
КТО Я ТАКОЙ?
_________
Меня зовут Влад, живу в Чехии 7 лет, за это время побывал в 36 странах мира, нажил прекрасные знакомства и вырос в доходе в десятки раз. Здесь я делюсь опытом и помогаю сориентироваться в ИИ хаосе и мире стартапов, приправляя это всё рассказами из жизни.
Про что этот канал?
• ИИ и как внедрять его в бизнес
• Стартапы, деньги, рост
• Путешествия
• Делюсь опытом и мотивирую
Посты:
Деньги: как рос мой доход, на что трачу
Про стартапы: ч1, ч2, ч3
RAG: нужен ли он тебе?, векторные бд, context vs prompt engineering
Менторство, консультации – здесь
boosty (пустой)
За недолгую карьеру успел поработать в продуктовых стартапах и корпорат-галерах, сейчас я ИИ инженер, достаточно много путешествую и учу китайский.
Навигация по каналу:
Все посты в канале разделены по тэгам
#ai - всё, что касается ИИ
#startup - про стартапы, терминология, лайфхаки
#money - про деньги
#travel - покатушки и красивые фоточки
#dev_help - практическая помощь в разработке, полезные тулы
#university - я закончил вуз в Чехии, работал в лаборатории AI в Сингапуре, считаю, что в айти спокойно можно без уника, но люблю но эту тему порассуждать
#news- инфоповоды
#life - лайф контент о том, что меня окружает
Узнать подробнее про мой путь и подтянуть понимание английского можно тут (ютуб на омериканском)
Если ты из Праги и хочешь встретится лично, то приходи на шахматы, пражские шахматы тут.
_________
Меня зовут Влад, живу в Чехии 7 лет, за это время побывал в 36 странах мира, нажил прекрасные знакомства и вырос в доходе в десятки раз. Здесь я делюсь опытом и помогаю сориентироваться в ИИ хаосе и мире стартапов, приправляя это всё рассказами из жизни.
Про что этот канал?
• ИИ и как внедрять его в бизнес
• Стартапы, деньги, рост
• Путешествия
• Делюсь опытом и мотивирую
Посты:
Деньги: как рос мой доход, на что трачу
Про стартапы: ч1, ч2, ч3
RAG: нужен ли он тебе?, векторные бд, context vs prompt engineering
Менторство, консультации – здесь
boosty (пустой)
За недолгую карьеру успел поработать в продуктовых стартапах и корпорат-галерах, сейчас я ИИ инженер, достаточно много путешествую и учу китайский.
Навигация по каналу:
Все посты в канале разделены по тэгам
#ai - всё, что касается ИИ
#startup - про стартапы, терминология, лайфхаки
#money - про деньги
#travel - покатушки и красивые фоточки
#dev_help - практическая помощь в разработке, полезные тулы
#university - я закончил вуз в Чехии, работал в лаборатории AI в Сингапуре, считаю, что в айти спокойно можно без уника, но люблю но эту тему порассуждать
#news- инфоповоды
#life - лайф контент о том, что меня окружает
Узнать подробнее про мой путь и подтянуть понимание английского можно тут (ютуб на омериканском)
Если ты из Праги и хочешь встретится лично, то приходи на шахматы, пражские шахматы тут.
Telegram
Багодельня Соколовского 👾
Метрика роста
Надо оптимизировать доход в час, лучшая метрика, чтобы видеть как вы растёте.
Уже давно взял себе за правило трекать каждый час своей реальной работы, для этого использую Toggl, бесплатной версии хватает с головой, советую.
Делюсь своей табличкой…
Надо оптимизировать доход в час, лучшая метрика, чтобы видеть как вы растёте.
Уже давно взял себе за правило трекать каждый час своей реальной работы, для этого использую Toggl, бесплатной версии хватает с головой, советую.
Делюсь своей табличкой…
Вот вам кое-что полезное
Часто спрашивают есть ли какие-то скрытые секреты как раскрыть потенциал Cursor на всю, так вот, нашёл тут ещё одну полезную штуку кроме cursor.rules.
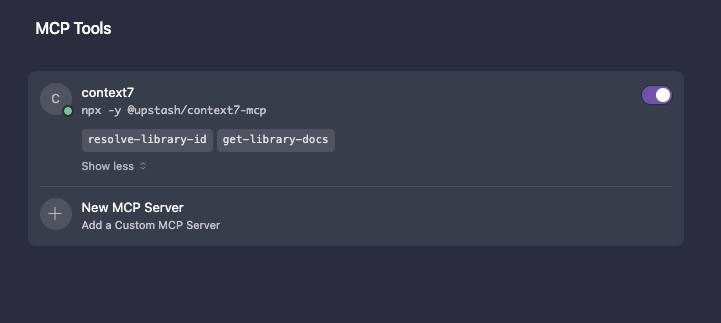
Первый MCP сервер, который я подключил к своему Cursor — Context7 от Upstash.
В чём проблема: AI выдаёт код из 2022 года. Старые API, устаревший синтаксис, несуществующие функции. В ручную подтягивать документацию забываешь, да и от лишних движений хочется избавляться.
Context7 с этим помогает – подтягивает актуальную документацию прямо во время генерации кода.
Всё, что вам нужно знать найдёте тут.
С вас репост и огонёчек 🥰
#ai #dev_help
@makebugger
Часто спрашивают есть ли какие-то скрытые секреты как раскрыть потенциал Cursor на всю, так вот, нашёл тут ещё одну полезную штуку кроме cursor.rules.
Первый MCP сервер, который я подключил к своему Cursor — Context7 от Upstash.
В чём проблема: AI выдаёт код из 2022 года. Старые API, устаревший синтаксис, несуществующие функции. В ручную подтягивать документацию забываешь, да и от лишних движений хочется избавляться.
Context7 с этим помогает – подтягивает актуальную документацию прямо во время генерации кода.
Всё, что вам нужно знать найдёте тут.
С вас репост и огонёчек 🥰
#ai #dev_help
@makebugger
{kind=link}
🔥17
Пару дней назад раскошелился на Claude Code, уверен большинство слышало, но скорее всего не пробовало этого зверя.
ROI тут просто конфетка, за 100 бачей вы получаете себе супер умного бадди который пишет довольно неплохой код со скоростью света.
Пару часов назад Антропики сделали аннаунсмент, что теперь можно подтягивать remote MCP servers, работает как сказка.
