
Привет!
Сейчас немного тихо так как я взял небольшую передышку и приехал на недельку-другую в северную столицу отпраздновать юбилей 🤗
В скором времени выпущу мини видео гайд по достаточно полезной платформе для написания комплексных [LLM] workflows, она пока ещё не очень хайповая, но по стечению обстоятельств работаю с ней уже в третьей компании и везде девы выделяют приятнейший developer experience.
Называется temporal.io
Зачем нам очередной тул?
- Если делаете что-то более комплексное, чем один API запрос. (например, взять документ, перевести его в png картинки, послать запрос на Optical Character Recognition (OCR), потом переслать то, что вылезло из OCR в LLM…). Более конвенциональным решением бы было использовать celery, но dev experience и дебагинг комплексных workflows – боль.
- Temporal может заморозить workflow в ожидании inputa человека (Human-in-the-Loop). Если вы верите в то, что сила агентов не в полной автоматизации человеческого труда, а в умной интеграции агентов с людьми, то вам точно понравится temporal. (это мы в проде прям использовали на очень крупном проекте, работало безупречно, LLM делало работу которую перепроверяли наши gig workers, после того как проверка прошла workflow возобновлялся)
- Temporal гарантирует выполнение даже при сбоях. Если ваш сервер упал посередине обработки 100-страничного документа на 73 странице — workflow автоматически продолжится с того же места после перезапуска. В celery такой таск просто пропадёт.
- классный UI и sdk
#dev_help
@makebugger
Сейчас немного тихо так как я взял небольшую передышку и приехал на недельку-другую в северную столицу отпраздновать юбилей 🤗
В скором времени выпущу мини видео гайд по достаточно полезной платформе для написания комплексных [LLM] workflows, она пока ещё не очень хайповая, но по стечению обстоятельств работаю с ней уже в третьей компании и везде девы выделяют приятнейший developer experience.
Называется temporal.io
Зачем нам очередной тул?
- Если делаете что-то более комплексное, чем один API запрос. (например, взять документ, перевести его в png картинки, послать запрос на Optical Character Recognition (OCR), потом переслать то, что вылезло из OCR в LLM…). Более конвенциональным решением бы было использовать celery, но dev experience и дебагинг комплексных workflows – боль.
- Temporal может заморозить workflow в ожидании inputa человека (Human-in-the-Loop). Если вы верите в то, что сила агентов не в полной автоматизации человеческого труда, а в умной интеграции агентов с людьми, то вам точно понравится temporal. (это мы в проде прям использовали на очень крупном проекте, работало безупречно, LLM делало работу которую перепроверяли наши gig workers, после того как проверка прошла workflow возобновлялся)
- Temporal гарантирует выполнение даже при сбоях. Если ваш сервер упал посередине обработки 100-страничного документа на 73 странице — workflow автоматически продолжится с того же места после перезапуска. В celery такой таск просто пропадёт.
- классный UI и sdk
#dev_help
@makebugger
temporal.io
Durable Execution Solutions
Build invincible apps with Temporal's open source durable execution platform. Eliminate complexity and ship features faster. Talk to an expert today!
🔥3❤2👍2🤩2
Бенчмарки
Каждый месяц нам дропают новые модели с бенчмарками.
Многие провайдеры тренят свои модельки с главной целью – выиграть новый бенч и нагнать хайпа. Большинство бенчей –💩.
Но я тут нашёл хороший бенч который к сожалению не обновлялся с мая, лучшие модели из этого топа соответствуют настроениям в индустрии, anthropic модели всё так же лучше всего справляются с tool calling, а reasoning + tool calling это, по сути, самый важный скил моделей, который помогает им решать комплексные задачи типа кодинга и любых кастомных агентов.
Бенч строится над симулятором DevOpsa 😅 (faktorio), если не играли, то не пробуйте, затягивает безумно, если играли и слезли, то респект, таким людям как вам даже гер0ин по зубам..
Надеемся, что скоро волонтёры затестят новую kimi.ai модель и мы наконец узнаем оправдан ли хайп вокруг этого свежего релиза.
#ai
@makebugger
Каждый месяц нам дропают новые модели с бенчмарками.
Многие провайдеры тренят свои модельки с главной целью – выиграть новый бенч и нагнать хайпа. Большинство бенчей –💩.
Но я тут нашёл хороший бенч который к сожалению не обновлялся с мая, лучшие модели из этого топа соответствуют настроениям в индустрии, anthropic модели всё так же лучше всего справляются с tool calling, а reasoning + tool calling это, по сути, самый важный скил моделей, который помогает им решать комплексные задачи типа кодинга и любых кастомных агентов.
Бенч строится над симулятором DevOpsa 😅 (faktorio), если не играли, то не пробуйте, затягивает безумно, если играли и слезли, то респект, таким людям как вам даже гер0ин по зубам..
Надеемся, что скоро волонтёры затестят новую kimi.ai модель и мы наконец узнаем оправдан ли хайп вокруг этого свежего релиза.
#ai
@makebugger
arc.net
Quote from “Multi-Agent Coordination in Factorio: FLE v0.2 Release”
👍3
This media is not supported in the widget
VIEW IN TELEGRAM
❤7👍4🔥1
Аларм! GPT-5
Совсем скоро начнётся презентация нового поколения моделей от OpenAI 🫣
GPT-4 была выпущена уже больше двух лет назад и тогда это был прорыв на фоне gpt-3.5, мы сразу же начали интегрировать её в продукт.
Полезная выжимка из презентации:
• GPT-5 такая же умная как топовые reasoning модели и такая же быстрая как gpt4o
• Лучшая модель по SWE бенчмарку, даже лучше чем недавний Opus 4.1
• Hallucination rate в 5-6 раз меньше, чем у o3
• Цены на новые модели в комментах
• Много косметических апгрейдов в ChatGPT, цвета можете у чатов менять)) выкатили интеграцию с GMail и Google Calendar
#news
@makebugger
https://www.youtube.com/live/0Uu_VJeVVfo?si=pCsF_R1DGZTC9JFK
Совсем скоро начнётся презентация нового поколения моделей от OpenAI 🫣
GPT-4 была выпущена уже больше двух лет назад и тогда это был прорыв на фоне gpt-3.5, мы сразу же начали интегрировать её в продукт.
Полезная выжимка из презентации:
• GPT-5 такая же умная как топовые reasoning модели и такая же быстрая как gpt4o
• Лучшая модель по SWE бенчмарку, даже лучше чем недавний Opus 4.1
• Hallucination rate в 5-6 раз меньше, чем у o3
• Цены на новые модели в комментах
• Много косметических апгрейдов в ChatGPT, цвета можете у чатов менять)) выкатили интеграцию с GMail и Google Calendar
#news
@makebugger
https://www.youtube.com/live/0Uu_VJeVVfo?si=pCsF_R1DGZTC9JFK
YouTube
Introducing GPT-5
Sam Altman, Greg Brockman, Sebastien Bubeck, Mark Chen, Yann Dubois, Brian Fioca, Adi Ganesh, Oliver Godement, Saachi Jain, Christina Kaplan, Christina Kim, Elaine Ya Le, Felipe Millon, Michelle Pokrass, Jakub Pachocki, Max Schwarzer, Rennie Song, Ruochen…
🤯2❤1
Эйджиай не будет
Уже целых два дня я активно пробую GPT-5 в Cursor, через API и в ChatGPT, если коротко: «Всё очень плохо», в первую очередь потому, что ожидания на этот релиз были завышены.
О скачке который мы испытали с gpt-3.5 до gpt-4 и речи быть не может.
GPT-5 это не просто новая модель, а система оркестрации моделей, как кажется, созданная в первую очередь для оптимизации стоимости.
Теперь вы не можете выбрать самую дорогую и качественную o3 в ChatGPT по своему желанию, есть только GPT-5 и GPT-5 Thinking и они выступают маршрутизатором для перенаправления ваших запросов в другие модели под капотом, если GPT-5 и Сэм Алтман решат, что вам можно воспользоваться o3, то тогда её вызовут, но вы об этом даже не узнаете.
Бенчмарки с презентации – наебалово, не понятно для кого надо было выдумывать все эти цифры и выставлять свою модель SOTA, если это вскроется через пару дней. Модель ооочень далека от Opus.
