Почти все о методах оптимизации нейросетей
Серия статей о почти всех используемых в современных библиотеках для нейронных сетей методах оптимизации. Начиная от просто градиентного спуска и заканчивая модификациями Adam, такими как NAdam, AdamNC, AMSGrad.
7 статей, 33 минуты, если верить оценкам medium, но кто же им поверит (умножайте примерно на 4).
1. Gradient Descent and Stochastic Gradient Descent https://bit.ly/2wqdFqM
2. Momentum and Nesterov Accelerated https://bit.ly/2Xiz4Oy
3. Adagrad https://bit.ly/2JLMoHZ
4. Adadelta and RMSProp https://bit.ly/2EFMFIb
5. RMSProp+Momentum and Adam https://bit.ly/2QwwC4r
6. Nadam https://bit.ly/2HLnKVL
7. AMSGrad and AdamNC https://bit.ly/2JSBRuT
А вот почти то же, на русском и с классными гифками https://habr.com/ru/post/318970/.
Серия статей о почти всех используемых в современных библиотеках для нейронных сетей методах оптимизации. Начиная от просто градиентного спуска и заканчивая модификациями Adam, такими как NAdam, AdamNC, AMSGrad.
7 статей, 33 минуты, если верить оценкам medium, но кто же им поверит (умножайте примерно на 4).
1. Gradient Descent and Stochastic Gradient Descent https://bit.ly/2wqdFqM
2. Momentum and Nesterov Accelerated https://bit.ly/2Xiz4Oy
3. Adagrad https://bit.ly/2JLMoHZ
4. Adadelta and RMSProp https://bit.ly/2EFMFIb
5. RMSProp+Momentum and Adam https://bit.ly/2QwwC4r
6. Nadam https://bit.ly/2HLnKVL
7. AMSGrad and AdamNC https://bit.ly/2JSBRuT
А вот почти то же, на русском и с классными гифками https://habr.com/ru/post/318970/.
Medium
Gradient Descent and Stochastic Gradient Descent Algorithms for Neural Networks
Everyone who ever have trained Neural Networks, chances are, have been stumbled with Gradient Descent algorithm or its variations. These…
Говорящие головы из Сколково
Ура! Вот и наши соотечественники попали в СМИ со своими достижениями в области deep learning.
Они научились генерировать видео «говорящей головы» используя несколько или даже одно статическое изображение. Видео генерирует даже ракурсы, не представленные на фото. Это надо просто увидеть (ссылка на видео ниже).
А почитать можно, как они это сделали. До этого требовались видео длиной несколько минут или большой датасет фотографий и много часов обучения на GPU.
Ребята же придумали как сделать мета-обучение, чтобы потом всего на нескольких фото за несколько тренировочных шагов обучить модель под конкретного человека.
Их сеть показала отличные результаты при проверке на живых людях. Людям показывали 3 статических изображения одного человека, нужно угадать, где фейк.
Их лучшая модель показала результат 33%, то есть люди не догадались, где фейк и выбирали наугад.
Дальше немного о том, как.
Основа модели - генеративно-состязательная сеть(Generative adversarial network - GAN), которая состоит из 2х частей: генератора и дискриминатора. Они обучаются так: генератор создает изображения, а дискриминатор пытается отличить фейк от реального. Причем вывод дискриминатора используется для обновления весов генератора. Получается своего рода соревнование.
Их модель в итоге состоит из трех сетей: embedder, генератор и дискриминатор.
1. Embedder учится из исходного изображения и позы (landmark image, получен отдельным методом) получать вектор, который содержит информацию об индивидуальных чертах человека, независимо от позы и мимики.
2. Генератор, используя этот вектор и новую позу, генерирует фейковое изображение.
3. Дискриминатор, используя фейковое изображение и позу определяет насколько оно реалистично и соответствует позе.
Получается, большая часть уникальной информации о человеке содержится в сети embedder. Значит, чтобы генерировать изображения нового человека, нужно переобучить только эту сеть и немного дообучить (fine-tune) генератор и дискриминатор.
Саму идею иметь отдельный embedder позаимствовали из пары работ по генерации речи. Поменяли область использования, добавили состязательный (adversarial) компонент, поколдовали и вуаля.
https://arxiv.org/pdf/1905.08233.pdf
Ура! Вот и наши соотечественники попали в СМИ со своими достижениями в области deep learning.
Они научились генерировать видео «говорящей головы» используя несколько или даже одно статическое изображение. Видео генерирует даже ракурсы, не представленные на фото. Это надо просто увидеть (ссылка на видео ниже).
А почитать можно, как они это сделали. До этого требовались видео длиной несколько минут или большой датасет фотографий и много часов обучения на GPU.
Ребята же придумали как сделать мета-обучение, чтобы потом всего на нескольких фото за несколько тренировочных шагов обучить модель под конкретного человека.
Их сеть показала отличные результаты при проверке на живых людях. Людям показывали 3 статических изображения одного человека, нужно угадать, где фейк.
Их лучшая модель показала результат 33%, то есть люди не догадались, где фейк и выбирали наугад.
Дальше немного о том, как.
Основа модели - генеративно-состязательная сеть(Generative adversarial network - GAN), которая состоит из 2х частей: генератора и дискриминатора. Они обучаются так: генератор создает изображения, а дискриминатор пытается отличить фейк от реального. Причем вывод дискриминатора используется для обновления весов генератора. Получается своего рода соревнование.
Их модель в итоге состоит из трех сетей: embedder, генератор и дискриминатор.
1. Embedder учится из исходного изображения и позы (landmark image, получен отдельным методом) получать вектор, который содержит информацию об индивидуальных чертах человека, независимо от позы и мимики.
2. Генератор, используя этот вектор и новую позу, генерирует фейковое изображение.
3. Дискриминатор, используя фейковое изображение и позу определяет насколько оно реалистично и соответствует позе.
Получается, большая часть уникальной информации о человеке содержится в сети embedder. Значит, чтобы генерировать изображения нового человека, нужно переобучить только эту сеть и немного дообучить (fine-tune) генератор и дискриминатор.
Саму идею иметь отдельный embedder позаимствовали из пары работ по генерации речи. Поменяли область использования, добавили состязательный (adversarial) компонент, поколдовали и вуаля.
https://arxiv.org/pdf/1905.08233.pdf
Кросс-валидация для временных рядов
7-минутная статья о том, как разбивать данные на train-validation-test сеты, если данные - это временные ряды.
Вкратце, разбивать надо вдоль оси времени. То есть, тренировочные данные идут хронологически до валидационных. Валидационные до тестовых. Потому что модель не должна иметь никакую информацию о будущем.
В статье есть очень понятные картинки о том, как именно разбивать.
