
Forwarded from Малоизвестное интересное
За последнее десятилетие ИИ превратился в самую мифологизированную область прогресса, вокруг которой формируется новая техно-религия всезнания больших данных и всемогущества машинного обучения.
С каждым настоящим достижением в области ИИ мы наблюдаем параллельный рост шумихи, мифов, заблуждений и неточностей. Эти недоразумения способствуют непрозрачности систем ИИ, делая их в глазах общественности волшебными, непостижимыми и недоступными.
О новом проекте команды Даниэля Лойфера «Мифы об ИИ», цель которого помочь распутать и развенчать некоторые из этих вводящих в заблуждение идей, - в моем новом посте на 5 мин.
- на Medium http://bit.do/fHxvt
- на Яндекс Дзен https://clck.ru/QK3fS
#ИИ
С каждым настоящим достижением в области ИИ мы наблюдаем параллельный рост шумихи, мифов, заблуждений и неточностей. Эти недоразумения способствуют непрозрачности систем ИИ, делая их в глазах общественности волшебными, непостижимыми и недоступными.
О новом проекте команды Даниэля Лойфера «Мифы об ИИ», цель которого помочь распутать и развенчать некоторые из этих вводящих в заблуждение идей, - в моем новом посте на 5 мин.
- на Medium http://bit.do/fHxvt
- на Яндекс Дзен https://clck.ru/QK3fS
#ИИ
Medium
Восемь мифов об ИИ
«Люди живут в мире мифов. Мифы формируются на основе личного опыта или извлекаются из той среды, в которой человек живет… Мифологично не…
Forwarded from Малоизвестное интересное
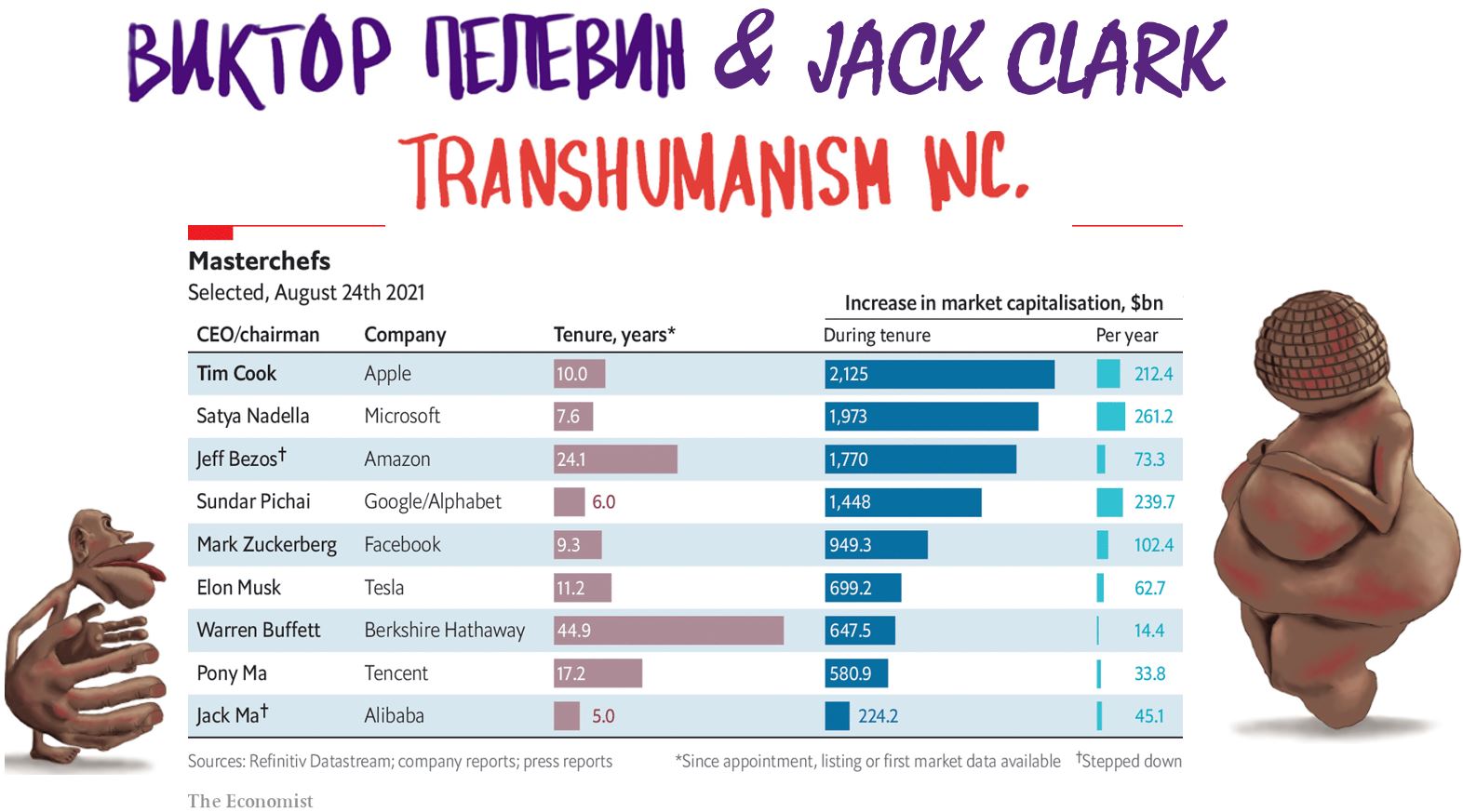
Призрак бродит по планете, призрак трансгуманизма.
Манифест Джека Кларка на Stanford HAI.
Два весьма знаменательных события этой недели – (1) в литературе и (2) в разработке ИИ, - удивительным образом сошлись в своем базовом тезисе.
• Первое событие – роман Виктора Пелевина TRANSHUMANISM INC., опубликованный вчера в России.
• Второе – «Манифест» Джека Кларка «Big models: What has happened, where are we going, and who gets to build them», с которым он выступил 23-го августа в Стэнфордском институте человеко-ориентированного ИИ (HAI).
Базовый тезис обоих текстов один и тот же:
мейнстримный тренд развития ИИ, ведет к тому, что невиданные в истории человечества материальные и нематериальные блага
• получат лишь самые богатые бизнесмены, высокие правительственные чиновники и ведущие разработчики ИИ,
• а подавляющему большинству людей эти сверхценные блага просто не достанутся.
В романе Пелевина:
«В будущем богатые люди смогут отделить свой мозг от старящегося тела - и станут жить почти вечно в особом “баночном” измерении. Туда уйдут вожди, мировые олигархи и архитекторы миропорядка. Там будет возможно все. Но в банку пустят не каждого. На земле останется зеленая посткарбоновая цивилизация, уменьшенная до размеров обслуживающего персонала, и слуг-биороботов».
Мало знакомым с положением дел в разработке ИИ такой прогноз кажется антиутопической пугалкой. Они полагаются на коммодизацию ИИ-приложений, что, по их мнению, приведет со временем к радикальному удешевлению приложений и сделает их доступными для большинства (типа современных бесплатных приложений для перевода, генерации текстов и всевозможных игр с фотографиями себя и других). Вот типичный пример такого рассуждения (4).
В отличие от таких критиков, Джек Кларк, 100%-но согласен с Пелевиным, что никакая коммодизация не спасет.
При этом Кларк – один из самых осведомленных экспертов по ИИ в мире, известностью в кругах ИИ разработчиков не уступающий Пелевину в современном российской литбомонде (погуглите, если кто не знает).
Логика «манифеста» Кларка, представленного им на Stanford HAI, не сложнее логики «Манифеста Коммунистической партии» Маркса и Энгельса.
