
📖 Why I’ve stopped exporting defaults from my JavaScript modules
Сегодня на повестке статья из далёкого и спокойного 2019 “Why I've stopped exporting defaults from my JavaScript modules”.
В статье автор предлагает отказаться от экспортов по-умолчанию в JavaScript. Я бы выделил 2 причины, которые кажутся для меня наиболее важными:
1️⃣ Дефолтные экспорты не указывают имя функции или класса, которую вы импортируете, что может (и будет) вызывать неконсистентность в именовании.
В одном файле вы можете указать имя
А в другом файле, другой разработчик может указать имя
В случае с именованными экспортами, вы не можете просто присвоить рандомное имя, оно должно совпадать с именем экспортируемой функции/класса/объекта
- При этом, если в глобальном поиске вы напишите
- При этом вы также просто сможете переименовать компонент во всей кодовой базе, потому что везде используется одно и тоже имя.
2️⃣ Когнитивная нагрузка замедляет разработку. Если вы используете дефолтные экспорты, вам придётся самостоятельно, каждый раз указывать название импорта. В случае с именованными экспортами ваша IDE наверняка подскажет вам имя, как только вы начнёте печатать и вам останется лишь нажать Enter.
3️⃣ Если вы всегда используете именованные экспорты, вам больше не нужно выбирать между именованными и дефолтными экспортами. Например, если изначально в файле вы экспортировали только одну функцию и теперь вам нужно экспортировать ещё одну, вам не придётся заменить везде неименованные импорты на именованные.
⚠️ Исключения
К сожалению, в некоторых ситуациях нельзя использовать именованные экспорты. Одним из примеров может служить
🤖 ESlint
Чтобы убедиться, что все разработчики используют именованные экспорты, вы можете использовать правило import/no-default-export
Когда я добавлял это правило в наш проект, я наткнулся на GitLab issue, где команда Гитлаба планировали перейти с дефолтных экспортов на именованные. Они также ссылаются на эту статью.
- Оригинал на английском
- Перевод на русский
#linters #eslint #javascript #architecture #fridayreading
Сегодня на повестке статья из далёкого и спокойного 2019 “Why I've stopped exporting defaults from my JavaScript modules”.
В статье автор предлагает отказаться от экспортов по-умолчанию в JavaScript. Я бы выделил 2 причины, которые кажутся для меня наиболее важными:
1️⃣ Дефолтные экспорты не указывают имя функции или класса, которую вы импортируете, что может (и будет) вызывать неконсистентность в именовании.
В одном файле вы можете указать имя
LinkedList import LinkedList from "./linked-list.js";А в другом файле, другой разработчик может указать имя
Listimport List from "./linked-list.js";В случае с именованными экспортами, вы не можете просто присвоить рандомное имя, оно должно совпадать с именем экспортируемой функции/класса/объекта
import { LinkedList } from "./linked-list.js";- При этом, если в глобальном поиске вы напишите
LinkedList вы сможете без всяких проблем найти все использования этой переменной.- При этом вы также просто сможете переименовать компонент во всей кодовой базе, потому что везде используется одно и тоже имя.
2️⃣ Когнитивная нагрузка замедляет разработку. Если вы используете дефолтные экспорты, вам придётся самостоятельно, каждый раз указывать название импорта. В случае с именованными экспортами ваша IDE наверняка подскажет вам имя, как только вы начнёте печатать и вам останется лишь нажать Enter.
3️⃣ Если вы всегда используете именованные экспорты, вам больше не нужно выбирать между именованными и дефолтными экспортами. Например, если изначально в файле вы экспортировали только одну функцию и теперь вам нужно экспортировать ещё одну, вам не придётся заменить везде неименованные импорты на именованные.
⚠️ Исключения
К сожалению, в некоторых ситуациях нельзя использовать именованные экспорты. Одним из примеров может служить
React.lazy(() ⇒ import('../path')) используемый для код сплитинга и ленивой загрузки.🤖 ESlint
Чтобы убедиться, что все разработчики используют именованные экспорты, вы можете использовать правило import/no-default-export
Когда я добавлял это правило в наш проект, я наткнулся на GitLab issue, где команда Гитлаба планировали перейти с дефолтных экспортов на именованные. Они также ссылаются на эту статью.
- Оригинал на английском
- Перевод на русский
#linters #eslint #javascript #architecture #fridayreading
Human Who Codes
Why I've stopped exporting defaults from my JavaScript modules - Human Who Codes
After years of fighting with default exports, I've changed my ways.