Кроме этого в scikit-learn есть класс TimeSeriesSplit, но он разбивает только на train-test, валидацию все равно делать самим.
Статья: https://towardsdatascience.com/time-series-nested-cross-validation-76adba623eb9
TimeSeriesSplit: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.TimeSeriesSplit.html
7-минутная статья о том, как разбивать данные на train-validation-test сеты, если данные - это временные ряды.
Вкратце, разбивать надо вдоль оси времени. То есть, тренировочные данные идут хронологически до валидационных. Валидационные до тестовых. Потому что модель не должна иметь никакую информацию о будущем.
В статье есть очень понятные картинки о том, как именно разбивать.
Кроме этого в scikit-learn есть класс TimeSeriesSplit, но он разбивает только на train-test, валидацию все равно делать самим.
Статья: https://towardsdatascience.com/time-series-nested-cross-validation-76adba623eb9
TimeSeriesSplit: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.TimeSeriesSplit.html
Medium
Time Series Nested Cross-Validation
This blog post discusses the pitfalls of using traditional cross-validation with time series data. Specifically, we address 1) splitting a…
Халявные знания
Вот и закончились 2 соревнования на Kaggle, проводимые в рамках международной конференции CVPR: Google Landmark Recognition and Google Landmark Retrieval.
Суть их была в том, чтобы научиться распознавать достопримечательности на картинках.
То есть в первом соревновании (Recognition) надо было по фотографии Эйфелевой башни сказать, что это именно она. А во втором (Retrieval), имея фотографию Эйфелевой башни, найти из базы все остальные фотографии с ней.
Датасет при этом в обоих случаях был огромен, порядка 500 гигов и 4 миллиона фотографий для Recognition и 85 гигов и 760 тысяч в базе для Retrieval.
Круто то, что по правилам этих соревнований, призеры должны теперь запостить статью на arXiv с подробным описанием подхода.
А чтобы получить свой денежный приз нужно еще и в opensource выложить код.
Вот такое счастье всем, даром.
https://www.kaggle.com/c/landmark-recognition-2019/discussion/94514#latest-543946
https://www.kaggle.com/c/landmark-retrieval-2019/discussion/94515#latest-543948
Вот и закончились 2 соревнования на Kaggle, проводимые в рамках международной конференции CVPR: Google Landmark Recognition and Google Landmark Retrieval.
Суть их была в том, чтобы научиться распознавать достопримечательности на картинках.
То есть в первом соревновании (Recognition) надо было по фотографии Эйфелевой башни сказать, что это именно она. А во втором (Retrieval), имея фотографию Эйфелевой башни, найти из базы все остальные фотографии с ней.
Датасет при этом в обоих случаях был огромен, порядка 500 гигов и 4 миллиона фотографий для Recognition и 85 гигов и 760 тысяч в базе для Retrieval.
Круто то, что по правилам этих соревнований, призеры должны теперь запостить статью на arXiv с подробным описанием подхода.
А чтобы получить свой денежный приз нужно еще и в opensource выложить код.
Вот такое счастье всем, даром.
https://www.kaggle.com/c/landmark-recognition-2019/discussion/94514#latest-543946
https://www.kaggle.com/c/landmark-retrieval-2019/discussion/94515#latest-543948
{kind=link}
Два в одном
Иллюстративная статья о том, как подружить автоэнкодеры и GAN и получить инструмент, который решает 2 задачи: кластеризации и поиска аномалий. И все это для временных рядов.
Напомню, что автоэнкодеры учатся представлять данные в компактном виде, а потом восстанавливать из него. Состоят из 2х частей: энкодер и декодер.
А GAN - generative adversarial network состоит также из двух частей: генератор и дискриминатор. Во время обучения они соревнуются таким образом: генератор пытается генерировать данные, подобные реальным, а дискриминатор пытается отличить сгенерированные и реальные.
Так вот декодер (2ая часть autoencoder) выступает здесь генератором (1ая часть GAN). Состоит он из двух слоев bidirectional LSTM.
Идея не нова, оригинальная статья еще из 2015 года (от людей из University of Toronto, Google Brain и OpenAI).
Конкретно в этой статье очень понятный код на Keras, подробное вступление, из которого можно понять-вспомнить основы этих сетей и в качестве данных взяты не изображения MNIST, a я данные обменного курса EUR-USD.
Ссылка отсюда
Иллюстративная статья о том, как подружить автоэнкодеры и GAN и получить инструмент, который решает 2 задачи: кластеризации и поиска аномалий. И все это для временных рядов.
Напомню, что автоэнкодеры учатся представлять данные в компактном виде, а потом восстанавливать из него. Состоят из 2х частей: энкодер и декодер.
А GAN - generative adversarial network состоит также из двух частей: генератор и дискриминатор. Во время обучения они соревнуются таким образом: генератор пытается генерировать данные, подобные реальным, а дискриминатор пытается отличить сгенерированные и реальные.
Так вот декодер (2ая часть autoencoder) выступает здесь генератором (1ая часть GAN). Состоит он из двух слоев bidirectional LSTM.
Идея не нова, оригинальная статья еще из 2015 года (от людей из University of Toronto, Google Brain и OpenAI).
Конкретно в этой статье очень понятный код на Keras, подробное вступление, из которого можно понять-вспомнить основы этих сетей и в качестве данных взяты не изображения MNIST, a я данные обменного курса EUR-USD.
Ссылка отсюда
Вложенные капсульные сети
Свежачок прямо от команды Хинтона.
Вдохновились они идеей о том, что люди, в отличие от нейросетей, учатся распознавать объекты почти сами и не используют такое большое количество картинок для обучения, как нейронки.
Поэтому поменяли подход с попиксельной обработки изображений на обработки с помощью "капсул".
Капсула - это часть модели, которая описывает абстрактную сущность.
В данном случае используется 2 типа капсул: для объектов и для их частей. То есть часть - это какой-то простой элемент, который может встречаться в разных объектах. А объект это что-то уникальное, состоящее из частей.
Набор и размещение объектов и определяют изображение.
Сеть состоит из 2х подсетей: одна учится описывать наличие частей и их размещение. А вторая учится имея набор частей и их размещение собирать из них объекты, то есть выдавать информацию о том, сколько объектов, как они выглядят и как расположены. Вот эта информация в векторном виде и может быть использована далее например для классификация изображений.
Обе части сети - это автоэнкодеры, то есть сначала они представляют входную информацию, например изображение, в определенном сжатом виде, а потом могут из него восстановить эту информацию.
Так вот на вход первой подсети подается изображение, а сжатый вид - это вектор, описывающий наличие частей и их позу.
Для второй подсети на вход подается вектор из первой подсети, а получается сжатый вектор, описывающий набор объектов, их вид и позу.