Зачем большому бизнесу делиться сверхприбылью? Ведь до сих пор монополисты БигТеха этого не делали, лишь увеличивая свою капитализацию на десятки и сотни ярдов в год (см. 3).
Что же предлагает Кларк?
Вот логика его предложения.
А) Дальнейшее развитие ИИ решающим образом зависит от совершенствования «Больших моделей» (так Кларк именует базовые модели, которые учат на масштабируемых «больших данных», и они могут быть адаптированы для широкого круга задач нижестоящего уровня – напр. BERT, GPT-3, CLIP).
Б) Доводка и обучение Больших моделей – весьма дорогое дело. И потому это делается сейчас лишь китами БигТеха. Они забирают себе академические разработки таких моделей и совершенствуют их уже без «академиков».
В) «Академики» далее оказываются вне игры. А киты БигТеха, хоть со скрипом, но все же вынуждены делиться достижениями Больших моделей с правительством.
Г) Если все оставить как есть, основными выгодопреобретателями развития ИИ останутся киты БигТеха и высокие чиновники. А большинство людей будут лишь хлебать негативные последствия внедрения все более мощных приложений (типа тотального контроля и т.п.)
Д) Изменить положение вещей может лишь одно - Большие модели должны обучаться и совершенствоваться не БигТехом, а в академической среде (и Кларк пишет, как к этому идти)
Скорее всего, на «манифест» Кларка киты БигТеха отреагируют так же, как на роман Пелевина – не заметят или свысока покуражатся (как было с фильмом «Социальная дилемма»).
Что ж. Над манифестом компартии тоже куражились. Но для 1/7 части мира вышло только хуже. Сейчас же речь о всем мире.
Ссылки:
1 (видео)
2 (слайды)
3 (скорость обогащения)
4 (критика тезиса)
#ИИ
Манифест Джека Кларка на Stanford HAI.
Два весьма знаменательных события этой недели – (1) в литературе и (2) в разработке ИИ, - удивительным образом сошлись в своем базовом тезисе.
• Первое событие – роман Виктора Пелевина TRANSHUMANISM INC., опубликованный вчера в России.
• Второе – «Манифест» Джека Кларка «Big models: What has happened, where are we going, and who gets to build them», с которым он выступил 23-го августа в Стэнфордском институте человеко-ориентированного ИИ (HAI).
Базовый тезис обоих текстов один и тот же:
мейнстримный тренд развития ИИ, ведет к тому, что невиданные в истории человечества материальные и нематериальные блага
• получат лишь самые богатые бизнесмены, высокие правительственные чиновники и ведущие разработчики ИИ,
• а подавляющему большинству людей эти сверхценные блага просто не достанутся.
В романе Пелевина:
«В будущем богатые люди смогут отделить свой мозг от старящегося тела - и станут жить почти вечно в особом “баночном” измерении. Туда уйдут вожди, мировые олигархи и архитекторы миропорядка. Там будет возможно все. Но в банку пустят не каждого. На земле останется зеленая посткарбоновая цивилизация, уменьшенная до размеров обслуживающего персонала, и слуг-биороботов».
Мало знакомым с положением дел в разработке ИИ такой прогноз кажется антиутопической пугалкой. Они полагаются на коммодизацию ИИ-приложений, что, по их мнению, приведет со временем к радикальному удешевлению приложений и сделает их доступными для большинства (типа современных бесплатных приложений для перевода, генерации текстов и всевозможных игр с фотографиями себя и других). Вот типичный пример такого рассуждения (4).
В отличие от таких критиков, Джек Кларк, 100%-но согласен с Пелевиным, что никакая коммодизация не спасет.
При этом Кларк – один из самых осведомленных экспертов по ИИ в мире, известностью в кругах ИИ разработчиков не уступающий Пелевину в современном российской литбомонде (погуглите, если кто не знает).
Логика «манифеста» Кларка, представленного им на Stanford HAI, не сложнее логики «Манифеста Коммунистической партии» Маркса и Энгельса.
Зачем большому бизнесу делиться сверхприбылью? Ведь до сих пор монополисты БигТеха этого не делали, лишь увеличивая свою капитализацию на десятки и сотни ярдов в год (см. 3).
Что же предлагает Кларк?
Вот логика его предложения.
А) Дальнейшее развитие ИИ решающим образом зависит от совершенствования «Больших моделей» (так Кларк именует базовые модели, которые учат на масштабируемых «больших данных», и они могут быть адаптированы для широкого круга задач нижестоящего уровня – напр. BERT, GPT-3, CLIP).
Б) Доводка и обучение Больших моделей – весьма дорогое дело. И потому это делается сейчас лишь китами БигТеха. Они забирают себе академические разработки таких моделей и совершенствуют их уже без «академиков».
В) «Академики» далее оказываются вне игры. А киты БигТеха, хоть со скрипом, но все же вынуждены делиться достижениями Больших моделей с правительством.
Г) Если все оставить как есть, основными выгодопреобретателями развития ИИ останутся киты БигТеха и высокие чиновники. А большинство людей будут лишь хлебать негативные последствия внедрения все более мощных приложений (типа тотального контроля и т.п.)
Д) Изменить положение вещей может лишь одно - Большие модели должны обучаться и совершенствоваться не БигТехом, а в академической среде (и Кларк пишет, как к этому идти)
Скорее всего, на «манифест» Кларка киты БигТеха отреагируют так же, как на роман Пелевина – не заметят или свысока покуражатся (как было с фильмом «Социальная дилемма»).
Что ж. Над манифестом компартии тоже куражились. Но для 1/7 части мира вышло только хуже. Сейчас же речь о всем мире.
Ссылки:
1 (видео)
2 (слайды)
3 (скорость обогащения)
4 (критика тезиса)
#ИИ
{kind=link}
Forwarded from Малоизвестное интересное
В 2022 ИИ превзойдет людей в физике и в сложных игровых модельных средах.
Вся самая актуальная и нужная информация об ИИ в 2021 и прогнозах на 2022.
Два прогнозируемых потрясающих прорыва ИИ в следующем году:
✔️ ИИ от DeepMind совершит открытие в физике (возможно, это будет открытие в области удержания термояда).
✔️ ИИ уйдет в недосягаемый отрыв (как в шахматах и Го), соревнуясь с людьми в сложных игровых средах, моделирующих изощренные виртуальные миры.
Так считают Натан Бенайх и Ян Хогарт – серийные инвесторы в ИИ-ориентированные стартапы - 4й год подряд делающие невозможное. 4й раз они в октябре выпускают уникальный отчет о текущем состоянии дел в области ИИ такого качества (глубина проникновения в предмет, фокусировка на главное, видение за деревьями леса), что все индустриальные аналитики, консультанты и профэксперты нервно курят 😎.
188-слайдовый отчет содержит «сухой остаток» четко структурированного описания прогресса в области ИИ, уделяя особое внимание ключевым событиям последних 12 месяцев.
https://www.stateof.ai/
В завершение отчета, как и прошлые разы, даны конкретные прогнозы на грядущие 12 мес (из прошлогодних восьми сбылись пять с половиной (!)). Среди новых прогнозов, помимо двух названных, такой: ИИ-мир станет трехполярным.
✔️ Возглавляемый Дарио Амодеи стартап Anthropic (это команда звездных профи, отколовшаяся от OpenAI и привлекшая звездных инвесторов) предъявит миру свои крупномасштабные ИИ системы, что превратит Anthropic в 3-го ключевого игрока мира в области AGI.
