Одна из причин возникновения закона степенного скейлинга для эффективности работы нейросетей состоит в масштабно-инвариантной структуре обучающих данных.
Представим, что у нас есть массив данных – набор точек в многомерном пространстве – которые мы хотим подвергнуть анализу главных компонент, чтобы выделить в нем существенную часть. Для этого мы считаем ковариационную матрицу массива данных и смотрим на спектр ее собственных значений λ, говорящих о том, насколько сильно данные варьируются в различных направлениях многомерного пространства. Если несколько λ особенно велики, а остальные гораздо меньше, то данные располагаются приблизительно на гиперплоскости – линейной оболочке собственных векторов, отвечающей большим λ.
Оказывается, что для естественных больших данных это не так: как видно на рисунке, спектры λ для картинок CIFAR-10 и для текстов из Википедии являются степенными и не демонстрируют щелей. При росте объема выборки T протяженность этой степенной зависимости увеличивается.
#нейронные_сети
Представим, что у нас есть массив данных – набор точек в многомерном пространстве – которые мы хотим подвергнуть анализу главных компонент, чтобы выделить в нем существенную часть. Для этого мы считаем ковариационную матрицу массива данных и смотрим на спектр ее собственных значений λ, говорящих о том, насколько сильно данные варьируются в различных направлениях многомерного пространства. Если несколько λ особенно велики, а остальные гораздо меньше, то данные располагаются приблизительно на гиперплоскости – линейной оболочке собственных векторов, отвечающей большим λ.
Оказывается, что для естественных больших данных это не так: как видно на рисунке, спектры λ для картинок CIFAR-10 и для текстов из Википедии являются степенными и не демонстрируют щелей. При росте объема выборки T протяженность этой степенной зависимости увеличивается.
#нейронные_сети
🤔2
Как было описано в предыдущем посте, одна из причин возникновения закона степенного скейлинга – в том, что обучающие данные имеют масштабно-инвариантную (фрактальную) структуру. Поэтому, чем больше объем обучающих данных T, тем больше информации о них нейросеть может уловить, причем при T → ∞ предел роста эффективности обучения на больших данных не просматривается.
Откуда тогда возникает степенной скейлинг еще и по N – числу параметров нейросети? Авторы показывают, что если повторить анализ спектра собственных значений λ ковариационной матрицы, но не для исходных обучающих данных, а для данных, пропущенных через случайные нелинейные функции, то можно продлить степенной хвост спектра λ. Как показано на двух примерах на рисунке, при росте числа нелинейных функций N этот хвост продлевается все дальше.
Таким образом, пропускание данных через нелинейные функции, осуществляемое нейросетью при формировании их скрытых представлений, позволяет еще сильнее расширить их естественное разнообразие.
#нейронные_сети
Откуда тогда возникает степенной скейлинг еще и по N – числу параметров нейросети? Авторы показывают, что если повторить анализ спектра собственных значений λ ковариационной матрицы, но не для исходных обучающих данных, а для данных, пропущенных через случайные нелинейные функции, то можно продлить степенной хвост спектра λ. Как показано на двух примерах на рисунке, при росте числа нелинейных функций N этот хвост продлевается все дальше.
Таким образом, пропускание данных через нелинейные функции, осуществляемое нейросетью при формировании их скрытых представлений, позволяет еще сильнее расширить их естественное разнообразие.
#нейронные_сети
👍2
В этой теоретической работе показан удивительный результат: оказывается, движение атома гелия через углеродную нанотрубку структуры (5, 5) удовлетворяет критерию сверхтекучести Ландау – даже без всякой бозе-конденсации, для единственного атома!
Вдоль оси нанотрубки система является пространственно периодической, так что авторы рассматривают зонную структуру возможных возбуждений – фононов и плазмонов. Как показано на графике снизу, даже с учетом процессов переброса (Umklapp scattering) существует небольшая область импульсов атома гелия kᵢ (синяя полоса), в которой не находится доступных возбуждений, отвечающих рассеяниям на различные m-е векторы обратной решетки (красные линии).
Критическая скорость здесь относительно невелика – 200 м/с, что отвечает температуре 20 К. Однако даже при комнатной температуре оказывается, что плотность нормальной компоненты составляет порядка 0.1%. То есть даже при комнатной температуре атомы гелия могут проходить через нанотрубки почти без трения.
#сверхтекучесть #отвал_башки
Вдоль оси нанотрубки система является пространственно периодической, так что авторы рассматривают зонную структуру возможных возбуждений – фононов и плазмонов. Как показано на графике снизу, даже с учетом процессов переброса (Umklapp scattering) существует небольшая область импульсов атома гелия kᵢ (синяя полоса), в которой не находится доступных возбуждений, отвечающих рассеяниям на различные m-е векторы обратной решетки (красные линии).
Критическая скорость здесь относительно невелика – 200 м/с, что отвечает температуре 20 К. Однако даже при комнатной температуре оказывается, что плотность нормальной компоненты составляет порядка 0.1%. То есть даже при комнатной температуре атомы гелия могут проходить через нанотрубки почти без трения.
#сверхтекучесть #отвал_башки
👀4🤨1
Соотношение неопределенностей Робертсона-Шредингера σ(X)σ(Z) ≥ ½|<ψ|[X,Z]|ψ>|, более известное как соотношение неопределенностей Гейзенберга, говорят о невозможности одновременно точно определить две несовместимые между собой наблюдаемые величины, представленные некоммутирующими операторами X и Z.
Иногда эта несовместимость формулируется как принцип дополнительности Бора: на классическом уровне, доступном для коммуникации исследователям, мы можем описывать квантовую систему в рамках одной из двух дополнительных картин (например, пространственно-координатной и импульсно-энергетической), но не обеими одновременно.
Несмотря на свои многочисленные применения, соотношение неопределенностей Робертсона-Шредингера не очень-то годится на роль математического выражения принципа дополнительности, потому что завязано на спектры операторов наблюдаемых величин. Если мы трактуем принцип дополнительности как невозможность полного определения и передачи информации о значениях двух несовместимых величин, то здесь важны лишь вероятности, связанные с вектором состояния квантовой системы и собственными векторами операторов X и Z. А вот собственные значения операторов X и Z – это, с точки зрения теории информации, всего лишь метки, которые можно переобозначать без изменения информационного содержания. Но в соотношение неопределенностей Робертсона-Шредингера они входят, что излишне.
