
Бизнес в Европе — запрещён
Есть у меня друг архитектор и захотелось ему в бизнес попробовать. Подкинул он мне идею поставить в Праге фотоавтомат для туристов, я софт напишу, с людьми договорюсь, а он концепт разработает и чертёж начертит.
С собственником договорились, локация – пушка. Человек который всё это сварит у нас есть, камера куплена, софт уже частично работает, вроде бы готово всё, но не тут то было 😇
Финальный босс это бюрократы-архитекторы из одного городского департамента, сходил я туда в общем, чуть ли не с порога мне дали знать, что я говно и звать меня никак, фотоавтомат никакой культурной ценности не несёт и шёл бы я нахуй в общем.
Всё бы ничего, но на главной площади нашего города красуется тайская массажка с пластиковой кришной в мой рост и на каждом углу банчат «травой» для туристов, короче, переименовали коррупцию в лоббизм и успокоились🙌
Ну а што нам… мы люди простые, будемподжигать двери стучаться дальше, авось одобрят в другом месте…
#life #business
@makebugger
Есть у меня друг архитектор и захотелось ему в бизнес попробовать. Подкинул он мне идею поставить в Праге фотоавтомат для туристов, я софт напишу, с людьми договорюсь, а он концепт разработает и чертёж начертит.
С собственником договорились, локация – пушка. Человек который всё это сварит у нас есть, камера куплена, софт уже частично работает, вроде бы готово всё, но не тут то было 😇
Финальный босс это бюрократы-архитекторы из одного городского департамента, сходил я туда в общем, чуть ли не с порога мне дали знать, что я говно и звать меня никак, фотоавтомат никакой культурной ценности не несёт и шёл бы я нахуй в общем.
Всё бы ничего, но на главной площади нашего города красуется тайская массажка с пластиковой кришной в мой рост и на каждом углу банчат «травой» для туристов, короче, переименовали коррупцию в лоббизм и успокоились🙌
Ну а што нам… мы люди простые, будем
#life #business
@makebugger
🤩2🕊1
Google уже победил в ИИ-гонке, пока другие меряются бенчмарками
Пока большинство не технических людей смотрят на OpenAI и ChatGPT, Google тихо строит самую мощную ИИ-экосистему на рынке.
И вот почему это игра в одни ворота:
YouTube — бездонный источник данных.
Недавно узнал, что 80% всего интернет-трафика — это видео! OpenAI покупает WindSurf чисто из-за данных, а Google просто имеет их — бесплатно и в промышленных масштабах. Мы сами десятилетиями всё туда несли. Это колоссальное преимущество.
VEO 3 — не просто фича, а фундамент 🎬
Генерация видео из текста уже сейчас топчик, но главное не в ней самой, а в том, что Google тренирует мультимодальные модели на таких объёмах данных, о которых Anthropic и OpenAI могут только мечтать. Представьте, что это значит для будущего ИИ ассистентов.
Финальный босс: ваш персональный ИИ 🤖
Gmail, Calendar, Docs, Meet, Chrome, Android — это не просто сервисы. Это ваш самый большой цифровой след, который Google аккумулирует годами. И хотя Google не особо зарабатывает на железе (тот же Pixel почти в минус продаётся ради софта), они получают главное — вы пользуетесь их ПО.
Всё это становится основой для персонального ИИ, который будет знать вас лучше, чем кто-либо. Представьте: ассистент, который помнит все ваши мейлы, знает расписание, понимает ваш стиль письма, видел все YouTube-поиски и может генерить видео под ваши задачи. Страшно, но удобно.
А Apple? Мне один инвестор с прошлого стартапа, который 10 лет вёл ML-тим в Apple, говорил, что они не хранят данные, поэтому Siri такая тупая. Частично верю 😅.
Мой совет:
Не «фанбойте» одному провайдеру! Никогда не покупайте подписку на год ни на один из ИИ сервисов.
Гоу попробуем юзать NotebookLM, этот продукт 💯 будет стрелять.
#ai
@makebugger
Пока большинство не технических людей смотрят на OpenAI и ChatGPT, Google тихо строит самую мощную ИИ-экосистему на рынке.
И вот почему это игра в одни ворота:
YouTube — бездонный источник данных.
Недавно узнал, что 80% всего интернет-трафика — это видео! OpenAI покупает WindSurf чисто из-за данных, а Google просто имеет их — бесплатно и в промышленных масштабах. Мы сами десятилетиями всё туда несли. Это колоссальное преимущество.
VEO 3 — не просто фича, а фундамент 🎬
Генерация видео из текста уже сейчас топчик, но главное не в ней самой, а в том, что Google тренирует мультимодальные модели на таких объёмах данных, о которых Anthropic и OpenAI могут только мечтать. Представьте, что это значит для будущего ИИ ассистентов.
Финальный босс: ваш персональный ИИ 🤖
Gmail, Calendar, Docs, Meet, Chrome, Android — это не просто сервисы. Это ваш самый большой цифровой след, который Google аккумулирует годами. И хотя Google не особо зарабатывает на железе (тот же Pixel почти в минус продаётся ради софта), они получают главное — вы пользуетесь их ПО.
Всё это становится основой для персонального ИИ, который будет знать вас лучше, чем кто-либо. Представьте: ассистент, который помнит все ваши мейлы, знает расписание, понимает ваш стиль письма, видел все YouTube-поиски и может генерить видео под ваши задачи. Страшно, но удобно.
А Apple? Мне один инвестор с прошлого стартапа, который 10 лет вёл ML-тим в Apple, говорил, что они не хранят данные, поэтому Siri такая тупая. Частично верю 😅.
Мой совет:
Не «фанбойте» одному провайдеру! Никогда не покупайте подписку на год ни на один из ИИ сервисов.