Если вы хотите сделать бесшовный апгрейд с предыдущих моделей на gpt-5 через API, то этого у вас тоже не получится, они зарелизили breaking changes, gpt-5 не принимает такие параметры как temperature (вы больше не можете регулировать креативность модели) и max_token (модель сама решит, когда ей надо остановится).
Короче,
• индустрия в целом движется по хорошему вектору
• с каждой следующей презентацией OpenAI теряет лидерство и преимущество «первой на рынке»
• никого пока не заменяют, все продолжаем работать
#news #ai
@makebugger
thumbnail мне было лень делать, видео дублирует информацию из поста, поддержите лайком)
https://youtu.be/cCr6-Lm7r24?si=d2v4nC1ckF_J6yho
Уже целых два дня я активно пробую GPT-5 в Cursor, через API и в ChatGPT, если коротко: «Всё очень плохо», в первую очередь потому, что ожидания на этот релиз были завышены.
О скачке который мы испытали с gpt-3.5 до gpt-4 и речи быть не может.
GPT-5 это не просто новая модель, а система оркестрации моделей, как кажется, созданная в первую очередь для оптимизации стоимости.
Теперь вы не можете выбрать самую дорогую и качественную o3 в ChatGPT по своему желанию, есть только GPT-5 и GPT-5 Thinking и они выступают маршрутизатором для перенаправления ваших запросов в другие модели под капотом, если GPT-5 и Сэм Алтман решат, что вам можно воспользоваться o3, то тогда её вызовут, но вы об этом даже не узнаете.
Бенчмарки с презентации – наебалово, не понятно для кого надо было выдумывать все эти цифры и выставлять свою модель SOTA, если это вскроется через пару дней. Модель ооочень далека от Opus.
Если вы хотите сделать бесшовный апгрейд с предыдущих моделей на gpt-5 через API, то этого у вас тоже не получится, они зарелизили breaking changes, gpt-5 не принимает такие параметры как temperature (вы больше не можете регулировать креативность модели) и max_token (модель сама решит, когда ей надо остановится).
Короче,
• индустрия в целом движется по хорошему вектору
• с каждой следующей презентацией OpenAI теряет лидерство и преимущество «первой на рынке»
• никого пока не заменяют, все продолжаем работать
#news #ai
@makebugger
thumbnail мне было лень делать, видео дублирует информацию из поста, поддержите лайком)
https://youtu.be/cCr6-Lm7r24?si=d2v4nC1ckF_J6yho
YouTube
GPT-5 – ПРОВАЛ ЛЕТА?
https://t.me/makebugger – Телеграмм канал о ИИ и не только
GPT-5 с точки зрения разработчика оказалось провальным релизом, вы этом видео расскажу почему и поделюсь эмоциями от использования модели на протяжении последних 3 дней.
GPT-5 с точки зрения разработчика оказалось провальным релизом, вы этом видео расскажу почему и поделюсь эмоциями от использования модели на протяжении последних 3 дней.
❤16👍4
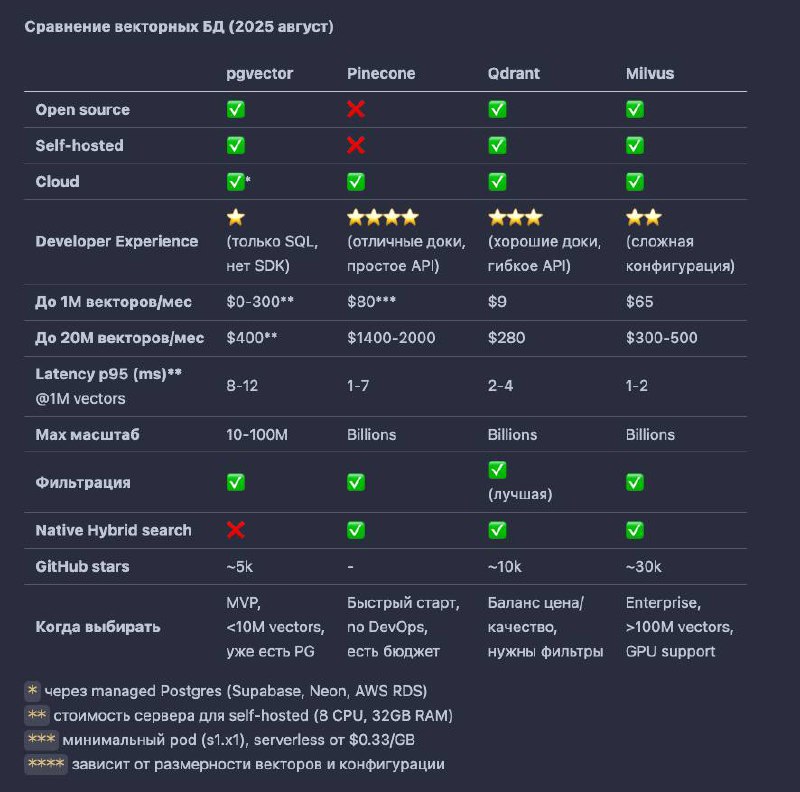
Cделал умный поиск для одного известного IT сообщества. Делюсь опытом.
В ядре умного поиска (semantic search) всегда кроется завсегдатый RAG.
Что мы знаем про RAG – берёшь документы, режешь на чанки, засовываешь в векторную БД.
А в какую векторную БД сохранять эмбединги?
Есть Pinecone, QDrant, Milvus, недавно запустившийся jстартап моего друга topk.
В принципе, оно все очень похожи…
какие вопросы стоит задать, чтобы выбрать подходящую?
• self-hosted или cloud?
С self-hosted больше мороки, но всё под контролем, cloud очень быстро можно setupнуть, отлично когда нет времени на DevOps
• какая ожидаемая нагрузка?
если вы не пишете второй фейсбук, а количество векторов меньше 1М, то речь о крошечных объёмах, вам не нужна супер пропускная векторная БД
• вы уже используете Postgres?
не стоит привносить новую зависимость, если вы знаете, что не будете скейлить приложение на масштабы нетфликса, стоит использовать pgvector
PgVector это расширение для вашего обычного Postgres которое добавляет новый тип
выбрав этот вариант вместо любой другой векторной БД, вам не нужно будет думать о скейлинге и бэкапе отдельной БД, а инженеры в вашей команде уже будут знать как с этим работать
В случае когда вы хотите написать быстрое PoC, или если знаете, что будут огромные объёмы >1М векторов, или когда pgvector уже не справляется — тогда смотрим на специализированные решения. Делюсь табличкой!
TL;DR:
pgvector — если уже есть Postgres и <10M векторов
Pinecone — если нужно запустить экстра быстро и есть $70+/месяц
Qdrant — оптимальный выбор по соотношению цена/качество/функционал
Milvus — когда реально большие объёмы и нужна максимальная производительность
#ai #dev_help
@makebugger
В ядре умного поиска (semantic search) всегда кроется завсегдатый RAG.
Что мы знаем про RAG – берёшь документы, режешь на чанки, засовываешь в векторную БД.
А в какую векторную БД сохранять эмбединги?
Есть Pinecone, QDrant, Milvus, недавно запустившийся jстартап моего друга topk.
В принципе, оно все очень похожи…
какие вопросы стоит задать, чтобы выбрать подходящую?
• self-hosted или cloud?
С self-hosted больше мороки, но всё под контролем, cloud очень быстро можно setupнуть, отлично когда нет времени на DevOps
• какая ожидаемая нагрузка?
если вы не пишете второй фейсбук, а количество векторов меньше 1М, то речь о крошечных объёмах, вам не нужна супер пропускная векторная БД
• вы уже используете Postgres?
не стоит привносить новую зависимость, если вы знаете, что не будете скейлить приложение на масштабы нетфликса, стоит использовать pgvector
PgVector это расширение для вашего обычного Postgres которое добавляет новый тип
vector
выбрав этот вариант вместо любой другой векторной БД, вам не нужно будет думать о скейлинге и бэкапе отдельной БД, а инженеры в вашей команде уже будут знать как с этим работать
В случае когда вы хотите написать быстрое PoC, или если знаете, что будут огромные объёмы >1М векторов, или когда pgvector уже не справляется — тогда смотрим на специализированные решения. Делюсь табличкой!
