
Почему не нужно указывать размер освобождаемого блока для free()
Второй пост в формате телеграф статьи. Поговорим о том, как так вышло, что не нужно указывать размер освобождаемой памяти для функции free. Поговорим про API, отправимся в прошлое на 40 лет назад и представим, как принималось это решение.
Понимаю, что формат лонгридов подходит не всем в нашем hectic lifestyle мире. Но тема реально интересная, особенно, если вы никогда об этом не задумывались.
Накидайте реакций на этот пост, если вам нравится такой формат, чтобы я понимал, что это востребовано в нашем маленьком(пока что) коммьюнити.
Ссылочка на статью: https://telegra.ph/Pochemu-ne-nuzhno-ukazyvat-razmer-osvobozhdaemogo-bloka-dlya-free-12-07
Stay cool.
#hardcore #OS #memory #howitworks
Второй пост в формате телеграф статьи. Поговорим о том, как так вышло, что не нужно указывать размер освобождаемой памяти для функции free. Поговорим про API, отправимся в прошлое на 40 лет назад и представим, как принималось это решение.
Понимаю, что формат лонгридов подходит не всем в нашем hectic lifestyle мире. Но тема реально интересная, особенно, если вы никогда об этом не задумывались.
Накидайте реакций на этот пост, если вам нравится такой формат, чтобы я понимал, что это востребовано в нашем маленьком(пока что) коммьюнити.
Ссылочка на статью: https://telegra.ph/Pochemu-ne-nuzhno-ukazyvat-razmer-osvobozhdaemogo-bloka-dlya-free-12-07
Stay cool.
#hardcore #OS #memory #howitworks
Telegraph
Почему не нужно указывать размер освобождаемого блока для free()
Мы уже знаем, почему стандартный сишный аллокатор при удалении не просит указывать количество освобождаемых байт. Это более подробно раскрывается тут и тут. Вопрос скорее в другом. Почему вообще malloc+free было создано таким образом. Поскольку C - это язык…
Продолжение про вызов метода через указатель
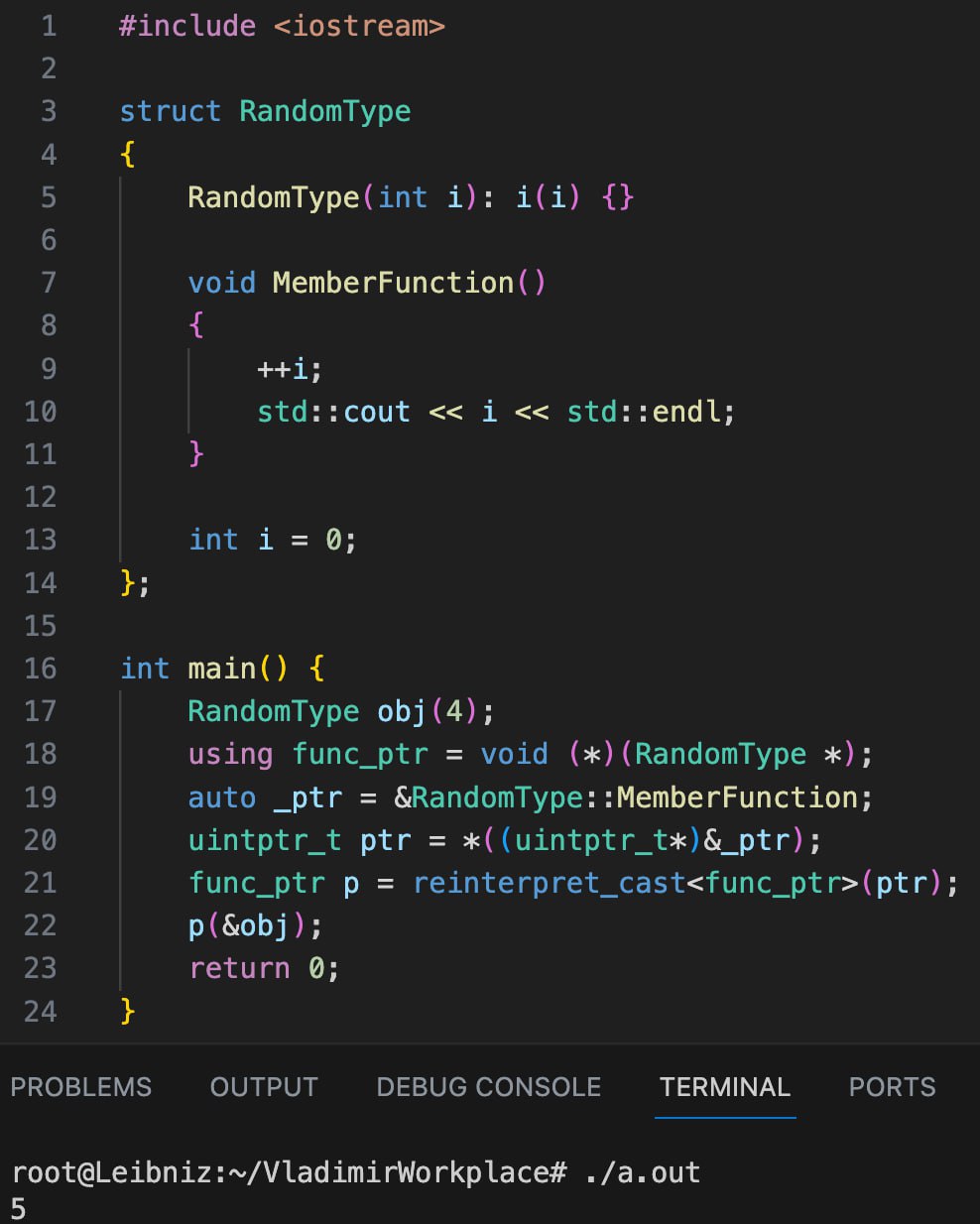
В прошлом мы выяснили, как можно вызвать нестатический метод класса через указатель. Пост с кодом находится здесь. Для удобства, прикреплю его и к сюда. Сегодня мы попробуем разобраться, почему код такой и он еще и рабочий? Пойдем по порядку. Совсем тривиальные вещи затрагиваться не будут, будут только важные в контексте объяснения.
18 строка - Объявляется синоним к типу указателя на функцию, которая ничего не возвращает и принимает указатель на тип RandomType. Позже будет понятно, зачем это нужно.
19 строка - Есть 2 возможных синтаксиса для получения указателя на функцию: с амперсантом(сюрприз, кто не знал) и без. Без амперсанта не работает, потому такой синтаксис уже используется для вызова статических методов и будет путаница. Итак, мы получили какого-то неизвестного нам типа указатель на функцию. Идем дальше.
