
{kind=link}
Вопрос 2. Что выведется в консоль?
(интерфейс В теперь расширяет интерфейс А)
(интерфейс В теперь расширяет интерфейс А)
Anonymous Poll
29%
А
41%
В
31%
Ошибка компиляции
Интерфейсы, часть 2: методы по умолчанию
Когда готовила материал по дефолтным методам, то перечитала почти все переписки разработчиков этой фичи. Огромное удовольствие — следить за спором опытных людей с высокой инженерной культурой и мощными теоретическими знаниями. Профессионализм завораживает🥰
Но я расскажу вам итог. В java 8 появилась новая возможность — методы с заданной реализацией:
❓Зачем?
1️⃣ Облегчить изменения API
Во времена java 7 в интерфейсах были только определения методов:
Задача дефолтных методов — сгладить этот процесс, предоставить приемлемую или временную альтернативу. В JDK основная цель дефолтных методов — поддержка Stream API в коллекциях.
2️⃣ Вспомогательные методы
Которые не входят в прямую функциональность интерфейса, но их удобно добавить сюда, а не в каждый класс реализации. Нарушается принцип Interface segregation и часто похоже на костыль. Не одобряю, но такое встречается🙂
3️⃣ Комбинации базовых методов
Мы обсуждали это в прошлом посте. В интерфейсе есть методы, которые по сути — комбинация других методов этого же интерфейса.
Для таких комбинаций можно сделать статический метод. Он вызываются через имя интерфейса и недоступен у экземпляров. Если это неудобно, метод можно сделать как метод по умолчанию.
Пример: интерфейс
Правила такие:
🔸 Если в классе переопределён метод по умолчанию — используется метод класса
🔸 Если один интерфейс наследуется от другого — используется метод наследника
🔸 В остальных случаях — ошибка компиляции
Отсюда ответы на вопросы перед постом:
1️⃣ Ошибка компиляции
2️⃣ Напечатается В
Когда готовила материал по дефолтным методам, то перечитала почти все переписки разработчиков этой фичи. Огромное удовольствие — следить за спором опытных людей с высокой инженерной культурой и мощными теоретическими знаниями. Профессионализм завораживает🥰
Но я расскажу вам итог. В java 8 появилась новая возможность — методы с заданной реализацией:
interface Adapter {
default int get() {…}
}
Класс, который реализует интерфейс, переопределяет такой метод при необходимости.❓Зачем?
1️⃣ Облегчить изменения API
Во времена java 7 в интерфейсах были только определения методов:
interface Collection<Т> {
void add(Т);
Т get();
}
Чтобы добавить, удалить или поменять сигнатуру метода нужно одновременно поменять код и в интерфейсе, и во всех реализациях. Если всё в рамках одного проекта, то проблем нет. Но если мы пишем библиотеку, то задача усложняется. Пользователи могут столкнутся с проблемами совместимости при переходе на новую версию.Задача дефолтных методов — сгладить этот процесс, предоставить приемлемую или временную альтернативу. В JDK основная цель дефолтных методов — поддержка Stream API в коллекциях.
2️⃣ Вспомогательные методы
Которые не входят в прямую функциональность интерфейса, но их удобно добавить сюда, а не в каждый класс реализации. Нарушается принцип Interface segregation и часто похоже на костыль. Не одобряю, но такое встречается🙂
3️⃣ Комбинации базовых методов
Мы обсуждали это в прошлом посте. В интерфейсе есть методы, которые по сути — комбинация других методов этого же интерфейса.
Для таких комбинаций можно сделать статический метод. Он вызываются через имя интерфейса и недоступен у экземпляров. Если это неудобно, метод можно сделать как метод по умолчанию.
Пример: интерфейс
Comparator
Цепочка из 2 компараторов — это 2 вызова compare и объединение результатов. Логика всегда одинакова, и нет смысла дублировать её в каждом подклассе:default Comparator thenComparing(Comparator) {…};
❓Что если класс реализует 2 интерфейса с методами по умолчанию?Правила такие:
🔸 Если в классе переопределён метод по умолчанию — используется метод класса
🔸 Если один интерфейс наследуется от другого — используется метод наследника
🔸 В остальных случаях — ошибка компиляции
Отсюда ответы на вопросы перед постом:
1️⃣ Ошибка компиляции
2️⃣ Напечатается В
Интерфейсы, часть 3: разница с абстрактным классом
Отличия интерфейса и абстрактного класса — супер популярный вопрос на собеседовании. Во времена java 7 ответ был простой: "В интерфейсе нет реализаций".
Сейчас мир стал сложнее, и в интерфейсе есть приватные, статические и дефолтные методы с готовой реализацией. Это сближает интерфейсы с абстрактными классами.
❓В чём теперь разница интерфейса и абстрактного класса?
🛠 Функциональность
В абстрактный класс можно добавить многое:
▪️Конструктор
▪️Реализация экземплярных методов
▪️Нестатические поля
▪️private static поля
▪️Модификаторы final, synchronized, protected
Интерфейс сильно ограничен:
▪️Только статические поля
▪️Методам с реализацией недоступны экземплярные поля, поэтому их возможности слабее
✍🏻 Синтаксис
Абстрактный класс:
▫️ Ключевое слово
▫️ Класс реализует не больше одного абстрактного класса
Интерфейс:
▫️ Ключевое слово
▫️ Класс может реализовать несколько интерфейсов
▫️ 5 лет назад интерфейсам было модно добавлять суффикс able: Iterable, Comparable. Норма сегодняшнего дня — называть интерфейс по тем же правилам, что и класс.
💫 Назначение
Абстрактный класс — шаблон класса. Вспомогательная структура, чтобы не дублировать код в классах одной иерархии.
Интерфейс описывает методы для верхнеуровнего взаимодействия с классом, модулем или системой.
⭐️ Репутация
Абстрактный класс сокращает объем необходимого кода, когда иерархия классов конечна или известна заранее. Большое количество абстрактных классов считается анти-паттерном, у такой системы плохая читаемость, и в неё сложно вносить изменения.
Интерфейс используется в большинстве паттернов GoF и принципах SOLID. Поддерживает инкапсуляцию.
Отличия интерфейса и абстрактного класса — супер популярный вопрос на собеседовании. Во времена java 7 ответ был простой: "В интерфейсе нет реализаций".
Сейчас мир стал сложнее, и в интерфейсе есть приватные, статические и дефолтные методы с готовой реализацией. Это сближает интерфейсы с абстрактными классами.
❓В чём теперь разница интерфейса и абстрактного класса?
🛠 Функциональность
В абстрактный класс можно добавить многое:
▪️Конструктор
▪️Реализация экземплярных методов
▪️Нестатические поля
▪️private static поля
▪️Модификаторы final, synchronized, protected
Интерфейс сильно ограничен:
▪️Только статические поля
▪️Методам с реализацией недоступны экземплярные поля, поэтому их возможности слабее
✍🏻 Синтаксис
Абстрактный класс:
▫️ Ключевое слово
extends
▫️ В имени часто содержится Abstract, Template, Base▫️ Класс реализует не больше одного абстрактного класса
Интерфейс:
▫️ Ключевое слово
implements ▫️ Класс может реализовать несколько интерфейсов
▫️ 5 лет назад интерфейсам было модно добавлять суффикс able: Iterable, Comparable. Норма сегодняшнего дня — называть интерфейс по тем же правилам, что и класс.
