
Задачи на сообразительность
Иногда на собеседованиях дают "задачку на сообразительность". Перевернуть строку, поделить торт на части, бросить шар из окна и так далее.
Когда я была джуниором, то не любила такие задачи. От волнения мыслительные способности опускались на уровень обезьянки. Я могла минуту смотреть на задачу с абсолютной пустотой в голове.
У сеньоров тоже бывает ступор. Человек несколько лет заботился о микросервисах, проводил сложные интеграции и вникал в запутанные бизнес-требования. Задачи вроде "сколько шариков вытащить из ящика" для него крайне непривычны.
Что мне помогало: решить перед собеседованием несколько подобных задач. Тогда на самом собесе мозг включается быстрее.
Ниже — плейлист для практики
🎵 Программистские
▫️ Развернуть строку: abc → cba
▫️ Развернуть число: 123 → 321
▫️ Для массива чисел и заданного числа найти пары элементов, которые в сумме равны этому числу
Пример: массив [5,7,8,2,12,30,10,16], требуемая сумма — 15
Ответ: 5 и 10, 7 и 8
▫️ Найти в массиве числа, у которых нет дубликата в этом же массиве: [1,2,3,1,2] → 3
▫️ Проверить, является ли строка палиндромом (читается одинаково слева направо и справа налево)
▫️ Проверить, является ли число палиндромом
▫️ Проверить, являются ли строки анаграммами (состоят из одних и тех же букв)
▫️ Проверить, является ли числа анаграммами
▫️ Вывести слова в строке в обратном порядке
▫️ Реализовать игру FizzBuzz. Написать алгоритм, который выводит числа от 1 до N. Если число делится на 3 — выводить fizz, если на 5 — buzz, если на 3 и 5 — fizz buzz
▫️ Посчитать статистику символов в строке
java → j:1, a:2, v:1
▫️ Найти наибольший общий делитель двух чисел
▫️ Написать конвертер систем счисления: обычных чисел в римские, десятеричную систему в двоичную, 8- и 16-ричную
Больше задач ищите на LeetCode, уровень Easy и Medium. Учить решения бесполезно, так как у задач много вариаций🙂
🎵 Предметные
▪️ В ящике 100 белых и 100 черных шаров. Сколько шаров нужно вытащить, чтобы среди них было 2 одноцветных?
▪️ Есть 15 одинаковых с виду шариков, но один чуть тяжелее других. Сколько нужно взвешиваний, чтобы найти этот шар?
▪️ Как из полного сосуда ёмкостью в 12л отлить половину, пользуясь двумя пустыми сосудами ёмкостью в 8л и 5л?
▪️ Есть 8 батареек, 4 из них рабочие. Фонарику нужно 2 батарейки. Сколько пар нужно протестировать, чтобы найти рабочую?
Задачки такого типа классно решать в компании или вместе с детьми🙂 Ссылка на 50 других задач
Иногда на собеседованиях дают "задачку на сообразительность". Перевернуть строку, поделить торт на части, бросить шар из окна и так далее.
Когда я была джуниором, то не любила такие задачи. От волнения мыслительные способности опускались на уровень обезьянки. Я могла минуту смотреть на задачу с абсолютной пустотой в голове.
У сеньоров тоже бывает ступор. Человек несколько лет заботился о микросервисах, проводил сложные интеграции и вникал в запутанные бизнес-требования. Задачи вроде "сколько шариков вытащить из ящика" для него крайне непривычны.
Что мне помогало: решить перед собеседованием несколько подобных задач. Тогда на самом собесе мозг включается быстрее.
Ниже — плейлист для практики
🎵 Программистские
▫️ Развернуть строку: abc → cba
▫️ Развернуть число: 123 → 321
▫️ Для массива чисел и заданного числа найти пары элементов, которые в сумме равны этому числу
Пример: массив [5,7,8,2,12,30,10,16], требуемая сумма — 15
Ответ: 5 и 10, 7 и 8
▫️ Найти в массиве числа, у которых нет дубликата в этом же массиве: [1,2,3,1,2] → 3
▫️ Проверить, является ли строка палиндромом (читается одинаково слева направо и справа налево)
▫️ Проверить, является ли число палиндромом
▫️ Проверить, являются ли строки анаграммами (состоят из одних и тех же букв)
▫️ Проверить, является ли числа анаграммами
▫️ Вывести слова в строке в обратном порядке
▫️ Реализовать игру FizzBuzz. Написать алгоритм, который выводит числа от 1 до N. Если число делится на 3 — выводить fizz, если на 5 — buzz, если на 3 и 5 — fizz buzz
▫️ Посчитать статистику символов в строке
java → j:1, a:2, v:1
▫️ Найти наибольший общий делитель двух чисел
▫️ Написать конвертер систем счисления: обычных чисел в римские, десятеричную систему в двоичную, 8- и 16-ричную
Больше задач ищите на LeetCode, уровень Easy и Medium. Учить решения бесполезно, так как у задач много вариаций🙂
🎵 Предметные
▪️ В ящике 100 белых и 100 черных шаров. Сколько шаров нужно вытащить, чтобы среди них было 2 одноцветных?
▪️ Есть 15 одинаковых с виду шариков, но один чуть тяжелее других. Сколько нужно взвешиваний, чтобы найти этот шар?
▪️ Как из полного сосуда ёмкостью в 12л отлить половину, пользуясь двумя пустыми сосудами ёмкостью в 8л и 5л?
▪️ Есть 8 батареек, 4 из них рабочие. Фонарику нужно 2 батарейки. Сколько пар нужно протестировать, чтобы найти рабочую?
Задачки такого типа классно решать в компании или вместе с детьми🙂 Ссылка на 50 других задач
Вопрос 1: в чём разница checked и unchecked исключений?
Anonymous Poll
11%
checked можно ловить в блоке try-catch, unchecked — нельзя
3%
checked ожидаются JVM, поэтому затраты на поддержку ниже
82%
Обработка checked исключений обязательна и проверяется во время компиляции
4%
checked исключения показывают ошибки бизнес-логики, unchecked — плохо написанный код
Вопрос 2: рассмотрим простое веб-приложение на Spring. В запросах часто передается ID пользователей. Если ID некорректный, бросается UserNotFoundException. Как его реализовать?
Anonymous Poll
8%
class UserNotFoundException extends Throwable
1%
class UserNotFoundException extends Error
31%
class UserNotFoundException extends Exception
60%
class UserNotFoundException extends RuntimeException
Исключения: сhecked или unchecked?
Сегодня пост о разнице между типами исключений и о том, какой тип выбрать для ошибок бизнес-логики.
Основы
🔸Checked исключения — наследники класса Exception:
🔸Unchecked исключения — наследники класса RuntimeException:
Оба типа можно поймать в блоке try-catch. Единственная техническая разница между checked и unchecked — обязательная обработка checked исключений. На уровне JVM разницы нет — производительность обоих типов одинакова.
За что отвечают стандартные исключения JDK
▫️ checked говорят об ошибках с "внешними" причинами: файл не найден, поток прервали, сокет закрыт, указанный класс не найден. Исключения показывают возможные проблемы, которые в будущем могут повториться
▫️ unchecked указывают на ошибки в коде: передали null вместо объекта, пришёл некорректный аргумент, нельзя привести объект к указанному типу. Исправляются при обнаружении, и в будущем такая ошибка не ожидается
Ошибки бизнес-логики
Не найден пользователь, не хватает прав, превышен лимит снятия денег со счёта. Какие это исключения: checked или unchecked?
В старых статьях по java и на многих курсах ответ однозначен. Исключения должны быть checked, чтобы ошибка не дошла до пользователя.
На JavaRush и в других статьях пишут, что checked исключения никто не использует, потому что это неудобно.
Кто же прав?
