
Важливість дизайну API
Коли я перший раз імплементував OAuth (звичайний, ніяк не пов’язаний із JWT, а то подумаєте ще) — а це була авторизація через Twitter — я втратив на те майже тиждень. Це було у 2009 році, і я тут подивився у Вікіпедію, що його навіть ще не стандартизували тоді. 🤪
Другий раз, авжеж, йшло сильно простіше, але все одно, заплутатися в ногах (до чого тут ноги?!), різних урлах, різних іменах цих урлів, хто кого куди посилає, хто, нарешті, кому лікар?! — дуже легко. Взагалі розклад виглядав так: береш якийсь django-oauth (чи шо там ще, різне бувало), читаєш 3 рази доку, з твітером працює, з фейсбуком спочатку натупив, потім працює, гугл щось знов змінив… Ладно, запинав це все, а через рік хочеться когось додати, і виявляється, що ніхто не знає, що робить.
Більше того, цей django-oauth (підставте сюди назву своєї ліби) хитрим чином мутиться навколо авторизації і змусити його забрати у фейсбука імейл, а потім ще й змержити цей логін з користувачем з тим самим імейлом — нетривіально взагалі. І ніхто ж не напише інтеграцію цю своїми руками і як йому хочеться — ну бо ліньки ж, це ж знов ту документацію про ноги читати.
І не те щоб я не розумів, що відбувається. Ну наче розумів, так, мене той перший раз із Твіттером якби роздуплив. Але доки були дуже мутні, я хотів то запинати пошвидше і не вкладався морально, і якось чіткості в голові не було.
Аж тут якось я натрапив на oauth.two — малесеньку лібу на кложі, фактично без залежностей, але головне: з фантастичним дизайном. Вона не робить HTTP-запити, не взаємодіє з базою, і взагалі має менше 50 рядків коду. Здавалося б, 50 рядків! Що вона там може?
Вона дає малесеньку абстрацію, клієнта для OAuth2-сервера, який потребує трохи конфігурації: урл для першого редиректа, урл для отримання аксес-токену, айді/секрет, і можливо скоупи. Ти прям береш і слухняно підставляєш потрібні значення, а ліба тобі взамін генерує потрібні запити — не робить їх сама, роби чим ти там в проєкті робиш, твоє діло — в лібі тільки власне протокол імплементований всередині.
Вона структурує роботу, яку треба зробити, і робить її очікуваною і зрозумілою. Найліпший результат з нею був, коли Епл на вихідних реджектнула Кастівську апку, бо треба зробити авторизацію через епл, якщо у вас вже є через гугл. І зранку ми це обговорили, а до обіду вже випустили реліз з працюючою авторизацією.
І коли обговорювали, як же круто, що наші розробники такі швидкі, панове розробники сказали: ну це Саня просто кльово систему авторизації зробив. Приємно, авжеж, але це не я! Це все маленька фантастична бібліотечка. Всього 50 рядків коду, а різкість наводить ой-вей. 😁
Оце — вершина дизайну. Simplicity is the ultimate sophistication.
Коли я перший раз імплементував OAuth (звичайний, ніяк не пов’язаний із JWT, а то подумаєте ще) — а це була авторизація через Twitter — я втратив на те майже тиждень. Це було у 2009 році, і я тут подивився у Вікіпедію, що його навіть ще не стандартизували тоді. 🤪
Другий раз, авжеж, йшло сильно простіше, але все одно, заплутатися в ногах (до чого тут ноги?!), різних урлах, різних іменах цих урлів, хто кого куди посилає, хто, нарешті, кому лікар?! — дуже легко. Взагалі розклад виглядав так: береш якийсь django-oauth (чи шо там ще, різне бувало), читаєш 3 рази доку, з твітером працює, з фейсбуком спочатку натупив, потім працює, гугл щось знов змінив… Ладно, запинав це все, а через рік хочеться когось додати, і виявляється, що ніхто не знає, що робить.
Більше того, цей django-oauth (підставте сюди назву своєї ліби) хитрим чином мутиться навколо авторизації і змусити його забрати у фейсбука імейл, а потім ще й змержити цей логін з користувачем з тим самим імейлом — нетривіально взагалі. І ніхто ж не напише інтеграцію цю своїми руками і як йому хочеться — ну бо ліньки ж, це ж знов ту документацію про ноги читати.
І не те щоб я не розумів, що відбувається. Ну наче розумів, так, мене той перший раз із Твіттером якби роздуплив. Але доки були дуже мутні, я хотів то запинати пошвидше і не вкладався морально, і якось чіткості в голові не було.
Аж тут якось я натрапив на oauth.two — малесеньку лібу на кложі, фактично без залежностей, але головне: з фантастичним дизайном. Вона не робить HTTP-запити, не взаємодіє з базою, і взагалі має менше 50 рядків коду. Здавалося б, 50 рядків! Що вона там може?
Вона дає малесеньку абстрацію, клієнта для OAuth2-сервера, який потребує трохи конфігурації: урл для першого редиректа, урл для отримання аксес-токену, айді/секрет, і можливо скоупи. Ти прям береш і слухняно підставляєш потрібні значення, а ліба тобі взамін генерує потрібні запити — не робить їх сама, роби чим ти там в проєкті робиш, твоє діло — в лібі тільки власне протокол імплементований всередині.
Вона структурує роботу, яку треба зробити, і робить її очікуваною і зрозумілою. Найліпший результат з нею був, коли Епл на вихідних реджектнула Кастівську апку, бо треба зробити авторизацію через епл, якщо у вас вже є через гугл. І зранку ми це обговорили, а до обіду вже випустили реліз з працюючою авторизацією.
І коли обговорювали, як же круто, що наші розробники такі швидкі, панове розробники сказали: ну це Саня просто кльово систему авторизації зробив. Приємно, авжеж, але це не я! Це все маленька фантастична бібліотечка. Всього 50 рядків коду, а різкість наводить ой-вей. 😁
Оце — вершина дизайну. Simplicity is the ultimate sophistication.
🔥81❤5😁3
Design in Practice
Рич Хікі (автор Clojure і багатьох дуже кльових доповідей про філософію програмування) минулого тижня на Clojure/Conj зробив дуже кльову доповідь. Нарешті!
Не доповідь навіть, а інструктаж — про те, як дизайнити зміни. Мова взагалі не за програмування, здається мені, що буде цінно подивитися будь-кому. Він прям крок за кроком розповідає свій дизайн-процес: як визначити проблему, як розібратися в солюшенах тощо.
Цікаво, що раніше його доповіді мене чіпляли капітально, не міг відірватися — а ця якась трохи нудна вийшла. Але може саме тому, що це не розповідь була, а інструкція. :) Шкода, що він не зібрав то все до купи і не роздуплив мене років на 6-7 раніше, дуже б стало в нагоді в Касті. :)
Рич Хікі (автор Clojure і багатьох дуже кльових доповідей про філософію програмування) минулого тижня на Clojure/Conj зробив дуже кльову доповідь. Нарешті!
Не доповідь навіть, а інструктаж — про те, як дизайнити зміни. Мова взагалі не за програмування, здається мені, що буде цінно подивитися будь-кому. Він прям крок за кроком розповідає свій дизайн-процес: як визначити проблему, як розібратися в солюшенах тощо.