TL;DR:
pgvector — если уже есть Postgres и <10M векторов
Pinecone — если нужно запустить экстра быстро и есть $70+/месяц
Qdrant — оптимальный выбор по соотношению цена/качество/функционал
Milvus — когда реально большие объёмы и нужна максимальная производительность
#ai #dev_help
@makebugger
{kind=link}
❤24🔥4
Наша паранойя
Последнее время всё больше взаимодействую с коллегами с российского айти рынка и заметил интересную особенность: люди буквально помешаны на self-hosted решениях. Главное, чтобы в облако ни байтика не просочилось.
Все очень обеспокоены безопасностью данных: кому мы их передаём, где хостим модель, а не тренируют ли модель на наших данных. Параноя на каждом шагу.
На US/EU рынке ни минуты не тратят на переизобретение велосипедов. Тут работает презумпция доверия: если главный бизнес компании - это векторные БД в облаке, значит они там всё продумали и обеспечили безопасность. У них весь бизнес на этом держится, какой им смысл рисковать репутацией?
А на российском и СНГ рынке многие хотят делать кастомные решения, искренне веря, что за пару недель накодят внутренний аналог того, на базе чего целые компании строятся.
У меня есть теория, львиную долю российского IT-рынка жрут банки и госконторы, где такая паранойя действительно оправдана. Но айтишники из этих компаний переносят свой секьюрити майндсет в стартапы, где нужно продукты делать и кусок рынка отхватить, а не заниматься мастурбацией на тему “а вдруг омериканцы наш код украдут”.
В итоге команды обкладываются своими security best practices: квантизованный DeepSeek на ноутбуке вместо Cursor - ну чтобы кодбазу не слить проклятым империалистам.
А то вдруг они там в Кремниевой долине увидят гениальную переменную is_voronezh и сразу поймут, как составить конкуренцию.
Лучше уж месяц мучиться с самописным решением, чем дать заокеанским шпионам возможность подсмотреть, как мы комментарии на русском пишем. Они же сразу наш уникальный бизнес-процесс вычислят и начнут с нами конкурировать за клиентов из четвёртого ЖЭКа.
А между тем успешная компания - это вообще не только про код. Это про то, умеешь ли ты решать проблемы людей, продавать, строить процессы. Если завтра Google открыто выложит весь свой код, сколько конкурентов реально появится? Примерно ноль. Потому что дело не в коде, а в том, что за ним стоит.
Но нет, давайте лучше еще месяц будем пилить свой велосипед и гордиться тем, что наши православные переменные не видел ни один американский сервер.
Не говорю, что не нужно заниматься безопасностью, нужно, но то сколько вниманию этому уделяется меня удивляет.
#business
@makebugger
Последнее время всё больше взаимодействую с коллегами с российского айти рынка и заметил интересную особенность: люди буквально помешаны на self-hosted решениях. Главное, чтобы в облако ни байтика не просочилось.
Все очень обеспокоены безопасностью данных: кому мы их передаём, где хостим модель, а не тренируют ли модель на наших данных. Параноя на каждом шагу.
На US/EU рынке ни минуты не тратят на переизобретение велосипедов. Тут работает презумпция доверия: если главный бизнес компании - это векторные БД в облаке, значит они там всё продумали и обеспечили безопасность. У них весь бизнес на этом держится, какой им смысл рисковать репутацией?
А на российском и СНГ рынке многие хотят делать кастомные решения, искренне веря, что за пару недель накодят внутренний аналог того, на базе чего целые компании строятся.
У меня есть теория, львиную долю российского IT-рынка жрут банки и госконторы, где такая паранойя действительно оправдана. Но айтишники из этих компаний переносят свой секьюрити майндсет в стартапы, где нужно продукты делать и кусок рынка отхватить, а не заниматься мастурбацией на тему “а вдруг омериканцы наш код украдут”.
В итоге команды обкладываются своими security best practices: квантизованный DeepSeek на ноутбуке вместо Cursor - ну чтобы кодбазу не слить проклятым империалистам.
А то вдруг они там в Кремниевой долине увидят гениальную переменную is_voronezh и сразу поймут, как составить конкуренцию.
Лучше уж месяц мучиться с самописным решением, чем дать заокеанским шпионам возможность подсмотреть, как мы комментарии на русском пишем. Они же сразу наш уникальный бизнес-процесс вычислят и начнут с нами конкурировать за клиентов из четвёртого ЖЭКа.
А между тем успешная компания - это вообще не только про код. Это про то, умеешь ли ты решать проблемы людей, продавать, строить процессы. Если завтра Google открыто выложит весь свой код, сколько конкурентов реально появится? Примерно ноль. Потому что дело не в коде, а в том, что за ним стоит.
Но нет, давайте лучше еще месяц будем пилить свой велосипед и гордиться тем, что наши православные переменные не видел ни один американский сервер.
Не говорю, что не нужно заниматься безопасностью, нужно, но то сколько вниманию этому уделяется меня удивляет.
#business
@makebugger
👍17❤2👏2🤩1
Люди за это деньги платят
"Не используйте технологию в продукте только потому, что это круто!"
Некоторые ML инженеры имеют черту усложнять решение проблемы с самого начала. В контексте LLM они сразу же хотят утонуть в файн тюнинге... Подбор гиперпараметров, наблюдать за validation loss и чистить датасеты!!! ведь это и есть настоящая ЭЙАЙ наука, скажут они.
По факту, в контексте LLM, в большинстве случаев это over-engineering, то бишь использование огромной кувалды для забивания гвоздиков.
Предлагаю свой ментальный фреймворк для решения задач любого типа:
Шаг 0.
Ты уверен, что хочешь спуститься в бездну галлиционирющих ЛЛМ? Может быть задача решается с помощью regex или обычной проги?
Если да, то можешь смотреть прикреплённую блок-схему.
<смотрит блок схему🤔 >
<досмотрел, ставит огонёчек, репостит>
TL;DR
Ты не хочешь тюнить большую языковую модель, поверь мне!!!
- Поддержка продукта построенного над натюненой моделью будет куда более комплексной чем использование API
- Подготовить хороший датасет это дни или недели скучнейшей работы
- Тренировка стоит деньги, например H100 сейчас стоит 3$ в час, это несколько десятков миллионов input токенов для gemini
- Скорее всего ты просто сломаешь модель и она станет тупее первого grokа
- Если что-то выглядит/звучит круто, это не значит, что это стоит сразу же применять
- Через 4 месяца выходит новая модель, будешь всё перетюнивать?
#ai #dev_help
@makebugger
"Не используйте технологию в продукте только потому, что это круто!"
Некоторые ML инженеры имеют черту усложнять решение проблемы с самого начала. В контексте LLM они сразу же хотят утонуть в файн тюнинге... Подбор гиперпараметров, наблюдать за validation loss и чистить датасеты!!! ведь это и есть настоящая ЭЙАЙ наука, скажут они.
По факту, в контексте LLM, в большинстве случаев это over-engineering, то бишь использование огромной кувалды для забивания гвоздиков.
Предлагаю свой ментальный фреймворк для решения задач любого типа:
Шаг 0.
Ты уверен, что хочешь спуститься в бездну галлиционирющих ЛЛМ? Может быть задача решается с помощью regex или обычной проги?
Если да, то можешь смотреть прикреплённую блок-схему.
<смотрит блок схему
<досмотрел, ставит огонёчек, репостит>
TL;DR
Тюнить модель != RAG
когда вы тюните модель вы изменяете параметры нейронной сети, во время RAG вы просто обогащаете контекст модели
Ты не хочешь тюнить большую языковую модель, поверь мне!!!
- Поддержка продукта построенного над натюненой моделью будет куда более комплексной чем использование API
- Подготовить хороший датасет это дни или недели скучнейшей работы
- Тренировка стоит деньги, например H100 сейчас стоит 3$ в час, это несколько десятков миллионов input токенов для gemini
- Скорее всего ты просто сломаешь модель и она станет тупее первого grokа
- Если что-то выглядит/звучит круто, это не значит, что это стоит сразу же применять
- Через 4 месяца выходит новая модель, будешь всё перетюнивать?