Исключения бизнес-логики — ожидаемые события, которые нужно обработать. Пользователь должен увидеть не стектрейс, а красивое сообщение💅
Многие фреймворки облегчают работу с исключениями. Если в Spring задать обработчик для UserNotFoundException, то туда попадут UserNotFoundException из любой части сервиса. Spring в любом случае их поймает, поэтому исключения бизнес-логики делают unchecked. Код получается гораздо чище.
По этой же причине checked иногда переводят в unchecked:
▫️ Если приложение написано на чистой java, то исключения бизнес-логики будут скорее всего checked
▫️ Если приложение использует фреймворк, который перехватывает исключения, их можно сделать unchecked
Правильные ответы на вопросы перед постом:
⭐️Вопрос 1: обработка checked исключений обязательна и проверяется на этапе компиляции
⭐️Вопрос 2: на практике чаще встречается
Сегодня пост о разнице между типами исключений и о том, какой тип выбрать для ошибок бизнес-логики.
Основы
🔸Checked исключения — наследники класса Exception:
class IOException extends Exception
Явно указываются в определении метода:void write(int c) throws IOException
Код с обработкой исключения обязателен, иначе программа не скомпилируется🔸Unchecked исключения — наследники класса RuntimeException:
class NullPointerException extends RuntimeException
О них не пишут в сигнатуре методов и редко ловят в блоке try-catch. Компилятор не предупредит о возможных ошибках, но иногда о них предупреждает IDE.Оба типа можно поймать в блоке try-catch. Единственная техническая разница между checked и unchecked — обязательная обработка checked исключений. На уровне JVM разницы нет — производительность обоих типов одинакова.
За что отвечают стандартные исключения JDK
▫️ checked говорят об ошибках с "внешними" причинами: файл не найден, поток прервали, сокет закрыт, указанный класс не найден. Исключения показывают возможные проблемы, которые в будущем могут повториться
▫️ unchecked указывают на ошибки в коде: передали null вместо объекта, пришёл некорректный аргумент, нельзя привести объект к указанному типу. Исправляются при обнаружении, и в будущем такая ошибка не ожидается
Ошибки бизнес-логики
Не найден пользователь, не хватает прав, превышен лимит снятия денег со счёта. Какие это исключения: checked или unchecked?
В старых статьях по java и на многих курсах ответ однозначен. Исключения должны быть checked, чтобы ошибка не дошла до пользователя.
На JavaRush и в других статьях пишут, что checked исключения никто не использует, потому что это неудобно.
Кто же прав?
Исключения бизнес-логики — ожидаемые события, которые нужно обработать. Пользователь должен увидеть не стектрейс, а красивое сообщение💅
Многие фреймворки облегчают работу с исключениями. Если в Spring задать обработчик для UserNotFoundException, то туда попадут UserNotFoundException из любой части сервиса. Spring в любом случае их поймает, поэтому исключения бизнес-логики делают unchecked. Код получается гораздо чище.
По этой же причине checked иногда переводят в unchecked:
catch (SQLException e)
{ throw new IllegalStateException(e); }
Резюме▫️ Если приложение написано на чистой java, то исключения бизнес-логики будут скорее всего checked
▫️ Если приложение использует фреймворк, который перехватывает исключения, их можно сделать unchecked
Правильные ответы на вопросы перед постом:
⭐️Вопрос 1: обработка checked исключений обязательна и проверяется на этапе компиляции
⭐️Вопрос 2: на практике чаще встречается
extends RuntimeException
но вариант extends Exception тоже ок{kind=link}
{kind=link}
BigDecimal
В этом посте обсудим, зачем нужен этот класс и как не ошибиться при использовании.
Ответ на первый вопрос перед постом — false. Сумма 0.1 и 0.2 равна 0.30000000000000004.
Запустим тот же пример на Python 2.7:
Oracle подробно объясняет этот феномен на 80 страницах. Главная проблема в том, как десятичная часть хранится в двоичном формате.
Целые числа записываются через степень двойки однозначно:
С 0.2 похожая ситуация, поэтому результат получается искажённым.
Python 2.7 использует для вычислений ту же систему, но показывает меньше знаков после запятой. Поэтому ответ выглядит нормально. Python 3 выводит больше знаков и результат похож на результат java:
Если хранить целую и дробную часть одинаково, то для вычислений не нужно дополнительных преобразований. Результат считается быстро, а уровень погрешности на практике низкий. В нашем примере ошибка на 16 разрядов ниже основного значения, в большинстве случаев это ок.
Для точных вычислений используются три основных метода:
🔸Ограниченная точность (limited-precision decimal)
🔸Символьная логика (symbolic calculations)
🔸Длинная арифметика (arbitrary-precision decimal)
BigDecimal использует последний подход. Число 12.345 хранится как пара:
▫️целое значение: 12345
▫️количество десятичных знаков: 3
За счёт этого BigDecimal хранит числа без потери точности. Целая часть хранится либо в переменной int, либо в массиве. Размер числа ограничен только количеством доступной памяти.
Из минусов:
❌ Медленные вычисления
❌ Большой расход памяти
❌ Много промежуточных объектов
❌ Менее выразительный код
Теперь ответ на второй вопрос перед постом:
объекты
В конструктор
0.20000000000000001110223...
Поэтому объект BigDecimal будет хранить это число, а не 0.2
Это самая частая ошибка при работе с BigDecimal. Для чисел с запятой надёжнее передавать в конструктор строку.
В этом посте обсудим, зачем нужен этот класс и как не ошибиться при использовании.
Ответ на первый вопрос перед постом — false. Сумма 0.1 и 0.2 равна 0.30000000000000004.
Запустим тот же пример на Python 2.7:
print(0.1 + 0.2)Почему python справился с примером, а java — нет? Как писать на java высоконагруженные приложения, если она не может сложить 0.1 и 0.2?😒
0.3
Oracle подробно объясняет этот феномен на 80 страницах. Главная проблема в том, как десятичная часть хранится в двоичном формате.
Целые числа записываются через степень двойки однозначно:
9 = 8 + 1 = 2^3 + 2^0 → 1001Десятичная часть выражается через отрицательную степень двойки. Иногда получается нормально:
0.5 = 2^(-1) → 0.1Иногда не очень:
0.1 = 2^(-4) + 2^(-5) + 2^(-8) + … →Если перевести это обратно в десятичную форму, видно, что хранится там совсем не 0.1, а 0.100000001490116119384765625
0.00111101110011001100110011001
С 0.2 похожая ситуация, поэтому результат получается искажённым.
Python 2.7 использует для вычислений ту же систему, но показывает меньше знаков после запятой. Поэтому ответ выглядит нормально. Python 3 выводит больше знаков и результат похож на результат java:
print(0.1 + 0.2)❓Зачем использовать такую неточную систему?
0.30000000000000004
Если хранить целую и дробную часть одинаково, то для вычислений не нужно дополнительных преобразований. Результат считается быстро, а уровень погрешности на практике низкий. В нашем примере ошибка на 16 разрядов ниже основного значения, в большинстве случаев это ок.
Для точных вычислений используются три основных метода:
🔸Ограниченная точность (limited-precision decimal)
🔸Символьная логика (symbolic calculations)
🔸Длинная арифметика (arbitrary-precision decimal)
BigDecimal использует последний подход. Число 12.345 хранится как пара:
▫️целое значение: 12345
▫️количество десятичных знаков: 3
За счёт этого BigDecimal хранит числа без потери точности. Целая часть хранится либо в переменной int, либо в массиве. Размер числа ограничен только количеством доступной памяти.
Из минусов:
❌ Медленные вычисления
❌ Большой расход памяти
❌ Много промежуточных объектов
❌ Менее выразительный код
Теперь ответ на второй вопрос перед постом:
объекты
BigDecimal(0.2) и BigDecimal("0.2") НЕ равны.В конструктор
BigDecimal(0.2)передаётся примитив double, в котором вместо 0.2 лежит
0.20000000000000001110223...