Цікаво, що раніше його доповіді мене чіпляли капітально, не міг відірватися — а ця якась трохи нудна вийшла. Але може саме тому, що це не розповідь була, а інструкція. :) Шкода, що він не зібрав то все до купи і не роздуплив мене років на 6-7 раніше, дуже б стало в нагоді в Касті. :)
🔥40❤4
Наче й очевидно, що журналістика трошечки вмерла, але все одно іноді смішно. Олег Гороховський вчора написав “ми зайняли перше місце в рейтингу форбс.уа”, і я чомусь сподівався там побачити щось цікаве.
А там оцінюють апки (не будемо придиратися до використання слова “додаток”, так?) по дуже-дуже важливим кожен день критеріям! Чи можна відкрити валютний депозит прямо в апці? Чи можна оскаржити операцію без звертання в кол-центр? Чи можна відновити доступ через Дію (доречі, ніде не можна, і звідки взялося взагалі питання — не дуже зрозуміло мені)?
Ну такі, щоденні речі. 😏 Прям глянув таблички і одразу зрозумів, яким з них користуватися зручно, а яким ні. 🤣
Окей, ви не пішли до знайомого дизайнера, який би хоч трошки розібрав юзабіліті тих застосунків, добре — хоча здається, що й можна було б пошукати такого. Але ж можна сфокусуватися в першу чергу на тому, що потрібно щоденно?
Чи легко знайти щось в історії витрати? Чи вона завантажується хвилину і пошуку там взагалі немає? Чи важко розшарити підтвердження оплати в інстаграм? Чи важко взагалі ту оплату зробити (hint: за оплату IBAN’ом у всіх двійка)? Що там взагалі зі швидкодією?
Та короче, можна було б просто сісти і на контрасті між різними апками сформулювати питання. Але пан директор платіжної асоціації порівняв цікаві йому параметри, а форбс опублікував як “рейтинг додатків” (як же ж мене тригерить це слово 😵💫) — і Sense, яким неможливо користуватися, бо хрін там здає де шо знаходиться, на другому місці. Робочий стіл my ass, от шо.
А там оцінюють апки (не будемо придиратися до використання слова “додаток”, так?) по дуже-дуже важливим кожен день критеріям! Чи можна відкрити валютний депозит прямо в апці? Чи можна оскаржити операцію без звертання в кол-центр? Чи можна відновити доступ через Дію (доречі, ніде не можна, і звідки взялося взагалі питання — не дуже зрозуміло мені)?
Ну такі, щоденні речі. 😏 Прям глянув таблички і одразу зрозумів, яким з них користуватися зручно, а яким ні. 🤣
Окей, ви не пішли до знайомого дизайнера, який би хоч трошки розібрав юзабіліті тих застосунків, добре — хоча здається, що й можна було б пошукати такого. Але ж можна сфокусуватися в першу чергу на тому, що потрібно щоденно?
Чи легко знайти щось в історії витрати? Чи вона завантажується хвилину і пошуку там взагалі немає? Чи важко розшарити підтвердження оплати в інстаграм? Чи важко взагалі ту оплату зробити (hint: за оплату IBAN’ом у всіх двійка)? Що там взагалі зі швидкодією?
Та короче, можна було б просто сісти і на контрасті між різними апками сформулювати питання. Але пан директор платіжної асоціації порівняв цікаві йому параметри, а форбс опублікував як “рейтинг додатків” (як же ж мене тригерить це слово 😵💫) — і Sense, яким неможливо користуватися, бо хрін там здає де шо знаходиться, на другому місці. Робочий стіл my ass, от шо.
❤27😁11💯7
Минулого тижня Anthropic — це такий конкурент OpenAI — оголосив, що тепер в їх моделі Claude тепер можна запхати контексту на 100 тисяч токенів. Якщо ви не стежите за всією двіжухою, то в GPT4 звичайне обмеження — це 8 тисяч токенів, але є спеціальна варіація на 32 тисячі (вона ще й в два рази більше коштує).
Токен — це така одиниця споживання в ML-моделях, приблизно як склад слова. OpenAI каже, що це десь ¾ англійського слова, для української мови скорше десь ½. Тобто, обмеження в 100 тисяч токенів — це десь 75 тисяч англійських слів.
Це фантастика і об’єктивно прорив — їх багато за останній час, але це напевно найбільша новина з анонсування ChatGPT, імхо.
Вони там приводять в приклад, що замінили один рядочок в книжці “Великий Гетсбі”, і попросили знайти, що вибивається з тексту. І воно спожило 72 тисячі слів і видало відповідь за 22 секунди! 🤯 Ціна зараз на модель з таким контекстом така сама, як на звичайну, тому в instant-версії (швидша і тупіша, як gpt-3.5 типу) такий експеримент коштував би всього порядка 30 центів!
Вже є всякі сервіси типу “поговори із пдфкою”, але вони ділять пдфку на частинки, а потім схожі на запитання частинки віддають в модельку як префікс до запитання. Очевидно, що якість відповідей на більш загальні чи складні запитання не дуже висока виходить, і Клавдія (хтива тітка принца) в цьому випадку буде просто несамовито крута.
Я оце мрію, що хтось працює мож над якоюсь заморозкою стану, щоб можна було засунути книжечку і потім додатково їй питання задавати. Власне всі чати зараз stateless, для генерації нової відповіді в модельку відправляються всі питання і відповіді — сама вона нічого не запам’ятовує. А шкода, дуже хотілося б не парсити Гетсбі для кожного питання наново. :-)
Токен — це така одиниця споживання в ML-моделях, приблизно як склад слова. OpenAI каже, що це десь ¾ англійського слова, для української мови скорше десь ½. Тобто, обмеження в 100 тисяч токенів — це десь 75 тисяч англійських слів.
Це фантастика і об’єктивно прорив — їх багато за останній час, але це напевно найбільша новина з анонсування ChatGPT, імхо.
Вони там приводять в приклад, що замінили один рядочок в книжці “Великий Гетсбі”, і попросили знайти, що вибивається з тексту. І воно спожило 72 тисячі слів і видало відповідь за 22 секунди! 🤯 Ціна зараз на модель з таким контекстом така сама, як на звичайну, тому в instant-версії (швидша і тупіша, як gpt-3.5 типу) такий експеримент коштував би всього порядка 30 центів!
Вже є всякі сервіси типу “поговори із пдфкою”, але вони ділять пдфку на частинки, а потім схожі на запитання частинки віддають в модельку як префікс до запитання. Очевидно, що якість відповідей на більш загальні чи складні запитання не дуже висока виходить, і Клавдія (хтива тітка принца) в цьому випадку буде просто несамовито крута.
Я оце мрію, що хтось працює мож над якоюсь заморозкою стану, щоб можна було засунути книжечку і потім додатково їй питання задавати. Власне всі чати зараз stateless, для генерації нової відповіді в модельку відправляються всі питання і відповіді — сама вона нічого не запам’ятовує. А шкода, дуже хотілося б не парсити Гетсбі для кожного питання наново. :-)
❤24🔥13🤯3
Не секрет, що написати пост про виступ заздалегідь для мене важче, ніж власне підготувати виступ. :) Тому може ви нічого і не чули, але сьогодні ввечері буде онлайн-мітап DEV Challenge, і я там трохи порозмовляю на тему того, як взагалі взаємодіяти зі змінами і з бізнесом, який їх хоче.
Я так розумію, що посилання на трансляцію буде, якщо зареєструватися. Мій виступ заплановано на 18:35.
Не можу обіцяти, що зірву якісь покрови і після того виступу можна буде жити по-новому. Це скоріш зібраний в одне місце мій власний погляд на те, як повинна працювати компанія. Певен, що після мітапу буде запис, тому не переживайте, якщо сьогодні ввечері немає часу. :)
P.S. Тема виступу - “Embrace the Change”, а не те, що здається по картинці. 😁
P.P.S Мітап — англійською.
