
Как бы вы определили метод hashcode для этого класса?
Anonymous Poll
34%
return id;
2%
return username;
0%
return balance;
24%
return Objects.hash(id, username);
6%
return Objects.hash(username, balance);
18%
return Objects.hash(id, username, balance);
3%
return 13;
14%
Можно вообще не определять hashcode
Hashcode для Hibernate сущностей
Год новый, а темы всё те же. В декабрьском адвенте разгорелась горячая дискуссия на тему hashcode. Встал такой вопрос:
Как определить hashcode для сущностей Hibernate? Что делать, если объект пока не сохранён в БД и у него нет id?
В этом вопросе часто упоминается статья Thorben Janssen Ultimate Guide to Implementing equals() and hashCode() with Hibernate
В самом конце там вывод: если для сущности id генерируется в БД, то hashcode должен возвращать константу.
Почему это не лучший вариант?
Контракт соблюдается, всё работает корректно. Но задача хэша — быстрая проверка схожести объектов. Мы теряем преимущество быстрого поиска, и хэшсет будет работать как список. Так будет и для новых объектов, и для уже сохранённых (у которых id есть).
Другие авторы рекомендуют считать хэш Hibernate сущностей на основе всех полей кроме id. В чём недостатки такого решения:
❌ Если поля изменяемые, есть шанс потерять объект внутри HashSet
❌ Цель хэша — быстрая проверка. Если считать хэш всех полей, с тем же успехом можно использовать списки и сравнение через equals
Что же делать?
1️⃣ Использовать для хэша любое неизменяемое поле
Даже если поле не уникальное, распределение хэшей будет лучше, чем у константы
2️⃣ Не использовать хэш-структуры для новых объектов
Новые объекты собирать в список:
🔸 Hashcode нужен только, когда структура используется в hash-based структурах. Если новые объекты не складываются в HashSet или HashMap, то проблемы вообще нет
🔸 Если вы хотите возвращать в хэшкод константу, рассмотрите вариант хранения сущностей в ArrayList или TreeSet
Ответ на вопрос перед постом: зависит от сценариев использования. Если новые объекты User собираются в коллекцию, я бы складывала в список, а hashcode реализовала как
И более глобальные выводы:
Хороших материалов по разработке мало. Но даже в хороших легко свернуть не туда. Статья Thorben Janssen в целом ок, но итог немного сбивает с толку. Сравните:
💁🏼♂️ "Если для сущности id генерируется в БД, hashcode должен возвращать константу"
💁🏼 "Если новые Hibernate сущности складываются в hash структуры, и у них нет final полей, то для соблюдения контракта можно использовать в hashcode константу"
Второй вариант корректнее, но первый проще и лучше запоминается.
Не попадайте в эту ловушку. Задача разработчика — разобраться в сценариях, оценить варианты и найти подходящий😌
Год новый, а темы всё те же. В декабрьском адвенте разгорелась горячая дискуссия на тему hashcode. Встал такой вопрос:
Как определить hashcode для сущностей Hibernate? Что делать, если объект пока не сохранён в БД и у него нет id?
В этом вопросе часто упоминается статья Thorben Janssen Ultimate Guide to Implementing equals() and hashCode() with Hibernate
В самом конце там вывод: если для сущности id генерируется в БД, то hashcode должен возвращать константу.
Почему это не лучший вариант?
Контракт соблюдается, всё работает корректно. Но задача хэша — быстрая проверка схожести объектов. Мы теряем преимущество быстрого поиска, и хэшсет будет работать как список. Так будет и для новых объектов, и для уже сохранённых (у которых id есть).
Другие авторы рекомендуют считать хэш Hibernate сущностей на основе всех полей кроме id. В чём недостатки такого решения:
❌ Если поля изменяемые, есть шанс потерять объект внутри HashSet
❌ Цель хэша — быстрая проверка. Если считать хэш всех полей, с тем же успехом можно использовать списки и сравнение через equals
Что же делать?
1️⃣ Использовать для хэша любое неизменяемое поле
Даже если поле не уникальное, распределение хэшей будет лучше, чем у константы
2️⃣ Не использовать хэш-структуры для новых объектов
Новые объекты собирать в список:
List users = …Тогда в хэшкоде можно спокойно использовать id и для уже сохранённых объектов хэшсет будет работать как надо:
users.forEach(u -> session.save(u));
Set users = …Итого:
if (!users.contains(…)) {…}
🔸 Hashcode нужен только, когда структура используется в hash-based структурах. Если новые объекты не складываются в HashSet или HashMap, то проблемы вообще нет
🔸 Если вы хотите возвращать в хэшкод константу, рассмотрите вариант хранения сущностей в ArrayList или TreeSet
Ответ на вопрос перед постом: зависит от сценариев использования. Если новые объекты User собираются в коллекцию, я бы складывала в список, а hashcode реализовала как
return id; Но ситуации бывают разные, решение не универсально.И более глобальные выводы:
Хороших материалов по разработке мало. Но даже в хороших легко свернуть не туда. Статья Thorben Janssen в целом ок, но итог немного сбивает с толку. Сравните:
💁🏼♂️ "Если для сущности id генерируется в БД, hashcode должен возвращать константу"
💁🏼 "Если новые Hibernate сущности складываются в hash структуры, и у них нет final полей, то для соблюдения контракта можно использовать в hashcode константу"
Второй вариант корректнее, но первый проще и лучше запоминается.
Не попадайте в эту ловушку. Задача разработчика — разобраться в сценариях, оценить варианты и найти подходящий😌
Типы кэшей
Если спросить разработчика, что такое кэш, он скорее всего ответит:
— Кэш — хранилище типа ключ-значение. Позволяет снизить количество запросов к БД, другому сервису или не выполнять повторно сложные вычисления
Это, безусловно, правда, но не вся. В этом посте кратко опишу, что ещё умеют делать кэши и какие они бывают.
1️⃣ Кэш внутри сервиса
Хранится только в оперативной памяти. При выключении сервиса кэш пропадает. При включении — заполняется. Популярны два варианта:
🔸 ConcurrentHashMap: полностью ручное управление. Разработчик пишет код по наполнению кэша, обновлению и удалению значений
🔸 Google Guava Cache: более продвинутый вариант. Очищает кэш, уведомляет об удалении, предоставляет статистику
2️⃣ Удалённый кэш
Не связан с конкретным сервисом и запущен в отдельном процессе
✅ Доступен для нескольких сервисов
✅ Хранит данные на нескольких уровнях — в оперативной памяти и на диске
3️⃣ Распределённый кэш
Данные хранятся в нескольких процессах. Один экземпляр обычно называют нодой
✅ Шардирование. Распределяем данные по разным нодам и в итоге храним больше данных
✅ Репликация. Дублируем данные на разные ноды и повышаем доступность
Уровни 2-3 это скорее ступени эволюции кэшей. Большинство реализаций находятся на уровне 4:
4️⃣ In-memory data grid (IMDG)
Распределённый кэш с дополнительными фичами. Например:
▫️ Атомарный апдейт (вместо чтения и перезаписи)
▫️ Подписка на изменения в кэше
▫️ Поддержка транзакций
▫️ SQL-like запросы
▫️ Средства синхронизации (распределённый lock, очередь)
▫️ Продвинутый мониторинг
▫️ Выполнение скриптов
У многих кэшей есть платная и бесплатная версии. Многие фичи из списка выше доступны только платно.
В вакансиях чаще всего встречается Redis, чуть отстаёт Hazelcast. Также видела в проектах Memcached, Ehcache, Aerospike, Ignite/GridGain, Coherence. В их описании нет слова "кэш", как минимум distributed real-time in-memory streaming data platform🙂
Рекомендую погулять по документации того же Redis или Hazelcast, может для вашего проекта найдётся что-то полезное.
Если спросить разработчика, что такое кэш, он скорее всего ответит:
— Кэш — хранилище типа ключ-значение. Позволяет снизить количество запросов к БД, другому сервису или не выполнять повторно сложные вычисления
Это, безусловно, правда, но не вся. В этом посте кратко опишу, что ещё умеют делать кэши и какие они бывают.
1️⃣ Кэш внутри сервиса
Хранится только в оперативной памяти. При выключении сервиса кэш пропадает. При включении — заполняется. Популярны два варианта:
🔸 ConcurrentHashMap: полностью ручное управление. Разработчик пишет код по наполнению кэша, обновлению и удалению значений
🔸 Google Guava Cache: более продвинутый вариант. Очищает кэш, уведомляет об удалении, предоставляет статистику
2️⃣ Удалённый кэш
Не связан с конкретным сервисом и запущен в отдельном процессе
✅ Доступен для нескольких сервисов
✅ Хранит данные на нескольких уровнях — в оперативной памяти и на диске
3️⃣ Распределённый кэш
Данные хранятся в нескольких процессах. Один экземпляр обычно называют нодой
✅ Шардирование. Распределяем данные по разным нодам и в итоге храним больше данных
✅ Репликация. Дублируем данные на разные ноды и повышаем доступность
Уровни 2-3 это скорее ступени эволюции кэшей. Большинство реализаций находятся на уровне 4:
4️⃣ In-memory data grid (IMDG)
Распределённый кэш с дополнительными фичами. Например:
▫️ Атомарный апдейт (вместо чтения и перезаписи)
▫️ Подписка на изменения в кэше
▫️ Поддержка транзакций
▫️ SQL-like запросы
▫️ Средства синхронизации (распределённый lock, очередь)
▫️ Продвинутый мониторинг
▫️ Выполнение скриптов
У многих кэшей есть платная и бесплатная версии. Многие фичи из списка выше доступны только платно.