👍3
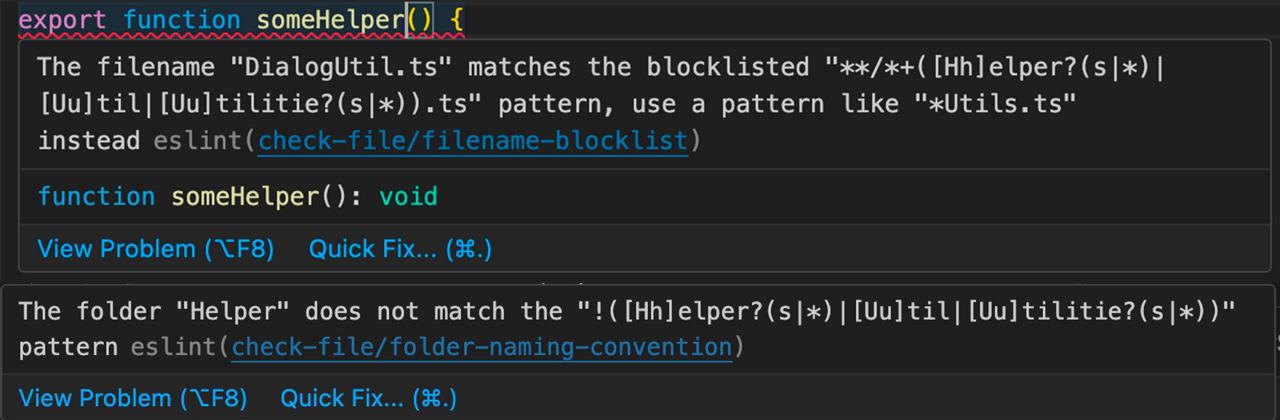
Проверка именования файлов и папок с помощью плагина eslint-plugin-import
Во время код ревью, можно заметить, что мы часто оставляем одни и те же комментарии об именованиях или каких-то соглашениях (которые описаны в вики, и которые никто не читает). В такой момент, нужно задуматься можно ли эти проверки как-то оптимизировать. Например недавно я писал пост о том как контролировать импорты в JS с помощью import/no-restricted-path. Сегодня я хочу рассказать о проверке именования файлов и папок.
Наверняка в вашем проекте есть какая-то определённая структура организации папок, например, это могут быть папки:
- /models
- /services
- /stores
- /pages
И скорее всего все файлы в этих папках должны иметь определённый суффикс:
- Model
- Service
- Store
- Page
И уж точно, в каждом проекте есть утилитные файлы для строк, массивов или ваших внутренних бизнес моделей. И как такие файлы только не именуют:
- Helper/Helpers
- Util/Utils
- Utility/Utilities
Чтобы избежать всей этой путаницы и обеспечить единое именование файлов можно использовать плагин
Плагин содержит несколько плавил:
1️⃣ check-file/filename-blocklist
Синтаксис следующий — вы описываете объект, у которого:
- ключи — запрещённые паттерны
- значения — тот паттерн, который рекомендуется использовать.
Например, если мы хотим обеспечить единое именование утилитных методов, чтобы все они оканчивались на `Utils`, то нам нужно запретить использование суффиксов: Helper, Util, Utilities. Также, нужно учесть, что:
- Первая буква может быть как в верхнем, так и в нижнем регистрах
- Все суффиксы могут быть как в единственном, так и во множественном числе
Описание такого правила будет выглядеть так:
2️⃣ check-file/folder-naming-convention
Это правило позволяет нам задать паттерн именования папок:
- ключ — паттерн для папок, которые необходимо валидировать
- значение — паттерн, которому папки должны удовлетворять. В нашем случае, паттерну удовлетворяют все папки, которые не называются Helpers, Util, Utilities.
Все правила описываются с помощью glob-паттернов). Протестировать свой паттерн можно тут.
#linters #javascript #archtecture
Во время код ревью, можно заметить, что мы часто оставляем одни и те же комментарии об именованиях или каких-то соглашениях (которые описаны в вики, и которые никто не читает). В такой момент, нужно задуматься можно ли эти проверки как-то оптимизировать. Например недавно я писал пост о том как контролировать импорты в JS с помощью import/no-restricted-path. Сегодня я хочу рассказать о проверке именования файлов и папок.
Наверняка в вашем проекте есть какая-то определённая структура организации папок, например, это могут быть папки:
- /models
- /services
- /stores
- /pages
И скорее всего все файлы в этих папках должны иметь определённый суффикс:
- Model
- Service
- Store
- Page
И уж точно, в каждом проекте есть утилитные файлы для строк, массивов или ваших внутренних бизнес моделей. И как такие файлы только не именуют:
- Helper/Helpers
- Util/Utils
- Utility/Utilities
Чтобы избежать всей этой путаницы и обеспечить единое именование файлов можно использовать плагин
eslint-plugin-importПлагин содержит несколько плавил:
1️⃣ check-file/filename-blocklist
Синтаксис следующий — вы описываете объект, у которого:
- ключи — запрещённые паттерны
- значения — тот паттерн, который рекомендуется использовать.
Например, если мы хотим обеспечить единое именование утилитных методов, чтобы все они оканчивались на `Utils`, то нам нужно запретить использование суффиксов: Helper, Util, Utilities. Также, нужно учесть, что:
- Первая буква может быть как в верхнем, так и в нижнем регистрах
- Все суффиксы могут быть как в единственном, так и во множественном числе
Описание такого правила будет выглядеть так:
plugins: [
'check-file',
],
rules: {
"check-file/filename-blocklist": [
"error",
{
"**/*+([Hh]elper?(s|*)|[Uu]til|[Uu]tilitie?(s|*)).ts": "*Utils.ts"
}
]
}
2️⃣ check-file/folder-naming-convention
Это правило позволяет нам задать паттерн именования папок:
- ключ — паттерн для папок, которые необходимо валидировать
- значение — паттерн, которому папки должны удовлетворять. В нашем случае, паттерну удовлетворяют все папки, которые не называются Helpers, Util, Utilities.
"check-file/folder-naming-convention": [
"error",
{
"src/**/": "!([Hh]elper?(s|*)|[Uu]til|[Uu]tilitie?(s|*))"
}
]
Все правила описываются с помощью glob-паттернов). Протестировать свой паттерн можно тут.
