
#easy
Задача: 125. Valid Palindrome
Фраза является палиндромом, если после преобразования всех заглавных букв в строчные и удаления всех неалфавитно-цифровых символов она читается одинаково как слева направо, так и справа налево. Алфавитно-цифровые символы включают в себя буквы и цифры.
Для данной строки s верните true, если она является палиндромом, и false в противном случае.
Пример:
👨💻 Алгоритм:
1️⃣ Поскольку входная строка содержит символы, которые нам нужно игнорировать при проверке на палиндром, становится трудно определить реальную середину нашего палиндромического ввода.
2️⃣ Вместо того, чтобы двигаться от середины наружу, мы можем двигаться внутрь к середине! Если начать перемещаться внутрь, с обоих концов входной строки, мы можем ожидать увидеть те же символы в том же порядке.
3️⃣ Результирующий алгоритм прост:
1. Установите два указателя, один на каждом конце входной строки.
2. Если ввод является палиндромом, оба указателя должны указывать на эквивалентные символы в любой момент времени.
3. Если это условие не выполняется в какой-либо момент времени, мы прерываемся и возвращаемся раньше.
4. Мы можем просто игнорировать неалфавитно-цифровые символы, продолжая двигаться дальше.
5. Продолжайте перемещение внутрь, пока указатели не встретятся в середине.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 125. Valid Palindrome
Фраза является палиндромом, если после преобразования всех заглавных букв в строчные и удаления всех неалфавитно-цифровых символов она читается одинаково как слева направо, так и справа налево. Алфавитно-цифровые символы включают в себя буквы и цифры.
Для данной строки s верните true, если она является палиндромом, и false в противном случае.
Пример:
Input: s = "A man, a plan, a canal: Panama"
Output: true
Explanation: "amanaplanacanalpanama" is a palindrome.
1. Установите два указателя, один на каждом конце входной строки.
2. Если ввод является палиндромом, оба указателя должны указывать на эквивалентные символы в любой момент времени.
3. Если это условие не выполняется в какой-либо момент времени, мы прерываемся и возвращаемся раньше.
4. Мы можем просто игнорировать неалфавитно-цифровые символы, продолжая двигаться дальше.
5. Продолжайте перемещение внутрь, пока указатели не встретятся в середине.
class Solution:
def isPalindrome(self, s: str) -> bool:
i, j = 0, len(s) - 1
while i < j:
while i < j and not s[i].isalnum():
i += 1
while i < j and not s[j].isalnum():
j -= 1
if s[i].lower() != s[j].lower():
return False
i += 1
j -= 1
return True
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3❤1
#Hard
Задача: 126.Word Ladder II
Последовательность преобразований от слова beginWord до слова endWord с использованием словаря wordList — это последовательность слов beginWord -> s1 -> s2 -> ... -> sk, для которой выполняются следующие условия:
Каждая пара соседних слов отличается ровно одной буквой.
Каждое si для 1 <= i <= k находится в wordList. Отметим, что beginWord не обязательно должно быть в wordList.
sk == endWord.
Для двух слов, beginWord и endWord, и словаря wordList, вернуть все самые короткие последовательности преобразований от beginWord до endWord или пустой список, если такая последовательность не существует. Каждая последовательность должна возвращаться в виде списка слов [beginWord, s1, s2, ..., sk].
Пример:
👨💻 Алгоритм:
1️⃣ Сохранение слов из списка слов (wordList) в хэш-таблицу (unordered set) для эффективного удаления слов в процессе поиска в ширину (BFS).
2️⃣ Выполнение BFS, добавление связей в список смежности (adjList). После завершения уровня удалять посещенные слова из wordList.
3️⃣ Начать с beginWord и отслеживать текущий путь как currPath, просматривать все возможные пути, и когда путь ведет к endWord, сохранять путь в shortestPaths.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 126.Word Ladder II
Последовательность преобразований от слова beginWord до слова endWord с использованием словаря wordList — это последовательность слов beginWord -> s1 -> s2 -> ... -> sk, для которой выполняются следующие условия:
Каждая пара соседних слов отличается ровно одной буквой.
Каждое si для 1 <= i <= k находится в wordList. Отметим, что beginWord не обязательно должно быть в wordList.
sk == endWord.
Для двух слов, beginWord и endWord, и словаря wordList, вернуть все самые короткие последовательности преобразований от beginWord до endWord или пустой список, если такая последовательность не существует. Каждая последовательность должна возвращаться в виде списка слов [beginWord, s1, s2, ..., sk].
Пример:
Input: beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
Output: [["hit","hot","dot","dog","cog"],["hit","hot","lot","log","cog"]]
Explanation: There are 2 shortest transformation sequences:
"hit" -> "hot" -> "dot" -> "dog" -> "cog"
"hit" -> "hot" -> "lot" -> "log" -> "cog"
class Solution:
def __init__(self):
self.adjList = {}
self.currPath = []
self.shortestPaths = []
def findNeighbors(self, word, wordSet):
neighbors = []
charList = list(word)
for i in range(len(charList)):
oldChar = charList[i]
for c in "abcdefghijklmnopqrstuvwxyz":
if c != oldChar:
charList[i] = c
newWord = "".join(charList)
if newWord in wordSet:
neighbors.append(newWord)
charList[i] = oldChar
return neighbors
def backtrack(self, source, destination):
if source == destination:
self.shortestPaths.append(self.currPath[::-1])
for neighbor in self.adjList.get(source, []):
self.currPath.append(neighbor)
self.backtrack(neighbor, destination)
self.currPath.pop()
def bfs(self, beginWord, endWord, wordSet):
q = deque([beginWord])
wordSet.discard(beginWord)
isEnqueued = {beginWord: True}
while q:
visited = []
for _ in range(len(q)):
currWord = q.popleft()
neighbors = self.findNeighbors(currWord, wordSet)
for neighbor in neighbors:
if neighbor not in isEnqueued:
q.append(neighbor)
isEnqueued[neighbor] = True
self.adjList[neighbor] = []
self.adjList[neighbor].append(currWord)
visited.append(neighbor)
for word in visited:
wordSet.discard(word)
def findLadders(self, beginWord, endWord, wordList):
wordSet = set(wordList)
self.bfs(beginWord, endWord, wordSet)
self.currPath = [endWord]
self.backtrack(endWord, beginWord)
return self.shortestPaths
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3
#Hard
Задача: 127. Word Ladder
Секвенция трансформации от слова beginWord к слову endWord с использованием словаря wordList представляет собой последовательность слов beginWord -> s1 -> s2 -> ... -> sk, при которой:
Каждая пара соседних слов отличается ровно одной буквой.
Каждый элемент si для 1 <= i <= k присутствует в wordList. Отметим, что beginWord не обязан быть в wordList.
sk равно endWord.
Для двух слов, beginWord и endWord, и словаря wordList, верните количество слов в кратчайшей секвенции трансформации от beginWord к endWord, или 0, если такая секвенция не существует.
Пример:
👨💻 Алгоритм:
1️⃣ Препроцессинг списка слов: Осуществите препроцессинг заданного списка слов (wordList), чтобы найти все возможные промежуточные состояния слов. Сохраните эти состояния в словаре, где ключом будет промежуточное слово, а значением — список слов, имеющих то же промежуточное состояние.