💫 Назначение
Абстрактный класс — шаблон класса. Вспомогательная структура, чтобы не дублировать код в классах одной иерархии.
Интерфейс описывает методы для верхнеуровнего взаимодействия с классом, модулем или системой.
⭐️ Репутация
Абстрактный класс сокращает объем необходимого кода, когда иерархия классов конечна или известна заранее. Большое количество абстрактных классов считается анти-паттерном, у такой системы плохая читаемость, и в неё сложно вносить изменения.
Интерфейс используется в большинстве паттернов GoF и принципах SOLID. Поддерживает инкапсуляцию.
Настоящий сеньор
Иногда в айтишных разговорах проскакивают фразы:
— Я уже полгода сеньор, но чувствую себя мидлом
— Вроде сеньор, но задачи делаю те же, что и раньше
— Мне слишком много платят за ту ерунду, которую я делаю
Это типичный синдром самозванца, и жить с ним неприятно. Что может помочь:
1️⃣ Признать текущие заслуги
"Настоящий сеньор" — это как настоящий мужчина. Как будто он делает что-то особенное, чтобы стань "настоящим".
Сеньором не делают заранее, должность выдают по факту. Будучи мидлом вы уже делали сеньорные задачи. Так что на текущем проекте вы точно на своём месте👍
2️⃣ Следить за общей ситуацией
Даже если не хотите менять работу, полезно раз в полгода-год следить за рынком:
◾️ Обновить резюме и вписать последние достижения
◾️ Посмотреть 20 вакансий HeadHunter и наметить план развития
◾️ Походить по собеседованиям и увидеть свои пробелы. Если получится оффер, то самооценка взлетит до небес🙂
В одной компании тебя зовут в СТО, в другой даже джуниором не возьмут. Все проекты разные, и требования везде разные. Расскажу своё видение, чем отличается сеньор от мидла:
Hard skills
▪️ Ориентироваться в популярных технологиях. Зачем нужны, плюсы-минусы, аналоги. Список технологий можно взять здесь. Он 2020 года, но ситуация не слишком поменялась
▪️ Настроить простой CI
▪️ Поднять систему с нуля с простой архитектурой (микросервисы, БД, очереди)
▪️ Работать с перфоманс проблемами. Знать, где посмотреть логи, что смотреть и как проверить, что проблема ушла
▪️ Целостное восприятие IT
Тут сложно дать конкретный список. Просто очень странно выглядит сеньор, который не знает, что такое DNS и как масштабировать БД.
Soft skills
▪️ Самостоятельность
Сеньор может взять любую задачу и продвинуть её решение. Прикинуть, на каком уровне решать задачу (на фронте, в бизнес-логике, поправить конфиги, исправить ошибку в БД). Разбить на подзадачи и определить приоритеты. Сформулировать вопрос, если не хватает данных или компетенций. Предложить разные решения для разных требований
▪️ Контроль джуниоров и мидлов — провести онбординг и код-ревью, понятно отвечать на вопросы и делегировать подходящие задачи
▪️ Психологическая зрелость (не знаю как ещё назвать) — принимать решения в условиях неопределённости, признавать свою неправоту и незнание. Не заметать проблемы под ковёр и понимать приоритеты. Уважительно и продуктивно общаться. Понимать, когда устал/раздражён, и не принимать серьёзных решений в этом состоянии. Спокойно удалять свой код, если он не нужен.
Но ещё раз — чётких стандартов нет. Каждый, кто уже стал сеньором, заслужил этот грейд, проделал большой путь и хорошо делал свою работу🔥
Иногда в айтишных разговорах проскакивают фразы:
— Я уже полгода сеньор, но чувствую себя мидлом
— Вроде сеньор, но задачи делаю те же, что и раньше
— Мне слишком много платят за ту ерунду, которую я делаю
Это типичный синдром самозванца, и жить с ним неприятно. Что может помочь:
1️⃣ Признать текущие заслуги
"Настоящий сеньор" — это как настоящий мужчина. Как будто он делает что-то особенное, чтобы стань "настоящим".
Сеньором не делают заранее, должность выдают по факту. Будучи мидлом вы уже делали сеньорные задачи. Так что на текущем проекте вы точно на своём месте👍
2️⃣ Следить за общей ситуацией
Даже если не хотите менять работу, полезно раз в полгода-год следить за рынком:
◾️ Обновить резюме и вписать последние достижения
◾️ Посмотреть 20 вакансий HeadHunter и наметить план развития
◾️ Походить по собеседованиям и увидеть свои пробелы. Если получится оффер, то самооценка взлетит до небес🙂
В одной компании тебя зовут в СТО, в другой даже джуниором не возьмут. Все проекты разные, и требования везде разные. Расскажу своё видение, чем отличается сеньор от мидла:
Hard skills
▪️ Ориентироваться в популярных технологиях. Зачем нужны, плюсы-минусы, аналоги. Список технологий можно взять здесь. Он 2020 года, но ситуация не слишком поменялась
▪️ Настроить простой CI
▪️ Поднять систему с нуля с простой архитектурой (микросервисы, БД, очереди)
▪️ Работать с перфоманс проблемами. Знать, где посмотреть логи, что смотреть и как проверить, что проблема ушла
▪️ Целостное восприятие IT
Тут сложно дать конкретный список. Просто очень странно выглядит сеньор, который не знает, что такое DNS и как масштабировать БД.
Soft skills
▪️ Самостоятельность
Сеньор может взять любую задачу и продвинуть её решение. Прикинуть, на каком уровне решать задачу (на фронте, в бизнес-логике, поправить конфиги, исправить ошибку в БД). Разбить на подзадачи и определить приоритеты. Сформулировать вопрос, если не хватает данных или компетенций. Предложить разные решения для разных требований
▪️ Контроль джуниоров и мидлов — провести онбординг и код-ревью, понятно отвечать на вопросы и делегировать подходящие задачи
▪️ Психологическая зрелость (не знаю как ещё назвать) — принимать решения в условиях неопределённости, признавать свою неправоту и незнание. Не заметать проблемы под ковёр и понимать приоритеты. Уважительно и продуктивно общаться. Понимать, когда устал/раздражён, и не принимать серьёзных решений в этом состоянии. Спокойно удалять свой код, если он не нужен.
Но ещё раз — чётких стандартов нет. Каждый, кто уже стал сеньором, заслужил этот грейд, проделал большой путь и хорошо делал свою работу🔥
Работа с задачами в Intellij iDEA
Полезно для тех, кто часто переключается между задачами.
1️⃣ Для энтерпрайза
В IDEA можно присоединиться к JIRA или другому таск трекеру, и у каждой задачи автоматически будет свой контекст.
Контекст — это открытые вкладки и git ветка.
Переключаетесь на другую задачу — автоматически открывается её набор вкладок и меняется ветка в гите.
