
Сортировка списка и костыль в JDK
Вести абстрактные разговоры о разработке легко и приятно. Можно два часа рассуждать, что такое хорошее API, но гораздо полезнее обсудить конкретные примеры. Сегодня разберём метод сортировки.
Если показать вопрос перед постом питонисту, он однозначно выберет
Класс Integer реализует интерфейс
Однако в интерфейсе List нет такого метода, только
(
Сейчас расскажу:)
Java создавался как язык для больших и долгоживущих приложений, и его основные ценности — стабильность и обратная совместимость.
C начала 2000-х в JDK есть метод
В больших компаниях классы JDK часто расширяли удобными методами, в том числе сортировкой в функциональном стиле:
Но есть проблема. Допустим, на проекте есть такой класс:
Многие проекты полагаются на свой sort, поэтому разработчики JDK не стали добавлять его в интерфейс. Метод sort(Comparator) использовался редко, поэтому теперь он с нами.
У Stream API нет проблем с совместимостью, так что для стримов есть прекрасный метод sorted(). Для коллекций метод sorted() есть в Kotlin💖
(обратите внимание на суффикс -ed, всё по правилам функционального подхода)
Ответ на вопрос перед постом: отсортировать список можно так:
✅
Вести абстрактные разговоры о разработке легко и приятно. Можно два часа рассуждать, что такое хорошее API, но гораздо полезнее обсудить конкретные примеры. Сегодня разберём метод сортировки.
Если показать вопрос перед постом питонисту, он однозначно выберет
list.sort(). Хотя бы потому что в питоне есть такой метод.Класс Integer реализует интерфейс
Comparable, сортировка чисел — базовая функциональность любого языка программирования. Так что метод sort() максимально логичен.Однако в интерфейсе List нет такого метода, только
void sort(Comparator<? super E> c) {…}
Для элементарной операции сортировки чисел приходится писатьlist.sort(Comparator.naturalOrder())Код с Comparator.naturalOrder() похож на какой-то костыль. Под капотом не происходит ничего особенного, реализация компаратора очень простая:
(
с1, с2) -> c1.compareTo(c2)
❓ Так зачем писать так сложно? Почему в интерфейсе List нет метода sort()?Сейчас расскажу:)
Java создавался как язык для больших и долгоживущих приложений, и его основные ценности — стабильность и обратная совместимость.
C начала 2000-х в JDK есть метод
Collections.sort(List). Статический метод, который меняет внутреннее состояние аргумента. Сейчас это порицается, но в те времена было норм.В больших компаниях классы JDK часто расширяли удобными методами, в том числе сортировкой в функциональном стиле:
CustomList sorted = list.sort();Спустя много лет стало понятно, что экземплярные методы сортировки — это классно, и надо добавить такой метод в JDK. Чтобы текущие реализации списков не сломались, это должен быть дефолтный метод в интерфейсе List.
Но есть проблема. Допустим, на проекте есть такой класс:
public class CustomList implements List {
public CustomList sort() {…}
}
Допустим, в java 8 в интерфейс List добавили методdefault void sort() {…}
Старый метод не может переопределить дефолтный. тк возвращаемые значения не совместимы. Поэтому проекты, которые определили свой функциональный sort в начале 2000-х, перестанут компилироваться. Пользователи будут недовольны.Многие проекты полагаются на свой sort, поэтому разработчики JDK не стали добавлять его в интерфейс. Метод sort(Comparator) использовался редко, поэтому теперь он с нами.
У Stream API нет проблем с совместимостью, так что для стримов есть прекрасный метод sorted(). Для коллекций метод sorted() есть в Kotlin💖
(обратите внимание на суффикс -ed, всё по правилам функционального подхода)
Ответ на вопрос перед постом: отсортировать список можно так:
✅
list.sort(Comparator.naturalOrder());
✅ list = list.stream().sorted().toList();
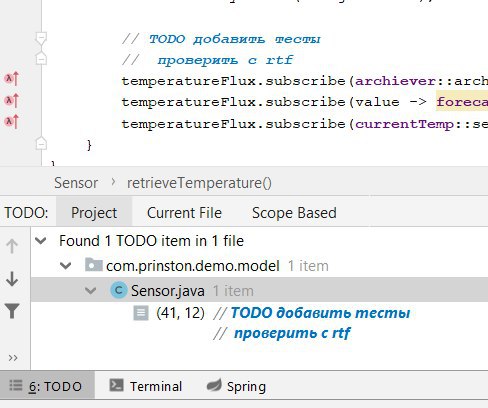
Если вам понравился list.sort(), значит у вас хороший вкус на API. К сожалению, у java свои загоны, поэтому этого метода в JDK нет.Intellij IDEA: комментарии TODO
Часто встречаются ситуации, когда нужно запомнить место в коде:
⭐️ Внести изменения по задаче, но чуть позже
⭐️ Отметить непокрытый тестами код
⭐️ Обсудить метод с коллегой
Для таких случаев в IDEA есть специальный тип комментариев. Он начинается со слов
Если списка нет, ищите его через View → Tool Windows → TODO
Помимо стандартных
Очень удобно использовать TODO для текущих задач, чтобы ничего не забыть. Чтобы отметить код, который исправит кто-то другой, не забудьте закинуть соответствующую задачу в бэклог:)
Часто встречаются ситуации, когда нужно запомнить место в коде:
⭐️ Внести изменения по задаче, но чуть позже
⭐️ Отметить непокрытый тестами код
⭐️ Обсудить метод с коллегой
Для таких случаев в IDEA есть специальный тип комментариев. Он начинается со слов
TODO и выглядит так:// TODO добавить тестыВсе такие комментарии можно посмотреть в окне TODO внизу экрана. Через него же можно перейти в нужное место кода в один клик.
Если списка нет, ищите его через View → Tool Windows → TODO
Помимо стандартных
TODO и FIXME можно добавить свои метки, например, OPTIMIZE, ASK, TEST. Сделать это можно в File → Settings → Editor → TODOОчень удобно использовать TODO для текущих задач, чтобы ничего не забыть. Чтобы отметить код, который исправит кто-то другой, не забудьте закинуть соответствующую задачу в бэклог:)
{kind=link}
В классе Order есть поле sum (сумма заказа). Мы хотим отсортировать заказы от большей суммы к меньшей. Что написать внутри метода orders.sort(…)?
Anonymous Poll
36%
(o1, o2) -> (int) (o1.getSum() - o2.getSum())
64%
(o1, o2) -> (int) (o2.getSum() - o1.getSum())
Как написать компаратор
Компаратор задаёт правило сравнения элементов между собой. Делает он это с помощью метода
▫️ число больше нуля — первый элемент больше второго
▫️ 0 — элементы равны
▫️ число меньше нуля — первый меньше второго
Простейшая и популярная реализация — вычесть одно значение из другого:
Я всегда сомневаюсь, что из чего вычитать. Если вы отвечали на опрос дольше одной секунды, значит мы в одном лагере:) Компаратор — совсем не то место, где мозг должен спотыкаться.