Если пишите какой-то webapp, то вот must have MCP это:
• playwright или puppeteer (новый молодёжный Selenium, запускает ваш браузер в headless моде, может автоматически просматривать работает ли сайт, кликать кнопочки и тд)
• context7 (писал выше)
никаких memory bankов вам не надо, они избыточно съедают контекст, вот эти два МЦП, и клодя вам в автономном режими напишет целую систему.
Не пожалейте денег, понимаю, что сейчас все эти ИИ подписки съедают очень много, но Claude Code как по мне намного лучше курсора, если вы не боитесь работать в терминале. Вроде как её можно и к курсору подключить, этого не делал..
Тут хороший гайд от создателя этого CLI, must have на прочтение перед тем как погрузитесь в этот прекрасный мир.
#ai #dev_help
@makebugger
ROI тут просто конфетка, за 100 бачей вы получаете себе супер умного бадди который пишет довольно неплохой код со скоростью света.
Пару часов назад Антропики сделали аннаунсмент, что теперь можно подтягивать remote MCP servers, работает как сказка.
Если пишите какой-то webapp, то вот must have MCP это:
• playwright или puppeteer (новый молодёжный Selenium, запускает ваш браузер в headless моде, может автоматически просматривать работает ли сайт, кликать кнопочки и тд)
• context7 (писал выше)
никаких memory bankов вам не надо, они избыточно съедают контекст, вот эти два МЦП, и клодя вам в автономном режими напишет целую систему.
Не пожалейте денег, понимаю, что сейчас все эти ИИ подписки съедают очень много, но Claude Code как по мне намного лучше курсора, если вы не боитесь работать в терминале. Вроде как её можно и к курсору подключить, этого не делал..
Тут хороший гайд от создателя этого CLI, must have на прочтение перед тем как погрузитесь в этот прекрасный мир.
#ai #dev_help
@makebugger
👍5❤1
TypeScript – будущее AI Engineering?
Я не нагнетаю, ближайшие Х лет этого точно не произойдёт, но я вижу чёткий тренд на использование TypeScript в AI-powered проектах. И я не уверен, что это вообще когда-то произойдёт, но...
Почему это может произойти?
• Например, я писал Voice бота, которому звонишь и тебе отвечает LLM голосом (OpenAI real-time API). Чтобы программа такого типа нормально скейлилась и шустро работала – Pythonа просто не достаточно. Latency упала с 200ms до 40ms после перехода на TS.
• Менеджить BackEnd в Python и FrontEnd в TS – это боль, если вы хоть раз работали на таком мультиязычном проекте, вы меня поймёте. Постоянные проблемы с типами и форматом данных, которые передаются между BE и FE, дебажить это – сплошной ад. Если бы все эти ошибки вскрывались на этапе транспиляции TS в JS, экономилось бы кучу времени и нервов.
• Просто в большинстве случаем нет другой причины использовать Python, кроме как "ну наши разработчики лучше знакомы с Python стеком". В большинстве проектов не используется тот хвалёный ML tooling (numpy, pytorch, tensorflow), из-за которого все DS и ML люди пишут в Pythonе, всё через API и SDK.
Почему ещё не скоро?
• SDK для популярных AI frameworkов типа LangGraph в JS/TS отстают от Python SDK на несколько версий, доки – старьё, коммьюнити всё ещё ооочень маленькое.
• Всё-таки переучивать целые команды будет намного дороже, чем смириться с огромными недостатками Python для этих целей.
Некоторый тулинг, который может пригодиться в таких проектах, в Python реализован на 5+, spacy библиотека, например.
Кстати, недавно написал своё первое приложение на NextJS, Claude Code написало 80% за меня) А я выучил огромное количество TypeScript-specific вещей на практике.
А вы не заглядывались в сторону TS?
#ai #dev_help
@makebugger
Я не нагнетаю, ближайшие Х лет этого точно не произойдёт, но я вижу чёткий тренд на использование TypeScript в AI-powered проектах. И я не уверен, что это вообще когда-то произойдёт, но...
Почему это может произойти?
• Например, я писал Voice бота, которому звонишь и тебе отвечает LLM голосом (OpenAI real-time API). Чтобы программа такого типа нормально скейлилась и шустро работала – Pythonа просто не достаточно. Latency упала с 200ms до 40ms после перехода на TS.
• Менеджить BackEnd в Python и FrontEnd в TS – это боль, если вы хоть раз работали на таком мультиязычном проекте, вы меня поймёте. Постоянные проблемы с типами и форматом данных, которые передаются между BE и FE, дебажить это – сплошной ад. Если бы все эти ошибки вскрывались на этапе транспиляции TS в JS, экономилось бы кучу времени и нервов.
• Просто в большинстве случаем нет другой причины использовать Python, кроме как "ну наши разработчики лучше знакомы с Python стеком". В большинстве проектов не используется тот хвалёный ML tooling (numpy, pytorch, tensorflow), из-за которого все DS и ML люди пишут в Pythonе, всё через API и SDK.
Почему ещё не скоро?
• SDK для популярных AI frameworkов типа LangGraph в JS/TS отстают от Python SDK на несколько версий, доки – старьё, коммьюнити всё ещё ооочень маленькое.
• Всё-таки переучивать целые команды будет намного дороже, чем смириться с огромными недостатками Python для этих целей.
Некоторый тулинг, который может пригодиться в таких проектах, в Python реализован на 5+, spacy библиотека, например.
Кстати, недавно написал своё первое приложение на NextJS, Claude Code написало 80% за меня) А я выучил огромное количество TypeScript-specific вещей на практике.
А вы не заглядывались в сторону TS?
#ai #dev_help
@makebugger
👍18❤2🤔1
Привет!
Сейчас немного тихо так как я взял небольшую передышку и приехал на недельку-другую в северную столицу отпраздновать юбилей 🤗
В скором времени выпущу мини видео гайд по достаточно полезной платформе для написания комплексных [LLM] workflows, она пока ещё не очень хайповая, но по стечению обстоятельств работаю с ней уже в третьей компании и везде девы выделяют приятнейший developer experience.
Называется temporal.io
Зачем нам очередной тул?
- Если делаете что-то более комплексное, чем один API запрос. (например, взять документ, перевести его в png картинки, послать запрос на Optical Character Recognition (OCR), потом переслать то, что вылезло из OCR в LLM…). Более конвенциональным решением бы было использовать celery, но dev experience и дебагинг комплексных workflows – боль.
