
Дайджест статей 21/08/2021
Обдурить Шаи-Хулуда
https://habr.com/ru/post/573766/
Как в Datalake объединить слишком большое количество небольших файлов в несколько больших с помощью Apache Spark
https://habr.com/ru/post/572522/
Как не утонуть в озере данных: инструкция от РСХБ
https://habr.com/ru/company/rshb/blog/573322/
Обдурить Шаи-Хулуда
https://habr.com/ru/post/573766/
Как в Datalake объединить слишком большое количество небольших файлов в несколько больших с помощью Apache Spark
https://habr.com/ru/post/572522/
Как не утонуть в озере данных: инструкция от РСХБ
https://habr.com/ru/company/rshb/blog/573322/
Хабр
Обдурить Шаи-Хулуда
Привет, Хабр! Сегодня поговорим о «больших данных» в кибербезопасности, а точнее, о том насколько легко - или сложно - обойти защиту, использующую Big Data. Иначе говоря, как надурить и объегорить...
3 Themes Surface in the 2021 Hype Cycle for Emerging Technologies
https://www.gartner.com/smarterwithgartner/3-themes-surface-in-the-2021-hype-cycle-for-emerging-technologies/
https://www.gartner.com/smarterwithgartner/3-themes-surface-in-the-2021-hype-cycle-for-emerging-technologies/
Всем привет! Я заранее прошу прощения за саморекламу, но хочется поделиться радостью 🙂 Да и в целом не совсем оффтопик же 🙂
Текстовая модель ruRoberta-large finetune, которую разработал SberDevices, стала лучшей по пониманию текста в соответствии с оценкой главного русскоязычного бенчмарка для оценки больших текстовых моделей Russian SuperGLUE.
https://gazeta.ru/tech/news/2021/08/25/n_16429268.shtml
Текстовая модель ruRoberta-large finetune, которую разработал SberDevices, стала лучшей по пониманию текста в соответствии с оценкой главного русскоязычного бенчмарка для оценки больших текстовых моделей Russian SuperGLUE.
https://gazeta.ru/tech/news/2021/08/25/n_16429268.shtml
Газета.Ru
Языковые модели от SberDevices стали лучшими в мире по пониманию текстов на русском языке
Текстовая модель ruRoberta-large finetune, которую разработал SberDevices, стала лучшей по пониманию текста в соответствии с оценкой главного русскоязычного бенчмарка для оценки больших текстовых моделей Russian SuperGLUE, уступая по точности только человеку…
Дайджест статей 27/08/2021
Как мы внедряем машинное зрение на Стойленском ГОКе
https://habr.com/ru/company/redmadrobot/blog/571504/
Airbyte для управления потоками данных – репликация Яндекс.Метрика в S3
https://habr.com/ru/company/otus/blog/574704/
Хитрый сплав: как мы соединили дата-сайентистов, разработчиков и технологов и чем это помогло металлургии
https://habr.com/ru/company/evraz/blog/573340/
Как мы внедрили BI-платформу и начали развивать self-service аналитику
https://habr.com/ru/post/574890/?utm_source=habrahabr&utm_medium=rss&utm_campaign=574890
Чего компании ждут от Data Scientist в 2021
https://habr.com/ru/post/574674/?utm_source=habrahabr&utm_medium=rss&utm_campaign=574674
Как мы внедряем машинное зрение на Стойленском ГОКе
https://habr.com/ru/company/redmadrobot/blog/571504/
Airbyte для управления потоками данных – репликация Яндекс.Метрика в S3
https://habr.com/ru/company/otus/blog/574704/
Хитрый сплав: как мы соединили дата-сайентистов, разработчиков и технологов и чем это помогло металлургии
https://habr.com/ru/company/evraz/blog/573340/
Как мы внедрили BI-платформу и начали развивать self-service аналитику
https://habr.com/ru/post/574890/?utm_source=habrahabr&utm_medium=rss&utm_campaign=574890
Чего компании ждут от Data Scientist в 2021
https://habr.com/ru/post/574674/?utm_source=habrahabr&utm_medium=rss&utm_campaign=574674
Хабр
Как мы внедряем машинное зрение на Стойленском ГОКе
Вместе с группой НЛМК рассказываем, как машинное зрение сделает процесс по перевозке сырья на Стойленском горно-обогатительном комбинате безопаснее и в перспективе позволит сократить...