Вот этот вектор и есть представление изображение, которое можно использовать для кластеризации/классификации.
Пока всё очень сырое, работает на датасете MNIST и SVHN (the Street View House Numbers). На CIFAR пишут не очень работает.
Свежачок прямо от команды Хинтона.
Вдохновились они идеей о том, что люди, в отличие от нейросетей, учатся распознавать объекты почти сами и не используют такое большое количество картинок для обучения, как нейронки.
Поэтому поменяли подход с попиксельной обработки изображений на обработки с помощью "капсул".
Капсула - это часть модели, которая описывает абстрактную сущность.
В данном случае используется 2 типа капсул: для объектов и для их частей. То есть часть - это какой-то простой элемент, который может встречаться в разных объектах. А объект это что-то уникальное, состоящее из частей.
Набор и размещение объектов и определяют изображение.
Сеть состоит из 2х подсетей: одна учится описывать наличие частей и их размещение. А вторая учится имея набор частей и их размещение собирать из них объекты, то есть выдавать информацию о том, сколько объектов, как они выглядят и как расположены. Вот эта информация в векторном виде и может быть использована далее например для классификация изображений.
Обе части сети - это автоэнкодеры, то есть сначала они представляют входную информацию, например изображение, в определенном сжатом виде, а потом могут из него восстановить эту информацию.
Так вот на вход первой подсети подается изображение, а сжатый вид - это вектор, описывающий наличие частей и их позу.
Для второй подсети на вход подается вектор из первой подсети, а получается сжатый вектор, описывающий набор объектов, их вид и позу.
Вот этот вектор и есть представление изображение, которое можно использовать для кластеризации/классификации.
Пока всё очень сырое, работает на датасете MNIST и SVHN (the Street View House Numbers). На CIFAR пишут не очень работает.
akosiorek.github.io
Stacked Capsule Autoencoders
Objects play a central role in computer vision and, increasingly, machine learning research.With many applications depending on object detection in images an...
Два убийцы Берта
Недавно вышли две статьи, которые представляют модели, работающие лучше предыдущего state-of-the-art в области обработки естественного языка BERT.
Эти модели: XLNet и SpanBERT (все ссылки в конце).
BERT
Для начала про BERT. Эта технология предобучения. То есть она использует существующую архитектуру нейросети и из нового вносит только саму технику обучения.
Использована может быть для решения очень многих задач, таких как построение систем вопрос-ответ, генерация текста, анализ тональности.
Архитектура сети, которую использует BERT, называется Transformer. Она была представлена в статье "Attention is all you need". Это sequence-to-sequence модель, то есть на входе и на выходе - последовательности. При этом она не использует рекуррентные структуры типа RNN и LSTM. Вместо этого она полностью основывается на механизме attention. Этот механизм позволяет определять какие части входной последовательности важны для решения задачи, то есть использует информацию из всей входной последовательности, а не только запомненную внутри сети.
BERT использует эту архитектуру с добавлением направления справа-налево, то есть позволяя сети "видеть" последующие входящие значения. Поэтому и называется Bidirectional Encoder Representations from Transformers.
Основной же интерес представляет сам способ тренировки сети. Она тренируется на двух задачах: восстановления слова, замененного на символ [MASK] и предсказания, является ли второе предложение продолжением первого (masked language model и next sentence prediction).
Предобучив модель таким образом, можно использовать её на очень многих задачах, которые подразумевают на входе последовательность или две последовательности (как, например, система вопрос-ответ). Дообучение при этом происходит естественно гораздо быстрее-дешевле, чем с нуля.
XLNet
Использует другой тип сети Transformer под названием TransformerXL (eXtra-Large). Этот трансформер как раз не отказывается полностью от рекуррентной части и за счёт этого обучается более длинным зависимостям между словами-токенами.
Кроме этого, XLNet использует вместо masked language model permutation language model. То есть решает проблему, когда в предложении два слова заменены на [MASK] и BERT предсказывает их независимо.
Например, возьмем предложение "New York is a city". Предсказать нужно "New York". То есть BERT имеет на входе "[MASK] [MASK] is a city" и слова "New" и "York" будут предсказаны независимо. XLNet предскажет сначала одно, например "New", а потом, имея "New .. is a city", предскажет "York".
По результатам XLNet обгоняет BERT больше чем по 20 задачам, есть одно "но". Использует чуть больше данных для предобучения, гигов так на 100 🙂.
SpanBERT
Три основных отличия от BERT:
1. [MASK] закрывает целые непрерывные куски предложения
2. Дополнительная целевая функция, которая помогает модели предсказывать скрытую часть, используя только пограничные токены (то, что до и после [MASK])
3. Предобучение только на целых предложениях без использования next sentence prediction.
Обгоняет BERT на двух задачах: вопрос-ответ и разрешение кореферентных имен (coreference resolution).
BERT - https://arxiv.org/pdf/1810.04805.pdf
SpanBERT - https://arxiv.org/pdf/1907.10529.pdf
XLNET - https://arxiv.org/pdf/1906.08237.pdf
Transformer - https://arxiv.org/pdf/1706.03762.pdf
TransformerXL - https://arxiv.org/pdf/1901.02860.pdf
Недавно вышли две статьи, которые представляют модели, работающие лучше предыдущего state-of-the-art в области обработки естественного языка BERT.
Эти модели: XLNet и SpanBERT (все ссылки в конце).
BERT
Для начала про BERT. Эта технология предобучения. То есть она использует существующую архитектуру нейросети и из нового вносит только саму технику обучения.
Использована может быть для решения очень многих задач, таких как построение систем вопрос-ответ, генерация текста, анализ тональности.
Архитектура сети, которую использует BERT, называется Transformer. Она была представлена в статье "Attention is all you need". Это sequence-to-sequence модель, то есть на входе и на выходе - последовательности. При этом она не использует рекуррентные структуры типа RNN и LSTM. Вместо этого она полностью основывается на механизме attention. Этот механизм позволяет определять какие части входной последовательности важны для решения задачи, то есть использует информацию из всей входной последовательности, а не только запомненную внутри сети.
BERT использует эту архитектуру с добавлением направления справа-налево, то есть позволяя сети "видеть" последующие входящие значения. Поэтому и называется Bidirectional Encoder Representations from Transformers.
Основной же интерес представляет сам способ тренировки сети. Она тренируется на двух задачах: восстановления слова, замененного на символ [MASK] и предсказания, является ли второе предложение продолжением первого (masked language model и next sentence prediction).
Предобучив модель таким образом, можно использовать её на очень многих задачах, которые подразумевают на входе последовательность или две последовательности (как, например, система вопрос-ответ). Дообучение при этом происходит естественно гораздо быстрее-дешевле, чем с нуля.
