Пара слов об архитектуре нейросети
На ранних стадиях для направления диффузии используется более глубокая, «идейная» информация о смысле входной текстовой фразы, генерируемая языковой моделью (тоже отдельной, предварительно обученной нейросетью) T5. На более поздних стадиях с более высокими весом используется уже другой способ направления – основанный на CLIP-вложении, которое, по опыту, в большей мере отражает точность деталей.
Это чем-то похоже на работу реального художника: сначала, на основе идеи он или она набрасывает общие контуры будущей картины, а в конце уже заботится о реалистичности мелких деталей.
#нейронные_сети #популярное
eDiff-I. Главное ее новшество в том, что обратная диффузия при генерации изображения проводится в три стадии, причем на каждой стадии – отдельной моделью. Эти модели (expert denoisers, по терминологии авторов) отличаются друг от друга тем, в какой мере и как именно обратная диффузия направляется на основе текстовой фразы.На ранних стадиях для направления диффузии используется более глубокая, «идейная» информация о смысле входной текстовой фразы, генерируемая языковой моделью (тоже отдельной, предварительно обученной нейросетью) T5. На более поздних стадиях с более высокими весом используется уже другой способ направления – основанный на CLIP-вложении, которое, по опыту, в большей мере отражает точность деталей.
Это чем-то похоже на работу реального художника: сначала, на основе идеи он или она набрасывает общие контуры будущей картины, а в конце уже заботится о реалистичности мелких деталей.
#нейронные_сети #популярное
Еще одно новшество нейросети
Например, как показано на рисунке сверху, пользователь дает программе задание нарисовать магический портал рядом с заброшенным городом на фоне звездного неба и т.д., а также прикладывает изображение-маску, где разными цветами указано, где – приблизительно – нужно рисовать портал, где город, где небо и т.д. В результате нейросеть не просто рисует картинку по текстовому описанию, но и использует информацию с заданной маски для пространственного структурирования изображения.
Как показано внизу, архитектурно это реализуется при помощи механизма внимания: генерация изображения в пределах области маски каждого цвета в большей степени направляется теми словами из входной текстовой фразы, которые этому цвету отвечают. При этом соответствие между словами и областями изображения переводится на уровень семантической информации (embeddings) о тексте и генерируемом изображениии.
#нейронные_сети #популярное
eDiff-I – это предоставляемая ей возможность «рисования словами».Например, как показано на рисунке сверху, пользователь дает программе задание нарисовать магический портал рядом с заброшенным городом на фоне звездного неба и т.д., а также прикладывает изображение-маску, где разными цветами указано, где – приблизительно – нужно рисовать портал, где город, где небо и т.д. В результате нейросеть не просто рисует картинку по текстовому описанию, но и использует информацию с заданной маски для пространственного структурирования изображения.
Как показано внизу, архитектурно это реализуется при помощи механизма внимания: генерация изображения в пределах области маски каждого цвета в большей степени направляется теми словами из входной текстовой фразы, которые этому цвету отвечают. При этом соответствие между словами и областями изображения переводится на уровень семантической информации (embeddings) о тексте и генерируемом изображениии.
#нейронные_сети #популярное
👍3
CLIP (Contrastive Language-Image Pre-training) – это метод связывания текстов с изображениями, используемый многими современными нейросетями для генерации изображений по текстовому описанию. В этой работе он был впервые представлен и протестирован.
Традиционно нейронные сети обучались распознаванию и генерации изображений на основе датасетов, организованных как пары изображений и прилагающихся к ним меток, жестко разбитых на классы. Например, база
• Распознавание образов – генерация меток жестко заданного формата «здесь изображено X» на основе изображения.
• Превращение изображения в свободное текстовое описание вида «это фотография мужчины на мотоцикле, одетого в синюю куртку».
• Генерация изображений методом обратной диффузии на основе свободных текстовых описаний.
Идея метода, на самом деле, очень простая. Представим, что у нас имеется уже обученная нейросеть, распознающая изображения, то есть превращающая картинку A в вектор I = f(A), содержащий высокоуровневую информацию о ее содержании и стиле. Такая высокоуровневая информация, называемая словом embedding (вложение), получается через пропускание изображения через многослойную нейросеть, которая обучается распознаванию образов на основе имеющегося датасета с жестко заданными метками или сжатию изображения с его последующей распаковкой. Также берем обученную языковую модель – еще одну нейросеть, превращающую текстовую строку B в вектор T = g(B), содержащий высокоуровневую информацию о ее содержании. Обучение языковой модели может проводиться отдельно, для каких-то своих задач типа машинного перевода, поиска связи или противоречий между двумя предложениями и т.д. Главное, чтобы у нас имелась функция g, извлекающая суть из текстовой строки.
