
Пароли: salt and pepper
Пароли пользователей нужно беречь. Для защиты используется целый комплекс мер: от безопасной передачи по сети до шифрования данных на уровне БД.
Сегодня поговорим о способе защиты, с которым может встретиться любой бэкендер — соли🧂. Обсудим, что это и зачем она нужна.
Начнём с основ. Почему нельзя хранить пароль как обычный текст?
🥷🏼 Любой человек с доступом к БД сделает select, запишет логин-пароль и никто об этом не узнает
🥷🏼 Злоумышленник найдёт бэкап БД и прочитает данные
Первый логичный шаг — хранить не сам пароль, а его хэш. Операция однонаправленная: проверить введённый пароль можно, а вот получить пароль из хэша нельзя.
Почему хэш — это недостаточно безопасно?
Злоумышленник может воспользоваться rainbow tables🌈. Это база, где хранятся миллиарды хэшей разных строк. Это не какой-то даркнет, есть много сайтов с таким функционалом. Например, этот.
И здесь на сцену выходит наш главный герой🦸♂️
Соль — это последовательность символов, которая добавляется к паролю перед рассчётом хэша:
Пароль:
Соль генерируется случайным образом, у каждого пользователя она своя. Может хранится вместе с паролем или в отдельном поле в БД.
🌶 Pepper
При доступе к БД можно прочитать и засоленный пароль, и саму соль. Восстановить исходный пароль сложно, но если очень хочется, то можно. Чтобы усилить защиту, используется вариация под названием pepper (или secret salt). В этом случае последовательность символов, которая добавляется к паролю, хранится не в БД, а в другом месте.
Spring Security
К счастью, Spring предлагает готовые энкодеры, которые упрощают манипуляции с солью:
🔸
🔸
Ответ на вопрос перед постом: соль помогает в случае, когда злоумышленник прочитал из базы поле password. Она снижает вероятность, что по хэшу можно восстановить исходный пароль.
Ставь огонёк, если пароли в твоей системе надёжно защищены🔥
Пароли пользователей нужно беречь. Для защиты используется целый комплекс мер: от безопасной передачи по сети до шифрования данных на уровне БД.
Сегодня поговорим о способе защиты, с которым может встретиться любой бэкендер — соли🧂. Обсудим, что это и зачем она нужна.
Начнём с основ. Почему нельзя хранить пароль как обычный текст?
🥷🏼 Любой человек с доступом к БД сделает select, запишет логин-пароль и никто об этом не узнает
🥷🏼 Злоумышленник найдёт бэкап БД и прочитает данные
Первый логичный шаг — хранить не сам пароль, а его хэш. Операция однонаправленная: проверить введённый пароль можно, а вот получить пароль из хэша нельзя.
Почему хэш — это недостаточно безопасно?
Злоумышленник может воспользоваться rainbow tables🌈. Это база, где хранятся миллиарды хэшей разных строк. Это не какой-то даркнет, есть много сайтов с таким функционалом. Например, этот.
И здесь на сцену выходит наш главный герой🦸♂️
Соль — это последовательность символов, которая добавляется к паролю перед рассчётом хэша:
Пароль:
qwerty
Соль: 34%$b
В БД записываем хэш от qwerty34%$b
Если злоумышленник узнал хэш пароля, вероятность, что этот хэш найдётся в rainbow table ощутимо снижается.Соль генерируется случайным образом, у каждого пользователя она своя. Может хранится вместе с паролем или в отдельном поле в БД.
🌶 Pepper
При доступе к БД можно прочитать и засоленный пароль, и саму соль. Восстановить исходный пароль сложно, но если очень хочется, то можно. Чтобы усилить защиту, используется вариация под названием pepper (или secret salt). В этом случае последовательность символов, которая добавляется к паролю, хранится не в БД, а в другом месте.
Spring Security
К счастью, Spring предлагает готовые энкодеры, которые упрощают манипуляции с солью:
🔸
BCryptPasswordEncoder
генерирует соль и хранит её в итоговой строке. Разработчику ничего делать не надо, всё работает само:)🔸
Pbkdf2PasswordEncoder
тоже сам разбирается с солью, плюс можно передать pepper в конструкторе объекта. Ответ на вопрос перед постом: соль помогает в случае, когда злоумышленник прочитал из базы поле password. Она снижает вероятность, что по хэшу можно восстановить исходный пароль.
Ставь огонёк, если пароли в твоей системе надёжно защищены🔥
{kind=link}
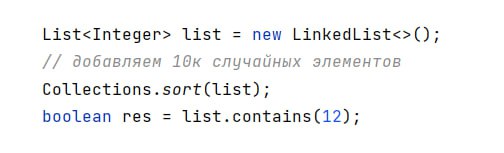
В LinkedList list добавили 10к элементов и отсортировали с помощью Collections.sort. Какая сложность будет у операции list.contains(12)?
Anonymous Poll
7%
O(1)
20%
О(log n)
68%
O(n)
4%
O(n^2)
Bloom filter
Прошлый пост получил нереальное количество огонёчков, было супер приятно, спасибо за реакции❤️
Сегодня начну серию постов "компутер саенс лайт".
Расскажу о структурах данных, которые используются в популярных библиотеках. Вряд ли вы будете писать их самостоятельно, но полезно понимать, зачем они нужны. Плюс это очень интересно:)
Первый участник — Bloom filter (фильтр Блума). Помогает узнать, есть элемент во множестве или нет.
❓ Зачем нужна отдельная структура, когда есть метод contains?
В LinkedList contains последовательно обходит коллекцию, даже если элементы отсортированы. Это долго, сложность такого подхода составляет O(n). В бинарном дереве contains выполнится быстрее, за O(log n).
Но есть ситуации, когда даже такой поиск нежелателен: данных очень много, они не отсортированы или хранятся на диске. В этих случаях проверка займёт уйму времени.
Здесь на помощь приходит Bloom filter — вероятностная структура данных для быстрого contains. Если фильтр вернул
▫️ true — элемент скорее всего есть. Но может и нет
▫️ false — элемента 100% нет
Более формально: это структура с возможным false positive ответом
Принцип работы
В основе лежит bitSet, набор битов. Возьмём для примера bitSet длиной 8:
☝️ Считаем хэш тремя разными функциями, получаем H1, H2, H3
✌️ Вычисляем индексы в bitSet. Берём остаток от деления H1, H2, H3 на 8. Пусть это будет 0, 2 и 3
💅 Обновляем соответствующие индексы в фильтре. Получится
Как проверить, был ли добавлен элемент в фильтр?
🔸 Считаем хэш элемента 3 функциями
🔸 Получаем 3 индекса и считываем биты
🔸 Если среди них хотя бы один 0, значит элемента в фильтре нет
Здесь можно поиграться и углубиться в детали.
Фильтры Блума активно используются в базах данных, роутерах, при проверке чёрных списков. Много примеров ищите здесь.
Готовая реализация
❓ Как возможны false positive результаты? Если фильтр вернул true, почему элемента Х может не быть?
Другие элементы могут занять индексы, которые используются для проверки элемента Х. Поэтому фильтр вернёт true, хотя Х не был добавлен.
❓ Как размер фильтра влияет на вероятность false positive ответов?
Чем больше размер фильтра, тем ниже шанс, что индексы элементов будут пересекаться. Вероятность false positive снижается, но увеличивается размер занятой памяти.
Прошлый пост получил нереальное количество огонёчков, было супер приятно, спасибо за реакции❤️
Сегодня начну серию постов "компутер саенс лайт".
Расскажу о структурах данных, которые используются в популярных библиотеках. Вряд ли вы будете писать их самостоятельно, но полезно понимать, зачем они нужны. Плюс это очень интересно:)
Первый участник — Bloom filter (фильтр Блума). Помогает узнать, есть элемент во множестве или нет.
❓ Зачем нужна отдельная структура, когда есть метод contains?
В LinkedList contains последовательно обходит коллекцию, даже если элементы отсортированы. Это долго, сложность такого подхода составляет O(n). В бинарном дереве contains выполнится быстрее, за O(log n).
Но есть ситуации, когда даже такой поиск нежелателен: данных очень много, они не отсортированы или хранятся на диске. В этих случаях проверка займёт уйму времени.
Здесь на помощь приходит Bloom filter — вероятностная структура данных для быстрого contains. Если фильтр вернул
▫️ true — элемент скорее всего есть. Но может и нет
▫️ false — элемента 100% нет
Более формально: это структура с возможным false positive ответом
Принцип работы
В основе лежит bitSet, набор битов. Возьмём для примера bitSet длиной 8:
00000000Чтобы добавить в фильтр элемент Х:
☝️ Считаем хэш тремя разными функциями, получаем H1, H2, H3
✌️ Вычисляем индексы в bitSet. Берём остаток от деления H1, H2, H3 на 8. Пусть это будет 0, 2 и 3
💅 Обновляем соответствующие индексы в фильтре. Получится
10110000
Повторяем для всех элементов списка/дерева/множества/etc.Как проверить, был ли добавлен элемент в фильтр?