Есть интеграция с популярными таск трекерами: JIRA, Trello, Github, Bugzilla и тд
Как подключить:
File → Settings → Tools → Tasks → Servers → Плюсик в правом верхнем углу
2️⃣ Для личных проектов
Можно сделать свой таск трекер внутри идеи:
Tools → Tasks & Contexts → Open Task
Дальше вводите название задачи. Их список затем доступен в правом верхнем углу.
ОЧЕНЬ полезно, если вы часто переключаетесь между задачами и цените свои вкладочки🥰
У таск трекера в IDEA есть близкая фича — можно следить, сколько времени потрачено на каждую задачу:
File → Settings → Tools → Tasks → Time Tracking → Enable Time Tracking
IDEA показывает только полное время работы. Нельзя посмотреть статистику за день и внести её в корпоративный трекер, так что для рабочих проектов эта фича скорее бесполезна.
Полезно для тех, кто часто переключается между задачами.
1️⃣ Для энтерпрайза
В IDEA можно присоединиться к JIRA или другому таск трекеру, и у каждой задачи автоматически будет свой контекст.
Контекст — это открытые вкладки и git ветка.
Переключаетесь на другую задачу — автоматически открывается её набор вкладок и меняется ветка в гите.
Есть интеграция с популярными таск трекерами: JIRA, Trello, Github, Bugzilla и тд
Как подключить:
File → Settings → Tools → Tasks → Servers → Плюсик в правом верхнем углу
2️⃣ Для личных проектов
Можно сделать свой таск трекер внутри идеи:
Tools → Tasks & Contexts → Open Task
Дальше вводите название задачи. Их список затем доступен в правом верхнем углу.
ОЧЕНЬ полезно, если вы часто переключаетесь между задачами и цените свои вкладочки🥰
У таск трекера в IDEA есть близкая фича — можно следить, сколько времени потрачено на каждую задачу:
File → Settings → Tools → Tasks → Time Tracking → Enable Time Tracking
IDEA показывает только полное время работы. Нельзя посмотреть статистику за день и внести её в корпоративный трекер, так что для рабочих проектов эта фича скорее бесполезна.
Сбой в работе Wildberries
Сегодня необычный пост — расскажу вам новости и слухи🙂
С 14 марта в работе Wildberries наблюдались сбои — главная страница открывается, но пропали данные о прошлых заказах, новые заказы не оформляются, а в личном кабинете не отображается имя пользователя. Компания пишет о технических сбоях, но в интернете ходят слухи, что это хакерская атака.
Известных деталей мало, а я не спец в кибербезопасности. Пишу свои предположения на основе слухов и похожих случаев. На самом деле может быть по-другому.
Вероятный ход событий:
1️⃣ Сотрудник в Wildberries получил письмо со ссылкой, щёлкнул по ней и скачал дроппер.
Дроппер — программа, которая устанавливает другое вредоносное ПО и по возможности нейтрализует защиту ОС. В Windows дропперы часто выключают службу, которая предупреждает о попытках внести изменения в систему.
Письмо выглядит правдоподобно — красивая разметка, официальный стиль, актуальные новости. Это самое популярное начало атаки:
🔸 В начале пандемии COVID-19 компаниям приходили "рекомендации" по безопасной работе
🔸 Руководителю одного банка пришло письмо “журналистки РБК” с просьбой об интервью. Ссылка ведёт якобы на календарь, чтобы назначить удобное время
🔸 Во время белорусских протестов компаниям-партнёрам приходила рассылка: "Мы бастуем, поэтому к вам может прийти прокуратура с проверкой. Посмотрите по ссылке список интересующих их документов"
2️⃣ Сотрудник вышел из корпоративной сети, и дроппер скачал вредоносное ПО, который настроил удалённый доступ к компьютеру сотрудника.
Но может сотрудник сделал всё сам. Плохие люди тоже встречаются.
3️⃣ В продакшн внедряются маячки из Cobalt Strike
Cobalt Strike — это легальный инструмент тестирования безопасности, используется как безопасниками, так и хакерами. По статистике около 2/3 атак на крупные компании выполняется с помощью Cobalt
4️⃣ Удаляются резервные копии
5️⃣ Оставшиеся данные шифруются
6️⃣ Компании приходит письмо
"Пришлите столько-то биткоинов на этот кошелёк и получите дешифратор".
Иногда добавляются угрозы рассекретить информацию. Дальше всё зависит от инфраструктуры. Если у компании все бэкапы в одной подсети, и они уничтожены, то дело плохо. Всё хорошо, если остались репликации в других местах.
❓ Что с картами?
Вайдберрис пишет, что эти данные защищены по стандартам PCI DSS. Но по слухам в Даркнет утекли данные 100к российских карт за последние 3 дня. Я на всякий случай перевыпустила свою карту.
Надеюсь, в ближайшее время появится больше информации, и сама компания опишет ситуацию из первых рук. Тогда опыт Wildberries поможет другим компаниям🙏
Сегодня необычный пост — расскажу вам новости и слухи🙂
С 14 марта в работе Wildberries наблюдались сбои — главная страница открывается, но пропали данные о прошлых заказах, новые заказы не оформляются, а в личном кабинете не отображается имя пользователя. Компания пишет о технических сбоях, но в интернете ходят слухи, что это хакерская атака.
Известных деталей мало, а я не спец в кибербезопасности. Пишу свои предположения на основе слухов и похожих случаев. На самом деле может быть по-другому.
Вероятный ход событий:
1️⃣ Сотрудник в Wildberries получил письмо со ссылкой, щёлкнул по ней и скачал дроппер.
Дроппер — программа, которая устанавливает другое вредоносное ПО и по возможности нейтрализует защиту ОС. В Windows дропперы часто выключают службу, которая предупреждает о попытках внести изменения в систему.
Письмо выглядит правдоподобно — красивая разметка, официальный стиль, актуальные новости. Это самое популярное начало атаки:
🔸 В начале пандемии COVID-19 компаниям приходили "рекомендации" по безопасной работе
🔸 Руководителю одного банка пришло письмо “журналистки РБК” с просьбой об интервью. Ссылка ведёт якобы на календарь, чтобы назначить удобное время
🔸 Во время белорусских протестов компаниям-партнёрам приходила рассылка: "Мы бастуем, поэтому к вам может прийти прокуратура с проверкой. Посмотрите по ссылке список интересующих их документов"
2️⃣ Сотрудник вышел из корпоративной сети, и дроппер скачал вредоносное ПО, который настроил удалённый доступ к компьютеру сотрудника.
Но может сотрудник сделал всё сам. Плохие люди тоже встречаются.
3️⃣ В продакшн внедряются маячки из Cobalt Strike
Cobalt Strike — это легальный инструмент тестирования безопасности, используется как безопасниками, так и хакерами. По статистике около 2/3 атак на крупные компании выполняется с помощью Cobalt
4️⃣ Удаляются резервные копии
5️⃣ Оставшиеся данные шифруются
6️⃣ Компании приходит письмо
"Пришлите столько-то биткоинов на этот кошелёк и получите дешифратор".
Иногда добавляются угрозы рассекретить информацию. Дальше всё зависит от инфраструктуры. Если у компании все бэкапы в одной подсети, и они уничтожены, то дело плохо. Всё хорошо, если остались репликации в других местах.
❓ Что с картами?