20 строка - Это трюк, который позволяет превратить указатель на функцию в указатель на число. Это необходимо для того, чтобы скастовать указатель _ptr из 19 строки к указателю на функцию типа func_ptr. Такого рода касты очень опасные и ведут к неопределенному поведению. Поэтому компиляторы просто их запрещают. Поэтому и нужно какое-то прокси состояние. Только компиляторы также запрещают кастовать указатель на функцию к указателю на число. Поэтому в ход идет наращивание индирекции указателя.
Мы можем посмотреть не на сам указатель, а на ячейку памяти, которая хранит наш указатель. И сказать, что по этому адресу лежит не указатель на функцию, а указатель на число. Вот так сделать можно. А потом кастуем указатель на число к указателю на функцию. Так тоже можно сделать.
И, наконец, важнейший пункт. Помните в книжках всегда говорили, что в методы скрытно передается указатель на вызывающий его объект this? Так вот сейчас вам скорее всего впервые понадобится это знание на практике!
Методы неполиморфных классов - те же самые обычные функции(кто не знал). От остальных их отличает лишь этот параметр this, который скрытно передается первым аргументом. Именно поэтому, чтобы вызвать нестатический метод, нам нужен объект. Чтобы передать его первым параметром в функцию. Иначе вызов будет не соответствовать сигнатуре.
Поэтому мы берем созданный на стеке объект, находим адрес первого байта и передаем его в метод в качестве аргумента.
И вуаля. Все работает. Выводится пятёрочка.
Кто понял, тот понял. Кто не понял - сорян, я сделал, что мог. Но есть хорошая новость - эту задачу можно решить и более щедящим способом, хоть и не таким элегантным с точки зрения важности первого аргумента. В будущем разберем его.
Из этого поста надо вынести главное: ООП - лишь абстракция над более примитивными и низкоуровневыми конструкциями. Уметь оперировать абстракциями - полезнейший навык в нашем мире. Чем более сложные абстракции ты обрабатываешь, тем больше понимаешь мир и эффективнее решаешь задачи. Однако знать те самые кирпичики, на которых строятся сложные конструкции - не менее важная вещь. Только полная картина мира дает полное понимание происходящего.
Конструируй абстракции и погружайся в детали. Stay cool.
#fun #memory #howitworks #cppcore #hardcore
В прошлом мы выяснили, как можно вызвать нестатический метод класса через указатель. Пост с кодом находится здесь. Для удобства, прикреплю его и к сюда. Сегодня мы попробуем разобраться, почему код такой и он еще и рабочий? Пойдем по порядку. Совсем тривиальные вещи затрагиваться не будут, будут только важные в контексте объяснения.
18 строка - Объявляется синоним к типу указателя на функцию, которая ничего не возвращает и принимает указатель на тип RandomType. Позже будет понятно, зачем это нужно.
19 строка - Есть 2 возможных синтаксиса для получения указателя на функцию: с амперсантом(сюрприз, кто не знал) и без. Без амперсанта не работает, потому такой синтаксис уже используется для вызова статических методов и будет путаница. Итак, мы получили какого-то неизвестного нам типа указатель на функцию. Идем дальше.
20 строка - Это трюк, который позволяет превратить указатель на функцию в указатель на число. Это необходимо для того, чтобы скастовать указатель _ptr из 19 строки к указателю на функцию типа func_ptr. Такого рода касты очень опасные и ведут к неопределенному поведению. Поэтому компиляторы просто их запрещают. Поэтому и нужно какое-то прокси состояние. Только компиляторы также запрещают кастовать указатель на функцию к указателю на число. Поэтому в ход идет наращивание индирекции указателя.
Мы можем посмотреть не на сам указатель, а на ячейку памяти, которая хранит наш указатель. И сказать, что по этому адресу лежит не указатель на функцию, а указатель на число. Вот так сделать можно. А потом кастуем указатель на число к указателю на функцию. Так тоже можно сделать.
И, наконец, важнейший пункт. Помните в книжках всегда говорили, что в методы скрытно передается указатель на вызывающий его объект this? Так вот сейчас вам скорее всего впервые понадобится это знание на практике!
Методы неполиморфных классов - те же самые обычные функции(кто не знал). От остальных их отличает лишь этот параметр this, который скрытно передается первым аргументом. Именно поэтому, чтобы вызвать нестатический метод, нам нужен объект. Чтобы передать его первым параметром в функцию. Иначе вызов будет не соответствовать сигнатуре.
Поэтому мы берем созданный на стеке объект, находим адрес первого байта и передаем его в метод в качестве аргумента.
И вуаля. Все работает. Выводится пятёрочка.
Кто понял, тот понял. Кто не понял - сорян, я сделал, что мог. Но есть хорошая новость - эту задачу можно решить и более щедящим способом, хоть и не таким элегантным с точки зрения важности первого аргумента. В будущем разберем его.
Из этого поста надо вынести главное: ООП - лишь абстракция над более примитивными и низкоуровневыми конструкциями. Уметь оперировать абстракциями - полезнейший навык в нашем мире. Чем более сложные абстракции ты обрабатываешь, тем больше понимаешь мир и эффективнее решаешь задачи. Однако знать те самые кирпичики, на которых строятся сложные конструкции - не менее важная вещь. Только полная картина мира дает полное понимание происходящего.
Конструируй абстракции и погружайся в детали. Stay cool.
#fun #memory #howitworks #cppcore #hardcore
{kind=link}
Рефлексия
Вам когда-нибудь хотелось получить значение enum'а, который имеет имя, соответствующее определенной строке? Или например во время выполнения на основе данных конфига выбрать подходящий класс для обработки? Или вызвать метод класса с помощью строки, содержащей его имя? Да все это в плюсах можно сделать, но какой ценой. Нужны эти нагромождения условных конструкций, которые смотрятся просто ужасно и от которых глаза вытекают из орбит. Почему нельзя сделать так, чтобы существовала какая-то структура, типа словаря, к которому можно обращаться в рантайме и выбирать произвольный тип, из которого я хочу создать объект?
Ответ прост. Можно. Но не в плюсах)
Эта фича называется рефлексией. То есть это способность программы получать информацию о своей структуре и изменять ее. Простым языком: она позволяет вам вызывать методы объектов, создавать новые объекты, модифицировать их, даже не зная имён интерфейсов, полей, методов во время компиляции. Из-за такой природы рефлексии её труднее реализовать в статически типизированных языках, поскольку ошибки типизации должны быть отловлены во время компиляции, а не исполнения программы, чтобы все работало корректно. И хоть это возможно для байт-код языков, типа жабы и Си за решеткой, но для плюсов это сделать очень трудно. Вы конечно сами где-нибудь можете набросать какой-то код, который будет имитировать рефлексию, но полноценного стандартного решения рантайм рефлексии мы не получить не можем и на это есть несколько причин.
