Материалы с близкой к нулю диэлектрической проницаемостью ε (epsilon-near-zero-, или ENZ-материалы) обладают необычными оптическими свойствами: длина волны в них становится близкой к бесконечности, а значит, и фаза волны «растекается» по материалу однородно. Как следствие, помещенные а такой материал объекты становятся почти невидимыми, поскольку свет обтекает их, не меняя фазу волны.
Этот эксперимент подтверждает теоретические ожидания. Сверху показан двухщелевой эксперимент двумерной оптики, в котором между металлическими слоями помещен тонкий слой SiO₂. По мере увеличения свободной длины волны света λ наблюдаемые на выходе интерференционные линии становятся реже и шире, и в пределе λ = 1.29 мкм, где ε(SiO₂) ≈ 0, они уширяются до бесконечности.
Снизу показан эксперимент с обтеканием препятствия: по мере увеличения λ, наблюдаемая на выходе тень от препятствия сначала сменятся пятном Пуассона, а затем исчезает. Таким образом, при ε ≈ 0 свет игнорирует препятствие.
#фотоника #электродинамика
Этот эксперимент подтверждает теоретические ожидания. Сверху показан двухщелевой эксперимент двумерной оптики, в котором между металлическими слоями помещен тонкий слой SiO₂. По мере увеличения свободной длины волны света λ наблюдаемые на выходе интерференционные линии становятся реже и шире, и в пределе λ = 1.29 мкм, где ε(SiO₂) ≈ 0, они уширяются до бесконечности.
Снизу показан эксперимент с обтеканием препятствия: по мере увеличения λ, наблюдаемая на выходе тень от препятствия сначала сменятся пятном Пуассона, а затем исчезает. Таким образом, при ε ≈ 0 свет игнорирует препятствие.
#фотоника #электродинамика
👍3
Как мы знаем, дифракция в дальнем поле дает картину пространственного фурье-образа изучаемого объекта. Этот же принцип, в целом, работает и для дифракции электронов на кристаллах: электроны, рассеиваясь на периодическом электростатическом потенциале, дают фурье-образ в виде дискретных рефлексов, отвечающих изменениям электронного волнового вектора на векторы обратной решетки.
Но это справедливо только если электроны претерпевают преимущественно однократное рассеяние – такое приближение называется кинематической теорией дифракции. Для плотных и относительно толстых мишеней нужно пользоваться динамической теорией дифракции, учитывая многократное рассеяние электронов, – или, фактически, решая уравнение Шредингера для распространяющейся в потенциале кристалла электронной волны.
В этой работе демонстрируется, как динамическая теория дифракции согласуется с экспериментами по электронной дифракции на монокристаллах золота на порядок лучше (отклонение 2.1%), чем кинематическая (с отклонением 21%).
#твердое_тело
Но это справедливо только если электроны претерпевают преимущественно однократное рассеяние – такое приближение называется кинематической теорией дифракции. Для плотных и относительно толстых мишеней нужно пользоваться динамической теорией дифракции, учитывая многократное рассеяние электронов, – или, фактически, решая уравнение Шредингера для распространяющейся в потенциале кристалла электронной волны.
В этой работе демонстрируется, как динамическая теория дифракции согласуется с экспериментами по электронной дифракции на монокристаллах золота на порядок лучше (отклонение 2.1%), чем кинематическая (с отклонением 21%).
#твердое_тело
👍3
Динамика спина описывается дифференциальными уравнениями первого порядка (для скорости), в отличие от уравнений второго порядка (для ускорения), описывающих движение массивных тел. Это значит, что спин не имеет инерции.
Тем не менее, многие эксперименты по спиновой динамике показывают, что она демонстрирует эффективную инерцию, происхождение которой приписывается взаимодействию спина с окружением. Авторы этой теоретической работы рассмотрели макроскопически большой спин, взаимодействующий с термостатом Кальдейры-Леггетта (набором независимых осцилляторов) и вывели для него квазиклассические уравнения движения.
В результате им удалось показать, что появление инерции у спина – это универсальное явление, обусловленное высокочастотной асимптотикой его взаимодействия с термостатом (точнее, спектральной плотности термостата, показанной на рисунке). Низкочастотная же – линейная по частоте – асимптотика спектральной плотности (зеленая линия) дает затухание Гильберта.