#linters #javascript #archtecture
{kind=link}
👍3
🍂 Проваливание промисов
Когда вы передаете в
Подробнее о промисах в статье "У нас проблемы с промисами".
#interview #frontend #javascript
Когда вы передаете в
then() что-то отличное от функции (например, промис), это интерпретируется как then(null) и в следующий по цепочке промис «проваливается» результат предыдущего.Подробнее о промисах в статье "У нас проблемы с промисами".
#interview #frontend #javascript
📖️️️️️️ Каррирование и частичное применение
Каррирование и частичное применение — две концепции из функционального программирования, которые очень часто путают из-за их схожести (а я пишу этот пост, чтобы наконец-то запомнить).
И частичное применение, и каррирование, реализуются как функции, принимающие в качестве параметра другую функцию.
Частичное применение — функция
Каррирование — функция
Подробнее
- Карринг vs Частичное применение функции — C#
- Каррирование функций в JavaScript
- Реализация функции каррирования
- Function: length
#fridayreading #frontend #javascript #functionalprogramming
Каррирование и частичное применение — две концепции из функционального программирования, которые очень часто путают из-за их схожести (а я пишу этот пост, чтобы наконец-то запомнить).
И частичное применение, и каррирование, реализуются как функции, принимающие в качестве параметра другую функцию.
Частичное применение — функция
partialApply, принимающая первым параметром функцию — fn, а остальные параметры — часть параметров функции fn. Функция partialApply возвращает функцию, которая в качестве параметров принимает недостающие аргументы функции fn.Каррирование — функция
curry, которая принимает единственный параметр — функцию fn, и возвращает каррированную функцию fn. Можно сказать, что каррированная функция fn — функция аккумулятор, которая будет накапливать переданные аргументы до тех пор, пока не будет передано достаточно параметров для вызова исходной функции. Параметры можно передавать в любом количестве.Подробнее
- Карринг vs Частичное применение функции — C#
- Каррирование функций в JavaScript
- Реализация функции каррирования
- Function: length
#fridayreading #frontend #javascript #functionalprogramming
{kind=link}
👍4❤1
💻️️️️️️ Array.prototype.sort
Как будет отсортирован следующий массив
🥱 Предыстория
На выходных я решал литкод, и в задаче 3sum было необходимо отсортировать массив по возрастанию, перед тем как перейти к основной реализации алгоритма.
Я написал решение, подебажил на бумаге — всё работает, отправляю код на проверку — не работает 🤷♂️. Перепроверяю всё глазами — ну должно же работать!
Сдаюсь и начинаю дебажить в VS Code и вижу, что сортировка массива работает не так как я ожидал.
ℹ️ Объяснение
Если перейти на MDN и прочитать документацию Array.prototype.sort(), то станет всё понятно.
Метод
Таким образом, числа в данном случае сортируются на основе их строкового представления. Например, '-10' будет идти перед '-2', потому что строка '10' идет перед строкой '2' в лексикографическом порядке.
Чтобы выполнить числовую сортировку массива, нужно предоставить функцию сравнения методу
Это даст вам
#javascript #frontend #algorithms
Как будет отсортирован следующий массив
[-1, 0, 1, 2, -1, -4, -2, -3, 3, 0, 4].sort()? 🥱 Предыстория
На выходных я решал литкод, и в задаче 3sum было необходимо отсортировать массив по возрастанию, перед тем как перейти к основной реализации алгоритма.
Я написал решение, подебажил на бумаге — всё работает, отправляю код на проверку — не работает 🤷♂️. Перепроверяю всё глазами — ну должно же работать!
Сдаюсь и начинаю дебажить в VS Code и вижу, что сортировка массива работает не так как я ожидал.
ℹ️ Объяснение
Если перейти на MDN и прочитать документацию Array.prototype.sort(), то станет всё понятно.
Метод
sort() в JavaScript преобразует элементы в строки и затем сравнивает их последовательности значений кодов UTF-16. Это означает, что при сортировке числа рассматриваются как строки.Таким образом, числа в данном случае сортируются на основе их строкового представления. Например, '-10' будет идти перед '-2', потому что строка '10' идет перед строкой '2' в лексикографическом порядке.
Чтобы выполнить числовую сортировку массива, нужно предоставить функцию сравнения методу
sort(), как показано здесь:[-1, 0, 1, 2, -1, -4, -2, -3, 3, 0, 4].sort((a, b) => a - b);
Это даст вам
[-4, -3, -2, -1, -1, 0, 0, 1, 2, 3, 4] — числовую сортировку.#javascript #frontend #algorithms
{kind=link}
👍2🤣2
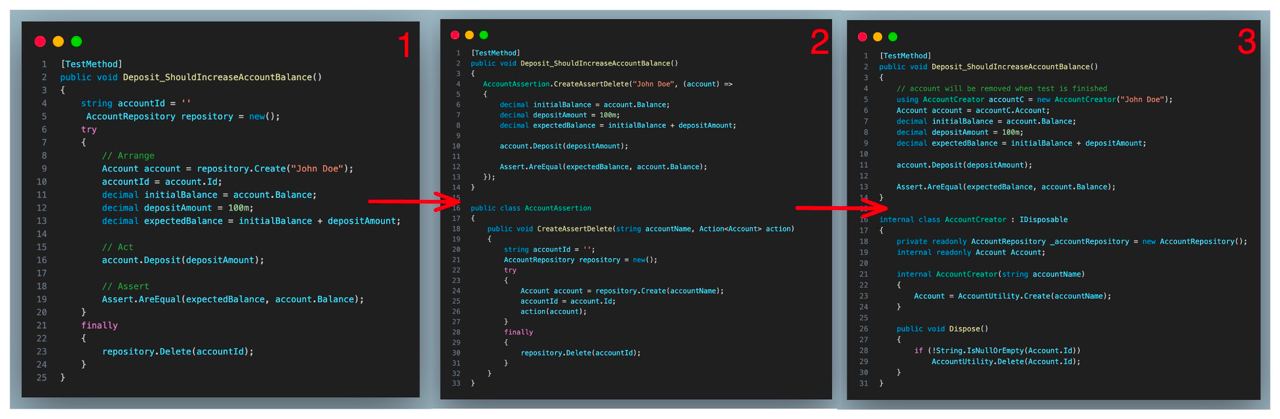
🧹 Тестирование — подчищаем за собой
Так исторически сложилось, что у нас на проекте нет юнит тестов, только интеграционные и e2e.
