Отдых
Мы уже поговорили о том, что важно отдыхать. Но это было в контексте отпуска и такого, основательного релакса. Но знаете, какое самое крутое состояние? Когда тебе не нужен отпуск. Тебе базово очень нравится твоя жизнь и ты не доводишь себя до такой усталости, что уже вынужден уходить на долгий перерыв, чтобы не сгореть дотла.
Но как этого достигнуть?
Грамотное распределение рабочего времени и перерывов - один из способов.
У вас есть 8 часов рабочего времени. Дада, дорогие программисты. Ни 10 и ни 12. Хардворк энивеа вычеркиваем из списка своих жизненных девизов. Надо работать не тяжело, а с умом. Нам голову создатели придумали не только для того, чтобы в нее есть. Работать долго может только четко выстроенная система.
И в эти 8 часов нужно впихнуть весь обьем насущных задач. Цель - амбициозная и нетривиальная. Но умные дяди придумали некоторые схемы, которые помогут несколько систематизировать этот хаос.
Для начала нужно составлять план на день. Желательно письменно, но можно и в голове, если вы Джимми Нейтроны. Это помогает видеть конкретные цели, при достижении которых мозг выделит дофамин, давая вам приятные ощущения и мотивацию двигаться дальше. Вам же приятно закрывать тикеты в жире? С собственным микропланированием вы можете закрывать несколько задач за день! Сколько приятных эмоций от зачеркивания пунков в своем плане, мммм.
Далее - приоритизация задач. Схем существует куча, но приведу ту, которая мне больше всего нравится.
Разделяем весь спектр задач на простые, средние и тяжелые. Как только у вас появилось это разбиение, вы делаете не более 1 тяжелой задачи + не более 3-х средних задач + не более 5 легких задач в день. Схема 1+3+5.
Разделение задач по сложности - вполне соответствует реальности среднего рабочего дня. Нужно ответить на почту, создать задачи, провести собес, сходить на митинг и тд. Все это разные по затрате энергии действия и очевидно, что это нужно учитывать при планировании своего дня.
Вот мы получили шаблон, куда мы можем вставлять свои реальные задачи. Теперь осталось только понять, сколько по времени выполнять таски разной сложности, чтобы появился адекватный мэтчинг.
Обычно цифры такие: тяжелая задача - 3-4 часа, средняя - 30-40 мин, легкая - 10 мин.
Счетоводы уже все посчитали и напряглись: даже при максимальных цифрах пропадает 1 час. Куда он тратится?
На отдых
Какое бы у вас не было суперское внимание, оно понижается при непрерывной и вовлеченной работе.
Делайте себе перерывы.
Для тех, кто работает из офиса - это вполне органичная вещь. Пошел, кофеек с коллегой попил, мозги переключились, отдохнули и готовы разрывать эти ваши си-плюс-плюсы.
Но для удаленщиков перерывы не естественны. И парадокс в том, что именно им больше всего они и нужны! Отсутствие естественных отвлекающих факторов приводит к тому, что человек садится за стол в 9 и до вечера прожевывает пятой точкой дырку в этом стуле, зачастую без обеда. Кстати, ставь лайк, если пролеживаешь дырку в диване и зарабатываешь остеохондроз aka работаешь лежа(посмотрим сколько нас).
Завершил какой-то логический блок - отдохнул. Надолго застрял - отдохнул. Даже по гостам нужно делать перерывы. Да, может не так много суммарно. Но мы ж программисты. Мы тонкие и творческие личности🦋🌸. Нам можно.
Опять же. Этот пост - не руководство к действию, которое нужно выполнить в строгости. Мы, как и бизнес, должны быть agile и подстраивать свои концепции под ситуацию. Иногда надо и поработать побольше. Иногда, когда чувствуешь, что не вывозишь, отдохнуть побольше.
В общем, вроде простые рекомендации, но внедряя их вы ощущите всю мощь успешного успеха и расти будете не до синьора/лида/Илона Маска, а до самих просторов космоса.
Stay smarter. Stay cool.
#fun #commertial
Мы уже поговорили о том, что важно отдыхать. Но это было в контексте отпуска и такого, основательного релакса. Но знаете, какое самое крутое состояние? Когда тебе не нужен отпуск. Тебе базово очень нравится твоя жизнь и ты не доводишь себя до такой усталости, что уже вынужден уходить на долгий перерыв, чтобы не сгореть дотла.
Но как этого достигнуть?
Грамотное распределение рабочего времени и перерывов - один из способов.
У вас есть 8 часов рабочего времени. Дада, дорогие программисты. Ни 10 и ни 12. Хардворк энивеа вычеркиваем из списка своих жизненных девизов. Надо работать не тяжело, а с умом. Нам голову создатели придумали не только для того, чтобы в нее есть. Работать долго может только четко выстроенная система.
И в эти 8 часов нужно впихнуть весь обьем насущных задач. Цель - амбициозная и нетривиальная. Но умные дяди придумали некоторые схемы, которые помогут несколько систематизировать этот хаос.
Для начала нужно составлять план на день. Желательно письменно, но можно и в голове, если вы Джимми Нейтроны. Это помогает видеть конкретные цели, при достижении которых мозг выделит дофамин, давая вам приятные ощущения и мотивацию двигаться дальше. Вам же приятно закрывать тикеты в жире? С собственным микропланированием вы можете закрывать несколько задач за день! Сколько приятных эмоций от зачеркивания пунков в своем плане, мммм.
Далее - приоритизация задач. Схем существует куча, но приведу ту, которая мне больше всего нравится.
Разделяем весь спектр задач на простые, средние и тяжелые. Как только у вас появилось это разбиение, вы делаете не более 1 тяжелой задачи + не более 3-х средних задач + не более 5 легких задач в день. Схема 1+3+5.
Разделение задач по сложности - вполне соответствует реальности среднего рабочего дня. Нужно ответить на почту, создать задачи, провести собес, сходить на митинг и тд. Все это разные по затрате энергии действия и очевидно, что это нужно учитывать при планировании своего дня.
Вот мы получили шаблон, куда мы можем вставлять свои реальные задачи. Теперь осталось только понять, сколько по времени выполнять таски разной сложности, чтобы появился адекватный мэтчинг.
Обычно цифры такие: тяжелая задача - 3-4 часа, средняя - 30-40 мин, легкая - 10 мин.
Счетоводы уже все посчитали и напряглись: даже при максимальных цифрах пропадает 1 час. Куда он тратится?
На отдых
Какое бы у вас не было суперское внимание, оно понижается при непрерывной и вовлеченной работе.
Делайте себе перерывы.
Для тех, кто работает из офиса - это вполне органичная вещь. Пошел, кофеек с коллегой попил, мозги переключились, отдохнули и готовы разрывать эти ваши си-плюс-плюсы.
Но для удаленщиков перерывы не естественны. И парадокс в том, что именно им больше всего они и нужны! Отсутствие естественных отвлекающих факторов приводит к тому, что человек садится за стол в 9 и до вечера прожевывает пятой точкой дырку в этом стуле, зачастую без обеда. Кстати, ставь лайк, если пролеживаешь дырку в диване и зарабатываешь остеохондроз aka работаешь лежа(посмотрим сколько нас).
Завершил какой-то логический блок - отдохнул. Надолго застрял - отдохнул. Даже по гостам нужно делать перерывы. Да, может не так много суммарно. Но мы ж программисты. Мы тонкие и творческие личности🦋🌸. Нам можно.
Опять же. Этот пост - не руководство к действию, которое нужно выполнить в строгости. Мы, как и бизнес, должны быть agile и подстраивать свои концепции под ситуацию. Иногда надо и поработать побольше. Иногда, когда чувствуешь, что не вывозишь, отдохнуть побольше.
В общем, вроде простые рекомендации, но внедряя их вы ощущите всю мощь успешного успеха и расти будете не до синьора/лида/Илона Маска, а до самих просторов космоса.
Stay smarter. Stay cool.
#fun #commertial
{kind=link}
❤33👍9🫡7🔥3❤🔥2😁2
Ковариантные возвращаемые типы
Есть такое интересное понятие, о котором вы возможно ни разу не слышали. Пример из поста выше с методами clone и create можно было написать иначе:
Вы скажете: "Сигнатуры не совпадают! Код не скомпилируется!".
А я скажу: "Shape и Circle - ковариантные типы". С++ разрешает наследнику переопределять методы с возвращаемым типом, который является наследником типа метода из базового класса. Говорят, что это даже называется идиомой С++.
Какие юзкейсы у этой идиомы? По факту всего один. Представьте, что все методы возвращают один тип Shape. Вы создали объект Circle в куче и присвоили указатель на него к указателю на Circle. Тогда при клонировании объекта Circle вам вернется указатель на объект базового класса. И по хорошему его надо динамик кастить к Circle, чтобы работать с конкретным типом наследника. А это оверхэд:
Выглядит не очень. Посмотрим, как изменится код, если методы Circle будут возвращать указатель на Circle:
Выглядит намного лучше. Но вот вопрос: почему вы нигде не увидите в коде применения ковариантных типов?
Потому что этот подход не работает с умными указателями, которые де факто являются стандартом при возвращении объектов из фабрик. std::unique_ptr<Circle> не является наследником std::unique_ptr<Shape>, поэтому они и не ковариантные типы и сигнатуры методов будут несовместимы.
Возвращение сырых указателей - супер bad practice, один только этот факт заставляет отказаться от такого подхода.
Тем более полиморфные объекты и придумали для того, чтобы использовать их полиморфно. То есть через ссылку или указатель на базовый класс. Зачем оперировать полиморфным объектом с указателем на конкретный тип - не очень понятно.
Раньше, до изобретения умных указателей, идиома была легитимна. Теперь же она отправилась на свалку истории.
Только что вы прочитали очередную статью про совсем ненужную хрень. Ставьте 🗿, если ваше лицо сейчас на него похоже)
Stay poker-faced. Stay cool.
#fun #cppcore
Есть такое интересное понятие, о котором вы возможно ни разу не слышали. Пример из поста выше с методами clone и create можно было написать иначе:
class Shape {
public:
virtual ~Shape() { } // A virtual destructor
// ...
virtual Shape* clone() const = 0; // Uses the copy constructor
virtual Shape* create() const = 0; // Uses the default constructor
};
class Circle : public Shape {
public:
Circle* clone() const override;
Circle* create() const override;
// ...