🔸 Считаем хэш элемента 3 функциями
🔸 Получаем 3 индекса и считываем биты
🔸 Если среди них хотя бы один 0, значит элемента в фильтре нет
Здесь можно поиграться и углубиться в детали.
Фильтры Блума активно используются в базах данных, роутерах, при проверке чёрных списков. Много примеров ищите здесь.
Готовая реализация
BloomFilter есть в библиотеке Google Guavа.❓ Как возможны false positive результаты? Если фильтр вернул true, почему элемента Х может не быть?
Другие элементы могут занять индексы, которые используются для проверки элемента Х. Поэтому фильтр вернёт true, хотя Х не был добавлен.
❓ Как размер фильтра влияет на вероятность false positive ответов?
Чем больше размер фильтра, тем ниже шанс, что индексы элементов будут пересекаться. Вероятность false positive снижается, но увеличивается размер занятой памяти.
B-tree
Если жизнь занесёт вас в чтение материалов по БД, то с вероятностью 90% там встретится B-tree. Собственно, о нём сегодня и расскажу.
Обычное двоичное дерево подходит для данных, которые помещаются в оперативку. Тогда можно без проблем прыгать по дереву и быстро его перестраивать.
Ситуация меняется, если данных много, и они записываются на диск. Обращение к диску в тысячи раз медленнее, чем обращение к оперативке. Чтобы скорость работы осталась терпимой, нужно реже обращаться к диску и как следствие — меньше прыгать по дереву.
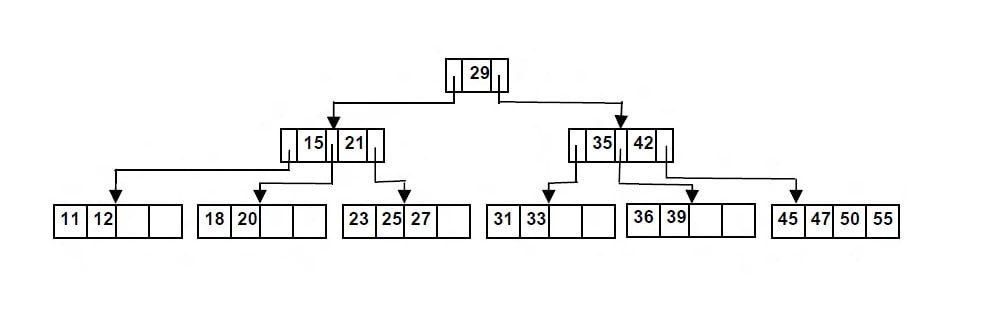
В долговременной памяти данные хранятся и читаются блоками по 4-8 Кб. Под размер блоков как раз и заточено B-tree: каждый узел занимает один блок и содержит сотни элементов. КПД чтения одного блока увеличивается, высота дерева уменьшается. Таким образом структура отлично работает в условиях, когда чтение — затратная операция.
Высота редко превышает 3. Дерево с высотой 4 вмещает до 256 TB данных!
Такая вот несложная структура, то что надо для пятницы:) Пример B-tree — на картинке внизу. Визуализация тут
Вариации:
🌴
🌲
❓ Что означает B?
Часто говорят, что B означает
Моя любимая версия, что B означает Boeing, потому что эту структуру придумали и описали в Boeing Research Labs. Но точно неизвестно, что значит B.
❓ Что ещё почитать на эту тему?
Информации выше вполне хватит обычному разработчику. Всё, что дальше — пугающе сложно:)
B-tree редко используются в одиночку. В индексах БД они работают в паре с
🔸 Bloom filter, чтобы не искать элементы, которых нет
🔸 Write ahead log (WAL), чтобы не потерять изменения во время перезаписи блока
🔸 Bitmap, чтобы следить за наполненностью блоков
Про работу B-tree в Postgre можно подробнее узнать в этой статье и с помощью библиотеки pageinspect.
Итого: B-tree пригодится для размещения данных, которые лежат на диске. В основном это индексы БД и файловые системы. Основная фишка — размер узла B-tree равен размеру блока на диске🌳
Если жизнь занесёт вас в чтение материалов по БД, то с вероятностью 90% там встретится B-tree. Собственно, о нём сегодня и расскажу.
Обычное двоичное дерево подходит для данных, которые помещаются в оперативку. Тогда можно без проблем прыгать по дереву и быстро его перестраивать.
Ситуация меняется, если данных много, и они записываются на диск. Обращение к диску в тысячи раз медленнее, чем обращение к оперативке. Чтобы скорость работы осталась терпимой, нужно реже обращаться к диску и как следствие — меньше прыгать по дереву.
В долговременной памяти данные хранятся и читаются блоками по 4-8 Кб. Под размер блоков как раз и заточено B-tree: каждый узел занимает один блок и содержит сотни элементов. КПД чтения одного блока увеличивается, высота дерева уменьшается. Таким образом структура отлично работает в условиях, когда чтение — затратная операция.
Высота редко превышает 3. Дерево с высотой 4 вмещает до 256 TB данных!
Такая вот несложная структура, то что надо для пятницы:) Пример B-tree — на картинке внизу. Визуализация тут
Вариации:
🌴
B+ tree: элементы хранятся только в листьях. В узел помещается больше ссылок, высота дерева уменьшается ещё больше. Конечные данные лежат рядом, поэтому последовательный доступ получается чуть быстрее🌲
B* tree: блоки заполняются экономнее, чем в классическом B-tree. Дерево занимает меньше памяти, но изменения выполняются дольше❓ Что означает B?
Часто говорят, что B означает
Balanced. Но другие деревья тоже балансируются, не только B-tree.Моя любимая версия, что B означает Boeing, потому что эту структуру придумали и описали в Boeing Research Labs. Но точно неизвестно, что значит B.
❓ Что ещё почитать на эту тему?
Информации выше вполне хватит обычному разработчику. Всё, что дальше — пугающе сложно:)
B-tree редко используются в одиночку. В индексах БД они работают в паре с
🔸 Bloom filter, чтобы не искать элементы, которых нет
🔸 Write ahead log (WAL), чтобы не потерять изменения во время перезаписи блока
🔸 Bitmap, чтобы следить за наполненностью блоков
Про работу B-tree в Postgre можно подробнее узнать в этой статье и с помощью библиотеки pageinspect.
Итого: B-tree пригодится для размещения данных, которые лежат на диске. В основном это индексы БД и файловые системы. Основная фишка — размер узла B-tree равен размеру блока на диске🌳
{kind=link}
ConcurrentSkipListSet - это …
Anonymous Poll
5%
Набор элементов, допускающий повторы
10%
Набор элементов без повторов
14%
Список, фильтрующий элементы по некоторому правилу, допускающий повторы
50%
Список, фильтрующий элементы по некоторому правилу, без повторов элементов
4%
Cортированный список, допускающий повторы
17%
Cортированный список без повторов
Skip List
Сегодня расскажу о структуре данных Skip List. Хочу сделать упор не на деталях реализации, а на том, зачем он нужен. И почему в java Skip List есть только в многопоточном варианте.
Кто вообще использует связные списки?
Давным-давно мы сравнивали
В большинстве энтерпрайзных задач
✅ В инфраструктурных задачах вставка в середину более актуальна.
✅ Многие структуры используют связный список косвенно: элементы ссылаются друг на друга для упрощения обхода или дополнительной сортировки.
Взять ту же
Самая проблемная операция
Как устроен Skip List
Чтобы искать элементы быстрее, добавляем для исходного списка несколько уровней со ссылками.
Пример — на картинке под постом. Чтобы найти пятёрку, движемся от верхнего уровня к нижнему.
В реальности на верхних уровнях промежутки больше, и мы быстрее приходим к нужному месту. В идеальном случае за O(log N).
❓ Это разве не дерево теперь?
Действительно, алгоритм поиска очень похож. Но чем Skip List отличается от дерева:
🔸 Балансировка
В деревьях очень строгие правила, при добавлении-удалении дерево часто перестраивается. Зато мы получаем высокую и стабильную скорость поиска.
В Skip List более расслабленный подход. Новый элемент добавляется в основной список, а вопрос с наличием ссылки на верхних уровнях решается через рандом.
В целом структура получается нормально сбалансированной. Одни элементы будут находиться быстрее, другие медленнее, в среднем время поиска стремится к O(log N).
🔸 Расположение элементов
В Skip List все элементы хранятся на нижнем уровне. Добавление-удаление происходит очень легко — надо переписать всего пару ссылок.
