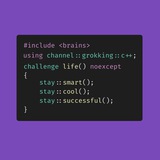
Квиз
#новичкам
Сегодня простенький #quiz на повтор материала. Настолько простенький, что может показаться очевидным. Но не дайте себя обмануть, хорошенько обдумайте и правильно ответьте. Ответ выложу вечером.
У меня к вам всего один вопрос. Что будет в результате попытки компиляции и запуска этого кода?
#новичкам
Сегодня простенький #quiz на повтор материала. Настолько простенький, что может показаться очевидным. Но не дайте себя обмануть, хорошенько обдумайте и правильно ответьте. Ответ выложу вечером.
У меня к вам всего один вопрос. Что будет в результате попытки компиляции и запуска этого кода?
#include <iostream>
int id;
int main()
{
std::cout << id;
}
Принтуем уникальный указатель
#новичкам
Умные указатели делают нашу жизнь намного проще. Они не только такие умные, что нам не стоит беспокоиться о менеджменте памяти. Они еще и очень удобные с точки зрения использования. Мы пользуемся умным указателем почти также, как мы бы пользовались обычным указателем. Все операторы перегружены так, чтобы мы вообще не видели разницу.
И мы понимаем, что это обертка, когда нам нужно достать сам сырой указатель и вызвать метод get().
Один из таких случаев - вывод указателя в поток. Если мы захотим вывести на консоль адрес объекта, то нам нужно будет вызывать метод get.
Но это же странно!
Да, это скорее нужно в каких-то отладочно-логировачных целях и ничего более.
Но нужно же!
Че им стоило перегрузить оператор<<, чтобы мы могли непосредственно сам объект уникального указателя сериализовывать?
Видимо больших затрат. Но ребята поднатужились и справились. В С++20 мы можем выводить сам объект без метода get()!
Ну и конечно в этом случае на консоли появится адрес объекта.
Смысл вывода умного указателя на поток всегда был понятен, поэтому хорошо, что комитет включил такое небольшое изменение в стандарт. Теперь уникальный указатель стал еще более тонкой оберткой.
Make small changes. Stay cool.
#cpp20 #cppcore
#новичкам
Умные указатели делают нашу жизнь намного проще. Они не только такие умные, что нам не стоит беспокоиться о менеджменте памяти. Они еще и очень удобные с точки зрения использования. Мы пользуемся умным указателем почти также, как мы бы пользовались обычным указателем. Все операторы перегружены так, чтобы мы вообще не видели разницу.
И мы понимаем, что это обертка, когда нам нужно достать сам сырой указатель и вызвать метод get().
Один из таких случаев - вывод указателя в поток. Если мы захотим вывести на консоль адрес объекта, то нам нужно будет вызывать метод get.
auto u_ptr = std::make_unique<Type>();
std::cout << u_ptr.get() << std::endl;
Но это же странно!
Да, это скорее нужно в каких-то отладочно-логировачных целях и ничего более.
Но нужно же!
Че им стоило перегрузить оператор<<, чтобы мы могли непосредственно сам объект уникального указателя сериализовывать?
Видимо больших затрат. Но ребята поднатужились и справились. В С++20 мы можем выводить сам объект без метода get()!
auto u_ptr = std::make_unique<Type>();
std::cout << u_ptr << std::endl;
Ну и конечно в этом случае на консоли появится адрес объекта.
Смысл вывода умного указателя на поток всегда был понятен, поэтому хорошо, что комитет включил такое небольшое изменение в стандарт. Теперь уникальный указатель стал еще более тонкой оберткой.
Make small changes. Stay cool.
#cpp20 #cppcore
Различаем преинкремент и постинкремент
#новичкам
Новичкам всегда не просто даются перегрузки операторов. Не то, чтобы кому-то часто приходится перегружать операторы. Но уж эти *нкременты точно редко. Из-за этого особенности постоянно забываются. Давайте же во всем разберемся.