В вакансиях чаще всего встречается Redis, чуть отстаёт Hazelcast. Также видела в проектах Memcached, Ehcache, Aerospike, Ignite/GridGain, Coherence. В их описании нет слова "кэш", как минимум distributed real-time in-memory streaming data platform🙂
Рекомендую погулять по документации того же Redis или Hazelcast, может для вашего проекта найдётся что-то полезное.
Оптимизация запросов
В этом после хочу рассказать основы оптимизации запросов в БД. Буду говорить на примере Postgre, но в других БД процесс похож.
Шаг 0. Вспоминаем основы
При выполнении запроса участвуют два процесса:
▪️ Планировщик — составляет план выполнения запроса. Какие таблицы обойти, что проверить и в какой последовательности
▪️ Исполнитель — извлекает данные по заданному плану
Разработчик может создать дополнительные структуры данных — индексы. Индексы помогают быстрее выполнять запросы, но занимают много места. Если данные в таблице занимают 1 ГБ, то индекс с id займёт 250 МБ.
Шаг 1. Ищем, что оптимизировать
Смотрим таблицу
Ищем запросы, которые выполняются часто или долго.
Шаг 2. Работаем с конкретным запросом
Для экспериментов берём тестовую базу с большим количеством данных. Минимум миллион записей, иначе эффект оптимизаций не будет заметен.
Прогоняем запрос через EXPLAIN ANALYZE:
▪️ planning time — время планирования запроса
▪️ execution time — время выполнения запроса. Работаем с этим значением
Можно поиграть с условиями, порядком соединения таблиц и разными функциями. Обратите внимание на способ обхода таблицы:
🔸 поиск по условию (where name = …)
🔸 проверка уникальности поля
🔸 проверка внешнего ключа (foreign key)
Решение здесь простое — добавить индекс по проблемному полю. Базовый вариант выглядит так:
▫️ Запустить
▫️ Порадоваться снижению execution time
Для оптимизаций популярных и тяжёлых запросов добавление индекса оправдано. Разумеется, не нужно добавлять индексы для всех запросов и всех условий. Индексы занимают много места и замедляют запись в базу.
В оптимизации запросов огромное количество нюансов, но большинство проблем решается кэшем и добавлением индекса. Более сложные случаи лучше обсуждать с коллегами DBA😌
В этом после хочу рассказать основы оптимизации запросов в БД. Буду говорить на примере Postgre, но в других БД процесс похож.
Шаг 0. Вспоминаем основы
При выполнении запроса участвуют два процесса:
▪️ Планировщик — составляет план выполнения запроса. Какие таблицы обойти, что проверить и в какой последовательности
▪️ Исполнитель — извлекает данные по заданному плану
Разработчик может создать дополнительные структуры данных — индексы. Индексы помогают быстрее выполнять запросы, но занимают много места. Если данные в таблице занимают 1 ГБ, то индекс с id займёт 250 МБ.
Шаг 1. Ищем, что оптимизировать
Смотрим таблицу
pg_stat_statements — там собирается статистика по запросам. Чтобы получить достоверные данные, берём статистику с продакшн базы.Ищем запросы, которые выполняются часто или долго.
Шаг 2. Работаем с конкретным запросом
Для экспериментов берём тестовую базу с большим количеством данных. Минимум миллион записей, иначе эффект оптимизаций не будет заметен.
Прогоняем запрос через EXPLAIN ANALYZE:
EXPLAIN ANALYZE SELECT * FROM users where name = ’K’;EXPLAIN пишет только план выполнения запроса. EXPLAIN ANALYZE выполняет запрос и показывает
▪️ planning time — время планирования запроса
▪️ execution time — время выполнения запроса. Работаем с этим значением
Можно поиграть с условиями, порядком соединения таблиц и разными функциями. Обратите внимание на способ обхода таблицы:
Index Scan using name_index on — при выполнении запроса используется индекс, и это отличноSeq Scan on означает, что происходит долгий последовательный обход таблицы. Причиной может быть🔸 поиск по условию (where name = …)
🔸 проверка уникальности поля
🔸 проверка внешнего ключа (foreign key)
Решение здесь простое — добавить индекс по проблемному полю. Базовый вариант выглядит так:
CREATE INDEX index_name ON users(name);Дальше всё просто:
▫️ Запустить
EXPLAIN ANALYZE
▫️ Увидеть в плане выполнения новый индекс▫️ Порадоваться снижению execution time
Для оптимизаций популярных и тяжёлых запросов добавление индекса оправдано. Разумеется, не нужно добавлять индексы для всех запросов и всех условий. Индексы занимают много места и замедляют запись в базу.
В оптимизации запросов огромное количество нюансов, но большинство проблем решается кэшем и добавлением индекса. Более сложные случаи лучше обсуждать с коллегами DBA😌
Форматы обучения
Сегодня чуть подробнее расскажу про формат и внутрянку курса!
Помните декабрьский адвент? Он занимал мало времени и отлично справился со своей задачей: повторить материал или закрыть небольшие пробелы. Поэтому я так часто повторяла, что это не курс.
В случае с курсом подход другой.
Его задача — научить человека правильно пользоваться java.util.concurrent. Поэтому каждая тема разбирается до мелочей и обязательно закрепляется на практике.
Как выглядит каждый урок:
▫️ Небольшая лекция (до 20 минут)
▫️ Тесты на закрепление и вопросы с собеседований
▫️ Практика: решение типовых энтерпрайзных задач и код-ревью уже написанного кода
В среднем прохождение занимает 4 часа в неделю. Вся учёба идёт асинхронно, вы сами решаете, как распределить нагрузку по неделе.
👨🦱 “Курс очень плотный и нельзя расслабляться, совмещать с работой и прочим бытом непросто, но все реально. Главное не копить это на конец недели, а делать понемногу каждый день”
👨🦱 ”Приготовьтесь, вы будете очень много слушать, читать и перечитывать, ковыряться в доках, в исходниках библиотек, перевернете весь интернет в поисках ответов на уточняющие вопросы”
👨🦱 ”Насыщенные домашние задания. Не "повтори услышанное за преподавателем" и не "а не вольтметром ли измеряется напряжение", часто приходилось действительно попотеть. Вопросы отчасти перекрываются с материалом лекций, а отчасти расширяют его, что особенно круто - когда что-то откопал своими усилиями, запоминается оно гораздо лучше”
Варианты обучения:
1️⃣ С обратной связью (моей)
Самый эффективный способ. Проверяю все практические задания, вижу именно ваши пробелы и помогаю их устранить.
👨🦱 “Я бы брал курс с обратной связью, так как преподаватель задает вопросы на понимание используемых инструментов и процессов, что мотивирует лучше разобраться в теме”
👨🦱 ”Обратная связь - самая сильная и самая замечательная часть этого курса, что означает, что, даже если в теме что-то не устраивает, всегда можно спросить по интересующим именно вас моментам”
👨🦱 ”Задачи больше на понимание, с подводными камнями, комментарии преподавателя бесценны 😍 Не нужно писать тонны кода, но нужно разобраться, что происходит, и залезть в документацию”
Размер группы ограничен, сейчас осталось 12 мест
2️⃣ Без обратной связи
Основной педагогический челлендж любого курса — организовать адекватную самостоятельную работу.
Практические задания на этом тарифе тоже есть, но требуют больше вовлечения от ученика. Для заданий с кодом есть юнит-тесты и примеры реализаций. Для код-ревью — набор вопросов, которые помогут прийти к верному решению. Например, даётся код и к нему вопросы:
❓ Какие гарантии даёт метод А?
❓ У какого объекта захвачен монитор в методе Б?
❓ А в методе Ц?
И только потом ❓ Какие проблемы возможны в этом коде?
Путь к ответу длиннее, но более последовательный. По статистике ответов такой подход работает лучше! Путь к успеху — не забивать на непонятные моменты и стараться найти ответ в предложенных материалах.
Если вы дисциплинированы, готовы разобраться в многопоточке и потратить меньше денег, то возьмите тариф без обратной связи, он тоже классный!
Запись на оба тарифа здесь → http://fillthegaps.ru/mt
Сегодня чуть подробнее расскажу про формат и внутрянку курса!
Помните декабрьский адвент? Он занимал мало времени и отлично справился со своей задачей: повторить материал или закрыть небольшие пробелы. Поэтому я так часто повторяла, что это не курс.
В случае с курсом подход другой.
Его задача — научить человека правильно пользоваться java.util.concurrent. Поэтому каждая тема разбирается до мелочей и обязательно закрепляется на практике.
Как выглядит каждый урок:
▫️ Небольшая лекция (до 20 минут)
▫️ Тесты на закрепление и вопросы с собеседований
▫️ Практика: решение типовых энтерпрайзных задач и код-ревью уже написанного кода
В среднем прохождение занимает 4 часа в неделю. Вся учёба идёт асинхронно, вы сами решаете, как распределить нагрузку по неделе.
