Внимание или выравнивание?
Механизм attention одна из самых мощных идей, продвинувших обработку естественного языка (и не только) в последние годы.
Что же в нем такого увлекательного?
Изначально он был предложен для сетей типа sequence-to-sequence, то есть на входе и на выходе последовательность. В оригинальной статье используется для машинного перевода с английского на французский.
На картинке слева показаны веса α, которые и определяют механизм attention. Они задают то, сколько "внимания" (attention) нужно уделять каждому слову из входного предложения. Например, для перевода слова européenne использовалось только слово European из оригинала. А при переводе артикля la использовалось не только the, но еще и area, что выглядит логичным, ведь не зная рода существительного, определенный артикль на французский не перевести.
На картинке справа изображено, как примерно работают эти веса. Сеть, взятая за основу, состоит из 2х частей: энкодера и декодера. Обе части используют рекуррентные блоки, такие как GRU и LSTM. На картинке самих этих блоков нет, есть только их выходные значения h и s.
Веса α тренируются как часть общей архитектуры и получаются из подсети, на вход которой подается представление очередного входного слова и предыдущее состояние декодера. Авторы называют эту подсеть alignment model. То есть такие веса выполняют задачу выравнивания - сопоставления слова и его перевода.
Таким образом, с плеч реккурентных блоков снимается необходимость запоминать информацию, далекую от текущего входного значения. Эта информация и так будет использована напрямую с помощью attention.
На основе этого механизма и была построена сеть Transformer, которая обеспечила появление BERT и XLNet, о которых был пост раньше.
https://arxiv.org/pdf/1409.0473.pdf
Механизм attention одна из самых мощных идей, продвинувших обработку естественного языка (и не только) в последние годы.
Что же в нем такого увлекательного?
Изначально он был предложен для сетей типа sequence-to-sequence, то есть на входе и на выходе последовательность. В оригинальной статье используется для машинного перевода с английского на французский.
На картинке слева показаны веса α, которые и определяют механизм attention. Они задают то, сколько "внимания" (attention) нужно уделять каждому слову из входного предложения. Например, для перевода слова européenne использовалось только слово European из оригинала. А при переводе артикля la использовалось не только the, но еще и area, что выглядит логичным, ведь не зная рода существительного, определенный артикль на французский не перевести.
На картинке справа изображено, как примерно работают эти веса. Сеть, взятая за основу, состоит из 2х частей: энкодера и декодера. Обе части используют рекуррентные блоки, такие как GRU и LSTM. На картинке самих этих блоков нет, есть только их выходные значения h и s.
Веса α тренируются как часть общей архитектуры и получаются из подсети, на вход которой подается представление очередного входного слова и предыдущее состояние декодера. Авторы называют эту подсеть alignment model. То есть такие веса выполняют задачу выравнивания - сопоставления слова и его перевода.
Таким образом, с плеч реккурентных блоков снимается необходимость запоминать информацию, далекую от текущего входного значения. Эта информация и так будет использована напрямую с помощью attention.
На основе этого механизма и была построена сеть Transformer, которая обеспечила появление BERT и XLNet, о которых был пост раньше.
https://arxiv.org/pdf/1409.0473.pdf
{kind=link}
Disentangled representation - это представление данных в виде независимых факторов. То есть изменение одного фактора в самих данных, например, цвета объекта, ведёт к изменению одного фактора в представлении, к изменению, например, одного измерения.
На картинке показано, какими могут быть сами факторы: цвет фона и пола, цвет объекта, его размер, форма и угол камеры.
То есть идеальное представление могло бы иметь, к примеру, вид вектора, в котором каждое измерение отвечает за один фактор.
На картинке показано, какими могут быть сами факторы: цвет фона и пола, цвет объекта, его размер, форма и угол камеры.
То есть идеальное представление могло бы иметь, к примеру, вид вектора, в котором каждое измерение отвечает за один фактор.
Эта статья от Google AI получила Best Paper Award на международной конференции по машинному обучению ICML 2019.
Очевидно, что не только благодаря тому, что авторы произвели вычисления, стоящие примерно 2.5 года на GPU (на NVIDIA P100). Хотя они еще и выложили в сеть полученные модели и код.
Дело в том, что авторы провели исследование, проверяющее распространённые предположения в области disentangled representation learning (обучение распутанных представлений - картинка выше).
Авторы проверили и доказали теоретически тот факт, что невозможно получить disentangled representation, не внося в модель и датасет 'inductive bias', то есть предположения об изначальном распределении.
Также исследования показали, что увеличение "распутанности" представления не ведет к уменьшению количества примеров, необходимых для решения задач, например, классификации. А это ведь одна из целей использования распутанных представлений.
Так что если вы хотели заняться обучением распутанных представлений, то вот вам советы от Google AI:
- Не пытайтесь получить хорошие disentangled representations, проводя обучение без учителя.
- Найдите и покажите конкретные выгоды от disentangled representations для вашей задачи. Возможно, это будет интерпретируемость модели.
- Проведите исследования на разных датасетах, чтобы проверить применимы ли ваши выводы в общем. Делайте их также воспроизводимыми. Для этого используйте, конечно, библиотеку от гугла 😌
Очевидно, что не только благодаря тому, что авторы произвели вычисления, стоящие примерно 2.5 года на GPU (на NVIDIA P100). Хотя они еще и выложили в сеть полученные модели и код.
Дело в том, что авторы провели исследование, проверяющее распространённые предположения в области disentangled representation learning (обучение распутанных представлений - картинка выше).
