
Принтуем с fold expression
Для начала разберем, как бы все выглядело до С++17.
Задача - вывести на экран все аргументы функции подряд. Не так уж и сложно. Код будет выглядеть примерно вот так:
Это будет работать, но не очень прикольно выводить аргументы прям подряд символами. Нужно какое-то форматирование. Например, между аргументами выводить пробел, а в конце перенести строку. Тут уже все несколько усложняется...
Нам мало того, что пришлось использовать базу рекурсии, так еще и прокси-функцию, которая допиливает форматирование. Слишко МНОГА БУКАВ. Ща исправим.
Вот так будет выглядеть базовый принт без форматирования на fold expression:
Уже лучше. Точнее не так. Проще не бывает уже)
Как видите, здесь я использую бинарный левый фолд. В качестве инициализатора выступает стандартный поток вывода и он слева не только потому, что так обычно принято, а потому что оператор << также применяется например для бинарного сдвига. И чтобы мы всегда именно в поток писали, нужно, чтобы слева всегда был нужный поток. Тогда будет вызываться соответствующая перегрузка для ostream'ов и каждый раз будет возвращаться ссылка на этот поток. Таким образом мы и будем продолжать писать именно в него.
Но как тут быть с форматингом? args тут просто раскроются в последовательность "arg1 << arg2 << arg3" и тд
И непонятно, как в таких условиях добавить вывод пробела, не придумывая нагромождения в виде проксей и прочего. Для решения этой проблемы надо воспользоваться двумя хаками:
1️⃣ Не обязательно использовать сырой пакет параметров. Можно использовать функцию, принимающую этот пак.
2️⃣ Применяя оператор запятую, мы можем в операндах выполнять любое выражение, даже возвращающее void.
Получается такая штука:
Здесь мы за счет лямбды и запятой выполняем каждый раз отдельную операцию вывода в поток с пробелом. А затем вместо init выражения подставляем вывод конца строки.
Прикольный хак, я считаю! В нем много нюансов, но его явно можно взять себе на вооружение и использовать в специфичных кейсах.
Hack this life. Stay cool.
#cpp17 #template
Для начала разберем, как бы все выглядело до С++17.
Задача - вывести на экран все аргументы функции подряд. Не так уж и сложно. Код будет выглядеть примерно вот так:
void print() {
}
template<typename T1, typename... T>
void print(T1 s, T... ts) {
std::cout << s;
print(ts...);
}
print(1.7, -2, "qwe");
// Output: 1.7-2qweЭто будет работать, но не очень прикольно выводить аргументы прям подряд символами. Нужно какое-то форматирование. Например, между аргументами выводить пробел, а в конце перенести строку. Тут уже все несколько усложняется...
void print_impl() {
}
template<typename T1, typename... T>
void print_impl(T1 s, T... ts) {
std::cout << ' ' << s;
print_impl(ts...);
}
template<typename T1, typename... T>
void print(T1 s, T... ts) {
std::cout << s;
print_impl(ts...);
std::cout << std::endl;
}
print(1.7, -2, "qwe");
print("You", ", our subscribers,", "are", "the", "best!!");
// Output:
// 1.7 -2 qwe
// You , our subscribers, are the best!!Нам мало того, что пришлось использовать базу рекурсии, так еще и прокси-функцию, которая допиливает форматирование. Слишко МНОГА БУКАВ. Ща исправим.
Вот так будет выглядеть базовый принт без форматирования на fold expression:
template<typename... Args>
void print(Args&&... args) {
(std::cout << ... << args);
}
print(1.7, -2, "qwe");
// Output: 1.7-2qwe
Уже лучше. Точнее не так. Проще не бывает уже)
Как видите, здесь я использую бинарный левый фолд. В качестве инициализатора выступает стандартный поток вывода и он слева не только потому, что так обычно принято, а потому что оператор << также применяется например для бинарного сдвига. И чтобы мы всегда именно в поток писали, нужно, чтобы слева всегда был нужный поток. Тогда будет вызываться соответствующая перегрузка для ostream'ов и каждый раз будет возвращаться ссылка на этот поток. Таким образом мы и будем продолжать писать именно в него.
Но как тут быть с форматингом? args тут просто раскроются в последовательность "arg1 << arg2 << arg3" и тд
И непонятно, как в таких условиях добавить вывод пробела, не придумывая нагромождения в виде проксей и прочего. Для решения этой проблемы надо воспользоваться двумя хаками:
1️⃣ Не обязательно использовать сырой пакет параметров. Можно использовать функцию, принимающую этот пак.
2️⃣ Применяя оператор запятую, мы можем в операндах выполнять любое выражение, даже возвращающее void.
Получается такая штука:
template<typename ...Args>
void print(Args&&... args) {
auto print_with_space = [](const auto& v) { std::cout << v << ' '; };
(print_with_space(args), ... , (std::cout << std::endl));
}
print(1.7, -2, "qwe");
print("You, "are", "the", "best!!");
// Output:
// 1.7 -2 qwe
// You are the best!!
Здесь мы за счет лямбды и запятой выполняем каждый раз отдельную операцию вывода в поток с пробелом. А затем вместо init выражения подставляем вывод конца строки.
Прикольный хак, я считаю! В нем много нюансов, но его явно можно взять себе на вооружение и использовать в специфичных кейсах.
Hack this life. Stay cool.
#cpp17 #template
{kind=link}
Почему не работает?
При подготовке постов увидел один вопрос на стековерфлоу и решил его разобрать здесь. Не рокет сайенс, но кому-то будет интересно чуть-чуть подумать и поразмышлять.
Что произойдет при попытке компиляции и запуска следующего кода?
Ответ не то, чтобы сильно интригующий, но все же оставлю его под спойлерами, чтобы была возможно подумать, а не сразу ответ читать.
Компиляция завершится успешно, но при выполнении будет сегфолт. На вот этой строчке "AndR(false, (*pb = true));".
Коротко разберем происходящее. Допустим я хочу проверить короткосхемность логического И во всех ипостасях. То есть в обычном виде и в виде fold expression. Для fold выражения нужны функции шаблонные. Вот я и определяю 2 штуки для правой и левой свертки. Ну и есть использование оператора в обычном виде.
Проверять короткосхемность я буду с помощью записи по нулевому указателю. Мы все знаем, что аяаяй, так делать нельзя, но в учебных целях для понимания происходящего - можно.
Так вот. Свойство short circuit дает операции право не вычислять следующие аргументы после того, как ответ уже будет известен. В нашем случае, первый аргумент - false и по идее дальше вычислений быть не должно.
Так и делается во второй строчке функции main. Но вот все падает на 3-й.
Хотя казалось бы должно упасть на 4-й, потому что там так фолд раскрывается, что первым будет учтен последний аргумент. Поэтому первый false нас не защитит от разыменования нулевого указателя.
На 4-й бы тоже упало, если бы не было третьей строчки. Но не по той причине, которую я указал.
Дело в том, что вызов функции - это не вызов оператора напрямую. Если для оператора разрешена короткосхемность, то аргументы вычисляются по порядку по мере выполнения оператора. Для функций же их аргументы обязаны быть вычислены до входа в функцию. Поэтому мы даже не входим в функцию, а падаем при вычислении аргумента - присваивании по нулевому указателю.
Теперь, чтобы старшим ребятам не совсем скучно было, задам вопрос. Как сделать так, чтобы все-таки не упасть в функции, но в какой-то форме передать такие же параметры в качестве аргументов? Отписывайте в комментах свои варианты.
Train your brain. Stay cool.
#template #cpp17
При подготовке постов увидел один вопрос на стековерфлоу и решил его разобрать здесь. Не рокет сайенс, но кому-то будет интересно чуть-чуть подумать и поразмышлять.
Что произойдет при попытке компиляции и запуска следующего кода?
#include <type_traits>
template<typename... Args>
constexpr bool AndL(Args&&... args)
{
return (... && std::forward<decltype(args)>(args));
}
template<typename... Args>
constexpr bool AndR(Args&&... args)
{
return (std::forward<decltype(args)>(args) && ...);
}
int main()
{
bool* pb = nullptr;
false && (*pb = true);
AndR(false, (*pb = true));
AndL(false, (*pb = true));
}
Ответ не то, чтобы сильно интригующий, но все же оставлю его под спойлерами, чтобы была возможно подумать, а не сразу ответ читать.
Коротко разберем происходящее. Допустим я хочу проверить короткосхемность логического И во всех ипостасях. То есть в обычном виде и в виде fold expression. Для fold выражения нужны функции шаблонные. Вот я и определяю 2 штуки для правой и левой свертки. Ну и есть использование оператора в обычном виде.
Проверять короткосхемность я буду с помощью записи по нулевому указателю. Мы все знаем, что аяаяй, так делать нельзя, но в учебных целях для понимания происходящего - можно.