В дереве элементы находятся в узлах со строгой структурой. Вставка и удаление часто приводят к ребалансировке.
Резюме
✍️ Связные списки редко используются в энтерпрайзе, но часто в инфраструктуре (кэши, БД). Основной сценарий здесь — поиск. И сам по себе, и для работы с текущими значениями.
✍️ Дерево не всегда подойдёт, тк часто балансируется. В нагруженных системах лишняя суета ни к чему😑
✍️ Чтобы ускорить поиск в связном списке, добавляем дополнительные уровни. Получаем Skip List!
Сортированные структуры в JDK
В однопоточной среде для хранения сортированных элементов чаще используют
Поддерживать дерево в многопоточной среде сложно как раз из-за балансировки. Чтобы дерево безопасно сбалансировалось, лучше заблокировать его целиком, что снижает общую пропускную способность.
В многопоточной среде для той же задачи используется
Ответ на вопрос перед постом
Сегодня расскажу о структуре данных Skip List. Хочу сделать упор не на деталях реализации, а на том, зачем он нужен. И почему в java Skip List есть только в многопоточном варианте.
Кто вообще использует связные списки?
Давным-давно мы сравнивали
ArrayList (список на основе массива) и LinkedList (связный список). В большинстве энтерпрайзных задач
LinkedList проиграл. Вставка в середину редко встречается в бизнес-логике, в основном мы работаем со списком как с хранилищем данных. Но✅ В инфраструктурных задачах вставка в середину более актуальна.
SortedSet в Redis — сортированный список уникальных элементов. Элементы часто добавляются и удаляются из произвольных мест, логично взять за основу именно LinkedList. В очереди с приоритетами и secondary indexes тоже пригодится связный список.✅ Многие структуры используют связный список косвенно: элементы ссылаются друг на друга для упрощения обхода или дополнительной сортировки.
Взять ту же
LinkedHashMap из JDK — хэшмэп, в котором элементы связаны между собой в порядке добавления.Самая проблемная операция
LinkedList — поиск элемента. Даже в сортированном списке приходится ходить по ссылкам последовательно. Это долго.Как устроен Skip List
Чтобы искать элементы быстрее, добавляем для исходного списка несколько уровней со ссылками.
Пример — на картинке под постом. Чтобы найти пятёрку, движемся от верхнего уровня к нижнему.
В реальности на верхних уровнях промежутки больше, и мы быстрее приходим к нужному месту. В идеальном случае за O(log N).
❓ Это разве не дерево теперь?
Действительно, алгоритм поиска очень похож. Но чем Skip List отличается от дерева:
🔸 Балансировка
В деревьях очень строгие правила, при добавлении-удалении дерево часто перестраивается. Зато мы получаем высокую и стабильную скорость поиска.
В Skip List более расслабленный подход. Новый элемент добавляется в основной список, а вопрос с наличием ссылки на верхних уровнях решается через рандом.
В целом структура получается нормально сбалансированной. Одни элементы будут находиться быстрее, другие медленнее, в среднем время поиска стремится к O(log N).
🔸 Расположение элементов
В Skip List все элементы хранятся на нижнем уровне. Добавление-удаление происходит очень легко — надо переписать всего пару ссылок.
В дереве элементы находятся в узлах со строгой структурой. Вставка и удаление часто приводят к ребалансировке.
Резюме
✍️ Связные списки редко используются в энтерпрайзе, но часто в инфраструктуре (кэши, БД). Основной сценарий здесь — поиск. И сам по себе, и для работы с текущими значениями.
✍️ Дерево не всегда подойдёт, тк часто балансируется. В нагруженных системах лишняя суета ни к чему😑
✍️ Чтобы ускорить поиск в связном списке, добавляем дополнительные уровни. Получаем Skip List!
Сортированные структуры в JDK
В однопоточной среде для хранения сортированных элементов чаще используют
TreeMap/Set. Это красно-чёрное дерево. Балансируется при каждом изменении, поиск работает быстро и стабильно.Поддерживать дерево в многопоточной среде сложно как раз из-за балансировки. Чтобы дерево безопасно сбалансировалось, лучше заблокировать его целиком, что снижает общую пропускную способность.
В многопоточной среде для той же задачи используется
ConcurrentSkipListMap/Set. Изменения очень локальные: меняется несколько ссылок, а большая часть списка остаётся неизменной. Поэтому одновременно со структурой могут работать больше потоков.Ответ на вопрос перед постом
ConcurrentSkipListSet — сортированный список без повторов. Skip List — название базовой структуры данных, Set — признак уникальности элементов.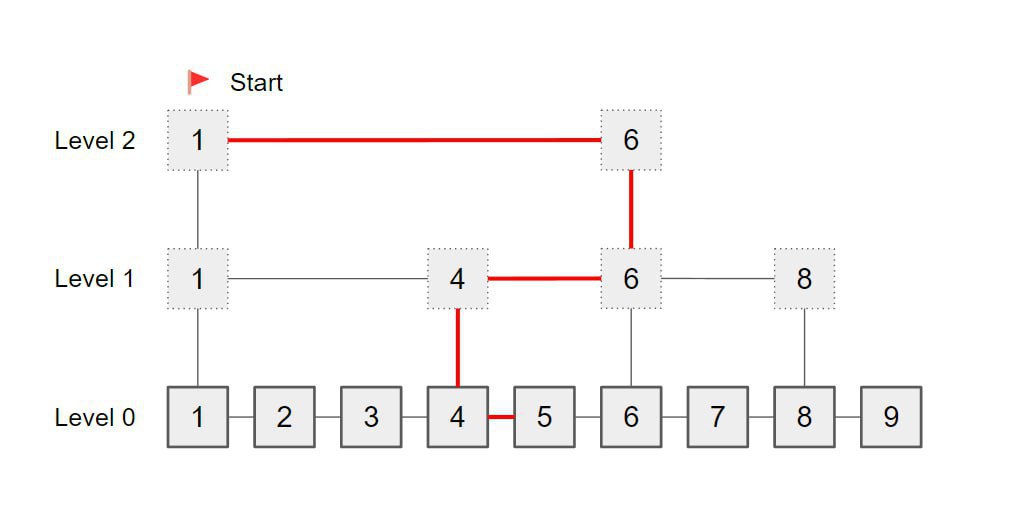{kind=link}
Разделение строк и велосипеды
Простой способ разделить строку на части — встроенный метод
Исходный код split выглядит как-то так:
Разделитель — один символ
Сразу видим fast path для разделителей из одного символа. Алгоритм в этом случае не использует регулярку и выполняется быстрее. Но проверка, что строка-разделитель является символом, занимает 10(!) строк.
🚲 Напишем свой split — изменим тип входных данных на char, чтобы проверку делал компилятор:
Разделитель — несколько символов
Также в глаза бросается работа с регуляркой, если разделитель состоит из нескольких символов. Компиляция регулярного выражения выполняется долго, для набора строк кажется разумным выполнить её один раз:
Насколько это поможет — проверим в бенчмарке.
С другой стороны, кажется, что регулярка — это слишком серьёзное решение. Если разделитель — двоеточие с пробелом, то мощь регулярного выражения здесь не нужна.
🚲 Поэтому напишем второй велосипед, который очень похож на первый. Будем искать в исходной строке подстроку-разделитель. По полученным индексам делить строку на части.
Оба велосипеда припаркованы тут: 🚲🚲
Оценим готовые решения
Библиотека Apache Commons предлагает метод split, но работает он чуть по-другому. Метод ищет только первый разделитель и делит строку максимум на две части:
Результаты
на картинке внизу. Результаты на разных железках могут отличаться.
🔸 Оба велосипеда в пух и прах разбили стандартный split.
К слову, это не первый велосипед, который выигрывает у JDK. Такое уже случалось при сравнение строк. Надо бы завести тикет по этим кейсам:)
🔸 Если строка делится только на две части — подойдёт split из Apache Commons
❗️Для нормальной нагрузки и однократного вызова подойдёт стандартный
Не могу не отметить, что хотя подобные задачи появляются редко, они приносят море удовольствия. Разобрать код в деталях, найти пути улучшения, и в итоге метод выполняется в 2 раза быстрее, красота😊
Простой способ разделить строку на части — встроенный метод
split:"123-456-789".split("-") → [123, 456, 789]
Сегодня разберём, насколько оптимально работает метод, и как написать код быстрее, чем JDK. Исходный код split выглядит как-то так:
public String[] split(String regex) {
if (разделитель — один символ)
пройтись по всем символам. Встречаем разделитель - извлекаем подстроку
} else {
Pattern.compile(regex).split(this)
}
Разберём обе ветки этого кодаРазделитель — один символ
Сразу видим fast path для разделителей из одного символа. Алгоритм в этом случае не использует регулярку и выполняется быстрее. Но проверка, что строка-разделитель является символом, занимает 10(!) строк.