Еще один недостаток этого соотношения – контринтуитивное (опять-таки, с точки зрения теории информации) поведение стандартных отклонений σ(X) и σ(Z). Вот пример: допустим, что величина X в текущем состоянии системы принимает значения +1, 0, –1, каждое c вероятностями 1/3. В этом случае σ(X) = √<(X – <X>)²> = 1/√3. Если мы спроецируем нашу систему на собственный вектор |φ₀><φ₀| оператора X, отвечающий собственному значению 0 (то есть измерим наблюдаемую, отвечающую на вопрос «принимает ли X значение 0?») и получим отрицательный ответ, то после измерения величина X будет принимать уже два оставшихся значения +1 и –1 с равными вероятностями 1/2. В этом состоянии σ(X) = 1/√2 – это больше, чем предыдущее значение 1/√3.
Получается парадоксальная штука: мы провели над системой измерений, получили некоторую информацию о ее состоянии (а именно, что X ≠ 0), а стандартное отклонение σ(X) не уменьшилось, а возросло. Поэтому σ(X) не является мерой неопределенности величины X, хорошо определенной с точки зрения теории информации. А значит, и соотношение неопределенностей Робертсона-Шредингера с информационной точки зрения не особенно осмысленно.
#квантовая_механика #информация #объяснения
Иногда эта несовместимость формулируется как принцип дополнительности Бора: на классическом уровне, доступном для коммуникации исследователям, мы можем описывать квантовую систему в рамках одной из двух дополнительных картин (например, пространственно-координатной и импульсно-энергетической), но не обеими одновременно.
Несмотря на свои многочисленные применения, соотношение неопределенностей Робертсона-Шредингера не очень-то годится на роль математического выражения принципа дополнительности, потому что завязано на спектры операторов наблюдаемых величин. Если мы трактуем принцип дополнительности как невозможность полного определения и передачи информации о значениях двух несовместимых величин, то здесь важны лишь вероятности, связанные с вектором состояния квантовой системы и собственными векторами операторов X и Z. А вот собственные значения операторов X и Z – это, с точки зрения теории информации, всего лишь метки, которые можно переобозначать без изменения информационного содержания. Но в соотношение неопределенностей Робертсона-Шредингера они входят, что излишне.
Еще один недостаток этого соотношения – контринтуитивное (опять-таки, с точки зрения теории информации) поведение стандартных отклонений σ(X) и σ(Z). Вот пример: допустим, что величина X в текущем состоянии системы принимает значения +1, 0, –1, каждое c вероятностями 1/3. В этом случае σ(X) = √<(X – <X>)²> = 1/√3. Если мы спроецируем нашу систему на собственный вектор |φ₀><φ₀| оператора X, отвечающий собственному значению 0 (то есть измерим наблюдаемую, отвечающую на вопрос «принимает ли X значение 0?») и получим отрицательный ответ, то после измерения величина X будет принимать уже два оставшихся значения +1 и –1 с равными вероятностями 1/2. В этом состоянии σ(X) = 1/√2 – это больше, чем предыдущее значение 1/√3.
Получается парадоксальная штука: мы провели над системой измерений, получили некоторую информацию о ее состоянии (а именно, что X ≠ 0), а стандартное отклонение σ(X) не уменьшилось, а возросло. Поэтому σ(X) не является мерой неопределенности величины X, хорошо определенной с точки зрения теории информации. А значит, и соотношение неопределенностей Робертсона-Шредингера с информационной точки зрения не особенно осмысленно.
#квантовая_механика #информация #объяснения
Как говорилось в предыдущем посте, соотношение неопределенностей Робертсона-Шредингера не особо полезно с точки зрения теории информации. Его альтернативой являются энтропийные соотношения неопределенностей, имеющие дело не со стандартными отклонениями, а с энтропиями измеряемых величин.
Простейший вариант таких соотношений показан на рисунке: сумма энтропий Шеннона H(X) и H(Z) результатов измерений двух наблюдаемых X и Z ограничена снизу убывающей функцией log(1/c) величины c. Эта величина определяется как максимальное перекрытие |X> и |Z> (собственных векторов X и Z), то есть максимальный квадрат модуля их попарных скалярных произведений.
Если наборы собственных векторов X и Z почти совпадают, то c ≈ 1, так что log(1/c) ≈ 0, и наблюдаемые X, Z могут быть измерены одновременно с почти нулевой энтропией. Если же их направления максимально не совпадают, то log(1/c) достигает верхнего предела log(d), где d – размерность гильбертова пространства системы.
#квантовая_механика #информация #объяснения
Простейший вариант таких соотношений показан на рисунке: сумма энтропий Шеннона H(X) и H(Z) результатов измерений двух наблюдаемых X и Z ограничена снизу убывающей функцией log(1/c) величины c. Эта величина определяется как максимальное перекрытие |X> и |Z> (собственных векторов X и Z), то есть максимальный квадрат модуля их попарных скалярных произведений.
Если наборы собственных векторов X и Z почти совпадают, то c ≈ 1, так что log(1/c) ≈ 0, и наблюдаемые X, Z могут быть измерены одновременно с почти нулевой энтропией. Если же их направления максимально не совпадают, то log(1/c) достигает верхнего предела log(d), где d – размерность гильбертова пространства системы.
#квантовая_механика #информация #объяснения
Судя по списку авторов, в этой статье уже произошло квантовое запутывание с генерацией нелокальной информации.
#цитаты #квантовая_механика #информация
#цитаты #квантовая_механика #информация
Теория квантовой информации позволяет посмотреть свежим взглядом на школьную арифметику:
оказывается, 2 – это не 1 плюс 1, а 1 или 1.
Например, если Маша дает Пете 2 яблока, это означает, что Петя может взять себе и скушать только одно из этих яблок, но не оба сразу.
#цитаты #квантовая_механика #квантовые_вычисления #информация
оказывается, 2 – это не 1 плюс 1, а 1 или 1.