Поэтому объект BigDecimal будет хранить это число, а не 0.2
Это самая частая ошибка при работе с BigDecimal. Для чисел с запятой надёжнее передавать в конструктор строку.
Статистика вакансий HeadHunter (Мск+Спб)
Проанализировала 1120 вакансий java разработчиков на HH с точки зрения зарплат и основных технологий.
👶 Junior
Вакансий: 39 или 3% от общего количества
Половина вакансий в категории "без опыта", половина требует опыт "от года до трёх".
Зарплата указана в 36% случаев, диапазон 15-110к
Что используется:
▫️ Реляционные БД: Postgres, Oracle, общение с ними через Hibernate и JPA
▫️ Spring: MVC, Boot
▫️ Системы сборки: maven/gradle примерно поровну
▫️ git
▫️ Devops-штуки: docker, Openshift, Jenkins, Ansible
▫️ Kafka
▫️ В каждой третьей вакансии упоминается фронтэнд: JS/React/CSS
▫️ В каждой пятой — Kotlin
👩💻Middle (от года до трёх лет)
Вакансий: 382 или 34% от общего количества
Здесь самые секретные зарплаты — конкретные цифры указаны только в 27% вакансий, диапазон 32-400к
Что используется:
▫️ Реляционные БД: Postgres, Oracle, общение через Hibernate
▫️ Spring: Boot, Cloud, Data
▫️ Devops: docker, Kubernetes, Openshift, Linux, Jenkins
▫️ Системы сборки: maven встречается в 2 раза чаще gradle
▫️ Kafka
▫️ Kotlin в 15% вакансий
🧙Senior (3-6 лет опыта)
Вакансий: 648 или 58% от общего количества
Зарплаты указаны в 45% случаев, диапазон 120-700к
Что используется:
▫️ Реляционные БД: Postgre, Oracle
▫️ NoSQL: Redis
▫️ Spring: Boot, Data, Security, Cloud
▫️ Devops: docker, Kubernetes, Openshift, Linux, Jenkins)
▫️ Kafka
▫️ Kotlin в каждом пятом проекте
⭐️ Stars (6+ лет)
Вакансий: 51 или 4% от общего количества
Зарплата указана в 71% случаев, диапазон 160-1050к
Много вакансий на английском, что накладывает свой отпечаток🙂 Кандидат должен быть strong and passionate, ловить opportunity и отвечать за evolution. Упор на soft skills, много обязанностей по менторингу, архитектуре и общению с бизнесом. Каждая пятая вакансия упоминает релокацию.
Из технического:
▫️ В реляционных БД доминирует Postgre
▫️ NoSQL — Redis, MongoDB
▫️ Брокеры: Kafka и RabbitMQ
▫️ Docker, Kubernetes
▫️ Spring
▫️ Kotlin — 27% вакансий
Общее впечатление — вакансий стало раза в полтора больше, чем год назад. Технологии в вакансиях стали скучнее — редко упоминается AWS и GCP, список NoSQL заметно похудел. Зато Kotlin и Gradle набирают обороты.
Годы идут, но самый популярный стек остаётся тем же: Spring + Postgre + Kafka (+ иногда Redis)
Проанализировала 1120 вакансий java разработчиков на HH с точки зрения зарплат и основных технологий.
👶 Junior
Вакансий: 39 или 3% от общего количества
Половина вакансий в категории "без опыта", половина требует опыт "от года до трёх".
Зарплата указана в 36% случаев, диапазон 15-110к
Что используется:
▫️ Реляционные БД: Postgres, Oracle, общение с ними через Hibernate и JPA
▫️ Spring: MVC, Boot
▫️ Системы сборки: maven/gradle примерно поровну
▫️ git
▫️ Devops-штуки: docker, Openshift, Jenkins, Ansible
▫️ Kafka
▫️ В каждой третьей вакансии упоминается фронтэнд: JS/React/CSS
▫️ В каждой пятой — Kotlin
👩💻Middle (от года до трёх лет)
Вакансий: 382 или 34% от общего количества
Здесь самые секретные зарплаты — конкретные цифры указаны только в 27% вакансий, диапазон 32-400к
Что используется:
▫️ Реляционные БД: Postgres, Oracle, общение через Hibernate
▫️ Spring: Boot, Cloud, Data
▫️ Devops: docker, Kubernetes, Openshift, Linux, Jenkins
▫️ Системы сборки: maven встречается в 2 раза чаще gradle
▫️ Kafka
▫️ Kotlin в 15% вакансий
🧙Senior (3-6 лет опыта)
Вакансий: 648 или 58% от общего количества
Зарплаты указаны в 45% случаев, диапазон 120-700к
Что используется:
▫️ Реляционные БД: Postgre, Oracle
▫️ NoSQL: Redis
▫️ Spring: Boot, Data, Security, Cloud
▫️ Devops: docker, Kubernetes, Openshift, Linux, Jenkins)
▫️ Kafka
▫️ Kotlin в каждом пятом проекте
⭐️ Stars (6+ лет)
Вакансий: 51 или 4% от общего количества
Зарплата указана в 71% случаев, диапазон 160-1050к
Много вакансий на английском, что накладывает свой отпечаток🙂 Кандидат должен быть strong and passionate, ловить opportunity и отвечать за evolution. Упор на soft skills, много обязанностей по менторингу, архитектуре и общению с бизнесом. Каждая пятая вакансия упоминает релокацию.
Из технического:
▫️ В реляционных БД доминирует Postgre
▫️ NoSQL — Redis, MongoDB
▫️ Брокеры: Kafka и RabbitMQ
▫️ Docker, Kubernetes
▫️ Spring
▫️ Kotlin — 27% вакансий
Общее впечатление — вакансий стало раза в полтора больше, чем год назад. Технологии в вакансиях стали скучнее — редко упоминается AWS и GCP, список NoSQL заметно похудел. Зато Kotlin и Gradle набирают обороты.
Годы идут, но самый популярный стек остаётся тем же: Spring + Postgre + Kafka (+ иногда Redis)
Где пригодится интерфейс Supplier
Функциональные интерфейсы появились в java 8 и помогают писать код в функциональном стиле:
🔸 Function преобразует элемент в новое значение:
Популярные версии:
1️⃣ Кастомизация экземпляра. Передаём другой Supplier — возвращается другой экземпляр.
Для этой задачи проще указать интерфейс в параметрах
2️⃣ Реализация фабрики
Вариант из Effective Java, item 5. Источник авторитетный, но исходная цель Supplier здесь ускользает.
Во-первых, зачем передавать в параметры метода фабрику? Почему бы не создать экземпляр ранее и передать его?
Во-вторых, цель фабричного метода — упростить создание сложных объектов или отдавать разные объекты в зависимости от параметров. Supplier не содержит параметров и слабо подходит под эту задачу.
Цель Supplier — ленивая инициализация. Объект создаётся, когда он нужен, либо не создаётся вообще.
Игрушечный пример:
Другой пример — метод Optional orElseGet(Supplier supplier). Новый объект создаётся только, если Optional пуст.
Supplier участвует в сдвиге java в сторону функциональности. Function, Predicate и Concumer организуют функции высшего порядка, а Supplier — ленивые вычисления. Полезно в двух случаях:
✅ Когда объект может не пригодиться внутри метода
✅ Инициализировать объект нужно в момент вызова, не раньше. Например, у объекта в конструкторе есть LocalTime.now()
Функциональные интерфейсы появились в java 8 и помогают писать код в функциональном стиле:
🔸 Function преобразует элемент в новое значение:
stream().map(x → x.toString())🔸 Через Predicate передаётся условие фильтрации:
stream.filter(x → x > 5)🔸 Consumer используется в Stream API и библиотечных классах как терминальная операция:
list.forEach(e → System.out::println)🔸 Supplier ничего не принимает, но возвращает значение:
Stream.generate(() -> LocalTime.now())Function, Predicate и Concumer активно используются за пределами Stream API, а вот что делать с Supplier — не всем понятно. Зачем определять метод
void m(Supplier<List> list)вместо
void m(List list) ?Популярные версии:
1️⃣ Кастомизация экземпляра. Передаём другой Supplier — возвращается другой экземпляр.