- Temporal может заморозить workflow в ожидании inputa человека (Human-in-the-Loop). Если вы верите в то, что сила агентов не в полной автоматизации человеческого труда, а в умной интеграции агентов с людьми, то вам точно понравится temporal. (это мы в проде прям использовали на очень крупном проекте, работало безупречно, LLM делало работу которую перепроверяли наши gig workers, после того как проверка прошла workflow возобновлялся)
- Temporal гарантирует выполнение даже при сбоях. Если ваш сервер упал посередине обработки 100-страничного документа на 73 странице — workflow автоматически продолжится с того же места после перезапуска. В celery такой таск просто пропадёт.
- классный UI и sdk
#dev_help
@makebugger
Сейчас немного тихо так как я взял небольшую передышку и приехал на недельку-другую в северную столицу отпраздновать юбилей 🤗
В скором времени выпущу мини видео гайд по достаточно полезной платформе для написания комплексных [LLM] workflows, она пока ещё не очень хайповая, но по стечению обстоятельств работаю с ней уже в третьей компании и везде девы выделяют приятнейший developer experience.
Называется temporal.io
Зачем нам очередной тул?
- Если делаете что-то более комплексное, чем один API запрос. (например, взять документ, перевести его в png картинки, послать запрос на Optical Character Recognition (OCR), потом переслать то, что вылезло из OCR в LLM…). Более конвенциональным решением бы было использовать celery, но dev experience и дебагинг комплексных workflows – боль.
- Temporal может заморозить workflow в ожидании inputa человека (Human-in-the-Loop). Если вы верите в то, что сила агентов не в полной автоматизации человеческого труда, а в умной интеграции агентов с людьми, то вам точно понравится temporal. (это мы в проде прям использовали на очень крупном проекте, работало безупречно, LLM делало работу которую перепроверяли наши gig workers, после того как проверка прошла workflow возобновлялся)
- Temporal гарантирует выполнение даже при сбоях. Если ваш сервер упал посередине обработки 100-страничного документа на 73 странице — workflow автоматически продолжится с того же места после перезапуска. В celery такой таск просто пропадёт.
- классный UI и sdk
#dev_help
@makebugger
temporal.io
Durable Execution Solutions
Build invincible apps with Temporal's open source durable execution platform. Eliminate complexity and ship features faster. Talk to an expert today!
🔥3❤2👍2🤩2
Cделал умный поиск для одного известного IT сообщества. Делюсь опытом.
В ядре умного поиска (semantic search) всегда кроется завсегдатый RAG.
Что мы знаем про RAG – берёшь документы, режешь на чанки, засовываешь в векторную БД.
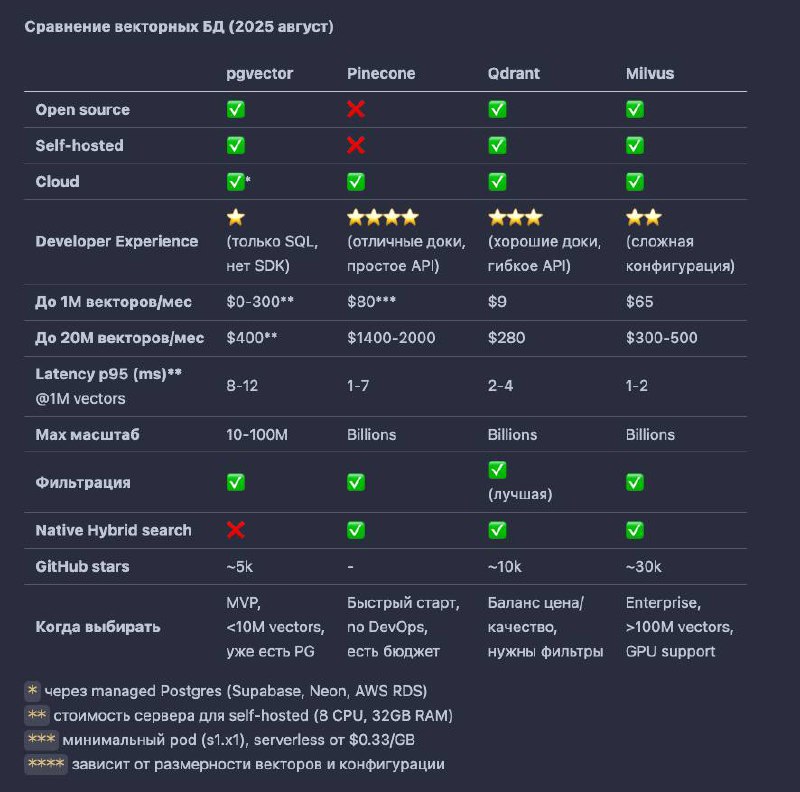
А в какую векторную БД сохранять эмбединги?
Есть Pinecone, QDrant, Milvus, недавно запустившийся jстартап моего друга topk.
В принципе, оно все очень похожи…
какие вопросы стоит задать, чтобы выбрать подходящую?
• self-hosted или cloud?
С self-hosted больше мороки, но всё под контролем, cloud очень быстро можно setupнуть, отлично когда нет времени на DevOps
• какая ожидаемая нагрузка?
если вы не пишете второй фейсбук, а количество векторов меньше 1М, то речь о крошечных объёмах, вам не нужна супер пропускная векторная БД
• вы уже используете Postgres?
не стоит привносить новую зависимость, если вы знаете, что не будете скейлить приложение на масштабы нетфликса, стоит использовать pgvector
PgVector это расширение для вашего обычного Postgres которое добавляет новый тип
выбрав этот вариант вместо любой другой векторной БД, вам не нужно будет думать о скейлинге и бэкапе отдельной БД, а инженеры в вашей команде уже будут знать как с этим работать
В случае когда вы хотите написать быстрое PoC, или если знаете, что будут огромные объёмы >1М векторов, или когда pgvector уже не справляется — тогда смотрим на специализированные решения. Делюсь табличкой!
TL;DR:
pgvector — если уже есть Postgres и <10M векторов
Pinecone — если нужно запустить экстра быстро и есть $70+/месяц
Qdrant — оптимальный выбор по соотношению цена/качество/функционал
Milvus — когда реально большие объёмы и нужна максимальная производительность
#ai #dev_help
@makebugger
В ядре умного поиска (semantic search) всегда кроется завсегдатый RAG.
