
Ще не мав досвіду написання технічного матеріалу українською мовою. Завжди намагався звертатися до якомога ширшої аудиторії у своїх публікаціях.
Але колись все змінюється. Я вирішив додатково ділитися своїми нотатками з україномовною публікою. Чому?
По-перше, я нікого цього не робив. Я вже тривалий час живу за межами України і в мене дефолтова мова — англійська, особливо коли це стосується технологій, програмування, тощо. Як бачу це як можливість для власного розвитку та підтримки мовних навичок українською.
По-друге, мені хочеться поділитися моїми ідеями та думками з українською спільнотою окремо. Адже, я виріс та став програмістом саме в Україні. Принаймні, в мене є якесь відчуття того що нам є про що поговорити!
Власне, про що я (ми) тут будемо говорити?
Я програмую плюс-мінус все своє життя, тобто десь 30 (або навіть трохи більше) років, якщо рахувати підлітковий період. І в мене сформувалась одна ідея-фікс:
Дуже багато чого в нашій індустрії переускладнено. Дуже багато нашаровано технологій, програм, бібліотек, мов, форматів, тощо. Я хочу потрапити до паралельної реальності, де все простіше, швидше і взагалі, можна отримати більше задоволення від роботи.
Отже, я шукаю як спрощувати своє (а іноді, мабуть, і ваше) життя за клавіатурою.
Іноді це означає подивитися на проблему з іншого боку. Іноді — написати щось таке, що не існує. А іноді просто пожалітися що в минулому все було краще (ніт).
Поїхали! Наступний допис незабаром.
Але колись все змінюється. Я вирішив додатково ділитися своїми нотатками з україномовною публікою. Чому?
По-перше, я нікого цього не робив. Я вже тривалий час живу за межами України і в мене дефолтова мова — англійська, особливо коли це стосується технологій, програмування, тощо. Як бачу це як можливість для власного розвитку та підтримки мовних навичок українською.
По-друге, мені хочеться поділитися моїми ідеями та думками з українською спільнотою окремо. Адже, я виріс та став програмістом саме в Україні. Принаймні, в мене є якесь відчуття того що нам є про що поговорити!
Власне, про що я (ми) тут будемо говорити?
Я програмую плюс-мінус все своє життя, тобто десь 30 (або навіть трохи більше) років, якщо рахувати підлітковий період. І в мене сформувалась одна ідея-фікс:
Дуже багато чого в нашій індустрії переускладнено. Дуже багато нашаровано технологій, програм, бібліотек, мов, форматів, тощо. Я хочу потрапити до паралельної реальності, де все простіше, швидше і взагалі, можна отримати більше задоволення від роботи.
Отже, я шукаю як спрощувати своє (а іноді, мабуть, і ваше) життя за клавіатурою.
Іноді це означає подивитися на проблему з іншого боку. Іноді — написати щось таке, що не існує. А іноді просто пожалітися що в минулому все було краще (ніт).
Поїхали! Наступний допис незабаром.
{kind=link}
👍4🔥1
Паравендорінг — або “усьо своє ношу з собою”
Декілька років тому мене реально почало хвилювати те, як я додаю залежності до моїх проектів. Вони майже завжди приходять з якихось там серверів, і кожного разу коли я розгортаю проект, або працюю з форком, це трохи геморой.
Якщо зв’язок такий собі або нема його взагалі (я тоді дуже багато часу в літаках проводив), або автор видалив чи переніс свою бібліотеку, то ой.
В принципі, багато хто вирішує цю проблему за допомогою вендорінгу. Взяли, скачали те що нам потрібно, додали до репозіторію. Он, h2o так робить. В принципі, працює, але стає не так вже прикольно якщо хочеться ще підтягувати нові апдейти, розглядати зміни та робити форки, або додавати якісь окремі патчі.
Можна ще git subtree робити. В принципі непогана штука, але весь імпортований код живе в твоєї (головної) гілці. Неприкольно.
І тоді мені прийшла такая думка: в принципі, git же ж дозволяє зберігати ланцюжки які починається з чого завгодно. І їх в принципі може бути багато. То ми можемо просто наімпортувати проектів від яких залежимо і зробити так щоб garbage collector їх не видалив. Того часу я тупо git tag’і там робив щоб вони посилались на потрібні коміти, ну й якось працювало.
А доставати ці залежності можно було “самоклонуванням”, щось накшталт
І от нещодавно, я вирішив нарешті написати тулзу яка це все буде робити для мене, ще й краще.
Замість тегів, можна змержити залежності у сусідньої, незалежної від основної, гілці. І таким чином це гілка буде утримувати git від сміттєзборки. Ну і треба записати десь, які власне є там tags у самих залежностей щоб можна їх було доставати навіть без зв’язку.
От так і народився git-paravendor. Він ще трішечки експериментальний, але мені вже подобається.
Ось тут приклад як сам git-paravendor достає свої залежності:
(
А от тут та сама “незалежна” гілка в якої лише один конфіг файл та купа історії залежностей, і нічого зайвого.
Таким чином, вся історія всіх залежностей приїде разом з
Подивимося як це поїде далі. В мене є декілька ідей як ще це все вдосконалити. А до того часу, вважайте що це експеримент (це попередження, не забувайте бекапитись)!
Декілька років тому мене реально почало хвилювати те, як я додаю залежності до моїх проектів. Вони майже завжди приходять з якихось там серверів, і кожного разу коли я розгортаю проект, або працюю з форком, це трохи геморой.
Якщо зв’язок такий собі або нема його взагалі (я тоді дуже багато часу в літаках проводив), або автор видалив чи переніс свою бібліотеку, то ой.
В принципі, багато хто вирішує цю проблему за допомогою вендорінгу. Взяли, скачали те що нам потрібно, додали до репозіторію. Он, h2o так робить. В принципі, працює, але стає не так вже прикольно якщо хочеться ще підтягувати нові апдейти, розглядати зміни та робити форки, або додавати якісь окремі патчі.
Можна ще git subtree робити. В принципі непогана штука, але весь імпортований код живе в твоєї (головної) гілці. Неприкольно.
І тоді мені прийшла такая думка: в принципі, git же ж дозволяє зберігати ланцюжки які починається з чого завгодно. І їх в принципі може бути багато. То ми можемо просто наімпортувати проектів від яких залежимо і зробити так щоб garbage collector їх не видалив. Того часу я тупо git tag’і там робив щоб вони посилались на потрібні коміти, ну й якось працювало.
А доставати ці залежності можно було “самоклонуванням”, щось накшталт
git clone $(pwd) dep/mydep && <git checkout версію>
І от нещодавно, я вирішив нарешті написати тулзу яка це все буде робити для мене, ще й краще.
Замість тегів, можна змержити залежності у сусідньої, незалежної від основної, гілці. І таким чином це гілка буде утримувати git від сміттєзборки. Ну і треба записати десь, які власне є там tags у самих залежностей щоб можна їх було доставати навіть без зв’язку.
От так і народився git-paravendor. Він ще трішечки експериментальний, але мені вже подобається.
Ось тут приклад як сам git-paravendor достає свої залежності:
bats_ref=$(shell cargo run --quiet -- show-ref bats-core v1.9.0)
...
git clone . --no-checkout test/bats
cd test/bats && git checkout ${bats_ref}
(
cargo run бо ми ж тестуємо робочу версію “на місці”)А от тут та сама “незалежна” гілка в якої лише один конфіг файл та купа історії залежностей, і нічого зайвого.
Таким чином, вся історія всіх залежностей приїде разом з
git clone але не буде мозолити мені очі.Подивимося як це поїде далі. В мене є декілька ідей як ще це все вдосконалити. А до того часу, вважайте що це експеримент (це попередження, не забувайте бекапитись)!
👍2
Якщо ви прийшли до цього каналу з мого твітеру, то мабуть ви вже чули від мене про Omnigres.
Якщо ні, то, якщо дуже коротко, це такий сервер застосунків (application server) інтегрований безпосередньо у Postgres, тобто у базу даних.
У багатьох виникає питання: а навіщо?
Звісно, є серйозні та цікаві причини чому це може бути гарною ідеєю, типу механічної симпатії, комунікаційного оверхеда, тощо. Ми про все це скоро ще поговорим.
Але насправді, моїм першим спонуканням було бажання уникнути розробки нових проектів, оскільки я постійно зіштовхувався з різними девопс- та інтеграційними питаннями. Загалом, це не складно, але набридло.
Отже, мені наснилася така мрія: я хотів, щоб можна було розгортати один сервер і, взагалі кажучи, більше нічого б не потребувалося.