};
Circle* Circle::clone() const { return new Circle(this); }
Circle* Circle::create() const { return new Circle(); }Вы скажете: "Сигнатуры не совпадают! Код не скомпилируется!".
А я скажу: "Shape и Circle - ковариантные типы". С++ разрешает наследнику переопределять методы с возвращаемым типом, который является наследником типа метода из базового класса. Говорят, что это даже называется идиомой С++.
Какие юзкейсы у этой идиомы? По факту всего один. Представьте, что все методы возвращают один тип Shape. Вы создали объект Circle в куче и присвоили указатель на него к указателю на Circle. Тогда при клонировании объекта Circle вам вернется указатель на объект базового класса. И по хорошему его надо динамик кастить к Circle, чтобы работать с конкретным типом наследника. А это оверхэд:
Circle *circle1 = new Circle();
Shape *shape = d1->clone();
Circle *circle2 = dynamic_cast<Circle *>(shape);
if(circle2) {
// Use circle2 here.
}
Выглядит не очень. Посмотрим, как изменится код, если методы Circle будут возвращать указатель на Circle:
Circle *circle1 = new Circle();
Circle *circle2 = d1->clone();
Выглядит намного лучше. Но вот вопрос: почему вы нигде не увидите в коде применения ковариантных типов?
Потому что этот подход не работает с умными указателями, которые де факто являются стандартом при возвращении объектов из фабрик. std::unique_ptr<Circle> не является наследником std::unique_ptr<Shape>, поэтому они и не ковариантные типы и сигнатуры методов будут несовместимы.
Возвращение сырых указателей - супер bad practice, один только этот факт заставляет отказаться от такого подхода.
Тем более полиморфные объекты и придумали для того, чтобы использовать их полиморфно. То есть через ссылку или указатель на базовый класс. Зачем оперировать полиморфным объектом с указателем на конкретный тип - не очень понятно.
Раньше, до изобретения умных указателей, идиома была легитимна. Теперь же она отправилась на свалку истории.
Только что вы прочитали очередную статью про совсем ненужную хрень. Ставьте 🗿, если ваше лицо сейчас на него похоже)
Stay poker-faced. Stay cool.
#fun #cppcore
{kind=link}
🗿60👍27🔥9❤6😁6🆒1
Найди летающих друзей
Сегодня будет не по С++ контент, но я не мог мимо этого пройти. Надеюсь вы сейчас никуда не спешите и у вас есть огнетушитель под рукой, будет жарко.
В общем, недавно в твиттере завирусился японский "'экспресс" тест на деменцию. Задача очень простая - найти на картинке бабочку, летучую мышь и утку. Все это надо сделать за 10 мин. Успели - молодцы. Не успели - скорее всего ваша разработческая карьера продлится не так долго, как вы этого ожидаете.
У меня не хватает усидчивости на такие штуки. Через 3 минуты безрезультатного поиска мне захотелось с криками "лайт вейт бэйбэээ" выкинуть что-нибудь тяжелое из окна и я понял, что пора залезать в комменты и ловить спойлеры. Буду верить, что раз я искал не 10 мин, это все не считается.
❤️ - нашел всех за 10 мин.
🤬 - где эта ср*ная бабочка?!
Keep calm. Stay cool.
#fun
Сегодня будет не по С++ контент, но я не мог мимо этого пройти. Надеюсь вы сейчас никуда не спешите и у вас есть огнетушитель под рукой, будет жарко.
В общем, недавно в твиттере завирусился японский "'экспресс" тест на деменцию. Задача очень простая - найти на картинке бабочку, летучую мышь и утку. Все это надо сделать за 10 мин. Успели - молодцы. Не успели - скорее всего ваша разработческая карьера продлится не так долго, как вы этого ожидаете.
У меня не хватает усидчивости на такие штуки. Через 3 минуты безрезультатного поиска мне захотелось с криками "лайт вейт бэйбэээ" выкинуть что-нибудь тяжелое из окна и я понял, что пора залезать в комменты и ловить спойлеры. Буду верить, что раз я искал не 10 мин, это все не считается.
❤️ - нашел всех за 10 мин.
🤬 - где эта ср*ная бабочка?!
Keep calm. Stay cool.
#fun
2❤97🤬30😁8🤔4🤯1😱1
Теория заговора
Вот живет программист по С++ своей прекрасной и беззаботной жизнью. Все у него хорошо: код пишется, баги фиксятся, деньги мутятся. И имя у него такое прекрасное - Иннокентий.
Иногда он лазается по cppreference, чтобы освежить знания по каким-то фичам или узнать что-то новое. Представим себе, что он зашел просмотреть на доку std::atoi и видит там такой фрагмент:
Ничего необычного, просто определяется std::initializer_list<const char *> и записываются туда разные строки. Ну ладно, работает дальше.
А дальше ищет статейку по std::variant. И находит там вот какой отрывок:
Почему-то он обратил внимание на число 42. "Где-то я его уже видел.". И вспоминает, что недавно видел это же число в коде для std::atoi. Это, конечно, немного странно - подумал, он. Но решил, что это просто случайность.
Приходит наш герой домой с работы и, как каждый уважающий себя программист, вместо ужина садится писать свой пет-проект. А вы не знали, что программисты могут годами жить на диете "код+кофе"?
Пишет он какое-то многопоточное приложение. Чтобы адекватно писать такие штуки, нужны глубокие знания о модели памяти в С++ и как работает синхронизация данных в многопроцессорном мире. Поэтому кодер снова идет на cppreference и находит там статейку про std::memory_order. Читает, читает. И херак, вылупил глаза в экран. "Это уже очень странно". А увидел он следующий фрагмент:
Опять это 42! "Что за приколы такие? Это что, любимое число плюсовиков, что они его везде пихают?". На том и порешил. Не нервничать же по поводу чьего-то любимого числа. Может именно на этот день рождения Страуструпу подарили маленького щеночка....
В общем, затерпели и забыли.
Иннокентий только начинает писать свой проект и ему нужен хороший сборочный скрипт. Выбор языка пал на модномолодежный питухон, поэтому он полез в документацию изучать базовый синтаксис питона. И тут на тебе:
Whatafuck? Страуструп здесь уже никак не может быть замешан. Ситуация больше похожа на массонский заговор. Кенни не выдержал и пошел распутывать тайну века.
Оказалось, что это отсылка на книгу Дугласа Адамса "Автостопом по галактике". Там люди создали супермощный супекомпьютер только с одной целью - узнать ответ на "Главный вопрос жизни, Вселенной и всего такого". Этот вопрос настолько сложный и комплексный, что на нахождение ответа суперкомпьютер потратил целых 7.5 млн лет вычислений. И в окончании выдал: "42".
Роман вышел в период расцвета sci-fi, поэтому оставил глубокий отпечаток в массовой культуре. Оно появлялось в популярных сериалах типа "Остаться в живых". Даже один из радиотелескопов НАСА использует ровно 42 тарелки в честь отсылки к произведению.
Неудивительно, что гики по всему миру начали пихать это число во всех места в качестве пасхалки. Сейчас почти где-угодно встречая 42, вы можете быть на 99% уверены, что это именно отсылка на "Автостопом по галактике".
Так и была разгадана величайшая из тайн иллюминатов и Иннокентий довольный пошел спать. The end.
Make references to the great things. Stay cool.
#fun
Вот живет программист по С++ своей прекрасной и беззаботной жизнью. Все у него хорошо: код пишется, баги фиксятся, деньги мутятся. И имя у него такое прекрасное - Иннокентий.
Иногда он лазается по cppreference, чтобы освежить знания по каким-то фичам или узнать что-то новое. Представим себе, что он зашел просмотреть на доку std::atoi и видит там такой фрагмент:
const auto data =
{
"42",
"0x2A", // treated as "0" and junk "x2A", not as hexadecimal
"3.14159",
"31337 with words",
"words and 2",
"-012345",
"10000000000" // note: out of int32_t range
};
Ничего необычного, просто определяется std::initializer_list<const char *> и записываются туда разные строки. Ну ладно, работает дальше.
А дальше ищет статейку по std::variant. И находит там вот какой отрывок:
int main()
{
std::variant<int, float> v, w;
v = 42; // v contains int
int i = std::get<int>(v);
assert(42 == i); // succeeds
w = std::get<int>(v);
w = std::get<0>(v); // same effect as the previous line
w = v; // same effect as the previous line
...
}
Почему-то он обратил внимание на число 42. "Где-то я его уже видел.". И вспоминает, что недавно видел это же число в коде для std::atoi. Это, конечно, немного странно - подумал, он. Но решил, что это просто случайность.
Приходит наш герой домой с работы и, как каждый уважающий себя программист, вместо ужина садится писать свой пет-проект. А вы не знали, что программисты могут годами жить на диете "код+кофе"?
Пишет он какое-то многопоточное приложение. Чтобы адекватно писать такие штуки, нужны глубокие знания о модели памяти в С++ и как работает синхронизация данных в многопроцессорном мире. Поэтому кодер снова идет на cppreference и находит там статейку про std::memory_order. Читает, читает. И херак, вылупил глаза в экран. "Это уже очень странно". А увидел он следующий фрагмент:
std::vector<int> data;
std::atomic<int> flag = {0};
void thread_1()
{
data.push_back(42);
flag.store(1, std::memory_order_release);
}
Опять это 42! "Что за приколы такие? Это что, любимое число плюсовиков, что они его везде пихают?". На том и порешил. Не нервничать же по поводу чьего-то любимого числа. Может именно на этот день рождения Страуструпу подарили маленького щеночка....
В общем, затерпели и забыли.
Иннокентий только начинает писать свой проект и ему нужен хороший сборочный скрипт. Выбор языка пал на модномолодежный питухон, поэтому он полез в документацию изучать базовый синтаксис питона. И тут на тебе:
x = int(input("Please enter an integer: "))
Please enter an integer: 42
if x < 0:
x = 0
print('Negative changed to zero')
elif x == 0:
print('Zero')
elif x == 1:
print('Single')
else:
print('More')Whatafuck? Страуструп здесь уже никак не может быть замешан. Ситуация больше похожа на массонский заговор. Кенни не выдержал и пошел распутывать тайну века.