1️⃣ Язык C++ имеет совместимость с языком C и является его логическим приемником. Поэтому он стремится быть эффективным и близким к машинному коду. Полноценная рефлексия встроенная в язык требует дополнительные значительные вычислительные и ресурсные затраты, что может не соответствовать целям C++ для высокой производительности и низкого уровня абстракции. Как говорится, не плати за то, чем не пользуешься(слоган эмбеддед разработчиков по жизни).
2️⃣ Сюрприз: эффективность кода. Компиляторы с++ знамениты тем, что издеваются над нашим кодом во всех непристойных позициях и выдают самый эффективный машинный код. Они могут разворачивать циклы, встраивать функции и даже целые классы. Это все нужно для максимальной скорости и работает только за счет того, что все известно на момент компиляции. Что позволяет избегать накладных расходов и предоставлять предсказуемое поведение(не всегда). А рефлексия может нарушить эту предсказуемость, а значит и производительность.
Тем не менее плюсы медленно, но верно продвигаются в расширении рефлексивной функциональности. Мало того, что шаблонная магия позволяет из коробки делать очень многие вещи, так и в современных стандартах появляются такие штуки, как std::any, std::experimental::source_location и тд. Вряд ли когда-нибудь завезут что-то стандартное, подходящее всем и для любых целей, если за 40 лет этого так и не случилось ни с одной библиотекой или модулем. Но тенденция явно позитивная. А в пропоузале к С++26 есть даже целый раздел, посвященный статической рефлексии. Так что per aspera ad astra.
Stay optimistic. Stay cool.
#howitworks #hardcore
Вам когда-нибудь хотелось получить значение enum'а, который имеет имя, соответствующее определенной строке? Или например во время выполнения на основе данных конфига выбрать подходящий класс для обработки? Или вызвать метод класса с помощью строки, содержащей его имя? Да все это в плюсах можно сделать, но какой ценой. Нужны эти нагромождения условных конструкций, которые смотрятся просто ужасно и от которых глаза вытекают из орбит. Почему нельзя сделать так, чтобы существовала какая-то структура, типа словаря, к которому можно обращаться в рантайме и выбирать произвольный тип, из которого я хочу создать объект?
Ответ прост. Можно. Но не в плюсах)
Эта фича называется рефлексией. То есть это способность программы получать информацию о своей структуре и изменять ее. Простым языком: она позволяет вам вызывать методы объектов, создавать новые объекты, модифицировать их, даже не зная имён интерфейсов, полей, методов во время компиляции. Из-за такой природы рефлексии её труднее реализовать в статически типизированных языках, поскольку ошибки типизации должны быть отловлены во время компиляции, а не исполнения программы, чтобы все работало корректно. И хоть это возможно для байт-код языков, типа жабы и Си за решеткой, но для плюсов это сделать очень трудно. Вы конечно сами где-нибудь можете набросать какой-то код, который будет имитировать рефлексию, но полноценного стандартного решения рантайм рефлексии мы не получить не можем и на это есть несколько причин.
1️⃣ Язык C++ имеет совместимость с языком C и является его логическим приемником. Поэтому он стремится быть эффективным и близким к машинному коду. Полноценная рефлексия встроенная в язык требует дополнительные значительные вычислительные и ресурсные затраты, что может не соответствовать целям C++ для высокой производительности и низкого уровня абстракции. Как говорится, не плати за то, чем не пользуешься(слоган эмбеддед разработчиков по жизни).
2️⃣ Сюрприз: эффективность кода. Компиляторы с++ знамениты тем, что издеваются над нашим кодом во всех непристойных позициях и выдают самый эффективный машинный код. Они могут разворачивать циклы, встраивать функции и даже целые классы. Это все нужно для максимальной скорости и работает только за счет того, что все известно на момент компиляции. Что позволяет избегать накладных расходов и предоставлять предсказуемое поведение(не всегда). А рефлексия может нарушить эту предсказуемость, а значит и производительность.
Тем не менее плюсы медленно, но верно продвигаются в расширении рефлексивной функциональности. Мало того, что шаблонная магия позволяет из коробки делать очень многие вещи, так и в современных стандартах появляются такие штуки, как std::any, std::experimental::source_location и тд. Вряд ли когда-нибудь завезут что-то стандартное, подходящее всем и для любых целей, если за 40 лет этого так и не случилось ни с одной библиотекой или модулем. Но тенденция явно позитивная. А в пропоузале к С++26 есть даже целый раздел, посвященный статической рефлексии. Так что per aspera ad astra.
Stay optimistic. Stay cool.
#howitworks #hardcore
{kind=link}
Базовая формулировка Pimpl Idiom
Пускай у нас есть класс, который выполняет определенную фильтрацию изображения. Для определенности положим, что это фильтр удаления шумов. Для этого нам нужен будет видимый класс NoiseReductionFilter для использования функциональности фильтра, и класс имплементации NoiseReductionFilterImpl, который будет инкапсулировать конкретную реализацию фильтра. Зачем нам вообще нужно такое разделение? Этим классом будет пользоваться потенциально много народу, поэтому мы не хотим раскрывать хоть какие-нибудь детали реализации, чтобы люди не делали своих предположений о реализации и не делали опасных низкоуровневых трюков. Это может навредить нашей интеллектуальной собственности или репутации проекта, если его будут неправильно использовать. Причина немного надутая, но большие проекты просто обязаны заботиться о таких вещах. Окей пишем(осторожно псевдокод):
В чем проблема этого кода? Для начала, мы тут вообще ничего не скрыли. Тип NoiseReductionFilterImpl должен быть определен в момент компиляции и определен он в известном файле NoiseReductionFilterImpl.hpp, к котором все, кому ни попадя имеют доступ. Ни о какой конфиденциальности речи быть не может.
Image processing - очень быстро развивающаяся область. Сейчас все больше проектов переходят с консервативных методов к использованию нейросетей. Поэтому, очевидно, что этот класс тоже будет довольно активно развиваться. А мы хотим поддерживать ABI совместимость с проектами пользователей и не ломать их проекты своими новыми версиями. В данном случае такого не получится сделать, потому что очень большой перечень изменений может сломать ABI и реально поменять реализацию без поломки бинарной совместимости невозможно.
Какое здесь может быть решение проблемы?
Убрать подключение NoiseReductionFilterImpl.hpp и сделать закрытый член класса указателем на тип NoiseReductionFilterImpl. Но раз мы убрали заголовочник с объявлением типа, тогда мы не можем использовать указатель на этот тип. Или можем?