Гоу попробуем юзать NotebookLM, этот продукт 💯 будет стрелять.
#ai
@makebugger
Google NotebookLM
Google NotebookLM | AI Research Tool & Thinking Partner
Meet NotebookLM, the AI research tool and thinking partner that can analyze your sources, turn complexity into clarity and transform your content.
🔥5
Ну что, братья-яблочники, как вам это «жидкое стекло»? Пока что жидковато — с утра уже трое знакомых написали: не обновляйся, побереги нервы.
Из важного — Эпл наконец-то открыли доступ к своим ИИ-моделям для разработчиков.
Сири как была мемом, так и осталась. Классический кейс: вышли первыми — остались последними. Ни одного внятного упоминания.
Что ещё? Все операционки теперь гордо носят номер 26 — в честь моего следующего дня рождения, видимо. Такой вот тихий намёк на фокус на 2026 год. Надеемся всей семьёй на то самое “One more thing”.
#news
@makebugger
Из важного — Эпл наконец-то открыли доступ к своим ИИ-моделям для разработчиков.
Сири как была мемом, так и осталась. Классический кейс: вышли первыми — остались последними. Ни одного внятного упоминания.
Что ещё? Все операционки теперь гордо носят номер 26 — в честь моего следующего дня рождения, видимо. Такой вот тихий намёк на фокус на 2026 год. Надеемся всей семьёй на то самое “One more thing”.
#news
@makebugger
Вышло новое интервью с командой Cursor — вы, наверное слышали, что fork VSCode за год дошёл до $300М выручки.
Выжимка самого интересного для тех кому лень:
• они уже давно сами используют свой продукт для его разработки. То есть буквально Cursor строится с помощью Cursor.
• новая штука — Background Agent. Можешь скинуть задачу в фон, и ИИ будет над ней работать в отдельной виртуалке (мб что-то типа E2B sandbox) с полным набором dev-инструментов, пока ты занимаешься другими делами. Когда нужно — быстро перехватываешь управление.
Куда движется индустрия:
• понимание бизнес проблемы, верификация и ревью кода – главные скиллы будущего. Я себя всегда заставляю читать ВСЁ, что я апрувлю в курсоре, это очень сложно, но очень важно)
• у Cursor по их словам уже 90%+ кода проходит через ИИ. Вопрос не в том, случится ли это повсеместно, а в том, будешь ли ты среди тех, кто это строит, или среди тех, кто просто использует готовые инструменты. Уже появляется новый класс инженеров, которые работают на более высоком уровне — фокус на дизайне, архитектуре, описании взаимодействий, а не на низкоуровневых деталях.
https://www.youtube.com/watch?v=BGgsoIgbT_Y
#news
@makebugger
Выжимка самого интересного для тех кому лень:
• они уже давно сами используют свой продукт для его разработки. То есть буквально Cursor строится с помощью Cursor.
• новая штука — Background Agent. Можешь скинуть задачу в фон, и ИИ будет над ней работать в отдельной виртуалке (мб что-то типа E2B sandbox) с полным набором dev-инструментов, пока ты занимаешься другими делами. Когда нужно — быстро перехватываешь управление.
Куда движется индустрия:
• понимание бизнес проблемы, верификация и ревью кода – главные скиллы будущего. Я себя всегда заставляю читать ВСЁ, что я апрувлю в курсоре, это очень сложно, но очень важно)
• у Cursor по их словам уже 90%+ кода проходит через ИИ. Вопрос не в том, случится ли это повсеместно, а в том, будешь ли ты среди тех, кто это строит, или среди тех, кто просто использует готовые инструменты. Уже появляется новый класс инженеров, которые работают на более высоком уровне — фокус на дизайне, архитектуре, описании взаимодействий, а не на низкоуровневых деталях.
https://www.youtube.com/watch?v=BGgsoIgbT_Y
#news
@makebugger
YouTube
How Cursor is building the future of AI coding with Claude
Cursor’s Jacob Jackson, Lukas Möller and Aman Sanger join Anthropic's Alex Albert to talk about the changing landscape of software development.
0:00 Introduction
0:34 Cursor’s growth
1:57 Progression of models
3:09 Building Cursor with Cursor
5:17 Spectrum…
0:00 Introduction
0:34 Cursor’s growth
1:57 Progression of models
3:09 Building Cursor with Cursor
5:17 Spectrum…
👍5
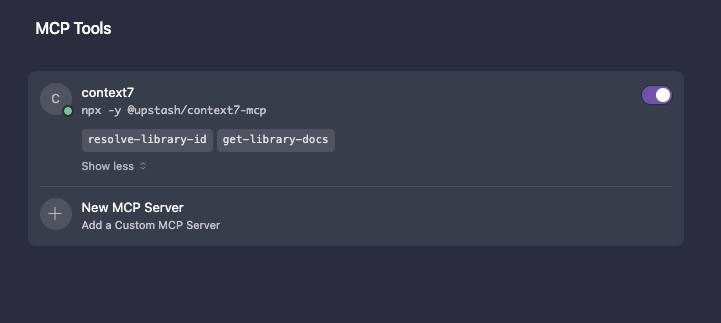
Вот вам кое-что полезное
Часто спрашивают есть ли какие-то скрытые секреты как раскрыть потенциал Cursor на всю, так вот, нашёл тут ещё одну полезную штуку кроме cursor.rules.
Первый MCP сервер, который я подключил к своему Cursor — Context7 от Upstash.
В чём проблема: AI выдаёт код из 2022 года. Старые API, устаревший синтаксис, несуществующие функции. В ручную подтягивать документацию забываешь, да и от лишних движений хочется избавляться.