#твердое_тело #открытые_квантовые_системы
Тем не менее, многие эксперименты по спиновой динамике показывают, что она демонстрирует эффективную инерцию, происхождение которой приписывается взаимодействию спина с окружением. Авторы этой теоретической работы рассмотрели макроскопически большой спин, взаимодействующий с термостатом Кальдейры-Леггетта (набором независимых осцилляторов) и вывели для него квазиклассические уравнения движения.
В результате им удалось показать, что появление инерции у спина – это универсальное явление, обусловленное высокочастотной асимптотикой его взаимодействия с термостатом (точнее, спектральной плотности термостата, показанной на рисунке). Низкочастотная же – линейная по частоте – асимптотика спектральной плотности (зеленая линия) дает затухание Гильберта.
#твердое_тело #открытые_квантовые_системы
👍2❤1
В этой работе сотрудников OpenAI описывается довольно сложно устроенная нейросеть, генерирующая изображения при помощи метода обратной диффузии, направляемой на основе высокоуровневой информации о каком-то уже существующем изображении (она называется здесь CLIP embedding) в комбинации (если нужно) с текстовым описанием.
Помимо обычной генерации изображений по текстовому описанию, она может решать и другие задачи:
▪️ Высокоуровневое варьирование заданного изображения.
▪️ Плавная интерполяция между двумя изображениями.
▪️ Плавное изменение заданного изображения в сторону заданного текстового описания.
На рисунке показаны примеры интерполяции между парами изображений, причем для каждой интерполяция можно создавать бесконечное число вариантов. Интерполяция проводится в пространстве скрытого представления изображения, содержащего иерархически структурированную информацию о его содержании и стиле, поэтому и сами изображения плавно меняются и по общей структуре, и по мелким деталям.
#нейронные_сети #популярное
Помимо обычной генерации изображений по текстовому описанию, она может решать и другие задачи:
▪️ Высокоуровневое варьирование заданного изображения.
▪️ Плавная интерполяция между двумя изображениями.
▪️ Плавное изменение заданного изображения в сторону заданного текстового описания.
На рисунке показаны примеры интерполяции между парами изображений, причем для каждой интерполяция можно создавать бесконечное число вариантов. Интерполяция проводится в пространстве скрытого представления изображения, содержащего иерархически структурированную информацию о его содержании и стиле, поэтому и сами изображения плавно меняются и по общей структуре, и по мелким деталям.
#нейронные_сети #популярное
Типографическая атака.png
3.3 MB
На этом рисунке иллюстрируется, как нейросеть из статьи из предыдущего поста справляется с так называемыми типографическими атаками – попытками запутать нейросеть, распознающую изображение или производящую его варьирование, поместив на фоне изображения одного объекта надпись с названием чего-то другого.
Здесь нейросети предъявляются изображения, показанные сверху, и дается задание сгенерировать их слегка измененные варианты. Результаты такой генерации показаны снизу: в большинстве случаев нейросеть оказывается устойчивой к типографическим атакам, рисуя именно яблоко с надписями “iPod” и “pizza” (или чем-то похожим), а не сами айпод или пиццу.
Что парадоксально, та часть нейросети, которая распознает исходное изображения, генерируя его структурированное скрытое представление, в случае второй картинки определяет его как айпод, а не яблоко сорта “Granny Smith” – но все равно создает потом варианты картины с яблоком.
#нейронные_сети #популярное
Здесь нейросети предъявляются изображения, показанные сверху, и дается задание сгенерировать их слегка измененные варианты. Результаты такой генерации показаны снизу: в большинстве случаев нейросеть оказывается устойчивой к типографическим атакам, рисуя именно яблоко с надписями “iPod” и “pizza” (или чем-то похожим), а не сами айпод или пиццу.
Что парадоксально, та часть нейросети, которая распознает исходное изображения, генерируя его структурированное скрытое представление, в случае второй картинки определяет его как айпод, а не яблоко сорта “Granny Smith” – но все равно создает потом варианты картины с яблоком.
