
Salami Slicing: от одного исследования ко множеству публикаций
“Тактика салями” в академическом мире (Salami Slicing) — неуместное разделение одной публикации на ряд публикаций с идентичными или очень похожими данными в каждой статье. Термин, широко используемый в теоретико-игровом моделировании, как нельзя лучше подходит для описания подхода, нацеленного на искусственное завышение публикационной активности.
Попытка дважды опубликовать результаты, полученные в ходе выполнения одного исследования, — этически неприемлемая практика, она не только может приводить к искажению исследовательских выводов, но и может навредить академическому сообществу по ряду других причин:
🔹 создает дополнительную работу для читателей, будущих авторов, рецензентов и редакторов;
🔹 идет рука об руку с самоплагиатом;
🔹 приводит к дублированию публикаций.
Такая стратегия наиболее опасна для молодых исследователей, которые могут привыкнуть анализировать данные частями, забывая, что в таком случае из поля зрения ускользают более ценные выводы, которые можно было бы изложить в ходе одного исследования.
Очевидно, что опубликовать многокомпонентные исследования гораздо сложнее, чем более простые, как минимум, из-за объема работы, которую необходимо провести авторам и редакторам перед публикацией статьи. Поддаваясь искушению пойти по более лёгкому пути, исследователи в долгосрочной перспективе могут значительно снизить свои шансы на публикации во влиятельных журналах.
Дополнительная сложность заключается в том, что Salami Slicing легче идентифицировать в количественных исследованиях, чем в качественных. В дискуссиях о том, что же понимать под “неоправданной сегментацией”, исследователи сформулировали вопросы, положительные ответы на которые помогут распознать этот вид академического мошенничества:
💠 каждая публикация проверяет одну гипотезу?
💠 две (и более) публикации основываются на одном и том же массиве данных?
💠 исследования сообщают об одних и тех же результатах?/приходят к одним и тем же выводам?
Однако принудительное применение таких правил к некоторым исследованиям (например, в социальных науках) сводит сложные исследовательские вопросы к простым «данным», лишая их более глубокого контекста и значения.
Мигель Ройг, исследователь в области академической честности, в своем гайде на эту тему рекомендует напоминать себе следующее: “Если результаты одного сложного исследования наилучшим образом можно представить как “связанное” единое целое, их не следует разбивать на отдельные статьи”.
“Тактика салями” — явление хоть и не новое, но тяжело отслеживаемое, особенно в условиях высококонкурентной и ориентированной на публикации академической реальности. Следует помнить, что как и в случае с другими формами избыточности и фактического дублирования статей, неоправданная сегментация исследования приводит к искажению информации, заставляя ничего не подозревающих читателей верить в то, что данные, представленные в каждом кусочке салями (т. е. в журнальной статье), получены независимо друг от друга.
P.S.
Этот пост продолжает серию заметок о недобросовестных исследовательских практиках и мошенничестве в академическом мире. Мы публикуем серию карточек на эту тему, чтобы нашим подписчикам было проще не заблудиться в dark side of publishing.
#SalamiSlicing #тактикасалями #обзор
“Тактика салями” в академическом мире (Salami Slicing) — неуместное разделение одной публикации на ряд публикаций с идентичными или очень похожими данными в каждой статье. Термин, широко используемый в теоретико-игровом моделировании, как нельзя лучше подходит для описания подхода, нацеленного на искусственное завышение публикационной активности.
Попытка дважды опубликовать результаты, полученные в ходе выполнения одного исследования, — этически неприемлемая практика, она не только может приводить к искажению исследовательских выводов, но и может навредить академическому сообществу по ряду других причин:
🔹 создает дополнительную работу для читателей, будущих авторов, рецензентов и редакторов;
🔹 идет рука об руку с самоплагиатом;
🔹 приводит к дублированию публикаций.
Такая стратегия наиболее опасна для молодых исследователей, которые могут привыкнуть анализировать данные частями, забывая, что в таком случае из поля зрения ускользают более ценные выводы, которые можно было бы изложить в ходе одного исследования.
Очевидно, что опубликовать многокомпонентные исследования гораздо сложнее, чем более простые, как минимум, из-за объема работы, которую необходимо провести авторам и редакторам перед публикацией статьи. Поддаваясь искушению пойти по более лёгкому пути, исследователи в долгосрочной перспективе могут значительно снизить свои шансы на публикации во влиятельных журналах.
Дополнительная сложность заключается в том, что Salami Slicing легче идентифицировать в количественных исследованиях, чем в качественных. В дискуссиях о том, что же понимать под “неоправданной сегментацией”, исследователи сформулировали вопросы, положительные ответы на которые помогут распознать этот вид академического мошенничества:
💠 каждая публикация проверяет одну гипотезу?
💠 две (и более) публикации основываются на одном и том же массиве данных?
💠 исследования сообщают об одних и тех же результатах?/приходят к одним и тем же выводам?
Однако принудительное применение таких правил к некоторым исследованиям (например, в социальных науках) сводит сложные исследовательские вопросы к простым «данным», лишая их более глубокого контекста и значения.
Мигель Ройг, исследователь в области академической честности, в своем гайде на эту тему рекомендует напоминать себе следующее: “Если результаты одного сложного исследования наилучшим образом можно представить как “связанное” единое целое, их не следует разбивать на отдельные статьи”.
“Тактика салями” — явление хоть и не новое, но тяжело отслеживаемое, особенно в условиях высококонкурентной и ориентированной на публикации академической реальности. Следует помнить, что как и в случае с другими формами избыточности и фактического дублирования статей, неоправданная сегментация исследования приводит к искажению информации, заставляя ничего не подозревающих читателей верить в то, что данные, представленные в каждом кусочке салями (т. е. в журнальной статье), получены независимо друг от друга.
P.S.
Этот пост продолжает серию заметок о недобросовестных исследовательских практиках и мошенничестве в академическом мире. Мы публикуем серию карточек на эту тему, чтобы нашим подписчикам было проще не заблудиться в dark side of publishing.
#SalamiSlicing #тактикасалями #обзор
Коротко и ясно: зависит ли цитируемость статьи от длины заголовка?
Большинство исследователей настаивают на том, что заголовки опубликованных работ должны быть относительно краткими, так как заголовки — это первая, а иногда и единственная информация, которую читатель получает из публикации.
Результаты опроса (впрочем, довольно старого), в котором приняли участие более 5000 человек, показали, что читатель научных журналов просматривает в среднем 1142 заголовка, 204 аннотации и 97 статей в год. Растущий поток информации и повышающаяся конкуренция в академической среде приводят к тому, что читателю, вероятнее всего, проще откинуть статью с витиеватым заголовком, не вникая в ее содержание (не случайно некоторые научные журналы ограничивают количество слов в заголовках). Как мы недавно видели, короткий и броский заголовок действительно может привлечь внимание.
С другой стороны, согласно теории поисковой оптимизации (SEO), длинный заголовок может помочь в поиске статьи по ключевым словам, благодаря чему статья привлекает больше внимания, и, соответственно, чаще цитируется. Исследователи Шанхайского университета финансов и экономики (SUFE) называют это информативным эффектом (informative effect), а факторы, подтверждающие положительную корреляцию между короткими заголовками и цитированием статей, — эффектом лаконичности (succinct effect).
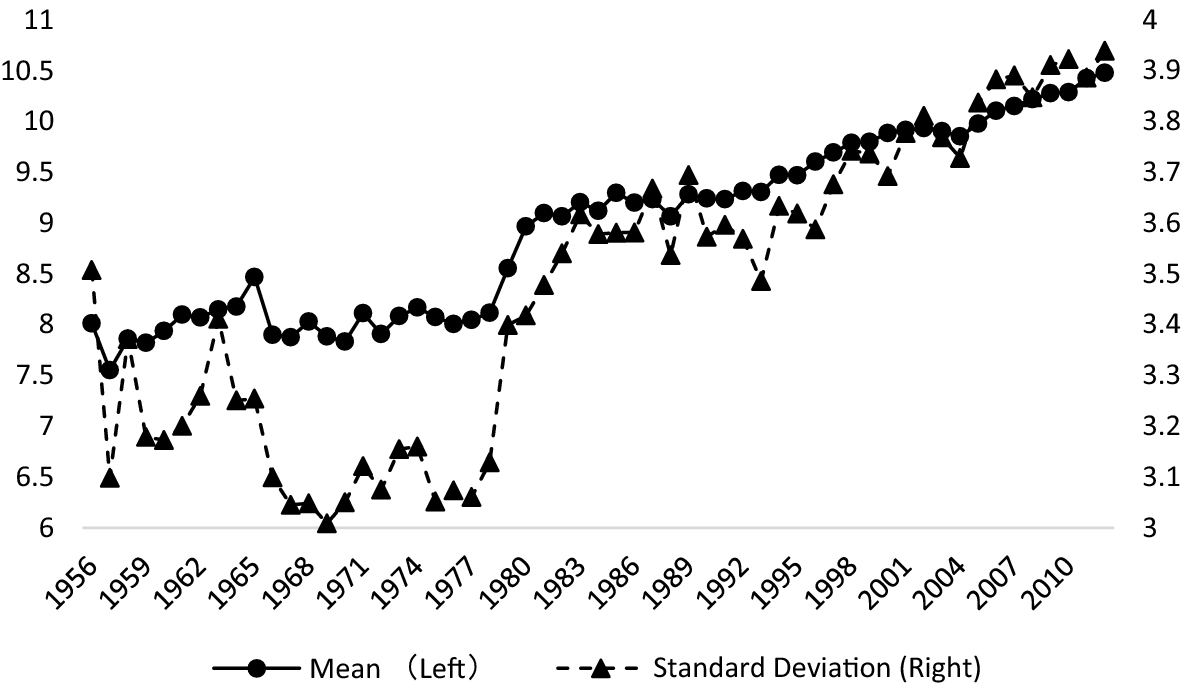
На основе выборки из более чем 300 000 статей SSCI по экономике с 1956 по 2012 год они определили, что статьи с короткими названиями лучше цитировались в период, когда поиск литературы не был так тесно связан с цифровыми технологиями (1956–2000 годы), а уже с 2001 года наблюдается рост цитируемости статей с длинными заголовками.
Здесь необходимо отметить несколько аспектов. Во-первых, сами авторы стали использовать больше слов в заголовке (см. график). В частности, в 2010–2012 годах в заголовке в среднем было 10,4 слова, что на 33% больше, чем 7,8 слов в 1956–1958 годах.
Согласно исследованию, в XXI веке количество цитирований статьи должно возрастать на 0,60% с каждым дополнительным словом, добавленным в название статьи. Следует отметить, что, помимо длины заголовка, в исследовании были учтены другие факторы, которые могут влиять на количество цитирований:
💠 Количество страниц в статье. Статьи тоже стали длиннее, а такие статьи, согласно некоторым исследованиям, чаще цитируют.
💠 Число соавторов. Было обнаружено, что чем больше соавторов, тем больше цитирований, так как статья привлекает больше внимания.
💠 Количество ссылок в работе. Чем больше в статье ссылок на предыдущие работы, тем больше доверия она вызывает. Также обширный список источников связан с формой взаимного альтруизма — «Я цитирую вас, а вы цитируете меня».
💠 Алфавитный порядок авторов. Первого автора из списка чаще цитируют и упоминают.
💠 Порядок статьи в выпуске. Первые статьи в выпуске, как правило, больше скачивают и цитируют.
На данном этапе развития науки почти весь поиск литературы осуществляется в онлайн-базах данных, причем многие поиски ограничиваются ключевыми словами. По мнению авторов исследования, статьи с краткими названиями были более привлекательны в предыдущие десятилетия, но с развитием интернета информативный эффект начал превосходить эффект лаконичности. Исследователям не стоит жалеть время на выбор заголовка публикации, так как число статей и журналов, к которым можно получить онлайн-доступ, постоянно растет. А мы планируем вскоре вернуться к этой теме со своим исследованием, чтобы слегка освежить данные, полученные в оригинальной статье.
#цитирование #SSCI #обзор
Большинство исследователей настаивают на том, что заголовки опубликованных работ должны быть относительно краткими, так как заголовки — это первая, а иногда и единственная информация, которую читатель получает из публикации.
Результаты опроса (впрочем, довольно старого), в котором приняли участие более 5000 человек, показали, что читатель научных журналов просматривает в среднем 1142 заголовка, 204 аннотации и 97 статей в год. Растущий поток информации и повышающаяся конкуренция в академической среде приводят к тому, что читателю, вероятнее всего, проще откинуть статью с витиеватым заголовком, не вникая в ее содержание (не случайно некоторые научные журналы ограничивают количество слов в заголовках). Как мы недавно видели, короткий и броский заголовок действительно может привлечь внимание.
С другой стороны, согласно теории поисковой оптимизации (SEO), длинный заголовок может помочь в поиске статьи по ключевым словам, благодаря чему статья привлекает больше внимания, и, соответственно, чаще цитируется. Исследователи Шанхайского университета финансов и экономики (SUFE) называют это информативным эффектом (informative effect), а факторы, подтверждающие положительную корреляцию между короткими заголовками и цитированием статей, — эффектом лаконичности (succinct effect).
На основе выборки из более чем 300 000 статей SSCI по экономике с 1956 по 2012 год они определили, что статьи с короткими названиями лучше цитировались в период, когда поиск литературы не был так тесно связан с цифровыми технологиями (1956–2000 годы), а уже с 2001 года наблюдается рост цитируемости статей с длинными заголовками.
Здесь необходимо отметить несколько аспектов. Во-первых, сами авторы стали использовать больше слов в заголовке (см. график). В частности, в 2010–2012 годах в заголовке в среднем было 10,4 слова, что на 33% больше, чем 7,8 слов в 1956–1958 годах.
Согласно исследованию, в XXI веке количество цитирований статьи должно возрастать на 0,60% с каждым дополнительным словом, добавленным в название статьи. Следует отметить, что, помимо длины заголовка, в исследовании были учтены другие факторы, которые могут влиять на количество цитирований:
💠 Количество страниц в статье. Статьи тоже стали длиннее, а такие статьи, согласно некоторым исследованиям, чаще цитируют.
💠 Число соавторов. Было обнаружено, что чем больше соавторов, тем больше цитирований, так как статья привлекает больше внимания.
💠 Количество ссылок в работе. Чем больше в статье ссылок на предыдущие работы, тем больше доверия она вызывает. Также обширный список источников связан с формой взаимного альтруизма — «Я цитирую вас, а вы цитируете меня».
💠 Алфавитный порядок авторов. Первого автора из списка чаще цитируют и упоминают.
💠 Порядок статьи в выпуске. Первые статьи в выпуске, как правило, больше скачивают и цитируют.
На данном этапе развития науки почти весь поиск литературы осуществляется в онлайн-базах данных, причем многие поиски ограничиваются ключевыми словами. По мнению авторов исследования, статьи с краткими названиями были более привлекательны в предыдущие десятилетия, но с развитием интернета информативный эффект начал превосходить эффект лаконичности. Исследователям не стоит жалеть время на выбор заголовка публикации, так как число статей и журналов, к которым можно получить онлайн-доступ, постоянно растет. А мы планируем вскоре вернуться к этой теме со своим исследованием, чтобы слегка освежить данные, полученные в оригинальной статье.
#цитирование #SSCI #обзор
{kind=link}
«Стоковые» члены редколлегии в хищнических журналах
Как мы упоминали ранее, хищнические издательства часто пользуются без авторизации личными данными ученых и включают их в редакционные коллегии своих журналов (если эти редколлегии, конечно, вообще есть).
В июльском выпуске Learned Publishing вышла статья, посвященная описанию «стоковых» персонажей (stock characters) хищнических редколлегий, под которыми автор подразумевает ученых, которые одновременно входят в редколлегии 20 и более недобросовестных журналов.