Я так розумію, що посилання на трансляцію буде, якщо зареєструватися. Мій виступ заплановано на 18:35.
Не можу обіцяти, що зірву якісь покрови і після того виступу можна буде жити по-новому. Це скоріш зібраний в одне місце мій власний погляд на те, як повинна працювати компанія. Певен, що після мітапу буде запис, тому не переживайте, якщо сьогодні ввечері немає часу. :)
P.S. Тема виступу - “Embrace the Change”, а не те, що здається по картинці. 😁
P.P.S Мітап — англійською.
Linkedin
#dev_challenge | DEV Challenge
We present to you Alexander Solovyov, the speaker at the "How to become great CTO" meetup.
Alexander Solovyov is an experienced software developer. He enjoys efficient and simple solutions, solving real-world problems, and balancing good code quality with…
Alexander Solovyov is an experienced software developer. He enjoys efficient and simple solutions, solving real-world problems, and balancing good code quality with…
🔥52❤5🤯2
Consulting
Як пишуть панове американці, I’m excited to announce, що я відкритий для консультування. :)
Допоможу розібратися з архітектурними проблемами, розберуся з проблемою і спрощу до стану зрозумілості, вмію організовувати і реорганізовувати команди і розробку, щось розумію про швидкодію систем в цілому і про швидкодію веба конкретно. Короч, здається, що є, чим поділитися, тож якщо у вас є болюче місце, або хочеться почути якоїсь думки зі сторони — пишіть.
Очевидно, цей пост не зовсім для аудиторії цього каналу (бо є якась така смутна думка, що це більшою частиною програмісти), але якщо ви його розшарите тим, кому це може бути цікаво (здається, що кудись в сторону CEO/CTO/CMO) — буду вам дуже вдячний. Якщо у вас раптом є ідеї, куди б можна було піти в сторону потрібної аудиторії — теж капець вдячний буду (можна і в приватні повідомлення, якщо публічно не хочеться). Я б може не проти піти кудись на інтерв’ю…
В мене не дуже великий досвід консалтингу, тому й відгуків поки що не дуже багато накопичив — дивіться мою сторіночку про консалтинг. :)
P.S. Консалтити компанії з російським походженням не готовий абсолютно.
Як пишуть панове американці, I’m excited to announce, що я відкритий для консультування. :)
Допоможу розібратися з архітектурними проблемами, розберуся з проблемою і спрощу до стану зрозумілості, вмію організовувати і реорганізовувати команди і розробку, щось розумію про швидкодію систем в цілому і про швидкодію веба конкретно. Короч, здається, що є, чим поділитися, тож якщо у вас є болюче місце, або хочеться почути якоїсь думки зі сторони — пишіть.
Очевидно, цей пост не зовсім для аудиторії цього каналу (бо є якась така смутна думка, що це більшою частиною програмісти), але якщо ви його розшарите тим, кому це може бути цікаво (здається, що кудись в сторону CEO/CTO/CMO) — буду вам дуже вдячний. Якщо у вас раптом є ідеї, куди б можна було піти в сторону потрібної аудиторії — теж капець вдячний буду (можна і в приватні повідомлення, якщо публічно не хочеться). Я б може не проти піти кудись на інтерв’ю…
В мене не дуже великий досвід консалтингу, тому й відгуків поки що не дуже багато накопичив — дивіться мою сторіночку про консалтинг. :)
P.S. Консалтити компанії з російським походженням не готовий абсолютно.
❤62🔥22😁2💯1
На HN обговорюють, як прискорили завантаження Вікіпедії на 300 мс. Якщо вам ліньки читати, то коротка версія така: там код на жсі пробігався по купі елементів, щоби навісити хендлери — і цей цикл виходив дуже довгим. В одному випадку вдалося просто видалити код, в іншому замінити на делегацію подій.
Але поговорити мені хочеться за інше: частина обговорення пішла про те, що Вікіпедія (та й сам HN) швидше грузяться для анонимів, аніж для залогінених користувачів. Бо анонімам віддається кешована сторінка, а для користувача треба відрендерити персональну сторіночку. Бо там ім’я користувача є, всіляки лайки/апвоти, ну короч, все як завжди.
З однієї сторони, хочеться, щоб всі були залогінені. З іншої — воно ж додаткового навантаження генерує немало. Неприємно, так?
Є кльовий підхід: віддавати всім версію для анонімних користувачів, а потім, коли вже все завантажилося, всілякі LCP пройшли і користувач дивиться на сайт, догружати кастомізації для залогіненого користувача. Це, очевидно, потребує деяких жертв — щоби верстка була схожа і не було зсувів та значних візуальних змін, щоби основний контент не залежав від користувача… Але якщо ці умови виконати, то відкривається дивний світ різкого зниження навантаження на сервер. :)
На Касті таким чином підгружаються хедер і вподобайки на товарах, і ніхто того взагалі не палить. :) #cache #performance
Але поговорити мені хочеться за інше: частина обговорення пішла про те, що Вікіпедія (та й сам HN) швидше грузяться для анонимів, аніж для залогінених користувачів. Бо анонімам віддається кешована сторінка, а для користувача треба відрендерити персональну сторіночку. Бо там ім’я користувача є, всіляки лайки/апвоти, ну короч, все як завжди.
З однієї сторони, хочеться, щоб всі були залогінені. З іншої — воно ж додаткового навантаження генерує немало. Неприємно, так?
Є кльовий підхід: віддавати всім версію для анонімних користувачів, а потім, коли вже все завантажилося, всілякі LCP пройшли і користувач дивиться на сайт, догружати кастомізації для залогіненого користувача. Це, очевидно, потребує деяких жертв — щоби верстка була схожа і не було зсувів та значних візуальних змін, щоби основний контент не залежав від користувача… Але якщо ці умови виконати, то відкривається дивний світ різкого зниження навантаження на сервер. :)
На Касті таким чином підгружаються хедер і вподобайки на товарах, і ніхто того взагалі не палить. :) #cache #performance
❤49💯12🔥8
Мене тут вчора Simple Joys of Scaling Up спонукала порахувати, як дорого на AWS EC2 буде коштувати нормальна залізяка, щоби власне був simple joy, а не total despair. Сенс статті у тому, що з часів винаходу Dremel’а (який ми знаємо під назвою BigQuery) у 2008-му році багато чого змінилося у залізі, і тепер ефективніше не вигадувати розкидування даних на купі залізяк, а просто взяти один величезний комп і там все порахувати.
Тож я глянув на амазон, і для порівняння на хецнер. Чомусь отак лоб в лоб ціни на схожі залізяки я не порівнював, і виявилося що це прям eye-opening досвід. Авжеж, прямо порівняти важко, але візьмемо приблизно той конфіг, на який я знаю ціну на залізяки. У хецнера Epyc на 32 ядра, 512 гб пам’яті і 2 nvme по терабайту виходить в 330€/місяць. В амазоні точно такий накастовати важко, бо схожий і найдешевший з NVMe на борту
Тобто різниця в ціні — у 5-6 разів (будемо щедрими, коли на амазон спускаєш грошей, він дає трохи знижок). Якщо перекладати на справжні залізяки, ми колись приблизно таке купили за 10к доларів. Глянув що зараз - наче приблизно 8 тисяч виходить. Тобто порівняно з хецнером залізяка окупається за 24 місяці, а з амазоном - за 5! Менше ніж за півроку!
Ain’t that absurd? AWS просто друкує гроші! Ладно, жартую, він не друкує, він як поламаний Робін Гуд — відбирає у всіх (вас) і віддає шерифу, хехе.