В Java 8 в интерфейсе
✅ Не надо вспоминать, что из чего вычитать
✅ Легко сделать сравнение в обратном порядке:
Важные нюансы:
1️⃣ comparing*
В интерфейсе
отсортировать по полю А в обратном порядке, дубликаты отсортировать по Б
Методы
Если в списке нет null объектов, но в поле sum возможен null, придётся писать так:
Ответ на вопрос перед постом:
Компаратор задаёт правило сравнения элементов между собой. Делает он это с помощью метода
compare:public int compare(T o1, T o2) {…}
Если метод вернул▫️ число больше нуля — первый элемент больше второго
▫️ 0 — элементы равны
▫️ число меньше нуля — первый меньше второго
Простейшая и популярная реализация — вычесть одно значение из другого:
(o1, o2) -> (int) (o1.getSum() - o2.getSum())❓ Что с этим не так?
Я всегда сомневаюсь, что из чего вычитать. Если вы отвечали на опрос дольше одной секунды, значит мы в одном лагере:) Компаратор — совсем не то место, где мозг должен спотыкаться.
В Java 8 в интерфейсе
Comparator появился удобный метод:orders.sort(comparing(Order::getSum))Что классно:
✅ Не надо вспоминать, что из чего вычитать
✅ Легко сделать сравнение в обратном порядке:
comparing(Order::getSum).reversed()✅ Можно учесть null:
nullsFirst(comparing(Order::getSum))✅ Удобно сортировать по нескольким полям:
nullLast(…)
comparing(Order::getSum).thenComparing(Order::getId)Самостоятельно обрабатывать null и писать сложные сортировки очень утомительно. Помню, как с удовольствием удаляла из проекта компараторы на 20 строк после перехода на Java 8😊
Важные нюансы:
1️⃣ comparing*
В интерфейсе
Comparator также доступны методы comparingInt, comparingLong и comparingDouble. Используются для полей примитивного типа, чтобы избежать лишнего боксинга. Если в классе OrderLong id → используем comparing(Order::getId)
long id → comparingLong(Order::getId)
Не указывайте тип лишний раз. Для работы с объектами подойдёт обычный comparing
2️⃣ Нетривиальная работа с null*
В обычных методах легко понять, что происходит: comparing(A).reversed().thenComparing(Б)=
отсортировать по полю А в обратном порядке, дубликаты отсортировать по Б
Методы
null* выбиваются из этой схемы.nullsFirst(comparing(Order::getSum))означает, что первыми будут null объекты, а существующие заказы отсортируются по сумме. Этот компаратор работает для такого кода:
orders.add(null); // эти элементы будут впередиorders.add(new Order(…)); // эти отсортируются по полю sum Если в списке нет null объектов, но в поле sum возможен null, придётся писать так:
…comparing(Order::getSum, nullsFirst(naturalOrder()));Сравнение по нескольким nullable полям выглядит совсем плохо. К счастью, на практике такие задачи встречаются редко.
Ответ на вопрос перед постом:
(o1, o2) -> (int) (o2.getSum() - o1.getSum())Но лучше использовать
comparing(Order::getSum).reversed() ✨Структура проекта и качество кода, часть 1
Структура проекта — это то, как мы раскладываем классы по папочкам. Хорошая структура помогает не только ориентироваться в проекте, но и писать более качественный код.
Сейчас покажу, как это работает.
Разделение по слоям
Начнём с структуры, которая встречается в большинстве туториалов и пет-проектах начинающих:
📂 controller
— UserController, TicketController
📂 service
— UserService, TicketService
📂 repository
— UserRepository, TicketRepository
Чтобы классы могли использовать друг друга, все классы и методы должны быть
В такой структуре естественным путём повышается связность. Если в
Всё связано со всем. Поменяешь в одном месте — сломается в другом. В пет-проекте с этим можно справиться, но для коммерческих проектов такая структура не подходит
Разделение по функциям
Складываем в один пекедж всё, связанное с какой-то сущностью. Оставляем 1-2 класса с модификатором
📂 user
— UserController, UserService, UserRepository
📂 ticket
— TicketController, TicketService, TicketRepository
📂 export
— ExportService, ExcelFormatter
Дефолтный модификатор ограничивает доступ между пэкеджами. Если
✅ Связность классов снижается, упрощается поддержка и тестирование
😐 Каждый класс решает не бизнес-задачу, а инфраструктурную.
😐 Высокая связность между бизнес-кейсами. Появляются десятки универсальных методов, которые "переиспользуются" в бизнес-сценариях. Например, создание и редактирование пользователя часто делают через один метод. Меняем одно — неизбежно задеваем похожие сценарии.
Разделение по бизнес-кейсам
Складываем в один пекедж все классы, связанные с бизнес-процессом. Большинство классов стоит с
📂 newUser
— NewUserController, NewUserService, UserRepository
📂 buyTicket
— BuyTicketController, BuyTicketService, TicketRepository
📂 refundTicket — …
📂 export — …
Количество классов увеличивается, но они становятся меньше и более изолированными. Связность между бизнес-сценариями максимально снижается.
Итого: чёткая структура проекта и модификаторы доступа снижают связность между компонентами на уровне компиляции.
Однако очень мало проектов используют эту практику. Не потому что разработчики плохие, а потому что на большинстве проектов этот подход не сработает. Почему так получается и кто виноват — расскажу в следующем посте:)
Структура проекта — это то, как мы раскладываем классы по папочкам. Хорошая структура помогает не только ориентироваться в проекте, но и писать более качественный код.
Сейчас покажу, как это работает.
Разделение по слоям
Начнём с структуры, которая встречается в большинстве туториалов и пет-проектах начинающих:
📂 controller
— UserController, TicketController
📂 service
— UserService, TicketService
📂 repository
— UserRepository, TicketRepository
Чтобы классы могли использовать друг друга, все классы и методы должны быть
public. В такой структуре естественным путём повышается связность. Если в
UserService хочется узнать номер билета, то самое простое — добавить TicketRepository и вызвать нужный метод. Всё связано со всем. Поменяешь в одном месте — сломается в другом. В пет-проекте с этим можно справиться, но для коммерческих проектов такая структура не подходит
Разделение по функциям
Складываем в один пекедж всё, связанное с какой-то сущностью. Оставляем 1-2 класса с модификатором
public, остальным даём дефолтный модификатор доступа: 📂 user
— UserController, UserService, UserRepository
📂 ticket
— TicketController, TicketService, TicketRepository
📂 export
— ExportService, ExcelFormatter
Дефолтный модификатор ограничивает доступ между пэкеджами. Если
UserService хочет сформировать отчёт по пользователям, он вынужден идти через ExportService, потому что ExcelFormatter ему не виден.✅ Связность классов снижается, упрощается поддержка и тестирование
😐 Каждый класс решает не бизнес-задачу, а инфраструктурную.