👨🦱 “Курс очень плотный и нельзя расслабляться, совмещать с работой и прочим бытом непросто, но все реально. Главное не копить это на конец недели, а делать понемногу каждый день”
👨🦱 ”Приготовьтесь, вы будете очень много слушать, читать и перечитывать, ковыряться в доках, в исходниках библиотек, перевернете весь интернет в поисках ответов на уточняющие вопросы”
👨🦱 ”Насыщенные домашние задания. Не "повтори услышанное за преподавателем" и не "а не вольтметром ли измеряется напряжение", часто приходилось действительно попотеть. Вопросы отчасти перекрываются с материалом лекций, а отчасти расширяют его, что особенно круто - когда что-то откопал своими усилиями, запоминается оно гораздо лучше”
Варианты обучения:
1️⃣ С обратной связью (моей)
Самый эффективный способ. Проверяю все практические задания, вижу именно ваши пробелы и помогаю их устранить.
👨🦱 “Я бы брал курс с обратной связью, так как преподаватель задает вопросы на понимание используемых инструментов и процессов, что мотивирует лучше разобраться в теме”
👨🦱 ”Обратная связь - самая сильная и самая замечательная часть этого курса, что означает, что, даже если в теме что-то не устраивает, всегда можно спросить по интересующим именно вас моментам”
👨🦱 ”Задачи больше на понимание, с подводными камнями, комментарии преподавателя бесценны 😍 Не нужно писать тонны кода, но нужно разобраться, что происходит, и залезть в документацию”
Размер группы ограничен, сейчас осталось 12 мест
2️⃣ Без обратной связи
Основной педагогический челлендж любого курса — организовать адекватную самостоятельную работу.
Практические задания на этом тарифе тоже есть, но требуют больше вовлечения от ученика. Для заданий с кодом есть юнит-тесты и примеры реализаций. Для код-ревью — набор вопросов, которые помогут прийти к верному решению. Например, даётся код и к нему вопросы:
❓ Какие гарантии даёт метод А?
❓ У какого объекта захвачен монитор в методе Б?
❓ А в методе Ц?
И только потом ❓ Какие проблемы возможны в этом коде?
Путь к ответу длиннее, но более последовательный. По статистике ответов такой подход работает лучше! Путь к успеху — не забивать на непонятные моменты и стараться найти ответ в предложенных материалах.
Если вы дисциплинированы, готовы разобраться в многопоточке и потратить меньше денег, то возьмите тариф без обратной связи, он тоже классный!
Запись на оба тарифа здесь → http://fillthegaps.ru/mt
Задачки на ООП
На собеседованиях на middle позицию последнее время часто дают задачки на объектно-ориентированный дизайн. Определяется ситуация и требования, для них кандидат рисует диаграмму классов и определяет API. Код не пишется, но можно обсудить конкретные шаги для некоторых сценариев.
Очень классный тип заданий! Занимают 15-30 минут, выполняются прямо на собесе, отлично проверяют прикладные навыки кандидата👌
Поделюсь тремя примерами для тренировки.
1️⃣ Библиотека
У каждой книги есть несколько копий. Пользователь может взять до 5 книг на месяц. Затем он может продлить использование ещё на месяц.
Если книги не возвращены в срок, система генерирует алерт.
Если нужной книги в библиотеке нет, пользователь может её зарезервировать. Как только она появится, библиотекарь увидит сообщение “пользователь Х зарезервировал книгу Y”. Библиотекарь звонит пользователю X, и в течение 5 дней книга ждёт своего читателя.
Напомню задание: определить API и нарисовать диаграмму классов.
Усложнение: у библиотеки есть несколько филиалов. Пользователь может заказать книгу и сдать её в любой филиал.
2️⃣ Парковка
На парковке доступно определённое количество мест. Они могут быть 3х размеров — S, M и L.
На парковку заезжают транспортные средства разных типов — мотоциклы, легковые автомобили и грузовые. Они занимают места следующим образом:
▫️ S — помещается один мотоцикл
▫️ M — два мотоцикла или одна легковушка
▫️ L — 4 мотоцикла, 2 легковушки или один грузовичок
Паркинг должен показывать количество свободных мест всех типов.
При въезде транспортного средства ему нужно указать, на какое место встать. Чем плотнее заставлена парковка — тем лучше.
Для каждого транспортного средства своя ставка. Также прайс зависит от времени стоянки. Например, для легкового автомобиля:
💲 первые 10 минут — бесплатно
💲 следующие 50 минут — 300 рублей
💲 1-3 час — 250 рублей в час
💲 3 час и далее — 200 рублей в час
Оплата считается, когда транспортное средство покидает парковку.
3️⃣ Автомат с едой
В автомате есть несколько слотов. В каждом слоте лежит товар с указанной ценой.
В начале работы в автомате есть какое-то количество денег каких-то номиналов. Автомат принимает оплату картой и наличные, может выдавать сдачу. Если отдать сдачу невозможно, продажа отменяется, а деньги возвращаются покупателю.
В автомате есть рулон с чеками. После каждой успешной транзакции покупателю выдаётся чек. Нет чеков — продажа не совершается.
В системе три роли:
👨 Оператор. Ставит новый рулон с чеками, балансирует наличные деньги
🙎♂️ Покупатель. Выбирает товар, способ оплаты и вносит деньги. При оплате наличными получает сдачу. Если сдачи нет, забирает свои деньги назад. Если всё ок, покупатель забирает чек и товар
🤵 Менеджер. Видит статистику по операциям и балансирует наличку
Таких задач море: бронь мест в отеле или билетов в кинотеатре, дизайн StackOverflow или Twitter как монолитного приложения, имитация шахмат или покера. Плюс огромное количество вариаций и усложнений.
Если вы только подбираетесь к Junior позиции, можете взять эти примеры как основу для пет-проекта. Добавьте Spring, БД, потокобезопасность, юнит-тесты — и проект для портфолио готов👌
На собеседованиях на middle позицию последнее время часто дают задачки на объектно-ориентированный дизайн. Определяется ситуация и требования, для них кандидат рисует диаграмму классов и определяет API. Код не пишется, но можно обсудить конкретные шаги для некоторых сценариев.
Очень классный тип заданий! Занимают 15-30 минут, выполняются прямо на собесе, отлично проверяют прикладные навыки кандидата👌
Поделюсь тремя примерами для тренировки.
1️⃣ Библиотека
У каждой книги есть несколько копий. Пользователь может взять до 5 книг на месяц. Затем он может продлить использование ещё на месяц.
Если книги не возвращены в срок, система генерирует алерт.
Если нужной книги в библиотеке нет, пользователь может её зарезервировать. Как только она появится, библиотекарь увидит сообщение “пользователь Х зарезервировал книгу Y”. Библиотекарь звонит пользователю X, и в течение 5 дней книга ждёт своего читателя.
Напомню задание: определить API и нарисовать диаграмму классов.
Усложнение: у библиотеки есть несколько филиалов. Пользователь может заказать книгу и сдать её в любой филиал.
2️⃣ Парковка
На парковке доступно определённое количество мест. Они могут быть 3х размеров — S, M и L.
На парковку заезжают транспортные средства разных типов — мотоциклы, легковые автомобили и грузовые. Они занимают места следующим образом:
▫️ S — помещается один мотоцикл
▫️ M — два мотоцикла или одна легковушка
▫️ L — 4 мотоцикла, 2 легковушки или один грузовичок
Паркинг должен показывать количество свободных мест всех типов.
При въезде транспортного средства ему нужно указать, на какое место встать. Чем плотнее заставлена парковка — тем лучше.
Для каждого транспортного средства своя ставка. Также прайс зависит от времени стоянки. Например, для легкового автомобиля:
💲 первые 10 минут — бесплатно
💲 следующие 50 минут — 300 рублей
💲 1-3 час — 250 рублей в час
💲 3 час и далее — 200 рублей в час
Оплата считается, когда транспортное средство покидает парковку.
3️⃣ Автомат с едой
В автомате есть несколько слотов. В каждом слоте лежит товар с указанной ценой.
В начале работы в автомате есть какое-то количество денег каких-то номиналов. Автомат принимает оплату картой и наличные, может выдавать сдачу. Если отдать сдачу невозможно, продажа отменяется, а деньги возвращаются покупателю.
В автомате есть рулон с чеками. После каждой успешной транзакции покупателю выдаётся чек. Нет чеков — продажа не совершается.
В системе три роли:
👨 Оператор. Ставит новый рулон с чеками, балансирует наличные деньги
🙎♂️ Покупатель. Выбирает товар, способ оплаты и вносит деньги. При оплате наличными получает сдачу. Если сдачи нет, забирает свои деньги назад. Если всё ок, покупатель забирает чек и товар
🤵 Менеджер. Видит статистику по операциям и балансирует наличку
Таких задач море: бронь мест в отеле или билетов в кинотеатре, дизайн StackOverflow или Twitter как монолитного приложения, имитация шахмат или покера. Плюс огромное количество вариаций и усложнений.
Если вы только подбираетесь к Junior позиции, можете взять эти примеры как основу для пет-проекта. Добавьте Spring, БД, потокобезопасность, юнит-тесты — и проект для портфолио готов👌
Читали Designing Data Intensive Applications (книжку с кабаном)?
Anonymous Poll
7%
Да, полностью прочитал
14%
Начинал, но не закончил
4%
Читал выборочные главы
44%
Нет, но планирую
31%
Нет, и пока не хочу
Книги для разработчиков
Читать или не читать книги — вопрос индивидуальный. Огромное количество информации есть в виде статей, видяшек и туториалов. Для проработки точечных вопросов это отличный вариант.
Книги — штука фундаментальная. Для выбранной темы вы получите последовательное изложение и множество деталей. В этом их огромный плюс. Заметила по себе и многим знакомым: чем старше по грейду становишься, тем больше тянет на книжки:)
В посте поделюсь полезными приёмами по работе с книгами на примере Designing Data Intensive Applications. Она же "книжка с кабаном" или DDIA.