Есть операторы инкремента и декремента. Первые увеличивают значение на какую-то условную единицк, вторые - уменьшаю. Они подразделяются на 2 формы: пре- и пост-. Далее будем все разбирать на примере операторов инкремента, для декремента все аналогично, только меняете плюс на минус.
Преинкремент - увеличивает значение на единицу и возвращает ссылку на уже увеличенное значение. Синтаксис использования такой:
Постинкремент - делает копию исходного числа, увеличивает на единицу оригинал, и возвращает копию по значению. Синтаксис использования такой:
Обычно внешний вид перегрузки операторов внутри описания класса такой:
Например, оператор копирования вызывается с помощью оператора присваивания(=). Поэтому подставляем в шаблон на место
Но теперь возникает вопрос. С++ не различает функции, у которых то же имя, то же те же аргументы, но разные возвращаемые значения. У нас как раз такая ситуация: названия одинаковые(operator++), возвращаемые значения разные(в одном случае возвращаем по ссылке, во втором - по значению) и одинаково отсутствуют аргументы. Если бы мы определили операторы так:
То была бы примерно такая ошибка компиляции:
Что же делать?
Примерно таким же вопросом задался Страуструп и сделал ход конем(правда конь ходил на костылях). Он связал префиксный оператор с человеческой формой объявления, а постфиксный - с вот такой:
Он ввел безымянный интовый параметр функции. Теперь чисто технически, компилятор сможет различить 2 вызова этих операторов и правильно заметчить эти вызовы на нужные определения.
Если видит префикс - выбирает оператор без аргумента, видит постфикс - выбирает с аргументом.
Вопрос, почему тип аргумента именно int - остается открытым. Наверное так было проще.
Итого, так перегружаются операторы инкремента:
Think of your decisions twice. Stay cool.
#cppcore
#новичкам
Новичкам всегда не просто даются перегрузки операторов. Не то, чтобы кому-то часто приходится перегружать операторы. Но уж эти *нкременты точно редко. Из-за этого особенности постоянно забываются. Давайте же во всем разберемся.
Есть операторы инкремента и декремента. Первые увеличивают значение на какую-то условную единицк, вторые - уменьшаю. Они подразделяются на 2 формы: пре- и пост-. Далее будем все разбирать на примере операторов инкремента, для декремента все аналогично, только меняете плюс на минус.
Преинкремент - увеличивает значение на единицу и возвращает ссылку на уже увеличенное значение. Синтаксис использования такой:
++value.Постинкремент - делает копию исходного числа, увеличивает на единицу оригинал, и возвращает копию по значению. Синтаксис использования такой:
value++.Обычно внешний вид перегрузки операторов внутри описания класса такой:
возвращаемое_значение operator{символы_вызова_оператора}(аргументы).Например, оператор копирования вызывается с помощью оператора присваивания(=). Поэтому подставляем в шаблон на место
возвращаемое_значение ссылку на объект, на место символы_вызова_оператора подставляем =, на место аргументов - const Type&. Получается так:Type& operator=(const Type&);
Но теперь возникает вопрос. С++ не различает функции, у которых то же имя, то же те же аргументы, но разные возвращаемые значения. У нас как раз такая ситуация: названия одинаковые(operator++), возвращаемые значения разные(в одном случае возвращаем по ссылке, во втором - по значению) и одинаково отсутствуют аргументы. Если бы мы определили операторы так:
Type& operator++() {
value_ += 1;
return *this;
}
Type operator++() {
auto tmp_value = *this;
value_ += 1;
return tmp_value;
}То была бы примерно такая ошибка компиляции:
functions that differ only in their return type cannot be overloaded.Что же делать?
Примерно таким же вопросом задался Страуструп и сделал ход конем(правда конь ходил на костылях). Он связал префиксный оператор с человеческой формой объявления, а постфиксный - с вот такой:
Type operator++(int) {
auto tmp_value = *this;
value_ += 1;
return tmp_value;
}Он ввел безымянный интовый параметр функции. Теперь чисто технически, компилятор сможет различить 2 вызова этих операторов и правильно заметчить эти вызовы на нужные определения.