UserRepository — точка доступа к таблице users. UserService — класс по работе с классом User. Классы становятся огромными😐 Высокая связность между бизнес-кейсами. Появляются десятки универсальных методов, которые "переиспользуются" в бизнес-сценариях. Например, создание и редактирование пользователя часто делают через один метод. Меняем одно — неизбежно задеваем похожие сценарии.
Разделение по бизнес-кейсам
Складываем в один пекедж все классы, связанные с бизнес-процессом. Большинство классов стоит с
default модификатором и недоступна за пределами пэкеджа: 📂 newUser
— NewUserController, NewUserService, UserRepository
📂 buyTicket
— BuyTicketController, BuyTicketService, TicketRepository
📂 refundTicket — …
📂 export — …
Количество классов увеличивается, но они становятся меньше и более изолированными. Связность между бизнес-сценариями максимально снижается.
Итого: чёткая структура проекта и модификаторы доступа снижают связность между компонентами на уровне компиляции.
Однако очень мало проектов используют эту практику. Не потому что разработчики плохие, а потому что на большинстве проектов этот подход не сработает. Почему так получается и кто виноват — расскажу в следующем посте:)
Структура проекта и качество кода, часть 2
В прошлом посте мы рассмотрели основные структуры, по которым делаются проекты. Структура помогает легко ориентироваться в коде, плюс снижает связность между компонентами за счёт модификаторов доступа.
Просто так использовать
Но кое-что разрушает эту прекрасную картину: ✨фреймворки✨
Чтобы Spring мог сотворить волшебство, приходится немного жертвовать изоляцией. Начиная с public репозиториев и заканчивая одним контекстом на всё приложение.
При использовании спринга (или других фреймворков) связность между компонентами меньше ограничивается и с течением времени растёт.
Но выход есть!
Поделить функциональность не на пэкеджи, а на Maven/Gradle модули:
📂 registration
— 📂 src
— Controller, Service, Repository
— 📂 test
pom.xml
📂 export
⚠️ Обратите внимание, каждый модуль — просто набор классов и тестов, а не отдельный микросервис!
Связность при таком подходе снижается ещё больше:
✅ У каждого модуля свой набор зависимостей
✅ Нет общего контекста
Можно, наверное, поделить приложение на java модули, но модули Maven/Gradle встречаются гораздо чаще.
Совсем большие проекты идут ещё дальше. В Hexagonal/Clean/Onion/… architecture каждый бизнес-сценарий делится на модули бизнес-правил, адаптеров, инфраструктуры и тд.
✅ Минимальная связность, ультра простое тестирование
😐 Количество модулей, классов и интерфейсов увеличивается в разы
😐 Легко скатиться в карго-культ, нужен опыт для правильной реализации
Резюме
Spring — классный фреймворк, и здорово облегчает рутинные задачи. Но у него есть тёмная сторона — благодаря общему контексту связность кода неизбежно повышается. Чтобы проект не превратился в болото, в первую очередь нужен высокий профессиональный уровень всей команды.
Если приложение большое, имеет смысл поделить его на отдельные модули. У каждого бизнес-процесса будет свой контекст и набор зависимостей. Поддерживать такую структуру будет гораздо проще👍
В прошлом посте мы рассмотрели основные структуры, по которым делаются проекты. Структура помогает легко ориентироваться в коде, плюс снижает связность между компонентами за счёт модификаторов доступа.
Просто так использовать
default класс из другого пэкеджа (то есть повысить связность) не получится, код не скомпилируется. Либо придётся менять модификатор доступа, что точно будет заметно на ревью.Но кое-что разрушает эту прекрасную картину: ✨фреймворки✨
Чтобы Spring мог сотворить волшебство, приходится немного жертвовать изоляцией. Начиная с public репозиториев и заканчивая одним контекстом на всё приложение.
При использовании спринга (или других фреймворков) связность между компонентами меньше ограничивается и с течением времени растёт.
Но выход есть!
Поделить функциональность не на пэкеджи, а на Maven/Gradle модули:
📂 registration
— 📂 src
— Controller, Service, Repository
— 📂 test
pom.xml
📂 export
⚠️ Обратите внимание, каждый модуль — просто набор классов и тестов, а не отдельный микросервис!
Связность при таком подходе снижается ещё больше:
✅ У каждого модуля свой набор зависимостей
✅ Нет общего контекста
Можно, наверное, поделить приложение на java модули, но модули Maven/Gradle встречаются гораздо чаще.
Совсем большие проекты идут ещё дальше. В Hexagonal/Clean/Onion/… architecture каждый бизнес-сценарий делится на модули бизнес-правил, адаптеров, инфраструктуры и тд.
✅ Минимальная связность, ультра простое тестирование
😐 Количество модулей, классов и интерфейсов увеличивается в разы
😐 Легко скатиться в карго-культ, нужен опыт для правильной реализации
Резюме
Spring — классный фреймворк, и здорово облегчает рутинные задачи. Но у него есть тёмная сторона — благодаря общему контексту связность кода неизбежно повышается. Чтобы проект не превратился в болото, в первую очередь нужен высокий профессиональный уровень всей команды.
Если приложение большое, имеет смысл поделить его на отдельные модули. У каждого бизнес-процесса будет свой контекст и набор зависимостей. Поддерживать такую структуру будет гораздо проще👍
Анонс курса по многопоточке
Старт: 5 июня
Длительность: 9 недель
Кто давно ждал и уже готов → http://fillthegaps.ru/mt
Теперь подробнее. У курса две основные задачи:
✅ Научиться писать хороший многопоточный код
Разберём типовые энтерпрайзные задачи, огромное количество кейсов, лучших практик и возможных ошибок. Сравним производительность разных решений для разных ситуаций
✅ Подготовимся к собеседованиям, где требуется concurrency. Обсудим стандартные и нестандартные вопросы, порешаем тестовые задания
Что говорят ученики:
👨🦱 “Курс понравился тем, что он "от разработчиков разработчикам": примеры реальных библиотек для разбора, приближенные к реальным задачи для кодинга”
👨🦱 ”Курс очень интенсивный, охватывает не только многопоточку, но и смежные темы, учит разным лайфхакам полезным для практического использования, обращает внимание на темы, которые легко или упустить, изучая тему самостоятельно, или вообще можно никогда не узнать без курса”
👨🦱 ”Есть очень много свежей информации, которую сконцентрировано в едином источнике не получить”
👨🦱 “Это не с нуля совсем курс, и больше про правду разработки, разбавленную вопросами с собесов, а не про чистые знания.”
Отзывы целиком можно почитать тут
Для какого уровня курс?
