
std::make_unique. Part 2
Вчера мы поговорили о том, почему вам стоит всегда использовать std::make_unique вместо std::unique_ptr(new ...). Однако может вы и убедились, что фича крутая и ей надо пользоваться всегда, но, как бы я этого не хотел, это не всегда возможно. То, что фича крутая - это беспортно! Просто в некоторых ситуациях вы не сможете ее применить. Поэтому сегодня рассмотрим эти ограничения. Ситуации значит такие:
1️⃣ Вам нужен кастомный делитер. Например, для логирования. Или для закрытия файла, если в умный указатель вы положили файл. Делитер нужно передавать, как параметр шаблона класса, а std::make_unique не умеет принимать второй параметр шаблона. Поэтому вы просто не сможете с ее помощью создать объект с кастомным удалителем. Скорее всего такой дизайн функции был продиктован простотой ее использования и следованием более понятной модели владения и инкапсуляции ресурсов. Когда ответственность за владение и удаление ресурсов ложится целиком на класс указателя.
2️⃣ Если у вас уже есть сырой указатель и вы хотите сделать из него смарт поинтер. Дело в том, что std::make_unique делает perfect-forwarding своих аргументов в аргументы конструктора целевого объекта. И получается, что передавая в функцию Type *, вы говорите - создай новый объект на основе Type *. И в большинстве ситуаций это не то, что вы хотите. У вас уже есть существующий объект и вам хочется именно его обезопасить. С make_unique такого не получится.
3️⃣ Если у вашего класса конструктор объявлен как private или protected. По идее, make_unique - внешний код для вашего класса. И если вы не хотите разрешать внешнему коду создавать объекты какого-то класса, то нужно быть готовым, что объекты такого класса нельзя будет создать через std::make_unique. В этом случае придется пользоваться конструкцией std::unique_ptr(new Type(...)). Этот пункт довольно болезненный в проектах, где у многих классов есть фабричные методы.
4️⃣ std::make_unique плохо работает с initializer_list. Например, вы не сможете скомпилировать такой код:
make_unique<TypeWithMapInitialization>({})
мы бы хотели создать объект с пустой мапой, но не можем этого сделать вот таким элегантным образом. Придется делать вот так:
make_unique<TypeWithMapInitialization>(std::map<std::string, std::map<std::string, std::string>>({}))
или придется использовать new для простоты:
unique_ptr<TypeWithDeepMap>(new TypeWithDeepMap({}))
5️⃣ И наконец, не ограничение, а скорее отличие make_unique<Type>() от unique_ptr<Type>(new Type()). Первое выражение выполняет так называемую default initialization, а второе - value initialization. Это довольно сложнопонимаемые явления, может как-нибудь отдельный пост на это запипю. Но просто для базового понимания, например, int x; - default initialization, в х будет лежать мусор. А int x{}; - value initialization и в х будет лежать 0. Повторюсь, не все так просто. Но такое отличие есть и его надо иметь ввиду при выборе нужного выражения, чтобы получить ожидаемое поведение.
Закончить я хочу так. Как часто вам нужны кастомные делитеры, приватные конструкторы? Как часто нужно передавать список инициализации в конструктор или создавать пустые объекты? Думаю, что таких кейсов явно немного. А, если и много, то поспрашивайте у коллег, мне кажется, что у них не так)
Поэтому всем рекомендую пользоваться std::make_unique, несмотря на все эти редкие и мелкие ограничения.
Stay unique. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
Вчера мы поговорили о том, почему вам стоит всегда использовать std::make_unique вместо std::unique_ptr(new ...). Однако может вы и убедились, что фича крутая и ей надо пользоваться всегда, но, как бы я этого не хотел, это не всегда возможно. То, что фича крутая - это беспортно! Просто в некоторых ситуациях вы не сможете ее применить. Поэтому сегодня рассмотрим эти ограничения. Ситуации значит такие:
1️⃣ Вам нужен кастомный делитер. Например, для логирования. Или для закрытия файла, если в умный указатель вы положили файл. Делитер нужно передавать, как параметр шаблона класса, а std::make_unique не умеет принимать второй параметр шаблона. Поэтому вы просто не сможете с ее помощью создать объект с кастомным удалителем. Скорее всего такой дизайн функции был продиктован простотой ее использования и следованием более понятной модели владения и инкапсуляции ресурсов. Когда ответственность за владение и удаление ресурсов ложится целиком на класс указателя.
2️⃣ Если у вас уже есть сырой указатель и вы хотите сделать из него смарт поинтер. Дело в том, что std::make_unique делает perfect-forwarding своих аргументов в аргументы конструктора целевого объекта. И получается, что передавая в функцию Type *, вы говорите - создай новый объект на основе Type *. И в большинстве ситуаций это не то, что вы хотите. У вас уже есть существующий объект и вам хочется именно его обезопасить. С make_unique такого не получится.
3️⃣ Если у вашего класса конструктор объявлен как private или protected. По идее, make_unique - внешний код для вашего класса. И если вы не хотите разрешать внешнему коду создавать объекты какого-то класса, то нужно быть готовым, что объекты такого класса нельзя будет создать через std::make_unique. В этом случае придется пользоваться конструкцией std::unique_ptr(new Type(...)). Этот пункт довольно болезненный в проектах, где у многих классов есть фабричные методы.
4️⃣ std::make_unique плохо работает с initializer_list. Например, вы не сможете скомпилировать такой код:
make_unique<TypeWithMapInitialization>({})
мы бы хотели создать объект с пустой мапой, но не можем этого сделать вот таким элегантным образом. Придется делать вот так:
make_unique<TypeWithMapInitialization>(std::map<std::string, std::map<std::string, std::string>>({}))
или придется использовать new для простоты:
unique_ptr<TypeWithDeepMap>(new TypeWithDeepMap({}))
5️⃣ И наконец, не ограничение, а скорее отличие make_unique<Type>() от unique_ptr<Type>(new Type()). Первое выражение выполняет так называемую default initialization, а второе - value initialization. Это довольно сложнопонимаемые явления, может как-нибудь отдельный пост на это запипю. Но просто для базового понимания, например, int x; - default initialization, в х будет лежать мусор. А int x{}; - value initialization и в х будет лежать 0. Повторюсь, не все так просто. Но такое отличие есть и его надо иметь ввиду при выборе нужного выражения, чтобы получить ожидаемое поведение.
Закончить я хочу так. Как часто вам нужны кастомные делитеры, приватные конструкторы? Как часто нужно передавать список инициализации в конструктор или создавать пустые объекты? Думаю, что таких кейсов явно немного. А, если и много, то поспрашивайте у коллег, мне кажется, что у них не так)
Поэтому всем рекомендую пользоваться std::make_unique, несмотря на все эти редкие и мелкие ограничения.
Stay unique. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
{kind=link}
Идиома NVI
В публикации под названием "C++ Coding Standards: 101 Rules, Guidelines, and Best Practices" есть такая строчка: Consider making virtual functions nonpublic, and public functions nonvirtual. По-русски - рассмотрите возможности сделать виртуальные функции непубличными, а публичные функции - невиртуальными. Для кого-то сейчас это предложение звучит, как минимум, странно. "Я ж всегда определял полиморфный интерфейс классов публичным. И зачем вообще делать виртуальные методы непубличными? " Уверяю вас, что эту строчку написали вполне уважаемые в международном коммьюнити люди - Андрей Александреску и Герб Саттер. Фигню они вряд ли скажут, поэтому сейчас постараюсь объяснить, какие идеи лежат за этими словами.
Иногда хорошие практики организации кода оформляют в виде идиом. И для выражения выше появилась такая идиома(хотя не знаю, что появилось раньше:курица или яйцоидиома или эта цитата). Называется она non-virtual interface idiom. Говорящее название)
Мотивация
Представьте себе какую-нибудь обычную иерархию классов. Очень часто полиморфные методы классов в ней выполняют какую-то общую работу. Это может быть обработка ошибок, логирование, сбор мониторингов, вызов какого-то общего метода, захват общего мьютекса, вы работаете с данными на низком уровне, а потом запаковываете в одинаковый формат и выдаете наружу и тд. Перечислять можно реально долго. Я бы даже так сказал: полифорфные методы с развитием проекта практически обречены обретать общую функциональность. То есть даже если ее не было, она с большой вероятностью появится. К чему это будет приводить? Желание изменить один аспект поведения объектов приводит к изменению кода по всей иерархии классов. Это увеличивает сложность внедрения новой или обслуживающей функциональности. А там еще и копипаст ошибки могут подьехать. Можно забыть в каком-то наследнике добавить то, что нужно. В общем беда.
А если нужно подкорректировать API без особого изменения кор-функциональности? Тогда опять придется править по всей иерархии.
А если надо подкорректировать кор-функциональнальность, без изменения апи и общей функциональности? Тоже самое.
Виртуальные функции же могут быть еще и перегружены. Тогда очень легко сделать ошибку и скрыть некоторые из перегрузок во время переопределения. Тогда будут вызываться методы базового класса, хотя вы ожидаете другого поведения.
Все это следствия одной проблемы: наследование - пожалуй самая сильная форма связывания классов между собой. Когда метрика связывания высокая, то в приложение очень сложно вносить изменения. В этом корень.
Но есть один способ, который поможет несколько смягчить проблему - введение еще одного уровня индирекции. А точнее - перенаправление кор-функциональности из публичных невиртуальных методов базового класса в непубличные виртуальные. Тем самым вы четко разделяете пользовательский интерфейс и реализацию. Это и увеличивает инкапсуляцию, потому что кор-интерфейс может даже иметь сигнатуру, отличную от того, что выдается наружу. Вы скрываете от пользователя информацию, которую ему потенциально не нужно знать. Ну мы здесь все понимаем, какие преимущества дает инкапсуляция, что уж я буду распинаться.