XLNet
Использует другой тип сети Transformer под названием TransformerXL (eXtra-Large). Этот трансформер как раз не отказывается полностью от рекуррентной части и за счёт этого обучается более длинным зависимостям между словами-токенами.
Кроме этого, XLNet использует вместо masked language model permutation language model. То есть решает проблему, когда в предложении два слова заменены на [MASK] и BERT предсказывает их независимо.
Например, возьмем предложение "New York is a city". Предсказать нужно "New York". То есть BERT имеет на входе "[MASK] [MASK] is a city" и слова "New" и "York" будут предсказаны независимо. XLNet предскажет сначала одно, например "New", а потом, имея "New .. is a city", предскажет "York".
По результатам XLNet обгоняет BERT больше чем по 20 задачам, есть одно "но". Использует чуть больше данных для предобучения, гигов так на 100 🙂.
SpanBERT
Три основных отличия от BERT:
1. [MASK] закрывает целые непрерывные куски предложения
2. Дополнительная целевая функция, которая помогает модели предсказывать скрытую часть, используя только пограничные токены (то, что до и после [MASK])
3. Предобучение только на целых предложениях без использования next sentence prediction.
Обгоняет BERT на двух задачах: вопрос-ответ и разрешение кореферентных имен (coreference resolution).
BERT - https://arxiv.org/pdf/1810.04805.pdf
SpanBERT - https://arxiv.org/pdf/1907.10529.pdf
XLNET - https://arxiv.org/pdf/1906.08237.pdf
Transformer - https://arxiv.org/pdf/1706.03762.pdf
TransformerXL - https://arxiv.org/pdf/1901.02860.pdf
Победить самый большой датасет
По результатам Google Landmark Retrieval и Google Landmark Recognition 2019 были опубликованы 4 статьи с описаниями призовых решений. Уже был пост про то, что авторы обязаны объяснить подход и поделиться кодом.
Интересно в этих статьях конечно же их пересечение: что такого, помимо упорства авторов, позволило эффективнее всего решить задачи.
Задачи было две: в Retrieval - получить список изображений с той же достопримечательностью, что и в тестовой картинке. В Recognition - определить, что за достопримечательность на картинке, и есть ли она там вообще.
И всё это на самом большом на текущий момент публичном датасете для retrieval и recognition The Google Landmark Dataset (GLD) V2.
Так вот выигрышные подходы объединяет 5 техник:
1. Использование нескольких глобальных дескрипторов (описывающих изображение целиком), полученных на основе популярных архитектур CNN: ResNet-101 , ResNeXt-101, SE-ResNet-101, SE-ResNeXt-101, InceptionV4 и похожих.
2. Дескрипторы этих моделей собираются в один с помощью применения в разном порядке: пулинга - чаще всего generalized mean (GeM) pooling; снижения размерности - PCA, AUW, просто fully-connected layer; нормализации; конкатенации.
3. Использования локальных дескрипторов (описывающих ключевые точки изображения) в разных подзадачах, чаще всего вместе с пространственной верификацией, то есть нахождением соотношения между ключевыми точками двух картинок. В качестве самих дескрипторов используются классические SURF, SIFT или дескрипторы на основе CNN - DELF и DELFv2. Для пространственной верификации RANSAC.
4. Использование k nearest neighbours для классификации. В качестве метрики - просто евклидово расстояние. Для поиска кандидатов на retrieval - тоже часто brute-force поиск по евклидовому расстоянию.
5. После простого поиска ближайших соседей происходит переранжирование обычно с использованием дополнительного показателя доверия (confidence score), рассчитанного с помощью другой меры схожести, другого датасета или с привлечением локальных дескрипторов.
А дальше - кто во что горазд. Очень много моделей были испробовано авторами до получения результата. В основном, все начиналось с какой-то одной архитектуры CNN и уже потом объединялось несколько дескрипторов, добавлялись методы расширения запроса и увеличения базы данных (query expansion и database augmentation) и всяческие способы переранжирования.
Сами статьи:
1 место Recognition: https://arxiv.org/pdf/1906.11874.pdf
2 место Retrieval, 2 место Recognition: https://arxiv.org/pdf/1906.03990.pdf
1 место Retrieval, 3 место Recognition: https://arxiv.org/pdf/1906.04087.pdf
3 место Retrieval: https://arxiv.org/pdf/1906.04944.pdf
По результатам Google Landmark Retrieval и Google Landmark Recognition 2019 были опубликованы 4 статьи с описаниями призовых решений. Уже был пост про то, что авторы обязаны объяснить подход и поделиться кодом.
Интересно в этих статьях конечно же их пересечение: что такого, помимо упорства авторов, позволило эффективнее всего решить задачи.
Задачи было две: в Retrieval - получить список изображений с той же достопримечательностью, что и в тестовой картинке. В Recognition - определить, что за достопримечательность на картинке, и есть ли она там вообще.
И всё это на самом большом на текущий момент публичном датасете для retrieval и recognition The Google Landmark Dataset (GLD) V2.
Так вот выигрышные подходы объединяет 5 техник:
1. Использование нескольких глобальных дескрипторов (описывающих изображение целиком), полученных на основе популярных архитектур CNN: ResNet-101 , ResNeXt-101, SE-ResNet-101, SE-ResNeXt-101, InceptionV4 и похожих.
2. Дескрипторы этих моделей собираются в один с помощью применения в разном порядке: пулинга - чаще всего generalized mean (GeM) pooling; снижения размерности - PCA, AUW, просто fully-connected layer; нормализации; конкатенации.
3. Использования локальных дескрипторов (описывающих ключевые точки изображения) в разных подзадачах, чаще всего вместе с пространственной верификацией, то есть нахождением соотношения между ключевыми точками двух картинок. В качестве самих дескрипторов используются классические SURF, SIFT или дескрипторы на основе CNN - DELF и DELFv2. Для пространственной верификации RANSAC.
4. Использование k nearest neighbours для классификации. В качестве метрики - просто евклидово расстояние. Для поиска кандидатов на retrieval - тоже часто brute-force поиск по евклидовому расстоянию.
5. После простого поиска ближайших соседей происходит переранжирование обычно с использованием дополнительного показателя доверия (confidence score), рассчитанного с помощью другой меры схожести, другого датасета или с привлечением локальных дескрипторов.
А дальше - кто во что горазд. Очень много моделей были испробовано авторами до получения результата. В основном, все начиналось с какой-то одной архитектуры CNN и уже потом объединялось несколько дескрипторов, добавлялись методы расширения запроса и увеличения базы данных (query expansion и database augmentation) и всяческие способы переранжирования.