Для этой задачи проще указать интерфейс в параметрах
2️⃣ Реализация фабрики
Вариант из Effective Java, item 5. Источник авторитетный, но исходная цель Supplier здесь ускользает.
Во-первых, зачем передавать в параметры метода фабрику? Почему бы не создать экземпляр ранее и передать его?
Во-вторых, цель фабричного метода — упростить создание сложных объектов или отдавать разные объекты в зависимости от параметров. Supplier не содержит параметров и слабо подходит под эту задачу.
Цель Supplier — ленивая инициализация. Объект создаётся, когда он нужен, либо не создаётся вообще.
Игрушечный пример:
public Connection init(Supplier<Connection> connSupplier) {
// взять коннекшн из пула
return connSupplier.get();
}
Если выполнение не дойдёт до connSupplier, новый объект создан не будет. В варианте public Connection init(Connection conn)для вызова метода нужно передать УЖЕ готовый экземпляр.
Другой пример — метод Optional orElseGet(Supplier supplier). Новый объект создаётся только, если Optional пуст.
Supplier участвует в сдвиге java в сторону функциональности. Function, Predicate и Concumer организуют функции высшего порядка, а Supplier — ленивые вычисления. Полезно в двух случаях:
✅ Когда объект может не пригодиться внутри метода
✅ Инициализировать объект нужно в момент вызова, не раньше. Например, у объекта в конструкторе есть LocalTime.now()
Задачи для собеседований
Как выглядят собеседования в прекрасной России будущего:
▫️ нет вопросов на внимательность
▫️ нет вопросов о PhantomReference и методах сервлетов
▫️ алгоритмы спрашивают, только если они используются на проекте
▫️ одна сессия не превышает часа, в сумме процесс найма длится не больше трёх часов
▫️ к собеседованиям вообще не нужно готовиться🥰
В этом посте поделюсь парой идей, как приблизить это светлое время.
Цель собеседования — найти сообразительного и внимательного человека. Он хорошо знает язык программирования и технологии, понятно излагает мысли и пишет симпатичный код.
Теоретические вопросы ок, но полезно посмотреть, как человек работает с кодом. Тестовые задания ок, но занимают много времени, поэтому сеньоры и мидлы часто отказываются их делать.
Посмотреть на человека "в деле" можно проще — обсудить уже готовый код и на его основе решить небольшую задачку. Удивительно, но даже задания меньше 20 строк люди делают по-разному.
Что можно обсудить:
1️⃣ Пет-проджект или предыдущие наработки кандидата
Если проект большой и сложный, попросите показать два самых интересных класса.
Плюс: вы видите код первый раз, можно лучше оценить soft skills кандидата и его подход к написанию кода
Минус: пет-проект может быть далёк от задач и стека целевого проекта
2️⃣ Часть текущего проекта (куда ищем кандидата)
▫️ Показать упрощённую версию или обсудить код ключевых классов. Транзакции, стратегии работы с кэшем, работа с БД, многопоточка и другие важные темы на конкретных примерах
▫️ Найдите в истории проекта несложную задачку и обсудите путь решения. Помните, что человек видит код первый раз и волнуется. Будьте добры к кандидату:)
3️⃣ Код опенсорсных проектов или произвольные сниппеты кода
4️⃣ Прикладные алгоритмические задачки
Прекрасно подойдут, если в проекте неплохая нагрузка и много задач на оптимизацию.
Пример задания: сравнить две строки без учёта регистра:
▫️ предложить несколько вариантов (минимум 3)
▫️ оценить, когда какой вариант быстрее
Задача интересная, основана на реальных событиях, а для решения нужен только исходный код String.
Ответ выложу в следующем посте!
Как выглядят собеседования в прекрасной России будущего:
▫️ нет вопросов на внимательность
▫️ нет вопросов о PhantomReference и методах сервлетов
▫️ алгоритмы спрашивают, только если они используются на проекте
▫️ одна сессия не превышает часа, в сумме процесс найма длится не больше трёх часов
▫️ к собеседованиям вообще не нужно готовиться🥰
В этом посте поделюсь парой идей, как приблизить это светлое время.
Цель собеседования — найти сообразительного и внимательного человека. Он хорошо знает язык программирования и технологии, понятно излагает мысли и пишет симпатичный код.
Теоретические вопросы ок, но полезно посмотреть, как человек работает с кодом. Тестовые задания ок, но занимают много времени, поэтому сеньоры и мидлы часто отказываются их делать.
Посмотреть на человека "в деле" можно проще — обсудить уже готовый код и на его основе решить небольшую задачку. Удивительно, но даже задания меньше 20 строк люди делают по-разному.
Что можно обсудить:
1️⃣ Пет-проджект или предыдущие наработки кандидата
Если проект большой и сложный, попросите показать два самых интересных класса.
Плюс: вы видите код первый раз, можно лучше оценить soft skills кандидата и его подход к написанию кода
Минус: пет-проект может быть далёк от задач и стека целевого проекта
2️⃣ Часть текущего проекта (куда ищем кандидата)
▫️ Показать упрощённую версию или обсудить код ключевых классов. Транзакции, стратегии работы с кэшем, работа с БД, многопоточка и другие важные темы на конкретных примерах
▫️ Найдите в истории проекта несложную задачку и обсудите путь решения. Помните, что человек видит код первый раз и волнуется. Будьте добры к кандидату:)
3️⃣ Код опенсорсных проектов или произвольные сниппеты кода
4️⃣ Прикладные алгоритмические задачки
Прекрасно подойдут, если в проекте неплохая нагрузка и много задач на оптимизацию.
Пример задания: сравнить две строки без учёта регистра:
▫️ предложить несколько вариантов (минимум 3)
▫️ оценить, когда какой вариант быстрее
Задача интересная, основана на реальных событиях, а для решения нужен только исходный код String.
Ответ выложу в следующем посте!
Как сравнить строки без учёта регистра
В этом посте расскажу, как решить задачу из предыдущего поста и сделать метод быстрее, чем в JDK.
Напомню задачу: сравнить две строки без учёта регистра и оценить производительность в разных ситуациях.
Шаг 1. Смотрим подходящие методы в классе String
Строки могут сильно и слабо отличаться по регистру.
Скорее всего, алгоритмы для пустых, коротких и длинных строк одни и те же, так что не будем различать эти случаи.
Шаг 3. Углубляемся в реализацию
🔸 toLowerCase + equals
▫️ Для каждой строки создаёт копию в нижнем регистре. Затем включается обычный equals:
▫️ Сравнивает длины строк. Если не равны, сразу возвращается false
▫️ Сравнивает по одному символу, пока не дойдёт до конца строки или пока символы не будут разными
✖️В начале целиком обходим s1 и s2, чтобы создать копии в нижнем регистре. Когда длины строк отличаются (что можно узнать сразу), эта работа бесполезна
✖️ Если строки мало отличаются по регистру, то приведение всех символов к одному регистру будет лишним
🔸 compareToIgnoreCase cравнивает элементы по порядку. Если символы не равны — вызывает апперкейс и сравнивает ещё раз.