Дальше мы берем набор n изображений Aᵢ и отвечающих к ним текстовых строк Bᵢ свободного формата и вычисляем наборы их вложений – векторов Iᵢ = f(Aᵢ) и Tᵢ = g(Bᵢ). Для этих векторов мы вычисляем матрицу попарных перекрытий Iᵤ•Tᵥ = (Tᵥ)ᵀ(W_T)ᵀ(W_I)Iᵤ, имеющую размер n×n. По сути, это скалярные произведения векторов Iᵤ и Tᵥ, но проводимые в пространстве с метрикой (W_T)ᵀ(W_I), где W_I и W_T – матрицы весов, которые обучаются. Критерий их обучения в том, чтобы получившаяся матрица перекрытий Iᵤ•Tᵥ была как можно ближе к единичной δᵤᵥ, то есть чтобы такая матрица как можно более точно сопоставляла каждое исходное изображение Aᵤ именно с текстовой строкой Bᵤ, а не с какими-либо другими. Подгонка W_I и W_T производится стандартными методами типа градиентного спуска с использованием множества наборов, каждый из которых состоит из n пар изображений и текстовых строк.
Итогом обучения является, собственно, скалярная функция I•T, дающая информацию о том, насколько сильно изображение A отвечает текстовой строке B, и наоборот. Ключевое преимущество метода CLIP – в том, что его можно обучать на связках изображений с текстовыми строками, имеющими свободный формат, не укладывающийся в жесткие классы типа «изображения самолетов» или «изображения котов». Это позволяет использовать для обучения гигантские датасеты, собранные из интернета и содержащие десятки миллионов и даже миллиарды изображений – вместо традиционных баз данных типа
#нейронные_сети #популярное
Традиционно нейронные сети обучались распознаванию и генерации изображений на основе датасетов, организованных как пары изображений и прилагающихся к ним меток, жестко разбитых на классы. Например, база
MNIST содержит изображения рукописных цифр с пометками о том, какая именно цифра на ней изображена, а картинки CIFAR-10 разбиты на 10 классов: кошки, собаки, самолеты, лягушки и т.д. Метод CLIP позволяет выйти за границы жестких классов, создав двунаправленные ассоциации между изображениями и текстовыми строками свободного формата. Такие ассоциации могут использоваться для разных задач:• Распознавание образов – генерация меток жестко заданного формата «здесь изображено X» на основе изображения.
• Превращение изображения в свободное текстовое описание вида «это фотография мужчины на мотоцикле, одетого в синюю куртку».
• Генерация изображений методом обратной диффузии на основе свободных текстовых описаний.
Идея метода, на самом деле, очень простая. Представим, что у нас имеется уже обученная нейросеть, распознающая изображения, то есть превращающая картинку A в вектор I = f(A), содержащий высокоуровневую информацию о ее содержании и стиле. Такая высокоуровневая информация, называемая словом embedding (вложение), получается через пропускание изображения через многослойную нейросеть, которая обучается распознаванию образов на основе имеющегося датасета с жестко заданными метками или сжатию изображения с его последующей распаковкой. Также берем обученную языковую модель – еще одну нейросеть, превращающую текстовую строку B в вектор T = g(B), содержащий высокоуровневую информацию о ее содержании. Обучение языковой модели может проводиться отдельно, для каких-то своих задач типа машинного перевода, поиска связи или противоречий между двумя предложениями и т.д. Главное, чтобы у нас имелась функция g, извлекающая суть из текстовой строки.
Дальше мы берем набор n изображений Aᵢ и отвечающих к ним текстовых строк Bᵢ свободного формата и вычисляем наборы их вложений – векторов Iᵢ = f(Aᵢ) и Tᵢ = g(Bᵢ). Для этих векторов мы вычисляем матрицу попарных перекрытий Iᵤ•Tᵥ = (Tᵥ)ᵀ(W_T)ᵀ(W_I)Iᵤ, имеющую размер n×n. По сути, это скалярные произведения векторов Iᵤ и Tᵥ, но проводимые в пространстве с метрикой (W_T)ᵀ(W_I), где W_I и W_T – матрицы весов, которые обучаются. Критерий их обучения в том, чтобы получившаяся матрица перекрытий Iᵤ•Tᵥ была как можно ближе к единичной δᵤᵥ, то есть чтобы такая матрица как можно более точно сопоставляла каждое исходное изображение Aᵤ именно с текстовой строкой Bᵤ, а не с какими-либо другими. Подгонка W_I и W_T производится стандартными методами типа градиентного спуска с использованием множества наборов, каждый из которых состоит из n пар изображений и текстовых строк.