Context7 с этим помогает – подтягивает актуальную документацию прямо во время генерации кода.
Всё, что вам нужно знать найдёте тут.
С вас репост и огонёчек 🥰
#ai #dev_help
@makebugger
Часто спрашивают есть ли какие-то скрытые секреты как раскрыть потенциал Cursor на всю, так вот, нашёл тут ещё одну полезную штуку кроме cursor.rules.
Первый MCP сервер, который я подключил к своему Cursor — Context7 от Upstash.
В чём проблема: AI выдаёт код из 2022 года. Старые API, устаревший синтаксис, несуществующие функции. В ручную подтягивать документацию забываешь, да и от лишних движений хочется избавляться.
Context7 с этим помогает – подтягивает актуальную документацию прямо во время генерации кода.
Всё, что вам нужно знать найдёте тут.
С вас репост и огонёчек 🥰
#ai #dev_help
@makebugger
{kind=link}
🔥17
This media is not supported in your browser
VIEW IN TELEGRAM
Установил Codex в репозиторий софта для моего шахматного клуба, даю ему задачи с телефона, делаю ревью с телефона и пушу в прод, Vercel всё автоматически деплоит, на маленьком проекте работает как сказка.
Будущее софтвэр девелопмента 😁
Будущее софтвэр девелопмента 😁
😁1
Увидел такую интересную штуку — efficient compute frontier 🤯
Это такая граница, которую нейронки пока не могут пересечь, как ни старайся.
Каждый кто тренил какие-нибудь сетки - видел, что ошибка сначала быстро падает, потом очень медленно «конвёджится». Ок, думаешь — залью больше вычислений, сделаю модель побольше, и будет умнее. Но не тут-то было.
Складывается чёткая закономерность:
ни одна модель не может пробить определённый уровень качества, независимо от архитектуры и алгоритма обучения. Это и называется efficient compute frontier — типа физического закона в мире ИИ.
В интернетах вычитал, что это может быть compression limiter: место, где текущие методы сжатия (матрицы, умножения, attention’ы) натыкаются на предел абстракции. Чтобы перепрыгнуть через эту границу, нужна совершенно иная структура сжатия информации, не матричная. Пока такой у нас нет 🙃
То есть, чтобы сильно улучшить результат, тебе нужно не просто больше compute, а другая парадигма вообще
#ai
@makebugger
Это такая граница, которую нейронки пока не могут пересечь, как ни старайся.
Каждый кто тренил какие-нибудь сетки - видел, что ошибка сначала быстро падает, потом очень медленно «конвёджится». Ок, думаешь — залью больше вычислений, сделаю модель побольше, и будет умнее. Но не тут-то было.
Складывается чёткая закономерность:
ни одна модель не может пробить определённый уровень качества, независимо от архитектуры и алгоритма обучения. Это и называется efficient compute frontier — типа физического закона в мире ИИ.
В интернетах вычитал, что это может быть compression limiter: место, где текущие методы сжатия (матрицы, умножения, attention’ы) натыкаются на предел абстракции. Чтобы перепрыгнуть через эту границу, нужна совершенно иная структура сжатия информации, не матричная. Пока такой у нас нет 🙃
То есть, чтобы сильно улучшить результат, тебе нужно не просто больше compute, а другая парадигма вообще
#ai
@makebugger
❤1👍1
Пару дней назад раскошелился на Claude Code, уверен большинство слышало, но скорее всего не пробовало этого зверя.
ROI тут просто конфетка, за 100 бачей вы получаете себе супер умного бадди который пишет довольно неплохой код со скоростью света.
Пару часов назад Антропики сделали аннаунсмент, что теперь можно подтягивать remote MCP servers, работает как сказка.
Если пишите какой-то webapp, то вот must have MCP это:
• playwright или puppeteer (новый молодёжный Selenium, запускает ваш браузер в headless моде, может автоматически просматривать работает ли сайт, кликать кнопочки и тд)
• context7 (писал выше)
никаких memory bankов вам не надо, они избыточно съедают контекст, вот эти два МЦП, и клодя вам в автономном режими напишет целую систему.
Не пожалейте денег, понимаю, что сейчас все эти ИИ подписки съедают очень много, но Claude Code как по мне намного лучше курсора, если вы не боитесь работать в терминале. Вроде как её можно и к курсору подключить, этого не делал..
Тут хороший гайд от создателя этого CLI, must have на прочтение перед тем как погрузитесь в этот прекрасный мир.
#ai #dev_help
@makebugger
ROI тут просто конфетка, за 100 бачей вы получаете себе супер умного бадди который пишет довольно неплохой код со скоростью света.
Пару часов назад Антропики сделали аннаунсмент, что теперь можно подтягивать remote MCP servers, работает как сказка.
Если пишите какой-то webapp, то вот must have MCP это:
• playwright или puppeteer (новый молодёжный Selenium, запускает ваш браузер в headless моде, может автоматически просматривать работает ли сайт, кликать кнопочки и тд)
• context7 (писал выше)
никаких memory bankов вам не надо, они избыточно съедают контекст, вот эти два МЦП, и клодя вам в автономном режими напишет целую систему.
Не пожалейте денег, понимаю, что сейчас все эти ИИ подписки съедают очень много, но Claude Code как по мне намного лучше курсора, если вы не боитесь работать в терминале. Вроде как её можно и к курсору подключить, этого не делал..
Тут хороший гайд от создателя этого CLI, must have на прочтение перед тем как погрузитесь в этот прекрасный мир.
#ai #dev_help
@makebugger
👍5❤1
Важно понимать, что большинство проектов которые сейчас строятся над LLM это не про решение конкретной бизнес задачи «внедрим чат бота – сэкономим 300кк в наносекунду».