✔️ Uppercase происходит только при необходимости. Если разница в регистрах небольшая (s1=java, s2=Java), то этот подход будет быстрее
✖️ Цель метода — сравнить строки, поэтому нет быстрой проверки длины
🔸 regionMatches берёт символы из строк s1 и s2, сразу делает uppercase и сравнивает
✔️ Если строки по регистрам сильно отличаются, предварительный апперкейс ускорит проверку
✖️ Метод работает с подстроками произвольной длины, поэтому нет быстрой проверки длин
🔸 equalsIgnoreCase сравнивает длины строк, потом вызывает regionMatches
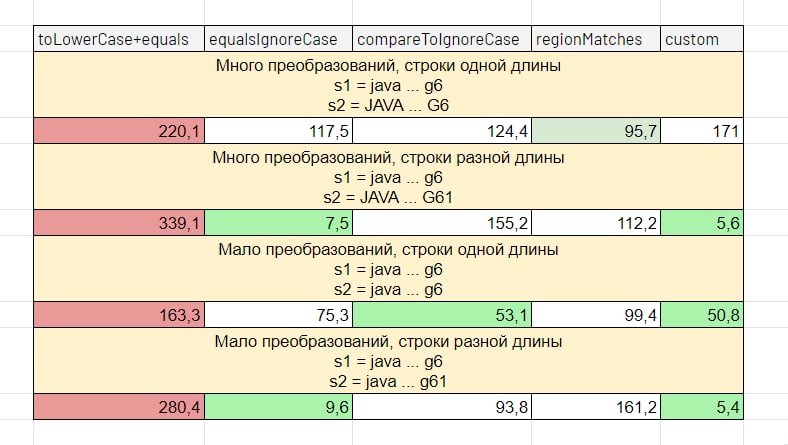
Итог
▪️ Если строки разной длины, то однозначно побеждает equalsIgnoreCase
▪️ Если длины одинаковы и
— регистры не сильно отличаются, то побеждает compareToIgnoreCase
— нужно много преобразований — regionMatches
equalsIgnoreCase для каждого символа делается апперкейс. Если строки по регистрам слабо отличаются, то это явно лишнее. Для таких случаев подойдёт кастомный метод:
Ниже — бенчмарки всех вариантов. Результаты на разных железках могут отличаться!
В этом посте расскажу, как решить задачу из предыдущего поста и сделать метод быстрее, чем в JDK.
Напомню задачу: сравнить две строки без учёта регистра и оценить производительность в разных ситуациях.
Шаг 1. Смотрим подходящие методы в классе String
s1.toLowerCase().equals(s2.toLowerCase())Шаг 2. Предположим возможные ситуации
s1.equalsIgnoreCase(s2)
s1.compareToIgnoreCase(s2) != 0
s1.regionMatches(true, 0, s2, 0, s2.length())
Строки могут сильно и слабо отличаться по регистру.
Скорее всего, алгоритмы для пустых, коротких и длинных строк одни и те же, так что не будем различать эти случаи.
Шаг 3. Углубляемся в реализацию
🔸 toLowerCase + equals
▫️ Для каждой строки создаёт копию в нижнем регистре. Затем включается обычный equals:
▫️ Сравнивает длины строк. Если не равны, сразу возвращается false
▫️ Сравнивает по одному символу, пока не дойдёт до конца строки или пока символы не будут разными
✖️В начале целиком обходим s1 и s2, чтобы создать копии в нижнем регистре. Когда длины строк отличаются (что можно узнать сразу), эта работа бесполезна
✖️ Если строки мало отличаются по регистру, то приведение всех символов к одному регистру будет лишним
🔸 compareToIgnoreCase cравнивает элементы по порядку. Если символы не равны — вызывает апперкейс и сравнивает ещё раз.
✔️ Uppercase происходит только при необходимости. Если разница в регистрах небольшая (s1=java, s2=Java), то этот подход будет быстрее
✖️ Цель метода — сравнить строки, поэтому нет быстрой проверки длины
🔸 regionMatches берёт символы из строк s1 и s2, сразу делает uppercase и сравнивает
✔️ Если строки по регистрам сильно отличаются, предварительный апперкейс ускорит проверку
✖️ Метод работает с подстроками произвольной длины, поэтому нет быстрой проверки длин
🔸 equalsIgnoreCase сравнивает длины строк, потом вызывает regionMatches
Итог
▪️ Если строки разной длины, то однозначно побеждает equalsIgnoreCase
▪️ Если длины одинаковы и
— регистры не сильно отличаются, то побеждает compareToIgnoreCase
— нужно много преобразований — regionMatches
equalsIgnoreCase для каждого символа делается апперкейс. Если строки по регистрам слабо отличаются, то это явно лишнее. Для таких случаев подойдёт кастомный метод:
if (s1.length() != s2.length()) {
return false;
}
return s1.compareToIgnoreCase(s2) != 0;
Лучшее из двух миров — быстрая проверка по длине и нет лишних апперкейсов. Ниже — бенчмарки всех вариантов. Результаты на разных железках могут отличаться!
{kind=link}
Как освоить многопоточное программирование
Как вы знаете, у меня есть классный курс по многопоточке. Он классный и сильно упрощает освоение темы. Но не всем подходит такой формат, поэтому поделюсь планом, как разобраться в теме самостоятельно.
Многопоточность — сложная часть java core, поэтому разработчика от неё часто ограждают. Большинство проектов используют модель thread-per-request: каждый запрос изолирован, и взаимодействия потоков как будто нет.
Во многих проектах знания многопоточки не понадобятся, особенно если вы джуниор или мидл. Но чем выше нагрузка, тем сложнее поддерживать изоляцию. Так что рекомендую уделить этой теме внимание.
Теория
Шаг 1: любой курс на ютубе или юдеми для быстрого обзора
Шаг 2: книга Java Concurrency in Practice + документация к каждому классу java.util.concurrent
В книге отлично описаны основы и возможные проблемы многопоточки. Многие практические решения устарели, поэтому ищите в JDK альтернативы.
Шаг 3: видяшки Романа Елизарова и Алексея Шипилёва
Дают хороший ответ на вопросы "почему" и "зачем". Смотреть только после предыдущего шага, иначе можно утонуть в деталях и не понять главного
Шаг 4 (опциональный): прочитать The Art of Multiprocessor Programming
Не про джаву, но теоретические аспекты многопоточности раскрыты на тысячу процентов.
❓Почему так много теории?
Потому что между железом, внутрянкой JVM и архитектурой сервера очень тесная связь. Без этого фундамента получаются такие ситуации:
😟 Локально всё работает, тесты проходят, а на продакшене непонятные ошибки
😟 Одна многопоточная фича работает, но почему-то отваливается другая
😟 Вроде ничего не сделал, а метрики стали в два раза хуже
Практика
Идеальный вариант — делать многопоточные задачки под присмотром опытных коллег. Если такой возможности пока нет:
🔸 Поискать куски многопоточки в текущем проекте. Даже если их мало, разберите от и до — что, зачем, почему такие параметры, как можно по-другому
🔸 Изучить код опенсорсных проектов, которые точно содержат многопоточку — Kafka, Hadoop, Tinkoff invest API, etc
С этим багажом можно спокойно идти на собеседование в классный проект и нарабатывать навыки + периодически повторять материалы из шага 2
Или всё же взять курс, где вся теория шаг за шагом + море практики на основе реальных задач:)
Как вы знаете, у меня есть классный курс по многопоточке. Он классный и сильно упрощает освоение темы. Но не всем подходит такой формат, поэтому поделюсь планом, как разобраться в теме самостоятельно.
Многопоточность — сложная часть java core, поэтому разработчика от неё часто ограждают. Большинство проектов используют модель thread-per-request: каждый запрос изолирован, и взаимодействия потоков как будто нет.
Во многих проектах знания многопоточки не понадобятся, особенно если вы джуниор или мидл. Но чем выше нагрузка, тем сложнее поддерживать изоляцию. Так что рекомендую уделить этой теме внимание.
Теория
Шаг 1: любой курс на ютубе или юдеми для быстрого обзора
Шаг 2: книга Java Concurrency in Practice + документация к каждому классу java.util.concurrent
В книге отлично описаны основы и возможные проблемы многопоточки. Многие практические решения устарели, поэтому ищите в JDK альтернативы.