Иногда в тестах приходится подчищать за собой — удалять созданные во время выполнения теста объекты в базе, чтобы не влиять на результат других тестов. Это конечно, лишь ухудшает читабельность кода.
Мы прошли некоторую эволюцию подходов для создания и удаления объектов:
1. Мы использовали
2. Перешли к использованию функций с колбэками. Утилитная функция создаёт и удаляет объект, а мы передаём лишь колбэк, в котором описываем логику теста и нужные нам проверки.
3. Внедрили
Использование паттерна с классами
Такой подход не ограничивается только лишь C# — в TypeScript 5.2. уже появилась поддержка
#csharp #javascript #typescript #tests
Так исторически сложилось, что у нас на проекте нет юнит тестов, только интеграционные и e2e.
Иногда в тестах приходится подчищать за собой — удалять созданные во время выполнения теста объекты в базе, чтобы не влиять на результат других тестов. Это конечно, лишь ухудшает читабельность кода.
Мы прошли некоторую эволюцию подходов для создания и удаления объектов:
1. Мы использовали
try/finally , где все созданные объекты удаляются внутри блока finally. Выглядит сомнительно, когда нужно городить подобную конструкцию во многих тестах.2. Перешли к использованию функций с колбэками. Утилитная функция создаёт и удаляет объект, а мы передаём лишь колбэк, в котором описываем логику теста и нужные нам проверки.
3. Внедрили
IDisposable классы, которые мы называем Creator’ами. Они делают то же самое, что и функции с колбэками, но не добавляют ненужную вложенность, что улучшает читаемость кода. Они чем-то напоминают PageObjectModel в e2e тестах. Использование паттерна с классами
IDisposable также подходит для активации определенной настройки только в рамках одного теста и отключения её по завершении теста.Такой подход не ограничивается только лишь C# — в TypeScript 5.2. уже появилась поддержка
using и, возможно, скоро она появится и в JavaScript. #csharp #javascript #typescript #tests
{kind=link}
👍5
Forwarded from Dev News от Максима Соснова
New client-side hooks coming to React 19
Статья рассказывает про новые API, которые, предположительно, будут в react 19. Пока они доступны в канареечном релизе React
В статье рассказывается про:
-
-
- Возможность передавать специфичный action в form
-
-
-
- Асинхронные транзишны
Постараюсь коротко рассказать про это API
Также улучшили работу с формами. У форм есть проп action, в который теперь можно закидывать функцию - обработчик формы
Самой сложной API для меня оказался хук
Я понял, что это работает вот так
Если я понял неправильно, а вы - правильно - отпишитесь, пожалуйста, в комментах, как это работает на самом деле.
Также добавили возможность делать асинхронные transitions в React. До этого было требование, чтобы транзишны были синхронными
https://marmelab.com/blog/2024/01/23/react-19-new-hooks.html
#development #javascript #react #react19 #reactHooks
Статья рассказывает про новые API, которые, предположительно, будут в react 19. Пока они доступны в канареечном релизе React
В статье рассказывается про:
-
use(Promise) -
use(Context)- Возможность передавать специфичный action в form
-
useFormState-
useFormStatus-
useOptimistic- Асинхронные транзишны
Постараюсь коротко рассказать про это API
use(Promise) позволяет дождаться выполнения Promise. Выглядит как сахар для удобного ожидания промиса внутри Suspence. Также отличается от классических хуков тем, что этот можно использовать внутри циклов и условийimport { use } from 'react';
function MessageComponent({ messagePromise }) {
const message = use(messagePromise);
// ...