Вайдберрис пишет, что эти данные защищены по стандартам PCI DSS. Но по слухам в Даркнет утекли данные 100к российских карт за последние 3 дня. Я на всякий случай перевыпустила свою карту.
Надеюсь, в ближайшее время появится больше информации, и сама компания опишет ситуацию из первых рук. Тогда опыт Wildberries поможет другим компаниям🙏
Списки — простая структура данных и популярная тема на собеседованиях.
Просят рассказать про строение, оценить сложность операций и случаи использования. Отвечаешь, что в
Но это немного скучно, поэтому решила описать более жизненные кейсы и подробнее написать про строение. И самое главное — измерить время работы операций!
🔸 Часть 1: вводная. Строение списков и основные операции
🔸 Часть 2: жизненная. Что и когда использовать в коде
Просят рассказать про строение, оценить сложность операций и случаи использования. Отвечаешь, что в
ArrayList быстрый доступ по индексу, а в LinkedList легко вставлять элементы в середину списка. Получаешь оффер🙂Но это немного скучно, поэтому решила описать более жизненные кейсы и подробнее написать про строение. И самое главное — измерить время работы операций!
🔸 Часть 1: вводная. Строение списков и основные операции
🔸 Часть 2: жизненная. Что и когда использовать в коде
{kind=link}
Какой список в коде выше заполняется быстрее?
Anonymous Poll
17%
ArrayList в 6 раз быстрее
12%
LinkedList в 6 раз быстрее
21%
ArrayList быстрее в 1.5 раза
20%
LinkedList быстрее в 1.5 раза
30%
Примерно одинаково
Списки, часть 1: строение и основные операции
1. Внутреннее устройство
В сердце ArrayList лежит массив:
Структура LinkedList чуть сложнее. Каждый элемент оборачивается в класс:
В объекте LinkedList хранится ссылка на первый и последний элемент списка:
ArrayList просто обращается по индексу массива
LinkedList идёт долгим путём. Берёт элемент first идёт по ссылкам, пока не дойдёт до i-го элемента. Затем либо возвращает значение, либо обновляет.
Кажется, что второй подход гораздо дольше. И это правда🙂
Чтобы получить 5000-ый элемент в списке из 10к элементов ArrayList тратит 6 наносекунд, а LinkedList — 8750. Чем больше элементов, тем больше разница.
3. Вставка в середину списка
ArrayList
Допустим, для списка 🟧🟧🟧🟧 вызвали метод add(2, 🦄)
Создаётся новый массив размером +1:
⬜️⬜️⬜️⬜️⬜️
Все элементы старого списка копируются туда так, чтобы образовалось свободное место для нового элемента:
🟧🟧⬜️🟧🟧
Обновляем элемент:
🟧🟧🦄🟧🟧
LinkedList
Рассмотрим тот же метод add(2, 🦄):
▫️ Создаём элемент списка с двумя ссылками: ⬅️🦄➡️
▫️ Идём до текущего элемента 2 и получаем ссылки на элементы 1 и 3
▫️ У элемента 1 обновляем ссылку на next, у 3 — на prev
Само добавление простое, но перед ним нужно пройтись по списку. Это долго, поэтому LinkedList и здесь проигрывает по скорости.
4. Заполнение списка
(см код в вопросе перед постом)
ArrayList
▫️ Создаётся пустой массив
▫️ При первом add размер увеличивается до 10
▫️ При добавлении 11 элемента создаётся новый массив размером 15. Предыдущие элементы копируются, затем добавляется новый
▫️ И так далее: когда места не хватает, создаётся массив в 1.5 раза больше
LinkedList
У текущего tail элемента обновляется ссылка next. Новый объект записывается как tail.
Что работает быстрее?
Интуиция подсказывает, что LinkedList, так как для ArrayList нужно часто переносить элементы в новый массив. На самом деле операции копирования выполняются быстро, так как элементы лежат в памяти рядом, а у процессоров хорошая поддержка этой операции.
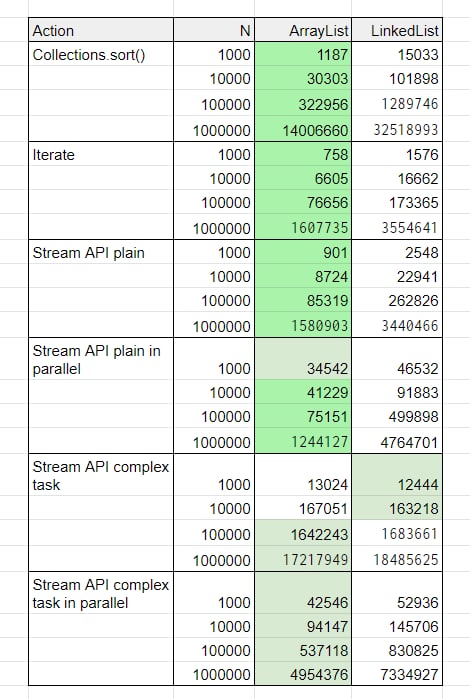
Бенчмарки показывают, что до 100к элементов разницы нет, а потом побеждает ArrayList. А при миллионе элементов ArrayList копируется реже и в итоге заполняется в два раза быстрее.
Внизу таблица JMH бенчмарков с моего компьютера. На других железках результаты могут отличаться.
Ответ на вопрос перед постом: для 50к элементов время почти одинаковое.
1. Внутреннее устройство
В сердце ArrayList лежит массив:
Object[] elementData;Размер массива задаётся в конструкторе:
new ArrayList(50). Значение по умолчанию — пустой массив.Структура LinkedList чуть сложнее. Каждый элемент оборачивается в класс:
private static class Node {
E item;
Node next;
Node prev;
}
Т.е сам элемент списка + указатели на следующий и предыдущий элемент.В объекте LinkedList хранится ссылка на первый и последний элемент списка:
Node first;2. Доступ по индексу: list.get(i) или list.set(i)
Node last;
ArrayList просто обращается по индексу массива
LinkedList идёт долгим путём. Берёт элемент first идёт по ссылкам, пока не дойдёт до i-го элемента. Затем либо возвращает значение, либо обновляет.
Кажется, что второй подход гораздо дольше. И это правда🙂
Чтобы получить 5000-ый элемент в списке из 10к элементов ArrayList тратит 6 наносекунд, а LinkedList — 8750. Чем больше элементов, тем больше разница.
3. Вставка в середину списка
ArrayList
Допустим, для списка 🟧🟧🟧🟧 вызвали метод add(2, 🦄)
Создаётся новый массив размером +1:
⬜️⬜️⬜️⬜️⬜️
Все элементы старого списка копируются туда так, чтобы образовалось свободное место для нового элемента:
🟧🟧⬜️🟧🟧
Обновляем элемент:
🟧🟧🦄🟧🟧
LinkedList
Рассмотрим тот же метод add(2, 🦄):
▫️ Создаём элемент списка с двумя ссылками: ⬅️🦄➡️
▫️ Идём до текущего элемента 2 и получаем ссылки на элементы 1 и 3
▫️ У элемента 1 обновляем ссылку на next, у 3 — на prev
Само добавление простое, но перед ним нужно пройтись по списку. Это долго, поэтому LinkedList и здесь проигрывает по скорости.
