
Модель ViT-G/14, обученная в режиме contrastive-tuning LiT, обходит такой же CLIP в zero-shot на ImageNet: 84.5% vs 76.2%, соответсвенно.
p.s.: Нейминг is all you need: ViT и LiT! Изящно
📄 Paper LiT🔥
Contrastive Language–Image Pre-training подход в CLIP подарил нам полноценный Zero-shot для классификации изображений. Теперь сеть не нужно дооубучать под новый домен, достаточно лишь удачно описать нужный класс на естественном языке.
🔓 В CLIP и текстовая и визуальная “башня” контрастив модели учились с нуля. u - unlocked from-scratch
🔐 Возникает вопрос: не будет ли лучше взять претрейны моделей (e.g.: ResNet, ViT, MLP-Mixer), и дальше файнтюнить их в режиме contrastive language–image? U - unlocked from a pre-trained model
🔒 Авторы показали, что лучше всего работает подход с полностью замороженной визуальной “башней”!
Модель ViT-G/14, обученная в режиме contrastive-tuning LiT, обходит такой же CLIP в zero-shot на ImageNet: 84.5% vs 76.2%, соответсвенно.
p.s.: Нейминг is all you need: ViT и LiT! Изящно
📄 Paper LiT🔥
This media is not supported in your browser
VIEW IN TELEGRAM
🧸 Сегодня каналу «Мишин Лернинг» исполняется 1 год!
Год назад я решил начать вести канал про машинное обучение. Кстати, нейминг придумала моя хорошая подруга из шутки «Ма́шин лернинг».
За это время мы с вами прочли стопку пейперов, одолели 444 поста, посмотрели много лекций, запустили десятки колабов!
Поделюсь, тем, что я сделал благодаря вам:
▪️ ТГ канал Мишин Лернинг
▪️ YouTube канал Transformer
▪️ Проект Трансформер
▪️ ТГ канал моих? картин Нейроэстетика
▪️ Инстаграм канал Нейроэстетика
Инстаграм завел только сегодня. Добавим работы эпохи
И, главное! Подарок:
🎁 По итогам голосования мы выбрали тему: Нейросеть DALL•E: Искусство Искусственного Интеллекта. Так что жду вас всех 29-го ноября в 19:30 на youtube. Если зайдет, то будут ещё ивенты по этой тематике!
Год назад я решил начать вести канал про машинное обучение. Кстати, нейминг придумала моя хорошая подруга из шутки «Ма́шин лернинг».
За это время мы с вами прочли стопку пейперов, одолели 444 поста, посмотрели много лекций, запустили десятки колабов!
Поделюсь, тем, что я сделал благодаря вам:
▪️ ТГ канал Мишин Лернинг
▪️ YouTube канал Transformer
▪️ Проект Трансформер
▪️ ТГ канал моих? картин Нейроэстетика
▪️ Инстаграм канал Нейроэстетика
Инстаграм завел только сегодня. Добавим работы эпохи
нейромодерна в свою ленту?И, главное! Подарок:
🎁 По итогам голосования мы выбрали тему: Нейросеть DALL•E: Искусство Искусственного Интеллекта. Так что жду вас всех 29-го ноября в 19:30 на youtube. Если зайдет, то будут ещё ивенты по этой тематике!
⚠️ Закрытая ссылка на анонс Azure OpenAI Service: доступ к Copilot & GPT-3!
📼 https://youtu.be/mD_tJMZmZ7U
В видео показано как можно будет, используя Microsoft Visual Studio, создать приложение для интеллектуального просмотра и описания спортивных матчей всего за пару минут, используя Copilot и GPT-3:
1. Описать на естественном языке, что нужно создать react app
2. Описать на естественном языке, что нужен компонент для просмотра видео
3. Используя GPT-3, получить выжимку спортивных комментариев, или даже полноценную статью по итогам матча
Хороший шаг, Microsoft!
📼 https://youtu.be/mD_tJMZmZ7U
В видео показано как можно будет, используя Microsoft Visual Studio, создать приложение для интеллектуального просмотра и описания спортивных матчей всего за пару минут, используя Copilot и GPT-3:
1. Описать на естественном языке, что нужно создать react app
2. Описать на естественном языке, что нужен компонент для просмотра видео
3. Используя GPT-3, получить выжимку спортивных комментариев, или даже полноценную статью по итогам матча
Хороший шаг, Microsoft!
YouTube
Satya Nadella Ignite 2021: Azure OpenAI Service
Microsoft chairman and CEO Satya Nadella announces Azure OpenAI Service at Ignite 2021.
Enjoy this video with audio descriptions: https://youtu.be/qCldi8Xzruo
Subscribe to Microsoft on YouTube here: https://aka.ms/SubscribeToYouTube
Follow us on social:…
Enjoy this video with audio descriptions: https://youtu.be/qCldi8Xzruo
Subscribe to Microsoft on YouTube here: https://aka.ms/SubscribeToYouTube
Follow us on social:…