
{kind=link}
#medium
Задача: 89. Gray Code
Последовательность Грея с n-битами — это последовательность из 2^n целых чисел, где:
1. Каждое число находится в включающем диапазоне от 0 до 2^n - 1,
2. Первое число равно 0,
3. Каждое число встречается в последовательности не более одного раза,
4. Двоичное представление каждой пары соседних чисел отличается ровно на один бит,
5. Двоичное представление первого и последнего чисел отличается ровно на один бит.
Для заданного числа n возвращается любая допустимая последовательность Грея с n-битами.
Пример:
👨💻 Алгоритм:
1️⃣ Инициализируйте список результатов для хранения последовательности решений. Добавьте 0 в список перед вызовом вспомогательного метода, так как все последовательности Грея начинаются с 0.
2️⃣ Инициализируйте множество visited. Это позволяет отслеживать числа, присутствующие в текущей последовательности, чтобы избежать повторения.
Начните с числа 0.
В функции grayCodeHelper() используйте цикл for, чтобы найти каждое возможное число (next), которое может быть сгенерировано путем изменения одного бита последнего числа в списке результатов (current). Делайте это, переключая i-ый бит на каждой итерации. Поскольку максимально возможное количество битов в любом числе последовательности равно n, необходимо переключить n битов.
3️⃣ Если next не присутствует в множестве использованных чисел (isPresent), добавьте его в список результатов и множество isPresent.
Продолжайте поиск с next.
Если grayCodeHelper(next) возвращает true, это означает, что допустимая последовательность найдена. Дальнейший поиск не требуется (ранняя остановка). Это раннее завершение улучшает время выполнения.
Если с next не найдена допустимая последовательность, удаляем его из списка результатов и множества isPresent и продолжаем поиск.
При достижении базового условия, когда длина текущей последовательности равна 2^n, возвращаем true.
Выход из цикла for означает, что с current в качестве последнего числа не найдена допустимая последовательность кода Грея. Поэтому возвращаем false.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 89. Gray Code
Последовательность Грея с n-битами — это последовательность из 2^n целых чисел, где:
1. Каждое число находится в включающем диапазоне от 0 до 2^n - 1,
2. Первое число равно 0,
3. Каждое число встречается в последовательности не более одного раза,
4. Двоичное представление каждой пары соседних чисел отличается ровно на один бит,
5. Двоичное представление первого и последнего чисел отличается ровно на один бит.
Для заданного числа n возвращается любая допустимая последовательность Грея с n-битами.
Пример:
Input: n = 2
Output: [0,1,3,2]
Explanation:
The binary representation of [0,1,3,2] is [00,01,11,10].
- 00 and 01 differ by one bit
- 01 and 11 differ by one bit
- 11 and 10 differ by one bit
- 10 and 00 differ by one bit
[0,2,3,1] is also a valid gray code sequence, whose binary representation is [00,10,11,01].
- 00 and 10 differ by one bit
- 10 and 11 differ by one bit
- 11 and 01 differ by one bit
- 01 and 00 differ by one bit
Начните с числа 0.
В функции grayCodeHelper() используйте цикл for, чтобы найти каждое возможное число (next), которое может быть сгенерировано путем изменения одного бита последнего числа в списке результатов (current). Делайте это, переключая i-ый бит на каждой итерации. Поскольку максимально возможное количество битов в любом числе последовательности равно n, необходимо переключить n битов.
Продолжайте поиск с next.
Если grayCodeHelper(next) возвращает true, это означает, что допустимая последовательность найдена. Дальнейший поиск не требуется (ранняя остановка). Это раннее завершение улучшает время выполнения.
Если с next не найдена допустимая последовательность, удаляем его из списка результатов и множества isPresent и продолжаем поиск.
При достижении базового условия, когда длина текущей последовательности равна 2^n, возвращаем true.
Выход из цикла for означает, что с current в качестве последнего числа не найдена допустимая последовательность кода Грея. Поэтому возвращаем false.
class Solution:
def grayCode(self, n: int):
result = [0]
isPresent = {0}
self.grayCodeHelper(result, n, isPresent)
return result
def grayCodeHelper(self, result, n, isPresent):
if len(result) == (1 << n):
return True
current = result[-1]
for i in range(n):
nextNum = current ^ (1 << i)
if nextNum not in isPresent:
isPresent.add(nextNum)
result.append(nextNum)
if self.grayCodeHelper(result, n, isPresent):
return True
isPresent.remove(nextNum)
result.pop()
return False
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1
{kind=link}
#medium
Задача: 90. Subsets II
Дан массив целых чисел nums, который может содержать повторяющиеся элементы. Верните все возможные подмножества (степенной набор).
Результирующий набор не должен содержать дублирующихся подмножеств. Возвращаемый результат может быть в любом порядке.
Пример:
👨💻 Алгоритм:
1️⃣ Отсортируйте массив nums. Сортировка необходима для того, чтобы все сгенерированные подмножества также были отсортированы. Это помогает идентифицировать дубликаты.
2️⃣ Инициализируйте maxNumberOfSubsets максимальным количеством подмножеств, которые можно сгенерировать, т.е., 2 в степени n.
Инициализируйте множество, seen, типа string, для хранения всех сгенерированных подмножеств. Добавление всех отсортированных подмножеств в множество дает нам возможность отловить любые дублирующие подмножества.
3️⃣ Итерируйте от 0 до maxNumberOfSubsets - 1. Установленные биты в двоичном представлении subsetIndex указывают на позицию элементов в массиве nums, которые присутствуют в текущем подмножестве.
Инициализируйте строку hashcode, которая будет хранить список чисел в текущемSubset в виде строки, разделенной запятыми. hashcode необходим для уникальной идентификации каждого подмножества с помощью множества.
Выполните внутренний цикл for от j = 0 до n - 1, чтобы проверить позицию установленных битов в subsetIndex. Если на позиции j установлен бит, добавьте nums[j] в текущее подмножество currentSubset и добавьте nums[j] в строку hashcode.
Добавьте текущее подмножество currentSubset в seen и в список подмножеств, если сгенерированный hashcode еще не в seen.
Верните подмножества.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 90. Subsets II
Дан массив целых чисел nums, который может содержать повторяющиеся элементы. Верните все возможные подмножества (степенной набор).
Результирующий набор не должен содержать дублирующихся подмножеств. Возвращаемый результат может быть в любом порядке.
Пример:
Input: nums = [1,2,2]
Output: [[],[1],[1,2],[1,2,2],[2],[2,2]]
Инициализируйте множество, seen, типа string, для хранения всех сгенерированных подмножеств. Добавление всех отсортированных подмножеств в множество дает нам возможность отловить любые дублирующие подмножества.