Авторы проверили и доказали теоретически тот факт, что невозможно получить disentangled representation, не внося в модель и датасет 'inductive bias', то есть предположения об изначальном распределении.
Также исследования показали, что увеличение "распутанности" представления не ведет к уменьшению количества примеров, необходимых для решения задач, например, классификации. А это ведь одна из целей использования распутанных представлений.
Так что если вы хотели заняться обучением распутанных представлений, то вот вам советы от Google AI:
- Не пытайтесь получить хорошие disentangled representations, проводя обучение без учителя.
- Найдите и покажите конкретные выгоды от disentangled representations для вашей задачи. Возможно, это будет интерпретируемость модели.
- Проведите исследования на разных датасетах, чтобы проверить применимы ли ваши выводы в общем. Делайте их также воспроизводимыми. Для этого используйте, конечно, библиотеку от гугла 😌
GitHub
GitHub - google-research/disentanglement_lib: disentanglement_lib is an open-source library for research on learning disentangled…
disentanglement_lib is an open-source library for research on learning disentangled representations. - google-research/disentanglement_lib
State-of-the-art всего и вся
Потрясающий сайт, конечно.
Если вы еще не видели (вы же не успеваете следить за всем?), то paperswithcode.com сделали раздел sota - state-of-the-art.
В нем 1222 задачи машинного обучения разбиты по разделам, и для каждой задачи показаны публичные датасеты и методы, которые лучше всего решают эту задачу на этом датасете.
Кроме того, это все можно самим редактировать и добавлять новые данные.
Долго объяснять, проще посмотреть https://paperswithcode.com/sota.
Потрясающий сайт, конечно.
Если вы еще не видели (вы же не успеваете следить за всем?), то paperswithcode.com сделали раздел sota - state-of-the-art.
В нем 1222 задачи машинного обучения разбиты по разделам, и для каждой задачи показаны публичные датасеты и методы, которые лучше всего решают эту задачу на этом датасете.
Кроме того, это все можно самим редактировать и добавлять новые данные.
Долго объяснять, проще посмотреть https://paperswithcode.com/sota.
huggingface.co
Trending Papers - Hugging Face
Your daily dose of AI research from AK
Недавно они выложили еще и видео об истории ImageNet.
Twitter
Papers with Code
An Animated History of ImageNet : from AlexNet to FixResNeXt-101. See the full table and add more results here: https://t.co/TVEM3X3LIu https://t.co/zmyXWrXyAJ
DeepLabv3+
Semantic segmentation - эта задача попиксельной классификации изображений, то есть каждому пикселю нужно присвоить класс, например, "дорога", "автомобиль", "дерево". Решать её нужно в области беспилотного транспорта, контроля качества изделий, анализа медицинских изображений, обработки изображений со спутников.
Одна из недавних моделей, которая хорошо показала себя на этой задаче на разных датасетах - DeepLabv3+.
Как понятно из названия, она у разработчиков не первая 🙂 Их было 3 до этого: v1, v2, v3.
Все они используют atrous convolution (картинка внизу). Этот термин взят из вейвлет-анализа и звучал как "algorithme à trous", где trous означает дыра. Еще называется dilated convolution. Фильтр умножается не на оригинальный сигнал, а на сигнал, взятый с определенным rate. Это то же самое, что использовать фильтр, прореженный нулями. Такой вид свертки позволяет получать информацию на разных масштабах изображения. "Масштаб" задается параметром rate.
Появлялись версии DeepLab так:
- DeepLabv1 2014 год - предложено использование atrous convolution;
- DeepLabv2 2016 год - atrous convolution используется в составе Atrous Spatial Pyramid Pooling, то есть параллельное использование слоев atrous convolution с разным rate - картинка внизу;
- DeepLabv3 2017 год - Atrous Spatial Pyramid Pooling объединяется с информацией уровня всего изображения - image-level feature;
- DeepLabv3+ 2018 год - добавляется decoder, предыдущая версия сети используется как encoder. Это позволяет лучше обрабатывать пиксели на границах объектов.
В последней версии DeepLabv3+ в качестве основы используется сеть Xception и предобучение на датасете JFT-300M. Особая прелесть, что открыты исходники на TensorFlow.
Бонусом небольшой обзор статей, включая методы, обогнавшие DeepLabv3+ на некоторых датасетах https://heartbeat.fritz.ai/a-2019-guide-to-semantic-segmentation-ca8242f5a7fc
DeepLabv1 - https://arxiv.org/pdf/1412.7062v4.pdf
DeepLabv2 - https://arxiv.org/pdf/1606.00915v2.pdf
DeepLabv3 - https://arxiv.org/pdf/1706.05587.pdf
DeepLabv3+ - https://arxiv.org/pdf/1802.02611v3.pdf
Semantic segmentation - эта задача попиксельной классификации изображений, то есть каждому пикселю нужно присвоить класс, например, "дорога", "автомобиль", "дерево". Решать её нужно в области беспилотного транспорта, контроля качества изделий, анализа медицинских изображений, обработки изображений со спутников.
Одна из недавних моделей, которая хорошо показала себя на этой задаче на разных датасетах - DeepLabv3+.
Как понятно из названия, она у разработчиков не первая 🙂 Их было 3 до этого: v1, v2, v3.
Все они используют atrous convolution (картинка внизу). Этот термин взят из вейвлет-анализа и звучал как "algorithme à trous", где trous означает дыра. Еще называется dilated convolution. Фильтр умножается не на оригинальный сигнал, а на сигнал, взятый с определенным rate. Это то же самое, что использовать фильтр, прореженный нулями. Такой вид свертки позволяет получать информацию на разных масштабах изображения. "Масштаб" задается параметром rate.