Если видит префикс - выбирает оператор без аргумента, видит постфикс - выбирает с аргументом.
Вопрос, почему тип аргумента именно int - остается открытым. Наверное так было проще.
Итого, так перегружаются операторы инкремента:
struct Type {
Type& operator++() {
value_ += 1;
return *this;
}
Type operator++(int) {
auto tmp_value = *this;
value_ += 1;
return tmp_value;
}
private:
IntegerLikeType value_;
};
Think of your decisions twice. Stay cool.
#cppcore
{kind=link}
Виртуальная дружественная функция
#новичкам
Вчера мы поговорили о том, что таких функций не бывает, но очень хочется получить альтернативу. Хочется изменять работу функции в зависимости от динамического типа, который в нее передается.
Ну и на самом деле ничего сложного здесь нет. Можно ведь сделать полиморфный метод, который будет вызываться в этой функции. И вот его поведение мы можем изменять примерно как нашей душеньке захочется.
Рассмотрим банальный пример - сериализация объекта в поток. Обычно для такой задачи используют дружественный оператор <<. Но вот хотелось бы сериализовать в зависимости от динамического типа. Фигня вопрос.
Есть у нас класс человека с его именем и фамилией. Есть класс налогоплательщика, который наследуется от человека и добавляет к полям ИНН. Допустим, мы хотим как-то выводить на консоль содержимое этих людей(в смысле поля; расчленением мы не занимаемся, не в Питере живем все-таки). Можно конечно в каждом классе определять свой оператор или выводить на консоль результат работы метода to_str, но это лишний апи и лишний код.
Мы просто в базовом классе определяем другана и говорим, чтобы он вызывал виртуальный метод. И все.
Да, это очень просто. Но подход скрытия деталей реализации за закрытым виртуальным методом используется, например в идиоме невиртуального интерфейса и еще невесть где. Поэтому о даже о таком приеме надо знать и применять его в подходящих ситуациях.
Have a real friends. Stay cool.
#cppcore
#новичкам
Вчера мы поговорили о том, что таких функций не бывает, но очень хочется получить альтернативу. Хочется изменять работу функции в зависимости от динамического типа, который в нее передается.
Ну и на самом деле ничего сложного здесь нет. Можно ведь сделать полиморфный метод, который будет вызываться в этой функции. И вот его поведение мы можем изменять примерно как нашей душеньке захочется.
Рассмотрим банальный пример - сериализация объекта в поток. Обычно для такой задачи используют дружественный оператор <<. Но вот хотелось бы сериализовать в зависимости от динамического типа. Фигня вопрос.
struct Person {
Person(const std::string &first_name,
const std::string &last_name) : first_name_{first_name},
last_name_{last_name} {}
friend std::ostream& operator<<(std::ostream& o, const Person& b) {
return o << b.to_str();
}
protected:
virtual std::string to_str() const{
return first_name_ + " " + last_name_;
}
private:
std::string first_name_;
std::string last_name_;
};
struct TaxPayer : Person {
TaxPayer(const std::string first_name,
const std::string last_name,
const std::string itn) : Person{first_name, last_name}, itn_{itn} {}
protected:
virtual std::string to_str() const{
return Person::to_str() + " " + itn_;
}
private:
std::string itn_;
};
int main() {
auto prs1 = std::make_unique<Person>("Ter", "Minator");
auto prs2 = std::make_unique<TaxPayer>("Ace", "Ventura", "0000");
std::cout << *prs1 << std::endl;
std::cout << *prs2 << std::endl;
}
// OUTPUT:
// Ter Minator
// Ace Ventura 0000Есть у нас класс человека с его именем и фамилией. Есть класс налогоплательщика, который наследуется от человека и добавляет к полям ИНН. Допустим, мы хотим как-то выводить на консоль содержимое этих людей(в смысле поля; расчленением мы не занимаемся, не в Питере живем все-таки). Можно конечно в каждом классе определять свой оператор или выводить на консоль результат работы метода to_str, но это лишний апи и лишний код.