Чи це ідеальне порівняння? Та ні, багато інших умов, у амазона ще, наприклад, диких грошей коштує трафік. Чи воно коректне? Та достатньо, щоби робити якісь висновки, імхо.
Авжеж, поки вся інфраструктура коштує копійки, можна і на авсі сидіти, щоби еластичність, щоби супутні сервіси, і все таке інше. Тобто при затратах в 300 доларів на місяць, коли паралельно ще є 2-3 програмісти, не сильно багато сенсу оптимізувати їх до 100 на місяць. Але коли інфраструктура на пару порядків більше, то оптимізацією можна знайти бюджету на пару програмістів.
Тільки не співайте мені в коментарях, що на AWS можна зекономити на адмінах — це ж давно вже неправда. З еластичністю теж якось так себе, здається — можна просто нагрести заліза із запасом і все одно буде в три рази дешевше кожен місяць.
У твітері вже були відповіді за те, шо платити в 5-10 разів більше за авс не западло, бо там же ж є CloudFormation і SQS! Теж по неадекватним цінам, і теж не без власних цікавих моментів — але ж кожен хоче бути експертом по AWS, тому це ще й плюс. 😐 А ще згадали за те, що готелі теж значно дорожчі за зйомні квартири, бо всі бізнеси такі волатильні, що ти постійно то береш, то віддаєш
Може за SLA ще треба згадати? Даунтайм у Касти через те що залізо здохло за всі роки був один раз. А даунтайм через те шо щось неправильно в коді, неправильно в конфігу, навантаження виросло не там де очікували, щось вдало оновили (постгрес кхм)… Ну власне всі інші даунтайми. :) Тому я очікую, що результат по аптайму буде приблизно однаковий. 😁
В хецнера, авжеж, є свої мінуси. Але оце коли порахуєш конкретні цифри, кейс Бейзкемпа стає зрозумілішим.
Тож я глянув на амазон, і для порівняння на хецнер. Чомусь отак лоб в лоб ціни на схожі залізяки я не порівнював, і виявилося що це прям eye-opening досвід. Авжеж, прямо порівняти важко, але візьмемо приблизно той конфіг, на який я знаю ціну на залізяки. У хецнера Epyc на 32 ядра, 512 гб пам’яті і 2 nvme по терабайту виходить в 330€/місяць. В амазоні точно такий накастовати важко, бо схожий і найдешевший з NVMe на борту
r6gd.metal — це гравітон, виходить 2700$/місяць (1700$, якщо брати reserved), а i3.metal — 3600/2500$ (щось схоже в хецнері — 385€).Тобто різниця в ціні — у 5-6 разів (будемо щедрими, коли на амазон спускаєш грошей, він дає трохи знижок). Якщо перекладати на справжні залізяки, ми колись приблизно таке купили за 10к доларів. Глянув що зараз - наче приблизно 8 тисяч виходить. Тобто порівняно з хецнером залізяка окупається за 24 місяці, а з амазоном - за 5! Менше ніж за півроку!
Ain’t that absurd? AWS просто друкує гроші! Ладно, жартую, він не друкує, він як поламаний Робін Гуд — відбирає у всіх (вас) і віддає шерифу, хехе.
Чи це ідеальне порівняння? Та ні, багато інших умов, у амазона ще, наприклад, диких грошей коштує трафік. Чи воно коректне? Та достатньо, щоби робити якісь висновки, імхо.
Авжеж, поки вся інфраструктура коштує копійки, можна і на авсі сидіти, щоби еластичність, щоби супутні сервіси, і все таке інше. Тобто при затратах в 300 доларів на місяць, коли паралельно ще є 2-3 програмісти, не сильно багато сенсу оптимізувати їх до 100 на місяць. Але коли інфраструктура на пару порядків більше, то оптимізацією можна знайти бюджету на пару програмістів.
Тільки не співайте мені в коментарях, що на AWS можна зекономити на адмінах — це ж давно вже неправда. З еластичністю теж якось так себе, здається — можна просто нагрести заліза із запасом і все одно буде в три рази дешевше кожен місяць.
У твітері вже були відповіді за те, шо платити в 5-10 разів більше за авс не западло, бо там же ж є CloudFormation і SQS! Теж по неадекватним цінам, і теж не без власних цікавих моментів — але ж кожен хоче бути експертом по AWS, тому це ще й плюс. 😐 А ще згадали за те, що готелі теж значно дорожчі за зйомні квартири, бо всі бізнеси такі волатильні, що ти постійно то береш, то віддаєш
i3.metal. Можна непогано зекономити, якщо його юзати не більше 4 годин в день. Жартую, мав на увазі можна вийти в приблизно ті самі витрати.Може за SLA ще треба згадати? Даунтайм у Касти через те що залізо здохло за всі роки був один раз. А даунтайм через те шо щось неправильно в коді, неправильно в конфігу, навантаження виросло не там де очікували, щось вдало оновили (постгрес кхм)… Ну власне всі інші даунтайми. :) Тому я очікую, що результат по аптайму буде приблизно однаковий. 😁
В хецнера, авжеж, є свої мінуси. Але оце коли порахуєш конкретні цифри, кейс Бейзкемпа стає зрозумілішим.
❤32💯16
Rewrite/Restart
На HN розкопали пост Вілла Ларсона про запуск Digg v4. Я розумію, що це сталося у 2010 році, тож більшість із вас навіть цієї назви не знають, але це була дуже серйозна подія в ті часи — замість того, щоб потроху вмирати, дігг вирішив себе вбити одним пострілом.
Ну, так це виглядало мені. :) Я його взагалі ніколи не любив, реддит був моєю тусовкою в ті часи, і наприкінці 10 та в 11 році аудиторія в реддита росла неймовірно швидко — за рахунок еміграції з digg’a. Наприклад, /r/programming перетворився на помийку саме тоді. 😁
Рекомендую почитати статтю — це мало не ідеальний приклад того, як не треба перезапускатися. 😁 Вони не залишили собі способу відкатитися назад, написали тонни гівняного кода людьми, які не шарили в інструментах (почитайте за баг, який він шукав цілий місяць), повністю змінили сховище, повністю змінили інтерфейс, нічого не протестували, замінили увесь сайт просто в один момент…
Цікавий момент, що Вілл більшою частиною за технічні проблеми згадує, але, наприклад, у реддита користувачі не розбіглися від його технічних траблів — а вони були. Я от пригадую, що основне незадоволення діггом4 було про інтерфейс, і коментарі на HN більш-менш підтверджують ці спогади — бо жодні технічні проблеми не відганяють лояльних користувачів так, як це роблять невдалі продуктові рішення.
Я рік тому відео про те саме зняв, якщо ви раптом не бачили: як переписати систему, щоби бізнес від того не вмер?
На HN розкопали пост Вілла Ларсона про запуск Digg v4. Я розумію, що це сталося у 2010 році, тож більшість із вас навіть цієї назви не знають, але це була дуже серйозна подія в ті часи — замість того, щоб потроху вмирати, дігг вирішив себе вбити одним пострілом.