4. Заполнение списка
(см код в вопросе перед постом)
ArrayList
▫️ Создаётся пустой массив
▫️ При первом add размер увеличивается до 10
▫️ При добавлении 11 элемента создаётся новый массив размером 15. Предыдущие элементы копируются, затем добавляется новый
▫️ И так далее: когда места не хватает, создаётся массив в 1.5 раза больше
LinkedList
У текущего tail элемента обновляется ссылка next. Новый объект записывается как tail.
Что работает быстрее?
Интуиция подсказывает, что LinkedList, так как для ArrayList нужно часто переносить элементы в новый массив. На самом деле операции копирования выполняются быстро, так как элементы лежат в памяти рядом, а у процессоров хорошая поддержка этой операции.
Бенчмарки показывают, что до 100к элементов разницы нет, а потом побеждает ArrayList. А при миллионе элементов ArrayList копируется реже и в итоге заполняется в два раза быстрее.
Внизу таблица JMH бенчмарков с моего компьютера. На других железках результаты могут отличаться.
Ответ на вопрос перед постом: для 50к элементов время почти одинаковое.
{kind=link}
Списки, часть 2: что и когда использовать
В большинстве статей пишут, что LinkedList подходит для частой вставки или удаления элементов. На JavaRush также упоминают обход списка с периодической вставкой.
В теории всё так, но обычно в энтерпрайзе менее изысканные задачи:
🔸 Заполнить список
🔸 Отсортировать (встроенной функцией, конечно)
🔸 Обойти все элементы
🔸 Сделать что-нибудь с помощью Stream API
Для этих сценариев я сделала бенчмарки. У Stream API выделила 4 случая:
▫️ Простой однопоточный: stream→filter→collect
▫️ Сложный однопоточный: stream→map→filter→map→filter→collect
▫️ Простой с опцией parallel()
▫️ Сложный с опцией parallel()
Начнём с заполнения списка.
В прошлом посте выяснили, что до 100к элементов между списками почти нет разницы. ArrayList тратит много времени на копирование, а LinkedList — на создание обёрток и соединение ссылок.
Если количество элементов известно заранее, его можно указать в конструкторе:
Также ArrayList однозначно победил в номинациях:
🔹 Сортировка
🔹 Обход через цикл for
🔹 Простые Stream API
🔹 Любые Stream API с опцией parallel()
В сложных однопоточных Stream API большая часть вычислений идёт на что-то полезное, и влияние оверхеда снижается. Ожидаемо:)
Ещё факты против LinkedList:
🔸 Большинство классов JDK используют ArrayList для внутренних задач
🔸 Joshua Bloch (автор класса и книжки Effective Java) в 2015 написал твит:
На картинке часть моих бенчмарков. N — количество элементов в списке. Зелёный цвет обозначает победителя в категории. Ярко-зелёный — разница значений более 50%.
❗️Результаты на разных железках могут отличаться ❗️
В большинстве статей пишут, что LinkedList подходит для частой вставки или удаления элементов. На JavaRush также упоминают обход списка с периодической вставкой.
В теории всё так, но обычно в энтерпрайзе менее изысканные задачи:
🔸 Заполнить список
🔸 Отсортировать (встроенной функцией, конечно)
🔸 Обойти все элементы
🔸 Сделать что-нибудь с помощью Stream API
Для этих сценариев я сделала бенчмарки. У Stream API выделила 4 случая:
▫️ Простой однопоточный: stream→filter→collect
▫️ Сложный однопоточный: stream→map→filter→map→filter→collect
▫️ Простой с опцией parallel()
▫️ Сложный с опцией parallel()
Начнём с заполнения списка.
В прошлом посте выяснили, что до 100к элементов между списками почти нет разницы. ArrayList тратит много времени на копирование, а LinkedList — на создание обёрток и соединение ссылок.
Если количество элементов известно заранее, его можно указать в конструкторе:
List list = new ArrayList(25);Без лишнего копирования и переносов разница в скорости становится ошеломительной — список заполняется на 20-80% быстрее!
Также ArrayList однозначно победил в номинациях:
🔹 Сортировка
🔹 Обход через цикл for
🔹 Простые Stream API
🔹 Любые Stream API с опцией parallel()
В сложных однопоточных Stream API большая часть вычислений идёт на что-то полезное, и влияние оверхеда снижается. Ожидаемо:)
Ещё факты против LinkedList:
🔸 Большинство классов JDK используют ArrayList для внутренних задач
🔸 Joshua Bloch (автор класса и книжки Effective Java) в 2015 написал твит:
"Does anyone actually use LinkedList? I wrote it, and I never use it."Но аналоги LinkedList иногда встречаются. В Scala для неизменяемого списка за основу взят именно двусвязный. Возможно, это лучше для каких-то сценариев, но пока не знаю для каких.
На картинке часть моих бенчмарков. N — количество элементов в списке. Зелёный цвет обозначает победителя в категории. Ярко-зелёный — разница значений более 50%.
❗️Результаты на разных железках могут отличаться ❗️
{kind=link}
Небольшой апдейт: в scala список односвязный
Спасибо неравнодушным подписчикам!
Спасибо неравнодушным подписчикам!
Что такое идемпотентность?
Anonymous Poll
10%
Отсутствие сайд-эффектов при вызове метода
18%
Однократный side effect при многократном вызове метода
5%
Отсутствие исключений при повторном вызове с теми же параметрами
59%
Одно и то же возвращаемое значение при одинаковых входных данных
8%
Что-то с мужчинами после 50
Идемпотентность
Идемпотентная операция — операция, которая при многократном вызове оставляет систему в одном и том же состоянии. Это значит, что:
🔸 Возвращаемый результат один и тот же
🔸 Сайд эффекты не накапливаются
Неважно сколько раз вызван метод — эффект будет одинаковый. Что может быть сайд-эффектом: запись в БД, обновление статистики, запись в файл, изменение общих переменных.
Примеры идемпотентных операций:
✅ Удалить элемент с id=50
(10 вызовов → 1 удаление)
❌ Удалить элемент максимального размера
(10 вызовов → 10 удалённых элементов)
✅ Прочитать число из БД, умножить результат на 2 и вернуть пользователю
❌ Прочитать число из БД и обновить статистику запросов
В чём смысл?
Идемпотентные операции повышают устойчивость системы.
Допустим, мы отправили запрос на сервер, и соединение пропало. Спустя 3 секунды восстановилось. Возникает дилемма:
🤔 Отправить запрос ещё раз? Но вдруг он уже был обработан…
🤔 Может не отправлять? А если предыдущий пропал…
Запрос либо дублируется, либо теряется. Для идемпотентного запроса такой проблемы нет, можно спокойно отправить его ещё раз.
На собеседованиях вопрос идемпотентности обычно обсуждают со стороны HTTP вызовов. Нужно сказать, что
Но жизнь чуть сложнее.
🔹 Во-первых, идемпотентность зависит от бизнес-логики, а не от выбранного метода
Здесь самое сложное — держать под контролем сайд эффекты. Возьмём как пример увеличение счётчика в БД:
Добавить в таблицу (и сущность) поле version. Клиент передаёт номер текущей версии при обновлении. Запрос получается такой:
Клиент генерирует ID и добавляет его в хэдер HTTP запроса:
Процесс фильтрации дубликатов называется дедупликацией.