В период с 2017 по 2023 год Майк Даунс (Mike Downes) тщательно изучал тысячи редакционных коллегий журналов, издатели которых входят в Список Билла (Beall's List). Им были обнаружены 96 исследователей, каждый из которых состоит в редколлегиях от 20 до 503 журналов (по состоянию на 2023 год).
В выборку вошли только хищнические журналы, редакционная политика которых допускает три этических нарушения:
🔹 фабрикация дат рецензирования статей;
🔹 кража личных данных;
🔹 заполнение архивов фальшивыми статьями.
По мнению автора, «стоковые» персонажи встречались настолько часто, что можно уверенно воспринимать их присутствие или отсутствие в качестве полноценного критерия, отличающего честного издателя от недобросовестного.
Такие персонажи, как правило, обращают на себя внимание за счет следующих «красных флагов»:
🔹 невозможность обнаружить профиль ученого на сайте вуза, в котором он якобы работает;
🔹 членство в редколлегиях журналов по двум и более несвязанным темам;
🔹 такой ученый практически никогда не встречается в редколлегии влиятельного журнала.
Конечно, информация о членах редколлегии может быть украдена полностью или частично, т.е. в некоторых случаях ученые не знают, что выступают в такой роли, но иногда исследователи добровольно вступают в такие редколлегии (в таких случаях они там же публикуют свои работы). Очевидно, что членство в совете редколлегии хищнического журнала, которое указано в разделе «Достижения» или в каком-либо схожем разделе биографии исследователя, нельзя назвать кражей личных данных.
Опасность заключается в том, что если имя ученого упоминается в хищнических редколлегиях сначала один, два, а потом несколько раз, и исследователь не замечает этого (или не хочет замечать), такое лицо легко становится типичной жертвой кражи личных данных.
Майк Даунс отмечает, что после его переписки с рядом «стоковых» персонажей, нескольким авторам, внесенным в редколлегии без их согласия, удалось немного исправить ситуацию. Например, один исследователь, который когда-то входил в 361 редколлегии, на данный момент состоит в 118. Однако существуют и мертвые «стоковые» персонажи, которые не могут за себя постоять (так, например, один профессор уже четвертый год после смерти продолжает занимать должность главного редактора журнала).
«Стоковые» персонажи включают в редакционные коллегии, чтобы создать впечатление, что журнал соответствует академическим стандартам. Согласно опросу автора, «стоковых» персонажей и многих других ученых, появлявшихся в редакционных коллегиях хищнических издательств, часто объединяет смутное воспоминание о том, что они согласились стать членом редакционной коллегии много лет назад и с тех пор больше ничего об этом не слышали. Внимательность в таких вопросах может помочь вовремя заметить кражу личных данных исследователя и принять соответствующие меры.
#predatoryjournals #хищническиежурналы #редколлегия #обзор
Как мы упоминали ранее, хищнические издательства часто пользуются без авторизации личными данными ученых и включают их в редакционные коллегии своих журналов (если эти редколлегии, конечно, вообще есть).
В июльском выпуске Learned Publishing вышла статья, посвященная описанию «стоковых» персонажей (stock characters) хищнических редколлегий, под которыми автор подразумевает ученых, которые одновременно входят в редколлегии 20 и более недобросовестных журналов.
В период с 2017 по 2023 год Майк Даунс (Mike Downes) тщательно изучал тысячи редакционных коллегий журналов, издатели которых входят в Список Билла (Beall's List). Им были обнаружены 96 исследователей, каждый из которых состоит в редколлегиях от 20 до 503 журналов (по состоянию на 2023 год).
В выборку вошли только хищнические журналы, редакционная политика которых допускает три этических нарушения:
🔹 фабрикация дат рецензирования статей;
🔹 кража личных данных;
🔹 заполнение архивов фальшивыми статьями.
По мнению автора, «стоковые» персонажи встречались настолько часто, что можно уверенно воспринимать их присутствие или отсутствие в качестве полноценного критерия, отличающего честного издателя от недобросовестного.
Такие персонажи, как правило, обращают на себя внимание за счет следующих «красных флагов»:
🔹 невозможность обнаружить профиль ученого на сайте вуза, в котором он якобы работает;
🔹 членство в редколлегиях журналов по двум и более несвязанным темам;
🔹 такой ученый практически никогда не встречается в редколлегии влиятельного журнала.
Конечно, информация о членах редколлегии может быть украдена полностью или частично, т.е. в некоторых случаях ученые не знают, что выступают в такой роли, но иногда исследователи добровольно вступают в такие редколлегии (в таких случаях они там же публикуют свои работы). Очевидно, что членство в совете редколлегии хищнического журнала, которое указано в разделе «Достижения» или в каком-либо схожем разделе биографии исследователя, нельзя назвать кражей личных данных.
Опасность заключается в том, что если имя ученого упоминается в хищнических редколлегиях сначала один, два, а потом несколько раз, и исследователь не замечает этого (или не хочет замечать), такое лицо легко становится типичной жертвой кражи личных данных.
Майк Даунс отмечает, что после его переписки с рядом «стоковых» персонажей, нескольким авторам, внесенным в редколлегии без их согласия, удалось немного исправить ситуацию. Например, один исследователь, который когда-то входил в 361 редколлегии, на данный момент состоит в 118. Однако существуют и мертвые «стоковые» персонажи, которые не могут за себя постоять (так, например, один профессор уже четвертый год после смерти продолжает занимать должность главного редактора журнала).
«Стоковые» персонажи включают в редакционные коллегии, чтобы создать впечатление, что журнал соответствует академическим стандартам. Согласно опросу автора, «стоковых» персонажей и многих других ученых, появлявшихся в редакционных коллегиях хищнических издательств, часто объединяет смутное воспоминание о том, что они согласились стать членом редакционной коллегии много лет назад и с тех пор больше ничего об этом не слышали. Внимательность в таких вопросах может помочь вовремя заметить кражу личных данных исследователя и принять соответствующие меры.
#predatoryjournals #хищническиежурналы #редколлегия #обзор
Некоммерческое издание публикаций не снижает их стоимости
Современная научная публикационная деятельность сталкивается с серьезными финансовыми вызовами. Растущая стоимость публикационного процесса увеличивает потребность в некоммерческих моделях публикаций. Однако существует вероятность того, что популярность таких моделей может ограничить рост издательств, но так и не привести к удешевлению процесса публикации. В сегодняшнем обзоре мы рассмотрим посвященное этой теме недавнее исследование Роба Джонсона, главы компании Research Consulting в области исследовательской политики.
Инициатива ЕС по снижению стоимости публикации
В мае 2023 года Совет ЕС назвал текущие расходы на публикации неприемлемыми:
«Расходы на платный доступ к статьям и их публикацию становятся непосильными, а каналы публикаций для исследователей часто находятся в руках частных компаний, которые зачастую контролируют интеллектуальную собственность на статьи».
Совет призвал Комиссию и EC поддержать политику, направленную на создание некоммерческой, открытой и многоформатной модели научных изданий, не влекущей за собой никаких расходов для авторов и читателей.
В своем исследовании Р. Джонсон указывает, что существующие издательства уменьшают расходы на процесс публикации путем использования государственных субсидий или масштабирования объема выпускаемых публикаций. Это же наблюдение подтверждает отчет Массачусетского технологического института «Доступ к науке и стипендиям: ключевые вопросы о будущем публикации научных работ», в котором предлагается два способа увеличения прибыли коммерческих изданий: увеличение количества публикаций и снижение расходов.
О состоянии коммерческих изданий свидетельствуют данные инициативы OpenAPC при библиотеке Билефельдского университета, которая публикует наборы данных о сборах, выплачиваемых университетами и исследовательскими институтами за статьи в журналах открытого доступа.
Создание Open Research Europe и сценарии развития
Сложившуюся ситуацию, как описано в инициативе ЕС, предлагается решить при помощи создания ORE — издательской платформы открытого доступа на некоммерческой основе. Предполагается, что эта платформа будет работать как независимое юридическое лицо, что позволит оценить полную стоимость публикационного цикла. Большинство услуг, связанных с производством публикаций, таких как редакционные, производственные или технологические функции, будут выполняться сторонними поставщиками, но допускается возможность реализации платформы на базе уже существующей академической или международной организации. Однако, насколько создание ORE решит проблему роста стоимости публикаций?
В 2023 году Р. Джонсон представил отчет о потенциале создания ORE. В нем рассматриваются вероятные внутренние и внешние факторы, потенциально способные повлиять на рост опубликованных материалов, а также предполагаемый рост расходов в период с 2026 по 2030 годы.
Р. Джонсон смоделировал несколько сценариев возможного роста публикаций под эгидой ORE. Им были выделены пять основных категорий предполагаемых затрат:
а) расходы на производство статей,
б) маркетинг и вовлечение сообщества,
в) разработка и обслуживание платформы,
г) зарплаты и оклады,
д) административные накладные расходы.
В результате расчеты автора показывают, что даже при самом оптимистичном сценарии маловероятно, что стоимость одной публикации будет значительно ниже текущих коммерческих расценок.
В целом исследование показывает, что, с учетом всех категорий расходов, некоммерческие модели издания слабо способствуют уменьшению стоимости публикационного процесса. Р. Джонсон указывает, что политика развития издательств открытого доступа предполагает две крайние стратегии: сохранение качества ценой потери доли влияния и доходности, либо наращивание объемов издаваемых материалов, рискуя потерять доверие читателей к качеству.
#обзор #OpenResearchEurope #коммерциализация
Современная научная публикационная деятельность сталкивается с серьезными финансовыми вызовами. Растущая стоимость публикационного процесса увеличивает потребность в некоммерческих моделях публикаций. Однако существует вероятность того, что популярность таких моделей может ограничить рост издательств, но так и не привести к удешевлению процесса публикации. В сегодняшнем обзоре мы рассмотрим посвященное этой теме недавнее исследование Роба Джонсона, главы компании Research Consulting в области исследовательской политики.
Инициатива ЕС по снижению стоимости публикации
В мае 2023 года Совет ЕС назвал текущие расходы на публикации неприемлемыми:
«Расходы на платный доступ к статьям и их публикацию становятся непосильными, а каналы публикаций для исследователей часто находятся в руках частных компаний, которые зачастую контролируют интеллектуальную собственность на статьи».
Совет призвал Комиссию и EC поддержать политику, направленную на создание некоммерческой, открытой и многоформатной модели научных изданий, не влекущей за собой никаких расходов для авторов и читателей.
В своем исследовании Р. Джонсон указывает, что существующие издательства уменьшают расходы на процесс публикации путем использования государственных субсидий или масштабирования объема выпускаемых публикаций. Это же наблюдение подтверждает отчет Массачусетского технологического института «Доступ к науке и стипендиям: ключевые вопросы о будущем публикации научных работ», в котором предлагается два способа увеличения прибыли коммерческих изданий: увеличение количества публикаций и снижение расходов.
О состоянии коммерческих изданий свидетельствуют данные инициативы OpenAPC при библиотеке Билефельдского университета, которая публикует наборы данных о сборах, выплачиваемых университетами и исследовательскими институтами за статьи в журналах открытого доступа.
Создание Open Research Europe и сценарии развития
Сложившуюся ситуацию, как описано в инициативе ЕС, предлагается решить при помощи создания ORE — издательской платформы открытого доступа на некоммерческой основе. Предполагается, что эта платформа будет работать как независимое юридическое лицо, что позволит оценить полную стоимость публикационного цикла. Большинство услуг, связанных с производством публикаций, таких как редакционные, производственные или технологические функции, будут выполняться сторонними поставщиками, но допускается возможность реализации платформы на базе уже существующей академической или международной организации. Однако, насколько создание ORE решит проблему роста стоимости публикаций?
В 2023 году Р. Джонсон представил отчет о потенциале создания ORE. В нем рассматриваются вероятные внутренние и внешние факторы, потенциально способные повлиять на рост опубликованных материалов, а также предполагаемый рост расходов в период с 2026 по 2030 годы.
Р. Джонсон смоделировал несколько сценариев возможного роста публикаций под эгидой ORE. Им были выделены пять основных категорий предполагаемых затрат:
а) расходы на производство статей,
б) маркетинг и вовлечение сообщества,
в) разработка и обслуживание платформы,
г) зарплаты и оклады,
д) административные накладные расходы.
В результате расчеты автора показывают, что даже при самом оптимистичном сценарии маловероятно, что стоимость одной публикации будет значительно ниже текущих коммерческих расценок.
В целом исследование показывает, что, с учетом всех категорий расходов, некоммерческие модели издания слабо способствуют уменьшению стоимости публикационного процесса. Р. Джонсон указывает, что политика развития издательств открытого доступа предполагает две крайние стратегии: сохранение качества ценой потери доли влияния и доходности, либо наращивание объемов издаваемых материалов, рискуя потерять доверие читателей к качеству.
#обзор #OpenResearchEurope #коммерциализация
{kind=link}
Использование ИИ в технологическом трансфере
Месяц назад в Nature вышла заметка основателя “Научного центра науки и инноваций Северо-Западного университета” Дашунь Вана (Dashun Wang), посвященная использованию алгоритмов ИИ для выявления ученых, нуждающихся в поддержке их научных результатов для практического приложения.
Во время пилотного проекта исследовательской группы Вана обнаружилось, что одна исследовательница в области биологии не знала о влиянии своих научных работ на рынок, но в результате знакомства с подразделением технологического трансфера она узнала, что частные компании широко цитируют ее исследования в своих патентах, и подала заявку на регистрацию своего изобретения. Этот пример сподвигнул Вана задаться вытекающими из этого кейса вопросами: можно ли выявить исследователей с невостребованным инновационным потенциалом и каким образом?
В течение нескольких лет исследовательский коллектив Вана работал с различными университетами США, пытаясь найти оптимальные способы максимизировать результаты научной деятельности.
В ходе исследования обнаружились некоторые потворяющиеся паттерны, например:
- женщины реже патентуют свои работы, чем мужчины (причем разница — от двух до десяти раз в зависимости от области), при одинаковом (судя по цитируемости) уровне работы;
- преподаватели с постоянным контрактом подают заявки чаще, чем те, кто трудоустроен по временному контракту.
Кроме того, выяснилось, что существует довольно много ученых, которые не стремятся к трансферу технологий, не взаимодействуют с соответствующим департаментом (а такие есть почти во всех университетах), не подают заявки на патенты.
Ван и его коллеги полагают, что публикующиеся ежегодно наборы данных о миллионах статей, препринтов и грантовых заявок можно анализировать при помощи ИИ, чтобы выявить пробелы и узкие места, которые мешают технологическим прорывам.
Одним из главных хайлайтов статьи является утверждение Вана о дихотомии между фундаментальными и прикладными исследованиями и условиями современности: сложно спрогнозировать какие исследования найдут непосредственное технологическое применение.
Вывод Вана состоит в том, что исследования были бы намного влиятельней, если бы университеты использовали инструменты ИИ с целью поиска научных результатов своих сотрудников, к которым применим технологический трансфер.
#обзор #искусственныйинтеллект #патенты
Месяц назад в Nature вышла заметка основателя “Научного центра науки и инноваций Северо-Западного университета” Дашунь Вана (Dashun Wang), посвященная использованию алгоритмов ИИ для выявления ученых, нуждающихся в поддержке их научных результатов для практического приложения.
Во время пилотного проекта исследовательской группы Вана обнаружилось, что одна исследовательница в области биологии не знала о влиянии своих научных работ на рынок, но в результате знакомства с подразделением технологического трансфера она узнала, что частные компании широко цитируют ее исследования в своих патентах, и подала заявку на регистрацию своего изобретения. Этот пример сподвигнул Вана задаться вытекающими из этого кейса вопросами: можно ли выявить исследователей с невостребованным инновационным потенциалом и каким образом?