Появлялись версии DeepLab так:
- DeepLabv1 2014 год - предложено использование atrous convolution;
- DeepLabv2 2016 год - atrous convolution используется в составе Atrous Spatial Pyramid Pooling, то есть параллельное использование слоев atrous convolution с разным rate - картинка внизу;
- DeepLabv3 2017 год - Atrous Spatial Pyramid Pooling объединяется с информацией уровня всего изображения - image-level feature;
- DeepLabv3+ 2018 год - добавляется decoder, предыдущая версия сети используется как encoder. Это позволяет лучше обрабатывать пиксели на границах объектов.
В последней версии DeepLabv3+ в качестве основы используется сеть Xception и предобучение на датасете JFT-300M. Особая прелесть, что открыты исходники на TensorFlow.
Бонусом небольшой обзор статей, включая методы, обогнавшие DeepLabv3+ на некоторых датасетах https://heartbeat.fritz.ai/a-2019-guide-to-semantic-segmentation-ca8242f5a7fc
DeepLabv1 - https://arxiv.org/pdf/1412.7062v4.pdf
DeepLabv2 - https://arxiv.org/pdf/1606.00915v2.pdf
DeepLabv3 - https://arxiv.org/pdf/1706.05587.pdf
DeepLabv3+ - https://arxiv.org/pdf/1802.02611v3.pdf
{kind=link}
Deep learning vs реальная жизнь
Разрабатывать новые эффективные модели это круто, но ещё круче их применять в жизни. Тут возникает столько обстоятельств, что конечно ни одной машине не справиться.
Возьмём только одну сферу, очень важную, анализ медицинских изображений. На этой неделе вышло 2 статьи, которые объединяет один факт - они появились, потому что все наши любимые крутые алгоритмы столкнулись с реальной жизнью.
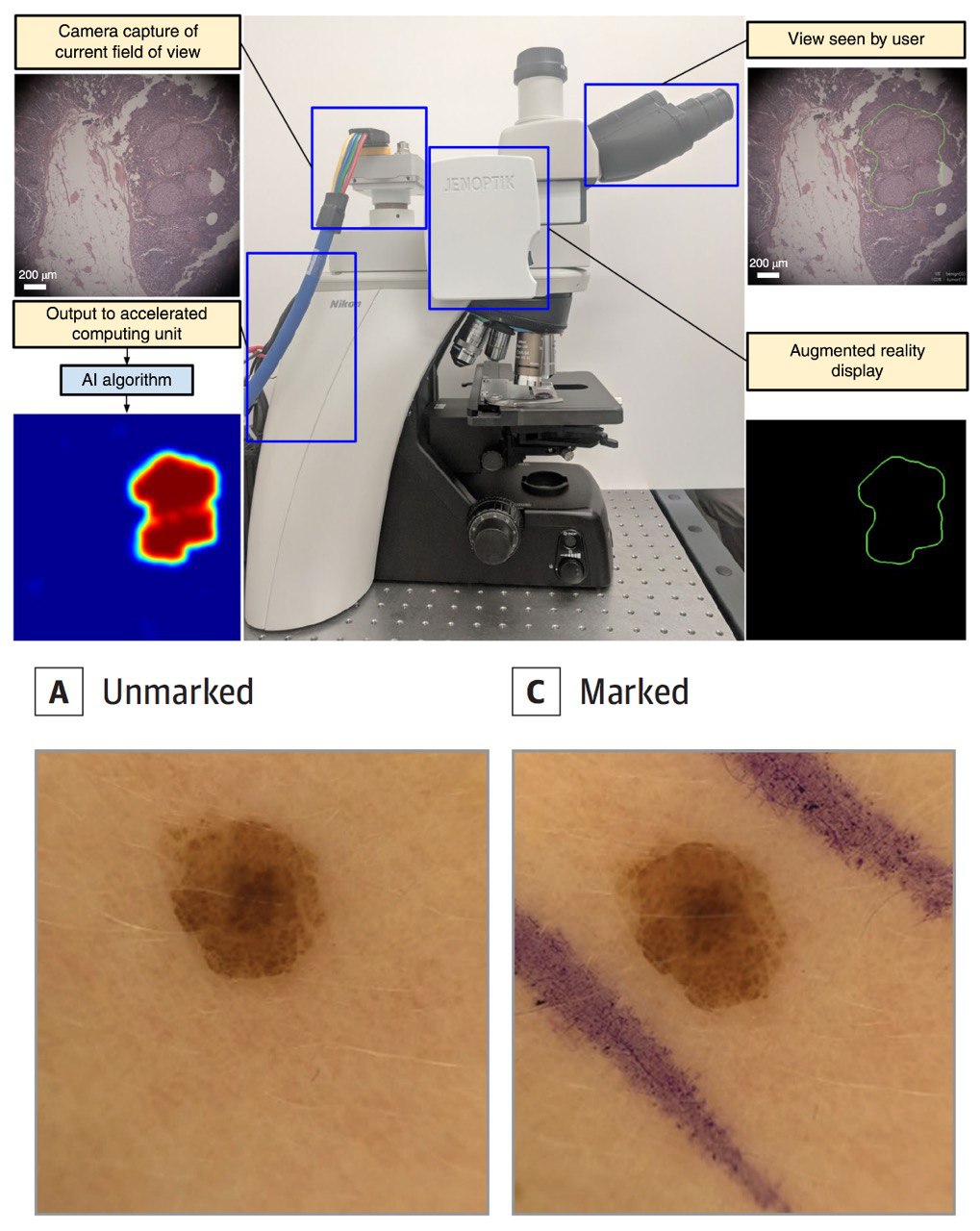
В первой, авторы из Google Health разработали микроскоп дополненной реальности. На самом деле, это обычный микроскоп с камерой и дисплеем, подсоединённый к обычному компьютеру с видеокартой (все будет стоить несколько тысяч долларов).