Можно вынести всю общую функциональность в метод базового класса, а наследнико-специфичиные задачи решать с помощью внутреннего виртуального интерфейса. Можно вносить изменения и в общую, и в кор функциональности, не затрагивая при этом друг друга. Одно изменение дизайна, а сколько радостей оно приносит!
Следование идиоме действительно дает гибкость в проектировании классов и интерфейсов. Однако эта гибкость идет вместе с ответственностью за возросшую сложность системы. Теперь вам нужно поддерживать 2 интерфейса: внутренний и внешний. Если не очень аккуратно проектировать базовый класс, то не так уж и сложно нарваться на проблемы.
Так что
Stay well-designed. Stay cool.
#design #goodpractice
В публикации под названием "C++ Coding Standards: 101 Rules, Guidelines, and Best Practices" есть такая строчка: Consider making virtual functions nonpublic, and public functions nonvirtual. По-русски - рассмотрите возможности сделать виртуальные функции непубличными, а публичные функции - невиртуальными. Для кого-то сейчас это предложение звучит, как минимум, странно. "Я ж всегда определял полиморфный интерфейс классов публичным. И зачем вообще делать виртуальные методы непубличными? " Уверяю вас, что эту строчку написали вполне уважаемые в международном коммьюнити люди - Андрей Александреску и Герб Саттер. Фигню они вряд ли скажут, поэтому сейчас постараюсь объяснить, какие идеи лежат за этими словами.
Иногда хорошие практики организации кода оформляют в виде идиом. И для выражения выше появилась такая идиома(хотя не знаю, что появилось раньше:
Мотивация
Представьте себе какую-нибудь обычную иерархию классов. Очень часто полиморфные методы классов в ней выполняют какую-то общую работу. Это может быть обработка ошибок, логирование, сбор мониторингов, вызов какого-то общего метода, захват общего мьютекса, вы работаете с данными на низком уровне, а потом запаковываете в одинаковый формат и выдаете наружу и тд. Перечислять можно реально долго. Я бы даже так сказал: полифорфные методы с развитием проекта практически обречены обретать общую функциональность. То есть даже если ее не было, она с большой вероятностью появится. К чему это будет приводить? Желание изменить один аспект поведения объектов приводит к изменению кода по всей иерархии классов. Это увеличивает сложность внедрения новой или обслуживающей функциональности. А там еще и копипаст ошибки могут подьехать. Можно забыть в каком-то наследнике добавить то, что нужно. В общем беда.
А если нужно подкорректировать API без особого изменения кор-функциональности? Тогда опять придется править по всей иерархии.
А если надо подкорректировать кор-функциональнальность, без изменения апи и общей функциональности? Тоже самое.
Виртуальные функции же могут быть еще и перегружены. Тогда очень легко сделать ошибку и скрыть некоторые из перегрузок во время переопределения. Тогда будут вызываться методы базового класса, хотя вы ожидаете другого поведения.
Все это следствия одной проблемы: наследование - пожалуй самая сильная форма связывания классов между собой. Когда метрика связывания высокая, то в приложение очень сложно вносить изменения. В этом корень.
Но есть один способ, который поможет несколько смягчить проблему - введение еще одного уровня индирекции. А точнее - перенаправление кор-функциональности из публичных невиртуальных методов базового класса в непубличные виртуальные. Тем самым вы четко разделяете пользовательский интерфейс и реализацию. Это и увеличивает инкапсуляцию, потому что кор-интерфейс может даже иметь сигнатуру, отличную от того, что выдается наружу. Вы скрываете от пользователя информацию, которую ему потенциально не нужно знать. Ну мы здесь все понимаем, какие преимущества дает инкапсуляция, что уж я буду распинаться.
Можно вынести всю общую функциональность в метод базового класса, а наследнико-специфичиные задачи решать с помощью внутреннего виртуального интерфейса. Можно вносить изменения и в общую, и в кор функциональности, не затрагивая при этом друг друга. Одно изменение дизайна, а сколько радостей оно приносит!
Следование идиоме действительно дает гибкость в проектировании классов и интерфейсов. Однако эта гибкость идет вместе с ответственностью за возросшую сложность системы. Теперь вам нужно поддерживать 2 интерфейса: внутренний и внешний. Если не очень аккуратно проектировать базовый класс, то не так уж и сложно нарваться на проблемы.
Так что
Stay well-designed. Stay cool.
#design #goodpractice
{kind=link}
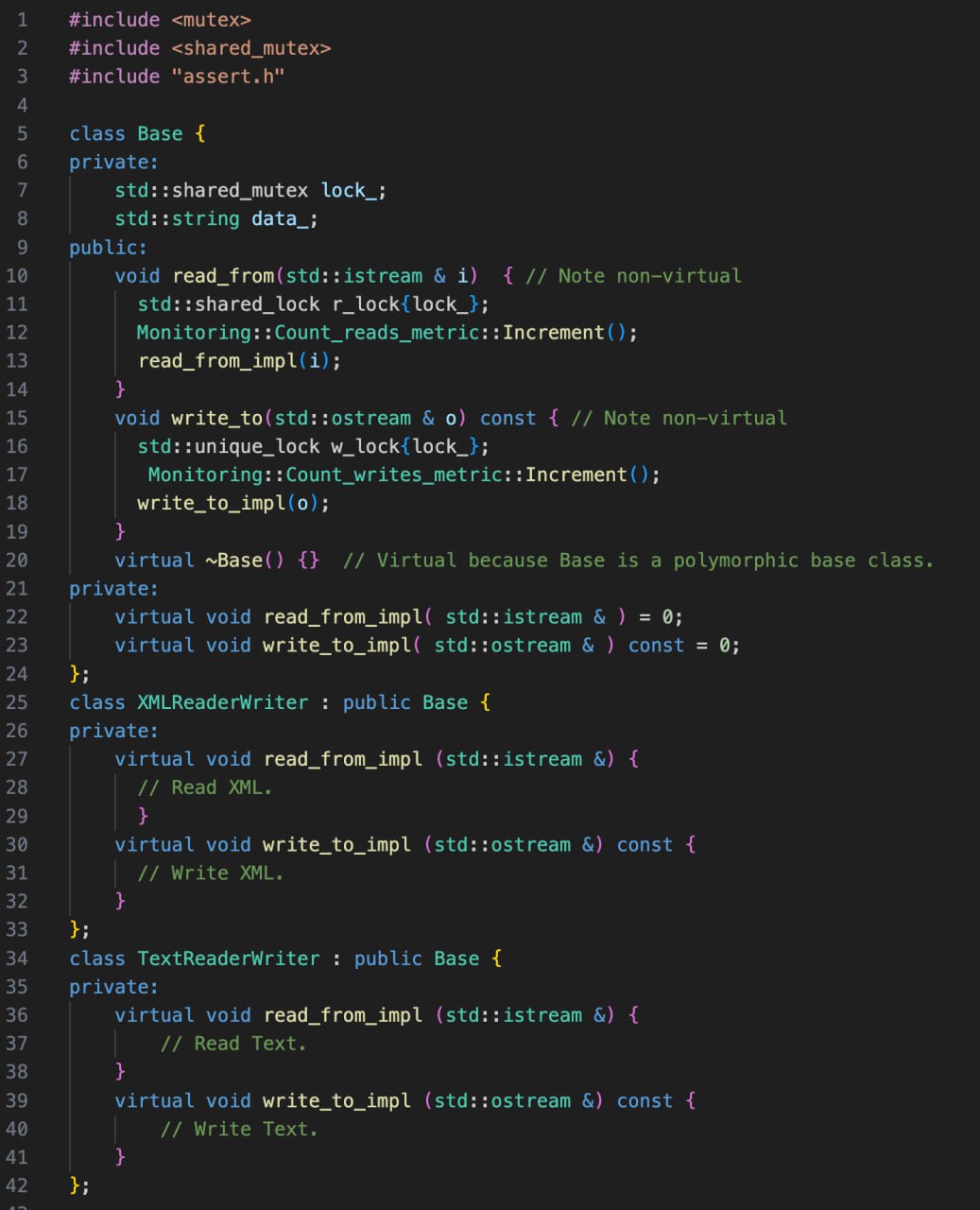
Удаленные функции
Упоминали об этом вскользь, но, думаю, что стоит подсветить эту тему отдельно.
Все мы знаем, что, если нам нужно запретить объекту копироваться, то нужно пометить его копирующий конструктор и копирующий оператор присваивания как =delete;
Но помечать удаленной можно вообще любую функцию!
Этой частью функциональности вы будете пользоваться намного реже, но не стоит ее игнорировать. Это может значительно повысить безопасность ваших приложений или сократить возможность неожиданного поведения.