В течение нескольких лет исследовательский коллектив Вана работал с различными университетами США, пытаясь найти оптимальные способы максимизировать результаты научной деятельности.
В ходе исследования обнаружились некоторые потворяющиеся паттерны, например:
- женщины реже патентуют свои работы, чем мужчины (причем разница — от двух до десяти раз в зависимости от области), при одинаковом (судя по цитируемости) уровне работы;
- преподаватели с постоянным контрактом подают заявки чаще, чем те, кто трудоустроен по временному контракту.
Кроме того, выяснилось, что существует довольно много ученых, которые не стремятся к трансферу технологий, не взаимодействуют с соответствующим департаментом (а такие есть почти во всех университетах), не подают заявки на патенты.
Ван и его коллеги полагают, что публикующиеся ежегодно наборы данных о миллионах статей, препринтов и грантовых заявок можно анализировать при помощи ИИ, чтобы выявить пробелы и узкие места, которые мешают технологическим прорывам.
Одним из главных хайлайтов статьи является утверждение Вана о дихотомии между фундаментальными и прикладными исследованиями и условиями современности: сложно спрогнозировать какие исследования найдут непосредственное технологическое применение.
Вывод Вана состоит в том, что исследования были бы намного влиятельней, если бы университеты использовали инструменты ИИ с целью поиска научных результатов своих сотрудников, к которым применим технологический трансфер.
#обзор #искусственныйинтеллект #патенты
Анализ цитирований в российских публикациях в Web of Science
В последнем выпуске Journal of Scientometric Research в соавторстве с Дарьей Мальцевой (ВШЭ) вышла статья, посвященная библиометрическому анализу российской науки на базе 1,38 млн публикаций российских (со)авторов.
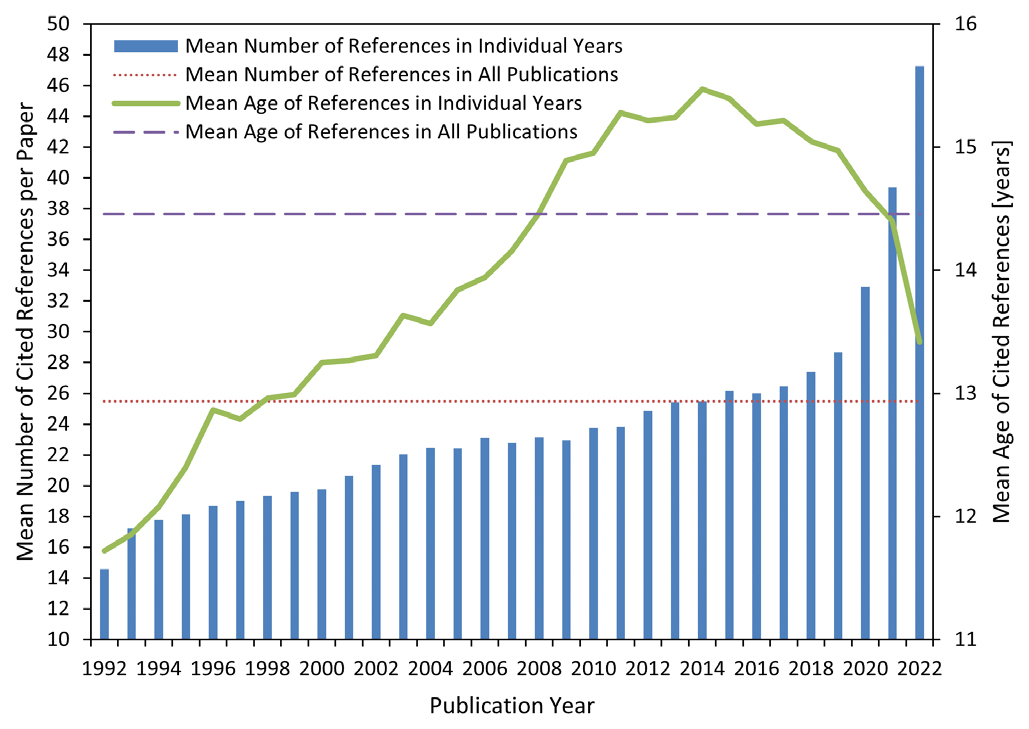
В основе работы — использование метода спектроскопии года публикации цитируемых работ (RPYS — Reference Publication Year Spectroscopy), разработанного в 2013 Вернером Марксом. Этот метод, как правило, применяется для более ограниченных датасетов (например, для публикаций одного исследователя, журнала или научной дисциплины). Для обработки миллионов записей данных метод был масштабирован авторами исследования с использованием СУБД, что позволило проанализировать исторические корни российской науки.
В качестве исходных данных был взят массив статей, индексированных в WoS до мая 2022 года, у которых хотя бы один из авторов имеет российскую аффилиацию, в виде текстовых файлов. Почти все статьи приходятся на период с 1992 по 2022 гг, до 1992 публикаций крайне мало. Общее количество ссылок в описанном массиве — более 32 млн, при этом 1,66 млн ведут на статьи, входящие в исходный датасет.
Согласно результатам исследования:
🔹 Количество ссылок в статьях заметно возросло с течением времени: если в 1992 г. в публикации приводилось в среднем 15 ссылок, то в 2022 г. их было 47.
🔹 Один из основных объектов анализа — разница в «возрасте» между статьей и публикациями, которая она цитирует. Подавляющее большинство ссылок приходится на группу 20+ лет — это означает, что российская наука в значительной степени опиралась на более «старые» фундаментальные исследования.
🔹 Общий средний возраст цитируемых статей составил 14,5 лет, и в рассматриваемый период (с 1992 по 2022) он увеличился примерно на 14%. Следует отметить и динамику: так, средний возраст достигает пика (15,5 лет) в 2014 г., а затем снижается. Таким образом, авторы публикаций, написанных после 2014 года, начинают чаще цитировать более «свежие» статьи.
Если говорить о научных журналах, то во все периоды чаще всего цитировались Physical Review Letters, Physical Review B, Physical Review D, The Astrophysical Journal, The Journal of Chemical Physics и Journal of the American Chemical Society, а также Nature и Science. До 2000 года в топ-10 входили также «Доклады Академии Наук СССР», но после 2000-х цитировать их практически перестали.
Так или иначе, подавляющее число цитирований приходится на долю естественных наук, что отмечают и сами авторы.
#обзор #цитирования #RPYS #WebofScience
В последнем выпуске Journal of Scientometric Research в соавторстве с Дарьей Мальцевой (ВШЭ) вышла статья, посвященная библиометрическому анализу российской науки на базе 1,38 млн публикаций российских (со)авторов.
В основе работы — использование метода спектроскопии года публикации цитируемых работ (RPYS — Reference Publication Year Spectroscopy), разработанного в 2013 Вернером Марксом. Этот метод, как правило, применяется для более ограниченных датасетов (например, для публикаций одного исследователя, журнала или научной дисциплины). Для обработки миллионов записей данных метод был масштабирован авторами исследования с использованием СУБД, что позволило проанализировать исторические корни российской науки.
В качестве исходных данных был взят массив статей, индексированных в WoS до мая 2022 года, у которых хотя бы один из авторов имеет российскую аффилиацию, в виде текстовых файлов. Почти все статьи приходятся на период с 1992 по 2022 гг, до 1992 публикаций крайне мало. Общее количество ссылок в описанном массиве — более 32 млн, при этом 1,66 млн ведут на статьи, входящие в исходный датасет.
Согласно результатам исследования:
🔹 Количество ссылок в статьях заметно возросло с течением времени: если в 1992 г. в публикации приводилось в среднем 15 ссылок, то в 2022 г. их было 47.
🔹 Один из основных объектов анализа — разница в «возрасте» между статьей и публикациями, которая она цитирует. Подавляющее большинство ссылок приходится на группу 20+ лет — это означает, что российская наука в значительной степени опиралась на более «старые» фундаментальные исследования.
🔹 Общий средний возраст цитируемых статей составил 14,5 лет, и в рассматриваемый период (с 1992 по 2022) он увеличился примерно на 14%. Следует отметить и динамику: так, средний возраст достигает пика (15,5 лет) в 2014 г., а затем снижается. Таким образом, авторы публикаций, написанных после 2014 года, начинают чаще цитировать более «свежие» статьи.
Если говорить о научных журналах, то во все периоды чаще всего цитировались Physical Review Letters, Physical Review B, Physical Review D, The Astrophysical Journal, The Journal of Chemical Physics и Journal of the American Chemical Society, а также Nature и Science. До 2000 года в топ-10 входили также «Доклады Академии Наук СССР», но после 2000-х цитировать их практически перестали.
Так или иначе, подавляющее число цитирований приходится на долю естественных наук, что отмечают и сами авторы.
#обзор #цитирования #RPYS #WebofScience
{kind=link}
Библиометрия за пределами цитирования: индекс упоминаний
Современные практики цитирования появились относительно недавно, из-за чего научные базы данных сталкиваются с проблемой неполноты учтенных ссылок: например, WoS гарантирует достоверность ссылок лишь с 1980 года, а Scopus — с 1996. При этом ссылки на источники всегда были неотъемлемой частью науки.
В недавней статье ученые из Нидерландов описывают метод, предназначенный для решения данной проблемы — индексирование упоминаний, расширяющее понятие научной ссылки.
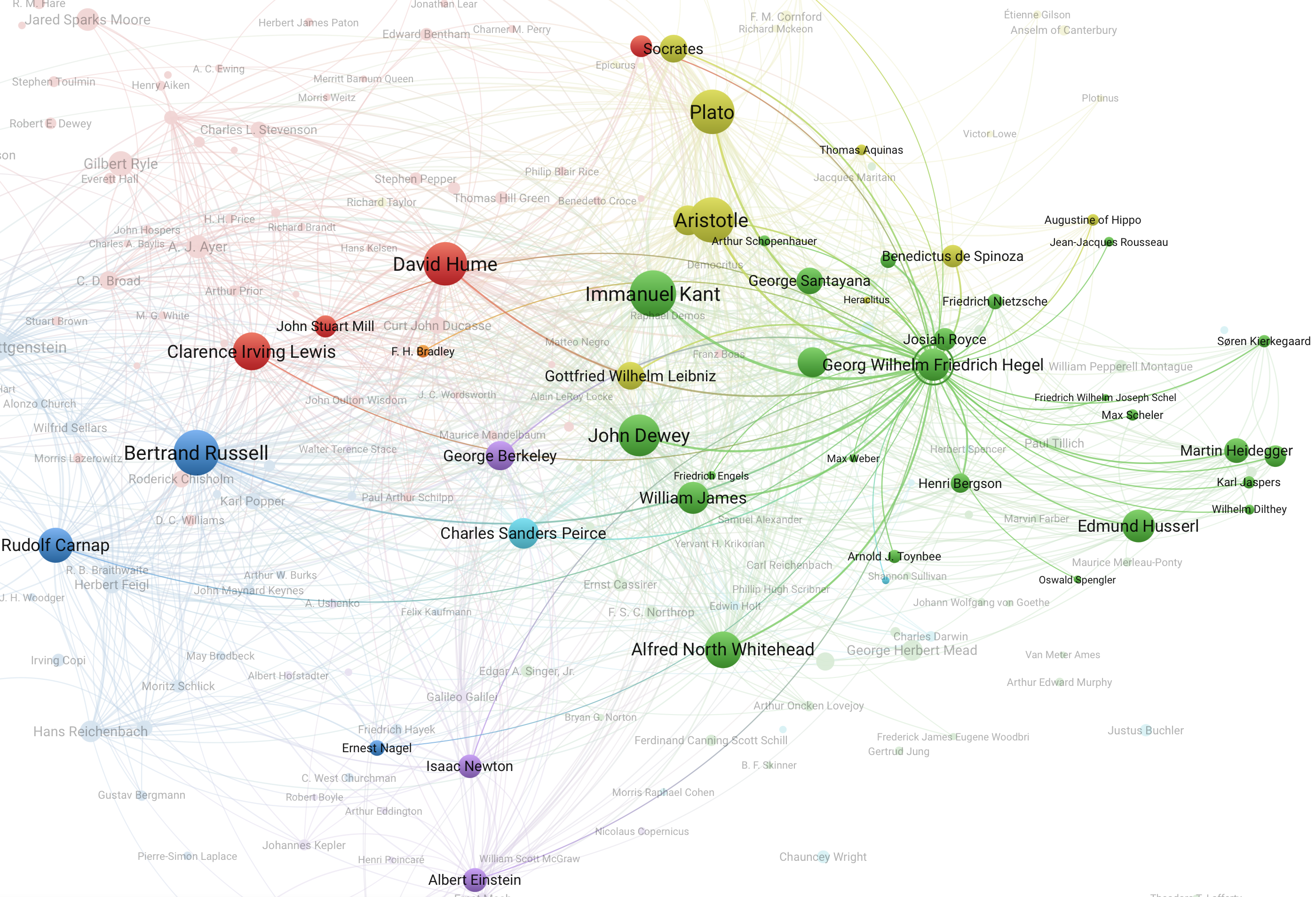
Предлагаемый метод состоит из двух основных этапов: текст-майнинг и соотнесение упоминаний с источниками. Авторы ограничили выборку периодом с 1890 по 1979 гг., использовав тексты англоязычной философии. Корпус включает 1 095 765 упоминаний, извлеченных из 22 977 статей в 12 журналах. Распознавание имеет естественные ограничения: например, омонимию фамилий (Рой Вуд Селларс и Уилфред Селларс) — в таком случае учитывается контекст и смежные упоминания. В итоге предложенный алгоритм позволил успешно распознать 93% упоминаний.
При помощи этого метода авторы проанализировали корпус публикаций по философии — дисциплине, где стандартизированные цитаты не использовались вплоть до 1970-х годов, что делает ее удобной областью для демонстрации возможностей нового инструмента.
В статье предлагается несколько кейсов использования индекса. Например, общее число упоминаний персон, сравнение канонов упоминаний в главных англоязычных университетах или изменение трендов упоминаний с течением времени.
В качестве примера одного из кейсов прикладываем к посту скриншот визуализации при помощи VOSviewer сети совместных упоминаний в американских журналах в период с 1950-1959 гг. Интерактивную версию можно посмотреть по ссылке.
Индекс упоминаний стал основой для сервиса EDHIPHY (enriched data for the history of philosophy), на котором размещена база данных упоминаний о философах в журнальных статьях. Авторы предлагают использовать сервис для проведения собственных исследований.
Анализ упоминаний дополняет традиционные методы анализа цитирований, поскольку он применим ко многим историческим периодам и научным областям, где ссылки не имеют форму цитаты. Авторы статьи полагают, что в перспективе анализ упоминаний может быть распространен на всю историю науки.
#обзор #базыданных #индексы #сети
Современные практики цитирования появились относительно недавно, из-за чего научные базы данных сталкиваются с проблемой неполноты учтенных ссылок: например, WoS гарантирует достоверность ссылок лишь с 1980 года, а Scopus — с 1996. При этом ссылки на источники всегда были неотъемлемой частью науки.
В недавней статье ученые из Нидерландов описывают метод, предназначенный для решения данной проблемы — индексирование упоминаний, расширяющее понятие научной ссылки.
Предлагаемый метод состоит из двух основных этапов: текст-майнинг и соотнесение упоминаний с источниками. Авторы ограничили выборку периодом с 1890 по 1979 гг., использовав тексты англоязычной философии. Корпус включает 1 095 765 упоминаний, извлеченных из 22 977 статей в 12 журналах. Распознавание имеет естественные ограничения: например, омонимию фамилий (Рой Вуд Селларс и Уилфред Селларс) — в таком случае учитывается контекст и смежные упоминания. В итоге предложенный алгоритм позволил успешно распознать 93% упоминаний.