Сами статьи:
1 место Recognition: https://arxiv.org/pdf/1906.11874.pdf
2 место Retrieval, 2 место Recognition: https://arxiv.org/pdf/1906.03990.pdf
1 место Retrieval, 3 место Recognition: https://arxiv.org/pdf/1906.04087.pdf
3 место Retrieval: https://arxiv.org/pdf/1906.04944.pdf
{kind=link}
Внимание или выравнивание?
Механизм attention одна из самых мощных идей, продвинувших обработку естественного языка (и не только) в последние годы.
Что же в нем такого увлекательного?
Изначально он был предложен для сетей типа sequence-to-sequence, то есть на входе и на выходе последовательность. В оригинальной статье используется для машинного перевода с английского на французский.
На картинке слева показаны веса α, которые и определяют механизм attention. Они задают то, сколько "внимания" (attention) нужно уделять каждому слову из входного предложения. Например, для перевода слова européenne использовалось только слово European из оригинала. А при переводе артикля la использовалось не только the, но еще и area, что выглядит логичным, ведь не зная рода существительного, определенный артикль на французский не перевести.
На картинке справа изображено, как примерно работают эти веса. Сеть, взятая за основу, состоит из 2х частей: энкодера и декодера. Обе части используют рекуррентные блоки, такие как GRU и LSTM. На картинке самих этих блоков нет, есть только их выходные значения h и s.
Веса α тренируются как часть общей архитектуры и получаются из подсети, на вход которой подается представление очередного входного слова и предыдущее состояние декодера. Авторы называют эту подсеть alignment model. То есть такие веса выполняют задачу выравнивания - сопоставления слова и его перевода.
Таким образом, с плеч реккурентных блоков снимается необходимость запоминать информацию, далекую от текущего входного значения. Эта информация и так будет использована напрямую с помощью attention.
На основе этого механизма и была построена сеть Transformer, которая обеспечила появление BERT и XLNet, о которых был пост раньше.
https://arxiv.org/pdf/1409.0473.pdf
Механизм attention одна из самых мощных идей, продвинувших обработку естественного языка (и не только) в последние годы.
Что же в нем такого увлекательного?
Изначально он был предложен для сетей типа sequence-to-sequence, то есть на входе и на выходе последовательность. В оригинальной статье используется для машинного перевода с английского на французский.
На картинке слева показаны веса α, которые и определяют механизм attention. Они задают то, сколько "внимания" (attention) нужно уделять каждому слову из входного предложения. Например, для перевода слова européenne использовалось только слово European из оригинала. А при переводе артикля la использовалось не только the, но еще и area, что выглядит логичным, ведь не зная рода существительного, определенный артикль на французский не перевести.
На картинке справа изображено, как примерно работают эти веса. Сеть, взятая за основу, состоит из 2х частей: энкодера и декодера. Обе части используют рекуррентные блоки, такие как GRU и LSTM. На картинке самих этих блоков нет, есть только их выходные значения h и s.
Веса α тренируются как часть общей архитектуры и получаются из подсети, на вход которой подается представление очередного входного слова и предыдущее состояние декодера. Авторы называют эту подсеть alignment model. То есть такие веса выполняют задачу выравнивания - сопоставления слова и его перевода.
Таким образом, с плеч реккурентных блоков снимается необходимость запоминать информацию, далекую от текущего входного значения. Эта информация и так будет использована напрямую с помощью attention.
На основе этого механизма и была построена сеть Transformer, которая обеспечила появление BERT и XLNet, о которых был пост раньше.
https://arxiv.org/pdf/1409.0473.pdf
{kind=link}
Disentangled representation - это представление данных в виде независимых факторов. То есть изменение одного фактора в самих данных, например, цвета объекта, ведёт к изменению одного фактора в представлении, к изменению, например, одного измерения.
На картинке показано, какими могут быть сами факторы: цвет фона и пола, цвет объекта, его размер, форма и угол камеры.
То есть идеальное представление могло бы иметь, к примеру, вид вектора, в котором каждое измерение отвечает за один фактор.
На картинке показано, какими могут быть сами факторы: цвет фона и пола, цвет объекта, его размер, форма и угол камеры.
То есть идеальное представление могло бы иметь, к примеру, вид вектора, в котором каждое измерение отвечает за один фактор.
Эта статья от Google AI получила Best Paper Award на международной конференции по машинному обучению ICML 2019.
Очевидно, что не только благодаря тому, что авторы произвели вычисления, стоящие примерно 2.5 года на GPU (на NVIDIA P100). Хотя они еще и выложили в сеть полученные модели и код.
Дело в том, что авторы провели исследование, проверяющее распространённые предположения в области disentangled representation learning (обучение распутанных представлений - картинка выше).
Авторы проверили и доказали теоретически тот факт, что невозможно получить disentangled representation, не внося в модель и датасет 'inductive bias', то есть предположения об изначальном распределении.
Также исследования показали, что увеличение "распутанности" представления не ведет к уменьшению количества примеров, необходимых для решения задач, например, классификации. А это ведь одна из целей использования распутанных представлений.
Так что если вы хотели заняться обучением распутанных представлений, то вот вам советы от Google AI:
- Не пытайтесь получить хорошие disentangled representations, проводя обучение без учителя.
- Найдите и покажите конкретные выгоды от disentangled representations для вашей задачи. Возможно, это будет интерпретируемость модели.
- Проведите исследования на разных датасетах, чтобы проверить применимы ли ваши выводы в общем. Делайте их также воспроизводимыми. Для этого используйте, конечно, библиотеку от гугла 😌
Очевидно, что не только благодаря тому, что авторы произвели вычисления, стоящие примерно 2.5 года на GPU (на NVIDIA P100). Хотя они еще и выложили в сеть полученные модели и код.
Дело в том, что авторы провели исследование, проверяющее распространённые предположения в области disentangled representation learning (обучение распутанных представлений - картинка выше).
Авторы проверили и доказали теоретически тот факт, что невозможно получить disentangled representation, не внося в модель и датасет 'inductive bias', то есть предположения об изначальном распределении.
Также исследования показали, что увеличение "распутанности" представления не ведет к уменьшению количества примеров, необходимых для решения задач, например, классификации. А это ведь одна из целей использования распутанных представлений.
Так что если вы хотели заняться обучением распутанных представлений, то вот вам советы от Google AI:
- Не пытайтесь получить хорошие disentangled representations, проводя обучение без учителя.
- Найдите и покажите конкретные выгоды от disentangled representations для вашей задачи. Возможно, это будет интерпретируемость модели.
- Проведите исследования на разных датасетах, чтобы проверить применимы ли ваши выводы в общем. Делайте их также воспроизводимыми. Для этого используйте, конечно, библиотеку от гугла 😌
GitHub
GitHub - google-research/disentanglement_lib: disentanglement_lib is an open-source library for research on learning disentangled…
disentanglement_lib is an open-source library for research on learning disentangled representations. - google-research/disentanglement_lib
State-of-the-art всего и вся
Потрясающий сайт, конечно.
