
Forwarded from Заметки Честного HR #ЗЧHR
https://youtu.be/pWSUBdxq568
Брюс Эккель Философия java
https://kotlinlang.org/docs/getting-started.html
Канал Дениса: https://t.me/javaKotlinDevOps
Please open Telegram to view this post
VIEW IN TELEGRAM
YouTube
Java&Kotlin&Devops
Java&Kotlin&Devops
Приглашенный эксперт: Денис Орехов
Подписывайся на Дениса: https://t.me/javaKotlinDevOps
#1c #java #kotlin #devops #ЯHR #КристинаОрехова #ДенисОрехов
Приглашенный эксперт: Денис Орехов
Подписывайся на Дениса: https://t.me/javaKotlinDevOps
#1c #java #kotlin #devops #ЯHR #КристинаОрехова #ДенисОрехов
🔥9
Всем привет в 2023 году!
Уже писал про плюсы Kotlin, забыл про еще один - язык подталкивает к правильному написанию кода по умолчанию. Что имеется в виду:
1) все типы по умолчанию not null, для nullable типа нужно добавить ? к названию типа. String и String? Что дает: уменьшает число переменных с null в программе, следовательно, уменьшает число NPE
2) все коллекции по умолчанию immutable, чтобы создать изменяемую коллекцию надо использовать метод с mutable в названии: listOf(1,2) и mutableListOf(1,2). Что дает: упрощает оптимизацию байт-кода компилятором или JVM.
3) все классы и методы по умолчанию final, чтобы сделать открытый для расширения метод или класс - нужно указать ключевое слово open. Это приводит к тому, что открытыми будут только те классы и методы, которым это точно нужно)
Сюда же я бы добавил паттерны, реализованные в языке Kotlin. По сути это и синтаксический сахар, и эталонные реализации по умолчанию, уменьшающие вероятность ошибок при самостоятельной реализации:
4) синглтон - объявление класса-синглтона с помощью ключевого слова object
5) делегат - делегирование функционала класса или отдельного property через ключевое слово by
Почему важно по умолчанию показывать, как писать код правильно?
Приведу два примера:
1) Когда давным давном в далекой галктике Borland была среды быстрой разработки (RAD) Delphi. Хорошая была IDE, сделала одну большую ошибку - сильно завязалась на Windows и проиграла конкуренцию Visual Studio при массовом переходе на .NET.
Но был еще один серьезный недостаток. При создании нового проекта по умолчанию создавалось 3 файла: файл проекта, файл формы с UI компонентами и файл для обработчиков событий на форме. БольшАя часть разработчиков в файле для обработчиков хранила и бизнес-логику - Model + Controller. Лично я первое время делал именно так((( А всего-то надо было сделать еще один файл, назвать его скажем Logic.pas.
2) Еще похожий случай более близкий к нам по времени. Есть такой язык PHP. Язык простой в обучении, без компиляции, с нестрогой типизацией, с мощными и простыми средствами для обработки HTTP запросов, генерации HTML и работой с БД. Такая простота приводит к тому, что опять же многие PHP разработчики не думают о разделении кода по классам. Получаются огромные php скрипты, где смешаны M, V и C.
#kotlin #languages #nullsafety
Уже писал про плюсы Kotlin, забыл про еще один - язык подталкивает к правильному написанию кода по умолчанию. Что имеется в виду:
1) все типы по умолчанию not null, для nullable типа нужно добавить ? к названию типа. String и String? Что дает: уменьшает число переменных с null в программе, следовательно, уменьшает число NPE
2) все коллекции по умолчанию immutable, чтобы создать изменяемую коллекцию надо использовать метод с mutable в названии: listOf(1,2) и mutableListOf(1,2). Что дает: упрощает оптимизацию байт-кода компилятором или JVM.
3) все классы и методы по умолчанию final, чтобы сделать открытый для расширения метод или класс - нужно указать ключевое слово open. Это приводит к тому, что открытыми будут только те классы и методы, которым это точно нужно)
Сюда же я бы добавил паттерны, реализованные в языке Kotlin. По сути это и синтаксический сахар, и эталонные реализации по умолчанию, уменьшающие вероятность ошибок при самостоятельной реализации:
4) синглтон - объявление класса-синглтона с помощью ключевого слова object
5) делегат - делегирование функционала класса или отдельного property через ключевое слово by
Почему важно по умолчанию показывать, как писать код правильно?
Приведу два примера:
1) Когда давным давном в далекой галктике Borland была среды быстрой разработки (RAD) Delphi. Хорошая была IDE, сделала одну большую ошибку - сильно завязалась на Windows и проиграла конкуренцию Visual Studio при массовом переходе на .NET.
Но был еще один серьезный недостаток. При создании нового проекта по умолчанию создавалось 3 файла: файл проекта, файл формы с UI компонентами и файл для обработчиков событий на форме. БольшАя часть разработчиков в файле для обработчиков хранила и бизнес-логику - Model + Controller. Лично я первое время делал именно так((( А всего-то надо было сделать еще один файл, назвать его скажем Logic.pas.
2) Еще похожий случай более близкий к нам по времени. Есть такой язык PHP. Язык простой в обучении, без компиляции, с нестрогой типизацией, с мощными и простыми средствами для обработки HTTP запросов, генерации HTML и работой с БД. Такая простота приводит к тому, что опять же многие PHP разработчики не думают о разделении кода по классам. Получаются огромные php скрипты, где смешаны M, V и C.
#kotlin #languages #nullsafety
👍3
Всем привет!
Интересный и выглядящий логичным подход к оценке задач в Agile нашел вот тут https://www.youtube.com/watch?v=vk6dl7-3B5I
Наверное большинство тех, кто сталкивался с Agile, знает о Story Point.
В чем их проблема:
1) авторы методологии Scrum не предполагали использования Story Point для оценки задач внутри спринта
2) они плохо применимы для оценки задач разной природы: бэк-разработка, фронт-разработка, аналитика, тестирование - всей командой. Зато хорошо подходят для оценки сторей и эпиков, которые с течением времени становятся похожими
3) спринт имеет четкую дату окончания, а story point по определению не должен быть завязан на время. Да, есть burndown chart, он может показать что, что-то идет не так. Но не может показать что именно. На это тратится время команды на дейли\ретро
4) размер story point может быть разным у членов команды из-за разного бэкграунда, что снижает точность оценки
5) абстрактность story point не дает понимания сроков как для бизнеса, так и не способствует взаимодействию внутри команды для подстройки порядка задач для выполнения целей спринта
Альтернатива - capacity planning, о нем говорится в ролике. Эта техника решает все проблемы, указанные выше. Хотя и сложнее для внедрения.
Да, еще есть диаграммы Ганта, о них тоже говорится в ролике. IMHO можно считать данную технику гибкой версией Ганта
#agile #scrum
Интересный и выглядящий логичным подход к оценке задач в Agile нашел вот тут https://www.youtube.com/watch?v=vk6dl7-3B5I
Наверное большинство тех, кто сталкивался с Agile, знает о Story Point.
В чем их проблема:
1) авторы методологии Scrum не предполагали использования Story Point для оценки задач внутри спринта
2) они плохо применимы для оценки задач разной природы: бэк-разработка, фронт-разработка, аналитика, тестирование - всей командой. Зато хорошо подходят для оценки сторей и эпиков, которые с течением времени становятся похожими
3) спринт имеет четкую дату окончания, а story point по определению не должен быть завязан на время. Да, есть burndown chart, он может показать что, что-то идет не так. Но не может показать что именно. На это тратится время команды на дейли\ретро
4) размер story point может быть разным у членов команды из-за разного бэкграунда, что снижает точность оценки
5) абстрактность story point не дает понимания сроков как для бизнеса, так и не способствует взаимодействию внутри команды для подстройки порядка задач для выполнения целей спринта
Альтернатива - capacity planning, о нем говорится в ролике. Эта техника решает все проблемы, указанные выше. Хотя и сложнее для внедрения.
Да, еще есть диаграммы Ганта, о них тоже говорится в ролике. IMHO можно считать данную технику гибкой версией Ганта
#agile #scrum
YouTube
SMPL: Николай Алименков: "Rise and fall of story points. Capacity-based planning from the trenches"
Доклад Николая Алименкова с конференции Simplicity Day: Agile Magic 2020 с темой "Rise and fall of story points. Capacity-based planning from the trenches."