Инициализируйте строку hashcode, которая будет хранить список чисел в текущемSubset в виде строки, разделенной запятыми. hashcode необходим для уникальной идентификации каждого подмножества с помощью множества.
Выполните внутренний цикл for от j = 0 до n - 1, чтобы проверить позицию установленных битов в subsetIndex. Если на позиции j установлен бит, добавьте nums[j] в текущее подмножество currentSubset и добавьте nums[j] в строку hashcode.
Добавьте текущее подмножество currentSubset в seen и в список подмножеств, если сгенерированный hashcode еще не в seen.
Верните подмножества.
class Solution:
def subsetsWithDup(self, nums):
n = len(nums)
nums.sort()
maxNumberOfSubsets = 2**n
seen = set()
subsets = []
for subsetIndex in range(maxNumberOfSubsets):
currentSubset = []
hashcode = ""
for j in range(n):
mask = 2**j
isSet = mask & subsetIndex
if isSet != 0:
currentSubset.append(nums[j])
hashcode += str(nums[j]) + ","
if hashcode not in seen:
subsets.append(currentSubset)
seen.add(hashcode)
return subsets
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3
{kind=link}
#medium
Задача: 91. Decode Ways
Сообщение, содержащее буквы от A до Z, можно закодировать в числа с использованием следующего соответствия:
- 'A' -> "1"
- 'B' -> "2"
- ...
- 'Z' -> "26"
Для декодирования закодированного сообщения все цифры должны быть сгруппированы и затем отображены обратно в буквы с использованием обратного соответствия (существует несколько способов). Например, "11106" можно представить как:
- "AAJF" с группировкой (1 1 10 6)
- "KJF" с группировкой (11 10 6)
Обратите внимание, что группировка (1 11 06) недопустима, потому что "06" не может быть преобразовано в 'F', так как "6" отличается от "06".
Для данной строки s, содержащей только цифры, верните количество способов декодирования.
Тестовые случаи сформированы таким образом, что ответ укладывается в 32-битное целое число.
Пример:
👨💻 Алгоритм:
1️⃣ Входим в рекурсию с данной строкой, начиная с индекса 0.
2️⃣ Для окончательного случая рекурсии мы проверяем конец строки. Если мы достигли конца строки, возвращаем 1. Каждый раз, когда мы входим в рекурсию, это для подстроки исходной строки. Если первый символ в подстроке равен 0, то прекращаем этот путь, возвращая 0. Таким образом, этот путь не будет влиять на количество способов.
3️⃣ Мемоизация помогает снизить сложность, которая иначе была бы экспоненциальной. Мы проверяем словарь memo, чтобы увидеть, существует ли уже результат для данной подстроки. Если результат уже находится в memo, мы возвращаем этот результат. В противном случае количество способов для данной строки определяется путем рекурсивного вызова функции с индексом +1 для следующей подстроки и индексом +2 после проверки на валидность двузначного декодирования. Результат также сохраняется в memo с ключом как текущий индекс, чтобы сохранить его для будущих пересекающихся подзадач.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 91. Decode Ways
Сообщение, содержащее буквы от A до Z, можно закодировать в числа с использованием следующего соответствия:
- 'A' -> "1"
- 'B' -> "2"
- ...
- 'Z' -> "26"
Для декодирования закодированного сообщения все цифры должны быть сгруппированы и затем отображены обратно в буквы с использованием обратного соответствия (существует несколько способов). Например, "11106" можно представить как:
- "AAJF" с группировкой (1 1 10 6)
- "KJF" с группировкой (11 10 6)
Обратите внимание, что группировка (1 11 06) недопустима, потому что "06" не может быть преобразовано в 'F', так как "6" отличается от "06".
Для данной строки s, содержащей только цифры, верните количество способов декодирования.
Тестовые случаи сформированы таким образом, что ответ укладывается в 32-битное целое число.
Пример:
Input: s = "12"
Output: 2
Explanation: "12" could be decoded as "AB" (1 2) or "L" (12).
from functools import lru_cache
class Solution:
@lru_cache(maxsize=None)
def recursiveWithMemo(self, index, s) -> int:
if index == len(s):
return 1
if s[index] == "0":
return 0
if index == len(s) - 1:
return 1
answer = self.recursiveWithMemo(index + 1, s)
if int(s[index: index + 2]) <= 26:
answer += self.recursiveWithMemo(index + 2, s)
return answer
def numDecodings(self, s: str) -> int:
return self.recursiveWithMemo(0, s)
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3🤔1
{kind=link}
#medium
Задача: 92. Reverse Linked List II
Дан указатель на начало односвязного списка и два целых числа left и right, где left <= right. Необходимо перевернуть узлы списка, начиная с позиции left и заканчивая позицией right, и вернуть измененный список.
Пример:
👨💻 Алгоритм:
1️⃣ Определяем рекурсивную функцию, которая будет отвечать за переворачивание части односвязного списка. Назовем эту функцию
2️⃣ Также у нас есть указатель
В рекурсивном вызове, учитывая
3️⃣ До тех пор, пока мы не достигнем
Таким образом, мы откатываемся, как только
Оттуда при каждом откате указатель
Мы прекращаем обмены, когда
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 92. Reverse Linked List II
Дан указатель на начало односвязного списка и два целых числа left и right, где left <= right. Необходимо перевернуть узлы списка, начиная с позиции left и заканчивая позицией right, и вернуть измененный список.