Мені також спало на думку, що в принципі, більшість стандартних систем це здебільшого купа SQL-запитів та API викликів помножені на різноманітні оптимізації. Звісно, це спрощення але корисне спрощення. Так чи інакше, ми в основному просто маніпулюємо даними.
У стандартному застосунку HTTP-сервер отримує запит, передає його до якогось там контролеру (сервлету, скрипту, тощо), а там ми біжимо до бази даних і власне запитуєм її, чекаєм на відповідь, і потім її повертаємо до клієнта.
Отже я і вирішив спробувати: а чи не можна це все спростити та позбутися зайвого? Чи можна якось скоротити цей ланцюжок?
Мій вибір зупинився на Postgres, оскільки він популярний, в ньому вже дуже багато всього, і для нього можна писати розширення.
Для початку, додав HTTP-сервер (бо куди ж без нього?) та ще кілька розширень і на ньому вже можна писати невеличкі застосунки. HTTP клієнт та інші цікаві штуки на підході.
Я мрію, що скоро на цьому можна бути розробляти і більш серйозні проекти, але завдяки суттєвому спрощенню, можна буде це робити швидше та й навіть самі проекти будуть працювати швидше (спойлер: здається, якщо HTTP сервер сидить разом з базою і не треба бігати через сокети до неї, то в принципі, це може прискорити роботу).
Головне, щоб збереглась суть: це має бути просто. Бо треба ж і себе любити.
Якщо ні, то, якщо дуже коротко, це такий сервер застосунків (application server) інтегрований безпосередньо у Postgres, тобто у базу даних.
У багатьох виникає питання: а навіщо?
Звісно, є серйозні та цікаві причини чому це може бути гарною ідеєю, типу механічної симпатії, комунікаційного оверхеда, тощо. Ми про все це скоро ще поговорим.
Але насправді, моїм першим спонуканням було бажання уникнути розробки нових проектів, оскільки я постійно зіштовхувався з різними девопс- та інтеграційними питаннями. Загалом, це не складно, але набридло.
Отже, мені наснилася така мрія: я хотів, щоб можна було розгортати один сервер і, взагалі кажучи, більше нічого б не потребувалося.
Мені також спало на думку, що в принципі, більшість стандартних систем це здебільшого купа SQL-запитів та API викликів помножені на різноманітні оптимізації. Звісно, це спрощення але корисне спрощення. Так чи інакше, ми в основному просто маніпулюємо даними.
У стандартному застосунку HTTP-сервер отримує запит, передає його до якогось там контролеру (сервлету, скрипту, тощо), а там ми біжимо до бази даних і власне запитуєм її, чекаєм на відповідь, і потім її повертаємо до клієнта.
Отже я і вирішив спробувати: а чи не можна це все спростити та позбутися зайвого? Чи можна якось скоротити цей ланцюжок?
Мій вибір зупинився на Postgres, оскільки він популярний, в ньому вже дуже багато всього, і для нього можна писати розширення.
Для початку, додав HTTP-сервер (бо куди ж без нього?) та ще кілька розширень і на ньому вже можна писати невеличкі застосунки. HTTP клієнт та інші цікаві штуки на підході.
Я мрію, що скоро на цьому можна бути розробляти і більш серйозні проекти, але завдяки суттєвому спрощенню, можна буде це робити швидше та й навіть самі проекти будуть працювати швидше (спойлер: здається, якщо HTTP сервер сидить разом з базою і не треба бігати через сокети до неї, то в принципі, це може прискорити роботу).
Головне, щоб збереглась суть: це має бути просто. Бо треба ж і себе любити.
{kind=link}
👍8🤔2🔥1
Ми обслуговуємо монстрів з минулого.
Мені здається, що якась частина наших проблем зі створенням сучасних систем та їхньою складністю полягає у тому що ми будуємо на досить-таки старому фундаменті: операційні системи, які вирішували задачі актуальні для модус операнді тих часів. Ми вимушені будувати, користуючись примітивами та абстракціями з (далекого) минулого.
У минулому були UNIX сервери з багатьма користувачами які заходили до своїх акаунтів та щось там запускали. Були десктопи з користувачем за монітором. Були сервера які необхідно було якось адмініструвати. Головний об’єднуючий елемент, мені здається, там у тому, що операційні системи цих комп’ютерів власне обслуговували ресурси самого комп’ютера: процесори, пам’ять, диск, периферію, і т.д.
Але сучасні системи, особливо такі що вже аж ніяк не вміщуються на один сервер, не оперують на рівні цих понятть.
Ми використовуємо файлові системи як засіб записати та запустити наші програми, а також для того, щоб сервер баз даних записував свої гігантськи масиви даних кудись. Ми не дуже користуємось файловою системою для обміну даними поміж програмами.
Ми ізолюємо не на рівні прав доступу до файлів, а шляхом розділення на (віртуальні) сервери чи контейнери/ізольовані групи процесів.
Модель виконання програми як якогось бінарніка на одному комп’ютері має сенс на великих UNIX серверах минулого (або сьогодні на десктопі), але зараз нам цікаво динамічно запускати якісь функції десь: наприклад, на серверах де є ще достатньо ресурсів (scheduling), ближче до користувачів (edge functions), чи ближче до даних (щоб опрацьовувати їх швидше). Нам цікаво запускати ці функції паралельно на багатьох серверах (наприклад, щось типу map/reduce).
Сучасні системи орієнтовані на зовнішні ресурси комп’ютера: на ресурси “хмарних” технологій, зовнішні сервіси, оркестрацію/синхронізацію процесів, тощо. Системи минулого будувались здебільшого виходячи з того що “ресурс” це був от той досить дорогий та великий комп’ютер.
Отже десь рік або два тому я замислився, якщо відкинути здоровий глузд, чи не можна спробувати та уявити операційну систему для сучасних проблем, побудовану абсолютно з нуля і яка буде надавати новий набір системних API. Замість “застарілого” POSIX це буде якійсь новий набір API, орієнтований на мережеві моделі побудування програмного забезпечення. Умовний NOSIX.
Якщо ми не здійснимо повного переписування і залишимо мови програмування без змін, то цей інтерфейс може навіть, в основі своїй, виглядати як С API (але можливо з асинхронним I/O за замовчуванням).
І от тоді можна було б спробувати відповісти на питання типу:
• як може виглядати базовий умовний інтерфейс для збереження та реплікації даних, гарантій з т.з. їх збереження або наявності, і як на його базі будувати більш складні штуки типу навіть реляційних баз даних?
• як запускати (потенційно ненадійний) скомпільований код?
• чи можна зробити транзакції на рівні базового API а не тільки для баз даних?
• як формулювати модель регулювання доступу до ресурсів?
• як/чи можна переносити код якій десь зараз виконується, на інше залізо?
Звісно, це все належить до сфери досліджень, адже з практичною точки зору, нам потрібні рішення які працюватимуть вже вчора. Проте, чому б не помріяти?
Мені здається, що якась частина наших проблем зі створенням сучасних систем та їхньою складністю полягає у тому що ми будуємо на досить-таки старому фундаменті: операційні системи, які вирішували задачі актуальні для модус операнді тих часів. Ми вимушені будувати, користуючись примітивами та абстракціями з (далекого) минулого.
У минулому були UNIX сервери з багатьма користувачами які заходили до своїх акаунтів та щось там запускали. Були десктопи з користувачем за монітором. Були сервера які необхідно було якось адмініструвати. Головний об’єднуючий елемент, мені здається, там у тому, що операційні системи цих комп’ютерів власне обслуговували ресурси самого комп’ютера: процесори, пам’ять, диск, периферію, і т.д.
Але сучасні системи, особливо такі що вже аж ніяк не вміщуються на один сервер, не оперують на рівні цих понятть.
Ми використовуємо файлові системи як засіб записати та запустити наші програми, а також для того, щоб сервер баз даних записував свої гігантськи масиви даних кудись. Ми не дуже користуємось файловою системою для обміну даними поміж програмами.
Ми ізолюємо не на рівні прав доступу до файлів, а шляхом розділення на (віртуальні) сервери чи контейнери/ізольовані групи процесів.
Модель виконання програми як якогось бінарніка на одному комп’ютері має сенс на великих UNIX серверах минулого (або сьогодні на десктопі), але зараз нам цікаво динамічно запускати якісь функції десь: наприклад, на серверах де є ще достатньо ресурсів (scheduling), ближче до користувачів (edge functions), чи ближче до даних (щоб опрацьовувати їх швидше). Нам цікаво запускати ці функції паралельно на багатьох серверах (наприклад, щось типу map/reduce).