Суть в том, что не во всех клиниках есть возможность оцифровывать изображения тканей и потом ещё и обрабатывать их с помощью алгоритмов deep learning. А ещё далеко не во всех клиниках есть возможность нанять специалиста, который, посмотрев в микроскоп, скажет «да, вот это рак». Такова реальность. Но зато многие клиники могут закупить камеры и дисплеи и компьютеры обычной мощности, которые будут помогать в постановке диагнозов.
Если про технические подробности, то там просто натренированная сеть Inception V3 с модификациями, которая выдаёт область, классифицированную как рак.
Вторая статья ещё интереснее. Там натренировали сеть на изображениях меланомы (рак кожи) и чего-то похожего на неё, но неопасного. Один момент, на изображениях с меланомой часто были также хирургические отметины маркером. Сеть связала эти факты и предсказывала наличие меланомы в случае наличия отметок маркером. Таким образом, что число ложноположительных результатов заметно увеличилось, чем при отсутствии отметок.
Конечно, можно сказать, а зачем использовать датасет с отметками. Но речь о том, что в большинстве реальных случаев использования deep learning, нужно осознавать ограничения финансовые, физические, организационные, а также наличие непредвиденных фич и тех же adversarial examples в реальных данных.
Разрабатывать новые эффективные модели это круто, но ещё круче их применять в жизни. Тут возникает столько обстоятельств, что конечно ни одной машине не справиться.
Возьмём только одну сферу, очень важную, анализ медицинских изображений. На этой неделе вышло 2 статьи, которые объединяет один факт - они появились, потому что все наши любимые крутые алгоритмы столкнулись с реальной жизнью.
В первой, авторы из Google Health разработали микроскоп дополненной реальности. На самом деле, это обычный микроскоп с камерой и дисплеем, подсоединённый к обычному компьютеру с видеокартой (все будет стоить несколько тысяч долларов).
Суть в том, что не во всех клиниках есть возможность оцифровывать изображения тканей и потом ещё и обрабатывать их с помощью алгоритмов deep learning. А ещё далеко не во всех клиниках есть возможность нанять специалиста, который, посмотрев в микроскоп, скажет «да, вот это рак». Такова реальность. Но зато многие клиники могут закупить камеры и дисплеи и компьютеры обычной мощности, которые будут помогать в постановке диагнозов.
Если про технические подробности, то там просто натренированная сеть Inception V3 с модификациями, которая выдаёт область, классифицированную как рак.
Вторая статья ещё интереснее. Там натренировали сеть на изображениях меланомы (рак кожи) и чего-то похожего на неё, но неопасного. Один момент, на изображениях с меланомой часто были также хирургические отметины маркером. Сеть связала эти факты и предсказывала наличие меланомы в случае наличия отметок маркером. Таким образом, что число ложноположительных результатов заметно увеличилось, чем при отсутствии отметок.
Конечно, можно сказать, а зачем использовать датасет с отметками. Но речь о том, что в большинстве реальных случаев использования deep learning, нужно осознавать ограничения финансовые, физические, организационные, а также наличие непредвиденных фич и тех же adversarial examples в реальных данных.
{kind=link}
Так что там с Робертой?
Многие из вас наверняка уже слышали о RoBERTa - модель от фейсбука, которая обгоняет BERT и XLNet на таких бенчмарках, как GLUE и SQuAD. Об этих моделях был пост раньше.
Авторы модели подняли интересный вопрос о важности выбора архитектуры модели и функции потерь по сравнению с такими более техническими деталями обучения как: размер датасета, время обучения, размер батча.
Цель у них была такая: воспроизвести BERT, упростить и дообучить модель так, чтобы лучше понять её возможности. И они её достигли.
То есть архитектуру они не меняли, из функции потерь убрали часть про next sentence prediction (NSP), остальные параметры обучения увеличили: больше размер батча, дольше время обучения, длиннее предложения и больше данных.
Все это по отдельности позволило получить результаты лучше, чем в обычном BERT.
Всё это вместе позволило обогнать существующие модели на 4 из 9 задач в GLUE и перегнать в среднем.
Кроме того, учитывая, сколько уже моделей превзошли человека в GLUE, Facebook AI вместе с DeepMind и университетом Нью-Йорка создали новый бенчмарк SuperGLUE, в котором RoBERTa тоже на первом месте, но ещё отстает от человека.
Ну и закончу на том, что в удобной библиотеке от Huggingface PyTorch-Transformers, которая позволяет использовать последние модели, основанные на архитектуре Transformer, теперь тоже есть RoBERTa.
Многие из вас наверняка уже слышали о RoBERTa - модель от фейсбука, которая обгоняет BERT и XLNet на таких бенчмарках, как GLUE и SQuAD. Об этих моделях был пост раньше.
Авторы модели подняли интересный вопрос о важности выбора архитектуры модели и функции потерь по сравнению с такими более техническими деталями обучения как: размер датасета, время обучения, размер батча.
Цель у них была такая: воспроизвести BERT, упростить и дообучить модель так, чтобы лучше понять её возможности. И они её достигли.