Предварительный ресёрч
Помогает понять, стоит ли тратить время на книгу, насколько интересны темы и подходят ли они вам по уровню. Лучше потратить один час на исследование, чем десятки часов на бесполезную или неактуальную книгу. Что можно сделать:
🔸 Пройтись по заключению к каждой главе
Обычно это 1-2 страницы с концентратом информации и главными выводами
🔸 Посмотреть краткое содержание
У популярных книг на youtube есть плейлисты с кратким содержанием. Чтобы найти — просто напишете в поиске название книги. Например, вот плейлист для DDIA. Каждая глава пересказывается за 10-15 минут.
🔸 Прочитать конспект
Многие пишут конспекты по книгам и делятся ими с окружающим миром. Найти очень просто:
Как прочитать книгу, в которой больше 10 страниц
Большой объём часто вгоняет в тоску. Что может здесь помочь:
🔹 Читать в группе
Объединиться с коллегами или друзьями и установить распорядок. Например, выбираете главу, которую надо прочитать за неделю, в пятницу созваниваетесь и обсуждаете прочитанное.
🔹 Присоединиться к читальному клубу
Я знаю только один, сейчас они читают Art of Multiprocessor Programming и Effective Java. Подписчик подсказал ещё вот этот. В крупных компаниях организуют похожие клубы, это надо узнать у HR.
🔹 Маленькие шаги
Поставьте себе выполнимый план и придерживайтесь его. Допустим, каждый день читать по 10 страниц или по 20 минут. Важно удобно встроить чтение в вашу жизнь. Например, если после работы нет сил, то попробуйте читать до работы.
🔹 Не читать целиком
Прочитать только интересную главу или пропускать главы, которые кажутся очевидными. Но если чувствуете высокий уровень книги, лучше прочитать полностью.
🔹 Не читать🙂
Если автор нудный или чтение идёт тяжело, можно взять темы из содержания и последовательно искать их на Youtube или в гугле. Не для всех книг подойдёт, но для некоторых норм.
Что советуешь прочитать?
Универсальных рекомендаций нет, всё зависит от текущих задач и ваших интересов. Джуниорам полезно прочитать Effective Java. Хочется погрузиться в недра БД — Database Internals. Активно следите за продом — Site Reliability Engeneering от гугла. Прочитали DDIA и хотите продолжения — Designing Distributed System. Разобраться в операционных системах или сетях — Таненбаум.
Это я сама себе советую, а надо ли вам это читать — не знаю:) Спросите у старших коллег, они наверняка подскажут что-то релевантное вашему опыту и задачам проекта.
Читать или не читать книги — вопрос индивидуальный. Огромное количество информации есть в виде статей, видяшек и туториалов. Для проработки точечных вопросов это отличный вариант.
Книги — штука фундаментальная. Для выбранной темы вы получите последовательное изложение и множество деталей. В этом их огромный плюс. Заметила по себе и многим знакомым: чем старше по грейду становишься, тем больше тянет на книжки:)
В посте поделюсь полезными приёмами по работе с книгами на примере Designing Data Intensive Applications. Она же "книжка с кабаном" или DDIA.
Предварительный ресёрч
Помогает понять, стоит ли тратить время на книгу, насколько интересны темы и подходят ли они вам по уровню. Лучше потратить один час на исследование, чем десятки часов на бесполезную или неактуальную книгу. Что можно сделать:
🔸 Пройтись по заключению к каждой главе
Обычно это 1-2 страницы с концентратом информации и главными выводами
🔸 Посмотреть краткое содержание
У популярных книг на youtube есть плейлисты с кратким содержанием. Чтобы найти — просто напишете в поиске название книги. Например, вот плейлист для DDIA. Каждая глава пересказывается за 10-15 минут.
🔸 Прочитать конспект
Многие пишут конспекты по книгам и делятся ими с окружающим миром. Найти очень просто:
[название книги] summaryХорошие конспекты по DDIA: покороче и подлиннее.
Как прочитать книгу, в которой больше 10 страниц
Большой объём часто вгоняет в тоску. Что может здесь помочь:
🔹 Читать в группе
Объединиться с коллегами или друзьями и установить распорядок. Например, выбираете главу, которую надо прочитать за неделю, в пятницу созваниваетесь и обсуждаете прочитанное.
🔹 Присоединиться к читальному клубу
Я знаю только один, сейчас они читают Art of Multiprocessor Programming и Effective Java. Подписчик подсказал ещё вот этот. В крупных компаниях организуют похожие клубы, это надо узнать у HR.
🔹 Маленькие шаги
Поставьте себе выполнимый план и придерживайтесь его. Допустим, каждый день читать по 10 страниц или по 20 минут. Важно удобно встроить чтение в вашу жизнь. Например, если после работы нет сил, то попробуйте читать до работы.
🔹 Не читать целиком
Прочитать только интересную главу или пропускать главы, которые кажутся очевидными. Но если чувствуете высокий уровень книги, лучше прочитать полностью.
🔹 Не читать🙂
Если автор нудный или чтение идёт тяжело, можно взять темы из содержания и последовательно искать их на Youtube или в гугле. Не для всех книг подойдёт, но для некоторых норм.
Что советуешь прочитать?
Универсальных рекомендаций нет, всё зависит от текущих задач и ваших интересов. Джуниорам полезно прочитать Effective Java. Хочется погрузиться в недра БД — Database Internals. Активно следите за продом — Site Reliability Engeneering от гугла. Прочитали DDIA и хотите продолжения — Designing Distributed System. Разобраться в операционных системах или сетях — Таненбаум.
Это я сама себе советую, а надо ли вам это читать — не знаю:) Спросите у старших коллег, они наверняка подскажут что-то релевантное вашему опыту и задачам проекта.
Мы планируем поместить в HashMap 1000 элементов. Какое МИНИМАЛЬНОЕ число указать в конструкторе new HashMap<…,…>(❓), чтобы Map лишний раз не перестраивалась?
Anonymous Poll
17%
Ничего не указывать
20%
1000
23%
1024
26%
1500
10%
2048
6%
Integer.MAX_VALUE
Java 20: новый костыль в HashMap
На вопрос выше логично ответить
Итак, что происходит внутри HashMap?
Ячейки хэш-таблицы (или бакеты) хранятся в переменной
При вызове
Кажется, что всё в порядке, но мы забыли про ребалансировку😒
HashMap хорошо работает, когда в каждом бакете 0 или 1 элемент. Тогда скорость поиска и добавления будет той самой О(1).
Когда элементов становится больше, растёт шанс, что в один бакет попадёт несколько элементов. Поэтому в определённый момент HashMap удваивает количество бакетов и перераспределяет элементы. За момент, когда пора начать эту операцию, отвечает поле
Его первое значение считается как [планируемое число элементов * 0.75], т.е когда HashMap заполнен на 3/4. При удвоении числа бакетов threshold тоже удваивается.
И смотрите, что получается:
🔹 Мы хотим добавить в мэп 1000 элементов и вызываем конструктор с подходящим параметром initialCapacity:
🔹 Рассчитывается threshold: 1024*0,75 = 768
🔹 Добавляется 768 элементов
🔹 Приходит 769 элемент, начинается ребалансировка:
▫️ количество бакетов удваивается, теперь их 2048
▫️ текущие элементы распределяются между ними
▫️ новый threshold удваивается, теперь это 1538
Что получилось: мы пообещали добавить в HashMap 1000 элементов. Сдержали обещание, но перестройка мэп всё равно произошла.
Чтобы HashMap работал оптимально, нужно учесть ребалансировку и передать в конструктор, например, 1500. Надо знать детали реализации, чтобы получить то, что хотим.
И это образцовое нарушение инкапсуляции🤌
В java 20 в HashMap добавили костыльный метод, который исправляет ситуацию:
Почему это костыль? Потому что исходная проблема не решается. Жизнь пользователя не становится легче, ему нужно запомнить "чтобы задать размер мэп — не пользуйся конструктором, пользуйся специальным методом".
Хороший API — понятный, удобный и дружелюбный. Пользователю легко выбрать нужный метод, все параметры хорошо описаны в документации. Когнитивная нагрузка при использовании минимальна, нет подводных камней и обходных путей. Для собеседований сложно придумать вопрос с подвохом🙂
Важные заметки:
🔸 В JDK много образцового кода, и я рекомендую изучать исходники как можно чаще. HashMap — неприятное исключение
🔸 В ConcurrentHashMap всё хорошо.
На вопрос выше логично ответить
new HashMap<>(1000). Сначала расскажу, почему этот ответ не походит. Потом наглядно покажу нарушение инкапсуляции, и что за костыль добавили в Java 20.Итак, что происходит внутри HashMap?
Ячейки хэш-таблицы (или бакеты) хранятся в переменной
Node[] table как простой массив.При вызове
new HashMap() без параметров создаётся 16 бакетов. Если передать параметр с размером, то берётся ближайшая степень двойки. new HashMap(1000) создаёт массив из 1024 элементов.Кажется, что всё в порядке, но мы забыли про ребалансировку😒
HashMap хорошо работает, когда в каждом бакете 0 или 1 элемент. Тогда скорость поиска и добавления будет той самой О(1).