Например, если Маша дает Пете 2 яблока, это означает, что Петя может взять себе и скушать только одно из этих яблок, но не оба сразу.
#цитаты #квантовая_механика #квантовые_вычисления #информация
👍3
Интересная работа, в которой описывается и доказывается математически принцип дополнительности для локальной и нелокальной информации о квантовых системах. Его можно считать некоторым аналогом принципа дополнительности Бора: утверждения о том, что любую квантовую систему мы можем описывать в рамках одной из двух дополнительных картин (например, координатной и импульсной), но не двумя одновременно.
«Описывать» в данном случае подразумевает определение статистики наблюдаемых величин и дальнейшее использование полученной информации в нашей классической жизни: передача ее по классическим каналам связи от одних исследователей к другим, публикация полученных результатов, использование информации для извлечения работы, для решения вычислительных задач и т.д. Действительно, поскольку операторы координаты и импульса не коммутируют, мы не можем работать одновременно с полной совместной статистикой этих величин, а должны ограничиваться одной из них (или неким компромиссом между ними, как это делается в представлении когерентных состояний).
В этой работе показано, что, похожим образом, дополнительными – то есть взаимно несовместимыми – являются локальная и нелокальная информация об одной и той же квантовой системе, состоящей из двух или большего числа пространственно разнесенных подсистем (parties). Локальная информация – это та информация, которая может быть получена в результате набора локальных операций (унитарных преобразований над каждой подсистемой и проведения локальных измерений над ними) и классических коммуникаций (передачи сигналов по классическим каналам связи о результатах локальных измерений).
Более точно ее можно определить как I_l – число бит информации, которую можно получить в результате набора локальных операций и классических коммуникаций. Иными словами, это число получаемых чистых сепарабельных кубитов. Локальная информация имеет важный практический смысл: к примеру, ее можно использовать для того, чтобы превращать теплоту в работу, потому что при доступе к термостату с температурой T каждый бит локальной информации позволяет извлечь T ln 2 работы. Можно ввести еще такую величину, как I_cor = I_l – I_LO – разность между локальной информацией I_l и той информацией I_LO, которую мы можем получить только локальными операциями, без классических коммуникаций между подсистемами. То есть I_cor – это та локальная информация, которую мы можем извлечь из существующих корреляций между подсистемами.
Нелокальную информацию можно определить как число E_D синглетных максимально запутанных пар кубитов (|0>₁|1>₂ – |0>₁|1>₂)√2, распределенных по разным подсистемам, которые мы можем очистить, то есть получить в чистом виде в результате набора локальных операций и классических коммуникаций. Величина E_D имеет важный практический смысл: это число кубитов, которые мы можем подвергнуть квантовой телепортации, используя текущее состояние нашей системы как ресурс, который будет использован в ходе телепортации.
Авторы доказывают следующее неравенство: I_cor(P) + E_D(P) ≤ n/2, где n – полное число кубитов в системе. Неравенство говорит о том, что сумма локальной информации I_cor(P) и нелокальной информации E_D(P), получаемых в ходе одного и того же набора P локальных операций и классических коммуникаций, не может превышать универсального предела n/2. Таким образом, локальная и нелокальная информация взаимно дополнительны: в ходе любого набора операций P мы можем получить максимум локальной информации (использовав ее, например, для превращения тепла в работу), но тогда потеряем нелокальную информацию. А можем, наоборот, получить максимум нелокальной информации (потратив ее на телепортацию), но тогда потеряем локальную информацию. Одновременно получить максимум и локальной информации, и нелокальной информации невозможно.
#квантовая_механика #квантовые_вычисления #информация #отвал_башки
«Описывать» в данном случае подразумевает определение статистики наблюдаемых величин и дальнейшее использование полученной информации в нашей классической жизни: передача ее по классическим каналам связи от одних исследователей к другим, публикация полученных результатов, использование информации для извлечения работы, для решения вычислительных задач и т.д. Действительно, поскольку операторы координаты и импульса не коммутируют, мы не можем работать одновременно с полной совместной статистикой этих величин, а должны ограничиваться одной из них (или неким компромиссом между ними, как это делается в представлении когерентных состояний).
В этой работе показано, что, похожим образом, дополнительными – то есть взаимно несовместимыми – являются локальная и нелокальная информация об одной и той же квантовой системе, состоящей из двух или большего числа пространственно разнесенных подсистем (parties). Локальная информация – это та информация, которая может быть получена в результате набора локальных операций (унитарных преобразований над каждой подсистемой и проведения локальных измерений над ними) и классических коммуникаций (передачи сигналов по классическим каналам связи о результатах локальных измерений).
Более точно ее можно определить как I_l – число бит информации, которую можно получить в результате набора локальных операций и классических коммуникаций. Иными словами, это число получаемых чистых сепарабельных кубитов. Локальная информация имеет важный практический смысл: к примеру, ее можно использовать для того, чтобы превращать теплоту в работу, потому что при доступе к термостату с температурой T каждый бит локальной информации позволяет извлечь T ln 2 работы. Можно ввести еще такую величину, как I_cor = I_l – I_LO – разность между локальной информацией I_l и той информацией I_LO, которую мы можем получить только локальными операциями, без классических коммуникаций между подсистемами. То есть I_cor – это та локальная информация, которую мы можем извлечь из существующих корреляций между подсистемами.
Нелокальную информацию можно определить как число E_D синглетных максимально запутанных пар кубитов (|0>₁|1>₂ – |0>₁|1>₂)√2, распределенных по разным подсистемам, которые мы можем очистить, то есть получить в чистом виде в результате набора локальных операций и классических коммуникаций. Величина E_D имеет важный практический смысл: это число кубитов, которые мы можем подвергнуть квантовой телепортации, используя текущее состояние нашей системы как ресурс, который будет использован в ходе телепортации.
Авторы доказывают следующее неравенство: I_cor(P) + E_D(P) ≤ n/2, где n – полное число кубитов в системе. Неравенство говорит о том, что сумма локальной информации I_cor(P) и нелокальной информации E_D(P), получаемых в ходе одного и того же набора P локальных операций и классических коммуникаций, не может превышать универсального предела n/2. Таким образом, локальная и нелокальная информация взаимно дополнительны: в ходе любого набора операций P мы можем получить максимум локальной информации (использовав ее, например, для превращения тепла в работу), но тогда потеряем нелокальную информацию. А можем, наоборот, получить максимум нелокальной информации (потратив ее на телепортацию), но тогда потеряем локальную информацию. Одновременно получить максимум и локальной информации, и нелокальной информации невозможно.