Давать резюме прекрасно выполненной работы бессмысленно - каждый найдет здесь интересное и нужное на свой вкус.
Мне же остается, в качестве тизера, привести по одному из выводов каждого из 4-х тематических разделов отчета.
Исследования
- ИИ-национализм торжествует в разработке больших языковых моделей (LLM), - каждая страна хочет иметь свою суверенную LLM.
Таланты
- Академические группы с трудом конкурируют за вычислительные ресурсы, в то время как 88 % ведущих преподавателей ИИ получают финансирование от Big Tech.
Индустрия
- Компании, связанные с полупроводниками, значительно ускоряются по мере того, как страны стремятся к суверенитету в цепочке поставок.
Социально-политические аспекты
- ИИ в буквальном смысле становится движком гонки вооружений: автономное оружие развертывается на поле боя, и регулярно проводятся испытания новых разработок.
В общем, читайте сами этот наиполезнейший отчет с десятками графиков, диаграмм и картинок.
Мой рассказ об отчетах
2018 (https://t.me/theworldisnoteasy/545),
2019 (https://t.me/theworldisnoteasy/816),
2020 (https://t.me/theworldisnoteasy/1135),
- их ценность в том, что там много полезной инфы, ставшей с тех пор еще более актуальной.
#ИИ
Вся самая актуальная и нужная информация об ИИ в 2021 и прогнозах на 2022.
Два прогнозируемых потрясающих прорыва ИИ в следующем году:
✔️ ИИ от DeepMind совершит открытие в физике (возможно, это будет открытие в области удержания термояда).
✔️ ИИ уйдет в недосягаемый отрыв (как в шахматах и Го), соревнуясь с людьми в сложных игровых средах, моделирующих изощренные виртуальные миры.
Так считают Натан Бенайх и Ян Хогарт – серийные инвесторы в ИИ-ориентированные стартапы - 4й год подряд делающие невозможное. 4й раз они в октябре выпускают уникальный отчет о текущем состоянии дел в области ИИ такого качества (глубина проникновения в предмет, фокусировка на главное, видение за деревьями леса), что все индустриальные аналитики, консультанты и профэксперты нервно курят 😎.
188-слайдовый отчет содержит «сухой остаток» четко структурированного описания прогресса в области ИИ, уделяя особое внимание ключевым событиям последних 12 месяцев.
https://www.stateof.ai/
В завершение отчета, как и прошлые разы, даны конкретные прогнозы на грядущие 12 мес (из прошлогодних восьми сбылись пять с половиной (!)). Среди новых прогнозов, помимо двух названных, такой: ИИ-мир станет трехполярным.
✔️ Возглавляемый Дарио Амодеи стартап Anthropic (это команда звездных профи, отколовшаяся от OpenAI и привлекшая звездных инвесторов) предъявит миру свои крупномасштабные ИИ системы, что превратит Anthropic в 3-го ключевого игрока мира в области AGI.
Давать резюме прекрасно выполненной работы бессмысленно - каждый найдет здесь интересное и нужное на свой вкус.
Мне же остается, в качестве тизера, привести по одному из выводов каждого из 4-х тематических разделов отчета.
Исследования
- ИИ-национализм торжествует в разработке больших языковых моделей (LLM), - каждая страна хочет иметь свою суверенную LLM.
Таланты
- Академические группы с трудом конкурируют за вычислительные ресурсы, в то время как 88 % ведущих преподавателей ИИ получают финансирование от Big Tech.
Индустрия
- Компании, связанные с полупроводниками, значительно ускоряются по мере того, как страны стремятся к суверенитету в цепочке поставок.
Социально-политические аспекты
- ИИ в буквальном смысле становится движком гонки вооружений: автономное оружие развертывается на поле боя, и регулярно проводятся испытания новых разработок.
В общем, читайте сами этот наиполезнейший отчет с десятками графиков, диаграмм и картинок.
Мой рассказ об отчетах
2018 (https://t.me/theworldisnoteasy/545),
2019 (https://t.me/theworldisnoteasy/816),
2020 (https://t.me/theworldisnoteasy/1135),
- их ценность в том, что там много полезной инфы, ставшей с тех пор еще более актуальной.
#ИИ
www.stateof.ai
State of AI Report 2024
The State of AI Report analyses the most interesting developments in AI. Read and download here.
Forwarded from Малоизвестное интересное
Четыре важнейших откровения человека №1 в области ИИ.
Демис Хассабис о переопределении правил в Большой игре с ИИ.
Лекция Демиса Хассабиса, прочитанная им в лектории нобелевского лауреата Джона Кендрю, по своей значимости соизмерима с нобелевской.
Назову лишь четыре ключевые момента из сказанного Хассабисом. Каждый из них заслуживает серьезной научной дискуссии и может существенно повлиять на траекторию исследований и разработок в области ИИ.
✔️ Основа превосходства ИИ от DeepMind над людьми и прочими машинными интеллектами в его более изощрённой интуиции (вычислительная мощности и много данных тоже важны, но это не главное).
✔️ Главная цель в области ИИ – не его превращение в универсального решателя, типа людей (ака AGI), а в решении с помощью ИИ тех важных задач, которые люди решить не могут.
✔️ Разговоры о «черном ящике» ИИ не конструктивны. Если ИИ завтра изобретет лекарство от рака, никто не станет укорять его в необъяснимости действия этого лекарства. Сначала нужно решить задачу с помощью ИИ, а потом, возможно, уйдут годы, прежде чем люди поймут это решение.
✔️ DeepMind действительно разрабатывает ИИ для удержания плазмы термояда. Официально об этом еще не сообщалось, но работы идут.
Демис Хассабис «Использование ИИ для ускорения научных открытий»
https://www.youtube.com/watch?v=sm-VkgVX-2o
#ИИ
Демис Хассабис о переопределении правил в Большой игре с ИИ.
Лекция Демиса Хассабиса, прочитанная им в лектории нобелевского лауреата Джона Кендрю, по своей значимости соизмерима с нобелевской.
Назову лишь четыре ключевые момента из сказанного Хассабисом. Каждый из них заслуживает серьезной научной дискуссии и может существенно повлиять на траекторию исследований и разработок в области ИИ.
✔️ Основа превосходства ИИ от DeepMind над людьми и прочими машинными интеллектами в его более изощрённой интуиции (вычислительная мощности и много данных тоже важны, но это не главное).
✔️ Главная цель в области ИИ – не его превращение в универсального решателя, типа людей (ака AGI), а в решении с помощью ИИ тех важных задач, которые люди решить не могут.
✔️ Разговоры о «черном ящике» ИИ не конструктивны. Если ИИ завтра изобретет лекарство от рака, никто не станет укорять его в необъяснимости действия этого лекарства. Сначала нужно решить задачу с помощью ИИ, а потом, возможно, уйдут годы, прежде чем люди поймут это решение.
✔️ DeepMind действительно разрабатывает ИИ для удержания плазмы термояда. Официально об этом еще не сообщалось, но работы идут.
Демис Хассабис «Использование ИИ для ускорения научных открытий»
https://www.youtube.com/watch?v=sm-VkgVX-2o
#ИИ
YouTube
Kendrew Lecture 2021 pt1 - Using AI to accelerate scientific discovery - Demis Hassabis
MRC Laboratory of Molecular Biology John Kendrew Lecture 2021 part 1
Using AI to accelerate scientific discovery
Speaker: Demis Hassabis, Founder and CEO, DeepMind.
Abstract:
The past decade has seen incredible advances in the field of Artificial Intelligence…
Using AI to accelerate scientific discovery
Speaker: Demis Hassabis, Founder and CEO, DeepMind.
