
Оптимизация LIMIT / OFFSET
Также рассмотрим тему в рамках синхронизации (т.к. проблема стара и бояниста как этот мир) и в преддверии статейки про Cursor API.
❓Что плохого в LIMIT и OFFSET?
На малых объёмах данных никто и ничего не почувствует. Но долгоживущие проекты, в которые постоянно складываются данные рано или поздно сталкиваются с тем, что всё больше запросов появляется в slow.log, а запрос обычной постраничной пагинации отрабатывает 3-5 секунд(!).
Всё дело в том, что выполняя запрос типа
Рисунок наглядно изображает такую ситуацию. База читает первые 10 записей, после этого вставляется новая запись, которая смещает все прочитанные записи на 1. Затем база берет новую страницу из 10 следующих записей и начинает не с 11-й, как должна, а с 10-й, дублируя эту запись. Есть и другие аномалии, связанные с использованием этого выражения, но эта — самая распространенная.
⁉️О Боже, что же делать?!
Вместо комбинации OFFSET и LIMIT стоит использовать конструкцию
Конечно, у этого подхода могут есть свои ограничения: проблемно сортировать, нет нормальной возможности читать страницы непоследовательно и т.д. Однако он отлично подойдет для бесконечного скроллинга, или если вам нужно отдать большие объемы данных по API.
#mysql #junior #source
Также рассмотрим тему в рамках синхронизации (т.к. проблема стара и бояниста как этот мир) и в преддверии статейки про Cursor API.
❓Что плохого в LIMIT и OFFSET?
На малых объёмах данных никто и ничего не почувствует. Но долгоживущие проекты, в которые постоянно складываются данные рано или поздно сталкиваются с тем, что всё больше запросов появляется в slow.log, а запрос обычной постраничной пагинации отрабатывает 3-5 секунд(!).
Всё дело в том, что выполняя запрос типа
mysql> SELECT * FROM table_name ORDER BY id LIMIT 10 OFFSET 8000001;
Mysql сначала пройдется по первым 8000001 записям (которые нам не нужны) и только потом выберет нужные 10. И это еще не всё! Если между чтением двух страниц данных с диска другая операция вставит новую запись, что произойдет в этом случае?Рисунок наглядно изображает такую ситуацию. База читает первые 10 записей, после этого вставляется новая запись, которая смещает все прочитанные записи на 1. Затем база берет новую страницу из 10 следующих записей и начинает не с 11-й, как должна, а с 10-й, дублируя эту запись. Есть и другие аномалии, связанные с использованием этого выражения, но эта — самая распространенная.
⁉️О Боже, что же делать?!
Вместо комбинации OFFSET и LIMIT стоит использовать конструкцию
mysql> SELECT * FROM table_name WHERE id > 8000000 LIMIT 10;
Вот что мы можем выиграть по времени. Конечно, у этого подхода могут есть свои ограничения: проблемно сортировать, нет нормальной возможности читать страницы непоследовательно и т.д. Однако он отлично подойдет для бесконечного скроллинга, или если вам нужно отдать большие объемы данных по API.
#mysql #junior #source
{kind=link}
👍1
Как хранить UUID в MySQL?
К сожалению реалии таковы, что просто написать "никак" не получится, т.к. MySQL всё еще занимает лидирующие позиции по использованию в веб разработке, не смотря на все его недостатки.
🙈 Многие по-умолчанию сохраняют
Хранить как BINARY.