Что мы знаем про RAG – берёшь документы, режешь на чанки, засовываешь в векторную БД.
А в какую векторную БД сохранять эмбединги?
Есть Pinecone, QDrant, Milvus, недавно запустившийся jстартап моего друга topk.
В принципе, оно все очень похожи…
какие вопросы стоит задать, чтобы выбрать подходящую?
• self-hosted или cloud?
С self-hosted больше мороки, но всё под контролем, cloud очень быстро можно setupнуть, отлично когда нет времени на DevOps
• какая ожидаемая нагрузка?
если вы не пишете второй фейсбук, а количество векторов меньше 1М, то речь о крошечных объёмах, вам не нужна супер пропускная векторная БД
• вы уже используете Postgres?
не стоит привносить новую зависимость, если вы знаете, что не будете скейлить приложение на масштабы нетфликса, стоит использовать pgvector
PgVector это расширение для вашего обычного Postgres которое добавляет новый тип
vector
выбрав этот вариант вместо любой другой векторной БД, вам не нужно будет думать о скейлинге и бэкапе отдельной БД, а инженеры в вашей команде уже будут знать как с этим работать
В случае когда вы хотите написать быстрое PoC, или если знаете, что будут огромные объёмы >1М векторов, или когда pgvector уже не справляется — тогда смотрим на специализированные решения. Делюсь табличкой!
TL;DR:
pgvector — если уже есть Postgres и <10M векторов
Pinecone — если нужно запустить экстра быстро и есть $70+/месяц
Qdrant — оптимальный выбор по соотношению цена/качество/функционал
Milvus — когда реально большие объёмы и нужна максимальная производительность
#ai #dev_help
@makebugger
{kind=link}
❤24🔥4
Люди за это деньги платят
"Не используйте технологию в продукте только потому, что это круто!"
Некоторые ML инженеры имеют черту усложнять решение проблемы с самого начала. В контексте LLM они сразу же хотят утонуть в файн тюнинге... Подбор гиперпараметров, наблюдать за validation loss и чистить датасеты!!! ведь это и есть настоящая ЭЙАЙ наука, скажут они.
По факту, в контексте LLM, в большинстве случаев это over-engineering, то бишь использование огромной кувалды для забивания гвоздиков.
Предлагаю свой ментальный фреймворк для решения задач любого типа:
Шаг 0.
Ты уверен, что хочешь спуститься в бездну галлиционирющих ЛЛМ? Может быть задача решается с помощью regex или обычной проги?
Если да, то можешь смотреть прикреплённую блок-схему.
<смотрит блок схему🤔 >
<досмотрел, ставит огонёчек, репостит>
TL;DR
Ты не хочешь тюнить большую языковую модель, поверь мне!!!
- Поддержка продукта построенного над натюненой моделью будет куда более комплексной чем использование API
- Подготовить хороший датасет это дни или недели скучнейшей работы
- Тренировка стоит деньги, например H100 сейчас стоит 3$ в час, это несколько десятков миллионов input токенов для gemini
- Скорее всего ты просто сломаешь модель и она станет тупее первого grokа
- Если что-то выглядит/звучит круто, это не значит, что это стоит сразу же применять
- Через 4 месяца выходит новая модель, будешь всё перетюнивать?
#ai #dev_help
@makebugger
"Не используйте технологию в продукте только потому, что это круто!"
Некоторые ML инженеры имеют черту усложнять решение проблемы с самого начала. В контексте LLM они сразу же хотят утонуть в файн тюнинге... Подбор гиперпараметров, наблюдать за validation loss и чистить датасеты!!! ведь это и есть настоящая ЭЙАЙ наука, скажут они.
По факту, в контексте LLM, в большинстве случаев это over-engineering, то бишь использование огромной кувалды для забивания гвоздиков.
Предлагаю свой ментальный фреймворк для решения задач любого типа:
Шаг 0.
Ты уверен, что хочешь спуститься в бездну галлиционирющих ЛЛМ? Может быть задача решается с помощью regex или обычной проги?
Если да, то можешь смотреть прикреплённую блок-схему.
<смотрит блок схему
<досмотрел, ставит огонёчек, репостит>
TL;DR
Тюнить модель != RAG
когда вы тюните модель вы изменяете параметры нейронной сети, во время RAG вы просто обогащаете контекст модели
Ты не хочешь тюнить большую языковую модель, поверь мне!!!
- Поддержка продукта построенного над натюненой моделью будет куда более комплексной чем использование API
- Подготовить хороший датасет это дни или недели скучнейшей работы
- Тренировка стоит деньги, например H100 сейчас стоит 3$ в час, это несколько десятков миллионов input токенов для gemini
- Скорее всего ты просто сломаешь модель и она станет тупее первого grokа
- Если что-то выглядит/звучит круто, это не значит, что это стоит сразу же применять
- Через 4 месяца выходит новая модель, будешь всё перетюнивать?
#ai #dev_help
@makebugger
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥13❤12👍9
Когда все результаты выдачи с первой страницы гугла окрашиваются в фиолетовый я прибегаю к EXA.ai
Это очень мощный гибридный поисковой движок который совмещает в себе классический гугл и семантический поиск.
Например, вы хотите постучаться во все финтех стартапы которые недавно получили инвестиции и расширяют команду (см. скриншот)
В exa.ai это один текстовый запрос и вы получаете ссылки прямо на лендинги этих компаний где во вкладке Careers красуются интересующие вас позиции.
Попробуйте хоть раз и вы удивитесь как легко можно сделать комплексный рисёрч и какие спрятанные сокровища появляются в выдаче.
Единственный минус это достаточно агрессивные лимиты и высокий прайсинг, но на пару глубоких рисёрчев в месяц хватит, можете выгрузить результаты в CSV и использовать для чего угодно.
Пользуйтесь 🥰
#ai #dev_help
@makebugger
Это очень мощный гибридный поисковой движок который совмещает в себе классический гугл и семантический поиск.
Например, вы хотите постучаться во все финтех стартапы которые недавно получили инвестиции и расширяют команду (см. скриншот)
В exa.ai это один текстовый запрос и вы получаете ссылки прямо на лендинги этих компаний где во вкладке Careers красуются интересующие вас позиции.
Попробуйте хоть раз и вы удивитесь как легко можно сделать комплексный рисёрч и какие спрятанные сокровища появляются в выдаче.