Люди в мире Agile используют Story Points - для Agile коучей и тренеров это самый простой способ…
Люди в мире Agile используют Story Points - для Agile коучей и тренеров это самый простой способ…
👍4
Всем привет!
Что делать, если производительности БД не хватает при рабочей нагрузке?
Варианты от простого к сложному.
1) добавить в таблицы индексы и\или партиции. Индекс ускоряет выборку по полю(ям), представляя собой хранимую на диске отдельно от данных таблицы структуру, например, содержащую соответствие между значением в поле и номером строки. Реализован может быть в виде B-дерева.
В общем случае индекс нужен по полям, которые есть в WHERE. Но индекс не бесплатен из-за замедления вставки записей, поэтому по возможности стоит провести нагрузочное тестирование и изучить план выполнения запросов.
Партиция (table partition) - это по сути подтаблица, которая сужает область поиска и блокировки. Также партиция - отдельная единица хранения, т.е. их можно разносить по разным дискам, что хорошо влияет на производительность. Партиции чаже всего делают по дате, в этом случае запись будет идти как правило в одну партицию - последнюю, а чтение из всех. Кроме того разбиение по дате упрощает удаление архивных данных из таблицы, т.к. операции чтения, изменения и удаления можно проводить над партициями.
На примере Oracle детали: https://docs.oracle.com/en/database/oracle/oracle-database/19/vldbg/partition-concepts.html#GUID-DD6FC751-735F-48EF-BFC6-F636C2451701
2) оптимизация запроса. Вот тут можно почитать детальнее https://www.datacamp.com/tutorial/sql-tutorial-query, вот по-русски, но есть проблемы с переводом https://habr.com/ru/post/465547/
3) batching - выполнение write запросов к БД в пакетном режиме. Детали см. https://www.baeldung.com/jpa-hibernate-batch-insert-update
4) уменьшение размера транзакции. Чем длиннее транзакция, тем больше вероятность блокировки параллельных транзакций
5) использование оптимистичных блокировок вместо пессимистичных https://www.codeflow.site/ru/article/jpa-optimistic-locking
6) переход от JPA к обычному SQL. Это палка о двух концах, т.к. Hibernate может сделать усложненный\лишний запрос, но он это делает предсказуемым образом, такие запросы легко оптимизировать. Чтобы написать оптимальный SQL запрос самому, то ... нужно хорошо знать SQL (спасибо, кэп). Поэтому рекомендую начинать все же с Hibernate и его Java API, и переходить к HQL, Native SQL только в случае проблем.
7) кэширование. Тут три варианта: кэширование на клиенте, промежуточный сервис кэширования и кэширование на сервере СУБД. Последним мы управляем ограничено, первый более менее понятен, поэтому я хотел остановиться на промежуточном сервисе кэширования. Важны два аспекта. Во-первых если БД имеет размер не более 16\32\128 или же 256 Гб, то в теории можно всю ее засунуть в оперативную память, что сильно ускорит чтение. Во-вторых кэш можно шардировать, т.е. распределить по разным серверам. Это умеют практически все распределенные кэши: Ignite, Memcached, Redis, Hazelcast.
8) реплицирование данных для чтения. Т.е. для записи остатается один узел, ведущий, с него все изменения реплицируются на ведомые. Чтение идет с ведомых узлов. Репликация может быть выполнена средствами СУБД (например, Oracle GoldenGate для Oracle), с помощью CDC библиотек, читающих лог транзакций БД (самая известная Debezium https://www.baeldung.com/debezium-intro) или на прикладном уровне. Проблема данного решения несогласованном чтении из-за задержек репликации. Решением может быть или игнорирование чтения устаревших записей, или наложение требований на фиксацию записи и на чтение. Требования описываются формулой R + W > N, где N - число реплик, W - число узлов, запись на которых должна быть подтверждена, прежде, чем мы ответим клиенту об успешности записи, R - число узлов, с которых должна быть прочитана запись и выбрана последняя версия. О том как определить последнюю версию записи можно сделать отдельный пост
9) вертикальное мастабирование БД. Тут мы сильно ограничены, т.е. не бывает серверов с 64 ядрами или с террабайтами ОЗУ
Что делать, если производительности БД не хватает при рабочей нагрузке?
Варианты от простого к сложному.
1) добавить в таблицы индексы и\или партиции. Индекс ускоряет выборку по полю(ям), представляя собой хранимую на диске отдельно от данных таблицы структуру, например, содержащую соответствие между значением в поле и номером строки. Реализован может быть в виде B-дерева.
В общем случае индекс нужен по полям, которые есть в WHERE. Но индекс не бесплатен из-за замедления вставки записей, поэтому по возможности стоит провести нагрузочное тестирование и изучить план выполнения запросов.
Партиция (table partition) - это по сути подтаблица, которая сужает область поиска и блокировки. Также партиция - отдельная единица хранения, т.е. их можно разносить по разным дискам, что хорошо влияет на производительность. Партиции чаже всего делают по дате, в этом случае запись будет идти как правило в одну партицию - последнюю, а чтение из всех. Кроме того разбиение по дате упрощает удаление архивных данных из таблицы, т.к. операции чтения, изменения и удаления можно проводить над партициями.
На примере Oracle детали: https://docs.oracle.com/en/database/oracle/oracle-database/19/vldbg/partition-concepts.html#GUID-DD6FC751-735F-48EF-BFC6-F636C2451701
2) оптимизация запроса. Вот тут можно почитать детальнее https://www.datacamp.com/tutorial/sql-tutorial-query, вот по-русски, но есть проблемы с переводом https://habr.com/ru/post/465547/
3) batching - выполнение write запросов к БД в пакетном режиме. Детали см. https://www.baeldung.com/jpa-hibernate-batch-insert-update
4) уменьшение размера транзакции. Чем длиннее транзакция, тем больше вероятность блокировки параллельных транзакций
5) использование оптимистичных блокировок вместо пессимистичных https://www.codeflow.site/ru/article/jpa-optimistic-locking
6) переход от JPA к обычному SQL. Это палка о двух концах, т.к. Hibernate может сделать усложненный\лишний запрос, но он это делает предсказуемым образом, такие запросы легко оптимизировать. Чтобы написать оптимальный SQL запрос самому, то ... нужно хорошо знать SQL (спасибо, кэп). Поэтому рекомендую начинать все же с Hibernate и его Java API, и переходить к HQL, Native SQL только в случае проблем.
7) кэширование. Тут три варианта: кэширование на клиенте, промежуточный сервис кэширования и кэширование на сервере СУБД. Последним мы управляем ограничено, первый более менее понятен, поэтому я хотел остановиться на промежуточном сервисе кэширования. Важны два аспекта. Во-первых если БД имеет размер не более 16\32\128 или же 256 Гб, то в теории можно всю ее засунуть в оперативную память, что сильно ускорит чтение. Во-вторых кэш можно шардировать, т.е. распределить по разным серверам. Это умеют практически все распределенные кэши: Ignite, Memcached, Redis, Hazelcast.
8) реплицирование данных для чтения. Т.е. для записи остатается один узел, ведущий, с него все изменения реплицируются на ведомые. Чтение идет с ведомых узлов. Репликация может быть выполнена средствами СУБД (например, Oracle GoldenGate для Oracle), с помощью CDC библиотек, читающих лог транзакций БД (самая известная Debezium https://www.baeldung.com/debezium-intro) или на прикладном уровне. Проблема данного решения несогласованном чтении из-за задержек репликации. Решением может быть или игнорирование чтения устаревших записей, или наложение требований на фиксацию записи и на чтение. Требования описываются формулой R + W > N, где N - число реплик, W - число узлов, запись на которых должна быть подтверждена, прежде, чем мы ответим клиенту об успешности записи, R - число узлов, с которых должна быть прочитана запись и выбрана последняя версия. О том как определить последнюю версию записи можно сделать отдельный пост
9) вертикальное мастабирование БД. Тут мы сильно ограничены, т.е. не бывает серверов с 64 ядрами или с террабайтами ОЗУ
Oracle Help Center
VLDB and Partitioning Guide
Partitioning enhances the performance, manageability, and availability of a wide variety of applications and helps reduce the total cost of ownership for storing large amounts of data.