Пример:
Input: head = [1,2,3,4,5], left = 2, right = 4
Output: [1,4,3,2,5]
recurse. Функция принимает три параметра: m, начальную точку переворота, n, конечную точку переворота, и указатель right, который начинается с узла n в связанном списке и движется назад вместе с откатом рекурсии. Если это пока не ясно, следующие диаграммы помогут.left, который начинается с узла m в связанном списке и движется вперед. В Python мы должны использовать глобальную переменную для этого, которая изменяется с каждым вызовом рекурсии. В других языках, где изменения, сделанные в вызовах функций, сохраняются, мы можем рассматривать этот указатель как дополнительную переменную для функции recurse.В рекурсивном вызове, учитывая
m, n и right, мы проверяем, равно ли n единице. Если это так, дальше двигаться не нужно.n = 1, мы продолжаем двигать указатель right на один шаг вперед, после чего делаем рекурсивный вызов с уменьшенным на один значением n. В то же время мы продолжаем двигать указатель left вперед до тех пор, пока m не станет равным 1. Когда мы говорим, что указатель движется вперед, мы имеем в виду pointer.next.Таким образом, мы откатываемся, как только
n достигает 1. В этот момент указатель right находится на последнем узле подсписка, который мы хотим перевернуть, и left уже достиг первого узла этого подсписка. Тогда мы меняем данные и перемещаем указатель left на один шаг вперед с помощью left = left.next. Нам нужно, чтобы это изменение сохранялось в процессе отката.Оттуда при каждом откате указатель
right движется на один шаг назад. Это и есть та симуляция, о которой мы всё время говорили. Обратное движение симулируется откатом.Мы прекращаем обмены, когда
right == left, что происходит, если размер подсписка нечетный, или right.next == left, что происходит в процессе отката для четного подсписка, когда указатель right пересекает left. Мы используем глобальный булевый флаг для остановки обменов, как только эти условия выполнены.class Solution:
def reverseBetween(
self, head: Optional[ListNode], m: int, n: int
) -> Optional[ListNode]:
if not head:
return None
left, right = head, head
stop = False
def recurseAndReverse(right, m, n):
nonlocal left, stop
if n == 1:
return
right = right.next
if m > 1:
left = left.next
recurseAndReverse(right, m - 1, n - 1)
if left == right or right.next == left:
stop = True
if not stop:
left.val, right.val = right.val, left.val
left = left.next
recurseAndReverse(right, m, n)
return head
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1💊1
#medium
Задача: 93. Restore IP Addresses
Сообщение, содержащее буквы от A до Z, можно закодировать в числа с использованием следующего соответствия:
- 'A' -> "1"
- 'B' -> "2"
- ...
- 'Z' -> "26"
Для декодирования закодированного сообщения все цифры должны быть сгруппированы и затем отображены обратно в буквы с использованием обратного соответствия (существует несколько способов). Например, "11106" можно представить как:
- "AAJF" с группировкой (1 1 10 6)
- "KJF" с группировкой (11 10 6)
Обратите внимание, что группировка (1 11 06) недопустима, потому что "06" не может быть преобразовано в 'F', так как "6" отличается от "06".
Для данной строки s, содержащей только цифры, верните количество способов декодирования.
Тестовые случаи сформированы таким образом, что ответ укладывается в 32-битное целое число.
Пример:
👨💻 Алгоритм:
1️⃣ Входим в рекурсию с данной строкой, начиная с индекса 0.
2️⃣ Для окончательного случая рекурсии мы проверяем конец строки. Если мы достигли конца строки, возвращаем 1. Каждый раз, когда мы входим в рекурсию, это для подстроки исходной строки. Если первый символ в подстроке равен 0, то прекращаем этот путь, возвращая 0. Таким образом, этот путь не будет влиять на количество способов.
3️⃣ Мемоизация помогает снизить сложность, которая иначе была бы экспоненциальной. Мы проверяем словарь memo, чтобы увидеть, существует ли уже результат для данной подстроки. Если результат уже находится в memo, мы возвращаем этот результат. В противном случае количество способов для данной строки определяется путем рекурсивного вызова функции с индексом +1 для следующей подстроки и индексом +2 после проверки на валидность двузначного декодирования. Результат также сохраняется в memo с ключом как текущий индекс, чтобы сохранить его для будущих пересекающихся подзадач.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 93. Restore IP Addresses
Сообщение, содержащее буквы от A до Z, можно закодировать в числа с использованием следующего соответствия:
- 'A' -> "1"
- 'B' -> "2"
- ...
- 'Z' -> "26"
Для декодирования закодированного сообщения все цифры должны быть сгруппированы и затем отображены обратно в буквы с использованием обратного соответствия (существует несколько способов). Например, "11106" можно представить как:
- "AAJF" с группировкой (1 1 10 6)
- "KJF" с группировкой (11 10 6)
Обратите внимание, что группировка (1 11 06) недопустима, потому что "06" не может быть преобразовано в 'F', так как "6" отличается от "06".
Для данной строки s, содержащей только цифры, верните количество способов декодирования.
Тестовые случаи сформированы таким образом, что ответ укладывается в 32-битное целое число.
Пример:
Input: s = "12"
Output: 2
Explanation: "12" could be decoded as "AB" (1 2) or "L" (12).
class Solution(object):
def valid(self, s, start, length):
return length == 1 or (
s[start] != "0"
and (length < 3 or s[start : start + length] <= "255")
)
def helper(self, s, startIndex, dots, ans):
remainingLength = len(s) - startIndex
remainingNumberOfIntegers = 4 - len(dots)
if (
remainingLength > remainingNumberOfIntegers * 3
or remainingLength < remainingNumberOfIntegers
):
return
if len(dots) == 3:
if self.valid(s, startIndex, remainingLength):
temp = ""
last = 0
for dot in dots:
temp += s[last : last + dot] + "."
last += dot
temp += s[startIndex:]
ans.append(temp)
return
for curPos in range(1, min(4, remainingLength + 1)):
dots.append(curPos)
if self.valid(s, startIndex, curPos):
self.helper(s, startIndex + curPos, dots, ans)
dots.pop()
def restoreIpAddresses(self, s):
answer = []
self.helper(s, 0, [], answer)
return answer
Please open Telegram to view this post
VIEW IN TELEGRAM
LeetCode
Restore IP Addresses - LeetCode
Can you solve this real interview question? Restore IP Addresses - A valid IP address consists of exactly four integers separated by single dots. Each integer is between 0 and 255 (inclusive) and cannot have leading zeros.
* For example, "0.1.2.201" and…
* For example, "0.1.2.201" and…
👍2
{kind=link}
#easy
Задача: 94. Binary Tree Inorder Traversal
Дан корень бинарного дерева. Верните обход значений его узлов в симметричном порядке.
Пример:
👨💻 Алгоритм:
Метод решения этой задачи использует рекурсию. Это классический метод, и он простой. Мы можем определить вспомогательную функцию для реализации рекурсии.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 94. Binary Tree Inorder Traversal
Дан корень бинарного дерева. Верните обход значений его узлов в симметричном порядке.
Пример:
Input: root = [1,null,2,3]
Output: [1,3,2]
Метод решения этой задачи использует рекурсию. Это классический метод, и он простой. Мы можем определить вспомогательную функцию для реализации рекурсии.
class Solution:
def inorderTraversal(self, root):
res = []
self.helper(root, res)
return res
def helper(self, root, res):
if root is not None:
self.helper(root.left, res)
res.append(root.val)
self.helper(root.right, res)
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3
{kind=link}
#medium
Задача: 95. Unique Binary Search Trees II
Дано целое число n. Верните все структурно уникальные деревья бинарного поиска (BST), которые содержат ровно n узлов с уникальными значениями от 1 до n. Ответ может быть представлен в любом порядке.