Оказалось, что это отсылка на книгу Дугласа Адамса "Автостопом по галактике". Там люди создали супермощный супекомпьютер только с одной целью - узнать ответ на "Главный вопрос жизни, Вселенной и всего такого". Этот вопрос настолько сложный и комплексный, что на нахождение ответа суперкомпьютер потратил целых 7.5 млн лет вычислений. И в окончании выдал: "42".
Роман вышел в период расцвета sci-fi, поэтому оставил глубокий отпечаток в массовой культуре. Оно появлялось в популярных сериалах типа "Остаться в живых". Даже один из радиотелескопов НАСА использует ровно 42 тарелки в честь отсылки к произведению.
Неудивительно, что гики по всему миру начали пихать это число во всех места в качестве пасхалки. Сейчас почти где-угодно встречая 42, вы можете быть на 99% уверены, что это именно отсылка на "Автостопом по галактике".
Так и была разгадана величайшая из тайн иллюминатов и Иннокентий довольный пошел спать. The end.
Make references to the great things. Stay cool.
#fun
{kind=link}
👍56❤14🔥8😁7🗿4🤯3
Квиз
Вчера в комментах наш подписчик Вячеслав скинул интересный примерчик, который здорово показывает вашу плюсовую интуицию. Поэтому захотелось разобрать его в рамках поста. Ну и для интереса предлагаю вам поучаствовать в #quiz и испытать свою интуицию. Код до боли краток, и до еще большей боли бессмысленен и ужасен. Но все же.
Какой будет результат попытки компиляции и запуска следующего кода?
Have a meaning in your life. Stay cool.
#fun
Вчера в комментах наш подписчик Вячеслав скинул интересный примерчик, который здорово показывает вашу плюсовую интуицию. Поэтому захотелось разобрать его в рамках поста. Ну и для интереса предлагаю вам поучаствовать в #quiz и испытать свою интуицию. Код до боли краток, и до еще большей боли бессмысленен и ужасен. Но все же.
Какой будет результат попытки компиляции и запуска следующего кода?
#include <iostream>
int main () {
std::cout << +-!!"" << std::endl;
return 0;
}
Have a meaning in your life. Stay cool.
#fun
👍15❤4🔥3🤬3
Как узнать четное ли число
Вы сейчас подумали, типа "wtf, он шо нас за идиотов держит". Но погодите, щас все объясню.
Есть одно условие: нельзя использовать операции целочисленного деления и брать остаток от деления. Вот это уже задачка не для второклассников и обычный человек вряд ли с ней справится. Но программист может. Хотя и не любой, судя по моему небольшому опросу😆)
Сделайте паузу, скушайте твикс и подумайте. Знаю, что у нас крутое коммьюнити и все с легкостью решат эту задачу. Но если вдруг, вы не решили, то просто посидите на литкоде, там таких задачек навалом и вы довольно быстро выработаете интуицию к решению в принципе любых алгоритмических задач, включая такие.
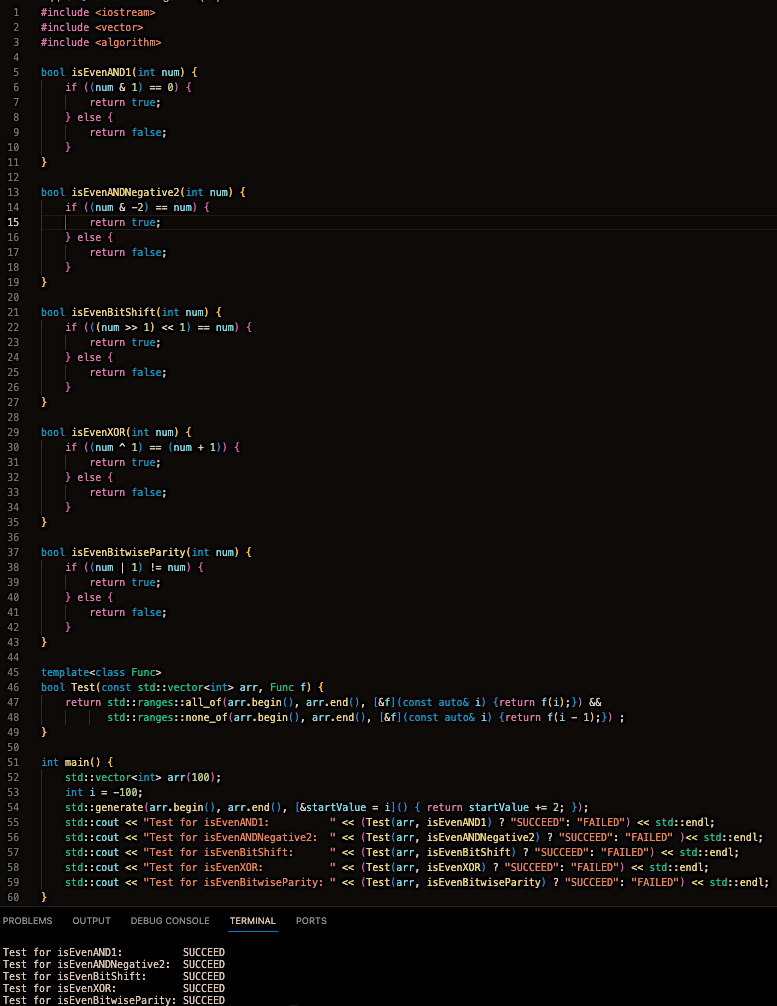
В общем. Нужно просто проверить последний бит. Если он ноль - число четное, если нет - число нечетное. Все очень просто. Делается это с помощью битового & с единичкой.
Но во время написания этого поста мне пришла идея задать эту задачку ChatGPT, в тему недавнего поста про него. Правда я попросил сгенерировать 3 примера. Чисто из интереса. И результат меня сильно удивил. Все 3 примера были правильные, среди них было решение из абзаца выше, но было и еще 2, о которых я и не думал. После этого попросил нагенерить еще 2 примера. И они тоже были верные. Конечно, все из них использовали битовые операции, но как филигранно!
Очень интересно решение с битовым умножением на -2. Дело в том, что -2 в памяти компьютера представляется как 111...1110. Поэтому умножение любого числа на -2 будет давать то же самое число, только если последний бит был выставлен в 0.
Короче говоря решил с вами поделиться этим небольшим открытием. Просто еще один пример, что языковые модели реально могут в реально простые задачи. Ниже вы можете посмотреть все 5 способов решения. Некоторые правда пришлось все-таки подредактировать, но это мелочи.
Stay amazed. Stay cool.
#fun
Вы сейчас подумали, типа "wtf, он шо нас за идиотов держит". Но погодите, щас все объясню.
Есть одно условие: нельзя использовать операции целочисленного деления и брать остаток от деления. Вот это уже задачка не для второклассников и обычный человек вряд ли с ней справится. Но программист может. Хотя и не любой, судя по моему небольшому опросу😆)
Сделайте паузу, скушайте твикс и подумайте. Знаю, что у нас крутое коммьюнити и все с легкостью решат эту задачу. Но если вдруг, вы не решили, то просто посидите на литкоде, там таких задачек навалом и вы довольно быстро выработаете интуицию к решению в принципе любых алгоритмических задач, включая такие.
В общем. Нужно просто проверить последний бит. Если он ноль - число четное, если нет - число нечетное. Все очень просто. Делается это с помощью битового & с единичкой.
Но во время написания этого поста мне пришла идея задать эту задачку ChatGPT, в тему недавнего поста про него. Правда я попросил сгенерировать 3 примера. Чисто из интереса. И результат меня сильно удивил. Все 3 примера были правильные, среди них было решение из абзаца выше, но было и еще 2, о которых я и не думал. После этого попросил нагенерить еще 2 примера. И они тоже были верные. Конечно, все из них использовали битовые операции, но как филигранно!
Очень интересно решение с битовым умножением на -2. Дело в том, что -2 в памяти компьютера представляется как 111...1110. Поэтому умножение любого числа на -2 будет давать то же самое число, только если последний бит был выставлен в 0.
Короче говоря решил с вами поделиться этим небольшим открытием. Просто еще один пример, что языковые модели реально могут в реально простые задачи. Ниже вы можете посмотреть все 5 способов решения. Некоторые правда пришлось все-таки подредактировать, но это мелочи.
Stay amazed. Stay cool.
#fun
{kind=link}
4❤🔥38👍23❤5👎3😱3🥱3
Достигаем недостижимое
В прошлом посте вот такой код:
Приводил к очень неожиданным сайд-эффектам. При его компиляции клангом выводился принт, хотя в функции main мы нигде не вызываем unreachable.
Темная магия это или проделки ГосДепа узнаем дальше.
Для начала, этот код содержит UB. Согласно стандарту программа должна производить какие-то обозримые эффекты. Или завершиться, или работать с вводом-выводом, или работать с volatile переменными, или выполнять синхронизирующие операции. Это требования forward progress. Если программа ничего из этого не делает - код содержит UB.
Так вот у нас пустой бесконечный цикл. То есть предполагается, что он будет работать бесконечно и ничего полезного не делать.
Тут очень важно понять одну вещь. Компилятор следует не вашей логике и ожиданиям, как должна работать программа. У него есть фактически инструкция(стандарт), которой он следует.
По стандарту программа, содержащая бесконечные циклы без side-эффектов, содержит UB и компилятор имеет право делать с этим циклом все, что ему захочется.
В данном случае он просто удаляет цикл. Но он не только удаляет цикл. Но еще и удаляет инструкцию возврата из main.
В нормальных программах функция main в ассемблере представляет из себя следующее:
ret - инструкция возврата из функции. И код функции main выполняется, пока не достигнет этой инструкции.
Так вот в нашем случае этой инструкции нет и код продолжает выполнение дальше. А дальше у нас очень удобненько расположилась функция с принтом, вывод которой мы и видим. Выглядит это так:
Почему удаляется return - не так уж очевидно и для самих разработчиков компилятора. У них есть тред обсуждения этого вопроса, который не привел к какому-то знаменателю. Так что не буду городить догадок.
Справедливости ради стоит сказать, что в 19-м шланге поменяли это поведение и теперь таких неожиданностей нет.