#ai #dev_help
@makebugger
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥13❤12👍9
Главный капитал – люди
В 2022 году я пол года жил и учился в Сингапуре, у меня есть куча историй оттуда, но сегодня хочу рассказать как я вообще туда попал.
Я просто нормально учился в университете и написал один имейл профессору со связями. Всё. (письмо скину в комменты)
До переезда в Чехию я никогда в жизни я никуда из РФ не выезжал, поэтому гештальт «ездить по миру» у меня был совсем не закрыт. Написал я как-то самому заряженному профессору факультета который больше всего кайфовал от процесса преподавания, что мол давай меня куда-нибудь заграницу отправим, диплом писать, кайфовать и курить бамбук.
Он мне ответил полотном текста и предложил, Швейцарию, Испанию, Германию, Израиль, Китай, Сингапур… мне.. челику из Армавира. Поехал я в итоге в банановый Сингапур, это был первый и последний раз в жизни когда мне пригодился мой красный аттестат за 10-11 классы, он нужен был для получения стипендии (в месяц сингапурцы платили 1500 S$, а от Чехии я достал единовременную выплату 4000 €) писал диплом, катался по юго восточной азии и жил.
Мораль простая: успешные в своём деле люди очень охотно подтягивают тех, кто показывает интерес. Нужно только проявить минимальную инициативу и иметь огонь в глазах. Такие люди заряжаются от молодых и кайфуют от того, что могут им помочь. Через этого же профа, кстати, познакомился с фаундером стартапа, где проработал больше двух лет.
Если вы ещё учитесь и у вас есть возможность, то обязательно скатайтесь куда-нибудь по обмену, когда вам 20-25 лет такой опыт бесценен и останется в вами навсегда. Не нужно боятся растянуть учёбу и потерять время, всех денег мира вы всё равно не заработаете, а такие поездки это как маленькая жизнь внутри вашей обычно жизни.
#life #university
@makebugger
В 2022 году я пол года жил и учился в Сингапуре, у меня есть куча историй оттуда, но сегодня хочу рассказать как я вообще туда попал.
Я просто нормально учился в университете и написал один имейл профессору со связями. Всё. (письмо скину в комменты)
До переезда в Чехию я никогда в жизни я никуда из РФ не выезжал, поэтому гештальт «ездить по миру» у меня был совсем не закрыт. Написал я как-то самому заряженному профессору факультета который больше всего кайфовал от процесса преподавания, что мол давай меня куда-нибудь заграницу отправим, диплом писать, кайфовать и курить бамбук.
Он мне ответил полотном текста и предложил, Швейцарию, Испанию, Германию, Израиль, Китай, Сингапур… мне.. челику из Армавира. Поехал я в итоге в банановый Сингапур, это был первый и последний раз в жизни когда мне пригодился мой красный аттестат за 10-11 классы, он нужен был для получения стипендии (в месяц сингапурцы платили 1500 S$, а от Чехии я достал единовременную выплату 4000 €) писал диплом, катался по юго восточной азии и жил.
Мораль простая: успешные в своём деле люди очень охотно подтягивают тех, кто показывает интерес. Нужно только проявить минимальную инициативу и иметь огонь в глазах. Такие люди заряжаются от молодых и кайфуют от того, что могут им помочь. Через этого же профа, кстати, познакомился с фаундером стартапа, где проработал больше двух лет.
Если вы ещё учитесь и у вас есть возможность, то обязательно скатайтесь куда-нибудь по обмену, когда вам 20-25 лет такой опыт бесценен и останется в вами навсегда. Не нужно боятся растянуть учёбу и потерять время, всех денег мира вы всё равно не заработаете, а такие поездки это как маленькая жизнь внутри вашей обычно жизни.
#life #university
@makebugger
🔥22❤10👍8🤩2
Стартапы это очень крутой опыт прокачаться как инженер, понять как устроен айти бизнес, разобраться с инвестиционными терминами и обзавестись кучей связей с заряженными людьми.
Если вы в начале своей карьеры, то однозначно рекомендую стартап (желательно с американским юр лицом) по нескольким причинам:
1. Ты станешь швейцарским ножом который сегодня пишет код, завтра принимает участие в общении с клиентом на user interview, а послезавтра общается с PMом о том какие фичи стоит добавить в следующий релиз. Ты будешь понимать как устроен весь цикл разработки продукта.
2. Ты понимаешь как устроены стартапы и венчурные инвестиции, что такое pre-seed, seed, series A, как работают stock options и почему важно знать vesting period. (ниже будет словарик терминов)
3. Связи, пожалуй самая важная причина присоединиться к стартапу, окружи себя крутыми инженерами с бизнес майндсетом и забудь про то, что работу надо искать на linkedin или hh, самые жирные вакансии заполняются через сарафан и обычно не доходят до размещения на этих платформах.
Моё предположение, что на моей нынешней работе мне накинули ~1k $ только из-за того, что в стартапе где я работал до этого у меня была хорошая репутация 🤫, а в Чехии/Словакии все фаундеры друг друга знают и все +- друг про друга слышали, так и накинули косарик по блату.
Небольшой словарик терминов, как обещал:
• pre-seed – самый первый раунд инвестиций, обычно выдаётся тупо на то, чтобы вы проверили идею и попробовали найти клиента, самое главное набрать крутую команду, от этого зависит успех нормального pre-seedа
pre-seed не выдаётся на продукт, можете иметь какую угодно идею, если VC/angel investor вас не знает, стартаповского опыта у вас нет, а команда состоит из ноу неймов, то получить деньги на первый рывок будет сложновато.
обычно 500k-1kk$
звучит как будто это много денег, но это тратится на зарплаты, разработку и первые маркетинговые потуги, runway обычно на год-два.
• VC - venture capital или венчурный капиталист – инвестиционный фонд, вкладывающий деньги в стартапы, обычно в 30-50 штук, надеясь, что чтото да выстрелит, один из самый популярных фондов это YC. Вы прямо сейчас можете подать туда заявку :)
• angel investor - частное лицо, вкладывающее свои собственные деньги. Обычно это те, кто уже успешно экзитли (exit) из своих стартапов и теперь хотят поиграть в инвесторов или просто очень богатые люди которым интересен айти рынок.
• runway - это важный показатель который должны сообщать всем совладельцам компании на каждом all hands🙌🏿 созвоне. Означает этот показатель сколько месяцев ваш стартап протянет на текущих деньгах до банкротства.
runway = кол-ва денег в банке / на месячный money burn rate
Фууф, что-то я разогнался.. продолжать или утомил вас этими амерскими словечками..? Интересна вообще эта тема🔥 ?
#startup
@makebugger
Если вы в начале своей карьеры, то однозначно рекомендую стартап (желательно с американским юр лицом) по нескольким причинам:
1. Ты станешь швейцарским ножом который сегодня пишет код, завтра принимает участие в общении с клиентом на user interview, а послезавтра общается с PMом о том какие фичи стоит добавить в следующий релиз. Ты будешь понимать как устроен весь цикл разработки продукта.
2. Ты понимаешь как устроены стартапы и венчурные инвестиции, что такое pre-seed, seed, series A, как работают stock options и почему важно знать vesting period. (ниже будет словарик терминов)
3. Связи, пожалуй самая важная причина присоединиться к стартапу, окружи себя крутыми инженерами с бизнес майндсетом и забудь про то, что работу надо искать на linkedin или hh, самые жирные вакансии заполняются через сарафан и обычно не доходят до размещения на этих платформах.
Моё предположение, что на моей нынешней работе мне накинули ~1k $ только из-за того, что в стартапе где я работал до этого у меня была хорошая репутация 🤫, а в Чехии/Словакии все фаундеры друг друга знают и все +- друг про друга слышали, так и накинули косарик по блату.
Небольшой словарик терминов, как обещал:
• pre-seed – самый первый раунд инвестиций, обычно выдаётся тупо на то, чтобы вы проверили идею и попробовали найти клиента, самое главное набрать крутую команду, от этого зависит успех нормального pre-seedа
pre-seed не выдаётся на продукт, можете иметь какую угодно идею, если VC/angel investor вас не знает, стартаповского опыта у вас нет, а команда состоит из ноу неймов, то получить деньги на первый рывок будет сложновато.