Middle и выше
✔️ Есть рассрочка на 3 и 6 месяцев
✔️ Принимаются карты любых банков
✔️ Курс можно оплатить за счёт компании
Аналогов у курса нет. Вообще:)
С каждым потоком программа становится лучше, задания интереснее, а учёба приятнее. Если хотите разобраться с многопоточкой, и вам близок мой стиль изложения — записывайтесь, будет очень полезно!
http://fillthegaps.ru/mt
Старт: 5 июня
Длительность: 9 недель
Кто давно ждал и уже готов → http://fillthegaps.ru/mt
Теперь подробнее. У курса две основные задачи:
✅ Научиться писать хороший многопоточный код
Разберём типовые энтерпрайзные задачи, огромное количество кейсов, лучших практик и возможных ошибок. Сравним производительность разных решений для разных ситуаций
✅ Подготовимся к собеседованиям, где требуется concurrency. Обсудим стандартные и нестандартные вопросы, порешаем тестовые задания
Что говорят ученики:
👨🦱 “Курс понравился тем, что он "от разработчиков разработчикам": примеры реальных библиотек для разбора, приближенные к реальным задачи для кодинга”
👨🦱 ”Курс очень интенсивный, охватывает не только многопоточку, но и смежные темы, учит разным лайфхакам полезным для практического использования, обращает внимание на темы, которые легко или упустить, изучая тему самостоятельно, или вообще можно никогда не узнать без курса”
👨🦱 ”Есть очень много свежей информации, которую сконцентрировано в едином источнике не получить”
👨🦱 “Это не с нуля совсем курс, и больше про правду разработки, разбавленную вопросами с собесов, а не про чистые знания.”
Отзывы целиком можно почитать тут
Для какого уровня курс?
Middle и выше
✔️ Есть рассрочка на 3 и 6 месяцев
✔️ Принимаются карты любых банков
✔️ Курс можно оплатить за счёт компании
Аналогов у курса нет. Вообще:)
С каждым потоком программа становится лучше, задания интереснее, а учёба приятнее. Если хотите разобраться с многопоточкой, и вам близок мой стиль изложения — записывайтесь, будет очень полезно!
http://fillthegaps.ru/mt
Что изменилось в этом потоке?
Курс — мой любимый пет-проект, который я развиваю уже третий год.
Казалось бы, уже 7 потоков прошло. Всем всё нравится — половину мест с обратной связью уже разобрали, отзывы отличные. Что ещё улучшать? А вот есть что:)
✅ Практические задания
Практика — самая сильная часть курса. Теория осталась плюс-минус такой же с 2021 года, а практическая часть постоянно развивается. Тесты, написание кода, анализ реального кода, лабораторные работы — только так появляется уверенность при работе с многопоточкой.
Для этого потока добавила пару классных примеров из Spring core на разбор, отшлифовала формулировки тестов, написала несколько гайдов для самопроверки для тарифа без обратной связи
✅ Предобучение
До прохождения курса многие вообще не трогали многопоточку. И для некоторых учеников нагрузка оказывается очень серьёзной.
Чтобы чуть снизить уровень стресса, учёба теперь делится на два шага:
1. Предобучение — в спокойном темпе изучить основы и потренироваться на простых примерах
2. Основной курс — закрепить основы и углубиться в детали
В итоге
▫️ Новички чуть больше работают с базой и основной курс зайдёт легче (я надеюсь)
▫️ Опытные ребята пропускают предобучение и не тратят время на лёгкие задачки
Подготовительный этап совсем небольшой, поэтому решила сделать его открытым. Если хотите подтянуть основы многопоточности — welcome
✅ Налоговый вычет
Если вы платите налоги в России, то в следующем году можно подать заявление в налоговую и вернуть 13% стоимости курса!!!
Ученики февральского потока тоже могут оформить вычет! Как это сделать и какие документы нужны — написала на сайте в разделе "популярные вопросы".
https://fillthegaps.ru/mt
Курс — мой любимый пет-проект, который я развиваю уже третий год.
Казалось бы, уже 7 потоков прошло. Всем всё нравится — половину мест с обратной связью уже разобрали, отзывы отличные. Что ещё улучшать? А вот есть что:)
✅ Практические задания
Практика — самая сильная часть курса. Теория осталась плюс-минус такой же с 2021 года, а практическая часть постоянно развивается. Тесты, написание кода, анализ реального кода, лабораторные работы — только так появляется уверенность при работе с многопоточкой.
Для этого потока добавила пару классных примеров из Spring core на разбор, отшлифовала формулировки тестов, написала несколько гайдов для самопроверки для тарифа без обратной связи
✅ Предобучение
До прохождения курса многие вообще не трогали многопоточку. И для некоторых учеников нагрузка оказывается очень серьёзной.
Чтобы чуть снизить уровень стресса, учёба теперь делится на два шага:
1. Предобучение — в спокойном темпе изучить основы и потренироваться на простых примерах
2. Основной курс — закрепить основы и углубиться в детали
В итоге
▫️ Новички чуть больше работают с базой и основной курс зайдёт легче (я надеюсь)
▫️ Опытные ребята пропускают предобучение и не тратят время на лёгкие задачки
Подготовительный этап совсем небольшой, поэтому решила сделать его открытым. Если хотите подтянуть основы многопоточности — welcome
✅ Налоговый вычет
Если вы платите налоги в России, то в следующем году можно подать заявление в налоговую и вернуть 13% стоимости курса!!!
Ученики февральского потока тоже могут оформить вычет! Как это сделать и какие документы нужны — написала на сайте в разделе "популярные вопросы".
https://fillthegaps.ru/mt
Последний день для ранних пташек
Сегодня последний день, когда можно вписаться на курс как early bird🦅
Курс строится вокруг java.util.concurrent — боевой лошадки каждого нагруженного сервиса. В деталях изучим все классы, концепты и практическое применение. Разберём огромное количество кейсов, лучших практик и возможных ошибок.
Ну и по мелочи — разберёмся с тестированием многопоточки, сравним разные подходы (реактивщина, Project Loom, корутины), подготовимся к собеседованиям. Всё шаг за шагом и с картинками:)
👨🦱 “Курс великолепный, не пожалел ни одного рубля, что потратил. Это уникальный курс в своем сегменте, особенно на русском рынке. Всем советую, на курсе вы найдете все ответы на интересующие вас вопросы. Более того из курса вы сможете узнать то, что просто нет в открытом доступе нигде, исключительно авторские наработки. Однозначно советую всем бэкэнд разработчикам, даже если вы не особо используете многопточку - это очень поможет вам в понимании многопоточного кода фреймворков и вообще сильно улучшит ваш кругозор. Советую брать с обратной связью - сильно увеличивает пользу от курса.”
Старт: 5 июня
Длительность: 9 недель
✅ Оплата за счёт компании
✅ Рассрочка на 3 или 6 месяцев
✅ Налоговый вычет 13%
Завтра цена вырастет, присоединяйтесь сегодня!
http://fillthegaps.ru/mt
Сегодня последний день, когда можно вписаться на курс как early bird🦅
Курс строится вокруг java.util.concurrent — боевой лошадки каждого нагруженного сервиса. В деталях изучим все классы, концепты и практическое применение. Разберём огромное количество кейсов, лучших практик и возможных ошибок.