#квантовая_механика #квантовые_вычисления #информация #отвал_башки
Physical Review A
Mutually exclusive aspects of information carried by physical systems: Complementarity between local and nonlocal information
Complex physical systems contain information which, under some well-defined processes can differentiate between local and nonlocal information. Both these fundamental aspects of information are defined operationally. Local information is locally accessible…
Простейший пример взаимной дополнительности локальной и нелокальной информации, описанной в предыдущем посте, возникает в случае двух максимально запутанных кубитов.
Если у нас имеется белловская пара в состоянии (|0>₁|1>₂ – |0>₁|1>₂)√2, то мы можем извлечь из нее 1 бит локальной информации. Например, Алиса измеряет состояние своего кубита и отправляет результат Бобу по классическому каналу связи, а Боб инвертирует свой кубит, если у Алисы получилось состояние |0>, и не трогает его в противном случае. Таким образом, у Боба окажется кубит, достоверно находящийся в состоянии |0>. Его можно потом использовать – например, привести в максимально смешанное состояние, превратив благодаря этому теплоту в работу.
Это пример протокола, в котором мы, в ходе набора локальных операций и классических коммуникаций, получаем 1 бит локальной информации, но полностью теряем нелокальную информацию: после пересылки результата измерения по классическому каналу связи квантовая запутанность кубитов разрушается. Но можем, напротив, использовать исходное состояние двух кубитов для извлечения нелокальной информации – а именно, для стандартной квантовой телепортации одного кубита. Можно показать, что после этого состояния двух исходных кубитов, использованных в качестве ресурса для осуществления телепортации, будут максимально смешанными, так что из них уже нельзя будет извлечь никакой локальной информации. Оба этих случая попадают под описанное выше неравенство I_cor(P) + E_D(P) ≤ n/2 = 1 для системы n = 2 кубитов. В первом случае 1 + 0 ≤ 1, во втором 0 + 1 ≤ 1.
Примечательно, что если вся совместная квантовая система находится в чистом состоянии, то это вместо этого неравенства можно записать равенство max[I_cor] + max[E_D] = I_M, где I_M – взаимная информация подсистем, а максимумы берутся по всем возможным протоколам P. В случае белловской пары кубитов I_M = 2, и это часто трактуется в таком духе, что взаимная информация складывается из «классической» части (1 бита, обусловленного скоррелированностью состояний кубитов) и существенно квантовой части (1 бита, содержащего информацию об относительной фазе двух кубитов). Указанное выше равенство 1 + 1 = 2 выражает такую трактовку на математическом уровне.
Но любопытно, что на практике, используя лишь локальные операции и классические коммуникации, мы не можем использовать оба этих бита взаимной информации одновременно. Мы извлекаем лишь первый из них (локальную информацию), либо второй (нелокальную информацию). В этом смысл утверждения авторов о том, что 2 – это не 1 + 1, а 1 или 1.
#квантовая_механика #квантовые_вычисления #информация #отвал_башки
Если у нас имеется белловская пара в состоянии (|0>₁|1>₂ – |0>₁|1>₂)√2, то мы можем извлечь из нее 1 бит локальной информации. Например, Алиса измеряет состояние своего кубита и отправляет результат Бобу по классическому каналу связи, а Боб инвертирует свой кубит, если у Алисы получилось состояние |0>, и не трогает его в противном случае. Таким образом, у Боба окажется кубит, достоверно находящийся в состоянии |0>. Его можно потом использовать – например, привести в максимально смешанное состояние, превратив благодаря этому теплоту в работу.
Это пример протокола, в котором мы, в ходе набора локальных операций и классических коммуникаций, получаем 1 бит локальной информации, но полностью теряем нелокальную информацию: после пересылки результата измерения по классическому каналу связи квантовая запутанность кубитов разрушается. Но можем, напротив, использовать исходное состояние двух кубитов для извлечения нелокальной информации – а именно, для стандартной квантовой телепортации одного кубита. Можно показать, что после этого состояния двух исходных кубитов, использованных в качестве ресурса для осуществления телепортации, будут максимально смешанными, так что из них уже нельзя будет извлечь никакой локальной информации. Оба этих случая попадают под описанное выше неравенство I_cor(P) + E_D(P) ≤ n/2 = 1 для системы n = 2 кубитов. В первом случае 1 + 0 ≤ 1, во втором 0 + 1 ≤ 1.
Примечательно, что если вся совместная квантовая система находится в чистом состоянии, то это вместо этого неравенства можно записать равенство max[I_cor] + max[E_D] = I_M, где I_M – взаимная информация подсистем, а максимумы берутся по всем возможным протоколам P. В случае белловской пары кубитов I_M = 2, и это часто трактуется в таком духе, что взаимная информация складывается из «классической» части (1 бита, обусловленного скоррелированностью состояний кубитов) и существенно квантовой части (1 бита, содержащего информацию об относительной фазе двух кубитов). Указанное выше равенство 1 + 1 = 2 выражает такую трактовку на математическом уровне.
Но любопытно, что на практике, используя лишь локальные операции и классические коммуникации, мы не можем использовать оба этих бита взаимной информации одновременно. Мы извлекаем лишь первый из них (локальную информацию), либо второй (нелокальную информацию). В этом смысл утверждения авторов о том, что 2 – это не 1 + 1, а 1 или 1.
#квантовая_механика #квантовые_вычисления #информация #отвал_башки
Physical Review A
Mutually exclusive aspects of information carried by physical systems: Complementarity between local and nonlocal information
Complex physical systems contain information which, under some well-defined processes can differentiate between local and nonlocal information. Both these fundamental aspects of information are defined operationally. Local information is locally accessible…
В некоторых материалах и диапазонах частот групповая скорость распространяющейся в ней волны оказывается отрицательной. Казалось бы, это противоречит принципу причинности: волновой пакет как целое будет распространяться не вперед, а назад, так что на выходе сигнал появится раньше, чем на входе.