Так вот. Свойство short circuit дает операции право не вычислять следующие аргументы после того, как ответ уже будет известен. В нашем случае, первый аргумент - false и по идее дальше вычислений быть не должно.
Так и делается во второй строчке функции main. Но вот все падает на 3-й.
Хотя казалось бы должно упасть на 4-й, потому что там так фолд раскрывается, что первым будет учтен последний аргумент. Поэтому первый false нас не защитит от разыменования нулевого указателя.
Дело в том, что вызов функции - это не вызов оператора напрямую. Если для оператора разрешена короткосхемность, то аргументы вычисляются по порядку по мере выполнения оператора. Для функций же их аргументы обязаны быть вычислены до входа в функцию. Поэтому мы даже не входим в функцию, а падаем при вычислении аргумента - присваивании по нулевому указателю.
Теперь, чтобы старшим ребятам не совсем скучно было, задам вопрос. Как сделать так, чтобы все-таки не упасть в функции, но в какой-то форме передать такие же параметры в качестве аргументов? Отписывайте в комментах свои варианты.
Train your brain. Stay cool.
#template #cpp17
{kind=link}
Вычисления по короткой схеме vs ленивые вычисления Ч1
Вчера Евгений поднял тему различий short circuited evaluation и lazy evaluation. Действительно важная тема для обсуждений. Потому что многие путают. Это конечно почти ни на что не влияет, но прояснить все же нужно.
Разберемся с ленивыми вычислениями. Если описать этот термин лозунгом, то это будет что-то типа "вычисли меня, когда я буду нужен". Для плюсов это ненативный термин. Потому что это strict language. В таких языках, например, все параметры функции должны быть вычислены до входа в функцию. Однако, есть языки(Scala, Haskell), где такого условия нет и аргумент вычисляется только тогда, когда он нужен в теле функции. Это значит, что функция может выдать результат, даже не вычислив всех аргументов! То есть вычисление аргумента откладывается до того момента, когда его значение будет нужно.
Но такие вычисления применимы не только к вычислению аргументов, естественно. Чтобы было понятно, давайте приведу несколько примеров, но в плюсовом контексте.
Логгер-синглтон. Не хотим мы запариваться над сложным и безопасным логгером, поэтому напишем его очень просто и безобразно:
Обратите внимание, что конструктор у класса приватный, поэтому вы можете создать объект только через статический метод instance. И объект на самом деле создастся только тогда, когда он вам понадобится и вы вызовете метод instance. Статические переменные функций хоть и имеют глобальный скоуп, но создаются только при первом вызове конкретной функции, когда она стала нужна в коде.
Можно чуть сложнее придумать:
Здесь мы определяем ленивую структурку, которая может выполнять какую-то бинарную операцию над какими-то объектами. Причем делает она это в операторе преобразования к типу результата бинарной операции. Это довольно важный момент. Пример и так довольно сложный, поэтому не буду мудрить с compile-time проверками правильности типов.
Дальше с помощью этой структурки я хочу лениво посчитать сумму тензоров нулевой размерности(просто посчитать сумму чиселок - не комильфо, а так я как будто бы математик в 10-м поколении).
Создаю совсем простенький класс этого тензора. А затем класс операции сложения тензоров. Это по факту функтор, в котором дополнительно хранится тип результата, и который выполняет реальное сложение тензоров при вызове оператора() с двумя тензорами. Для проверки момента реальных вычислений я вставил консольный вывод
И вишенка на торте - перегружаю оператор+ для того, чтобы он на сложение двух тензоров возвращал не тензор, а нашу ленивую структурку.
Ну и теперь магия в действии. ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ.
Differentiate the meanings of things. Stay cool.
#template #cppcore #cpp17
Вчера Евгений поднял тему различий short circuited evaluation и lazy evaluation. Действительно важная тема для обсуждений. Потому что многие путают. Это конечно почти ни на что не влияет, но прояснить все же нужно.
Разберемся с ленивыми вычислениями. Если описать этот термин лозунгом, то это будет что-то типа "вычисли меня, когда я буду нужен". Для плюсов это ненативный термин. Потому что это strict language. В таких языках, например, все параметры функции должны быть вычислены до входа в функцию. Однако, есть языки(Scala, Haskell), где такого условия нет и аргумент вычисляется только тогда, когда он нужен в теле функции. Это значит, что функция может выдать результат, даже не вычислив всех аргументов! То есть вычисление аргумента откладывается до того момента, когда его значение будет нужно.
Но такие вычисления применимы не только к вычислению аргументов, естественно. Чтобы было понятно, давайте приведу несколько примеров, но в плюсовом контексте.
Логгер-синглтон. Не хотим мы запариваться над сложным и безопасным логгером, поэтому напишем его очень просто и безобразно:
class Logger{
Logger() {}
public:
static Logger * instance() {
static Logger myinstance;
return &myinstance;
}
void Log(const std::string str) {
std::cout << str << std::endl;
}
};Обратите внимание, что конструктор у класса приватный, поэтому вы можете создать объект только через статический метод instance. И объект на самом деле создастся только тогда, когда он вам понадобится и вы вызовете метод instance. Статические переменные функций хоть и имеют глобальный скоуп, но создаются только при первом вызове конкретной функции, когда она стала нужна в коде.
Можно чуть сложнее придумать:
template<typename O, typename T1, typename T2>
struct Lazy
{
Lazy(T1 const& l,T2 const& r)
:lhs(l),rhs(r) {}
typedef typename O::Result Result;
operator Result() const
{
O op;
return op(lhs,rhs);
}
private:
T1 const& lhs;
T2 const& rhs;
};
struct ZeroDimentionalTensor
{
ZeroDimentionalTensor(int n) : a{n} {}
int a;
};
using ZDTensor = ZeroDimentionalTensor;
struct ZDTensorAdd
{
using Result = ZDTensor;
Result operator()(ZDTensor const& lhs,ZDTensor const& rhs) const
{
Result r = lhs.a + rhs.a;
std::cout << "Actual calculation" << std::endl;
return r;
}
};
Lazy<ZDTensorAdd,ZDTensor,ZDTensor> operator+(ZDTensor const& lhs,ZDTensor const& rhs)
{
return Lazy<ZDTensorAdd,ZDTensor,ZDTensor>(lhs,rhs);
}
int main() {
ZDTensor a{1};
ZDTensor b{2};
std::cout << "Check" << std::endl;
auto sum = a + b;
std::cout << "Check" << std::endl;
bool external_parameter = true;
ZDTensor c{0};
if (std::cout << "Condition" << std::endl; external_parameter) {
c = sum;
} else {
c = 5;
}
std::cout << c.a << std::endl;
}
Здесь мы определяем ленивую структурку, которая может выполнять какую-то бинарную операцию над какими-то объектами. Причем делает она это в операторе преобразования к типу результата бинарной операции. Это довольно важный момент. Пример и так довольно сложный, поэтому не буду мудрить с compile-time проверками правильности типов.
Дальше с помощью этой структурки я хочу лениво посчитать сумму тензоров нулевой размерности(просто посчитать сумму чиселок - не комильфо, а так я как будто бы математик в 10-м поколении).
Создаю совсем простенький класс этого тензора. А затем класс операции сложения тензоров. Это по факту функтор, в котором дополнительно хранится тип результата, и который выполняет реальное сложение тензоров при вызове оператора() с двумя тензорами. Для проверки момента реальных вычислений я вставил консольный вывод
И вишенка на торте - перегружаю оператор+ для того, чтобы он на сложение двух тензоров возвращал не тензор, а нашу ленивую структурку.
Ну и теперь магия в действии. ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ.
Differentiate the meanings of things. Stay cool.
#template #cppcore #cpp17
{kind=link}
if constexpr
Вчера мы обсуждали, что до 17-го стандарта было довольно сложно писать шаблонный код, сценарии которого зависели от типа шаблонных параметров. Появляются проблемы с дублированием кода и с фактической невозможностью писать зависящий от конкретного типа код, потому что в каких-то ветках он может просто не скомпилироваться. Но с этими проблемами справляется фича С++17 - if constexpr.
if constexpr - расширение обычной условной конструкции с двумя дополнениями/ограничениями.
1️⃣ Условие проверяется в compile-time. И нужная ветка выбирается тоже на этом этапе. Это значит, что выражение в условии должно быть тоже вычислимым на этапе компиляции. То есть должно быть constexpr. Это несколько ограничивает его функционал(например constexpr функции могут вычисляться и во время компиляции, и во время выполнения). Хотя учитывая, что конструкция используется в шаблонном коде, для разделения поведения в зависимости от шаблонного параметра, и других кейсов я особо не вижу, то это не совсем и ограничения.
2️⃣Если одна из веток условий выбрана, то другая ветка будет отброшена(discarded) и она не будет компилироваться!