При помощи этого метода авторы проанализировали корпус публикаций по философии — дисциплине, где стандартизированные цитаты не использовались вплоть до 1970-х годов, что делает ее удобной областью для демонстрации возможностей нового инструмента.
В статье предлагается несколько кейсов использования индекса. Например, общее число упоминаний персон, сравнение канонов упоминаний в главных англоязычных университетах или изменение трендов упоминаний с течением времени.
В качестве примера одного из кейсов прикладываем к посту скриншот визуализации при помощи VOSviewer сети совместных упоминаний в американских журналах в период с 1950-1959 гг. Интерактивную версию можно посмотреть по ссылке.
Индекс упоминаний стал основой для сервиса EDHIPHY (enriched data for the history of philosophy), на котором размещена база данных упоминаний о философах в журнальных статьях. Авторы предлагают использовать сервис для проведения собственных исследований.
Анализ упоминаний дополняет традиционные методы анализа цитирований, поскольку он применим ко многим историческим периодам и научным областям, где ссылки не имеют форму цитаты. Авторы статьи полагают, что в перспективе анализ упоминаний может быть распространен на всю историю науки.
#обзор #базыданных #индексы #сети
{kind=link}
Качество исследования vs влияние: дискуссия о подходе к оценке публикаций
Зачастую ценность результатов научных исследований определяется не только их качеством. Важную роль могут играть также ненаучные факторы, не относящиеся напрямую к научному содержанию: объем публикации, особенности издания, упоминаемые аффилиации, репутация авторов и т.п.
В недавней статье исследователи, входящие в число рецензентов журнала Scientometrics, ставят вопрос о том, что должно быть ориентиром в оценке публикации: достаточно ли оценивать качество работы или следует руководствоваться более широким понятием научного влияния?
С одной стороны, в большинстве стран и институтов научная политика ориентирована на эффективное распределение средств для увеличения пользы от научных работ и максимизации их социального влияния.
С другой стороны, авторы указывают, что существующие во многих странах системы оценки научных исследований — например, британская программа REF 2021 — ориентированы в основном именно на оценку качества публикации (оригинальность, значимость, логичность), используя в качестве метода преимущественно экспертное рецензирование. Хотя в британской программе социальный импакт тоже учитывается, но имеет меньший вес по сравнению с оценкой качества (60% против 25%).
В последние годы эта проблема обсуждается довольно активно. Так, в 2022 году в рамках инициативы Coalition for Advancing Research Assessment (CoARA) было сформулировано «Соглашение о реформировании оценки научных исследований», что привело к очередному витку наукометрической дискуссии: стоит ли оценивать исследования на основе качества ограниченного числа работ или на основе влияния неограниченного числа только индексируемых публикаций.
В статье авторы предполагают, что выбор подхода, ориентированного на оценку влияния публикации, может быть оправдан потенциальной ролью ненаучных факторов. Чтобы оценить их значимость, авторы использовали, с одной стороны, экспертные оценки, которые рецензенты присвоили 6 446 публикациям в рамках первой итальянской процедуры по оценке публикаций (Research Assessment Exercise) за период 2001-2003 гг., а с другой – показатели научного влияния, которое измерялось через цитируемость публикаций согласно данным Web of Science с нормировкой на области и окна цитирования. На основе этих данных были построены 3 прогностические модели со случайными эффектами, включающие:
1. только ненаучные факторы;
2. ненаучные факторы и экспертную оценку, присвоенную рецензентами;
3. ненаучные факторы и краткосрочный импакт, измеряемый ранним цитированием.
Сравнение моделей показало, что прогностическая точность первой регрессионной модели с точки зрения коэффициента детерминации схожа со второй. Таким образом, дорогостоящая качественная экспертная оценка несущественно отличалась в точности предсказаний от количественной оценки, основанной на ненаучных параметрах.
Выяснилось, что для положительного долгосрочного влияния важны следующие факторы: наличие иностранных соавторов, их репутация, длина публикации и импакт-фактор журнала; процент самоцитирований и «возраст» цитируемых статей, напротив, имеют отрицательное влияние. Общее количество авторов и наличие открытого доступа оказались практически незначимыми факторами.
Хотя качественное рецензирование остается важной частью оценки исследований, включение и учет ненаучных факторов, описываемых количественными методами, могут дать более полное представление о влиянии публикаций. В то же время, оглядываясь на отечественный опыт проведения процедуры оценки, Д. Косяков и А. Гуськов еще в 2019 году подчеркивали, что он тяготеет скорее к обратной крайности: качественная оценка по большей части исключалась в пользу формальных количественных метрик.
Нахождение баланса представляется важной задачей в рамках совершенствования государственной политики в области оценки научных организаций и исследовательских коллективов.
#обзор #рецензирование #экспертныеоценки
Зачастую ценность результатов научных исследований определяется не только их качеством. Важную роль могут играть также ненаучные факторы, не относящиеся напрямую к научному содержанию: объем публикации, особенности издания, упоминаемые аффилиации, репутация авторов и т.п.
В недавней статье исследователи, входящие в число рецензентов журнала Scientometrics, ставят вопрос о том, что должно быть ориентиром в оценке публикации: достаточно ли оценивать качество работы или следует руководствоваться более широким понятием научного влияния?
С одной стороны, в большинстве стран и институтов научная политика ориентирована на эффективное распределение средств для увеличения пользы от научных работ и максимизации их социального влияния.
С другой стороны, авторы указывают, что существующие во многих странах системы оценки научных исследований — например, британская программа REF 2021 — ориентированы в основном именно на оценку качества публикации (оригинальность, значимость, логичность), используя в качестве метода преимущественно экспертное рецензирование. Хотя в британской программе социальный импакт тоже учитывается, но имеет меньший вес по сравнению с оценкой качества (60% против 25%).
В последние годы эта проблема обсуждается довольно активно. Так, в 2022 году в рамках инициативы Coalition for Advancing Research Assessment (CoARA) было сформулировано «Соглашение о реформировании оценки научных исследований», что привело к очередному витку наукометрической дискуссии: стоит ли оценивать исследования на основе качества ограниченного числа работ или на основе влияния неограниченного числа только индексируемых публикаций.
В статье авторы предполагают, что выбор подхода, ориентированного на оценку влияния публикации, может быть оправдан потенциальной ролью ненаучных факторов. Чтобы оценить их значимость, авторы использовали, с одной стороны, экспертные оценки, которые рецензенты присвоили 6 446 публикациям в рамках первой итальянской процедуры по оценке публикаций (Research Assessment Exercise) за период 2001-2003 гг., а с другой – показатели научного влияния, которое измерялось через цитируемость публикаций согласно данным Web of Science с нормировкой на области и окна цитирования. На основе этих данных были построены 3 прогностические модели со случайными эффектами, включающие:
1. только ненаучные факторы;
2. ненаучные факторы и экспертную оценку, присвоенную рецензентами;
3. ненаучные факторы и краткосрочный импакт, измеряемый ранним цитированием.
Сравнение моделей показало, что прогностическая точность первой регрессионной модели с точки зрения коэффициента детерминации схожа со второй. Таким образом, дорогостоящая качественная экспертная оценка несущественно отличалась в точности предсказаний от количественной оценки, основанной на ненаучных параметрах.
Выяснилось, что для положительного долгосрочного влияния важны следующие факторы: наличие иностранных соавторов, их репутация, длина публикации и импакт-фактор журнала; процент самоцитирований и «возраст» цитируемых статей, напротив, имеют отрицательное влияние. Общее количество авторов и наличие открытого доступа оказались практически незначимыми факторами.
Хотя качественное рецензирование остается важной частью оценки исследований, включение и учет ненаучных факторов, описываемых количественными методами, могут дать более полное представление о влиянии публикаций. В то же время, оглядываясь на отечественный опыт проведения процедуры оценки, Д. Косяков и А. Гуськов еще в 2019 году подчеркивали, что он тяготеет скорее к обратной крайности: качественная оценка по большей части исключалась в пользу формальных количественных метрик.
Нахождение баланса представляется важной задачей в рамках совершенствования государственной политики в области оценки научных организаций и исследовательских коллективов.
#обзор #рецензирование #экспертныеоценки
Большие языковые модели в наукометрии, или зачем нам SciBERT
Не все научные публикации одинаковы с точки зрения их влияния на социальную реальность. Нередко показатель цитируемости и импакт-фактор журнала дают нам некоторое представление о том, насколько серьезная работа перед нами, однако даже недавний пример с сетью взаимосвязей между первыми работами, которые цитируют статью Хопфилда о нейронных сетях, показывает, что одной только высокой цитируемости недостаточно: например, работы уже второго «поколения» цитирований получали в разы больше внимания, чем изначальный труд. Кроме того, не секрет, что в отдельных областях большее внимание привлекают обзоры по научным областям: обычно они цитируются довольно активно, поскольку обобщают информацию по какой-либо тематике, но в то же время не каждый обзор представляет из себя что-то большее, чем простое фиксирование текущего положения дел.
В сентябре Scientometrics опубликовали статью китайских исследователей, в которой описывается метод интеллектуального распознавания высококачественных научных работ на основе метасемантических сетей, задействующих deep learning и LLM-технологии. Раньше это было практически нереализуемой задачей: методы оценки научных статей ограничивались качественным (на основе рецензирования) и количественным (на основе библиометрических показателей) подходами. Недостатки этих методов хорошо изучены — в первом случае это проблемы с воспроизводимостью, неполнота знаний у рецензентов и возможный конфликт интересов, а во втором — временной лаг и разная чувствительность показателей, которая неизбежно влияет на финальную оценку.
Авторы предлагают новый подход к определению качества научной статьи как взвешенной суммы импакт-фактора журнала и средневзвешенной цитируемости статьи, где веса определяются методом информационной энтропии, а потом для «высококачественных» и «низкокачественных» работ строится упомянутая метасемантическая сеть на основе известной языковой модели SciBERT (одна из вариаций еще более широко известной модели BERT от Google). Таким образом, в перспективе это позволит измерять качество статей напрямую по их содержанию, без временного лага.
Кстати, еще одну вариацию BERT (SPS-BERT) уже другой исследовательский коллектив использовал для прогнозирования появления прорывных технологий. Согласно их результатам, этот метод позволяет предсказать индекс прорыва (о котором мы писали ранее) точнее, чем все прочие существующие методы. По крайней мере, на наборах данных DBLP и PubMed.
LLM вообще приобретают всё большую популярность в нашей среде. Тот же Scientometrics в сентябре опубликовал call for papers по теме «искусственный интеллект в наукометрии» (подача заявок до 28 февраля 2025 года).
Оставляя в стороне многократно обсуждаемые вопросы этичности использования инструментов ИИ в различных сферах, мы можем сказать, что перспективы их использования в сфере наукометрии скорее радуют. Языковые модели открывают широкий простор для совершенно новых исследований и выводов, а кроме того, предлагают принципиально иные подходы к оценке научных исследований.
#LLM #обзор #SciBERT
Не все научные публикации одинаковы с точки зрения их влияния на социальную реальность. Нередко показатель цитируемости и импакт-фактор журнала дают нам некоторое представление о том, насколько серьезная работа перед нами, однако даже недавний пример с сетью взаимосвязей между первыми работами, которые цитируют статью Хопфилда о нейронных сетях, показывает, что одной только высокой цитируемости недостаточно: например, работы уже второго «поколения» цитирований получали в разы больше внимания, чем изначальный труд. Кроме того, не секрет, что в отдельных областях большее внимание привлекают обзоры по научным областям: обычно они цитируются довольно активно, поскольку обобщают информацию по какой-либо тематике, но в то же время не каждый обзор представляет из себя что-то большее, чем простое фиксирование текущего положения дел.
В сентябре Scientometrics опубликовали статью китайских исследователей, в которой описывается метод интеллектуального распознавания высококачественных научных работ на основе метасемантических сетей, задействующих deep learning и LLM-технологии. Раньше это было практически нереализуемой задачей: методы оценки научных статей ограничивались качественным (на основе рецензирования) и количественным (на основе библиометрических показателей) подходами. Недостатки этих методов хорошо изучены — в первом случае это проблемы с воспроизводимостью, неполнота знаний у рецензентов и возможный конфликт интересов, а во втором — временной лаг и разная чувствительность показателей, которая неизбежно влияет на финальную оценку.
Авторы предлагают новый подход к определению качества научной статьи как взвешенной суммы импакт-фактора журнала и средневзвешенной цитируемости статьи, где веса определяются методом информационной энтропии, а потом для «высококачественных» и «низкокачественных» работ строится упомянутая метасемантическая сеть на основе известной языковой модели SciBERT (одна из вариаций еще более широко известной модели BERT от Google). Таким образом, в перспективе это позволит измерять качество статей напрямую по их содержанию, без временного лага.
Кстати, еще одну вариацию BERT (SPS-BERT) уже другой исследовательский коллектив использовал для прогнозирования появления прорывных технологий. Согласно их результатам, этот метод позволяет предсказать индекс прорыва (о котором мы писали ранее) точнее, чем все прочие существующие методы. По крайней мере, на наборах данных DBLP и PubMed.
LLM вообще приобретают всё большую популярность в нашей среде. Тот же Scientometrics в сентябре опубликовал call for papers по теме «искусственный интеллект в наукометрии» (подача заявок до 28 февраля 2025 года).
Оставляя в стороне многократно обсуждаемые вопросы этичности использования инструментов ИИ в различных сферах, мы можем сказать, что перспективы их использования в сфере наукометрии скорее радуют. Языковые модели открывают широкий простор для совершенно новых исследований и выводов, а кроме того, предлагают принципиально иные подходы к оценке научных исследований.
#LLM #обзор #SciBERT
{kind=link}
Оценка экономической ценности открытого доступа: взгляд пользователей
Общественное мнение относительно преимуществ и недостатков открытого доступа к исследовательским данным нередко балансирует между полярными точками зрения. С одной стороны, инвестиции в открытый доступ могут восприниматься как напрасные расходы, а сама дискуссия о его важности может смещать фокус с поддержки исследований на развитие инфраструктуры для распространения научного знания. С другой стороны, поддержка открытого доступа воспринимается многими как естественный способ ускорения научного прогресса, что в свою очередь влияет на реализацию различных проектов и повышает ценность таких инвестиций. Именно поэтому в последнее время интерес к оценке открытого доступа расширяется не только с точки зрения наукометрического анализа, но и с позиции измерения экономического эффекта отдачи.
Исследователи из Оксфордского центра биомедицинских исследований и Национальной научной библиотекой Китая, в недавно опубликованной в Research Evaluation работе выяснили, как сами потребители открытого доступа (обычные пользователи, не издательства и компании) оценивают его экономическую пользу.
Опираясь на метод условной оценки (Contingent Valuation Method), ученые проанализировали пользовательские стратегии взаимодействия с бесплатной платформой открытых данных Национального центра данных фундаментальной науки (NBSDC, Китай).
Результаты опроса (всего 322 участника) помогли прояснить пользовательскую вовлеченность в среду БД на разных уровнях (цели и частота посещений, значимость площадки). Все опрашиваемые так или иначе были вовлечены в академическую сферу и занимались исследованиями и/или преподаванием, большинство (74 %) было связано с научно-исследовательскими учреждениями, остальные — с университетами.
В общей сложности 85 % респондентов указали, что экономическая выгода, создаваемая для них платформой, является «значимой» или «очень значимой», 12 % оценили её как «нейтральную», а 1 % как «низкую».
Перейдя к измерениям экономической «стоимости» платформы открытого доступа, исследователи определили, что основные возможные источники ее ценообразования (т.е. то, за что пользователь может потенциально заплатить) — это:
•просмотры (чтение статей, посещение сайта);
•запросы доступа;
•загрузки;
•периодическая подписка (ежемесячная и ежегодная).