Abstract:
The past decade has seen incredible advances in the field of Artificial Intelligence…
Forwarded from Малоизвестное интересное
Что сулит планируемый Китаем 30-тикратный отрыв от США в ИИ?
Все медиа мира взахлеб обсуждают новую языковую модель PaLM от Google. Эта супергигантская ИИ-система обучалась на 540 миллиардов параметров (втрое больше, чем у знаменитой GPT-3), за счет чего удалось совершить очередной прорыв в качестве обработки языка.
Система PaLM способна рассуждать, применяя арифметическое и логическое мышление.
Она на раз-два решает задачи типа: «У Роджера 5 теннисных мячей. Он покупает еще 2 упаковки мячей. В каждой упаковке по 3 мяча. Сколько теннисных мячей теперь у Роджера?»
PaLM умеет объяснять
Например, шутку
«Я собирался лететь в гости к семье 6 апреля. Но мама сказала, что у отчима поэтические чтения в этот вечер, и я решил лететь 7го»
PaLM объясняет так
«Шутка в том, что мать говорящего пытается уговорить его пойти на поэтические чтения отчима, но говорящий не хочет идти, и поэтому он меняет свой рейс на следующий день после поэтических чтений».
PaLM выстраивает цепочки рассуждений.
Например, систему спрашивают:
«Дженни смотрит в окно и видит под собой очень красивое облако. Она отстегивает ремень безопасности и направляется в туалет. Возможно ли, что Дженнифер движется со скоростью более 300 миль в час относительно Земли?»
Цепочка рассуждений PaLM:
«300 миль в час – это около 480 км/ч. Это, примерно, скорость коммерческого самолёта. Облака обычно находятся ниже самолётов, поэтому Дженнифер, вероятно, летит на самолёте»
Следовательно, ответ «Да».
А теперь внимание.
✔️ ИИ системы PaLM умеет все вышеупомянутое (и много больше) используя в языковой модели для предварительного обучения до 540 млрд параметров.
✔️ ИИ-платформу BaGuaLu – совместную разработку Университета Цинхуа, Alibaba Group, Zhejiang Lab и Пекинской академии искусственного интеллекта: уже обучают на 2-х триллионах параметров; до конца года планируют довести до 14,5 трлн, а потом и до 174 трлн параметров.
Это значит, что уже до конца года у Китая может появиться отрыв в мощности языковых моделей от США в несколько десятков раз.
Ну а что будут уметь столь огромные модели с числом параметров, превосходящим число синапсов в человеческом мозге, мы не знаем. Но это может оказаться для человечества большим откровением.
Подробней см. презентацию BaGuaLu, сделанную на PPoPP несколько дней назад
https://www.youtube.com/watch?v=T3-6WH1GyRw
И описание BaGuaLu в ACM https://dl.acm.org/doi/10.1145/3503221.3508417
#Китай #БазисныеМодели #ИИ
Все медиа мира взахлеб обсуждают новую языковую модель PaLM от Google. Эта супергигантская ИИ-система обучалась на 540 миллиардов параметров (втрое больше, чем у знаменитой GPT-3), за счет чего удалось совершить очередной прорыв в качестве обработки языка.
Система PaLM способна рассуждать, применяя арифметическое и логическое мышление.
Она на раз-два решает задачи типа: «У Роджера 5 теннисных мячей. Он покупает еще 2 упаковки мячей. В каждой упаковке по 3 мяча. Сколько теннисных мячей теперь у Роджера?»
PaLM умеет объяснять
Например, шутку
«Я собирался лететь в гости к семье 6 апреля. Но мама сказала, что у отчима поэтические чтения в этот вечер, и я решил лететь 7го»
PaLM объясняет так
«Шутка в том, что мать говорящего пытается уговорить его пойти на поэтические чтения отчима, но говорящий не хочет идти, и поэтому он меняет свой рейс на следующий день после поэтических чтений».
PaLM выстраивает цепочки рассуждений.
Например, систему спрашивают:
«Дженни смотрит в окно и видит под собой очень красивое облако. Она отстегивает ремень безопасности и направляется в туалет. Возможно ли, что Дженнифер движется со скоростью более 300 миль в час относительно Земли?»
Цепочка рассуждений PaLM:
«300 миль в час – это около 480 км/ч. Это, примерно, скорость коммерческого самолёта. Облака обычно находятся ниже самолётов, поэтому Дженнифер, вероятно, летит на самолёте»
Следовательно, ответ «Да».
А теперь внимание.
✔️ ИИ системы PaLM умеет все вышеупомянутое (и много больше) используя в языковой модели для предварительного обучения до 540 млрд параметров.
✔️ ИИ-платформу BaGuaLu – совместную разработку Университета Цинхуа, Alibaba Group, Zhejiang Lab и Пекинской академии искусственного интеллекта: уже обучают на 2-х триллионах параметров; до конца года планируют довести до 14,5 трлн, а потом и до 174 трлн параметров.
Это значит, что уже до конца года у Китая может появиться отрыв в мощности языковых моделей от США в несколько десятков раз.
Ну а что будут уметь столь огромные модели с числом параметров, превосходящим число синапсов в человеческом мозге, мы не знаем. Но это может оказаться для человечества большим откровением.
Подробней см. презентацию BaGuaLu, сделанную на PPoPP несколько дней назад
https://www.youtube.com/watch?v=T3-6WH1GyRw
И описание BaGuaLu в ACM https://dl.acm.org/doi/10.1145/3503221.3508417
#Китай #БазисныеМодели #ИИ
YouTube
BAGUALU: Targeting Brain Scale Pretrained Models with over 37 Million Cores
Forwarded from Малоизвестное интересное
Белая книга ИИ 2022.
Китайский взгляд на состояние и перспективы ИИ в Китае и в мире.
Вышедший в апреле документ Китайской академии информационных и коммуникационных технологий (CAICT) оперативно и точно переведен коллегами из CSET.
Китайский взгляд на развитие ИИ с недавнего времени стал не менее (если не более) важен, чем взгляд США. И поэтому для каждого интересующегося ИИ данный документ – мастрид. По сути, это одновременно аналитическое резюме и дорожная карта развития ИИ Китая на «14-ю пятилетку» (2021-2025).