👍2
10) горизонтальное масштабирование. Поддерживается Kafka (хотя она не является в чистом виде хранилищем), Cassandra, Riak и многими noSQL СУБД. Проблемы: переход с реляционной БД на noSQL не всегда возможен из-за структуры БД, отсутствия опыта работы с noSQL. Кроме того к проблемам несогласованного чтения добавляются проблемы несогласованной записи, они же конфликты записи. Тоже отдельная большая тема.
#storage #performance #jpa
#storage #performance #jpa
👍1
Всем привет!
Есть такая шутка: в мире существует 10 конкурирующих фреймворков, делающих что-то полезное. Дайте сделаем один, самый лучший, который заменит их всех! ... Прошло время. У нам 11 конкурирующих фреймворков)))
Работает часто, хотя бывают исключения: k8s, Docker.
И работает не только для технологий, но и для методологий.
Если почитать книжки или статьи по DevOps, то ключевая мысль: DevOps - это совместная работа у Dev и Ops, общие цели, и в результате мы снимаем противоречия между Dev и Ops. Да, стоит добавить, что аббревиатура некоректна и в ней забыли как минимум тестировщиков и безопасников.
Что у нас по факту? К командам Dev и Ops добавляется команда DevOps, а число источников проблем возврастает до 3: Dev vs Ops, Dev vs DevOps, Ops vs DevOps )))
#devops
Есть такая шутка: в мире существует 10 конкурирующих фреймворков, делающих что-то полезное. Дайте сделаем один, самый лучший, который заменит их всех! ... Прошло время. У нам 11 конкурирующих фреймворков)))
Работает часто, хотя бывают исключения: k8s, Docker.
И работает не только для технологий, но и для методологий.
Если почитать книжки или статьи по DevOps, то ключевая мысль: DevOps - это совместная работа у Dev и Ops, общие цели, и в результате мы снимаем противоречия между Dev и Ops. Да, стоит добавить, что аббревиатура некоректна и в ней забыли как минимум тестировщиков и безопасников.
Что у нас по факту? К командам Dev и Ops добавляется команда DevOps, а число источников проблем возврастает до 3: Dev vs Ops, Dev vs DevOps, Ops vs DevOps )))
#devops
😱2👍1
Всем привет!
Пару слов про NoSQL СУБД.
Во-первых про название. Оно историческое, и не нужно воспринимать его строго. Хотя абсолютное большинство NoSQL БД не реализуют стандарт SQL, у многих есть SQL-подобный API.
А во-вторых - это некое объединение от противного: все не реляционные хранилища попадают в категорию NoSQL. Поэтому более правильно было бы назвать эту категорию хранилищ - NoRelational.
Чем же они принципиально отличаются от RDBMS - реляционных СУБД?
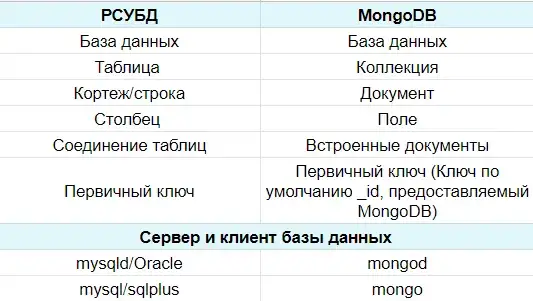
0) Во всех RDBMS используется общий набор понятий: cхема, таблица, запись, столбец. В NoSQL хранилищах другая терминология, различающаяся и от RDBMS, и между собой.
Вот сравнение Mongo и RDBMS https://miro.medium.com/max/640/1*l9pvYpv5HBZh0qZRrXcU-w.webp
А вот Cassandra и RDBMS https://dzone.com/refcardz/apache-cassandra#section-2
Я далее буду использовать термины из RDBMS для простоты.
Такая неразбериха вызвана тем, что, как я уже писал, у NoSQL СУБД не так много общего. Более того они делятся на 4 категории (и в будущем их может стать больше):
а) ключ-значение
б) документные
в) семейства столбцов
г) графовые
Ключ-значение - самые простые, если ключ и некий blob. По сути это Java Map, где value - byte[]. Поиск идет по ключу. Документные и семейства столбцов можно рассматривать как усложнение "ключ-значения". В первом случае blob превращается в документ, например, JSON, с некой структурой, по отдельным полям документа можно строить индексы. В другом - blob делится на столбцы, причем столбцы тоже могут содержать столбцы, а могут - blob. Графовые - отдельная ветка, ее ключевое преимущество: можно определить множество связей между объектами, которые рассчитываются при обновлении данных и поэтому запросы поиска связанных значений через множество уровней существенно быстрее RDBMS, т.к. не нужно join-ить в runtime.
1) нет строгой схемы данных, контролируемой на сервере. Почему я говорю строгой? Потому что какая-то структура на сервере все же определена.
В любом случае у "записи" есть ключ, у документных БД и семейств столбцов мы определяем ряд "столбцов", по которым есть индексы.
Но главное: у разных записей может быть разный набор столбцов, и точной структуры данных сервер не знает.
И тут есть проблема - прикладному коду структуру знать нужно, т.е. какая-то схема нужна. И храниться она может только на клиенте.
А отсюда проблем две:
а) синхронизация схемы между сервисами. Если мы придерживаемся микросервисной архитектуры, где за взаимодействие с БД отвечает один сервис, то проблема исчезает. Если же нет - придется эту схему создать, например, в формате OpenAPI или в виде DTO библиотеки
б) обновление данных. В RDBMS все просто - переключаешь пользователей на другое плечо, обновляешь БД, обновляешь приложение, возвращаешь пользователей. В NoSQL два пути - или обновление на клиенте при чтении и последующая запись, или задача в scheduler для фонового обновления данных.
В любом случае есть переходный период, в течение которого в коде будет if (version == X) else при чтении. А если проблему обновления данных не решать, то появится дерево if-ов, а это плохо(
Из отсутствия схемы следует, что NoSQL хорошо подходит для случая, когда структура данных не определена изначально и\или часто меняется
2) первые три типа NoSQL БД объединяет то, что их архитектура очень хорошо подходит для хранения агрегатов из DDD - Domain Driven Development. Это могут быть данные о сессии клиента или содержимое корзины заказов. Т.е. любая многоуровневая структура, идентифицируемая ключом и сохраняемая и загружаемая целиком. Работа с агрегатом как с одним целым особенно важна, т.к. именно тут NoSQL бьет RDBMS с его JOIN-ами по скорости загрузки данных. Внутри агрегата данные обновляются атомарно. JOIN-ить агрегаты можно только на клиенте. Соответственно, хотя схему данных можно менять, но границы агрегатов лучше продумывать заранее.
Пару слов про NoSQL СУБД.
Во-первых про название. Оно историческое, и не нужно воспринимать его строго. Хотя абсолютное большинство NoSQL БД не реализуют стандарт SQL, у многих есть SQL-подобный API.
А во-вторых - это некое объединение от противного: все не реляционные хранилища попадают в категорию NoSQL. Поэтому более правильно было бы назвать эту категорию хранилищ - NoRelational.
Чем же они принципиально отличаются от RDBMS - реляционных СУБД?
0) Во всех RDBMS используется общий набор понятий: cхема, таблица, запись, столбец. В NoSQL хранилищах другая терминология, различающаяся и от RDBMS, и между собой.
Вот сравнение Mongo и RDBMS https://miro.medium.com/max/640/1*l9pvYpv5HBZh0qZRrXcU-w.webp
А вот Cassandra и RDBMS https://dzone.com/refcardz/apache-cassandra#section-2
Я далее буду использовать термины из RDBMS для простоты.
Такая неразбериха вызвана тем, что, как я уже писал, у NoSQL СУБД не так много общего. Более того они делятся на 4 категории (и в будущем их может стать больше):
а) ключ-значение
б) документные
в) семейства столбцов
г) графовые
Ключ-значение - самые простые, если ключ и некий blob. По сути это Java Map, где value - byte[]. Поиск идет по ключу. Документные и семейства столбцов можно рассматривать как усложнение "ключ-значения". В первом случае blob превращается в документ, например, JSON, с некой структурой, по отдельным полям документа можно строить индексы. В другом - blob делится на столбцы, причем столбцы тоже могут содержать столбцы, а могут - blob. Графовые - отдельная ветка, ее ключевое преимущество: можно определить множество связей между объектами, которые рассчитываются при обновлении данных и поэтому запросы поиска связанных значений через множество уровней существенно быстрее RDBMS, т.к. не нужно join-ить в runtime.