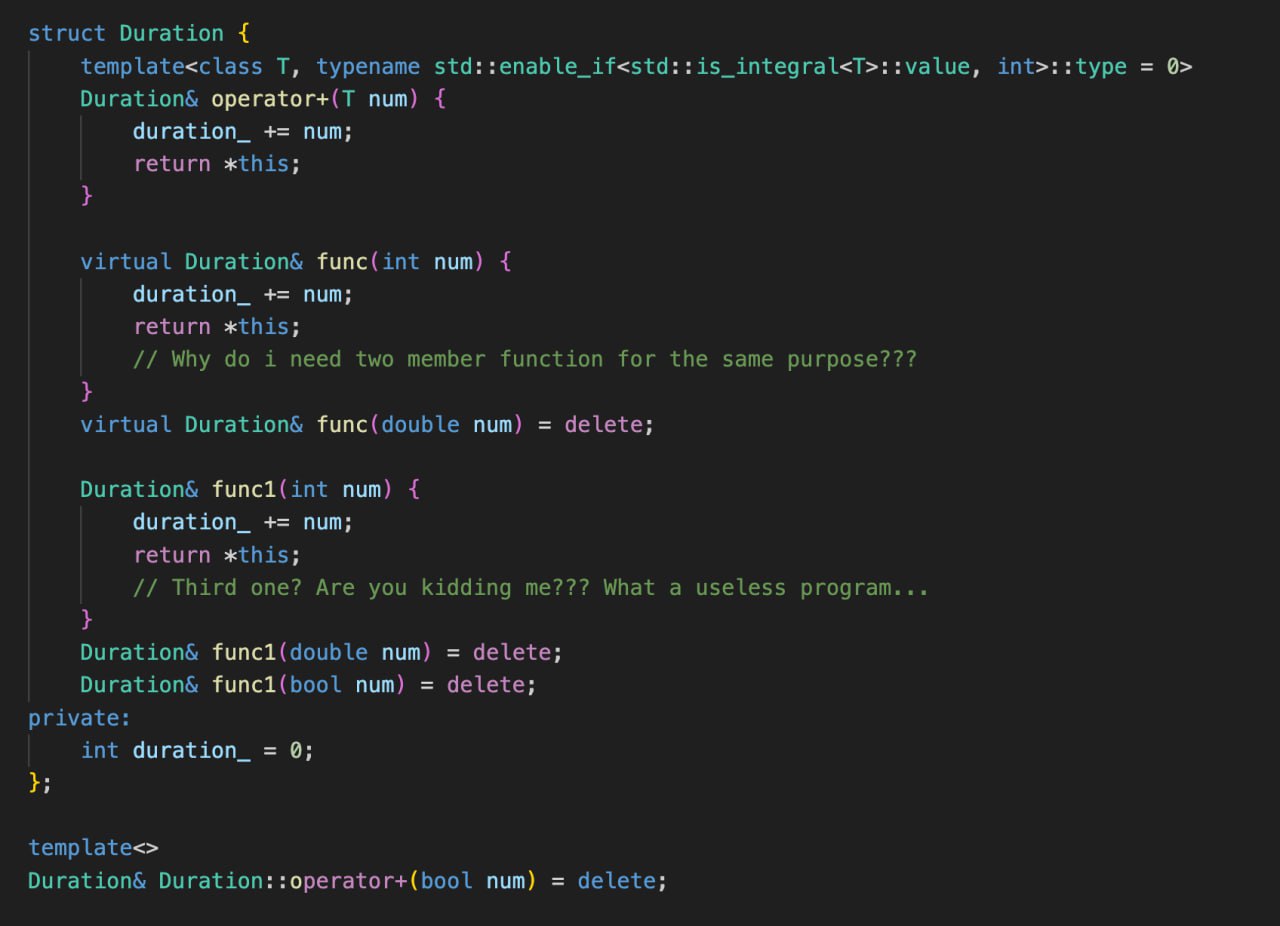
Допустим, у вас есть класс Duration(зачем он вам нужен это большой вопрос, но для примера покатит). Он отвечает за репрезентацию разницы в датах в миллисекундах. Легко можно представить необходимость переопределить оператор + для этого класса, чтобы эту длительность увеличивать за счет обычного числа. Итак пишем:
Duration& Duration::operator+(int num) {
duration_ += num;
return *this;
}
Все хорошо. А если мы туда передадим 5.5? Дробное число неявно преобразуется к инту и мы получим не совсем тот ответ, который могли бы ожидать. И единственный способ запретить такое поведение - объявить нежелательные перегрузки, как =delete.
Duration& Duration::operator+(double num) = delete;
Duration& Duration::operator+(bool num) = delete;
Удаление первой перегрузки также отбросит и float варинт, так как компилятор предпочтет преобразовать float к double, а не к int.
Какая-то выдуманная проблема, скажите вы, и решить ее можно через sfinae. Просто через шаблон запретить подстановки ненужных типов. Благо с 17-х плюсов пользоваться шаблонами стало попроще с помощью CTAD и не надо никакие шаблонные аргументы указывать. Давайте посмотрим, как это выглядит:
template<class T, typename std::enable_if<std::is_integral<T>::value, int>::type = 0>
Duration& Duration::operator+(T num) {
duration_ += num;
return *this;
}
Здесь проверяется, что тип должен быть числом, и только тогда метод сможет инстанцироваться. В чем проблема? Проблема в том, что bool - тоже целочисленный тип. Как же быть? Ровно так же:
template<>
Duration& Duration::operator+(bool num) = delete;
Решение через шаблоны рабочее, но не всегда его возможно применить. Например, вы не можете иметь шаблонный виртуальный метод. Поэтому можно пользоваться только удалением ненужных перегрузок.
Какова мораль. Используйте удаленные функции, когда это необходимо. И шаблонную, и обычную, и виртуальную функцию можно удалить. Это очень гибкий инструмент, предотвращающий неправильное использование вашего класса.
Stay safe. Stay cool
#cpp11 #cpp17 #goodpractice
Упоминали об этом вскользь, но, думаю, что стоит подсветить эту тему отдельно.
Все мы знаем, что, если нам нужно запретить объекту копироваться, то нужно пометить его копирующий конструктор и копирующий оператор присваивания как =delete;
Но помечать удаленной можно вообще любую функцию!
Этой частью функциональности вы будете пользоваться намного реже, но не стоит ее игнорировать. Это может значительно повысить безопасность ваших приложений или сократить возможность неожиданного поведения.
Допустим, у вас есть класс Duration(зачем он вам нужен это большой вопрос, но для примера покатит). Он отвечает за репрезентацию разницы в датах в миллисекундах. Легко можно представить необходимость переопределить оператор + для этого класса, чтобы эту длительность увеличивать за счет обычного числа. Итак пишем:
Duration& Duration::operator+(int num) {
duration_ += num;
return *this;
}
Все хорошо. А если мы туда передадим 5.5? Дробное число неявно преобразуется к инту и мы получим не совсем тот ответ, который могли бы ожидать. И единственный способ запретить такое поведение - объявить нежелательные перегрузки, как =delete.
Duration& Duration::operator+(double num) = delete;
Duration& Duration::operator+(bool num) = delete;
Удаление первой перегрузки также отбросит и float варинт, так как компилятор предпочтет преобразовать float к double, а не к int.
Какая-то выдуманная проблема, скажите вы, и решить ее можно через sfinae. Просто через шаблон запретить подстановки ненужных типов. Благо с 17-х плюсов пользоваться шаблонами стало попроще с помощью CTAD и не надо никакие шаблонные аргументы указывать. Давайте посмотрим, как это выглядит:
template<class T, typename std::enable_if<std::is_integral<T>::value, int>::type = 0>
Duration& Duration::operator+(T num) {
duration_ += num;
return *this;
}
Здесь проверяется, что тип должен быть числом, и только тогда метод сможет инстанцироваться. В чем проблема? Проблема в том, что bool - тоже целочисленный тип. Как же быть? Ровно так же:
template<>
Duration& Duration::operator+(bool num) = delete;
Решение через шаблоны рабочее, но не всегда его возможно применить. Например, вы не можете иметь шаблонный виртуальный метод. Поэтому можно пользоваться только удалением ненужных перегрузок.
Какова мораль. Используйте удаленные функции, когда это необходимо. И шаблонную, и обычную, и виртуальную функцию можно удалить. Это очень гибкий инструмент, предотвращающий неправильное использование вашего класса.
Stay safe. Stay cool
#cpp11 #cpp17 #goodpractice
{kind=link}
Еще про именование сущностей
В прошлом мы поговорили о том, что нужно создавать абстракции из деталей реализации. Не нужно тащить везде вместе кучу разных переменных. Нужно их объединить в именованный класс. Это повышает читаемость кода и скрывает ненужную на данном уровне понимания информацию.
Однако мы не всегда можем это сделать. Классы должны быть неделимыми с архитектурной точки зрения. Не нужно объединять все в одно. Но даже когда мы имеем завершенный и правильно спроектированный класс, встает проблема, что в названии множества из таких классов не записано их предназначение. Ну тут как бы все логично. Разработчики класса матрицы не знают, как конкретно будет использоваться их класс. С их точки зрения они предоставляют инструмент, кирпичик, который потом ляжет в основу программ пользователей. Проблема проявляется именно на уровне пользовательского кода. Представим, что полноценная программа - это часовой механизм. Неведомая куча каких-то шестеренок, пружинок и прочих финтифлюшек. Глядя на каждый компонент механизма, я понимаю, что он из себя представляет. Но я не понимаю главного: Нахера он нужен именно в этом месте? Какую роль выполняет? Вот также с сущностями в коде. Конечно, давать обстоятельные имена объектам - дело благородное и богоугодное. Но хотелось бы всегда давать имена классам, которые мы используем. Чисто как еще один инструмент для превращения кода в текст на естественном языке. И в плюсах так делать можно!
Алиасинг типов, введенный в С++11, дает нам удобный механизм определения синонимов типов. Это как typedef, только на стероидах. Не будем сейчас говорить о их различиях. Нам важна суть. Мы можем написать:
using ResponseFrequencyByInstance = std::unordered_map<instance_id, size_t>;
И получим человеческое название для структуры, которая хранит частоту ответов, присылаемых от разных инстансов сервиса. И нам уже не важно, что конкретно лежит в основе этой структуры. По названию видно ее предназначение, а нам только это и нужно. А имена этих объектов могут включать уже другую информацию, такую как: единицу измерения отрезка времени(секунды, миллисекунды) или указание конкретного сервиса, для которого собирается статистика. Конечно, всегда рядом с именем объекта мы постоянно должны будем помнить его тип, чтобы получить всю информацию о нем. Однако современные IDE сильно облегчили нашу жизнь в этом плане. Простым наведением курсора на объект мы увидим плашку с типом этого объекта.