Ну и по мелочи — разберёмся с тестированием многопоточки, сравним разные подходы (реактивщина, Project Loom, корутины), подготовимся к собеседованиям. Всё шаг за шагом и с картинками:)
👨🦱 “Курс великолепный, не пожалел ни одного рубля, что потратил. Это уникальный курс в своем сегменте, особенно на русском рынке. Всем советую, на курсе вы найдете все ответы на интересующие вас вопросы. Более того из курса вы сможете узнать то, что просто нет в открытом доступе нигде, исключительно авторские наработки. Однозначно советую всем бэкэнд разработчикам, даже если вы не особо используете многопточку - это очень поможет вам в понимании многопоточного кода фреймворков и вообще сильно улучшит ваш кругозор. Советую брать с обратной связью - сильно увеличивает пользу от курса.”
Старт: 5 июня
Длительность: 9 недель
✅ Оплата за счёт компании
✅ Рассрочка на 3 или 6 месяцев
✅ Налоговый вычет 13%
Завтра цена вырастет, присоединяйтесь сегодня!
http://fillthegaps.ru/mt
{kind=link}
Конструкция <E extends Enum<E>> в определении Enum нужна чтобы
Anonymous Poll
9%
Запретить наследование от сгенерированного класса
12%
Разработчик не мог создать наследника Enum
35%
Ограничить использование дженериков внутри enum
16%
Предотвратить рекурсивное наследование классов
27%
Не допустить сравнения разных enum между собой
Self-referential generic, часть 1
Кто участвовал в декабрьском адвенте, точно помнит, что
В определении класса
Чтобы понять, какая проблема решается, представим, что этой конструкции нет. И определение енама выглядит так:
Есть более важный момент. Пользователь может спокойно сравнить животное и конвертер, ошибка возникнет только в рантайме. Это выглядит странно, ведь enum Animal и enum Converter никак не связаны между собой.
Здесь дженерик выходит на сцену:
✅ При компиляции происходит проверка типов:
Self-referential generic позволяет использовать дочерний тип в интерфейсах и методах родителя. Для некоторых кейсов этот приём здорово упрощает код и снижает количество ошибок. В следующем посте покажу ещё один пример использования.
Ответ на вопрос перед постом: self-referential generic помогает ограничить сравнение разных enum между собой.
Кто участвовал в декабрьском адвенте, точно помнит, что
еnum компилируется в наследник класса Enum:public enum Animal {WOLF, TIGER}
↓public class Animal extends Enum {
public static final Animal WOLF;
public static final Animal TIGER;
}
Подробнее об этом и енамах в целом можно почитать тут — раз, два и три.В определении класса
Enum используется конструкция, которая называется self-referential generic (или self-bound type, или recursive generic):EnumᐸE extends EnumᐸEᐳᐳВ этом посте расскажу, что это такое и зачем нужно.
Чтобы понять, какая проблема решается, представим, что этой конструкции нет. И определение енама выглядит так:
public abstract class MyEnum implements ComparableᐸMyEnumᐳПользователь определяет enum Animal и enum Converter. Компилятор превращает это в классы
Animal extends MyEnumКаждый класс должен реализовать интерфейс
Converter extends MyEnum
ComparableᐸMyEnumᐳ и метод compareTo. Чтобы не сравнивать животных и конвертеры, придётся использовать instanceof: public final int compareTo(MyEnum o) {
if (o instanceOf Animal other) {
// сравниваем зверюшек
// return ...
}
throw IllegalArgumentException();
}
В самом instanceOf нет ничего плохого. Тем более этот код генерируется при компиляции и остаётся за кадром.Есть более важный момент. Пользователь может спокойно сравнить животное и конвертер, ошибка возникнет только в рантайме. Это выглядит странно, ведь enum Animal и enum Converter никак не связаны между собой.
Здесь дженерик выходит на сцену:
public abstract class EnumᐸE extends EnumᐸEᐳᐳ implements ComparableᐸEᐳ🔸 Добавляем параметр E, совместимый с классом
Enum
🔸 Используем E в интерфейсе Comparable
🔸 Компилируем enum Animal вpublic class Animal extends EnumᐸAnimalᐳ🔸 Теперь
Comparable использует тип Animal, и метод compareTo станет таким:public int compareTo(Animal o)✅ Убрали
instanceOf, код стал меньше и быстрее✅ При компиляции происходит проверка типов:
Animal zebra = Animal.ZEBRA;❌
Converter csv = Converter.CSV;
zebra.compareTo(csv); // не скомпилируется!Self-referential generic позволяет использовать дочерний тип в интерфейсах и методах родителя. Для некоторых кейсов этот приём здорово упрощает код и снижает количество ошибок. В следующем посте покажу ещё один пример использования.
Ответ на вопрос перед постом: self-referential generic помогает ограничить сравнение разных enum между собой.
Self-referential generic, часть 2
В прошлом посте мы выяснили, зачем self-referential generic нужен в
Дано: класс Delivery с информацией о доставке. Метод cancelled делает заказ недействительным. У класса есть наследник FastDelivery, в котором дополнительно хранится ID курьера:
🔸 Добавляем параметр в родителя
🔹 Метод create и его переопределение позволяют использовать поля, доступные в наследнике и вернуть нужный объект
🔹 Self-referential generic помогает вернуть нужный тип в методе cancelled
Готовый код доступен здесь
Резюме
Рассмотрите использование self-referential generic, когда
▫️ У вас есть иерархия
▫️ Родительский тип упоминается в аргументах или возвращаемом значении
Дополнительная типизация снизит количество кода, вытащит ошибки на этап компиляции и для некоторых случаев окажется очень изящным решением✨
В прошлом посте мы выяснили, зачем self-referential generic нужен в
Enum: для использования дочернего типа при реализации интерфейса родителя. Это довольно экзотичный кейс. Сегодня покажу более практичный пример, как дженерики облегчили работу с иерархией и неизменяемыми переменными.Дано: класс Delivery с информацией о доставке. Метод cancelled делает заказ недействительным. У класса есть наследник FastDelivery, в котором дополнительно хранится ID курьера:
class Delivery {
final long id;
final boolean isActive;
public Delivery(long id, boolean isActive) {…}
public Delivery cancelled() {
return new Delivery(this.id, false);
}
}
class FastDelivery extends Delivery {
private final long courierId;
public FastDelivery(…) {…}
public long getCourierId() {
return courierId;
}
}
Проблема: метод cancelled возвращает объект типа Delivery, и мы теряем информацию о курьере:FastDelivery fast = new FastDelivery(…);В такой ситуации помогут self-referential generic и небольшой обходной манёвр:
Delivery cancelled = fast.cancelled();
❌ long id = fast.getCourierId();
🔸 Добавляем параметр в родителя
public class DeliveryᐸT extends DeliveryᐸTᐳᐳ🔸 Создаём метод create, который возвращает нужный экземпляр
protected T create(long id, boolean isActive) {
return (T) new Delivery(id, isActive);
}
🔸 Используем этот метод в cancelledpublic T cancelled() {
return create(this.id, false);
}
🔸 Определяем параметр в наследникеpublic class FastDelivery extends DeliveryᐸFastDeliveryᐳ🔸 Переопределяем метод create в наследнике
protected FastDelivery create(long id, boolean isActive) {
return new FastDelivery(this.id, this.isActive, courierId);
}
Всё! Теперь информация не теряется:FastDelivery fast = new FastDelivery(…);Здесь используется комбо двух приёмов:
FastDelivery cancelled = fast.cancelled();
✅ long id = cancelled.getCourierId();
🔹 Метод create и его переопределение позволяют использовать поля, доступные в наследнике и вернуть нужный объект
🔹 Self-referential generic помогает вернуть нужный тип в методе cancelled
Готовый код доступен здесь
Резюме
Рассмотрите использование self-referential generic, когда
▫️ У вас есть иерархия
▫️ Родительский тип упоминается в аргументах или возвращаемом значении
Дополнительная типизация снизит количество кода, вытащит ошибки на этап компиляции и для некоторых случаев окажется очень изящным решением✨
Что подразумевается под Consistency в аббревиатуре ACID?