Ну, так це виглядало мені. :) Я його взагалі ніколи не любив, реддит був моєю тусовкою в ті часи, і наприкінці 10 та в 11 році аудиторія в реддита росла неймовірно швидко — за рахунок еміграції з digg’a. Наприклад, /r/programming перетворився на помийку саме тоді. 😁
Рекомендую почитати статтю — це мало не ідеальний приклад того, як не треба перезапускатися. 😁 Вони не залишили собі способу відкатитися назад, написали тонни гівняного кода людьми, які не шарили в інструментах (почитайте за баг, який він шукав цілий місяць), повністю змінили сховище, повністю змінили інтерфейс, нічого не протестували, замінили увесь сайт просто в один момент…
Цікавий момент, що Вілл більшою частиною за технічні проблеми згадує, але, наприклад, у реддита користувачі не розбіглися від його технічних траблів — а вони були. Я от пригадую, що основне незадоволення діггом4 було про інтерфейс, і коментарі на HN більш-менш підтверджують ці спогади — бо жодні технічні проблеми не відганяють лояльних користувачів так, як це роблять невдалі продуктові рішення.
Я рік тому відео про те саме зняв, якщо ви раптом не бачили: як переписати систему, щоби бізнес від того не вмер?
🔥14🤯5
Тільки згадали історію, як себе вбив Digg, як Реддит вирішив спробувати повторити цей трюк. 😁 Історія така: у реддита активно огидний сайт для мобіл (вони намагаються загнати всіх відвідувачів в апку), не дуже кльова офіційна апка (не нагадує Твіттер?), і тому дуже велика кількість людей користується сторонніми апками. Я дуже довго юзав Alien Blue, потім його реддит купив і викинув — трансформував у пацавату офіційну апку — і я перейшов на Apollo.
Реддит, схоже, готується до IPO, чи ще якісь цікаві зміни у них відбуваються, і вони анонсували всім альтернативним клієнтам, що за доступ до API треба буде платити. “Ні-ні, ми в жодному разі не вразилися ідеєю твіттера чаржити 42 тисячі на місяць” казали вони на дзвінках. :)
Але раптово виявилося що збрехали і запропонували платити по 12 тисяч доларів за 50 млн запитів. 🤣 Це левел цін на GPT-моделі, processing-heavy штуки всілякі. Автор Apollo порахував, що це приблизно виходить 2.5$ за користувача на місяць (або 20$ млн в місяць за всіх, що явно трохи задофіга для безкоштовної апки).
Зрозуміло, що це неадекватна ціна, але наскільки неадекватна? Той самий Кристіан (автор аполло) порахував, що реддит по найвищим оцінкам заробляє 12 центів на користувачі на місяць, тобто це як мінімум на порядок неадекватна ціна. Я думаю, що він оптиміст, і там насправді 2-3 центи.
Очевидно, що цей прасинг — не для того, щоб апки щось платили, це для того, щоб прогнати їх з платформи, при цьому не забороняючи їх одним махом, як зробив Твіттер. Ну бо це ж погано з репутаційної точки зору? Наче те шо вони роблять, чимось відрізняється…
Не думаю, що вони зможуть себе вбити, бо альтернатив (як було з діггом) особливо немає, але якусь популярність вони собі трошки приб’ють. Я регулярно на реддиті зависаю, але вбогу офіційну апку наврядчи поставлю (Твіттер не поставив і пишу туди рідше як результат). Гудбай, Реддит!
Реддит, схоже, готується до IPO, чи ще якісь цікаві зміни у них відбуваються, і вони анонсували всім альтернативним клієнтам, що за доступ до API треба буде платити. “Ні-ні, ми в жодному разі не вразилися ідеєю твіттера чаржити 42 тисячі на місяць” казали вони на дзвінках. :)
Але раптово виявилося що збрехали і запропонували платити по 12 тисяч доларів за 50 млн запитів. 🤣 Це левел цін на GPT-моделі, processing-heavy штуки всілякі. Автор Apollo порахував, що це приблизно виходить 2.5$ за користувача на місяць (або 20$ млн в місяць за всіх, що явно трохи задофіга для безкоштовної апки).
Зрозуміло, що це неадекватна ціна, але наскільки неадекватна? Той самий Кристіан (автор аполло) порахував, що реддит по найвищим оцінкам заробляє 12 центів на користувачі на місяць, тобто це як мінімум на порядок неадекватна ціна. Я думаю, що він оптиміст, і там насправді 2-3 центи.
Очевидно, що цей прасинг — не для того, щоб апки щось платили, це для того, щоб прогнати їх з платформи, при цьому не забороняючи їх одним махом, як зробив Твіттер. Ну бо це ж погано з репутаційної точки зору? Наче те шо вони роблять, чимось відрізняється…
Не думаю, що вони зможуть себе вбити, бо альтернатив (як було з діггом) особливо немає, але якусь популярність вони собі трошки приб’ють. Я регулярно на реддиті зависаю, але вбогу офіційну апку наврядчи поставлю (Твіттер не поставив і пишу туди рідше як результат). Гудбай, Реддит!
💯29🤯12❤2😁1
На тижні прийшлося написати невеличкий парсер, для розбору пошукового запиту (ну, знаєте, “шось OR (шось AND шось)”, трошки більш заморочено). І, мушу визнати, це було боляче. :) У мене в житті ніколи не було періоду, коли б я займався парсерами довго, і тому кожен раз я розбираюся, пишу, роблю паузу в кілька років — і приходиться розбиратися мало не з нульовими знаннями, забувається все дуже сильно.
Це дуже бісить! Написання простого рекурсивного спуску (recursive descent) — дуже проста річ, яка повинна бути в арсеналі кожного програміста. Бо відсутність розуміння, що ти це можеш зробити сам — приводить до того, що в потрібний момент ти не побачиш короткого шляху.
Авжеж, це частково вирішується написанням поста в блог, який мені самому буде легко проглянути і згадати що до чого. :) Я й так зараз просто уважно почитав код Твінспарка, ггг. :)
Але ж його більше ніхто і не прочитає, про парсинг і так тищі раз написано, то може зробити стрім? З написанням простого парсеру на джаваскрипті, без пріоритетів операторів (EDIT: капець, я не знав, чи забув, що в AND та OR є пріоритети - але робити їх не хочу все одно), щось невеличке. Цікаво б таке було взагалі? Десь сьогодні о 17 чи 18? Я думаю, що навіть з поясненнями це буде година-півтори.
Це дуже бісить! Написання простого рекурсивного спуску (recursive descent) — дуже проста річ, яка повинна бути в арсеналі кожного програміста. Бо відсутність розуміння, що ти це можеш зробити сам — приводить до того, що в потрібний момент ти не побачиш короткого шляху.
Авжеж, це частково вирішується написанням поста в блог, який мені самому буде легко проглянути і згадати що до чого. :) Я й так зараз просто уважно почитав код Твінспарка, ггг. :)
Але ж його більше ніхто і не прочитає, про парсинг і так тищі раз написано, то може зробити стрім? З написанням простого парсеру на джаваскрипті, без пріоритетів операторів (EDIT: капець, я не знав, чи забув, що в AND та OR є пріоритети - але робити їх не хочу все одно), щось невеличке. Цікаво б таке було взагалі? Десь сьогодні о 17 чи 18? Я думаю, що навіть з поясненнями це буде година-півтори.