#нейронные_сети #популярное
❤1
image_2023-10-11_14-28-45.png
2.5 MB
А вот еще любопытный пример: нейросети предъявляются изображения, показанные справа, и дается задание сгенерировать что-то похожее на них. При этом исходное изображение нейросеть сначала превращает в структурированное представление, называемое CLIP embedding, на основе которого производится генерация нового изображения.
Здесь авторы обрезают 2048-мерный вектор этого представления, беря только 20, 30, 40, 80, 120, 160, 200 и 320 самых значащих его компонент (которые определяются методом анализа главных компонент). Сгенерированные изображения, показанные слева направо, воспроизводят все больше деталей оригинала по мере того, как мы увеличиваем количество учитываемых компонент структурированного представления.
К примеру, в верхней строке картинок сначала воспроизводится базовая информация о том, что на изображении должны быть хоть какая-то еда и тарелка, а на поздних стадиях появляется уже информация о бутылке и деревянном столе внизу.
#нейронные_сети #популярное
Здесь авторы обрезают 2048-мерный вектор этого представления, беря только 20, 30, 40, 80, 120, 160, 200 и 320 самых значащих его компонент (которые определяются методом анализа главных компонент). Сгенерированные изображения, показанные слева направо, воспроизводят все больше деталей оригинала по мере того, как мы увеличиваем количество учитываемых компонент структурированного представления.
К примеру, в верхней строке картинок сначала воспроизводится базовая информация о том, что на изображении должны быть хоть какая-то еда и тарелка, а на поздних стадиях появляется уже информация о бутылке и деревянном столе внизу.
#нейронные_сети #популярное
Diep-Deep: вот так нейросеть пытается справиться с задачей генерации изображения по текстовому описанию "A sign that says deep learning".
Неплохая попытка, но в целом задача оказывается невыполненной, что авторы приписывают недостаточной разрешающей способности скрытого CLIP-представления, на основе которого производится генерация.
#нейронные_сети #цитаты
Неплохая попытка, но в целом задача оказывается невыполненной, что авторы приписывают недостаточной разрешающей способности скрытого CLIP-представления, на основе которого производится генерация.
#нейронные_сети #цитаты
Статья о социальной термодинамике 2.0, посвященная памяти Карла Маркса.
При помощи уравнения Ван-дер-Ваальса автор описывает переход от капитализма к коммунизму по мере развития производительных сил. При низком уровне их развития (что отвечает низкой температуре) у нас сосуществуют два общественных класса – пролетариат и буржуазия, – что отвечает разделению жидкой и газообразной фаз. При высоком же уровне развития производительных сил противоречия между классами стираются и наступает коммунизм, подобно тому, как при сверхкритической температуре исчезает различие между жидкостью и газом.
#термодинамика #общество #цитаты
При помощи уравнения Ван-дер-Ваальса автор описывает переход от капитализма к коммунизму по мере развития производительных сил. При низком уровне их развития (что отвечает низкой температуре) у нас сосуществуют два общественных класса – пролетариат и буржуазия, – что отвечает разделению жидкой и газообразной фаз. При высоком же уровне развития производительных сил противоречия между классами стираются и наступает коммунизм, подобно тому, как при сверхкритической температуре исчезает различие между жидкостью и газом.
#термодинамика #общество #цитаты
😁5🌚3
Квазиклассическое квантование Бора-Зоммерфельда подразумевает, что действие вдоль замкнутой траектории должно квантоваться как ∮p•dr = 2πħ(n+1/2), откуда можно найти квантованные энергии. В этой работе квазиклассическое квантование обобщено на системы с неэрмитовым гамильтонианом H и комплексным спектром энергий.
При этом классическая траектория движения, задаваемая вторым законом Ньютона d²r/dt² = –∂H/∂p, будет также комплексной. Авторы показывают, что для того, чтобы такая траектория – хоть и комплексная – была замкнутой, шаги во времени dt тоже должны быть комплексными. Найдя замкнутую траекторию в комплексном пространстве r, проходимую системой за комплексный период времени, можно найти квазиклассический спектр комплексных же энергий.
На рисунке показан пример комплексного осциллятора с комплексной частотой колебаний: при движении в комплексном времени (слева) траектория может быть сделана замкнутой, а при движении в вещественном времени (справа) замкнуть ее невозможно.