Шаг 3: видяшки Романа Елизарова и Алексея Шипилёва
Дают хороший ответ на вопросы "почему" и "зачем". Смотреть только после предыдущего шага, иначе можно утонуть в деталях и не понять главного
Шаг 4 (опциональный): прочитать The Art of Multiprocessor Programming
Не про джаву, но теоретические аспекты многопоточности раскрыты на тысячу процентов.
❓Почему так много теории?
Потому что между железом, внутрянкой JVM и архитектурой сервера очень тесная связь. Без этого фундамента получаются такие ситуации:
😟 Локально всё работает, тесты проходят, а на продакшене непонятные ошибки
😟 Одна многопоточная фича работает, но почему-то отваливается другая
😟 Вроде ничего не сделал, а метрики стали в два раза хуже
Практика
Идеальный вариант — делать многопоточные задачки под присмотром опытных коллег. Если такой возможности пока нет:
🔸 Поискать куски многопоточки в текущем проекте. Даже если их мало, разберите от и до — что, зачем, почему такие параметры, как можно по-другому
🔸 Изучить код опенсорсных проектов, которые точно содержат многопоточку — Kafka, Hadoop, Tinkoff invest API, etc
С этим багажом можно спокойно идти на собеседование в классный проект и нарабатывать навыки + периодически повторять материалы из шага 2
Или всё же взять курс, где вся теория шаг за шагом + море практики на основе реальных задач:)
Переключение между задачами
Иногда во время работы над одной задачей нужно переключиться на другую: поправить пул реквест или сделать хотфикс. Если текущие изменения не готовы для полноценного коммита, можно использовать stash или shelve.
Stash
Изменения сохранятся в локальном git репозитории, а текущая ветка почистится. Можно спокойно переключаться на другую задачу.
Вернуть изменения на место:
🔸
🔸
🔸 В IDEA: VCS → Git → Unstash Changes...
Что важно:
✅ Сохраняются ВСЕ текущие изменения в ветке
✅ Обратно применяются ВСЕ изменения в стэше
✅ Изменения хранятся в локальном git репозитории
Shelve
Удобная фича IDEA для сохранения части изменений:
VCS → Shelve Changes...
Галочками отмечаем, что сохранить.
Чтобы вернуть обратно:
Вкладка Git (Alt + 9 или найдите внизу) → Shelve
Отмечайте, какие изменения применить к коду
✅ Можно выбрать, что сохранять
✅ Можно указать, что восстановить
✅ Изменения хранятся в локальном IDEA проекте
Иногда во время работы над одной задачей нужно переключиться на другую: поправить пул реквест или сделать хотфикс. Если текущие изменения не готовы для полноценного коммита, можно использовать stash или shelve.
Stash
Изменения сохранятся в локальном git репозитории, а текущая ветка почистится. Можно спокойно переключаться на другую задачу.
git stash save "stash name"В IDEA: VCS → Git → Stash Changes...
Вернуть изменения на место:
🔸
git stash apply "stash name"
и оставить stash в локальном репозитории🔸
git stash pop "stash name"
и удалить стэш🔸 В IDEA: VCS → Git → Unstash Changes...
Что важно:
✅ Сохраняются ВСЕ текущие изменения в ветке
✅ Обратно применяются ВСЕ изменения в стэше
✅ Изменения хранятся в локальном git репозитории
Shelve
Удобная фича IDEA для сохранения части изменений:
VCS → Shelve Changes...
Галочками отмечаем, что сохранить.
Чтобы вернуть обратно:
Вкладка Git (Alt + 9 или найдите внизу) → Shelve
Отмечайте, какие изменения применить к коду
✅ Можно выбрать, что сохранять
✅ Можно указать, что восстановить
✅ Изменения хранятся в локальном IDEA проекте
Пет-проекты в резюме: основные ошибки
Раньше пет-проект в резюме джуниора был редким явлением и сильно выделял кандидата среди других. Сейчас ссылки на гитхаб встречаются чаще, да и джуниоров стало больше. В этом посте кратко расскажу о 6 ошибках, которые портят впечатление и снижают вероятность приглашения на собес.
1️⃣ Нерабочий проект
Видно, что код не работает и ни разу не запускался, много пустых файлов и TODO комментариев
Как лучше: выкладывать готовые фичи, задачи в разработке описать в README
2️⃣ Устаревшие технологии и подходы
XML конфигурация в Spring, сервлеты, JSP, Spring 3 и другие старые версии популярных библиотек и фреймворков
Как лучше: учиться по туториалам не старше 5 лет
3️⃣ Слишком сложный код
▪️ Интерфейс и абстрактный класс для каждой сущности
▪️ Классы с одним полем и геттерами-сеттерами
▪️ Функциональные интерфейсы из функциональных интерфейсов
4️⃣ Тяжело читаемый код
▫️ Непонятные имена методов, классов и переменных
▫️ Методы с сайд-эффектами, там где их быть не должно
▫️ Длинные методы
▫️ DRY любой ценой
▫️ Методы возвращают комбинации из Map, List, Pair и примитивов
▫️ Процедуры вместо функций
Что я имею в виду:
❌ filter(List input, List output);
✅ List filtered = filter(input);
5️⃣ Нет бизнес-логики
Вариант 1: простейший CRUD для двух сущностей
Как лучше: если не хватает идей, возьмите любое приложение или сайт и реализуйте 5 интересных фич оттуда
Вариант 2: 300 классов с простейшими функциями. Яркий пример — игры со множеством персонажей и предметов. Непонятно, куда смотреть и что происходит
Как лучше: сфокусировать бизнес-логику в нескольких классах, разбить код на пакеты, написать README
6️⃣ Неоднородный код
Когда части проекта копируются из разных источников как есть. Смешивается xml, yaml и Java-based конфигурация, документированные и стильные блоки кода находятся рядом с неформатированным безумием
Как лучше: не слепо копировать код, а понять решение и адаптировать под проект
⭐️ Бонусный пункт: не ориентироваться в проекте
Когда на этапе собеседования человек отвечает на вопросы по собственному коду вот так:
😐 Я забыл, зачем это
😐 Тут надо переделать
😐 Сюда не смотрите
😐 Не знаю, зачем, но без этого не работает
Как лучше: пусть в пет-проджекте будут не все технологии, но вы понимаете, что происходит, готовы обсудить решения и ответить на дополнительные вопросы.
Раньше пет-проект в резюме джуниора был редким явлением и сильно выделял кандидата среди других. Сейчас ссылки на гитхаб встречаются чаще, да и джуниоров стало больше. В этом посте кратко расскажу о 6 ошибках, которые портят впечатление и снижают вероятность приглашения на собес.
1️⃣ Нерабочий проект
Видно, что код не работает и ни разу не запускался, много пустых файлов и TODO комментариев
Как лучше: выкладывать готовые фичи, задачи в разработке описать в README
2️⃣ Устаревшие технологии и подходы
XML конфигурация в Spring, сервлеты, JSP, Spring 3 и другие старые версии популярных библиотек и фреймворков
Как лучше: учиться по туториалам не старше 5 лет
3️⃣ Слишком сложный код
▪️ Интерфейс и абстрактный класс для каждой сущности
▪️ Классы с одним полем и геттерами-сеттерами
▪️ Функциональные интерфейсы из функциональных интерфейсов
4️⃣ Тяжело читаемый код
▫️ Непонятные имена методов, классов и переменных
▫️ Методы с сайд-эффектами, там где их быть не должно
▫️ Длинные методы
▫️ DRY любой ценой
▫️ Методы возвращают комбинации из Map, List, Pair и примитивов
▫️ Процедуры вместо функций
Что я имею в виду:
❌ filter(List input, List output);
✅ List filtered = filter(input);
5️⃣ Нет бизнес-логики
Вариант 1: простейший CRUD для двух сущностей
Как лучше: если не хватает идей, возьмите любое приложение или сайт и реализуйте 5 интересных фич оттуда
Вариант 2: 300 классов с простейшими функциями. Яркий пример — игры со множеством персонажей и предметов. Непонятно, куда смотреть и что происходит
Как лучше: сфокусировать бизнес-логику в нескольких классах, разбить код на пакеты, написать README
6️⃣ Неоднородный код
Когда части проекта копируются из разных источников как есть. Смешивается xml, yaml и Java-based конфигурация, документированные и стильные блоки кода находятся рядом с неформатированным безумием
Как лучше: не слепо копировать код, а понять решение и адаптировать под проект
⭐️ Бонусный пункт: не ориентироваться в проекте
Когда на этапе собеседования человек отвечает на вопросы по собственному коду вот так:
😐 Я забыл, зачем это
😐 Тут надо переделать
😐 Сюда не смотрите
😐 Не знаю, зачем, но без этого не работает
Как лучше: пусть в пет-проджекте будут не все технологии, но вы понимаете, что происходит, готовы обсудить решения и ответить на дополнительные вопросы.