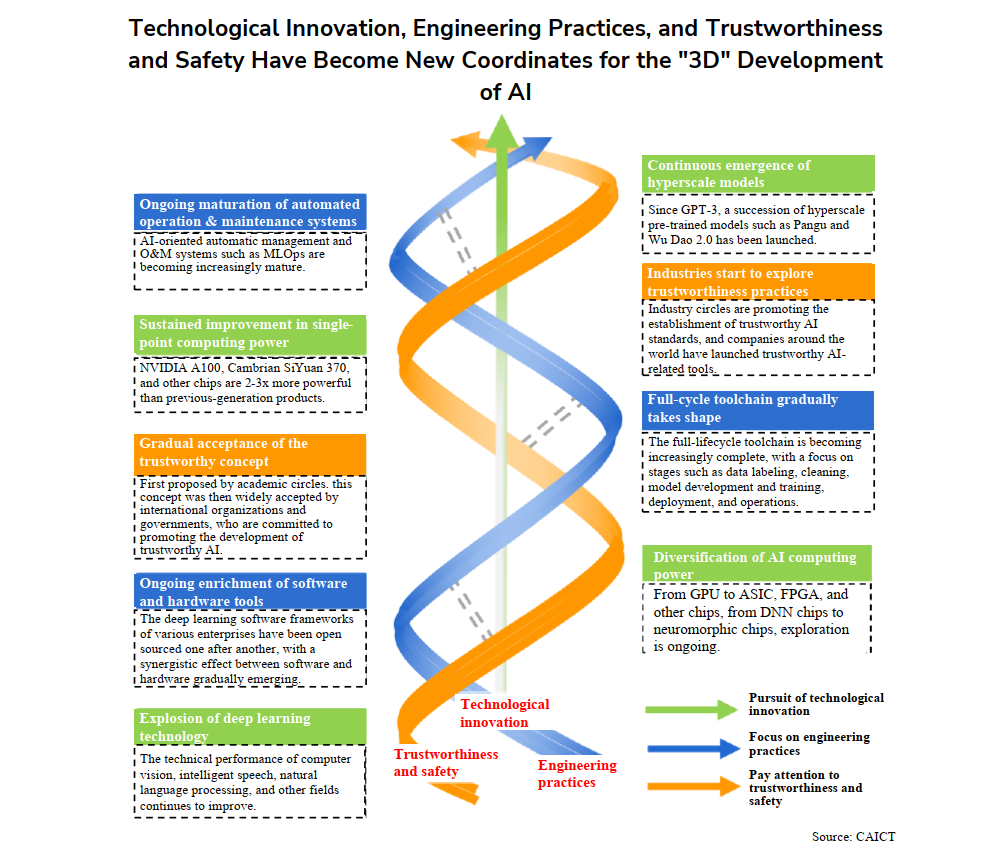
Документ фиксирует новую стадию и направление развития в «трехмерных» (3D) координатах: технологические инновации, инженерные практики (工程实践), надежность и безопасность(可信安全).
1. Инновации делают ставку на совершенствование алгоритмов и достижение сумасшедшей вычислительной мощности.
2. Инженерные практики делают ставку на индустриальную интеллектуализацию - перестройку бизнес и производственных процессов нескольких сотен индустрий (лидирующая роль здесь возложена не на специалистов ИИ или IT, а на отраслевых инженеров.
3. Правовая, стандартизующая и регламентирующая основа разработки и применения ИИ (AI governance) направлена на обеспечение надежности и безопасности применений с учетом требований прозрачности, достоверности и непредвзятости решений и рекомендаций со стороны ИИ. Ответственность за AI governance возложена на триаду правительство – отраслевые организации – предприятия.
Детали читайте в Белой книге.
Я же лишь отмечу следующее.
✔️ Китаю видятся такие роли основных мировых лидеров в ИИ:
• США – пущай себе генерят инновации (в этом им нет пока равных).
• Великобритания делает ставку на ИИ индустриализацию, и это хорошо, т.к. они будут мостом между американскими инновациями и процессами индустриальной интеллектуализации Китая.
• Япония фокусируется на совершенствовании ИИ-инфраструктуры и приложениях, и это тоже хорошо, ибо в этих вопросах японцы себя отлично зарекомендовали в других индустриях (от бытовой электроники до автомобилей).
• Других мировых лидеров в ИИ нет и на ближайшую пятилетку не предвидится.
✔️ Китай сделал ставку на Большие модели.
Их большие модели Pangu и Wu Dao 2.0 уже перешагнули пороги в 1 трлн параметров и 10 Тбайт (для сравнения в объявленной Сбером в апреле «эксклюзивной модели ruDALL-E XXL» 12 млрд параметров).
Перевод Белой книги ИИ 2022
Оригинал
#ИИ #Китай #ИИгонка
Китайский взгляд на состояние и перспективы ИИ в Китае и в мире.
Вышедший в апреле документ Китайской академии информационных и коммуникационных технологий (CAICT) оперативно и точно переведен коллегами из CSET.
Китайский взгляд на развитие ИИ с недавнего времени стал не менее (если не более) важен, чем взгляд США. И поэтому для каждого интересующегося ИИ данный документ – мастрид. По сути, это одновременно аналитическое резюме и дорожная карта развития ИИ Китая на «14-ю пятилетку» (2021-2025).
Документ фиксирует новую стадию и направление развития в «трехмерных» (3D) координатах: технологические инновации, инженерные практики (工程实践), надежность и безопасность(可信安全).
1. Инновации делают ставку на совершенствование алгоритмов и достижение сумасшедшей вычислительной мощности.
2. Инженерные практики делают ставку на индустриальную интеллектуализацию - перестройку бизнес и производственных процессов нескольких сотен индустрий (лидирующая роль здесь возложена не на специалистов ИИ или IT, а на отраслевых инженеров.
3. Правовая, стандартизующая и регламентирующая основа разработки и применения ИИ (AI governance) направлена на обеспечение надежности и безопасности применений с учетом требований прозрачности, достоверности и непредвзятости решений и рекомендаций со стороны ИИ. Ответственность за AI governance возложена на триаду правительство – отраслевые организации – предприятия.
Детали читайте в Белой книге.
Я же лишь отмечу следующее.
✔️ Китаю видятся такие роли основных мировых лидеров в ИИ:
• США – пущай себе генерят инновации (в этом им нет пока равных).
• Великобритания делает ставку на ИИ индустриализацию, и это хорошо, т.к. они будут мостом между американскими инновациями и процессами индустриальной интеллектуализации Китая.
• Япония фокусируется на совершенствовании ИИ-инфраструктуры и приложениях, и это тоже хорошо, ибо в этих вопросах японцы себя отлично зарекомендовали в других индустриях (от бытовой электроники до автомобилей).
• Других мировых лидеров в ИИ нет и на ближайшую пятилетку не предвидится.
✔️ Китай сделал ставку на Большие модели.
Их большие модели Pangu и Wu Dao 2.0 уже перешагнули пороги в 1 трлн параметров и 10 Тбайт (для сравнения в объявленной Сбером в апреле «эксклюзивной модели ruDALL-E XXL» 12 млрд параметров).
Перевод Белой книги ИИ 2022
Оригинал
#ИИ #Китай #ИИгонка
{kind=link}
Forwarded from Малоизвестное интересное
Отставание России от США в области ИИ уже колоссально.
А через несколько лет оно увеличится до трёх километров.
Так уж получилось, что прогресс в области ИИ во многом определяется наличием огромных вычислительных мощностей, требуемых для обучения гигантских нейросетей-трансформеров.
Грег Брокман (соучредитель и СТО OpenAI) формулирует это так:
«Мы думаем, что наибольшую выгоду получит тот, у кого самый большой компьютер».
Я уже демонстрировал, насколько критично наличие мощного компьютинга для обучения Больших моделей в посте «Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке».
Место России на карте мира по вычислительной мощности суперкомпьютеров более чем скромное. В списке ТОР500 суперкомпьютеров на этот год у США 149 систем, а у России 7. При этом, только одна из систем США по своей производительности превышает производительность всех российских систем (см. мой пост). Председатель оргкомитета суперкомпьютерного форума России, д.ф.м.н, член-корр. РАН Сергей Абрамов оценивает отставание России от США в области суперкомпьютинга примерно в 10 лет.
Но в области обучения больших моделей для ИИ-приложений ситуация еще хуже. Здесь мало вычислительной мощности обычных серверов и требуются специальные ускорители вычислений. Спецы по машинному обучению из Яндекса это комментируют так.
«Например, если обучать модель с нуля на обычном сервере, на это потребуется 40 лет, а если на одном GPU-ускорителе V100 — 10 лет. Но хорошая новость в том, что задача обучения легко параллелится, и если задействовать хотя бы 256 тех же самых V100, соединить их быстрым интерконнектом, то задачу можно решить всего за две недели.»