#неэрмитовы_системы
При этом классическая траектория движения, задаваемая вторым законом Ньютона d²r/dt² = –∂H/∂p, будет также комплексной. Авторы показывают, что для того, чтобы такая траектория – хоть и комплексная – была замкнутой, шаги во времени dt тоже должны быть комплексными. Найдя замкнутую траекторию в комплексном пространстве r, проходимую системой за комплексный период времени, можно найти квазиклассический спектр комплексных же энергий.
На рисунке показан пример комплексного осциллятора с комплексной частотой колебаний: при движении в комплексном времени (слева) траектория может быть сделана замкнутой, а при движении в вещественном времени (справа) замкнуть ее невозможно.
#неэрмитовы_системы
👍2
Статистика энергий ε = ħ²k²/2m и импульсов k частиц в идеальном бозе- или ферми-газе описывается распределениями Бозе-Эйнштейна и Ферми-Дирака n(k) = [exp{(ħ²k²/2m – μ)/T} ∓ 1]⁻¹, которые подразумевают очень быстрое (гауссово) убывание в пределе больших импульсов k → ∞. Но в газе взаимодействующих частиц это уже не так: если взаимодействие, как часто бывает в атомных газах, является короткодействующим и описывается эффективной длиной рассеяния, то асимптотика чисел заполнения при k → ∞ имеет вид n(k) = С/k⁴.
Коэффициент пропорциональности C называется контактом Тана (Tan’s contact). Примечательно, что он связан с производной полной энергии газа по длине рассеяния аналогом теоремы вириала. В этом эксперименте асимптотика чисел заполнения и, соответственно, контакт Тана для бозе-конденсата атомов в ловушке были измерены с довольно высокой точностью. На графике можно видеть сравнение между теорией и экспериментом для ловушек разной формы и разных методов измерения.
#атомные_газы #бозе_конденсация
Коэффициент пропорциональности C называется контактом Тана (Tan’s contact). Примечательно, что он связан с производной полной энергии газа по длине рассеяния аналогом теоремы вириала. В этом эксперименте асимптотика чисел заполнения и, соответственно, контакт Тана для бозе-конденсата атомов в ловушке были измерены с довольно высокой точностью. На графике можно видеть сравнение между теорией и экспериментом для ловушек разной формы и разных методов измерения.
#атомные_газы #бозе_конденсация
В этой работе метод обратной диффузии был сформулирован в виде задачи предсказания шума – именно в таком виде он сейчас широко используется для генерации изображений нейронными сетями.
В ходе прямой диффузии x_(t–1) → x_t вектор изображения совершает случайный шаг и одновременно сжимается в меру коэффициента √α_t. Как показано на рисунке, за t шагов эти сжатия и случайные шаги ϵ (то есть шум) накапливаются: начиная c исходной точки x₀, которая берется из библиотеки изображений q(x₀), мы оказываемся в точке x_t.
Дальше идея такая: мы подгоняем функцию ϵ_θ(x_t, t), которая достаточно гибкая и генерируется нейросетью, таким образом, чтобы при всех x₀ из обучающей выборки и при любых количествах шагов t она предсказывала случайный гауссов шум ϵ. Для этого при обучении минимизируется функция ошибок L_simple. При обратной же диффузии (sampling) на каждом шаге x_t → x_(t–1) мы осуществляем перемасштабирование и вычитаем ϵ_θ(x_t, t), отменяя шум – это называется словом denoising.
#нейронные_сети #объяснения
В ходе прямой диффузии x_(t–1) → x_t вектор изображения совершает случайный шаг и одновременно сжимается в меру коэффициента √α_t. Как показано на рисунке, за t шагов эти сжатия и случайные шаги ϵ (то есть шум) накапливаются: начиная c исходной точки x₀, которая берется из библиотеки изображений q(x₀), мы оказываемся в точке x_t.
Дальше идея такая: мы подгоняем функцию ϵ_θ(x_t, t), которая достаточно гибкая и генерируется нейросетью, таким образом, чтобы при всех x₀ из обучающей выборки и при любых количествах шагов t она предсказывала случайный гауссов шум ϵ. Для этого при обучении минимизируется функция ошибок L_simple. При обратной же диффузии (sampling) на каждом шаге x_t → x_(t–1) мы осуществляем перемасштабирование и вычитаем ϵ_θ(x_t, t), отменяя шум – это называется словом denoising.