Если вы еще не видели (вы же не успеваете следить за всем?), то paperswithcode.com сделали раздел sota - state-of-the-art.
В нем 1222 задачи машинного обучения разбиты по разделам, и для каждой задачи показаны публичные датасеты и методы, которые лучше всего решают эту задачу на этом датасете.
Кроме того, это все можно самим редактировать и добавлять новые данные.
Долго объяснять, проще посмотреть https://paperswithcode.com/sota.
Потрясающий сайт, конечно.
Если вы еще не видели (вы же не успеваете следить за всем?), то paperswithcode.com сделали раздел sota - state-of-the-art.
В нем 1222 задачи машинного обучения разбиты по разделам, и для каждой задачи показаны публичные датасеты и методы, которые лучше всего решают эту задачу на этом датасете.
Кроме того, это все можно самим редактировать и добавлять новые данные.
Долго объяснять, проще посмотреть https://paperswithcode.com/sota.
huggingface.co
Trending Papers - Hugging Face
Your daily dose of AI research from AK
Недавно они выложили еще и видео об истории ImageNet.
Twitter
Papers with Code
An Animated History of ImageNet : from AlexNet to FixResNeXt-101. See the full table and add more results here: https://t.co/TVEM3X3LIu https://t.co/zmyXWrXyAJ
DeepLabv3+
Semantic segmentation - эта задача попиксельной классификации изображений, то есть каждому пикселю нужно присвоить класс, например, "дорога", "автомобиль", "дерево". Решать её нужно в области беспилотного транспорта, контроля качества изделий, анализа медицинских изображений, обработки изображений со спутников.
Одна из недавних моделей, которая хорошо показала себя на этой задаче на разных датасетах - DeepLabv3+.
Как понятно из названия, она у разработчиков не первая 🙂 Их было 3 до этого: v1, v2, v3.
Все они используют atrous convolution (картинка внизу). Этот термин взят из вейвлет-анализа и звучал как "algorithme à trous", где trous означает дыра. Еще называется dilated convolution. Фильтр умножается не на оригинальный сигнал, а на сигнал, взятый с определенным rate. Это то же самое, что использовать фильтр, прореженный нулями. Такой вид свертки позволяет получать информацию на разных масштабах изображения. "Масштаб" задается параметром rate.
Появлялись версии DeepLab так:
- DeepLabv1 2014 год - предложено использование atrous convolution;
- DeepLabv2 2016 год - atrous convolution используется в составе Atrous Spatial Pyramid Pooling, то есть параллельное использование слоев atrous convolution с разным rate - картинка внизу;
- DeepLabv3 2017 год - Atrous Spatial Pyramid Pooling объединяется с информацией уровня всего изображения - image-level feature;
- DeepLabv3+ 2018 год - добавляется decoder, предыдущая версия сети используется как encoder. Это позволяет лучше обрабатывать пиксели на границах объектов.
В последней версии DeepLabv3+ в качестве основы используется сеть Xception и предобучение на датасете JFT-300M. Особая прелесть, что открыты исходники на TensorFlow.
Бонусом небольшой обзор статей, включая методы, обогнавшие DeepLabv3+ на некоторых датасетах https://heartbeat.fritz.ai/a-2019-guide-to-semantic-segmentation-ca8242f5a7fc
DeepLabv1 - https://arxiv.org/pdf/1412.7062v4.pdf
DeepLabv2 - https://arxiv.org/pdf/1606.00915v2.pdf
DeepLabv3 - https://arxiv.org/pdf/1706.05587.pdf
DeepLabv3+ - https://arxiv.org/pdf/1802.02611v3.pdf
Semantic segmentation - эта задача попиксельной классификации изображений, то есть каждому пикселю нужно присвоить класс, например, "дорога", "автомобиль", "дерево". Решать её нужно в области беспилотного транспорта, контроля качества изделий, анализа медицинских изображений, обработки изображений со спутников.
Одна из недавних моделей, которая хорошо показала себя на этой задаче на разных датасетах - DeepLabv3+.
Как понятно из названия, она у разработчиков не первая 🙂 Их было 3 до этого: v1, v2, v3.
Все они используют atrous convolution (картинка внизу). Этот термин взят из вейвлет-анализа и звучал как "algorithme à trous", где trous означает дыра. Еще называется dilated convolution. Фильтр умножается не на оригинальный сигнал, а на сигнал, взятый с определенным rate. Это то же самое, что использовать фильтр, прореженный нулями. Такой вид свертки позволяет получать информацию на разных масштабах изображения. "Масштаб" задается параметром rate.
Появлялись версии DeepLab так:
- DeepLabv1 2014 год - предложено использование atrous convolution;
- DeepLabv2 2016 год - atrous convolution используется в составе Atrous Spatial Pyramid Pooling, то есть параллельное использование слоев atrous convolution с разным rate - картинка внизу;
- DeepLabv3 2017 год - Atrous Spatial Pyramid Pooling объединяется с информацией уровня всего изображения - image-level feature;
- DeepLabv3+ 2018 год - добавляется decoder, предыдущая версия сети используется как encoder. Это позволяет лучше обрабатывать пиксели на границах объектов.
В последней версии DeepLabv3+ в качестве основы используется сеть Xception и предобучение на датасете JFT-300M. Особая прелесть, что открыты исходники на TensorFlow.
Бонусом небольшой обзор статей, включая методы, обогнавшие DeepLabv3+ на некоторых датасетах https://heartbeat.fritz.ai/a-2019-guide-to-semantic-segmentation-ca8242f5a7fc
DeepLabv1 - https://arxiv.org/pdf/1412.7062v4.pdf
DeepLabv2 - https://arxiv.org/pdf/1606.00915v2.pdf
DeepLabv3 - https://arxiv.org/pdf/1706.05587.pdf
DeepLabv3+ - https://arxiv.org/pdf/1802.02611v3.pdf
{kind=link}
Deep learning vs реальная жизнь
Разрабатывать новые эффективные модели это круто, но ещё круче их применять в жизни. Тут возникает столько обстоятельств, что конечно ни одной машине не справиться.
Возьмём только одну сферу, очень важную, анализ медицинских изображений. На этой неделе вышло 2 статьи, которые объединяет один факт - они появились, потому что все наши любимые крутые алгоритмы столкнулись с реальной жизнью.