Мы просто в базовом классе определяем другана и говорим, чтобы он вызывал виртуальный метод. И все.
Да, это очень просто. Но подход скрытия деталей реализации за закрытым виртуальным методом используется, например в идиоме невиртуального интерфейса и еще невесть где. Поэтому о даже о таком приеме надо знать и применять его в подходящих ситуациях.
Have a real friends. Stay cool.
#cppcore
{kind=link}
Возвращаем ссылку в std::optional
#новичкам
В прошлом посте я упоминал, что методы front и back последовательных контейнеров играют в ящик, если их пытаться вызвать на пустом контейнере. Это приводит к UB.
Один из довольно известных приемов для обработки таких ситуаций - возвращать не ссылку на объект, а std::optional. Это такая фича С++17 и класс, который может хранить или не хранить объект.
Теперь, если контейнер пустой - можно возвращать std::nullopt, который создает std::optional без объекта внутри. Если в нем есть элементы, то возвращать ссылку.
Только вот проблема: std::optional нельзя создавать с ссылочным типом. А копировать объект ну вот никак не хочется. А если он очень тяжелый? Мы программисты и тяжести поднимать не любим.
И вроде бы ситуация безвыходная. Но нет! Решение есть!
Можно возвращать std::optional<std::reference_wrapper<T>>. std::reference_wrapper - это такая обертка над ссылками, чтобы они вели себя как кошерные объекты со своими блэкджеком, конструкторами, деструкторами и прочими прелестями.
Это абсолютно легально и теперь у вас никакого копирования нет!
И в добавок есть нормальная безопасная проверка.
Пользуйтесь.
Stay safe. Stay cool.
#cpp17 #STL #goodpractice
#новичкам
В прошлом посте я упоминал, что методы front и back последовательных контейнеров играют в ящик, если их пытаться вызвать на пустом контейнере. Это приводит к UB.
Один из довольно известных приемов для обработки таких ситуаций - возвращать не ссылку на объект, а std::optional. Это такая фича С++17 и класс, который может хранить или не хранить объект.
Теперь, если контейнер пустой - можно возвращать std::nullopt, который создает std::optional без объекта внутри. Если в нем есть элементы, то возвращать ссылку.
Только вот проблема: std::optional нельзя создавать с ссылочным типом. А копировать объект ну вот никак не хочется. А если он очень тяжелый? Мы программисты и тяжести поднимать не любим.
И вроде бы ситуация безвыходная. Но нет! Решение есть!
Можно возвращать std::optional<std::reference_wrapper<T>>. std::reference_wrapper - это такая обертка над ссылками, чтобы они вели себя как кошерные объекты со своими блэкджеком, конструкторами, деструкторами и прочими прелестями.
Это абсолютно легально и теперь у вас никакого копирования нет!
std::optional<std::reference_wrapper<T>> Container::front() {
if (data_.empty()) {
return std::nullopt;
}
return std::ref(data_[0]);
}И в добавок есть нормальная безопасная проверка.
Пользуйтесь.
Stay safe. Stay cool.
#cpp17 #STL #goodpractice
{kind=link}
Дедлокаем код
#новичкам
Частый вопрос на собесах или даже на скринингах - сколько минимум нужно мьютексов, чтобы гарантировано скрафтить дедлок.
Прежде, чем приступим к разбору, небольшое введение.
Deadlock - это ситуация, когда два или более потока оказываются заблокированными и не могут продолжить свою работу, так как каждый из них ожидает ресурс, который удерживает другой заблокированный поток. В результате, ни один из потоков не может завершиться, а система оказывается в застойном состоянии.