Еще как можем. Есть такое понятие, как forward declaration. Мы можем сказать компилятору, что есть вот такой класс NoiseReductionFilterImpl и мы даём слово, что опишем и определим его, но пока не скажем тебе где. И тогда мы можем объявить приватный член класса, как указатель на NoiseReductionFilterImpl, но никак не использовать его. И нам это сойдет с рук. Компилятор потом сам отыщет определение этого класса и удачно разрезолвит все символы. Сейчас покажу, как это будет выглядеть.
Скажу сразу, этот код нельзя использовать как он есть здесь. Он просто, чтобы показать концепцию, и не использует необходимых фичей новых стандартов. Что здесь происходит. Мы вынесли определение в файл реализации. А значит никто, кроме нас не сможет увидеть или даже намек почуять, как реализована функциональность (не берем в расчет реверс-инженеров). Это будут просто инструкции, которые будут подгружаться во время выполнения кода клиента.
Обычно файл NoiseReductionFilter.hpp не меняется, так как это публичное апи, а указатель на реализацию дает нам возможность вертеть имплементацией как нам хочется.
Но есть и негативные последствия использования идиомы.
Продолжение в комментах…
#cppcore #design #howitworks #memory
Пускай у нас есть класс, который выполняет определенную фильтрацию изображения. Для определенности положим, что это фильтр удаления шумов. Для этого нам нужен будет видимый класс NoiseReductionFilter для использования функциональности фильтра, и класс имплементации NoiseReductionFilterImpl, который будет инкапсулировать конкретную реализацию фильтра. Зачем нам вообще нужно такое разделение? Этим классом будет пользоваться потенциально много народу, поэтому мы не хотим раскрывать хоть какие-нибудь детали реализации, чтобы люди не делали своих предположений о реализации и не делали опасных низкоуровневых трюков. Это может навредить нашей интеллектуальной собственности или репутации проекта, если его будут неправильно использовать. Причина немного надутая, но большие проекты просто обязаны заботиться о таких вещах. Окей пишем(осторожно псевдокод):
// NoiseReductionFilter.hpp
#include "NoiseReductionFilterImpl.hpp"
struct NoiseReductionFilter {
Filter();
private:
NoiseReductionFilterImpl impl;
};
// NoiseReductionFilter.cpp
NoiseReductionFilter::Filter() {
impl.FilterImpl();
}
В чем проблема этого кода? Для начала, мы тут вообще ничего не скрыли. Тип NoiseReductionFilterImpl должен быть определен в момент компиляции и определен он в известном файле NoiseReductionFilterImpl.hpp, к котором все, кому ни попадя имеют доступ. Ни о какой конфиденциальности речи быть не может.
Image processing - очень быстро развивающаяся область. Сейчас все больше проектов переходят с консервативных методов к использованию нейросетей. Поэтому, очевидно, что этот класс тоже будет довольно активно развиваться. А мы хотим поддерживать ABI совместимость с проектами пользователей и не ломать их проекты своими новыми версиями. В данном случае такого не получится сделать, потому что очень большой перечень изменений может сломать ABI и реально поменять реализацию без поломки бинарной совместимости невозможно.
Какое здесь может быть решение проблемы?
Убрать подключение NoiseReductionFilterImpl.hpp и сделать закрытый член класса указателем на тип NoiseReductionFilterImpl. Но раз мы убрали заголовочник с объявлением типа, тогда мы не можем использовать указатель на этот тип. Или можем?
Еще как можем. Есть такое понятие, как forward declaration. Мы можем сказать компилятору, что есть вот такой класс NoiseReductionFilterImpl и мы даём слово, что опишем и определим его, но пока не скажем тебе где. И тогда мы можем объявить приватный член класса, как указатель на NoiseReductionFilterImpl, но никак не использовать его. И нам это сойдет с рук. Компилятор потом сам отыщет определение этого класса и удачно разрезолвит все символы. Сейчас покажу, как это будет выглядеть.
// NoiseReductionFilter.hpp
struct NoiseReductionFilter {
Filter();
private:
struct NoiseReductionFilterImpl; // forward declaration
NoiseReductionFilterImpl * impl;
};
// NoiseReductionFilter.cpp
struct NoiseReductionFilter::NoiseReductionFilterImpl {
// implement functionality
};
NoiseReductionFilter::NoiseReductionFilter() : impl (new NoiseReductionFilter::NoiseReductionFilterImpl){}
NoiseReductionFilter::~NoiseReductionFilter() {
delete impl;
impl = nullptr;
}
void NoiseReductionFilter::filter() {
impl->FilterImpl();
}
Скажу сразу, этот код нельзя использовать как он есть здесь. Он просто, чтобы показать концепцию, и не использует необходимых фичей новых стандартов. Что здесь происходит. Мы вынесли определение в файл реализации. А значит никто, кроме нас не сможет увидеть или даже намек почуять, как реализована функциональность (не берем в расчет реверс-инженеров). Это будут просто инструкции, которые будут подгружаться во время выполнения кода клиента.
Обычно файл NoiseReductionFilter.hpp не меняется, так как это публичное апи, а указатель на реализацию дает нам возможность вертеть имплементацией как нам хочется.
Но есть и негативные последствия использования идиомы.
Продолжение в комментах…
#cppcore #design #howitworks #memory
{kind=link}
Реальное предназначение inline
В этом посте мы говорили о том, почему встраивание функций - важная задача для перформанса приложения. И что ключевое слово inline изначально предназначалось для того, чтобы указывать компилятору, какую функцию ему нужно встроить. Но программы уже давно намного умнее людей в очень специфических задачах. И компилятор стал настолько умным, что он теперь без нашего прямого указания может самостоятельно встраивать функции, которые даже не помечены inline. А также имеет полное право игнорировать наши прямые указания на встраивание. В случае прямого указания он обязан выполнить проверку возможности встраивания, но при оптимизациях компилятор и так это делает.
Но тогда смысл ключевого слова inline несколько теряется в тумане. Все равно все используют оптимизации в продакшене. Тогда есть ли реальная польза от использования inline?
Есть! Сейчас все разберем.
В чем прикол. Прикол в том, что для того, чтобы компилятор смог встроить функцию, ее определение ОБЯЗАНО быть видно в той единице трансляции, в которой она используется. Именно на этапе компиляции. Как можно встроить код, которого нет сейчас в доступе?
Почему это нельзя сделать на этапе линковки? Линкер резолвит проблему символов. Он сопоставляет имена с их содержимым. Линкер от слова link - связка. Для встраивания функции нужно иметь доступ к ее исходникам и информации вокруг вызова функции. Такого доступа у линкера нет. Да и задачи кодогенерации у него нет.