То есть архитектуру они не меняли, из функции потерь убрали часть про next sentence prediction (NSP), остальные параметры обучения увеличили: больше размер батча, дольше время обучения, длиннее предложения и больше данных.
Все это по отдельности позволило получить результаты лучше, чем в обычном BERT.
Всё это вместе позволило обогнать существующие модели на 4 из 9 задач в GLUE и перегнать в среднем.
Кроме того, учитывая, сколько уже моделей превзошли человека в GLUE, Facebook AI вместе с DeepMind и университетом Нью-Йорка создали новый бенчмарк SuperGLUE, в котором RoBERTa тоже на первом месте, но ещё отстает от человека.
Ну и закончу на том, что в удобной библиотеке от Huggingface PyTorch-Transformers, которая позволяет использовать последние модели, основанные на архитектуре Transformer, теперь тоже есть RoBERTa.
{kind=link}
Computation graph
Недавно мне попалась очередная подборка "44 часто задаваемых вопроса в Deep Learning" с ответами. Предположительно для подготовки к собеседованиям.
Помимо всяких скучных вопросов типа чем Machine Learning отличается от Deep Learning (кто-то реально такое спрашивает?) был вопрос "Что такое Computation Graph?" И автор дает ответ: "Это несколько операций в TensorFlow, организованных в виде графа". Не советую отвечать так. Это покажет, что с понятием computation graph вы встречались только в документации к tensorflow.
Computation graph это способ представления вычислений в виде графа. Чаще всего в узлах находятся операторы, а в ребрах - переменные. Можно и наоборот.
В любом случае такое представление помогает организовать backpropagation, используя chain rule of calculus или правило дифференцирования сложной функции. Очень базово и понятно это изображено на картинке, взятой из книжки Deep Learning.
А какие базовые вопросы у вас спрашивали на реальных собеседованиях?
Недавно мне попалась очередная подборка "44 часто задаваемых вопроса в Deep Learning" с ответами. Предположительно для подготовки к собеседованиям.
Помимо всяких скучных вопросов типа чем Machine Learning отличается от Deep Learning (кто-то реально такое спрашивает?) был вопрос "Что такое Computation Graph?" И автор дает ответ: "Это несколько операций в TensorFlow, организованных в виде графа". Не советую отвечать так. Это покажет, что с понятием computation graph вы встречались только в документации к tensorflow.
Computation graph это способ представления вычислений в виде графа. Чаще всего в узлах находятся операторы, а в ребрах - переменные. Можно и наоборот.
В любом случае такое представление помогает организовать backpropagation, используя chain rule of calculus или правило дифференцирования сложной функции. Очень базово и понятно это изображено на картинке, взятой из книжки Deep Learning.
А какие базовые вопросы у вас спрашивали на реальных собеседованиях?
{kind=link}
PyTorch vs TensorFlow 2.0
Основное отличие PyTorch от TensorFlow было в том, что PyTorch использует динамический граф вычислений, а TensorFlow статический. То есть TensorFlow сначала строит граф вычислений, а потом повторяет одни и те же вычисления для разных входных значений.
PyTorch же создает граф для каждого входного значения. Это позволяет в PyTorch использовать циклы, условия и другие способы изменения порядка выполнения (control flow) в зависимости от входного значения.
Отличием это было, потому что вот-вот появится TensorFlow 2.0 и уже вышел pre-release, в котором появился eager execution, то есть интерактивный режим.
Он выполняет вычисления сразу, что позволяет упростить отладку и использовать порядок выполнения Python вместо графа вычислений. И никаких больше
Однако, в документации всё же советуют отлаживать код в eager execution, а запускать в продакшн уже в graph execution, потому что это "обеспечит лучшую распределенную производительность".
Основное отличие PyTorch от TensorFlow было в том, что PyTorch использует динамический граф вычислений, а TensorFlow статический. То есть TensorFlow сначала строит граф вычислений, а потом повторяет одни и те же вычисления для разных входных значений.
PyTorch же создает граф для каждого входного значения. Это позволяет в PyTorch использовать циклы, условия и другие способы изменения порядка выполнения (control flow) в зависимости от входного значения.
Отличием это было, потому что вот-вот появится TensorFlow 2.0 и уже вышел pre-release, в котором появился eager execution, то есть интерактивный режим.
Он выполняет вычисления сразу, что позволяет упростить отладку и использовать порядок выполнения Python вместо графа вычислений. И никаких больше
session.run().Однако, в документации всё же советуют отлаживать код в eager execution, а запускать в продакшн уже в graph execution, потому что это "обеспечит лучшую распределенную производительность".
{kind=link}
Numpy-ml
"Когда-нибудь мечтали, чтобы у вас была не эффективно написанная, но понятная библиотека ML алгоритмов, реализованная только с использованием numpy? Нет?"
Хватит мечтать, все уже сделали за вас. Остается только смотреть и изучать, для самых увлеченных - делать pull request'ы.
https://github.com/ddbourgin/numpy-ml
Автор не использует автоматическое дифференцирование и все производные задаёт формулами явно, ведь библиотека предназначена в основном для изучения алгоритмов.
Иногда там все очень просто и понятно, иногда чуть посложнее.
Например, активация ReLU выглядит примерно так:
"Когда-нибудь мечтали, чтобы у вас была не эффективно написанная, но понятная библиотека ML алгоритмов, реализованная только с использованием numpy? Нет?"