Итогом обучения является, собственно, скалярная функция I•T, дающая информацию о том, насколько сильно изображение A отвечает текстовой строке B, и наоборот. Ключевое преимущество метода CLIP – в том, что его можно обучать на связках изображений с текстовыми строками, имеющими свободный формат, не укладывающийся в жесткие классы типа «изображения самолетов» или «изображения котов». Это позволяет использовать для обучения гигантские датасеты, собранные из интернета и содержащие десятки миллионов и даже миллиарды изображений – вместо традиционных баз данных типа
CIFAR-10, созданных и расклассифицированных вручную. А, как известно, чем шире наборы обучающих данных, тем лучше и результат.#нейронные_сети #популярное
👍2
А вот пара иллюстраций работы метода CLIP.
Сверху показан процесс его обучения: наборы изображений и текстовых строк пропускаются через свои нейросети-кодировщики, которые предварительно обучены на других задачах и создают по ним наборы векторов-вложений Iᵤ и Tᵥ. Между этими векторами считаются попарные скалярные произведения Iᵤ•Tᵥ, которые должны быть как можно большими при u = v и меньшими при u ≠ v – в этом цель обучения матриц весов, с которыми такие произведения вычисляются.
Снизу показан пример того, как обученную CLIP-модель можно использовать для распознавания образов: на основе предложений “A photo of a dog”, “A photo of a plane” и т.д. вычисляются векторы Tᵥ, а на основе имеющейся картинки считается вектор I₁. Тот из векторов Tᵥ, для которого перекрытие I₁•Tᵥ максимально, отвечает наиболее вероятному классу объекта на изображении – в данном случае “dog”.
#нейронные_сети #популярное
Сверху показан процесс его обучения: наборы изображений и текстовых строк пропускаются через свои нейросети-кодировщики, которые предварительно обучены на других задачах и создают по ним наборы векторов-вложений Iᵤ и Tᵥ. Между этими векторами считаются попарные скалярные произведения Iᵤ•Tᵥ, которые должны быть как можно большими при u = v и меньшими при u ≠ v – в этом цель обучения матриц весов, с которыми такие произведения вычисляются.
Снизу показан пример того, как обученную CLIP-модель можно использовать для распознавания образов: на основе предложений “A photo of a dog”, “A photo of a plane” и т.д. вычисляются векторы Tᵥ, а на основе имеющейся картинки считается вектор I₁. Тот из векторов Tᵥ, для которого перекрытие I₁•Tᵥ максимально, отвечает наиболее вероятному классу объекта на изображении – в данном случае “dog”.
#нейронные_сети #популярное
👍1
Zero-shot prediction – это термин, часто встречающийся в статье по методу CLIP. Его можно перевести как «предсказание (или распознавание) без подготовки» или «с нулевым числом касаний». Это способность распознавать объекты, которые не встречались в обучающей выборке.
К примеру, человек легко распознает на показанных картинках изображения двухголового кота и котобуса (гибрида кота с автобусом) – даже если никогда в жизни не видел ни двухголовых котов, ни котобусов. Человек делает это по ассоциации, путем связывания слов «кот», «голова» и «автобус» с изображениями ранее виденных объектов, а затем комбинирования этих слов в предложение по правилам русского языка.
Именно на такое способна CLIP-модель: к примеру, она может с высокой вероятностью определить, что на картинке изображен зеленый банан, даже если при обучении ей никогда не показывать зеленые бананы, а показывать только желтые бананы и зеленые не-бананы. Модель сама свяжет образ банана и зеленый цвет.
#нейронные_сети #популярное
К примеру, человек легко распознает на показанных картинках изображения двухголового кота и котобуса (гибрида кота с автобусом) – даже если никогда в жизни не видел ни двухголовых котов, ни котобусов. Человек делает это по ассоциации, путем связывания слов «кот», «голова» и «автобус» с изображениями ранее виденных объектов, а затем комбинирования этих слов в предложение по правилам русского языка.
Именно на такое способна CLIP-модель: к примеру, она может с высокой вероятностью определить, что на картинке изображен зеленый банан, даже если при обучении ей никогда не показывать зеленые бананы, а показывать только желтые бананы и зеленые не-бананы. Модель сама свяжет образ банана и зеленый цвет.
#нейронные_сети #популярное
Еще одна любопытная штука из статьи по методу CLIP. Ее авторы сравнивали способность CLIP-модели к распознаванию образов с человеческими способностями. Для этого они заставили 5 человек просмотреть по 3996 изображений котов и собак и отнести каждое животное к одной из 37 пород (или дать ответ «не знаю»).
Как показано на графике зеленым цветом, в случае zero-shot-распознавания (когда людей предварительно не знакомили с тем, как выглядит каждая порода) точность человеческих ответов была в среднем около 54%, в то время как нейросеть, тоже никогда не видевшая эти породы, определяла их с точностью 93.5% (синяя линия). Если же людям предварительно показывали по 1 изображению каждой породы (one-shot, оранжевая линия), точность их ответов возрастала в среднем до 75.5% – в основном, за счет сокращения доли ответов «не знаю».