🔥87💯6❤4😁2
Я сприйняв 50 вогників на попередньому пості як сигнал, що таки цікаво, тому давайте, сьогодні на 18:00 за Києвом стрім про написання рекурсивного спуску на JavaScript’і, будемо парсити якусь нескладну мову. Я поки не вирішив яку, то можна в коментарях пропонувати, але вагаюся між шелом (
Чистий жс, ніяких генераторів, взагалі все по хардкору. Приходьте допомагати теж, бо я не прям експерт, я просто раз на три роки пишу якийсь простий парсер і втомився кожен раз згадувати, як це робити, тож хочу закріпити трохи в голові. :)
Не забудьте розшарити другу, бо як він інакше дізнається про стрім? :)
cmd arg1 arg2; cmd “arg 3”), спрощеною версією ікселевських формул (=if(true, 1+2, “ha ha”)), чи там синтаксису для пошуку (типу what and why or when). Хз, пропонуйте в коментарях.Чистий жс, ніяких генераторів, взагалі все по хардкору. Приходьте допомагати теж, бо я не прям експерт, я просто раз на три роки пишу якийсь простий парсер і втомився кожен раз згадувати, як це робити, тож хочу закріпити трохи в голові. :)
Не забудьте розшарити другу, бо як він інакше дізнається про стрім? :)
YouTube
Пишемо простий парсер
Давайте напишемо простий рекурсивний спуск, щоби розібратися, як воно взагалі робиться. Це доволі корисний інструмент, доволі простий, і регулярно (pun intended) стає в нагоді.
Результат: https://gist.github.com/piranha/81544fca192032a6a461999c1cfdb625
…
Результат: https://gist.github.com/piranha/81544fca192032a6a461999c1cfdb625
…
🔥43❤4😁2
через дивний глюк ютуба і обс стрім буде тут: https://www.youtube.com/watch?v=hRiTbk1_R_k
YouTube
Пишемо простий парсер
Давайте напишемо простий рекурсивний спуск, щоби розібратися, як воно взагалі робиться. Це доволі корисний інструмент, доволі простий, і регулярно (pun intended) стає в нагоді.
Результат: https://gist.github.com/piranha/81544fca192032a6a461999c1cfdb625
…
Результат: https://gist.github.com/piranha/81544fca192032a6a461999c1cfdb625
…
❤13
Я вчора трохи здивувався тої кількості порад “та просто візьми лібу” для рішення абсолютно простої проблеми. Не тільки здивувався, а посеред стріму навіть розізлився на чувака, який скіпнув все обговорення того на початку і прийшов принести свою мудрість. :)
Я порефлексував на це все і прийшов до двох думок.
Перша, конкретно про ситуацію: уявляєте, як я роблю стрім “дивіться як писати сортування”, і всі радять викликати
Друга цікавіша! Не можна абстракцією собі назавжди закривати розуміння. Мої пости про орми та про фреймворки пам’ятаєте? Це саме воно, хоча я й не зміг цю думку тоді сформулювати.
Власне: не вмієш нічого? Авжеж, візьми фреймворк, зроби щось, а потім почни його розбирати на запчастини. Чому форми працюють саме так? Чи можна краще? Як працює HTTP? Та сама історія з ORM: це гарна стартова точка, але якщо ти на тому старті так і залишишся, то це буде трошки сумно. Авжеж, можливо ти пішов розвиватися у іншому напрямку, і ORM для тебе тільки інструмент для досягнення мети — але тут я напевно про кардинально інші напрямки, а не про “я розвиваюся у зарплаті, а не в технологіях”. :)
А сумно буде, бо нерозуміння абстракцій, особливо критичних для твоєї роботи — приводить до неефективності. Бо мало в світі ідеальних абстракцій, і всі вони трохи протікають. ОРМи, наприклад, дуже погана абстракція — вона і протікає, і складна.
Генератори парсерів, здається, краще — вони не так дико протікають, але вони доволі складні, реально треба витратити час на розуміння. А рекурсивний спуск — він простий як двері, і підходить не тільки для тексту, а для будь-яких списків, а чи й навіть потоків.
Нажаль, жодної людини не вистачить на те, щоб пробити всі абстракції, і я не намагаюся, скажімо, свій GC написати — але розібратися у принципах було дуже цікаво. Тож якщо ви досі ніколи не дивилися, наприклад, як працює хоча б quicksort, дуже раджу! Він вражаюче ефективний, простий і доступний.
Широта світогляду розвиває людину, а запиратися у мушлі — моветон. :)
Я порефлексував на це все і прийшов до двох думок.
Перша, конкретно про ситуацію: уявляєте, як я роблю стрім “дивіться як писати сортування”, і всі радять викликати
.sort()? Не здається смішним? :)Друга цікавіша! Не можна абстракцією собі назавжди закривати розуміння. Мої пости про орми та про фреймворки пам’ятаєте? Це саме воно, хоча я й не зміг цю думку тоді сформулювати.
Власне: не вмієш нічого? Авжеж, візьми фреймворк, зроби щось, а потім почни його розбирати на запчастини. Чому форми працюють саме так? Чи можна краще? Як працює HTTP? Та сама історія з ORM: це гарна стартова точка, але якщо ти на тому старті так і залишишся, то це буде трошки сумно. Авжеж, можливо ти пішов розвиватися у іншому напрямку, і ORM для тебе тільки інструмент для досягнення мети — але тут я напевно про кардинально інші напрямки, а не про “я розвиваюся у зарплаті, а не в технологіях”. :)
А сумно буде, бо нерозуміння абстракцій, особливо критичних для твоєї роботи — приводить до неефективності. Бо мало в світі ідеальних абстракцій, і всі вони трохи протікають. ОРМи, наприклад, дуже погана абстракція — вона і протікає, і складна.
Генератори парсерів, здається, краще — вони не так дико протікають, але вони доволі складні, реально треба витратити час на розуміння. А рекурсивний спуск — він простий як двері, і підходить не тільки для тексту, а для будь-яких списків, а чи й навіть потоків.
Нажаль, жодної людини не вистачить на те, щоб пробити всі абстракції, і я не намагаюся, скажімо, свій GC написати — але розібратися у принципах було дуже цікаво. Тож якщо ви досі ніколи не дивилися, наприклад, як працює хоча б quicksort, дуже раджу! Він вражаюче ефективний, простий і доступний.
Широта світогляду розвиває людину, а запиратися у мушлі — моветон. :)
💯67❤29
У Реддіта повстання ком’юніті у повний зріст. 🤣 Спочатку багато великих сабредитів позакривалися (перейшли в приватний режим), і spez (Стів Хофман, засновник та наразі CEO) почав розповідати у інтерв’ю, що “модератори тримають у заручниках всю ком’юніті”.
Тож великі саби на кшталт r/pics зробили голосування, і в них тепер нові правила — можна постити тільки фотки Джона Олівера. Шкода, я так і не зрозумів, чому саме його — але r/pics повністю з фотожаб з ним останні дні і це капець, сміюся кожен раз як відкриваю глянути, шо там. 🤣
P.S. Джон Олівер підтримує протест — і в своєму твіттері купу фотожаб напостив. 😁
Тож великі саби на кшталт r/pics зробили голосування, і в них тепер нові правила — можна постити тільки фотки Джона Олівера. Шкода, я так і не зрозумів, чому саме його — але r/pics повністю з фотожаб з ним останні дні і це капець, сміюся кожен раз як відкриваю глянути, шо там. 🤣
P.S. Джон Олівер підтримує протест — і в своєму твіттері купу фотожаб напостив. 😁
❤17😁9🤯3👍1
Бачили анонс телеграма про сторіз? Там після нього ще є відео, авжеж, але мене зацікавила одна конкретна фраза:
> Speaking of channels, they will benefit from more exposure and subscribers: once we launch the ability to repost messages from channels to stories, going viral on Telegram will become a lot easier.
Телеграм намагається вирішити свою основну траблу — абсолютно мертве розповсюдження. В середньому телеграмівський пост отримує на порядок (чесний, десятичний :) більше енгейджмента, аніж твіттерний, — і зі зростанням аудиторії воно не особливо падає. Але при тому більше-менш вдалий твіттерний пост роз’їжджається з дикою швидкістю і більшість інтеракшена в твіттері з не-підписниками.