Теперь мы можем давать понятные имена любым классам на свой выбор, если видим потребность в более детальной проработке смыслов.
Новичков скорее всего будет отпугивать обилие использование этих алиасов, но это фактически необходимость для поддержания ясности кода и действительно рабочая вещь.
Stay helpful. Stay cool.
#cpp11 #design #goodpractice
В прошлом мы поговорили о том, что нужно создавать абстракции из деталей реализации. Не нужно тащить везде вместе кучу разных переменных. Нужно их объединить в именованный класс. Это повышает читаемость кода и скрывает ненужную на данном уровне понимания информацию.
Однако мы не всегда можем это сделать. Классы должны быть неделимыми с архитектурной точки зрения. Не нужно объединять все в одно. Но даже когда мы имеем завершенный и правильно спроектированный класс, встает проблема, что в названии множества из таких классов не записано их предназначение. Ну тут как бы все логично. Разработчики класса матрицы не знают, как конкретно будет использоваться их класс. С их точки зрения они предоставляют инструмент, кирпичик, который потом ляжет в основу программ пользователей. Проблема проявляется именно на уровне пользовательского кода. Представим, что полноценная программа - это часовой механизм. Неведомая куча каких-то шестеренок, пружинок и прочих финтифлюшек. Глядя на каждый компонент механизма, я понимаю, что он из себя представляет. Но я не понимаю главного: Нахера он нужен именно в этом месте? Какую роль выполняет? Вот также с сущностями в коде. Конечно, давать обстоятельные имена объектам - дело благородное и богоугодное. Но хотелось бы всегда давать имена классам, которые мы используем. Чисто как еще один инструмент для превращения кода в текст на естественном языке. И в плюсах так делать можно!
Алиасинг типов, введенный в С++11, дает нам удобный механизм определения синонимов типов. Это как typedef, только на стероидах. Не будем сейчас говорить о их различиях. Нам важна суть. Мы можем написать:
using ResponseFrequencyByInstance = std::unordered_map<instance_id, size_t>;
И получим человеческое название для структуры, которая хранит частоту ответов, присылаемых от разных инстансов сервиса. И нам уже не важно, что конкретно лежит в основе этой структуры. По названию видно ее предназначение, а нам только это и нужно. А имена этих объектов могут включать уже другую информацию, такую как: единицу измерения отрезка времени(секунды, миллисекунды) или указание конкретного сервиса, для которого собирается статистика. Конечно, всегда рядом с именем объекта мы постоянно должны будем помнить его тип, чтобы получить всю информацию о нем. Однако современные IDE сильно облегчили нашу жизнь в этом плане. Простым наведением курсора на объект мы увидим плашку с типом этого объекта.
Теперь мы можем давать понятные имена любым классам на свой выбор, если видим потребность в более детальной проработке смыслов.
Новичков скорее всего будет отпугивать обилие использование этих алиасов, но это фактически необходимость для поддержания ясности кода и действительно рабочая вещь.
Stay helpful. Stay cool.
#cpp11 #design #goodpractice
{kind=link}
Ретроспектива
Ретроспективой называют регулярные встречи разработчиков для анализа процессов, возникших неудобств и проблем. Это помогает не только выявить и исправить текущие проблемы, улучшить процессы, но и закрепить успешные практики.
«Нормальные люди… считают, что если не сломано – не чини. Инженеры считают, что если не сломано – значит недостаточно улучшено» – Скотт Адамс.
Я глубоко убежден, что всё находится в вечной градации: либо развивается, либо деградирует. Причем, деградация – это неявно определенное поведение по умолчанию компилятором жизни 😅 В основном, потому что развивается что-то другое, более естественное, чем разработка ПО. Следовательно, необходимо явно определять поведение, влияющее на наше развитие в контексте коллективной разработки.
Одним из таких инструментов самоорганизации является ретроспектива. Какие преимущества она несёт?
• Улучшение процессов
Нет смысла тратить время зря, если это не является целью встречи. Возможно, это другое собрание.
• Укрепление команды
Общие психотравмы объединяют 🤣 На самом деле, открытое общение помогает лучше понимать друг друга и доверять. Так же, это помогает вовлечь в процесс новых сотрудников.
• Целеполагание
Умение четко формулировать цели и находить пути к их достижению - это двигатель развития людей.
• Извлечение уроков и закрепление практик
Распространение ценных единиц информации, т.е. мемов, является важной составляющей в теории эволюции. Давайте учиться не только на своих, но и на чужих ошибках, а так же сбережем ближнего.
Следствием всех этих действий становится сокращение эмоционально истощающих неудобств, стрессов и фрустраций; избавление от рутины, которая так хорошо замыливает глаза.
В книге «То как мы работаем, – не работает» Tony Schwartz пишет, что умение экономить силы на работе и эффективно их восполнять во время отдыха НАПРЯМУЮ определяет вашу продуктивность. Я полностью согласен с этим утверждением.
Если что-то идет туго, скорее всего, надо пересмотреть способ достижения результата. Чем раньше это сделаешь, тем меньше разочаруешься в будущем.
А вы проводите ретро у себя в команде? Помогает ли вам это?
#goodpractice
Ретроспективой называют регулярные встречи разработчиков для анализа процессов, возникших неудобств и проблем. Это помогает не только выявить и исправить текущие проблемы, улучшить процессы, но и закрепить успешные практики.
«Нормальные люди… считают, что если не сломано – не чини. Инженеры считают, что если не сломано – значит недостаточно улучшено» – Скотт Адамс.
Я глубоко убежден, что всё находится в вечной градации: либо развивается, либо деградирует. Причем, деградация – это неявно определенное поведение по умолчанию компилятором жизни 😅 В основном, потому что развивается что-то другое, более естественное, чем разработка ПО. Следовательно, необходимо явно определять поведение, влияющее на наше развитие в контексте коллективной разработки.
Одним из таких инструментов самоорганизации является ретроспектива. Какие преимущества она несёт?
• Улучшение процессов
Нет смысла тратить время зря, если это не является целью встречи. Возможно, это другое собрание.
• Укрепление команды
Общие психотравмы объединяют 🤣 На самом деле, открытое общение помогает лучше понимать друг друга и доверять. Так же, это помогает вовлечь в процесс новых сотрудников.
• Целеполагание
Умение четко формулировать цели и находить пути к их достижению - это двигатель развития людей.
• Извлечение уроков и закрепление практик
Распространение ценных единиц информации, т.е. мемов, является важной составляющей в теории эволюции. Давайте учиться не только на своих, но и на чужих ошибках, а так же сбережем ближнего.
Следствием всех этих действий становится сокращение эмоционально истощающих неудобств, стрессов и фрустраций; избавление от рутины, которая так хорошо замыливает глаза.
В книге «То как мы работаем, – не работает» Tony Schwartz пишет, что умение экономить силы на работе и эффективно их восполнять во время отдыха НАПРЯМУЮ определяет вашу продуктивность. Я полностью согласен с этим утверждением.
Если что-то идет туго, скорее всего, надо пересмотреть способ достижения результата. Чем раньше это сделаешь, тем меньше разочаруешься в будущем.
А вы проводите ретро у себя в команде? Помогает ли вам это?
#goodpractice
{kind=link}
И еще раз про именование сущностей
В прошлых постах тут и тут мы говорили больше про чистоту и понятность кода. Здесь поговорим немного про безопасность.
Люди часто пишут код, описывая больше технические детали, а не абстракции и способы взаимодействия с ними. Типа если функция хочет обрабатывать токены слов и их частоту в тексте, люди напишут void func(std::unordered_map<std::string, size_t> token_frequency). Что в этом плохого? Ну повторю себя отсюда, что так уменьшаются возможности по подробному описанию сущности и раскрываются ненужные для верхнеуровневого чтения кода детали. Но это полбеды. Еще одна проблема - я могу передать в эту функцию любое неупорядоченное отображение строки в число. С совершенно другим смыслом. По случайности, неосторожности, из любопытства. Неважно. Объект будет нести другой смысл, его не для этого создавали. Однако я могу его использовать, как аргумент для этой функции. Пример может показаться игрушечным и безобидным. Это лишь, чтобы показать суть. В своем самописном условном телеграмм-боте вы можете не запариваться над такими вещами. Там нет особого смысла в безопасности и размножении сущностей.
А по-настоящему раскрывается эта проблема там, где есть запрос на безопасность. Например, в приложениях, широко использующих криптографию. Обычно там есть несколько методов шифрования и несколько типов объектов, которые этому шифрованию подвергаются. Очевидно, что ключи для разных алгоритмов должны иметь разный тип. Даже тот же RSA не имеет фиксированного размера для ключей, а для AES - имеет. Но вот не так очевидно, что ключи одного алгоритма должны иметь разные типы для каждого из объектов, которые будут зашифрованы этими ключами. Условно, для банковского приложения, ключ AES для шифрования сообщений пользователя и его банковской истории должны иметь разный тип, хотя структура ключа одна и та же. Делается это для того, чтобы программист оперировал именно теми сущностями, которые нужны именно под эту конкретную задачу. Чтобы не было случайно или специально в виде ключа для сообщений был подсунут ключ для банковской истории. Нужно осознанно создать объект подходящего класса и оперировать им в подходящих местах. Все это повышает безопасность приложения и данных.
Есть же алиасинг, скажете вы. Зачем явно плодить сущности? Проблема юзингов и тайпдефов в том, что они не отличимы для компилятора от типов оригиналов. И соотвественно, они взаимозаменяемы. Да, синонимы хороши для понятности кода. Но если мы хотим обезопасить наш код - этот способ не пойдет.
Не нужно оборачивать каждый контейнер в кастомный класс, это излишне. Но нужно проектировать системы так, чтобы их нельзя было использовать не по заданному сценарию.