Занятно, что и люди, и нейросеть – по понятным причинам – легче всего распознавали мопса и сфинкса, а труднее всего – рэгдолла и английского кокер-спаниэля.
#нейронные_сети #популярное
Как показано на графике зеленым цветом, в случае zero-shot-распознавания (когда людей предварительно не знакомили с тем, как выглядит каждая порода) точность человеческих ответов была в среднем около 54%, в то время как нейросеть, тоже никогда не видевшая эти породы, определяла их с точностью 93.5% (синяя линия). Если же людям предварительно показывали по 1 изображению каждой породы (one-shot, оранжевая линия), точность их ответов возрастала в среднем до 75.5% – в основном, за счет сокращения доли ответов «не знаю».
Занятно, что и люди, и нейросеть – по понятным причинам – легче всего распознавали мопса и сфинкса, а труднее всего – рэгдолла и английского кокер-спаниэля.
#нейронные_сети #популярное
Давая людям задание распознать породы котов и собак на изображениях, учоные опасались, что результаты будут низкими из-за слабой мотивированности испытуемых – действительно, мало кто по доброй воле захочет просматривать 3996 картинок и классифицировать их аж по 37 породам.
Но высокая производительностькожаных мешков людей в других задачах восстановила их веру в человечество.
#цитаты #нейронные_сети
Но высокая производительность
#цитаты #нейронные_сети
Эффект Вайсенберга (Weissenberg effect) заключается в том, что жидкость «наматывается» на вращающийся стержень, скапливаясь вблизи него – вместо того, чтобы отбрасываться центробежными силами. Он наблюдается в случае неньютоновских жидкостей, демонстрирующих вязкоупругость – сочетание вязкости с упругостью в зависимости от характерного времени механического воздействия.
Вязкоупругая жидкость ведет себя как упругое твердое тело, если подвергать ее быстрым воздействиям механических сил, и начинает течь с постоянной вязкостью, как нормальная жидкость, при длительном воздействии. Вращающийся стержень создает вблизи себя высокие скорости потока жидкости, на которых она «твердеет» и поэтому наматывается на стержень.
#гидродинамика #популярное
Вязкоупругая жидкость ведет себя как упругое твердое тело, если подвергать ее быстрым воздействиям механических сил, и начинает течь с постоянной вязкостью, как нормальная жидкость, при длительном воздействии. Вращающийся стержень создает вблизи себя высокие скорости потока жидкости, на которых она «твердеет» и поэтому наматывается на стержень.
#гидродинамика #популярное
YouTube
The Weissenberg Effect
When a rod mounted in a hand drill is dipped into a liquid and rotated, for certain non-Newtonian fluids the liquid will climb the rod - sometimes to quite spectacular heights.
Such rob climbing behaviour is referred to as the Weissenberg Effect. Shearing…
Such rob climbing behaviour is referred to as the Weissenberg Effect. Shearing…
👍2
А в этом видео демонстрируется эффект Вайсенберга, возникающий без стержня (rodless Weissenberg effect). Он состоит в том, что жидкость над погруженным в нее вращающимся диском скапливается в центре, образуя холм, – вместо вогнутой параболической поверхности, создаваемой центробежными силами во вращающейся жидкости.
#гидродинамика #популярное
#гидродинамика #популярное
YouTube
Rodless Weissenberg effect
This video shows a well-known effect in viscoelastic flows: the rod-climbing (or Weissenberg) effect. We reproduced this flow without the need of a rod; the fluid climbs onto itself! It is a nice demonstration of the effect of viscoelasticty in a simple flow.
В некоторых источниках эффект Вайсенберга объясняется тем, что молекулы полимера, растворенные в жидкости, очень длинные и потому наматываются на стержень как спагетти на вилку. Не уверен, что такое объяснение применимо для всех наблюдаемых случаев, но огромная длина полимерных молекул действительно может давать начало интересным эффектам.
Здесь демонстрируется, как жидкость «выливает из сосуда сама себя» – как через сифон, но только не требующий шланга. Молекулы полимера настолько длинные, что их части, оказавшиеся снаружи сосуда, тянут за собой оставшиеся в сосуде части.
#гидродинамика #популярное
Здесь демонстрируется, как жидкость «выливает из сосуда сама себя» – как через сифон, но только не требующий шланга. Молекулы полимера настолько длинные, что их части, оказавшиеся снаружи сосуда, тянут за собой оставшиеся в сосуде части.
#гидродинамика #популярное
YouTube
A Liquid That Pours Itself! The Self-Siphoning Fluid: Polyethylene Glycol
In this video I showcase a really neat high-molecular weight polymer that can self-siphon and pour itself our of a beaker. The reason it can do this is because it can be made to have a very high molecular weight. The solution I used had a MW of 1,000,000.…
👍2
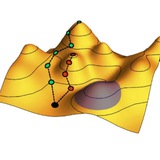
Эта задача на термодинамический цикл натолкнула меня на определенные размышления. В ней предлагается посчитать КПД термодинамического цикла, имеющего на pV-диаграмме форму прямоугольного треугольника.