В этой работе рассматривается электронный аналог подобного вещества: соединенные последовательно полосовые усилители, каждый из которых в большей части спектра дает отрицательную групповую задержку проходящего через него волнового пакета. При пропускании через такую систему волновых пакетов их «центры масс» на выходе оказываются опережающими таковые на входе, потому что передняя часть пакета усиливается сильнее задней.
Это и есть проявление отрицательной групповой скорости: как видно на графиках справа, в среднем пакет выходит из системы раньше, чем входит. Но начальный фронт сигнала появляется на выходе одновременно со входным, так что принцип причинности здесь не нарушается.
#электродинамика #объяснения
В этой работе рассматривается электронный аналог подобного вещества: соединенные последовательно полосовые усилители, каждый из которых в большей части спектра дает отрицательную групповую задержку проходящего через него волнового пакета. При пропускании через такую систему волновых пакетов их «центры масс» на выходе оказываются опережающими таковые на входе, потому что передняя часть пакета усиливается сильнее задней.
Это и есть проявление отрицательной групповой скорости: как видно на графиках справа, в среднем пакет выходит из системы раньше, чем входит. Но начальный фронт сигнала появляется на выходе одновременно со входным, так что принцип причинности здесь не нарушается.
#электродинамика #объяснения
👍2
Как мы все помним из курса оптики, вблизи частоты резонансного поглощения нормальная дисперсия, то есть растущая n(ω), сменяется аномальной, то есть убывающей n(ω), а затем снова нормальной. Это означает, что групповая скорость отрицательна вблизи резонанса, положительна вдали от него и два раза переходит через ±∞ между этими областями.
Как я писал в предыдущем посте, аномальное поведение групповой скорости не противоречит принципу причинности. Групповая скорость определяет лишь скорость распространения «центра масс» волнового пакета, а начальный фронт импульса никогда не распространяется быстрее скорости света. Если групповая скорость отрицательна, время средней задержки импульса при прохождении через вещество тоже отрицательно, если же уходит в ±∞, то время задержки зануляется.
Вот эксперимент с допированным фосфидом галлия, где хорошо видно, как ведет себя измеренная задержка импульса вблизи экситонного резонанса – ровно так, как описывается теорией.
#электродинамика #объяснения
Как я писал в предыдущем посте, аномальное поведение групповой скорости не противоречит принципу причинности. Групповая скорость определяет лишь скорость распространения «центра масс» волнового пакета, а начальный фронт импульса никогда не распространяется быстрее скорости света. Если групповая скорость отрицательна, время средней задержки импульса при прохождении через вещество тоже отрицательно, если же уходит в ±∞, то время задержки зануляется.
Вот эксперимент с допированным фосфидом галлия, где хорошо видно, как ведет себя измеренная задержка импульса вблизи экситонного резонанса – ровно так, как описывается теорией.
#электродинамика #объяснения
👍2
Еще насчет групповой скорости: ситуация, при которой она оказывается отрицательной и обеспечивает «сверхсветовой» режим распространения импульсов – не что-то атипичное и патологическое. Напротив, существование областей частот, в которой групповая скорость ведет себя аномально, неизбежно вытекает из принципа причинности.
В этой работе при помощи соотношений Крамерса-Кронига доказываются две теоремы. Согласно первой теореме, в любой среде с линейным откликом – неважно, поглощающей, активной или смешанной – должны существовать значения частот, при которых групповая скорость v_g либо превышает скорость света, либо уходит в бесконечность, либо отрицательна. Вторая теорема гласит, что при той частоте, где поглощение достигает абсолютного максимума, групповая скорость обязана быть отрицательной. Интуитивно это понятно, поскольку в пике поглощения мы имеем аномальную дисперсию.
Hа рисунке показан пример поведения групповой задержки L/v_g в материале с полосами поглощения и усиления.
#электродинамика #объяснения
В этой работе при помощи соотношений Крамерса-Кронига доказываются две теоремы. Согласно первой теореме, в любой среде с линейным откликом – неважно, поглощающей, активной или смешанной – должны существовать значения частот, при которых групповая скорость v_g либо превышает скорость света, либо уходит в бесконечность, либо отрицательна. Вторая теорема гласит, что при той частоте, где поглощение достигает абсолютного максимума, групповая скорость обязана быть отрицательной. Интуитивно это понятно, поскольку в пике поглощения мы имеем аномальную дисперсию.
Hа рисунке показан пример поведения групповой задержки L/v_g в материале с полосами поглощения и усиления.
#электродинамика #объяснения
👍2
В этой работе теоретически рассмотрен магнонный спиновый конденсатор – аналог конденсатора, в котором на обкладках вместо противоположных электрических зарядов накапливаются магноны с противоположными спинами.
Он состоит из двух ферромагнетиков, играющих роль обкладок и связанных обменным XXZ-взаимодействием между электронными спинами. Спиновые токи, поступающие на них из прилегающих электродов, накапливаются и создают разность химических потенциалов магнонов, аналогичную напряжению на конденсаторе.
Как в случае обычного конденсатора, емкость магнонного конденсатора складывается из классической и квантовой емкости. Квантовая емкость обусловлена сжимаемостью магнонного газа в каждой обкладке, а классическая – XXZ-взаимодействием обкладок (в то время как в обычном конденсаторе она обусловлена электростатическим взаимодействием). Интересно, что у магнонного конденсатора классическая емкость обратно пропорциональна площади обкладок, а еще она может быть как положительной, так и отрицательной.
#магнетизм
Он состоит из двух ферромагнетиков, играющих роль обкладок и связанных обменным XXZ-взаимодействием между электронными спинами. Спиновые токи, поступающие на них из прилегающих электродов, накапливаются и создают разность химических потенциалов магнонов, аналогичную напряжению на конденсаторе.
Как в случае обычного конденсатора, емкость магнонного конденсатора складывается из классической и квантовой емкости. Квантовая емкость обусловлена сжимаемостью магнонного газа в каждой обкладке, а классическая – XXZ-взаимодействием обкладок (в то время как в обычном конденсаторе она обусловлена электростатическим взаимодействием). Интересно, что у магнонного конденсатора классическая емкость обратно пропорциональна площади обкладок, а еще она может быть как положительной, так и отрицательной.