Anonymous Poll
63%
У данных, записанных в БД, нет противоречий
11%
Если значение записано в БД, его тут же можно прочитать с любого сервера
5%
Если значение записано в БД, его тут же можно прочитать с этого сервера
20%
Ограничения (constraints) выполняются в любой момент времени
Понятия в БД, часть 1. ACID
Когда я была беспечным джуниором, то представляла базу данных как всемогущий цилиндр. Записываешь туда что-то, а потом читаешь.
Но база данных — это обычная программа со своими сложностями и ограничениями. В следующих постах расскажу о принципах работы БД. Где на неё можно положиться, а где надо решать проблемы самому.
Есть популярный вопрос на собесах про свойства БД. Предполагается, что кандидат назовёт аббревиатуру ACID и cкажет 4 главных слова — ✨Atomicity, Consistency, Isolation, Durability✨ Сегодня и поговорим об этих прекрасных буквах.
Когда БД обозначена как ACID-compliant, ожидается:
🔸 A — Atomicity
Можно объединить несколько операций в одну транзакцию. Если произойдёт ошибка, уже сделанные операции в группе отменятся.
Благодаря этому можно не держать в коде несколько версий данных "на всякий случай" и восстанавливаться после ошибок гораздо проще
🔸 C — Consistency
Ограничения в БД (constraints) соблюдаются всегда и везде. Если две транзакции захотят записать одинаковые значения в UNIQUE колонку, одна транзакция завершится ошибкой.
На практике большинство проверок находятся в коде, поэтому у базы здесь мало работы
🔸 I — Isolation
Каждая транзакция выполняется так, как будто других транзакций не существует.
На практике внутри БД происходит лютая многопоточка, с одними структурами одновременно работают десятки и сотни транзакций.
Единственный способ надёжно изолировать транзакции друг от друга — запускать их последовательно. Это медленно, поэтому у БД есть менее строгие уровни изоляции. С ними база работает быстрее, но возможны аномалии в данных.
Важный момент: constaints для одной строки (CHECK, UNIQUE и тд) железно выполняются. Аномалии встречаются в транзакциях, где изменения состоят из нескольких шагов или меняются несколько строк.
Чтобы перевести 100 рублей с одного аккаунта на другой, нужно снять с первого аккаунта 100 рублей и добавить их на баланс второго. Целостность данных в середине процесса ненадолго нарушится. От уровня изоляции зависит, заметят ли это несоответствие другие транзакции.
Подробно поговорим об этом в следующем посте!
🔸 D — Durability
Если данные записаны в БД, они не потеряются. Здесь два пути:
▫️ Запись на носитель, например, жёсткий диск или SSD
▫️ Отправка копий на другие сервера
100% надёжности на тысячи лет не будет, но сохранность данных — наименее проблемный пункт из всех остальных
Резюме
ACID не даёт гарантий на уровне "записал и забыл". Целостность данных лежит на бизнес-логике, а в коде учитываются возможные ошибки неполной изоляции.
Поэтому сегодня ACID чаще встречается не в техническом описании, а в маркетинговых текстах рядом с цифровой трансформацией и дизайн-мышлением. Многие БД не берут на себя грех называться ACID-compliant, а используют более мягкую аббревиатуру BASE. Её тоже обсудим чуть позже✨
Когда я была беспечным джуниором, то представляла базу данных как всемогущий цилиндр. Записываешь туда что-то, а потом читаешь.
Но база данных — это обычная программа со своими сложностями и ограничениями. В следующих постах расскажу о принципах работы БД. Где на неё можно положиться, а где надо решать проблемы самому.
Есть популярный вопрос на собесах про свойства БД. Предполагается, что кандидат назовёт аббревиатуру ACID и cкажет 4 главных слова — ✨Atomicity, Consistency, Isolation, Durability✨ Сегодня и поговорим об этих прекрасных буквах.
Когда БД обозначена как ACID-compliant, ожидается:
🔸 A — Atomicity
Можно объединить несколько операций в одну транзакцию. Если произойдёт ошибка, уже сделанные операции в группе отменятся.
Благодаря этому можно не держать в коде несколько версий данных "на всякий случай" и восстанавливаться после ошибок гораздо проще
🔸 C — Consistency
Ограничения в БД (constraints) соблюдаются всегда и везде. Если две транзакции захотят записать одинаковые значения в UNIQUE колонку, одна транзакция завершится ошибкой.
На практике большинство проверок находятся в коде, поэтому у базы здесь мало работы
🔸 I — Isolation
Каждая транзакция выполняется так, как будто других транзакций не существует.
На практике внутри БД происходит лютая многопоточка, с одними структурами одновременно работают десятки и сотни транзакций.
Единственный способ надёжно изолировать транзакции друг от друга — запускать их последовательно. Это медленно, поэтому у БД есть менее строгие уровни изоляции. С ними база работает быстрее, но возможны аномалии в данных.
Важный момент: constaints для одной строки (CHECK, UNIQUE и тд) железно выполняются. Аномалии встречаются в транзакциях, где изменения состоят из нескольких шагов или меняются несколько строк.
Чтобы перевести 100 рублей с одного аккаунта на другой, нужно снять с первого аккаунта 100 рублей и добавить их на баланс второго. Целостность данных в середине процесса ненадолго нарушится. От уровня изоляции зависит, заметят ли это несоответствие другие транзакции.
Подробно поговорим об этом в следующем посте!
🔸 D — Durability
Если данные записаны в БД, они не потеряются. Здесь два пути:
▫️ Запись на носитель, например, жёсткий диск или SSD
▫️ Отправка копий на другие сервера
100% надёжности на тысячи лет не будет, но сохранность данных — наименее проблемный пункт из всех остальных
Резюме
ACID не даёт гарантий на уровне "записал и забыл". Целостность данных лежит на бизнес-логике, а в коде учитываются возможные ошибки неполной изоляции.