Structured concurrency
В java 19 войдёт новый JEP в стадии "инкубатор" — Structured concurrency. В этом посте расскажу, зачем он нужен и какую проблему решает.
Многопоточка многих пугает своей сложностью. Но на самом деле java — очень дружелюбный язык, и новый JEP — отличный тому пример.
Как выполнить большую задачу быстрее? Разбить на подзадачи, отправить в экзекьютор и объединить результаты:
👎 Мы узнаем об этом только при вызове
Так как подзадачи логически не связаны между собой, программист должен добавить прерывания и механизмы отслеживания ошибок.
Новый JEP берёт часть забот на себя:
▪️
▪️
▪️
▪️Забираем результаты через
С первого взгляда всё то же самое. Но самое интересное происходит в первой строке, где определяются правила взаимодействия подзадач:
🔸
🔸
Бонус — JVM в курсе связей между задачами, поэтому в тред дампе подзадачи будут в древовидной структуре.
❓ Чем
В текущих вариантах при ошибке другие задачи не прерываются, в лучшем случае задачи удаляются из очереди
❓ Что классного в этом JEP?
Что по сути эта фича необязательна. Хоть кто-нибудь жаловался, что подзадачи в тред дампе не связаны? Что неудобно следить за исключениями в подзадачах?
Нет, никто не жаловался. Но разработчики java изучают сценарии использования языка и стараются облегчить жизнь пользователям❤️
В java 19 войдёт новый JEP в стадии "инкубатор" — Structured concurrency. В этом посте расскажу, зачем он нужен и какую проблему решает.
Многопоточка многих пугает своей сложностью. Но на самом деле java — очень дружелюбный язык, и новый JEP — отличный тому пример.
Как выполнить большую задачу быстрее? Разбить на подзадачи, отправить в экзекьютор и объединить результаты:
Future f1=executor.submit(…);Что будет, если в задаче для
Future f2=executor.submit(…);
…
return f1.get() + f2.get();
f1 выбросится исключение?👎 Мы узнаем об этом только при вызове
f1.get()
👎 Задача в f2 продолжит работу, хотя это бессмысленно. В лучшем случае она просто потратит процессорное времяТак как подзадачи логически не связаны между собой, программист должен добавить прерывания и механизмы отслеживания ошибок.
Новый JEP берёт часть забот на себя:
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Future f1=scope.fork(…);
Future f2=scope.fork(…);
scope.join();
scope.throwIfFailed();
return f1.resultNow()+f2.resultNow();
}
Что происходит:▪️
scope.fork — задачи запускаются в едином логическом блоке▪️
scope.join — ждём завершения подзадач▪️
scope.throwIfFailed — пробрасываем исключение, если оно возникло в одной из подзадач. Другим методом можно получить экземпляр исключения и обработать его сразу▪️Забираем результаты через
resultNow и объединяемС первого взгляда всё то же самое. Но самое интересное происходит в первой строке, где определяются правила взаимодействия подзадач:
🔸
ShutdownOnFailure — если хотя бы одна подзадача выбросит исключение, остальные будут прерваны. Обработку прерывания всё ещё пишет разработчик, но java берёт на себя всю работу по отслеживанию и обновлению статусов🔸
ShutdownOnSuccess — когда хотя бы одна задача завершится, остальные прерываютсяБонус — JVM в курсе связей между задачами, поэтому в тред дампе подзадачи будут в древовидной структуре.
❓ Чем
ShutdownOnSuccess отличается от методов anyOf в экзекьюторах и CompletableFuture?В текущих вариантах при ошибке другие задачи не прерываются, в лучшем случае задачи удаляются из очереди
❓ Что классного в этом JEP?
Что по сути эта фича необязательна. Хоть кто-нибудь жаловался, что подзадачи в тред дампе не связаны? Что неудобно следить за исключениями в подзадачах?
Нет, никто не жаловался. Но разработчики java изучают сценарии использования языка и стараются облегчить жизнь пользователям❤️
Невозможно не рассказать — сейчас на Хабре идёт сезон джавы.
Все статьи под этим тэгом дополнительно продвигаются хабром. Если есть чем поделиться, то сейчас идеальный момент!
Для лучших статей заявлены призы, так что авторы стараются — есть много симпатичных статей с картинками и подробными примерами. Качество материала разное. Есть милая статья об AssertJ, некомпетентная про виртуальные потоки и обстоятельный справочник по Spring. Вот список статей, может найдёте что-то интересное для себя.
Теперь обратно к этому каналу. На этой неделе расскажу принцип работы двух популярных брокеров сообщений:
🐰 Сегодня про RabbitMQ
🐞 В четверг про Kafka
Все статьи под этим тэгом дополнительно продвигаются хабром. Если есть чем поделиться, то сейчас идеальный момент!
Для лучших статей заявлены призы, так что авторы стараются — есть много симпатичных статей с картинками и подробными примерами. Качество материала разное. Есть милая статья об AssertJ, некомпетентная про виртуальные потоки и обстоятельный справочник по Spring. Вот список статей, может найдёте что-то интересное для себя.
Теперь обратно к этому каналу. На этой неделе расскажу принцип работы двух популярных брокеров сообщений:
🐰 Сегодня про RabbitMQ
🐞 В четверг про Kafka
Message brokers, часть 1: RabbitMQ
Оба брокера реализуют паттерн publish/subscribe. Его основные участники это
🔸 Producer — отправляет сообщения. Сообщение состоит из ключа, значения и хэдеров
🔸 Consumer — принимает сообщения
🔸 Message broker — компонент для обмена сообщениями, разворачивается отдельно
Основная структура данных для распределения сообщений — очередь. Обычно в системе целое море продюсеров, очередей и консьюмеров. Чтобы упростить общение между ними, RabbitMQ использует промежуточный слой — exchangers.
Принцип работы:
Продюсеры просто отправляют сообщение в эксченджер. Оттуда оно распределяется в подходящие очереди в зависимости от ключа, хэдеров и настроек эксченджера. Сообщение копируется во все подходящие очереди.
Консьюмер подсоединяется к интересным очередям и забирает оттуда сообщения.
Чтобы было понятно, как это выглядит, посмотрите на картинку внизу поста👇
Сообщение удаляется из очереди после прочтения. Отсюда идут следующие схемы:
▫️ Если сообщение должны прочитать несколько получателей — у каждого должна быть своя очередь, куда это сообщение попадёт.
Пример: сообщение order.from-A.to-C. vip попадает в две очереди — order.from-A.* и order.*.*.vip
▫️ Если нужно распределить сообщения между получателями, консьюмеры подключаются к одной очереди. RabbitMQ распределяет сообщения между ними равномерно по принципу round-robin.
Пример: сообщение order.from-A.to-B и order.from-A.to-C распределяются между консюмерами С1 и С2
Рэббит использует push модель — каждое сообщение из очереди вызывает коллбэк на консьюмере. Это нужно, чтобы равномерно распределять сообщения между получателями.