Как я понял, тонкость задачи в том, что, когда мы идем вдоль гипотенузы, на части этого пути температура растет, на другой части – убывает. Это нужно учитывать при расчете КПД η = (Q₁– Q₂)/Q₁, где Q₁ и Q₂ – количества теплоты, полученного от нагревателя и отданного холодильнику. А именно, часть тепла, полученного рабочим телом вдоль «нагревающейся» части гипотенузы, нужно включить в Q₁, а часть тепла, отданного холодильнику вдоль «охлаждающейся» части гипотенузы, нужно включить в Q₂.
Но вот в чем проблема с таким решением: здесь предполагается, что, в ходе движения вдоль гипотенузы, мы как-то оперативно переключаем контакт рабочего тела с нагревателем на контакт его с холодильником (или наоборот), когда скорость изменения температуры меняет знак. Всегда ли можно технически это реализовать? А если термодинамический цикл идет не вдоль гипотенузы, а вдоль извилистой кривой, где процессы приема и отдачи тепла сменяют друг друга каждую миллисекунду? Сможем ли мы достаточно оперативно переключать рабочее тело от нагревателя к холодильнику и обратно?
Если подумать, то способ расчета КПД, традиционно предлагаемый в таких задачах, основывается на двух скрытых предположениях. Во-первых, правило «все тепло, которое рабочее тело получает, оно получает именно от нагревателя, а все тепло, которое оно отдает, оно отдает именно холодильнику» подразумевает неравновесность теплопередачи, ее обязательную направленность от более горячего тела к холодному. Нагреватель теплее, чем рабочее тело – поэтому тепло идет только в одном направлении, от первого ко второму. Аналогично, холодильник холоднее рабочего тела – поэтому может только принимать от него тепло, но не наоборот.
Однако это противоречит традиционному же для таких задач предположению о квазиравновесности, или бесконечной медленности реализации теплового цикла – в противном случае школьные формулы для расчета количества переданной теплоты и количества работы были бы неприменимы из-за потерь энергии на диссипацию. Если процесс квазиравновесный, то есть в каждый момент времени рабочее тело находится в тепловом равновесии с нагревателем или холодильником, то тепло спокойно может двигаться в любую сторону. И при движении вдоль гипотенузы ничто нам не мешает, в принципе, совершать теплообмен только с нагревателем, сначала принимая от него теплоту, а потом отдавая ее обратно тоже нагревателю. Таким образом, традиционное правило расчета КПД в подобных задачах внутренне противоречиво и не обязательно отвечает реальной практике работы тепловых машин.
Второе скрытое предположение более тонкое: КПД η определяется как отношение «полезной работы» A = Q₁ – Q₂ к количеству теплоты Q₁, полученной от нагревателя. Почему мы делим работу именно на Q₁? Потому что хотим понять, какая доля затраченных термодинамических ресурсов пошла на полезное дело, а таковым ресурсом считается именно теплота нагревателя Q₁. Здесь предполагается, что работа нагревателя «стоит денег», а работа холодильника «бесплатна». Действительно, для нагрева мы вынуждены, как правило, сжигать некое топливо, а холодильником служит атмосфера, в которую отработанные газы просто выбрасываются.
Но можно представить и другие ситуации, где ценным ресурсом будет именно холодильник. Например, в космических аппаратах, совершающих полеты вблизи Солнца, или на очень горячей планете, или глубоко в недрах Земли – здесь тепло бесплатно и его сколько угодно, а проблемой становится именно отвод тепла куда-то наружу. В этих случаях больший практический смысл имели бы другие определения КПД, например η´ = (Q₁– Q₂)/Q₂.
#термодинамика #популярное #объяснения
Как я понял, тонкость задачи в том, что, когда мы идем вдоль гипотенузы, на части этого пути температура растет, на другой части – убывает. Это нужно учитывать при расчете КПД η = (Q₁– Q₂)/Q₁, где Q₁ и Q₂ – количества теплоты, полученного от нагревателя и отданного холодильнику. А именно, часть тепла, полученного рабочим телом вдоль «нагревающейся» части гипотенузы, нужно включить в Q₁, а часть тепла, отданного холодильнику вдоль «охлаждающейся» части гипотенузы, нужно включить в Q₂.