Поэтому сегодня ACID чаще встречается не в техническом описании, а в маркетинговых текстах рядом с цифровой трансформацией и дизайн-мышлением. Многие БД не берут на себя грех называться ACID-compliant, а используют более мягкую аббревиатуру BASE. Её тоже обсудим чуть позже✨
Ваня и Даша — брат и сестра, у каждого на счету 500р. Ваня перевёл Даше 100р. Банк делает это в рамках одной транзакции. Мама смотрит в приложении балансы и видит 400 и 500 рублей. Обновляет данные и видит 400 и 600. На каком уровне изоляции это возможно?
Anonymous Poll
6%
Ни на одном
66%
READ_UNCOMMITED
14%
READ_COMMITED
6%
REPETABLE_READ
3%
SERIALIZABLE
5%
На всех
Понятия в БД, часть 2. Уровни изоляции
Изоляция в ACID говорит: транзакция должна выполняется так, как будто других транзакций нет.
Единственный надёжный способ добиться этого — запускать транзакции последовательно. Это медленно, поэтому БД поддерживает менее строгие модели изоляции. База работает быстрее, но возможны аномалии данных.
В этом посте углубимся в детали: что за аномалии, что за уровни изоляции, и какие проблемы они решают.
Проблемы давно известны — dirty reads, write skews и тд. Чем больше проблем решает БД, тем больше кода нужно выполнить, и тем медленнее она работает. Уровни изоляции позволяют найти баланс между скоростью и корректностью.
В SQL стандарте их 4:
В стандарте SQL три основные проблемы:
🔸 Dirty reads — грязные чтения
Транзакция 1 обновляет поле Х. Другие транзакции видят новое значения Х до того, как транзакция 1 завершится.
В вопросе с переводом денег как раз возникла такая ситуация. Транзакция перевода ещё не завершилась, а другая транзакция прочитала промежуточные значения.
Проблема возникает только на уровне READ_UNCOMMITED.
🔸 Nonrepeatable reads — неповторяющиеся чтения
Транзакция 2 читает поле X и работает с ним. В это время транзакция 3 обновляет поле Х. В итоге транзакция 2 работает с устаревшим значением.
Более формально, "неповторяющееся чтение" означает, что чтение одного поля в начале и конце транзакции даёт разные результаты. Но редко кто читает одно поле дважды, на практике получается либо бесполезная транзакция с устаревшими данными, либо несогласованные данные внутри транзакции.
Проблема остро проявляется для долгих запросов, например, бэкапов или аналитики. Решается на уровне REPEATABLE_READ и выше.
🔸 Фантомные чтения
Транзакция 3 проверяет условие по большому количеству записей. Транзакция 4 меняет выборку, например, добавляет новую запись. Если условие в транзакции 3 перестанет выполнятся, транзакция 3 этого не заметит.
Важно, что условие касается не одного поля, а многих. В этом разница с неповторяющимся чтением. Там меняется одно конкретное поле, а в фантомном чтении меняется вся выборка, по которому проверяется условие.
Проблема решается на уровне SERIALIZABLE.
Подробные примеры и схемы аномалий есть в Википедии. У многих проблем есть вариации, поэтому аномалий получается больше, чем уровней изоляции.
Каждая БД сама решает, какие проблемы и вариации на каких уровнях решать. У MS SQL 5 уровней изоляции, у Oracle 3. Многие NoSQL базы не поддерживают транзакции, поэтому для них указывать тип изоляции бессмысленно. В универсальных адаптерах типа JDBC, Hibernate и Spring Data уровней столько, сколько в стандарте — 4.
Ещё одна проблема, которой нет в SQL стандарте, но которая встречается на практике:
🔸 Потерянный апдейт
Транзакции работают с одними данными и не учитывают друг друга.
Пример: транзакция 5 и транзакция 6 одновременно прочитали значение счётчика. Каждая транзакция прибавила к значению единицу и обновила поле счётчика. Вначале они прочитали одно значение, и получается, что один инкремент потерялся.
Проблема решается не только уровнями изоляции, но и SQL конструкциями:
🔹 Атомарный апдейт:
⭐️ Выбирать уровень изоляции с учётом вероятности и критичности проблем
⭐️ Уточнить в документации БД, какие проблемы решает выбранный уровень
⭐️ Писать код с учётом возможных аномалий
⭐️ Помнить о потерянных апдейтах
Изоляция в ACID говорит: транзакция должна выполняется так, как будто других транзакций нет.
Единственный надёжный способ добиться этого — запускать транзакции последовательно. Это медленно, поэтому БД поддерживает менее строгие модели изоляции. База работает быстрее, но возможны аномалии данных.
В этом посте углубимся в детали: что за аномалии, что за уровни изоляции, и какие проблемы они решают.
Проблемы давно известны — dirty reads, write skews и тд. Чем больше проблем решает БД, тем больше кода нужно выполнить, и тем медленнее она работает. Уровни изоляции позволяют найти баланс между скоростью и корректностью.
В SQL стандарте их 4:
▫️ READ_UNCOMMITEDКаждый уровень гарантирует решение чёткого списка проблем. Остальные решаются либо в коде сервиса, либо никак (если проблема не актуальна).
▫️ READ_COMMITED
▫️ REPEATABLE_READ
▫️ SERIALIZABLE
В стандарте SQL три основные проблемы:
🔸 Dirty reads — грязные чтения
Транзакция 1 обновляет поле Х. Другие транзакции видят новое значения Х до того, как транзакция 1 завершится.
В вопросе с переводом денег как раз возникла такая ситуация. Транзакция перевода ещё не завершилась, а другая транзакция прочитала промежуточные значения.
Проблема возникает только на уровне READ_UNCOMMITED.
🔸 Nonrepeatable reads — неповторяющиеся чтения
Транзакция 2 читает поле X и работает с ним. В это время транзакция 3 обновляет поле Х. В итоге транзакция 2 работает с устаревшим значением.
Более формально, "неповторяющееся чтение" означает, что чтение одного поля в начале и конце транзакции даёт разные результаты. Но редко кто читает одно поле дважды, на практике получается либо бесполезная транзакция с устаревшими данными, либо несогласованные данные внутри транзакции.
Проблема остро проявляется для долгих запросов, например, бэкапов или аналитики. Решается на уровне REPEATABLE_READ и выше.
🔸 Фантомные чтения
Транзакция 3 проверяет условие по большому количеству записей. Транзакция 4 меняет выборку, например, добавляет новую запись. Если условие в транзакции 3 перестанет выполнятся, транзакция 3 этого не заметит.
Важно, что условие касается не одного поля, а многих. В этом разница с неповторяющимся чтением. Там меняется одно конкретное поле, а в фантомном чтении меняется вся выборка, по которому проверяется условие.
Проблема решается на уровне SERIALIZABLE.
Подробные примеры и схемы аномалий есть в Википедии. У многих проблем есть вариации, поэтому аномалий получается больше, чем уровней изоляции.
Каждая БД сама решает, какие проблемы и вариации на каких уровнях решать. У MS SQL 5 уровней изоляции, у Oracle 3. Многие NoSQL базы не поддерживают транзакции, поэтому для них указывать тип изоляции бессмысленно. В универсальных адаптерах типа JDBC, Hibernate и Spring Data уровней столько, сколько в стандарте — 4.