Stay safe. Stay cool.
#goodpractice #design
В прошлых постах тут и тут мы говорили больше про чистоту и понятность кода. Здесь поговорим немного про безопасность.
Люди часто пишут код, описывая больше технические детали, а не абстракции и способы взаимодействия с ними. Типа если функция хочет обрабатывать токены слов и их частоту в тексте, люди напишут void func(std::unordered_map<std::string, size_t> token_frequency). Что в этом плохого? Ну повторю себя отсюда, что так уменьшаются возможности по подробному описанию сущности и раскрываются ненужные для верхнеуровневого чтения кода детали. Но это полбеды. Еще одна проблема - я могу передать в эту функцию любое неупорядоченное отображение строки в число. С совершенно другим смыслом. По случайности, неосторожности, из любопытства. Неважно. Объект будет нести другой смысл, его не для этого создавали. Однако я могу его использовать, как аргумент для этой функции. Пример может показаться игрушечным и безобидным. Это лишь, чтобы показать суть. В своем самописном условном телеграмм-боте вы можете не запариваться над такими вещами. Там нет особого смысла в безопасности и размножении сущностей.
А по-настоящему раскрывается эта проблема там, где есть запрос на безопасность. Например, в приложениях, широко использующих криптографию. Обычно там есть несколько методов шифрования и несколько типов объектов, которые этому шифрованию подвергаются. Очевидно, что ключи для разных алгоритмов должны иметь разный тип. Даже тот же RSA не имеет фиксированного размера для ключей, а для AES - имеет. Но вот не так очевидно, что ключи одного алгоритма должны иметь разные типы для каждого из объектов, которые будут зашифрованы этими ключами. Условно, для банковского приложения, ключ AES для шифрования сообщений пользователя и его банковской истории должны иметь разный тип, хотя структура ключа одна и та же. Делается это для того, чтобы программист оперировал именно теми сущностями, которые нужны именно под эту конкретную задачу. Чтобы не было случайно или специально в виде ключа для сообщений был подсунут ключ для банковской истории. Нужно осознанно создать объект подходящего класса и оперировать им в подходящих местах. Все это повышает безопасность приложения и данных.
Есть же алиасинг, скажете вы. Зачем явно плодить сущности? Проблема юзингов и тайпдефов в том, что они не отличимы для компилятора от типов оригиналов. И соотвественно, они взаимозаменяемы. Да, синонимы хороши для понятности кода. Но если мы хотим обезопасить наш код - этот способ не пойдет.
Не нужно оборачивать каждый контейнер в кастомный класс, это излишне. Но нужно проектировать системы так, чтобы их нельзя было использовать не по заданному сценарию.
Stay safe. Stay cool.
#goodpractice #design
{kind=link}
Реальная ценность ссылок
Да и помните, как вводятся ссылки в учебных целях? Помню читал, что они нужны, чтобы внутри функции изменять переменную и эти изменения отразились в вызывающем блоке кода. И это удобнее указателя, потому что не нужно его разыменовывать. Все. С таким подходом естественно, что никто нихрена не понимает предназначения ссылок. Может только я так криво читал книжки. Это очень на меня похоже. Но раз я такой есть, значит есть и другие, похожие на меня. Поэтому этот пост для всех тех, кто читаешь книжки затылком, или просто новичков, которые не писали много кода.
Как бы функционал-то правильный, никто не спорит. С помощью ссылки в функции действительно можно проводить манипуляции с тем же самым объектом, что мы в нее передали и эти изменения отражаются на этом оригинальном объекте. На этом все основано. Но из этого поначалу довольно сложно сформулировать реальные кейсы использования ссылок. Собсна, погнали их разбирать.
У них есть 5 функции(ну или это я столько придумал)
1️⃣ Предотвращение лишнего копирования объекта при передаче в функцию. Ссылка - обертка над указателем, поэтому она занимает всего 4|8 байт и позволяет получить доступ к памяти, где находится объект. Опять же, наверняка в книжках объясняется, что ссылка - это обертка, но, как мне кажется, черезчур большой акцент делается на возможности изменения объекта, на который ссылается псевдоним. В очень многих ситуациях, когда в функции один из параметров - ссылка, она используется как read-only сущность. Тогда она помечена как const. Поэтому она лишь задает значение другим сущностям. А раз так, то нам в целом и нужен этот функционал изменения оригинального объекта и можно подумать, что в этом случае нужно по значению принимать аргумент. А вот нет. Тогда у нас будет дополнительное копирование. Нам такого не нужно. Мы общество без лишних копирований! Поэтому можно воспользоваться свойством, что ссылка - обертка над указателем. А значит мы можем с ее помощью без копирований задать значение другим объектам.
2️⃣ Output параметры. Уже ближе к способности изменения оригинального объекта. Иногда не хватает одного возвращаемого значения в функции, поэтому прибегают к использованию output параметров, чтобы функция передала нужную информацию через них. Есть конечно туплы или можно запилить отдельный класс, который в себе будет инкапсулировать нужные параметры, и возвращать его. Но туплы не очень информативные, так как у их элементов нет своих имен, а постоянно плодить сущности - не всегда удобно. Поэтому на помощь могут прийти output параметры. В этом случае они передаются по неконстантной ссылке. Просто в функцию передаются "пустые" объекты, то есть только что дефолтно созданные. И в этой функции на них нанизывается нужная информация. Которую мы потом может достать с помощью такой ссылочной семантики.
3️⃣ Изменение оригинального объекта. Эт вот та история, с которой я начал. Но! По моему опыту, это не самый популярный кейс использования ссылок. Попробую объяснить. Для кастомных классов очень часто приходится использовать std::shared_ptr, если время его жизни больше времени жизни скоупа. Тогда этот указатель везде передается по константной ссылке, хотя и объект, на который он указывает, можно изменять. Если нужно изменить какой-то объект, который создан на стеке, это нужно скорее делать через его собственные методы, а не сторонние функции. Так объект становится актором и проще воспринимать действия, которые происходят с ним происходят. Это вот та самая инкапсуляция.
4️⃣ Предоставление доступа к содержимому класса, без раскрытия приватных членов. Таким свойством обладает неконстантный operator[] для контейнеров STL. Вектору опасно предоставлять доступ к буфферу данных, где хранятся все объекты. Но более менее безопасно давать доступ к отдельным элементам для возможности их модификации. Это очень похожая на прошлый пример механика. Только в качестве текущего стейта выступает объект со своим содержимым, а модифицирующей функцией - текущая функция, в которой применяем operator[].
ПРОДОЛЖЕНИЕ В КОММЕНТАХ
#cppcore #goodpractice #design #STL
Да и помните, как вводятся ссылки в учебных целях? Помню читал, что они нужны, чтобы внутри функции изменять переменную и эти изменения отразились в вызывающем блоке кода. И это удобнее указателя, потому что не нужно его разыменовывать. Все. С таким подходом естественно, что никто нихрена не понимает предназначения ссылок. Может только я так криво читал книжки. Это очень на меня похоже. Но раз я такой есть, значит есть и другие, похожие на меня. Поэтому этот пост для всех тех, кто читаешь книжки затылком, или просто новичков, которые не писали много кода.
Как бы функционал-то правильный, никто не спорит. С помощью ссылки в функции действительно можно проводить манипуляции с тем же самым объектом, что мы в нее передали и эти изменения отражаются на этом оригинальном объекте. На этом все основано. Но из этого поначалу довольно сложно сформулировать реальные кейсы использования ссылок. Собсна, погнали их разбирать.
У них есть 5 функции(ну или это я столько придумал)
1️⃣ Предотвращение лишнего копирования объекта при передаче в функцию. Ссылка - обертка над указателем, поэтому она занимает всего 4|8 байт и позволяет получить доступ к памяти, где находится объект. Опять же, наверняка в книжках объясняется, что ссылка - это обертка, но, как мне кажется, черезчур большой акцент делается на возможности изменения объекта, на который ссылается псевдоним. В очень многих ситуациях, когда в функции один из параметров - ссылка, она используется как read-only сущность. Тогда она помечена как const. Поэтому она лишь задает значение другим сущностям. А раз так, то нам в целом и нужен этот функционал изменения оригинального объекта и можно подумать, что в этом случае нужно по значению принимать аргумент. А вот нет. Тогда у нас будет дополнительное копирование. Нам такого не нужно. Мы общество без лишних копирований! Поэтому можно воспользоваться свойством, что ссылка - обертка над указателем. А значит мы можем с ее помощью без копирований задать значение другим объектам.
2️⃣ Output параметры. Уже ближе к способности изменения оригинального объекта. Иногда не хватает одного возвращаемого значения в функции, поэтому прибегают к использованию output параметров, чтобы функция передала нужную информацию через них. Есть конечно туплы или можно запилить отдельный класс, который в себе будет инкапсулировать нужные параметры, и возвращать его. Но туплы не очень информативные, так как у их элементов нет своих имен, а постоянно плодить сущности - не всегда удобно. Поэтому на помощь могут прийти output параметры. В этом случае они передаются по неконстантной ссылке. Просто в функцию передаются "пустые" объекты, то есть только что дефолтно созданные. И в этой функции на них нанизывается нужная информация. Которую мы потом может достать с помощью такой ссылочной семантики.
3️⃣ Изменение оригинального объекта. Эт вот та история, с которой я начал. Но! По моему опыту, это не самый популярный кейс использования ссылок. Попробую объяснить. Для кастомных классов очень часто приходится использовать std::shared_ptr, если время его жизни больше времени жизни скоупа. Тогда этот указатель везде передается по константной ссылке, хотя и объект, на который он указывает, можно изменять. Если нужно изменить какой-то объект, который создан на стеке, это нужно скорее делать через его собственные методы, а не сторонние функции. Так объект становится актором и проще воспринимать действия, которые происходят с ним происходят. Это вот та самая инкапсуляция.