Но вот в чем проблема с таким решением: здесь предполагается, что, в ходе движения вдоль гипотенузы, мы как-то оперативно переключаем контакт рабочего тела с нагревателем на контакт его с холодильником (или наоборот), когда скорость изменения температуры меняет знак. Всегда ли можно технически это реализовать? А если термодинамический цикл идет не вдоль гипотенузы, а вдоль извилистой кривой, где процессы приема и отдачи тепла сменяют друг друга каждую миллисекунду? Сможем ли мы достаточно оперативно переключать рабочее тело от нагревателя к холодильнику и обратно?
Если подумать, то способ расчета КПД, традиционно предлагаемый в таких задачах, основывается на двух скрытых предположениях. Во-первых, правило «все тепло, которое рабочее тело получает, оно получает именно от нагревателя, а все тепло, которое оно отдает, оно отдает именно холодильнику» подразумевает неравновесность теплопередачи, ее обязательную направленность от более горячего тела к холодному. Нагреватель теплее, чем рабочее тело – поэтому тепло идет только в одном направлении, от первого ко второму. Аналогично, холодильник холоднее рабочего тела – поэтому может только принимать от него тепло, но не наоборот.
Однако это противоречит традиционному же для таких задач предположению о квазиравновесности, или бесконечной медленности реализации теплового цикла – в противном случае школьные формулы для расчета количества переданной теплоты и количества работы были бы неприменимы из-за потерь энергии на диссипацию. Если процесс квазиравновесный, то есть в каждый момент времени рабочее тело находится в тепловом равновесии с нагревателем или холодильником, то тепло спокойно может двигаться в любую сторону. И при движении вдоль гипотенузы ничто нам не мешает, в принципе, совершать теплообмен только с нагревателем, сначала принимая от него теплоту, а потом отдавая ее обратно тоже нагревателю. Таким образом, традиционное правило расчета КПД в подобных задачах внутренне противоречиво и не обязательно отвечает реальной практике работы тепловых машин.
Второе скрытое предположение более тонкое: КПД η определяется как отношение «полезной работы» A = Q₁ – Q₂ к количеству теплоты Q₁, полученной от нагревателя. Почему мы делим работу именно на Q₁? Потому что хотим понять, какая доля затраченных термодинамических ресурсов пошла на полезное дело, а таковым ресурсом считается именно теплота нагревателя Q₁. Здесь предполагается, что работа нагревателя «стоит денег», а работа холодильника «бесплатна». Действительно, для нагрева мы вынуждены, как правило, сжигать некое топливо, а холодильником служит атмосфера, в которую отработанные газы просто выбрасываются.
Но можно представить и другие ситуации, где ценным ресурсом будет именно холодильник. Например, в космических аппаратах, совершающих полеты вблизи Солнца, или на очень горячей планете, или глубоко в недрах Земли – здесь тепло бесплатно и его сколько угодно, а проблемой становится именно отвод тепла куда-то наружу. В этих случаях больший практический смысл имели бы другие определения КПД, например η´ = (Q₁– Q₂)/Q₂.
#термодинамика #популярное #объяснения
Telegram
Кроссворд Тьюринга
♻️ Физика - неделя 3. Задача 2: цикл с подвохом.
Эту задачу можно смело представить как «99,9% людей решают эту задачу неправильно»! Даже если речь идёт о людях, знающих базовую термодинамику. Надеюсь, я вас заинтриговала, теперь расскажу про саму задачу…
Эту задачу можно смело представить как «99,9% людей решают эту задачу неправильно»! Даже если речь идёт о людях, знающих базовую термодинамику. Надеюсь, я вас заинтриговала, теперь расскажу про саму задачу…
🔥2
Краевые дислокации – это дефекты кристаллической структуры в виде линий, на которых одна из атомных плоскостей резко обрывается. Будучи топологическими дефектами, линии дислокаций не могут просто так рассосаться, но зато могут перемещаться по кристаллу. Как видно на рисунке, проход дислокации от одного края кристалла до другого приводит к его сдвиговой деформации – вот почему наличие дислокаций заметно снижает прочность металлов, делая их текучими под нагрузкой.
Казалось бы, самый очевидный способ сделать металл более упругим и менее текучим – это попытаться избавиться от дислокаций. Но технически это очень сложно. Поэтому испокон веков кузнецы для упрочнения металлов применяли противоположный подход: создать в кристаллической решетке как можно больше дислокаций и запутать их. Линии дислокаций отталкиваются друг от дружки – поэтому, множество раз деформируя металлическую полоску, расплющивая ее и складывая, можно добиться того, что дислокации перепутаются и лишатся подвижности.
#твердое_тело #популярное
Казалось бы, самый очевидный способ сделать металл более упругим и менее текучим – это попытаться избавиться от дислокаций. Но технически это очень сложно. Поэтому испокон веков кузнецы для упрочнения металлов применяли противоположный подход: создать в кристаллической решетке как можно больше дислокаций и запутать их. Линии дислокаций отталкиваются друг от дружки – поэтому, множество раз деформируя металлическую полоску, расплющивая ее и складывая, можно добиться того, что дислокации перепутаются и лишатся подвижности.