Это про давление со стороны инвесторов и ФОМО. Работаю в галере и большинство клиентов приходят именно с таким запросом «У нас скоро новый раунд инвестиций, нужно внедрить какой-то ИИ, чтобы оценка компании выросла».
Бизнес внедряет все эти чат бот интерфейсы не потому, что чётко понимает как это принесёт деньги, а потому что «надо», если не внедрим – отстанем.
Результат: куча проектов, где никто толком не знает ROI, но все делают вид, что это стратегически важно.
Большинство пока больше тратит на эксперименты, чем зарабатывает.
Это не значит, что AI бесполезен. Но стоит понимать текущие реалии рынка. Пока что это больше относится к США и ЕС.
Это чистая лихорадка – посмотрите на количество AI Engineer позиции на линке…
когда все добывали золото было выгодно продавать кирки, а сейчас..? 🤔
#ai #startup #business
@makebugger
Это про давление со стороны инвесторов и ФОМО. Работаю в галере и большинство клиентов приходят именно с таким запросом «У нас скоро новый раунд инвестиций, нужно внедрить какой-то ИИ, чтобы оценка компании выросла».
Бизнес внедряет все эти чат бот интерфейсы не потому, что чётко понимает как это принесёт деньги, а потому что «надо», если не внедрим – отстанем.
Результат: куча проектов, где никто толком не знает ROI, но все делают вид, что это стратегически важно.
Большинство пока больше тратит на эксперименты, чем зарабатывает.
Это не значит, что AI бесполезен. Но стоит понимать текущие реалии рынка. Пока что это больше относится к США и ЕС.
Это чистая лихорадка – посмотрите на количество AI Engineer позиции на линке…
когда все добывали золото было выгодно продавать кирки, а сейчас..? 🤔
#ai #startup #business
@makebugger
❤7
Метрика роста
Надо оптимизировать доход в час, лучшая метрика, чтобы видеть как вы растёте.
Уже давно взял себе за правило трекать каждый час своей реальной работы, для этого использую Toggl, бесплатной версии хватает с головой, советую.
Делюсь своей табличкой для падняяятия матывации. Как можете заметить, самый быстрый рост – найти вторую работу, на это меня подтолкнули 10% повышения и понимание, что усилия на работе != рост по зп.
Всегда приятно посмотреть и вспомнить как семь лет назад ходил и обнимал детей в ростовой кукле додо птицы 👨🦰
#money #life
@makebugger
Надо оптимизировать доход в час, лучшая метрика, чтобы видеть как вы растёте.
Уже давно взял себе за правило трекать каждый час своей реальной работы, для этого использую Toggl, бесплатной версии хватает с головой, советую.
Делюсь своей табличкой для падняяятия матывации. Как можете заметить, самый быстрый рост – найти вторую работу, на это меня подтолкнули 10% повышения и понимание, что усилия на работе != рост по зп.
Всегда приятно посмотреть и вспомнить как семь лет назад ходил и обнимал детей в ростовой кукле додо птицы 👨🦰
#money #life
@makebugger
🔥13💅5❤3👍1💯1
TypeScript – будущее AI Engineering?
Я не нагнетаю, ближайшие Х лет этого точно не произойдёт, но я вижу чёткий тренд на использование TypeScript в AI-powered проектах. И я не уверен, что это вообще когда-то произойдёт, но...
Почему это может произойти?
• Например, я писал Voice бота, которому звонишь и тебе отвечает LLM голосом (OpenAI real-time API). Чтобы программа такого типа нормально скейлилась и шустро работала – Pythonа просто не достаточно. Latency упала с 200ms до 40ms после перехода на TS.
• Менеджить BackEnd в Python и FrontEnd в TS – это боль, если вы хоть раз работали на таком мультиязычном проекте, вы меня поймёте. Постоянные проблемы с типами и форматом данных, которые передаются между BE и FE, дебажить это – сплошной ад. Если бы все эти ошибки вскрывались на этапе транспиляции TS в JS, экономилось бы кучу времени и нервов.
• Просто в большинстве случаем нет другой причины использовать Python, кроме как "ну наши разработчики лучше знакомы с Python стеком". В большинстве проектов не используется тот хвалёный ML tooling (numpy, pytorch, tensorflow), из-за которого все DS и ML люди пишут в Pythonе, всё через API и SDK.
Почему ещё не скоро?
• SDK для популярных AI frameworkов типа LangGraph в JS/TS отстают от Python SDK на несколько версий, доки – старьё, коммьюнити всё ещё ооочень маленькое.
• Всё-таки переучивать целые команды будет намного дороже, чем смириться с огромными недостатками Python для этих целей.
Некоторый тулинг, который может пригодиться в таких проектах, в Python реализован на 5+, spacy библиотека, например.
Кстати, недавно написал своё первое приложение на NextJS, Claude Code написало 80% за меня) А я выучил огромное количество TypeScript-specific вещей на практике.
А вы не заглядывались в сторону TS?
#ai #dev_help
@makebugger
Я не нагнетаю, ближайшие Х лет этого точно не произойдёт, но я вижу чёткий тренд на использование TypeScript в AI-powered проектах. И я не уверен, что это вообще когда-то произойдёт, но...
Почему это может произойти?
• Например, я писал Voice бота, которому звонишь и тебе отвечает LLM голосом (OpenAI real-time API). Чтобы программа такого типа нормально скейлилась и шустро работала – Pythonа просто не достаточно. Latency упала с 200ms до 40ms после перехода на TS.
• Менеджить BackEnd в Python и FrontEnd в TS – это боль, если вы хоть раз работали на таком мультиязычном проекте, вы меня поймёте. Постоянные проблемы с типами и форматом данных, которые передаются между BE и FE, дебажить это – сплошной ад. Если бы все эти ошибки вскрывались на этапе транспиляции TS в JS, экономилось бы кучу времени и нервов.