❓ Выглядит как лишняя сложность, нужна ли вообще идемпотентность?
Исходная проблема — что делать с только что отправленными запросами при потере связи. Идемпотентность и повторная отправка — рабочий способ, но не единственный. О другом расскажу в следующем посте.
Идемпотентная операция — операция, которая при многократном вызове оставляет систему в одном и том же состоянии. Это значит, что:
🔸 Возвращаемый результат один и тот же
🔸 Сайд эффекты не накапливаются
Неважно сколько раз вызван метод — эффект будет одинаковый. Что может быть сайд-эффектом: запись в БД, обновление статистики, запись в файл, изменение общих переменных.
Примеры идемпотентных операций:
✅ Удалить элемент с id=50
(10 вызовов → 1 удаление)
❌ Удалить элемент максимального размера
(10 вызовов → 10 удалённых элементов)
✅ Прочитать число из БД, умножить результат на 2 и вернуть пользователю
❌ Прочитать число из БД и обновить статистику запросов
В чём смысл?
Идемпотентные операции повышают устойчивость системы.
Допустим, мы отправили запрос на сервер, и соединение пропало. Спустя 3 секунды восстановилось. Возникает дилемма:
🤔 Отправить запрос ещё раз? Но вдруг он уже был обработан…
🤔 Может не отправлять? А если предыдущий пропал…
Запрос либо дублируется, либо теряется. Для идемпотентного запроса такой проблемы нет, можно спокойно отправить его ещё раз.
На собеседованиях вопрос идемпотентности обычно обсуждают со стороны HTTP вызовов. Нужно сказать, что
GET, PUT and DELETE идемпотентные, а POST — нет.Но жизнь чуть сложнее.
🔹 Во-первых, идемпотентность зависит от бизнес-логики, а не от выбранного метода
Здесь самое сложное — держать под контролем сайд эффекты. Возьмём как пример увеличение счётчика в БД:
UPDATE t SET value=value+1Как сделать его идемпотентным?
Добавить в таблицу (и сущность) поле version. Клиент передаёт номер текущей версии при обновлении. Запрос получается такой:
UPDATE t SET value=value+1, version=version+1 WHERE version=88🔹 Во-вторых, POST запросы можно сделать идемпотентными. Например так:
Клиент генерирует ID и добавляет его в хэдер HTTP запроса:
Idempotency-Key: 4872934Сервис хранит у себя список ID недавних запросов. Если операции с таким ID ещё не было, сервис начнет выполнение.
Процесс фильтрации дубликатов называется дедупликацией.
❓ Выглядит как лишняя сложность, нужна ли вообще идемпотентность?
Исходная проблема — что делать с только что отправленными запросами при потере связи. Идемпотентность и повторная отправка — рабочий способ, но не единственный. О другом расскажу в следующем посте.
Гарантии доставки
Вспомним проблему из прошлого поста.
Мы отправили запрос, соединение тут же пропало и восстановилось через 3 секунды. Что делать с запросом?
Если запрос идемпотентный, спокойно повторяем отправку.
❓А если нет?
Тогда выбираем одну из трёх стратегий: at least once, at most once или exactly once.
Вообще эти термины используются для месседж брокеров и доставки сообщений, но те же принципы верны для HTTP запросов и любого взаимодействия.
В чём суть:
1️⃣ At most once
Получатель не хочет разбираться с дубликатами, и потеря сообщений это ок. Поэтому повторно ничего не отправляем.
2️⃣ At least once
В процесс общения добавляется 1 шаг — уведомление о получении. Отправитель повторяет запрос, пока не получит уведомление.
✅ Сообщение точно будет доставлено
❌ Может быть доставлено несколько раз
3️⃣ Exactly once
Идеальный вариант: когда дубликаты не нужны, и потеря сообщений неприемлема.
Общая схема простая. У каждого сообщения есть ID. Получатель ведёт список полученных ID и для каждого сообщения
▫️ Отправляет уведомление о получении
▫️ Проверяет, не приходило ли такое сообщение раньше. Если да — отбрасывает его, если нет — обрабатывает
Выглядит легко, но в распределённых системах задача усложняется. Что угодно может отвалиться, данные нужно реплицировать, адреса постоянно меняются и тд. В Kafka гарантия exactly once появилась только в 2017 году, и документ с дизайном занимает 67 страниц.
❓ Что делать с этим знанием?
Узнать, какая стратегия используется на вашем проекте, и есть ли дополнительные требования к коду. Для разработчика этого достаточно, обычно все заботы о гарантиях берут на себя архитекторы🤓
❓ Что почитать о сложностях exactly-once в распределённых системах?
▫️ Семантика exactly-once в Apache Kafka
▫️ Подробный разбор проблем на примере очереди Amazon (англ)
▫️ Сборник статей про exactly-once (англ)
Вспомним проблему из прошлого поста.
Мы отправили запрос, соединение тут же пропало и восстановилось через 3 секунды. Что делать с запросом?
Если запрос идемпотентный, спокойно повторяем отправку.
❓А если нет?
Тогда выбираем одну из трёх стратегий: at least once, at most once или exactly once.
Вообще эти термины используются для месседж брокеров и доставки сообщений, но те же принципы верны для HTTP запросов и любого взаимодействия.
В чём суть:
1️⃣ At most once
Получатель не хочет разбираться с дубликатами, и потеря сообщений это ок. Поэтому повторно ничего не отправляем.
2️⃣ At least once
В процесс общения добавляется 1 шаг — уведомление о получении. Отправитель повторяет запрос, пока не получит уведомление.
✅ Сообщение точно будет доставлено
❌ Может быть доставлено несколько раз
3️⃣ Exactly once
Идеальный вариант: когда дубликаты не нужны, и потеря сообщений неприемлема.
Общая схема простая. У каждого сообщения есть ID. Получатель ведёт список полученных ID и для каждого сообщения
▫️ Отправляет уведомление о получении
▫️ Проверяет, не приходило ли такое сообщение раньше. Если да — отбрасывает его, если нет — обрабатывает
Выглядит легко, но в распределённых системах задача усложняется. Что угодно может отвалиться, данные нужно реплицировать, адреса постоянно меняются и тд. В Kafka гарантия exactly once появилась только в 2017 году, и документ с дизайном занимает 67 страниц.
❓ Что делать с этим знанием?
Узнать, какая стратегия используется на вашем проекте, и есть ли дополнительные требования к коду. Для разработчика этого достаточно, обычно все заботы о гарантиях берут на себя архитекторы🤓
❓ Что почитать о сложностях exactly-once в распределённых системах?
▫️ Семантика exactly-once в Apache Kafka
▫️ Подробный разбор проблем на примере очереди Amazon (англ)
▫️ Сборник статей про exactly-once (англ)
Как вы связываете компоненты в рабочем проекте? Где ставите Autowired?
Anonymous Poll
74%
Через конструктор
9%
Через сеттеры
28%
Ставим Autowired просто над полями
Spring: где ставить Autowired
Аннотацию Autowired можно ставить над конструктором, сеттером и просто над полем.