Единственный минус это достаточно агрессивные лимиты и высокий прайсинг, но на пару глубоких рисёрчев в месяц хватит, можете выгрузить результаты в CSV и использовать для чего угодно.
Пользуйтесь 🥰
#ai #dev_help
@makebugger
🤩14🔥4👍2
Самый полезный пост про кастомные MCP в вашей жизни
Если вы последний год не жили под камнем, то вы точно слышали заморскую аббревиатуру MCP (эм си пи). Это такой протокол, который позволяет языковым моделям взаимодействовать с внешними функциями и сервисами.
Он работает по принципу Remote Procedure Call, то есть модель может вызвать функцию, которая исполняется на другом сервере или в другом приложении.
Короче, чтобы каждый не писал кастомные tools для взаимодействия с внешними ресурсами и сервисами, ребята из Anthropic решили стандартизировать всё это мракобесие и теперь вы можете без забот подключить к вашему кодинг агенту кучу MCP tools (о самом полезном MCP я писал 👉 тут) с помощью которых он может взаимодействовать с различными системами во время выполнения поставленной задачи.
Но если с использованием MCP всё понятно, то как нам написать свой кастомный MCP server? В интернете есть куча стартапов и SaaS (пример) которые сгенерируют вам готовый MCP сервер по вашей OpenAPI спецификации, но проблема в том, что это жёсткий антипаттерн, который, к сожалению, в индустрии встречается крайне часто.
Ну а чо, просто обернуть готовые REST эндпоинты в MCP tools и готово, теперь агент может взаимодействовать с нашим приложением, бюджет освоен, стейкхолдеры с довольным лицом и покрасневшими щёчками добавляют плашку «эй ай копайлот» к своему продукту.
Почему это плохо и так делать не надо?
Давайте представим ситуацию у нас есть проект где есть users и teams.
Есть следующие эндпоинты:
Вы заворачиваете эти эндпоинты в MCP tools один в один. Дело сделано.
Теперь представьте, что юзер просит агента: «Добавь Сашу из команды маркетинга в команду разработки».
Простой запрос, в UI вы бы просто выбрали человека из дропдауна и нажали кнопочку. Но агент с вашими REST-обёртками начинает танцевать балет из пяти актов:
Пять вызовов вместо одного. И это я ещё упростил, в реальности там может быть проверка прав доступа, валидация, логирование и всякая другая хрень.
Но это ещё не всё, дальше веселее. Проблема номер два – UUID это кошмар для LLM. Языковые модели галлюцинируют UUID-ы как проклятые. Они могут решить что
a1b2c3d4-e5f6-7890-abcd-ef1234567890
это валидный айдишник пользователя просто потому что он похож на UUID который вы передали в контексте.
И вот ваш агент пытается обновить пользователя который не существует, получает 404, начинает ретраиться, жрёт токены и в итоге сдаётся, а юзер сидит и думает «ну и хрень это вашэ эй-ай».
К тому же, UUID токенизируется крайне неэффективно. Один UUID это примерно 23 токена в зависимости от модели, а если у вас в ответе приходит массив из сотни пользователей с их UUIDs, то сами можете представить качество такого context engineering’а.
Что делать с UUID почитайте 👉 тут.
Итак, наш запрос: «Добавь Сашу из маркетинга в команду разработки»
Это конкретное действие с понятной бизнес-логикой. Но ваш REST API думает ресурсами: юзер, команда, их свойства.
а получает набор CRUD операций которые надо самому оркестрировать.
И вот агент начинает дирижировать этим оркестром: проверить, получить, обновить, проверить ещё раз… А если где-то в середине что-то упало? У REST API нет транзакционности. Через несколько запросов вы останетесь с Сашей, который наполовину в маркетинге и наполовину в разработке…
А как же правильно?
Ответ в комментах (место закончилось)
👇
#dev_help #ai
@makebugger
Если вы последний год не жили под камнем, то вы точно слышали заморскую аббревиатуру MCP (эм си пи). Это такой протокол, который позволяет языковым моделям взаимодействовать с внешними функциями и сервисами.
Он работает по принципу Remote Procedure Call, то есть модель может вызвать функцию, которая исполняется на другом сервере или в другом приложении.
Короче, чтобы каждый не писал кастомные tools для взаимодействия с внешними ресурсами и сервисами, ребята из Anthropic решили стандартизировать всё это мракобесие и теперь вы можете без забот подключить к вашему кодинг агенту кучу MCP tools (о самом полезном MCP я писал 👉 тут) с помощью которых он может взаимодействовать с различными системами во время выполнения поставленной задачи.
Но если с использованием MCP всё понятно, то как нам написать свой кастомный MCP server? В интернете есть куча стартапов и SaaS (пример) которые сгенерируют вам готовый MCP сервер по вашей OpenAPI спецификации, но проблема в том, что это жёсткий антипаттерн, который, к сожалению, в индустрии встречается крайне часто.
Ну а чо, просто обернуть готовые REST эндпоинты в MCP tools и готово, теперь агент может взаимодействовать с нашим приложением, бюджет освоен, стейкхолдеры с довольным лицом и покрасневшими щёчками добавляют плашку «эй ай копайлот» к своему продукту.
Почему это плохо и так делать не надо?
Давайте представим ситуацию у нас есть проект где есть users и teams.
Есть следующие эндпоинты:
• GET /user/:id – получить конкретного пользователя по айдишнику
• PUT /user/:id – изменить информацию о пользователе
• GET /teams – получить все команды
• GET /teams/:id – получить конкретную команду по айдишнику
Вы заворачиваете эти эндпоинты в MCP tools один в один. Дело сделано.
Теперь представьте, что юзер просит агента: «Добавь Сашу из команды маркетинга в команду разработки».
Простой запрос, в UI вы бы просто выбрали человека из дропдауна и нажали кнопочку. Но агент с вашими REST-обёртками начинает танцевать балет из пяти актов:
1. Вызывает GET /users чтобы найти всех Саш
2. Парсит ответ в поисках нужного Саши
3. Вызывает GET /teams чтобы найти команду маркетинга (проверить что Саша там)
4. Вызывает GET /teams снова чтобы найти команду разработки
5. Наконец вызывает PUT /user/:id с UUID Саши
Пять вызовов вместо одного. И это я ещё упростил, в реальности там может быть проверка прав доступа, валидация, логирование и всякая другая хрень.