4️⃣ Предоставление доступа к содержимому класса, без раскрытия приватных членов. Таким свойством обладает неконстантный operator[] для контейнеров STL. Вектору опасно предоставлять доступ к буфферу данных, где хранятся все объекты. Но более менее безопасно давать доступ к отдельным элементам для возможности их модификации. Это очень похожая на прошлый пример механика. Только в качестве текущего стейта выступает объект со своим содержимым, а модифицирующей функцией - текущая функция, в которой применяем operator[].
ПРОДОЛЖЕНИЕ В КОММЕНТАХ
#cppcore #goodpractice #design #STL
Защищенные методы vs защищенные поля
ООП - вещь занятная и многогранная. Почему-то пришла в голову аналогия с математикой: есть начальные заданные правила(принципы и аксиомы), благодаря которым выводятся весьма нетривиальные следствия. Сегодня поговорим о довольно базовом следствии, которое однако далеко не у всех в голове есть.
Есть у вас класс и вы хотите дать его наследникам и только им возможность изменять поля класса. И у нас для этого есть два подхода: объявить поля protected и дать возможность наследникам изменять их напрямую или ввести protected методы, которые определяют полный набор изменений этих полей. Какой вариант более предпочтительный и почему?
Сразу раскрою карты: лучше определять защищенный интерфейс вместо прямого доступа к полям. Для этого есть несколько причин:
💥 Как только член класса становится более "доступен", чем private, вы даете гарантии другим классам о том, как этот член будет себя вести. Точнее никаких гарантий вы не даете. Поскольку поле совершенно неконтролируемо, размещение его "в дикой природе" открывает вашему классу и классам, которые наследуют от вашего класса или взаимодействуют с ним, прекрасный вид на саванну, а точнее море ошибок. Нет никакого способа узнать, когда меняется поле, нет никакого способа контролировать, кто или что его меняет.
💥 Если вы хотите хоть что-то похожее на безопасное приложения, вам нужны всякого рода проверки . Иногда они могут занимать несколько строчек кода. И если ваш код зависит от какого-то состояния класса, то при каждом использовании защищенного поля, вам нужно проверять, все ли с ним в порядке, все ли валидно. Насколько же проще вынести все такие проверки в защищенный метод и закрыть у себя в голове этот гештальт.
💥Когда вы определяете защищенный интерфейс, вы автоматически ограничиваете наследников в использовании ваших приватных членов, которые могли бы быть защищенными. А ограничения в программировании - это хорошо! Чем меньше вы позволяете сделать непотребств со своим классом или использовать его вне предполагаемых сценариях использования - тем лучше!
💥 Это даже тестирование упрощает. Есть четкие сценарии поведения, которые можно проверить на корректность. Очень легко с такими исходными данными писать тесты. А легкость тестирования мотивирует его в принципе делать, а не класть на него лысину(ставь лайк, если понял game of words).
💥 Количество наследников у класса может быть много и все будут завязаны на самостоятельном управлении protected членами. А если в будущем обработка этих полей изменится, то необходимы будут изменения во всех наследниках. Защищенный интерфейс делает все такие изменения локализованными в родительском классе, то есть в одном месте. Это снижает стоимость внесения изменений.
Инкапсуляция - гениальная вещь. Придерживаясь этого принципа, вы защищайте свои данные непреднамеренного изменения и позволяете изменениям не распространяться за пределы одного класса.
Protect your secrets. Stay cool.
#OOP #goodpractice #design
ООП - вещь занятная и многогранная. Почему-то пришла в голову аналогия с математикой: есть начальные заданные правила(принципы и аксиомы), благодаря которым выводятся весьма нетривиальные следствия. Сегодня поговорим о довольно базовом следствии, которое однако далеко не у всех в голове есть.
Есть у вас класс и вы хотите дать его наследникам и только им возможность изменять поля класса. И у нас для этого есть два подхода: объявить поля protected и дать возможность наследникам изменять их напрямую или ввести protected методы, которые определяют полный набор изменений этих полей. Какой вариант более предпочтительный и почему?
Сразу раскрою карты: лучше определять защищенный интерфейс вместо прямого доступа к полям. Для этого есть несколько причин:
💥 Как только член класса становится более "доступен", чем private, вы даете гарантии другим классам о том, как этот член будет себя вести. Точнее никаких гарантий вы не даете. Поскольку поле совершенно неконтролируемо, размещение его "в дикой природе" открывает вашему классу и классам, которые наследуют от вашего класса или взаимодействуют с ним, прекрасный вид на саванну, а точнее море ошибок. Нет никакого способа узнать, когда меняется поле, нет никакого способа контролировать, кто или что его меняет.
💥 Если вы хотите хоть что-то похожее на безопасное приложения, вам нужны всякого рода проверки . Иногда они могут занимать несколько строчек кода. И если ваш код зависит от какого-то состояния класса, то при каждом использовании защищенного поля, вам нужно проверять, все ли с ним в порядке, все ли валидно. Насколько же проще вынести все такие проверки в защищенный метод и закрыть у себя в голове этот гештальт.
💥Когда вы определяете защищенный интерфейс, вы автоматически ограничиваете наследников в использовании ваших приватных членов, которые могли бы быть защищенными. А ограничения в программировании - это хорошо! Чем меньше вы позволяете сделать непотребств со своим классом или использовать его вне предполагаемых сценариях использования - тем лучше!
💥 Это даже тестирование упрощает. Есть четкие сценарии поведения, которые можно проверить на корректность. Очень легко с такими исходными данными писать тесты. А легкость тестирования мотивирует его в принципе делать, а не класть на него лысину(ставь лайк, если понял game of words).
💥 Количество наследников у класса может быть много и все будут завязаны на самостоятельном управлении protected членами. А если в будущем обработка этих полей изменится, то необходимы будут изменения во всех наследниках. Защищенный интерфейс делает все такие изменения локализованными в родительском классе, то есть в одном месте. Это снижает стоимость внесения изменений.
Инкапсуляция - гениальная вещь. Придерживаясь этого принципа, вы защищайте свои данные непреднамеренного изменения и позволяете изменениям не распространяться за пределы одного класса.
Protect your secrets. Stay cool.
#OOP #goodpractice #design
{kind=link}
Construct on first use idiom
Давайте здесь по-подробнее остановимся. Вещь важная. Предыдущий пост. #опытным
Название говорящее и говорит оно нам, что объект будет конструироваться при первом использовании, а не когда-то заранее. То есть это ленивые вычисления.
Суть в том, чтобы создавать объект только в тот момент, когда он нам понадобиться. Так мы можем четко контролировать момент его инициализации. Делается это с помощью статических локальных переменных.
Мы помним, что они инициализируются при первом вызове функции и существуют они до смерти всей программы. Таким образом, если мы из функции будем возвращать ссылку на эту переменную, то есть сделаем такой геттер, то мы функционально будем иметь глобальную переменную, для которой мы контролируем начало ее жизни.
Вернемся к примеру и посмотрим, как это выглядит. Было так:
а теперь стало так:
Переменная
Теперь следите за руками: мы берем и оборачивает переменную, задающую значение, в функцию-геттер, которая просто выдает наружу значение этой переменной. Но инициализироваться
Теперь результат компиляции не зависит от порядка файлов, которые передаются на вход. Что так
Если у класса есть статическое поле и создание класса зависит от этого статического поля, то попробуйте перенести это поле внутрь статической функции(пример из этого поста):
Теперь во всех местах использования бывшего статического поля, мы вызывает статический метод. Таким образом наша мапа создается ровно по первому нашему хотению и создавать статический объект класса InitializationTest теперь абсолютно безопасно.
Если у вас есть 2 статических объекта пользовательского типа и инициализация одного из них предполагает использование другого, то можно сделать так(пример нагло украден у подписчика Бобра из этого коммента)
В этом примере создание объекта класса AnotherSingleton зависит от объекта Singleton. Поэтому мы запрещаем плебесам создавать объекты класса Singleton, а создаем его один раз в статической функции геттера инстанса объекта и дальше везде используем только этот инстанс.
Заключение в комментах
Solve your problems. Stay cool.
#cppcore #goodpractice #design
Давайте здесь по-подробнее остановимся. Вещь важная. Предыдущий пост. #опытным
Название говорящее и говорит оно нам, что объект будет конструироваться при первом использовании, а не когда-то заранее. То есть это ленивые вычисления.
Суть в том, чтобы создавать объект только в тот момент, когда он нам понадобиться. Так мы можем четко контролировать момент его инициализации. Делается это с помощью статических локальных переменных.
Мы помним, что они инициализируются при первом вызове функции и существуют они до смерти всей программы. Таким образом, если мы из функции будем возвращать ссылку на эту переменную, то есть сделаем такой геттер, то мы функционально будем иметь глобальную переменную, для которой мы контролируем начало ее жизни.