Что нужно, чтобы на этапе компиляции, компилятор видел определение функции? Ее можно определить в цппшнике, тогда все будет четко. Но такую функцию нельзя переиспользовать. Она будет тупо скрыта от всех других единиц трансляции. Ее можно было бы переиспользовать. Тогда нужно было бы везде forward declaration вставлять, что очень неудобно. И она видна будет только во время линковки. Во время компиляции ни одна другая единица трансляции ее не увидит. Поэтому нам это не подходит.
Тогда второй способ с потенциальной возможностью переиспользования: вынести определение в хэдер. Тогда всем единицам трансляции, которые подключают хэдер, будет доступно определение нашей функции. Но вот есть проблема - тогда во всех единицах трансляции будет определение нашей функции. А это нарушение ODR.
Как выходить из ситуации? Можно пометить функцию как static. Тогда в каждой единице трансляции будет своя копия функции. Но это ведет к дублированию кода функции и увеличению размера бинарника. Это нам не подходит.
Выходит, что у нас только одно решение. Разрешить inline функциям находиться в хэдерах и не нарушать ODR! Тогда нам нужны некоторые оговорки: мы разрешаем определению одной и той же inline функции быть в разных единицах трансляции, но тогда все эти определения должны быть идентичные. Потому что как бы предполагается, что они все определены в одном месте КОДА. Линкер потом объединяет все определения функции в одно(на самом деле выбирает одно из них, а другие откидывает). И вот у нас уже один экземпляр функции на всю программу.
Что мы имеем по итогу. Если мы хотим поместить определение обычной функции в хэдэр, то нам настучит по башке линкер со своим multiple definition и мы уйдем грустные в закат. Но теперь у нас есть другой вид функций, которые как бы должны быть встроены, но никто этого не гарантирует, и которые можно определять в хэдерах. Такие функции могут быть встроены с той же вероятностью, что и все остальные, поэтому от этой части смысла никакого нет. Получается, что мы можем пометить нашу функцию inline и тогда она ее просто можно будет определять в заголовочниках. Гениально.
Ох и непростая тема! Советую пару раз прочитать этот пост, чтобы хорошо все усвоить. Информация очень глубокая и фундаментальная. Пишите в комментах, что непонятно. И замечания тоже пишите.
Dig deeper. Stay cool.
#cppcore #compiler #hardcore #design #howitworks
В этом посте мы говорили о том, почему встраивание функций - важная задача для перформанса приложения. И что ключевое слово inline изначально предназначалось для того, чтобы указывать компилятору, какую функцию ему нужно встроить. Но программы уже давно намного умнее людей в очень специфических задачах. И компилятор стал настолько умным, что он теперь без нашего прямого указания может самостоятельно встраивать функции, которые даже не помечены inline. А также имеет полное право игнорировать наши прямые указания на встраивание. В случае прямого указания он обязан выполнить проверку возможности встраивания, но при оптимизациях компилятор и так это делает.
Но тогда смысл ключевого слова inline несколько теряется в тумане. Все равно все используют оптимизации в продакшене. Тогда есть ли реальная польза от использования inline?
Есть! Сейчас все разберем.
В чем прикол. Прикол в том, что для того, чтобы компилятор смог встроить функцию, ее определение ОБЯЗАНО быть видно в той единице трансляции, в которой она используется. Именно на этапе компиляции. Как можно встроить код, которого нет сейчас в доступе?
Почему это нельзя сделать на этапе линковки? Линкер резолвит проблему символов. Он сопоставляет имена с их содержимым. Линкер от слова link - связка. Для встраивания функции нужно иметь доступ к ее исходникам и информации вокруг вызова функции. Такого доступа у линкера нет. Да и задачи кодогенерации у него нет.
Что нужно, чтобы на этапе компиляции, компилятор видел определение функции? Ее можно определить в цппшнике, тогда все будет четко. Но такую функцию нельзя переиспользовать. Она будет тупо скрыта от всех других единиц трансляции. Ее можно было бы переиспользовать. Тогда нужно было бы везде forward declaration вставлять, что очень неудобно. И она видна будет только во время линковки. Во время компиляции ни одна другая единица трансляции ее не увидит. Поэтому нам это не подходит.
Тогда второй способ с потенциальной возможностью переиспользования: вынести определение в хэдер. Тогда всем единицам трансляции, которые подключают хэдер, будет доступно определение нашей функции. Но вот есть проблема - тогда во всех единицах трансляции будет определение нашей функции. А это нарушение ODR.
Как выходить из ситуации? Можно пометить функцию как static. Тогда в каждой единице трансляции будет своя копия функции. Но это ведет к дублированию кода функции и увеличению размера бинарника. Это нам не подходит.
Выходит, что у нас только одно решение. Разрешить inline функциям находиться в хэдерах и не нарушать ODR! Тогда нам нужны некоторые оговорки: мы разрешаем определению одной и той же inline функции быть в разных единицах трансляции, но тогда все эти определения должны быть идентичные. Потому что как бы предполагается, что они все определены в одном месте КОДА. Линкер потом объединяет все определения функции в одно(на самом деле выбирает одно из них, а другие откидывает). И вот у нас уже один экземпляр функции на всю программу.
Что мы имеем по итогу. Если мы хотим поместить определение обычной функции в хэдэр, то нам настучит по башке линкер со своим multiple definition и мы уйдем грустные в закат. Но теперь у нас есть другой вид функций, которые как бы должны быть встроены, но никто этого не гарантирует, и которые можно определять в хэдерах. Такие функции могут быть встроены с той же вероятностью, что и все остальные, поэтому от этой части смысла никакого нет. Получается, что мы можем пометить нашу функцию inline и тогда она ее просто можно будет определять в заголовочниках. Гениально.
Ох и непростая тема! Советую пару раз прочитать этот пост, чтобы хорошо все усвоить. Информация очень глубокая и фундаментальная. Пишите в комментах, что непонятно. И замечания тоже пишите.
Dig deeper. Stay cool.
#cppcore #compiler #hardcore #design #howitworks
{kind=link}
Static
Ключевое слово static не зря вызывает столько вопросов. Его можно применять к куче разных сущностей и везде поведение будет разным. Поэтому поначалу это все довольно сложно усвоить. Будем потихоньку разбирать каждый аспект применения static в подробностях, но сейчас соберу все вместе и кратко расскажу о ключевых особенностях каждого.
Всего есть 5 возможных способа применить static:
👉🏿 К глобальным переменным. Есть у вас файлик и вы в нем определили глобальную переменную std::string ж = "опа";. Такой неконстантной глобальной переменной автоматически присваивается внешнее связывание. То есть все единицы трансляции могут увидеть эту переменную и использовать ее(через forward declaration). Как только вы пометите ее как static, тип связывания изменится на внутреннее. Это значит, что никакие другие единицы трансляции не смогут получить доступ к конкретно этому экземпляру строки. Время жизни переменной в этом случае не особо меняется.