Но это ещё не всё, дальше веселее. Проблема номер два – UUID это кошмар для LLM. Языковые модели галлюцинируют UUID-ы как проклятые. Они могут решить что
a1b2c3d4-e5f6-7890-abcd-ef1234567890
это валидный айдишник пользователя просто потому что он похож на UUID который вы передали в контексте.
И вот ваш агент пытается обновить пользователя который не существует, получает 404, начинает ретраиться, жрёт токены и в итоге сдаётся, а юзер сидит и думает «ну и хрень это вашэ эй-ай».
К тому же, UUID токенизируется крайне неэффективно. Один UUID это примерно 23 токена в зависимости от модели, а если у вас в ответе приходит массив из сотни пользователей с их UUIDs, то сами можете представить качество такого context engineering’а.
Что делать с UUID почитайте 👉 тут.
Итак, наш запрос: «Добавь Сашу из маркетинга в команду разработки»
Это конкретное действие с понятной бизнес-логикой. Но ваш REST API думает ресурсами: юзер, команда, их свойства.
Агент хочет выполнить действие
moveUserToTeam(user: "Саша из маркетинга", targetTeam: "разработка")
а получает набор CRUD операций которые надо самому оркестрировать.
И вот агент начинает дирижировать этим оркестром: проверить, получить, обновить, проверить ещё раз… А если где-то в середине что-то упало? У REST API нет транзакционности. Через несколько запросов вы останетесь с Сашей, который наполовину в маркетинге и наполовину в разработке…
А как же правильно?
Ответ в комментах (место закончилось)
#dev_help #ai
@makebugger
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥41❤11👍5
Важное о ЭМ СИ ПИ – да, опять
_
Антропики опубликовали действительно важную статью о проблемах MCP серверов. О некоторых косяках я уже писал 👉тут, сейчас на работе мы разрабатываем проект, где эти проблемы раскрылись во всей красе и разрушили изначальные планы по срокам.
Что не так с текущим подходом
У нас есть supervisor агент, делегирующий работу на reAct субагентов, которые напрямую взаимодействуют с MCP тулами. Всё ломается, когда агент должен оркестрировать что-то сложнее чем "добавь нового пользователя". Например: "измени команду пользователя X на команду с названием Z".
Допустим, что наш MCP сервер это просто обёртка над RESTом с классическими CRUDами:
см. прикреплённую картинку для наглядности.
Проблема1️⃣
Декларация ВСЕХ тулов включается в контекст при каждом вызове модели, даже если тебе нужно использовать 10% из них. В контекст летит куча мусора, который никак не помогает модели выполнить задачу. Единственные кто в выигрыше – провайдеры моделей, которые получают больше денег за токены из-за MCP серверов, которые ты накатил в своё IDE и забываешь их выключать когда они тебе не особо нужны😏
Проблема2️⃣
Промежуточные результаты жрут контекст. Чтобы изменить команду юзера X, нужно 3 вызова MCP тулов — каждый постепенно наполняет окно своим выводом и ошибками. О context management писал 👉тут.
Почему лучше дать модели писать код
На рабочих созвонах с другими AI-чадами мы пришли к выводу: надо дать модели возможность просто писать и исполнять код. Код модели пишут куда лучше, чем вызывают тулы, и это логично. До 2023 года парадигмы tool calling вообще не существовало – провайдеры тренируют модели вызывать тулы на синтетических данных, которых никогда не было на GitHub. Заставлять LLM работать через tool calling это как отправить Прелепина на месячные курсы китайского, а потом попросить написать роман на этом языке. Мб получится... но партия не будет довольна (ни та, ни та)!😏
Решение от Anthropic
Вместо прямого вызова тулов представить MCP серверы как код-библиотеки. Агент взаимодействует с ними через написание и исполнение кода.
MCP серверы представляются как файловая структура с TypeScript функциями:
Агент загружает в контекст только те тулы, которые нужны для задачи, исследуя файловую систему.
Что это даёт на практике?
• Progressive disclosure: Модель навигирует по файлам и читает определения по требованию, а не все сразу. В примере Anthropic это сокращает использование токенов со 150,000 до 2,000 – экономия 98.7%.
• Фильтрация данных: Агент обрабатывает большие датасеты в среде исполнения. Вместо загрузки 10,000 строк из таблицы, можно отфильтровать нужные в коде и вернуть только 5.
• Эффективный control flow: Циклы, условия и обработка ошибок через привычные паттерны кода вместо цепочки отдельных tool calls.
• Privacy: Промежуточные результаты остаются в среде исполнения и не попадают в контекст модели. Можно даже автоматически токенизировать PII — модель видит [EMAIL_1], а реальные данные текут напрямую между системами.
• State persistence: Агент может сохранять промежуточные результаты в файлы и создавать переиспользуемые функции. Это завязывается с концепцией Skills с которой я ещё не до конца разобрался и мнения на этот счёт не имею, но идея в том, что со временем агент САМ наращивает свой тулбокс высокоуровневых возможностей.
AI инжиниринг сейчас — это как web development до 2010. Всё пишется в сыром HTML/CSS + JS, ещё непонятно, что мы будем использовать через 3-5 лет. Однозначных best practices просто нет, все учатся на ходу.
Экспертов с 15+ годами опыта в этой сфере не существует, а интервью на AI Engineer часто проводят люди, которые сами перекатились в ИИ-тусовку буквально вчера. И, лично для меня, в этом и кайф этой ниши 🚀
[источник]
#dev_help #ai
@makebugger
_
Антропики опубликовали действительно важную статью о проблемах MCP серверов. О некоторых косяках я уже писал 👉тут, сейчас на работе мы разрабатываем проект, где эти проблемы раскрылись во всей красе и разрушили изначальные планы по срокам.
Что не так с текущим подходом
У нас есть supervisor агент, делегирующий работу на reAct субагентов, которые напрямую взаимодействуют с MCP тулами. Всё ломается, когда агент должен оркестрировать что-то сложнее чем "добавь нового пользователя". Например: "измени команду пользователя X на команду с названием Z".
Допустим, что наш MCP сервер это просто обёртка над RESTом с классическими CRUDами:
get_user(), update_user(), create_user(), delete_user(), get_team(), update_team()...
см. прикреплённую картинку для наглядности.