🚲 Напишем свой split — изменим тип входных данных на char, чтобы проверку делал компилятор:
split(String regex) → split(char delim)Остальной код остаётся тем же. Мы только убрали лишние условия. Потом проверим, стало ли лучше:)
Разделитель — несколько символов
Также в глаза бросается работа с регуляркой, если разделитель состоит из нескольких символов. Компиляция регулярного выражения выполняется долго, для набора строк кажется разумным выполнить её один раз:
List<String> list = ……
❌ list.stream().map(s -> s.split(": "))…
✅ Pattern p = Pattern.compile(": ");
list.stream().map(s -> splitPattern.split(s))
Насколько это поможет — проверим в бенчмарке.
С другой стороны, кажется, что регулярка — это слишком серьёзное решение. Если разделитель — двоеточие с пробелом, то мощь регулярного выражения здесь не нужна.
🚲 Поэтому напишем второй велосипед, который очень похож на первый. Будем искать в исходной строке подстроку-разделитель. По полученным индексам делить строку на части.
Оба велосипеда припаркованы тут: 🚲🚲
Оценим готовые решения
Библиотека Apache Commons предлагает метод split, но работает он чуть по-другому. Метод ищет только первый разделитель и делит строку максимум на две части:
StringUtils.split("1-2-3", "-");
// получим 2 строки: "1" и "2-3"
Ставим минус за неспортивное поведение, но включаем метод в наши эксперименты.Результаты
на картинке внизу. Результаты на разных железках могут отличаться.
🔸 Оба велосипеда в пух и прах разбили стандартный split.
String#split слишком универсальный, и как любое универсальное решение, проигрывает кастомизированному. Если деление строк — ваш hot spot, не стесняйтесь написать свой метод. К слову, это не первый велосипед, который выигрывает у JDK. Такое уже случалось при сравнение строк. Надо бы завести тикет по этим кейсам:)
🔸 Если строка делится только на две части — подойдёт split из Apache Commons
❗️Для нормальной нагрузки и однократного вызова подойдёт стандартный
String#split. Оптимизации нужны, когда деление строк происходит очень часто. Не могу не отметить, что хотя подобные задачи появляются редко, они приносят море удовольствия. Разобрать код в деталях, найти пути улучшения, и в итоге метод выполняется в 2 раза быстрее, красота😊
{kind=link}
IDEA: live templates
Хейтеры говорят, что java многословная. Похоже, они пишут код в блокноте, потому что IDEA помогает писать код со скоростью мысли🚀
Есть две полезные фичи: live templates и code completion.
1️⃣ Live templates
Это по сути аббревиатуры для кода. Вводите 4 символа, нажимаете Enter, и они разворачиваются в 40!
🔸 Простые
▫️ St → String
▫️ sout
System.out.println();
▫️ main
Разворачиваются в методы с параметрами для автозаполнения. Перемещаться между полями можно через Tab:
▫️ fori
Есть для Java, Kotlin, JS, Groovy, для разработки под Android и React.
2️⃣ Code completion
Это дополнение имен на основе контекста.
🔸 Начните набирать начало класса/метода:
▫️ Int → Integer
▫️ Cust → Customer
🔸 Для классов наберите заглавные буквы:
▫️ NPE → NullPointerException
▫️ CHM → ConcurrentHashMap
🔸 Добавьте синтаксическую конструкцию:
▫️ count == 4.if
Хейтеры говорят, что java многословная. Похоже, они пишут код в блокноте, потому что IDEA помогает писать код со скоростью мысли🚀
Есть две полезные фичи: live templates и code completion.
1️⃣ Live templates
Это по сути аббревиатуры для кода. Вводите 4 символа, нажимаете Enter, и они разворачиваются в 40!
🔸 Простые
▫️ St → String
▫️ sout
System.out.println();
▫️ main
public static void main(String[] args) {}
▫️ prsfprivate static final🔸 Сложные
Разворачиваются в методы с параметрами для автозаполнения. Перемещаться между полями можно через Tab:
▫️ fori
for (int i=0; i< ; i++) {}
▫️ ifnif (args == null) {}
▫️ mxMath.max(, );▫️ lazy
if (obj == null)Полный список live templates: File → Settings→ Editor → Live Templates.
{ obj = new Integer(); }
Есть для Java, Kotlin, JS, Groovy, для разработки под Android и React.
2️⃣ Code completion
Это дополнение имен на основе контекста.
🔸 Начните набирать начало класса/метода:
▫️ Int → Integer
▫️ Cust → Customer
🔸 Для классов наберите заглавные буквы:
▫️ NPE → NullPointerException
▫️ CHM → ConcurrentHashMap
🔸 Добавьте синтаксическую конструкцию:
▫️ count == 4.if
if (count == 4) {}
▫️ list.forfor(Integer i : list) {}
▫️ obj.optOptional.of(obj)▫️ answer.switch
switch (answer) {}
Полный список: File → Settings → Editor → General → Postfix Completion. Есть варианты для Java, Kotlin и JS.12 factor app: кодовая база
12 factor app — чеклист из 12 пунктов для адаптации сервиса к облаку.
Список появился в 2017 году, и был модным года до 20. Упоминание 12 факторов на собеседовании производило вау-эффект и приводило интервьюеров в восторг:)
Большинство идей до сих пор актуальны. Но
🤔 Оригинальный текст очень формальный, иногда это просто набор терминов и процессов. Не написано, в чём смысл, и какая проблема решается. Когда цель непонятна, работа превращается в карго культ или бесполезные движения
🤔 Не всегда понятны конкретные шаги. Иногда это "делайте хорошо, плохо не делайте"
🤔 Некоторые рекомендации в оригинальном тексте слишком жёсткие или устарели
Так что потихоньку пройдусь по всем пунктам, объясню суть и дам более актуальные рекомендации, чем в оригинале.
Первый пункт посвящён работе с кодовой базой и звучит так: one codebase tracked in revision control, many deploys
Приложение полностью отслеживается системой контроля версий.
Экземпляр запущенного приложения называется deploy. Неважно, где он запущен — в проде, локально у разработчика или в тестовой среде. Хотя в жизни чаще используются другие термины (билд, артефакт или просто сервис), дальше буду использовать оригинальный термин.
🔸 У каждого сервиса своя кодовая база в одном репозитории.
🔸 У разных приложений разные кодовые базы. Общий код выделяется в библиотеку/модуль и импортируется через менеджер зависимостей.
🔸 У каждого приложения одна кодовая база, но на разных средах могут использоваться разные версии. Например, локально у разработчика запускается ветка с фичей, тестировщик работает с мастером, на проде разворачивается релизная ветка.
В чем смысл ограничений: если продакшн использует одну кодовую базу, а разработка и тестирование — немного другую, однажды появится ошибка, которая воспроизведётся только на продакшене.
На практике вполне нормально, что для разных сред код работает по-разному. Обычно изменения касаются внешних компонентов.
Яркий пример — платёжная система. Работать с настоящими деньгами — непозволительная роскошь, поэтому для разработки и тестирования используются либо заглушки, либо специальные песочницы.
Как проверить приложение:
✅ В коде нет условий вроде
✅ Общие модули импортируются через менеджер зависимостей — Maven или Gradle
✅ Финальный этап тестирования происходит на версии, которая потом отправится в продакшн
12 factor app — чеклист из 12 пунктов для адаптации сервиса к облаку.
Список появился в 2017 году, и был модным года до 20. Упоминание 12 факторов на собеседовании производило вау-эффект и приводило интервьюеров в восторг:)
Большинство идей до сих пор актуальны. Но
🤔 Оригинальный текст очень формальный, иногда это просто набор терминов и процессов. Не написано, в чём смысл, и какая проблема решается. Когда цель непонятна, работа превращается в карго культ или бесполезные движения
🤔 Не всегда понятны конкретные шаги. Иногда это "делайте хорошо, плохо не делайте"
🤔 Некоторые рекомендации в оригинальном тексте слишком жёсткие или устарели
Так что потихоньку пройдусь по всем пунктам, объясню суть и дам более актуальные рекомендации, чем в оригинале.
Первый пункт посвящён работе с кодовой базой и звучит так: one codebase tracked in revision control, many deploys
Приложение полностью отслеживается системой контроля версий.
Экземпляр запущенного приложения называется deploy. Неважно, где он запущен — в проде, локально у разработчика или в тестовой среде. Хотя в жизни чаще используются другие термины (билд, артефакт или просто сервис), дальше буду использовать оригинальный термин.
🔸 У каждого сервиса своя кодовая база в одном репозитории.
🔸 У разных приложений разные кодовые базы. Общий код выделяется в библиотеку/модуль и импортируется через менеджер зависимостей.