}
use(Context) это аналог useContext, но можно использовать внутри циклов и условных блоковТакже улучшили работу с формами. У форм есть проп action, в который теперь можно закидывать функцию - обработчик формы
<form action={handleSubmit}>. Само по себе это мало что дает, но вместе с этой возможностью идут новые хуки, которые позволяют получить стейт и статус формы - useFormState и useFormStatus. Используя комбинацию этих API можно удобно работать с нативными формами.Самой сложной API для меня оказался хук
useOptimistic. Пришлось из статьи перейти в доку реакта, чтоб почитать подробнее, как это работает. Как я понял, useOptimistic позволяет врапнуть другой стейт и изменить его, пока врапнутый стейт не изменился. И это может быть полезно для оптимистичных апдейтов UI (техника, когда мы отрисовываем экран исходя из того, что асинхронное действие завершится успехом)Я понял, что это работает вот так
function MyComponent() {
// Объявляем стейт
const [state, setState] = useState([])
// Врапуем его с помощью нового хука
// в optimisticState изначально будет лежать state
// В колбеке описываем, как обрабатывать оптимистичные изменения
const [optimisticState, addOptimistic] = useOptimistic(state, (state, newItem) => [...state, newItem])
// Предположим мы делаем запрос на did mount
useEffect(async () => {
const itemToAdd = {}
// добавляем оптимистичный апдейт
addOptimistic(itemToAdd)
// делаем запрос
const realItemToAdd = await fetch(url)
// после завершения запроса, меняем корневой стейт
// мы рендерим optimisticState, но после обновления state
// optimisticState обновиться до state
setState([...state, realItemToAdd])
}, [])
return <div> {optimisticState} </div>
}
Если я понял неправильно, а вы - правильно - отпишитесь, пожалуйста, в комментах, как это работает на самом деле.
Также добавили возможность делать асинхронные transitions в React. До этого было требование, чтобы транзишны были синхронными
https://marmelab.com/blog/2024/01/23/react-19-new-hooks.html
#development #javascript #react #react19 #reactHooks
Marmelab
New client-side hooks coming to React 19
Data fetching and form handling are about to get easier in React, and not just in SSR apps.
❤3
function(): Promise 🆚 async function(): PromiseСуществует небольшая, но довольно важная разница между функцией, которая просто возвращает промис, и функцией, которая была объявлена с помощью ключевого слова
async.Пример
function fn(obj) {
const someProp = obj.someProp
return Promise.resolve(someProp)
}
async function asyncFn(obj) {
const someProp = obj.someProp
return Promise.resolve(someProp)
}
asyncFn().catch(err => console.error('Catched')) // => 'Catched'
fn().catch(err => console.error('Catched')) // => TypeError: Cannot read property 'someProp' of undefined
- при объявлении функции с ключевым словом
async JavaScript гарантирует, что функция вернёт Promise, даже если в ней произошла ошибка- если функция возвращает
Promise, но объявлена без async то catch не поймает ошибку, если в функции произошла ошибка- дело в том, что ошибки произошедшие внутри конструктора
new Promise((resolve, reject) => { throw new ... }) промиса ловятся. Когда мы добавляем async, то по сути заворачиваем тело функции в new Promise((resolve, reject) ⇒ { })То есть, чтобы сделать функции из примера идентичными, нужно завернуть первую функцию в промис.
function fn(obj) {
return new Promise((resolve, reject) => {
const someProp = obj.someProp;
resolve(someProp);
});
}
https://habr.com/ru/articles/475260/
#javascript #frontend
Хабр
Разница между асинхронной функцией и функцией, возвращающей промис
Существует небольшая, но довольно важная разница между функцией, которая просто возвращает промис, и функцией, которая была объявлена с помощью ключевого слова async . Взгляните на следующий фрагмент...
👍23🔥5❤4
🤝 Как подружить React.lazy с дефолтным экспортом
У нас в проекте используются только именованные экспорты. Почему — писал здесь.
Но
Чтобы решить проблему старая дока реакта предлагает создать промежуточный файл, который ре-экспортирует компонент с дефолтным экспортом.
Но как по мне — совсем не красиво.
Но что такое дефолтный экспорт? Когда мы используем динамическую загрузку модулей с помощью
То есть если мы экспортируем компонент
#javascript #react
У нас в проекте используются только именованные экспорты. Почему — писал здесь.
Но
React.lazy работает только с дефолтными экспортами, и раньше нам приходилось успокаивать eslint, приговаривая // eslint-disable-next-line import/no-default-export.Чтобы решить проблему старая дока реакта предлагает создать промежуточный файл, который ре-экспортирует компонент с дефолтным экспортом.
export { MyComponent as default } from "./ManyComponents.js";
Но как по мне — совсем не красиво.
Но что такое дефолтный экспорт? Когда мы используем динамическую загрузку модулей с помощью
import, в промисе получим модуль. А дефолтный экспорт будет храниться в поле default, именованные экспорты будут храниться в соответствующих полях модуля. То есть если мы экспортируем компонент
Markdown с помощью именованного экспорта, то мы сможем получить к нему доступ через одноимённое свойство Markdown на загруженном модуле.
import React, { lazy, Suspense } from "react";
import { MySpinner } from "@private/design-system";
const MarkdownPreview = lazy(async () => {
const module = await import('./myModule');
// преобразуем именованный экспорт в дефолтный
return { default: module.Markdown };
});
export const LazyMarkdownPreview = () => {
return (
<Suspense fallback={MySpinner}>
<MarkdownPreview />
</Suspense>
);
};
#javascript #react
👍14❤3🔥2
🔄 Обновляем caniuse-lite
Когда стали использовать реакт, мы взяли стандартный create-react-app, в котором использовался
Потом мы, конечно, совершенно забыли как работает
Так в чём проблема? 🤔
То, есть запрос
А это значит, что
- async/await преобразуется в длинную партянку кода в ES5
- стрелочные функции
- никаких
- в код попадают ненужные полифилы
В общем, если давно не обновляли
Если у вас pnpm монорепозиторий — используйте команду:
Мы обновились и наши жирные бандлы прилично похудели.