Ещё одна проблема, которой нет в SQL стандарте, но которая встречается на практике:
🔸 Потерянный апдейт
Транзакции работают с одними данными и не учитывают друг друга.
Пример: транзакция 5 и транзакция 6 одновременно прочитали значение счётчика. Каждая транзакция прибавила к значению единицу и обновила поле счётчика. Вначале они прочитали одно значение, и получается, что один инкремент потерялся.
Проблема решается не только уровнями изоляции, но и SQL конструкциями:
🔹 Атомарный апдейт:
UPDATE test SET x=x-1 where id=1;🔹 Блокировка строки:
SELECT * FROM test WHERE id = 1 FOR UPDATE;Итого. Как учитывать внутрянку БД в написании кода:
⭐️ Выбирать уровень изоляции с учётом вероятности и критичности проблем
⭐️ Уточнить в документации БД, какие проблемы решает выбранный уровень
⭐️ Писать код с учётом возможных аномалий
⭐️ Помнить о потерянных апдейтах
Что означает Consistency в рамках CAP теоремы?
Anonymous Poll
51%
У данных, записанных в БД, нет противоречий
24%
Если значение записано в БД, его тут же можно прочитать с любого сервера
5%
Если значение записано в БД, его тут же можно прочитать с этого сервера
20%
Ограничения (constraints) выполняются в любой момент времени
Понятия в БД, часть 3. CAP, BASE, PACELC
Аббревиатура ACID появилась в 1983 году и относилась тогда к реляционным БД небольшого размера. В 2023 БД уже большие и распределённые. С ними связаны три понятия — CAP теорема, BASE и PACELC теорема. С ними и разберёмся в этом посте.
CAP теорема говорит, что распределённая система может обеспечить не больше двух гарантий из трёх:
🔸 Consistency — при каждом чтении читается последнее значение. Неважно, один сервер в системе или тысяча. Эта определение целостности отличается от определения в ACID
🔸 Availability — каждый запрос возвращает ответ
🔸 Partition tolerance — система продолжает работать несмотря на задержки в связи серверов и отказ некоторых из них
Речь идёт о распределённых системах, так что без Partition tolerance никак. Если во время запроса пропала связь между серверами, придётся делать выбор:
🤔 Отменить запрос. Это упор на консистенси — доступность снижается, зато ответ будет точным. Такие системы условно называют CP системами
🤔 Выполнить запрос без учёта данных с отвалившихся серверов. Такие системы часто называют AP системы
У целостности и доступности тоже есть градации:
▫️Доступность считается высокой от 90% до 99.999999%
▫️У целостности 15+ различных моделей
100% гарантий никто не даёт, и деление систем на СР и АР довольно условное. У большинства БД и брокеров можно настроить баланс между доступностью и целостностью для разных ситуаций.
Расширением CAP теоремы является теорема PACELC:
🔹 Если связь между серверами нарушается, придётся выбирать между целостностью данных и доступностью. Об этом говорится в CAP
🔹 При нормальной работе встаёт выбор между низкими задержками (Latency) и целостностью (Consistency). Чем чаще синхронизируются сервера, тем выше задержки и целостность данных
И ACID, и CAP теорема обещают больше, чем есть на деле. Более честен акроним BASE:
▪️ Basically Available — некоторые сервера могут быть недоступны, но в целом система работает
▪️ Soft state — некоторые данные могут не сразу попасть на другие сервера
▪️ Eventual consistency — но однажды точно попадут
Неопределённость, слабые гарантии — всё это реалии разработки распределённых систем.
Теперь ответ на вопрос перед постом. Термин "целостность" по-разному трактуется в ACID и CAP теореме. Грубо говоря:
▫️ ACID consistency — в данных нет аномалий
▫️ CAP consistency — данные на всех серверах одинаковые
Может быть ситуация, когда в БД выставлен уровень Serializable и отличная целостность по ACID, но так себе целостность по CAP, и сервера синхронизируются раз в час. Может быть и наоборот, и вообще в любых сочетаниях✨
Аббревиатура ACID появилась в 1983 году и относилась тогда к реляционным БД небольшого размера. В 2023 БД уже большие и распределённые. С ними связаны три понятия — CAP теорема, BASE и PACELC теорема. С ними и разберёмся в этом посте.
CAP теорема говорит, что распределённая система может обеспечить не больше двух гарантий из трёх:
🔸 Consistency — при каждом чтении читается последнее значение. Неважно, один сервер в системе или тысяча. Эта определение целостности отличается от определения в ACID
🔸 Availability — каждый запрос возвращает ответ
🔸 Partition tolerance — система продолжает работать несмотря на задержки в связи серверов и отказ некоторых из них
Речь идёт о распределённых системах, так что без Partition tolerance никак. Если во время запроса пропала связь между серверами, придётся делать выбор:
🤔 Отменить запрос. Это упор на консистенси — доступность снижается, зато ответ будет точным. Такие системы условно называют CP системами
🤔 Выполнить запрос без учёта данных с отвалившихся серверов. Такие системы часто называют AP системы
У целостности и доступности тоже есть градации:
▫️Доступность считается высокой от 90% до 99.999999%
▫️У целостности 15+ различных моделей
100% гарантий никто не даёт, и деление систем на СР и АР довольно условное. У большинства БД и брокеров можно настроить баланс между доступностью и целостностью для разных ситуаций.
Расширением CAP теоремы является теорема PACELC:
🔹 Если связь между серверами нарушается, придётся выбирать между целостностью данных и доступностью. Об этом говорится в CAP
🔹 При нормальной работе встаёт выбор между низкими задержками (Latency) и целостностью (Consistency). Чем чаще синхронизируются сервера, тем выше задержки и целостность данных
И ACID, и CAP теорема обещают больше, чем есть на деле. Более честен акроним BASE:
▪️ Basically Available — некоторые сервера могут быть недоступны, но в целом система работает
▪️ Soft state — некоторые данные могут не сразу попасть на другие сервера
▪️ Eventual consistency — но однажды точно попадут
Неопределённость, слабые гарантии — всё это реалии разработки распределённых систем.
Теперь ответ на вопрос перед постом. Термин "целостность" по-разному трактуется в ACID и CAP теореме. Грубо говоря:
▫️ ACID consistency — в данных нет аномалий
▫️ CAP consistency — данные на всех серверах одинаковые
Может быть ситуация, когда в БД выставлен уровень Serializable и отличная целостность по ACID, но так себе целостность по CAP, и сервера синхронизируются раз в час. Может быть и наоборот, и вообще в любых сочетаниях✨
Во многих системах к паролю добавляют последовательность символов или соль (salt). От какой атаки это помогает?
Anonymous Poll
12%
Злоумышленник узнал логин и перебирает популярные пароли на странице входа
13%
Пакет с паролем перехватывается на транспортном уровне
61%
Злоумышленник получил полный бэкап БД (в поле password хранится хэш пароля)
8%
Пользователь вводит логин и пароль на фишинговой странице логина
5%
Злоумышленник переписывает поле password