🔸 У каждого приложения одна кодовая база, но на разных средах могут использоваться разные версии. Например, локально у разработчика запускается ветка с фичей, тестировщик работает с мастером, на проде разворачивается релизная ветка.
В чем смысл ограничений: если продакшн использует одну кодовую базу, а разработка и тестирование — немного другую, однажды появится ошибка, которая воспроизведётся только на продакшене.
На практике вполне нормально, что для разных сред код работает по-разному. Обычно изменения касаются внешних компонентов.
Яркий пример — платёжная система. Работать с настоящими деньгами — непозволительная роскошь, поэтому для разработки и тестирования используются либо заглушки, либо специальные песочницы.
Как проверить приложение:
✅ В коде нет условий вроде
if (env == dev). Переключение между заглушками и настоящими системами происходит через конфиг✅ Общие модули импортируются через менеджер зависимостей — Maven или Gradle
✅ Финальный этап тестирования происходит на версии, которая потом отправится в продакшн
12 factor app: зависимости
Продолжаем разбирать признаки здорового сервиса. Второй пункт рекомендует
Для java приложений нужные модули и библиотеки описываются в pom.xml или build.gradle файле. Тогда приложение будет собираться на любой среде, где есть среда исполнения и установленный менеджер зависимостей. Не будет проблем с локальной разработкой и настройкой CI.
Dependency isolation часто пропускают при обсуждении 12 факторов, потому что непонятно, что это такое:) Оригинальный текст и правда звучит туманно: ☁️no implicit dependencies “leak in” from the surrounding system☁️
Вообще это означает, что версия каждой зависимости должна быть чётко определена.
Альтернатива — опция latest для Docker образов и gradle зависимостей.
Почему это не ок? Допустим, приложение использует библиотеку Х версии 1 во время разработки и всех стадий тестирования. Затем у библиотеки Х выходит версия 2, которая использует другое API. Вторая версия подтягивается во время релиза, и продакшн погружается во мрак🌑
Таких сюрпризов не будет, если обозначить версию явно
🔹 в pom/build файле проекта
🔹 в BOM файле
🔹 в родительском pom/build
В большинстве компаний используются специальные инструменты для работы с зависимостями — Artifactory или Nexus. Они нужны, чтобы
🔸 хранить приватные артефакты — корпоративные модули или библиотеки
🔸 кэшировать библиотеки, чтобы экономить трафик
🔸 использовать проверенные службой безопасности артефакты
При использовании Artifactory/Nexus конфликты версий случаются редко. Но есть и обратная сторона: апгрейд библиотеки превращается в увлекательное бюрократическое приключение:)
Как проверить приложение:
✅ Для сборки проекта достаточно команды maven/gradle
✅ Для всех сред используется один pom/build файл
✅ Если в компании используется Artifactory или Nexus, не добавляйте явно другие репозитории
12 factor app — классный документ, он объединяет важные моменты, которые часто остаются в стороне. Работа с зависимостями, кодовой базой и остальные 10 пунктов — это БАЗА. Обычно она описана в недрах Confluence или передаётся из уст в уста:)
Объединить все важные знания в один документ — прекрасная идея, а для нас — отличный способ закрыть возможные пробелы🧡
Продолжаем разбирать признаки здорового сервиса. Второй пункт рекомендует
Explicitly declare and isolate dependenciesРазберём его подробнее.
Для java приложений нужные модули и библиотеки описываются в pom.xml или build.gradle файле. Тогда приложение будет собираться на любой среде, где есть среда исполнения и установленный менеджер зависимостей. Не будет проблем с локальной разработкой и настройкой CI.
Dependency isolation часто пропускают при обсуждении 12 факторов, потому что непонятно, что это такое:) Оригинальный текст и правда звучит туманно: ☁️no implicit dependencies “leak in” from the surrounding system☁️
Вообще это означает, что версия каждой зависимости должна быть чётко определена.
Альтернатива — опция latest для Docker образов и gradle зависимостей.
Почему это не ок? Допустим, приложение использует библиотеку Х версии 1 во время разработки и всех стадий тестирования. Затем у библиотеки Х выходит версия 2, которая использует другое API. Вторая версия подтягивается во время релиза, и продакшн погружается во мрак🌑
Таких сюрпризов не будет, если обозначить версию явно
🔹 в pom/build файле проекта
🔹 в BOM файле
🔹 в родительском pom/build
В большинстве компаний используются специальные инструменты для работы с зависимостями — Artifactory или Nexus. Они нужны, чтобы
🔸 хранить приватные артефакты — корпоративные модули или библиотеки
🔸 кэшировать библиотеки, чтобы экономить трафик
🔸 использовать проверенные службой безопасности артефакты
При использовании Artifactory/Nexus конфликты версий случаются редко. Но есть и обратная сторона: апгрейд библиотеки превращается в увлекательное бюрократическое приключение:)
Как проверить приложение:
✅ Для сборки проекта достаточно команды maven/gradle
✅ Для всех сред используется один pom/build файл
✅ Если в компании используется Artifactory или Nexus, не добавляйте явно другие репозитории
12 factor app — классный документ, он объединяет важные моменты, которые часто остаются в стороне. Работа с зависимостями, кодовой базой и остальные 10 пунктов — это БАЗА. Обычно она описана в недрах Confluence или передаётся из уст в уста:)
Объединить все важные знания в один документ — прекрасная идея, а для нас — отличный способ закрыть возможные пробелы🧡
Пользовались уже ChatGPT для работы? Как впечатления?
Anonymous Poll
17%
Использую часто, нравится
27%
Попробовал пару раз, было полезно
17%
Использовал, но не впечатлился
39%
Нет ещё
ChatGPT внутри IDEA
Общаться с нейросетью через текстовое окошко — популярная форма работы с ChatGPT, но не единственная.
Я попробовала 3 варианта интеграции нейросетей с IDEA:
▫️ AI Assistant от Jetbrains
▫️ Самый популярный плагин на основе ChatGPT — EasyCode
▫️ Помощника от Amazon — CodeWhisperer
В этом посте поделюсь впечатлениями!
🤖 AI Assistant от JetBrains
Полноценный assistant пока не вышел в релиз и доступен только в билде 2023.2 EAP 6 (скачивается отдельно). Альтернатива — подключить плагин AI Assistant, работает только для IDEA Ultimate.
Основные фичи:
✅ Пообщаться с нейросетью
в отдельной вкладке, не выходя из IDE. Сейчас это прокси к ChatGPT, в будущем появится больше моделей
✅ Узнать, что делает выделенный код, возможные проблемы и варианты рефакторинга
Здесь пока нет вау-эффекта. Объяснение получается слишком длинным, рефакторинг и поиск проблем работают только для простых случаев. Но уверена, что эти фичи будут развиваться
🔥 Написать документацию
Пока моя любимая фича. Набираете перед методом
✅ Написать сообщение для коммита
При коммите появляется кнопка ✨ (без шуток, так и выглядит). ИИ описывает изменения в стиле: "в классе А добавился метод B, в классе C изменилась реализация метода D". Очень многословно, пока not recommend
🤖 Плагин ChatGPT - EasyCode
Самый популярный плагин по работе с ChatGPT. Лучший вариант, если у вас IDEA Community, и хочется попробовать ИИ прямо сейчас. Основные фичи такие же, как в AI Assistant:
✅ Окошко для общения
✅ Получить объяснение, что делает выделенный код
✅ Узнать варианты рефакторинга
Но есть кое-что, чего в у JetBrains пока нет: опция Write Unit Tests🔥
Тесты ужасно примитивные, но идея чудесная! Возлагаю на этот функционал большие надежды
🤖 CodeWhisperer от Amazon
Не самый известный вариант, но самый интригующий. Амазон пишет, что натренировал модель на огромном количестве кода, и контрольная группа увеличила productivity на десятки процентов.
Установить CodeWhisperer чуть сложнее, чем предыдущие варианты: поставить плагин AWS Toolkit, зарегистрироваться и привязать учётку к IDEA.
Название CodeWhisperer очень точно отображает поведение. В предыдущих плагинах надо явно спрашивать совет у ИИ, а здесь помощник шепчет рекомендации, даже если не просишь. Причём они появляются не в отдельном месте, а сразу в коде призрачным шрифтом.
Меня это бесит, но формат real-time рекомендаций выглядит круто. В менее навязчивой форме будет вообще отлично💛
Другие фичи:
✅ Поиск OWASP уязвимостей в коде + идеи по исправлению
✅ Посмотреть похожий код в open-source проекте
По этим функциям ничего сказать не могу. В моём проекте не оказалось уязвимостей и не нашлось кода, похожего на open-source проекты. Но звучит интересно.