• Просто в большинстве случаем нет другой причины использовать Python, кроме как "ну наши разработчики лучше знакомы с Python стеком". В большинстве проектов не используется тот хвалёный ML tooling (numpy, pytorch, tensorflow), из-за которого все DS и ML люди пишут в Pythonе, всё через API и SDK.
Почему ещё не скоро?
• SDK для популярных AI frameworkов типа LangGraph в JS/TS отстают от Python SDK на несколько версий, доки – старьё, коммьюнити всё ещё ооочень маленькое.
• Всё-таки переучивать целые команды будет намного дороже, чем смириться с огромными недостатками Python для этих целей.
Некоторый тулинг, который может пригодиться в таких проектах, в Python реализован на 5+, spacy библиотека, например.
Кстати, недавно написал своё первое приложение на NextJS, Claude Code написало 80% за меня) А я выучил огромное количество TypeScript-specific вещей на практике.
А вы не заглядывались в сторону TS?
#ai #dev_help
@makebugger
👍18❤2🤔1
Привет!
Сейчас немного тихо так как я взял небольшую передышку и приехал на недельку-другую в северную столицу отпраздновать юбилей 🤗
В скором времени выпущу мини видео гайд по достаточно полезной платформе для написания комплексных [LLM] workflows, она пока ещё не очень хайповая, но по стечению обстоятельств работаю с ней уже в третьей компании и везде девы выделяют приятнейший developer experience.
Называется temporal.io
Зачем нам очередной тул?
- Если делаете что-то более комплексное, чем один API запрос. (например, взять документ, перевести его в png картинки, послать запрос на Optical Character Recognition (OCR), потом переслать то, что вылезло из OCR в LLM…). Более конвенциональным решением бы было использовать celery, но dev experience и дебагинг комплексных workflows – боль.
- Temporal может заморозить workflow в ожидании inputa человека (Human-in-the-Loop). Если вы верите в то, что сила агентов не в полной автоматизации человеческого труда, а в умной интеграции агентов с людьми, то вам точно понравится temporal. (это мы в проде прям использовали на очень крупном проекте, работало безупречно, LLM делало работу которую перепроверяли наши gig workers, после того как проверка прошла workflow возобновлялся)
- Temporal гарантирует выполнение даже при сбоях. Если ваш сервер упал посередине обработки 100-страничного документа на 73 странице — workflow автоматически продолжится с того же места после перезапуска. В celery такой таск просто пропадёт.
- классный UI и sdk
#dev_help
@makebugger
Сейчас немного тихо так как я взял небольшую передышку и приехал на недельку-другую в северную столицу отпраздновать юбилей 🤗
В скором времени выпущу мини видео гайд по достаточно полезной платформе для написания комплексных [LLM] workflows, она пока ещё не очень хайповая, но по стечению обстоятельств работаю с ней уже в третьей компании и везде девы выделяют приятнейший developer experience.
Называется temporal.io
Зачем нам очередной тул?
- Если делаете что-то более комплексное, чем один API запрос. (например, взять документ, перевести его в png картинки, послать запрос на Optical Character Recognition (OCR), потом переслать то, что вылезло из OCR в LLM…). Более конвенциональным решением бы было использовать celery, но dev experience и дебагинг комплексных workflows – боль.
- Temporal может заморозить workflow в ожидании inputa человека (Human-in-the-Loop). Если вы верите в то, что сила агентов не в полной автоматизации человеческого труда, а в умной интеграции агентов с людьми, то вам точно понравится temporal. (это мы в проде прям использовали на очень крупном проекте, работало безупречно, LLM делало работу которую перепроверяли наши gig workers, после того как проверка прошла workflow возобновлялся)
- Temporal гарантирует выполнение даже при сбоях. Если ваш сервер упал посередине обработки 100-страничного документа на 73 странице — workflow автоматически продолжится с того же места после перезапуска. В celery такой таск просто пропадёт.
- классный UI и sdk
#dev_help
@makebugger
temporal.io
Durable Execution Solutions
Build invincible apps with Temporal's open source durable execution platform. Eliminate complexity and ship features faster. Talk to an expert today!
🔥3❤2👍2🤩2
Бенчмарки
Каждый месяц нам дропают новые модели с бенчмарками.
Многие провайдеры тренят свои модельки с главной целью – выиграть новый бенч и нагнать хайпа. Большинство бенчей –💩.
Но я тут нашёл хороший бенч который к сожалению не обновлялся с мая, лучшие модели из этого топа соответствуют настроениям в индустрии, anthropic модели всё так же лучше всего справляются с tool calling, а reasoning + tool calling это, по сути, самый важный скил моделей, который помогает им решать комплексные задачи типа кодинга и любых кастомных агентов.
Бенч строится над симулятором DevOpsa 😅 (faktorio), если не играли, то не пробуйте, затягивает безумно, если играли и слезли, то респект, таким людям как вам даже гер0ин по зубам..
Надеемся, что скоро волонтёры затестят новую kimi.ai модель и мы наконец узнаем оправдан ли хайп вокруг этого свежего релиза.
#ai
@makebugger
Каждый месяц нам дропают новые модели с бенчмарками.
Многие провайдеры тренят свои модельки с главной целью – выиграть новый бенч и нагнать хайпа. Большинство бенчей –💩.
Но я тут нашёл хороший бенч который к сожалению не обновлялся с мая, лучшие модели из этого топа соответствуют настроениям в индустрии, anthropic модели всё так же лучше всего справляются с tool calling, а reasoning + tool calling это, по сути, самый важный скил моделей, который помогает им решать комплексные задачи типа кодинга и любых кастомных агентов.