Когда элементов становится больше, растёт шанс, что в один бакет попадёт несколько элементов. Поэтому в определённый момент HashMap удваивает количество бакетов и перераспределяет элементы. За момент, когда пора начать эту операцию, отвечает поле
threshold.Его первое значение считается как [планируемое число элементов * 0.75], т.е когда HashMap заполнен на 3/4. При удвоении числа бакетов threshold тоже удваивается.
И смотрите, что получается:
🔹 Мы хотим добавить в мэп 1000 элементов и вызываем конструктор с подходящим параметром initialCapacity:
new HashMap(1000);
🔹 Создаётся 1024 бакета (ближайшая степень двойки)🔹 Рассчитывается threshold: 1024*0,75 = 768
🔹 Добавляется 768 элементов
🔹 Приходит 769 элемент, начинается ребалансировка:
▫️ количество бакетов удваивается, теперь их 2048
▫️ текущие элементы распределяются между ними
▫️ новый threshold удваивается, теперь это 1538
Что получилось: мы пообещали добавить в HashMap 1000 элементов. Сдержали обещание, но перестройка мэп всё равно произошла.
Чтобы HashMap работал оптимально, нужно учесть ребалансировку и передать в конструктор, например, 1500. Надо знать детали реализации, чтобы получить то, что хотим.
И это образцовое нарушение инкапсуляции🤌
В java 20 в HashMap добавили костыльный метод, который исправляет ситуацию:
HashMap.newHashMap(1000);
Внутри произойдёт вычисление 1000 / 0.75 = 1334, в итоге создаётся 2048 бакетов.Почему это костыль? Потому что исходная проблема не решается. Жизнь пользователя не становится легче, ему нужно запомнить "чтобы задать размер мэп — не пользуйся конструктором, пользуйся специальным методом".
Хороший API — понятный, удобный и дружелюбный. Пользователю легко выбрать нужный метод, все параметры хорошо описаны в документации. Когнитивная нагрузка при использовании минимальна, нет подводных камней и обходных путей. Для собеседований сложно придумать вопрос с подвохом🙂
Важные заметки:
🔸 В JDK много образцового кода, и я рекомендую изучать исходники как можно чаще. HashMap — неприятное исключение
🔸 В ConcurrentHashMap всё хорошо.
new ConcurrentHashMap(1000) сразу создаёт 2048 бакетов и не занимается лишними балансировкамиJUnit: самое важное
Информация ниже не новая, но очень важная. Так что грех не повторить:)
Ниже особенности и фичи JUnit, которые полезно знать большинству разработчиков. Если что-то заинтересовало и непонятно — поможет JUnit 5 User Guide
1️⃣ Жизненный цикл теста
Каждый тест — это метод с аннотацией
Через аннотацию
Чтобы выполнить что-то до или после выполнения теста, используются методы с аннотациями:
Благодаря этому тесты выполняются независимо.
Этим JUnit отличается от TestNG, где создаётся один экземпляр класса на все тестовые методы. Если хочется как в TestNG, добавьте над классом аннотацию
Сердце каждого теста - методы с приставкой assert*:
3️⃣ Группировка тестов
Аннотация
Можно указывать тэги в системе сборки и при запуске тестов из IDE.
4️⃣ Отключение тестов
Аннотация
▫️ операционной системы
Помогают запустить один тест с разными аргументами. Выглядит так:
Вместо готового списка можно брать значения
🔸 из CSV файла
▫️ Через ассерт
▫️ Hamсrest, AssertJ — расширенные библиотеки методов-ассертов
▫️ Mockito для заглушек. Добавляете библиотеку в pom.xml или build.gradle, а в тест - аннотацию
▫️ Java Faker — генератор данных для тестов
Ещё я когда-то писала 2 хороших поста на тему, чем отличается JUnit 4 от Unit 5. Если вас удивляет, почему там разные аннотации и почему версии не совместимы друг с другом, то почитайте:)
Информация ниже не новая, но очень важная. Так что грех не повторить:)
Ниже особенности и фичи JUnit, которые полезно знать большинству разработчиков. Если что-то заинтересовало и непонятно — поможет JUnit 5 User Guide
1️⃣ Жизненный цикл теста
Каждый тест — это метод с аннотацией
@Test.Через аннотацию
@DisplayName задаётся симпатичное имя теста в отчёте.Чтобы выполнить что-то до или после выполнения теста, используются методы с аннотациями:
▫️ @Before, @BeforeAllJUnit создаёт новый экземпляр класса на каждый тестовый метод. Класс
▫️ @After, @AfterAll
ServiceTest с пятью методами @Test во время запуска превратится в 5 экземпляров класса ServiceTest.Благодаря этому тесты выполняются независимо.
Этим JUnit отличается от TestNG, где создаётся один экземпляр класса на все тестовые методы. Если хочется как в TestNG, добавьте над классом аннотацию
@TestInstance(Lifecycle.PER_CLASS)
2️⃣ ПроверкиСердце каждого теста - методы с приставкой assert*:
🔸 assertTrueВ самом JUnit мало методов, более удобные ассерты есть в библиотеках Hamсrest и AssertJ. AssertJ, на мой взгляд, более читабельный, но Hamсrest используется чаще.
🔸 assertEquals
🔸 assertInstanceOf
3️⃣ Группировка тестов
Аннотация
@Tag("groupName") объединяет тесты в группы. Работает и для одного теста, и для класса.Можно указывать тэги в системе сборки и при запуске тестов из IDE.
4️⃣ Отключение тестов
Аннотация
@Disabled. Есть продвинутые варианты, можно отключить тесты для▫️ операционной системы
@DisabledOnOs(WINDOWS)▫️ версии java
@DisabledOnJre(JAVA_9)▫️ системных переменных:
@DisabledForJreRange(min = JAVA_9)
@DisabledIfSystemProperty(named = "ci-server", matches = "true")5️⃣ Параметризированные тесты
@DisabledIfEnvironmentVariable(named = "ENV", matches = ".*development.*")
Помогают запустить один тест с разными аргументами. Выглядит так:
@ParameterizedTestТакой тест запустится дважды - с аргументом 100 и -14.
@ValueSource(ints={100,-14})
public void test(int input) {}
Вместо готового списка можно брать значения
🔸 из CSV файла
@CsvSource
🔸 из метода @MethodSource
6️⃣ Проверка таймаута▫️ Через ассерт
assertTimeout(ofMinutes(2), ()->{});
▫️ Через аннотацию@Timeout(value=42,unit=SECONDS)7️⃣ Полезные библиотеки
▫️ Hamсrest, AssertJ — расширенные библиотеки методов-ассертов
▫️ Mockito для заглушек. Добавляете библиотеку в pom.xml или build.gradle, а в тест - аннотацию
@ExtendWith(MockitoExtension.class)
▫️ Testcontainers для запуска внешних компонентов в докере. Добавляем библиотеку, аннотацию @Testcontainers над классом и @Container над компонентом▫️ Java Faker — генератор данных для тестов
Ещё я когда-то писала 2 хороших поста на тему, чем отличается JUnit 4 от Unit 5. Если вас удивляет, почему там разные аннотации и почему версии не совместимы друг с другом, то почитайте:)
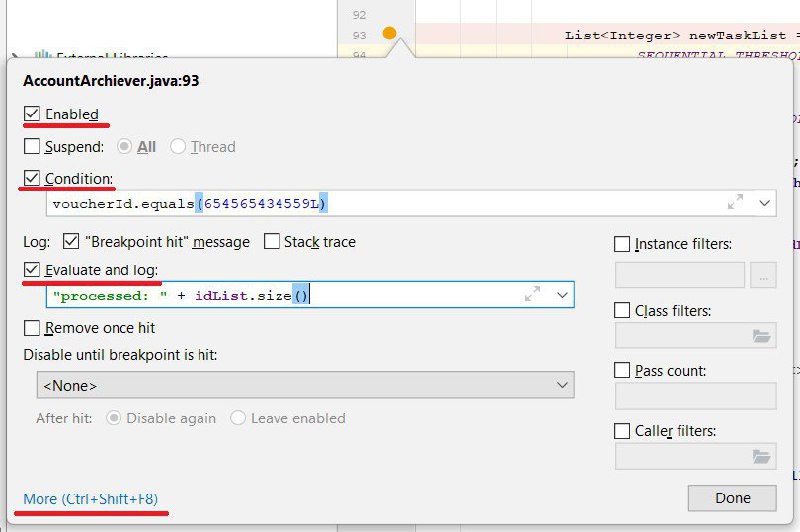
Брейкпойнты в Intellij IDEA
Когда я была джуниором-мидлом, проводила в дебаге 80% рабочего времени. Скучаю по временам, когда можно спокойно работать с кодом целый день. Не копаться в гигантских логах, не ходить на митинги по полдня, не делать код-ревью всей команды.
Если вам доступно удовольствие писать код — цените его:)
Большинство разработчиков пользуются только базовым дебагом в IDEA: щёлкнуть рядом с номером строки, чтобы добавить или удалить брейкпойнт. Чтобы отладка стала быстрой и приятной, есть 4 классные фичи:
1️⃣ Условия остановки
Если метод часто вызывается, или брейкпойнт стоит в цикле, не тратьте время на ожидание нужных значений:
🔹Правый щелчок по брейкпойнту
🔹Добавить в Condition условие остановки — можно использовать все доступные переменные, объекты и методы
2️⃣ Изменение параметров в динамике
Чтобы посмотреть, как меняются переменные, их обычно выводят в консоль через System.out.println. Более продвинутый вариант:
🔸Зажать Shift и добавить брейкпойнт
🔸Щёлкнуть галочку
Отладчик не будет останавливать выполнение, а запишет в консоль значение выражения.