Что не понравилось:
😒 Нет окошка "просто спросить". Можно попросить написать код в самом классе, но без диалога и дальнейших уточнений
😒 Нет кнопок с базовыми действиями вроде "сгенерировать документацию". Все запросы надо писать целиком и самостоятельно
😒 Неудобный интерфейс и мутная документация
Хотелось удалить помощник через 5 минут после использования. Непонятно, какие ключевые слова использовать, что за странные кнопки со стрелками, неудобно смотреть предложенные варианты. В документации никаких примеров.
CodeWhisperer выглядит как сырой продукт, но очень аутентичный.
Общее впечатление
Интеграция ИИ в IDE делает первые робкие шаги. Мне понравилась генерация документации, за остальным пока буду наблюдать со стороны:)
Для ваших задач выводы могут отличаться. Попробуйте сами, все инструменты в посте — бесплатные, а установка не занимает много времени🔥
Общаться с нейросетью через текстовое окошко — популярная форма работы с ChatGPT, но не единственная.
Я попробовала 3 варианта интеграции нейросетей с IDEA:
▫️ AI Assistant от Jetbrains
▫️ Самый популярный плагин на основе ChatGPT — EasyCode
▫️ Помощника от Amazon — CodeWhisperer
В этом посте поделюсь впечатлениями!
🤖 AI Assistant от JetBrains
Полноценный assistant пока не вышел в релиз и доступен только в билде 2023.2 EAP 6 (скачивается отдельно). Альтернатива — подключить плагин AI Assistant, работает только для IDEA Ultimate.
Основные фичи:
✅ Пообщаться с нейросетью
в отдельной вкладке, не выходя из IDE. Сейчас это прокси к ChatGPT, в будущем появится больше моделей
✅ Узнать, что делает выделенный код, возможные проблемы и варианты рефакторинга
Здесь пока нет вау-эффекта. Объяснение получается слишком длинным, рефакторинг и поиск проблем работают только для простых случаев. Но уверена, что эти фичи будут развиваться
🔥 Написать документацию
Пока моя любимая фича. Набираете перед методом
/**, появляется кнопка Suggest documentation. Классно заполняется краткое описание и смысл входных-выходных параметров. Требует немного правок, но здорово экономит время!✅ Написать сообщение для коммита
При коммите появляется кнопка ✨ (без шуток, так и выглядит). ИИ описывает изменения в стиле: "в классе А добавился метод B, в классе C изменилась реализация метода D". Очень многословно, пока not recommend
🤖 Плагин ChatGPT - EasyCode
Самый популярный плагин по работе с ChatGPT. Лучший вариант, если у вас IDEA Community, и хочется попробовать ИИ прямо сейчас. Основные фичи такие же, как в AI Assistant:
✅ Окошко для общения
✅ Получить объяснение, что делает выделенный код
✅ Узнать варианты рефакторинга
Но есть кое-что, чего в у JetBrains пока нет: опция Write Unit Tests🔥
Тесты ужасно примитивные, но идея чудесная! Возлагаю на этот функционал большие надежды
🤖 CodeWhisperer от Amazon
Не самый известный вариант, но самый интригующий. Амазон пишет, что натренировал модель на огромном количестве кода, и контрольная группа увеличила productivity на десятки процентов.
Установить CodeWhisperer чуть сложнее, чем предыдущие варианты: поставить плагин AWS Toolkit, зарегистрироваться и привязать учётку к IDEA.
Название CodeWhisperer очень точно отображает поведение. В предыдущих плагинах надо явно спрашивать совет у ИИ, а здесь помощник шепчет рекомендации, даже если не просишь. Причём они появляются не в отдельном месте, а сразу в коде призрачным шрифтом.
Меня это бесит, но формат real-time рекомендаций выглядит круто. В менее навязчивой форме будет вообще отлично💛
Другие фичи:
✅ Поиск OWASP уязвимостей в коде + идеи по исправлению
✅ Посмотреть похожий код в open-source проекте
По этим функциям ничего сказать не могу. В моём проекте не оказалось уязвимостей и не нашлось кода, похожего на open-source проекты. Но звучит интересно.
Что не понравилось:
😒 Нет окошка "просто спросить". Можно попросить написать код в самом классе, но без диалога и дальнейших уточнений
😒 Нет кнопок с базовыми действиями вроде "сгенерировать документацию". Все запросы надо писать целиком и самостоятельно
😒 Неудобный интерфейс и мутная документация
Хотелось удалить помощник через 5 минут после использования. Непонятно, какие ключевые слова использовать, что за странные кнопки со стрелками, неудобно смотреть предложенные варианты. В документации никаких примеров.
CodeWhisperer выглядит как сырой продукт, но очень аутентичный.
Общее впечатление
Интеграция ИИ в IDE делает первые робкие шаги. Мне понравилась генерация документации, за остальным пока буду наблюдать со стороны:)
Для ваших задач выводы могут отличаться. Попробуйте сами, все инструменты в посте — бесплатные, а установка не занимает много времени🔥
12 factor app: конфиг
Где хранить конфиги? На каком этапе передать их приложению?
Эти вопросы обсуждаются в третьем пункте 12 factor app, который звучит как
Store config in the environment
Разберём, что это значит:)
Конфигурация — это всё, чем отличаются запущенные приложения на разных средах. Например,
✅ Адреса, логины, пароли, токены внешних сервисов
✅ Специфичные значения для конкретного сервиса: имя хоста, порт
✅ Управляющие параметры: имя профайла, флажки и прочие свойства
Не являются конфигом:
❌ Классы спринга с аннотацией @Configuration. Это описание компонентов и связей, часть исходного кода
❌ Описания и состав профайлов. В спринге это аннотация @Profile. Причина та же: профайлы описаны в кодовой базе, которая не меняется. Но вот параметр, который задаёт, какой именно профайл нужен — это конфиг
Не конфиг:
Где хранить конфиги?
Оригинальный документ категоричен: конфиг должен передаваться через environment переменные, а конфиг-файлы не должны существовать. Потому что:
🔸 Рано или поздно сервис с продакшн конфигами попадёт в лапки разработчиков, и они сделают delete table users
🔸 Файлы с конфигами расползаются по всей системе, это небезопасно и сложно в управлении
🔸 Environment переменные не зависят от ОС, фреймворка и языка разработки
Мотивация понятна, но на практике всё работает не так:) Конфиги группируются в файлы, а в гите часто хранится дефолтный файлик для разработки.
Конфиги могут лежать в другом сервисе, например, в Kubernetes, Zookeeper или даже в HashiCorp Vault. Последний поддерживает версионирование и следит, кто и когда запрашивал данные.
Для ежедневной разработки есть следующие best practices:
✅ В параметрах конфига нет префикса среды выполнения, а в коде — логики по их разделению:
Кажется, что это само собой разумеется, но нет:) В 2020 году утекли личные данные 243 миллионов бразильцев, потому что пароль БД был записан константой в исходном коде сервиса минздрава. А согласно этому исследованию более 100к GitHub репозиториев содержат токены и криптографические ключи прямо в исходном коде. Будем надеяться, что это всё pet проекты, которые нигде не используются🤞
Где хранить конфиги? На каком этапе передать их приложению?
Эти вопросы обсуждаются в третьем пункте 12 factor app, который звучит как
Store config in the environment
Разберём, что это значит:)
Конфигурация — это всё, чем отличаются запущенные приложения на разных средах. Например,
✅ Адреса, логины, пароли, токены внешних сервисов
✅ Специфичные значения для конкретного сервиса: имя хоста, порт
✅ Управляющие параметры: имя профайла, флажки и прочие свойства
Не являются конфигом:
❌ Классы спринга с аннотацией @Configuration. Это описание компонентов и связей, часть исходного кода
❌ Описания и состав профайлов. В спринге это аннотация @Profile. Причина та же: профайлы описаны в кодовой базе, которая не меняется. Но вот параметр, который задаёт, какой именно профайл нужен — это конфиг
Не конфиг:
@ConfigurationА вот это конфиг:
@Profile(”dev”)
public class DBConfiguration {…}
-Dspring.profiles.active=devЗадача разработчика простая: отделить конфигурацию от основного кода. Тогда приложение легко запустить и настроить на работу в разных средах.
Где хранить конфиги?
Оригинальный документ категоричен: конфиг должен передаваться через environment переменные, а конфиг-файлы не должны существовать. Потому что:
🔸 Рано или поздно сервис с продакшн конфигами попадёт в лапки разработчиков, и они сделают delete table users
🔸 Файлы с конфигами расползаются по всей системе, это небезопасно и сложно в управлении
🔸 Environment переменные не зависят от ОС, фреймворка и языка разработки
Мотивация понятна, но на практике всё работает не так:) Конфиги группируются в файлы, а в гите часто хранится дефолтный файлик для разработки.
Конфиги могут лежать в другом сервисе, например, в Kubernetes, Zookeeper или даже в HashiCorp Vault. Последний поддерживает версионирование и следит, кто и когда запрашивал данные.