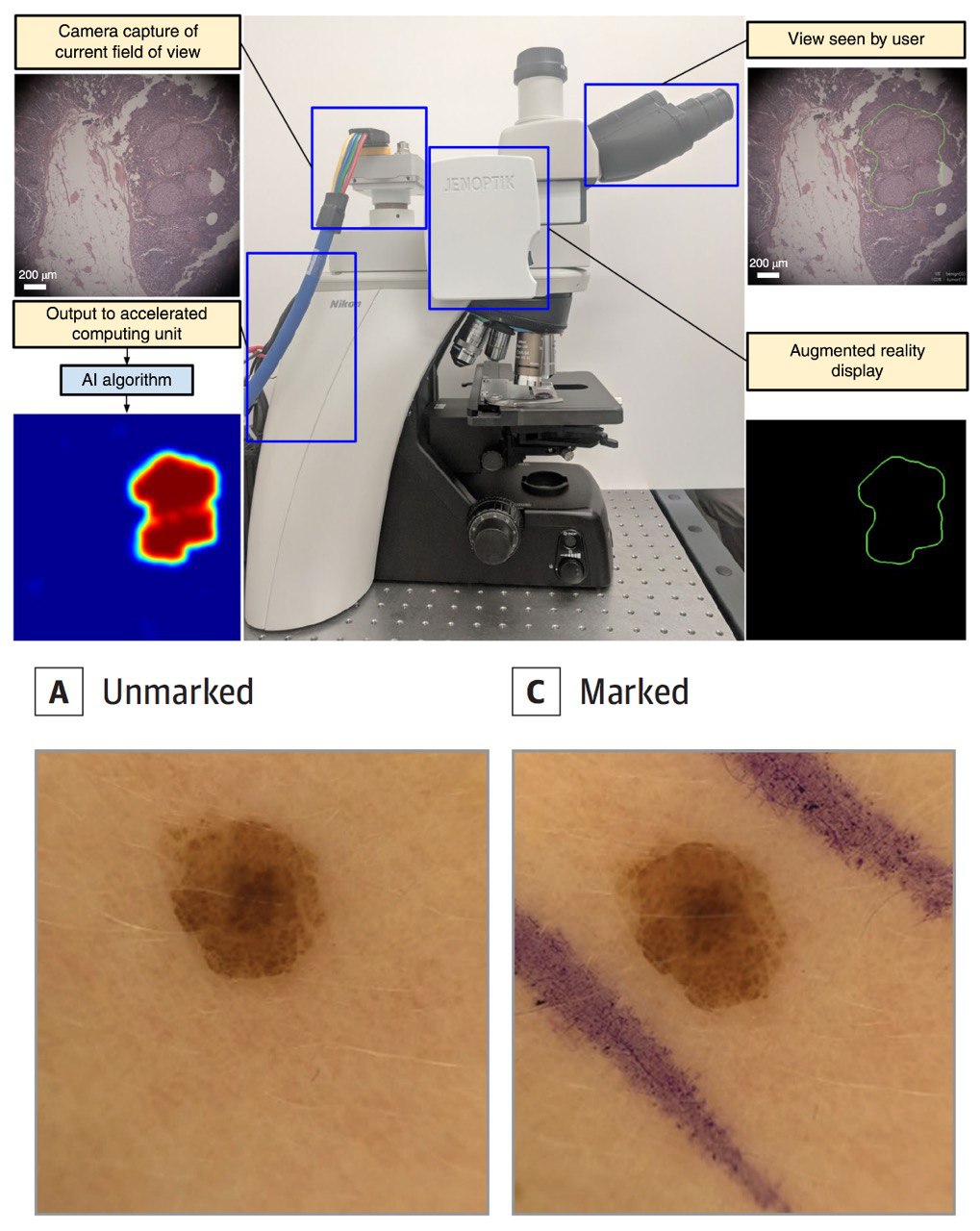
В первой, авторы из Google Health разработали микроскоп дополненной реальности. На самом деле, это обычный микроскоп с камерой и дисплеем, подсоединённый к обычному компьютеру с видеокартой (все будет стоить несколько тысяч долларов).
Суть в том, что не во всех клиниках есть возможность оцифровывать изображения тканей и потом ещё и обрабатывать их с помощью алгоритмов deep learning. А ещё далеко не во всех клиниках есть возможность нанять специалиста, который, посмотрев в микроскоп, скажет «да, вот это рак». Такова реальность. Но зато многие клиники могут закупить камеры и дисплеи и компьютеры обычной мощности, которые будут помогать в постановке диагнозов.
Если про технические подробности, то там просто натренированная сеть Inception V3 с модификациями, которая выдаёт область, классифицированную как рак.
Вторая статья ещё интереснее. Там натренировали сеть на изображениях меланомы (рак кожи) и чего-то похожего на неё, но неопасного. Один момент, на изображениях с меланомой часто были также хирургические отметины маркером. Сеть связала эти факты и предсказывала наличие меланомы в случае наличия отметок маркером. Таким образом, что число ложноположительных результатов заметно увеличилось, чем при отсутствии отметок.
Конечно, можно сказать, а зачем использовать датасет с отметками. Но речь о том, что в большинстве реальных случаев использования deep learning, нужно осознавать ограничения финансовые, физические, организационные, а также наличие непредвиденных фич и тех же adversarial examples в реальных данных.
Разрабатывать новые эффективные модели это круто, но ещё круче их применять в жизни. Тут возникает столько обстоятельств, что конечно ни одной машине не справиться.
Возьмём только одну сферу, очень важную, анализ медицинских изображений. На этой неделе вышло 2 статьи, которые объединяет один факт - они появились, потому что все наши любимые крутые алгоритмы столкнулись с реальной жизнью.
В первой, авторы из Google Health разработали микроскоп дополненной реальности. На самом деле, это обычный микроскоп с камерой и дисплеем, подсоединённый к обычному компьютеру с видеокартой (все будет стоить несколько тысяч долларов).
Суть в том, что не во всех клиниках есть возможность оцифровывать изображения тканей и потом ещё и обрабатывать их с помощью алгоритмов deep learning. А ещё далеко не во всех клиниках есть возможность нанять специалиста, который, посмотрев в микроскоп, скажет «да, вот это рак». Такова реальность. Но зато многие клиники могут закупить камеры и дисплеи и компьютеры обычной мощности, которые будут помогать в постановке диагнозов.
Если про технические подробности, то там просто натренированная сеть Inception V3 с модификациями, которая выдаёт область, классифицированную как рак.
Вторая статья ещё интереснее. Там натренировали сеть на изображениях меланомы (рак кожи) и чего-то похожего на неё, но неопасного. Один момент, на изображениях с меланомой часто были также хирургические отметины маркером. Сеть связала эти факты и предсказывала наличие меланомы в случае наличия отметок маркером. Таким образом, что число ложноположительных результатов заметно увеличилось, чем при отсутствии отметок.