#нейронные_сети #объяснения
Для обучения нейросетей генерации изображений по текстовым описаниям нужны большие библиотеки референсов: готовых изображений с прилагающимся к ним текстами.
Здесь исследователи проанализировали одну из таких новых библиотек и пришли в ужас: посмотрите сами, какие изображения в этой библиотеке привязаны к фразам "best president" и "worst president"!
#цитаты #нейронные_сети
Здесь исследователи проанализировали одну из таких новых библиотек и пришли в ужас: посмотрите сами, какие изображения в этой библиотеке привязаны к фразам "best president" и "worst president"!
#цитаты #нейронные_сети
Вот это крутой эксперимент, в котором реализованы короткие пути к адиабатичности – невозможный в классической термодинамике способ быстро изменить состояние квантовой системы без потери энергий на диссипацию.
Газ атомов-фермионов ⁶Li помещался в вытянутую гармоническую ловушку, которая затем быстро сжималась в 4 раза до сферической формы. Обычно при этом происходит возбуждение атомного газа с совершением дополнительной работы. Но если частоты ловушки в направлении сжатия ω_x и в двух других направлениях ω_y = ω_z менять по определенному протоколу, показанному на графиках синими точками, то возбуждения газа удается избежать. Здесь помогает масштабная инвариантность ферми-газа в унитарном режиме.
На графике снизу показана измеренная неадиабатическая работа Q* – превышение реально совершаемой работы над идеальным адиабатическим пределом. При использовании короткого пути к адиабатичности в конце протокола она зануляется, а при наивном сжатии (коричневые точки) – нет.
#атомные_газы #квантовая_термодинамика
Газ атомов-фермионов ⁶Li помещался в вытянутую гармоническую ловушку, которая затем быстро сжималась в 4 раза до сферической формы. Обычно при этом происходит возбуждение атомного газа с совершением дополнительной работы. Но если частоты ловушки в направлении сжатия ω_x и в двух других направлениях ω_y = ω_z менять по определенному протоколу, показанному на графиках синими точками, то возбуждения газа удается избежать. Здесь помогает масштабная инвариантность ферми-газа в унитарном режиме.
На графике снизу показана измеренная неадиабатическая работа Q* – превышение реально совершаемой работы над идеальным адиабатическим пределом. При использовании короткого пути к адиабатичности в конце протокола она зануляется, а при наивном сжатии (коричневые точки) – нет.
#атомные_газы #квантовая_термодинамика
Интересная работа по теории обучения нейросетей, в которой обсуждается недавно открытый закон степенного скейлинга, возникающий в больших языковых моделях – таких, как GPT-3, LaMDA и Palm.
Этот закон состоит в том, что минимальная величина функции ошибок на тестовой выборке, достигаемая в ходе обучения и характеризующая эффективность работы нейросети, спадает степенным образом как функция либо числа элементов обучающей выборки T, либо числа параметров нейросети N – в зависимости от того, какая из этих величин является «бутылочным горлышком». Иллюстрация такой зависимости показана на рисунке: при росте объема обучающих данных T величина ошибки L падает степенным образом, пока не упрется в плато. А величина такого плато сама зависит от числа параметров нейросети N, степенным образом снижаясь при его увеличении.
Закон можно использовать для прогнозирования того, насколько сильно нам нужно увеличивать или объем данных, или размер сети, если мы хотим добиться улучшения качества ее работы.
#нейронные_сети
Этот закон состоит в том, что минимальная величина функции ошибок на тестовой выборке, достигаемая в ходе обучения и характеризующая эффективность работы нейросети, спадает степенным образом как функция либо числа элементов обучающей выборки T, либо числа параметров нейросети N – в зависимости от того, какая из этих величин является «бутылочным горлышком». Иллюстрация такой зависимости показана на рисунке: при росте объема обучающих данных T величина ошибки L падает степенным образом, пока не упрется в плато. А величина такого плато сама зависит от числа параметров нейросети N, степенным образом снижаясь при его увеличении.
Закон можно использовать для прогнозирования того, насколько сильно нам нужно увеличивать или объем данных, или размер сети, если мы хотим добиться улучшения качества ее работы.