#твердое_тело #популярное
🔥4
Параксиальное распространение света через материал с показателем преломления, медленно меняющимся вдоль направления распространения, позволяет реализовывать аналог эволюции волновой функции согласно уравнению Шредингера, где роль времени играет координата вдоль светового пучка.
Если материал обладает кубической оптической нелинейностью, то вместо уравнения Шредингера можно реализовывать нелинейное уравнение Гросса-Питаевского, где волна взаимодействует сама с собой. Точнее, мы имеем дело с системой двух связанных уравнений Гросса-Питаевского для волн разных поляризаций. В этой работе теоретически показано, что если материал обладает неоднородностью спиральной формы, это заставляет волновой пакет вращаться, как если бы система была помещена во вращающийся сосуд.
На диаграммах для поляризации и фазы волновой функции можно видеть, как при таком вращении образуются квантованные вихри. Получается, что полностью оптическая система демонстрирует черты сверхтекучего поведения.
#фотоника #сверхтекучесть
Если материал обладает кубической оптической нелинейностью, то вместо уравнения Шредингера можно реализовывать нелинейное уравнение Гросса-Питаевского, где волна взаимодействует сама с собой. Точнее, мы имеем дело с системой двух связанных уравнений Гросса-Питаевского для волн разных поляризаций. В этой работе теоретически показано, что если материал обладает неоднородностью спиральной формы, это заставляет волновой пакет вращаться, как если бы система была помещена во вращающийся сосуд.
На диаграммах для поляризации и фазы волновой функции можно видеть, как при таком вращении образуются квантованные вихри. Получается, что полностью оптическая система демонстрирует черты сверхтекучего поведения.
#фотоника #сверхтекучесть
Это пример решетки взаимодействующих кубитов, реализующих поверхностный код (surface code) – метод коррекции ошибок, оптимизированный для расположения кубитов на плоскости.
Основные кубиты, несущие информацию, показаны здесь зелеными кругами, а синими треугольниками и красными крестиками обозначены вспомогательные кубиты, служащие для контроля четности числа возбуждений и относительных фаз. А именно, каждый кубит контроля четности числа возбуждений (треугольник) несет в себе информацию о величине <Z₁Z₂> двух соединенных с ним основных кубитов. Если величина Z у одного из них перевернется, это можно будет отследить по состоянию вспомогательного кубита и потом скорректировать. Аналогично, кубит контроля относительной фазы (крестик) несет информацию о величине < X₁X₂>, которая изменится при случайном перевороте относительной фазы двух основных кубитов.
Серыми областями на рисунке показаны схемы проведенных экспериментов, где отрабатывалась коррекция ошибок при помощи поверхностного кода.
#квантовые_вычисления
Основные кубиты, несущие информацию, показаны здесь зелеными кругами, а синими треугольниками и красными крестиками обозначены вспомогательные кубиты, служащие для контроля четности числа возбуждений и относительных фаз. А именно, каждый кубит контроля четности числа возбуждений (треугольник) несет в себе информацию о величине <Z₁Z₂> двух соединенных с ним основных кубитов. Если величина Z у одного из них перевернется, это можно будет отследить по состоянию вспомогательного кубита и потом скорректировать. Аналогично, кубит контроля относительной фазы (крестик) несет информацию о величине < X₁X₂>, которая изменится при случайном перевороте относительной фазы двух основных кубитов.
Серыми областями на рисунке показаны схемы проведенных экспериментов, где отрабатывалась коррекция ошибок при помощи поверхностного кода.
#квантовые_вычисления
Красивый эксперимент, в котором двумерный бозе-конденсат атомов размешивался лазерным лучом и по тому, нагрелся ли он за счет диссипации, делался вывод о наличии или отсутствии в нем сверхтекучести.
Как видно на графиках, при начальной температуре атомного облака выше критической его температура после размешивания повышается – причем тем сильнее, чем выше скорость вращения лазерного луча. Это проявление обычного трения, переводящего работу лазерного луча в тепло. Если же начальная температура была ниже критической, то до определенного порога скорости температура не повышается, потому что атомное облако, будучи сверхтекучим, не увлекается лучом и не поддерживает диссипацию энергии. Только при превышении критической скорости температура начинает повышаться.
Кстати говоря, нормальная компонента – поддерживающая обычную диссипацию – во втором случае тоже присутствует, но не проявляется из-за того, что оттеснена на периферию облака, куда лазерный луч не достает.
#атомные_газы #сверхтекучесть
Как видно на графиках, при начальной температуре атомного облака выше критической его температура после размешивания повышается – причем тем сильнее, чем выше скорость вращения лазерного луча. Это проявление обычного трения, переводящего работу лазерного луча в тепло. Если же начальная температура была ниже критической, то до определенного порога скорости температура не повышается, потому что атомное облако, будучи сверхтекучим, не увлекается лучом и не поддерживает диссипацию энергии. Только при превышении критической скорости температура начинает повышаться.