1) нет строгой схемы данных, контролируемой на сервере. Почему я говорю строгой? Потому что какая-то структура на сервере все же определена.
В любом случае у "записи" есть ключ, у документных БД и семейств столбцов мы определяем ряд "столбцов", по которым есть индексы.
Но главное: у разных записей может быть разный набор столбцов, и точной структуры данных сервер не знает.
И тут есть проблема - прикладному коду структуру знать нужно, т.е. какая-то схема нужна. И храниться она может только на клиенте.
А отсюда проблем две:
а) синхронизация схемы между сервисами. Если мы придерживаемся микросервисной архитектуры, где за взаимодействие с БД отвечает один сервис, то проблема исчезает. Если же нет - придется эту схему создать, например, в формате OpenAPI или в виде DTO библиотеки
б) обновление данных. В RDBMS все просто - переключаешь пользователей на другое плечо, обновляешь БД, обновляешь приложение, возвращаешь пользователей. В NoSQL два пути - или обновление на клиенте при чтении и последующая запись, или задача в scheduler для фонового обновления данных.
В любом случае есть переходный период, в течение которого в коде будет if (version == X) else при чтении. А если проблему обновления данных не решать, то появится дерево if-ов, а это плохо(
Из отсутствия схемы следует, что NoSQL хорошо подходит для случая, когда структура данных не определена изначально и\или часто меняется
2) первые три типа NoSQL БД объединяет то, что их архитектура очень хорошо подходит для хранения агрегатов из DDD - Domain Driven Development. Это могут быть данные о сессии клиента или содержимое корзины заказов. Т.е. любая многоуровневая структура, идентифицируемая ключом и сохраняемая и загружаемая целиком. Работа с агрегатом как с одним целым особенно важна, т.к. именно тут NoSQL бьет RDBMS с его JOIN-ами по скорости загрузки данных. Внутри агрегата данные обновляются атомарно. JOIN-ить агрегаты можно только на клиенте. Соответственно, хотя схему данных можно менять, но границы агрегатов лучше продумывать заранее.
{kind=link}
👍3
3) нет никаких нормальных форм, дублирование данных не то что допустимо, а, наоборот, скорее является правилом. Т.е. если у нас есть агрегат клиента и агрегат заказа, то адрес доставки просто задублируется в обоих записях. Отсюда встает проблема обновления.
Решения:
а) не обновлять, если данные типа истории операций
б) фоновый процесс для обновления
4) ну и еще раз вернемся к термину NoSQL - основным способов доступа к данным является клиентский модуль для вашего языка или REST API, хотя может быть доступно и SQL-подобное API.
На сегодня все, если интересно - пишите, продолжу.
#noSQL #RDBMS
Решения:
а) не обновлять, если данные типа истории операций
б) фоновый процесс для обновления
4) ну и еще раз вернемся к термину NoSQL - основным способов доступа к данным является клиентский модуль для вашего языка или REST API, хотя может быть доступно и SQL-подобное API.
На сегодня все, если интересно - пишите, продолжу.
#noSQL #RDBMS
👍3
Всем привет!
В прошлом посте я "забыл" про еще один, возможно ключевой аспект NoSQL хранилищ. А именно способность к горизонтальному масштабированию.
Почему ключевой - потому что причиной возникновения многих если не всех NoSQL решений стала недостаточная производительность RDBMS. А производительность начиная с некоторого момента (оптимальная архитектура, оптимальный запрос к СУБД, есть все индексы) прямо связана с возможностью масштабирования.
RDBMS как правило масштабируются горизонтально, а как я уже писал для этого способа есть физические ограничения - частота и число ядер процессора, сложность материнской платы.
Да, для реляционных СУБД часто есть репликация master-slave из коробки https://www.dmosk.ru/miniinstruktions.php?mini=postgresql-replication#master. Все примеры здесь и далее приведу для PostgreSQL.
Но в системе master-slave все равно есть узкое место в виде master-а, через которого идут все записи. Т.е. решение подходит для отчетных БД и для систем, где нагрузка на чтение в разы больше нагрузки на запись.
Да, есть сторонние библиотеки для репликации master-master https://github.com/bucardo/bucardo
Но появились они относительно недавно (думаю в ответ на популярность NoSQL). Часто это сторонние решения, и в любом случае гибкость SQL в плане выборки данных и строгая транзакционность плохо сочетаются с работой в режиме master-master.
Этих проблем нет в NoSQL, более того, они изначально проектируются для разрешения конфликтов чтения и записи с помощью таких средств, как вектора изменений, автоматический выбор master-а, обновление при чтении, возможность настройки степени согласованности данных. Это отдельная большая тема, в одном посте ее раскрыть невозможно.
Да, важное замечание - это не касается графовых хранилищ, т.к. для выборки может понадобиться обойти весь граф, а, следовательно, он должен храниться на одном сервере, в этом они похожи на традиционные реляционные СУБД.
#NoSQL #scalability
В прошлом посте я "забыл" про еще один, возможно ключевой аспект NoSQL хранилищ. А именно способность к горизонтальному масштабированию.
Почему ключевой - потому что причиной возникновения многих если не всех NoSQL решений стала недостаточная производительность RDBMS. А производительность начиная с некоторого момента (оптимальная архитектура, оптимальный запрос к СУБД, есть все индексы) прямо связана с возможностью масштабирования.
RDBMS как правило масштабируются горизонтально, а как я уже писал для этого способа есть физические ограничения - частота и число ядер процессора, сложность материнской платы.
Да, для реляционных СУБД часто есть репликация master-slave из коробки https://www.dmosk.ru/miniinstruktions.php?mini=postgresql-replication#master. Все примеры здесь и далее приведу для PostgreSQL.
Но в системе master-slave все равно есть узкое место в виде master-а, через которого идут все записи. Т.е. решение подходит для отчетных БД и для систем, где нагрузка на чтение в разы больше нагрузки на запись.
Да, есть сторонние библиотеки для репликации master-master https://github.com/bucardo/bucardo
Но появились они относительно недавно (думаю в ответ на популярность NoSQL). Часто это сторонние решения, и в любом случае гибкость SQL в плане выборки данных и строгая транзакционность плохо сочетаются с работой в режиме master-master.
Этих проблем нет в NoSQL, более того, они изначально проектируются для разрешения конфликтов чтения и записи с помощью таких средств, как вектора изменений, автоматический выбор master-а, обновление при чтении, возможность настройки степени согласованности данных. Это отдельная большая тема, в одном посте ее раскрыть невозможно.
Да, важное замечание - это не касается графовых хранилищ, т.к. для выборки может понадобиться обойти весь граф, а, следовательно, он должен храниться на одном сервере, в этом они похожи на традиционные реляционные СУБД.
#NoSQL #scalability
www.dmosk.ru
Настройка репликации PostgreSQL. Отказоустойчивый кластер баз данных Postgre
Пошаговая инструкция по настройке асинхронной потоковой репликации на СУБД PostgreSQL. Подготовка сервера, редактирование конфигурационных файлов, настройка Master, Slave.
Всем привет!
При изучении NoSQL СУБД может возникнуть вопрос - ага, тут у нас ключ-значение, где-то я это уже видел. А, распределенные кэши. Redis, EhCache, Memcached, Hazelcast, Ignite. В чем разница? Это тоже NoSQL?
Если посмотреть на рейтинг СУБД https://db-engines.com/en/ranking - то да, все они там есть. Кстати, хороший сайт, аналог рейтинга Tiobe для языков программирования. Там даже Microsoft Access есть) Сайт хороший, но мне такой критерий определения: СУБД или нет - не очень нравится.
Я бы сказал: критерий отнесения к NoSQL хранилищам в персистентности, а если быть точным - позиционируют ли создатели системы ее как долговременное хранилище данных. Почему это важно? Если разработчики не предполагают, что в их системе можно долго, а в предельном случае вечно хранить данные, то там наверняка не будет необходимых для этого средств. Это могут быть утилиты для резервного копирования, а оно нужно даже при наличии репликации для возможности отката при порче данных из-за программной ошибки\взлома. Или тонких настроек взаимодействия с файловой системой. Или гарантии персистентности при сбое сервера сразу после ответа клиенту об успешной записи, которая (гарантия) обычно обеспечивается предварительной записью в Write Ahead Log (WAL) или лог транзакций. И чего-то еще, что я не знаю т.к. не являюсь DBA.