Благодаря этим особенностям, наш пример с функцией to_str будет выглядеть вот так:
А пример со сравнением чисел так:
Стоит сделать важную оговорку: если ветка не участвует в компиляции, это не значит, что там можно все, что угодно писать. Это вам не препроцессор, который полностью стирает строчки без следа. В любой ветке код должен быть корректным. Например, вот скомпилировав такой код:
Получим ошибку: error: use of undeclared identifier 'Life_without_coding'. Эх. Не прожить нам без кода...
Имена функций реально должны существовать, синтаксис должен соблюдаться, аргументы должны передаваться правильно(ну или хотя бы их количество должно совпадать, если вы передаете только шаблонные аргументы куда-то дальше) и так далее.
После того, как компилятор проверит отсутствие ошибок, он просто не будет дальше посылать отброшенную ветку на генерацию кода. Примерно так это и работает.
Choose the right path. Stay cool.
#cpp17 #template #compiler
Вчера мы обсуждали, что до 17-го стандарта было довольно сложно писать шаблонный код, сценарии которого зависели от типа шаблонных параметров. Появляются проблемы с дублированием кода и с фактической невозможностью писать зависящий от конкретного типа код, потому что в каких-то ветках он может просто не скомпилироваться. Но с этими проблемами справляется фича С++17 - if constexpr.
if constexpr - расширение обычной условной конструкции с двумя дополнениями/ограничениями.
1️⃣ Условие проверяется в compile-time. И нужная ветка выбирается тоже на этом этапе. Это значит, что выражение в условии должно быть тоже вычислимым на этапе компиляции. То есть должно быть constexpr. Это несколько ограничивает его функционал(например constexpr функции могут вычисляться и во время компиляции, и во время выполнения). Хотя учитывая, что конструкция используется в шаблонном коде, для разделения поведения в зависимости от шаблонного параметра, и других кейсов я особо не вижу, то это не совсем и ограничения.
2️⃣Если одна из веток условий выбрана, то другая ветка будет отброшена(discarded) и она не будет компилироваться!
Благодаря этим особенностям, наш пример с функцией to_str будет выглядеть вот так:
template <typename T>
std::string to_str(T t) {
if constexpr (std::is_same_v<T, std::string>) // строка или преобразуемый в строку
return t;
else
return std::to_string(t);
}
А пример со сравнением чисел так:
template <class T>
constexpr T absolute(T arg) {
return arg < 0 ? -arg : arg;
}
template <class T>
constexpr auto precision_threshold = T(0.000001);
template <class T>
constexpr bool is_equal(T a, T b) {
if constexpr (is_floating_point_v<T>)
return absolute(a - b) < precision_threshold<T>;
else
return a == b;}
Стоит сделать важную оговорку: если ветка не участвует в компиляции, это не значит, что там можно все, что угодно писать. Это вам не препроцессор, который полностью стирает строчки без следа. В любой ветке код должен быть корректным. Например, вот скомпилировав такой код:
template <typename T>
std::string to_str(T t) {
if constexpr (std::is_same_v<T, std::string>)
Life_without_coding();
else
return std::to_string(t);
}
auto str = to_str(5);
Получим ошибку: error: use of undeclared identifier 'Life_without_coding'. Эх. Не прожить нам без кода...
Имена функций реально должны существовать, синтаксис должен соблюдаться, аргументы должны передаваться правильно(ну или хотя бы их количество должно совпадать, если вы передаете только шаблонные аргументы куда-то дальше) и так далее.
После того, как компилятор проверит отсутствие ошибок, он просто не будет дальше посылать отброшенную ветку на генерацию кода. Примерно так это и работает.
Choose the right path. Stay cool.
#cpp17 #template #compiler
{kind=link}
Возвращаемый тип при if constexpr
Ещё одним интересным местом функционала if constexpr, является возможность возвращения совершенно разных типов из одной функции (естественно, не одновременно). То есть с использованием if constexpr мы можем иметь несколько return выражений, каждое из которых возвращает объект типа, который не конвертируется в другой. Разумеется, все такие return должны быть спрятаны в блоки кода, которые будут выбрасываться на этапе компиляции.
Представим, что вы захотели совершить пакость и посмеяться над своими тиммейтами. Вы написали функцию GetStringNumber, которая возвращает строковое представление числа, которое вы в него передали. Но вы затеяли подлянку, и если в функцию передать строку с числом, то она попытается вернуть его в виде интегрального типа. Типа у коллег код похерится, если они случайно передадут туда строку. Эта функция будет выглядеть примерно так:
Здесь мы используем фичу С++14, благодаря которой компилятор сам выводит тип возвращаемого значения.
Очевидно, что для различных веток, функция GetStringNumber будет иметь разный тип возвращаемого значения: в первом случае std::string, а во втором int. И это работает! Правда, мы легко можем всё сломать, для этого достаточно добавить ещё один return, находящийся вне условий, который будет несовместим с двумя прочими. Если мы перестараемся со своими шаловливыми мыслями, то можем написать и что-то такое:
Такой код уже, очевидно, не соберётся. Потому что ветки условия будут возвращать типы, не приводимые к тому, что мы возвращаем в самом конце. Это в плюсах делать запрещено.
Такая вот интересная особенность нашлась. Поделитесь им в комментариях практическими примерами использования if constexpr. Думаю, многим пригодится опыт наших замечательных комментаторов)
Apply things in an unusual ways. Stay cool.
#cpp17 #cpp14 #template
Ещё одним интересным местом функционала if constexpr, является возможность возвращения совершенно разных типов из одной функции (естественно, не одновременно). То есть с использованием if constexpr мы можем иметь несколько return выражений, каждое из которых возвращает объект типа, который не конвертируется в другой. Разумеется, все такие return должны быть спрятаны в блоки кода, которые будут выбрасываться на этапе компиляции.
Представим, что вы захотели совершить пакость и посмеяться над своими тиммейтами. Вы написали функцию GetStringNumber, которая возвращает строковое представление числа, которое вы в него передали. Но вы затеяли подлянку, и если в функцию передать строку с числом, то она попытается вернуть его в виде интегрального типа. Типа у коллег код похерится, если они случайно передадут туда строку. Эта функция будет выглядеть примерно так:
template <typename T>
auto GetStringNumber(T val)
{
if constexpr (std::is_arithmetic_v<T>)
return std::to_string(val);
else if constexpr(std::is_same_v<T, std::string>)
return std::stoi(val);
}
Здесь мы используем фичу С++14, благодаря которой компилятор сам выводит тип возвращаемого значения.
Очевидно, что для различных веток, функция GetStringNumber будет иметь разный тип возвращаемого значения: в первом случае std::string, а во втором int. И это работает! Правда, мы легко можем всё сломать, для этого достаточно добавить ещё один return, находящийся вне условий, который будет несовместим с двумя прочими. Если мы перестараемся со своими шаловливыми мыслями, то можем написать и что-то такое:
template <typename T>
auto GetStringNumber(T val)
{
if constexpr (std::is_arithmetic_v<T>)
return std::to_string(val);
else if constexpr(std::is_same_v<T, std::string>)
return std::stoi(val);
return std::vector<std::string>{"Joke has gone too far"};
}
Такой код уже, очевидно, не соберётся. Потому что ветки условия будут возвращать типы, не приводимые к тому, что мы возвращаем в самом конце. Это в плюсах делать запрещено.
Такая вот интересная особенность нашлась. Поделитесь им в комментариях практическими примерами использования if constexpr. Думаю, многим пригодится опыт наших замечательных комментаторов)
Apply things in an unusual ways. Stay cool.
#cpp17 #cpp14 #template
{kind=link}
static_assert и if constexpr
Вернемся к прошлому примеру с функцией to\_str, но сделаем ее немножко безопасней.
Все просто. Функция std::to_string имеет перегрузки только для тривиальных арифметических типов, поэтому чтобы ее использовать и получить ошибку, нужно провести проверку на эту арифметичность. Если переданный в функцию to\_str тип не конструируется в строку или не является арифметическим типом, то не совсем понятно, как такой тип переводить в строку. Точнее так: в каждом конкретном случае мы можем сказать как, но общего поведения нет. Поэтому, чтобы детектировать такие нештатные ситуации, я поставлю ассерт времени компиляции.
И вроде всё хорошо, но да не всё...
Дело в том, что при попытке скомпилировать этот пример, процесс прервется на этом ассерте даже в том случае, когда мы попадем в первые две ветки.
Тут в чем прикол. Согласно стандарту, если хотя бы в одной из веток if constexpr не может быть сгенерировано ни одной валидной специализации, то программа - ill-formed и это ошибка. И вправду, false всегда будет false, как бы мы там не тужились родить что-то валидное.
Но даже сам cppreference предлагает нам способ обойти эту неприятную бяку. Мы можем подставить вместо false шаблонное constexpr типазависимое выражение, которое будет возвращать false. И тогда все магическим образом заработает.
Видимо из-за того, что шаблон можно вручную специализировать, то теоритически возможна специализация, которая будет возвращать true. И даже если она еще не инстанцирована, то возможность-то остается. Поэтому компилятор пропускает такую конструкцию.