2️⃣ Использование очереди для обхода: Поместите в очередь кортеж, содержащий
3️⃣ Поиск кратчайшего пути через BFS (обход в ширину): Пока в очереди есть элементы, получите первый элемент очереди. Для каждого слова определите все промежуточные преобразования и проверьте, не являются ли эти преобразования также преобразованиями других слов из списка. Для каждого найденного слова, которое имеет общее промежуточное состояние с текущим словом, добавьте в очередь пару (слово, уровень + 1), где уровень — это уровень текущего слова. Если вы достигли искомого слова, его уровень покажет длину кратчайшей последовательности преобразования.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 127. Word Ladder
Секвенция трансформации от слова beginWord к слову endWord с использованием словаря wordList представляет собой последовательность слов beginWord -> s1 -> s2 -> ... -> sk, при которой:
Каждая пара соседних слов отличается ровно одной буквой.
Каждый элемент si для 1 <= i <= k присутствует в wordList. Отметим, что beginWord не обязан быть в wordList.
sk равно endWord.
Для двух слов, beginWord и endWord, и словаря wordList, верните количество слов в кратчайшей секвенции трансформации от beginWord к endWord, или 0, если такая секвенция не существует.
Пример:
Input: beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
Output: 5
Explanation: One shortest transformation sequence is "hit" -> "hot" -> "dot" -> "dog" -> cog", which is 5 words long.
beginWord и число 1, где 1 обозначает уровень узла. Вам нужно вернуть уровень узла endWord, так как он будет представлять длину кратчайшей последовательности преобразования. Используйте словарь посещений, чтобы избежать циклов.from collections import defaultdict, deque
from typing import List
class Solution:
def ladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int:
if endWord not in wordList or not endWord or not beginWord or not wordList:
return 0
L = len(beginWord)
all_combo_dict = defaultdict(list)
for word in wordList:
for i in range(L):
all_combo_dict[word[:i] + "*" + word[i + 1:]].append(word)
queue = deque([(beginWord, 1)])
visited = {beginWord: True}
while queue:
current_word, level = queue.popleft()
for i in range(L):
intermediate_word = current_word[:i] + "*" + current_word[i + 1:]
for word in all_combo_dict[intermediate_word]:
if word == endWord:
return level + 1
if word not in visited:
visited[word] = True
queue.append((word, level + 1))
all_combo_dict[intermediate_word] = []
return 0
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1
{kind=link}
#Medium
Задача: 129. Sum Root to Leaf Numbers
Вам дан корень бинарного дерева, содержащего только цифры от 0 до 9.
Каждый путь от корня до листа в дереве представляет собой число.
Например, путь от корня до листа 1 -> 2 -> 3 представляет число 123.
Верните общую сумму всех чисел от корня до листа. Тестовые случаи созданы таким образом, что ответ поместится в 32-битное целое число.
Листовой узел — это узел без детей.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация:
Создайте переменные для хранения суммы чисел (rootToLeaf) и текущего числа (currNumber), а также стек для обхода дерева, начиная с корневого узла.
2️⃣ Обход дерева:
Используйте стек для глубинного обхода дерева (DFS), обновляя currNumber путём умножения на 10 и добавления значения узла. Для каждого листа добавляйте currNumber к rootToLeaf.
3️⃣ Возвращение результата:
По завершении обхода всех узлов возвращайте rootToLeaf, содержащую сумму всех чисел от корня до листьев дерева.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 129. Sum Root to Leaf Numbers
Вам дан корень бинарного дерева, содержащего только цифры от 0 до 9.
Каждый путь от корня до листа в дереве представляет собой число.
Например, путь от корня до листа 1 -> 2 -> 3 представляет число 123.
Верните общую сумму всех чисел от корня до листа. Тестовые случаи созданы таким образом, что ответ поместится в 32-битное целое число.
Листовой узел — это узел без детей.
Пример:
Input: root = [1,2,3]
Output: 25
Explanation:
The root-to-leaf path 1->2 represents the number 12.
The root-to-leaf path 1->3 represents the number 13.
Therefore, sum = 12 + 13 = 25.
Создайте переменные для хранения суммы чисел (rootToLeaf) и текущего числа (currNumber), а также стек для обхода дерева, начиная с корневого узла.
Используйте стек для глубинного обхода дерева (DFS), обновляя currNumber путём умножения на 10 и добавления значения узла. Для каждого листа добавляйте currNumber к rootToLeaf.
По завершении обхода всех узлов возвращайте rootToLeaf, содержащую сумму всех чисел от корня до листьев дерева.
class Solution:
def sumNumbers(self, root: TreeNode) -> int:
root_to_leaf = curr_number = 0
while root:
if root.left:
predecessor = root.left
steps = 1
while predecessor.right and predecessor.right is not root:
predecessor = predecessor.right
steps += 1
if predecessor.right is None:
curr_number = curr_number * 10 + root.val
predecessor.right = root
root = root.left
else:
if predecessor.left is None:
root_to_leaf += curr_number
for _ in range(steps):
curr_number //= 10
predecessor.right = None
root = root.right
else:
curr_number = curr_number * 10 + root.val
if root.right is None:
root_to_leaf += curr_number
root = root.right
return root_to_leaf
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3
#Medium
Задача: 130. Surrounded Regions
Вам дана матрица размером m на n, которая содержит буквы 'X' и 'O'. Захватите регионы, которые окружены:
Соединение: Ячейка соединена с соседними ячейками по горизонтали или вертикали.
Регион: Для формирования региона соедините каждую ячейку 'O'.
Окружение: Регион окружён ячейками 'X', если можно соединить регион с ячейками 'X', и ни одна из ячеек региона не находится на краю доски.
Окруженный регион захватывается путём замены всех 'O' на 'X' в исходной матрице.
Пример:
👨💻 Алгоритм:
1️⃣ Выбор начальных ячеек и инициация DFS:
Начинаем с выбора всех ячеек, расположенных на границах доски.
Затем, начиная с каждой выбранной ячейки на границе, выполняем обход в глубину (DFS).
2️⃣ Логика и выполнение DFS:
Если ячейка на границе оказывается 'O', это означает, что эта ячейка "жива", вместе с другими ячейками 'O', соединёнными с этой граничной ячейкой. Две ячейки считаются соединёнными, если между ними существует путь, состоящий только из букв 'O'.
Цель нашего обхода DFS будет заключаться в том, чтобы отметить все такие связанные ячейки 'O', которые исходят из границы, каким-либо отличительным символом, например, 'E'.
3️⃣ Классификация и финальная обработка ячеек:
После обхода всех граничных ячеек мы получаем три типа ячеек:
Ячейки с буквой 'X': эти ячейки можно считать стеной.
Ячейки с буквой 'O': эти ячейки не затрагиваются в нашем обходе DFS, то есть они не имеют соединения с границей, следовательно, они захвачены. Эти ячейки следует заменить на букву 'X'.
Ячейки с буквой 'E': это ячейки, отмеченные в ходе нашего обхода DFS, то есть ячейки, имеющие хотя бы одно соединение с границами, следовательно, они не захвачены. В результате мы должны вернуть этим ячейкам их исходную букву 'O'.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 130. Surrounded Regions
Вам дана матрица размером m на n, которая содержит буквы 'X' и 'O'. Захватите регионы, которые окружены:
Соединение: Ячейка соединена с соседними ячейками по горизонтали или вертикали.
Регион: Для формирования региона соедините каждую ячейку 'O'.
Окружение: Регион окружён ячейками 'X', если можно соединить регион с ячейками 'X', и ни одна из ячеек региона не находится на краю доски.
Окруженный регион захватывается путём замены всех 'O' на 'X' в исходной матрице.