#нейронные_сети
👍3
Одна из причин возникновения закона степенного скейлинга для эффективности работы нейросетей состоит в масштабно-инвариантной структуре обучающих данных.
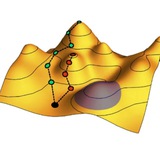
Представим, что у нас есть массив данных – набор точек в многомерном пространстве – которые мы хотим подвергнуть анализу главных компонент, чтобы выделить в нем существенную часть. Для этого мы считаем ковариационную матрицу массива данных и смотрим на спектр ее собственных значений λ, говорящих о том, насколько сильно данные варьируются в различных направлениях многомерного пространства. Если несколько λ особенно велики, а остальные гораздо меньше, то данные располагаются приблизительно на гиперплоскости – линейной оболочке собственных векторов, отвечающей большим λ.
Оказывается, что для естественных больших данных это не так: как видно на рисунке, спектры λ для картинок CIFAR-10 и для текстов из Википедии являются степенными и не демонстрируют щелей. При росте объема выборки T протяженность этой степенной зависимости увеличивается.
#нейронные_сети
Представим, что у нас есть массив данных – набор точек в многомерном пространстве – которые мы хотим подвергнуть анализу главных компонент, чтобы выделить в нем существенную часть. Для этого мы считаем ковариационную матрицу массива данных и смотрим на спектр ее собственных значений λ, говорящих о том, насколько сильно данные варьируются в различных направлениях многомерного пространства. Если несколько λ особенно велики, а остальные гораздо меньше, то данные располагаются приблизительно на гиперплоскости – линейной оболочке собственных векторов, отвечающей большим λ.
Оказывается, что для естественных больших данных это не так: как видно на рисунке, спектры λ для картинок CIFAR-10 и для текстов из Википедии являются степенными и не демонстрируют щелей. При росте объема выборки T протяженность этой степенной зависимости увеличивается.
#нейронные_сети
🤔2
Как было описано в предыдущем посте, одна из причин возникновения закона степенного скейлинга – в том, что обучающие данные имеют масштабно-инвариантную (фрактальную) структуру. Поэтому, чем больше объем обучающих данных T, тем больше информации о них нейросеть может уловить, причем при T → ∞ предел роста эффективности обучения на больших данных не просматривается.
Откуда тогда возникает степенной скейлинг еще и по N – числу параметров нейросети? Авторы показывают, что если повторить анализ спектра собственных значений λ ковариационной матрицы, но не для исходных обучающих данных, а для данных, пропущенных через случайные нелинейные функции, то можно продлить степенной хвост спектра λ. Как показано на двух примерах на рисунке, при росте числа нелинейных функций N этот хвост продлевается все дальше.
Таким образом, пропускание данных через нелинейные функции, осуществляемое нейросетью при формировании их скрытых представлений, позволяет еще сильнее расширить их естественное разнообразие.
#нейронные_сети
Откуда тогда возникает степенной скейлинг еще и по N – числу параметров нейросети? Авторы показывают, что если повторить анализ спектра собственных значений λ ковариационной матрицы, но не для исходных обучающих данных, а для данных, пропущенных через случайные нелинейные функции, то можно продлить степенной хвост спектра λ. Как показано на двух примерах на рисунке, при росте числа нелинейных функций N этот хвост продлевается все дальше.
Таким образом, пропускание данных через нелинейные функции, осуществляемое нейросетью при формировании их скрытых представлений, позволяет еще сильнее расширить их естественное разнообразие.
#нейронные_сети
👍2
В этой теоретической работе показан удивительный результат: оказывается, движение атома гелия через углеродную нанотрубку структуры (5, 5) удовлетворяет критерию сверхтекучести Ландау – даже без всякой бозе-конденсации, для единственного атома!
Вдоль оси нанотрубки система является пространственно периодической, так что авторы рассматривают зонную структуру возможных возбуждений – фононов и плазмонов. Как показано на графике снизу, даже с учетом процессов переброса (Umklapp scattering) существует небольшая область импульсов атома гелия kᵢ (синяя полоса), в которой не находится доступных возбуждений, отвечающих рассеяниям на различные m-е векторы обратной решетки (красные линии).