обычно 500k-1kk$
звучит как будто это много денег, но это тратится на зарплаты, разработку и первые маркетинговые потуги, runway обычно на год-два.
• VC - venture capital или венчурный капиталист – инвестиционный фонд, вкладывающий деньги в стартапы, обычно в 30-50 штук, надеясь, что чтото да выстрелит, один из самый популярных фондов это YC. Вы прямо сейчас можете подать туда заявку :)
• angel investor - частное лицо, вкладывающее свои собственные деньги. Обычно это те, кто уже успешно экзитли (exit) из своих стартапов и теперь хотят поиграть в инвесторов или просто очень богатые люди которым интересен айти рынок.
• runway - это важный показатель который должны сообщать всем совладельцам компании на каждом all hands🙌🏿 созвоне. Означает этот показатель сколько месяцев ваш стартап протянет на текущих деньгах до банкротства.
runway = кол-ва денег в банке / на месячный money burn rate
Фууф, что-то я разогнался.. продолжать или утомил вас этими амерскими словечками..? Интересна вообще эта тема
#startup
@makebugger
Please open Telegram to view this post
VIEW IN TELEGRAM
Y Combinator
Y Combinator created a new model for funding early stage startups. Four times a year we invest in a large number of startups.
🔥24❤12👍7
К моему удивлению ещё не все знают, что такое OpenRouter.
OpenRouter это единый API через который вы можете обращаться к моделям разных провайдеров посредством единого интерфейса и легко переключаться между ними. Оставаться vendor-agnostic (не быть привязанным к конкретному вендору) это сейчас критично важно☝️
Кстати, там дают бесплатные кредиты🤫 а пополнять можно даже криптой.
Также, отвечая на вопрос, «а как держать руку на пульсе в столь динамичной индустрии?», open router статистика это отличный способ узнать какая модель сейчас популярна у разработчиков в категории программирование, у академиков или у маркетологов.
В следующий раз когда будете думать какую модель использовать в конкретном домене, то этот сайт можно использовать как стартовую точку.
Зайдите, потыкайтеу, уверен, кому-то будет полезно🙌
#ai
@makebugger
OpenRouter это единый API через который вы можете обращаться к моделям разных провайдеров посредством единого интерфейса и легко переключаться между ними. Оставаться vendor-agnostic (не быть привязанным к конкретному вендору) это сейчас критично важно
Кстати, там дают бесплатные кредиты
Также, отвечая на вопрос, «а как держать руку на пульсе в столь динамичной индустрии?», open router статистика это отличный способ узнать какая модель сейчас популярна у разработчиков в категории программирование, у академиков или у маркетологов.
В следующий раз когда будете думать какую модель использовать в конкретном домене, то этот сайт можно использовать как стартовую точку.
Зайдите, потыкайтеу, уверен, кому-то будет полезно
#ai
@makebugger
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥15
META Superintelligence Lab совместно с National University of Singapore под шумок зарелизили Rethinking RAG based Decoding (REFRAG).
Для начала кратко напомню как выглядит базовый RAG-pipeline:
1. Берём пользовательский INPUT и получаем из него эмбеддинг
2. Используем этот эмбеддинг как query для того, чтобы достать релевантные знания из векторной базы данных которые мы предварительно заэмбедели
3. Включаем эти данные в промпт вместе с оригинальным пользовательским INPUTом
4. Посылаем промпт в LLM и получаем ответ основанный на контексте из релевантных данных
Проблема в том, что когда ты достаёшь из базы 10-20-50 чанков контекста (а в энтерпрайзе это норма), твой промпт превращается в войну и мир. LLM должна обработать всю эту простыню через attention механизм, который имеет квадратичную сложность O(n²). То есть если контекст увеличился в 2 раза, вычисления растут в 4 раза, а память под KV-cache вообще улетает в космос.
И тут в игру вступает REFRAG.
Ребята посмотрели на attention patterns в RAG и увидели интересную штуку - большинство чанков между собой вообще не взаимодействуют (логично, кстати)! Attention между разными документами почти нулевой, получается блочно-диагональная матрица. Зачем тогда платить полную цену?
Их решение: сжимать каждый чанк из 16-32 токенов в один dense embedding через lightweight encoder (RoBERTa). Вместо 10к токенов в декодер летит всего 300-600 chunk embeddings.
Для тех кому сложно представить, я тут создал простенькую визуализацию с помощью Anthropic Artifacts.
Но самое умное - они обучили RL-policy, которая понимает какие чанки критичные. Если в документе есть точные цифры, даты, формулы, то система их не сжимает, а оставляет как raw tokens. Гениально же!
Что в итоге получилось:
• 30.85× ускорение time-to-first-token (у предыдущего SOTA было всего 8×)
• Контекст можно расширить в 16 раз без потери производительности
• На weak retriever сценариях (когда половина документов - мусор) REFRAG даже обгоняет baseline, потому что может обработать больше контекста за то же время
Код обещают выложить тут. Жду не дождусь потыкать на своих проектах.
#ai #news
@makebugger
Для начала кратко напомню как выглядит базовый RAG-pipeline:
1. Берём пользовательский INPUT и получаем из него эмбеддинг
2. Используем этот эмбеддинг как query для того, чтобы достать релевантные знания из векторной базы данных которые мы предварительно заэмбедели
3. Включаем эти данные в промпт вместе с оригинальным пользовательским INPUTом
4. Посылаем промпт в LLM и получаем ответ основанный на контексте из релевантных данных
Проблема в том, что когда ты достаёшь из базы 10-20-50 чанков контекста (а в энтерпрайзе это норма), твой промпт превращается в войну и мир. LLM должна обработать всю эту простыню через attention механизм, который имеет квадратичную сложность O(n²). То есть если контекст увеличился в 2 раза, вычисления растут в 4 раза, а память под KV-cache вообще улетает в космос.
И тут в игру вступает REFRAG.
Ребята посмотрели на attention patterns в RAG и увидели интересную штуку - большинство чанков между собой вообще не взаимодействуют (логично, кстати)! Attention между разными документами почти нулевой, получается блочно-диагональная матрица. Зачем тогда платить полную цену?
Их решение: сжимать каждый чанк из 16-32 токенов в один dense embedding через lightweight encoder (RoBERTa). Вместо 10к токенов в декодер летит всего 300-600 chunk embeddings.
Для тех кому сложно представить, я тут создал простенькую визуализацию с помощью Anthropic Artifacts.
Но самое умное - они обучили RL-policy, которая понимает какие чанки критичные. Если в документе есть точные цифры, даты, формулы, то система их не сжимает, а оставляет как raw tokens. Гениально же!
Что в итоге получилось:
• 30.85× ускорение time-to-first-token (у предыдущего SOTA было всего 8×)
• Контекст можно расширить в 16 раз без потери производительности
• На weak retriever сценариях (когда половина документов - мусор) REFRAG даже обгоняет baseline, потому что может обработать больше контекста за то же время
Код обещают выложить тут. Жду не дождусь потыкать на своих проектах.
#ai #news
@makebugger
🔥18
На днях получаю копеечку за недавний экзит стартапа где я провёл прекрасные 2 года своей жизни, и самое время разобрать ещё один бэтч стартаповых словечек связанных с компенсацией, пока еще свежо в памяти 😂
Stock Options - право купить акции компании по фиксированной цене (strike price). Ключевое слово “право” - можешь купить, а можешь и не покупать.
Vesting - это период за который ты “зарабатываешь” свои опционы. У меня было 4 года с 1 годом cliff. То есть первый год вообще ничего не получаешь (чтобы те кто в компании не задержится не получили свой кусок пирога), зато после года сразу 25%, дальше каждый месяц по чуть-чуть.
Exercise shares - когда ты реально покупаешь акции по strike price. Я не exercised ни одного опциона, потому что ждал экзита (и правильно сделал), после того как нас купили все наши стоки exercised (даже у тех кто пришёл в компанию месяц назад и получил больше опционов чем те, кто работал несколько лет).