В телеграмі при тому хоч якось роз’їжджаються тільки пости, які ну прям критично чіпляють почуття людей (тобто те, що JWT відстій — допомогло кільком з вас знайти мій канал 😁), і то потроху. Не знаю, як саме буде репост із канала в сторіз виглядати, але дуже цікаво, що вийде. Телеграм давно вже інструмент для створення приватних соцмереж, якщо вони знайдуть спосіб крос-запилення цих ком’юніті — це буде дуже потужний інструмент.
> Speaking of channels, they will benefit from more exposure and subscribers: once we launch the ability to repost messages from channels to stories, going viral on Telegram will become a lot easier.
Телеграм намагається вирішити свою основну траблу — абсолютно мертве розповсюдження. В середньому телеграмівський пост отримує на порядок (чесний, десятичний :) більше енгейджмента, аніж твіттерний, — і зі зростанням аудиторії воно не особливо падає. Але при тому більше-менш вдалий твіттерний пост роз’їжджається з дикою швидкістю і більшість інтеракшена в твіттері з не-підписниками.
В телеграмі при тому хоч якось роз’їжджаються тільки пости, які ну прям критично чіпляють почуття людей (тобто те, що JWT відстій — допомогло кільком з вас знайти мій канал 😁), і то потроху. Не знаю, як саме буде репост із канала в сторіз виглядати, але дуже цікаво, що вийде. Телеграм давно вже інструмент для створення приватних соцмереж, якщо вони знайдуть спосіб крос-запилення цих ком’юніті — це буде дуже потужний інструмент.
💯21😁5❤4
Менеджмент і лоу-перформери
Спочатку мав розмову, яка підштовхнула до цього посту, а на наступний день слухав третій випуск Hackers Incorporated — і там DHH озвучив ту саму думку, тільки в профіль.
Не витрачайте часу на лоу-перформерів. Набагато ефективніше витрачати час на хай-перформерів. Девід це назвав cuddling management, але це в принципі те саме, що helicopter parenting — не треба сидіти з людьми, як з дітьми. Неможливо навчити людину плавати — можна допомогти, підштовхнути, підказати, виправити, але рухати своїми руками і ногами може тільки вона сама.
Коли береш нову людину, пояснюєш їй бази, показуєш, де задавати питання, і лишаєш розвиватися. Якщо це вдалий найм для твоєї команди — в неї буде прогрес, якщо ні — прогресу не буде і значить треба прощатися. І затягувати з цим точно не треба, це не робить послугу ні компанії, ні людині, ні тобі — чим довше затягнути, тим болючіше це буде робити.
Цікавий факт, що не зважаючи на твої переживання, що 1 людина це може чверть команди (наприклад), швидкість команди завжди росте, коли ти прощаєшся з low performer’ом. Бо і не відволікає, і наскільки ж приємніше працювати в команді крутих спеціалістів. :)
Це, авжеж, якщо мета твоя — побудувати ефективну команду. Якщо хочеться побудувати велику команду, то, напевно, стратегія повинна бути іншою, але тут я не спеціаліст.
Спочатку мав розмову, яка підштовхнула до цього посту, а на наступний день слухав третій випуск Hackers Incorporated — і там DHH озвучив ту саму думку, тільки в профіль.
Не витрачайте часу на лоу-перформерів. Набагато ефективніше витрачати час на хай-перформерів. Девід це назвав cuddling management, але це в принципі те саме, що helicopter parenting — не треба сидіти з людьми, як з дітьми. Неможливо навчити людину плавати — можна допомогти, підштовхнути, підказати, виправити, але рухати своїми руками і ногами може тільки вона сама.
Коли береш нову людину, пояснюєш їй бази, показуєш, де задавати питання, і лишаєш розвиватися. Якщо це вдалий найм для твоєї команди — в неї буде прогрес, якщо ні — прогресу не буде і значить треба прощатися. І затягувати з цим точно не треба, це не робить послугу ні компанії, ні людині, ні тобі — чим довше затягнути, тим болючіше це буде робити.
Цікавий факт, що не зважаючи на твої переживання, що 1 людина це може чверть команди (наприклад), швидкість команди завжди росте, коли ти прощаєшся з low performer’ом. Бо і не відволікає, і наскільки ж приємніше працювати в команді крутих спеціалістів. :)
Це, авжеж, якщо мета твоя — побудувати ефективну команду. Якщо хочеться побудувати велику команду, то, напевно, стратегія повинна бути іншою, але тут я не спеціаліст.
Hackers Incorporated
Ben Orenstein and Adam Wathan on surviving the transition from dev to founder.
🔥36❤10💯4🤯3
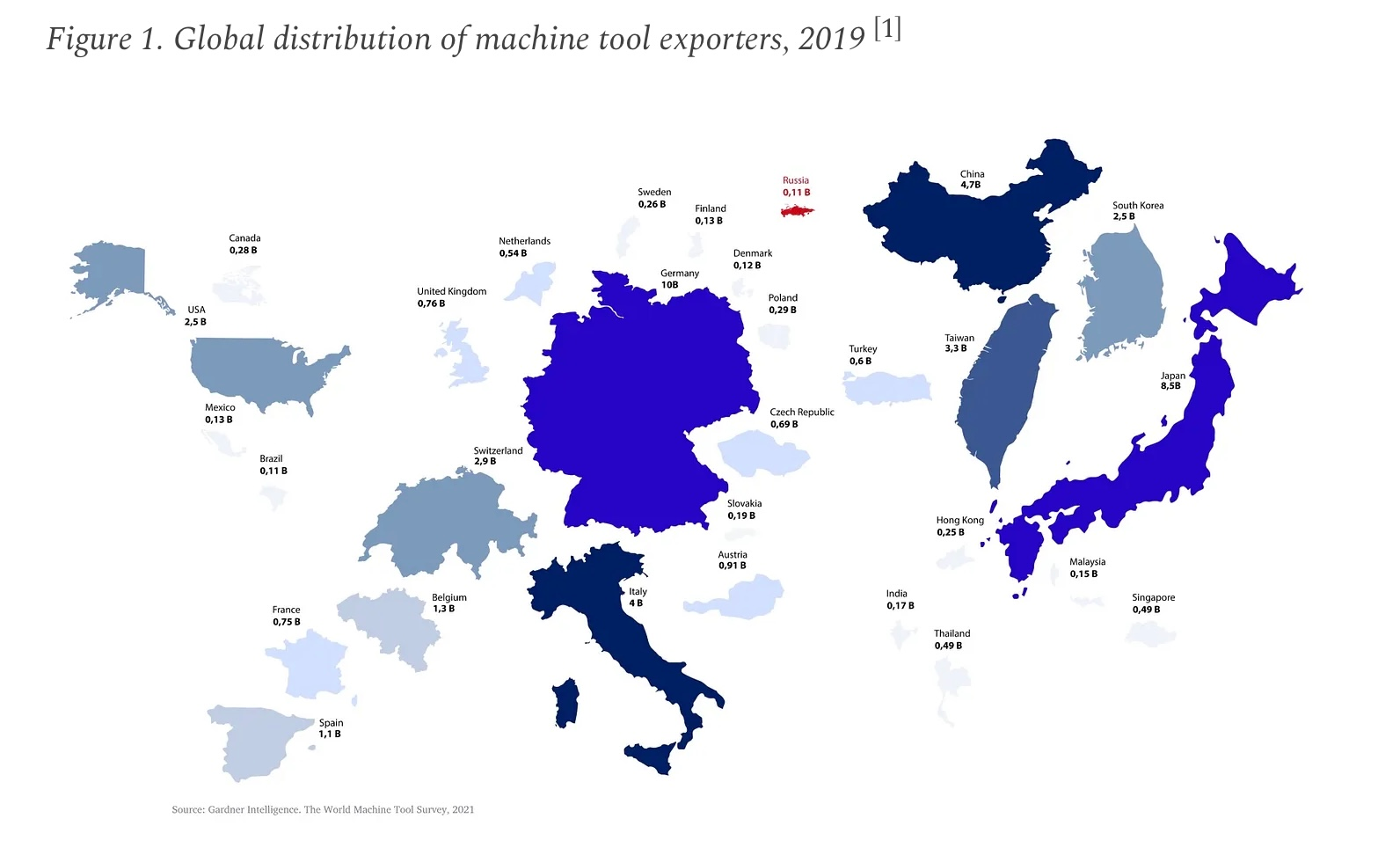
Каміль Галеєв в твіттері пише про те що санкції очевидно неефективні — бо росія досі клепає ракети. І його поінт в тому, що найвужче місце для них — це високоточні верстати, які дуже навіть реально заблокувати! Бо основними їх постачальниками є зовсім не Китай, який складно змусити імплементувати санкції, а країни, які санкції проти росії взагалі-то підтримують: Німеччина, Японія, Тайвань та таке інше. Не знаю, чи підхватить цю історію хтось далі і чи щось відбудеться (нема ідей, як тому посприяти можна), але статистика мене вразила.