👉🏿 К локальным переменным функции. В этом случае переменная будет продолжать принадлежать функции, но теперь ее время жизни с автоматического изменится на статическое. То есть переменная будет продолжать жить между вызовами функции и сохранять свое значение с предыдущего вызова. Такие переменные гарантированно инициализируются атомарно и один раз при самом первом вызове функции.
👉🏿 К полям класса. В отличии от обычных членов класса, для доступа к которым нужен объект, для статических полей объект не нужен. Представьте, что это глобальная переменная, которая "присоединена" к классу. Это поле видно всем, кому доступно определение класса, и к нему можно обратиться с помощью имени класса, типа такого Type::static_member. Также такие поля доступны в методах класса. Короче. Ничего особенного, просто глобальная переменная принадлежащая классу.
👉🏿 К свободным функциям. Ситуация очень похожа на ситуацию с глобальными переменными. По сути изменяется только тип связывания. Такую функцию нельзя увидеть из другой единицы трансляции.
👉🏿 К методам класса. Ситуация похожа на применение static к полям класса. Это свободная функция, которая присоединена к классу. Однако у нее есть еще одно преимущество, что такие методы имеют возможность доступа ко всем полям класса. Если каким-то образом заиметь объект того же самого класса внутри статического метода, то можно пользоваться плюшками доступа ко всем полям.
Как видно, что прошлись сильно по верхам. Я специально не затрагивал нюансы и описывал все крупными мазками. Нюансы будут, когда будем все подробно разбирать.
Вот такая многогранная вещь этот static. Ждите следующих частей, будет жарко🔥.
Stay hot. Stay cool.
#cppcore #howitworks
Ключевое слово static не зря вызывает столько вопросов. Его можно применять к куче разных сущностей и везде поведение будет разным. Поэтому поначалу это все довольно сложно усвоить. Будем потихоньку разбирать каждый аспект применения static в подробностях, но сейчас соберу все вместе и кратко расскажу о ключевых особенностях каждого.
Всего есть 5 возможных способа применить static:
👉🏿 К глобальным переменным. Есть у вас файлик и вы в нем определили глобальную переменную std::string ж = "опа";. Такой неконстантной глобальной переменной автоматически присваивается внешнее связывание. То есть все единицы трансляции могут увидеть эту переменную и использовать ее(через forward declaration). Как только вы пометите ее как static, тип связывания изменится на внутреннее. Это значит, что никакие другие единицы трансляции не смогут получить доступ к конкретно этому экземпляру строки. Время жизни переменной в этом случае не особо меняется.
👉🏿 К локальным переменным функции. В этом случае переменная будет продолжать принадлежать функции, но теперь ее время жизни с автоматического изменится на статическое. То есть переменная будет продолжать жить между вызовами функции и сохранять свое значение с предыдущего вызова. Такие переменные гарантированно инициализируются атомарно и один раз при самом первом вызове функции.
👉🏿 К полям класса. В отличии от обычных членов класса, для доступа к которым нужен объект, для статических полей объект не нужен. Представьте, что это глобальная переменная, которая "присоединена" к классу. Это поле видно всем, кому доступно определение класса, и к нему можно обратиться с помощью имени класса, типа такого Type::static_member. Также такие поля доступны в методах класса. Короче. Ничего особенного, просто глобальная переменная принадлежащая классу.
👉🏿 К свободным функциям. Ситуация очень похожа на ситуацию с глобальными переменными. По сути изменяется только тип связывания. Такую функцию нельзя увидеть из другой единицы трансляции.
👉🏿 К методам класса. Ситуация похожа на применение static к полям класса. Это свободная функция, которая присоединена к классу. Однако у нее есть еще одно преимущество, что такие методы имеют возможность доступа ко всем полям класса. Если каким-то образом заиметь объект того же самого класса внутри статического метода, то можно пользоваться плюшками доступа ко всем полям.
Как видно, что прошлись сильно по верхам. Я специально не затрагивал нюансы и описывал все крупными мазками. Нюансы будут, когда будем все подробно разбирать.
Вот такая многогранная вещь этот static. Ждите следующих частей, будет жарко🔥.
Stay hot. Stay cool.
#cppcore #howitworks
{kind=link}
Как работает динамический полиморфизм?
#новичкам
Продолжаем серию постов! В предыдущих статьях мы немного познакомились с возможностями полиморфных классов. Давайте подумаем, как же эта штука работает? По возможности, на собеседованиях интересуются этим вопросом 😉
Наверняка у вас так или иначе пробегал вопрос в голове: как же во время выполнения программы получается выбрать нужную реализацию метода, обращаясь к указателю лишь базового класса?
Это подталкивает к мысли, что объект полиморфного класса хранит какой-то секретик и владеет информацией о том, какие реализации методов надо вызывать.
Объекты полиморфных классов отличаются тем, что содержат в себе скрытый указатель на дополнительный участок памяти. В частности, размер объекта полиморфного класса немного больше:
Несмотря на то, что в
Данный скрытый указатель ведет в статическую область памяти, где лежит таблица виртуальных методов. Эта таблица представляет собой массив указателей на методы полиморфных наследников, в том числе и переопределенные. В общем случае, компилятор генерирует такие инструкции, которые будут разыменовывать эти указатели и совершать вызов нужной реализации. Это называется косвенным вызовом, indirect call.
Независимо от типа указателя на объект полиморфного класса, его скрытый указатель будет смотреть именно на ту таблицу, которая ассоциирована с конструированным классом:
Таким образом, и получается отвязать тип указателя от набора методов, которые должны быть вызваны.
Таблицы виртуальных методов генерируются на каждый полиморфный класс (не объект!), чтобы учесть все переопределения методов. Компилятор анализирует объявленные виртуальные методы и пронумеровывает их, а затем в этом порядке размещает в таблице. Например, для базового класса она будет выглядеть так:
А для наследованного класса уже вот так:
В конкретно взятых табличках всего две ячейки, которые хранят адрес на свою реализацию виртуального метода. В момент вызова, нам будет известен порядковый номер виртуального метода, а значит и его ячейку в таблице.
В общем случае, без каких либо оптимизаций, вызов виртуального метода состоит из следующих шагов:
1. Прочитать скрытый виртуальный указатель на таблицу
2. Сместить значение загруженного указателя до записи в таблице с адресом вызываемого метода
3. Прочитать адрес метода
4. Выполнить косвенный вызов по прочитанному адресу
Давайте мысленно препарируем участок вызывающего кода:
Думаю, что по моим комментариям к коду, а именно п. 6, видно, что даже сама программа не знает, что именно она вызывает, пока этого не сделает. Именно поэтому эта механика называется динамический полиморфизм.