Пример:
👨💻 Алгоритм:
1️⃣ Создайте хеш-карту memo, где memo[(start, end)] содержит список корневых узлов всех возможных BST (деревьев бинарного поиска) с диапазоном значений узлов от start до end. Реализуем рекурсивную функцию allPossibleBST, которая принимает начальный диапазон значений узлов start, конечный диапазон end и memo в качестве параметров. Она возвращает список TreeNode, соответствующих всем BST, которые могут быть сформированы с этим диапазоном значений узлов. Вызываем allPossibleBST(1, n, memo) и выполняем следующее:
2️⃣ Объявляем список TreeNode под названием res для хранения списка корневых узлов всех возможных BST. Если start > end, мы добавляем null в res и возвращаем его. Если мы уже решили эту подзадачу, т.е. memo содержит пару (start, end), мы возвращаем memo[(start, end)].
3️⃣ Выбираем значение корневого узла от i = start до end, увеличивая i на 1 после каждой итерации. Рекурсивно вызываем leftSubtrees = allPossibleBST(start, i - 1, memo) и rightSubTrees = allPossibleBST(i + 1, end, memo). Перебираем все пары между leftSubtrees и rightSubTrees и создаем новый корень со значением i для каждой пары. Добавляем корень новообразованного BST в res. Устанавливаем memo[(start, end)] = res и возвращаем res.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 95. Unique Binary Search Trees II
Дано целое число n. Верните все структурно уникальные деревья бинарного поиска (BST), которые содержат ровно n узлов с уникальными значениями от 1 до n. Ответ может быть представлен в любом порядке.
Пример:
Input: n = 3
Output: [[1,null,2,null,3],[1,null,3,2],[2,1,3],[3,1,null,null,2],[3,2,null,1]]
class Solution:
def allPossibleBST(self, start, end, memo):
res = []
if start > end:
res.append(None)
return res
if (start, end) in memo:
return memo[(start, end)]
for i in range(start, end + 1):
leftSubTrees = self.allPossibleBST(start, i - 1, memo)
rightSubTrees = self.allPossibleBST(i + 1, end, memo)
for left in leftSubTrees:
for right in rightSubTrees:
root = TreeNode(i, left, right)
res.append(root)
memo[(start, end)] = res
return res
def generateTrees(self, n: int) -> List[Optional[TreeNode]]:
memo = {}
return self.allPossibleBST(1, n, memo)
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 96. Unique Binary Search Trees
Дано целое число n. Верните количество структурно уникальных деревьев бинарного поиска (BST), которые содержат ровно n узлов с уникальными значениями от 1 до n.
Пример:
👨💻 Алгоритм:
1️⃣ Задача состоит в том, чтобы рассчитать количество уникальных BST (бинарных деревьев поиска). Для этого мы можем определить две функции:
G(n): количество уникальных BST для последовательности длины n.
F(i, n): количество уникальных BST, где число i является корнем BST (1 ≤ i ≤ n).
Как видно, G(n) - это именно та функция, которая нам нужна для решения задачи.
2️⃣ Позднее мы увидим, что G(n) можно вывести из F(i, n), которая, в свою очередь, рекурсивно относится к G(n).
Следуя идее из раздела "Интуиция", мы видим, что общее количество уникальных BST G(n) равно сумме BST F(i, n) с перечислением каждого числа i (1 ≤ i ≤ n) в качестве корня. Таким образом,
G(n) = ∑ F(i, n) для i от 1 до n.
В частности, для базовых случаев есть только одна комбинация для построения BST из последовательности длиной 1 (только корень) или ничего (пустое дерево). То есть G(0) = 1, G(1) = 1.
3️⃣ Дана последовательность от 1 до n, мы выбираем число i из последовательности в качестве корня, тогда количество уникальных BST с указанным корнем, определенным как F(i, n), является декартовым произведением количества BST для его левого и правого поддеревьев, как показано ниже:
Например, F(3,7) - количество уникальных деревьев BST с числом 3 в качестве корня. Для построения уникального BST из всей последовательности [1, 2, 3, 4, 5, 6, 7] с 3 в качестве корня, мы должны построить поддерево из его левой подпоследовательности [1, 2] и другое поддерево из правой подпоследовательности [4, 5, 6, 7], а затем соединить их вместе (то есть декартово произведение). Теперь хитрость заключается в том, что мы можем рассматривать количество уникальных BST из последовательности [1,2] как G(2), и количество уникальных BST из последовательности [4, 5, 6, 7] как G(4). Для G(n) не имеет значения содержание последовательности, а только длина последовательности. Следовательно, F(3,7) = G(2)⋅G(4). Обобщая пример, мы можем вывести следующую формулу:
F(i, n) = G(i−1)⋅G(n−i)
Объединяя формулы (1), (2), мы получаем рекурсивную формулу для G(n), то есть
G(n) = ∑ G(i−1)⋅G(n−i) для i от 1 до n.
Чтобы вычислить результат функции, мы начинаем с меньшего числа, так как значение G(n) зависит от значений G(0)...G(n−1).
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 96. Unique Binary Search Trees
Дано целое число n. Верните количество структурно уникальных деревьев бинарного поиска (BST), которые содержат ровно n узлов с уникальными значениями от 1 до n.
Пример:
Input: n = 3
Output: 5
G(n): количество уникальных BST для последовательности длины n.
F(i, n): количество уникальных BST, где число i является корнем BST (1 ≤ i ≤ n).
Как видно, G(n) - это именно та функция, которая нам нужна для решения задачи.
Следуя идее из раздела "Интуиция", мы видим, что общее количество уникальных BST G(n) равно сумме BST F(i, n) с перечислением каждого числа i (1 ≤ i ≤ n) в качестве корня. Таким образом,
G(n) = ∑ F(i, n) для i от 1 до n.
В частности, для базовых случаев есть только одна комбинация для построения BST из последовательности длиной 1 (только корень) или ничего (пустое дерево). То есть G(0) = 1, G(1) = 1.