Stay predictable. Stay cool.
#fun #cppcore #compiler
В прошлом посте вот такой код:
int main() {
while(1);
return 0;
}
void unreachable() {
std::cout << "Hello, World!" << std::endl;
}Приводил к очень неожиданным сайд-эффектам. При его компиляции клангом выводился принт, хотя в функции main мы нигде не вызываем unreachable.
Темная магия это или проделки ГосДепа узнаем дальше.
Для начала, этот код содержит UB. Согласно стандарту программа должна производить какие-то обозримые эффекты. Или завершиться, или работать с вводом-выводом, или работать с volatile переменными, или выполнять синхронизирующие операции. Это требования forward progress. Если программа ничего из этого не делает - код содержит UB.
Так вот у нас пустой бесконечный цикл. То есть предполагается, что он будет работать бесконечно и ничего полезного не делать.
Тут очень важно понять одну вещь. Компилятор следует не вашей логике и ожиданиям, как должна работать программа. У него есть фактически инструкция(стандарт), которой он следует.
По стандарту программа, содержащая бесконечные циклы без side-эффектов, содержит UB и компилятор имеет право делать с этим циклом все, что ему захочется.
В данном случае он просто удаляет цикл. Но он не только удаляет цикл. Но еще и удаляет инструкцию возврата из main.
В нормальных программах функция main в ассемблере представляет из себя следующее:
main:
// Perform some code
ret
ret - инструкция возврата из функции. И код функции main выполняется, пока не достигнет этой инструкции.
Так вот в нашем случае этой инструкции нет и код продолжает выполнение дальше. А дальше у нас очень удобненько расположилась функция с принтом, вывод которой мы и видим. Выглядит это так:
main:
unreachable():
push rax
mov rdi, qword ptr [rip + std::cout@GOTPCREL]
lea rsi, [rip + .L.str]
call std::basic_ostream<char, std::char_traits<char>>...
Почему удаляется return - не так уж очевидно и для самих разработчиков компилятора. У них есть тред обсуждения этого вопроса, который не привел к какому-то знаменателю. Так что не буду городить догадок.
Справедливости ради стоит сказать, что в 19-м шланге поменяли это поведение и теперь таких неожиданностей нет.
Stay predictable. Stay cool.
#fun #cppcore #compiler
{kind=link}
15🔥42👍10😁10❤4❤🔥2👎1
Программа без main?
Все мы знаем, что функция main - входная точка в программу. С нее начинается исполнение программы, если не считать глобальные переменные.
Без функции main программа просто не запустится.
Или нет?
Может быть мы можем что-нибудь нахимичить, чтобы, например, написать Hello, World без main?
Оказывается, можем. Однако, естественно, это все непереносимо. Но она на то и магия, что у разных магов свои заклинания.
Скомпилируем вот такую программу под gcc с флагом -nostartfiles:
И на консоли появится наша горячо-любимая надпись:
Для любителей поиграться с кодом вот вам ссылочка на годболт.
А вот что за такая функция _start и какой все-таки код выполняется до main, мы поговорим в следующий раз.
Make impossible things. Stay cool.
#fun #cppcore
Все мы знаем, что функция main - входная точка в программу. С нее начинается исполнение программы, если не считать глобальные переменные.
Без функции main программа просто не запустится.
Или нет?
Может быть мы можем что-нибудь нахимичить, чтобы, например, написать Hello, World без main?
Оказывается, можем. Однако, естественно, это все непереносимо. Но она на то и магия, что у разных магов свои заклинания.
Скомпилируем вот такую программу под gcc с флагом -nostartfiles:
#include <iostream>
int my_fun();
void _start()
{
int x = my_fun();
exit(x);
}
int my_fun()
{
std::cout << "Hello, World!\n";
return 0;
}
И на консоли появится наша горячо-любимая надпись:
Hello, World!Для любителей поиграться с кодом вот вам ссылочка на годболт.
А вот что за такая функция _start и какой все-таки код выполняется до main, мы поговорим в следующий раз.
Make impossible things. Stay cool.
#fun #cppcore
{kind=link}
🔥50👍19😁8❤🔥5❤4👎1
BUG
Еще одно слово, которое мы постоянно используем, вроде как знаем его значение, но понятие не имеем о его ориджине. Даже те, кто знает английский, не сразу доходят до скрытых взаимосвязей.
Дело в том, что на инглише "bug" - это жук и иногда какое-то обобщенное название рандомного насекомого.
И как жуки связаны с программными ошибками?
Словом "баг" еще в позапрошлом столетии нарекали какие-то неполадки с электротехникой. В те времена эти технологии были "новинкой" и страдали от всяких детских проблем. Поэтому скорее всего эти проблемы сравнивали с жуками из-за их схожести с маленькими, надоедливыми насекомыми, мешающими работать. Они постоянно где-то прячутся, неожиданно появляются и непонятно откуда вылезают. Томас Эдисон писал:
Поэтому такое значение слова было в принципе всегда известно. Но по отношению к программной ошибке термин стал употребляться после одного знаменитого случая(по одной из версий).
В 1946 году в работе компьютера Марк-2 ( Harvard Mark-II) обнаружили ошибку. Тогда ЭВМ были размером с баттхертом либералов после победы Трампа. Все работало на больших элементах, лампах и реле и время от времени какой-то из элементов выходил из строя. Это вполне нормальная тема для тех лет. И в этот раз научный сотрудник Грейс Хоппер отследила проблему и была удивлена, обнаружив сгоревшего мотылька, попавшего на контакты. Бездыханный трупик мотылька был извлечен и приклеен к отчету липкой лентой с комментарием «First actual case of bug being found.» («Первый реальный случай нахождения жучка»). Press F.
После этого случая термин разлетелся из уст в уста. Тогда программисты занимались не только софтиной, но и плотно работали с железками и, в принципе, с электроникой. Им уже было знакомо называть багами проблемы в технике. Теперь к значению добавились и программные ошибки.
Так этот жук стал самым знаменитым жуком в мире и увековечил память о себе в умах программистов и не только.
Можно кстати сделать один небольшой шажок вперед и понять, что примерно оттуда же растут ноги у слова «дебаггер» (debugger) – буквально «избавитель от жучков». Так что у нас есть что-то общее с дезинсекторами...
Dig to the origin. Stay cool.
#fun
Еще одно слово, которое мы постоянно используем, вроде как знаем его значение, но понятие не имеем о его ориджине. Даже те, кто знает английский, не сразу доходят до скрытых взаимосвязей.
Дело в том, что на инглише "bug" - это жук и иногда какое-то обобщенное название рандомного насекомого.
И как жуки связаны с программными ошибками?
Словом "баг" еще в позапрошлом столетии нарекали какие-то неполадки с электротехникой. В те времена эти технологии были "новинкой" и страдали от всяких детских проблем. Поэтому скорее всего эти проблемы сравнивали с жуками из-за их схожести с маленькими, надоедливыми насекомыми, мешающими работать. Они постоянно где-то прячутся, неожиданно появляются и непонятно откуда вылезают. Томас Эдисон писал:
Так было со всеми моими изобретениями. Первый шаг — интуиция, которая приходит как вспышка, затем возникают трудности — устройство отказывается работать, и именно тогда проявляются „жучки“ — как называют эти мелкие ошибки и трудности — и требуются месяцы пристального наблюдения, исследований и усилий, прежде чем дело дойдёт до коммерческого успеха или неудачи.
Поэтому такое значение слова было в принципе всегда известно. Но по отношению к программной ошибке термин стал употребляться после одного знаменитого случая(по одной из версий).
В 1946 году в работе компьютера Марк-2 ( Harvard Mark-II) обнаружили ошибку. Тогда ЭВМ были размером с баттхертом либералов после победы Трампа. Все работало на больших элементах, лампах и реле и время от времени какой-то из элементов выходил из строя. Это вполне нормальная тема для тех лет. И в этот раз научный сотрудник Грейс Хоппер отследила проблему и была удивлена, обнаружив сгоревшего мотылька, попавшего на контакты. Бездыханный трупик мотылька был извлечен и приклеен к отчету липкой лентой с комментарием «First actual case of bug being found.» («Первый реальный случай нахождения жучка»). Press F.
После этого случая термин разлетелся из уст в уста. Тогда программисты занимались не только софтиной, но и плотно работали с железками и, в принципе, с электроникой. Им уже было знакомо называть багами проблемы в технике. Теперь к значению добавились и программные ошибки.
Так этот жук стал самым знаменитым жуком в мире и увековечил память о себе в умах программистов и не только.
Можно кстати сделать один небольшой шажок вперед и понять, что примерно оттуда же растут ноги у слова «дебаггер» (debugger) – буквально «избавитель от жучков». Так что у нас есть что-то общее с дезинсекторами...
Dig to the origin. Stay cool.
#fun
{kind=link}
❤🔥34👍10🔥9❤6👎3⚡1
CamelCase vs Under_Score
Вдохновился прошлым постом и родилось это.
Есть такое ощущение, что программирование - одна из самых холиварных специальностей в мире. А в добавок к этому программисты по своему складу характера зачастую сами по себе ярые холиварщики. Это взрывоопасное комбо, которое приводит к смешным для стороннего человека проблемам.
Одна из них - как записывать многословные переменные. Уже десятилетиями люди спорят и никак не могут выработать один универсальный вариант. Поэтому приходится писать этот пост, чтобы во всем разобраться.
В настоящее время существует много стандартов наименования переменных, но два из них являются наиболее популярными среди программистов: это camel case («Верблюжья» нотация) и underscore (именование переменных с использованием символа нижнего подчеркивания в качестве разделителя).
Верблюжья нотация является стандартом в языке Java и в его неродственнике JavaScript, хотя ее можно встретить также и в других местах. Согласно этому стандарту, все слова в названии начинаются с прописной буквы, кроме первого. При этом, естественно, не используется никаких разделителей вроде нижнего подчеркивания. Пример: яШоколадныйЗаяцЯЛасковыйМерзавец. Обычно данный стандарт применяют к именам функций и переменных, при этом в именах классов, структур, интерфейсов используется стандарт UpperCamelCase(первая буква заглавная).