Пример:
Input: board = [["X"]]
Output: [["X"]]
Начинаем с выбора всех ячеек, расположенных на границах доски.
Затем, начиная с каждой выбранной ячейки на границе, выполняем обход в глубину (DFS).
Если ячейка на границе оказывается 'O', это означает, что эта ячейка "жива", вместе с другими ячейками 'O', соединёнными с этой граничной ячейкой. Две ячейки считаются соединёнными, если между ними существует путь, состоящий только из букв 'O'.
Цель нашего обхода DFS будет заключаться в том, чтобы отметить все такие связанные ячейки 'O', которые исходят из границы, каким-либо отличительным символом, например, 'E'.
После обхода всех граничных ячеек мы получаем три типа ячеек:
Ячейки с буквой 'X': эти ячейки можно считать стеной.
Ячейки с буквой 'O': эти ячейки не затрагиваются в нашем обходе DFS, то есть они не имеют соединения с границей, следовательно, они захвачены. Эти ячейки следует заменить на букву 'X'.
Ячейки с буквой 'E': это ячейки, отмеченные в ходе нашего обхода DFS, то есть ячейки, имеющие хотя бы одно соединение с границами, следовательно, они не захвачены. В результате мы должны вернуть этим ячейкам их исходную букву 'O'.
class Solution(object):
def solve(self, board: List[List[str]]) -> None:
if not board or not board[0]:
return
self.ROWS = len(board)
self.COLS = len(board[0])
from itertools import product
borders = list(product(range(self.ROWS), [0, self.COLS - 1])) + list(
product([0, self.ROWS - 1], range(self.COLS))
)
for row, col in borders:
self.DFS(board, row, col)
for r in range(self.ROWS):
for c in range(self.COLS):
if board[r][c] == "O":
board[r][c] = "X"
elif board[r][c] == "E":
board[r][c] = "O"
def DFS(self, board: List[List[str]], row: int, col: int) -> None:
if board[row][col] != "O":
return
board[row][col] = "E"
if col < self.COLS - 1:
self.DFS(board, row, col + 1)
if row < self.ROWS - 1:
self.DFS(board, row + 1, col)
if col > 0:
self.DFS(board, row, col - 1)
if row > 0:
self.DFS(board, row - 1, col)
Please open Telegram to view this post
VIEW IN TELEGRAM
❤1👍1
#Medium
Задача: 131. Palindrome Partitioning
Дана строка s. Разделите строку таким образом, чтобы каждая подстрока разделения была палиндромом. Верните все возможные варианты разделения строки s на палиндромы.
Пример:
👨💻 Алгоритм:
1️⃣ Инициация рекурсивного обхода:
В алгоритме обратного отслеживания (backtracking) мы рекурсивно пробегаем по строке, используя метод поиска в глубину (depth-first search). Для каждого рекурсивного вызова задаётся начальный индекс строки start.
Итеративно генерируем все возможные подстроки, начиная с индекса start. Индекс end увеличивается от start до конца строки.
2️⃣ Проверка на палиндром и продолжение поиска:
Для каждой сгенерированной подстроки проверяем, является ли она палиндромом.
Если подстрока оказывается палиндромом, она становится потенциальным кандидатом. Добавляем подстроку в currentList и выполняем поиск в глубину для оставшейся части строки. Если текущая подстрока заканчивается на индексе end, то end+1 становится начальным индексом для следующего рекурсивного вызова.
3️⃣ Возврат (Backtracking) и сохранение результатов:
Возвращаемся, если начальный индекс start больше или равен длине строки, и добавляем currentList в результат.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 131. Palindrome Partitioning
Дана строка s. Разделите строку таким образом, чтобы каждая подстрока разделения была палиндромом. Верните все возможные варианты разделения строки s на палиндромы.
Пример:
Input: s = "aab"
Output: [["a","a","b"],["aa","b"]]
В алгоритме обратного отслеживания (backtracking) мы рекурсивно пробегаем по строке, используя метод поиска в глубину (depth-first search). Для каждого рекурсивного вызова задаётся начальный индекс строки start.
Итеративно генерируем все возможные подстроки, начиная с индекса start. Индекс end увеличивается от start до конца строки.
Для каждой сгенерированной подстроки проверяем, является ли она палиндромом.
Если подстрока оказывается палиндромом, она становится потенциальным кандидатом. Добавляем подстроку в currentList и выполняем поиск в глубину для оставшейся части строки. Если текущая подстрока заканчивается на индексе end, то end+1 становится начальным индексом для следующего рекурсивного вызова.
Возвращаемся, если начальный индекс start больше или равен длине строки, и добавляем currentList в результат.
class Solution:
def partition(self, s: str) -> List[List[str]]:
result = []
self.dfs(s, [], result)
return result
def isPalindrome(self, s: str) -> bool:
return s == s[::-1]
def dfs(self, s: str, path: List[str], result: List[List[str]]):
if not s:
result.append(path)
return
for i in range(1, len(s) + 1):
if self.isPalindrome(s[:i]):
self.dfs(s[i:], path + [s[:i]], result)
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2
#Hard
Задача: 132. Palindrome Partitioning II
Дана строка s. Разделите строку так, чтобы каждая подстрока разделения была палиндромом.
Верните минимальное количество разрезов, необходимых для разделения строки s на палиндромы.
Пример:
👨💻 Алгоритм:
1️⃣ Определение задачи и начальные условия:
Алгоритм обратного отслеживания реализуется путём рекурсивного изучения кандидатов-подстрок. Мы определяем рекурсивный метод findMinimumCut, который находит минимальное количество разрезов для подстроки, начинающейся с индекса start и заканчивающейся на индексе end.
Чтобы найти минимальное количество разрезов, мы также должны знать минимальное количество разрезов, которые были найдены ранее для других разделений на палиндромы. Эта информация отслеживается в переменной minimumCut.
Начальное значение minimumCut будет равно максимально возможному количеству разрезов в строке, что равно длине строки минус один (т.е. разрез между каждым символом).
2️⃣ Генерация подстрок и рекурсивный поиск:
Теперь, когда мы знаем начальные и конечные индексы, мы должны сгенерировать все возможные подстроки, начиная с индекса start. Для этого мы будем держать начальный индекс постоянным. currentEndIndex обозначает конец текущей подстроки.
3️⃣ Условие палиндрома и рекурсивное разделение:
Если текущая подстрока является палиндромом, мы сделаем разрез после currentEndIndex и рекурсивно найдем минимальный разрез для оставшейся строки
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 132. Palindrome Partitioning II
Дана строка s. Разделите строку так, чтобы каждая подстрока разделения была палиндромом.
Верните минимальное количество разрезов, необходимых для разделения строки s на палиндромы.
Пример:
Input: s = "aab"
Output: 1
Explanation: The palindrome partitioning ["aa","b"] could be produced using 1 cut.
Алгоритм обратного отслеживания реализуется путём рекурсивного изучения кандидатов-подстрок. Мы определяем рекурсивный метод findMinimumCut, который находит минимальное количество разрезов для подстроки, начинающейся с индекса start и заканчивающейся на индексе end.
Чтобы найти минимальное количество разрезов, мы также должны знать минимальное количество разрезов, которые были найдены ранее для других разделений на палиндромы. Эта информация отслеживается в переменной minimumCut.
Начальное значение minimumCut будет равно максимально возможному количеству разрезов в строке, что равно длине строки минус один (т.е. разрез между каждым символом).