Например, F(3,7) - количество уникальных деревьев BST с числом 3 в качестве корня. Для построения уникального BST из всей последовательности [1, 2, 3, 4, 5, 6, 7] с 3 в качестве корня, мы должны построить поддерево из его левой подпоследовательности [1, 2] и другое поддерево из правой подпоследовательности [4, 5, 6, 7], а затем соединить их вместе (то есть декартово произведение). Теперь хитрость заключается в том, что мы можем рассматривать количество уникальных BST из последовательности [1,2] как G(2), и количество уникальных BST из последовательности [4, 5, 6, 7] как G(4). Для G(n) не имеет значения содержание последовательности, а только длина последовательности. Следовательно, F(3,7) = G(2)⋅G(4). Обобщая пример, мы можем вывести следующую формулу:
F(i, n) = G(i−1)⋅G(n−i)
Объединяя формулы (1), (2), мы получаем рекурсивную формулу для G(n), то есть
G(n) = ∑ G(i−1)⋅G(n−i) для i от 1 до n.
Чтобы вычислить результат функции, мы начинаем с меньшего числа, так как значение G(n) зависит от значений G(0)...G(n−1).
class Solution:
def numTrees(self, n: int) -> int:
G = [0] * (n + 1)
G[0], G[1] = 1, 1
for i in range(2, n + 1):
for j in range(1, i + 1):
G[i] += G[j - 1] * G[i - j]
return G[n]
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1
{kind=link}
#medium
Задача: 97. Interleaving String
Даны строки s1, s2 и s3. Необходимо определить, может ли строка s3 быть сформирована путем чередования строк s1 и s2.
Чередование двух строк s и t — это конфигурация, при которой s и t делятся на n и m подстрок соответственно так, что:
s = s1 + s2 + ... + sn
t = t1 + t2 + ... + tm
|n - m| ≤ 1
Чередование может быть таким: s1 + t1 + s2 + t2 + s3 + t3 + ... или t1 + s1 + t2 + s2 + t3 + s3 + ...
Примечание: a + b означает конкатенацию строк a и b.
Пример:
👨💻 Алгоритм:
1️⃣ В рекурсивном подходе, описанном выше, рассматривается каждая возможная строка, образованная путем чередования двух заданных строк. Однако возникают случаи, когда та же часть s1 и s2 уже была обработана, но в разных порядках (перестановках). Независимо от порядка обработки, если результирующая строка до этого момента совпадает с требуемой строкой (s3), окончательный результат зависит только от оставшихся частей s1 и s2, а не от уже обработанной части. Таким образом, рекурсивный подход приводит к избыточным вычислениям.
2️⃣ Эту избыточность можно устранить, используя мемоизацию вместе с рекурсией. Для этого мы поддерживаем три указателя i, j, k, которые соответствуют индексу текущего символа s1, s2, s3 соответственно. Также мы поддерживаем двумерный массив memo для отслеживания обработанных до сих пор подстрок. memo[i][j] хранит 1/0 или -1 в зависимости от того, была ли текущая часть строк, то есть до i-го индекса для s1 и до j-го индекса для s2, уже оценена. Мы начинаем с выбора текущего символа s1 (на который указывает i). Если он совпадает с текущим символом s3 (на который указывает k), мы включаем его в обработанную строку и вызываем ту же функцию рекурсивно как: is_Interleave(s1, i+1, s2, j, s3, k+1, memo).
3️⃣ Таким образом, мы вызвали функцию, увеличив указатели i и k, поскольку часть строк до этих индексов уже была обработана. Аналогично, мы выбираем один символ из второй строки и продолжаем. Рекурсивная функция заканчивается, когда одна из двух строк s1 или s2 полностью обработана. Если, скажем, строка s1 полностью обработана, мы напрямую сравниваем оставшуюся часть s2 с оставшейся частью s3. Когда происходит возврат из рекурсивных вызовов, мы сохраняем значение, возвращенное рекурсивными функциями, в массиве мемоизации memo соответственно, так что когда оно встречается в следующий раз, рекурсивная функция не будет вызвана, но сам массив мемоизации вернет предыдущий сгенерированный результат.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 97. Interleaving String
Даны строки s1, s2 и s3. Необходимо определить, может ли строка s3 быть сформирована путем чередования строк s1 и s2.
Чередование двух строк s и t — это конфигурация, при которой s и t делятся на n и m подстрок соответственно так, что:
s = s1 + s2 + ... + sn
t = t1 + t2 + ... + tm
|n - m| ≤ 1
Чередование может быть таким: s1 + t1 + s2 + t2 + s3 + t3 + ... или t1 + s1 + t2 + s2 + t3 + s3 + ...
Примечание: a + b означает конкатенацию строк a и b.
Пример:
Input: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac"
Output: true
Explanation: One way to obtain s3 is:
Split s1 into s1 = "aa" + "bc" + "c", and s2 into s2 = "dbbc" + "a".
Interleaving the two splits, we get "aa" + "dbbc" + "bc" + "a" + "c" = "aadbbcbcac".
class Solution:
def isInterleave(self, s1: str, s2: str, s3: str) -> bool:
if len(s3) != len(s1) + len(s2):
return False
dp = [[False] * (len(s2) + 1) for _ in range(len(s1) + 1)]
for i in range(len(s1) + 1):
for j in range(len(s2) + 1):
if i == 0 and j == 0:
dp[i][j] = True
elif i == 0:
dp[i][j] = dp[i][j - 1] and s2[j - 1] == s3[i + j - 1]
elif j == 0:
dp[i][j] = dp[i - 1][j] and s1[i - 1] == s3[i + j - 1]
else:
dp[i][j] = (
dp[i - 1][j] and s1[i - 1] == s3[i + j - 1]
) or (dp[i][j - 1] and s2[j - 1] == s3[i + j - 1])
return dp[len(s1)][len(s2)]
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 98. Validate Binary Search Tree
Дан корень бинарного дерева. Определите, является ли это дерево допустимым бинарным деревом поиска (BST).
Допустимое BST определяется следующим образом:
Левое поддерево узла содержит только узлы с ключами, меньшими, чем ключ узла.
Правое поддерево узла содержит только узлы с ключами, большими, чем ключ узла.
Оба поддерева — левое и правое — также должны быть бинарными деревьями поиска.
Пример:
👨💻 Алгоритм:
1️⃣ Давайте воспользуемся порядком узлов при симметричном обходе (inorder traversal):
Левый -> Узел -> Правый.
Постордер:
Здесь узлы перечисляются в порядке их посещения, и вы можете следовать последовательности 1-2-3-4-5 для сравнения различных стратегий.
Порядок "Левый -> Узел -> Правый" при симметричном обходе означает, что для BST каждый элемент должен быть меньше следующего.
2️⃣ Следовательно, алгоритм с временной сложностью O(N) и пространственной сложностью O(N) может быть простым:
Вычислить список симметричного обхода inorder.
Проверить, меньше ли каждый элемент в списке inorder следующего за ним.
Постордер:
3️⃣ Нужно ли сохранять весь список симметричного обхода?