В стандарте underscore слова пишутся с маленькой буквы, а между ними стоит _ ( типа такого: йоу_собаки_я_наруто_узумаки). Обычно этот стандарт используется в названиях функций и переменных, а для названий классов, структур, интерфейсов используется стандарт UpperCamelCase. Обычно используется с родственных С языках.
Каждый из этих двух стандартов имеет свои сильные и слабые стороны. Вот основные:
👉🏿 Нижнее подчеркивание лучше читается: сравните стандарт_с_нижним_подчеркиванием и стандартНаписанияПрописнымиБуквами
👉🏿 Зато camel case делает более легким чтение строк, например:
my_first_var=my_second_var-my_third_var
и
myFirstVar=mySecondVar-myThirdVar
Очевидно, что camel case читается лучше: в случае с нижним подчеркиванием и оператором «минус» выражение с первого взгляда вообще можно принять за одну переменную.
👉🏿 Подчеркивание сложнее набирать. Даже при наличии intellisense, во многих случаях необходимо набирать символ нижнего подчеркивания. И имена получаются длиннее.
👉🏿 Camel Case непоследователен, потому что при использовании констант (которые иногда пишутся целиком заглавными буквами) нам приходится использовать нижнее подчеркивание. С другой стороны, стандарт underscore может быть полным, если вы решите использовать в названиях классов (структур, интерфейсов) нижнее подчеркивание в качестве разделителя.
👉🏿 Кроме того, для камел кейса не так уж и просто работать с аббревиатурами, которые обычно представлены в виде заглавных букв. Например, как вот правильно iLoveBDSM или iLoveBdsm?. Непонятно. Можете написать в комментах, как это по-вашему пишется)
В плюсах реально во многих проектах(и по моему опыту в частности) склоняются к использованию подчеркиваний в именах переменных и функций, а UpperCamelCase используется для имен классов. Но почему-то это нигде особо не упоминается и этому нигде не учат. Это как-то само приходит со временем.Хотя на начальном этапе карьеры, когда проходят первые ревью, то много непоняток в голове по поводу именований. Поэтому, вообще говоря, лучше заранее с командой обсудить этот вопрос и выработать ваш подробный код стайл, чтобы все были на одной волне по этому вопросу.
Расскажите в комментах, какую нотацию вы используете? Интересно иметь большую репрезентативную статистику.
Choose your style. Stay cool.
#fun
Вдохновился прошлым постом и родилось это.
Есть такое ощущение, что программирование - одна из самых холиварных специальностей в мире. А в добавок к этому программисты по своему складу характера зачастую сами по себе ярые холиварщики. Это взрывоопасное комбо, которое приводит к смешным для стороннего человека проблемам.
Одна из них - как записывать многословные переменные. Уже десятилетиями люди спорят и никак не могут выработать один универсальный вариант. Поэтому приходится писать этот пост, чтобы во всем разобраться.
В настоящее время существует много стандартов наименования переменных, но два из них являются наиболее популярными среди программистов: это camel case («Верблюжья» нотация) и underscore (именование переменных с использованием символа нижнего подчеркивания в качестве разделителя).
Верблюжья нотация является стандартом в языке Java и в его неродственнике JavaScript, хотя ее можно встретить также и в других местах. Согласно этому стандарту, все слова в названии начинаются с прописной буквы, кроме первого. При этом, естественно, не используется никаких разделителей вроде нижнего подчеркивания. Пример: яШоколадныйЗаяцЯЛасковыйМерзавец. Обычно данный стандарт применяют к именам функций и переменных, при этом в именах классов, структур, интерфейсов используется стандарт UpperCamelCase(первая буква заглавная).
В стандарте underscore слова пишутся с маленькой буквы, а между ними стоит _ ( типа такого: йоу_собаки_я_наруто_узумаки). Обычно этот стандарт используется в названиях функций и переменных, а для названий классов, структур, интерфейсов используется стандарт UpperCamelCase. Обычно используется с родственных С языках.
Каждый из этих двух стандартов имеет свои сильные и слабые стороны. Вот основные:
👉🏿 Нижнее подчеркивание лучше читается: сравните стандарт_с_нижним_подчеркиванием и стандартНаписанияПрописнымиБуквами
👉🏿 Зато camel case делает более легким чтение строк, например:
my_first_var=my_second_var-my_third_var
и
myFirstVar=mySecondVar-myThirdVar
Очевидно, что camel case читается лучше: в случае с нижним подчеркиванием и оператором «минус» выражение с первого взгляда вообще можно принять за одну переменную.
👉🏿 Подчеркивание сложнее набирать. Даже при наличии intellisense, во многих случаях необходимо набирать символ нижнего подчеркивания. И имена получаются длиннее.
👉🏿 Camel Case непоследователен, потому что при использовании констант (которые иногда пишутся целиком заглавными буквами) нам приходится использовать нижнее подчеркивание. С другой стороны, стандарт underscore может быть полным, если вы решите использовать в названиях классов (структур, интерфейсов) нижнее подчеркивание в качестве разделителя.
👉🏿 Кроме того, для камел кейса не так уж и просто работать с аббревиатурами, которые обычно представлены в виде заглавных букв. Например, как вот правильно iLoveBDSM или iLoveBdsm?. Непонятно. Можете написать в комментах, как это по-вашему пишется)
В плюсах реально во многих проектах(и по моему опыту в частности) склоняются к использованию подчеркиваний в именах переменных и функций, а UpperCamelCase используется для имен классов. Но почему-то это нигде особо не упоминается и этому нигде не учат. Это как-то само приходит со временем.Хотя на начальном этапе карьеры, когда проходят первые ревью, то много непоняток в голове по поводу именований. Поэтому, вообще говоря, лучше заранее с командой обсудить этот вопрос и выработать ваш подробный код стайл, чтобы все были на одной волне по этому вопросу.
Расскажите в комментах, какую нотацию вы используете? Интересно иметь большую репрезентативную статистику.
Choose your style. Stay cool.
#fun
{kind=link}
😁22🔥11❤5👍3❤🔥1🤣1
Помогите Доре найти проблему в коде
#опытным
Наткнулся на просторах всемирной сети на интересный пример:
Код работает и пример довольно игрушечный. Однако в этом С++ коде есть проблема/ы. Сможете ли вы их найти?
Это не то, чтобы рубрика #ревью, особо никакой цели и предназначения у кода нет. Просто интересно, как много разнообразных проблем и недостатков вы сможете найти в этом небольшом отрывке кода. Пишите свои мысли в комментариях под этим постом.
Critique your solutions. Stay cool.
#fun
#опытным
Наткнулся на просторах всемирной сети на интересный пример:
#include <cstdio>
void bar(char * s) {
printf("%s", s);
}
void foo() {
char s[] = "Hi! I'm a kind of a loooooooooooooooooooooooong string myself, you know...";
bar(s);
}
int main() {
foo();
}
Код работает и пример довольно игрушечный. Однако в этом С++ коде есть проблема/ы. Сможете ли вы их найти?
Это не то, чтобы рубрика #ревью, особо никакой цели и предназначения у кода нет. Просто интересно, как много разнообразных проблем и недостатков вы сможете найти в этом небольшом отрывке кода. Пишите свои мысли в комментариях под этим постом.
Critique your solutions. Stay cool.
#fun
🤔19👍6🔥4❤3😁1😎1
std::exchange
#опытным
В прошлом посте мы пасхалкой использовали std::exchange, давайте же разберем эту функцию по-подробнее.
По названию в целом понятно, что она делает - что-то обменивает. Но не как std::swap, меняет значения местами. Все немного хитрее.
Она заменяет старое значение новым и возвращает старое значение. Вот примерная реализация:
Как говорил Константин Владимиров: "единожды научившись использовать std::exchange, вы дальше будете делать std::exchange всю оставшуюся жизнь".
Понятное дело, что это не какой-нибудь std::move, который реально постоянно приходится использовать. Однако важен сам паттерн. Если посмотреть в кодовые базы, то будет куча мест, где можно использовать эту функцию. Приведу пару примеров работы std::exchange, чтобы вы поняли смысл.
Начнем со знакомого:
Мы определяем мутабельную лямбду(кстати это один из удачных примеров использования таких лямбд), которая может изменять свои захваченные по значению переменные current и step. Дальше на каждом вызове мы должны вернуть текущее значение current, но перед этим как-то его увеличить. Можно использовать прокси-переменную:
Но зачем, если у нас уже есть готовая и протестированная функция std::exchange? Это прекрасный способ немного уменьшить код и увеличить его читаемость.
Другой пример - генерация чисел Фибоначчи:
Хорошенько вдумайтесь и осознайте, что здесь происходит. Ну ведь красиво, правда?)
Если у вас есть вектор коллбэков, который вы постепенно копите и в какой-то момент обрабатываете все разом. Коллбэки безопасно выполнять вне лока. Но как их нормально обработать разом, чтобы 100500 раз не дергать мьютексы? На такой случай есть прикольная техника. Нужно под локом получить копию, а обрабатывать ее вне лока.
И все. Копию(на самом деле перемещенную копию) получаем под локом, а обрабатываем все без замков. Круто!
Ну и конечно, без принципа exchange не обойтись в lock-free программировании. Та же std::atomic_exchange работает ровно по той же логике.
Прикольная функция. Постарайтесь замечать самые банальные кейсы ее применения и со временем вы будет глубже ее понимать и использовать в более интересных ситуациях.
Be elegant. Stay cool.
#cppcore #cpp14 #concurrency #fun
#опытным
В прошлом посте мы пасхалкой использовали std::exchange, давайте же разберем эту функцию по-подробнее.
По названию в целом понятно, что она делает - что-то обменивает. Но не как std::swap, меняет значения местами. Все немного хитрее.
Она заменяет старое значение новым и возвращает старое значение. Вот примерная реализация:
template<class T, class U = T>
constexpr // Since C++20
T exchange(T& obj, U&& new_value) {
T old_value = std::move(obj);
obj = std::forward<U>(new_value);
return old_value;
}
Как говорил Константин Владимиров: "единожды научившись использовать std::exchange, вы дальше будете делать std::exchange всю оставшуюся жизнь".
Понятное дело, что это не какой-нибудь std::move, который реально постоянно приходится использовать. Однако важен сам паттерн. Если посмотреть в кодовые базы, то будет куча мест, где можно использовать эту функцию. Приведу пару примеров работы std::exchange, чтобы вы поняли смысл.