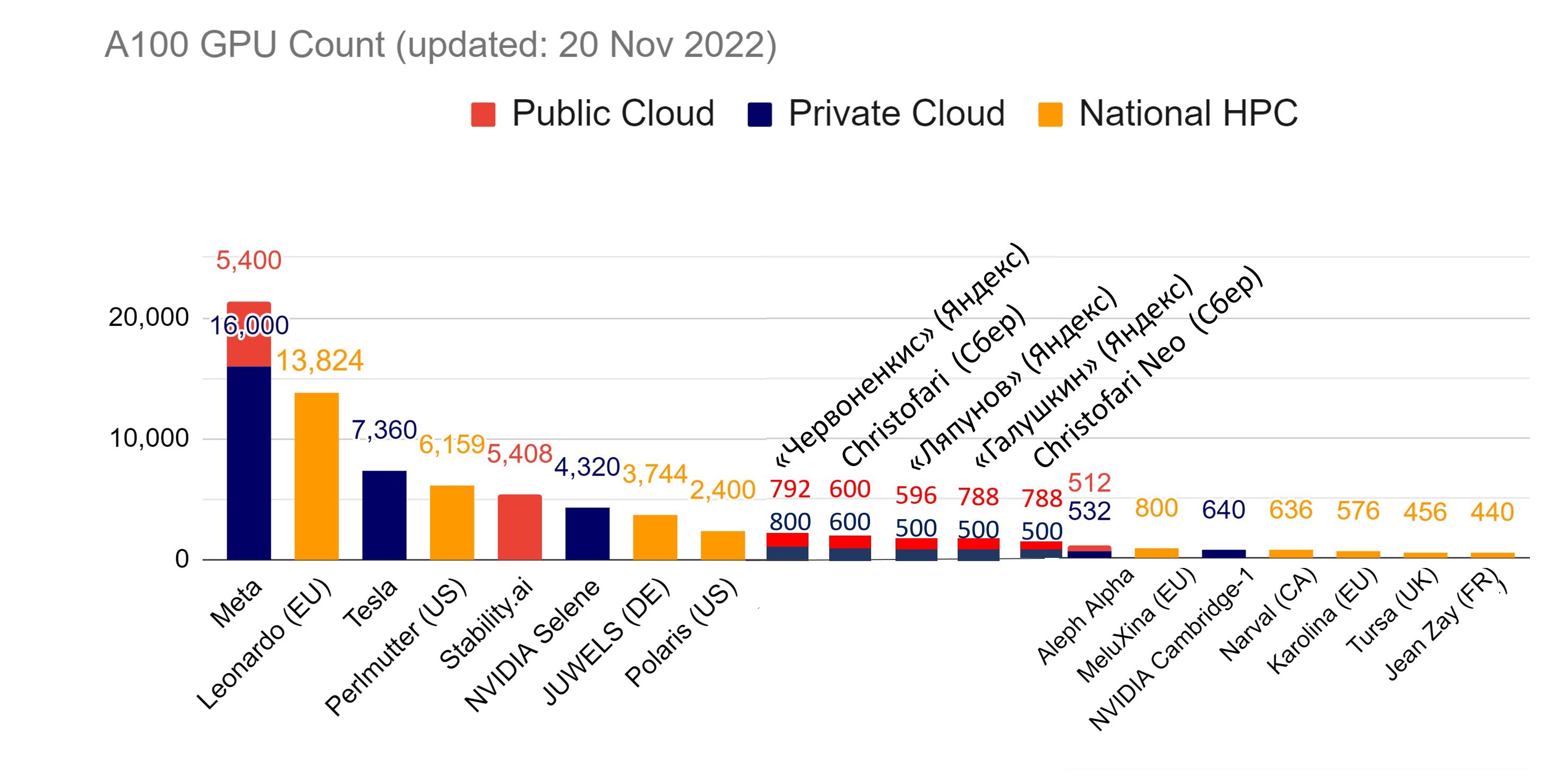
Поэтому, показатель числа GPU-ускорителей в вычислительных кластерах разных стран (общедоступных, частных и национальных) позволяет оценивать темпы развития систем ИИ в этих странах. Актуальная статистика данного показателя ведется в State of AI Report Compute Index. Состояние на 20 ноября приведено на приложенном рисунке, куда я добавил данные по пяти крупнейшим HPC-кластерам России (разбивка по public/private – моя оценка).
Из рисунка видно, что обучение больших моделей, занимающее на HPC-кластере всем известной американской компании дни и недели, будет требовать на HPC-кластере Яндекса месяцев, а то и лет.
Но это еще не вся беда. Введенные экспортные ограничения на поставку GPU-ускорителей в Россию и Китай за несколько лет многократно увеличат отрыв США в области обучения больших моделей для ИИ-приложений.
И этот отрыв будет измеряться уже не годами и даже не десятилетиями, а километрами, - как в старом советском анекдоте.
«Построили у нас самый мощный в мире компьютер и задали ему задачу, когда же наступит коммунизм. Компьютер думал, думал и выдал ответ: "Через 3 километра". На требование расшифровать столь странный ответ компьютер выдал:
— Каждая пятилетка — шаг к коммунизму.»
#ИИ #HPC #Россия #ЭкспортныйКонтроль
А через несколько лет оно увеличится до трёх километров.
Так уж получилось, что прогресс в области ИИ во многом определяется наличием огромных вычислительных мощностей, требуемых для обучения гигантских нейросетей-трансформеров.
Грег Брокман (соучредитель и СТО OpenAI) формулирует это так:
«Мы думаем, что наибольшую выгоду получит тот, у кого самый большой компьютер».
Я уже демонстрировал, насколько критично наличие мощного компьютинга для обучения Больших моделей в посте «Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке».
Место России на карте мира по вычислительной мощности суперкомпьютеров более чем скромное. В списке ТОР500 суперкомпьютеров на этот год у США 149 систем, а у России 7. При этом, только одна из систем США по своей производительности превышает производительность всех российских систем (см. мой пост). Председатель оргкомитета суперкомпьютерного форума России, д.ф.м.н, член-корр. РАН Сергей Абрамов оценивает отставание России от США в области суперкомпьютинга примерно в 10 лет.
Но в области обучения больших моделей для ИИ-приложений ситуация еще хуже. Здесь мало вычислительной мощности обычных серверов и требуются специальные ускорители вычислений. Спецы по машинному обучению из Яндекса это комментируют так.
«Например, если обучать модель с нуля на обычном сервере, на это потребуется 40 лет, а если на одном GPU-ускорителе V100 — 10 лет. Но хорошая новость в том, что задача обучения легко параллелится, и если задействовать хотя бы 256 тех же самых V100, соединить их быстрым интерконнектом, то задачу можно решить всего за две недели.»
Поэтому, показатель числа GPU-ускорителей в вычислительных кластерах разных стран (общедоступных, частных и национальных) позволяет оценивать темпы развития систем ИИ в этих странах. Актуальная статистика данного показателя ведется в State of AI Report Compute Index. Состояние на 20 ноября приведено на приложенном рисунке, куда я добавил данные по пяти крупнейшим HPC-кластерам России (разбивка по public/private – моя оценка).
Из рисунка видно, что обучение больших моделей, занимающее на HPC-кластере всем известной американской компании дни и недели, будет требовать на HPC-кластере Яндекса месяцев, а то и лет.
Но это еще не вся беда. Введенные экспортные ограничения на поставку GPU-ускорителей в Россию и Китай за несколько лет многократно увеличат отрыв США в области обучения больших моделей для ИИ-приложений.
И этот отрыв будет измеряться уже не годами и даже не десятилетиями, а километрами, - как в старом советском анекдоте.