#магнетизм
Какой статистикой описываются величины весов w межнейронных связей в большой обученной нейронной сети? Авторы этой работы подходят к такой задаче с точки зрения экономической теории игр: число связей с одним и тем же модулем весов |w| определяется компромиссом между выгодой (минимизацей функции потерь) от существования таких связей, издержками на их поддержание и соревнованием между связями. В равновесии Нэша суммарная полезность всех величин |w| достигает максимума.
Простейшая модель для полезности и издержек показывает, что в равновесии модули |w| должны следовать логнормальному распределению – то есть логарифм ln |w| должен иметь гауссово распределение. Как показано на графиках, эмпирическая статистика весов в современных больших нейронных сетях действительно описывается логнормальным распределением.
Интересно, что такая статистика проявляется, только когда число связей действительно большое – как минимум, несколько десятков тысяч, что можно считать аналогом термодинамического предела.
#нейронные_сети
Простейшая модель для полезности и издержек показывает, что в равновесии модули |w| должны следовать логнормальному распределению – то есть логарифм ln |w| должен иметь гауссово распределение. Как показано на графиках, эмпирическая статистика весов в современных больших нейронных сетях действительно описывается логнормальным распределением.
Интересно, что такая статистика проявляется, только когда число связей действительно большое – как минимум, несколько десятков тысяч, что можно считать аналогом термодинамического предела.
#нейронные_сети
Проникновение магнитных вихрей внутрь сверхпроводника иногда происходит в форме лавин. Если где-то на поверхности сверхпроводника 2-го рода температура, магнитное поле или электрический ток локально повышаются настолько, что магнитное поле превышает верхнее критическое, в него начинают проникать вихри. Движение вихрей приводит к выделению тепла, что еще сильнее облегчает проникновение новых вихрей и т.д. – возникает цепная реакция, которая останавливается, когда выделяющееся тепло достаточно сильно рассеивается по толще сверхпроводника.
На рисунке показан пример такой лавины в сверхпроводящем MgB₂, которая видна по проникновению магнитного поля (первая строка диаграмм), по локальному росту температуры (вторая строка) и по локальному уменьшению электрического поля из-за разрушения сверхпроводимости (третья строка). В ходе этой лавины в сверхпроводник проникло несколько миллионов вихрей.
#сверхпроводимость
На рисунке показан пример такой лавины в сверхпроводящем MgB₂, которая видна по проникновению магнитного поля (первая строка диаграмм), по локальному росту температуры (вторая строка) и по локальному уменьшению электрического поля из-за разрушения сверхпроводимости (третья строка). В ходе этой лавины в сверхпроводник проникло несколько миллионов вихрей.
#сверхпроводимость
Один из способов моделировать теоретически и реализовывать в эксперименте эволюцию открытых квантовых систем основан на столкновительной модели (collision model). В этой модели взаимодействие квантовой системы с окружением аппроксимируется в виде последовательности столкновений – актов взаимодействия с внешними, вспомогательными подсистемами, происходящих в определенные моменты времени.
Если каждая вспомогательная система представляет собой кубит, то после взаимодействия можно измерять его состояние и отбирать только те реализации эксперимента, в которых получен определенный результат – 0 или 1. Отбирая нужную последовательность нулей и единиц, получаемую в результате измерения состояний всех вспомогательных подсистем после актов их взаимодействия с нашей квантовой системой, можно отбирать заданную квантовую траекторию ее эволюции. С математической точки зрения, состояние системы пропускается при этом через квантовый канал с заданной последовательностью операторов Крауса.
#открытые_квантовые_системы
Если каждая вспомогательная система представляет собой кубит, то после взаимодействия можно измерять его состояние и отбирать только те реализации эксперимента, в которых получен определенный результат – 0 или 1. Отбирая нужную последовательность нулей и единиц, получаемую в результате измерения состояний всех вспомогательных подсистем после актов их взаимодействия с нашей квантовой системой, можно отбирать заданную квантовую траекторию ее эволюции. С математической точки зрения, состояние системы пропускается при этом через квантовый канал с заданной последовательностью операторов Крауса.
#открытые_квантовые_системы
В этой работе столкновительная модель была реализована на квантовом компьютере
Таким образом, здесь реализуется ансамбль квантовых траекторий системы, распределение которых можно смещать в нужную нам сторону по сравнению с равномерным распределением, которое возникает, если вспомогательные подсистемы никак не трогать.
Для случая, когда H – гамильтониан ферромагнитной цепочки 3 спинов, на рисунке показаны вероятности реализации траекторий (p₁,p₂,p₃). Видно, как изменение s = 0,±1, показанное разными цветами, позволяет смещать их веса, хотя из-за дефектов квантового чипа экспериментальные результаты (круги) заметно отклоняются от точного моделирования (линий на нижней панели).
#открытые_квантовые_системы
ibmq jakarta. При этом квантовые траектории системы, отвечающие последовательностям (pᵢ) результатов измерений pᵢ = 0, 1 над вспомогательными подсистемами, не жестко отбирались, а взвешивались с гиббсовскими весами exp(–sH(pᵢ)), где H(pᵢ) – заданный гамильтониан модели Изинга, s – ее обратная температура.Таким образом, здесь реализуется ансамбль квантовых траекторий системы, распределение которых можно смещать в нужную нам сторону по сравнению с равномерным распределением, которое возникает, если вспомогательные подсистемы никак не трогать.
Для случая, когда H – гамильтониан ферромагнитной цепочки 3 спинов, на рисунке показаны вероятности реализации траекторий (p₁,p₂,p₃). Видно, как изменение s = 0,±1, показанное разными цветами, позволяет смещать их веса, хотя из-за дефектов квантового чипа экспериментальные результаты (круги) заметно отклоняются от точного моделирования (линий на нижней панели).
#открытые_квантовые_системы
В этой работе решалась одна из задач, называемых термином epidemic inference – это задачи байесовского (вероятностного) вывода в применении к моделированию распространения эпидемий. К примеру, у нас имеется модель распространения эпидемии и набор отрывочных данных – результатов анализов, дающих информацию о состояниях xᵢ(t) (здоров, заражен или выздоровел) определенных людей i в некоторые моменты времени t.