Начнем со знакомого:
auto gen = [current = start, step]() mutable {
return std::exchange(current, current + step);
};
std::vector<int> numbers(5);
std::generate(numbers.begin(), numbers.end(), gen);Мы определяем мутабельную лямбду(кстати это один из удачных примеров использования таких лямбд), которая может изменять свои захваченные по значению переменные current и step. Дальше на каждом вызове мы должны вернуть текущее значение current, но перед этим как-то его увеличить. Можно использовать прокси-переменную:
int val = current;
current += step;
return val;
Но зачем, если у нас уже есть готовая и протестированная функция std::exchange? Это прекрасный способ немного уменьшить код и увеличить его читаемость.
Другой пример - генерация чисел Фибоначчи:
auto gen = [current = 0, next = 1]() mutable {
return current = std::exchange(next, current + next);
};
std::vector<int> fib(10);
std::generate(fib.begin(), fib.end(), gen);
for (int i = 0; i < fib.size(); ++i) {
std::cout << fib[i] << " ";
}
// OUTPUT:
// 1 1 2 3 5 8 13 21 34 55 Хорошенько вдумайтесь и осознайте, что здесь происходит. Ну ведь красиво, правда?)
Если у вас есть вектор коллбэков, который вы постепенно копите и в какой-то момент обрабатываете все разом. Коллбэки безопасно выполнять вне лока. Но как их нормально обработать разом, чтобы 100500 раз не дергать мьютексы? На такой случай есть прикольная техника. Нужно под локом получить копию, а обрабатывать ее вне лока.
class Dispatcher {
// ...
// All events are dispatched when we call process
void process() {
const auto tmp = [&] {
std::lock_guard lock{mutex_};
return std::exchange(callbacks_, {});
}();
for (const auto& callback : tmp) {
std::invoke(callback);
}
}
};И все. Копию(на самом деле перемещенную копию) получаем под локом, а обрабатываем все без замков. Круто!
Ну и конечно, без принципа exchange не обойтись в lock-free программировании. Та же std::atomic_exchange работает ровно по той же логике.
Прикольная функция. Постарайтесь замечать самые банальные кейсы ее применения и со временем вы будет глубже ее понимать и использовать в более интересных ситуациях.
Be elegant. Stay cool.
#cppcore #cpp14 #concurrency #fun
Telegram
Грокаем C++
Mutable lambdas
#опытным
Лямбда выражения имеют одну интересную особенность. И эта особенность аффектит то, что можно делать внутри лямбды.
Простой пример:
int val = 0;
auto lambda1 = [&val]() { std::cout << ++val << std::endl; };
auto lambda2 = [val]()…
#опытным
Лямбда выражения имеют одну интересную особенность. И эта особенность аффектит то, что можно делать внутри лямбды.
Простой пример:
int val = 0;
auto lambda1 = [&val]() { std::cout << ++val << std::endl; };
auto lambda2 = [val]()…
2❤27🔥14👍10😱2☃1
Ответ
#опытным
Ну что. Пора раскрывать карты.
Правильных ответов здесь несколько(не зря был квиз с множественным ответом) и все зависит от версии компилятора и опций компиляции. Интереснее всего смотреть, что получится при использовании например gcc9 без опций.
А получится вот что. Программа успешно скомпилируется и на консоли появится сообщение:
Да, да. Это она про вас, наши подписчики.
Дело вот в чем. Есть такой варнинг в gcc: warning: 'main' is usually a function [-Wmain].
Погодите, main "обычно" является функцией. Это что, может быть не так?
В С нет или не было прям жесткого требования на тип символа main. Он в целом может быть и массивом:
хоть указателем на функцию:
И вот здесь начинается пространство для экспериментов. Адрес main - это место, с которого код начинается исполняться. Если мы каким-то образом запихаем инструкции ассемблера в массив, то мы сможем выполнить код в такой программе!
Ну а дальше дело техники. Пишем прокси программу:
Компилируем ее и запускаем gdb для дизассемблирования main:
Ну и пожалуйста. Слева четко видим шестнадцатиричные числа, которые и представляют собой тело функции main.
Единственное, что осталось - вывести эти числа в десятиричной форме по 4 байта, как инты:
Делаем из этих чиселок массив и готово! Закодированная программа будет выполняться.
В более новых версиях компиляторов эту лавочку прикрыли, потому что на gcc10 и более такая прога сегфолтится.
Но в любом случае, очень прикольно, что есть такая возможность.
Можете поиграться с кодом на годболте. Также можно почитать статью, в которой автор подробно расписал историю исследования возможности так писать код.
Благодарю @PyXiion за предоставление материалов для этого поста.
Be amazed. Stay cool.
#fun #OS
#опытным
Ну что. Пора раскрывать карты.
Правильных ответов здесь несколько(не зря был квиз с множественным ответом) и все зависит от версии компилятора и опций компиляции. Интереснее всего смотреть, что получится при использовании например gcc9 без опций.
А получится вот что. Программа успешно скомпилируется и на консоли появится сообщение:
You are the best!
Да, да. Это она про вас, наши подписчики.
Дело вот в чем. Есть такой варнинг в gcc: warning: 'main' is usually a function [-Wmain].
Погодите, main "обычно" является функцией. Это что, может быть не так?
В С нет или не было прям жесткого требования на тип символа main. Он в целом может быть и массивом:
char main[10];
хоть указателем на функцию:
void (main)();
И вот здесь начинается пространство для экспериментов. Адрес main - это место, с которого код начинается исполняться. Если мы каким-то образом запихаем инструкции ассемблера в массив, то мы сможем выполнить код в такой программе!
Ну а дальше дело техники. Пишем прокси программу:
void main() {
__asm__ (
// print You are the best!
"movl $1, %eax;\n" /* 1 is the syscall number for write */
"movl $1, %ebx;\n" /* 1 is stdout and is the first argument */
// "movl $message, %esi;\n" /* load the address of string into the second argument*/
// instead use this to load the address of the string
// as 16 bytes from the current instruction
"leal 16(%eip), %esi;\n"
"movl $18, %edx;\n" /* third argument is the length of the string to print*/
"syscall;\n"
// call exit (so it doesn't try to run the string Hello World
// maybe I could have just used ret instead
"movl $60,%eax;\n"
"xorl %ebx,%ebx; \n"
"syscall;\n"
// Store the You are the best! inside the main function
"message: .ascii \"You are the best!\\n\";"
);
}Компилируем ее и запускаем gdb для дизассемблирования main:
(gdb) disass main
Dump of assembler code for function main:
0x0000000000001129 <+0>: endbr64
0x000000000000112d <+4>: push %rbp
0x000000000000112e <+5>: mov %rsp,%rbp
0x0000000000001131 <+8>: mov $0x1,%eax
0x0000000000001136 <+13>: mov $0x1,%ebx
0x000000000000113b <+18>: lea 0x10(%eip),%esi # 0x1152 <main+41>
0x0000000000001142 <+25>: mov $0x12,%edx
0x0000000000001147 <+30>: syscall
0x0000000000001149 <+32>: mov $0x3c,%eax
0x000000000000114e <+37>: xor %ebx,%ebx
0x0000000000001150 <+39>: syscall
0x0000000000001152 <+41>: pop %rcx
0x0000000000001153 <+42>: outsl %ds:(%rsi),(%dx)
0x0000000000001154 <+43>: jne 0x1176 <__libc_csu_init+6>
...
Ну и пожалуйста. Слева четко видим шестнадцатиричные числа, которые и представляют собой тело функции main.
Единственное, что осталось - вывести эти числа в десятиричной форме по 4 байта, как инты:
(gdb) x/16dw main
0x1129 <main>: -98693133 -443987883 440 113408
0x1139 <main+16>: -1922629632 4149 1227264 84869120
0x1149 <main+32>: 15544 266023168 1970231557 1701994784
0x1159 <main+48>: 1701344288 1936024096 -1878384268 258392925
Делаем из этих чиселок массив и готово! Закодированная программа будет выполняться.
В более новых версиях компиляторов эту лавочку прикрыли, потому что на gcc10 и более такая прога сегфолтится.
Но в любом случае, очень прикольно, что есть такая возможность.
Можете поиграться с кодом на годболте. Также можно почитать статью, в которой автор подробно расписал историю исследования возможности так писать код.
Благодарю @PyXiion за предоставление материалов для этого поста.
Be amazed. Stay cool.
#fun #OS
{kind=link}
❤🔥55🤯20🔥11❤8👍6
or and not
#новичкам
В С/C++ всегда был не очень дружелюбный синтаксис операторов. Показать вот такой код человеку, который не в зуб ногой в программировании:
есть вероятность, что он подумает, что его прокляли шаманы тумба-юмба.
Однако знали ли вы, что в С/C++ есть альтернативный синтаксис токенов? Символы операторов заменяются на короткие слова и код выше становится почти питонячьим:
Выглядит свежо! Хотя было доступно еще с С++98.
Вот полный список альтернативных токенов:
Последние токены для скобок - это конечно дичь. Но остальные - вполне интересные варианты.
В сях альтернативные токены были введены в С95, поэтому до этого момента токенов не было в языке. Но даже с их введением все продолжали использовать привычный синтаксис. Видимо поэтому мы так до сих пор и остались на уровне наскальной живописи.
А вы используете в продакшен коде альтернативные токены?
Evolve. Stay cool.
#fun #goodoldc
#новичкам
В С/C++ всегда был не очень дружелюбный синтаксис операторов. Показать вот такой код человеку, который не в зуб ногой в программировании:
if (x > 0 && y < 10 || !z) {
// ...
}есть вероятность, что он подумает, что его прокляли шаманы тумба-юмба.
Однако знали ли вы, что в С/C++ есть альтернативный синтаксис токенов? Символы операторов заменяются на короткие слова и код выше становится почти питонячьим:
if (x > 0 and y < 10 or not z) {
// ...
}Выглядит свежо! Хотя было доступно еще с С++98.
Вот полный список альтернативных токенов:
&& - and
&= - and_eq
& - bitand
| - bitor
~ - compl
!= - not_eq
|| - or
|= - or_eq
^ - xor
^= - xor_eq
{ - <%
} - %>
[ - <:
] - :>
# - %:
## - %:%:
Последние токены для скобок - это конечно дичь. Но остальные - вполне интересные варианты.