Redis - вообще говоря это первая NoSQL система, просто ее спроектировали как замену RDBMS еще до того, как появилось понятие NoSQL. Хотя Redis можно использовать как распределенный кэш. Поддерживает все необходимое для долгосрочного хранения данных https://redis.io/docs/management/persistence/
Memcached и EhCache. Это все-таки распределенные кэши с персистентностью, а не NoSQL. Может возникнуть вопрос - EhCache разве распределенный? Уже да - https://www.ehcache.org/documentation/3.1/caching-concepts.html Но судя по описанию архитектуры сервиса - уровень хранения на диске для Ehcache вторичен.
Аналогично Memcached - https://github.com/memcached/memcached/wiki/Extstore По умолчанию хранение на диске выключено. Цель дискового храненения - увеличение процента попадания в кэш.
Hazelcast и Ignite относятся к категории IMDG In-Memory Data Grid. Суть в том, что данные шардированы по разным серверам и есть возможность выполнять вычисления на одном сервере с данными. А это радикально увеличивает быстродействие и дает возможность в онлайне рассчитывать какую-то аналитику, подсказки и спецпредложения для клиента, выявлять фрод и т.д. Также можно сравнить IMDG с хранимыми процедурами в СУБД, которые тоже позволяли ускорить обработку данных, но в отличие от хранимых процедур код здесь написан на стандартных языках программирования.
При этом Hazelcast позиционирует себя как In-memory NoSQL - https://hazelcast.com/use-cases/in-memory-nosql/ В примерах использования в целом говорится о том же - https://hazelcast.com/use-cases/, см. сравнение с Cassandra, а это напомню NoSQL типа "семейство столбцов" - не замена, а способ улучшить производительность Cassandra. К слову - персистентность выключена по умолчанию и доступна только в Enterprise версии https://docs.hazelcast.com/hazelcast/5.2/storage/configuring-persistence
С Ignite интереснее. Есть 3 канала записи на диск - WAL, checkpointing (сброс незафиксированных данных на диск) и собственно запись данных на диск. Первые два должны обеспечивать достаточную надежность при сбоях https://ignite.apache.org/docs/latest/persistence/native-persistence
Себя позиционируют как NoSQL, только с SQL - хорошо звучит)))) - и транзакциями, правда ограниченными https://ignite.apache.org/faq.html
Но с другой стороны я знаю практический кейс, когда кластер Ignite очень долго допиливали и "тюнили" с целью заставить восстанавливаться в приемлемые сроки после сбоя. Прямо очень очень долго. Т.е. необходимый функционал есть, вопрос в отказоустойчивости и падении производительности при сбоях. Так что использовать Ignite как NoSQL хранилище можно, но осторожно, но с обязательным НТ и chaos engineering тестами.
#cache #imdg #nosql #rdbms
При изучении NoSQL СУБД может возникнуть вопрос - ага, тут у нас ключ-значение, где-то я это уже видел. А, распределенные кэши. Redis, EhCache, Memcached, Hazelcast, Ignite. В чем разница? Это тоже NoSQL?
Если посмотреть на рейтинг СУБД https://db-engines.com/en/ranking - то да, все они там есть. Кстати, хороший сайт, аналог рейтинга Tiobe для языков программирования. Там даже Microsoft Access есть) Сайт хороший, но мне такой критерий определения: СУБД или нет - не очень нравится.
Я бы сказал: критерий отнесения к NoSQL хранилищам в персистентности, а если быть точным - позиционируют ли создатели системы ее как долговременное хранилище данных. Почему это важно? Если разработчики не предполагают, что в их системе можно долго, а в предельном случае вечно хранить данные, то там наверняка не будет необходимых для этого средств. Это могут быть утилиты для резервного копирования, а оно нужно даже при наличии репликации для возможности отката при порче данных из-за программной ошибки\взлома. Или тонких настроек взаимодействия с файловой системой. Или гарантии персистентности при сбое сервера сразу после ответа клиенту об успешной записи, которая (гарантия) обычно обеспечивается предварительной записью в Write Ahead Log (WAL) или лог транзакций. И чего-то еще, что я не знаю т.к. не являюсь DBA.
Redis - вообще говоря это первая NoSQL система, просто ее спроектировали как замену RDBMS еще до того, как появилось понятие NoSQL. Хотя Redis можно использовать как распределенный кэш. Поддерживает все необходимое для долгосрочного хранения данных https://redis.io/docs/management/persistence/
Memcached и EhCache. Это все-таки распределенные кэши с персистентностью, а не NoSQL. Может возникнуть вопрос - EhCache разве распределенный? Уже да - https://www.ehcache.org/documentation/3.1/caching-concepts.html Но судя по описанию архитектуры сервиса - уровень хранения на диске для Ehcache вторичен.
Аналогично Memcached - https://github.com/memcached/memcached/wiki/Extstore По умолчанию хранение на диске выключено. Цель дискового храненения - увеличение процента попадания в кэш.
Hazelcast и Ignite относятся к категории IMDG In-Memory Data Grid. Суть в том, что данные шардированы по разным серверам и есть возможность выполнять вычисления на одном сервере с данными. А это радикально увеличивает быстродействие и дает возможность в онлайне рассчитывать какую-то аналитику, подсказки и спецпредложения для клиента, выявлять фрод и т.д. Также можно сравнить IMDG с хранимыми процедурами в СУБД, которые тоже позволяли ускорить обработку данных, но в отличие от хранимых процедур код здесь написан на стандартных языках программирования.
При этом Hazelcast позиционирует себя как In-memory NoSQL - https://hazelcast.com/use-cases/in-memory-nosql/ В примерах использования в целом говорится о том же - https://hazelcast.com/use-cases/, см. сравнение с Cassandra, а это напомню NoSQL типа "семейство столбцов" - не замена, а способ улучшить производительность Cassandra. К слову - персистентность выключена по умолчанию и доступна только в Enterprise версии https://docs.hazelcast.com/hazelcast/5.2/storage/configuring-persistence
С Ignite интереснее. Есть 3 канала записи на диск - WAL, checkpointing (сброс незафиксированных данных на диск) и собственно запись данных на диск. Первые два должны обеспечивать достаточную надежность при сбоях https://ignite.apache.org/docs/latest/persistence/native-persistence
Себя позиционируют как NoSQL, только с SQL - хорошо звучит)))) - и транзакциями, правда ограниченными https://ignite.apache.org/faq.html
Но с другой стороны я знаю практический кейс, когда кластер Ignite очень долго допиливали и "тюнили" с целью заставить восстанавливаться в приемлемые сроки после сбоя. Прямо очень очень долго. Т.е. необходимый функционал есть, вопрос в отказоустойчивости и падении производительности при сбоях. Так что использовать Ignite как NoSQL хранилище можно, но осторожно, но с обязательным НТ и chaos engineering тестами.
#cache #imdg #nosql #rdbms
DB-Engines
DB-Engines Ranking
Popularity ranking of database management systems.
👍2
Всем привет!
Я упомянул в предыдущем посте про Сhaos engineering. Хочу немного развить тему, тем более она стала популярна в последнее время.
Если описать вкратце - это контролируемая поломка системы.
Алгоритм такой:
1) определяем чтобы такого сломать. Очевидно, ломать нужно то, что с большей вероятностью может сломаться в ПРОДе
2) определяем как мы хотим, чтобы система вела себя при поломке
3) определяем как мы будем мониторить ее поведение
4) ломаем систему
5) сравниваем план и факт
6) опциально: заводим задачи на исправление))))
Вот тут подробнее https://habr.com/ru/company/flant/blog/460367/
Что интересно - тема chaos engineering "попала в топ" после того, как начался массовый переход в облака и в частности на k8s. И это неспроста.
Ключевой момент в chaos engineering - контролируемость эксперимента. Да, настоящих bare metal серверов все меньше, все чаще используются виртуалки. VMWare позволяет автоматизировать запуск и остановку отдельного сервера.
Но k8s и особенно Istio благодаря своим прокси на каждом узле (kube-proxy и envoy соответственно) позволяет централизовано управлять маршрутизацией. А это дает нам:
1) эмуляцию потери пакетов
2) эмуляцию увеличенных таймаутов
3) "виртуальное" отключение сервера - отключение трафика на сервер без отключения сервера, т.наз. blackhole. А это ускоряет тестирование.
4) отключение на уровне namespace
и какие-то более сложные сценарии.