Продолжение в комментариях 👇
#howitworks #cppcore
#новичкам
Продолжаем серию постов! В предыдущих статьях мы немного познакомились с возможностями полиморфных классов. Давайте подумаем, как же эта штука работает? По возможности, на собеседованиях интересуются этим вопросом 😉
Наверняка у вас так или иначе пробегал вопрос в голове: как же во время выполнения программы получается выбрать нужную реализацию метода, обращаясь к указателю лишь базового класса?
struct Base
{
virtual void vmethod_1();
virtual void vmethod_2();
};
struct Derived : public Base
{
void vmethod_2() override;
};
Base *data = new Derived();
// Calls Derived::vmethod_2()
data->vmethod_2();
Это подталкивает к мысли, что объект полиморфного класса хранит какой-то секретик и владеет информацией о том, какие реализации методов надо вызывать.
Объекты полиморфных классов отличаются тем, что содержат в себе скрытый указатель на дополнительный участок памяти. В частности, размер объекта полиморфного класса немного больше:
sizeof(Base) // returns 8
Несмотря на то, что в
Base нет никаких полей, в данном случае размер не будет равен одному байту. Класс Base формально пуст, но как раз под этот скрытый указатель резервируется доп. память: живой пример. На платформе x86-64 размер указателя равен 8 байт.Данный скрытый указатель ведет в статическую область памяти, где лежит таблица виртуальных методов. Эта таблица представляет собой массив указателей на методы полиморфных наследников, в том числе и переопределенные. В общем случае, компилятор генерирует такие инструкции, которые будут разыменовывать эти указатели и совершать вызов нужной реализации. Это называется косвенным вызовом, indirect call.
Независимо от типа указателя на объект полиморфного класса, его скрытый указатель будет смотреть именно на ту таблицу, которая ассоциирована с конструированным классом:
// Скрытый указатель объекта
// смотрит на vtable класса Base
Base *data = new Base();
// Скрытый указатель объекта
// смотрит на vtable класса Derived
Base *data = new Derived();
Таким образом, и получается отвязать тип указателя от набора методов, которые должны быть вызваны.
Таблицы виртуальных методов генерируются на каждый полиморфный класс (не объект!), чтобы учесть все переопределения методов. Компилятор анализирует объявленные виртуальные методы и пронумеровывает их, а затем в этом порядке размещает в таблице. Например, для базового класса она будет выглядеть так:
| vtable of Base |
|---------------------|
| &Base::vmethod_1 |
|---------------------|
| &Base::vmethod_2 |
А для наследованного класса уже вот так:
| vtable of Derived |
|---------------------|
| &Base::vmethod_1 |
|---------------------|
| &Derived::vmethod_2 |
В конкретно взятых табличках всего две ячейки, которые хранят адрес на свою реализацию виртуального метода. В момент вызова, нам будет известен порядковый номер виртуального метода, а значит и его ячейку в таблице.
В общем случае, без каких либо оптимизаций, вызов виртуального метода состоит из следующих шагов:
1. Прочитать скрытый виртуальный указатель на таблицу
2. Сместить значение загруженного указателя до записи в таблице с адресом вызываемого метода
3. Прочитать адрес метода
4. Выполнить косвенный вызов по прочитанному адресу
Давайте мысленно препарируем участок вызывающего кода:
void virtual_call(Base *object)
{
// 1. Разыменовываем указатель `data` на класс `Base`
// 2. Читаем указатель на vtable
// 3. Смещаемся на величину 1 указателя
// 4. Читаем указатель на `vmethod_2`
// 5. Вызываем данный метод
// 6. Ого! Оказывается, это была переопределение Derived::vmethod_2
object->vmethod_2();
}
Думаю, что по моим комментариям к коду, а именно п. 6, видно, что даже сама программа не знает, что именно она вызывает, пока этого не сделает. Именно поэтому эта механика называется динамический полиморфизм.
Продолжение в комментариях 👇
#howitworks #cppcore
{kind=link}
Как работает dynamic_cast? RTTI!
#опытным #fun
Продолжаем серию! В прошлой статье мы познакомились с таблицей виртуальных методов. Помимо этой таблицы, в этой же области памяти скрывается еще одна структура.
Как мы видели ранее, для полиморфных объектов существует специальный оператор dynamic_cast. Стандарт не регламентирует его реализацию, но чаще всего, для работы требуется дополнительная информация о типе полиморфного объекта RTTI (Run Time Type Information). Посмотреть эту структуру можно с помощью оператора
Содержимое RTTI зависит от компилятора, но как минимум там хранится
Операторы
Как же нам найти начало объекта RTTI? Не боги горшки обжигают, есть просто специальный указатель, который расположен прямо перед началом таблицы виртуальных методов. Он и ведёт к объекту RTTI:
Получив доступ к дополнительной информации остаётся выполнить приведение типа: upcast, downcast, sidecast/crosscast. Эта задача требует совершить поиск в ориентированном ациклическом графе (DAG, directed acyclic graph), что в рамках этой операции может быть трудоёмким, но необходимым для обработки общего случая. Теперь мы можем даже ответить, почему
Можем ли мы как-то ускорить работу? Мы можем просто запретить использовать
И такое ограничение будет автоматически подталкивать к пересмотру полученной архитектуры решения или разработке собственного механизма приведения типов.
На счет последнего надо много и долго думать. На стыке двух динамических библиотек, которые могут ничего не знать друг о друге, придется как-то проверять, что лежит в динамическом типе. Так же необходимо учитывать особенности множественного и виртуального наследования. От них можно и в принципе отказаться, но как запретить вышеупомянутые виды наследования в коде? Меня бы в первую очередь интересовала автономная и независимая жизнь проекта без пристального надзора хранителей знаний. Это задача, которая имеет много подводных камней или требует введения в проект ограничений, дополнительного контроля.
Если
#cppcore #howitworks
#опытным #fun
Продолжаем серию! В прошлой статье мы познакомились с таблицей виртуальных методов. Помимо этой таблицы, в этой же области памяти скрывается еще одна структура.