Forwarded from Малоизвестное интересное
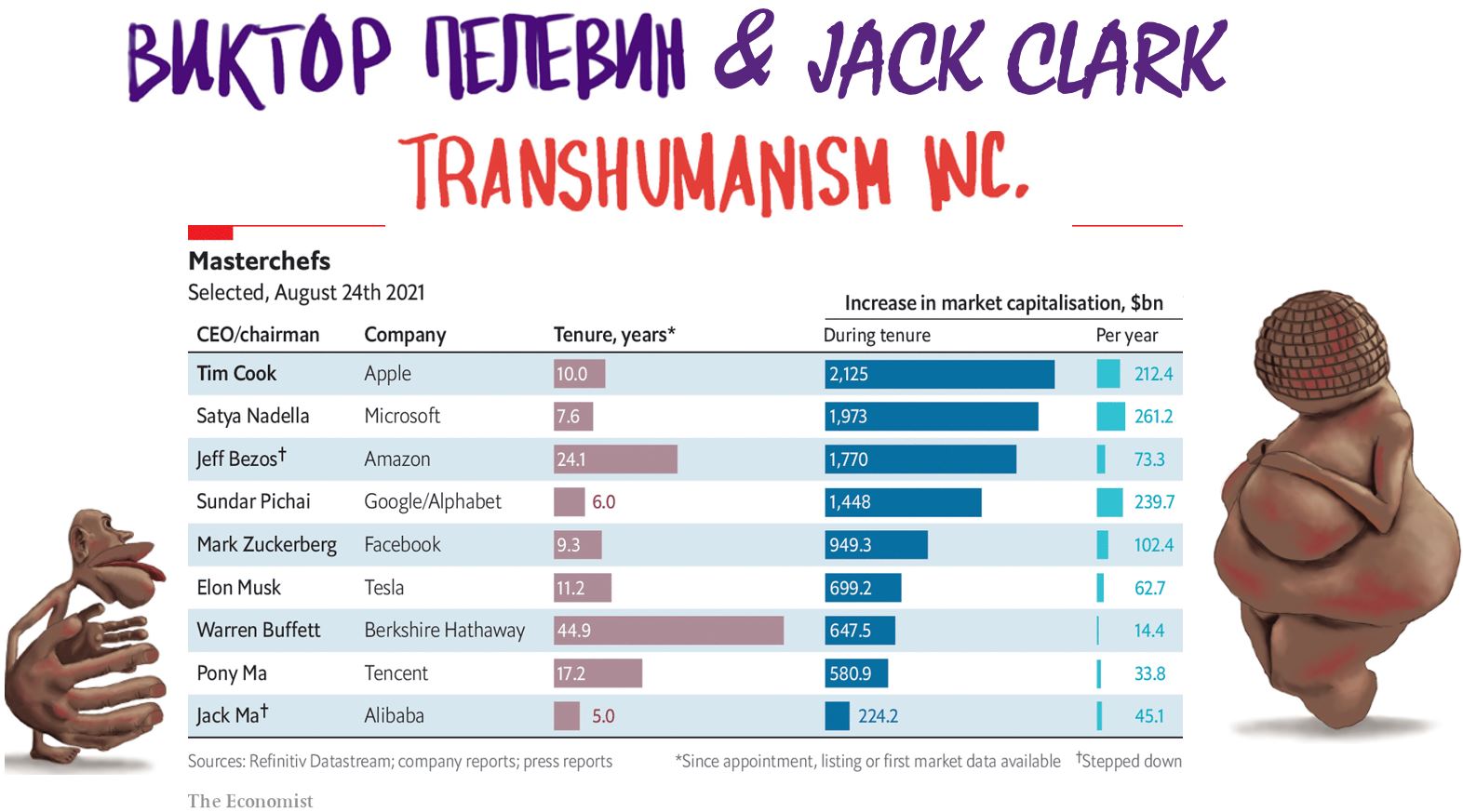
Призрак бродит по планете, призрак трансгуманизма.
Манифест Джека Кларка на Stanford HAI.
Два весьма знаменательных события этой недели – (1) в литературе и (2) в разработке ИИ, - удивительным образом сошлись в своем базовом тезисе.
• Первое событие – роман Виктора Пелевина TRANSHUMANISM INC., опубликованный вчера в России.
• Второе – «Манифест» Джека Кларка «Big models: What has happened, where are we going, and who gets to build them», с которым он выступил 23-го августа в Стэнфордском институте человеко-ориентированного ИИ (HAI).
Базовый тезис обоих текстов один и тот же:
мейнстримный тренд развития ИИ, ведет к тому, что невиданные в истории человечества материальные и нематериальные блага
• получат лишь самые богатые бизнесмены, высокие правительственные чиновники и ведущие разработчики ИИ,
• а подавляющему большинству людей эти сверхценные блага просто не достанутся.
В романе Пелевина:
«В будущем богатые люди смогут отделить свой мозг от старящегося тела - и станут жить почти вечно в особом “баночном” измерении. Туда уйдут вожди, мировые олигархи и архитекторы миропорядка. Там будет возможно все. Но в банку пустят не каждого. На земле останется зеленая посткарбоновая цивилизация, уменьшенная до размеров обслуживающего персонала, и слуг-биороботов».