В общем унификация в данном случае рулит!)
#haos_engeniring #k8s #istio
Я упомянул в предыдущем посте про Сhaos engineering. Хочу немного развить тему, тем более она стала популярна в последнее время.
Если описать вкратце - это контролируемая поломка системы.
Алгоритм такой:
1) определяем чтобы такого сломать. Очевидно, ломать нужно то, что с большей вероятностью может сломаться в ПРОДе
2) определяем как мы хотим, чтобы система вела себя при поломке
3) определяем как мы будем мониторить ее поведение
4) ломаем систему
5) сравниваем план и факт
6) опциально: заводим задачи на исправление))))
Вот тут подробнее https://habr.com/ru/company/flant/blog/460367/
Что интересно - тема chaos engineering "попала в топ" после того, как начался массовый переход в облака и в частности на k8s. И это неспроста.
Ключевой момент в chaos engineering - контролируемость эксперимента. Да, настоящих bare metal серверов все меньше, все чаще используются виртуалки. VMWare позволяет автоматизировать запуск и остановку отдельного сервера.
Но k8s и особенно Istio благодаря своим прокси на каждом узле (kube-proxy и envoy соответственно) позволяет централизовано управлять маршрутизацией. А это дает нам:
1) эмуляцию потери пакетов
2) эмуляцию увеличенных таймаутов
3) "виртуальное" отключение сервера - отключение трафика на сервер без отключения сервера, т.наз. blackhole. А это ускоряет тестирование.
4) отключение на уровне namespace
и какие-то более сложные сценарии.
В общем унификация в данном случае рулит!)
#haos_engeniring #k8s #istio
Хабр
Chaos Engineering: искусство умышленного разрушения. Часть 1
Прим. перев.: Рады поделиться переводом замечательного материала от старшего технологического евангелиста из AWS — Adrian Hornsby. В простых словах он объясняет важность экспериментов, призванных...
👍1
Всем привет!
Снова про NoSQL. NoSQL хорошо масштабируется, дает гибкую схему данных, но при этом мы теряем в гибкости запросов. В частности нельзя агрегировать данные - GROUP BY. Там же данные из разных агрегатов, собирать нужно со всех серверов кластера. Так? Нет)
Если RDBMS агрегирует можно сказать "просто" - по одному серверу, то NoSQL системы работают хитрее. Они используют технику MapReduce, автором которой является Google https://ru.wikipedia.org/wiki/MapReduce. Я опишу архитектуру MapReduce на примере Riak, в остальных хранилищах, подозреваю, алгоритм похож.
Для начала нужно задать 2 метода на одном из стандартных языков программирования: Map и Reduce. Их можно задавать при каждом запросе к БД, где нужна агрегация или прихранить на сервере, тогда получится аналог хранимой процедуры. Пусть клиенсткий запрос пришел на один из серверов кластера. Этот сервер пересылает его на другие сервера. Вначале выполняется метод Map на всех "строках" требуемой сущности, преобразуя строку в какое-то представление. Например, если взять агрегат Count - строка преобразует в 1. Код выполняется на параллельно на всех серверах. Далее на каждом сервере выполняется второй метод - reduce, который суммирует все результаты Map. Далее все результаты reduce возвращаются на исходный сервер и там снова выполняется reduce. Ответ возвращается клиенту. Если нужно - есть возможность задать условие фильтра, которое отфильтрует строки до передачи их в Map.
Решение IMHO красивое и быстрое. Кажется, на больших данных и сложном агрегировании может работать быстрее, чем в RDBMS за счет распараллеливания. Конечно зависит от агрегата, объема, СУБД.
Вот реализация Riak https://docs.riak.com/riak/kv/latest/developing/app-guide/advanced-mapreduce/index.html
Вот более сложно, в виде конвейера - Mongo https://www.mongodb.com/docs/manual/core/aggregation-pipeline/
Cassandra имеет ряд базовых функций: COUNT, SUM, MAX, MIN, AVG - из коробки, по позволяет создавать User-Defined Aggregates, работающих по тому же принципу: https://cassandra.apache.org/doc/latest/cassandra/cql/functions.html?highlight=aggregate#aggregate-functions
Из минусов - реализации MapReduce у всех разные, некий vendor-lock присутствует. Но учитывая, что API тоже у всех разное - он в любом случае будет)
#NoSQL
Снова про NoSQL. NoSQL хорошо масштабируется, дает гибкую схему данных, но при этом мы теряем в гибкости запросов. В частности нельзя агрегировать данные - GROUP BY. Там же данные из разных агрегатов, собирать нужно со всех серверов кластера. Так? Нет)
Если RDBMS агрегирует можно сказать "просто" - по одному серверу, то NoSQL системы работают хитрее. Они используют технику MapReduce, автором которой является Google https://ru.wikipedia.org/wiki/MapReduce. Я опишу архитектуру MapReduce на примере Riak, в остальных хранилищах, подозреваю, алгоритм похож.
Для начала нужно задать 2 метода на одном из стандартных языков программирования: Map и Reduce. Их можно задавать при каждом запросе к БД, где нужна агрегация или прихранить на сервере, тогда получится аналог хранимой процедуры. Пусть клиенсткий запрос пришел на один из серверов кластера. Этот сервер пересылает его на другие сервера. Вначале выполняется метод Map на всех "строках" требуемой сущности, преобразуя строку в какое-то представление. Например, если взять агрегат Count - строка преобразует в 1. Код выполняется на параллельно на всех серверах. Далее на каждом сервере выполняется второй метод - reduce, который суммирует все результаты Map. Далее все результаты reduce возвращаются на исходный сервер и там снова выполняется reduce. Ответ возвращается клиенту. Если нужно - есть возможность задать условие фильтра, которое отфильтрует строки до передачи их в Map.
Решение IMHO красивое и быстрое. Кажется, на больших данных и сложном агрегировании может работать быстрее, чем в RDBMS за счет распараллеливания. Конечно зависит от агрегата, объема, СУБД.
Вот реализация Riak https://docs.riak.com/riak/kv/latest/developing/app-guide/advanced-mapreduce/index.html
Вот более сложно, в виде конвейера - Mongo https://www.mongodb.com/docs/manual/core/aggregation-pipeline/
Cassandra имеет ряд базовых функций: COUNT, SUM, MAX, MIN, AVG - из коробки, по позволяет создавать User-Defined Aggregates, работающих по тому же принципу: https://cassandra.apache.org/doc/latest/cassandra/cql/functions.html?highlight=aggregate#aggregate-functions
Из минусов - реализации MapReduce у всех разные, некий vendor-lock присутствует. Но учитывая, что API тоже у всех разное - он в любом случае будет)
#NoSQL
👍3
Всем привет!
Сегодня побуду немного вашим кэпом, он же капитан очевидность))))
Не так давно писал про то, как важна "гигиена" в настройках с точки зрения сопровождения - неочевидные названия, дублирование, неиспользуемые настройки могут ввести в заблуждение и привести к ошибкам на ПРОМе.
Хочется развить эту тему.
На самом деле "костыли" и "мусор" вредны не только в настройках, но и в коде, в документации, в тестах. Даже если единственный потребитель - это сам разработчик, который их написал.
Представьте, что код, написанный сегодня, вы не будете трогать полгода. А через полгода прилетит большая задача, требующая этот код серьезно отрефакторить. Разберетесь в своем коде?))) Или проще сразу выкинуть и переписать?)
Ясно, что задача поддерживать код в чистоте, нелегка. Но в отличии от природы, сам код не очистится)))
Нужно выделять время на чистку. Нужно, чтобы "причесывание" кода вошло в привычку.
Небольшое отступление - выделять фиксированное время. "Причесывание", которое занимает больше времени, чем написание кода - не айс.
На какие вещи стоит обратить особое внимание:
1) неиспользуемый код и настройки, ненужные зависимости. IDEA вам в помощь в их поиске.
2) дублирование кода. Тут поможет SonarQube
3) неочевидные названия классов, полей, методов, настроек
4) уже не актуальные названия: класс изменил свой функционал, к классу добавился функционал и название его не отражает
5) код, по которому не непонятно, что он делает. Здесь конечно важен взгляд со стороны. Но если код непонятен внешнему наблюдателю, то через полгода он будет непонятен и вам. Ну и обычно это огромные методы, при просмотре сложно в голове удержать весь алгоритм.