Незаменимая фича для отладки многопоточных приложений, кода сторонних библиотек и удалённого дебага!
3️⃣ Отключение брейкпойнта
Ненужный брейкпойнт можно не удалять, а отключить:
▪️Щёлкнуть колёсиком по брейкпойнту
ИЛИ
▪️Правый щёлчок по брейкпойнту → снять галочку с Enabled
4️⃣ Массовое удаление
Когда в проекте много брейкпойнтов, IDE при дебаге немного тормозит. Чтобы удалить ненужные, откройте полный список:
▫️Правый клик по любому брейкпойнту
▫️Ссылка
▫️Удаляем ненужные
В этом окне ещё есть фильтры для выборочной остановки, но удобнее пользоваться условиями из первого пункта.
Когда я была джуниором-мидлом, проводила в дебаге 80% рабочего времени. Скучаю по временам, когда можно спокойно работать с кодом целый день. Не копаться в гигантских логах, не ходить на митинги по полдня, не делать код-ревью всей команды.
Если вам доступно удовольствие писать код — цените его:)
Большинство разработчиков пользуются только базовым дебагом в IDEA: щёлкнуть рядом с номером строки, чтобы добавить или удалить брейкпойнт. Чтобы отладка стала быстрой и приятной, есть 4 классные фичи:
1️⃣ Условия остановки
Если метод часто вызывается, или брейкпойнт стоит в цикле, не тратьте время на ожидание нужных значений:
🔹Правый щелчок по брейкпойнту
🔹Добавить в Condition условие остановки — можно использовать все доступные переменные, объекты и методы
2️⃣ Изменение параметров в динамике
Чтобы посмотреть, как меняются переменные, их обычно выводят в консоль через System.out.println. Более продвинутый вариант:
🔸Зажать Shift и добавить брейкпойнт
🔸Щёлкнуть галочку
Evaluate and log
🔸Вписать нужное выражениеОтладчик не будет останавливать выполнение, а запишет в консоль значение выражения.
Незаменимая фича для отладки многопоточных приложений, кода сторонних библиотек и удалённого дебага!
3️⃣ Отключение брейкпойнта
Ненужный брейкпойнт можно не удалять, а отключить:
▪️Щёлкнуть колёсиком по брейкпойнту
ИЛИ
▪️Правый щёлчок по брейкпойнту → снять галочку с Enabled
4️⃣ Массовое удаление
Когда в проекте много брейкпойнтов, IDE при дебаге немного тормозит. Чтобы удалить ненужные, откройте полный список:
▫️Правый клик по любому брейкпойнту
▫️Ссылка
More
▫️Слева видим список брейкпойнтов▫️Удаляем ненужные
В этом окне ещё есть фильтры для выборочной остановки, но удобнее пользоваться условиями из первого пункта.
{kind=link}
REST API
— неоднозначная тема, по которой часто много вопросов и споров. В этом посте я кратко расскажу, что такое REST API и как он связан с REST. И что самое интересное — покажу принципы REST API на реальных примерах.
Начнём сначала.
REST — это набор архитектурных принципов, которую описал Roy Fielding в диссертации 2000 года. Один из тезисов гласит, что взаимодействие между системами должно крутиться вокруг понятия ресурса.
REST API, в свою очередь, это набор рекомендаций для API: как составить URL-ы, что они принимают и возвращают. От REST здесь берётся только понятие ресурса. Остальное — частные интерпретации, в оригинальном документе ничего этого нет.
Под REST API обычно понимают следующий набор правил:
1️⃣ В основе пути — существительное во множественном числе
❌ https://www.youtube.com/watch?v=123
✅ https://rutube.ru/video/123
Множественное число встречается чаще, но на мой взгляд единственное тоже ок. Главное, чтобы в рамках проекта был единый стиль, и не смешивалось единственное и множественное
2️⃣ Иерархия ресурсов отражается в URL
Например, в магазине одежды есть раздел с футболками. Как это отразить в API:
❌ https://www.lamoda.ru/c/2478/clothes-futbolki/
✅ https://www.sportmaster.ru/catalog/zhenskaya_odezhda/futbolki/
3️⃣ Желаемые действия с ресурсом определяются через HTTP методы
Искусственный пример:
▫️ GET /users — вернуть список всех пользователей
▫️ GET /users/5 — получить пользователя с id=5
▫️ POST /users — добавить пользователя
▫️ PUT /users/5 — обновить пользователя с id=5 целиком
▫️ PATCH /users/5 — обновить часть полей у пользователя с id=5
Найти идеальный реальный пример у меня не получилось, но очень близок оказался HeadHunter API по работе с резюме. Там всё по канону, но для редактирования они используют PUT.
4️⃣ Вызов методов GET, DELETE, PUT, PATCH должен быть идемпотентным
Чтобы без проблем вызвать метод повторно, если что-то пошло не так
5️⃣ Методы PUT, POST and PATCH возвращают новый/обновлённый объект
6️⃣ Дополнительные параметры для метода GET указываются через ?, а тело метода остаётся пустым
GET /resumes?text=java&age_from=18 – поиск совершеннолетних кандидатов, в резюме которых встречается "java"
7️⃣ Информация для POST, PUT, PATCH запросов передаётся в теле метода
8️⃣ В качестве ответа возвращается соответствующий HTTP код
▫️ 1хх: информационные сообщения, чаще всего служебные. Для бизнес-логики они не используются
▫️ 2xx: всё супер
▫️ 3xx: redirect
▫️ 4xx: ошибка на стороне клиента
▫️ 5xx: ошибка на стороне сервера
Какие плюсы у REST API?
Плюс на самом деле только один — в таком API проще разобраться. У Stepik REST API нет документации, но и так понятно, что GET /api/courses возвращает список курсов.
Как видно по примерам, некоторые компании придерживаются подобных правил, некоторые — нет. Rutube более REST-API, чем Youtube, но для успеха продукта этого явно недостаточно🤭
— неоднозначная тема, по которой часто много вопросов и споров. В этом посте я кратко расскажу, что такое REST API и как он связан с REST. И что самое интересное — покажу принципы REST API на реальных примерах.
Начнём сначала.
REST — это набор архитектурных принципов, которую описал Roy Fielding в диссертации 2000 года. Один из тезисов гласит, что взаимодействие между системами должно крутиться вокруг понятия ресурса.
REST API, в свою очередь, это набор рекомендаций для API: как составить URL-ы, что они принимают и возвращают. От REST здесь берётся только понятие ресурса. Остальное — частные интерпретации, в оригинальном документе ничего этого нет.
Под REST API обычно понимают следующий набор правил:
1️⃣ В основе пути — существительное во множественном числе
❌ https://www.youtube.com/watch?v=123
✅ https://rutube.ru/video/123
Множественное число встречается чаще, но на мой взгляд единственное тоже ок. Главное, чтобы в рамках проекта был единый стиль, и не смешивалось единственное и множественное
2️⃣ Иерархия ресурсов отражается в URL
Например, в магазине одежды есть раздел с футболками. Как это отразить в API:
❌ https://www.lamoda.ru/c/2478/clothes-futbolki/
✅ https://www.sportmaster.ru/catalog/zhenskaya_odezhda/futbolki/
3️⃣ Желаемые действия с ресурсом определяются через HTTP методы
Искусственный пример:
▫️ GET /users — вернуть список всех пользователей
▫️ GET /users/5 — получить пользователя с id=5
▫️ POST /users — добавить пользователя
▫️ PUT /users/5 — обновить пользователя с id=5 целиком
▫️ PATCH /users/5 — обновить часть полей у пользователя с id=5
Найти идеальный реальный пример у меня не получилось, но очень близок оказался HeadHunter API по работе с резюме. Там всё по канону, но для редактирования они используют PUT.
4️⃣ Вызов методов GET, DELETE, PUT, PATCH должен быть идемпотентным
Чтобы без проблем вызвать метод повторно, если что-то пошло не так
5️⃣ Методы PUT, POST and PATCH возвращают новый/обновлённый объект
6️⃣ Дополнительные параметры для метода GET указываются через ?, а тело метода остаётся пустым
GET /resumes?text=java&age_from=18 – поиск совершеннолетних кандидатов, в резюме которых встречается "java"
7️⃣ Информация для POST, PUT, PATCH запросов передаётся в теле метода
8️⃣ В качестве ответа возвращается соответствующий HTTP код
▫️ 1хх: информационные сообщения, чаще всего служебные. Для бизнес-логики они не используются
▫️ 2xx: всё супер
▫️ 3xx: redirect
▫️ 4xx: ошибка на стороне клиента
▫️ 5xx: ошибка на стороне сервера
Какие плюсы у REST API?
Плюс на самом деле только один — в таком API проще разобраться. У Stepik REST API нет документации, но и так понятно, что GET /api/courses возвращает список курсов.
Как видно по примерам, некоторые компании придерживаются подобных правил, некоторые — нет. Rutube более REST-API, чем Youtube, но для успеха продукта этого явно недостаточно🤭
Java 21: String templates
Сегодня вышла java 20🥳
А в сентябре выходит java 21 (LTS) с интересной превью фичей — String templates. Про неё и расскажу в этом посте.
Есть две стратегии работы со строками:
🔸 Конкатенация — собираем строку по частям:
🔸 Интерполяция — замена переменных внутри шаблона:
В начале строки нужно добавить
❓ Зачем нужен префикс STR? Почему нельзя просто добавить новый функционал в строки?