Вернемся к примеру и посмотрим, как это выглядит. Было так:
// source.cpp
int quad(int n) {
return n * n;
}
auto staticA = quad(5);
// main.cpp
#include <iostream>
extern int staticA;
auto staticB = staticA;
int main() {
std::cout << "staticB: " << staticB << std::endl;
}
а теперь стало так:
// source.cpp
int quad(int n) {
return n * n;
}
int& GetStaticA() {
static int staticA = quad(5);
return staticA;
}
// main.cpp
#include <iostream>
int& GetStaticA();
static auto staticB = GetStaticA();
// just omit main
Переменная
staticB зависит от значения staticA и это может вызвать проблемы, если инициализации staticB произойдет первой.Теперь следите за руками: мы берем и оборачивает переменную, задающую значение, в функцию-геттер, которая просто выдает наружу значение этой переменной. Но инициализироваться
staticA будет ровно в момент первого вызова функции GetStaticA. Таким образом, мы форсим рантайм инициализировать staticA первым при любых обстоятельствах.Теперь результат компиляции не зависит от порядка файлов, которые передаются на вход. Что так
g++ main.cpp source.cpp, что так g++ source.cpp main.cpp, результат будет staticB: 25.Если у класса есть статическое поле и создание класса зависит от этого статического поля, то попробуйте перенести это поле внутрь статической функции(пример из этого поста):
using Map = std::map<std::string, std::unique_ptr<InitializationTest>>;
class InitializationTest {
public:
static Map& GetMap() {
static Map map;
return map;
}
static bool Create(std::string ID) {
GetMap().insert({ID, std::move(std::unique_ptr<InitializationTest>{new InitializationTest})});
return true;
}
private:
static Map map;
Test() = default;
};
static bool creation_result = InitializationTest::Create("qwe");
int main() {}
Теперь во всех местах использования бывшего статического поля, мы вызывает статический метод. Таким образом наша мапа создается ровно по первому нашему хотению и создавать статический объект класса InitializationTest теперь абсолютно безопасно.
Если у вас есть 2 статических объекта пользовательского типа и инициализация одного из них предполагает использование другого, то можно сделать так(пример нагло украден у подписчика Бобра из этого коммента)
// singleton.h
class Singleton {
public:
static Singleton& instance() {
static Singleton inst{};
return inst;
}
int makeSomethingUsefull(){}
private:
Singleton() = default;
};
//another_singleton.h
#include "singleton.h"
class AnotherSingleton {
public:
static AnotherSingleton& instance() {;
static AnotherSingleton inst{Singleton::instance().makeSomethingUsefull()};
return inst;
}
private:
AnotherSingleton(int param) : data{param} {};
int data;
};
В этом примере создание объекта класса AnotherSingleton зависит от объекта Singleton. Поэтому мы запрещаем плебесам создавать объекты класса Singleton, а создаем его один раз в статической функции геттера инстанса объекта и дальше везде используем только этот инстанс.
Заключение в комментах
Solve your problems. Stay cool.
#cppcore #goodpractice #design
Telegram
Грокаем C++
Решение static initialization order fiasco
Раз есть проблема - должно быть и решение. Сегодня поговорим о паре-тройке вариантов. Пост вдохновлен этим комментом нашего подписчика Антона.
Очевидно, что в комментах немного поразгоняли эту тему. Поэтому вот…
Раз есть проблема - должно быть и решение. Сегодня поговорим о паре-тройке вариантов. Пост вдохновлен этим комментом нашего подписчика Антона.
Очевидно, что в комментах немного поразгоняли эту тему. Поэтому вот…
Проблема Construct on first use idiom
#опытным
Прошлый пост показывает решение проблемы static initialization order fiasco. Однако даже этот прием имеет свои проблемы.
Дело в том, что мы сильно фокусировались на инициализации объекта и решали проблемы с ней. Но как насчет разрушения объекта? Мы подумали об этом? Not really.
Давайте возьмем классы, которые могут быть использованы для создания и статических объектов и любых других.
У нас все также 2 класса, но они уже не синглтоны, а могут создаваться в какой угодно области. Нам нужны статические объекты этих классов. И мы, как умные дяди, оградили себя от проблемы инициализации статиков, используя construct on first use idiom. Однако замечу, что в деструкторах наших классов они используют глобальную переменную another_global. И например, для объектов с автоматическим временем жизни это вообще не проблема, они свободно создаются и разрушаются.
Но что же будет, если так получится, что another_global удалится раньше, чем статические объекты наших классов? Правильно. Static deinitialization order fiasco. Обращение к уже разрушенному объекту - такое же UB, как и обращение к еще не инициализированному.
Кому-то очень сильно сейчас может свести багскулы, потому что логирование в деструкторах объектов, которые могут быть статиками - очень частая вещь, а соотвественно и потенциальная проблема. Подписчики могут подтвердить это в комментах.
Я сознательно тут в пример не ставлю синглтоны, потому что для них еще как-то можно осознать потенциальную проблему самостоятельно: объект один, мы четко понимаем, как он себя ведет, и можем подумать о его разрушении. Но в сегодняшнем примере при создании подобных классов обычно сильно не задумываются, что объект могут создать в статической области, а значит и о статической деинициализации не думают. Такая невнимательность может привести к трудноотловимым багам.
И это проблема не идиомы в целом, а подхода к созданию объекта. Есть и другой способ это делать:
Обратите внимание на магию. Мы внутри статических функций определяем не статические объекты, а статические указатели, к которым при первом вызове прикрепляем динамически созданные объекты. Вроде ничего кардинально не поменялось, но это на первый взгляд.
Мы никогда не вызываем delete. В конце программы разрушится только указатель, но не объект, на который он указывает. Обычно такая ситуация называется data leak, но в этом случае "вы не понимаете, это другое". Потому что при завершении программы ОС сама освобождает всю память, которая была занята программой и на самом деле ничего не утекает. Утечка памяти - это постоянное увеличение использования памяти программы со временем ее жизни. А тут мы один раз захватили эту память(и только эту!), но просто не отдали. Потребление памяти в течение программы не увеличивается. Как говорится: "Это норма!".
Этот вариант конечно не подойдет для тех случаев, если вам прям обязательно как-то сигнализировать о разрушении всех-превсех объектов этого класса и без этого никуда. Но он совершенно точно избавит вас от потенциальных проблем деинициализации(ее просто не будет хехе), если вам не важен деструктор статических объектов.
See drawbacks of your solutions. Stay cool.
#goodpractice #design #cppcore
#опытным
Прошлый пост показывает решение проблемы static initialization order fiasco. Однако даже этот прием имеет свои проблемы.
Дело в том, что мы сильно фокусировались на инициализации объекта и решали проблемы с ней. Но как насчет разрушения объекта? Мы подумали об этом? Not really.
Давайте возьмем классы, которые могут быть использованы для создания и статических объектов и любых других.
// ClassA.h
class ClassA {
public:
int makeSomethingUsefull(){}
~ClassA() { another_global.use_it();}
};
static ClassA& GetStaticClassA() {
static ClassA inst{};
return inst;
}
//another_singleton.h
#include "singleton.h"
class ClassB {
public:
ClassB(int param) : data{param} {};
~ClassB() { another_global.use_it();}
private:
int data;
};
static ClassB& GetStaticClassB() {;
static ClassB inst{GetStaticClassA().makeSomethingUsefull()};
return inst;
}
У нас все также 2 класса, но они уже не синглтоны, а могут создаваться в какой угодно области. Нам нужны статические объекты этих классов. И мы, как умные дяди, оградили себя от проблемы инициализации статиков, используя construct on first use idiom. Однако замечу, что в деструкторах наших классов они используют глобальную переменную another_global. И например, для объектов с автоматическим временем жизни это вообще не проблема, они свободно создаются и разрушаются.
Но что же будет, если так получится, что another_global удалится раньше, чем статические объекты наших классов? Правильно. Static deinitialization order fiasco. Обращение к уже разрушенному объекту - такое же UB, как и обращение к еще не инициализированному.
Кому-то очень сильно сейчас может свести багскулы, потому что логирование в деструкторах объектов, которые могут быть статиками - очень частая вещь, а соотвественно и потенциальная проблема. Подписчики могут подтвердить это в комментах.
Я сознательно тут в пример не ставлю синглтоны, потому что для них еще как-то можно осознать потенциальную проблему самостоятельно: объект один, мы четко понимаем, как он себя ведет, и можем подумать о его разрушении. Но в сегодняшнем примере при создании подобных классов обычно сильно не задумываются, что объект могут создать в статической области, а значит и о статической деинициализации не думают. Такая невнимательность может привести к трудноотловимым багам.
И это проблема не идиомы в целом, а подхода к созданию объекта. Есть и другой способ это делать:
// ClassA.h
// Here Class A definition
static ClassA& GetStaticClassA() {
static ClassA* inst = new ClassA{};
return *inst;
}
//another_singleton.h
#include "singleton.h"
// Here ClassB definition
static ClassB& GetStaticClassB() {;
static ClassB* inst = new ClassB{GetStaticClassA().makeSomethingUsefull()};
return *inst;
}
Обратите внимание на магию. Мы внутри статических функций определяем не статические объекты, а статические указатели, к которым при первом вызове прикрепляем динамически созданные объекты. Вроде ничего кардинально не поменялось, но это на первый взгляд.
Мы никогда не вызываем delete. В конце программы разрушится только указатель, но не объект, на который он указывает. Обычно такая ситуация называется data leak, но в этом случае "вы не понимаете, это другое". Потому что при завершении программы ОС сама освобождает всю память, которая была занята программой и на самом деле ничего не утекает. Утечка памяти - это постоянное увеличение использования памяти программы со временем ее жизни. А тут мы один раз захватили эту память(и только эту!), но просто не отдали. Потребление памяти в течение программы не увеличивается. Как говорится: "Это норма!".
Этот вариант конечно не подойдет для тех случаев, если вам прям обязательно как-то сигнализировать о разрушении всех-превсех объектов этого класса и без этого никуда. Но он совершенно точно избавит вас от потенциальных проблем деинициализации(ее просто не будет хехе), если вам не важен деструктор статических объектов.
See drawbacks of your solutions. Stay cool.
#goodpractice #design #cppcore
{kind=link}
C-style cast
#новичкам
Как уже неоднократно было нами отмечено, что язык C++ разрабатывался с поддержкой обратной совместимости языка C. В частности, в C++ поддерживается приведение в стиле C:
Это достаточно короткий и, на первый взгляд, интуитивно понятный оператор, за что его необоснованно любят использовать в C++.