6) рассинхрон кода и документации. Лучше всего, если документации будет мало или она будет генерироваться по коду. Имеет смысл описывать или общие вещи, например, как использовать и собирать ваш сервис, или код, назначение которого неочевидно, например, из-за бизнес-требований.
7) хардкод. Иногда можно, особенно как временное решение, главное не забывать о рефакторинге.
Что я забыл?
А так как я люблю читать и советовать книги - не могу не вспомнить и не порекомендовать классику: Чистый код Роберта Мартина https://www.litres.ru/book/chistyy-kod-sozdanie-analiz-i-refaktoring-6444478
Конспект по книге: https://habr.com/ru/post/485118/
#clean_code
Сегодня побуду немного вашим кэпом, он же капитан очевидность))))
Не так давно писал про то, как важна "гигиена" в настройках с точки зрения сопровождения - неочевидные названия, дублирование, неиспользуемые настройки могут ввести в заблуждение и привести к ошибкам на ПРОМе.
Хочется развить эту тему.
На самом деле "костыли" и "мусор" вредны не только в настройках, но и в коде, в документации, в тестах. Даже если единственный потребитель - это сам разработчик, который их написал.
Представьте, что код, написанный сегодня, вы не будете трогать полгода. А через полгода прилетит большая задача, требующая этот код серьезно отрефакторить. Разберетесь в своем коде?))) Или проще сразу выкинуть и переписать?)
Ясно, что задача поддерживать код в чистоте, нелегка. Но в отличии от природы, сам код не очистится)))
Нужно выделять время на чистку. Нужно, чтобы "причесывание" кода вошло в привычку.
Небольшое отступление - выделять фиксированное время. "Причесывание", которое занимает больше времени, чем написание кода - не айс.
На какие вещи стоит обратить особое внимание:
1) неиспользуемый код и настройки, ненужные зависимости. IDEA вам в помощь в их поиске.
2) дублирование кода. Тут поможет SonarQube
3) неочевидные названия классов, полей, методов, настроек
4) уже не актуальные названия: класс изменил свой функционал, к классу добавился функционал и название его не отражает
5) код, по которому не непонятно, что он делает. Здесь конечно важен взгляд со стороны. Но если код непонятен внешнему наблюдателю, то через полгода он будет непонятен и вам. Ну и обычно это огромные методы, при просмотре сложно в голове удержать весь алгоритм.
6) рассинхрон кода и документации. Лучше всего, если документации будет мало или она будет генерироваться по коду. Имеет смысл описывать или общие вещи, например, как использовать и собирать ваш сервис, или код, назначение которого неочевидно, например, из-за бизнес-требований.
7) хардкод. Иногда можно, особенно как временное решение, главное не забывать о рефакторинге.
Что я забыл?
А так как я люблю читать и советовать книги - не могу не вспомнить и не порекомендовать классику: Чистый код Роберта Мартина https://www.litres.ru/book/chistyy-kod-sozdanie-analiz-i-refaktoring-6444478
Конспект по книге: https://habr.com/ru/post/485118/
#clean_code
Хабр
«Чистый код» Роберт Мартин. Конспект. Как писать понятный и красивый код?
Я решил написать конспект книги, которая всем известна, а сам автор называет ее «Школой учителей Чистого кода». Пристальный взгляд Мартина как бы говорит: «Я т...
👍5
Всем привет!
Сегодня хочу рассказать про полезную библиотеку для Unit-тестирования - Instancio.
Ее цель - заполнение произвольными данными тестовых объектов. По умолчанию - произвольными и not null.
Но можно настройть селекторы для выбора определенных полей по маске (регулярке) и заполнении их данными по определенному алгоритму, определенными константами или null. Умеет заполнять коллекции и вложенные объекты.
Плюса я вижу два:
1) один очевидный - убрать boiler-plate код из тестового кода
2) второй не такой очевидный - при создании тестовых объектов руками часто во всех тестах используются одни и те же константы. Очевидные, типовые. Есть вероятность не попасть с выбранной тестовой константой в какие-то ветки тестовой логики, и т.об. не протестировать часть логики. Instancio же генерирует произвольные данные и может при очередном запуске помочь поймать редкую ошибку до того, как она проявится на ПРОМе.
Вот неплохая статья с примерами использования https://www.baeldung.com/java-test-data-instancio
#unittests #rare_test_libs
Сегодня хочу рассказать про полезную библиотеку для Unit-тестирования - Instancio.
Ее цель - заполнение произвольными данными тестовых объектов. По умолчанию - произвольными и not null.
Но можно настройть селекторы для выбора определенных полей по маске (регулярке) и заполнении их данными по определенному алгоритму, определенными константами или null. Умеет заполнять коллекции и вложенные объекты.
Плюса я вижу два:
1) один очевидный - убрать boiler-plate код из тестового кода
2) второй не такой очевидный - при создании тестовых объектов руками часто во всех тестах используются одни и те же константы. Очевидные, типовые. Есть вероятность не попасть с выбранной тестовой константой в какие-то ветки тестовой логики, и т.об. не протестировать часть логики. Instancio же генерирует произвольные данные и может при очередном запуске помочь поймать редкую ошибку до того, как она проявится на ПРОМе.
Вот неплохая статья с примерами использования https://www.baeldung.com/java-test-data-instancio
#unittests #rare_test_libs
Baeldung on Kotlin
Generate Unit Test Data in Java Using Instancio | Baeldung
Learn how to eliminate manual data setup in tests by auto-generating the data using Instancio.
👍5
Всем привет!
Иногда проект нужно мигрировать - перейти на новую версию платформы, фреймворк, новый формат конфигов. Для преобразований XML есть XSLT. Для JSON - целый зоопарк тулов - https://stackoverflow.com/questions/1618038/xslt-equivalent-for-json
А если нужно преобразовать Java? Есть библиотеки для семанитического анализа кода - вот неплохой список https://stackoverflow.com/questions/2261947/are-there-alternatives-to-cglib
Но анализ - это лишь часть миграции, да и как известно всегда можно добавить новый уровень абстракции)
Сегодня хочу рассказать про OpenRewrite - библиотеку, созданную специально для миграции или масштабного рефаторинга кода.
Введение: https://docs.openrewrite.org/running-recipes/getting-started
Пример кода миграции для произвольного Java класса: https://docs.openrewrite.org/authoring-recipes/writing-a-java-refactoring-recipe
В результате разбора кода строятся Lossless Semantic Trees (LSTs) - ациклические деревья с вложенными элементами, например: CompilationUnit -> Class -> Block of code. Код мигратора напоминает по принципу работы SAX парсер - если кто еще помнит такой)
Не обязательно самому писать код миграции, вот список готовых "рецептов":
https://docs.openrewrite.org/reference/recipes Там есть и преобразование json, xml, yml, maven pom, замена System.out на логгер, миграция с JUnit 4 на JUnit 5, миграция на проверок в модульных тестах с JUnit asserts на AssertJ. И даже миграция на Spring Boot https://www.infoq.com/news/2022/09/spring-boot-migrator
Важно - фреймворк содержит проверки корректности синтаксиса у получаемого кода, но не гарантирует, что код после миграции скомпилируется и будет работать как нужно.
Еще важно - для миграций можно и нужно писать модульные тесты.
#java #migration #refactoring
Иногда проект нужно мигрировать - перейти на новую версию платформы, фреймворк, новый формат конфигов. Для преобразований XML есть XSLT. Для JSON - целый зоопарк тулов - https://stackoverflow.com/questions/1618038/xslt-equivalent-for-json
А если нужно преобразовать Java? Есть библиотеки для семанитического анализа кода - вот неплохой список https://stackoverflow.com/questions/2261947/are-there-alternatives-to-cglib
Но анализ - это лишь часть миграции, да и как известно всегда можно добавить новый уровень абстракции)
Сегодня хочу рассказать про OpenRewrite - библиотеку, созданную специально для миграции или масштабного рефаторинга кода.