На самом деле, нет. Достаточно последнего добавленного элемента inorder, чтобы на каждом шаге убедиться, что дерево является BST (или нет). Следовательно, можно объединить оба шага в один и уменьшить используемое пространство.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 98. Validate Binary Search Tree
Дан корень бинарного дерева. Определите, является ли это дерево допустимым бинарным деревом поиска (BST).
Допустимое BST определяется следующим образом:
Левое поддерево узла содержит только узлы с ключами, меньшими, чем ключ узла.
Правое поддерево узла содержит только узлы с ключами, большими, чем ключ узла.
Оба поддерева — левое и правое — также должны быть бинарными деревьями поиска.
Пример:
Input: root = [2,1,3]
Output: true
Левый -> Узел -> Правый.
Постордер:
Здесь узлы перечисляются в порядке их посещения, и вы можете следовать последовательности 1-2-3-4-5 для сравнения различных стратегий.
Порядок "Левый -> Узел -> Правый" при симметричном обходе означает, что для BST каждый элемент должен быть меньше следующего.
Вычислить список симметричного обхода inorder.
Проверить, меньше ли каждый элемент в списке inorder следующего за ним.
Постордер:
На самом деле, нет. Достаточно последнего добавленного элемента inorder, чтобы на каждом шаге убедиться, что дерево является BST (или нет). Следовательно, можно объединить оба шага в один и уменьшить используемое пространство.
class Solution:
def isValidBST(self, root: TreeNode) -> bool:
def inorder(root):
if not root:
return True
if not inorder(root.left):
return False
if root.val <= self.prev:
return False
self.prev = root.val
return inorder(root.right)
self.prev = -math.inf
return inorder(root)
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2
{kind=link}
#medium
Задача: 99. Recover Binary Search Tree
Вам дан корень бинарного дерева поиска (BST), в котором значения ровно двух узлов дерева были поменяны местами по ошибке. Восстановите дерево, не изменяя его структуру.
Пример:
👨💻 Алгоритм:
1️⃣ Создайте симметричный обход дерева. Это должен быть почти отсортированный список, в котором поменяны местами только два элемента.
2️⃣ Определите два поменянных местами элемента x и y в почти отсортированном массиве за линейное время.
3️⃣ Повторно пройдите по дереву. Измените значение x на y и значение y на x.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 99. Recover Binary Search Tree
Вам дан корень бинарного дерева поиска (BST), в котором значения ровно двух узлов дерева были поменяны местами по ошибке. Восстановите дерево, не изменяя его структуру.
Пример:
Input: root = [1,3,null,null,2]
Output: [3,1,null,null,2]
Explanation: 3 cannot be a left child of 1 because 3 > 1. Swapping 1 and 3 makes the BST valid.
class Solution:
def recoverTree(self, root: TreeNode) -> None:
def inorder(r: TreeNode) -> List[int]:
return inorder(r.left) + [r.val] + inorder(r.right) if r else []
def find_two_swapped(nums: List[int]) -> (int, int):
n = len(nums)
x = y = (
None
)
for i in range(n - 1):
if nums[i + 1] < nums[i]:
y = nums[i + 1]
if x is None:
x = nums[i]
else:
break
return x, y
def recover(r: TreeNode, count: int) -> None:
if r:
if r.val == x or r.val == y:
r.val = y if r.val == x else x
count -= 1
if count == 0:
return
recover(r.left, count)
recover(r.right, count)
nums = inorder(root)
x, y = find_two_swapped(nums)
recover(root, 2)
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#easy
Задача: 100. Same Tree
Даны корни двух бинарных деревьев p и q. Напишите функцию, чтобы проверить, одинаковы ли они.
Два бинарных дерева считаются одинаковыми, если они структурно идентичны, и узлы имеют одинаковые значения.
Пример:
👨💻 Алгоритм:
Самая простая стратегия здесь — использовать рекурсию. Проверьте, не равны ли узлы p и q значению None, и равны ли их значения. Если все проверки пройдены успешно, проделайте то же самое для дочерних узлов рекурсивно.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 100. Same Tree
Даны корни двух бинарных деревьев p и q. Напишите функцию, чтобы проверить, одинаковы ли они.
Два бинарных дерева считаются одинаковыми, если они структурно идентичны, и узлы имеют одинаковые значения.
Пример:
Input: p = [1,2,3], q = [1,2,3]
Output: true
Самая простая стратегия здесь — использовать рекурсию. Проверьте, не равны ли узлы p и q значению None, и равны ли их значения. Если все проверки пройдены успешно, проделайте то же самое для дочерних узлов рекурсивно.
class Solution:
def isSameTree(self, p: TreeNode, q: TreeNode) -> bool:
if not p and not q:
return True
if not q or not p:
return False
if p.val != q.val:
return False
return self.isSameTree(p.right, q.right) and self.isSameTree(
p.left, q.left
)
Please open Telegram to view this post
VIEW IN TELEGRAM
👍6
{kind=link}
#easy
Задача: 101. Symmetric Tree
Дан корень бинарного дерева. Проверьте, является ли это дерево зеркальным отражением самого себя (то есть симметричным относительно своего центра).
Пример:
👨💻 Алгоритм:
1️⃣ Дерево симметрично, если левое поддерево является зеркальным отражением правого поддерева.
2️⃣ Следовательно, вопрос заключается в том, когда два дерева являются зеркальным отражением друг друга?
Два дерева являются зеркальным отражением друг друга, если:
- Их корни имеют одинаковое значение.
- Правое поддерево каждого дерева является зеркальным отражением левого поддерева другого дерева.
3️⃣ Это похоже на человека, смотрящего в зеркало. Отражение в зеркале имеет ту же голову, но правая рука отражения соответствует левой руке настоящего человека и наоборот.
Вышеописанное объяснение естественным образом превращается в рекурсивную функцию.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 101. Symmetric Tree
Дан корень бинарного дерева. Проверьте, является ли это дерево зеркальным отражением самого себя (то есть симметричным относительно своего центра).
Пример:
Input: root = [1,2,2,3,4,4,3]
Output: true
Два дерева являются зеркальным отражением друг друга, если:
- Их корни имеют одинаковое значение.
- Правое поддерево каждого дерева является зеркальным отражением левого поддерева другого дерева.