Многопоточка - это мир магии и чудес. Ошибки, которые появляются по причине плохой организации доступа потоков к ресурсам - самые трудновоспроизводимые и сложные для отладки. И никогда не знаешь откуда выстрелит. Да и сами ошибки принимают причудливые облики. Поэтому дедлоки могут по разному быть проявлены в коде, но поведение программы всегда при этом стабильно убогое - потоки не могут дальше продолжать производить работу.
В рамках текущего поста будем обсуждать так называемую циклическую блокировку. Ща поймете, о чем речь.
Стандартный ответ на вопрос из начала - 2. В одном потоке блочим в начале первый мьютекс, потом второй, а в другом потоке наоборот. Таким образом может произойти ситуация, когда оба потока захватили в заложники каждый по одному мьютексу и бесконечно висят в ожидании освобождения второго. Этого никогда не произойдет, потому что каждому нужен замок, который уже захватил другой поток и он его отдавать не собирается, пока пройдет всю критическую секцию. А он ее никогда не пройдет. В общем, собака пытается укусить себя за чресла.
Самый простой пример, который иллюстирует эту ситуацию:
Все канонично. В двух разных потоках пытаемся залочить замки в разном порядке. В итоге вывод будет такой:
И дальше программа будет бесконечно простаивать без дела, как тостер на вашей кухне.
Do useful work. Stay cool.
#concurrency
#новичкам
Частый вопрос на собесах или даже на скринингах - сколько минимум нужно мьютексов, чтобы гарантировано скрафтить дедлок.
Прежде, чем приступим к разбору, небольшое введение.
Deadlock - это ситуация, когда два или более потока оказываются заблокированными и не могут продолжить свою работу, так как каждый из них ожидает ресурс, который удерживает другой заблокированный поток. В результате, ни один из потоков не может завершиться, а система оказывается в застойном состоянии.
Многопоточка - это мир магии и чудес. Ошибки, которые появляются по причине плохой организации доступа потоков к ресурсам - самые трудновоспроизводимые и сложные для отладки. И никогда не знаешь откуда выстрелит. Да и сами ошибки принимают причудливые облики. Поэтому дедлоки могут по разному быть проявлены в коде, но поведение программы всегда при этом стабильно убогое - потоки не могут дальше продолжать производить работу.
В рамках текущего поста будем обсуждать так называемую циклическую блокировку. Ща поймете, о чем речь.
Стандартный ответ на вопрос из начала - 2. В одном потоке блочим в начале первый мьютекс, потом второй, а в другом потоке наоборот. Таким образом может произойти ситуация, когда оба потока захватили в заложники каждый по одному мьютексу и бесконечно висят в ожидании освобождения второго. Этого никогда не произойдет, потому что каждому нужен замок, который уже захватил другой поток и он его отдавать не собирается, пока пройдет всю критическую секцию. А он ее никогда не пройдет. В общем, собака пытается укусить себя за чресла.
Самый простой пример, который иллюстирует эту ситуацию:
std::mutex m1;
std::mutex m2;
std::thread t1([&m1, &m2] {
std::cout << "Thread 1. Acquiring m1." << std::endl;
m1.lock();
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::cout << "Thread 1. Acquiring m2." << std::endl;
m2.lock();
std::cout << "Thread 1 perform some work" << std::endl;
});
std::thread t2([&m1, &m2] {
std::cout << "Thread 2. Acquiring m2." << std::endl;
m2.lock();
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::cout << "Thread 2. Acquiring m1." << std::endl;
m1.lock();
std::cout << "Thread 2 perform some work" << std::endl;
});
t1.join();
t2.join();
Все канонично. В двух разных потоках пытаемся залочить замки в разном порядке. В итоге вывод будет такой:
Thread 1. Acquiring m1.
Thread 2. Acquiring m2.
Thread 2. Acquiring m1.
Thread 1. Acquiring m2.
И дальше программа будет бесконечно простаивать без дела, как тостер на вашей кухне.
Do useful work. Stay cool.
#concurrency
{kind=link}
Зачем локать мьютексы в разном порядке
#новичкам
Можете подумать, что раз всем так известно, что мьютексы опасно лочить в разном порядке, то почему вообще кому-то в голову может прийти наступить на грабли и накалякать такое своими программисткими пальчиками снова? Просто не пишите хреновый код и будет вам счастье.