Однако ситуация изменилась с приходом С++23, но об этом мы поговорим завтра.
Find loopholes in the system. Stay cool.
#cpp17 #template
Вернемся к прошлому примеру с функцией to\_str, но сделаем ее немножко безопасней.
template <typename T>
std::string to_str(T t) {
if constexpr (std::is_constructible_v<std::string, T>)
return t;
else if constexpr (std::is_arithmetic_v<T>)
return std::to_string(t);
else
static_assert(false, "cannot convert type to std::string");
}
Все просто. Функция std::to_string имеет перегрузки только для тривиальных арифметических типов, поэтому чтобы ее использовать и получить ошибку, нужно провести проверку на эту арифметичность. Если переданный в функцию to\_str тип не конструируется в строку или не является арифметическим типом, то не совсем понятно, как такой тип переводить в строку. Точнее так: в каждом конкретном случае мы можем сказать как, но общего поведения нет. Поэтому, чтобы детектировать такие нештатные ситуации, я поставлю ассерт времени компиляции.
И вроде всё хорошо, но да не всё...
Дело в том, что при попытке скомпилировать этот пример, процесс прервется на этом ассерте даже в том случае, когда мы попадем в первые две ветки.
Тут в чем прикол. Согласно стандарту, если хотя бы в одной из веток if constexpr не может быть сгенерировано ни одной валидной специализации, то программа - ill-formed и это ошибка. И вправду, false всегда будет false, как бы мы там не тужились родить что-то валидное.
Но даже сам cppreference предлагает нам способ обойти эту неприятную бяку. Мы можем подставить вместо false шаблонное constexpr типазависимое выражение, которое будет возвращать false. И тогда все магическим образом заработает.
template<typename>
inline constexpr bool dependent_false_v = false;
template <typename T>
std::string to_str(T t) {
if constexpr (std::is_constructible_v<std::string, T>)
return t;
else if constexpr (std::is_arithmetic_v<T>)
return std::to_string(t);
else
static_assert(dependent_false_v<T>, "cannot convert type to std::string");
}
Видимо из-за того, что шаблон можно вручную специализировать, то теоритически возможна специализация, которая будет возвращать true. И даже если она еще не инстанцирована, то возможность-то остается. Поэтому компилятор пропускает такую конструкцию.
Однако ситуация изменилась с приходом С++23, но об этом мы поговорим завтра.
Find loopholes in the system. Stay cool.
#cpp17 #template
{kind=link}
static_assert
Раз уж так много его обсуждаем, почему бы не рассказать о том, что это вообще такое.
Это фича С++11, которая позволяет прерывать компиляцию программы, если определенное условие не выполнено. Естественно, условие должно быть bool-constexpr выражением, иначе ничего не выйдет. static_assert на то и static, потому что работает во время компиляции. Рантайм выражения в это время не могут быть вычислены.
На данный момент доступны 2 вида этого ассерта:
static_assert(bool-constexpr, unevaluated-string)
static_assert(bool-constexpr)
Первая версия доступна с 11-х плюсов, вторая с 17-х. Первая добавляет к сообщению об ошибке вашу кастомную, но захардкоженую, строку для более полного и понятного контекста. Вторая такого поведения не предполагает, но оно и не всегда нужно.
Ну собственно, примеры вы уже видели. Хотя тут стоит сказать пару ласковых.
Мне кажется, что не стоит ставить ассерты на определенный тип шаблонных параметров шаблонных сущностей. Как верно указал Михаил в [этом комментарии](https://t.me/c/2009887601/2547), так будет сложно проверить на корректность перегрузку. Для такого рода ограничений лучше использовать концепты или sfinae. Единственное, что вы тогда потеряете вменяемое сообщение об ошибке и возможность его дополнить своим сообщением.
Статический ассерт может быть удобен для проверки размера структуры, которая взаимодействует с внешним миром. Например, низкоуровневый сетевой код может полагаться на один размер структуры, и какой-то нерадивый человек внес изменения в эту структуру и изменил ее размер без изменения всего связанного кода. Тогда возможны очень трудноотловимые ошибки. Этого можно избежать, поставив простой ассерт на размер этой структуры. И если размер вдруг изменится, то компиляция просто прервется. Тоже самое можно проводить и с размерами базовых типов. Правда тут возможно придется со всякими паддингами повозиться(эффективный рэндж беззнакового инта может быть [0, 65тыщ_что-то_там], а в памяти он будет занимать будет 4 байта).
Можно также проверять версию подключаемых библиотек, если они предоставляют свою версию в виде constexpr выражения, а не макроса(хотя это довольно редкое явление). Типа такого:
Ну и вообще, любые предположения о вашем коде, которые вы можете проверить в compile-time, стоит обернуть в эту конструкцию. Так вы убережете себя от долгих и бессмысленных сборок проектов, трудноотловимых багов и прочего. В общем, штука крутая.
Check your assumptions in advance. Stay cool.
#cpp11 #cpp17 #compiler
Раз уж так много его обсуждаем, почему бы не рассказать о том, что это вообще такое.
Это фича С++11, которая позволяет прерывать компиляцию программы, если определенное условие не выполнено. Естественно, условие должно быть bool-constexpr выражением, иначе ничего не выйдет. static_assert на то и static, потому что работает во время компиляции. Рантайм выражения в это время не могут быть вычислены.
На данный момент доступны 2 вида этого ассерта:
static_assert(bool-constexpr, unevaluated-string)
static_assert(bool-constexpr)
Первая версия доступна с 11-х плюсов, вторая с 17-х. Первая добавляет к сообщению об ошибке вашу кастомную, но захардкоженую, строку для более полного и понятного контекста. Вторая такого поведения не предполагает, но оно и не всегда нужно.
Ну собственно, примеры вы уже видели. Хотя тут стоит сказать пару ласковых.
Мне кажется, что не стоит ставить ассерты на определенный тип шаблонных параметров шаблонных сущностей. Как верно указал Михаил в [этом комментарии](https://t.me/c/2009887601/2547), так будет сложно проверить на корректность перегрузку. Для такого рода ограничений лучше использовать концепты или sfinae. Единственное, что вы тогда потеряете вменяемое сообщение об ошибке и возможность его дополнить своим сообщением.
Статический ассерт может быть удобен для проверки размера структуры, которая взаимодействует с внешним миром. Например, низкоуровневый сетевой код может полагаться на один размер структуры, и какой-то нерадивый человек внес изменения в эту структуру и изменил ее размер без изменения всего связанного кода. Тогда возможны очень трудноотловимые ошибки. Этого можно избежать, поставив простой ассерт на размер этой структуры. И если размер вдруг изменится, то компиляция просто прервется. Тоже самое можно проводить и с размерами базовых типов. Правда тут возможно придется со всякими паддингами повозиться(эффективный рэндж беззнакового инта может быть [0, 65тыщ_что-то_там], а в памяти он будет занимать будет 4 байта).
Можно также проверять версию подключаемых библиотек, если они предоставляют свою версию в виде constexpr выражения, а не макроса(хотя это довольно редкое явление). Типа такого:
#include "SomeVeryC++ishLibrary.hpp"
static_assert(SomeVeryC++ishLibrary.::Version > 2,
"Old versions of SomeVeryC++ishLibrary. are missing functionality to destroy the world.
It is very desired functionality so cannot process!");
class DestroyTheWorld {
// BOOM!!
};
Ну и вообще, любые предположения о вашем коде, которые вы можете проверить в compile-time, стоит обернуть в эту конструкцию. Так вы убережете себя от долгих и бессмысленных сборок проектов, трудноотловимых багов и прочего. В общем, штука крутая.
Check your assumptions in advance. Stay cool.
#cpp11 #cpp17 #compiler
{kind=link}
Фиксим неприятности
Сегодня коротко разберем, как обезопасить себя от проблем кода из предыдущего поста?
Просто надо использовать inline переменные! Но для этого понадобится С++17 и выше. Их и более менее все используют, но надо оговорку сделать.
Инлайн переменные также имеют внешнюю линковку, их определений может быть несколько в пределах одной программы, и по итогу компановщик также выберет одну из копий и весь остальной код будет ссылаться на нее. И в этом случае определение функции будет действительно единственным и доступным всем другим TU и это будет вполне легально.
Поэтому код будет выглядеть вот так:
constexpr и const имеют одинаковый линковочный смысл для переменных, поэтому замена вполне корректна. Да и просто constexpr переменная лучше смотрится с constexpr функций.
Fix your flaws. Stay cool.
#cpp17
Сегодня коротко разберем, как обезопасить себя от проблем кода из предыдущего поста?
Просто надо использовать inline переменные! Но для этого понадобится С++17 и выше. Их и более менее все используют, но надо оговорку сделать.
Инлайн переменные также имеют внешнюю линковку, их определений может быть несколько в пределах одной программы, и по итогу компановщик также выберет одну из копий и весь остальной код будет ссылаться на нее. И в этом случае определение функции будет действительно единственным и доступным всем другим TU и это будет вполне легально.