Введение: https://docs.openrewrite.org/running-recipes/getting-started
Пример кода миграции для произвольного Java класса: https://docs.openrewrite.org/authoring-recipes/writing-a-java-refactoring-recipe
В результате разбора кода строятся Lossless Semantic Trees (LSTs) - ациклические деревья с вложенными элементами, например: CompilationUnit -> Class -> Block of code. Код мигратора напоминает по принципу работы SAX парсер - если кто еще помнит такой)
Не обязательно самому писать код миграции, вот список готовых "рецептов":
https://docs.openrewrite.org/reference/recipes Там есть и преобразование json, xml, yml, maven pom, замена System.out на логгер, миграция с JUnit 4 на JUnit 5, миграция на проверок в модульных тестах с JUnit asserts на AssertJ. И даже миграция на Spring Boot https://www.infoq.com/news/2022/09/spring-boot-migrator
Важно - фреймворк содержит проверки корректности синтаксиса у получаемого кода, но не гарантирует, что код после миграции скомпилируется и будет работать как нужно.
Еще важно - для миграций можно и нужно писать модульные тесты.
#java #migration #refactoring
Stack Overflow
XSLT equivalent for JSON
Is there an XSLT equivalent for JSON? Something to allow me to do transformations on JSON like XSLT does to XML.
👍2
Всем привет!
Лайфхак для IntelliJ IDEA.
Оказывается Terminal в IDEA умный. В заголовке окна справа есть выдающее меню New Predefined Session, где можно выбрать тип терминала.
У меня на Windows выбор из:
1) PowerShell - по умолчанию
2) cmd
3) Windows Subsystem for Linux (WSL) - если в Windows установлен соответствующий компонент.
4) Git Bash
5) New ssh session - в настройках IDEA есть отдельное окно для управления ssh.
Для каждого типа терминала - один шаблон.
Опция новая, в документации ее описание не нашел, только тикеты в таск трекере IDEA.
Полезна она в первую очередь для тех, кто использует Windows.
Но не только - видел в таск-трекере запрос, на несколько шаблонов для одного типа терминала, например, с разными начальными путями или переменными среды.
Да, терминал по умолчанию, который открывается по кнопке +, можно переопределять на одноименной вкладке в настройках. Но набор предопределенных шаблонов все же удобнее.
Вдогонку еще про одну малоизвестную фичу: терминал может работать в режиме Run Anything https://www.jetbrains.com/help/idea/running-anything.html - т.е. команда будет запускаться не в консоли, а в IDEA. Само собой только та команда, которую IDEA распознала.
Детали см. https://www.jetbrains.com/help/idea/terminal-emulator.html#smart-command-execution
Учитывая наличие хорошего git client, http client, maven\Gradle интеграции - из IDEA во время работы можно не выходить)))
#IDEA
Лайфхак для IntelliJ IDEA.
Оказывается Terminal в IDEA умный. В заголовке окна справа есть выдающее меню New Predefined Session, где можно выбрать тип терминала.
У меня на Windows выбор из:
1) PowerShell - по умолчанию
2) cmd
3) Windows Subsystem for Linux (WSL) - если в Windows установлен соответствующий компонент.
4) Git Bash
5) New ssh session - в настройках IDEA есть отдельное окно для управления ssh.
Для каждого типа терминала - один шаблон.
Опция новая, в документации ее описание не нашел, только тикеты в таск трекере IDEA.
Полезна она в первую очередь для тех, кто использует Windows.
Но не только - видел в таск-трекере запрос, на несколько шаблонов для одного типа терминала, например, с разными начальными путями или переменными среды.
Да, терминал по умолчанию, который открывается по кнопке +, можно переопределять на одноименной вкладке в настройках. Но набор предопределенных шаблонов все же удобнее.
Вдогонку еще про одну малоизвестную фичу: терминал может работать в режиме Run Anything https://www.jetbrains.com/help/idea/running-anything.html - т.е. команда будет запускаться не в консоли, а в IDEA. Само собой только та команда, которую IDEA распознала.
Детали см. https://www.jetbrains.com/help/idea/terminal-emulator.html#smart-command-execution
Учитывая наличие хорошего git client, http client, maven\Gradle интеграции - из IDEA во время работы можно не выходить)))
#IDEA
IntelliJ IDEA Help
Run anything | IntelliJ IDEA
👍4
Всем привет!
Есть куча способов работать с реляционными СУБД в Java приложениях.
JPA, JPA JPQL, JPA Native Query, JPA Criteria API, Spring Data JDBC, Spring Data JPA, MyBatis, Jooq. Нативный JDBC в конце концов. Чистый Hibernate API не беру в расчет, т.к. подозреваю, что JPA его заборол)
А недавно я узнал про еще один - в нем соединяются JPA и стримы.
Речь о JPAStreamer https://jpastreamer.org/
Плюс статья на хабре https://habr.com/ru/post/568794/
Идея кажется интересной, т.к. благодаря автогенерации недостающих классов получаем строгую проверку типов на этапе компиляции. И запрос в теле метода, а не в аннотации.
При этом код выглядит более читаемый по сравнению с Criteria API, который так и не взлетел.
Если попытаться сравнить еще с чем-то - код похож на Jooq, но на основе JPA и со стримами. И на .NET LINQ.
Возникла мысль: неплохо бы сделать сравнение вышеперечисленных технологий. Имеет смысл?
#jpa #jdbc #rdbms
Есть куча способов работать с реляционными СУБД в Java приложениях.
JPA, JPA JPQL, JPA Native Query, JPA Criteria API, Spring Data JDBC, Spring Data JPA, MyBatis, Jooq. Нативный JDBC в конце концов. Чистый Hibernate API не беру в расчет, т.к. подозреваю, что JPA его заборол)
А недавно я узнал про еще один - в нем соединяются JPA и стримы.
Речь о JPAStreamer https://jpastreamer.org/
Плюс статья на хабре https://habr.com/ru/post/568794/
Идея кажется интересной, т.к. благодаря автогенерации недостающих классов получаем строгую проверку типов на этапе компиляции. И запрос в теле метода, а не в аннотации.
При этом код выглядит более читаемый по сравнению с Criteria API, который так и не взлетел.
Если попытаться сравнить еще с чем-то - код похож на Jooq, но на основе JPA и со стримами. И на .NET LINQ.
Возникла мысль: неплохо бы сделать сравнение вышеперечисленных технологий. Имеет смысл?
#jpa #jdbc #rdbms
JPAstreamer
JPAstreamer | Express Hibernate Queries as Java Streams
JPAstreamer is an open source toolkit that enriches the API of any JPA provider to allow processing data as standard Java Streams.
👍6
Всем привет!
Короткий пост про DDD. На мой взгляд это полезная технология, имеет смысл ее изучить. Но есть важный момент. Доменный слой это в первую очередь доменная логика. Доменные объекты нужны для использования в доменной логике, DTO и @Entity там быть не должно. Но есть куча приложений, где нет доменной логики, или она минимальная. Например, в middleware слое. Или реально микро микросервис) А доменный слой - это в нагрузку mapper-ы из/в DTO.
Поэтому вывод: не надо создавать доменный слой и использовать DDD везде и всегда. Во главу угла ставим целесообразность.
#ddd
Короткий пост про DDD. На мой взгляд это полезная технология, имеет смысл ее изучить. Но есть важный момент. Доменный слой это в первую очередь доменная логика. Доменные объекты нужны для использования в доменной логике, DTO и @Entity там быть не должно. Но есть куча приложений, где нет доменной логики, или она минимальная. Например, в middleware слое. Или реально микро микросервис) А доменный слой - это в нагрузку mapper-ы из/в DTO.
Поэтому вывод: не надо создавать доменный слой и использовать DDD везде и всегда. Во главу угла ставим целесообразность.
#ddd
👍1🔥1
Всем привет!
Наверняка все видели псевдографический баннер в логах при запуске Spring приложений. Так вот его текст можно менять, использовать в тексте переменные среды или даже написать логику его генерации на Java. И наконец его можно просто отключить. Делали: https://docs.spring.io/spring-boot/docs/current/reference/html/features.html#features.spring-application.banner Генератор псевдографики: https://devops.datenkollektiv.de/banner.txt/index.html
Фича наверное малополезная, но забавная)
#spring
Наверняка все видели псевдографический баннер в логах при запуске Spring приложений. Так вот его текст можно менять, использовать в тексте переменные среды или даже написать логику его генерации на Java. И наконец его можно просто отключить. Делали: https://docs.spring.io/spring-boot/docs/current/reference/html/features.html#features.spring-application.banner Генератор псевдографики: https://devops.datenkollektiv.de/banner.txt/index.html
Фича наверное малополезная, но забавная)
#spring
devops.datenkollektiv.de
Spring Boot banner.txt generator
Online Spring Boot Banner Generator (with FIGlet Fonts)