Критическая скорость здесь относительно невелика – 200 м/с, что отвечает температуре 20 К. Однако даже при комнатной температуре оказывается, что плотность нормальной компоненты составляет порядка 0.1%. То есть даже при комнатной температуре атомы гелия могут проходить через нанотрубки почти без трения.
#сверхтекучесть #отвал_башки
Вдоль оси нанотрубки система является пространственно периодической, так что авторы рассматривают зонную структуру возможных возбуждений – фононов и плазмонов. Как показано на графике снизу, даже с учетом процессов переброса (Umklapp scattering) существует небольшая область импульсов атома гелия kᵢ (синяя полоса), в которой не находится доступных возбуждений, отвечающих рассеяниям на различные m-е векторы обратной решетки (красные линии).
Критическая скорость здесь относительно невелика – 200 м/с, что отвечает температуре 20 К. Однако даже при комнатной температуре оказывается, что плотность нормальной компоненты составляет порядка 0.1%. То есть даже при комнатной температуре атомы гелия могут проходить через нанотрубки почти без трения.
#сверхтекучесть #отвал_башки
👀4🤨1
Соотношение неопределенностей Робертсона-Шредингера σ(X)σ(Z) ≥ ½|<ψ|[X,Z]|ψ>|, более известное как соотношение неопределенностей Гейзенберга, говорят о невозможности одновременно точно определить две несовместимые между собой наблюдаемые величины, представленные некоммутирующими операторами X и Z.
Иногда эта несовместимость формулируется как принцип дополнительности Бора: на классическом уровне, доступном для коммуникации исследователям, мы можем описывать квантовую систему в рамках одной из двух дополнительных картин (например, пространственно-координатной и импульсно-энергетической), но не обеими одновременно.
Несмотря на свои многочисленные применения, соотношение неопределенностей Робертсона-Шредингера не очень-то годится на роль математического выражения принципа дополнительности, потому что завязано на спектры операторов наблюдаемых величин. Если мы трактуем принцип дополнительности как невозможность полного определения и передачи информации о значениях двух несовместимых величин, то здесь важны лишь вероятности, связанные с вектором состояния квантовой системы и собственными векторами операторов X и Z. А вот собственные значения операторов X и Z – это, с точки зрения теории информации, всего лишь метки, которые можно переобозначать без изменения информационного содержания. Но в соотношение неопределенностей Робертсона-Шредингера они входят, что излишне.
Еще один недостаток этого соотношения – контринтуитивное (опять-таки, с точки зрения теории информации) поведение стандартных отклонений σ(X) и σ(Z). Вот пример: допустим, что величина X в текущем состоянии системы принимает значения +1, 0, –1, каждое c вероятностями 1/3. В этом случае σ(X) = √<(X – <X>)²> = 1/√3. Если мы спроецируем нашу систему на собственный вектор |φ₀><φ₀| оператора X, отвечающий собственному значению 0 (то есть измерим наблюдаемую, отвечающую на вопрос «принимает ли X значение 0?») и получим отрицательный ответ, то после измерения величина X будет принимать уже два оставшихся значения +1 и –1 с равными вероятностями 1/2. В этом состоянии σ(X) = 1/√2 – это больше, чем предыдущее значение 1/√3.
Получается парадоксальная штука: мы провели над системой измерений, получили некоторую информацию о ее состоянии (а именно, что X ≠ 0), а стандартное отклонение σ(X) не уменьшилось, а возросло. Поэтому σ(X) не является мерой неопределенности величины X, хорошо определенной с точки зрения теории информации. А значит, и соотношение неопределенностей Робертсона-Шредингера с информационной точки зрения не особенно осмысленно.
#квантовая_механика #информация #объяснения
Иногда эта несовместимость формулируется как принцип дополнительности Бора: на классическом уровне, доступном для коммуникации исследователям, мы можем описывать квантовую систему в рамках одной из двух дополнительных картин (например, пространственно-координатной и импульсно-энергетической), но не обеими одновременно.
Несмотря на свои многочисленные применения, соотношение неопределенностей Робертсона-Шредингера не очень-то годится на роль математического выражения принципа дополнительности, потому что завязано на спектры операторов наблюдаемых величин. Если мы трактуем принцип дополнительности как невозможность полного определения и передачи информации о значениях двух несовместимых величин, то здесь важны лишь вероятности, связанные с вектором состояния квантовой системы и собственными векторами операторов X и Z. А вот собственные значения операторов X и Z – это, с точки зрения теории информации, всего лишь метки, которые можно переобозначать без изменения информационного содержания. Но в соотношение неопределенностей Робертсона-Шредингера они входят, что излишне.