Мало знакомым с положением дел в разработке ИИ такой прогноз кажется антиутопической пугалкой. Они полагаются на коммодизацию ИИ-приложений, что, по их мнению, приведет со временем к радикальному удешевлению приложений и сделает их доступными для большинства (типа современных бесплатных приложений для перевода, генерации текстов и всевозможных игр с фотографиями себя и других). Вот типичный пример такого рассуждения (4).
В отличие от таких критиков, Джек Кларк, 100%-но согласен с Пелевиным, что никакая коммодизация не спасет.
При этом Кларк – один из самых осведомленных экспертов по ИИ в мире, известностью в кругах ИИ разработчиков не уступающий Пелевину в современном российской литбомонде (погуглите, если кто не знает).
Логика «манифеста» Кларка, представленного им на Stanford HAI, не сложнее логики «Манифеста Коммунистической партии» Маркса и Энгельса.
Зачем большому бизнесу делиться сверхприбылью? Ведь до сих пор монополисты БигТеха этого не делали, лишь увеличивая свою капитализацию на десятки и сотни ярдов в год (см. 3).
Что же предлагает Кларк?
Вот логика его предложения.
А) Дальнейшее развитие ИИ решающим образом зависит от совершенствования «Больших моделей» (так Кларк именует базовые модели, которые учат на масштабируемых «больших данных», и они могут быть адаптированы для широкого круга задач нижестоящего уровня – напр. BERT, GPT-3, CLIP).
Б) Доводка и обучение Больших моделей – весьма дорогое дело. И потому это делается сейчас лишь китами БигТеха. Они забирают себе академические разработки таких моделей и совершенствуют их уже без «академиков».
В) «Академики» далее оказываются вне игры. А киты БигТеха, хоть со скрипом, но все же вынуждены делиться достижениями Больших моделей с правительством.
Г) Если все оставить как есть, основными выгодопреобретателями развития ИИ останутся киты БигТеха и высокие чиновники. А большинство людей будут лишь хлебать негативные последствия внедрения все более мощных приложений (типа тотального контроля и т.п.)
Д) Изменить положение вещей может лишь одно - Большие модели должны обучаться и совершенствоваться не БигТехом, а в академической среде (и Кларк пишет, как к этому идти)
Скорее всего, на «манифест» Кларка киты БигТеха отреагируют так же, как на роман Пелевина – не заметят или свысока покуражатся (как было с фильмом «Социальная дилемма»).
Что ж. Над манифестом компартии тоже куражились. Но для 1/7 части мира вышло только хуже. Сейчас же речь о всем мире.
Ссылки:
1 (видео)
2 (слайды)
3 (скорость обогащения)
4 (критика тезиса)
#ИИ
Манифест Джека Кларка на Stanford HAI.
Два весьма знаменательных события этой недели – (1) в литературе и (2) в разработке ИИ, - удивительным образом сошлись в своем базовом тезисе.
• Первое событие – роман Виктора Пелевина TRANSHUMANISM INC., опубликованный вчера в России.
• Второе – «Манифест» Джека Кларка «Big models: What has happened, where are we going, and who gets to build them», с которым он выступил 23-го августа в Стэнфордском институте человеко-ориентированного ИИ (HAI).
Базовый тезис обоих текстов один и тот же:
мейнстримный тренд развития ИИ, ведет к тому, что невиданные в истории человечества материальные и нематериальные блага
• получат лишь самые богатые бизнесмены, высокие правительственные чиновники и ведущие разработчики ИИ,
• а подавляющему большинству людей эти сверхценные блага просто не достанутся.
В романе Пелевина:
«В будущем богатые люди смогут отделить свой мозг от старящегося тела - и станут жить почти вечно в особом “баночном” измерении. Туда уйдут вожди, мировые олигархи и архитекторы миропорядка. Там будет возможно все. Но в банку пустят не каждого. На земле останется зеленая посткарбоновая цивилизация, уменьшенная до размеров обслуживающего персонала, и слуг-биороботов».
Мало знакомым с положением дел в разработке ИИ такой прогноз кажется антиутопической пугалкой. Они полагаются на коммодизацию ИИ-приложений, что, по их мнению, приведет со временем к радикальному удешевлению приложений и сделает их доступными для большинства (типа современных бесплатных приложений для перевода, генерации текстов и всевозможных игр с фотографиями себя и других). Вот типичный пример такого рассуждения (4).
В отличие от таких критиков, Джек Кларк, 100%-но согласен с Пелевиным, что никакая коммодизация не спасет.
При этом Кларк – один из самых осведомленных экспертов по ИИ в мире, известностью в кругах ИИ разработчиков не уступающий Пелевину в современном российской литбомонде (погуглите, если кто не знает).
Логика «манифеста» Кларка, представленного им на Stanford HAI, не сложнее логики «Манифеста Коммунистической партии» Маркса и Энгельса.
Зачем большому бизнесу делиться сверхприбылью? Ведь до сих пор монополисты БигТеха этого не делали, лишь увеличивая свою капитализацию на десятки и сотни ярдов в год (см. 3).