«Построили у нас самый мощный в мире компьютер и задали ему задачу, когда же наступит коммунизм. Компьютер думал, думал и выдал ответ: "Через 3 километра". На требование расшифровать столь странный ответ компьютер выдал:
— Каждая пятилетка — шаг к коммунизму.»
#ИИ #HPC #Россия #ЭкспортныйКонтроль
{kind=link}
Forwarded from Малоизвестное интересное
Что за «потенциально страшный прорыв» совершили в OpenAI.
Секретный «проект Q*» создания «богоподобного ИИ».
Сегодняшний вал сенсационных заголовков, типа «OpenAI совершила прорыв в области искусственного интеллекта до увольнения Альтмана», «Исследователи OpenAI предупредили совет директоров о прорыве в области искусственного интеллекта перед отстранением генерального директора» и т.п., - для читателей моего канала не вовсе новости. Ибо об этом я написал еще 4 дня назад.
Но от этого вала новостей, публикуемых сегодня большинством мировых СМИ, уже нельзя отмахнуться, как от моего скромного поста. И это означает, что СМО (специальная медийная операция), внешне выглядевшая, как низкопробное, скандальное ТВ-шоу, вовсе таковой не была. Ибо имела под собой более чем веские основания – забрезжил революционный прорыв на пути к тому, что известный эксперт по ИИ Ян Хогарт назвал «богоподобным ИИ».
Из чего следовала необходимость срочных кардинальных действий и для Сама Альтмана, и для Microsoft:
• Microsoft – чтобы не оказаться с носом, уже вложив в OpenAI $13 млрд (дело в том, что по имеющемуся соглашению, все действующие договоренности между Microsoft и OpenAI остаются в силе, лишь до момента, когда совет директоров OpenAI решит, что их разработки вплотную подошли к созданию сильного ИИ (AGI). И с этого момента все договоренности могут быть пересмотрены).
• Сэму – чтобы успеть сорвать банк в игре, которую он еще 7 лет назад описал так:
«Скорее всего, ИИ приведет к концу света, но до того появятся великие компании».
И Сэму, и Microsoft требовалось одно и то же - немедленный перехват управления направлением разработок OpenAI в свои руки. И сделать это можно было, лишь освободившись от решающего влияния в совете директоров OpenAI сторонников «осторожного создания AGI на благо всему человечеству». Что и было сделано.
Однако, точного ответа, что за прорыв совершили исследователи OpenAI, мы пока не имеем.
Все утечки из среды разработчиков OpenAI упоминают некий «секретный «проект Q*» [1] по радикальному повышению производительности лингвоботов на основе LLM.
Известно, что эта работа велась, как минимум, по трем направлениям:
1. Совершенствование RAG (Retrieval Augmented Generation) – сначала поиск релевантной информации во внешней базе в целях формирования из нее оптимального промпта, и лишь затем обращение к системе за ответом). Кое-какие результаты такого совершенствования были недавно показаны на OpenAI DevDAy. И они впечатляют [2].
2. Комбинация Q-обучения и алгоритма A*.
Алгоритм A* — это способ нахождения кратчайшего пути от одной точки до другой на карте или в сети. Представьте, что вы ищете самый быстрый маршрут из одного города в другой. Алгоритм A* проверяет разные пути, оценивая, насколько они близки к цели и сколько еще предстоит пройти. Он выбирает путь, который, по его оценке, будет самым коротким. Этот алгоритм очень эффективен и используется во многих областях, например, в компьютерных играх для нахождения пути персонажей или в GPS-навигаторах.
Q-обучение — это метод обучения без учителя в области искусственного интеллекта, который используется для обучения программ принимать решения. Представьте, что вы учите робота находить выход из лабиринта. Вместо того чтобы прямо говорить ему, куда идти, вы оцениваете его действия, давая баллы за хорошие шаги и снимая за плохие. Со временем робот учится выбирать пути, приводящие к большему количеству баллов. Это и есть Q-обучение — метод, помогающий программам самостоятельно учиться на своем опыте.
3. Поиск траектории токена по дереву Монте-Карло в стиле AlphaGo. Это особенно имеет смысл в таких областях, как программирование и математика, где есть простой способ определить правильность (что может объяснять утечки о прорывном улучшении в проекте Q* способностей решения математических задач)
#ИИ #AGI
1 https://disk.yandex.ru/i/9zzI_STuNTJ6kA
2 https://habrastorage.org/r/w1560/getpro/habr/upload_files/f9a/994/b06/f9a994b060188b43ba61061270213bca.png
Секретный «проект Q*» создания «богоподобного ИИ».
Сегодняшний вал сенсационных заголовков, типа «OpenAI совершила прорыв в области искусственного интеллекта до увольнения Альтмана», «Исследователи OpenAI предупредили совет директоров о прорыве в области искусственного интеллекта перед отстранением генерального директора» и т.п., - для читателей моего канала не вовсе новости. Ибо об этом я написал еще 4 дня назад.
Но от этого вала новостей, публикуемых сегодня большинством мировых СМИ, уже нельзя отмахнуться, как от моего скромного поста. И это означает, что СМО (специальная медийная операция), внешне выглядевшая, как низкопробное, скандальное ТВ-шоу, вовсе таковой не была. Ибо имела под собой более чем веские основания – забрезжил революционный прорыв на пути к тому, что известный эксперт по ИИ Ян Хогарт назвал «богоподобным ИИ».
Из чего следовала необходимость срочных кардинальных действий и для Сама Альтмана, и для Microsoft:
• Microsoft – чтобы не оказаться с носом, уже вложив в OpenAI $13 млрд (дело в том, что по имеющемуся соглашению, все действующие договоренности между Microsoft и OpenAI остаются в силе, лишь до момента, когда совет директоров OpenAI решит, что их разработки вплотную подошли к созданию сильного ИИ (AGI). И с этого момента все договоренности могут быть пересмотрены).
• Сэму – чтобы успеть сорвать банк в игре, которую он еще 7 лет назад описал так:
«Скорее всего, ИИ приведет к концу света, но до того появятся великие компании».
И Сэму, и Microsoft требовалось одно и то же - немедленный перехват управления направлением разработок OpenAI в свои руки. И сделать это можно было, лишь освободившись от решающего влияния в совете директоров OpenAI сторонников «осторожного создания AGI на благо всему человечеству». Что и было сделано.
Однако, точного ответа, что за прорыв совершили исследователи OpenAI, мы пока не имеем.
Все утечки из среды разработчиков OpenAI упоминают некий «секретный «проект Q*» [1] по радикальному повышению производительности лингвоботов на основе LLM.
Известно, что эта работа велась, как минимум, по трем направлениям:
1. Совершенствование RAG (Retrieval Augmented Generation) – сначала поиск релевантной информации во внешней базе в целях формирования из нее оптимального промпта, и лишь затем обращение к системе за ответом). Кое-какие результаты такого совершенствования были недавно показаны на OpenAI DevDAy. И они впечатляют [2].
2. Комбинация Q-обучения и алгоритма A*.
Алгоритм A* — это способ нахождения кратчайшего пути от одной точки до другой на карте или в сети. Представьте, что вы ищете самый быстрый маршрут из одного города в другой. Алгоритм A* проверяет разные пути, оценивая, насколько они близки к цели и сколько еще предстоит пройти. Он выбирает путь, который, по его оценке, будет самым коротким. Этот алгоритм очень эффективен и используется во многих областях, например, в компьютерных играх для нахождения пути персонажей или в GPS-навигаторах.