Вот давайте вспомним все операторы приведения, про которые мы успели рассказать? У нас были посты про:
- static_cast
- reinterpret_cast
- const_cast
- dynamic_cast
У каждого из них есть своя область применения и соответствующий алгоритм приведения, а так же наборы проверок! Т.к. C-style cast сочетает в себе все вышеперечисленные операторы, то большая часть проверок просто отсутствует... Они не проверяют конкретный случай, что является очень опасным моментом.
В случае невозможности желаемого приведения, C-style cast совершит другое подходящее. Рассмотрим ошибку из живого примера:
Мы хотели привести
Давайте вспомним про приведение между ветками ромбовидного наследования из статьи про
Опустим тему с
И вот ладно, дело во внимательности и понимании предназначения операторов... C-style cast позволяет выполнить приведение к приватным предкам класса: живой пример. Вот от вас намеренно хотели скрыть возможность вмешательства в поведение предка, а вы это ограничение обошли и даже не заметили подвоха. Увидеть это на ревью так же сложно! Это ведет к очень забагованному поведению программы.
Оператор C-style cast скрывает в себе достаточно неочевидное поведение в некоторых ситуациях. Его сложно заметить, его сложно отлаживать. Возможно, что будет проще отказаться от него вовсе, чем помнить о всех подводных камнях. Предупреждения вам в помощь! Добавляйте опцию компилятора:
#cppcore #goodpractice
#новичкам
Как уже неоднократно было нами отмечено, что язык C++ разрабатывался с поддержкой обратной совместимости языка C. В частности, в C++ поддерживается приведение в стиле C:
int value = (int)arg;
Это достаточно короткий и, на первый взгляд, интуитивно понятный оператор, за что его необоснованно любят использовать в C++.
Вот давайте вспомним все операторы приведения, про которые мы успели рассказать? У нас были посты про:
- static_cast
- reinterpret_cast
- const_cast
- dynamic_cast
У каждого из них есть своя область применения и соответствующий алгоритм приведения, а так же наборы проверок! Т.к. C-style cast сочетает в себе все вышеперечисленные операторы, то большая часть проверок просто отсутствует... Они не проверяют конкретный случай, что является очень опасным моментом.
В случае невозможности желаемого приведения, C-style cast совершит другое подходящее. Рассмотрим ошибку из живого примера:
cpp
using PPrintableValue = PrintableValue *;
...
auto data = (PPrintableValue)value;
Мы хотели привести
value к типу PrintableValue (int64_t -> int32_t). Но в результате неудачного нейминга псевдонима мы ошиблись. Вдруг клавиша P залипла просто? Вдруг рефакторинг неудачно прошел? В итоге мы собрали программу, смогли её запустить и привели int64_t к int32_t*, а дальше его попытались разыменовать. На первый взгляд, ошибка непонятна: мы ожидали static_cast, а получили reinterpret_cast. В больших продуктах такие ошибки могут оставаться незамеченными, пока не будет проведено полное тестирование продукта (вами или клиентом).Давайте вспомним про приведение между ветками ромбовидного наследования из статьи про
dynamic_cast. Использование C-style приведения бездумно выполнит то, что от него попросили и вляпается в ошибку, хоть красненьким и не подчеркивается :) На самом деле он выполнит reinterpret_cast, но это логическая ошибка! Нам очевидно, что этот оператор не подходит по смыслу, но может подойти static_cast. Если мы попробуем это сделать, будет ошибка компиляции:error: invalid 'static_cast' from type 'Mother*' to type 'Father*':
Father *switched_son_of_father = static_cast<Father*>(son_of_mother);
Опустим тему с
const_cast, думаю, тут и так все понятно. И вот ладно, дело во внимательности и понимании предназначения операторов... C-style cast позволяет выполнить приведение к приватным предкам класса: живой пример. Вот от вас намеренно хотели скрыть возможность вмешательства в поведение предка, а вы это ограничение обошли и даже не заметили подвоха. Увидеть это на ревью так же сложно! Это ведет к очень забагованному поведению программы.
Оператор C-style cast скрывает в себе достаточно неочевидное поведение в некоторых ситуациях. Его сложно заметить, его сложно отлаживать. Возможно, что будет проще отказаться от него вовсе, чем помнить о всех подводных камнях. Предупреждения вам в помощь! Добавляйте опцию компилятора:
-Wold-style-cast
#cppcore #goodpractice
Member initialization. Best practices
#новичкам
Пост по запросу подписчика. Вот его вопрос.
И реально ведь непонятно, что делать. Столько разных вариантов и возможностей можно придумать для инициализации полей класса, что голова ходит кругом. Какой метод самый оптимальный? Сейчас и будем разбираться.
Здесь я буду приводить какое-то общие и распространенные принципы. К каждому можно придраться и сказать "а у нас в проекте по-другому!". Исключения и другие подходы есть везде. Если хотите высказать свои варианты - комменты открыты.
Начну с того, что нужно предпочитать инициализировать поля либо с помощью списка инициализации конструктора, либо с помощью default member initializer. Дело в том, что все поля на самом деле инициализируются до входа в конструктор! Если списком инициализации или default member initializer'ом не установлено, как поле должно инициализироваться, то в конструктор оно попадет инициализированным по умолчанию. Именно поэтому, например, не можете в конструкторе инициализировать объект класса, у которого нет конструктора по умолчанию. Будет ошибка компиляции и у вас потребуют дефолтный конструктор. Запомните: конструктор нужен для нетривиальных вещей. С простой иницализацией справятся ctor initialization list и инициализатор по умолчанию.
Далее. Остается 2 способа, как инициализировать. Какой из них выбрать и в какой пропорции смешивать?
CppCoreGuidelies говорят нам: "Prefer default member initializers to member initializers in constructors for constant initializers".
То есть, если инициализатор константный, то используйте default member initializer.
Причина: inplace инициализатор делает явным то, что именно эти дефолтовые значения будут использоваться во всех конструкторах. Пример:
Как в этом случае читатель кода поймет, была ли инициализация j специально пропущена(что скорее всего не очень гуд) или было ли для
Более адекватный вариант:
Красота. Все в одном месте, все четко и понятно. Тут используется одна фишка: у вас есть несколько конструкторов, которые могут выставлять значения полям, а могут и не выставлять. Вы в одном месте определяете дефолтные значения и в списках инициализации конструкторов переопределяете инициализирующее значение для нужного поля, так как список подавляет инициализатор по умолчанию.
Также это более читаемый вариант, так как все дефолтные значения находятся в одном месте и не нужно бегать глазами по коду в их поисках.
Используйте default member initializer и будет вам счастье!
Stay happy. Stay cool.
#cpp11 #cppcore #goodpractice
#новичкам
Пост по запросу подписчика. Вот его вопрос.
И реально ведь непонятно, что делать. Столько разных вариантов и возможностей можно придумать для инициализации полей класса, что голова ходит кругом. Какой метод самый оптимальный? Сейчас и будем разбираться.
Здесь я буду приводить какое-то общие и распространенные принципы. К каждому можно придраться и сказать "а у нас в проекте по-другому!". Исключения и другие подходы есть везде. Если хотите высказать свои варианты - комменты открыты.
Начну с того, что нужно предпочитать инициализировать поля либо с помощью списка инициализации конструктора, либо с помощью default member initializer. Дело в том, что все поля на самом деле инициализируются до входа в конструктор! Если списком инициализации или default member initializer'ом не установлено, как поле должно инициализироваться, то в конструктор оно попадет инициализированным по умолчанию. Именно поэтому, например, не можете в конструкторе инициализировать объект класса, у которого нет конструктора по умолчанию. Будет ошибка компиляции и у вас потребуют дефолтный конструктор. Запомните: конструктор нужен для нетривиальных вещей. С простой иницализацией справятся ctor initialization list и инициализатор по умолчанию.
Далее. Остается 2 способа, как инициализировать. Какой из них выбрать и в какой пропорции смешивать?
CppCoreGuidelies говорят нам: "Prefer default member initializers to member initializers in constructors for constant initializers".
То есть, если инициализатор константный, то используйте default member initializer.
Причина: inplace инициализатор делает явным то, что именно эти дефолтовые значения будут использоваться во всех конструкторах. Пример:
class X { // BAD
int i;
string s;
int j;
public:
X() :i{666}, s{"qqq"} { } // j is uninitialized
X(int ii) :i{ii} {} // s is "" and j is uninitialized
// ...
};Как в этом случае читатель кода поймет, была ли инициализация j специально пропущена(что скорее всего не очень гуд) или было ли для
s намеренным выставление его значения в "qqq" в первом случае и в пустую строку во втором случае(почти стопроцентный баг)? Все эти ошибки могут появиться при добавлении новых полей в класс. По классике: добавили новое поле, использовали его в методах, но вот в одном месте упустили инициализацию. Кейс настолько жизненный, что мое почтение.Более адекватный вариант:
class X2 {
int i {666};
string s {"qqq"};
int j {0};
public:
X2() = default; // all members are initialized to their defaults
X2(int ii) :i{ii} {} // s and j initialized to their defaults
// ...
};Красота. Все в одном месте, все четко и понятно. Тут используется одна фишка: у вас есть несколько конструкторов, которые могут выставлять значения полям, а могут и не выставлять. Вы в одном месте определяете дефолтные значения и в списках инициализации конструкторов переопределяете инициализирующее значение для нужного поля, так как список подавляет инициализатор по умолчанию.
Также это более читаемый вариант, так как все дефолтные значения находятся в одном месте и не нужно бегать глазами по коду в их поисках.
Используйте default member initializer и будет вам счастье!
Stay happy. Stay cool.
#cpp11 #cppcore #goodpractice
{kind=link}