Важный нюанс про типы акций:
Preferred stocks - привилегированные акции, их получают инвесторы и высший менеджмент. При продаже компании их выплачивают в первую очередь.
Common stocks - обычные акции, их получают сотрудники через опционы. Выплачивают после preferred.
На практике это означает что сначала карманы набивают инвесторы и топ-менеджмент, а крошки доедают обычные работяги. Но если экзит удачный, то и крошки тоже могут быть весьма сочными.
Очень важно чтобы у стартапа было американское LLC (аналог нашего ООО). В Америке законы касательно акций очень понятные и прозрачные. Если у компании только EU entity - с опционами вас скорее всего наебут, европейское право в этом плане гораздо менее employee-friendly.
Полезная штука - приложение Carta:
Показывает сколько у тебя vested/exercised опционов, текущую стоимость, всю историю. Очень удобно трекать свой потенциальный пейдей. Скрин своей Carta оставлю в комментах👇
Главное правило:
Equity это лотерейный билет. Может выстрелить, а может оказаться туалетной бумагой. Никогда не идите в стартап только ради опционов - базовая зарплата должна вас устраивать.
#startup #money
@makebugger
Stock Options - право купить акции компании по фиксированной цене (strike price). Ключевое слово “право” - можешь купить, а можешь и не покупать.
Vesting - это период за который ты “зарабатываешь” свои опционы. У меня было 4 года с 1 годом cliff. То есть первый год вообще ничего не получаешь (чтобы те кто в компании не задержится не получили свой кусок пирога), зато после года сразу 25%, дальше каждый месяц по чуть-чуть.
Exercise shares - когда ты реально покупаешь акции по strike price. Я не exercised ни одного опциона, потому что ждал экзита (и правильно сделал), после того как нас купили все наши стоки exercised (даже у тех кто пришёл в компанию месяц назад и получил больше опционов чем те, кто работал несколько лет).
Важный нюанс про типы акций:
Preferred stocks - привилегированные акции, их получают инвесторы и высший менеджмент. При продаже компании их выплачивают в первую очередь.
Common stocks - обычные акции, их получают сотрудники через опционы. Выплачивают после preferred.
На практике это означает что сначала карманы набивают инвесторы и топ-менеджмент, а крошки доедают обычные работяги. Но если экзит удачный, то и крошки тоже могут быть весьма сочными.
Очень важно чтобы у стартапа было американское LLC (аналог нашего ООО). В Америке законы касательно акций очень понятные и прозрачные. Если у компании только EU entity - с опционами вас скорее всего наебут, европейское право в этом плане гораздо менее employee-friendly.
Полезная штука - приложение Carta:
Показывает сколько у тебя vested/exercised опционов, текущую стоимость, всю историю. Очень удобно трекать свой потенциальный пейдей. Скрин своей Carta оставлю в комментах
Главное правило:
Equity это лотерейный билет. Может выстрелить, а может оказаться туалетной бумагой. Никогда не идите в стартап только ради опционов - базовая зарплата должна вас устраивать.
#startup #money
@makebugger
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥16
Media is too big
VIEW IN TELEGRAM
Кофе, горы, два хычина
Эти выходные мы с друзьями провели в горах Кавказа, интернета там и так не было, так что получился так называемый детокс.
Это мой первый хайк в России и с уверенностью могу сказать, что местные пейзажи ничем не уступают Альпам, ни по цене ни по красоте 😁 думаю, неплохо бы было предпринять следующие шаги: ослабить (убрать) местную мафию, после этого сюда потечёт больше разнородных инвестиций, как следствие появится конкуренция и мб упадут цены.. задать единый стиль архитектуры и всё, Архыз превращается в Гриндевальд.
УАЗик, коровьи кизяки, жёлтые крокусы, озеро рыбка и сахарные пики кавказских гор. Примерно так выглядел наш уикенд, желаю всем проводить побольше качественного времени со своими близкими людьми, если вы ещё не заметили, то лейт мотив моего канала — всё «это» про людей🍆
ИСКРЕННЕ посылаю вам лучи позитивной энергии и желаю хорошей рабочей недели!
#travel #life
@makebugger
Эти выходные мы с друзьями провели в горах Кавказа, интернета там и так не было, так что получился так называемый детокс.
Это мой первый хайк в России и с уверенностью могу сказать, что местные пейзажи ничем не уступают Альпам, ни по цене ни по красоте 😁 думаю, неплохо бы было предпринять следующие шаги: ослабить (убрать) местную мафию, после этого сюда потечёт больше разнородных инвестиций, как следствие появится конкуренция и мб упадут цены.. задать единый стиль архитектуры и всё, Архыз превращается в Гриндевальд.
УАЗик, коровьи кизяки, жёлтые крокусы, озеро рыбка и сахарные пики кавказских гор. Примерно так выглядел наш уикенд, желаю всем проводить побольше качественного времени со своими близкими людьми, если вы ещё не заметили, то лейт мотив моего канала — всё «это» про людей
ИСКРЕННЕ посылаю вам лучи позитивной энергии и желаю хорошей рабочей недели!
#travel #life
@makebugger
Please open Telegram to view this post
VIEW IN TELEGRAM
👍12❤5🔥3
Когда все результаты выдачи с первой страницы гугла окрашиваются в фиолетовый я прибегаю к EXA.ai
Это очень мощный гибридный поисковой движок который совмещает в себе классический гугл и семантический поиск.
Например, вы хотите постучаться во все финтех стартапы которые недавно получили инвестиции и расширяют команду (см. скриншот)
В exa.ai это один текстовый запрос и вы получаете ссылки прямо на лендинги этих компаний где во вкладке Careers красуются интересующие вас позиции.
Попробуйте хоть раз и вы удивитесь как легко можно сделать комплексный рисёрч и какие спрятанные сокровища появляются в выдаче.
Единственный минус это достаточно агрессивные лимиты и высокий прайсинг, но на пару глубоких рисёрчев в месяц хватит, можете выгрузить результаты в CSV и использовать для чего угодно.
Пользуйтесь 🥰
#ai #dev_help
@makebugger
Это очень мощный гибридный поисковой движок который совмещает в себе классический гугл и семантический поиск.
Например, вы хотите постучаться во все финтех стартапы которые недавно получили инвестиции и расширяют команду (см. скриншот)
В exa.ai это один текстовый запрос и вы получаете ссылки прямо на лендинги этих компаний где во вкладке Careers красуются интересующие вас позиции.
Попробуйте хоть раз и вы удивитесь как легко можно сделать комплексный рисёрч и какие спрятанные сокровища появляются в выдаче.
Единственный минус это достаточно агрессивные лимиты и высокий прайсинг, но на пару глубоких рисёрчев в месяц хватит, можете выгрузить результаты в CSV и использовать для чего угодно.
Пользуйтесь 🥰
#ai #dev_help
@makebugger
🤩14🔥4👍2
Как я не взял оффер от создателя word2vec
В марте месяце этого года когда я активно ходил по собесам с желанием выцепить самый жирный оффер на рынке появился «чешский Mistral» под названием Bottle Cap AI с амбицией сделать LLMs cheap and fast again.
Я тут же законнектился с их CEO и по совместительству главным инвестором который по его же словам готов инвестировать 10😖 зелени в незакрытые гештальты Томаша Миколова (создатель word2vec), после того как я имплементировал multi-token prediction (это было их тестовое) и рассказал какой я замотивированный и как со мной резонирует миссия Bottle Cap AI 🌚 ушёл на следующие собесы.
Через неделю после нашей встречи и вкусного обеда в ресторане Losteria, который конечно же оплатил интервьюер😁 мне дали оффер:
• Junior ML Researcher тайтл
• 5000€
• хардкорный рисёрч языковых моделей «на низком уровне», тюнинг параметров и имплементация безумных идей Томаша
• работа только из офиса
• и самое вкусное – 10 миллионов чешских крон «когда мы станем unicornом» (это примерно 250к $)
Придя домой и посчитав на сколько сильно меня пытаются обуть я, конечно, долго улыбался. Давайте посчитаем: 10 млн крон = ~250к долларов. Если компания достигнет оценки в миллиард (в этом случае компания считается unicornом), то 250к от миллиарда = 0.025%.