Теперь, когда мы знаем начальные и конечные индексы, мы должны сгенерировать все возможные подстроки, начиная с индекса start. Для этого мы будем держать начальный индекс постоянным. currentEndIndex обозначает конец текущей подстроки.
Если текущая подстрока является палиндромом, мы сделаем разрез после currentEndIndex и рекурсивно найдем минимальный разрез для оставшейся строки
class Solution:
def minCut(self, s: str) -> int:
return self.findMinimumCut(s, 0, len(s) - 1, len(s) - 1)
def findMinimumCut(self, s: str, start: int, end: int, minimumCut: int) -> int:
if start == end or self.isPalindrome(s, start, end):
return 0
for currentEndIndex in range(start, end + 1):
if self.isPalindrome(s, start, currentEndIndex):
minimumCut = min(
minimumCut,
1 + self.findMinimumCut(s, currentEndIndex + 1, end, minimumCut)
)
return minimumCut
def isPalindrome(self, s: str, start: int, end: int) -> bool:
while start < end:
if s[start] != s[end]:
return False
start += 1
end -= 1
return True
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2
{kind=link}
#medium
Задача: 133. Clone Graph
Дана ссылка на узел в связанном неориентированном графе.
Верните глубокую копию (клон) графа.
Каждый узел в графе содержит значение (целое число) и список (List[Node]) своих соседей.
Пример:
👨💻 Алгоритм:
1️⃣ Используйте хеш-таблицу для хранения ссылок на копии всех уже посещенных и скопированных узлов. Ключом будет узел оригинального графа, а значением — соответствующий клонированный узел клонированного графа. Хеш-таблица посещенных узлов также используется для предотвращения циклов.
2️⃣ Добавьте первый узел в очередь, клонируйте его и добавьте в хеш-таблицу посещенных.
3️⃣ Выполните обход в ширину (BFS): извлеките узел из начала очереди, посетите всех соседей этого узла. Если какой-либо сосед уже был посещен, получите его клон из хеш-таблицы посещенных; если нет, создайте клон и добавьте его в хеш-таблицу. Добавьте клоны соседей в список соседей клонированного узла.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 133. Clone Graph
Дана ссылка на узел в связанном неориентированном графе.
Верните глубокую копию (клон) графа.
Каждый узел в графе содержит значение (целое число) и список (List[Node]) своих соседей.
Пример:
Input: adjList = [[2,4],[1,3],[2,4],[1,3]]
Output: [[2,4],[1,3],[2,4],[1,3]]
Explanation: There are 4 nodes in the graph.
1st node (val = 1)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
2nd node (val = 2)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
3rd node (val = 3)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
4th node (val = 4)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
from collections import deque
class Node:
def __init__(self, val=0, neighbors=None):
self.val = val
self.neighbors = neighbors if neighbors is not None else []
class Solution:
def cloneGraph(self, node: Optional["Node"]) -> Optional["Node"]:
if not node:
return node
visited = {}
queue = deque([node])
visited[node] = Node(node.val, [])
while queue:
n = queue.popleft()
for neighbor in n.neighbors:
if neighbor not in visited:
visited[neighbor] = Node(neighbor.val, [])
queue.append(neighbor)
visited[n].neighbors.append(visited[neighbor])
return visited[node]
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2❤1
{kind=link}
#medium
Задача: 134. Gas Station
Вдоль кругового маршрута расположены n заправочных станций, на каждой из которых находится определённое количество топлива gas[i].
У вас есть автомобиль с неограниченным топливным баком, и для проезда от i-й станции к следующей (i + 1)-й станции требуется cost[i] топлива. Путешествие начинается с пустым баком на одной из заправочных станций.
Учитывая два массива целых чисел gas и cost, верните индекс начальной заправочной станции, если вы можете проехать вокруг цепи один раз по часовой стрелке, в противном случае верните -1. Если решение существует, оно гарантированно будет уникальным.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализируйте переменные curr_gain, total_gain и answer значением 0.
2️⃣ Пройдите по массивам gas и cost. Для каждого индекса i увеличивайте total_gain и curr_gain на gas[i] - cost[i].
Если curr_gain меньше 0, проверьте, может ли станция i + 1 быть начальной станцией: установите answer как i + 1, сбросьте curr_gain до 0 и повторите шаг 2.
3️⃣ По завершении итерации, если total_gain меньше 0, верните -1. В противном случае верните answer.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 134. Gas Station
Вдоль кругового маршрута расположены n заправочных станций, на каждой из которых находится определённое количество топлива gas[i].
У вас есть автомобиль с неограниченным топливным баком, и для проезда от i-й станции к следующей (i + 1)-й станции требуется cost[i] топлива. Путешествие начинается с пустым баком на одной из заправочных станций.
Учитывая два массива целых чисел gas и cost, верните индекс начальной заправочной станции, если вы можете проехать вокруг цепи один раз по часовой стрелке, в противном случае верните -1. Если решение существует, оно гарантированно будет уникальным.
Пример:
Input: gas = [1,2,3,4,5], cost = [3,4,5,1,2]
Output: 3
Explanation:
Start at station 3 (index 3) and fill up with 4 unit of gas. Your tank = 0 + 4 = 4
Travel to station 4. Your tank = 4 - 1 + 5 = 8
Travel to station 0. Your tank = 8 - 2 + 1 = 7
Travel to station 1. Your tank = 7 - 3 + 2 = 6
Travel to station 2. Your tank = 6 - 4 + 3 = 5
Travel to station 3. The cost is 5. Your gas is just enough to travel back to station 3.
Therefore, return 3 as the starting index.
Если curr_gain меньше 0, проверьте, может ли станция i + 1 быть начальной станцией: установите answer как i + 1, сбросьте curr_gain до 0 и повторите шаг 2.
class Solution:
def canCompleteCircuit(self, gas: List[int], cost: List[int]) -> int:
total_gain = 0
curr_gain = 0
answer = 0
for i in range(len(gas)):
total_gain += gas[i] - cost[i]
curr_gain += gas[i] - cost[i]
if curr_gain < 0:
curr_gain = 0
answer = i + 1
return answer if total_gain >= 0 else -1
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2
#hard
Задача: 135. Candy
В очереди стоят n детей. Каждому ребенку присвоено значение рейтинга, указанное в массиве целых чисел ratings.
Вы раздаете конфеты этим детям с соблюдением следующих требований:
Каждый ребенок должен получить как минимум одну конфету.
Дети с более высоким рейтингом должны получать больше конфет, чем их соседи.
Верните минимальное количество конфет, которое вам нужно иметь, чтобы распределить их среди детей.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация и первичное заполнение массивов:
Создайте два массива: left2right для расчета конфет с учетом только левых соседей и right2left для расчета с учетом только правых соседей. Изначально каждому ученику в обоих массивах присваивается по одной конфете.
2️⃣ Обход и обновление значений в массивах:
Проходите массив ratings слева направо, увеличивая значение в left2right для каждого ученика, чей рейтинг выше рейтинга его левого соседа.
Затем проходите массив справа налево, увеличивая значение в right2left для каждого ученика, чей рейтинг выше рейтинга его правого соседа.
3️⃣ Расчет минимального количества конфет:
Для каждого ученика определите максимальное значение конфет между left2right[i] и right2left[i], чтобы соответствовать требованиям к распределению конфет.
Суммируйте полученные значения для всех учеников, чтобы найти минимальное количество конфет, необходимое для соблюдения всех правил.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 135. Candy
В очереди стоят n детей. Каждому ребенку присвоено значение рейтинга, указанное в массиве целых чисел ratings.