#javascript #tools
Когда стали использовать реакт, мы взяли стандартный create-react-app, в котором использовался
browserslist. Конфиг был стандартный.
"browserslist": {
"production": [
">0.2%",
"not dead",
"not op_mini all"
],
"development": [
"last 1 chrome version",
"last 1 firefox version",
"last 1 safari version"
]
}
Потом мы, конечно, совершенно забыли как работает
browserslist, и успешно игнорирывали следующее сообщение при билде.
Browserslist: caniuse-lite is outdated. Please run:
npx update-browserslist-db@latest
Why you should do it regularly: https://github.com/browserslist/update-db#readme
Так в чём проблема? 🤔
caniuse-lite - легковесная версия, той самой базы caniuse.com. Время идёт, появляются новые версии браузеров, а мы используем старую базу, и все наши запросы ">0.2%" работают с браузерами пяти летней давности.То, есть запрос
">0.2%" выбирал браузеры, у которых доля рынка была больше 0.2% 5 лет назад.А это значит, что
- async/await преобразуется в длинную партянку кода в ES5
- стрелочные функции
() => {} заменяются на function() {}- никаких
let/const, только старокрестьянский var- в код попадают ненужные полифилы
В общем, если давно не обновляли
caniuse-lite открываем консоль и запускаем:
npx update-browserslist-db@latest
Если у вас pnpm монорепозиторий — используйте команду:
pnpm up caniuse-lite
Мы обновились и наши жирные бандлы прилично похудели.
407.31 KB (-100.86 KB) build/bundle-1.js
369.3 kB (-34.64 kB) build/bundle-2.js
220.67 KB (-18.86 kB) build/bundle-3.js
#javascript #tools
GitHub
GitHub - browserslist/update-db: CLI tool to update caniuse-lite to refresh target browsers from Browserslist config
CLI tool to update caniuse-lite to refresh target browsers from Browserslist config - browserslist/update-db
👍13🔥5❤4
🗿 Подводные камни при переходе с ES5 на ES6
Недавно мы с командой, наконец-то перешли с ES5 на ES6.
Всё прошло достаточно плавно, нам пришлось исправить всего несколько ошибок в рантайме. Почти все ошибки были в очень старых файлах, где были отключены проверки typescript с помощью @ts-nocheck.
Ошибка 1️⃣ — Action is not a constructor
Ошибка возникла в нескольких местах, где мы использовали стрелочную функцию в качестве конструктора. Раньше она не возникала, потому что стрелочная функция компилировалась в обычную
Ошибка 2️⃣ — Функции, объявленные через
Дело в том, что когда переменная объявляется глобально через
Ошибка 3️⃣ — Cannot access variable before initialization
Одна из ошибок случалась, когда мы пытались получить доступ к переменной
Раньше,
Были и другие ошибки, но они по сути вариации или комбинации тех ошибок, что я привел выше.
👉 Кстатии, размер бандлов уменьшился процентов на 20.
#TypeScript #JavaScript
Недавно мы с командой, наконец-то перешли с ES5 на ES6.
Всё прошло достаточно плавно, нам пришлось исправить всего несколько ошибок в рантайме. Почти все ошибки были в очень старых файлах, где были отключены проверки typescript с помощью @ts-nocheck.
Ошибка 1️⃣ — Action is not a constructor
Ошибка возникла в нескольких местах, где мы использовали стрелочную функцию в качестве конструктора. Раньше она не возникала, потому что стрелочная функция компилировалась в обычную
function.
const Action = () => {}; // ES6
const action = new Action(); // Action is not a constructor
var Action = function () {} // ES5
var action = new Action(); // Всё ОК
Ошибка 2️⃣ — Функции, объявленные через
let, больше не попадают в window
let openAction = function () {}
window.openAction() // window.openAction is not a function
// Раньше let заменялся на var и всё работало
var openAction = function () {}
window.openAction() // всё ок
Дело в том, что когда переменная объявляется глобально через
var, она автоматически становится свойством глобального объекта window. Подробнее тут.Ошибка 3️⃣ — Cannot access variable before initialization
Одна из ошибок случалась, когда мы пытались получить доступ к переменной
promise до её инициализации.
class Queue {
executing;
run(thenable) {
const promise = new Promise(async (resolve, reject) => {
// пытаемся получить значние promise
while (this.executing != promise) {
// ...
}
// ...
});
}
}
// Cannot access 'promise' before initialization
new Queue().run(Promise.resolve())
Раньше,
const превращался в var и ошибки не было. Это связано с понятием временной мертвой зоны TDZ, которая не возникает у переменных, объявленных через var.Были и другие ошибки, но они по сути вариации или комбинации тех ошибок, что я привел выше.
👉 Кстатии, размер бандлов уменьшился процентов на 20.
#TypeScript #JavaScript
👍11❤3
🚧 Почему виртуальный скролл ломается на больших данных
Сегодня хочу рассказать вам вот об этой статье How to Implement Virtual Scrolling Beyond the Browser's Limit.
Когда мы говорим, что нужно оптимизировать рендеринг большого количества элементов в браузере — чаще всего речь идёт о виртуальном скроллинге.
Обычно он реализуется так:
- есть элемент, назовём его
- внутри — контейнер
- этому контейнеру задаётся высота по формуле: высота одного элемента × общее количество элементов,
- при этом рендерятся только те элементы, которые попадают во
Но знаете ли вы, что у стандартного virtual scrolling, который использует нативный скроллбар, есть ограничения?