Для сравнения: обычные founding engineers получают 0.5-2% equity. То есть мне предлагали в 20-80 раз меньше стандартной доли при том же уровне риска и загруженности.
Долго я не думал и написал вежливый отказ, порекомендовав бывшего коллегу которому бы это могло быть интересно.
Почему я отказался?
• идти в рисёрч по моему мнению это почти всегда карьерный тупик, рынок таких специалистов крошечный, в основном никто кроме гигантов за рисерч платить не будет (я был в рисёрче, я общался с этими людьми, им не интересно ничего кроме их PhD тезиса)
• математика equity просто смехотворная
• работа с Томашем хоть и может звучать крутой в теории но на практике он показался мне выгоревшим гениальным рисёрчером которому наплевать на бизнес и продукт, а в эту авантюру он залез только для того, чтобы показать всем европейским регулятором которые годами не давали ему гранты, что он ещё может.
Несмотря на то, что я отказался я продолжил следить за ребятами но к сожалению за все эти месяцы
они не запостили ничего кроме одного PM графика (график для пиэмов и инвесторов которым всё равно, что значит X и Y оси и где не понятно откуда взялись данные).
После этого я сторговался с моим нынешним работодателем на оффер почти в 2 раза превышающий предложение от Bottle Cap AI.
А вы бы пошли работать к известному челику за зп ниже рынка ради опыта? 😏
#ai #startup #money
@makebugger
В марте месяце этого года когда я активно ходил по собесам с желанием выцепить самый жирный оффер на рынке появился «чешский Mistral» под названием Bottle Cap AI с амбицией сделать LLMs cheap and fast again.
Я тут же законнектился с их CEO и по совместительству главным инвестором который по его же словам готов инвестировать 10
Через неделю после нашей встречи и вкусного обеда в ресторане Losteria, который конечно же оплатил интервьюер
• Junior ML Researcher тайтл
• 5000€
• хардкорный рисёрч языковых моделей «на низком уровне», тюнинг параметров и имплементация безумных идей Томаша
• работа только из офиса
• и самое вкусное – 10 миллионов чешских крон «когда мы станем unicornом» (это примерно 250к $)
Придя домой и посчитав на сколько сильно меня пытаются обуть я, конечно, долго улыбался. Давайте посчитаем: 10 млн крон = ~250к долларов. Если компания достигнет оценки в миллиард (в этом случае компания считается unicornом), то 250к от миллиарда = 0.025%.
Для сравнения: обычные founding engineers получают 0.5-2% equity. То есть мне предлагали в 20-80 раз меньше стандартной доли при том же уровне риска и загруженности.
Долго я не думал и написал вежливый отказ, порекомендовав бывшего коллегу которому бы это могло быть интересно.
Почему я отказался?
• идти в рисёрч по моему мнению это почти всегда карьерный тупик, рынок таких специалистов крошечный, в основном никто кроме гигантов за рисерч платить не будет (я был в рисёрче, я общался с этими людьми, им не интересно ничего кроме их PhD тезиса)
• математика equity просто смехотворная
• работа с Томашем хоть и может звучать крутой в теории но на практике он показался мне выгоревшим гениальным рисёрчером которому наплевать на бизнес и продукт, а в эту авантюру он залез только для того, чтобы показать всем европейским регулятором которые годами не давали ему гранты, что он ещё может.
Несмотря на то, что я отказался я продолжил следить за ребятами но к сожалению за все эти месяцы
они не запостили ничего кроме одного PM графика (график для пиэмов и инвесторов которым всё равно, что значит X и Y оси и где не понятно откуда взялись данные).
После этого я сторговался с моим нынешним работодателем на оффер почти в 2 раза превышающий предложение от Bottle Cap AI.
А вы бы пошли работать к известному челику за зп ниже рынка ради опыта? 😏
#ai #startup #money
@makebugger
Please open Telegram to view this post
VIEW IN TELEGRAM
Про плохие стартапы ч. 1.
ч. 2
Два года назад после очередного ревью без значительного повышения зп и потухающими глазами я решаюсь найти вторую работу.
Собеситься пару раз в месяц было и остаётся для меня привычкой, так что первых лидов отхватить было не слишком сложно. Мой главный критерий – начать сотрудничать на парт тайм и со временем перекатиться на полную.
И вот на моём экране я вижу двух покемонов – Радек и Томаш, два визионерных не технических кофаундера, получившие деньги от инвестора который слышал, что эй ай это новый блокчейн, собрались вместе ради одной благородной цели – клонировать людей с помощью технологий искусственного интеллекта.
Как любые уважающие себя фаундеры аргументировали они это благородной целью – пенсионерам бывает грустно и одиноко и каждый из них мечтал бы поговорить со знаменитостью, Томашем Гариком Масариком, чешским боксёром или онлифанщицей (которая в последствии окажется девушкой одного из кофаундеров😨 , ссылочку в комменты скину кому надо😊 ).
«Какой же пиз*ец» - думаю я во время разговора с ними, как им могли дать деньги… но за спинами этих бизнесменов уже есть малоприбыльный проект по 3д сканированию помещений во Флориде. К тому, же про них написало уважаемое в Чехии техническое издание CzechCrunch и даже BusinessInfo.
«Ок», - говорю я, мы бьём по рукам и я начинаю работать на пол ставки. У ребят всё схвачено, стендапы 2 раза в неделю, куча микроскрвис, СТО без доли в компании и дискорд канал.
Сначала они не были уверены на какой из проектов меня кинуть потому что проектов и идей у ребят было как у Илона Маска, в итоге я присоединяюсь делать чешского конкурента character.ai – hitchat.ai/en
Почему хит чат спросите вы? Это название для проекта ребятам подсказала чат гпт, 2 слога, звучит прикольно, мне так объяснили.
Когда я присоединился к «команде», то первым делом решил выяснить, кем же являются мои коллеги которые работают на столь перспективном проекте уже не первый месяц.
Главный дев – ПеПе (чешское сокращение от имени Йозеф). У ПеПе 2 ипотеки, 2 открытых суда с девелоперами по ним же, избыточный вес и статус maintainerа в open source проекте Pydantic. Пока обе его квартиры купленные в ипотеку не предусмотрены для жилья (это и есть та причина по которой он судиться) ПеПе живёт на чердаке, прямо над офисом компании.
Да, ПеПе живёт и работает в офисе, кушает данисимо на камеру и смеётся над сходством моей фамилии с названием птицы. Позже он будет оставлять пасхалки в коде где будет называть нашу дружную семью hitchat – black company и просить о помощи, говоря, что Радек и Томаш его эксплуатируют и шантажируют.
СТО – приятный челик с заниженной самооценкой которому пообещали долю в перспективном европейском стартапе (в последствии окажется, что зп у него была меньше чем у меня и работал он в основном за долю). Работает безумно много, мало думает о бизнесе, много думает о качестве кода и микросервисах.
В первый месяц я менял текстовые промпты, описывающие характеристики различных чешских знаменитостей типа «Ты чешский президент Вацлав Гавел, отвечай как он…» и делал клонирование их голоса через eleven labs, получая за это 250$ в день, работал я от силы 1-2 часа.
…
Надо продолжать такой лонгрид или у вас внимания не хватает, чтобы такое полотно дочитывать?
#life #startup
@makebugger
ч. 2
Два года назад после очередного ревью без значительного повышения зп и потухающими глазами я решаюсь найти вторую работу.
Собеситься пару раз в месяц было и остаётся для меня привычкой, так что первых лидов отхватить было не слишком сложно. Мой главный критерий – начать сотрудничать на парт тайм и со временем перекатиться на полную.
И вот на моём экране я вижу двух покемонов – Радек и Томаш, два визионерных не технических кофаундера, получившие деньги от инвестора который слышал, что эй ай это новый блокчейн, собрались вместе ради одной благородной цели – клонировать людей с помощью технологий искусственного интеллекта.