Q-обучение — это метод обучения без учителя в области искусственного интеллекта, который используется для обучения программ принимать решения. Представьте, что вы учите робота находить выход из лабиринта. Вместо того чтобы прямо говорить ему, куда идти, вы оцениваете его действия, давая баллы за хорошие шаги и снимая за плохие. Со временем робот учится выбирать пути, приводящие к большему количеству баллов. Это и есть Q-обучение — метод, помогающий программам самостоятельно учиться на своем опыте.
3. Поиск траектории токена по дереву Монте-Карло в стиле AlphaGo. Это особенно имеет смысл в таких областях, как программирование и математика, где есть простой способ определить правильность (что может объяснять утечки о прорывном улучшении в проекте Q* способностей решения математических задач)
#ИИ #AGI
1 https://disk.yandex.ru/i/9zzI_STuNTJ6kA
2 https://habrastorage.org/r/w1560/getpro/habr/upload_files/f9a/994/b06/f9a994b060188b43ba61061270213bca.png
Яндекс Диск
Проект Q.JPG
Посмотреть и скачать с Яндекс Диска
Forwarded from Малоизвестное интересное
Помимо “процессора” и “памяти”, в мозге людей есть “машина времени”.
Это альтернативная когнитивная сущность принципиально отличает нас от ИИ.
Опубликованное в Nature Neuroscience исследование Йельского университета – это холодный душ для исследователей генеративного ИИ, полагающихся на его, хотя бы частичный, антропоморфизм (мол, это что-то типа самолета, похожего на птицу, но летающего с неподвижными крыльями).
Ведь можно бесконечно спорить, понимает ли большая языковая модель или нет, мыслит ли она или нет, способна ли на волевое действие или нет …, ибо все эти понятия расплывчаты и эфемерны. И пока нет даже гипотез, как эти феномены инструментально анализировать.
И тут вдруг исследователи из Йеля выкатывают инструментальное исследования (фМРТ + распознавание паттернов с помощью машинного обучения), из которого следует, что:
• травматические воспоминания людей – это вовсе не их память, типа обычных веселых, грустных или нейтральных воспоминаний о прошлом опыте людей, как-то и где-то записанных в мозге, подобно ячейкам памяти компьютеров, откуда их можно считывать по требованию;
• травматические воспоминания об ужасах войны, пережитом насилии и прочих корежущих душу кошмарах – это натуральные флешбэки, заставляющие не только сознание человека, но и все его тело снова переноситься (как бы на машине времени) в прошлое и заново переживать всю ту же душевную и физическую боль;
• отсюда все страшные последствия ПТСР - панические атаки, агрессивность, уход в себя, деформация личности, - возникающие у страдающих ПТСР в результате все повторяющихся и повторяющихся душевных и физических мучений, от которых нет спасения (как от платка, что снова и снова подавали Фриде, пока ее не избавила от этого ПТСР Маргарита);
• в отличие от памяти, у этих флешбэков и механизм иной, и способ обработки: память обрабатывается в мозге гиппокампом, а травматические флешбэки - задней поясной извилиной (областью мозга, обычно связанной с обработкой мыслей); порождаемые памятью и травматическими флешбэками паттерны мозговой активности абсолютно разные.
Наличие этой своеобразной «машины времени» в мозге людей, заставляющей всю его отелесненную сущность (а не только то, что мы называем «душой») заново и заново переносить весь спектр когда-то пережитых мучений, - это какой-то садистический трюк, придуманный эволюцией.
Зачем ей нужен этот садизм, науке еще предстоит объяснить.
Однако, наличие у людей альтернативной памяти когнитивной сущности можно считать установленным. И это убедительный аргумент против попыток антропоморфизации когнитивных механизмов ИИ.
• Спектр когнитивных отличий ИИ от людей широк и, видимо, будет еще расширяться по результатам новых исследований.
• Но и единственного когнитивного подобия – владения нашим языком, - для ИИ будет, скорее всего, достаточно для достижения интеллектуально превосходства над людьми в широчайшем перечне областей.
Ибо, как писал Л.Витгенштейн, “язык - это «форма жизни»”… общая для людей и ИИ, - добавлю я от себя.
Подробней:
- популярно https://www.livescience.com/health/neuroscience/traumatic-memories-are-processed-differently-in-ptsd
- научно https://www.nature.com/articles/s41593-023-01483-5
#ИИ #Язык #LLM
Это альтернативная когнитивная сущность принципиально отличает нас от ИИ.
Опубликованное в Nature Neuroscience исследование Йельского университета – это холодный душ для исследователей генеративного ИИ, полагающихся на его, хотя бы частичный, антропоморфизм (мол, это что-то типа самолета, похожего на птицу, но летающего с неподвижными крыльями).
Ведь можно бесконечно спорить, понимает ли большая языковая модель или нет, мыслит ли она или нет, способна ли на волевое действие или нет …, ибо все эти понятия расплывчаты и эфемерны. И пока нет даже гипотез, как эти феномены инструментально анализировать.
И тут вдруг исследователи из Йеля выкатывают инструментальное исследования (фМРТ + распознавание паттернов с помощью машинного обучения), из которого следует, что:
• травматические воспоминания людей – это вовсе не их память, типа обычных веселых, грустных или нейтральных воспоминаний о прошлом опыте людей, как-то и где-то записанных в мозге, подобно ячейкам памяти компьютеров, откуда их можно считывать по требованию;
• травматические воспоминания об ужасах войны, пережитом насилии и прочих корежущих душу кошмарах – это натуральные флешбэки, заставляющие не только сознание человека, но и все его тело снова переноситься (как бы на машине времени) в прошлое и заново переживать всю ту же душевную и физическую боль;
• отсюда все страшные последствия ПТСР - панические атаки, агрессивность, уход в себя, деформация личности, - возникающие у страдающих ПТСР в результате все повторяющихся и повторяющихся душевных и физических мучений, от которых нет спасения (как от платка, что снова и снова подавали Фриде, пока ее не избавила от этого ПТСР Маргарита);
• в отличие от памяти, у этих флешбэков и механизм иной, и способ обработки: память обрабатывается в мозге гиппокампом, а травматические флешбэки - задней поясной извилиной (областью мозга, обычно связанной с обработкой мыслей); порождаемые памятью и травматическими флешбэками паттерны мозговой активности абсолютно разные.
Наличие этой своеобразной «машины времени» в мозге людей, заставляющей всю его отелесненную сущность (а не только то, что мы называем «душой») заново и заново переносить весь спектр когда-то пережитых мучений, - это какой-то садистический трюк, придуманный эволюцией.
Зачем ей нужен этот садизм, науке еще предстоит объяснить.
Однако, наличие у людей альтернативной памяти когнитивной сущности можно считать установленным. И это убедительный аргумент против попыток антропоморфизации когнитивных механизмов ИИ.
• Спектр когнитивных отличий ИИ от людей широк и, видимо, будет еще расширяться по результатам новых исследований.
• Но и единственного когнитивного подобия – владения нашим языком, - для ИИ будет, скорее всего, достаточно для достижения интеллектуально превосходства над людьми в широчайшем перечне областей.
Ибо, как писал Л.Витгенштейн, “язык - это «форма жизни»”… общая для людей и ИИ, - добавлю я от себя.
Подробней:
- популярно https://www.livescience.com/health/neuroscience/traumatic-memories-are-processed-differently-in-ptsd
- научно https://www.nature.com/articles/s41593-023-01483-5
#ИИ #Язык #LLM
livescience.com
Traumatic memories are processed differently in PTSD
People with PTSD feel like they're reliving past experiences in the present. This may be tied to how the brain processes memories of those experiences.