Для ежедневной разработки есть следующие best practices:
✅ В параметрах конфига нет префикса среды выполнения, а в коде — логики по их разделению:
❌ @Value("dev.datasource")
✔️ @Value("datasource")
✅ В коде нет констант вроде "8080", "admin", имён хостов, логинов и паролейКажется, что это само собой разумеется, но нет:) В 2020 году утекли личные данные 243 миллионов бразильцев, потому что пароль БД был записан константой в исходном коде сервиса минздрава. А согласно этому исследованию более 100к GitHub репозиториев содержат токены и криптографические ключи прямо в исходном коде. Будем надеяться, что это всё pet проекты, которые нигде не используются🤞
Java 21: sequenced collections
или "фича, которая опоздала на 25 лет".
19 сентября выходит java 21, и среди прочего там будет JEP 431: Sequenced Collections.
В чём суть изменений?
В JDK добавится новый интерфейс
♨️ Пример 1: получить последний элемент в списке
Сейчас это так:
Сейчас это так:
В java 21 всё гораздо проще:
♨️ Пример 3: обойти LinkedHashSet
LinkedHashSet — список с уникальными элементами. Хотя это список, класс реализует только интерфейс Set. Поэтому работы с индексами нет вообще.
Получить первый элемент ещё можно:
В java 21 те же операции выполняются легко и просто:
В java 21 появится интерфейс SequencedCollection с методами
▫️
Новые методы появятся в
Было бы здорово увидеть эти методы 25 лет назад, но лучше поздно, чем никогда:)
или "фича, которая опоздала на 25 лет".
19 сентября выходит java 21, и среди прочего там будет JEP 431: Sequenced Collections.
В чём суть изменений?
В JDK добавится новый интерфейс
SequencedCollection. В него войдут методы, которые должны были появиться в джаве ещё в 98 году. Простые операции, для которых каждый раз пишется маленький велосипедик🚲♨️ Пример 1: получить последний элемент в списке
Сейчас это так:
last = list.get(list.size() - 1);
В java 21 наконец-то появится специальный метод: last = list.getLast();♨️ Пример 2: пройти список в обратном порядке
Сейчас это так:
for(int i=list.size(); i>0; i--){
int value = list.get(i));
}
Выглядит жутко. Альтернатива — использовать Collections.reverse:List<Integer> reversed = new ArrayList<>(list);Выглядит симпатичнее, но здесь море лишних действий: создаём новую(!) коллекцию, переставляем её элементы и только потом делаем обход.
Collections.reverse(reversed);
reversed.forEach(…);
В java 21 всё гораздо проще:
list.reversed().forEach(…)Метод
reversed не меняет исходную коллекцию и возвращает view с обратным порядком обхода.♨️ Пример 3: обойти LinkedHashSet
LinkedHashSet — список с уникальными элементами. Хотя это список, класс реализует только интерфейс Set. Поэтому работы с индексами нет вообще.
Получить первый элемент ещё можно:
first = linkedHashSet.iterator().next();А вот последний — никак, надо полностью обходить структуру. Код писать не буду, слишком громоздкий.
В java 21 те же операции выполняются легко и просто:
first = linkedHashSet.getFirst();Резюме
last = linkedHashSet.getLast();
В java 21 появится интерфейс SequencedCollection с методами
▫️
SequencedCollection<E> reversed()
▫️ void addFirst(E)
▫️ void addLast(E)
▫️ E getFirst()
▫️ E getLast()
▫️ E removeFirst()
▫️ E removeLast()
Плюс интерфейсы SequencedSet и SequencedMap с тем же функционалом.Новые методы появятся в
ArrayList, LinkedList, HashSet, LinkedHashMap, LinkedHashSet, частично в TreeSet и некоторых других классах.Было бы здорово увидеть эти методы 25 лет назад, но лучше поздно, чем никогда:)
Как я провалила курс по спрингу
В декабре прошлого года я проводила адвент-календарь по java. 21 день почти тысяча человек разбирали нюансы java core. В конце я спросила: какую тему ещё разобрать, где есть непонятки? Ответ был почти единогласным — Spring.
И я поставила цель на 2023 — сделать что-нибудь полезное по спрингу. Не для начинающих, с практическими фишками и лучшими практиками.
За 8 месяцев так ничего и не сделала😞
Я не склонна к самобичеванию, и попробовала разобраться, почему так получилось. Ответ лежал на поверхности.
Все силы идут на курс по многопоточке. Чуть появляется свободное время — бегу его улучшать. Хотя давно можно остановиться. Отзывы прекрасные, доходимость высокая. Хороший баланс между пользой и нагрузкой. Аналогов до сих пор нет ни в СНГ, ни в англоязычном мире.
И кажется, это отличный момент пойти дальше.
Следующий поток будет в октябре, и это будет последний раз в текущем виде. Дальше я пройдусь по бэклогу, сделаю рефакторинг, и курс останется только в варианте без обратной связи.
А со следующего года снова займусь образовательным творчеством. Руки чешутся взяться за спринг и другие темы!
Всё это похоже на чувства от принятого оффера. Когда на старом месте всё получается, и коллеги лапочки, но есть чувство, что можешь больше. Новый проект обещает что-то интересное, и ты с надеждой устремляешься в путь.
Так что кто хотел на курс с обратной связью — откладывать больше нельзя. Через пару недель объявлю набор, и в начале октября начнём🚀
В декабре прошлого года я проводила адвент-календарь по java. 21 день почти тысяча человек разбирали нюансы java core. В конце я спросила: какую тему ещё разобрать, где есть непонятки? Ответ был почти единогласным — Spring.
И я поставила цель на 2023 — сделать что-нибудь полезное по спрингу. Не для начинающих, с практическими фишками и лучшими практиками.
За 8 месяцев так ничего и не сделала😞
Я не склонна к самобичеванию, и попробовала разобраться, почему так получилось. Ответ лежал на поверхности.
Все силы идут на курс по многопоточке. Чуть появляется свободное время — бегу его улучшать. Хотя давно можно остановиться. Отзывы прекрасные, доходимость высокая. Хороший баланс между пользой и нагрузкой. Аналогов до сих пор нет ни в СНГ, ни в англоязычном мире.
И кажется, это отличный момент пойти дальше.
Следующий поток будет в октябре, и это будет последний раз в текущем виде. Дальше я пройдусь по бэклогу, сделаю рефакторинг, и курс останется только в варианте без обратной связи.
А со следующего года снова займусь образовательным творчеством. Руки чешутся взяться за спринг и другие темы!
Всё это похоже на чувства от принятого оффера. Когда на старом месте всё получается, и коллеги лапочки, но есть чувство, что можешь больше. Новый проект обещает что-то интересное, и ты с надеждой устремляешься в путь.
Так что кто хотел на курс с обратной связью — откладывать больше нельзя. Через пару недель объявлю набор, и в начале октября начнём🚀
Pattern matching: зачем?
Последние годы в джаву активно добавляется группа фич на тему pattern matching.
Тагир Валеев из Intellij IDEA в этом докладе рассказывает, какие это сложные фичи, как много челленджей стояло перед командой разработки. Но не говорит, зачем он вообще нужен.
Архитектор java Brian Goetz пишет, что pattern matching — не просто синтаксический сахар, а движение в сторону data oriented programming. Но это слабо применимо к большинству корпоративных систем, где доминирует ООП и изредка встречается функциональное программирование.
Большая часть моих знакомых считает паттерн матчинг "стрелкой вместо двоеточия в свиче":)
Так что сегодня расскажу, для каких задач пригодится pattern matching. В следующем посте обсудим реализацию в java.
Формат входных данных в энтерпрайзе обычно чётко определён. Если входящее сообщение не подходит по формату — это ошибка со стороны клиента.
Но бывает, что система работает со множеством источников данных, и выделить общий формат очень сложно.
Например, вы парсите чужие сайты/документы/дампы и достаёте оттуда что-то полезное. Знаю один проект, где бизнес-данные вытаскивают из логов(!) другой системы🤯
В итоге входные данные выглядят как
Паттерн — схема того, что мы ищем. Паттерн для поиска координат может выглядеть так:
▫️
▫️
Дальше идём по набору данных и проверяем их на соответствие паттерну.
Традиционно для такой задачи используется связка
Вот что нужно написать, чтобы проверить, является ли координатами массив
Ещё пример:
С if-ами эта конструкция будет гораздо объёмнее
Резюме
✅ Pattern matching нужен, когда мы пытаемся найти что-то знакомое в слабо- или неструктурированных данных.
✅ Большинство
✅ Разумеется, применить pattern matching можно и в других сценариях, но здесь видится наибольший профит в корпоративном царстве ООП.
В следующем посте распишу возможности pattern matching конкретно в джаве.