Вы раздаете конфеты этим детям с соблюдением следующих требований:
Каждый ребенок должен получить как минимум одну конфету.
Дети с более высоким рейтингом должны получать больше конфет, чем их соседи.
Верните минимальное количество конфет, которое вам нужно иметь, чтобы распределить их среди детей.
Пример:
Input: ratings = [1,0,2]
Output: 5
Explanation: You can allocate to the first, second and third child with 2, 1, 2 candies respectively.
Создайте два массива: left2right для расчета конфет с учетом только левых соседей и right2left для расчета с учетом только правых соседей. Изначально каждому ученику в обоих массивах присваивается по одной конфете.
Проходите массив ratings слева направо, увеличивая значение в left2right для каждого ученика, чей рейтинг выше рейтинга его левого соседа.
Затем проходите массив справа налево, увеличивая значение в right2left для каждого ученика, чей рейтинг выше рейтинга его правого соседа.
Для каждого ученика определите максимальное значение конфет между left2right[i] и right2left[i], чтобы соответствовать требованиям к распределению конфет.
Суммируйте полученные значения для всех учеников, чтобы найти минимальное количество конфет, необходимое для соблюдения всех правил.
class Solution:
def candy(self, ratings: List[int]) -> int:
sum = 0
n = len(ratings)
left2right = [1] * n
right2left = [1] * n
for i in range(1, n):
if ratings[i] > ratings[i - 1]:
left2right[i] = left2right[i - 1] + 1
for i in range(n - 2, -1, -1):
if ratings[i] > ratings[i + 1]:
right2left[i] = right2left[i + 1] + 1
for i in range(n):
sum += max(left2right[i], right2left[i])
return sum
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
#easy
Задача: 136. Single Number
Дан непустой массив целых чисел nums, в котором каждый элемент встречается дважды, кроме одного. Найдите этот единственный элемент.
Вы должны реализовать решение с линейной сложностью выполнения и использовать только постоянное дополнительное пространство.
Пример:
👨💻 Алгоритм:
1️⃣ Переберите все элементы в массиве nums.
2️⃣ Если какое-то число в nums новое для массива, добавьте его.
3️⃣ Если какое-то число уже есть в массиве, удалите его.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 136. Single Number
Дан непустой массив целых чисел nums, в котором каждый элемент встречается дважды, кроме одного. Найдите этот единственный элемент.
Вы должны реализовать решение с линейной сложностью выполнения и использовать только постоянное дополнительное пространство.
Пример:
Input: nums = [2,2,1]
Output: 1
class Solution(object):
def singleNumber(self, nums: List[int]) -> int:
no_duplicate_list = []
for i in nums:
if i not in no_duplicate_list:
no_duplicate_list.append(i)
else:
no_duplicate_list.remove(i)
return no_duplicate_list.pop()
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1
#medium
Задача: 137. Single Number II
Дан массив целых чисел nums, в котором каждый элемент встречается три раза, кроме одного, который встречается ровно один раз. Найдите этот единственный элемент и верните его.
Вы должны реализовать решение с линейной сложностью выполнения и использовать только постоянное дополнительное пространство.
Пример:
👨💻 Алгоритм:
1️⃣ Сортировка массива:
Отсортируйте массив nums. Это упорядочит все элементы так, чтобы одинаковые числа находились рядом.
2️⃣ Итерация с проверкой:
Используйте цикл for для перебора элементов массива от начала до nums.size() - 2 с шагом 3. Таким образом, каждый проверяемый индекс будет иметь следующий за ним индекс в пределах массива.
Если элемент на текущем индексе совпадает с элементом на следующем индексе (проверка nums[i] == nums[i + 1]), продолжайте следующую итерацию цикла.
3️⃣ Возврат уникального элемента:
Если элемент на текущем индексе не совпадает с следующим, значит, это искомый уникальный элемент, который встречается только один раз. В этом случае возвращайте элемент на текущем индексе.
Если до последнего элемента цикл не нашёл уникального элемента, возвращайте последний элемент массива nums[nums.size() - 1], поскольку он, очевидно, будет уникальным, если предыдущие проверки не выявили уникального элемента раньше.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 137. Single Number II
Дан массив целых чисел nums, в котором каждый элемент встречается три раза, кроме одного, который встречается ровно один раз. Найдите этот единственный элемент и верните его.
Вы должны реализовать решение с линейной сложностью выполнения и использовать только постоянное дополнительное пространство.
Пример:
Input: nums = [2,2,3,2]
Output: 3
Отсортируйте массив nums. Это упорядочит все элементы так, чтобы одинаковые числа находились рядом.
Используйте цикл for для перебора элементов массива от начала до nums.size() - 2 с шагом 3. Таким образом, каждый проверяемый индекс будет иметь следующий за ним индекс в пределах массива.
Если элемент на текущем индексе совпадает с элементом на следующем индексе (проверка nums[i] == nums[i + 1]), продолжайте следующую итерацию цикла.
Если элемент на текущем индексе не совпадает с следующим, значит, это искомый уникальный элемент, который встречается только один раз. В этом случае возвращайте элемент на текущем индексе.
Если до последнего элемента цикл не нашёл уникального элемента, возвращайте последний элемент массива nums[nums.size() - 1], поскольку он, очевидно, будет уникальным, если предыдущие проверки не выявили уникального элемента раньше.
class Solution:
def singleNumber(self, nums: List[int]) -> int:
nums.sort()
for i in range(0, len(nums) - 1, 3):
if nums[i] == nums[i + 1]:
continue
else:
return nums[i]
return nums[len(nums) - 1]
Please open Telegram to view this post
VIEW IN TELEGRAM
👍5
{kind=link}
#medium
Задача: 138. Copy List with Random Pointer
Дан связный список длиной n, в котором каждый узел содержит дополнительный случайный указатель (random pointer), который может указывать на любой узел в списке или быть равным null.
Создайте глубокую копию списка. Глубокая копия должна состоять из ровно n совершенно новых узлов, где каждый новый узел имеет значение, равное значению соответствующего оригинального узла. Указатели next и random новых узлов должны указывать на новые узлы в скопированном списке таким образом, чтобы указатели в оригинальном и скопированном списке представляли одно и то же состояние списка. Ни один из указателей в новом списке не должен указывать на узлы в оригинальном списке.
Например, если в оригинальном списке есть два узла X и Y, где X.random --> Y, то для соответствующих узлов x и y в скопированном списке, x.random должен указывать на y.
Верните голову скопированного связного списка.
Связный список представлен во входных/выходных данных как список из n узлов. Каждый узел представлен парой [val, random_index], где:
val: целое число, представляющее Node.val
random_index: индекс узла (в диапазоне от 0 до n-1), на который указывает случайный указатель, или null, если он не указывает ни на какой узел.
Вашему коду будет дана только голова оригинального связного списка.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация и начало обхода:
Начните обход графа со стартового узла (head). Создайте словарь visited_dictionary для отслеживания посещенных и клонированных узлов.
2️⃣ Проверка и клонирование узлов:
Для каждого текущего узла (current_node) проверьте, есть ли уже клонированная копия в visited_dictionary.
Если клонированная копия существует, используйте ссылку на этот клонированный узел.
Если клонированной копии нет, создайте новый узел (cloned_node_for_current_node), инициализируйте его и добавьте в visited_dictionary, где ключом будет current_node, а значением — созданный клон.