Что же предлагает Кларк?
Вот логика его предложения.
А) Дальнейшее развитие ИИ решающим образом зависит от совершенствования «Больших моделей» (так Кларк именует базовые модели, которые учат на масштабируемых «больших данных», и они могут быть адаптированы для широкого круга задач нижестоящего уровня – напр. BERT, GPT-3, CLIP).
Б) Доводка и обучение Больших моделей – весьма дорогое дело. И потому это делается сейчас лишь китами БигТеха. Они забирают себе академические разработки таких моделей и совершенствуют их уже без «академиков».
В) «Академики» далее оказываются вне игры. А киты БигТеха, хоть со скрипом, но все же вынуждены делиться достижениями Больших моделей с правительством.
Г) Если все оставить как есть, основными выгодопреобретателями развития ИИ останутся киты БигТеха и высокие чиновники. А большинство людей будут лишь хлебать негативные последствия внедрения все более мощных приложений (типа тотального контроля и т.п.)
Д) Изменить положение вещей может лишь одно - Большие модели должны обучаться и совершенствоваться не БигТехом, а в академической среде (и Кларк пишет, как к этому идти)
Скорее всего, на «манифест» Кларка киты БигТеха отреагируют так же, как на роман Пелевина – не заметят или свысока покуражатся (как было с фильмом «Социальная дилемма»).
Что ж. Над манифестом компартии тоже куражились. Но для 1/7 части мира вышло только хуже. Сейчас же речь о всем мире.
Ссылки:
1 (видео)
2 (слайды)
3 (скорость обогащения)
4 (критика тезиса)
#ИИ
{kind=link}
что бы все таки не отходить далеко от основной темы канала - управление данными, вот еще одна статья на тему разницы между DWH и DataLake.
Из значимого в статье я бы отметил, что решения предназначены для разных категорий пользователей: DWH для аналитиков, DL для саентистов.
Ну и хорошая стравнительная картинка.
https://www.smartdatacollective.com/understanding-the-differences-between-data-lakes-and-data-warehouses/?utm_source=feedburner&utm_medium=feed&utm_campaign=Smart+Data+Collective+%28all+posts%29
Из значимого в статье я бы отметил, что решения предназначены для разных категорий пользователей: DWH для аналитиков, DL для саентистов.
Ну и хорошая стравнительная картинка.
https://www.smartdatacollective.com/understanding-the-differences-between-data-lakes-and-data-warehouses/?utm_source=feedburner&utm_medium=feed&utm_campaign=Smart+Data+Collective+%28all+posts%29
друзья, я тут попробую прикрутить нативные комментарии к постам, прошу прощения если будет какой-то тестовый спам. спаибо заранее за понимание 🙂
Очень нравятся книги Сергея Шумского, думаю и эта достойна прочтения
https://www.ozon.ru/product/vospitanie-mashin-novaya-istoriya-razuma-shumskiy-sergey-a-283215977/
https://www.ozon.ru/product/vospitanie-mashin-novaya-istoriya-razuma-shumskiy-sergey-a-283215977/
www.ozon.ru
Воспитание машин: Новая история разума | Шумский Сергей А. - купить на OZON
Воспитание машин: Новая история разума | Шумский Сергей А. - купить в интернет-магазине OZON по выгодным ценам! Характеристики ✔ Фото ✔ Огромный ассортимент ✔ Настоящие отзывы покупателей!
Дайджест статей 04/09/2021
Essential Features of Data Quality Tool
http://www.datasciencecentral.com/xn/detail/6448529:BlogPost:1065569
Управление сложностью legacy-кода в Big Data проектах с помощью инструмента Datalog
https://habr.com/ru/post/576034/?utm_source=habrahabr&utm_medium=rss&utm_campaign=576034
6 правил по обеспечению качества данных для машинного обучения
https://habr.com/ru/post/573590/?utm_source=habrahabr&utm_medium=rss&utm_campaign=573590
В чем разница между DevOps и MLOps?
https://habr.com/ru/company/nixys/blog/573444/
Собственная методология разработки R&D-проектов в AI, от идеи до создания
https://habr.com/ru/company/selectel/blog/575692/
CI/CD Trend Report 2021: Key Takeaways
https://dzone.com/articles/cicd-trend-report-2021-key-takeaways
5 этапов, гарантирующих успешную разметку данных
https://habr.com/ru/post/574314/
Декларативное описание структур данных в RDBMS
https://habr.com/ru/post/575254/
Essential Features of Data Quality Tool
http://www.datasciencecentral.com/xn/detail/6448529:BlogPost:1065569
Управление сложностью legacy-кода в Big Data проектах с помощью инструмента Datalog
https://habr.com/ru/post/576034/?utm_source=habrahabr&utm_medium=rss&utm_campaign=576034
6 правил по обеспечению качества данных для машинного обучения
https://habr.com/ru/post/573590/?utm_source=habrahabr&utm_medium=rss&utm_campaign=573590
В чем разница между DevOps и MLOps?
https://habr.com/ru/company/nixys/blog/573444/
Собственная методология разработки R&D-проектов в AI, от идеи до создания
https://habr.com/ru/company/selectel/blog/575692/
CI/CD Trend Report 2021: Key Takeaways
https://dzone.com/articles/cicd-trend-report-2021-key-takeaways
5 этапов, гарантирующих успешную разметку данных
https://habr.com/ru/post/574314/
Декларативное описание структур данных в RDBMS
https://habr.com/ru/post/575254/
#AI
Интересное сочетание трендов.