Как любые уважающие себя фаундеры аргументировали они это благородной целью – пенсионерам бывает грустно и одиноко и каждый из них мечтал бы поговорить со знаменитостью, Томашем Гариком Масариком, чешским боксёром или онлифанщицей (которая в последствии окажется девушкой одного из кофаундеров
«Какой же пиз*ец» - думаю я во время разговора с ними, как им могли дать деньги… но за спинами этих бизнесменов уже есть малоприбыльный проект по 3д сканированию помещений во Флориде. К тому, же про них написало уважаемое в Чехии техническое издание CzechCrunch и даже BusinessInfo.
«Ок», - говорю я, мы бьём по рукам и я начинаю работать на пол ставки. У ребят всё схвачено, стендапы 2 раза в неделю, куча микроскрвис, СТО без доли в компании и дискорд канал.
Сначала они не были уверены на какой из проектов меня кинуть потому что проектов и идей у ребят было как у Илона Маска, в итоге я присоединяюсь делать чешского конкурента character.ai – hitchat.ai/en
Почему хит чат спросите вы? Это название для проекта ребятам подсказала чат гпт, 2 слога, звучит прикольно, мне так объяснили.
Когда я присоединился к «команде», то первым делом решил выяснить, кем же являются мои коллеги которые работают на столь перспективном проекте уже не первый месяц.
Главный дев – ПеПе (чешское сокращение от имени Йозеф). У ПеПе 2 ипотеки, 2 открытых суда с девелоперами по ним же, избыточный вес и статус maintainerа в open source проекте Pydantic. Пока обе его квартиры купленные в ипотеку не предусмотрены для жилья (это и есть та причина по которой он судиться) ПеПе живёт на чердаке, прямо над офисом компании.
Да, ПеПе живёт и работает в офисе, кушает данисимо на камеру и смеётся над сходством моей фамилии с названием птицы. Позже он будет оставлять пасхалки в коде где будет называть нашу дружную семью hitchat – black company и просить о помощи, говоря, что Радек и Томаш его эксплуатируют и шантажируют.
СТО – приятный челик с заниженной самооценкой которому пообещали долю в перспективном европейском стартапе (в последствии окажется, что зп у него была меньше чем у меня и работал он в основном за долю). Работает безумно много, мало думает о бизнесе, много думает о качестве кода и микросервисах.
В первый месяц я менял текстовые промпты, описывающие характеристики различных чешских знаменитостей типа «Ты чешский президент Вацлав Гавел, отвечай как он…» и делал клонирование их голоса через eleven labs, получая за это 250$ в день, работал я от силы 1-2 часа.
…
Надо продолжать такой лонгрид или у вас внимания не хватает, чтобы такое полотно дочитывать?
#life #startup
@makebugger
Please open Telegram to view this post
VIEW IN TELEGRAM
Как коллективная экономика вдруг оказалась эффективной (вроде)
В 2025 дата центры жрут ~1.5-2% всей электроэнергии мира. Из них примерно 15-24% уходят на ответы на наши глупые вопросы о том сколько R в слове strawberry 🍓
Так как датацентры по планете размазаны неравномерно, то цифры потребления по регионам следующие:
• США – 50% потребления всей энергии для дата центров
• Китай – 25%
• ЕС – 15%
• Остальные – 10%
У США в свою очередь всего лишь 15% запаса мощности, что означает, что на данный момент их энергосистема может выдать на 15% больше энергии, чем требуется в пиковые нагрузки.
У Китая 80-100%, пространство для масштабирования несоизмеримо больше.
Почему так произошло?
1. В США - всеми нами любимый капитализм, что означает, что окупаемость у коммерческих проектов должна быть 3-5 лет, иначе инвесторы просто не зайдут. Зачем строить сейчас если спроса на рынке тупо нет?
Разумный партия Китай в свою очередь планирует всё по пятилеткам, деньги на инфраструктуру не жалеют, даже если она никому не нужна, людям же работать надо!
2. США начали строить их сеть гораздо раньше китайцев, технологии старше, материалы уже не те, поэтому всё постепенно приходит в негодность.
(похожая ситуация была когда в РФ адопшн ApplePay был гораздо быстрее чем в Америке в связи с более навороченными терминалами оплаты и банкоматами).
Прибавьте к тому то, что разными участками сети владеют разные компании в разных штатах, что усложняет процесс договоров и согласований. Китай начал попозже и все решения принимать великий Си, удар!
3. США слишком хорошо оптимизировали существующую систему вместо того, чтобы строить больше. Все готовились к стабильному постепенному росту.
Тем временем в кулуарах РФ затевается многоходовочная диверсия, просыпается спящий агент Илья Сутскевер, чтобы нанести сокрушительный удар по американской энергосистеме (эдакий план Даллеса наоборот) и 30 ноября 2022 без предупреждения релизится ChatGPT, ну а дальше вы сами знаете, рост перестал быть линейный.
_
Получается парадоксальная ситуация: коллективная плановая экономика Китая оказалась эффективнее децентрализованного рынка США в подготовке к ИИ-буму. Не потому что у них лучше технологии или больше денег, а потому что они годами строили скучный фундамент без давления быстрой окупаемости, as simple as that.
Если экстраполировать это на нас с вами, то давайте и мы концентрироваться на базовых вещах - не гнаться за мимолётной прибылью, спорт 3 раза в неделю, проводить время с близкими, любить и не ругаться матом😊 окупится не через квартал, но зато через 10 лет будем с вами с запасом прочности 80%
(кстати, там новый sonnet выпустили)
источники:
омерика не готова!
как повысится потребление датацентров
+100 social credit
中国最好的国家!удар
#ai
@makebugger
В 2025 дата центры жрут ~1.5-2% всей электроэнергии мира. Из них примерно 15-24% уходят на ответы на наши глупые вопросы о том сколько R в слове strawberry 🍓
Так как датацентры по планете размазаны неравномерно, то цифры потребления по регионам следующие:
• США – 50% потребления всей энергии для дата центров
• Китай – 25%
• ЕС – 15%
• Остальные – 10%
У США в свою очередь всего лишь 15% запаса мощности, что означает, что на данный момент их энергосистема может выдать на 15% больше энергии, чем требуется в пиковые нагрузки.
У Китая 80-100%, пространство для масштабирования несоизмеримо больше.
Почему так произошло?
1. В США - всеми нами любимый капитализм, что означает, что окупаемость у коммерческих проектов должна быть 3-5 лет, иначе инвесторы просто не зайдут. Зачем строить сейчас если спроса на рынке тупо нет?
Разумный партия Китай в свою очередь планирует всё по пятилеткам, деньги на инфраструктуру не жалеют, даже если она никому не нужна, людям же работать надо!
2. США начали строить их сеть гораздо раньше китайцев, технологии старше, материалы уже не те, поэтому всё постепенно приходит в негодность.
(похожая ситуация была когда в РФ адопшн ApplePay был гораздо быстрее чем в Америке в связи с более навороченными терминалами оплаты и банкоматами).
Прибавьте к тому то, что разными участками сети владеют разные компании в разных штатах, что усложняет процесс договоров и согласований. Китай начал попозже и все решения принимать великий Си, удар!
3. США слишком хорошо оптимизировали существующую систему вместо того, чтобы строить больше. Все готовились к стабильному постепенному росту.
Тем временем в кулуарах РФ затевается многоходовочная диверсия, просыпается спящий агент Илья Сутскевер, чтобы нанести сокрушительный удар по американской энергосистеме (эдакий план Даллеса наоборот) и 30 ноября 2022 без предупреждения релизится ChatGPT, ну а дальше вы сами знаете, рост перестал быть линейный.
_
Получается парадоксальная ситуация: коллективная плановая экономика Китая оказалась эффективнее децентрализованного рынка США в подготовке к ИИ-буму. Не потому что у них лучше технологии или больше денег, а потому что они годами строили скучный фундамент без давления быстрой окупаемости, as simple as that.
Если экстраполировать это на нас с вами, то давайте и мы концентрироваться на базовых вещах - не гнаться за мимолётной прибылью, спорт 3 раза в неделю, проводить время с близкими, любить и не ругаться матом
(кстати, там новый sonnet выпустили)
источники:
омерика не готова!
как повысится потребление датацентров
+100 social credit
中国最好的国家!удар
#ai
@makebugger
Please open Telegram to view this post
VIEW IN TELEGRAM
👍22🔥4❤2🤩1