Поэтому код будет выглядеть вот так:
//header.hpp
inline constexpr int const_var = 3;
constexpr int gaga() {
return const_var;
}
//first.cpp
#include "header.hpp"
void boo() {
gaga();
}
//second.cpp
#include "header.hpp"
void kak_delaut_gucy() {
gaga();
}
constexpr и const имеют одинаковый линковочный смысл для переменных, поэтому замена вполне корректна. Да и просто constexpr переменная лучше смотрится с constexpr функций.
Fix your flaws. Stay cool.
#cpp17
{kind=link}
Правильно смешиваем static с inline
На мой взгляд предыдущее решение проблемы хоть и очень крутое, модное и молодежное, но иногда можно и лучше.
Например. Бывают случаи, когда в глобальную область выносят переменные, которые на самом деле не глобальные. Вообще, глобальные переменные - не самый хороший признак архитектуры кода. Они могут относиться к конкретным сущностям в коде, которые уже обособлены или могут быть выделены в будущем. Существование свободных функций хоть и допустимо, но тоже всегда должно подвергаться сомнению. Возможно эти функции про какую-то отдельную сущность и их стоит выделить в класс. Тогда можно попробовать некоторые другие вещи, помимо заинлайнивания переменной.
Если свободные функции перенести внутрь описания класса и сделать их явно или неявно inline, то с точки зрения этой функции ничего не изменится. У нее также осталась внешняя линковка и в любой единице транляции будет ее определение.
Но вот теперь можно в ее теле попробовать использовать статические поля класса. Здесь мы обсудили, что они имеют внешнее связывание. Они либо аллоцированы в одной единице трансляции в случае если они не inline, либо имеют определение в нескольких в случае inline. Если используется обычное статического поля внутри инлайн функции, то во всех ее определениях будет содержаться единственный экземпляра этого поля и все определения в разных единицах трансляции будут одинаковые. А при использовании inline статической переменной, то компановщик объединит все ее копии в одну и в итоге все будут ссылаться на одну сущность.
Выглядеть это может примерно так:
Дальше. Не обязательно глобальная переменная принадлежит какому-то классу. Они может принадлежать самой этой функции и больше нигде не использоваться. А нужна она была для сохранения состояния между вызовами функции. Тут очень напрашивается просто поместить эту статическую глобальную переменную и тогда она станет статической локальной переменной. С константами это конечно абсолютно бессмысленно делать, но для "переменных" переменных можно и это стоит упоминания. Тогда мы уже не можем говорить про constexpr(будет зависимость от рантаймового значения), поэтому дальше разговор только про inline.
Статические локальные переменные не имеют никакой линковки(к ним нельзя получить доступ вне функции), поэтому не совсем понятно, корректно ли такая конструкция себя будет вести в инлайн функциях. И оказывается корректно(из cppreference):
Нам гарантируют, что все определения инлайн функции будут ссылаться на одну и ту же сущность-статическую локальную переменную.
Выглядеть это может так:
В общем, смешивать inline и static - можно, но очень осторожно. Не противоречьте стандарту и никакое UB не овладеет вашим кодом.
Mix things properly. Stay cool.
#cpp17 #cppcore #compiler
На мой взгляд предыдущее решение проблемы хоть и очень крутое, модное и молодежное, но иногда можно и лучше.
Например. Бывают случаи, когда в глобальную область выносят переменные, которые на самом деле не глобальные. Вообще, глобальные переменные - не самый хороший признак архитектуры кода. Они могут относиться к конкретным сущностям в коде, которые уже обособлены или могут быть выделены в будущем. Существование свободных функций хоть и допустимо, но тоже всегда должно подвергаться сомнению. Возможно эти функции про какую-то отдельную сущность и их стоит выделить в класс. Тогда можно попробовать некоторые другие вещи, помимо заинлайнивания переменной.
Если свободные функции перенести внутрь описания класса и сделать их явно или неявно inline, то с точки зрения этой функции ничего не изменится. У нее также осталась внешняя линковка и в любой единице транляции будет ее определение.
Но вот теперь можно в ее теле попробовать использовать статические поля класса. Здесь мы обсудили, что они имеют внешнее связывание. Они либо аллоцированы в одной единице трансляции в случае если они не inline, либо имеют определение в нескольких в случае inline. Если используется обычное статического поля внутри инлайн функции, то во всех ее определениях будет содержаться единственный экземпляра этого поля и все определения в разных единицах трансляции будут одинаковые. А при использовании inline статической переменной, то компановщик объединит все ее копии в одну и в итоге все будут ссылаться на одну сущность.
Выглядеть это может примерно так:
//header.hpp
struct StrangeSounds {
static constexpr int gaga() {
return krya;
}
static const int krya = 3;
};
//first.cpp
#include "header.hpp"
void boo() {
StrangeSounds::gaga();
}
//second.cpp
#include "header.hpp"
void kak_delaut_gucy() {
StrangeSounds::gaga();
}
Дальше. Не обязательно глобальная переменная принадлежит какому-то классу. Они может принадлежать самой этой функции и больше нигде не использоваться. А нужна она была для сохранения состояния между вызовами функции. Тут очень напрашивается просто поместить эту статическую глобальную переменную и тогда она станет статической локальной переменной. С константами это конечно абсолютно бессмысленно делать, но для "переменных" переменных можно и это стоит упоминания. Тогда мы уже не можем говорить про constexpr(будет зависимость от рантаймового значения), поэтому дальше разговор только про inline.
Статические локальные переменные не имеют никакой линковки(к ним нельзя получить доступ вне функции), поэтому не совсем понятно, корректно ли такая конструкция себя будет вести в инлайн функциях. И оказывается корректно(из cppreference):
Function-local static objects in all definitions
of the same inline function (which may be
implicitly inline) all refer to the same object
defined in one translation unit, as long as the
function has external linkage.
Нам гарантируют, что все определения инлайн функции будут ссылаться на одну и ту же сущность-статическую локальную переменную.
Выглядеть это может так:
//header.hpp
inline int gaga() {
static int krya = 3;
return krya++;
}
//first.cpp
#include "header.hpp"
int boo() {
return gaga();
}
//second.cpp
#include "header.hpp"
int kak_delaut_gucy() {
return gaga();
}
В общем, смешивать inline и static - можно, но очень осторожно. Не противоречьте стандарту и никакое UB не овладеет вашим кодом.
Mix things properly. Stay cool.
#cpp17 #cppcore #compiler
{kind=link}
Инициализация статических полей класса. Ч3
В первой части мы разобрали порядок инициализации статических поле в случае их out-of-class определения. Однако в современных плюсах редко, кто вне описания класса инициализирует статические поля. Все потому что в С++17 появились инлайн переменные, которые позволяют не нарушать ODR при наличии их определения в разных единицах трансляции. Подробнее об этом тут. Эта фича позволила определять статические поля сразу внутри описания класса. Более подробно об этом тут.
Ну и встает вопрос: в каком порядке инициализируются inline static class members?
В целом, ответ такой же: в порядке определения. Только эти определения теперь совмещены с объявлением, поэтому можно сказать, что инициализация происходит в порядке появления этих полей в описании класса. Спасибо Артему Кузнецову, что указал в комментариях на эту особенность)
Ну и для того, чтобы пост был не таким скучным, давайте попробуем смешать обычные статические мемберы и инлайновые и посмотрим, как эта смесь будет себя вести.
Выглядит это примерно так:
Вывод будет таким:
В целом, картина довольно понятная. Если линкер ставит инициализацию статиков по порядку их определения, то здесь прослеживается та же история. Первыми инициализируются инлайны по порядку появления их в классе, а последним инициализируется неинлайновое поле, даже с учетом того, что оно объявлено между двумя первыми.
Так что порядок следования определений - наше все.
Rely on explicitly stated rules. Stay cool.
#cpp17 #cppcore
В первой части мы разобрали порядок инициализации статических поле в случае их out-of-class определения. Однако в современных плюсах редко, кто вне описания класса инициализирует статические поля. Все потому что в С++17 появились инлайн переменные, которые позволяют не нарушать ODR при наличии их определения в разных единицах трансляции. Подробнее об этом тут. Эта фича позволила определять статические поля сразу внутри описания класса. Более подробно об этом тут.
Ну и встает вопрос: в каком порядке инициализируются inline static class members?
В целом, ответ такой же: в порядке определения. Только эти определения теперь совмещены с объявлением, поэтому можно сказать, что инициализация происходит в порядке появления этих полей в описании класса. Спасибо Артему Кузнецову, что указал в комментариях на эту особенность)
Ну и для того, чтобы пост был не таким скучным, давайте попробуем смешать обычные статические мемберы и инлайновые и посмотрим, как эта смесь будет себя вести.