Сучасні системи орієнтовані на зовнішні ресурси комп’ютера: на ресурси “хмарних” технологій, зовнішні сервіси, оркестрацію/синхронізацію процесів, тощо. Системи минулого будувались здебільшого виходячи з того що “ресурс” це був от той досить дорогий та великий комп’ютер.
Отже десь рік або два тому я замислився, якщо відкинути здоровий глузд, чи не можна спробувати та уявити операційну систему для сучасних проблем, побудовану абсолютно з нуля і яка буде надавати новий набір системних API. Замість “застарілого” POSIX це буде якійсь новий набір API, орієнтований на мережеві моделі побудування програмного забезпечення. Умовний NOSIX.
Якщо ми не здійснимо повного переписування і залишимо мови програмування без змін, то цей інтерфейс може навіть, в основі своїй, виглядати як С API (але можливо з асинхронним I/O за замовчуванням).
І от тоді можна було б спробувати відповісти на питання типу:
• як може виглядати базовий умовний інтерфейс для збереження та реплікації даних, гарантій з т.з. їх збереження або наявності, і як на його базі будувати більш складні штуки типу навіть реляційних баз даних?
• як запускати (потенційно ненадійний) скомпільований код?
• чи можна зробити транзакції на рівні базового API а не тільки для баз даних?
• як формулювати модель регулювання доступу до ресурсів?
• як/чи можна переносити код якій десь зараз виконується, на інше залізо?
Звісно, це все належить до сфери досліджень, адже з практичною точки зору, нам потрібні рішення які працюватимуть вже вчора. Проте, чому б не помріяти?
{kind=link}
👍12🤔4
Я почав використовувати системи контролю версій десь у другій половині 90-их. Для мене це тоді означало CVS для опенсорс-проектів, та трохи Microsoft Visual SourceSafe на роботі. Потім це був Subversion та перехід з нього до Git, з вкрапленнями Perforce, darcs, mercurial, fossil та pijul в якості експериментів.
Загалом, системи контролю версій пройшли досить довгий еволюційний шлях і у цілому значно кращі, ніж вони були 10-20 років тому.
Але мені здається що вони трохи застрягли у концептуальному болоті яке ніхто не ставить під сумнів, принаймні “офіційно”.
Власне, (майже) всі ці системи так чи інакше користуються такими концепціями:
• Репозиторій, який часто транслюється до “проекту” (але якщо ми подивимося уважніше, факт того що є потреба у монорепозиторіях, каже нам, що може не все так просто)
• Коміт як дискретна точка у процесі роботи з вмістом репозиторію. Часто означає якусь атомарну зміну.
В принципі, нічого поганого в цьому нема. Дуже багато людей знайомі з цими концепціями, і ми зазвичай не думаємо про це занадто багато. Воно в принципі вирішує наші проблеми.
Принаймні, нам так здається.
Розробка кода – це про людей і як вони працюють та співпрацюють. І от тут виникає перший момент. Коли ми працюємо з репозиторіями, ми фокусуємось на цих проектах чи групах проектів. А як щодо нашої власної зручності?
Наприклад, якщо я маю більш ніж один комп’ютер, я вимушений синхронізувати не тільки вмист кожного репозиторія але й їх список, бо я працюю над багатьма проектами.
То чому б замість репозиторію на кожен проект чи групу проектів, не мати один “мій” репозиторій де збережено усю мою роботу? У такому режимі, можна було б уявити такий репозиторій десь у ~/.repository, а коли ми б запускали умовний
Тут навіть я є якісь натяки на оптимізацію: якщо якісь blob об’єкти зустрічаються у багатьох проектах, на диску вони не будуть продубльовани.
Мені здається, що можна навіть спробувати побудувати нашвидкоруч прототип цього на Git з сирітськими гілками.
Інша річ, яка мене час від часу дратує, це те що якщо я не напишу якийсь умовний
А які у вас є побажання стосовно систем контролю версій?
Загалом, системи контролю версій пройшли досить довгий еволюційний шлях і у цілому значно кращі, ніж вони були 10-20 років тому.
Але мені здається що вони трохи застрягли у концептуальному болоті яке ніхто не ставить під сумнів, принаймні “офіційно”.
Власне, (майже) всі ці системи так чи інакше користуються такими концепціями:
• Репозиторій, який часто транслюється до “проекту” (але якщо ми подивимося уважніше, факт того що є потреба у монорепозиторіях, каже нам, що може не все так просто)
• Коміт як дискретна точка у процесі роботи з вмістом репозиторію. Часто означає якусь атомарну зміну.
В принципі, нічого поганого в цьому нема. Дуже багато людей знайомі з цими концепціями, і ми зазвичай не думаємо про це занадто багато. Воно в принципі вирішує наші проблеми.
Принаймні, нам так здається.
Розробка кода – це про людей і як вони працюють та співпрацюють. І от тут виникає перший момент. Коли ми працюємо з репозиторіями, ми фокусуємось на цих проектах чи групах проектів. А як щодо нашої власної зручності?
Наприклад, якщо я маю більш ніж один комп’ютер, я вимушений синхронізувати не тільки вмист кожного репозиторія але й їх список, бо я працюю над багатьма проектами.
То чому б замість репозиторію на кожен проект чи групу проектів, не мати один “мій” репозиторій де збережено усю мою роботу? У такому режимі, можна було б уявити такий репозиторій десь у ~/.repository, а коли ми б запускали умовний
git commit то він би дивився де ми та складав зміни до “мого” репозиторію. Таким чином, якщо мені треба взяти всю мою роботу кудись, це все один репозиторій. І тоді функція обміну із зовнішнім світом просто б працювала з частиною цього репозиторію.Тут навіть я є якісь натяки на оптимізацію: якщо якісь blob об’єкти зустрічаються у багатьох проектах, на диску вони не будуть продубльовани.
Мені здається, що можна навіть спробувати побудувати нашвидкоруч прототип цього на Git з сирітськими гілками.
Інша річ, яка мене час від часу дратує, це те що якщо я не напишу якийсь умовний
git commit, то все ще я написав а потім поміняв, просто зникає. Undo працює тільки до якогось моменту, але якщо вийшов, скажімо, з редактора, то прощавайте відкати змін. Або я помилково зробив git reset --hard (трапляється, бо я дуже часто історію шела використовую навмання). Виникає питання: а чому система контролю не може зберігати потік змін і зробити коміт скоріш такою “крапкою” у процесі. Всі маленькі зміни, звісно, не потрапляють до “публічної” історії, але у вас є можливість подивитися на увесь процес змін локально. Як це реалізувати — це інше питання, але технічно це не неможливо.А які у вас є побажання стосовно систем контролю версій?
{kind=link}
🔥6🤔3
Коли я працюю над мікростартапами, у мене часто є дуже велика спокуса не надто економити на хостінгу та супутних сервісах, і сфокусуватись на product-market fit, пошуку клієнтів, тощо. А все інше – можна заощадити багато часу якщо заплатити за щось готове якщо воно працює тут і зараз.
Але це вже кілька разів приводило до того що якщо треба більше часу щоб власне “запуститись” та знайти достатньо клієнтів, то я дуже швидко починав витрачати більше, ніж сподівався. Власне, це трапилось і з HackerIntro, який я щойно зупинив, бо в мене не було достатньо енергії, фокусу або великого успіху в його маркетингу, а грошей воно мені витрачало щомісяця, і немало.
Один зі шляхів уникнути цієї проблеми – це спростити архітектуру та деплоймент системи (що я й намагаюсь досягти з Omnigres, окрім іншіх цілей). Але це не вирішує проблеми з сервісами, які напряму не стосуються власне програмного забезпечення.
Другий шлях – це “проігнорувати” бажання вирішити всі “супутні” проблеми (наприклад, системи підтримки, моніторінг, ToS, GDPR, і тому подібне) і купувати тільки те без чого справді не можна.
І третій – знайти сервіси які дуже ефективно та економно вирішують проблеми.
Отже, я хотів запитати тих з вас хто також у стартап просторі:
1. Покупку яких супутних сервісів ви навчилися пропускати?
2. Які ефективні та економні сервіси ви знаєте і готові завжди придбати та рекомендувати?
3. Які супутні сервіси ви розробили власноруч?
Але це вже кілька разів приводило до того що якщо треба більше часу щоб власне “запуститись” та знайти достатньо клієнтів, то я дуже швидко починав витрачати більше, ніж сподівався. Власне, це трапилось і з HackerIntro, який я щойно зупинив, бо в мене не було достатньо енергії, фокусу або великого успіху в його маркетингу, а грошей воно мені витрачало щомісяця, і немало.