Вышеописанное объяснение естественным образом превращается в рекурсивную функцию.
class Solution:
def isSymmetric(self, root):
return self.isMirror(root, root)
def isMirror(self, t1, t2):
if t1 is None and t2 is None:
return True
if t1 is None or t2 is None:
return False
return (
(t1.val == t2.val)
and self.isMirror(t1.right, t2.left)
and self.isMirror(t1.left, t2.right)
)
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔1
{kind=link}
#medium
Задача: 102. Binary Tree Level Order Traversal
Дан корень бинарного дерева. Верните обход узлов дерева по уровням (то есть слева направо, уровень за уровнем).
Пример:
👨💻 Алгоритм:
1️⃣ Самый простой способ решения задачи — использование рекурсии. Сначала убедимся, что дерево не пустое, а затем рекурсивно вызовем функцию helper(node, level), которая принимает текущий узел и его уровень в качестве аргументов.
2️⃣ Эта функция выполняет следующее:
Выходной список здесь называется levels, и, таким образом, текущий уровень — это просто длина этого списка len(levels). Сравниваем номер текущего уровня len(levels) с уровнем узла level. Если вы все еще на предыдущем уровне, добавьте новый, добавив новый список в levels.
3️⃣ Добавьте значение узла в последний список в levels.
Рекурсивно обработайте дочерние узлы, если они не равны None: helper(node.left / node.right, level + 1).
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 102. Binary Tree Level Order Traversal
Дан корень бинарного дерева. Верните обход узлов дерева по уровням (то есть слева направо, уровень за уровнем).
Пример:
Input: root = [3,9,20,null,null,15,7]
Output: [[3],[9,20],[15,7]]
Выходной список здесь называется levels, и, таким образом, текущий уровень — это просто длина этого списка len(levels). Сравниваем номер текущего уровня len(levels) с уровнем узла level. Если вы все еще на предыдущем уровне, добавьте новый, добавив новый список в levels.
Рекурсивно обработайте дочерние узлы, если они не равны None: helper(node.left / node.right, level + 1).
class Solution:
def levelOrder(self, root: TreeNode) -> List[List[int]]:
levels = []
if not root:
return levels
def helper(node: TreeNode, level: int) -> None:
if len(levels) == level:
levels.append([])
levels[level].append(node.val)
if node.left:
helper(node.left, level + 1)
if node.right:
helper(node.right, level + 1)
helper(root, 0)
return levels
Please open Telegram to view this post
VIEW IN TELEGRAM
❤2👍1
{kind=link}
#medium
Задача: 103. Binary Tree Zigzag Level Order Traversal
Дан корень бинарного дерева. Верните обход узлов дерева по уровням в виде зигзага (то есть слева направо, затем справа налево для следующего уровня и чередуйте далее).
Пример:
👨💻 Алгоритм:
1️⃣ Мы также можем реализовать поиск в ширину (BFS) с использованием одного цикла. Трюк заключается в том, что мы добавляем узлы для посещения в очередь, а узлы разных уровней разделяем с помощью какого-то разделителя (например, пустого узла). Разделитель отмечает конец уровня, а также начало нового уровня.
2️⃣ Здесь мы принимаем второй подход, описанный выше. Можно начать с обычного алгоритма BFS, к которому мы добавляем элемент порядка зигзага с помощью deque (двусторонней очереди).
3️⃣ Для каждого уровня мы начинаем с пустого контейнера deque, который будет содержать все значения данного уровня. В зависимости от порядка каждого уровня, т.е. либо слева направо, либо справа налево, мы решаем, с какого конца deque добавлять новый элемент.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 103. Binary Tree Zigzag Level Order Traversal
Дан корень бинарного дерева. Верните обход узлов дерева по уровням в виде зигзага (то есть слева направо, затем справа налево для следующего уровня и чередуйте далее).
Пример:
Input: root = [3,9,20,null,null,15,7]
Output: [[3],[20,9],[15,7]]
from collections import deque
class Solution:
def zigzagLevelOrder(self, root: TreeNode) -> List[List[int]]:
ret = []
level_list = deque()
if root is None:
return []
node_queue = deque([root, None])
is_order_left = True
while len(node_queue) > 0:
curr_node = node_queue.popleft()
if curr_node:
if is_order_left:
level_list.append(curr_node.val)
else:
level_list.appendleft(curr_node.val)
if curr_node.left:
node_queue.append(curr_node.left)
if curr_node.right:
node_queue.append(curr_node.right)
else:
ret.append(level_list)
if len(node_queue) > 0:
node_queue.append(None)
level_list = deque()
is_order_left = not is_order_left
return ret
Please open Telegram to view this post
VIEW IN TELEGRAM
👍1
{kind=link}
#easy
Задача: 104. Maximum Depth of Binary Tree
Дан корень бинарного дерева, верните его максимальную глубину.
Максимальная глубина бинарного дерева — это количество узлов вдоль самого длинного пути от корневого узла до самого удалённого листового узла.
Пример:
👨💻 Алгоритм:
1️⃣ Можно обойти дерево, используя стратегию поиска в глубину (DFS) или поиска в ширину (BFS).
2️⃣ Для данной задачи подойдет несколько способов.
3️⃣ Здесь мы демонстрируем решение, реализованное с использованием стратегии DFS и рекурсии.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 104. Maximum Depth of Binary Tree
Дан корень бинарного дерева, верните его максимальную глубину.
Максимальная глубина бинарного дерева — это количество узлов вдоль самого длинного пути от корневого узла до самого удалённого листового узла.
Пример:
Input: root = [3,9,20,null,null,15,7]
Output: 3
class Solution:
def maxDepth(self, root: TreeNode) -> int:
if root is None:
return 0
else:
left_height = self.maxDepth(root.left)
right_height = self.maxDepth(root.right)
return max(left_height, right_height) + 1
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2❤1
{kind=link}
#medium
Задача: 105. Construct Binary Tree from Preorder and Inorder Traversal
Даны два массива целых чисел: preorder и inorder, где preorder — это результат преордер обхода бинарного дерева, а inorder — результат инордер обхода того же дерева. Постройте и верните бинарное дерево.
Пример:
👨💻 Алгоритм:
1️⃣ Создайте хеш-таблицу для записи соотношения значений и их индексов в массиве inorder, чтобы можно было быстро найти позицию корня.
2️⃣ Инициализируйте переменную целочисленного типа preorderIndex для отслеживания элемента, который будет использоваться для создания корня. Реализуйте рекурсивную функцию arrayToTree, которая принимает диапазон массива inorder и возвращает построенное бинарное дерево:
Если диапазон пуст, возвращается null;
Инициализируйте корень элементом preorder[preorderIndex], затем увеличьте preorderIndex;
Рекурсивно используйте левую и правую части массива inorder для построения левого и правого поддеревьев.
3️⃣ Просто вызовите функцию рекурсии с полным диапазоном массива inorder.