Шумский в своей книге "Воспитание машин: Новая история разума" на цифрах доказывает, что общая вычислительная мощность всей имеющейся вычислительной техники уже превышает вычислительную мощность мозга.
Карелин очень много пишет в последнее время про перспективы разработки ИИ на основе базисных моделей. Это сверх большие модели, типа GPT-3, BERT и тп, имеющих миллиарды параметров и обучение которых требует миллионы долларов, что под силу только технологическим гигантам. При этом эти модели выглядят хотя и убого, с точки зрения когнитивных возможностей человека, но перспективными и есть гипотеза, что дальнейшее увеличение таких моделей это один из возможных путей к AGI. Встает задача, как получить такие вычислительные мощности, что бы можно было продолжить наращивать сложность и объем базисных моделей?
Я уже писал ранее про проект Folding at Home и про то, что объединение обычных пользовательских компьютеров в единую вычислительную сеть позволило увеличь общую вычислительную мощность проекта до 470 петафлопс (по состоянию на 2019 год, если не ошибаюсь). Таким образом, проект Folding@Home можно назвать самым мощным суперкомпьютером в мире, уступающим лишь Bitcoin, мощность которого составляет 80 704 291 петафлопс. Для сравнения, первую строчку в мировом рейтинге суперкомпьютеров TOP500 занимает система «Summit» с теоретической пиковой производительностью около 200 петафлопс.
И вот попалась инверсная работа ребят из Яндекса, которые разрабатывают метод децентрализованного обучения Distributed Deep Learning in Open Collaborations, который позволяет обучать DL модели на кластере распределенных дешёвых машин. Особенностью и проблемой тут является то, что участники такой распределенной вычислительной сети довольно ненадежны в том плане, что они могут случайно подключаться и отключаться от сети вне зависимости от статуса выполнения своей задачи. Так же свои сложности вносит и разнородность/ненадежность сети между участниками и разнообразие вычислительной мощности каждого участника. Пока разработки библиотеки (что интересно, на Python) в довольно начальном состоянии, но перспективы интересные. Подробно метод описан по ссылке ниже, так же приведены ссылки на материалы, github и тд.
Как итог - продолжаю идет о том, что будущее за распределенными децентрализованными решениями. А еще у меня тут постоянно посещает идея, что мы, возможно, не правильно вообще думаем, что AGI это аналог интеллекта одного человека. Очень может быть, что он больше будет похож на социальный интеллект всего человечества в целом. Меня довольно сильно интересует не только как функционирует каждый отдельный мозг как один элемент общей мыслительной сети всей совокупности людей, но и производные свойства типа shared knowledge и тд.
https://habr.com/ru/company/yandex/blog/574466/
Интересное сочетание трендов.
Шумский в своей книге "Воспитание машин: Новая история разума" на цифрах доказывает, что общая вычислительная мощность всей имеющейся вычислительной техники уже превышает вычислительную мощность мозга.
Карелин очень много пишет в последнее время про перспективы разработки ИИ на основе базисных моделей. Это сверх большие модели, типа GPT-3, BERT и тп, имеющих миллиарды параметров и обучение которых требует миллионы долларов, что под силу только технологическим гигантам. При этом эти модели выглядят хотя и убого, с точки зрения когнитивных возможностей человека, но перспективными и есть гипотеза, что дальнейшее увеличение таких моделей это один из возможных путей к AGI. Встает задача, как получить такие вычислительные мощности, что бы можно было продолжить наращивать сложность и объем базисных моделей?
Я уже писал ранее про проект Folding at Home и про то, что объединение обычных пользовательских компьютеров в единую вычислительную сеть позволило увеличь общую вычислительную мощность проекта до 470 петафлопс (по состоянию на 2019 год, если не ошибаюсь). Таким образом, проект Folding@Home можно назвать самым мощным суперкомпьютером в мире, уступающим лишь Bitcoin, мощность которого составляет 80 704 291 петафлопс. Для сравнения, первую строчку в мировом рейтинге суперкомпьютеров TOP500 занимает система «Summit» с теоретической пиковой производительностью около 200 петафлопс.