Бенч строится над симулятором DevOpsa 😅 (faktorio), если не играли, то не пробуйте, затягивает безумно, если играли и слезли, то респект, таким людям как вам даже гер0ин по зубам..
Надеемся, что скоро волонтёры затестят новую kimi.ai модель и мы наконец узнаем оправдан ли хайп вокруг этого свежего релиза.
#ai
@makebugger
arc.net
Quote from “Multi-Agent Coordination in Factorio: FLE v0.2 Release”
👍3
This media is not supported in the widget
VIEW IN TELEGRAM
❤7👍4🔥1
Аларм! GPT-5
Совсем скоро начнётся презентация нового поколения моделей от OpenAI 🫣
GPT-4 была выпущена уже больше двух лет назад и тогда это был прорыв на фоне gpt-3.5, мы сразу же начали интегрировать её в продукт.
Полезная выжимка из презентации:
• GPT-5 такая же умная как топовые reasoning модели и такая же быстрая как gpt4o
• Лучшая модель по SWE бенчмарку, даже лучше чем недавний Opus 4.1
• Hallucination rate в 5-6 раз меньше, чем у o3
• Цены на новые модели в комментах
• Много косметических апгрейдов в ChatGPT, цвета можете у чатов менять)) выкатили интеграцию с GMail и Google Calendar
#news
@makebugger
https://www.youtube.com/live/0Uu_VJeVVfo?si=pCsF_R1DGZTC9JFK
Совсем скоро начнётся презентация нового поколения моделей от OpenAI 🫣
GPT-4 была выпущена уже больше двух лет назад и тогда это был прорыв на фоне gpt-3.5, мы сразу же начали интегрировать её в продукт.
Полезная выжимка из презентации:
• GPT-5 такая же умная как топовые reasoning модели и такая же быстрая как gpt4o
• Лучшая модель по SWE бенчмарку, даже лучше чем недавний Opus 4.1
• Hallucination rate в 5-6 раз меньше, чем у o3
• Цены на новые модели в комментах
• Много косметических апгрейдов в ChatGPT, цвета можете у чатов менять)) выкатили интеграцию с GMail и Google Calendar
#news
@makebugger
https://www.youtube.com/live/0Uu_VJeVVfo?si=pCsF_R1DGZTC9JFK
YouTube
Introducing GPT-5
Sam Altman, Greg Brockman, Sebastien Bubeck, Mark Chen, Yann Dubois, Brian Fioca, Adi Ganesh, Oliver Godement, Saachi Jain, Christina Kaplan, Christina Kim, Elaine Ya Le, Felipe Millon, Michelle Pokrass, Jakub Pachocki, Max Schwarzer, Rennie Song, Ruochen…
🤯2❤1
Эйджиай не будет
Уже целых два дня я активно пробую GPT-5 в Cursor, через API и в ChatGPT, если коротко: «Всё очень плохо», в первую очередь потому, что ожидания на этот релиз были завышены.
О скачке который мы испытали с gpt-3.5 до gpt-4 и речи быть не может.
GPT-5 это не просто новая модель, а система оркестрации моделей, как кажется, созданная в первую очередь для оптимизации стоимости.
Теперь вы не можете выбрать самую дорогую и качественную o3 в ChatGPT по своему желанию, есть только GPT-5 и GPT-5 Thinking и они выступают маршрутизатором для перенаправления ваших запросов в другие модели под капотом, если GPT-5 и Сэм Алтман решат, что вам можно воспользоваться o3, то тогда её вызовут, но вы об этом даже не узнаете.
Бенчмарки с презентации – наебалово, не понятно для кого надо было выдумывать все эти цифры и выставлять свою модель SOTA, если это вскроется через пару дней. Модель ооочень далека от Opus.
Если вы хотите сделать бесшовный апгрейд с предыдущих моделей на gpt-5 через API, то этого у вас тоже не получится, они зарелизили breaking changes, gpt-5 не принимает такие параметры как temperature (вы больше не можете регулировать креативность модели) и max_token (модель сама решит, когда ей надо остановится).
Короче,
• индустрия в целом движется по хорошему вектору
• с каждой следующей презентацией OpenAI теряет лидерство и преимущество «первой на рынке»
• никого пока не заменяют, все продолжаем работать
#news #ai
@makebugger
thumbnail мне было лень делать, видео дублирует информацию из поста, поддержите лайком)
https://youtu.be/cCr6-Lm7r24?si=d2v4nC1ckF_J6yho
Уже целых два дня я активно пробую GPT-5 в Cursor, через API и в ChatGPT, если коротко: «Всё очень плохо», в первую очередь потому, что ожидания на этот релиз были завышены.
О скачке который мы испытали с gpt-3.5 до gpt-4 и речи быть не может.
GPT-5 это не просто новая модель, а система оркестрации моделей, как кажется, созданная в первую очередь для оптимизации стоимости.
Теперь вы не можете выбрать самую дорогую и качественную o3 в ChatGPT по своему желанию, есть только GPT-5 и GPT-5 Thinking и они выступают маршрутизатором для перенаправления ваших запросов в другие модели под капотом, если GPT-5 и Сэм Алтман решат, что вам можно воспользоваться o3, то тогда её вызовут, но вы об этом даже не узнаете.
Бенчмарки с презентации – наебалово, не понятно для кого надо было выдумывать все эти цифры и выставлять свою модель SOTA, если это вскроется через пару дней. Модель ооочень далека от Opus.
Если вы хотите сделать бесшовный апгрейд с предыдущих моделей на gpt-5 через API, то этого у вас тоже не получится, они зарелизили breaking changes, gpt-5 не принимает такие параметры как temperature (вы больше не можете регулировать креативность модели) и max_token (модель сама решит, когда ей надо остановится).