По имеющейся модели и этим данным мы хотим восстановить (вероятностным образом) остальную информацию о ходе распространения эпидемии: например, найти нулевого пациента (то наиболее правдоподобную статистику xᵢ(0)) или оценить риск последующего заражения для конкретного человека (распределение вероятностей xᵢ(t) для фиксированного i и разных t).
Известно, что подобные задачи сводятся к задаче о моделировании спинового стекла – NP-трудной задаче, нуждающейся в приближенных методах решения. В этой работе для решения использовался набор связанных нейронных сетей.
#оптимизация #стекла #нейронные_сети
По имеющейся модели и этим данным мы хотим восстановить (вероятностным образом) остальную информацию о ходе распространения эпидемии: например, найти нулевого пациента (то наиболее правдоподобную статистику xᵢ(0)) или оценить риск последующего заражения для конкретного человека (распределение вероятностей xᵢ(t) для фиксированного i и разных t).
Известно, что подобные задачи сводятся к задаче о моделировании спинового стекла – NP-трудной задаче, нуждающейся в приближенных методах решения. В этой работе для решения использовался набор связанных нейронных сетей.
#оптимизация #стекла #нейронные_сети
Вот горький урок современной практики машинного обучения: улучшения результатов проще всего добиться тупым увеличением размера модели или длительности ее обучения, а не изобретением хитроумных методов и тонкой подстройкой нейросетевых архитектур.
#цитаты #нейронные_сети
#цитаты #нейронные_сети
😢3👍1
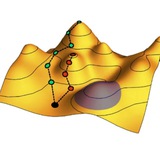
Небольшой комментарий к этому посту о важной работе, в которой задача обучения нейронной сети методу обратной диффузии сводится к задаче предсказания шума.
Цель метода обратной диффузии – уметь обращать вспять расплывание исходного облака осмысленных изображений, имеющего плотность q(x₀) и существующего в многомерном пространстве изображений, представленных векторами x. Здесь важно понимать, что обращению поддается не любая диффузия (на уровне блуждания одной частицы это невозможно), а расплывание лишь определенного облака. Оно идет, в среднем, вдоль определенных траекторий, примерный вид которых показан на рисунке.
Если мы найдем поле таких траекторий, то, двигаясь по ним в обратном направлении, мы можем обратить диффузию. Вот только нахождение этих траекторий – очень сложная вычислительная задача, особенно в пространстве огромной размерности. Метод предсказания шума дает остроумный рецепт их нахождения на практике путем подгонки любой достаточно гибкой функции ϵ_θ(x_t, t).
#нейронные_сети #объяснения
Цель метода обратной диффузии – уметь обращать вспять расплывание исходного облака осмысленных изображений, имеющего плотность q(x₀) и существующего в многомерном пространстве изображений, представленных векторами x. Здесь важно понимать, что обращению поддается не любая диффузия (на уровне блуждания одной частицы это невозможно), а расплывание лишь определенного облака. Оно идет, в среднем, вдоль определенных траекторий, примерный вид которых показан на рисунке.
Если мы найдем поле таких траекторий, то, двигаясь по ним в обратном направлении, мы можем обратить диффузию. Вот только нахождение этих траекторий – очень сложная вычислительная задача, особенно в пространстве огромной размерности. Метод предсказания шума дает остроумный рецепт их нахождения на практике путем подгонки любой достаточно гибкой функции ϵ_θ(x_t, t).
#нейронные_сети #объяснения
Метод обратной диффузии позволяет обращать зашумление изображений и превращать случайный шум в осмысленные картинки, «похожие» статистически на картинки из обучающей выборки. Но как получить не просто случайную картинку, а изображение определенного класса – например, изображение сиамского кота?
Простейший случай направления обратной диффузии называется classifier diffusion guidance. О нем я писал в этом посте, и он основан на использовании классификатора. Напомню, что классификатор – это отдельно обученная нейросеть, умеющая распознавать зрительные образы, то есть вычислять функцию p(y|x) – вероятность того, что изображение x принадлежит к классу y. При обратной диффузии на каждом шаге обновления изображения x⁽ᵗ⁻¹⁾ → x⁽ᵗ⁾ из него постепенно удаляется шум, так вектор x движется все ближе к множеству осмысленных картинок. Направление при помощи классификатора технически сводится к тому, что к шагам обратной диффузии добавляется, в меру некоторого коэффициента, градиент функции ∂p(y|x)/∂x – то есть мы смещаем траекторию обратной диффузию в сторону увеличения p(y|x) при заданной метке класса y (к примеру, класса изображений сиамских котов).
Проблема этого метода в том, что подобное движение вдоль градиента ∂p(y|x)/∂x аналогично враждебным атакам (или «взлому») нейросетей, призванных обмануть классификатор, подсунув ему изображение x, на котором функция p(y|x) достигает больших значений, но выглядящего для нас совершенно бессмысленно или неправильно. В этой работе был изобретен метод обратной диффузии, направляемый без использования классификатора (classifier-free diffusion guidance). Сейчас он является де-факто стандартом для нейросетевой генерации заданных изображений.
Чтобы понять, как работает этот метод, лучше вспомнить формулировку метода обратной диффузии в виде метода предсказания шума: перебирая различные изображения из обучающей выборки, мы подгоняем функцию ϵ_θ(x, t), которая для любого случайного вектора с гауссовым распределением ϵ дает нам решение уравнения ϵ_θ(x⁽ᵗ⁾, t) = ϵ, где точка x⁽ᵗ⁾ получается смещением из одной из точки x⁽⁰⁾ обучающей выборки (которые перебираются при обучении) на тот же вектор ϵ. При этом исходный вектор x⁽⁰⁾ и вектор ϵ перемасштабируются в зависимости от числа шагов t случайных блужданий, которые тоже перебираются при обучении.