Есть популярная рекомендация, что через конструктор — самое правильное. На эту тему написаны сотни(!) статей и ответов на StackOverflow. Даже Intellij IDEA подсказывает, что "Field injection is not recommended"
В большинстве моих проектов Autowired ставили над полем, потому что так короче. В этом посте разберёмся, откуда взялась эта рекомендация, и насколько она актуальна.
❓ В чём разница между способами с точки зрения Spring?
Только в порядке установки для каждого бина:
▫️ Циклические зависимости возможны везде
▫️ Прокси создаются корректно
▫️ Отсутствующие зависимости обнаруживаются при компиляции или на старте приложения
❓ Откуда взялась эта рекомендация?
Большинство авторов ссылаются на документацию. В разделе Dependency Injection указаны только два способа — конструктор и сеттер. Они универсальны и для XML конфигурации, и для аннотаций.
В этом же разделе стоит рекомендация — использовать конструктор для обязательных и final полей, сеттер — для необязательных.
Autowired над полями относится только к annotation-based конфигурации, поэтому находится в другом разделе. В документации нет ни единого упоминания, что Autowired над полями — это грех и хуже конструкторов и сеттеров.
Рассмотрим основные аргументы против Autowired над полем:
😱 Слишком просто добавлять новые зависимости. Класс легко может потерять единственную ответственность. А когда в конструкторе 10 параметров, это сразу заметно
💁 Единственная ответственность Autowired — внедрить зависимость. Следить за дизайном — задача программиста
😱 Зависимость от DI-контейнера. Класс с аннотациями нельзя использовать за пределами проекта
💁 Ни разу не было такой потребности
😱 Полям нельзя добавить final
💁 Жаль, конечно, но мало кто в рантайме заменяет сервисы и репозитории
😱 Autowired поля проставляются через Reflection
💁 Если вам важно, что делает фреймворк под капотом, посмотрите на класс Constructor Resolver, там рефлекшена в 10 раз больше
😱 Непонятно, какие зависимости обязательные, а какие нет
💁 По умолчанию все Autowired зависимости обязательные. Если что-то необязательно, то можно поставить флажок (required=false)
😱 Непонятно, как тестировать такие классы без поднятия контекста
💁 10 лет назад было действительно никак. Сейчас юнит-тесты легко писать с помощью Mockito аннотаций @InjectMocks и @MockBean
Итого
Autowired над полями — самый лаконичный способ внедрить зависимость. Я не нашла ни одного весомого аргумента против. Для типичного энтерпрайз приложения этот способ идеально подходит.
Лучшие практики и рекомендации формируются в своём контексте. Когда контекст меняется, практика может стать неактуальной. И это норм🙂
Аннотацию Autowired можно ставить над конструктором, сеттером и просто над полем.
Есть популярная рекомендация, что через конструктор — самое правильное. На эту тему написаны сотни(!) статей и ответов на StackOverflow. Даже Intellij IDEA подсказывает, что "Field injection is not recommended"
В большинстве моих проектов Autowired ставили над полем, потому что так короче. В этом посте разберёмся, откуда взялась эта рекомендация, и насколько она актуальна.
❓ В чём разница между способами с точки зрения Spring?
Только в порядке установки для каждого бина:
Конструктор→поля→сеттерыВ остальном механизмы спринга работают одинаково:
▫️ Циклические зависимости возможны везде
▫️ Прокси создаются корректно
▫️ Отсутствующие зависимости обнаруживаются при компиляции или на старте приложения
❓ Откуда взялась эта рекомендация?
Большинство авторов ссылаются на документацию. В разделе Dependency Injection указаны только два способа — конструктор и сеттер. Они универсальны и для XML конфигурации, и для аннотаций.
В этом же разделе стоит рекомендация — использовать конструктор для обязательных и final полей, сеттер — для необязательных.
Autowired над полями относится только к annotation-based конфигурации, поэтому находится в другом разделе. В документации нет ни единого упоминания, что Autowired над полями — это грех и хуже конструкторов и сеттеров.
Рассмотрим основные аргументы против Autowired над полем:
😱 Слишком просто добавлять новые зависимости. Класс легко может потерять единственную ответственность. А когда в конструкторе 10 параметров, это сразу заметно
💁 Единственная ответственность Autowired — внедрить зависимость. Следить за дизайном — задача программиста
😱 Зависимость от DI-контейнера. Класс с аннотациями нельзя использовать за пределами проекта
💁 Ни разу не было такой потребности
😱 Полям нельзя добавить final
💁 Жаль, конечно, но мало кто в рантайме заменяет сервисы и репозитории
😱 Autowired поля проставляются через Reflection
💁 Если вам важно, что делает фреймворк под капотом, посмотрите на класс Constructor Resolver, там рефлекшена в 10 раз больше
😱 Непонятно, какие зависимости обязательные, а какие нет
💁 По умолчанию все Autowired зависимости обязательные. Если что-то необязательно, то можно поставить флажок (required=false)
😱 Непонятно, как тестировать такие классы без поднятия контекста
💁 10 лет назад было действительно никак. Сейчас юнит-тесты легко писать с помощью Mockito аннотаций @InjectMocks и @MockBean
Итого
Autowired над полями — самый лаконичный способ внедрить зависимость. Я не нашла ни одного весомого аргумента против. Для типичного энтерпрайз приложения этот способ идеально подходит.
Лучшие практики и рекомендации формируются в своём контексте. Когда контекст меняется, практика может стать неактуальной. И это норм🙂
Postman: полезные фичи
Главная задача Postman — отправлять запросы в веб-сервисы через красивый интерфейс.
В этом посте я расскажу о других фичах Postman, которые облегчают жизнь строителям энтерпрайза. Может вам что-то пригодится🙂
1️⃣ Сохранять запросы в коллекции
Удобно группировать запросы по сервисам или фичам.
Рекомендую давать запросам осмысленные названия. Чтобы задать имя, нажмите на многоточие справа от запроса → Rename
2️⃣ Сформировать curl
cUrl — это консольная команда, которая отправляет запросы. Писать её иногда утомительно, и Postman может здесь помочь.
Справа от кнопки Send есть кнопка </>. Выбираете cURL и копируете запрос.
3️⃣ Переменные в запросах и входных параметрах
Выглядит это так:
Переменные задаются на вкладке Environments:
▫️ Глобальные переменные доступны всем
▫️ Environment — наборы переменных, которые переключаются в выпадающем списке справа от запроса. Удобно сделать наборы для локальных вызовов, удалённого и тестового стенда.
Чтобы использовать переменную, запишите её в двойные скобочки
Начните набирать {{ и найдите в списке переменные random*
Их гигантское количество — рандомные числа, даты, страны, цвета, емейлы, банковские счета и даже биткойн-кошельки
5️⃣ Отправлять WebSocket и gRPS запросы
Пока в стадии бета, но я этим фичам очень рада🥰
Как найти: в левом верхнем углу под иконкой Postman находится имя вокспейса. Рядом с ним две кнопки — New и Import. Жмёте на New, выбираете нужный протокол
6️⃣ Добавить набор хэдеров во все запросы коллекции
Это делается с помощью скриптов.