Очереди и связи задаются не в брокере, а в приложении. Роутинг сообщений получается супер гибким, и добавлять новых участников в систему легко. Из разных типов эксченджеров и очередей собирается огромное количество паттернов.
Главное в RabbitMQ:
✔️ Основной компонент — exchanger и связанные с ним очереди
✔️ Сообщения удаляются после прочтения
✔️ Push-модель
✔️ Гибкий роутинг сообщений
Оба брокера реализуют паттерн publish/subscribe. Его основные участники это
🔸 Producer — отправляет сообщения. Сообщение состоит из ключа, значения и хэдеров
🔸 Consumer — принимает сообщения
🔸 Message broker — компонент для обмена сообщениями, разворачивается отдельно
Основная структура данных для распределения сообщений — очередь. Обычно в системе целое море продюсеров, очередей и консьюмеров. Чтобы упростить общение между ними, RabbitMQ использует промежуточный слой — exchangers.
Принцип работы:
Продюсеры просто отправляют сообщение в эксченджер. Оттуда оно распределяется в подходящие очереди в зависимости от ключа, хэдеров и настроек эксченджера. Сообщение копируется во все подходящие очереди.
Консьюмер подсоединяется к интересным очередям и забирает оттуда сообщения.
Чтобы было понятно, как это выглядит, посмотрите на картинку внизу поста👇
Сообщение удаляется из очереди после прочтения. Отсюда идут следующие схемы:
▫️ Если сообщение должны прочитать несколько получателей — у каждого должна быть своя очередь, куда это сообщение попадёт.
Пример: сообщение order.from-A.to-C. vip попадает в две очереди — order.from-A.* и order.*.*.vip
▫️ Если нужно распределить сообщения между получателями, консьюмеры подключаются к одной очереди. RabbitMQ распределяет сообщения между ними равномерно по принципу round-robin.
Пример: сообщение order.from-A.to-B и order.from-A.to-C распределяются между консюмерами С1 и С2
Рэббит использует push модель — каждое сообщение из очереди вызывает коллбэк на консьюмере. Это нужно, чтобы равномерно распределять сообщения между получателями.
Очереди и связи задаются не в брокере, а в приложении. Роутинг сообщений получается супер гибким, и добавлять новых участников в систему легко. Из разных типов эксченджеров и очередей собирается огромное количество паттернов.
Главное в RabbitMQ:
✔️ Основной компонент — exchanger и связанные с ним очереди
✔️ Сообщения удаляются после прочтения
✔️ Push-модель
✔️ Гибкий роутинг сообщений
{kind=link}
Message brokers, часть 2: Kafka
Если RabbitMQ — это 100% очередь, то Kafka больше похожа на список, потому что данные после чтения не удаляются. В принципе это основное отличие двух брокеров, остальное — просто следствие.
Один список называется partition. Несколько partition можно объединить в группу, которая называется topic.
Консьюмеры читают данные из партишена или топика. Для каждого консюмера хранится индекс последнего прочитанного сообщения (offset). Когда получатель прочитает сообщение, Kafka сдвинет его offset. И в следующий раз этот получатель прочитает другие сообщения.
Если в partition 10 сообщений, то
🧔🏻 Один консьюмер прочитает сразу всё
👳🏻 Другой прочитает 5 и потом ещё 5
👩🏼🦰 Третий будет вычитывать по одному сообщению
И никто никому не мешает☺️
В рамках одного partition все консюмеры читают сообщения в одном порядке. Иногда это очень важная фича. Для топика из нескольких partition такой гарантии нет.
Поскольку данные не удаляются при чтении, получаются немного другие схемы работы:
🔸 Если сообщение должны прочитать несколько однотипных получателей, достаточно записать их в один partition
🔸 Если получатели разнотипные, то продюсер должен добавить данные в несколько партишенов.
Пример: чтобы сообщение “A to C vip” прочитали C1 и C4, продюсер отправляет запись в топик orders и vip_orders.
🔸 Если нужно распределить сообщения по получателям, то консьюмеры объединяются в consumer group с общим оффсетом
Резюме
▫️ В Kafka сообщения не пропадают при чтении, их можно читать несколько раз и пачками
▫️ Гарантия порядка сообщений в рамках одного partition
▫️ Kafka занимает горааааздо больше места на диске
▫️ Kafka использует pull модель — получатели сами решают, когда забрать сообщения. В RabbitMQ инициатива исходит от очереди, чтобы равномерно распределять сообщения
▫️ Разные схемы общения с продюсерами и консьюмерами. На картинке ниже я представила аналог схемы из предыдущего поста
▫️ Разные сценарии масштабирования и отказоустойчивости
▫️ Субъективное мнение — в рэббите проще распределять сообщения по получателям. Kafka подходит для накопления данных и более сложных сценариев
▫️Объективное — Kafka используется на бОльшем количестве проектов, пусть даже в качестве простой очереди😐
Общие черты двух брокеров:
🐰🐞 Отлично поддерживаются спрингом
🐰🐞 Можно настроить хранение сообщений на диске
🐰🐞 Нужно супер тщательно продумать схему работы и масштабирование
PS Эти посты — самые основы месседж брокеров, прямо вот верхушечка. Для дальнейшего изучения подойдёт эта серия статей, книги "RabbitMQ in Action" и "Kafka in Action".
Если RabbitMQ — это 100% очередь, то Kafka больше похожа на список, потому что данные после чтения не удаляются. В принципе это основное отличие двух брокеров, остальное — просто следствие.
Один список называется partition. Несколько partition можно объединить в группу, которая называется topic.
Консьюмеры читают данные из партишена или топика. Для каждого консюмера хранится индекс последнего прочитанного сообщения (offset). Когда получатель прочитает сообщение, Kafka сдвинет его offset. И в следующий раз этот получатель прочитает другие сообщения.
Если в partition 10 сообщений, то
🧔🏻 Один консьюмер прочитает сразу всё
👳🏻 Другой прочитает 5 и потом ещё 5
👩🏼🦰 Третий будет вычитывать по одному сообщению
И никто никому не мешает☺️
В рамках одного partition все консюмеры читают сообщения в одном порядке. Иногда это очень важная фича. Для топика из нескольких partition такой гарантии нет.
Поскольку данные не удаляются при чтении, получаются немного другие схемы работы:
🔸 Если сообщение должны прочитать несколько однотипных получателей, достаточно записать их в один partition
🔸 Если получатели разнотипные, то продюсер должен добавить данные в несколько партишенов.
Пример: чтобы сообщение “A to C vip” прочитали C1 и C4, продюсер отправляет запись в топик orders и vip_orders.
🔸 Если нужно распределить сообщения по получателям, то консьюмеры объединяются в consumer group с общим оффсетом
Резюме
▫️ В Kafka сообщения не пропадают при чтении, их можно читать несколько раз и пачками
▫️ Гарантия порядка сообщений в рамках одного partition
▫️ Kafka занимает горааааздо больше места на диске
▫️ Kafka использует pull модель — получатели сами решают, когда забрать сообщения. В RabbitMQ инициатива исходит от очереди, чтобы равномерно распределять сообщения
▫️ Разные схемы общения с продюсерами и консьюмерами. На картинке ниже я представила аналог схемы из предыдущего поста
▫️ Разные сценарии масштабирования и отказоустойчивости
▫️ Субъективное мнение — в рэббите проще распределять сообщения по получателям. Kafka подходит для накопления данных и более сложных сценариев
▫️Объективное — Kafka используется на бОльшем количестве проектов, пусть даже в качестве простой очереди😐
Общие черты двух брокеров:
🐰🐞 Отлично поддерживаются спрингом
🐰🐞 Можно настроить хранение сообщений на диске
🐰🐞 Нужно супер тщательно продумать схему работы и масштабирование
PS Эти посты — самые основы месседж брокеров, прямо вот верхушечка. Для дальнейшего изучения подойдёт эта серия статей, книги "RabbitMQ in Action" и "Kafka in Action".
{kind=link}