Пользователям было предложено оценить эти критерии как со стороны предоставляемой личной экономической выгоды, так и со стороны готовности за эту выгоду платить.
Согласно результатам, наиболее ценным для пользователей оказались просмотры (33 %), затем загрузка данных (16 %) и запросы к ним (13 %). Кроме того, предпочтение было отдано годовой подписке (25 %), а не ежемесячной (14 %). Однако когда речь зашла о реальной готовности платить за использование данных, на первое место вышли загрузки (27 %), а не просмотры (15 %) и запросы (11 %), а вот отношение к годовой (36 %) и ежемесячной (11 %) подпискам приблизительно соответствовало первоначальной оценке ценности подобного вида доступа.
На основе ответов авторы определили стоимость за просмотр, загрузку, запрос и подписку на данные. Исходя из общего количества просмотров на площадке (по состоянию на 2023 год — 33 млн), стоимость NBSDC составила около 165 млн юаней (более 23 млн долларов), а готовность пользователей платить — порядка 66 млн юаней (9 млн долларов).
Таким образом, пользовательское желание платить оказалось приблизительно в 2,5 раза ниже, чем пользовательская оценка значимости открытого доступа. Тем не менее полученный результат, по мнению авторов, является важным аргументом в пользу дальнейшего развития открытого доступа и непосредственно влияет на реализацию стратегий научной политики. Открытый доступ обладает не только неосязаемой научной, но и существенной экономической ценностью, что может послужить дальнейшим стимулом для его поддержки и развития во многих странах, включая Россию.
#OpenAccess #Открытыеданные #обзор #экономическаяоценкаданных
Общественное мнение относительно преимуществ и недостатков открытого доступа к исследовательским данным нередко балансирует между полярными точками зрения. С одной стороны, инвестиции в открытый доступ могут восприниматься как напрасные расходы, а сама дискуссия о его важности может смещать фокус с поддержки исследований на развитие инфраструктуры для распространения научного знания. С другой стороны, поддержка открытого доступа воспринимается многими как естественный способ ускорения научного прогресса, что в свою очередь влияет на реализацию различных проектов и повышает ценность таких инвестиций. Именно поэтому в последнее время интерес к оценке открытого доступа расширяется не только с точки зрения наукометрического анализа, но и с позиции измерения экономического эффекта отдачи.
Исследователи из Оксфордского центра биомедицинских исследований и Национальной научной библиотекой Китая, в недавно опубликованной в Research Evaluation работе выяснили, как сами потребители открытого доступа (обычные пользователи, не издательства и компании) оценивают его экономическую пользу.
Опираясь на метод условной оценки (Contingent Valuation Method), ученые проанализировали пользовательские стратегии взаимодействия с бесплатной платформой открытых данных Национального центра данных фундаментальной науки (NBSDC, Китай).
Результаты опроса (всего 322 участника) помогли прояснить пользовательскую вовлеченность в среду БД на разных уровнях (цели и частота посещений, значимость площадки). Все опрашиваемые так или иначе были вовлечены в академическую сферу и занимались исследованиями и/или преподаванием, большинство (74 %) было связано с научно-исследовательскими учреждениями, остальные — с университетами.
В общей сложности 85 % респондентов указали, что экономическая выгода, создаваемая для них платформой, является «значимой» или «очень значимой», 12 % оценили её как «нейтральную», а 1 % как «низкую».
Перейдя к измерениям экономической «стоимости» платформы открытого доступа, исследователи определили, что основные возможные источники ее ценообразования (т.е. то, за что пользователь может потенциально заплатить) — это:
•просмотры (чтение статей, посещение сайта);
•запросы доступа;
•загрузки;
•периодическая подписка (ежемесячная и ежегодная).
Пользователям было предложено оценить эти критерии как со стороны предоставляемой личной экономической выгоды, так и со стороны готовности за эту выгоду платить.
Согласно результатам, наиболее ценным для пользователей оказались просмотры (33 %), затем загрузка данных (16 %) и запросы к ним (13 %). Кроме того, предпочтение было отдано годовой подписке (25 %), а не ежемесячной (14 %). Однако когда речь зашла о реальной готовности платить за использование данных, на первое место вышли загрузки (27 %), а не просмотры (15 %) и запросы (11 %), а вот отношение к годовой (36 %) и ежемесячной (11 %) подпискам приблизительно соответствовало первоначальной оценке ценности подобного вида доступа.
На основе ответов авторы определили стоимость за просмотр, загрузку, запрос и подписку на данные. Исходя из общего количества просмотров на площадке (по состоянию на 2023 год — 33 млн), стоимость NBSDC составила около 165 млн юаней (более 23 млн долларов), а готовность пользователей платить — порядка 66 млн юаней (9 млн долларов).
Таким образом, пользовательское желание платить оказалось приблизительно в 2,5 раза ниже, чем пользовательская оценка значимости открытого доступа. Тем не менее полученный результат, по мнению авторов, является важным аргументом в пользу дальнейшего развития открытого доступа и непосредственно влияет на реализацию стратегий научной политики. Открытый доступ обладает не только неосязаемой научной, но и существенной экономической ценностью, что может послужить дальнейшим стимулом для его поддержки и развития во многих странах, включая Россию.
#OpenAccess #Открытыеданные #обзор #экономическаяоценкаданных
{kind=link}
CoARA vs ISSI: подходы к оценке публикаций
Не так давно, в сентябре, мы уже касались дискуссии о подходе к оценке публикаций: какие факторы следует учитывать при определении ценности научной работы, можно ли полагаться только на объективные количественные критерии или следует каким-то образом принимать во внимание дальнейшее научное и социальное влияние исследование?
Сегодня мы решили чуть больше рассказать об инициативе CoARA и ее критике. CoARA, или Коалиция по развитию оценки исследований, была основана в 2022 г., а в июле того же года был опубликован программный документ: Соглашение о реформировании оценки научных исследований, которое предполагает признание широкого спектра практик, видов деятельности и профессиональных траекторий в научно-исследовательской среде, а также активно продвигает включение качественных контрольных показателей в оценку научной работы одновременно со снижением влияния зависимости от показателей, основанных на количественных метриках. На 15 октября 2024 г. соглашение подписали 796 учреждений, включая государственные и частные университеты, институты и другие организации, которые имеют отношение к научной оценке. После подписания и вступления в Коалицию организация может принять участие в одной или нескольких рабочих группах (всего их 13).
Однако в статье Джованни Абрамо, президента ISSI, инициатива критикуется достаточно подробно. Во-первых, Коалиция была сформирована без участия ISSI (Международного общества наукометрии и инфометрии). Возможно, у учредителей CoARA возникли сомнения в использования количественного подхода со стороны ISSI, однако специалисты по наукометрии хорошо знают, в каких обстоятельствах следует применять метрики, а в каких — использовать экспертную оценку. Основной проблемой являются не сами метрики, а их применение без экспертных навыков.
Впрочем, одна их рабочих групп Коалиции так и называется «Ответственные показатели и индикаторы». Абрамо справедливо отмечает, что «ответственного» отношения мало, чтобы правильно использовать наукометрические инструменты, но, в целом, подходы в этом плане у них похожие.
Во-вторых, CoARA рассматривает рецензирование как основной метод оценки, поэтому сосредотачивается на оценке качества результата. Наукометрические методы, напротив, измеряют последующее влияние (различные показатели, связанные с цитируемостью), которое, разумеется, ни один рецензент предсказать не может. Кроме того, следует учитывать издержки рецензирования. В 2020 году рецензенты по всему миру потратили на рецензирование более 100 миллионов часов (более 10 тысяч лет!), а оценочная стоимость времени составляет $1,5 млрд в США, $600 млн в Китае и $400 млн в Великобритании (Aczel et al.).
Один из самых важных вопросов и наиболее ключевых отличий между позициями CoARA и Абрамо заключается в том, кто должен выбирать методы и индикаторы оценки — эксперты или пользователи? Разработчики политики CoARA выступают за пользователя, однако Абрамо вполне обоснованно на стороне экспертов-профессионалов.
Итак, Абрамо предлагает сохранить в качестве центрального элемента научной оценки количественные методы, применяемые к индексируемым работам, подчеркивая при этом, что у них есть сильные и слабые стороны. В заключении он поднимает другой вопрос: почему так широко распространились сомнения по поводу использования текущих наукометрических показателей? Возможно, это связано с тем, что ключевые идеи наукометрического сообщества игнорируются либо трактуются неверно. И именно в этом ключе следует прилагать дальнейшие усилия.
#обзор #рецензирование #экспертныеоценки #CoARA #ISSI
Не так давно, в сентябре, мы уже касались дискуссии о подходе к оценке публикаций: какие факторы следует учитывать при определении ценности научной работы, можно ли полагаться только на объективные количественные критерии или следует каким-то образом принимать во внимание дальнейшее научное и социальное влияние исследование?
Сегодня мы решили чуть больше рассказать об инициативе CoARA и ее критике. CoARA, или Коалиция по развитию оценки исследований, была основана в 2022 г., а в июле того же года был опубликован программный документ: Соглашение о реформировании оценки научных исследований, которое предполагает признание широкого спектра практик, видов деятельности и профессиональных траекторий в научно-исследовательской среде, а также активно продвигает включение качественных контрольных показателей в оценку научной работы одновременно со снижением влияния зависимости от показателей, основанных на количественных метриках. На 15 октября 2024 г. соглашение подписали 796 учреждений, включая государственные и частные университеты, институты и другие организации, которые имеют отношение к научной оценке. После подписания и вступления в Коалицию организация может принять участие в одной или нескольких рабочих группах (всего их 13).
Однако в статье Джованни Абрамо, президента ISSI, инициатива критикуется достаточно подробно. Во-первых, Коалиция была сформирована без участия ISSI (Международного общества наукометрии и инфометрии). Возможно, у учредителей CoARA возникли сомнения в использования количественного подхода со стороны ISSI, однако специалисты по наукометрии хорошо знают, в каких обстоятельствах следует применять метрики, а в каких — использовать экспертную оценку. Основной проблемой являются не сами метрики, а их применение без экспертных навыков.
Впрочем, одна их рабочих групп Коалиции так и называется «Ответственные показатели и индикаторы». Абрамо справедливо отмечает, что «ответственного» отношения мало, чтобы правильно использовать наукометрические инструменты, но, в целом, подходы в этом плане у них похожие.
Во-вторых, CoARA рассматривает рецензирование как основной метод оценки, поэтому сосредотачивается на оценке качества результата. Наукометрические методы, напротив, измеряют последующее влияние (различные показатели, связанные с цитируемостью), которое, разумеется, ни один рецензент предсказать не может. Кроме того, следует учитывать издержки рецензирования. В 2020 году рецензенты по всему миру потратили на рецензирование более 100 миллионов часов (более 10 тысяч лет!), а оценочная стоимость времени составляет $1,5 млрд в США, $600 млн в Китае и $400 млн в Великобритании (Aczel et al.).
Один из самых важных вопросов и наиболее ключевых отличий между позициями CoARA и Абрамо заключается в том, кто должен выбирать методы и индикаторы оценки — эксперты или пользователи? Разработчики политики CoARA выступают за пользователя, однако Абрамо вполне обоснованно на стороне экспертов-профессионалов.
Итак, Абрамо предлагает сохранить в качестве центрального элемента научной оценки количественные методы, применяемые к индексируемым работам, подчеркивая при этом, что у них есть сильные и слабые стороны. В заключении он поднимает другой вопрос: почему так широко распространились сомнения по поводу использования текущих наукометрических показателей? Возможно, это связано с тем, что ключевые идеи наукометрического сообщества игнорируются либо трактуются неверно. И именно в этом ключе следует прилагать дальнейшие усилия.
#обзор #рецензирование #экспертныеоценки #CoARA #ISSI
Три года «Выше квартилей» 🗓 🎆
Дорогие подписчики! Сегодня наш канал празднует свой третий день рождения. Мы традиционно составили подборку из десяти наиболее просматриваемых постов за прошедший год:
1️⃣ Академический угон: обзор публикаций о hijacked журналах
2️⃣ United2Act и борьба с paper mills
3️⃣ Чат-боты: цитировать или не цитировать?
4️⃣ Dark side of publishing
5️⃣ Королевство пустых зеркал
6️⃣ Retracted Articles: от репутационных проблем к аналитике по областям
7️⃣ Репозиторий НЦ на GitHub
8️⃣ Лейденский рейтинг: открытая версия
9️⃣ Les grands embrasements naissent de petites étincelles
1️⃣ 0️⃣ Обновление квартилей JCR
Уже второй год у нас активно выходила тематическая аналитика о нобелевских лауреатах под тегом #нобелевскаянеделя, практически каждую неделю — #обзор на одну из наиболее интересных свежих статей в нашей области и авторская #аналитика по различным библиометрическим базам и инструментам, а ежемесячно — #дайджест самых важных новостей в сфере науки и наукометрии со всего мира. Мы сделали цикл публикаций о недобросовестных исследовательских практиках, вели рубрику #историянаукометрии и неоднократно касались темы этичного использования #ИИ-инструментов в научной работе, а также во второй раз поучаствовали в фестивале науки «Республика ученых» ВШЭ.
Те из наших читателей, кто посещал фестиваль в прошлом году, возможно, помнят нашу наукометрическую викторину. И сегодня, в честь годовщины, мы хотим представить ее всем подписчикам нашего канала. Переходите по ссылке, играйте (с коллегами или друзьями) и делитесь впечатлениями!
Остаемся выше квартилей!
Дорогие подписчики! Сегодня наш канал празднует свой третий день рождения. Мы традиционно составили подборку из десяти наиболее просматриваемых постов за прошедший год:
Уже второй год у нас активно выходила тематическая аналитика о нобелевских лауреатах под тегом #нобелевскаянеделя, практически каждую неделю — #обзор на одну из наиболее интересных свежих статей в нашей области и авторская #аналитика по различным библиометрическим базам и инструментам, а ежемесячно — #дайджест самых важных новостей в сфере науки и наукометрии со всего мира. Мы сделали цикл публикаций о недобросовестных исследовательских практиках, вели рубрику #историянаукометрии и неоднократно касались темы этичного использования #ИИ-инструментов в научной работе, а также во второй раз поучаствовали в фестивале науки «Республика ученых» ВШЭ.
Те из наших читателей, кто посещал фестиваль в прошлом году, возможно, помнят нашу наукометрическую викторину. И сегодня, в честь годовщины, мы хотим представить ее всем подписчикам нашего канала. Переходите по ссылке, играйте (с коллегами или друзьями) и делитесь впечатлениями!
Остаемся выше квартилей!
Please open Telegram to view this post
VIEW IN TELEGRAM
Genially
HSE SCIENTOMETRICS BOARD
Публикуйся вновь и вновь: еще несколько слов о publish or perish по данным опросов
Научная политика может оказывать значительное влияние на индивидуальные стратегии публикации ученых. Давление академической культуры «публикуйся или умри» (publish or perish) вынуждает исследователей ориентироваться на формальные критерии оценки публикационной активности.
В Research Evaluation вышло исследование, в котором авторы изучили влияние (субъективно ощущаемого) внешнего давления на мотивацию к публикации и публикационные стратегии ученых. Авторы опирались на данные, собранные ZSoA по результатам онлайн-опроса ученых, работающих в вузах Германии, Австрии и Швейцарии. Выборка составила 11 100 исследователей, среди которых 22,19% — профессора, 39,42% — постдоки и 38,29% — ученые без научной степени.
К основным публикационным стратегиям авторы относят ориентацию исследователей на академическую репутацию, вероятность принятия статьи, скорость публикации, открытый доступ, международную или местную аудиторию.