Еще один недостаток этого соотношения – контринтуитивное (опять-таки, с точки зрения теории информации) поведение стандартных отклонений σ(X) и σ(Z). Вот пример: допустим, что величина X в текущем состоянии системы принимает значения +1, 0, –1, каждое c вероятностями 1/3. В этом случае σ(X) = √<(X – <X>)²> = 1/√3. Если мы спроецируем нашу систему на собственный вектор |φ₀><φ₀| оператора X, отвечающий собственному значению 0 (то есть измерим наблюдаемую, отвечающую на вопрос «принимает ли X значение 0?») и получим отрицательный ответ, то после измерения величина X будет принимать уже два оставшихся значения +1 и –1 с равными вероятностями 1/2. В этом состоянии σ(X) = 1/√2 – это больше, чем предыдущее значение 1/√3.
Получается парадоксальная штука: мы провели над системой измерений, получили некоторую информацию о ее состоянии (а именно, что X ≠ 0), а стандартное отклонение σ(X) не уменьшилось, а возросло. Поэтому σ(X) не является мерой неопределенности величины X, хорошо определенной с точки зрения теории информации. А значит, и соотношение неопределенностей Робертсона-Шредингера с информационной точки зрения не особенно осмысленно.
#квантовая_механика #информация #объяснения
Как говорилось в предыдущем посте, соотношение неопределенностей Робертсона-Шредингера не особо полезно с точки зрения теории информации. Его альтернативой являются энтропийные соотношения неопределенностей, имеющие дело не со стандартными отклонениями, а с энтропиями измеряемых величин.
Простейший вариант таких соотношений показан на рисунке: сумма энтропий Шеннона H(X) и H(Z) результатов измерений двух наблюдаемых X и Z ограничена снизу убывающей функцией log(1/c) величины c. Эта величина определяется как максимальное перекрытие |X> и |Z> (собственных векторов X и Z), то есть максимальный квадрат модуля их попарных скалярных произведений.
Если наборы собственных векторов X и Z почти совпадают, то c ≈ 1, так что log(1/c) ≈ 0, и наблюдаемые X, Z могут быть измерены одновременно с почти нулевой энтропией. Если же их направления максимально не совпадают, то log(1/c) достигает верхнего предела log(d), где d – размерность гильбертова пространства системы.
#квантовая_механика #информация #объяснения
Простейший вариант таких соотношений показан на рисунке: сумма энтропий Шеннона H(X) и H(Z) результатов измерений двух наблюдаемых X и Z ограничена снизу убывающей функцией log(1/c) величины c. Эта величина определяется как максимальное перекрытие |X> и |Z> (собственных векторов X и Z), то есть максимальный квадрат модуля их попарных скалярных произведений.
Если наборы собственных векторов X и Z почти совпадают, то c ≈ 1, так что log(1/c) ≈ 0, и наблюдаемые X, Z могут быть измерены одновременно с почти нулевой энтропией. Если же их направления максимально не совпадают, то log(1/c) достигает верхнего предела log(d), где d – размерность гильбертова пространства системы.
#квантовая_механика #информация #объяснения
Судя по списку авторов, в этой статье уже произошло квантовое запутывание с генерацией нелокальной информации.
#цитаты #квантовая_механика #информация
#цитаты #квантовая_механика #информация
Теория квантовой информации позволяет посмотреть свежим взглядом на школьную арифметику:
оказывается, 2 – это не 1 плюс 1, а 1 или 1.
Например, если Маша дает Пете 2 яблока, это означает, что Петя может взять себе и скушать только одно из этих яблок, но не оба сразу.
#цитаты #квантовая_механика #квантовые_вычисления #информация
оказывается, 2 – это не 1 плюс 1, а 1 или 1.
Например, если Маша дает Пете 2 яблока, это означает, что Петя может взять себе и скушать только одно из этих яблок, но не оба сразу.
#цитаты #квантовая_механика #квантовые_вычисления #информация
👍3