3️⃣ Рекурсивные вызовы для обработки связей:
Сделайте два рекурсивных вызова для каждого узла: один используя указатель random, другой — указатель next.
Эти вызовы отражают обработку "детей" текущего узла в терминах графа, где детьми являются узлы, на которые указывают указатели random и next.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 138. Copy List with Random Pointer
Дан связный список длиной n, в котором каждый узел содержит дополнительный случайный указатель (random pointer), который может указывать на любой узел в списке или быть равным null.
Создайте глубокую копию списка. Глубокая копия должна состоять из ровно n совершенно новых узлов, где каждый новый узел имеет значение, равное значению соответствующего оригинального узла. Указатели next и random новых узлов должны указывать на новые узлы в скопированном списке таким образом, чтобы указатели в оригинальном и скопированном списке представляли одно и то же состояние списка. Ни один из указателей в новом списке не должен указывать на узлы в оригинальном списке.
Например, если в оригинальном списке есть два узла X и Y, где X.random --> Y, то для соответствующих узлов x и y в скопированном списке, x.random должен указывать на y.
Верните голову скопированного связного списка.
Связный список представлен во входных/выходных данных как список из n узлов. Каждый узел представлен парой [val, random_index], где:
val: целое число, представляющее Node.val
random_index: индекс узла (в диапазоне от 0 до n-1), на который указывает случайный указатель, или null, если он не указывает ни на какой узел.
Вашему коду будет дана только голова оригинального связного списка.
Пример:
Input: head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
Output: [[7,null],[13,0],[11,4],[10,2],[1,0]]
Начните обход графа со стартового узла (head). Создайте словарь visited_dictionary для отслеживания посещенных и клонированных узлов.
Для каждого текущего узла (current_node) проверьте, есть ли уже клонированная копия в visited_dictionary.
Если клонированная копия существует, используйте ссылку на этот клонированный узел.
Если клонированной копии нет, создайте новый узел (cloned_node_for_current_node), инициализируйте его и добавьте в visited_dictionary, где ключом будет current_node, а значением — созданный клон.
Сделайте два рекурсивных вызова для каждого узла: один используя указатель random, другой — указатель next.
Эти вызовы отражают обработку "детей" текущего узла в терминах графа, где детьми являются узлы, на которые указывают указатели random и next.
class Solution:
def __init__(self):
self.visitedHash = {}
def copyRandomList(self, head: "Optional[Node]") -> "Optional[Node]":
if head == None:
return None
if head in self.visitedHash:
return self.visitedHash[head]
node = Node(head.val, None, None)
self.visitedHash[head] = node
node.next = self.copyRandomList(head.next)
node.random = self.copyRandomList(head.random)
return node
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1
#medium
Задача: 139. Word Break
Дана строка s и словарь строк wordDict. Верните true, если строку s можно разделить на последовательность одного или нескольких слов из словаря, разделённых пробелами.
Обратите внимание, что одно и то же слово из словаря может использоваться несколько раз при разделении.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация структур данных:
Преобразуйте wordDict в множество words для быстрой проверки вхождения.
Инициализируйте очередь queue начальным значением 0 (индекс начала строки) и множество seen для отслеживания посещённых индексов.
2️⃣ Обход в ширину (BFS):
Пока очередь не пуста, извлекайте первый элемент из очереди, обозначающий начальную позицию start.
Если start равен длине строки s, возвращайте true, так как достигнут конец строки, и строку можно разделить на слова из словаря.
Итерируйте end от start + 1 до s.length включительно. Для каждого end, проверьте, посещён ли он уже.
3️⃣ Проверка подстроки и обновление структур:
Проверьте подстроку начиная с start и заканчивая перед end. Если подстрока находится в множестве words, добавьте end в очередь и отметьте его в seen как посещённый.
Если BFS завершается и конечный узел не достигнут, возвращайте false.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 139. Word Break
Дана строка s и словарь строк wordDict. Верните true, если строку s можно разделить на последовательность одного или нескольких слов из словаря, разделённых пробелами.
Обратите внимание, что одно и то же слово из словаря может использоваться несколько раз при разделении.
Пример:
Input: s = "leetcode", wordDict = ["leet","code"]
Output: true
Explanation: Return true because "leetcode" can be segmented as "leet code".
Преобразуйте wordDict в множество words для быстрой проверки вхождения.
Инициализируйте очередь queue начальным значением 0 (индекс начала строки) и множество seen для отслеживания посещённых индексов.
Пока очередь не пуста, извлекайте первый элемент из очереди, обозначающий начальную позицию start.
Если start равен длине строки s, возвращайте true, так как достигнут конец строки, и строку можно разделить на слова из словаря.
Итерируйте end от start + 1 до s.length включительно. Для каждого end, проверьте, посещён ли он уже.
Проверьте подстроку начиная с start и заканчивая перед end. Если подстрока находится в множестве words, добавьте end в очередь и отметьте его в seen как посещённый.
Если BFS завершается и конечный узел не достигнут, возвращайте false.
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
words = set(wordDict)
queue = deque([0])
seen = set()
while queue:
start = queue.popleft()
if start == len(s):
return True
for end in range(start + 1, len(s) + 1):
if end in seen:
continue
if s[start:end] in words:
queue.append(end)
seen.add(end)
return False
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2
{kind=link}
#hard
Задача: 140. Word Break II
Дана строка s и словарь строк wordDict. Добавьте пробелы в строку s, чтобы построить предложение, в котором каждое слово является допустимым словом из словаря. Верните все такие возможные предложения в любом порядке.
Обратите внимание, что одно и то же слово из словаря может использоваться несколько раз при разделении.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация и начальный вызов:
Преобразуйте массив wordDict в множество wordSet для эффективного поиска.
Инициализируйте пустой массив results для хранения допустимых предложений.
Инициализируйте пустую строку currentSentence для отслеживания конструируемого предложения.
Вызовите функцию backtrack с исходной строкой s, множеством wordSet, текущим предложением currentSentence, массивом результатов results и начальным индексом, установленным в 0 — начало входной строки.
Верните results после завершения работы backtrack.
2️⃣ Функция backtrack:
Базовый случай: Если startIndex равен длине строки, добавьте currentSentence в results и вернитесь, так как это означает, что currentSentence представляет собой допустимое предложение.
Итерация по возможным значениям endIndex от startIndex + 1 до конца строки.
3️⃣ Обработка и рекурсия:
Извлеките подстроку word от startIndex до endIndex - 1.
Если word найдено в wordSet:
Сохраните текущее значение currentSentence в originalSentence.
Добавьте word к currentSentence (с пробелом, если это необходимо).
Рекурсивно вызовите backtrack с обновленным currentSentence и endIndex.
Сбросьте currentSentence к его исходному значению (originalSentence) для отката и попробуйте следующий endIndex.
Вернитесь из функции backtrack.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 140. Word Break II
Дана строка s и словарь строк wordDict. Добавьте пробелы в строку s, чтобы построить предложение, в котором каждое слово является допустимым словом из словаря. Верните все такие возможные предложения в любом порядке.
Обратите внимание, что одно и то же слово из словаря может использоваться несколько раз при разделении.
Пример:
Input: s = "catsanddog", wordDict = ["cat","cats","and","sand","dog"]
Output: ["cats and dog","cat sand dog"]
Преобразуйте массив wordDict в множество wordSet для эффективного поиска.
Инициализируйте пустой массив results для хранения допустимых предложений.
Инициализируйте пустую строку currentSentence для отслеживания конструируемого предложения.