Один зі шляхів уникнути цієї проблеми – це спростити архітектуру та деплоймент системи (що я й намагаюсь досягти з Omnigres, окрім іншіх цілей). Але це не вирішує проблеми з сервісами, які напряму не стосуються власне програмного забезпечення.
Другий шлях – це “проігнорувати” бажання вирішити всі “супутні” проблеми (наприклад, системи підтримки, моніторінг, ToS, GDPR, і тому подібне) і купувати тільки те без чого справді не можна.
І третій – знайти сервіси які дуже ефективно та економно вирішують проблеми.
Отже, я хотів запитати тих з вас хто також у стартап просторі:
1. Покупку яких супутних сервісів ви навчилися пропускати?
2. Які ефективні та економні сервіси ви знаєте і готові завжди придбати та рекомендувати?
3. Які супутні сервіси ви розробили власноруч?
{kind=link}
👍7
Багато років тому, одна із сінтаксічних проблем з якою я стикався у Ерлангу (та й не тільки) полягала в тому що читати код типу
Багато мов, включаючи Elixir, так чи інакше цю проблему вирішили, чи то з чимось типу pipe operator, чи то с UFCS (Universal Function Call Syntax).
А от SQL (яким я зараз займаюсь дуже багато) — ні.
І доводиться писати и вичитувати не дуже прозорі запити типу:
Не дуже зрозуміло з чого тут все починається і чим закінчується.
А якщо ми перепишемо це отак?
Значно краще! Тут можна зрозуміти (якщо знати про що ці
І мене це вже настількі достало, що так не можна, що я написав цього ранку прототип який власне це і робить за мене (див. скріншот). Я ще не знайшов нормального способу переписувати таким чином всі прямі запити до постгресу у сесії, але навіть якщо це неможливо, в мене все рівно є план написати вбудовану проксі/баунсер для постгресу. От воно ї зможе переписувати. А поки цього нема, можна переписувати запити використовуючи функцію
Запитання до читачів:
А які у вас є нарікання до SQL і що б ви хотіли покращити або виправити в ньому?
f(g(h(d))) досить складно ментально, бо треба знайти власне з чого все там починається (h(d)) і читати справа наліво.Багато мов, включаючи Elixir, так чи інакше цю проблему вирішили, чи то з чимось типу pipe operator, чи то с UFCS (Universal Function Call Syntax).
А от SQL (яким я зараз займаюсь дуже багато) — ні.
І доводиться писати и вичитувати не дуже прозорі запити типу:
select convert_from(convert_to('Hello', 'utf-8'), 'utf-8')Не дуже зрозуміло з чого тут все починається і чим закінчується.
А якщо ми перепишемо це отак?
select 'Hello' |> convert_to('utf-8') |> convert_from('utf-8')Значно краще! Тут можна зрозуміти (якщо знати про що ці
convert функції) що беремо текст, конвертуємо у bytea, і назад. Не дуже корисно, але це просто приклад 🥹І мене це вже настількі достало, що так не можна, що я написав цього ранку прототип який власне це і робить за мене (див. скріншот). Я ще не знайшов нормального способу переписувати таким чином всі прямі запити до постгресу у сесії, але навіть якщо це неможливо, в мене все рівно є план написати вбудовану проксі/баунсер для постгресу. От воно ї зможе переписувати. А поки цього нема, можна переписувати запити використовуючи функцію
extended_sql.Запитання до читачів:
А які у вас є нарікання до SQL і що б ви хотіли покращити або виправити в ньому?
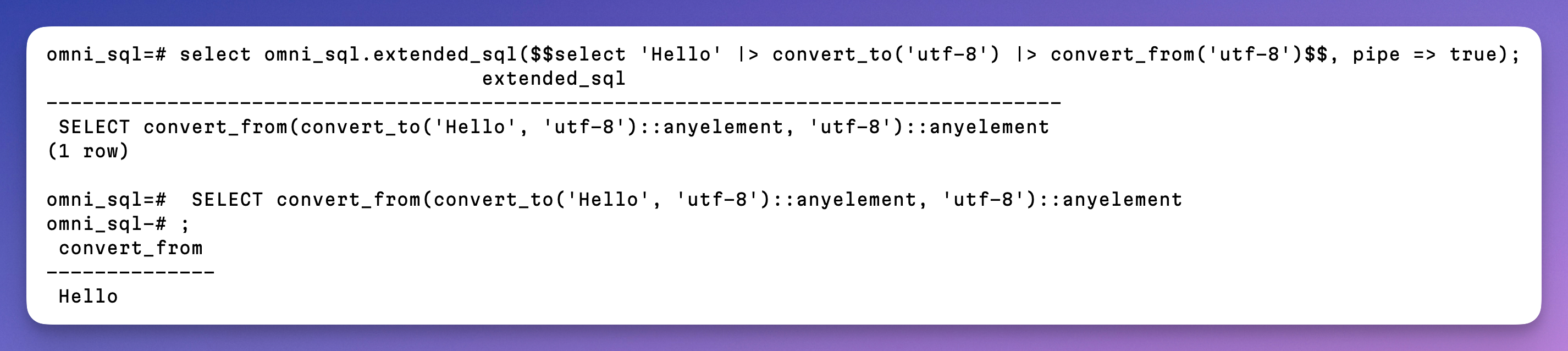{kind=link}
🔥5👍2
Дуже часто, коли розробляються нові програми, ми спочатку реалізуємо те, що виглядає простіше, аби отримати перші результати швидше. Але потім це часто призводить до того, що складні варіанти тим чи іншим чином просто не вписуються до загальної картинки, і доводиться або переписувати, або якось прикручувати, аби працювало. Або взагалі неможливі!
Я помітив, що останнім часом, в мене з'явилася тенденція спробувати атакувати складну частину або конфігурацію з майже самого початку. Ідея полягає у тому, що якщо це спрацює, то потім все інше буде значно простіше і принаймні, так чином ми подивимося на менш-трівіальні випадки.
Ось приклад з поточного досвіду:
Треба побудувати систему на кшталт nixpkgs (але простіше), де можна було б збирати бінарні білди покроково в ізоляції. Є спокуса почати з простого і зробити все це на базі умовного docker/podman. Це знайомо і буде працювати на лінуксі.
А що з іншими ОС? Ну, коли ми до того дійдем, там будемо розраховувати на якійсь варіант типу Docker Desktop та віртуальною машиною.
Ну добре, а що якщо ми хотіли б мати білди для, наприклад, macOS? Хмм.
Таким чином я дійшов до того, що треба спочатку сфокусуватись на більш складних варіантах. І от тут я кілька тижнів тому трохи почитав та погрався з Virtualization Framework. І що я вам можу сказати: якщо це спрацює, решта проекту буде, напевно, як свято! Бо API та можливості там, здається, розроблено так, щоб максимально уповільнити темпи росту віртуалізаціі на маку.
Почнемо з того, що немає API для отримання IP-адреси віртуальної машини яку ти щойно запустив. Ну гаразд, це можна обійти, подивившись на таблицю раутінгу. Якщо ми встановлюємо macOS, то я не знайшов варіанту, як налаштувати будь який крок у тих величезних ipfw файлах, з яких йде інсталяція. Щоб, наприклад, вказати пароль до адміністративного акаунта. Ну, добре, тут можна створити готові нові дискові образи з готовими інсталяціямі і налаштувати все там за допомогою скрипта. Для кожної версії. Але, годі, Xcode, навіть тільки якщо попросити його встановити тільки command line tools, через ssh без GUI принципово відмовляється встановлюватись!..
Шлях непростий, але вихід (майже) завжди є. Більш того, маючи готові інструменти та досвід для Virtualization Framework, їх можна бути використати для лінуксових білдів на macOS без інсталяції власне докеру чи чогось такого.
Після цього мені й Windows не буде страшний!
А як у вас з цим? “Happy case” спочатку чи ні?
Я помітив, що останнім часом, в мене з'явилася тенденція спробувати атакувати складну частину або конфігурацію з майже самого початку. Ідея полягає у тому, що якщо це спрацює, то потім все інше буде значно простіше і принаймні, так чином ми подивимося на менш-трівіальні випадки.
Ось приклад з поточного досвіду:
Треба побудувати систему на кшталт nixpkgs (але простіше), де можна було б збирати бінарні білди покроково в ізоляції. Є спокуса почати з простого і зробити все це на базі умовного docker/podman. Це знайомо і буде працювати на лінуксі.