Как мы видели ранее, для полиморфных объектов существует специальный оператор dynamic_cast. Стандарт не регламентирует его реализацию, но чаще всего, для работы требуется дополнительная информация о типе полиморфного объекта RTTI (Run Time Type Information). Посмотреть эту структуру можно с помощью оператора
typeid:cppОбратите внимание,
const auto &RTTI = typeid(object);
typeid возвращает read-only ссылку на объект std::type_info, т.к. эту область памяти нельзя изменять — она была сгенерирована компилятором на этапе компиляции.Содержимое RTTI зависит от компилятора, но как минимум там хранится
hash полиморфного класса и его имя, которые доступны из std::type_info. Маловероятно, что вам на этом потребуется построить какую-то логику приложения, но эта штука могла бы быть вам полезна при отладке / подсчёте статистики и т.д. Операторы
dynamic_cast и typeid получают доступ к этой структуре так же через скрытый виртуальный указатель, который подшивается к объектам полиморфного класса. Как мы знаем, этот указатель смотрит на начало таблицы виртуальных методов, коих может быть бесчисленное множество и варьироваться от наследника к наследнику.Как же нам найти начало объекта RTTI? Не боги горшки обжигают, есть просто специальный указатель, который расположен прямо перед началом таблицы виртуальных методов. Он и ведёт к объекту RTTI:
┌-─| ptr to RTTI | vtable pointer
| |----------------| <- looks here
| | vtable methods |
| |----------------|
└─>| RTTI object |
Получив доступ к дополнительной информации остаётся выполнить приведение типа: upcast, downcast, sidecast/crosscast. Эта задача требует совершить поиск в ориентированном ациклическом графе (DAG, directed acyclic graph), что в рамках этой операции может быть трудоёмким, но необходимым для обработки общего случая. Теперь мы можем даже ответить, почему
dynamic_cast такой медленный.Можем ли мы как-то ускорить работу? Мы можем просто запретить использовать
dynamic_cast 😄 Это можно сделать, отключив RTTI с помощью флага компиляции:-fno-rtti
И такое ограничение будет автоматически подталкивать к пересмотру полученной архитектуры решения или разработке собственного механизма приведения типов.
На счет последнего надо много и долго думать. На стыке двух динамических библиотек, которые могут ничего не знать друг о друге, придется как-то проверять, что лежит в динамическом типе. Так же необходимо учитывать особенности множественного и виртуального наследования. От них можно и в принципе отказаться, но как запретить вышеупомянутые виды наследования в коде? Меня бы в первую очередь интересовала автономная и независимая жизнь проекта без пристального надзора хранителей знаний. Это задача, которая имеет много подводных камней или требует введения в проект ограничений, дополнительного контроля.
Если
dynamic_cast становится бутылочным горлышком, то в первую очередь стоит пересмотреть именно архитектуру решения, а оптимизации оставить на крайний случай.#cppcore #howitworks
Девиртуализация вызовов. Ч2
#опытным
В предыдущем посте мы столкнулись с невозможностью девиртуализировать функцию
Получается, что нам достаточно ограничить внешнее связывание? Рассмотрим в примерах дальше 😊
Запрет на внешнее связывание 1
Итак, мы ведь знаем, что для конкретной функции можно запретить внешнее связывание, например, с помощью
Вызов функции
Кстати, П.2 может быть доказан лишь частично! Например,
В данном случае, с учетом всех наборов аргументов при вызове
Запрет на внешнее связывание 2
В предыдущих способах можно заметить, что сложности возникают с доказательством П.2 и П.4. Компилятор опасается, что в других единицах трансляции появятся либо новые перегрузки, либо будут вызваны функции с объектами других наследников полиморфных классов.
Учитывая особенности сборки проекта, разработчик может намеренно сообщить компилятору, что других единиц трансляции не будет. В частности, для LLVM Clang можно применить следующие опции:
В GCC можно вообще указать, что компилируемая единица и есть вся программа с помощью флага:
Он буквально разрешает считать, что компилятор знает ВСЕ известные перегрузки и их вызовы. Короче, отметит все функции ключевым словом
Запрет на внешнее связывание 3
Еще один способ показать компилятору, что новых полиморфных перегрузок не появится. Можно использовать unnamed namespace:
Теперь данное семейство полиморфных классов будет скрыто от других единиц трансляции, что доказывает компилятору П.3 и П.4, а так же П.2 по месту требования.
Вот такими несложными действиями можно сократить количество обращений к таблице виртуальных методов и ускорить выполнение вашего приложения 😉
#cppcore #hardcore #howitworks
#опытным
В предыдущем посте мы столкнулись с невозможностью девиртуализировать функцию
bar, т.к. мы не могли гарантировать отсутствие вызовов из других единиц трансляции.Получается, что нам достаточно ограничить внешнее связывание? Рассмотрим в примерах дальше 😊
Запрет на внешнее связывание 1
Итак, мы ведь знаем, что для конкретной функции можно запретить внешнее связывание, например, с помощью
static. Из живого примера:// direct call!
static void bar(Base &da, Base &db)
{
// push rbx
// mov rax, [rdi]
// mov rbx, rsi
da.vmethod(); // call DerivedA::vmethod()
// mov rdi, rbx
// pop rbx
db.vmethod(); // jmp DerivedB::vmethod()
}
Вызов функции
bar - единственный в данной единице трансляции, с конкретными наследниками Base. Следовательно, мы можем доказать П.2, П.4, П.3 (терминология из первой части).Кстати, П.2 может быть доказан лишь частично! Например,
bar можно вызывать с разными аргументами, тогда оптимизация будет совершена лишь частично:// indirect + direct call
static void bar(Base &da, Base &db)
{
// push rbx
// mov rax, [rdi]
// mov rbx, rsi
da.vmethod(); // call [[rax]]
// mov rdi, rbx
// pop rbx
db.vmethod(); // jmp DerivedB::vmethod()
}
В данном случае, с учетом всех наборов аргументов при вызове
foo, только второй vmethod может быть оптимизирован.Запрет на внешнее связывание 2
В предыдущих способах можно заметить, что сложности возникают с доказательством П.2 и П.4. Компилятор опасается, что в других единицах трансляции появятся либо новые перегрузки, либо будут вызваны функции с объектами других наследников полиморфных классов.
Учитывая особенности сборки проекта, разработчик может намеренно сообщить компилятору, что других единиц трансляции не будет. В частности, для LLVM Clang можно применить следующие опции:
-flto -fwhole-program-vtables -fvisibility=hidden
В GCC можно вообще указать, что компилируемая единица и есть вся программа с помощью флага:
-fwhole-program
Он буквально разрешает считать, что компилятор знает ВСЕ известные перегрузки и их вызовы. Короче, отметит все функции ключевым словом
static: живой пример.Запрет на внешнее связывание 3
Еще один способ показать компилятору, что новых полиморфных перегрузок не появится. Можно использовать unnamed namespace:
namespace
{
struct Base
{
virtual void vmethod();
};
struct Derived : public Base
{
void vmethod() override;
};
}
Теперь данное семейство полиморфных классов будет скрыто от других единиц трансляции, что доказывает компилятору П.3 и П.4, а так же П.2 по месту требования.
Вот такими несложными действиями можно сократить количество обращений к таблице виртуальных методов и ускорить выполнение вашего приложения 😉
#cppcore #hardcore #howitworks