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 105. Construct Binary Tree from Preorder and Inorder Traversal
Даны два массива целых чисел: preorder и inorder, где preorder — это результат преордер обхода бинарного дерева, а inorder — результат инордер обхода того же дерева. Постройте и верните бинарное дерево.
Пример:
Input: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
Output: [3,9,20,null,null,15,7]
Если диапазон пуст, возвращается null;
Инициализируйте корень элементом preorder[preorderIndex], затем увеличьте preorderIndex;
Рекурсивно используйте левую и правую части массива inorder для построения левого и правого поддеревьев.
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
def array_to_tree(left, right):
nonlocal preorder_index
if left > right:
return None
root_value = preorder[preorder_index]
root = TreeNode(root_value)
preorder_index += 1
root.left = array_to_tree(left, inorder_index_map[root_value] - 1)
root.right = array_to_tree(inorder_index_map[root_value] + 1, right)
return root
preorder_index = 0
inorder_index_map = {}
for index, value in enumerate(inorder):
inorder_index_map[value] = index
return array_to_tree(0, len(preorder) - 1)
Please open Telegram to view this post
VIEW IN TELEGRAM
❤2👍1
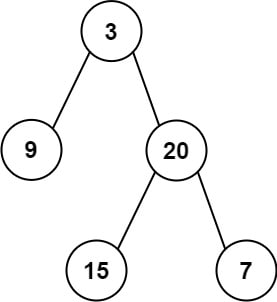{kind=link}
#medium
Задача: 106. Construct Binary Tree from Inorder and Postorder Traversal
Даны два массива целых чисел: inorder и postorder, где inorder — это массив обхода в глубину бинарного дерева слева направо, а postorder — это массив обхода в глубину после обработки всех потомков узла. Постройте и верните соответствующее бинарное дерево.
Пример:
👨💻 Алгоритм:
1️⃣ Создайте хэш-таблицу (hashmap) для хранения соответствия значений и их индексов в массиве обхода inorder.
2️⃣ Определите вспомогательную функцию
3️⃣ Выберите последний элемент в массиве обхода postorder в качестве корня. Значение корня имеет индекс
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 106. Construct Binary Tree from Inorder and Postorder Traversal
Даны два массива целых чисел: inorder и postorder, где inorder — это массив обхода в глубину бинарного дерева слева направо, а postorder — это массив обхода в глубину после обработки всех потомков узла. Постройте и верните соответствующее бинарное дерево.
Пример:
Input: inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
Output: [3,9,20,null,null,15,7]
helper, которая принимает границы левой и правой части текущего поддерева в массиве inorder. Эти границы используются для проверки, пусто ли поддерево. Если левая граница больше правой (in_left > in_right), то поддерево пустое и функция возвращает None.index в обходе inorder. Элементы от in_left до index - 1 принадлежат левому поддереву, а элементы от index + 1 до in_right — правому поддереву. Согласно логике обхода postorder, сначала рекурсивно строится правое поддерево helper(index + 1, in_right), а затем левое поддерево helper(in_left, index - 1). Возвращается корень.class Solution:
def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:
def helper(in_left: int, in_right: int) -> TreeNode:
if in_left > in_right:
return None
val = postorder.pop()
root = TreeNode(val)
index = idx_map[val]
root.right = helper(index + 1, in_right)
root.left = helper(in_left, index - 1)
return root
idx_map = {val: idx for idx, val in enumerate(inorder)}
return helper(0, len(inorder) - 1)
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2
Forwarded from Идущий к IT
10$ за техническое собеседование на английском языке:
1. Отправьте запись технического собеседования на английском языке файлом на этот аккаунт
2. Добавьте ссылку на вакансию или пришлите название компании и должность
3. Напишите номер кошелка USDT (Tether) на который отправить 10$
🛡 Важно:
– Запись будет использована только для сбора данных о вопросах
– Вы останетесь анонимны
– Запись нигде не будет опубликована
🤝 Условия:
– Внятный звук, различимая речь
– Допустимые профессии:
• Любые программисты
• DevOps
• Тестировщики
• Дата сайнтисты
• Бизнес/Системные аналитики
• Прожекты/Продукты
• UX/UI и продукт дизайнеры
1. Отправьте запись технического собеседования на английском языке файлом на этот аккаунт
2. Добавьте ссылку на вакансию или пришлите название компании и должность
3. Напишите номер кошелка USDT (Tether) на который отправить 10$
– Запись будет использована только для сбора данных о вопросах
– Вы останетесь анонимны
– Запись нигде не будет опубликована
– Внятный звук, различимая речь
– Допустимые профессии:
• Любые программисты
• DevOps
• Тестировщики
• Дата сайнтисты
• Бизнес/Системные аналитики
• Прожекты/Продукты
• UX/UI и продукт дизайнеры
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3
{kind=link}
#medium
Задача: 107. Binary Tree Level Order Traversal II
Дан корень бинарного дерева. Верните обход значений узлов снизу вверх по уровням (то есть слева направо, уровень за уровнем, от листа к корню).
Пример:
👨💻 Алгоритм:
1️⃣ Инициализируйте список вывода levels. Длина этого списка определяет, какой уровень в данный момент обновляется. Вам следует сравнить этот уровень len(levels) с уровнем узла level, чтобы убедиться, что вы добавляете узел на правильный уровень. Если вы все еще находитесь на предыдущем уровне, добавьте новый уровень, вставив новый список в levels.
2️⃣ Добавьте значение узла в последний уровень в levels.
3️⃣ Рекурсивно обработайте дочерние узлы, если они не равны None, используя функцию helper(node.left / node.right, level + 1).
😎 Решение:
🔥 ТОП ВОПРОСОВ С СОБЕСОВ
🔒 База собесов | 🔒 База тестовых
Задача: 107. Binary Tree Level Order Traversal II
Дан корень бинарного дерева. Верните обход значений узлов снизу вверх по уровням (то есть слева направо, уровень за уровнем, от листа к корню).
Пример:
Input: root = [3,9,20,null,null,15,7]
Output: [[15,7],[9,20],[3]]
class Solution:
def levelOrderBottom(self, root: Optional[TreeNode]) -> List[List[int]]:
levels = []
if not root:
return levels
def helper(node: Optional[TreeNode], level: int) -> None:
if len(levels) == level:
levels.append([])
levels[level].append(node.val)
if node.left:
helper(node.left, level + 1)
if node.right:
helper(node.right, level + 1)
helper(root, 0)
return levels[::-1]
Please open Telegram to view this post
VIEW IN TELEGRAM
👍2