Конечно, можно сказать, а зачем использовать датасет с отметками. Но речь о том, что в большинстве реальных случаев использования deep learning, нужно осознавать ограничения финансовые, физические, организационные, а также наличие непредвиденных фич и тех же adversarial examples в реальных данных.
{kind=link}
Так что там с Робертой?
Многие из вас наверняка уже слышали о RoBERTa - модель от фейсбука, которая обгоняет BERT и XLNet на таких бенчмарках, как GLUE и SQuAD. Об этих моделях был пост раньше.
Авторы модели подняли интересный вопрос о важности выбора архитектуры модели и функции потерь по сравнению с такими более техническими деталями обучения как: размер датасета, время обучения, размер батча.
Цель у них была такая: воспроизвести BERT, упростить и дообучить модель так, чтобы лучше понять её возможности. И они её достигли.
То есть архитектуру они не меняли, из функции потерь убрали часть про next sentence prediction (NSP), остальные параметры обучения увеличили: больше размер батча, дольше время обучения, длиннее предложения и больше данных.
Все это по отдельности позволило получить результаты лучше, чем в обычном BERT.
Всё это вместе позволило обогнать существующие модели на 4 из 9 задач в GLUE и перегнать в среднем.
Кроме того, учитывая, сколько уже моделей превзошли человека в GLUE, Facebook AI вместе с DeepMind и университетом Нью-Йорка создали новый бенчмарк SuperGLUE, в котором RoBERTa тоже на первом месте, но ещё отстает от человека.
Ну и закончу на том, что в удобной библиотеке от Huggingface PyTorch-Transformers, которая позволяет использовать последние модели, основанные на архитектуре Transformer, теперь тоже есть RoBERTa.
Многие из вас наверняка уже слышали о RoBERTa - модель от фейсбука, которая обгоняет BERT и XLNet на таких бенчмарках, как GLUE и SQuAD. Об этих моделях был пост раньше.
Авторы модели подняли интересный вопрос о важности выбора архитектуры модели и функции потерь по сравнению с такими более техническими деталями обучения как: размер датасета, время обучения, размер батча.
Цель у них была такая: воспроизвести BERT, упростить и дообучить модель так, чтобы лучше понять её возможности. И они её достигли.
То есть архитектуру они не меняли, из функции потерь убрали часть про next sentence prediction (NSP), остальные параметры обучения увеличили: больше размер батча, дольше время обучения, длиннее предложения и больше данных.
Все это по отдельности позволило получить результаты лучше, чем в обычном BERT.
Всё это вместе позволило обогнать существующие модели на 4 из 9 задач в GLUE и перегнать в среднем.
Кроме того, учитывая, сколько уже моделей превзошли человека в GLUE, Facebook AI вместе с DeepMind и университетом Нью-Йорка создали новый бенчмарк SuperGLUE, в котором RoBERTa тоже на первом месте, но ещё отстает от человека.
Ну и закончу на том, что в удобной библиотеке от Huggingface PyTorch-Transformers, которая позволяет использовать последние модели, основанные на архитектуре Transformer, теперь тоже есть RoBERTa.
{kind=link}
Computation graph
Недавно мне попалась очередная подборка "44 часто задаваемых вопроса в Deep Learning" с ответами. Предположительно для подготовки к собеседованиям.
Помимо всяких скучных вопросов типа чем Machine Learning отличается от Deep Learning (кто-то реально такое спрашивает?) был вопрос "Что такое Computation Graph?" И автор дает ответ: "Это несколько операций в TensorFlow, организованных в виде графа". Не советую отвечать так. Это покажет, что с понятием computation graph вы встречались только в документации к tensorflow.
Computation graph это способ представления вычислений в виде графа. Чаще всего в узлах находятся операторы, а в ребрах - переменные. Можно и наоборот.
В любом случае такое представление помогает организовать backpropagation, используя chain rule of calculus или правило дифференцирования сложной функции. Очень базово и понятно это изображено на картинке, взятой из книжки Deep Learning.
А какие базовые вопросы у вас спрашивали на реальных собеседованиях?
Недавно мне попалась очередная подборка "44 часто задаваемых вопроса в Deep Learning" с ответами. Предположительно для подготовки к собеседованиям.
Помимо всяких скучных вопросов типа чем Machine Learning отличается от Deep Learning (кто-то реально такое спрашивает?) был вопрос "Что такое Computation Graph?" И автор дает ответ: "Это несколько операций в TensorFlow, организованных в виде графа". Не советую отвечать так. Это покажет, что с понятием computation graph вы встречались только в документации к tensorflow.
Computation graph это способ представления вычислений в виде графа. Чаще всего в узлах находятся операторы, а в ребрах - переменные. Можно и наоборот.
В любом случае такое представление помогает организовать backpropagation, используя chain rule of calculus или правило дифференцирования сложной функции. Очень базово и понятно это изображено на картинке, взятой из книжки Deep Learning.
А какие базовые вопросы у вас спрашивали на реальных собеседованиях?
{kind=link}
PyTorch vs TensorFlow 2.0
Основное отличие PyTorch от TensorFlow было в том, что PyTorch использует динамический граф вычислений, а TensorFlow статический. То есть TensorFlow сначала строит граф вычислений, а потом повторяет одни и те же вычисления для разных входных значений.
PyTorch же создает граф для каждого входного значения. Это позволяет в PyTorch использовать циклы, условия и другие способы изменения порядка выполнения (control flow) в зависимости от входного значения.
Отличием это было, потому что вот-вот появится TensorFlow 2.0 и уже вышел pre-release, в котором появился eager execution, то есть интерактивный режим.
Он выполняет вычисления сразу, что позволяет упростить отладку и использовать порядок выполнения Python вместо графа вычислений. И никаких больше
Однако, в документации всё же советуют отлаживать код в eager execution, а запускать в продакшн уже в graph execution, потому что это "обеспечит лучшую распределенную производительность".
Основное отличие PyTorch от TensorFlow было в том, что PyTorch использует динамический граф вычислений, а TensorFlow статический. То есть TensorFlow сначала строит граф вычислений, а потом повторяет одни и те же вычисления для разных входных значений.
PyTorch же создает граф для каждого входного значения. Это позволяет в PyTorch использовать циклы, условия и другие способы изменения порядка выполнения (control flow) в зависимости от входного значения.
Отличием это было, потому что вот-вот появится TensorFlow 2.0 и уже вышел pre-release, в котором появился eager execution, то есть интерактивный режим.
Он выполняет вычисления сразу, что позволяет упростить отладку и использовать порядок выполнения Python вместо графа вычислений. И никаких больше
session.run().Однако, в документации всё же советуют отлаживать код в eager execution, а запускать в продакшн уже в graph execution, потому что это "обеспечит лучшую распределенную производительность".
{kind=link}