Они также выделяют следующие общие тенденции в публикациях:
🔹публиковаться стали больше, что влияет на рост коллабораций и развитие недобросовестных практик, таких как «тактика салями» (salami slicing);
🔹сдвиг от монографий и глав в книгах в сторону статей;
🔹рост публикаций на английском языке;
🔹ориентация на импакт-фактор при выборе журнала.
Молодые ученые, не занимающие штатные должности, испытывают более сильное давление, связанное с необходимостью публиковаться, в то время как давление, связанное с получением финансирования, выше в старших возрастных группах и среди тех, кто занимает штатные должности.
Согласно исследованию ученые не придерживаются исключительно какой-либо одной стратегии. Однако репутация журнала, публикация открытого доступа и международная аудитория являются приоритетными критериями при выборе изданий.
Выяснилось также, что чем выше воспринимаемое давление, тем с большей вероятностью исследователи будут фокусироваться на репутации журнала, быстрой публикации и международной специализированной аудитории.
Старшие научные сотрудники реже ориентируются на скорость публикации, в отличие от молодых ученых, и более ориентированы на открытый доступ и местную читательскую аудиторию, а также репутацию журнала, а не импакт-фактор.
Очевидно, что опытные ученые также свободнее в выборе тем публикации, что отразилось в результатах опроса. Молодые исследователи ориентируются на скорость принятия статьи, в связи с чем преимущественно не рискуют публиковать новаторские исследования, которые могут быть не приняты к публикации или негативно отразиться на их карьере.
Основные результаты показывают, что большое количество исследователей придерживаются стратегий публикаций, которые могут оказаться невыигрышными в долгосрочной перспективе. Они сосредотачиваются на отчетах о публикационной активности и публикуются в журналах с высоким рейтингом, т.е. вовлечены в «publication game».
По мнению авторов, возникающий принцип выживания ученых, наиболее адаптированных к формальным критериям, может представлять риск для будущего науки в целом.
#научнаяполитика #обзор #publishorperish #публикационныестратегии
Научная политика может оказывать значительное влияние на индивидуальные стратегии публикации ученых. Давление академической культуры «публикуйся или умри» (publish or perish) вынуждает исследователей ориентироваться на формальные критерии оценки публикационной активности.
В Research Evaluation вышло исследование, в котором авторы изучили влияние (субъективно ощущаемого) внешнего давления на мотивацию к публикации и публикационные стратегии ученых. Авторы опирались на данные, собранные ZSoA по результатам онлайн-опроса ученых, работающих в вузах Германии, Австрии и Швейцарии. Выборка составила 11 100 исследователей, среди которых 22,19% — профессора, 39,42% — постдоки и 38,29% — ученые без научной степени.
К основным публикационным стратегиям авторы относят ориентацию исследователей на академическую репутацию, вероятность принятия статьи, скорость публикации, открытый доступ, международную или местную аудиторию.
Они также выделяют следующие общие тенденции в публикациях:
🔹публиковаться стали больше, что влияет на рост коллабораций и развитие недобросовестных практик, таких как «тактика салями» (salami slicing);
🔹сдвиг от монографий и глав в книгах в сторону статей;
🔹рост публикаций на английском языке;
🔹ориентация на импакт-фактор при выборе журнала.
Молодые ученые, не занимающие штатные должности, испытывают более сильное давление, связанное с необходимостью публиковаться, в то время как давление, связанное с получением финансирования, выше в старших возрастных группах и среди тех, кто занимает штатные должности.
Согласно исследованию ученые не придерживаются исключительно какой-либо одной стратегии. Однако репутация журнала, публикация открытого доступа и международная аудитория являются приоритетными критериями при выборе изданий.
Выяснилось также, что чем выше воспринимаемое давление, тем с большей вероятностью исследователи будут фокусироваться на репутации журнала, быстрой публикации и международной специализированной аудитории.
Старшие научные сотрудники реже ориентируются на скорость публикации, в отличие от молодых ученых, и более ориентированы на открытый доступ и местную читательскую аудиторию, а также репутацию журнала, а не импакт-фактор.
Очевидно, что опытные ученые также свободнее в выборе тем публикации, что отразилось в результатах опроса. Молодые исследователи ориентируются на скорость принятия статьи, в связи с чем преимущественно не рискуют публиковать новаторские исследования, которые могут быть не приняты к публикации или негативно отразиться на их карьере.
Основные результаты показывают, что большое количество исследователей придерживаются стратегий публикаций, которые могут оказаться невыигрышными в долгосрочной перспективе. Они сосредотачиваются на отчетах о публикационной активности и публикуются в журналах с высоким рейтингом, т.е. вовлечены в «publication game».
По мнению авторов, возникающий принцип выживания ученых, наиболее адаптированных к формальным критериям, может представлять риск для будущего науки в целом.
#научнаяполитика #обзор #publishorperish #публикационныестратегии
Nothing Special в Special Issues? Об исследовании специальных (тематических) выпусков журналов
Специальные (тематические) выпуски неоднозначно влияют на формирование научного ландшафта. С одной стороны, они дают возможность ученым опубликовать экспериментальные и узкоспециализированные исследования, с другой — нередко открывают возможности для распространения некачественных материалов под видом тематического сборника.
Недавно в Learned Publishing вышла статья, авторы которой проанализировали специальные выпуски журналов, которые индексируются в Web of Science.
Согласно данным о 35 142 статьях из спецвыпусков с 2018 по 2022 год, ведущими издателями статей в тематических выпусках остаются доминирующие издательства на рынке научных журналов — Elsevier, Taylor & Francis, Springer Nature, MDPI, Wiley и Sage. В шестерку ведущих журналов по количеству статей входят: Neuropharmacology (Elsevier), Applied Sciences (MDPI), Neuroscience (Elsevier), Sustainability (MDPI), International Journal of Molecular Sciences (MDPI) и IEEE Transactions on Computer Aided Design of Integrated Circuits (IEEE).
Больше всего специальных выпусков выходят в науках об окружающей среде, электротехнике, образовании, менеджменте и нейронауках. А количество статей в спецвыпусках варьируется в зависимости от издательства и журнала. Например, в Wiley специальные выпуски состоят из 10–15 статей, в Elsevier — из 5–20 статей, в Springer — примерно из 6–8.
Исследования на базе Web of Science показывают, что специальные выпуски улучшают показатели цитирования и импакт-фактор журнала, хотя при этом они могут непропорционально увеличивать цитирования для неизвестных журналов и редко публикующихся ученых. Это может быть связано с тем, что приглашенные редакторы могут использовать социальные сети, профессиональные связи или рассылки для продвижения выпуска.
Решение о принятии статьи в спецвыпуск может исходить от главного редактора, издательства или быть результатом голосования на основе рецензий. Сложнее дело обстоит, если его принимает гостевой редактор, так как давление, с которым он может столкнуться, потенциально влияет на качество опубликованных материалов. Так, ему необходимо собрать достаточно работ, чтобы единоразово компенсировать долю отклоненных, а также найти квалифицированных рецензентов, что проблематично в случае новаторских тем, особенно если вокруг них еще нет устоявшихся сообществ исследователей. Иногда именно по вине гостевого редактора приходится отзывать целый выпуск.
Кроме того, для фабрик публикаций (paper mills) спецвыпуски являются излюбленными площадками. Эта проблема была поднята в связи с массовым отзывом статей, являющихся продуктом paper mills, из Hindawi и исключением более 50 журналов, включая 19 журналов Hindawi/Wiley, из Web of Science.
Помимо этого, эксплуатация моделей открытого доступа (OA) и высокие сборы за обработку статей (APC) могут стимулировать редакторов увеличивать количество статей, игнорируя их качество в пользу крупных доходов. В связи с чем большое количество специальных выпусков, особенно превышающее число плановых, — один из ключевых маркеров недобросовестной редакционной политики.
Модель, в которой редакционная коллегия журнала не участвует в процессе принятия статей и подбора рецензентов, сделала специальные выпуски не только наиболее уязвимым форматом для мошеннических практик, но и наиболее наглядным примером того, как издержки перехода к открытому доступу могут негативно влиять на издательское дело, редакторов, авторов и доверие к науке в целом.
#специальныевыпуски #spesialissues #открытыйдоступ #обзор #papermills
Специальные (тематические) выпуски неоднозначно влияют на формирование научного ландшафта. С одной стороны, они дают возможность ученым опубликовать экспериментальные и узкоспециализированные исследования, с другой — нередко открывают возможности для распространения некачественных материалов под видом тематического сборника.
Недавно в Learned Publishing вышла статья, авторы которой проанализировали специальные выпуски журналов, которые индексируются в Web of Science.
Согласно данным о 35 142 статьях из спецвыпусков с 2018 по 2022 год, ведущими издателями статей в тематических выпусках остаются доминирующие издательства на рынке научных журналов — Elsevier, Taylor & Francis, Springer Nature, MDPI, Wiley и Sage. В шестерку ведущих журналов по количеству статей входят: Neuropharmacology (Elsevier), Applied Sciences (MDPI), Neuroscience (Elsevier), Sustainability (MDPI), International Journal of Molecular Sciences (MDPI) и IEEE Transactions on Computer Aided Design of Integrated Circuits (IEEE).
Больше всего специальных выпусков выходят в науках об окружающей среде, электротехнике, образовании, менеджменте и нейронауках. А количество статей в спецвыпусках варьируется в зависимости от издательства и журнала. Например, в Wiley специальные выпуски состоят из 10–15 статей, в Elsevier — из 5–20 статей, в Springer — примерно из 6–8.
Исследования на базе Web of Science показывают, что специальные выпуски улучшают показатели цитирования и импакт-фактор журнала, хотя при этом они могут непропорционально увеличивать цитирования для неизвестных журналов и редко публикующихся ученых. Это может быть связано с тем, что приглашенные редакторы могут использовать социальные сети, профессиональные связи или рассылки для продвижения выпуска.
Решение о принятии статьи в спецвыпуск может исходить от главного редактора, издательства или быть результатом голосования на основе рецензий. Сложнее дело обстоит, если его принимает гостевой редактор, так как давление, с которым он может столкнуться, потенциально влияет на качество опубликованных материалов. Так, ему необходимо собрать достаточно работ, чтобы единоразово компенсировать долю отклоненных, а также найти квалифицированных рецензентов, что проблематично в случае новаторских тем, особенно если вокруг них еще нет устоявшихся сообществ исследователей. Иногда именно по вине гостевого редактора приходится отзывать целый выпуск.
Кроме того, для фабрик публикаций (paper mills) спецвыпуски являются излюбленными площадками. Эта проблема была поднята в связи с массовым отзывом статей, являющихся продуктом paper mills, из Hindawi и исключением более 50 журналов, включая 19 журналов Hindawi/Wiley, из Web of Science.
Помимо этого, эксплуатация моделей открытого доступа (OA) и высокие сборы за обработку статей (APC) могут стимулировать редакторов увеличивать количество статей, игнорируя их качество в пользу крупных доходов. В связи с чем большое количество специальных выпусков, особенно превышающее число плановых, — один из ключевых маркеров недобросовестной редакционной политики.
Модель, в которой редакционная коллегия журнала не участвует в процессе принятия статей и подбора рецензентов, сделала специальные выпуски не только наиболее уязвимым форматом для мошеннических практик, но и наиболее наглядным примером того, как издержки перехода к открытому доступу могут негативно влиять на издательское дело, редакторов, авторов и доверие к науке в целом.
#специальныевыпуски #spesialissues #открытыйдоступ #обзор #papermills
Open Editors: открытые данные о членах редколлегий 26 издательств
Редакторы научных журналов играют важную роль в академической среде: они легитимируют избранные исследования, контролируют рецензирование и влияют на карьеру ученых, (не) позволяя им публиковаться в своих журналах. В этом контексте исследователи изучают влияние и последствия их работы, например, анализируя состав редколлегий и гендерную представленность, международное разнообразие, социальные сети исследователей и их институциональную принадлежность.
К сожалению, анализ данных о «хранителях знаний» (gatekeepers of knowledge) сопряжен с одной распространенной проблемой: отсутствием единообразных данных о редколлегиях на сайтах журналов, что вынуждает исследователей тратить время на трудоемкий «ручной» сбор и обработку данных. Так, Taylor & Francis приводит информацию о редакторах в разных форматах, несмотря на то, что журналы принадлежат одному и тому же издательству. Помимо прочего, что такой подход, мягко говоря, далек от творческого и предлагает только «слепок» определенного момента, что затрудняет воспроизводимость исследований.
Авторы статьи, опубликованной в Research Evaluation, попытались решить эту проблему, разработав проект Open Editors, который содержит структурированные данные о 594 580 членах редколлегий 7352 научных журналов 26 издательств, включая 5 хищнических (predatory journals).
По оценкам OpenAlex за 2022 год, в мире существует около 16 780 научных издательств, соответственно, их едва ли можно представить в одном наборе данных. Выборка авторов, представленная на площадке, включает 15 из 44 крупных издательств (хотя эта группа представляет всего 0,26% от всех академических издательств, они ответственны за почти две трети (65%) общего объема научных публикаций в 2021 г.)
Научные журналы крайне неоднородны с точки зрения размеров их редакционных коллегий. Авторы проанализировали полученную выборку (кстати, в наборе есть редакторы, аффилированные с Вышкой) и обнаружили, что в среднем на журнал приходится 81 редактор, а медианное значение составляет 34 на журнал. Экстремальные выбросы относятся к Frontiers, например журнал Frontiers in Psychology включал 13 967 членов редколлегии. Помимо этого из общей картины выбивались такие мегажурналы, как PLoS ONE (9 001 члена редколлегии), PeerJ (1 673) и eLife (870).
Что касается географического разнообразия, то наибольшее число представителей различных стран встречается в журналах Frontiers (почти 60), за ним следуют мегажурналы PeerJ (46), eLife (41) и PLoS (24,5). Медианное значение составляет 11 для всех журналов и издательств. США доминируют в большинстве редколлегий издателей (22 из 26) и всегда входят в топ-5 представленных стран, Китай — в 20 из 26, Великобритания в 18 и Италия в 14.
Решения редакторов могут вносить вклад в интеллектуальные и общественные предубеждения, например, они могут быть обусловлены гомофилией или личными привязанностями. По этой причине дальнейшее изучение данных о редколлегиях может положительно сказаться на развитии науки в целом. Представленный срез может применяться как для практических целей оценки исследований, так и для изучения ландшафта научных публикаций, а также позволяет проводить критические исследования относительно разнообразия и инклюзивности в научной среде.
#openeditors #редколлегия #обзор #редакционнаяполитика #predatoryjournals
Редакторы научных журналов играют важную роль в академической среде: они легитимируют избранные исследования, контролируют рецензирование и влияют на карьеру ученых, (не) позволяя им публиковаться в своих журналах. В этом контексте исследователи изучают влияние и последствия их работы, например, анализируя состав редколлегий и гендерную представленность, международное разнообразие, социальные сети исследователей и их институциональную принадлежность.
К сожалению, анализ данных о «хранителях знаний» (gatekeepers of knowledge) сопряжен с одной распространенной проблемой: отсутствием единообразных данных о редколлегиях на сайтах журналов, что вынуждает исследователей тратить время на трудоемкий «ручной» сбор и обработку данных. Так, Taylor & Francis приводит информацию о редакторах в разных форматах, несмотря на то, что журналы принадлежат одному и тому же издательству. Помимо прочего, что такой подход, мягко говоря, далек от творческого и предлагает только «слепок» определенного момента, что затрудняет воспроизводимость исследований.
Авторы статьи, опубликованной в Research Evaluation, попытались решить эту проблему, разработав проект Open Editors, который содержит структурированные данные о 594 580 членах редколлегий 7352 научных журналов 26 издательств, включая 5 хищнических (predatory journals).