Короче,
• индустрия в целом движется по хорошему вектору
• с каждой следующей презентацией OpenAI теряет лидерство и преимущество «первой на рынке»
• никого пока не заменяют, все продолжаем работать
#news #ai
@makebugger
thumbnail мне было лень делать, видео дублирует информацию из поста, поддержите лайком)
https://youtu.be/cCr6-Lm7r24?si=d2v4nC1ckF_J6yho
YouTube
GPT-5 – ПРОВАЛ ЛЕТА?
https://t.me/makebugger – Телеграмм канал о ИИ и не только
GPT-5 с точки зрения разработчика оказалось провальным релизом, вы этом видео расскажу почему и поделюсь эмоциями от использования модели на протяжении последних 3 дней.
GPT-5 с точки зрения разработчика оказалось провальным релизом, вы этом видео расскажу почему и поделюсь эмоциями от использования модели на протяжении последних 3 дней.
❤16👍4
Cделал умный поиск для одного известного IT сообщества. Делюсь опытом.
В ядре умного поиска (semantic search) всегда кроется завсегдатый RAG.
Что мы знаем про RAG – берёшь документы, режешь на чанки, засовываешь в векторную БД.
А в какую векторную БД сохранять эмбединги?
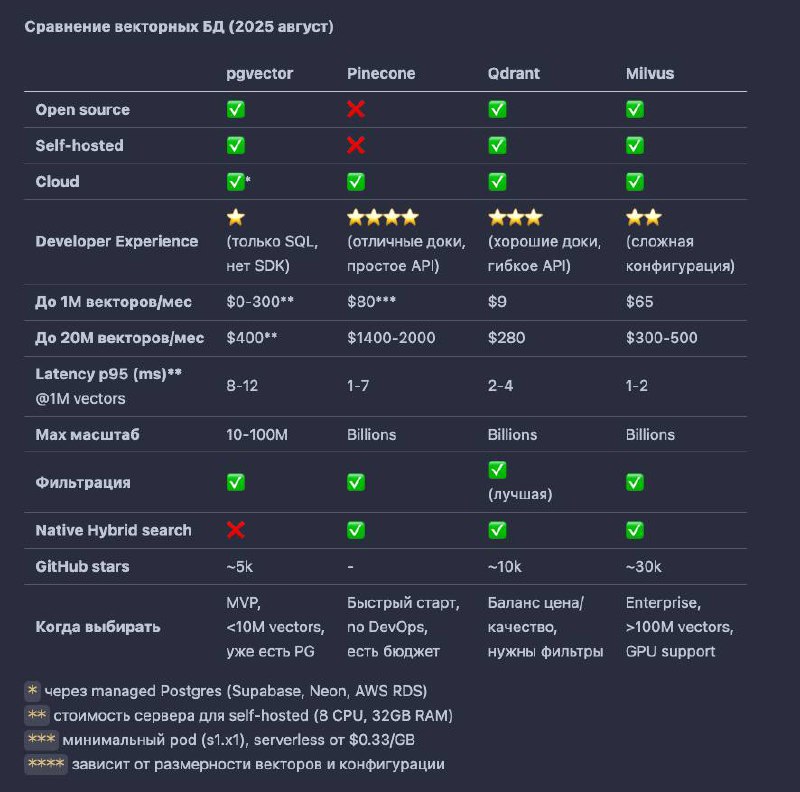
Есть Pinecone, QDrant, Milvus, недавно запустившийся jстартап моего друга topk.
В принципе, оно все очень похожи…
какие вопросы стоит задать, чтобы выбрать подходящую?
• self-hosted или cloud?
С self-hosted больше мороки, но всё под контролем, cloud очень быстро можно setupнуть, отлично когда нет времени на DevOps
• какая ожидаемая нагрузка?
если вы не пишете второй фейсбук, а количество векторов меньше 1М, то речь о крошечных объёмах, вам не нужна супер пропускная векторная БД
• вы уже используете Postgres?
не стоит привносить новую зависимость, если вы знаете, что не будете скейлить приложение на масштабы нетфликса, стоит использовать pgvector
PgVector это расширение для вашего обычного Postgres которое добавляет новый тип
выбрав этот вариант вместо любой другой векторной БД, вам не нужно будет думать о скейлинге и бэкапе отдельной БД, а инженеры в вашей команде уже будут знать как с этим работать
В случае когда вы хотите написать быстрое PoC, или если знаете, что будут огромные объёмы >1М векторов, или когда pgvector уже не справляется — тогда смотрим на специализированные решения. Делюсь табличкой!
TL;DR:
pgvector — если уже есть Postgres и <10M векторов
Pinecone — если нужно запустить экстра быстро и есть $70+/месяц
Qdrant — оптимальный выбор по соотношению цена/качество/функционал
Milvus — когда реально большие объёмы и нужна максимальная производительность
#ai #dev_help
@makebugger
В ядре умного поиска (semantic search) всегда кроется завсегдатый RAG.
Что мы знаем про RAG – берёшь документы, режешь на чанки, засовываешь в векторную БД.
А в какую векторную БД сохранять эмбединги?
Есть Pinecone, QDrant, Milvus, недавно запустившийся jстартап моего друга topk.
В принципе, оно все очень похожи…
какие вопросы стоит задать, чтобы выбрать подходящую?
• self-hosted или cloud?
С self-hosted больше мороки, но всё под контролем, cloud очень быстро можно setupнуть, отлично когда нет времени на DevOps
• какая ожидаемая нагрузка?
если вы не пишете второй фейсбук, а количество векторов меньше 1М, то речь о крошечных объёмах, вам не нужна супер пропускная векторная БД
• вы уже используете Postgres?