Хватит мечтать, все уже сделали за вас. Остается только смотреть и изучать, для самых увлеченных - делать pull request'ы.
https://github.com/ddbourgin/numpy-ml
Автор не использует автоматическое дифференцирование и все производные задаёт формулами явно, ведь библиотека предназначена в основном для изучения алгоритмов.
Иногда там все очень просто и понятно, иногда чуть посложнее.
Например, активация ReLU выглядит примерно так:
{kind=link}
All you need is everywhere
Если вы ещё сомневаетесь, что трансформеры повсюду, то вот еще одно тому доказательство.
Одиннадцать дней назад закончилось соревнование Predicting Molecular Properties на Kaggle.
Для пар атомов в молекулах, имея тип связи и структуру молекулы, нужно было предсказать константу связи.
Было дано еще много физической информации, но только для тренировочного сета, то есть использовать её напрямую не получилось бы.
Задача важна в области создания новых молекул для выполнения различных задач на клеточном уровне, в том числе для создания лекарств.
Так вот первые три места заняли архитектуры, основанные на архитектуре трансформер. Первое место использует трансформер на основе графового представления молекулы, второе использует трансформер на основе Attention is All You Need, третье место взяли за основу BERT, то есть фактически тот же Attention is All You Need.
Много магии добавилось на этапе выбора представления молекулы. Кроме того, все три команды использовали предсказания, агрегированные из 13-14 моделей (ensemble).
Еще есть интересная статья о том, как иногда проходит сам процесс принятия решений в командной работе на Kaggle. Автор - российский data scientist Андрей Лукьяненко, его команда заняла восьмое место и выиграла золотую медаль
1 место - https://www.kaggle.com/c/champs-scalar-coupling/discussion/106575
2 место - https://www.kaggle.com/c/champs-scalar-coupling/discussion/106468
3 место - https://www.kaggle.com/c/champs-scalar-coupling/discussion/106572
Если вы ещё сомневаетесь, что трансформеры повсюду, то вот еще одно тому доказательство.
Одиннадцать дней назад закончилось соревнование Predicting Molecular Properties на Kaggle.
Для пар атомов в молекулах, имея тип связи и структуру молекулы, нужно было предсказать константу связи.
Было дано еще много физической информации, но только для тренировочного сета, то есть использовать её напрямую не получилось бы.
Задача важна в области создания новых молекул для выполнения различных задач на клеточном уровне, в том числе для создания лекарств.
Так вот первые три места заняли архитектуры, основанные на архитектуре трансформер. Первое место использует трансформер на основе графового представления молекулы, второе использует трансформер на основе Attention is All You Need, третье место взяли за основу BERT, то есть фактически тот же Attention is All You Need.
Много магии добавилось на этапе выбора представления молекулы. Кроме того, все три команды использовали предсказания, агрегированные из 13-14 моделей (ensemble).
Еще есть интересная статья о том, как иногда проходит сам процесс принятия решений в командной работе на Kaggle. Автор - российский data scientist Андрей Лукьяненко, его команда заняла восьмое место и выиграла золотую медаль
1 место - https://www.kaggle.com/c/champs-scalar-coupling/discussion/106575
2 место - https://www.kaggle.com/c/champs-scalar-coupling/discussion/106468
3 место - https://www.kaggle.com/c/champs-scalar-coupling/discussion/106572
{kind=link}
CvxNets - выпуклая декомпозиция 3D
Буквально три дня назад вышла статья от Google Research и Google Hardware о представлении трехмерных объектов в виде набора выпуклых оболочек. Это представление обучается через нейронную сеть и дифференцируемо.
Если упростить до двумерного примера, то модель, имея выпуклый объект, может представить его в виде набора полуплоскостей (на картинке понятнее).
При этом возникает два представления объекта: в виде полигональной сетки (polygon mesh) и в виде индикаторной функции, которая отображает точку в 0, 1 (принадлежит объекту или нет).
Такое представление можно напрямую использовать в физических задачах типа симуляции столкновений. Оно также дает лучшее разбиение объекта на части, чем текущие методы и сравнимо в задаче реконструкции 3D изображение с state-of-the-art, которым является Occupancy Networks.
Разбиение на части также получается из модели напрямую. То есть модель одновременно описывает и поверхность, и 3D структуру, и разбиение на части. Кроме того, скрытое представление, обученное сетью, имеет семантическую нагрузку. Близкие вектора описывают объекты со схожей геометрией, например, похожие конструкции самолетов или шкафчик и колонку в форме параллелепипеда.
В статье очень много интересных картинок.
https://arxiv.org/pdf/1909.05736.pdf
Буквально три дня назад вышла статья от Google Research и Google Hardware о представлении трехмерных объектов в виде набора выпуклых оболочек. Это представление обучается через нейронную сеть и дифференцируемо.
Если упростить до двумерного примера, то модель, имея выпуклый объект, может представить его в виде набора полуплоскостей (на картинке понятнее).
При этом возникает два представления объекта: в виде полигональной сетки (polygon mesh) и в виде индикаторной функции, которая отображает точку в 0, 1 (принадлежит объекту или нет).
Такое представление можно напрямую использовать в физических задачах типа симуляции столкновений. Оно также дает лучшее разбиение объекта на части, чем текущие методы и сравнимо в задаче реконструкции 3D изображение с state-of-the-art, которым является Occupancy Networks.
Разбиение на части также получается из модели напрямую. То есть модель одновременно описывает и поверхность, и 3D структуру, и разбиение на части. Кроме того, скрытое представление, обученное сетью, имеет семантическую нагрузку. Близкие вектора описывают объекты со схожей геометрией, например, похожие конструкции самолетов или шкафчик и колонку в форме параллелепипеда.