Дело в том, что иногда это не совсем очевидно. Точнее почти всегда это не очевидно.
Программисты хоть и разные бывают, но ревью никто не отменял и такую броскую ошибку бы явно заметили. Поэтому не все так просто, как на первый взгляд кажется.
Разберем чуть более сложный пример:
Все просто. У нас есть пара объектов, которые используются в качестве разделяемых ресурсов (их могут изменять более 1 потока). Объекты могут обмениваться между собой данными.
Ну и по всем канонам нам же надо защитить оба объекта при свопе. Поэтому после захода в функцию обмена сначала лочим свой мьютекс, а потом мьютекс объекта с которым собираемся свопаться.
И вроде снаружи кажется, что мы всегда лочим в одном порядке. Пока мы не будем обменивать данные одних и тех же объектов в разных потоках в разном порядке. Тогда первый поток может залочить мьютекс первого объекта и, допустим, заснуть. А второй поток первым залочит мьютекс второго объекта. И все. Приплыли.
И это все еще может показаться детским садом и очевидушкой. Только вот сам момент взятия замка уже не выглядит так подозрительно. А сами объекты могут лежать в каких-то страшных структурах данных и могут быть разбросаны по коду. В таком случае все не так очевидно становится.
В следующий раз поговорим, как же не допускать такие ошибки.
Don't be obvious. Stay cool.
#concurrency
#новичкам
Можете подумать, что раз всем так известно, что мьютексы опасно лочить в разном порядке, то почему вообще кому-то в голову может прийти наступить на грабли и накалякать такое своими программисткими пальчиками снова? Просто не пишите хреновый код и будет вам счастье.
Дело в том, что иногда это не совсем очевидно. Точнее почти всегда это не очевидно.
Программисты хоть и разные бывают, но ревью никто не отменял и такую броскую ошибку бы явно заметили. Поэтому не все так просто, как на первый взгляд кажется.
Разберем чуть более сложный пример:
struct SomeSharedResource {
void swap(SomeSharedResource& obj) {
{
std::lock_guard lg{mtx};
// just for results reproducing
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard lg1{obj.mtx};
// handle swap
}
}
std::mutex mtx;
};
int main() {
SomeSharedResource resource1;
SomeSharedResource resource2;
std::mutex m2;
std::thread t1([&resource1, &resource2] {
resource1.swap(resource2);
std::cout << "1 Do some work" << std::endl;
});
std::thread t2([&resource1, &resource2] {
resource2.swap(resource1);
std::cout << "2 Do some work" << std::endl;
});
t1.join();
t2.join();
}Все просто. У нас есть пара объектов, которые используются в качестве разделяемых ресурсов (их могут изменять более 1 потока). Объекты могут обмениваться между собой данными.
Ну и по всем канонам нам же надо защитить оба объекта при свопе. Поэтому после захода в функцию обмена сначала лочим свой мьютекс, а потом мьютекс объекта с которым собираемся свопаться.
И вроде снаружи кажется, что мы всегда лочим в одном порядке. Пока мы не будем обменивать данные одних и тех же объектов в разных потоках в разном порядке. Тогда первый поток может залочить мьютекс первого объекта и, допустим, заснуть. А второй поток первым залочит мьютекс второго объекта. И все. Приплыли.
И это все еще может показаться детским садом и очевидушкой. Только вот сам момент взятия замка уже не выглядит так подозрительно. А сами объекты могут лежать в каких-то страшных структурах данных и могут быть разбросаны по коду. В таком случае все не так очевидно становится.
В следующий раз поговорим, как же не допускать такие ошибки.
Don't be obvious. Stay cool.
#concurrency
{kind=link}
Инкапсуляция и структуры
#новичкам
Всем мы знаем, что раскрывать детали реализации класса - это плохо, этого надо избегать и если вы помыслите об обратном, то придет серенький волчок и укусит за бочок.