Вызовите функцию backtrack с исходной строкой s, множеством wordSet, текущим предложением currentSentence, массивом результатов results и начальным индексом, установленным в 0 — начало входной строки.
Верните results после завершения работы backtrack.
Базовый случай: Если startIndex равен длине строки, добавьте currentSentence в results и вернитесь, так как это означает, что currentSentence представляет собой допустимое предложение.
Итерация по возможным значениям endIndex от startIndex + 1 до конца строки.
Извлеките подстроку word от startIndex до endIndex - 1.
Если word найдено в wordSet:
Сохраните текущее значение currentSentence в originalSentence.
Добавьте word к currentSentence (с пробелом, если это необходимо).
Рекурсивно вызовите backtrack с обновленным currentSentence и endIndex.
Сбросьте currentSentence к его исходному значению (originalSentence) для отката и попробуйте следующий endIndex.
Вернитесь из функции backtrack.
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> List[str]:
word_set = set(wordDict)
results = []
self._backtrack(s, word_set, [], results, 0)
return results
def _backtrack(self, s: str, word_set: set, current_sentence: List[str], results: List[str], start_index: int):
if start_index == len(s):
results.append(" ".join(current_sentence))
return
for end_index in range(start_index + 1, len(s) + 1):
word = s[start_index:end_index]
if word in word_set:
current_sentence.append(word)
self._backtrack(s, word_set, current_sentence, results, end_index)
current_sentence.pop()
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2🔥2
{kind=link}
#easy
Задача: 141. Linked List Cycle
Дана переменная head, которая является началом связного списка. Определите, содержит ли связный список цикл.
Цикл в связном списке существует, если существует узел в списке, до которого можно добраться снова, последовательно следуя по указателю next. Внутренне переменная pos используется для обозначения индекса узла, к которому подключен указатель next последнего узла. Обратите внимание, что pos не передается в качестве параметра.
Верните true, если в связном списке есть цикл. В противном случае верните false.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация структуры данных:
Создайте хеш-таблицу (или множество) для хранения ссылок на узлы, чтобы отслеживать уже посещённые узлы.
2️⃣ Обход списка:
Перемещайтесь по связному списку, начиная с головы (head), и проверяйте каждый узел по очереди.
3️⃣ Проверка на цикл:
Если текущий узел равен null, это означает, что вы достигли конца списка, и список не имеет циклов. В этом случае верните false.
Если текущий узел уже содержится в хеш-таблице, это означает, что вы вернулись к ранее посещённому узлу, и, следовательно, в списке присутствует цикл. Верните true.
Если ни одно из этих условий не выполнено, добавьте текущий узел в хеш-таблицу и продолжите обход списка.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 141. Linked List Cycle
Дана переменная head, которая является началом связного списка. Определите, содержит ли связный список цикл.
Цикл в связном списке существует, если существует узел в списке, до которого можно добраться снова, последовательно следуя по указателю next. Внутренне переменная pos используется для обозначения индекса узла, к которому подключен указатель next последнего узла. Обратите внимание, что pos не передается в качестве параметра.
Верните true, если в связном списке есть цикл. В противном случае верните false.
Пример:
Input: head = [3,2,0,-4], pos = 1
Output: true
Explanation: There is a cycle in the linked list, where the tail connects to the 1st node (0-indexed).
Создайте хеш-таблицу (или множество) для хранения ссылок на узлы, чтобы отслеживать уже посещённые узлы.
Перемещайтесь по связному списку, начиная с головы (head), и проверяйте каждый узел по очереди.
Если текущий узел равен null, это означает, что вы достигли конца списка, и список не имеет циклов. В этом случае верните false.
Если текущий узел уже содержится в хеш-таблице, это означает, что вы вернулись к ранее посещённому узлу, и, следовательно, в списке присутствует цикл. Верните true.
Если ни одно из этих условий не выполнено, добавьте текущий узел в хеш-таблицу и продолжите обход списка.
class Solution:
def hasCycle(self, head: ListNode) -> bool:
nodes_seen = set()
current = head
while current is not None:
if current in nodes_seen:
return True
nodes_seen.add(current)
current = current.next
return False
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2
{kind=link}
#medium
Задача: 142. Linked List Cycle II
Дана голова связного списка. Верните узел, с которого начинается цикл. Если цикла нет, верните null.
Цикл в связном списке существует, если есть такой узел в списке, до которого можно добраться снова, последовательно следуя по указателю next. Внутренне переменная pos используется для обозначения индекса узла, к которому подключен указатель next последнего узла (индексация с нуля). Она равна -1, если цикла нет. Обратите внимание, что pos не передается в качестве параметра.
Не модифицируйте связный список.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализация и начало обхода:
Инициализируйте узел указателем на голову связного списка и создайте пустое множество nodes_seen для отслеживания посещенных узлов.
Начните обход со связного списка, перемещая узел на один шаг за раз.
2️⃣ Проверка на наличие узла в множестве:
Для каждого посещенного узла проверьте, содержится ли он уже в множестве nodes_seen.
Если узел найден в множестве, это означает, что был найден цикл. Верните текущий узел как точку входа в цикл.
3️⃣ Добавление узла в множество или завершение обхода:
Если узел не найден в nodes_seen, добавьте его в множество и перейдите к следующему узлу.
Если узел становится равным null (конец списка), верните null. В списке нет цикла, так как в случае наличия цикла вы бы застряли в петле и не достигли бы конца списка.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 142. Linked List Cycle II
Дана голова связного списка. Верните узел, с которого начинается цикл. Если цикла нет, верните null.
Цикл в связном списке существует, если есть такой узел в списке, до которого можно добраться снова, последовательно следуя по указателю next. Внутренне переменная pos используется для обозначения индекса узла, к которому подключен указатель next последнего узла (индексация с нуля). Она равна -1, если цикла нет. Обратите внимание, что pos не передается в качестве параметра.
Не модифицируйте связный список.
Пример:
Input: head = [3,2,0,-4], pos = 1
Output: tail connects to node index 1
Explanation: There is a cycle in the linked list, where tail connects to the second node.
Инициализируйте узел указателем на голову связного списка и создайте пустое множество nodes_seen для отслеживания посещенных узлов.
Начните обход со связного списка, перемещая узел на один шаг за раз.
Для каждого посещенного узла проверьте, содержится ли он уже в множестве nodes_seen.
Если узел найден в множестве, это означает, что был найден цикл. Верните текущий узел как точку входа в цикл.
Если узел не найден в nodes_seen, добавьте его в множество и перейдите к следующему узлу.
Если узел становится равным null (конец списка), верните null. В списке нет цикла, так как в случае наличия цикла вы бы застряли в петле и не достигли бы конца списка.
class Solution:
def detectCycle(self, head: Optional[ListNode]) -> Optional[ListNode]:
nodes_seen = set()
node = head
while node is not None:
if node in nodes_seen:
return node
else:
nodes_seen.add(node)
node = node.next
return None
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1
{kind=link}
#medium
Задача: 143. Reorder List
Вам дана голова односвязного списка. Список можно представить в следующем виде:
L0 → L1 → … → Ln - 1 → Ln
Переупорядочите список так, чтобы он принял следующую форму:
L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → …
Вы не можете изменять значения в узлах списка. Можно изменять только сами узлы.
Пример:
👨💻 Алгоритм:
1️⃣ Нахождение середины списка и разделение его на две части:
Используйте два указателя, slow и fast, для нахождения середины списка. Указатель slow движется на один узел за шаг, а fast — на два узла. Когда fast достигает конца списка, slow окажется в середине.