Здесь 2 причины:
1️⃣ Для обратной совместимости
На джаве написано много кода, и наверняка какие-то строки содержат блоки \{}. Будет обидно, если этот код перестанет компилироваться. Поэтому строки для интерполяции нужно явно обозначить
2️⃣ Может быть не только STR😱
Здесь открывается портал в другой мир. По задумке авторов темплейты могут подставлять переменные, валидировать данные и делать преобразования. Например, так:
Но рано радоваться🙂 Из коробки этого не будет, только набор классов для кастомизации. Будем надеяться, что авторы библиотек возьмут фичу на вооружение.
❓ Как это работает? Выглядит как магия!
В JDK появится статическое поле StringProcessor STR, а строка
во время компиляции превратится в
Cинтаксический сахарок и никакого волшебства✨
Сегодня вышла java 20🥳
А в сентябре выходит java 21 (LTS) с интересной превью фичей — String templates. Про неё и расскажу в этом посте.
Есть две стратегии работы со строками:
🔸 Конкатенация — собираем строку по частям:
String str = "Hello, " + name + "!";Сюда же относится StringBuilder, метод concat и тд.
🔸 Интерполяция — замена переменных внутри шаблона:
String name = "Jake";В чистом виде в java такого нет. В Formatter и MessageFormat вместо переменных какие-то %s и %d, а переменные стоят отдельно:
String str = "Hello, ${name}!";
String.format("%d plus %d equals %d", x, y, x + y);
Для сравнения, как это выглядит в Kotlin:"$x plus $y equals ${x + y}"
Так вот, в java 21 появится интерполяция!В начале строки нужно добавить
STR., а переменные поместить в \{}
int x = 10, y = 20;Хорошо работает вместе с текстовыми блоками (многострочные строки в тройных кавычках):
String str = STR."\{x} + \{y} = \{x + y}";
// "10 + 20 = 30"
String name = "Joan";Внутри можно вызывать методы и писать блоки кода:
String phone = "555-123";
String json = STR."""
{
"name": "\{name}",
"phone":"\{phone}",
}
""";
String time = STR."The time is \{
DateTimeFormatter
.ofPattern("HH:mm:ss")
.format(LocalTime.now())
} right now";
//"The time is 09:01:45 right now"
Читаемость текста снижается, но если очень хочется — почему нет.❓ Зачем нужен префикс STR? Почему нельзя просто добавить новый функционал в строки?
Здесь 2 причины:
1️⃣ Для обратной совместимости
На джаве написано много кода, и наверняка какие-то строки содержат блоки \{}. Будет обидно, если этот код перестанет компилироваться. Поэтому строки для интерполяции нужно явно обозначить
2️⃣ Может быть не только STR😱
Здесь открывается портал в другой мир. По задумке авторов темплейты могут подставлять переменные, валидировать данные и делать преобразования. Например, так:
JSONObject json = JSON."{ id: \{id}}";
или даже так:ResultSet rs = DB."SELECT * FROM Person WHERE name = \{name}";
Для запросов в БД это, наверное, слишком, а вот для работы с JSON выглядит очень удобно.Но рано радоваться🙂 Из коробки этого не будет, только набор классов для кастомизации. Будем надеяться, что авторы библиотек возьмут фичу на вооружение.
❓ Как это работает? Выглядит как магия!
В JDK появится статическое поле StringProcessor STR, а строка
String str = STR."\{name}!"; во время компиляции превратится в
StringTemplate template = new StringTemplate(паттерн, параметры);
String str = STR.process(template);Cинтаксический сахарок и никакого волшебства✨
{kind=link}
Best practice: имена методов в ООП и функциональном подходе
В идеальном мире не нужно читать документацию и изучать внутрянку класса, чтобы правильно с ним работать. В этом посте расскажу best practice, о котором мало говорят, но который здорово повышает дружелюбность API.
Начнём с вопроса перед постом. Если не искать подвох, то в sum мы ждём 0+10+20=30.
Но подвох, разумеется, есть.
Давным-давно основной парадигмой разработки было ООП. Вся работа строилась на изменении объектов, и этот подход отражался в названиях методов:
Исключения встречались редко, их нужно было просто запомнить. С юных лет все знают, что String — неизменяемый, и просто вызвать метод недостаточно:
▫️ меняется текущий объект, и надо просто вызвать метод
или
▫️ создаётся новый объект, который надо куда-то присвоить
Для такого случая есть best practice:
✅ Когда метод меняет внутреннее состояние объекта, имя метода начинается с глагола
✅ Методы НЕизменяемых объектов используют другие конструкции
Простой пример. Чтобы изменить внутренние поля, используем метод
🔸 Причастия:
🔸 Предлоги и союзы:
🔸 Существительное в чистом виде:
❗️ Исключение: если класс использует Fluent API, обычно используются глаголы:
В идеальном мире не нужно читать документацию и изучать внутрянку класса, чтобы правильно с ним работать. В этом посте расскажу best practice, о котором мало говорят, но который здорово повышает дружелюбность API.
Начнём с вопроса перед постом. Если не искать подвох, то в sum мы ждём 0+10+20=30.
Но подвох, разумеется, есть.
BigInteger — неизменяемый класс. sum.add(10) создаёт новый объект, а исходная переменная не меняется. В итоге ни один add не влияет на sum. В консоль напечатается 0.Давным-давно основной парадигмой разработки было ООП. Вся работа строилась на изменении объектов, и этот подход отражался в названиях методов:
sum.add(4), user.setName("Alisa").Исключения встречались редко, их нужно было просто запомнить. С юных лет все знают, что String — неизменяемый, и просто вызвать метод недостаточно:
String str = " Java ";Последние годы растёт тренд на неизменяемость. При вызове метода должно быть понятно:
❌ str.trim();
✅ str = str.trim();
▫️ меняется текущий объект, и надо просто вызвать метод
или
▫️ создаётся новый объект, который надо куда-то присвоить
Для такого случая есть best practice:
✅ Когда метод меняет внутреннее состояние объекта, имя метода начинается с глагола
✅ Методы НЕизменяемых объектов используют другие конструкции
Простой пример. Чтобы изменить внутренние поля, используем метод
set*:order.setDeliveryDate(…);Создать новый объект на основе текущего — метод
with*:order = order.withDeliveryDate(…);Для более сложных операций нужно включить креативность. Здесь помогут:
🔸 Причастия:
order.cancel(); // изменить текущий объектOrder o = order.cancelled(); // создать новый🔸 Предлоги и союзы:
String s = str.toLowerCase();// вместо addDays
LocalDate l = now().plusDays(12);
🔸 Существительное в чистом виде:
String sub = str.substring(1);Цель здесь одна — показать, что текущий объект не меняется
❗️ Исключение: если класс использует Fluent API, обычно используются глаголы:
Optional opt = …Итого: с изменяемыми и неизменяемыми объектами работа идёт по-разному. Имена методов подсказывают, как правильно пользоваться классом. Хорошей практикой считается использовать глаголы для изменяемых объектов, и что-то другое для неизменяемых☀️
opt.map(…).filter(…)
Чем отличаются опции JVM, которые начинаются на -X, от опций, которые начинаются на -XX?
Anonymous Poll
6%
У -Х приоритет над -ХХ
6%
У -ХХ приоритет над -Х
13%
-Х работают на всех операционных системах, -ХХ специфичны для отдельных ОС и архитектур
15%
-ХХ могут быть удалены в будущем, -Х вряд ли
36%
-Х задаёт параметры JVM на старте, -ХХ определяет процесс работы
23%
Ничем, -X и -XX равнозначны
VM Options
— это параметры, которые указываются при запуске JVM. В этом посте расскажу, чем они отличаются, и как безопасно перейти на новую версию java. В конце будет список самых популярных (и полезных) опций.
Все JVM опции делятся на три группы:
⚙️ Стандартные
Пишутся через минус и поддерживаются всеми JVM.
Пример:
Начинаются на -Х и определяют базовые свойства JVM. Могут не работать во всех JVM, но если поддерживаются, то вряд ли удалятся.
Пример:
Начинаются на -ХХ и касаются внутренних механизмов JVM. Не поддерживаются всеми JVM, часто меняются и удаляются.
Пример:
Цикл отключения опций не совсем стандартный. В обычном коде что-то помечается Deprecated, и спустя время удаляется. VM Options используют более длинный цикл:
🔸 Deprecate: функционал работает, при запуске появляется warning
🔸 Obsolete: функция не выполняется, JVM пишет предупреждения
🔸 Expired: JVM не запускается
Многие опции очень нестабильны и часто меняются. Чтобы безопасно обновить версию java, нужно проверить набор опций через JaCoLine . Он подсветит устаревшие или уже бесполезные опции.
Полезные опции для java 11
(да, недавно вышла java 20, но самая популярная версия всё ещё 11)
1️⃣ Память
▫️ Начальный размер хипа:
▫️ Максимальный размер хипа:
▫️ Serial GC:
▫️ ZGC:
⚙️ Нестандартные:
— это параметры, которые указываются при запуске JVM. В этом посте расскажу, чем они отличаются, и как безопасно перейти на новую версию java. В конце будет список самых популярных (и полезных) опций.
Все JVM опции делятся на три группы:
⚙️ Стандартные
Пишутся через минус и поддерживаются всеми JVM.