Проблема
Декларация ВСЕХ тулов включается в контекст при каждом вызове модели, даже если тебе нужно использовать 10% из них. В контекст летит куча мусора, который никак не помогает модели выполнить задачу. Единственные кто в выигрыше – провайдеры моделей, которые получают больше денег за токены из-за MCP серверов, которые ты накатил в своё IDE и забываешь их выключать когда они тебе не особо нужны
Проблема
Промежуточные результаты жрут контекст. Чтобы изменить команду юзера X, нужно 3 вызова MCP тулов — каждый постепенно наполняет окно своим выводом и ошибками. О context management писал 👉тут.
Почему лучше дать модели писать код
На рабочих созвонах с другими AI-чадами мы пришли к выводу: надо дать модели возможность просто писать и исполнять код. Код модели пишут куда лучше, чем вызывают тулы, и это логично. До 2023 года парадигмы tool calling вообще не существовало – провайдеры тренируют модели вызывать тулы на синтетических данных, которых никогда не было на GitHub. Заставлять LLM работать через tool calling это как отправить Прелепина на месячные курсы китайского, а потом попросить написать роман на этом языке. Мб получится... но партия не будет довольна (ни та, ни та)!
Решение от Anthropic
Вместо прямого вызова тулов представить MCP серверы как код-библиотеки. Агент взаимодействует с ними через написание и исполнение кода.
MCP серверы представляются как файловая структура с TypeScript функциями:
servers/
├── user_management/
│ ├── getUser.ts
│ ├── updateUser.ts
│ ├── createUser.ts
│ └── index.ts
├── team_management/
│ ├── getTeam.ts
│ ├── updateTeam.ts
│ ├── createTeam.ts
│ └── index.ts
Агент загружает в контекст только те тулы, которые нужны для задачи, исследуя файловую систему.
Что это даёт на практике?
• Progressive disclosure: Модель навигирует по файлам и читает определения по требованию, а не все сразу. В примере Anthropic это сокращает использование токенов со 150,000 до 2,000 – экономия 98.7%.
• Фильтрация данных: Агент обрабатывает большие датасеты в среде исполнения. Вместо загрузки 10,000 строк из таблицы, можно отфильтровать нужные в коде и вернуть только 5.
• Эффективный control flow: Циклы, условия и обработка ошибок через привычные паттерны кода вместо цепочки отдельных tool calls.
• Privacy: Промежуточные результаты остаются в среде исполнения и не попадают в контекст модели. Можно даже автоматически токенизировать PII — модель видит [EMAIL_1], а реальные данные текут напрямую между системами.
• State persistence: Агент может сохранять промежуточные результаты в файлы и создавать переиспользуемые функции. Это завязывается с концепцией Skills с которой я ещё не до конца разобрался и мнения на этот счёт не имею, но идея в том, что со временем агент САМ наращивает свой тулбокс высокоуровневых возможностей.
AI инжиниринг сейчас — это как web development до 2010. Всё пишется в сыром HTML/CSS + JS, ещё непонятно, что мы будем использовать через 3-5 лет. Однозначных best practices просто нет, все учатся на ходу.
Экспертов с 15+ годами опыта в этой сфере не существует, а интервью на AI Engineer часто проводят люди, которые сами перекатились в ИИ-тусовку буквально вчера. И, лично для меня, в этом и кайф этой ниши 🚀
[источник]
#dev_help #ai
@makebugger
Please open Telegram to view this post
VIEW IN TELEGRAM
ImgBB
photo-2025-11-07-13-37-43 hosted at ImgBB
Image photo-2025-11-07-13-37-43 hosted on ImgBB
👍16🔥14
Желание эффективных менеджеров пихать ИИ туда куда не надо – главный источник финансирования автора этого канала
Итак, представим ситуацию1️⃣ , вы забыли пароль от аккаунта. Что делать?
До 2022 года вы бы нажали на кнопку «Забыл пароль» и сделали новый, так? Так?..
В ситуации ИИ революции, которая вихрем отбирает тёплые просиженные места у работяг, вы захотите написать ИИ Агенту🤖
после пинг-понга из пары сообщений, ошибки и медленной генерации токенов на половину экрана вы достигнете поставленной цели.
Зачем это делается?
1. Чтобы люди с культями смогли ресетнуть пароль голосом.
2. Чтобы у Соколовского была работа.
3. В этом году остался бюджет который надо куда-то потратить.
4. Чтобы потешить C-level кабанычей тем, что в компанию вошёл ИИ (теперь она воскреснет).
Все из выше перечисленных ответов верны. Я как честный и добросовестный ИИ Инженер интересуюсь
ответ убил (скриншот прикреплён).
Ситуация2️⃣ , допустим, вы разрабатываете приложение Яндекс Лавка, в голову менеджменту пришла идея добавить ИИ агента с которым вы будете мило беседовать и рассказывать какие вкусы читос вам нравится больше всего (конечно же пицца и кетчуп). Через этого агента можно сделать всё то же, что через графический интерфейс, только в разы медленнее и не до конца.
Я спрашиваю:
Ответ менеджмента:
выводы, как говорится, делайте сами.
Ситуации реальные, страшные и смешные. Сейчас все хотят купить ИИ, чтобы не отставать от конкурента, часто это доходит до абсурда.
Я не жалуюсь, тут в моём болоте ИИ Инжиниринга не ощущаю «очко на рынке» о котором все говорят, хотя может быть потому что я тот ещё туз😅
_
Полезное:
Для своих клиентов с кучей идей я всегда делаю Discovery фазу основной итог которой это матрица где Y это Business Value Potential, а X – Tech Feasibility (100 огоньков и скину пример в комменты👍 ), на этот график наносятся точки, где каждая точка это безумная идея менеджмента по внедрению ИИ с оценкой по технической и бизнес стороне.
Все точки делятся на три группы:
1. Рекомендую к покупке (клиенту легче купить готовое решение, чем платить за девелопмент)
2. Рекомендую делать самому (мой потенциальный заказ)
3. Деприоритизовано
Для части точек из первого квадранта вы хотите подготовить простенький Proof of Concept.
Сэкономили клиенту деньги, которые бы он потратил на разработку ненужных ему инструментов. Вот только большинство бизнесов не хотят за Discovery платить, предпочитая вбухать тысячи долларов в разработку мёртворождённого ИИ-калеки.
#dev_help #ai
@makebugger
Итак, представим ситуацию
До 2022 года вы бы нажали на кнопку «Забыл пароль» и сделали новый, так? Так?..