В статье очень много интересных картинок.
https://arxiv.org/pdf/1909.05736.pdf
{kind=link}
Есть такой исследователь из Оксфорда - Yarin Gal.
Он занимается Bayesian Deep Learning и с 2016 года является главным организатором Bayesian Deep Learning Workshop на NeurIPS.
Сквозной темой своих исследований он сам называет "понимание эмпирически разработанных техник машинного обучения".
Только с начала этого года появилось десять статей с его участием arxiv. Тем не менее самой цитируемой остается статья "Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning".
Основной её вывод в том, что dropout можно интерпретировать как байесовскую аппроксимацию широко известной вероятностной модели - гауссовского процесса. Такая интерпретация позволяет получить способ оценивать неопределенность предсказаний нейронной сети.
Как пишут авторы, выходное значения слоя softmax ошибочно интерпретируется как вероятность, но ею не является. Большое значение на выходе softmax не является показателем уверенности модели в результате. Байесовская интерпретация дропаута позволяет такую оценку получить, не жертвуя ни сложностью сети, ни точностью на тестовой выборке.
Он занимается Bayesian Deep Learning и с 2016 года является главным организатором Bayesian Deep Learning Workshop на NeurIPS.
Сквозной темой своих исследований он сам называет "понимание эмпирически разработанных техник машинного обучения".
Только с начала этого года появилось десять статей с его участием arxiv. Тем не менее самой цитируемой остается статья "Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning".
Основной её вывод в том, что dropout можно интерпретировать как байесовскую аппроксимацию широко известной вероятностной модели - гауссовского процесса. Такая интерпретация позволяет получить способ оценивать неопределенность предсказаний нейронной сети.
Как пишут авторы, выходное значения слоя softmax ошибочно интерпретируется как вероятность, но ею не является. Большое значение на выходе softmax не является показателем уверенности модели в результате. Байесовская интерпретация дропаута позволяет такую оценку получить, не жертвуя ни сложностью сети, ни точностью на тестовой выборке.
{kind=link}
Недавно также вышла статья, в авторах которой числятся Yarin Gal и Geoffrey Hinton. В ней рассказано о технике, которая позволяет существенно уменьшать размер сети, не сильно теряя в производительности.
Часто на практике используются способы уменьшения размера сети, которые отбрасывают веса, например, учитывая их размер. Они основаны на надежде на то, что размер весов подсети коррелирует с её производительностью. Авторы же предлагают, изначально, натренировать сеть так, чтобы она не теряла в производительности при конкретном способе последующего отбора весов.
Для этого нужно сначала выбрать критерий, на основе которого сеть будет уменьшаться (размер весов, например), и использовать targeted dropout во время обучения. Targeted - то есть такой, который будет в большей степени воздействовать на малые веса, подталкивая сеть уменьшать веса неважных подсетей.
Авторы показывают большую эффективность такого подхода по сравнению с другими техниками, особенно при сильном уменьшении размера. Также пишут, что это займет всего пару строчек в реализации на TensorFlow или PyTorch.
Learning Sparse Networks Using Targeted Dropout
https://arxiv.org/pdf/1905.13678.pdf
Часто на практике используются способы уменьшения размера сети, которые отбрасывают веса, например, учитывая их размер. Они основаны на надежде на то, что размер весов подсети коррелирует с её производительностью. Авторы же предлагают, изначально, натренировать сеть так, чтобы она не теряла в производительности при конкретном способе последующего отбора весов.
Для этого нужно сначала выбрать критерий, на основе которого сеть будет уменьшаться (размер весов, например), и использовать targeted dropout во время обучения. Targeted - то есть такой, который будет в большей степени воздействовать на малые веса, подталкивая сеть уменьшать веса неважных подсетей.
Авторы показывают большую эффективность такого подхода по сравнению с другими техниками, особенно при сильном уменьшении размера. Также пишут, что это займет всего пару строчек в реализации на TensorFlow или PyTorch.
Learning Sparse Networks Using Targeted Dropout
https://arxiv.org/pdf/1905.13678.pdf
Заметка о том, что работает и не работает из практик Agile в data science.
Часть 1
Часть 2
TL;DR
Работает:
- планирование и приоритезация
- разбиение на задачи с ограничением по времени
- ретроспективы и демо.
Что не работает и как быть:
- временные оценки - их можно заменить ограниченными по времени экспериментальными задачами
- быстро меняющиеся требования - собственно использование планирования и приоритезации с фиксацией задач хотя бы на время спринта должно показать бизнесу, что работа без переключения контекста эффективнее
- ожидание результата в виде кода в конце спринта - здесь поможет фиксация ожидаемого результата (вместо кода это могут быть результаты экспериментов, определение следующих шагов)
- слишком рьяное следование требованием бизнеса - выделять, например, 2-3 недели в квартал на инновации вместо работы над текущими задачами.
Там ещё есть интересный пример про то, как proof-of-concept занял 2 человеко-месяца, а внедрение в продакшн 117, то есть где-то в 60 раз больше. Такое тоже может быть и нужно это учитывать.
Согласны? Узнали?
Пользуетесь практиками agile в data science командах?
Часть 1
Часть 2
TL;DR
Работает:
- планирование и приоритезация
- разбиение на задачи с ограничением по времени
- ретроспективы и демо.