В сях альтернативные токены были введены в С95, поэтому до этого момента токенов не было в языке. Но даже с их введением все продолжали использовать привычный синтаксис. Видимо поэтому мы так до сих пор и остались на уровне наскальной живописи.
А вы используете в продакшен коде альтернативные токены?
Evolve. Stay cool.
#fun #goodoldc
{kind=link}
❤40👍11🔥8😱5👎3
Гайзенбаг
#новичкам
Человечеству свойственно все категоризировать и обзывать особенными именами. И конкретные виды багов не исключение.
Интересно, что многие из этих названий не соответствуют реальному явлению. Например, закон Стиглера, который не был открыт Стиглером и тд.
И Гайзенбаг примерно из той же серии.
Создатель впервые употребил этот термин в значении «ты смотришь на него — и он исчезает». Видимо он находил параллели с принципом неопределенности Гейзенберга, который говорит о том, что мы не можем одинаково хорошо измерить две любые характеристики частицы(например скорость и положение). Простыми словами: «чем более пристально вы глядите на один предмет, тем меньше внимания вы уделяете чему-то ещё».
Корректность параллелей вызывает большие сомнения.
Но это все лирика.
Что такой гейзенбаг?
На проде или в CI обнаружили багу. А она, собака, исчезает, как только мы пытаемся ее задетектировать, чтобы исправить.
Гайзенбаги возникают потому, что обычные попытки отладки программы, такие как добавление операторов вывода или запуск под отладчиком, обычно имеют побочный эффект — они изменяют поведение программы незаметными способами.
Например.
Один из распространенных примеров гейзенбага — ошибка, которая проявляется при компиляции программы с оптимизацией, но не проявляется при компиляции той же программы без оптимизации (что часто делается для исследования под отладчиком). При отладке значения, которые оптимизированная программа обычно хранит в регистрах, часто выталкиваются в основную память, что может изменить поведение программы. Да и даже просто компилятор может выкинуть кусок кода под оптимизациями, а под дебажной сборкой - оставить его.
Последнее может произойти не только с дебажной сборкой. Например, бесконечный цикл без сайдэффектов - это UB в С++, поэтому компилятор может его выкинуть. А если вы туда вставите принт, то сайдэффект появится и код попадет в бинарь.
Попытка отследить состояние программы может повлиять на тайминги исполнения, что может привести к видимому сокрытию состояния гонки и соответственно пропаже баги. И конкурентный код часто просто пронизан такими багами. В более привычном словаре их называют плавающими ошибками или спорадиками. В общем случае, это результат race condition, а конкретную причину можно находить долго и больно.
Люди часто винят в появление Гейзенбагов фазы Луны и космические лучи. Это конечно шутки, но подобное нельзя исключать.
Все же лучше качественно тестировать свое ПО, тогда тараканов в коде станет намного меньше.
Don't disappear. Stay cool
#fun
#новичкам
Человечеству свойственно все категоризировать и обзывать особенными именами. И конкретные виды багов не исключение.
Интересно, что многие из этих названий не соответствуют реальному явлению. Например, закон Стиглера, который не был открыт Стиглером и тд.
И Гайзенбаг примерно из той же серии.
Создатель впервые употребил этот термин в значении «ты смотришь на него — и он исчезает». Видимо он находил параллели с принципом неопределенности Гейзенберга, который говорит о том, что мы не можем одинаково хорошо измерить две любые характеристики частицы(например скорость и положение). Простыми словами: «чем более пристально вы глядите на один предмет, тем меньше внимания вы уделяете чему-то ещё».
Корректность параллелей вызывает большие сомнения.
Но это все лирика.
Что такой гейзенбаг?
На проде или в CI обнаружили багу. А она, собака, исчезает, как только мы пытаемся ее задетектировать, чтобы исправить.
Гайзенбаги возникают потому, что обычные попытки отладки программы, такие как добавление операторов вывода или запуск под отладчиком, обычно имеют побочный эффект — они изменяют поведение программы незаметными способами.
Например.
Один из распространенных примеров гейзенбага — ошибка, которая проявляется при компиляции программы с оптимизацией, но не проявляется при компиляции той же программы без оптимизации (что часто делается для исследования под отладчиком). При отладке значения, которые оптимизированная программа обычно хранит в регистрах, часто выталкиваются в основную память, что может изменить поведение программы. Да и даже просто компилятор может выкинуть кусок кода под оптимизациями, а под дебажной сборкой - оставить его.
Последнее может произойти не только с дебажной сборкой. Например, бесконечный цикл без сайдэффектов - это UB в С++, поэтому компилятор может его выкинуть. А если вы туда вставите принт, то сайдэффект появится и код попадет в бинарь.
Попытка отследить состояние программы может повлиять на тайминги исполнения, что может привести к видимому сокрытию состояния гонки и соответственно пропаже баги. И конкурентный код часто просто пронизан такими багами. В более привычном словаре их называют плавающими ошибками или спорадиками. В общем случае, это результат race condition, а конкретную причину можно находить долго и больно.
Люди часто винят в появление Гейзенбагов фазы Луны и космические лучи. Это конечно шутки, но подобное нельзя исключать.
Все же лучше качественно тестировать свое ПО, тогда тараканов в коде станет намного меньше.
Don't disappear. Stay cool
#fun
{kind=link}
❤21👍10🔥5😁5
Еще несколько именных багов
Мистер Хайзенберг не единственный, кто удостоялся чести дать свое имя багу. Сегодня расслабимся и покекаем, как нёрды ошибки называли.
🤓Борбаг(Bohrbug) — ошибка, которая, в противоположность гейзенбагу, не исчезает и не меняет своих свойств при попытке её обнаружения, аналогично стабильности модели электронных орбиталей Нильса Бора. Всегда воспроизводится при определенных условиях. Образцово-показательный баг. Не требует сил на воспроизведение.
🫠Мандельбаг(Mandelbug) — баг, названный в честь "отца" фрактальной математики Мендельброта. Типа эти баги очень сложные, непредсказуемые, вызваны нюансами взамодействия множества компонент программ и часто зависят от начальных условий. И этими характеристиками они похожи на фракталы. Есть конечно вопросики к неймингу, ну да ладно.
Такие баги имеют интересное свойство: их можно копать очень долго и в какой-то момент понимаешь, что проще переписать всю систему.
🤡Шрединбаг(Schrödinbug) — баг, существующий в суперпозиции. Код стабильно работает ровно до момента, когда вы читаете его и понимаете, что он не должен работать. После этого код начинает падать именно в этом месте. Сам факт осознания убивает функциональность. Наблюдатель заставляет волновую функцию коллапсировать в баг.
🤯Гинденбаг (Hindenbug) — катастрофический отказ. Не просто ломает функциональность, а делает это с огнем и спецэффектами. Назван в честь печально известного дирижабля "Гиндербург".
В современном мире докеров и кубернетисов Гинденбаги практически невозможны, потому что все приложения изолированы от исполняющей машины.
🧐Багсон Хиггса(Higgs-bugson) — теоретически предсказанный баг. Его существование доказано логами и пользовательскими reports, но воспроизвести в контролируемых условиях невозможно. Все знают, что он есть, но никто его не видел.
К этим багам можно отнести например UB, которое только в теории UB, а в реальности на конкретной архитектуре все нормально работает.
Give a proper name. Stay cool.
#fun
Мистер Хайзенберг не единственный, кто удостоялся чести дать свое имя багу. Сегодня расслабимся и покекаем, как нёрды ошибки называли.
🤓Борбаг(Bohrbug) — ошибка, которая, в противоположность гейзенбагу, не исчезает и не меняет своих свойств при попытке её обнаружения, аналогично стабильности модели электронных орбиталей Нильса Бора. Всегда воспроизводится при определенных условиях. Образцово-показательный баг. Не требует сил на воспроизведение.
🫠Мандельбаг(Mandelbug) — баг, названный в честь "отца" фрактальной математики Мендельброта. Типа эти баги очень сложные, непредсказуемые, вызваны нюансами взамодействия множества компонент программ и часто зависят от начальных условий. И этими характеристиками они похожи на фракталы. Есть конечно вопросики к неймингу, ну да ладно.
Такие баги имеют интересное свойство: их можно копать очень долго и в какой-то момент понимаешь, что проще переписать всю систему.
🤡Шрединбаг(Schrödinbug) — баг, существующий в суперпозиции. Код стабильно работает ровно до момента, когда вы читаете его и понимаете, что он не должен работать. После этого код начинает падать именно в этом месте. Сам факт осознания убивает функциональность. Наблюдатель заставляет волновую функцию коллапсировать в баг.
🤯Гинденбаг (Hindenbug) — катастрофический отказ. Не просто ломает функциональность, а делает это с огнем и спецэффектами. Назван в честь печально известного дирижабля "Гиндербург".
В современном мире докеров и кубернетисов Гинденбаги практически невозможны, потому что все приложения изолированы от исполняющей машины.
🧐Багсон Хиггса(Higgs-bugson) — теоретически предсказанный баг. Его существование доказано логами и пользовательскими reports, но воспроизвести в контролируемых условиях невозможно. Все знают, что он есть, но никто его не видел.
К этим багам можно отнести например UB, которое только в теории UB, а в реальности на конкретной архитектуре все нормально работает.
Give a proper name. Stay cool.
#fun
{kind=link}
❤24👍10😁9🔥8
enum struct
#опытным
В прошлом посте мы рассказали про enum class. И в 99.999% случаев эту сущность будут писать в коде именно, как enum class.
Но можно написать enum struct и это тоже будет работать!
Немного кто знает вообще о существовании такой конструкции. Свойства enum struct абсолютно аналогичны enum class и структуры перечислений были введены просто для консистентности и поддержания паритета в возможности использования двух ключевых слов.
Вот такой короткий и бесполезный факт из мира плюсов)
Be useful. Stay cool.
#fun #cpp11
#опытным
В прошлом посте мы рассказали про enum class. И в 99.999% случаев эту сущность будут писать в коде именно, как enum class.