А що з іншими ОС? Ну, коли ми до того дійдем, там будемо розраховувати на якійсь варіант типу Docker Desktop та віртуальною машиною.
Ну добре, а що якщо ми хотіли б мати білди для, наприклад, macOS? Хмм.
Таким чином я дійшов до того, що треба спочатку сфокусуватись на більш складних варіантах. І от тут я кілька тижнів тому трохи почитав та погрався з Virtualization Framework. І що я вам можу сказати: якщо це спрацює, решта проекту буде, напевно, як свято! Бо API та можливості там, здається, розроблено так, щоб максимально уповільнити темпи росту віртуалізаціі на маку.
Почнемо з того, що немає API для отримання IP-адреси віртуальної машини яку ти щойно запустив. Ну гаразд, це можна обійти, подивившись на таблицю раутінгу. Якщо ми встановлюємо macOS, то я не знайшов варіанту, як налаштувати будь який крок у тих величезних ipfw файлах, з яких йде інсталяція. Щоб, наприклад, вказати пароль до адміністративного акаунта. Ну, добре, тут можна створити готові нові дискові образи з готовими інсталяціямі і налаштувати все там за допомогою скрипта. Для кожної версії. Але, годі, Xcode, навіть тільки якщо попросити його встановити тільки command line tools, через ssh без GUI принципово відмовляється встановлюватись!..
Шлях непростий, але вихід (майже) завжди є. Більш того, маючи готові інструменти та досвід для Virtualization Framework, їх можна бути використати для лінуксових білдів на macOS без інсталяції власне докеру чи чогось такого.
Після цього мені й Windows не буде страшний!
А як у вас з цим? “Happy case” спочатку чи ні?
{kind=link}
🤔4🔥3
Короткий допис сьогодні, бо я все ще подорожую і енергії не завжди вистачає 😫
Нещодавно ми намагалися скрутити разом код на Clojure з pljava, щоб можна було писати Postgres-функції (або навіть бізнес-логіку для Omnigres!) на кложі.
Я раніше майже не писав на кложі, а до світу JVM зараз торкаюсь нерегулярно (хоча були часи, коли працював там активно). Власне, повернення до цього світу досить непогано висвітлює, наскільки можливо все зробити складним, якщо майже релігійно накопичувати нашарування ідей.
Одною з найбільших проблем виявилось те, що кложа плюс-мінус ігнорує той факт, що анотації в джаві іноді не просто так для краси, але ще й якось опрацьовуються. Там є така штука як Java Annotation Processing. Складно, звичайно, але дає хоч якийсь спосіб зробити щось з анотованим кодом.
pljava використовує це щоб, наприклад, згенерувати SQL код для функцій які будуть експортовані в постгрес.
В кложі трохи інша модель (яка можливо й простіша або, принаймні, елегантніша за звичайну модель у джаві). І, здається, простіше просто цю фічу проігнорувати, бо кложурісти (чи як їх називати?) краще це все макросом зроблять.
Але мені здається, що це локально нівелює той корисний факт що кложа є частиною JVM екосистеми, і такі випадки стають складними не тому що вони занадто складні, а тому що.
(“Тому що ви повинні страждати”. Ну, майже так)
Заради справедливості зазначу що я досі не повнистю розумію, де ці annotation processors запускаються в maven, gradle та інших білд-системах.
Але що робити коли це нашарування вже сталося і воно вже дуже стале?
Це, власне, де можна знайти дзен справжнього мистецтва програмування. Додавати легко, видаляти складніше, а видаляти без видалення (бо нашарування вже сталося і ми його аж ніяк не контролюємо) ще складніше.
Проблема ще й у тому, що майже ніколи на це часу, енергії та знаннь не вистачає.
Повертаючись до проблеми яку я описував: кложа зробила елегантнішу систему, але вона робить використання певних елементів екосистеми складнішими.
Тому для себе я такий тут висновок роблю: елегантні системи, які живуть на старому фундаменті, повинні мати “escape hatches” - засоби вирватись з кайданів і зробити все ще тобі потрібно, навіть якщо це не дуже красиво. Без нових абстракцій.
Бо результати завжди потрібні тут і зараз.
Нещодавно ми намагалися скрутити разом код на Clojure з pljava, щоб можна було писати Postgres-функції (або навіть бізнес-логіку для Omnigres!) на кложі.
Я раніше майже не писав на кложі, а до світу JVM зараз торкаюсь нерегулярно (хоча були часи, коли працював там активно). Власне, повернення до цього світу досить непогано висвітлює, наскільки можливо все зробити складним, якщо майже релігійно накопичувати нашарування ідей.
Одною з найбільших проблем виявилось те, що кложа плюс-мінус ігнорує той факт, що анотації в джаві іноді не просто так для краси, але ще й якось опрацьовуються. Там є така штука як Java Annotation Processing. Складно, звичайно, але дає хоч якийсь спосіб зробити щось з анотованим кодом.
pljava використовує це щоб, наприклад, згенерувати SQL код для функцій які будуть експортовані в постгрес.
В кложі трохи інша модель (яка можливо й простіша або, принаймні, елегантніша за звичайну модель у джаві). І, здається, простіше просто цю фічу проігнорувати, бо кложурісти (чи як їх називати?) краще це все макросом зроблять.
Але мені здається, що це локально нівелює той корисний факт що кложа є частиною JVM екосистеми, і такі випадки стають складними не тому що вони занадто складні, а тому що.
(“Тому що ви повинні страждати”. Ну, майже так)
Заради справедливості зазначу що я досі не повнистю розумію, де ці annotation processors запускаються в maven, gradle та інших білд-системах.
Але що робити коли це нашарування вже сталося і воно вже дуже стале?
Це, власне, де можна знайти дзен справжнього мистецтва програмування. Додавати легко, видаляти складніше, а видаляти без видалення (бо нашарування вже сталося і ми його аж ніяк не контролюємо) ще складніше.
Проблема ще й у тому, що майже ніколи на це часу, енергії та знаннь не вистачає.
Повертаючись до проблеми яку я описував: кложа зробила елегантнішу систему, але вона робить використання певних елементів екосистеми складнішими.
Тому для себе я такий тут висновок роблю: елегантні системи, які живуть на старому фундаменті, повинні мати “escape hatches” - засоби вирватись з кайданів і зробити все ще тобі потрібно, навіть якщо це не дуже красиво. Без нових абстракцій.
Бо результати завжди потрібні тут і зараз.
{kind=link}
👍3🔥2
Навздогін, мене часто дуже дратує коли бібліотеки ховають, наприклад, визначення типів. Типу, ось вам тип
Ну, я розумію що вони не є частиною публічного інтерфейсу, і воно буде змінюватися, і в ідеалі це дуже правильний підхід.
До речі, у деяких проектах нема доступу до якихось елементів типів не тому що це погана ідея, а тому що або руки не дійшли, або не подумали. Нещодавно бачив це на прикладі libfyaml.
Так чи інакше, є реальне життя. Треба використовувати цю бібліотеку сьогодні. Тут і зараз. І що накажете, робити форк? Це досить непрактично, бо потребує час, синхронізації, і т.і.
І от мені здається що libgit2 пропонує елементи досить цікавої моделі. Ви отримуєте нормальний стандартний інтерфейс, але якщо треба достукатись до певних деталей, то є .h-файли у директорії
Ба навіть що якщо просто дати можливість вказати що так, я знаю що я тут буду лізти і використовувати щось непублічне. Якщо використовувати C як приклад:
Так, воно колись зламається. Але дасть можливість з цією конкретною версією зробити щось працююче. А це може нам придбати час власне приготувати якійсь патч до бібліотеки щоб вирішити проблему раз і назавжди. Таким чином, і проблему вирішимо, і не треба жити певний час з форком (бо не всі проекти швидко приймають зміни)
А як ви вирішуєте цю проблему? Чи взагалі не вважаєте проблемою?
MyType, але що там всередині, це вам не можна використовувати.Ну, я розумію що вони не є частиною публічного інтерфейсу, і воно буде змінюватися, і в ідеалі це дуже правильний підхід.
До речі, у деяких проектах нема доступу до якихось елементів типів не тому що це погана ідея, а тому що або руки не дійшли, або не подумали. Нещодавно бачив це на прикладі libfyaml.
Так чи інакше, є реальне життя. Треба використовувати цю бібліотеку сьогодні. Тут і зараз. І що накажете, робити форк? Це досить непрактично, бо потребує час, синхронізації, і т.і.