Ну окей Італія і Швейцарія величезні: у Швейцарії ми й не сумнівалися, а Італія будує потяги, пароплави, машини, трактори і комбайни, всіляке гірськолижне обладнання і так далі — короч, воно очевидне. Але Бельгія, яка в два рази більше Франції експортує? Я розумію, що ця індустрія відносно невидима, але ж якісь корені повинні бути?
А Іспанія? От вже колиска машинобудування! 😁 Всі інші напевно більше цікаві, ніж вражаючі, раціоналізувати відносно зрозуміло як. Словаччина багато працює над тим, щоб бізнес йшов, Чехія традиційно багата на машинобудування, тому навіть комуністи це до кінця не вбили, з азійськими країнами взагалі жодного сюпризу нема — окрім може Сингапуру, місця наче й нема, а все одно одного порядку із Францією. :)
Ну окей Італія і Швейцарія величезні: у Швейцарії ми й не сумнівалися, а Італія будує потяги, пароплави, машини, трактори і комбайни, всіляке гірськолижне обладнання і так далі — короч, воно очевидне. Але Бельгія, яка в два рази більше Франції експортує? Я розумію, що ця індустрія відносно невидима, але ж якісь корені повинні бути?
А Іспанія? От вже колиска машинобудування! 😁 Всі інші напевно більше цікаві, ніж вражаючі, раціоналізувати відносно зрозуміло як. Словаччина багато працює над тим, щоб бізнес йшов, Чехія традиційно багата на машинобудування, тому навіть комуністи це до кінця не вбили, з азійськими країнами взагалі жодного сюпризу нема — окрім може Сингапуру, місця наче й нема, а все одно одного порядку із Францією. :)
{kind=link}
🤯24🔥5
Знаєте, чому Emacs — крутий? Не тому, що йому 30 років, і не тому, що він навіть кавоварками може керувати, і взагалі не тому що оті всі жарти які придумуються. Його головна якість не дуже очевидна, якщо не занурюватися в тему глибоко.
А крутий він тим, що це насправді платформа, а не редактор. Різниця в тому, що в нього механізм розширення функціональності і кастомізації — не через плагіни. Плагін це взагалі що? Це такий окремий модуль, який реалізує певний протокол інтеграції з батьківською програмою. Тобто є якийсь метод
Імакс працює зовсім не так! Скажімо, є функція
Авжеж, за десятиріччя існування там вже накопилася купа хелперів, різного рода плагінні системи, уніфікації всілякі — але базова база саме така.
Безперечно, є й мінуси — база для підтримки зворотньої сумісності неймовірних розмірів. Наприклад, Імакс довго був синхронним та однопоточним. Потім асинхронний ввід/вивід доробили, потім кооперативні треди… А ще в залежності від якості пакета він легко може конфліктувати з іншими, авжеж — хоча це не дуже часта ситуація.
Тим не менш, це саме те, що дозволяє Emacs’у бути чим завгодно. Якщо хочте, Emacs — це 1С текстових редакторів. 🤣
P.S. Платформа vs фреймворк vs конструктор. Фреймворк — це коли ти заповнюєш певні місця своєю логікою, конструктор — коли збираєш з модулів, платформа — це коли є працююча програма, від якої ти можеш відштовхнутися. В принципі, можна сказати, що Emacs — це ОС, тільки спеціалізована і трошки вище рівнем абстракції.
А крутий він тим, що це насправді платформа, а не редактор. Різниця в тому, що в нього механізм розширення функціональності і кастомізації — не через плагіни. Плагін це взагалі що? Це такий окремий модуль, який реалізує певний протокол інтеграції з батьківською програмою. Тобто є якийсь метод
on_open, який викликається, коли відкривається новий файл, і якщо ти його реалізував — його викличе редактор з певними аргументами, і ти зможеш зробити що хотів.Імакс працює зовсім не так! Скажімо, є функція
find-file, яка відкриває файл. Хочеш розширити її функціонал? Заміни її своєю! Тобто манкіпатчинг, або, як то кажуть, molding — створи свій імакс для себе, заміни все що хочеш тощо. Більше того, вона ж на ліспі написана, можна піти подивитися сорси, та замінити будь-яку з тих функцій, що використовуються всередині. Endless possibilities.Авжеж, за десятиріччя існування там вже накопилася купа хелперів, різного рода плагінні системи, уніфікації всілякі — але базова база саме така.
Безперечно, є й мінуси — база для підтримки зворотньої сумісності неймовірних розмірів. Наприклад, Імакс довго був синхронним та однопоточним. Потім асинхронний ввід/вивід доробили, потім кооперативні треди… А ще в залежності від якості пакета він легко може конфліктувати з іншими, авжеж — хоча це не дуже часта ситуація.
Тим не менш, це саме те, що дозволяє Emacs’у бути чим завгодно. Якщо хочте, Emacs — це 1С текстових редакторів. 🤣
P.S. Платформа vs фреймворк vs конструктор. Фреймворк — це коли ти заповнюєш певні місця своєю логікою, конструктор — коли збираєш з модулів, платформа — це коли є працююча програма, від якої ти можеш відштовхнутися. В принципі, можна сказати, що Emacs — це ОС, тільки спеціалізована і трошки вище рівнем абстракції.
🔥29❤6
Ого, TwinSpark.js в топі на Hacker News! А підіть апвотніть пліз, якщо вам не шкода, нехай ще трошки повисить. 😁
Це взагалі мені наука — якщо написати документацію, то з’являється якийсь рух навколо. :) Я наче і знаю, але осьо нагадування доволі явне відбулося.
А ще, якщо може десь юзаєте, то я на головну додав список сайтів, де воно використовується — пишіть, щоби розширити його.
Це взагалі мені наука — якщо написати документацію, то з’являється якийсь рух навколо. :) Я наче і знаю, але осьо нагадування доволі явне відбулося.
А ще, якщо може десь юзаєте, то я на головну додав список сайтів, де воно використовується — пишіть, щоби розширити його.
🔥76❤4