В ситуации ИИ революции, которая вихрем отбирает тёплые просиженные места у работяг, вы захотите написать ИИ Агенту
«Дорогой, ИИ Агент, пожалуйста переделай мне пароль, я его забыл»
после пинг-понга из пары сообщений, ошибки и медленной генерации токенов на половину экрана вы достигнете поставленной цели.
Зачем это делается?
1. Чтобы люди с культями смогли ресетнуть пароль голосом.
2. Чтобы у Соколовского была работа.
3. В этом году остался бюджет который надо куда-то потратить.
4. Чтобы потешить C-level кабанычей тем, что в компанию вошёл ИИ (теперь она воскреснет).
Все из выше перечисленных ответов верны. Я как честный и добросовестный ИИ Инженер интересуюсь
Не кажется ли вам, что здесь **уй не упал никакой ИИ и с ним будет больше мороки?
ответ убил (скриншот прикреплён).
Ситуация
Я спрашиваю:
А какой долгосрочный план для развития этого агента? В чём собственно цель?
Ответ менеджмента:
Полностью избавиться от графического интерфейса, чтобы пользователи через нашего бота продукты заказывали
выводы, как говорится, делайте сами.
Ситуации реальные, страшные и смешные. Сейчас все хотят купить ИИ, чтобы не отставать от конкурента, часто это доходит до абсурда.
Я не жалуюсь, тут в моём болоте ИИ Инжиниринга не ощущаю «очко на рынке» о котором все говорят, хотя может быть потому что я тот ещё туз
_
Полезное:
Для своих клиентов с кучей идей я всегда делаю Discovery фазу основной итог которой это матрица где Y это Business Value Potential, а X – Tech Feasibility (100 огоньков и скину пример в комменты
Все точки делятся на три группы:
1. Рекомендую к покупке (клиенту легче купить готовое решение, чем платить за девелопмент)
2. Рекомендую делать самому (мой потенциальный заказ)
3. Деприоритизовано
Для части точек из первого квадранта вы хотите подготовить простенький Proof of Concept.
Сэкономили клиенту деньги, которые бы он потратил на разработку ненужных ему инструментов. Вот только большинство бизнесов не хотят за Discovery платить, предпочитая вбухать тысячи долларов в разработку мёртворождённого ИИ-калеки.
#dev_help #ai
@makebugger
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥104
Планируете интеграцию ИИ в новом году?
Продолжая тему планирования и приоритизации ИИ проектов: 👉тут я уже говорил, что первый этап приоритизации может быть high-level оценкой с технической и бизнес стороны. Тут очень важно давать не объективную, а относительную оценку.
Это значит, что оценка сложности и импакта каждого проекта зависит от всех остальных проектов в выборке. Делается это для более лёгкой приоритизации действительно важных вещей, иначе точки на вашей системе координат имеют тенденцию быть очень кучными. Оценку всех инициатив лучше делать «взахлёб», чтобы в процессе анализа у вас сохранялся контекст всех остальных инициатив.
Процесс следующий:
1️⃣Анализ инициативы и первичная оценка от 1 до 10, где 1 это – у нас нет достаточной экспертизы, чтобы заделиверить проект в течение полугода, изначальные требования от системы нереалистичные, нынешние технологии этого не позволяют. А 10 это – есть вся необходимая экспертиза, сможем заделиверить за 40-60 MD (1 ManDay = 8 часов).
2️⃣По ходу прохождения списка инициатив нормально прыгать назад и подправлять оценку предыдущих. Оценка должна быть относительной, чтобы менеджменту было легче принять решения по приоритизации.
3️⃣После первичного прохождения инициатив нужно сделать ревью и добавить объяснение своей оценки в 2-3 предложениях. После этого ваш ПМ должен сделать похожее ментальное упражнение для всех инициатив с бизнес точки зрения.
4️⃣Из самых приоритетных инициатив первого квадранта вам нужно составить short list с детальной технической оценкой по нескольким параметрам.
Пример параметров:
• Ожидаемая точность модели
• Архитектура data пайплайн
• Хостинг и развертывание моделей
• Количество и типы источников данных
• Объем данных
• Необходимые интеграции с системами
• Доступность и готовность API
• Оценка стоимости
• Зависимость от задержек (Latency)
• Требуемая производительность системы
• Риски соответствия (Compliance) и безопасности
• Возможность масштабирования на другие кейсы.
…
Это всего лишь фреймворк процесса, а не догма.
#dev_help #ai
@makebugger
Продолжая тему планирования и приоритизации ИИ проектов: 👉тут я уже говорил, что первый этап приоритизации может быть high-level оценкой с технической и бизнес стороны. Тут очень важно давать не объективную, а относительную оценку.
Это значит, что оценка сложности и импакта каждого проекта зависит от всех остальных проектов в выборке. Делается это для более лёгкой приоритизации действительно важных вещей, иначе точки на вашей системе координат имеют тенденцию быть очень кучными. Оценку всех инициатив лучше делать «взахлёб», чтобы в процессе анализа у вас сохранялся контекст всех остальных инициатив.
Процесс следующий:
1️⃣Анализ инициативы и первичная оценка от 1 до 10, где 1 это – у нас нет достаточной экспертизы, чтобы заделиверить проект в течение полугода, изначальные требования от системы нереалистичные, нынешние технологии этого не позволяют. А 10 это – есть вся необходимая экспертиза, сможем заделиверить за 40-60 MD (1 ManDay = 8 часов).
2️⃣По ходу прохождения списка инициатив нормально прыгать назад и подправлять оценку предыдущих. Оценка должна быть относительной, чтобы менеджменту было легче принять решения по приоритизации.
3️⃣После первичного прохождения инициатив нужно сделать ревью и добавить объяснение своей оценки в 2-3 предложениях. После этого ваш ПМ должен сделать похожее ментальное упражнение для всех инициатив с бизнес точки зрения.
4️⃣Из самых приоритетных инициатив первого квадранта вам нужно составить short list с детальной технической оценкой по нескольким параметрам.
Пример параметров:
• Ожидаемая точность модели
• Архитектура data пайплайн
• Хостинг и развертывание моделей
• Количество и типы источников данных
• Объем данных
• Необходимые интеграции с системами
• Доступность и готовность API
• Оценка стоимости
• Зависимость от задержек (Latency)
• Требуемая производительность системы
• Риски соответствия (Compliance) и безопасности
• Возможность масштабирования на другие кейсы.
…
Это всего лишь фреймворк процесса, а не догма.
#dev_help #ai
@makebugger
🔥10