Когда мы задаём общую высоту контента, она может оказаться больше, чем максимально поддерживаемое значение в браузере. Я измерил локально и получил такие значения:
- Safari:
- Chrome:
- Firefox: после определённого значения значение сбрасывается в 0
Ограничения можете проверить сами.
👉 Здесь накидал небольшую демку.
Из-за этого нельзя доскроллить до самого конца списка — высота просто "обрезается".
Примеры:
На работе мне нужно было реализовать
Я использовал TanStack Virtual для виртуального скроллинга, но столкнулся с описанной выше проблемой — реальная высота контента была в два раза больше, чем поддерживают браузеры. Позже нашел, что в их репозитории есть ишью по этому поводу.
Чтобы обойти это ограничение, нужно отказаться от нативного скролла и реализовать собственную скролл-панель. В этом случае мы не задаём высоту контента, а сами рассчитываем, какие элементы должны рендериться, исходя из позиции скроллбара.
Выглядит это примерно так:
Демку, где рендерятся 3 миллиона элементов, можно посмотреть здесь.
Подробнее это всё разбирается в статье.
#JavaScript #Performance #Browser
Сегодня хочу рассказать вам вот об этой статье How to Implement Virtual Scrolling Beyond the Browser's Limit.
Когда мы говорим, что нужно оптимизировать рендеринг большого количества элементов в браузере — чаще всего речь идёт о виртуальном скроллинге.
Обычно он реализуется так:
- есть элемент, назовём его
viewport,- внутри — контейнер
content, в котором находится список всех элементов,- этому контейнеру задаётся высота по формуле: высота одного элемента × общее количество элементов,
- при этом рендерятся только те элементы, которые попадают во
viewport, а их позиция задаётся через transform: translateY(...).Но знаете ли вы, что у стандартного virtual scrolling, который использует нативный скроллбар, есть ограничения?
Когда мы задаём общую высоту контента, она может оказаться больше, чем максимально поддерживаемое значение в браузере. Я измерил локально и получил такие значения:
- Safari:
33,554,428px- Chrome:
16,777,200px- Firefox: после определённого значения значение сбрасывается в 0
Ограничения можете проверить сами.
👉 Здесь накидал небольшую демку.
Из-за этого нельзя доскроллить до самого конца списка — высота просто "обрезается".
Примеры:
<!-- Safari: высота обрежется до 33,554,428px -->
<div style="height: 9999999999999px;"></div>
<!-- Даже без прямого указания общей высоты -->
<!-- В сумме 40,000,000px, но всё равно обрежется -->
<div>
<div style="height: 20000000px"></div>
<div style="height: 20000000px"></div>
</div>
На работе мне нужно было реализовать
JsonViewer, который умеет отображать огромные JSON-файлы. Я использовал TanStack Virtual для виртуального скроллинга, но столкнулся с описанной выше проблемой — реальная высота контента была в два раза больше, чем поддерживают браузеры. Позже нашел, что в их репозитории есть ишью по этому поводу.
Чтобы обойти это ограничение, нужно отказаться от нативного скролла и реализовать собственную скролл-панель. В этом случае мы не задаём высоту контента, а сами рассчитываем, какие элементы должны рендериться, исходя из позиции скроллбара.
Выглядит это примерно так:
const ITEM_HEIGHT = 30;
// Генерируем список из 3 миллионов элементов
const items = Array.from({ length: 3000000 }, (_, i) => `Item ${i}`);
// 3,000,000 × 30px = 90,000,000px (> лимита браузера)
const totalHeight = ITEM_HEIGHT * items.length;
const viewportSize = 300;
export default function App() {
return (
<ScrollPane contentSize={totalHeight} viewportSize={viewportSize}>
{(scrollPosition) => {
// Вычисляем, какие элементы нужно отрендерить
const startIndex = Math.floor(scrollPosition / ITEM_HEIGHT);
const endIndex = Math.min(
Math.ceil((scrollPosition + viewportSize) / ITEM_HEIGHT) + 1,
items.length
);
const visibleItems = items.slice(startIndex, endIndex);
// Смещение первого видимого элемента
const startPosition = startIndex * ITEM_HEIGHT;
return (
<div
style={{
position: 'absolute',
top: startPosition - scrollPosition,
}}
>
{visibleItems.map((item) => (
<div key={item} style={{ height: ITEM_HEIGHT }}>
{item}
</div>
))}
</div>
);
}}
</ScrollPane>
);
}
Демку, где рендерятся 3 миллиона элементов, можно посмотреть здесь.
Подробнее это всё разбирается в статье.
#JavaScript #Performance #Browser
DEV Community
How to Implement Virtual Scrolling Beyond the Browser's Limit
Introduction I am currently developing a CSV editor called SmoothCSV. It uses the...
❤21
Регулярки в мультиязычных приложениях
Сегодня коротко и по делу: в феврале был на «Подлодке», и на докладе про i18n в React-приложениях был хороший пример про валидации форм.
Если вам нужно провалидировать имя регуляркой:
- ❌
- ✅ Используйте вариации следующих регулярок
-
-
#JavaScript
Сегодня коротко и по делу: в феврале был на «Подлодке», и на докладе про i18n в React-приложениях был хороший пример про валидации форм.