По оценкам OpenAlex за 2022 год, в мире существует около 16 780 научных издательств, соответственно, их едва ли можно представить в одном наборе данных. Выборка авторов, представленная на площадке, включает 15 из 44 крупных издательств (хотя эта группа представляет всего 0,26% от всех академических издательств, они ответственны за почти две трети (65%) общего объема научных публикаций в 2021 г.)
Научные журналы крайне неоднородны с точки зрения размеров их редакционных коллегий. Авторы проанализировали полученную выборку (кстати, в наборе есть редакторы, аффилированные с Вышкой) и обнаружили, что в среднем на журнал приходится 81 редактор, а медианное значение составляет 34 на журнал. Экстремальные выбросы относятся к Frontiers, например журнал Frontiers in Psychology включал 13 967 членов редколлегии. Помимо этого из общей картины выбивались такие мегажурналы, как PLoS ONE (9 001 члена редколлегии), PeerJ (1 673) и eLife (870).
Что касается географического разнообразия, то наибольшее число представителей различных стран встречается в журналах Frontiers (почти 60), за ним следуют мегажурналы PeerJ (46), eLife (41) и PLoS (24,5). Медианное значение составляет 11 для всех журналов и издательств. США доминируют в большинстве редколлегий издателей (22 из 26) и всегда входят в топ-5 представленных стран, Китай — в 20 из 26, Великобритания в 18 и Италия в 14.
Решения редакторов могут вносить вклад в интеллектуальные и общественные предубеждения, например, они могут быть обусловлены гомофилией или личными привязанностями. По этой причине дальнейшее изучение данных о редколлегиях может положительно сказаться на развитии науки в целом. Представленный срез может применяться как для практических целей оценки исследований, так и для изучения ландшафта научных публикаций, а также позволяет проводить критические исследования относительно разнообразия и инклюзивности в научной среде.
#openeditors #редколлегия #обзор #редакционнаяполитика #predatoryjournals
{kind=link}
Честные ошибки
Отозванные статьи ассоциируются с недобросовестным поведением и нарушением научной этики, что подкрепляется высоким вниманием к теме. В этом контексте едва ли заметны ретракции, причиной которых стали «честные ошибки» (honest errors/mistakes), т.е. ошибки, связанные с заблуждениями авторов, для которых действительно было важно внести вклад в науку.
На днях в Nature вышла заметка о «светлой стороне» отозванных статей. Новость ссылается на свежую статью журнала Royal Society Open Science, авторы которой рассмотрели публикации, отозванные из-за ошибок в данных (материалы были взяты из Retraction Watch). Основные выводы статьи сводятся к тому, что большинство непреднамеренных ошибок (авторы приводят 18 типов ошибок) возникают из-за невнимательности, т.е. неправильной обработки данных и некорректной интерпретации полученных на их основании результатов.
Ученые также провели опрос среди исследователей, вынужденных отозвать статью из-за «честных ошибок». Результаты показывают, что авторы испытывают сильный стресс как из-за удара по исследовательскому проекту, так и из-за рисков для научной репутации, так как это может отразиться на дальнейшей карьере ученого.
Из положительного: три четверти респондентов изменили свой рабочий процесс после ретракции, например, внедрили более строгие протоколы работы с данными. Многие из опрошенных отметили, что журналам следует давать подробные комментарии к отозванным статьям и тщательнее проверять материалы перед публикацией.
В январе этого года тему «честных ошибок» затронули и в Journal of Informetrics, где также сконцентрировались на ошибках данных (так как это самый распространенный тип ошибок). В статье авторы изучили, как на возникновение таких ошибок влияет работа команды, проанализировав 444 уведомления о ретракции статьи из WoS (на 16 мая 2023 года). Результаты исследования показали, что наибольшее количество отозванных статей из-за «честных ошибок» (203) — у небольших команд (в среднем 1,4 участников); у средних команд (5,9) — 189 отозванных статей; у больших команд (10,2) — 52 статьи.
По мнению авторов, большая команда предполагает больший контроль над исследованием и качественное критическое осмысление материала перед публикацией. Кроме того, научные проекты, для которых нужна большая команда, как правило, довольно сложные, и к ним предъявляются строгие стандарты качества. В командах среднего размера контроль между участниками размыт, исследователи чувствуют меньшую личную ответственность за управление ошибками, что приводит к «эффекту свидетеля» (bystander effect).
Исследовательская работа все чаще приобретает признаки «командной игры», что также подразумевает коллективную ответственность. Даже негативный опыт ретракции может принести плоды и изменить как исследовательские стратегии одного ученого, так и преобразовать стиль работы в команде.
#отозванныестатьи #retraction #обзор #honesterror
Использована иллюстрация Robert Neubecker
Отозванные статьи ассоциируются с недобросовестным поведением и нарушением научной этики, что подкрепляется высоким вниманием к теме. В этом контексте едва ли заметны ретракции, причиной которых стали «честные ошибки» (honest errors/mistakes), т.е. ошибки, связанные с заблуждениями авторов, для которых действительно было важно внести вклад в науку.
На днях в Nature вышла заметка о «светлой стороне» отозванных статей. Новость ссылается на свежую статью журнала Royal Society Open Science, авторы которой рассмотрели публикации, отозванные из-за ошибок в данных (материалы были взяты из Retraction Watch). Основные выводы статьи сводятся к тому, что большинство непреднамеренных ошибок (авторы приводят 18 типов ошибок) возникают из-за невнимательности, т.е. неправильной обработки данных и некорректной интерпретации полученных на их основании результатов.
Ученые также провели опрос среди исследователей, вынужденных отозвать статью из-за «честных ошибок». Результаты показывают, что авторы испытывают сильный стресс как из-за удара по исследовательскому проекту, так и из-за рисков для научной репутации, так как это может отразиться на дальнейшей карьере ученого.
Из положительного: три четверти респондентов изменили свой рабочий процесс после ретракции, например, внедрили более строгие протоколы работы с данными. Многие из опрошенных отметили, что журналам следует давать подробные комментарии к отозванным статьям и тщательнее проверять материалы перед публикацией.
В январе этого года тему «честных ошибок» затронули и в Journal of Informetrics, где также сконцентрировались на ошибках данных (так как это самый распространенный тип ошибок). В статье авторы изучили, как на возникновение таких ошибок влияет работа команды, проанализировав 444 уведомления о ретракции статьи из WoS (на 16 мая 2023 года). Результаты исследования показали, что наибольшее количество отозванных статей из-за «честных ошибок» (203) — у небольших команд (в среднем 1,4 участников); у средних команд (5,9) — 189 отозванных статей; у больших команд (10,2) — 52 статьи.
По мнению авторов, большая команда предполагает больший контроль над исследованием и качественное критическое осмысление материала перед публикацией. Кроме того, научные проекты, для которых нужна большая команда, как правило, довольно сложные, и к ним предъявляются строгие стандарты качества. В командах среднего размера контроль между участниками размыт, исследователи чувствуют меньшую личную ответственность за управление ошибками, что приводит к «эффекту свидетеля» (bystander effect).
Исследовательская работа все чаще приобретает признаки «командной игры», что также подразумевает коллективную ответственность. Даже негативный опыт ретракции может принести плоды и изменить как исследовательские стратегии одного ученого, так и преобразовать стиль работы в команде.
#отозванныестатьи #retraction #обзор #honesterror
Использована иллюстрация Robert Neubecker
{kind=link}
«Женская сила»: Международный день женщин и девочек в науке
В Международный день женщин и девочек в науке в очередной раз возвращаем наших читателей к теме «женской научной силы». Достижения женщин в науке неразрывно связаны с вопросами неравенства. Даже после перехода на постоянную должность они, как правило, получают более низкую зарплату, медленнее продвигаются по карьерной лестнице, с большим трудом добиваются финансирования на исследования. Дискриминация внутри исследовательской группы способствует невыгодному положению женщин в академии (женщин реже указывают как первого/последнего автора и реже цитируют).
Многие убеждены, что все эти трудности связаны с низкой академической продуктивностью женщин (ведь на них традиционно лежит бремя семейных обязательств). Такая точка зрения не всегда отражает истину. Женщины в целом действительно чаще покидают академическую среду и, следовательно, трек их публикационной активности короче, но на коротком временном отрезке нет ощутимой разницы в производительности между мужчинами и женщинами.
Ученые из Уханьского и Чикагского университетов проанализировали рост влияния «женской силы» на науку. Авторы использовали многоуровневую модель со смешанными эффектами для оценки влияния гендерного состава научного коллектива на исследования. Сначала они оценили степень представленности женщин-исследователей в командах, а затем изучили, как этот фактор взаимодействует с временным и дисциплинарным контекстами.
Авторы ограничили временную выборку двумя десятилетиями (с 2001 по 2020 гг.) и отобрали более 85 млн статей, обратившись к SciSciNet. После исключения статей, в которых им не удалось определить гендер автора (для более чем 20 % авторов из-за неполных имен), выборка сократилась до 56,8 млн статей и 265,7 млн записей об авторах. Полученные данные были разбиты по годам, областям и диапазонам импакт-фактора журнала, после чего авторы оценили результаты на случайной выборке (20 %).
В исследовании авторы затронули следующие вопросы:
🔹 Растет ли число команд, в состав которых входят женщины?
🔹 Как участие женщин влияет на публикации?
🔹 Какие в этом контексте существуют различия между разными научными категориями?
Результаты исследования показали, что с течением времени растет как число команд, в которых работают женщины, так и доля женщин в команде. В 2001 году публикации, в которых участвовала по крайней мере одна женщина-автор, составляли 42 % всех статей, а к 2020 году — уже 66 %. Науки о жизни, а также медицинские, гуманитарные и социальные науки демонстрируют более высокое соотношение женщин в команде по сравнению с инженерными, техническими, естественными и физическими науками (см. рис.).
При этом сбалансированный состав исследовательского коллектива с участием женщин-ученых может положительно быть связан со значимостью и видимостью исследований (такие работы цитируют чуть чаще), тогда как повышение доли женщин может даже приводить к увеличению вероятности появления прорывных исследований. В то же время женщины с большей легкостью интегрируют различные области знаний, что наиболее выражено в чисто женских командах и хорошо прослеживается при анализе источников публикаций. Это преимущество очевидно в естественных, физических и социальных науках и растет с течением времени.
По мнению авторов, возросшее научное разнообразие на самом деле охватывает множество аспектов: исследовательские фокусы и выбор тем, методологические предпочтения, понимание и интерпретацию результатов и, конечно, изменения в моделях сотрудничества. Эти отличия от исследовательских традиций, в которых доминируют мужчины, не только изменяют научную практику и поведение, но и меняют культуру и атмосферу команды. Растущее внимание к теме помогает выйти за рамки предрассудков и стереотипов в отношении женщин, ведь их участие в исследованиях играет одну из ключевых ролей в построении развивающейся, процветающей и здоровой научной экосистемы.
#обзор #женщинывнауке #международныйденьженщинвнауке #SciSciNet
В Международный день женщин и девочек в науке в очередной раз возвращаем наших читателей к теме «женской научной силы». Достижения женщин в науке неразрывно связаны с вопросами неравенства. Даже после перехода на постоянную должность они, как правило, получают более низкую зарплату, медленнее продвигаются по карьерной лестнице, с большим трудом добиваются финансирования на исследования. Дискриминация внутри исследовательской группы способствует невыгодному положению женщин в академии (женщин реже указывают как первого/последнего автора и реже цитируют).
Многие убеждены, что все эти трудности связаны с низкой академической продуктивностью женщин (ведь на них традиционно лежит бремя семейных обязательств). Такая точка зрения не всегда отражает истину. Женщины в целом действительно чаще покидают академическую среду и, следовательно, трек их публикационной активности короче, но на коротком временном отрезке нет ощутимой разницы в производительности между мужчинами и женщинами.
Ученые из Уханьского и Чикагского университетов проанализировали рост влияния «женской силы» на науку. Авторы использовали многоуровневую модель со смешанными эффектами для оценки влияния гендерного состава научного коллектива на исследования. Сначала они оценили степень представленности женщин-исследователей в командах, а затем изучили, как этот фактор взаимодействует с временным и дисциплинарным контекстами.
Авторы ограничили временную выборку двумя десятилетиями (с 2001 по 2020 гг.) и отобрали более 85 млн статей, обратившись к SciSciNet. После исключения статей, в которых им не удалось определить гендер автора (для более чем 20 % авторов из-за неполных имен), выборка сократилась до 56,8 млн статей и 265,7 млн записей об авторах. Полученные данные были разбиты по годам, областям и диапазонам импакт-фактора журнала, после чего авторы оценили результаты на случайной выборке (20 %).
В исследовании авторы затронули следующие вопросы:
🔹 Растет ли число команд, в состав которых входят женщины?
🔹 Как участие женщин влияет на публикации?
🔹 Какие в этом контексте существуют различия между разными научными категориями?
Результаты исследования показали, что с течением времени растет как число команд, в которых работают женщины, так и доля женщин в команде. В 2001 году публикации, в которых участвовала по крайней мере одна женщина-автор, составляли 42 % всех статей, а к 2020 году — уже 66 %. Науки о жизни, а также медицинские, гуманитарные и социальные науки демонстрируют более высокое соотношение женщин в команде по сравнению с инженерными, техническими, естественными и физическими науками (см. рис.).
При этом сбалансированный состав исследовательского коллектива с участием женщин-ученых может положительно быть связан со значимостью и видимостью исследований (такие работы цитируют чуть чаще), тогда как повышение доли женщин может даже приводить к увеличению вероятности появления прорывных исследований. В то же время женщины с большей легкостью интегрируют различные области знаний, что наиболее выражено в чисто женских командах и хорошо прослеживается при анализе источников публикаций. Это преимущество очевидно в естественных, физических и социальных науках и растет с течением времени.
По мнению авторов, возросшее научное разнообразие на самом деле охватывает множество аспектов: исследовательские фокусы и выбор тем, методологические предпочтения, понимание и интерпретацию результатов и, конечно, изменения в моделях сотрудничества. Эти отличия от исследовательских традиций, в которых доминируют мужчины, не только изменяют научную практику и поведение, но и меняют культуру и атмосферу команды. Растущее внимание к теме помогает выйти за рамки предрассудков и стереотипов в отношении женщин, ведь их участие в исследованиях играет одну из ключевых ролей в построении развивающейся, процветающей и здоровой научной экосистемы.
#обзор #женщинывнауке #международныйденьженщинвнауке #SciSciNet
{kind=link}
«Невидимые чернила»: о скрытых исправлениях в опубликованных статьях
В конце прошлого года мы рассказывали об исправлениях в опубликованных статьях: erratum и corrigendum. Обычно такие типы материалов редко привлекают внимание научного сообщества, но зачастую они являются наглядным доказательством ответственного отношения к науке и гарантируют сохранение научной целостности различных областей знаний. Однако сегодня, когда большинство научных трудов выпускается в электронном формате, возникают риски другого рода, получающие в последнее время все большее распространение: внесение авторских правок в публикации постфактум без соответствующего уведомления или попросту исчезновение статей без какой-либо пометки.
Ранее в научной литературе уже рассматривались случаи stealth retractions, или скрытых ретракций, в частности, Тайшера да Силва опубликовал довольно развернутую статью в 2015 году и вновь возвращался к этой теме в последующие годы применительно к более узким научным областям (кстати, на волне нападок на журнальную индустрию с исследователем отказывались работать отдельные редакции).
Встречаются и случаи stealth corrections, или скрытых исправлений. В недавней публикации Learned Publishing исследователи обратились к «научным детективам» и данным PubPeer, чтобы найти статьи, которые были изменены после публикации без выхода erratum. Таких нашлось 131, причем в 92 случаях исправления касались самого содержания статьи, в 27 случаях — выходной информации (например, статья «перемещается» из спецвыпуска в основной, меняется выпускающий редактор и др.), в 9 случаях изменялась информация об авторах, а в оставшихся — дополнительная информация (ethics statement и др.).