Разделите список на две части. Первая часть начинается от головы списка до slow, вторая — с узла после slow до конца списка.
2️⃣ Реверс второй половины списка:
Инициализируйте указатели prev как NULL и curr как slow. Перемещайтесь по второй половине списка и меняйте направление ссылок между узлами для реверсирования списка.
Продолжайте, пока не перестроите весь второй сегмент, теперь последний элемент первой части списка будет указывать на NULL, а prev станет новой головой второй половины списка.
3️⃣ Слияние двух частей списка в заданном порядке:
Начните с головы первой части списка (first) и головы реверсированной второй части (second).
Перекрестно связывайте узлы из первой и второй части, вставляя узлы из второй части между узлами первой части. Передвигайте указатели first и second соответственно после каждой вставки.
Продолжайте этот процесс до тех пор, пока узлы второй части не закончатся.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 143. Reorder List
Вам дана голова односвязного списка. Список можно представить в следующем виде:
L0 → L1 → … → Ln - 1 → Ln
Переупорядочите список так, чтобы он принял следующую форму:
L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → …
Вы не можете изменять значения в узлах списка. Можно изменять только сами узлы.
Пример:
Input: head = [1,2,3,4]
Output: [1,4,2,3]
Используйте два указателя, slow и fast, для нахождения середины списка. Указатель slow движется на один узел за шаг, а fast — на два узла. Когда fast достигает конца списка, slow окажется в середине.
Разделите список на две части. Первая часть начинается от головы списка до slow, вторая — с узла после slow до конца списка.
Инициализируйте указатели prev как NULL и curr как slow. Перемещайтесь по второй половине списка и меняйте направление ссылок между узлами для реверсирования списка.
Продолжайте, пока не перестроите весь второй сегмент, теперь последний элемент первой части списка будет указывать на NULL, а prev станет новой головой второй половины списка.
Начните с головы первой части списка (first) и головы реверсированной второй части (second).
Перекрестно связывайте узлы из первой и второй части, вставляя узлы из второй части между узлами первой части. Передвигайте указатели first и second соответственно после каждой вставки.
Продолжайте этот процесс до тех пор, пока узлы второй части не закончатся.
class Solution:
def reorderList(self, head: ListNode) -> None:
if not head:
return
slow = fast = head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
prev, curr = None, slow
while curr:
curr.next, prev, curr = prev, curr, curr.next
first, second = head, prev
while second.next:
first.next, first = second, first.next
second.next, second = first, second.next
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2🔥1
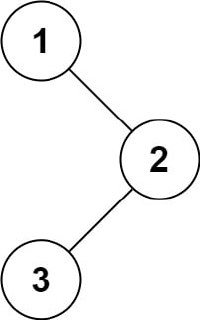{kind=link}
#easy
Задача: 144. Binary Tree Preorder Traversal
Дан корень бинарного дерева, верните предварительный обход значений его узлов.
Пример:
👨💻 Алгоритм:
1️⃣ Определение структуры узла дерева:
Определите класс TreeNode, который будет использоваться в реализации. Каждый узел TreeNode содержит значение и ссылки на левого и правого потомков.
2️⃣ Инициализация процесса обхода:
Начните обход с корневого узла дерева. Используйте стек для хранения узлов дерева, которые нужно обойти, начиная с корня.
3️⃣ Итеративный обход дерева:
На каждой итерации извлекайте текущий узел из стека и добавляйте его значение в выходной список.
Сначала добавьте в стек правого потомка (если он существует), затем левого потомка (если он существует). Это гарантирует, что узлы будут обрабатываться в порядке слева направо, так как стек работает по принципу LIFO (последний пришел - первый ушел).
Повторяйте процесс, пока стек не опустеет, что означает завершение обхода всех узлов.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 144. Binary Tree Preorder Traversal
Дан корень бинарного дерева, верните предварительный обход значений его узлов.
Пример:
Input: root = [1,null,2,3]
Output: [1,2,3]
Определите класс TreeNode, который будет использоваться в реализации. Каждый узел TreeNode содержит значение и ссылки на левого и правого потомков.
Начните обход с корневого узла дерева. Используйте стек для хранения узлов дерева, которые нужно обойти, начиная с корня.
На каждой итерации извлекайте текущий узел из стека и добавляйте его значение в выходной список.
Сначала добавьте в стек правого потомка (если он существует), затем левого потомка (если он существует). Это гарантирует, что узлы будут обрабатываться в порядке слева направо, так как стек работает по принципу LIFO (последний пришел - первый ушел).
Повторяйте процесс, пока стек не опустеет, что означает завершение обхода всех узлов.
class Solution(object):
def preorderTraversal(self, root: TreeNode) -> List[int]:
if root is None:
return []
stack, output = [
root,
], []
while stack:
root = stack.pop()
if root is not None:
output.append(root.val)
if root.right is not None:
stack.append(root.right)
if root.left is not None:
stack.append(root.left)
return output
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1
{kind=link}
#easy
Задача: 145. Binary Tree Postorder Traversal
Дан корень бинарного дерева, верните обход значений узлов в постпорядке.
Пример:
👨💻 Алгоритм:
1️⃣ Заполнение стека по стратегии право->узел->лево:
Инициируйте стек и добавьте в него корень дерева.
Перед тем как положить узел в стек, сначала добавьте его правого потомка, затем сам узел, а после — левого потомка. Это обеспечит последовательное извлечение узлов из стека в нужном порядке для постпорядкового обхода.
2️⃣ Извлечение узла из стека и проверка:
Извлекайте последний узел из стека, проверяя, является ли он левым листом (узел без потомков).
Если это так, добавьте значение узла в выходной список (массив значений). Если узел имеет потомков, продолжайте выполнение стека с добавлением дочерних узлов по той же стратегии.
3️⃣ Повторение процесса до опустошения стека:
Если извлеченный узел не является левым листом, необходимо обработать его потомков. Для этого, верните узел и его потомков в стек в правильном порядке, чтобы следующие итерации могли корректно обработать все узлы.
Повторяйте процесс до тех пор, пока стек не опустеет, что означает завершение обхода всех узлов.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 145. Binary Tree Postorder Traversal
Дан корень бинарного дерева, верните обход значений узлов в постпорядке.
Пример:
Input: root = [1,null,2,3]
Output: [3,2,1]
Инициируйте стек и добавьте в него корень дерева.
Перед тем как положить узел в стек, сначала добавьте его правого потомка, затем сам узел, а после — левого потомка. Это обеспечит последовательное извлечение узлов из стека в нужном порядке для постпорядкового обхода.
Извлекайте последний узел из стека, проверяя, является ли он левым листом (узел без потомков).
Если это так, добавьте значение узла в выходной список (массив значений). Если узел имеет потомков, продолжайте выполнение стека с добавлением дочерних узлов по той же стратегии.
Если извлеченный узел не является левым листом, необходимо обработать его потомков. Для этого, верните узел и его потомков в стек в правильном порядке, чтобы следующие итерации могли корректно обработать все узлы.
Повторяйте процесс до тех пор, пока стек не опустеет, что означает завершение обхода всех узлов.
class Solution(object):
def postorderTraversal(self, root: TreeNode) -> List[int]:
if root is None:
return []
stack, output = [
root,
], []
while stack:
root = stack.pop()
output.append(root.val)
if root.left is not None:
stack.append(root.left)
if root.right is not None:
stack.append(root.right)
return output[::-1]
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2