Кстати говоря, нормальная компонента – поддерживающая обычную диссипацию – во втором случае тоже присутствует, но не проявляется из-за того, что оттеснена на периферию облака, куда лазерный луч не достает.
#атомные_газы #сверхтекучесть
А здесь можно полюбоваться на зонную структуру оксида индия In₂O₃.
Слева – зонная структура, посчитанная методом функционала плотности с учетом U-члена (локального отталкивания электронов на узле) и спин-орбитального взаимодействия. Справа найденная отсюда теоретическая плотность электронных состояний сравнивается с экспериментами по фотоэлектронной спектроскопии.
Включение U-члена и спин-орбитального взаимодействия оказывается очень важным для правильного воспроизведения экспериментальных данных: без них не происходит нужной гибридизации 2s-электронов кислорода и 4d-электронов индия, дающей относительно малую щель между двумя нижними зонами.
#твердое_тело
Слева – зонная структура, посчитанная методом функционала плотности с учетом U-члена (локального отталкивания электронов на узле) и спин-орбитального взаимодействия. Справа найденная отсюда теоретическая плотность электронных состояний сравнивается с экспериментами по фотоэлектронной спектроскопии.
Включение U-члена и спин-орбитального взаимодействия оказывается очень важным для правильного воспроизведения экспериментальных данных: без них не происходит нужной гибридизации 2s-электронов кислорода и 4d-электронов индия, дающей относительно малую щель между двумя нижними зонами.
#твердое_тело
Иерархия доминирования в стаей голубей определяется тем, кто в какой очередности они принимают пищу, кто кого гоняет (доминирующий голубь движется на подчиненного, а тот пытается избежать сближения) и кто кого клюет. Но у них есть и вторая, параллельная иерархия лидерства, проявляющаяся при полете: лидирующие голуби задают направление полета стаи, а остальные за ними следуют.
В этой работе изучили иерархии доминирования и лидерства в трех стаях голубей при помощи автоматического трекинга и программной обработки видеозаписей. Оказалось, что иерархии доминирования и лидерства никак не связаны между собой и существуют параллельно – видимо, потому, что они требуют от голубей разных, не связанных друг с другом компетенций. Это демонстрируется на диаграммах снизу, где красным и зеленым цветом показано доминирование – иерархии приема пищи и клевания, – а синим цветом показана иерархия лидерства в полете. Как видно, красно-зеленая структура никак не скоррелирована с синей.
#биология #популярное #общество
В этой работе изучили иерархии доминирования и лидерства в трех стаях голубей при помощи автоматического трекинга и программной обработки видеозаписей. Оказалось, что иерархии доминирования и лидерства никак не связаны между собой и существуют параллельно – видимо, потому, что они требуют от голубей разных, не связанных друг с другом компетенций. Это демонстрируется на диаграммах снизу, где красным и зеленым цветом показано доминирование – иерархии приема пищи и клевания, – а синим цветом показана иерархия лидерства в полете. Как видно, красно-зеленая структура никак не скоррелирована с синей.
#биология #популярное #общество
👍2🤔2🤯1
«Смотрите, стайка голубьёв!» Эти видео демонстрируют, как определялись иерархии в стае голубей. На первом видео – видеозапись приема пищи, на которой положение каждого голубя отслеживает по прикрепленному к нему флагу цветному идентификатору. Доминирование определяется по тому, как один голубь блокирует доступ другого к кормушке.
Второе видео демонстрирует иерархию, проявляющуюся в избегании столкновений: доминирующий голубь движется на подчиненного, а тот пытается избежать сближения. Это можно определить автоматически по взаимным координатам голубей и векторам их скоростей. Доминирование же, проявляющееся в том, кто кого клюет и кто на кого нападает, люди определяли вручную, путем просмотра примерно половины видеозаписей.
На третьем видео показано, как определяется иерархия лидерства при стайном полете: если один голубь меняет направление полета первым, а другой делает это чуть позже, то первый считается лидером по сравнению со вторым.
#биология #популярное #общество
Второе видео демонстрирует иерархию, проявляющуюся в избегании столкновений: доминирующий голубь движется на подчиненного, а тот пытается избежать сближения. Это можно определить автоматически по взаимным координатам голубей и векторам их скоростей. Доминирование же, проявляющееся в том, кто кого клюет и кто на кого нападает, люди определяли вручную, путем просмотра примерно половины видеозаписей.
На третьем видео показано, как определяется иерархия лидерства при стайном полете: если один голубь меняет направление полета первым, а другой делает это чуть позже, то первый считается лидером по сравнению со вторым.
#биология #популярное #общество