Авторы прилагают к своему исследованию документ, содержащий краткое описание каждого кейса. Чаще всего, по-видимому, речь идет о технических ошибках, на которые мог повлиять человеческий фактор, однако даже в таком случае в академической среде требуется выпуск erratum/corrigendum (в качестве альтернативы предлагается доработать платформы для автоматического открытого и прозрачного логирования любых изменений).
По мнению авторов, сама возможность внесения скрытых исправлений в статью после публикации должна быть устранена, поскольку угрожает вышеупомянутой научной целостности, а кроме того, читатели должны иметь возможность самостоятельно определять, является ли изменение существенным или нет, а не полагаться на усмотрение редакторов.
Помимо опубликованного списка, авторы создали онлайн-таблицу, в которой просят регистрировать обнаруженные случаи скрытых исправлений. Пока, безусловно, сложно говорить о массовости обнаруженных кейсов, которые к тому же касаются зачастую политики отдельных изданий, но поддержать стремление коллег полезно, поскольку целостность является одним из ключевых параметров качества данных, а научная среда подразумевает, что любые действия должны протоколироваться, чтобы иметь возможность безошибочно отслеживать этапы научной работы.
#erratum #retraction #ретракция #обзор
В конце прошлого года мы рассказывали об исправлениях в опубликованных статьях: erratum и corrigendum. Обычно такие типы материалов редко привлекают внимание научного сообщества, но зачастую они являются наглядным доказательством ответственного отношения к науке и гарантируют сохранение научной целостности различных областей знаний. Однако сегодня, когда большинство научных трудов выпускается в электронном формате, возникают риски другого рода, получающие в последнее время все большее распространение: внесение авторских правок в публикации постфактум без соответствующего уведомления или попросту исчезновение статей без какой-либо пометки.
Ранее в научной литературе уже рассматривались случаи stealth retractions, или скрытых ретракций, в частности, Тайшера да Силва опубликовал довольно развернутую статью в 2015 году и вновь возвращался к этой теме в последующие годы применительно к более узким научным областям (кстати, на волне нападок на журнальную индустрию с исследователем отказывались работать отдельные редакции).
Встречаются и случаи stealth corrections, или скрытых исправлений. В недавней публикации Learned Publishing исследователи обратились к «научным детективам» и данным PubPeer, чтобы найти статьи, которые были изменены после публикации без выхода erratum. Таких нашлось 131, причем в 92 случаях исправления касались самого содержания статьи, в 27 случаях — выходной информации (например, статья «перемещается» из спецвыпуска в основной, меняется выпускающий редактор и др.), в 9 случаях изменялась информация об авторах, а в оставшихся — дополнительная информация (ethics statement и др.).
Авторы прилагают к своему исследованию документ, содержащий краткое описание каждого кейса. Чаще всего, по-видимому, речь идет о технических ошибках, на которые мог повлиять человеческий фактор, однако даже в таком случае в академической среде требуется выпуск erratum/corrigendum (в качестве альтернативы предлагается доработать платформы для автоматического открытого и прозрачного логирования любых изменений).
По мнению авторов, сама возможность внесения скрытых исправлений в статью после публикации должна быть устранена, поскольку угрожает вышеупомянутой научной целостности, а кроме того, читатели должны иметь возможность самостоятельно определять, является ли изменение существенным или нет, а не полагаться на усмотрение редакторов.
Помимо опубликованного списка, авторы создали онлайн-таблицу, в которой просят регистрировать обнаруженные случаи скрытых исправлений. Пока, безусловно, сложно говорить о массовости обнаруженных кейсов, которые к тому же касаются зачастую политики отдельных изданий, но поддержать стремление коллег полезно, поскольку целостность является одним из ключевых параметров качества данных, а научная среда подразумевает, что любые действия должны протоколироваться, чтобы иметь возможность безошибочно отслеживать этапы научной работы.
#erratum #retraction #ретракция #обзор
Успешный наставник — удача или наказание?
Наставничество имеет большое значение в построении карьеры ученого. Так, наставник может влиять на научные связи подопечного, цитируемость его работ и даже на трудоустройство, поэтому нередко начинающие исследователи стремятся работать под началом состоявшихся и успешных ученых. Наставники тоже получают от подопечных некоторую (преимущественно скромную) выгоду, например, удовлетворенность от работы, более высокую производительность, чем у «одиноких» коллег, и более широкие научные связи. Кроме того, успешные подопечные укрепляют институциональное признание наставника, ведь чем больше результативных подопечных — тем выше влияние и авторитет ученого.
На днях в Nature Human Behaviour вышла статья, авторы которой изучили влияние количества подопечных наставника на их выживаемость в академической среде. Связи между учеными и наставниками были извлечены из баз данных The Academic Family Tree и OpenAlex. Авторы собрали информацию о 1,5 млн ученых, опубликовавших в общем около 16 млн статей и сформировавших 1,8 млн менторских связей в области химии, нейронаук и физики (с 1980 по 2022 год). На базе полученных данных они построили генеалогические древа исследователей, а затем проанализировали их.
Согласно основным выводам, чем продуктивнее наставник, тем ниже «выживаемость» его подопечных в академической среде на ранних этапах карьеры (уровень «выживаемости» демонстрирует выраженную тенденцию к снижению после 2003 года во всех рассмотренных дисциплинах). Вероятно, это связано с тем, что высокопродуктивные и успешные наставники часто совмещают обязанности (проводят исследования, редактируют и рецензируют статьи, курируют студенческие работы и т.д.). Следовательно, молодым ученым в больших группах приходится конкурировать за их время и внимание.
Но есть и приятная сторона: цитируемость «выживших» подопечных из больших групп в целом выше, они также широко представлены среди 10 % наиболее цитируемых ученых. Эта закономерность остается неизменной во всех трех упомянутых областях. Более того, такие исследователи с большей вероятностью будут вести большую научную группу в «зрелом» академическом возрасте. Таким образом, работа с наставником, ведущим большую научную группу, все же может дать некоторые конкурентные преимущества.
Конечно, есть области, для которых эти тенденции не являются актуальными (в клеточной биологии студенты из больших групп имеют больше шансов «выжить», а в физике нет существенных различий в количестве цитирований среди подопечных из разных групп). Также стоит отметить, что количество соавторов на ранних этапах карьеры играет положительную, но незначительную роль в краткосрочном «выживании».
По мнению авторов, распределение внимания наставников имеет ключевое значение для академического процветания ученого. Несмотря на важную роль молодых ученых в научной экосистеме значительная часть начинающих исследователей слишком быстро покидает академическую среду, что действительно может быть связано с неверным типом наставничества. Это приводит не только к потере потенциальных новаторов, но и подсвечивает глубинные организационные проблемы, которые могут препятствовать удержанию и развитию талантов.
#обзор #наставничество #академическаягенеалогия #TheAcademicFamilyTree #OpenAlex
Использована иллюстрация Robert Neubecker
Наставничество имеет большое значение в построении карьеры ученого. Так, наставник может влиять на научные связи подопечного, цитируемость его работ и даже на трудоустройство, поэтому нередко начинающие исследователи стремятся работать под началом состоявшихся и успешных ученых. Наставники тоже получают от подопечных некоторую (преимущественно скромную) выгоду, например, удовлетворенность от работы, более высокую производительность, чем у «одиноких» коллег, и более широкие научные связи. Кроме того, успешные подопечные укрепляют институциональное признание наставника, ведь чем больше результативных подопечных — тем выше влияние и авторитет ученого.
На днях в Nature Human Behaviour вышла статья, авторы которой изучили влияние количества подопечных наставника на их выживаемость в академической среде. Связи между учеными и наставниками были извлечены из баз данных The Academic Family Tree и OpenAlex. Авторы собрали информацию о 1,5 млн ученых, опубликовавших в общем около 16 млн статей и сформировавших 1,8 млн менторских связей в области химии, нейронаук и физики (с 1980 по 2022 год). На базе полученных данных они построили генеалогические древа исследователей, а затем проанализировали их.
Согласно основным выводам, чем продуктивнее наставник, тем ниже «выживаемость» его подопечных в академической среде на ранних этапах карьеры (уровень «выживаемости» демонстрирует выраженную тенденцию к снижению после 2003 года во всех рассмотренных дисциплинах). Вероятно, это связано с тем, что высокопродуктивные и успешные наставники часто совмещают обязанности (проводят исследования, редактируют и рецензируют статьи, курируют студенческие работы и т.д.). Следовательно, молодым ученым в больших группах приходится конкурировать за их время и внимание.
Но есть и приятная сторона: цитируемость «выживших» подопечных из больших групп в целом выше, они также широко представлены среди 10 % наиболее цитируемых ученых. Эта закономерность остается неизменной во всех трех упомянутых областях. Более того, такие исследователи с большей вероятностью будут вести большую научную группу в «зрелом» академическом возрасте. Таким образом, работа с наставником, ведущим большую научную группу, все же может дать некоторые конкурентные преимущества.
Конечно, есть области, для которых эти тенденции не являются актуальными (в клеточной биологии студенты из больших групп имеют больше шансов «выжить», а в физике нет существенных различий в количестве цитирований среди подопечных из разных групп). Также стоит отметить, что количество соавторов на ранних этапах карьеры играет положительную, но незначительную роль в краткосрочном «выживании».
По мнению авторов, распределение внимания наставников имеет ключевое значение для академического процветания ученого. Несмотря на важную роль молодых ученых в научной экосистеме значительная часть начинающих исследователей слишком быстро покидает академическую среду, что действительно может быть связано с неверным типом наставничества. Это приводит не только к потере потенциальных новаторов, но и подсвечивает глубинные организационные проблемы, которые могут препятствовать удержанию и развитию талантов.
#обзор #наставничество #академическаягенеалогия #TheAcademicFamilyTree #OpenAlex
Использована иллюстрация Robert Neubecker
{kind=link}
Фабрики рецензий: цитируемость, лаконичность, шаблоны и не только
Помимо известных форм академического мошенничества, таких как paper mills, картелей цитирований и хищнических журналов, существует еще один вид (к счастью, не самый популярный) — фабрики рецензий (review mills), которые занимаются крупномасштабным выпуском научных рецензий. Их можно узнать по схожим аргументам независимо от тематики рецензируемых текстов, а также настойчивым просьбам добавлять ссылки на публикации самого рецензента (для искусственного роста цитирования).
Адам Дэй (Adam Day) в своей статье писал, что существует четыре варианта того, как могут выглядеть «фабрики рецензий»:
🔹 автор создает фейковый профиль ученого, а затем рекомендует его в качестве потенциального рецензента для своей статьи и пишет рецензию на собственную работу;
🔹 несколько авторов могут договориться о том, чтобы писать положительные рецензии друг для друга;
🔹 фейковые аккаунты, созданные «фабрикой публикаций» для выпуска статей, также могут быть приглашены для рецензирования;
🔹 «фабрика публикаций» может создать отдельный фейковый профиль рецензента и рекомендовать его для рецензирования.
Новый виток публичной дискуссии начался в прошлом году с подозрительной рецензии, опубликованной вместе со статьей в журнале MDPI Journal of Clinical Medicine, на которую обратила внимание Мария де лос Анхелес Овьедо-Гарсия (María de los Ángeles Oviedo-García). В рецензии говорилось, что авторы «должны сослаться на недавно опубликованные статьи, такие как…», а затем были указаны две статьи, соавтором которых являлся сам рецензент. После этого профессор Овьедо-Гарсия, которая до этого уже занималась вопросами, связанными с академическим мошенничеством, начала замечать другие рецензии со схожими формулировками. В общей сложности она обнаружила 85 таких рецензий в 23 журналах MDPI (в основном по химии и смежным наукам), опубликованных в период с 2022 по 2023 гг. Заметка об этом вышла на сайте Predatory Reports (на данный момент она недоступна, но есть копия на Web Archive). MDPI довольно быстро откликнулись, проведя внутреннее расследование и опубликовав его результаты.
Мария Овьедо-Гарсия активно ведет блог в X (Twitter), в котором отслеживает различные «странности», которые все еще встречаются в рецензиях и могут быть признаком недобросовестности рецензентов. Помимо требования ссылаться на статьи рецензента, часто встречается ситуация, когда рецензент в первом же предложении пишет, что не является экспертом по теме статьи (что не соответствует правилам рецензирования), а также ультракороткие рецензии (рекорд — всего 6 слов: "The paper is adequated to publish").
В статье 2024 г. профессор Овьедо-Гарсия подводит итоги своего расследования и отмечает, что, хотя основная вина лежит на недобросовестных рецензентах, редакторы (в том числе приглашенные) должны также следить за тем, чтобы рецензии на рукописи соответствовали принятым стандартам, тем более что издательство имеет возможность массово проверить тексты рецензий на предмет повторения формулировок.
#обзор #reviewmills #фабрикирецензий
Помимо известных форм академического мошенничества, таких как paper mills, картелей цитирований и хищнических журналов, существует еще один вид (к счастью, не самый популярный) — фабрики рецензий (review mills), которые занимаются крупномасштабным выпуском научных рецензий. Их можно узнать по схожим аргументам независимо от тематики рецензируемых текстов, а также настойчивым просьбам добавлять ссылки на публикации самого рецензента (для искусственного роста цитирования).
Адам Дэй (Adam Day) в своей статье писал, что существует четыре варианта того, как могут выглядеть «фабрики рецензий»:
🔹 автор создает фейковый профиль ученого, а затем рекомендует его в качестве потенциального рецензента для своей статьи и пишет рецензию на собственную работу;
🔹 несколько авторов могут договориться о том, чтобы писать положительные рецензии друг для друга;
🔹 фейковые аккаунты, созданные «фабрикой публикаций» для выпуска статей, также могут быть приглашены для рецензирования;
🔹 «фабрика публикаций» может создать отдельный фейковый профиль рецензента и рекомендовать его для рецензирования.
Новый виток публичной дискуссии начался в прошлом году с подозрительной рецензии, опубликованной вместе со статьей в журнале MDPI Journal of Clinical Medicine, на которую обратила внимание Мария де лос Анхелес Овьедо-Гарсия (María de los Ángeles Oviedo-García). В рецензии говорилось, что авторы «должны сослаться на недавно опубликованные статьи, такие как…», а затем были указаны две статьи, соавтором которых являлся сам рецензент. После этого профессор Овьедо-Гарсия, которая до этого уже занималась вопросами, связанными с академическим мошенничеством, начала замечать другие рецензии со схожими формулировками. В общей сложности она обнаружила 85 таких рецензий в 23 журналах MDPI (в основном по химии и смежным наукам), опубликованных в период с 2022 по 2023 гг. Заметка об этом вышла на сайте Predatory Reports (на данный момент она недоступна, но есть копия на Web Archive). MDPI довольно быстро откликнулись, проведя внутреннее расследование и опубликовав его результаты.
Мария Овьедо-Гарсия активно ведет блог в X (Twitter), в котором отслеживает различные «странности», которые все еще встречаются в рецензиях и могут быть признаком недобросовестности рецензентов. Помимо требования ссылаться на статьи рецензента, часто встречается ситуация, когда рецензент в первом же предложении пишет, что не является экспертом по теме статьи (что не соответствует правилам рецензирования), а также ультракороткие рецензии (рекорд — всего 6 слов: "The paper is adequated to publish").
В статье 2024 г. профессор Овьедо-Гарсия подводит итоги своего расследования и отмечает, что, хотя основная вина лежит на недобросовестных рецензентах, редакторы (в том числе приглашенные) должны также следить за тем, чтобы рецензии на рукописи соответствовали принятым стандартам, тем более что издательство имеет возможность массово проверить тексты рецензий на предмет повторения формулировок.
#обзор #reviewmills #фабрикирецензий