Однако, как и со многими такими догматами случается, не всегда нужно следовать этой концепции. Давайте посмотрим на следующий код:
Выглядит солидно. Сеттеры, геттеры, все дела. Но вот души в этом коде нет. Он какой-то.. Бесполезный чтоли.
Методы класса не делают ничего такого, что пользователь класса не смог бы сделать своими руками. Скорее руками это все сделать будет даже короче.
Этим грешат новички: поначитаются модных концепций(или не очень модных) и давай скрывать все члены.
Brah... Don't do this...
Здесь нет никаких инвариантов, которые нужно было бы сохранять. Интерфейс класса и так позволяет все, шо хош делать с объектом.
Если ваш класс используется просто как хранилище данных, то это ближе не к классу, а к сишной структуре. Сделайте вы уже поля открытыми и замените ключевое слово class на более подходящее struct.
Делов-то. Зато прошлым примером можно хорошо отчитываться за количество написанных строчек кода=)
Show your inner world to others. Stay cool.
#cppcore #goodpractice #OOP
#новичкам
Всем мы знаем, что раскрывать детали реализации класса - это плохо, этого надо избегать и если вы помыслите об обратном, то придет серенький волчок и укусит за бочок.
Однако, как и со многими такими догматами случается, не всегда нужно следовать этой концепции. Давайте посмотрим на следующий код:
class MyClass
{
int m_foo;
int m_bar;
public:
int addAll() const;
int getFoo() const;
void setFoo(int foo);
int getBar() const;
void setBar(int bar);
};
int MyClass::addAll() const
{
return m_foo + m_bar;
}
int MyClass::getFoo() const
{
return m_foo;
}
void MyClass::setFoo(int foo)
{
m_foo = foo;
}
int MyClass::getBar() const
{
return m_bar;
}
void MyClass::setBar(int bar)
{
m_bar = bar;
}
Выглядит солидно. Сеттеры, геттеры, все дела. Но вот души в этом коде нет. Он какой-то.. Бесполезный чтоли.
Методы класса не делают ничего такого, что пользователь класса не смог бы сделать своими руками. Скорее руками это все сделать будет даже короче.
Этим грешат новички: поначитаются модных концепций(или не очень модных) и давай скрывать все члены.
Brah... Don't do this...
Здесь нет никаких инвариантов, которые нужно было бы сохранять. Интерфейс класса и так позволяет все, шо хош делать с объектом.
Если ваш класс используется просто как хранилище данных, то это ближе не к классу, а к сишной структуре. Сделайте вы уже поля открытыми и замените ключевое слово class на более подходящее struct.
struct MyClass
{
int m_foo;
int m_bar;
}
Делов-то. Зато прошлым примером можно хорошо отчитываться за количество написанных строчек кода=)
Show your inner world to others. Stay cool.
#cppcore #goodpractice #OOP
{kind=link}
Получаем адрес перегрузки
#новичкам
Представьте, что у вас есть функция, которая вызывает любой коллбэк:
И есть другая функция, которую вы вызываете через call_callback.
Все работает прекрасно. Но теперь мы добавляем перегрузку func и пытаемся их вызвать через call_callback.
Получаем ошибку
Компилятор не может понять, какую конкретно перегрузку вы имели ввиду.
Дело в том, что имя функции неявно приводится к указателю на эту функцию. Тип указателя на функцию зависит от ее сигнатуры. И просто по имени невозможно понять, с какой сигнатурой функцию мы имеем ввиду.
Что же делать?
Дать компилятору подсказку и использовать static_cast.
Теперь все работает, как надо.
Give useful hints. Stay cool.