Спойлер:пока не впечатляет😑
Последние годы в джаву активно добавляется группа фич на тему pattern matching.
Тагир Валеев из Intellij IDEA в этом докладе рассказывает, какие это сложные фичи, как много челленджей стояло перед командой разработки. Но не говорит, зачем он вообще нужен.
Архитектор java Brian Goetz пишет, что pattern matching — не просто синтаксический сахар, а движение в сторону data oriented programming. Но это слабо применимо к большинству корпоративных систем, где доминирует ООП и изредка встречается функциональное программирование.
Большая часть моих знакомых считает паттерн матчинг "стрелкой вместо двоеточия в свиче":)
Так что сегодня расскажу, для каких задач пригодится pattern matching. В следующем посте обсудим реализацию в java.
Формат входных данных в энтерпрайзе обычно чётко определён. Если входящее сообщение не подходит по формату — это ошибка со стороны клиента.
Но бывает, что система работает со множеством источников данных, и выделить общий формат очень сложно.
Например, вы парсите чужие сайты/документы/дампы и достаёте оттуда что-то полезное. Знаю один проект, где бизнес-данные вытаскивают из логов(!) другой системы🤯
В итоге входные данные выглядят как
[Object, Object, Object]. Паттерн — схема того, что мы ищем. Паттерн для поиска координат может выглядеть так:
▫️
[Double, Double] — ищём массив из двух чисел с плавающей запятой▫️
[(-90;90), (-180,180)] — массив с двумя числами в указанных диапазонахДальше идём по набору данных и проверяем их на соответствие паттерну.
Традиционно для такой задачи используется связка
if + instanceOf. Вариант рабочий, но читаемость ужасная. Вот что нужно написать, чтобы проверить, является ли координатами массив
[Object, Object] data:if (data.length == 2 && data[0] instanceOf Double && data[1] instanceOf Double) {
double n = (Double) data[0];
double e = (Double) data[1];
if (n ≥ -90 && n≤ 90 && e ≥ -180 && e ≤ 180) {
// что-то делаем
}
}
В pattern matching многие проверки убираются под капот, и код выглядит симпатичнее:switch(data) {
case [(-90; 90), (-180, 180)]:
// что-то делаем
}
Близкий родственник паттерн матчинга — регулярные выражения. Строка — это набор символов, внутри этого набора ищутся паттерны. Можно сделать ту же работу через if, но регулярка удобнее. Плюс в строке элементы однородные (символы), а паттерн матчинг работает с разными типами данных.Ещё пример:
double discount = switch(transaction) {
case ["vip", Long, _, _, Double sum] → sum*0,9
case _ → 0
}
Здесь ищем список из 5 элементов, где первый — строка "vip", второй и пятый — число. Если нашли — можно сразу работать с полем sum. Если не нашли — используем паттерн по умолчанию _ С if-ами эта конструкция будет гораздо объёмнее
Резюме
✅ Pattern matching нужен, когда мы пытаемся найти что-то знакомое в слабо- или неструктурированных данных.
✅ Большинство
instanceOf и if отправляются под капот, и мы получаем более компактный код. ✅ Разумеется, применить pattern matching можно и в других сценариях, но здесь видится наибольший профит в корпоративном царстве ООП.
В следующем посте распишу возможности pattern matching конкретно в джаве.
Спойлер:
{kind=link}
Что будет напечатано в консоли? (используется Java 20)
Anonymous Poll
24%
Even Even
4%
Even Even Other
51%
Even Other Even
8%
Even Other Even Other
13%
Ошибка компиляции в одном из методов
Pattern matching: синтаксис
В прошлый раз мы обсудили pattern matching в вакууме. Сегодня обсудим, как он выглядит в java с учётом 21 версии, и чего не хватает в текущей реализации.
Под зонтик pattern matching относят много фич: sealed классы, records, обновление switch и instanceOf. Sealed и records в контексте pattern matching — специфичные кейсы data oriented programming, не будем о них. Cфокусируемся на более популярных сценариях:)
Итак, как pattern matching воплощается в синтаксисе:
1️⃣ Компактный instanceOf
Раньше для неизвестного типа выполнялись две операции: instanceOf и явное приведение типа:
В логическом И можно использовать переменную в том же if:
✅
❌
У древнейшей конструкции доступен новый синтаксис:
▫️ Стрелочка вместо двоеточия
▫️ Break в конце case по умолчанию, и его можно не писать
▫️ Можно объединить несколько case в один
Старый синтаксис никуда не делся, им можно пользоваться:
🔥 Ответ на вопрос перед постом: выведется
3️⃣ Присвоение элемента через switch
Раньше в case принимались только константы. Теперь можно проверить тип переменной:
❌ Нет работы с массивами
Один из кейсов pattern matching — работа с набором данных, в которых мы ищем определённые признаки. Такого в java пока нет:
❌ Нет паттернов по полям класса
Под капот спрятан только instanceOf, остальные условия выглядят как в обычном if. Вся работа с полями происходит через методы:
Резюме
В текущем виде pattern matching выглядит слабо, особенно по сравнению с другими языками. Покрыты только базовые кейсы, в таком виде область применения очень ограничена.
Возможно это лишь промежуточный этап. Посмотрим, как фича будет развиваться и использоваться✨
В прошлый раз мы обсудили pattern matching в вакууме. Сегодня обсудим, как он выглядит в java с учётом 21 версии, и чего не хватает в текущей реализации.
Под зонтик pattern matching относят много фич: sealed классы, records, обновление switch и instanceOf. Sealed и records в контексте pattern matching — специфичные кейсы data oriented programming, не будем о них. Cфокусируемся на более популярных сценариях:)
Итак, как pattern matching воплощается в синтаксисе:
1️⃣ Компактный instanceOf
Раньше для неизвестного типа выполнялись две операции: instanceOf и явное приведение типа:
if (obj instanceof String) {
String str = (String) obj;
// используем str
}
Теперь эти операции объединены. Рядом с instanceOf объявляем имя переменной и сразу ей пользуемся:if (obj instanceof String str) {
// используем str
}
Тонкий момент— переменная определяется только при успешном выполнении instanceOf, поэтому есть нюанс с областью видимости.В логическом И можно использовать переменную в том же if:
✅
if (obj instanceof String s && s.length() > 5)
Логическое ИЛИ такого не позволяет, будет ошибка компиляции:❌
if (obj instanceof String s || s.length() > 5)
2️⃣ Компактный switchУ древнейшей конструкции доступен новый синтаксис:
▫️ Стрелочка вместо двоеточия
▫️ Break в конце case по умолчанию, и его можно не писать
▫️ Можно объединить несколько case в один
Старый синтаксис никуда не делся, им можно пользоваться:
switch (value) {
case 1:
case 3: println("Odd"); break;
case 2:
case 4: println("Even"); break;
default: println("Other");
}
В "новом стиле" это будет так:switch (value) {
case 1,3 -> println("Odd");
case 2,4 -> println("Even");
default -> println("Other")
}
Важный момент — break добавляется по умолчанию только в вариант "со стрелочками". В "двоеточиях" break всё ещё добавляется вручную.🔥 Ответ на вопрос перед постом: выведется
Even Other Even. Чтобы работало как надо, нужно переписать на стрелочки или добавить break.3️⃣ Присвоение элемента через switch
int value = switch(…) {…};
4️⃣ Проверка в switch по типам и сложные caseРаньше в case принимались только константы. Теперь можно проверить тип переменной:
switch (obj) {
case Integer i -> …
case Long l -> …
case Double d -> …
}
Если произошёл мэтч, для переменной сразу доступна доп. информация, и можно добавить условия в case:switch (response) {
case String s when s.length() == 10 -> …
}
А теперь самое интересное! Обсудим, чего в текущей реализации нет: ❌ Нет работы с массивами
Один из кейсов pattern matching — работа с набором данных, в которых мы ищем определённые признаки. Такого в java пока нет:
double discount = switch(transaction) {
case ["vip", Long, _, _, Double sum] → sum*0,9
case _ → 0
}
В других языках такой функционал есть. Например, List patterns в С# или Matching sequences в питоне.❌ Нет паттернов по полям класса
Под капот спрятан только instanceOf, остальные условия выглядят как в обычном if. Вся работа с полями происходит через методы:
switch (figure) {
case Square s when s.getLength() != 10 → …
}
В том же питоне запись гораздо компактнее:match point:JEP Record Patterns мог быть как раз об этом, ведь records позиционируются как лаконичные контейнеры данных. Но увы.
case (0, 0): …
case (0, y): …
case _: …
Резюме
В текущем виде pattern matching выглядит слабо, особенно по сравнению с другими языками. Покрыты только базовые кейсы, в таком виде область применения очень ограничена.
Возможно это лишь промежуточный этап. Посмотрим, как фича будет развиваться и использоваться✨