Щёлкаете на коллекцию, переходите на вкладку pre-request Script, там пишете JS скрипт. Это несложно, там есть автозаполнение🙂 Для хедеров код выглядит так:
Больше подробностей — в документации
PS Убрала кнопку с сердечком, ставьте реакции, пожалуйста:) Так я буду понимать, какие темы нравятся, а какие не очень
Главная задача Postman — отправлять запросы в веб-сервисы через красивый интерфейс.
В этом посте я расскажу о других фичах Postman, которые облегчают жизнь строителям энтерпрайза. Может вам что-то пригодится🙂
1️⃣ Сохранять запросы в коллекции
Удобно группировать запросы по сервисам или фичам.
Рекомендую давать запросам осмысленные названия. Чтобы задать имя, нажмите на многоточие справа от запроса → Rename
2️⃣ Сформировать curl
cUrl — это консольная команда, которая отправляет запросы. Писать её иногда утомительно, и Postman может здесь помочь.
Справа от кнопки Send есть кнопка </>. Выбираете cURL и копируете запрос.
3️⃣ Переменные в запросах и входных параметрах
Выглядит это так:
http://{{host}}:8080/book/12
Очень удобно определить переменные хоста и данные авторизации. Тогда их можно не прописывать в каждом запросе и быстро менять.Переменные задаются на вкладке Environments:
▫️ Глобальные переменные доступны всем
▫️ Environment — наборы переменных, которые переключаются в выпадающем списке справа от запроса. Удобно сделать наборы для локальных вызовов, удалённого и тестового стенда.
Чтобы использовать переменную, запишите её в двойные скобочки
{{host}}
4️⃣ Добавлять рандом в запросы и входные параметрыНачните набирать {{ и найдите в списке переменные random*
Их гигантское количество — рандомные числа, даты, страны, цвета, емейлы, банковские счета и даже биткойн-кошельки
5️⃣ Отправлять WebSocket и gRPS запросы
Пока в стадии бета, но я этим фичам очень рада🥰
Как найти: в левом верхнем углу под иконкой Postman находится имя вокспейса. Рядом с ним две кнопки — New и Import. Жмёте на New, выбираете нужный протокол
6️⃣ Добавить набор хэдеров во все запросы коллекции
Это делается с помощью скриптов.
Щёлкаете на коллекцию, переходите на вкладку pre-request Script, там пишете JS скрипт. Это несложно, там есть автозаполнение🙂 Для хедеров код выглядит так:
pm.request.addHeader({key:'Header1',value:'value2'});
Если вам нужна особенная генерация входных параметров, это тоже легко сделать через скрипты.Больше подробностей — в документации
PS Убрала кнопку с сердечком, ставьте реакции, пожалуйста:) Так я буду понимать, какие темы нравятся, а какие не очень
String и неточный нейминг
Сегодня пост короткий, но полезный:
▪️ Увидите на простом примере, как важны имена методов
▪️ Узнаете, как оптимизировать работу со строками
Возьмём простую задачу — поменять в строке все буквы А на B. Идея подскажет три метода:
▫️ replace
▫️ replaceFirst
▫️ replaceAll
Что говорит здравый смысл? replaceFirst поменяет первую найденную букву, replace — непонятно, но вот replaceAll точно подходит, берём!
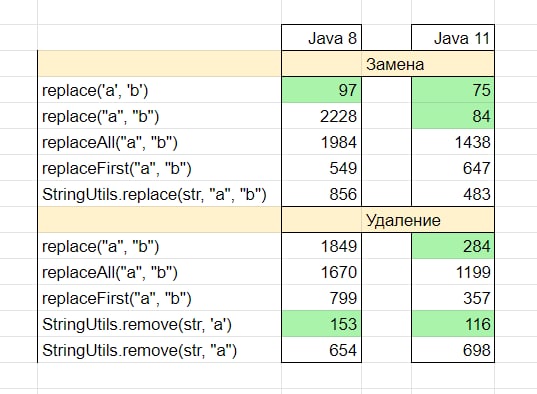
Посмотрим реализацию методов в java 11:
Также работает через RegEx, но заменяет только первое вхождение.
(в java 8 внутри replace тоже используются регулярки, и разница между replace и replaceAll очень туманна)
Что отсюда следует:
1️⃣ Переходите на java 11
2️⃣ Если вам не нужен функционал регулярок, используйте replace. Методы с Pattern.compile работают очень долго!
3️⃣ Давайте методам осмысленные имена. Должно быть понятно, что метод делает, и чем отличается от других. Автор методов replace* об этом не подумал, и теперь сотни проектов выбирают неподходящий вариант
❓ Есть ли разница между replace("a", "b") и replace('a', 'b')?
У replace два перегруженных варианта — для одиночных символов и для строк. В java 8 быстрее работает метод для символов, в java 11 между ними почти нет разницы
❓ Как удалить символы из строки?
В стандартной библиотеке нет метода remove. В java 11 для этой задачи подойдёт replace. В java 8 для критичных мест лучше взять StringUtils.remove из библиотеки Apache Commons Lang
Ниже — бенчмарки для разных джав и время в наносекундах. Результаты на разных железках могут отличаться!
Сегодня пост короткий, но полезный:
▪️ Увидите на простом примере, как важны имена методов
▪️ Узнаете, как оптимизировать работу со строками
Возьмём простую задачу — поменять в строке все буквы А на B. Идея подскажет три метода:
▫️ replace
▫️ replaceFirst
▫️ replaceAll
Что говорит здравый смысл? replaceFirst поменяет первую найденную букву, replace — непонятно, но вот replaceAll точно подходит, берём!
Посмотрим реализацию методов в java 11:
🔸 replace("A", "B")
Проверяет, что в строке вообще есть буквы А. Если да, создаётся новый массив символов и копируются значения исходной строки с заменой всех A на B🔸 replaceAll("A", "B")
Раскрывается в обработчик регулярных выражений:Pattern.compile("A").matcher(this).replaceAll("B")
🔸 replaceFirst("A", "B")Также работает через RegEx, но заменяет только первое вхождение.
(в java 8 внутри replace тоже используются регулярки, и разница между replace и replaceAll очень туманна)
Что отсюда следует:
1️⃣ Переходите на java 11
2️⃣ Если вам не нужен функционал регулярок, используйте replace. Методы с Pattern.compile работают очень долго!
3️⃣ Давайте методам осмысленные имена. Должно быть понятно, что метод делает, и чем отличается от других. Автор методов replace* об этом не подумал, и теперь сотни проектов выбирают неподходящий вариант
❓ Есть ли разница между replace("a", "b") и replace('a', 'b')?
У replace два перегруженных варианта — для одиночных символов и для строк. В java 8 быстрее работает метод для символов, в java 11 между ними почти нет разницы
❓ Как удалить символы из строки?
В стандартной библиотеке нет метода remove. В java 11 для этой задачи подойдёт replace. В java 8 для критичных мест лучше взять StringUtils.remove из библиотеки Apache Commons Lang
Ниже — бенчмарки для разных джав и время в наносекундах. Результаты на разных железках могут отличаться!
{kind=link}