І от мені здається що libgit2 пропонує елементи досить цікавої моделі. Ви отримуєте нормальний стандартний інтерфейс, але якщо треба достукатись до певних деталей, то є .h-файли у директорії
git2/sysБа навіть що якщо просто дати можливість вказати що так, я знаю що я тут буду лізти і використовувати щось непублічне. Якщо використовувати C як приклад:
#define LIBFOO_INTERNAL_API_V3.1 // "я знаю що я роблю, і це будуть мої проблеми"
#include <libfoo.h>
Так, воно колись зламається. Але дасть можливість з цією конкретною версією зробити щось працююче. А це може нам придбати час власне приготувати якійсь патч до бібліотеки щоб вирішити проблему раз і назавжди. Таким чином, і проблему вирішимо, і не треба жити певний час з форком (бо не всі проекти швидко приймають зміни)
А як ви вирішуєте цю проблему? Чи взагалі не вважаєте проблемою?
{kind=link}
👍2
Не писав деякий час, вибачте (багато чого відбувається!). Дуже короткий допис сьогодні, але по суті.
Коли SQL формувався, так сталось що порядок у
Але ж це реально незручно у практиці у сьогоднішніх умовах. Якщо починаєш писати
А ще отака біда: складні запити багаторядкові, і коли працюєш з такими, виходить що доводиться “стрибати” між початком запиту і кодом який власне опрацьовує результати, щоб перевірити що ми там, власне, понавибирали.
Я не перший з цього приводу переймався, і не я останній. Але стало у якійсь момент цікаво: а власне наскільки складно було б додати такий варіант
Виявляється, не дуже. Власне, поки що обійшлося невеличкими змінами до граматики. На додаток до класичного
Якщо комусь цікаві деталі, мій нашвидкоруч зроблений патч.
P.S. Я спробую знайти час розібратись як додати такий синтаксис до Омнігресу без того щоб використовувати пропатчений Постгрес. Є ідеї!
Коли SQL формувався, так сталось що порядок у
select-а, умовно кажучи, такий: “вибери ЦЕ, ЗВІДСИ[, якщо підпадає під УМОВИ]”Але ж це реально незручно у практиці у сьогоднішніх умовах. Якщо починаєш писати
select nam, то твій редактор не має можливості зробити автокомпліт. Бо ще ж не додано інформації про це. І от виходить що пишеш select from users, потім повертаєшся до селекту і починаєш додавати поля.А ще отака біда: складні запити багаторядкові, і коли працюєш з такими, виходить що доводиться “стрибати” між початком запиту і кодом який власне опрацьовує результати, щоб перевірити що ми там, власне, понавибирали.
Я не перший з цього приводу переймався, і не я останній. Але стало у якійсь момент цікаво: а власне наскільки складно було б додати такий варіант
select, який б вирішував ці проблеми? Звісно, з технічної сторони – я не маю й гадки стосовно того наскільки складно щось додати до стандарту. Отже, технічно, та й до Постгресу, звісно, бо я дуже активно з ним працюю.Виявляється, не дуже. Власне, поки що обійшлося невеличкими змінами до граматики. На додаток до класичного
select ... from ..., написав правила для from ... select .... Запрацювало! (дивись картинку)Якщо комусь цікаві деталі, мій нашвидкоруч зроблений патч.
P.S. Я спробую знайти час розібратись як додати такий синтаксис до Омнігресу без того щоб використовувати пропатчений Постгрес. Є ідеї!
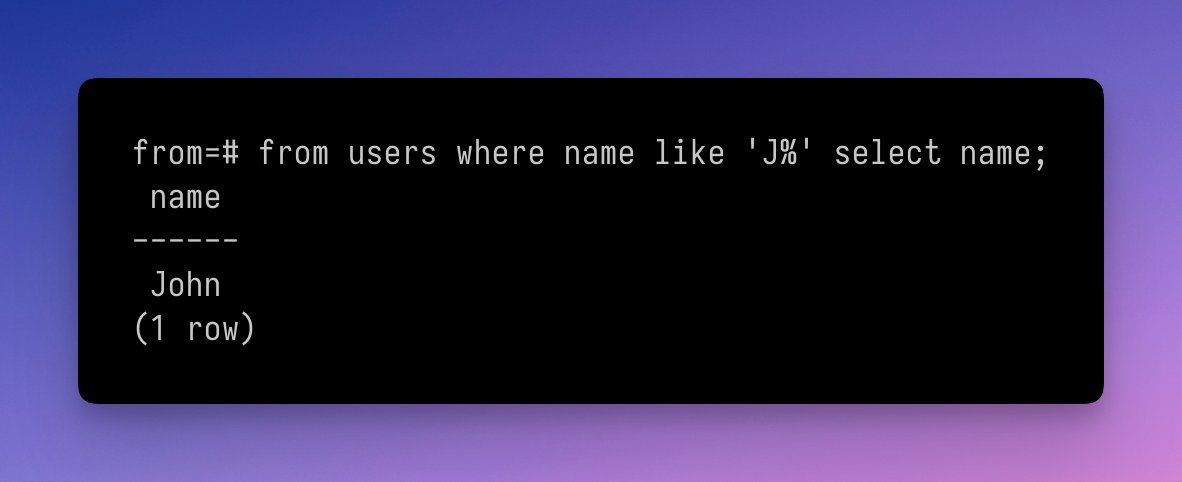{kind=link}
🔥10👍3🤔1
Короткий допис/опитування.
У поточному проекті (Омнігрес) моя головна мета — покращення робочого досвіду (development experience, DX) роботи з базою даних. Бо будемо чесні, він трішки засів у минулому, де були великі сервери і всі зміни проводились через DBA.
Нещодавно я працював над концепцією віртуальних файлових систем для постгресу (VFS) та її використанні для розгортання DDL та функцій як локально так і на продакшн (наприклад з Git VFS).
Але сьогодні мені хотілося би порушити трохи інший аспект: інтерактивні клієнти БД. Ми маємо REPL-подібні клієнти типу psql, є багато графічних та веб клієнтів. Проте, мені здається що концептуально багато з них відображають практики та підходи минулих часів. Можливо, пора критично переглянути робочий досвід у цьому напрямку.
Отже я хотів би запитати вас:
Якими клієнтами БД ви користуєтесь, чому, і що в них дратує чи навпаки? Як ви їх використовуєте в процесі розробки?
У поточному проекті (Омнігрес) моя головна мета — покращення робочого досвіду (development experience, DX) роботи з базою даних. Бо будемо чесні, він трішки засів у минулому, де були великі сервери і всі зміни проводились через DBA.
Нещодавно я працював над концепцією віртуальних файлових систем для постгресу (VFS) та її використанні для розгортання DDL та функцій як локально так і на продакшн (наприклад з Git VFS).
Але сьогодні мені хотілося би порушити трохи інший аспект: інтерактивні клієнти БД. Ми маємо REPL-подібні клієнти типу psql, є багато графічних та веб клієнтів. Проте, мені здається що концептуально багато з них відображають практики та підходи минулих часів. Можливо, пора критично переглянути робочий досвід у цьому напрямку.
Отже я хотів би запитати вас:
Якими клієнтами БД ви користуєтесь, чому, і що в них дратує чи навпаки? Як ви їх використовуєте в процесі розробки?
{kind=link}
Кілька тижнів тому я вирішив опанувати нову (для мене) мову програмування — Prolog. Чому так сталося і чи було це варто робити?
Майже з самого початку розробки Omnigres мені хотілось зробити щось корисне для розповсюдження розширень (extensions) для Postgres. Чому? Система управління розширеннями в постгресі досить обмежена: вона дає можливість знайти SQL файли для інсталяції або апгрейду/даунгрейду і робить заміну певних строк у цих файлах (типу власника, схеми чи шляху до .so-файлу). Але все, що стосується зборки та розповсюдження, – біда. Розбирайтесь самі. Найвідоміша система pgxn по суті є каталогом і мйже всі моменти стосовно залежностей майже повністю залишаються проблемою користувача. Нещодавно анонсований database.dev займається тільки TLE (trusted language extensions). Також нещодавно анонсований Trunk є трохи кращим, але досить обмеженим: runtime залежності не вирішені, і все досить сильно повʼязане наразі з докером.
Все це мене не досить влаштовувало. Я хочу фантастичного D3X (Development, Debugging and Deployment Experience): щоб все працювало на компʼютерах розробників (так, навіть на macOS і без постгресу у докері), щоб можна було інсталювати розширення із залежностями з рідних пакетів тієї дістрібуції лінукса що у вас на сервері, щоб можна було вказати залежності між розширеннями, пакетами, постгресом та ін.
Отже, я придбав цікавий домен (ще не анонсовано, але це postgres.pm) і вирішив зайнятись проблемою.