Пример:
-classpath, -server, -version
⚙️ НестандартныеНачинаются на -Х и определяют базовые свойства JVM. Могут не работать во всех JVM, но если поддерживаются, то вряд ли удалятся.
Пример:
-Xmx, -Xms
⚙️ ПродвинутыеНачинаются на -ХХ и касаются внутренних механизмов JVM. Не поддерживаются всеми JVM, часто меняются и удаляются.
Пример:
-XX:MaxGCPauseMillis=500
Некоторые продвинутые опции требуют дополнительных флажков. Для экспериментальных фич обязателен -XX:+UnlockExperimentalVMOptions. Многие фичи диагностики не заработают без -XX:+UnlockDiagnosticVMOptions
Количество опций часто меняется. В 11 версии OpenJDK 1504 опции, а в 17 на 200 опций меньше.Цикл отключения опций не совсем стандартный. В обычном коде что-то помечается Deprecated, и спустя время удаляется. VM Options используют более длинный цикл:
🔸 Deprecate: функционал работает, при запуске появляется warning
🔸 Obsolete: функция не выполняется, JVM пишет предупреждения
🔸 Expired: JVM не запускается
Многие опции очень нестабильны и часто меняются. Чтобы безопасно обновить версию java, нужно проверить набор опций через JaCoLine . Он подсветит устаревшие или уже бесполезные опции.
Полезные опции для java 11
(да, недавно вышла java 20, но самая популярная версия всё ещё 11)
1️⃣ Память
▫️ Начальный размер хипа:
-Xms256m в абсолютных значениях, -XX:InitialRAMPercentage=60 - в процентах от RAM▫️ Максимальный размер хипа:
-Xmx8g или -XX:MaxRAMPercentage=60
▫️ Снять heap dump при переполнении памяти: -XX:+HeapDumpOnOutOfMemoryError. Адрес выходного файла задаётся в -XX:HeapDumpPath
2️⃣ Сборщик мусора▫️ Serial GC:
-XX:+UseSerialGC
▫️ Parallel GC: -XX:+UseParalllGC
▫️ CMS: -XX:+UseConcMarkSweepGC
▫️ G1: -XX:+UseG1GC (вариант по умолчанию)▫️ ZGC:
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC
▫️ Shenandoah: -XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC
Вывести статистику сборщика при завершении работы: -XX:+UnlockDiagnosticVMOptions ‑XX:NativeMemoryTracking=summary ‑XX:+PrintNMTStatistics
Базовое логгирование коллектора: -Xlog:gc
Максимально информативное: -Xlog:gc*
3️⃣ Посмотреть все доступные опции⚙️ Нестандартные:
java -X
⚙️ Продвинутые: java -XX:+UnlockDiagnosticVMOptions -XX:+UnlockExperimentalVMOptions -XX:+PrintFlagsFinalHashMap и принципы SOLID
На большинстве собесов спрашивают одно и то же. Как работает HashMap, принципы ООП и SOLID, разница абстрактного класса и интерфейса, жизненный цикл бина.
Когда я была junior/middle, 80% вопросов повторялись на каждом собеседовании. И вопросы возникали уже у меня:
🤔 Как интервьюеры поймут, что я топчик, если спрашивают такую банальщину?
🤔 Почему в вакансии целая страница требований и технологий, но мы ничего из этого не обсуждаем?
🤔 Может на проекте всё очень плохо, а код написан на java 6?
И только когда я начала собеседовать людей, то поняла, зачем это всё.
Всё дело в специфике найма джуниоров и мидлов.
На каждом проекте свой стэк, задачи и особенности. С рынка вряд ли придёт человек, который с ходу вольётся в проект, зная все нюансы технологий. В любом случае он будет немного доучиваться.
Поэтому важно, чтобы человек имел крепкий фундамент и был приятным в общении на технические темы. И стандартные вопросы подходят для этого великолепно:
1️⃣ Это база🤌
Желание обсудить саги и агрегаты это здорово, но большую часть времени разработчик проводит с кодом. Stream API, коммиты, структуры данных — в этом не должно быть пробелов.
В далёкие времена на собесах обсуждали только теорию и давали тесты с безумным синтаксисом и пропущенными скобками. Это довольно бесполезно, но всё ещё встречается.
Сегодня собесы больше ориентируются на практику. Бывает, что кандидат лихо объясняет synchronization order, но не видит ошибок в простом многопоточном коде. Не смущайтесь лёгких заданий, они не так просты, как кажутся:)
Время собеседования очень ограничено. Выделенные 30-60 минут лучше потратить на базу. Если с ней всё хорошо — остальное приложится
2️⃣ Легко сравнить кандидатов между собой
Если 10 человек расскажут устройство HashMap, получится 10 разных ответов.
Первый кандидат расскажет так, что ничего не понятно. Второй закопается в объяснении работы хэша и свернёт с темы. Третий оттараторит заученный текст и не поймёт дополнительный вопрос. Из четвёртого придётся тащить каждое предложение.
Поэтому часто стандартных вопросов достаточно, чтобы понять, насколько приятно общаться с человеком и как глубоко он понимает базу. Умничку видно сразу🙂
❓ Если спрашивают банальщину — значит проект скучный?
Для младших грейдов вопросы могут вообще не коррелировать с будущими задачами. И наоборот — алгоритмы и system design не означают, что будущая работа будет интересной и разнообразной
❓ Как выделиться среди других кандидатов, если задают только общие вопросы?
Если вас позвали на собес, значит вы уже прошли жёсткие фильтры, и резюме оставило приятное впечатление. Ваша задача — его закрепить
Если интервьюер чем-то заинтересуется в вашем опыте, он обязательно спросит:)
❗️ Я отвечал на всё правильно, но оффер не прислали!
Причина может быть вообще не в вас. Может пришёл кандидат с более релевантным опытом, или бюджет перераспределили на другие цели.
Найм — очень субъективный процесс. Интервьюер всегда найдёт, к чему прицепится, если у вас фамилия, как у его бывшей жены. И наоборот, если с первых минут установился контакт, даже небольшие ошибки не испортят впечатления.
На большинстве собесов спрашивают одно и то же. Как работает HashMap, принципы ООП и SOLID, разница абстрактного класса и интерфейса, жизненный цикл бина.
Когда я была junior/middle, 80% вопросов повторялись на каждом собеседовании. И вопросы возникали уже у меня:
🤔 Как интервьюеры поймут, что я топчик, если спрашивают такую банальщину?
🤔 Почему в вакансии целая страница требований и технологий, но мы ничего из этого не обсуждаем?
🤔 Может на проекте всё очень плохо, а код написан на java 6?
И только когда я начала собеседовать людей, то поняла, зачем это всё.
Всё дело в специфике найма джуниоров и мидлов.
На каждом проекте свой стэк, задачи и особенности. С рынка вряд ли придёт человек, который с ходу вольётся в проект, зная все нюансы технологий. В любом случае он будет немного доучиваться.
Поэтому важно, чтобы человек имел крепкий фундамент и был приятным в общении на технические темы. И стандартные вопросы подходят для этого великолепно:
1️⃣ Это база🤌
Желание обсудить саги и агрегаты это здорово, но большую часть времени разработчик проводит с кодом. Stream API, коммиты, структуры данных — в этом не должно быть пробелов.
В далёкие времена на собесах обсуждали только теорию и давали тесты с безумным синтаксисом и пропущенными скобками. Это довольно бесполезно, но всё ещё встречается.
Сегодня собесы больше ориентируются на практику. Бывает, что кандидат лихо объясняет synchronization order, но не видит ошибок в простом многопоточном коде. Не смущайтесь лёгких заданий, они не так просты, как кажутся:)
Время собеседования очень ограничено. Выделенные 30-60 минут лучше потратить на базу. Если с ней всё хорошо — остальное приложится
2️⃣ Легко сравнить кандидатов между собой
Если 10 человек расскажут устройство HashMap, получится 10 разных ответов.
Первый кандидат расскажет так, что ничего не понятно. Второй закопается в объяснении работы хэша и свернёт с темы. Третий оттараторит заученный текст и не поймёт дополнительный вопрос. Из четвёртого придётся тащить каждое предложение.
Поэтому часто стандартных вопросов достаточно, чтобы понять, насколько приятно общаться с человеком и как глубоко он понимает базу. Умничку видно сразу🙂
❓ Если спрашивают банальщину — значит проект скучный?
Для младших грейдов вопросы могут вообще не коррелировать с будущими задачами. И наоборот — алгоритмы и system design не означают, что будущая работа будет интересной и разнообразной
❓ Как выделиться среди других кандидатов, если задают только общие вопросы?
Если вас позвали на собес, значит вы уже прошли жёсткие фильтры, и резюме оставило приятное впечатление. Ваша задача — его закрепить
Если интервьюер чем-то заинтересуется в вашем опыте, он обязательно спросит:)
❗️ Я отвечал на всё правильно, но оффер не прислали!
Причина может быть вообще не в вас. Может пришёл кандидат с более релевантным опытом, или бюджет перераспределили на другие цели.
Найм — очень субъективный процесс. Интервьюер всегда найдёт, к чему прицепится, если у вас фамилия, как у его бывшей жены. И наоборот, если с первых минут установился контакт, даже небольшие ошибки не испортят впечатления.
Как отсортировать список ArrayList<Integer> list?
Anonymous Poll
43%
list.sort()
34%
list.sort(Comparator.naturalOrder())
13%
list.stream().sorted().toList()
46%
list = list.stream().sorted().toList()