И вот попалась инверсная работа ребят из Яндекса, которые разрабатывают метод децентрализованного обучения Distributed Deep Learning in Open Collaborations, который позволяет обучать DL модели на кластере распределенных дешёвых машин. Особенностью и проблемой тут является то, что участники такой распределенной вычислительной сети довольно ненадежны в том плане, что они могут случайно подключаться и отключаться от сети вне зависимости от статуса выполнения своей задачи. Так же свои сложности вносит и разнородность/ненадежность сети между участниками и разнообразие вычислительной мощности каждого участника. Пока разработки библиотеки (что интересно, на Python) в довольно начальном состоянии, но перспективы интересные. Подробно метод описан по ссылке ниже, так же приведены ссылки на материалы, github и тд.
Как итог - продолжаю идет о том, что будущее за распределенными децентрализованными решениями. А еще у меня тут постоянно посещает идея, что мы, возможно, не правильно вообще думаем, что AGI это аналог интеллекта одного человека. Очень может быть, что он больше будет похож на социальный интеллект всего человечества в целом. Меня довольно сильно интересует не только как функционирует каждый отдельный мозг как один элемент общей мыслительной сети всей совокупности людей, но и производные свойства типа shared knowledge и тд.
https://habr.com/ru/company/yandex/blog/574466/
Хабр
DeDLOC: обучаем большие нейросети всем миром
Как показывает опыт последних лет, самые интересные результаты в deep learning получаются при использовании больших нейросетей, обученных на массивах неразмеченных данных. Правда, для создания...
Всем привет!
Когда меня спрашивают "что почитать про ИИ для новичка" я часто рекомендую книгу Роман Душкин "Искусственный интеллект".
Так вот теперь у всех есть возможность помочь в работе над второй книгой. Роман запускает новую программу на своём Патреоне. Те, кто станет патроном на 5 $ в месяц или выше, тот получит возможность читать главы новой книги, которую он пишет прямо сейчас. Вы сможете комментировать, давать замечания и, если уж на то пошло, при желании будете упомянуты в книге.
Так что подключайтесь: https://www.patreon.com/romandushkin
P. S.: кто станет патроном от 10 $ и выше, тот получит книги «ИИ» и «ИТС» с автографом в подарок
Когда меня спрашивают "что почитать про ИИ для новичка" я часто рекомендую книгу Роман Душкин "Искусственный интеллект".
Так вот теперь у всех есть возможность помочь в работе над второй книгой. Роман запускает новую программу на своём Патреоне. Те, кто станет патроном на 5 $ в месяц или выше, тот получит возможность читать главы новой книги, которую он пишет прямо сейчас. Вы сможете комментировать, давать замечания и, если уж на то пошло, при желании будете упомянуты в книге.
Так что подключайтесь: https://www.patreon.com/romandushkin
P. S.: кто станет патроном от 10 $ и выше, тот получит книги «ИИ» и «ИТС» с автографом в подарок
Patreon
Roman Dushkin is creating videos on High Technologies (AI, QC, NT, IoT, blockchain etc.) | Patreon
Become a patron of Roman Dushkin today: Get access to exclusive content and experiences on the world’s largest membership platform for artists and creators.
Data Management 2.0
Картинка выше на самом деле из статьи Reframing Data Management: Data Management 2.0 (ссылка ниже)
Очень правильные утверждения там делаются:
⁃ Данные сами по себе не представляют ценности - только применение данных в какой то конкретной бизнес-задаче приносит ценность и ценность данных появляется именно в момент их использования. Сами по себе “сырые” данные ничего не стоят.
⁃ Не все данные одинаково ценные - я бы тут сказал что это следствие из первого утверждение. Одни и те же данные могут иметь разную ценность в применении к разным задачам, и разные данные могут иметь разую ценность для одной и той же задачи
⁃ Данные, не в контексте бизнес-задачи - не стоят ничего (см пункт 1)
⁃ Превратить всех в инженеров данных непрактично и не масштабируемо - ну тут имеется ввиду что не надо заставлять всех подряд работать данными, доверьте дело профессионалам.
В целом интересная статья. Рекомендую изучить.
https://www.datasciencecentral.com/profiles/blogs/reframing-data-management-data-management-2-0
Картинка выше на самом деле из статьи Reframing Data Management: Data Management 2.0 (ссылка ниже)
Очень правильные утверждения там делаются:
⁃ Данные сами по себе не представляют ценности - только применение данных в какой то конкретной бизнес-задаче приносит ценность и ценность данных появляется именно в момент их использования. Сами по себе “сырые” данные ничего не стоят.
⁃ Не все данные одинаково ценные - я бы тут сказал что это следствие из первого утверждение. Одни и те же данные могут иметь разную ценность в применении к разным задачам, и разные данные могут иметь разую ценность для одной и той же задачи
⁃ Данные, не в контексте бизнес-задачи - не стоят ничего (см пункт 1)
⁃ Превратить всех в инженеров данных непрактично и не масштабируемо - ну тут имеется ввиду что не надо заставлять всех подряд работать данными, доверьте дело профессионалам.