Було багато ідей як це зробити. Але всі вони були навколо того факту що якщо ми хочемо будувати розширення у невідомих обставинах, нам потрібно щось типу експертної системи. А також того, що потрібна якась проста нотація для опису пакетів. Спочатку я намагався зробити це на CLIPS, але воно працює найкраще коли всі факти відомі і треба з ними щось зробити. У нашому випадку, це не дуже практично бо для багато чого треба опитувати систему напряму. І опитати про все-все-все нереально. Отжеж, я дійшов до потреби у backward chaining, спробував його реалізувати у вигляді патча до CLIPS, але засів там надовго бо це було не дуже просто.
Тут я вирішив себе перебороти, і спробувати щось типу Prolog’у. Бо я був в курсі, але ніколи не використовував. Тим паче що там є реалізації constraints що дуже корисно для штук типу пошуку сумісних версій. Та й синтаксис мене не дуже лякав, бо я багато років на Erlang писав.
Продовження у наступному пості.
P.S. Хто вгадає мій промпт для картинки?
Майже з самого початку розробки Omnigres мені хотілось зробити щось корисне для розповсюдження розширень (extensions) для Postgres. Чому? Система управління розширеннями в постгресі досить обмежена: вона дає можливість знайти SQL файли для інсталяції або апгрейду/даунгрейду і робить заміну певних строк у цих файлах (типу власника, схеми чи шляху до .so-файлу). Але все, що стосується зборки та розповсюдження, – біда. Розбирайтесь самі. Найвідоміша система pgxn по суті є каталогом і мйже всі моменти стосовно залежностей майже повністю залишаються проблемою користувача. Нещодавно анонсований database.dev займається тільки TLE (trusted language extensions). Також нещодавно анонсований Trunk є трохи кращим, але досить обмеженим: runtime залежності не вирішені, і все досить сильно повʼязане наразі з докером.
Все це мене не досить влаштовувало. Я хочу фантастичного D3X (Development, Debugging and Deployment Experience): щоб все працювало на компʼютерах розробників (так, навіть на macOS і без постгресу у докері), щоб можна було інсталювати розширення із залежностями з рідних пакетів тієї дістрібуції лінукса що у вас на сервері, щоб можна було вказати залежності між розширеннями, пакетами, постгресом та ін.
Отже, я придбав цікавий домен (ще не анонсовано, але це postgres.pm) і вирішив зайнятись проблемою.
Було багато ідей як це зробити. Але всі вони були навколо того факту що якщо ми хочемо будувати розширення у невідомих обставинах, нам потрібно щось типу експертної системи. А також того, що потрібна якась проста нотація для опису пакетів. Спочатку я намагався зробити це на CLIPS, але воно працює найкраще коли всі факти відомі і треба з ними щось зробити. У нашому випадку, це не дуже практично бо для багато чого треба опитувати систему напряму. І опитати про все-все-все нереально. Отжеж, я дійшов до потреби у backward chaining, спробував його реалізувати у вигляді патча до CLIPS, але засів там надовго бо це було не дуже просто.
Тут я вирішив себе перебороти, і спробувати щось типу Prolog’у. Бо я був в курсі, але ніколи не використовував. Тим паче що там є реалізації constraints що дуже корисно для штук типу пошуку сумісних версій. Та й синтаксис мене не дуже лякав, бо я багато років на Erlang писав.
Продовження у наступному пості.
P.S. Хто вгадає мій промпт для картинки?
{kind=link}
🔥6🤔1
Продовжуємо.
Перший день у Prolog був найважчим, адже кожні пʼять хвилин я намагався використовувати REPL (toplevel) щоб писати предикати прямо у запиті (без секції
Після усвідомлення цього, поїхало краще. Головна ідея, яка мені дуже подобається (принаймні, для певного класу проблем), це те, що правила описують “якщо X, то Y” і можна фокусуватись на результаті, а не на процесі його досягнення. Ми описуємо по суті відносини між речами. От простий приклад:
Тут, в принципі, все просто. Дали список, отримали довжину. Але все не так просто:
Тут ми бачимо, що насправді ми запитали, чи є довжина списку такою, як ми вказали (просто
Але навіть це ще не все, ми можемо згенерувати список заданої довжини:
Там ще дуже багато цікавого, але в мене тут простору не вистачить 😄. Отже, це дуже цікавий інструмент для того щоб описувати складні системи. Мене дуже тішить, коли досить складні проблему описуються дуже лінійно завдяки тому що предикати можуть дати більш ніш одну відповідь (non-deterministic predicates).
Я вирішив поки що зупинитись на SWI Prolog, але є ще багато цікавих імплементацій, як відкритих, так і комерційних. SWI має багато фіч, та його досить легко додати до програм на C/Rust/т.і. програми (я навіть почав розробляти plprolog бо це буде дуже цікавий інструмент для експертних систем у постгресі). Після кількох тижнів з “чистим” прологом я перейшов на Logtalk для того щоб краще організувати мій код. Рекомендую: автор вже на протязі більш ніж 20 років працює над ним, і робить це дуже активно.
Чи варто спробувати Prolog? Так, абсолютно! Щонайменше, це дасть можливість подивитися на проблеми під іншим кутом. Власне, сама мова дуже мінімалістична і можна будувати прототипи та реальні системи досить швидко. Дуже рекомендую лекції Power of Prolog.
На скріншоті: поточна ітерація того, як виглядають описи пакетів.
Є питання? Пишіть!
Перший день у Prolog був найважчим, адже кожні пʼять хвилин я намагався використовувати REPL (toplevel) щоб писати предикати прямо у запиті (без секції
[user].). Втім, варто запам’ятати, що у цій штуці ми ставимо питання. А всі дефініції або у файлі, або [user]. % тут щось описано^DПісля усвідомлення цього, поїхало краще. Головна ідея, яка мені дуже подобається (принаймні, для певного класу проблем), це те, що правила описують “якщо X, то Y” і можна фокусуватись на результаті, а не на процесі його досягнення. Ми описуємо по суті відносини між речами. От простий приклад:
?- length([1,2,3], L).L = 3.Тут, в принципі, все просто. Дали список, отримали довжину. Але все не так просто:
?- length([1,2,3], 3).true.?- length([1,2,3], 4).false.Тут ми бачимо, що насправді ми запитали, чи є довжина списку такою, як ми вказали (просто
L у прикладі – це змінна без значення). Більше того, ми можемо давати складні умови з обмеженнями:?- use_module(library(clpfd)). % бібліотека для integer constraintstrue.?- L #< 4 #\/ L #>6 , length([1,2,3], L).L = 3.?- L #< 4 #\/ L #>6 , length([1,2,3,4,5,6], L).false.?- L #< 4 #\/ L #>6 , length([1,2,3,4,5,6,7], L).L = 7.Але навіть це ще не все, ми можемо згенерувати список заданої довжини:
?- length(List, 5).List = [_, , , , ].?- L #< 4 #\/ L #>6 , length(List, L).L = 0,List = [] ;L = 1,List = [_] ;L = 2,List = [_, _] ;L = 3,List = [_, _, _] ;L = 7,List = [_, _, _, _, _, _, _] ;...Там ще дуже багато цікавого, але в мене тут простору не вистачить 😄. Отже, це дуже цікавий інструмент для того щоб описувати складні системи. Мене дуже тішить, коли досить складні проблему описуються дуже лінійно завдяки тому що предикати можуть дати більш ніш одну відповідь (non-deterministic predicates).
Я вирішив поки що зупинитись на SWI Prolog, але є ще багато цікавих імплементацій, як відкритих, так і комерційних. SWI має багато фіч, та його досить легко додати до програм на C/Rust/т.і. програми (я навіть почав розробляти plprolog бо це буде дуже цікавий інструмент для експертних систем у постгресі). Після кількох тижнів з “чистим” прологом я перейшов на Logtalk для того щоб краще організувати мій код. Рекомендую: автор вже на протязі більш ніж 20 років працює над ним, і робить це дуже активно.
Чи варто спробувати Prolog? Так, абсолютно! Щонайменше, це дасть можливість подивитися на проблеми під іншим кутом. Власне, сама мова дуже мінімалістична і можна будувати прототипи та реальні системи досить швидко. Дуже рекомендую лекції Power of Prolog.
На скріншоті: поточна ітерація того, як виглядають описи пакетів.
Є питання? Пишіть!