Если вам нужно провалидировать имя регуляркой:
- ❌
/^[a-zа-я]+$/i — не используйте, иначе, как минимум многие сербы не пройдут вашу форму- ✅ Используйте вариации следующих регулярок
-
/^\w+$/u — пропустит буквы любой письменности, но вместе с ними ещё цифры и «_», так что проверяйте их отдельно, если нельзя;-
/^\p{L}+$/u — строгий вариант: разрешает только буквы во всех языках, поэтому имена вроде Đorđe, Nguyễn или Łukasz проходят без проблем.#JavaScript
🔥12❤7
Недавно зашел на гитхаб. Открыл 2 вкладки, в одной из них я залогинился, во второй — нет. Когда открыл вторую, там увидел вот такое сообщение.
Думаю, а как гитхаб понял, что я залогинился в другой вкладке? Пошел смотреть в дев тулзах — соединения по вебсокетам не нашел.
Пошел гуглить, узнал, что существует
Накидал демку — нужно открыть несколько вкладок и просто нажать "+1", значение обновится во всех вкладках, при этом будет указано, в какой именно вкладке произошло изменение.
Использовать очень просто, создаёшь канал с именем, а дальше из одной вкладки можно отправлять сообщения, а в другой — слушать их и как-то на это реагировать.
👍 — было полезно
👀 — уже знали про
#browser #javascript
"You signed in with another tab or window. Reload to refresh your session."
Думаю, а как гитхаб понял, что я залогинился в другой вкладке? Пошел смотреть в дев тулзах — соединения по вебсокетам не нашел.
Пошел гуглить, узнал, что существует
BroadcastChannel, с помощью которого можно реализовать взаимодействие между вкладками. Не знаю, он ли используется на гитхабе, но фича интересная.Накидал демку — нужно открыть несколько вкладок и просто нажать "+1", значение обновится во всех вкладках, при этом будет указано, в какой именно вкладке произошло изменение.
Использовать очень просто, создаёшь канал с именем, а дальше из одной вкладки можно отправлять сообщения, а в другой — слушать их и как-то на это реагировать.
const channel = new BroadcastChannel('broadcast-demo');
button.addEventListener('click', () => {
channel.postMessage({
type: 'session:changed'
});
});
channel.onmessage = (event) => {
if (event.data.type === 'session:changed') {
console.log('Получили сообщение из другой вкладки');
}
};👍 — было полезно
👀 — уже знали про
BroadcastChannel#browser #javascript
👀38👍34❤1
Часто при генерации кода ИИ использует в JavaScript ключевое слово
Я, конечно, видел
Зачем он нужен?
Оператор void вычисляет переданное выражение и всегда возвращает
Но в примере с
👍 — если знали про void
❤️ — если тоже видели, но не использовали
😱 — если ИИ уже успел нагенерить вам такого в проекте
#frontend #javascript
void.Я, конечно, видел
void, но обычно где-то в минифицированном коде. Сам никогда не использовал, если не считать C# 😄, поэтому такое немного мозолит глаза:void fetchUser();
Зачем он нужен?
Оператор void вычисляет переданное выражение и всегда возвращает
undefined.const result = void fetchUser();
console.log(result); // undefined
Но в примере с
fetchUser смысл обычно другой: так явно показывают, что промис запускается «в фоне», а результат мы специально не ждём.void fetchUser()
.catch((error) => { console.error('Failed to fetch user', error);});
👍 — если знали про void
❤️ — если тоже видели, но не использовали
😱 — если ИИ уже успел нагенерить вам такого в проекте
#frontend #javascript
👍20❤19😱3
Я пару месяцев назад сделал экспорт постов из Телеги в свой блог написанный на Astro, и агент навайбкодил мне такую конструкцию —
Обычно он используется, когда данные приходят не все сразу, а постепенно: например, из API, базы данных, файла или постраничной загрузки.
Сообщения подгружаются постепенно:
Минимальный пример выглядит так:
Наиболее простой для понимания пример применения — пагинация. Мы можем инкапсулировать всю работу с получением данных в асинхронном генераторе, и пройтись по коллекции с помощью
⚠️ Важный момент:
👍 — было полезно
👀 — уже знали про
А выгруженные посты, можно посмотреть 👉 здесь.
#javascript
for await. for await (const message of client.iterMessages(entity, { reverse: false })) {
// ....
}for await...of — это цикл для перебора асинхронных коллекций.Обычно он используется, когда данные приходят не все сразу, а постепенно: например, из API, базы данных, файла или постраничной загрузки.
Сообщения подгружаются постепенно:
for await берёт сообщения одно за другим, а когда текущая загруженная порция заканчивается, iterMessages делает следующий запрос в Telegram за новой порцией.Минимальный пример выглядит так:
const delay = (value, ms) =>
new Promise((resolve) => setTimeout(() => resolve(value), ms));
async function* makeNumbers() {
yield await delay(1, 1000);
yield await delay(2, 1000);
yield await delay(3, 1000);
}
async function run() {
for await (const number of makeNumbers()) {
console.log(number);
}
}
run();
Наиболее простой для понимания пример применения — пагинация. Мы можем инкапсулировать всю работу с получением данных в асинхронном генераторе, и пройтись по коллекции с помощью
for await. Реальный пример можно посмотреть здесь или на второй картинке.⚠️ Важный момент:
for await работает последовательно. Он не запускает все итерации параллельно.👍 — было полезно
👀 — уже знали про
for awaitА выгруженные посты, можно посмотреть 👉 здесь.
#javascript
👍18👀13❤4🤡1