#cppcore
#новичкам
Представьте, что у вас есть функция, которая вызывает любой коллбэк:
template<class T, class... Args>
void call_callback(T callback, Args... args) {
callback(args...);
}
И есть другая функция, которую вы вызываете через call_callback.
int func() {
return 42;
}
call_callback(func);Все работает прекрасно. Но теперь мы добавляем перегрузку func и пытаемся их вызвать через call_callback.
int func() {
return 42;
}
int func(int num) {
return num;
}
call_callback(func);
call_callback(func, 42);Получаем ошибку
error: no matching function for call to
‘call_callback(<unresolved overloaded function type>)
Компилятор не может понять, какую конкретно перегрузку вы имели ввиду.
Дело в том, что имя функции неявно приводится к указателю на эту функцию. Тип указателя на функцию зависит от ее сигнатуры. И просто по имени невозможно понять, с какой сигнатурой функцию мы имеем ввиду.
Что же делать?
Дать компилятору подсказку и использовать static_cast.
call_callback(static_cast<int(*)()>(func));
call_callback(static_cast<int(*)(int)>(func), 42);
Теперь все работает, как надо.
Give useful hints. Stay cool.
#cppcore
{kind=link}
Почему перегрузки не могут иметь разные возвращаемые значения
#новичкам
Обычно люди просто принимают на веру факт, что перегрузки различаются только набором аргументов. Впрочем, как и все, что вливается в голову в начале обучения.
Но никогда не поздно задуматься над смыслом. А почему мы не можем перегружать функции по возвращаемому значению?
Может вот так абстрактно рассуждая, и не сразу придет ответ. Но на самом деле все просто, если посмотреть на конкретный пример. Давайте представим, что никаких запретов нет. Теперь перегрузки могут различаться только возвращаемым значением. И у нас есть 2 функции, почти одинаковые , но имеют разные возвращаемые значения.
Пускай мы хотим генерировать и целые числа, и дробные числа. И то, и то число, общее название оправдано.
Теперь попробуем вызвать первую версию.
А вы уверены, что мы сейчас вызвали именно первую версию? Флоат спокойно кастуется к инту. Ничего не мешает компилятору выбрать вторую версию для этого вызова.
Ситуация становится комичной, если использовать auto:
Тут как бы вообще нет ни намека на то, какую версию вызывать. Компилятор не умеет читать ваши мысли и намерения. Он не знает, какую версию вы хотели вызвать. Просто рандомно он выбрать не может. Появляется парадокс и вселенная схлопывается.
Вот и получили противоречие.
Компилятор просто не может отличить вызовы таких функций. Поэтому это и запрещено.
Don't be confusing. Stay cool.
#cppcore
#новичкам
Обычно люди просто принимают на веру факт, что перегрузки различаются только набором аргументов. Впрочем, как и все, что вливается в голову в начале обучения.
Но никогда не поздно задуматься над смыслом. А почему мы не можем перегружать функции по возвращаемому значению?
Может вот так абстрактно рассуждая, и не сразу придет ответ. Но на самом деле все просто, если посмотреть на конкретный пример. Давайте представим, что никаких запретов нет. Теперь перегрузки могут различаться только возвращаемым значением. И у нас есть 2 функции, почти одинаковые , но имеют разные возвращаемые значения.
int GetRandomNumber();
float GetRandomNumber();
Пускай мы хотим генерировать и целые числа, и дробные числа. И то, и то число, общее название оправдано.
Теперь попробуем вызвать первую версию.
int number = GetRandomNumber();
А вы уверены, что мы сейчас вызвали именно первую версию? Флоат спокойно кастуется к инту. Ничего не мешает компилятору выбрать вторую версию для этого вызова.
Ситуация становится комичной, если использовать auto:
auto number = GetRandomNumber();
Тут как бы вообще нет ни намека на то, какую версию вызывать. Компилятор не умеет читать ваши мысли и намерения. Он не знает, какую версию вы хотели вызвать. Просто рандомно он выбрать не может. Появляется парадокс и вселенная схлопывается.
Вот и получили противоречие.
Компилятор просто не может отличить вызовы таких функций. Поэтому это и запрещено.
Don't be confusing. Stay cool.
#cppcore
{kind=link}