Но можно написать enum struct и это тоже будет работать!
enum class FileMode { Read, Write, Append };
enum struct LogLevel { Debug, Info, Warning, Error };
int main() {
FileMode mode = FileMode::Read;
LogLevel level = LogLevel::Info;
std::cout << (mode == FileMode::Read) << std::endl;
std::cout << (level == LogLevel::Info) << std::endl;
}Немного кто знает вообще о существовании такой конструкции. Свойства enum struct абсолютно аналогичны enum class и структуры перечислений были введены просто для консистентности и поддержания паритета в возможности использования двух ключевых слов.
Вот такой короткий и бесполезный факт из мира плюсов)
Be useful. Stay cool.
#fun #cpp11
{kind=link}
2👍38😁24❤9🔥7🤣5
Как запустить cpp файл из консоли?
Да, да, именно запустить файл. Берете bash, берете файл. Как одно воткнуть в другое и получить результат работы программы?
Следите за пальцами:
Есть ли мы попытаемся запустить файл с этим содержимым через терминал, то будет выполняться следующая последовательность шагов:
1️⃣ Ядро смотрит на первые 2 байта файла и пытается найти там шебанг -
2️⃣ Если шебанга нет и файл не является исполняемым(как у нас), то файл считается shell-скриптом и исполняется с помощью текущего командного интерпретатора.
3️⃣ Для shell-скриптов символ # обозначает начало однострочного комментария, поэтому первая строчка игнорируется.
4️⃣ Интерпретатор встречает команду компиляции и выполняет ее.
5️⃣ Теперь мы пытаемся реально скомпилировать этот файл с помощью g++. На этапе препроцессинга ветка условия
6️⃣ После компиляции интерпретатор запускает исполняемый файл и завершает работу на инструкции
Напишите в терминале
И увидите заветные слова.
Дожили! Превратили С++ в питон...
PS: Большое спасибо за идею и материалы Даниилу @dkay7.
Have a fun. Stay cool.
#fun
Да, да, именно запустить файл. Берете bash, берете файл. Как одно воткнуть в другое и получить результат работы программы?
Следите за пальцами:
#if 0
g++ test.cpp -o test && ./test
exit 0
#endif
#include <iostream>
int main() {
std::cout << "Hello, World!" << std::endl;
}
Есть ли мы попытаемся запустить файл с этим содержимым через терминал, то будет выполняться следующая последовательность шагов:
1️⃣ Ядро смотрит на первые 2 байта файла и пытается найти там шебанг -
#!. Если нашла, то в этой строчке будет указан путь до нужного интерпретатора.2️⃣ Если шебанга нет и файл не является исполняемым(как у нас), то файл считается shell-скриптом и исполняется с помощью текущего командного интерпретатора.
3️⃣ Для shell-скриптов символ # обозначает начало однострочного комментария, поэтому первая строчка игнорируется.
4️⃣ Интерпретатор встречает команду компиляции и выполняет ее.
5️⃣ Теперь мы пытаемся реально скомпилировать этот файл с помощью g++. На этапе препроцессинга ветка условия
#if 0 выбросится из текста файла и компилироваться будет только реально С++ код.6️⃣ После компиляции интерпретатор запускает исполняемый файл и завершает работу на инструкции
exit 0. Остальной С++ код он уже не увидит.Напишите в терминале
chmod +x test.cpp
./test.cpp
И увидите заветные слова.
Дожили! Превратили С++ в питон...
PS: Большое спасибо за идею и материалы Даниилу @dkay7.
Have a fun. Stay cool.
#fun
10❤58🔥21👍18😁14🤯12👀3🗿3🐳1
Праздник Баг к нам приходит
Врываемся в новый год с поучительных историй.
На дворе 31 декабря 2к21 года. В России все нарезают салаты, готовятся веселиться и еще не знают, какой год их ждет впереди. На западе тоже все еще празднуют, хотя Рождество уже позади.
В первые минуты января сверкает салют, хлопаются хлопушки, шампанское переливается через края бокалов и перестает доставляться вся электронная почта, за обработку и доставку которой отвечал Microsoft Exchange Server.
Вот так в одну секунду по всему миру куча организаций перестала получать свою почту. В журнале событий сервера можно было найти такую запись: «Процесс сканирования FIP-FS Scan Process не прошел инициализацию. Ошибка: 0x8004005. Подробности ошибки: «Неопределенная ошибка» или «Код ошибки: 0x80004005». Описание ошибки: «Не удается преобразовать "2201010001" в длинное число».
Оказывается, что Exchange сохранял в журнале проверок антивируса даты в виде int32. Максимальным значением может быть 2147483647. У числа может быть всего 10 десятичных разрядов: первые 2 числа - последние 2 цифры года, дальше month/day/time. Для 2021 все было ок. Но чтобы представить первую секунду 2022 года нужно число 2201010001. А это уже перебор. Конвертация навернулась и полетели ошибки.
Эту проблему тогда обозвали Y2K22 bug, по аналогии с багом 2000 года(Y2K). В 20-м веке люди тоже часто обрабатывали только последние 2 цифры даты и в момент миллениума года сбрасывались просто до нуля.
Стоит ли говорить, что малварьный модель FIP-FS был скорее всего написан на С/C++?
Но не в этом дело. Если какой-то программист решил применить свою уникальную оптимизацию и не подумал чуть наперед, то здесь любым языком можно пакостей.
Вообще, ошибки связаные с переходом на новый год, не так уж и редки. У меня на проекте тоже был такой баг. Так что будьте внимательны при работе со временем. Хардкод и обрезание дат играют злую шутку.
А вы сталкивались с подобными ошибками? Расскажите в комментах.
Celebrate the holiday. Stay cool.
#fun
Врываемся в новый год с поучительных историй.
На дворе 31 декабря 2к21 года. В России все нарезают салаты, готовятся веселиться и еще не знают, какой год их ждет впереди. На западе тоже все еще празднуют, хотя Рождество уже позади.
В первые минуты января сверкает салют, хлопаются хлопушки, шампанское переливается через края бокалов и перестает доставляться вся электронная почта, за обработку и доставку которой отвечал Microsoft Exchange Server.
Вот так в одну секунду по всему миру куча организаций перестала получать свою почту. В журнале событий сервера можно было найти такую запись: «Процесс сканирования FIP-FS Scan Process не прошел инициализацию. Ошибка: 0x8004005. Подробности ошибки: «Неопределенная ошибка» или «Код ошибки: 0x80004005». Описание ошибки: «Не удается преобразовать "2201010001" в длинное число».
Оказывается, что Exchange сохранял в журнале проверок антивируса даты в виде int32. Максимальным значением может быть 2147483647. У числа может быть всего 10 десятичных разрядов: первые 2 числа - последние 2 цифры года, дальше month/day/time. Для 2021 все было ок. Но чтобы представить первую секунду 2022 года нужно число 2201010001. А это уже перебор. Конвертация навернулась и полетели ошибки.
Эту проблему тогда обозвали Y2K22 bug, по аналогии с багом 2000 года(Y2K). В 20-м веке люди тоже часто обрабатывали только последние 2 цифры даты и в момент миллениума года сбрасывались просто до нуля.
Стоит ли говорить, что малварьный модель FIP-FS был скорее всего написан на С/C++?
Но не в этом дело. Если какой-то программист решил применить свою уникальную оптимизацию и не подумал чуть наперед, то здесь любым языком можно пакостей.
Вообще, ошибки связаные с переходом на новый год, не так уж и редки. У меня на проекте тоже был такой баг. Так что будьте внимательны при работе со временем. Хардкод и обрезание дат играют злую шутку.
А вы сталкивались с подобными ошибками? Расскажите в комментах.
Celebrate the holiday. Stay cool.
#fun
{kind=link}
👍23❤10🔥6😁4🫡3
Привычно возводим в степень
Спасибо, @Ivaneo, за любезно предоставленную идею для поста.
Как же бесило в универе, что в С/С++ нет нормального оператора возведения в степень, приходится использовать библиотечную std::pow. В других же языках такое есть. Например в питоне и рубях это оператор
В С++ мы такого в общем виде получить, к сожалению, не можем. Но можем сделать даже лучше в очень определенном сценарии.
И в этом нам помогут пользовательские литералы. Смотрите сами:
Берем уникод символ двойки верхнего регистра и делаем его суффикстом пользовательского литерала. И получаем почти привычную работающую версию возведения в квадрат! Это конечно не совсем стандарт, но на основных компиляторах работает.
А если еще и суффикс убрать:
То будет вообще огонь! Прям как в школе учили.
Да, суффиксы без андерскора запрещено использовать, так как они зарезервированы для стандарта. Но тем не менее это работает с варнингами на gcc и msvc, но уже не собирается на кланге.
Забавный примерчик. Жаль, что это может работать только для литералов и не распространяется на все переменные.
Provide better solutions. Stay cool.
#fun
Спасибо, @Ivaneo, за любезно предоставленную идею для поста.
Как же бесило в универе, что в С/С++ нет нормального оператора возведения в степень, приходится использовать библиотечную std::pow. В других же языках такое есть. Например в питоне и рубях это оператор
**(2 ** 3), а в Lua и Julia - оператор ^(2 ^ 3).В С++ мы такого в общем виде получить, к сожалению, не можем. Но можем сделать даже лучше в очень определенном сценарии.
И в этом нам помогут пользовательские литералы. Смотрите сами:
long double operator ""_²(long double d)
{
return d * d;
}
int main()
{
auto d = 2.0_²;
std::cout << d << "\n";
}
// OUTPUT:
// 4
Берем уникод символ двойки верхнего регистра и делаем его суффикстом пользовательского литерала. И получаем почти привычную работающую версию возведения в квадрат! Это конечно не совсем стандарт, но на основных компиляторах работает.
А если еще и суффикс убрать:
long double operator ""²(long double d)
{
return d * d;
}
int main()
{
auto d = 2.0²;
std::cout << d << "\n";
}
То будет вообще огонь! Прям как в школе учили.
Да, суффиксы без андерскора запрещено использовать, так как они зарезервированы для стандарта. Но тем не менее это работает с варнингами на gcc и msvc, но уже не собирается на кланге.
Забавный примерчик. Жаль, что это может работать только для литералов и не распространяется на все переменные.
Provide better solutions. Stay cool.
#fun
❤24🤣22👍12🔥6😁3🤯1🗿1