Выглядит это примерно так:
struct Helper {
Helper(int num) : data{num} {
std::cout << "Helper " << num << std::endl;
}
private:
int data;
};
struct Class {
static inline Helper a{1};
static Helper b;
static inline Helper c{2};
};
Helper Class::b{3};
int main() {}
Вывод будет таким:
Helper 1
Helper 2
Helper 3
В целом, картина довольно понятная. Если линкер ставит инициализацию статиков по порядку их определения, то здесь прослеживается та же история. Первыми инициализируются инлайны по порядку появления их в классе, а последним инициализируется неинлайновое поле, даже с учетом того, что оно объявлено между двумя первыми.
Так что порядок следования определений - наше все.
Rely on explicitly stated rules. Stay cool.
#cpp17 #cppcore
{kind=link}
Динамическая инициализация
После статической инициализации в компайлтайме идет динамическая инициализация в рантайме. Хотелось бы сказать, что хоть здесь простой и понятный порядок, но нет. Это глобальные переменные и С++, поэтому будет немного больно.
Динамическая инициализация разделяется на 3 подгруппы:
1️⃣ Неупорядоченная динамическая инициализация. Она применяется только для статических полей шаблонных классов и шаблонных переменных, которые не специализированы явно(явно специализированные шаблоны - обычные классы). И вот порядок установки значений этих сущностей вообще неопределен. Куда понравится компилятору, туда и вставит.
2️⃣ Частично упорядоченная инициализация. Применяется для всех нешаблонных инлайн переменных. Есть 2 переменные: inline переменная А и В, которая не подходит под критерии применения первой подгруппы. Если А определена во всех единицах трансляции раньше В, то и ее инициализация происходит раньше. Здесь есть однана*бка особенность, которую мы увидим в примере.
3️⃣ Упорядоченная инициализация. Вот это то, что мы упоминали тут. Все переменные со static storage duration, которые не подходят под предыдущие подгруппы, инициализируются в порядке появления их определения в единице трансляции. Между разными единицами трансляции порядок инициализации не установлен.
Давайте на "простой" пример посмотрим:
Возможный вывод:
Здесь как раз все три типа проявляются.
Далее мы имеем уже упорядоченные вещи.
Это понятно. Но погодите:
Вот тут-то и кроется подвох: вы наверное подумали, что из факта "если А определено раньше В, то А инициализируется раньше" автоматически вытекает, что в обратном случае А инициализируется позже. Тут вас и подловили: не вытекает. Поэтому она и называется частично упорядоченной инициализацией. В обратном случае порядок неопределен.
Теперь все понятно:
Ну и статики
И теперь представьте свое лицо, когда вы сделали эти переменные зависимыми друг от друга, предполагая, что статики(со static storage duration) в одной единице трансляции инициализируются в порядке появления определения. Как минимум 🗿, а как максимум🤡.
Последние несколько постов по статикам так и наровят крикнуть: "Не используйте глобальные переменные!" Ну или хотя бы старайтесь не делать их зависимыми друг от друга. Потому что с порядком полный беспорядок, а с перекрестными зависимостями остается только надеяться, что заговор бабки-поветухи на продуктивную работу поможет не словить багов.
Decouple your program. Stay cool.
#cppcore #cpp17
После статической инициализации в компайлтайме идет динамическая инициализация в рантайме. Хотелось бы сказать, что хоть здесь простой и понятный порядок, но нет. Это глобальные переменные и С++, поэтому будет немного больно.
Динамическая инициализация разделяется на 3 подгруппы:
1️⃣ Неупорядоченная динамическая инициализация. Она применяется только для статических полей шаблонных классов и шаблонных переменных, которые не специализированы явно(явно специализированные шаблоны - обычные классы). И вот порядок установки значений этих сущностей вообще неопределен. Куда понравится компилятору, туда и вставит.
2️⃣ Частично упорядоченная инициализация. Применяется для всех нешаблонных инлайн переменных. Есть 2 переменные: inline переменная А и В, которая не подходит под критерии применения первой подгруппы. Если А определена во всех единицах трансляции раньше В, то и ее инициализация происходит раньше. Здесь есть одна
3️⃣ Упорядоченная инициализация. Вот это то, что мы упоминали тут. Все переменные со static storage duration, которые не подходят под предыдущие подгруппы, инициализируются в порядке появления их определения в единице трансляции. Между разными единицами трансляции порядок инициализации не установлен.
Давайте на "простой" пример посмотрим:
struct ShowOrderHelper {
ShowOrderHelper(int num) : data{num} {
std::cout << "Object initialized with data " << num << std::endl;
}
int data;
};
static ShowOrderHelper static_var1{3};
static ShowOrderHelper static_var2{4};
struct ClassWithInlineStaticVar {
static inline ShowOrderHelper inline_member{1};
};
inline ShowOrderHelper inline_var{2};
template <class T>
struct TemplateClassWithStaticVar {
static ShowOrderHelper static_member;
};
template <class T>
ShowOrderHelper TemplateClassWithStaticVar<T>::static_member{27};
Возможный вывод:
Object initialized with data 1
Object initialized with data 2
Object initialized with data 27
Object initialized with data 3
Object initialized with data 4
Здесь как раз все три типа проявляются.
static_member - статическое поле неспециализированного явно шаблона, поэтому установка ее значения в рандомном месте происходит.Далее мы имеем уже упорядоченные вещи.
inline_member определен раньше, чем inline_var, поэтому она и инициализируется раньше.Это понятно. Но погодите:
inline_member и inline_var определены позже статиков static_var1 и static_var2. Какого хера они инициализирутся раньше? Это же противоречит правилам частично упорядоченной динамической инициализации!Вот тут-то и кроется подвох: вы наверное подумали, что из факта "если А определено раньше В, то А инициализируется раньше" автоматически вытекает, что в обратном случае А инициализируется позже. Тут вас и подловили: не вытекает. Поэтому она и называется частично упорядоченной инициализацией. В обратном случае порядок неопределен.
Теперь все понятно:
inline_member инициализируется строго раньше inline_var, потому что определение стоит раньше. Но, как группа inline'ов, они расположены после static_var1 и static_var2 и в этом случае для них значение устанавливается в неизвестном порядке. В данном случае перед всеми инициализациями.Ну и статики
static_var1 и static_var2 инициализируются в ожидаемом порядке из-за применения упорядоченной инициализации.И теперь представьте свое лицо, когда вы сделали эти переменные зависимыми друг от друга, предполагая, что статики(со static storage duration) в одной единице трансляции инициализируются в порядке появления определения. Как минимум 🗿, а как максимум🤡.
Последние несколько постов по статикам так и наровят крикнуть: "Не используйте глобальные переменные!" Ну или хотя бы старайтесь не делать их зависимыми друг от друга. Потому что с порядком полный беспорядок, а с перекрестными зависимостями остается только надеяться, что заговор бабки-поветухи на продуктивную работу поможет не словить багов.
Decouple your program. Stay cool.
#cppcore #cpp17
{kind=link}
Рабочий Double-Checked Locking Pattern
#опытным
Мы уже довольно много говорим о нем и его проблемах. Давайте же сегодня обсудим решение.
Общее решение для проблем с когерентностью кэшей - использование барьеров памяти. Это инструкции, которые ограничивают виды переупорядочиваний операций, которые могут возникнуть при чтении и записи шареной памяти в многопроцессорной системе.
Даже просто применительно к этому паттерну коротко, но в деталях разобрать работу барьеров - задача нереальная, потому что барьеры памяти, сами по себе, не самая простая тема для понимания. Поэтому сегодня ограничимся лишь поверхностными пояснениями.
Вот как выглядела бы более менее работающая реализация паттерна блокировки с двойной проверкой до нашей эры(до С++11). Так как в то время в языке и стандартной библиотеке не было ничего, что связано с потоками, то для барьеров приходилось использовать platform-specific инструкции, часто с ассемблерными вставками.
Acquire барьер предотвращает переупорядочивание любого чтения, которое находится сверху от него, с любыми чтением/записью, которые следуют после барьера. Одна из проблем кода без барьеров: мы можем считать ненулевой указатель в tmp, но при этом результат операции инициализации объекта к нам еще не подтянется. Мы вернем из геттера неинициализированный указатель, что UB. Именно для предотвращения такого эффекта, в данном случае такой барьер нужен сверху для того, чтобы мы подтянули инициализированный объект из кэша другого ядра в случае, если мы все-таки считали ненулевой указатель.
Плюс он еще нужен, чтобы мы именно первой инструкцией считывали указатель и процессор не менял местами эту операцию со следующими. Может произойти так, что процессор поставит проверки всех условий перед записью указателя в tmp и это приведет к повторной инициализации синглтона.