Что не работает и как быть:
- временные оценки - их можно заменить ограниченными по времени экспериментальными задачами
- быстро меняющиеся требования - собственно использование планирования и приоритезации с фиксацией задач хотя бы на время спринта должно показать бизнесу, что работа без переключения контекста эффективнее
- ожидание результата в виде кода в конце спринта - здесь поможет фиксация ожидаемого результата (вместо кода это могут быть результаты экспериментов, определение следующих шагов)
- слишком рьяное следование требованием бизнеса - выделять, например, 2-3 недели в квартал на инновации вместо работы над текущими задачами.
Там ещё есть интересный пример про то, как proof-of-concept занял 2 человеко-месяца, а внедрение в продакшн 117, то есть где-то в 60 раз больше. Такое тоже может быть и нужно это учитывать.
Согласны? Узнали?
Пользуетесь практиками agile в data science командах?
Medium
Data Science and Agile: What works and what doesn’t work
A deeper look into the strengths and weaknesses of Agile in Data Science projects (Part 1 of 2)
Если байес нужен всем
Для тех, кто только начинает свой путь в байесовских методах, есть отличный курс на русском и материалы к нему.
Для тех, кто уже продолжает, есть записи с летней школы Deep Bayes (на английском).
И наконец, для тех, у кого нет так много времени, а пощупать хочется, небольшой курс от той же вышки на курсере.
Для тех, кто только начинает свой путь в байесовских методах, есть отличный курс на русском и материалы к нему.
Для тех, кто уже продолжает, есть записи с летней школы Deep Bayes (на английском).
И наконец, для тех, у кого нет так много времени, а пощупать хочется, небольшой курс от той же вышки на курсере.
YouTube
Курс «Байесовские методы в машинном обучении». Лекция 1 (Дмитрий Ветров)
Байесовский подход к теории вероятностей. Примеры байесовских рассуждений
Целью курса является освоение байесовского подхода к теории вероятностей и основных способов его применения при решении задач машинного обучения. Курс научит вас строить комплексные…
Целью курса является освоение байесовского подхода к теории вероятностей и основных способов его применения при решении задач машинного обучения. Курс научит вас строить комплексные…
5 книг
Классическая классика ML
Pattern Recognition and Machine Learning, Bishop
The Elements of Statistical Learning
Классика нейронок
Neural Networks and Learning Machines, Haykin
Нейросети
Deep Learning - здесь больше теории
Hands-On Machine Learning with Scikit-Learn and TensorFlow - здесь больше практики с примерами на Tensorflow
Классическая классика ML
Pattern Recognition and Machine Learning, Bishop
The Elements of Statistical Learning
Классика нейронок
Neural Networks and Learning Machines, Haykin
Нейросети
Deep Learning - здесь больше теории
Hands-On Machine Learning with Scikit-Learn and TensorFlow - здесь больше практики с примерами на Tensorflow
{kind=link}
Best paper award ICML 2019
Такую награду получило две статьи.
Про первую статью уже было тут.
Вторая статья называется Rates of Convergence for Sparse Variational Gaussian Process Regression.
Как и предполагает название, описывает она достижения в области сходимости регреcсии на основе гауссовских процессов.
Гауссовские процессы часто используют для задания априорных распределения в байесовских моделях. Их плюс в том, что известно аналитическое решение для апостериорного и маргинального распределения для регрессионной модели. Их минус - в вычислительной сложности O(N³) и O(N²) по памяти, где N - количество экземпляров в данных.
Известны алгоритмы, сводящие этот вывод к O(NM² + M³) по времени и O(NM + M²) по памяти, где M - это число "индуцирующих" переменных (inducing variables). В этом случае, настоящяя вычислительная сложность зависит от того, как увеличивается M при увеличении N с сохранением точности приближения.
В статье показано, что с большой вероятностью расстояние Кульбака-Лейблера (KL divergence) между аппроксимирующим и реальным распределением можно сделать сколь угодно малым при том, что M будет расти медленнее, чем N. В частности, если есть нормально распределенные данные размерности D и в качестве ядра ковариции используется squared exponential, то M может расти как логарифм от N по основанию D.
Заметки обо всём ICML:
https://david-abel.github.io/notes/icml_2019.pdf
Что такое регрессия на основе гауссовских процессов: длинное объяснение и короткое.
Такую награду получило две статьи.
Про первую статью уже было тут.
Вторая статья называется Rates of Convergence for Sparse Variational Gaussian Process Regression.
Как и предполагает название, описывает она достижения в области сходимости регреcсии на основе гауссовских процессов.
Гауссовские процессы часто используют для задания априорных распределения в байесовских моделях. Их плюс в том, что известно аналитическое решение для апостериорного и маргинального распределения для регрессионной модели. Их минус - в вычислительной сложности O(N³) и O(N²) по памяти, где N - количество экземпляров в данных.
Известны алгоритмы, сводящие этот вывод к O(NM² + M³) по времени и O(NM + M²) по памяти, где M - это число "индуцирующих" переменных (inducing variables). В этом случае, настоящяя вычислительная сложность зависит от того, как увеличивается M при увеличении N с сохранением точности приближения.
В статье показано, что с большой вероятностью расстояние Кульбака-Лейблера (KL divergence) между аппроксимирующим и реальным распределением можно сделать сколь угодно малым при том, что M будет расти медленнее, чем N. В частности, если есть нормально распределенные данные размерности D и в качестве ядра ковариции используется squared exponential, то M может расти как логарифм от N по основанию D.
Заметки обо всём ICML:
https://david-abel.github.io/notes/icml_2019.pdf
Что такое регрессия на основе гауссовских процессов: длинное объяснение и короткое.