В целом интересная статья. Рекомендую изучить.
https://www.datasciencecentral.com/profiles/blogs/reframing-data-management-data-management-2-0
Data Science Central
Reframing Data Management: Data Management 2.0 - DataScienceCentral.com
A cartoon making its way around social media asks the provocative question “Who wants clean data?” (Everyone raises their hands) and then asks, “Who wants to CLEAN the data?” (Nobody raises their hands). I took the cartoon one step further (apology for my…
Друзья, еще хочу отметить, что в этот замечательный день, аудтория нашего канала достигла важной отметки в 1К участников! Все основатели этого канала очень рады и говорят всем спасибо!
Интересная переписка в соседнем чате, где встретились авторы статьи про data mesh и архитектор платформы ГосТех от Сбера :)
Forwarded from And Sem
Простите, уважаемые коллеги, сейчас Чудо. Случилось.
Когда архитектор Платформы Сбера (ака-ГосТех?) находит в чате архитектора РТ Лабс, которые оба два ключевые игроки в рамках ЦТ, проводимой Минцифрой, то следует наполнить, поднять и вздрогнуть во славу этого чата (и не случайно, очевидно, это произошло в пятницу...)!
Кто с госами, думаю, понимают: НСУД - тема актуальная, ГосТех - не менее. Но как вы друг друга-то раньше не встретили?
И, пожалуй, НСУД все-таки не совсем распределенный дата-меш по здравой технологической логике, а дата-меш по вынужденной экономической потребности.
Проблема НСУД (как я его знаю) - он замещает управление данными управлением сбором данных и не решает глобальной задачи в госе (как я ее вижу, возможно заблуждаясь), которая имеет место, - перейти от работы на документах к управлению на данных.
Когда архитектор Платформы Сбера (ака-ГосТех?) находит в чате архитектора РТ Лабс, которые оба два ключевые игроки в рамках ЦТ, проводимой Минцифрой, то следует наполнить, поднять и вздрогнуть во славу этого чата (и не случайно, очевидно, это произошло в пятницу...)!
Кто с госами, думаю, понимают: НСУД - тема актуальная, ГосТех - не менее. Но как вы друг друга-то раньше не встретили?
И, пожалуй, НСУД все-таки не совсем распределенный дата-меш по здравой технологической логике, а дата-меш по вынужденной экономической потребности.
Проблема НСУД (как я его знаю) - он замещает управление данными управлением сбором данных и не решает глобальной задачи в госе (как я ее вижу, возможно заблуждаясь), которая имеет место, - перейти от работы на документах к управлению на данных.
Человеческий фактор в управлении данными
Accenture и Qlik представили исследование «Человеческий фактор в управлении данными» (Human Impact of Data Literacy), в котором было установлено, что низкий уровень компетенций сотрудников в области применения данных для принятия решений негативно влияет на развитие бизнеса.
Результаты исследования, проведённого среди 9 тысяч сотрудников по всему миру, показывают: только 25% опрошенных сотрудников готовы эффективно использовать данные в своей работе. И лишь 21% уверен в навыках грамотности в области использования данных: в способности читать, понимать, задавать вопросы и работать с данными. Кроме того, только 37% сотрудников доверяют своим решениям, когда они основываются на данных, и почти половина (48%) при принятии решений часто прибегают «к интуитивному ощущению».
Три четверти (74%) опрошенных сообщают, что чувствуют себя подавленными, работая с данными, и это влияет на их производительность. При этом 36% перегружены работой настолько, что ищут альтернативные методы выполнения задач — без использования данных.
Из-за болезней и стресса от информационной перегрузки, ежегодно сотрудники в среднем отсутствуют на работе более пяти дней (43 часа). Для бизнеса это выражается в потере доходов. По оценке экспертов, из-за прокрастинации и больничных, компании потеряли за год 109,4 млрд долларов в США; 15,16 млрд долларов в Японии; 13,17 млрд долларов в Великобритании; 10,9 млрд долларов во Франции; 9,4 млрд долларов в Австралии; 4,6 млрд долларов в Индии; 3,7 млрд долларов в Сингапуре; 3,2 млрд долларов в Швеции; и 23,7 млрд долларов в Германии.
37% респондентов считают, что обучение работе с данными поможет им работать более продуктивно.
Источник: https://www.accenture.com/ru-ru/about/company/human-impact-of-data-literacy
Отчет (англ.): https://thedataliteracyproject.org/files/downloads/Qlik_Accenture_Human_Impact_of_Data_Literacy.pdf
Accenture и Qlik представили исследование «Человеческий фактор в управлении данными» (Human Impact of Data Literacy), в котором было установлено, что низкий уровень компетенций сотрудников в области применения данных для принятия решений негативно влияет на развитие бизнеса.