Release барьер предотвращает переупорядочивание любого чтения/записи, которое находится сверху от него, с любой записью, которые следуют после барьера. Здесь также 2 составляющие. Первая: предотвращает переупорядочивание иницализации синглтона с присваиванием его указателя к
Объяснения не самые подробные и точные, но опять же, не было такой цели. Кто понимает - поймет, а кто не понимает - ждите статьи по модели памяти)
И вот как выглядела бы реализация этого паттерна на современном С++, если бы статические локальные переменные не гарантировали бы потокобезопасной инициализации:
Здесь мы только на всякий случай обернули указатель синглтона в атомик указатель, чтобы полностью быть так сказать в lock-free контексте. Барьеры на своих местах, а для залочивания мьютекса используем стандартный std::lock_guard с CTAD из 17-х плюсов.
Ставьте шампусик, если вам заходят такие посты с многопоточкой. Думаю, редко где в ру сегменте об этом пишут.
Establish your barriers. Stay cool.
#concurrency #cpp11 #cpp17
#опытным
Мы уже довольно много говорим о нем и его проблемах. Давайте же сегодня обсудим решение.
Общее решение для проблем с когерентностью кэшей - использование барьеров памяти. Это инструкции, которые ограничивают виды переупорядочиваний операций, которые могут возникнуть при чтении и записи шареной памяти в многопроцессорной системе.
Даже просто применительно к этому паттерну коротко, но в деталях разобрать работу барьеров - задача нереальная, потому что барьеры памяти, сами по себе, не самая простая тема для понимания. Поэтому сегодня ограничимся лишь поверхностными пояснениями.
Singleton* Singleton::getInstance() {
Singleton* tmp = m_instance;
... // insert acquire memory barrier
if (tmp == NULL) {
Lock lock;
tmp = m_instance;
if (tmp == NULL) {
tmp = new Singleton;
... // insert release memory barrier
m_instance = tmp;
}
}
return tmp;
}
Вот как выглядела бы более менее работающая реализация паттерна блокировки с двойной проверкой до нашей эры(до С++11). Так как в то время в языке и стандартной библиотеке не было ничего, что связано с потоками, то для барьеров приходилось использовать platform-specific инструкции, часто с ассемблерными вставками.
Acquire барьер предотвращает переупорядочивание любого чтения, которое находится сверху от него, с любыми чтением/записью, которые следуют после барьера. Одна из проблем кода без барьеров: мы можем считать ненулевой указатель в tmp, но при этом результат операции инициализации объекта к нам еще не подтянется. Мы вернем из геттера неинициализированный указатель, что UB. Именно для предотвращения такого эффекта, в данном случае такой барьер нужен сверху для того, чтобы мы подтянули инициализированный объект из кэша другого ядра в случае, если мы все-таки считали ненулевой указатель.
Плюс он еще нужен, чтобы мы именно первой инструкцией считывали указатель и процессор не менял местами эту операцию со следующими. Может произойти так, что процессор поставит проверки всех условий перед записью указателя в tmp и это приведет к повторной инициализации синглтона.
Release барьер предотвращает переупорядочивание любого чтения/записи, которое находится сверху от него, с любой записью, которые следуют после барьера. Здесь также 2 составляющие. Первая: предотвращает переупорядочивание иницализации синглтона с присваиванием его указателя к
m_instance. Это дает четкий порядок: в начале создаем объект, а потом m_instance указываем на него. Вторая гарантирует нам правильный порядок "отправки" изменений из текущего треда в точки назначения.Объяснения не самые подробные и точные, но опять же, не было такой цели. Кто понимает - поймет, а кто не понимает - ждите статьи по модели памяти)
И вот как выглядела бы реализация этого паттерна на современном С++, если бы статические локальные переменные не гарантировали бы потокобезопасной инициализации:
std::atomic<Singleton*> Singleton::m_instance;
std::mutex Singleton::m_mutex;
Singleton* Singleton::getInstance() {
Singleton* tmp = m_instance.load(std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_acquire);
if (tmp == nullptr) {
std::lock_guard lock(m_mutex);
tmp = m_instance.load(std::memory_order_relaxed);
if (tmp == nullptr) {
tmp = new Singleton;
std::atomic_thread_fence(std::memory_order_release);
m_instance.store(tmp, std::memory_order_relaxed);
}
}
return tmp;
}
Здесь мы только на всякий случай обернули указатель синглтона в атомик указатель, чтобы полностью быть так сказать в lock-free контексте. Барьеры на своих местах, а для залочивания мьютекса используем стандартный std::lock_guard с CTAD из 17-х плюсов.
Ставьте шампусик, если вам заходят такие посты с многопоточкой. Думаю, редко где в ру сегменте об этом пишут.
Establish your barriers. Stay cool.
#concurrency #cpp11 #cpp17
{kind=link}
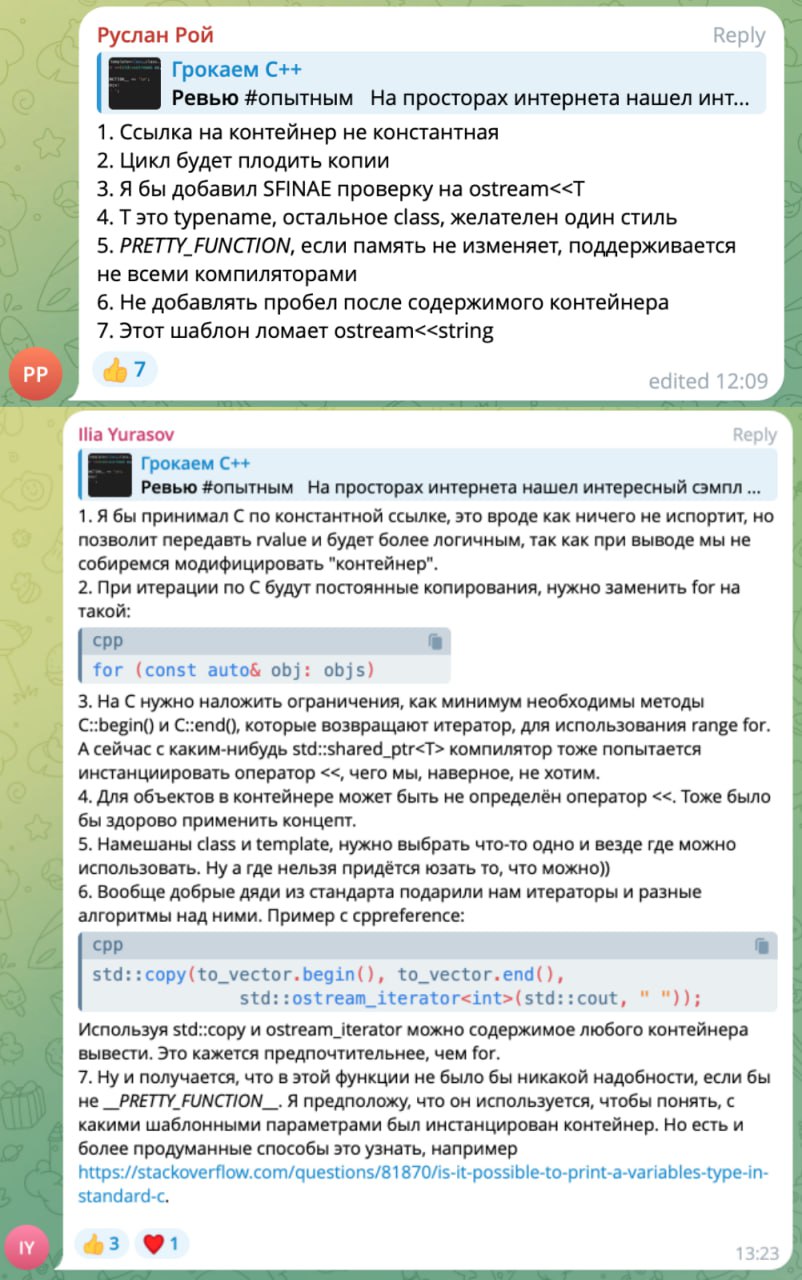
Результаты ревью
Круто вчера постарались, столько проблем нашли в этом маленьком кусочке кода. Больше всего проблем нашли два подписчика со скрина: я не смог выбрать из них одного, так как их пункты хоть и пересекаются, но все же дополняют друг друга различными мыслями. Давайте похлопаем нашим героям!👏👏👏👏👏👏
А теперь скомпануем все воедино. Напомню, что код был такой:
Сначала очевидное и то, что бросается в глаза. Все правильно поняли, что смысл кода - вывести элементы любого контейнера на выходной поток. Всвязи с этим следующие рассуждения:
❗️ Второй аргумент оператора принимается по значению, что ведет с излишним копированиям. Лучше использовать константную ссылку, так как мы не собираемся изменять значения контейнера.
❗️ В цикле тоже будут копирования, так как obj - объект, а не ссылка. Лучше использовать const auto &.
❗️ В первой строчке смешиваются class и typename. Это путает читателя, заставляя задумываться о тайном замысле использования разных ключевых слов. Лучше везде использовать class, так как Артем отметил , что до С++17 в шаблон-шаблонных параметрах нельзя было использовать typename.