Если обучающая выборка разбита на различные классы y, то мы подгоняем уже функцию ϵ_θ(x, y, t), зависящую дополнительно от y. При обучении функции ϵ_θ(x, y, t) при каждом y мы перебираем не все изображения x⁽⁰⁾ обучающей выборки, а лишь те, которые принадлежат к классу y. А еще некоторой вероятностью в качестве класса берется y = ∅ (пустое множество), что означает перебор всех изображений x⁽⁰⁾ без ограничений.
После того, как, уменьшением функции потерь, мы подогнали функции ϵ_θ(x, y, t) для всех имеющихся классов y и, дополнительно, функцию ϵ_θ(x, ∅, t), мы готовы к реализации обратной диффузии: на каждом шаге устранения шума x⁽ᵗ⁻¹⁾ → x⁽ᵗ⁾ мы вместо оригинальной ϵ_θ используем взвешенную линейную комбинацию (1 + w) ϵ_θ(x, y, t) – w ϵ_θ(x, ∅, t). Параметр w регулирует силу направления диффузии: чем он больше, тем в большей мере мы стремим обратную диффузию поближе к заданному классу y и подальше от общего множества картинок y = ∅. Более сильное направление обратной диффузии позволяет добиться от нейросети более точного выполнения задания, когда создаваемое изображение более строго соответствует нужному классу. Но происходит это ценой снижения разнообразия результатов.
Направление обратной диффузии без классификатора имеет ряд важных преимуществ. Во-первых, нам не нужен, собственно, классификатор – отдельная нейросеть, которую нужно разрабатывать и обучать. Во-вторых, мы защищены от эффектов враждебных атак. А дополнительная вычислительная нагрузка от обучения набора функций ϵ_θ(x, y, t) вместо исходной функции ϵ_θ(x, t) относительно невелика, поскольку сводится лишь к появлению у нейросети дополнительного входного сигнала y.
#нейронные_сети #популярное #объяснения
Простейший случай направления обратной диффузии называется classifier diffusion guidance. О нем я писал в этом посте, и он основан на использовании классификатора. Напомню, что классификатор – это отдельно обученная нейросеть, умеющая распознавать зрительные образы, то есть вычислять функцию p(y|x) – вероятность того, что изображение x принадлежит к классу y. При обратной диффузии на каждом шаге обновления изображения x⁽ᵗ⁻¹⁾ → x⁽ᵗ⁾ из него постепенно удаляется шум, так вектор x движется все ближе к множеству осмысленных картинок. Направление при помощи классификатора технически сводится к тому, что к шагам обратной диффузии добавляется, в меру некоторого коэффициента, градиент функции ∂p(y|x)/∂x – то есть мы смещаем траекторию обратной диффузию в сторону увеличения p(y|x) при заданной метке класса y (к примеру, класса изображений сиамских котов).
Проблема этого метода в том, что подобное движение вдоль градиента ∂p(y|x)/∂x аналогично враждебным атакам (или «взлому») нейросетей, призванных обмануть классификатор, подсунув ему изображение x, на котором функция p(y|x) достигает больших значений, но выглядящего для нас совершенно бессмысленно или неправильно. В этой работе был изобретен метод обратной диффузии, направляемый без использования классификатора (classifier-free diffusion guidance). Сейчас он является де-факто стандартом для нейросетевой генерации заданных изображений.
Чтобы понять, как работает этот метод, лучше вспомнить формулировку метода обратной диффузии в виде метода предсказания шума: перебирая различные изображения из обучающей выборки, мы подгоняем функцию ϵ_θ(x, t), которая для любого случайного вектора с гауссовым распределением ϵ дает нам решение уравнения ϵ_θ(x⁽ᵗ⁾, t) = ϵ, где точка x⁽ᵗ⁾ получается смещением из одной из точки x⁽⁰⁾ обучающей выборки (которые перебираются при обучении) на тот же вектор ϵ. При этом исходный вектор x⁽⁰⁾ и вектор ϵ перемасштабируются в зависимости от числа шагов t случайных блужданий, которые тоже перебираются при обучении.
Если обучающая выборка разбита на различные классы y, то мы подгоняем уже функцию ϵ_θ(x, y, t), зависящую дополнительно от y. При обучении функции ϵ_θ(x, y, t) при каждом y мы перебираем не все изображения x⁽⁰⁾ обучающей выборки, а лишь те, которые принадлежат к классу y. А еще некоторой вероятностью в качестве класса берется y = ∅ (пустое множество), что означает перебор всех изображений x⁽⁰⁾ без ограничений.
После того, как, уменьшением функции потерь, мы подогнали функции ϵ_θ(x, y, t) для всех имеющихся классов y и, дополнительно, функцию ϵ_θ(x, ∅, t), мы готовы к реализации обратной диффузии: на каждом шаге устранения шума x⁽ᵗ⁻¹⁾ → x⁽ᵗ⁾ мы вместо оригинальной ϵ_θ используем взвешенную линейную комбинацию (1 + w) ϵ_θ(x, y, t) – w ϵ_θ(x, ∅, t). Параметр w регулирует силу направления диффузии: чем он больше, тем в большей мере мы стремим обратную диффузию поближе к заданному классу y и подальше от общего множества картинок y = ∅. Более сильное направление обратной диффузии позволяет добиться от нейросети более точного выполнения задания, когда создаваемое изображение более строго соответствует нужному классу. Но происходит это ценой снижения разнообразия результатов.
Направление обратной диффузии без классификатора имеет ряд важных преимуществ. Во-первых, нам не нужен, собственно, классификатор – отдельная нейросеть, которую нужно разрабатывать и обучать. Во-вторых, мы защищены от эффектов враждебных атак. А дополнительная вычислительная нагрузка от обучения набора функций ϵ_θ(x, y, t) вместо исходной функции ϵ_θ(x, t) относительно невелика, поскольку сводится лишь к появлению у нейросети дополнительного входного сигнала y.
#нейронные_сети #популярное #объяснения
Telegram
Бассейн эргодичности
Некоторые популярные нейросети, занимающиеся генерацией изображений, такие как Midjorney, DALL-E и Stable Diffusion, работают по принципу обратной диффузии.
Этот принцип, основанный на идеях неравновесной термодинамики и методе Монте-Карло, заставляет генерируемое…
Этот принцип, основанный на идеях неравновесной термодинамики и методе Монте-Карло, заставляет генерируемое…
👍2