{kind=link}
👍6🤯6🔥5
Мене завжди дратував той факт, що для написання якоїсь бізнес-логіки на чомусь окрім SQL або PL/pgSQL, потрібно писати цей код всередині SQL файлу, наприклад:
Бо з цього моменту нормально з редактором там вже не попрацюєш, а зовнішні інструменти взагалі не розуміють таку структуру.
Отже, сьогодні я написав фічу в Омнігресі, щоб можна було просто покласти цю функцію у .py-файл і воно його підхопить.
У подальшому можна поліпшити підтримку того ж Python та інших мов, зокрема, використовувати інформацію з анотацій та типів. Але наразі цей простий як пробка підхід працює будь-де (принаймні, я так думаю).
(Деталі: https://docs.omnigres.org/omni_schema/reference/#multi-language-functions)
А що ще вам заважає додавати логіку до бази даних?
create function myfunction(myarg int) returns bool language python as $$
# а отут в нас Python
$$Бо з цього моменту нормально з редактором там вже не попрацюєш, а зовнішні інструменти взагалі не розуміють таку структуру.
Отже, сьогодні я написав фічу в Омнігресі, щоб можна було просто покласти цю функцію у .py-файл і воно його підхопить.
# SQL[[create function times_ten(a integer) returns integer]]
return a * 10У подальшому можна поліпшити підтримку того ж Python та інших мов, зокрема, використовувати інформацію з анотацій та типів. Але наразі цей простий як пробка підхід працює будь-де (принаймні, я так думаю).
(Деталі: https://docs.omnigres.org/omni_schema/reference/#multi-language-functions)
А що ще вам заважає додавати логіку до бази даних?
🔥8
Я тут написав статтю про архітектуру разом з автором SQLPage і вона зараз на front page Hacker News. Якщо знайдете, можете завітати до коментарів 😀
👍8🔥4
Коротка новина: нарешті зробив перший реліз досить нішевого інструмента, pg_yregress
Якщо ви знаєте що таке pg_regress але вам не дуже подобається з ним працювати, запрошую спробувати pg_yregress. Дозволяє структурувати тести краще, фокусуватись на предметі тестування, підтримує більш одного постгреса під тестом, тестування бінарних кодуваннь та т.і.
Максимально корисно для тестування розширеннь для Postgres, але цікаво подивитись і на інші юзкейзи.
Якщо ви знаєте що таке pg_regress але вам не дуже подобається з ним працювати, запрошую спробувати pg_yregress. Дозволяє структурувати тести краще, фокусуватись на предметі тестування, підтримує більш одного постгреса під тестом, тестування бінарних кодуваннь та т.і.
Максимально корисно для тестування розширеннь для Postgres, але цікаво подивитись і на інші юзкейзи.
👍4
Хвилинка самореклами. 🤡
Як ви можете пам’ятати, я Омнігресом займався з минулого року. Але в останні кілька місяців ми тут почали його трансформувати в реальний стартап щоб рухатись швидше і дати можливість тим хто з ним вирішує свої проблеми, мати реально якісний продукт.
Для тих хто не пам’ятає: Omnigres це такий uber-majestic monolith. Ми взяли постгрес і робимо з нього application runtime якій вміє ну майже все. І ваша бізнес логіка з нього не вилазить. Це робить розробку простішою, latency меншим, дає транзакціональність там де її ніколи не було, дає перспективи на дуже прості edge deployments, та ще багато чого.
Не всі з цим підходом згодні, але ми працюємо для тих кому це потрібно та чекаємо коли іншим набридне платити величезні гроші за мікросервіси які могли б бути SQL запитами 🫣
Чому я зараз вирішив прорекламуватись тут? Справа у тому що ми тепер починаємо будувати founding team інженерів. Це звичайно нелегка але цікава (для певної категорії людей) робота для тих хто готовий володіти проблемами та напрямками. Добра англійська абсолютно потрібна (інтернаціональна команда).
Початкова команда буде дуже невеличкою але рухатись будемо швидко.
Отже, приходьте до нашого гітхабу, та завітайте до діскорду де ми тусуємось. Ну або пишіть мені у телеграмі @yrashk
P.S. Вибачте за перерву у постах, останні місяці були ну дуже гарячі!
Як ви можете пам’ятати, я Омнігресом займався з минулого року. Але в останні кілька місяців ми тут почали його трансформувати в реальний стартап щоб рухатись швидше і дати можливість тим хто з ним вирішує свої проблеми, мати реально якісний продукт.
Для тих хто не пам’ятає: Omnigres це такий uber-majestic monolith. Ми взяли постгрес і робимо з нього application runtime якій вміє ну майже все. І ваша бізнес логіка з нього не вилазить. Це робить розробку простішою, latency меншим, дає транзакціональність там де її ніколи не було, дає перспективи на дуже прості edge deployments, та ще багато чого.
Не всі з цим підходом згодні, але ми працюємо для тих кому це потрібно та чекаємо коли іншим набридне платити величезні гроші за мікросервіси які могли б бути SQL запитами 🫣
Чому я зараз вирішив прорекламуватись тут? Справа у тому що ми тепер починаємо будувати founding team інженерів. Це звичайно нелегка але цікава (для певної категорії людей) робота для тих хто готовий володіти проблемами та напрямками. Добра англійська абсолютно потрібна (інтернаціональна команда).
Початкова команда буде дуже невеличкою але рухатись будемо швидко.
Отже, приходьте до нашого гітхабу, та завітайте до діскорду де ми тусуємось. Ну або пишіть мені у телеграмі @yrashk
P.S. Вибачте за перерву у постах, останні місяці були ну дуже гарячі!
{kind=link}
🔥9👍5
Тут ось яка ідея виникла: можливо іноді шукати програмістів з прямим релевантним досвідом у галузі це може бути свого роду ледарство. Це якось очевидно та й не оптимізує інші, непрямі навички, наприклад підходи до створення дуже швидкодійного софту, вирішення складних проблем, дотримання термінів, тощо
Як приклад: я от шукаю розробників із досвідом розробки розширень для постгресу, або навіть контрібуторів до постгресу. А може потрібно шукати хардкорних C++ гейм девелоперів які б зацікавились переходом на новий, відмінний стек та вдоволення потреб бізнес-клієнтів – та й перенесли б свої навички?
Знайомий запропонував інший приклад: шукати поміж Erlang розробників, бо вони всебічно розвинені та й ерланг системи завжди треба підтримувати і це тренує працювати з клієнтами 😜
А ви як думаєте?
Як приклад: я от шукаю розробників із досвідом розробки розширень для постгресу, або навіть контрібуторів до постгресу. А може потрібно шукати хардкорних C++ гейм девелоперів які б зацікавились переходом на новий, відмінний стек та вдоволення потреб бізнес-клієнтів – та й перенесли б свої навички?
Знайомий запропонував інший приклад: шукати поміж Erlang розробників, бо вони всебічно розвинені та й ерланг системи завжди треба підтримувати і це тренує працювати з клієнтами 😜
А ви як думаєте?
{kind=link}
🔥9👍2🤔1
У мене таке питання: чи є серед вас ті, хто ненавидить відлагодження SQL запитів? А як щодо шанувальників типобезпечного програмування? Якщо намалювати Вен-діаграму цих двох аудиторій, чи не вийде просто коло?
Я от до чого, мені реально набридло, що в Postgres типи є, але їх наче немає. Ну от, якого біса ми використовуємо той самий тип цілого числа для всіх (всіх!) ID-ідентифікаторів, а потім тупимо в екран, намагаючись зрозуміти, що з цим join'ом не так?
Це ж вже було! Це ж не нова проблема. Давайте просто для кожної реляції створимо свій цілочисельний тип. І замість того, щоб розбиратися, що пішло не так і чому дані виглядають дивно, просто отримаємо помилку ще на етапі планування!
Я знайщов час написати розширення та трохи порекламувати його тут у відео (англійською).
Мене от що цікавить: у вашій практиці такі помилки часто трапляються чи це моя особиста проблема?
Я от до чого, мені реально набридло, що в Postgres типи є, але їх наче немає. Ну от, якого біса ми використовуємо той самий тип цілого числа для всіх (всіх!) ID-ідентифікаторів, а потім тупимо в екран, намагаючись зрозуміти, що з цим join'ом не так?
Це ж вже було! Це ж не нова проблема. Давайте просто для кожної реляції створимо свій цілочисельний тип. І замість того, щоб розбиратися, що пішло не так і чому дані виглядають дивно, просто отримаємо помилку ще на етапі планування!
Я знайщов час написати розширення та трохи порекламувати його тут у відео (англійською).
Мене от що цікавить: у вашій практиці такі помилки часто трапляються чи це моя особиста проблема?
🔥4