❗️ Не очень выразительное название для аргумента, которым предполагается быть контейнеру. Хотя бы полностью написать Container.
❗️ Вывод элементов очень странный и кривой. Как минимум после последнего элемента будет ставиться пробел. Решить проблему можно с помощью стандартного алгоритма std::copy и интересного экспериментального итератора std::experimental::make_ostream_joiner, который может выводить элементы последовательности через разделитель, не записывая разделитель в конце! Выглядит это так:
На этом очевидные недостатки, которые мог выделить даже не очень разбирающийся в шаблонах читатель, заканчиваются.
Посмотрим чуть поглужбе. Функция используется для отладочных и учебных целей. Это понятно по использованию макроса PRETTY_FUNCTION. Он позволяет посмотреть полную сигнатуру функции с расшифровкой всех шаблонных параметров. Он довольно сильно помогает при обучении. Но к сожалению, этот макрос определен только под gcc/clang. Давайте уж не будем сильно внимание заострять на кроссплатформенности и целесообразности использования этой конструкции. В прод функция явно не пойдет. Д. А более интересные и кроссплатформенные варианты вывода сигнатуры функции можно посмотреть тут.
Однако автором этот кусок кода преподносился, как универсальный принт контейнеров STL. А вот тут уже залет! Потому что он не только не универсальный, но еще и не безопасный и корявый!.
🔞 Для класса std::string уже определен оператор вывода на поток, поэтому при наличии этого куска в общем коде мы просто не сможем выводить строку, так как компилятор найдет 2 подходящие перегрузки и не сможет из них выбрать лучшую. Можно ограничить тип контейнера с помощью sfinae/концептов.
🔞 Перегрузка не будет работать для мап. У них элементы - пары, которые не имеют собственной реализации вывода на поток. Да и вообще: если элементы "контейнера" не умеют выводиться на поток, то будет ошибка. Выход - поставить sfinae/концепт на существовании перегрузки на поток вывода для типа Т.
🔞 В предыдущем пункте я взял слово контейнер в кавычки. Все потому что сигнатура функции способна принимать любую шаблонную тварь, даже какой-нибудь std::shared_ptr. А для него уже перегружен оператор вывода. Опять компилятор не сможет выбрать из двух одинаковых перегрузок. Поэтому было бы неплохо поставить ограничение на существование методов begin() и end().
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Fix your flaws. Stay cool.
#template #STL #cppcore #cpp17 #cpp20
Круто вчера постарались, столько проблем нашли в этом маленьком кусочке кода. Больше всего проблем нашли два подписчика со скрина: я не смог выбрать из них одного, так как их пункты хоть и пересекаются, но все же дополняют друг друга различными мыслями. Давайте похлопаем нашим героям!👏👏👏👏👏👏
А теперь скомпануем все воедино. Напомню, что код был такой:
template<typename T, template<class,class...> class C, class... Args>
std::ostream& operator <<(std::ostream& os, C<T,Args...> objs)
{
os << PRETTY_FUNCTION << '\n';
for (auto obj : objs)
os << obj << ' ';
return os;
}
Сначала очевидное и то, что бросается в глаза. Все правильно поняли, что смысл кода - вывести элементы любого контейнера на выходной поток. Всвязи с этим следующие рассуждения:
❗️ Второй аргумент оператора принимается по значению, что ведет с излишним копированиям. Лучше использовать константную ссылку, так как мы не собираемся изменять значения контейнера.
❗️ В цикле тоже будут копирования, так как obj - объект, а не ссылка. Лучше использовать const auto &.
❗️ В первой строчке смешиваются class и typename. Это путает читателя, заставляя задумываться о тайном замысле использования разных ключевых слов. Лучше везде использовать class, так как Артем отметил , что до С++17 в шаблон-шаблонных параметрах нельзя было использовать typename.
❗️ Не очень выразительное название для аргумента, которым предполагается быть контейнеру. Хотя бы полностью написать Container.
❗️ Вывод элементов очень странный и кривой. Как минимум после последнего элемента будет ставиться пробел. Решить проблему можно с помощью стандартного алгоритма std::copy и интересного экспериментального итератора std::experimental::make_ostream_joiner, который может выводить элементы последовательности через разделитель, не записывая разделитель в конце! Выглядит это так:
std::copy(vec.begin(), vec.end(),
std::experimental::make_ostream_joiner(std::cout, ", "));
На этом очевидные недостатки, которые мог выделить даже не очень разбирающийся в шаблонах читатель, заканчиваются.
Посмотрим чуть поглужбе. Функция используется для отладочных и учебных целей. Это понятно по использованию макроса PRETTY_FUNCTION. Он позволяет посмотреть полную сигнатуру функции с расшифровкой всех шаблонных параметров. Он довольно сильно помогает при обучении. Но к сожалению, этот макрос определен только под gcc/clang. Давайте уж не будем сильно внимание заострять на кроссплатформенности и целесообразности использования этой конструкции. В прод функция явно не пойдет. Д. А более интересные и кроссплатформенные варианты вывода сигнатуры функции можно посмотреть тут.
Однако автором этот кусок кода преподносился, как универсальный принт контейнеров STL. А вот тут уже залет! Потому что он не только не универсальный, но еще и не безопасный и корявый!.
🔞 Для класса std::string уже определен оператор вывода на поток, поэтому при наличии этого куска в общем коде мы просто не сможем выводить строку, так как компилятор найдет 2 подходящие перегрузки и не сможет из них выбрать лучшую. Можно ограничить тип контейнера с помощью sfinae/концептов.
🔞 Перегрузка не будет работать для мап. У них элементы - пары, которые не имеют собственной реализации вывода на поток. Да и вообще: если элементы "контейнера" не умеют выводиться на поток, то будет ошибка. Выход - поставить sfinae/концепт на существовании перегрузки на поток вывода для типа Т.
🔞 В предыдущем пункте я взял слово контейнер в кавычки. Все потому что сигнатура функции способна принимать любую шаблонную тварь, даже какой-нибудь std::shared_ptr. А для него уже перегружен оператор вывода. Опять компилятор не сможет выбрать из двух одинаковых перегрузок. Поэтому было бы неплохо поставить ограничение на существование методов begin() и end().
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Fix your flaws. Stay cool.
#template #STL #cppcore #cpp17 #cpp20
{kind=link}
Опасности автоматического вывода типов
#новичкам
C++17 дал нам замечательную фичу CTAD. Это автоматический вывод шаблонных параметров класса по инициализатору.
Теперь, если вы хотите создать например пару строки и числа, то вместо этого:
Можно писать так:
Удобно? Безусловно! Только вот один вопросик есть.
Что будет, если я попытаюсь достать размер строки?
А будет ошибка
Пара-то на самом деле не из строки и числа, а из указателя и числа. Но это и правильно. Компилятор не умеет читать мысли, а четко работает с тем, что ему предоставили. В данном случае "Hello there!" действительно преобразуется в тип const char*. Если вы хотите std::string, то нужно явно показать это компилятору:
При более сложном коде могут возникать такие простыни ошибок компиляции, что без бутылки и не разберешься, что там на самом деле происходит.
Поэтому при использовании CTAD нужно тщательно следить за типами аргументов. Классы с не explicit конструкторами могут наделать большую невкусную кучу беспокойства.
Кстати, знаю адептов строгой типизации, которые даже auto не признают. А как вы относитесь к автоматическому выводу типов? Жду ваши мысли в комментах)
Be careful. Stay cool.
#cppcore #cpp17
#новичкам
C++17 дал нам замечательную фичу CTAD. Это автоматический вывод шаблонных параметров класса по инициализатору.
Теперь, если вы хотите создать например пару строки и числа, то вместо этого:
std::pair<std::string, int> pair{"Hello there!", 1};Можно писать так:
std::pair pair{"Hello there!", 1};Удобно? Безусловно! Только вот один вопросик есть.
Что будет, если я попытаюсь достать размер строки?
size_t size = pair.first.size();
А будет ошибка
error: request for member 'size' in 'a.std::pair<const char*, int>::first',
which is of non-class type 'const char*'
Пара-то на самом деле не из строки и числа, а из указателя и числа. Но это и правильно. Компилятор не умеет читать мысли, а четко работает с тем, что ему предоставили. В данном случае "Hello there!" действительно преобразуется в тип const char*. Если вы хотите std::string, то нужно явно показать это компилятору:
std::pair pair{std::string("Hello there!"), 1};При более сложном коде могут возникать такие простыни ошибок компиляции, что без бутылки и не разберешься, что там на самом деле происходит.
Поэтому при использовании CTAD нужно тщательно следить за типами аргументов. Классы с не explicit конструкторами могут наделать большую невкусную кучу беспокойства.
Кстати, знаю адептов строгой типизации, которые даже auto не признают. А как вы относитесь к автоматическому выводу типов? Жду ваши мысли в комментах)
Be careful. Stay cool.
#cppcore #cpp17