не стоит привносить новую зависимость, если вы знаете, что не будете скейлить приложение на масштабы нетфликса, стоит использовать pgvector
PgVector это расширение для вашего обычного Postgres которое добавляет новый тип
vector
выбрав этот вариант вместо любой другой векторной БД, вам не нужно будет думать о скейлинге и бэкапе отдельной БД, а инженеры в вашей команде уже будут знать как с этим работать
В случае когда вы хотите написать быстрое PoC, или если знаете, что будут огромные объёмы >1М векторов, или когда pgvector уже не справляется — тогда смотрим на специализированные решения. Делюсь табличкой!
TL;DR:
pgvector — если уже есть Postgres и <10M векторов
Pinecone — если нужно запустить экстра быстро и есть $70+/месяц
Qdrant — оптимальный выбор по соотношению цена/качество/функционал
Milvus — когда реально большие объёмы и нужна максимальная производительность
#ai #dev_help
@makebugger
{kind=link}
❤24🔥4
Наша паранойя
Последнее время всё больше взаимодействую с коллегами с российского айти рынка и заметил интересную особенность: люди буквально помешаны на self-hosted решениях. Главное, чтобы в облако ни байтика не просочилось.
Все очень обеспокоены безопасностью данных: кому мы их передаём, где хостим модель, а не тренируют ли модель на наших данных. Параноя на каждом шагу.
На US/EU рынке ни минуты не тратят на переизобретение велосипедов. Тут работает презумпция доверия: если главный бизнес компании - это векторные БД в облаке, значит они там всё продумали и обеспечили безопасность. У них весь бизнес на этом держится, какой им смысл рисковать репутацией?
А на российском и СНГ рынке многие хотят делать кастомные решения, искренне веря, что за пару недель накодят внутренний аналог того, на базе чего целые компании строятся.
У меня есть теория, львиную долю российского IT-рынка жрут банки и госконторы, где такая паранойя действительно оправдана. Но айтишники из этих компаний переносят свой секьюрити майндсет в стартапы, где нужно продукты делать и кусок рынка отхватить, а не заниматься мастурбацией на тему “а вдруг омериканцы наш код украдут”.
В итоге команды обкладываются своими security best practices: квантизованный DeepSeek на ноутбуке вместо Cursor - ну чтобы кодбазу не слить проклятым империалистам.
А то вдруг они там в Кремниевой долине увидят гениальную переменную is_voronezh и сразу поймут, как составить конкуренцию.
Лучше уж месяц мучиться с самописным решением, чем дать заокеанским шпионам возможность подсмотреть, как мы комментарии на русском пишем. Они же сразу наш уникальный бизнес-процесс вычислят и начнут с нами конкурировать за клиентов из четвёртого ЖЭКа.
А между тем успешная компания - это вообще не только про код. Это про то, умеешь ли ты решать проблемы людей, продавать, строить процессы. Если завтра Google открыто выложит весь свой код, сколько конкурентов реально появится? Примерно ноль. Потому что дело не в коде, а в том, что за ним стоит.
Но нет, давайте лучше еще месяц будем пилить свой велосипед и гордиться тем, что наши православные переменные не видел ни один американский сервер.
Не говорю, что не нужно заниматься безопасностью, нужно, но то сколько вниманию этому уделяется меня удивляет.
#business
@makebugger
Последнее время всё больше взаимодействую с коллегами с российского айти рынка и заметил интересную особенность: люди буквально помешаны на self-hosted решениях. Главное, чтобы в облако ни байтика не просочилось.
Все очень обеспокоены безопасностью данных: кому мы их передаём, где хостим модель, а не тренируют ли модель на наших данных. Параноя на каждом шагу.
На US/EU рынке ни минуты не тратят на переизобретение велосипедов. Тут работает презумпция доверия: если главный бизнес компании - это векторные БД в облаке, значит они там всё продумали и обеспечили безопасность. У них весь бизнес на этом держится, какой им смысл рисковать репутацией?
А на российском и СНГ рынке многие хотят делать кастомные решения, искренне веря, что за пару недель накодят внутренний аналог того, на базе чего целые компании строятся.
У меня есть теория, львиную долю российского IT-рынка жрут банки и госконторы, где такая паранойя действительно оправдана. Но айтишники из этих компаний переносят свой секьюрити майндсет в стартапы, где нужно продукты делать и кусок рынка отхватить, а не заниматься мастурбацией на тему “а вдруг омериканцы наш код украдут”.
В итоге команды обкладываются своими security best practices: квантизованный DeepSeek на ноутбуке вместо Cursor - ну чтобы кодбазу не слить проклятым империалистам.
А то вдруг они там в Кремниевой долине увидят гениальную переменную is_voronezh и сразу поймут, как составить конкуренцию.
Лучше уж месяц мучиться с самописным решением, чем дать заокеанским шпионам возможность подсмотреть, как мы комментарии на русском пишем. Они же сразу наш уникальный бизнес-процесс вычислят и начнут с нами конкурировать за клиентов из четвёртого ЖЭКа.
А между тем успешная компания - это вообще не только про код. Это про то, умеешь ли ты решать проблемы людей, продавать, строить процессы. Если завтра Google открыто выложит весь свой код, сколько конкурентов реально появится? Примерно ноль. Потому что дело не в коде, а в том, что за ним стоит.
Но нет, давайте лучше еще месяц будем пилить свой велосипед и гордиться тем, что наши православные переменные не видел ни один американский сервер.
Не говорю, что не нужно заниматься безопасностью, нужно, но то сколько вниманию этому уделяется меня удивляет.
#business
@makebugger
👍17❤2👏2🤩1