Результаты исследования, проведённого среди 9 тысяч сотрудников по всему миру, показывают: только 25% опрошенных сотрудников готовы эффективно использовать данные в своей работе. И лишь 21% уверен в навыках грамотности в области использования данных: в способности читать, понимать, задавать вопросы и работать с данными. Кроме того, только 37% сотрудников доверяют своим решениям, когда они основываются на данных, и почти половина (48%) при принятии решений часто прибегают «к интуитивному ощущению».
Три четверти (74%) опрошенных сообщают, что чувствуют себя подавленными, работая с данными, и это влияет на их производительность. При этом 36% перегружены работой настолько, что ищут альтернативные методы выполнения задач — без использования данных.
Из-за болезней и стресса от информационной перегрузки, ежегодно сотрудники в среднем отсутствуют на работе более пяти дней (43 часа). Для бизнеса это выражается в потере доходов. По оценке экспертов, из-за прокрастинации и больничных, компании потеряли за год 109,4 млрд долларов в США; 15,16 млрд долларов в Японии; 13,17 млрд долларов в Великобритании; 10,9 млрд долларов во Франции; 9,4 млрд долларов в Австралии; 4,6 млрд долларов в Индии; 3,7 млрд долларов в Сингапуре; 3,2 млрд долларов в Швеции; и 23,7 млрд долларов в Германии.
37% респондентов считают, что обучение работе с данными поможет им работать более продуктивно.
Источник: https://www.accenture.com/ru-ru/about/company/human-impact-of-data-literacy
Отчет (англ.): https://thedataliteracyproject.org/files/downloads/Qlik_Accenture_Human_Impact_of_Data_Literacy.pdf
Accenture
Использование данных негативно влияет на бизнес | Accenture
Accenture и Qlik представили исследование «Человеческий фактор в управлении данными» и выяснили, как бизнес использует данные в своей работе. Узнать больше.
Дайджест статей 12/09/2021
За эту неделю статей набралось не так много, но кажутся, что интересные.
Building a High-Performance Data Lake Using Apache Hudi and Alluxio at T3Go
https://dzone.com/articles/building-high-performance-data-lake-using-apache-hudi-alluxio
How Logical Data Fabric Accelerates Data Democratization
https://www.datasciencecentral.com/profiles/blogs/how-logical-data-fabric-accelerates-data-democratization
MLOps: Building a Feature Store? Here are the top things to keep in mind
https://towardsdatascience.com/mlops-building-a-feature-store-here-are-the-top-things-to-keep-in-mind-d0f68d9794c6
Model Experiments, Tracking and Registration using MLflow on Databricks
https://www.datasciencecentral.com/profiles/blogs/model-experiments-tracking-and-registration-using-mlflow-on
За эту неделю статей набралось не так много, но кажутся, что интересные.
Building a High-Performance Data Lake Using Apache Hudi and Alluxio at T3Go
https://dzone.com/articles/building-high-performance-data-lake-using-apache-hudi-alluxio
How Logical Data Fabric Accelerates Data Democratization
https://www.datasciencecentral.com/profiles/blogs/how-logical-data-fabric-accelerates-data-democratization
MLOps: Building a Feature Store? Here are the top things to keep in mind
https://towardsdatascience.com/mlops-building-a-feature-store-here-are-the-top-things-to-keep-in-mind-d0f68d9794c6
Model Experiments, Tracking and Registration using MLflow on Databricks
https://www.datasciencecentral.com/profiles/blogs/model-experiments-tracking-and-registration-using-mlflow-on
DZone
Building a High-Performance Data Lake Using Apache Hudi and Alluxio at T3Go
We built our data lake based on data orchestration for multiple stages of our data pipeline, including ingestion and analytics. In this blog, you will see ...
Data Engineering Annotated Monthly – August 2021
Вышел свежий дайджест новостей в области Data Engineering.
Что отметил:
Fairlens 0.1.0 - интересный фреймворк, предназначен для проверки датасетов на наличие проблем с этичностью и сенсетивными данными. Отражение современных трендов 🙂
Вышла Kafka 3.0.0 RC0 и обновились многие другие ключевые в области работы с данными продукты.
https://blog.jetbrains.com/big-data-tools/2021/09/06/data-engineering-annotated-monthly-august-2021/
Вышел свежий дайджест новостей в области Data Engineering.
Что отметил:
Fairlens 0.1.0 - интересный фреймворк, предназначен для проверки датасетов на наличие проблем с этичностью и сенсетивными данными. Отражение современных трендов 🙂
Вышла Kafka 3.0.0 RC0 и обновились многие другие ключевые в области работы с данными продукты.
https://blog.jetbrains.com/big-data-tools/2021/09/06/data-engineering-annotated-monthly-august-2021/
The JetBrains Blog
Data Engineering Annotated Monthly – August 2021 | The Big Data Tools Blog
August is usually a quiet month, with vacations taking their toll. But data engineering never stops. I’m Pasha Finkelshteyn and I will be your guide through this month’s news, my impressions of the de