🔨 Благо с выходом 8й версии MySQL часть танцев с бубном была перенесена в коробку и
❗️Для этого можно использовать
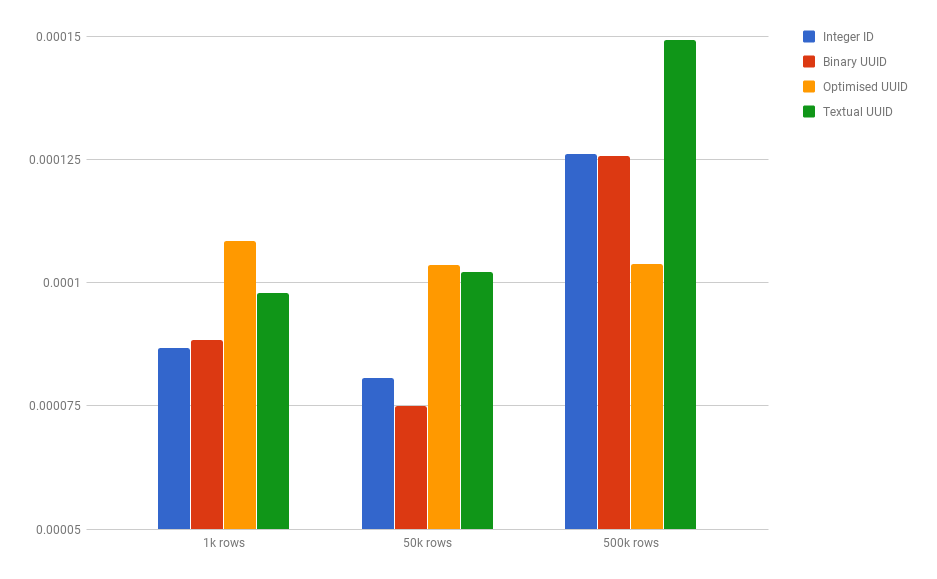
📊 Ну и самое интересное — сравнение!
📌 Выходит, что при малом кол-ве записей, наш оптимизированный
Безусловно, генерируемые id — довольно удобный инструмент, но всегда следует хорошо спроектировать решение в голове, прежде чем внедрить.
#PHP #MySQL #middle #source
К сожалению реалии таковы, что просто написать "никак" не получится, т.к. MySQL всё еще занимает лидирующие позиции по использованию в веб разработке, не смотря на все его недостатки.
🙈 Многие по-умолчанию сохраняют
UUID в CHAR(36) и не переживают по этому поводу. Действительно, если кол-во записей в вашей таблице < 50к, то вы скорее всего не заметите никаких проблем. Но что если в какой-то из таблиц их больше полумиллиона?Хранить как BINARY.
🔨 Благо с выходом 8й версии MySQL часть танцев с бубном была перенесена в коробку и
UUID_TO_BIN / BIN_TO_UUID уже делают всё за тебя. Они производят сжатие 32 символов (36 или более с разделителями) до 16-битного формата или обратно до формата, который снова можно прочесть.INSERT INTO t VALUES(UUID_TO_BIN(UUID()));👍 Мы уже получим буст, и очень неплохой, т.к. MySQL отлично индексирует
SELECT BIN_TO_UUID(id) FROM t;
BINARY, даже лучше, чем привычный автоинкрементный INT. И всё бы ничего, если бы не кластерный индекс, который как раз и используется у PRIMARY KEY. Это значит, что для его оптимизации мы должны иметь и упорядоченные UUID в базе. Но как это сделать?❗️Для этого можно использовать
UUID первой версии, в которой содержатся биты связанные со временем. А во время использования UUID_TO_BIN / BIN_TO_UUID использовать второй (необязательный, логический) аргумент:INSERT INTO t VALUES (UUID_TO_BIN (UUID (), true));Именно он переупорядочит биты, связанные со временем, так, чтобы последовательные сгенерированные значения были упорядочены и в индексе.
📊 Ну и самое интересное — сравнение!
📌 Выходит, что при малом кол-ве записей, наш оптимизированный
UUID работает медленнее остальных, при этом при 500к он обгоняет по показателям INT. И здесь возникает совсем другая история, а именно кол-во потребляемой памяти для большого кол-ва записей :) Безусловно, генерируемые id — довольно удобный инструмент, но всегда следует хорошо спроектировать решение в голове, прежде чем внедрить.
#PHP #MySQL #middle #source
{kind=link}
Использование индексов в MySQL
Чем больше мы пользуемся ORM, тем меньше задумываемся об оптимизации БД, до тех пор пока не прижмёт. В простых кейсах для ускорения запроса проблем не возникает, но если случай чуть сложнее чем "добавить индекс", то разработчики часто не знают за что хвататься. Здесь хочу оставить пару заметок, которые могут натолкнуть на различные решения в подобной ситуации.
👉 Все мы знаем, что индексы используются для быстрого поиска строк с определенными значениями столбцов. Без индекса MySQL будет начинать поиск с первой строки, а затем читать всю таблицу. Чем больше таблица, тем дороже эта операция.
❓ На что обратить внимание при оптимизации?
• Не исключен случай когда одна колонка используется в нескольких индексах. В таком случае MySQL выбирает индекс который вернет наименьшее кол-во строк (наиболее избирательный).
• При использовании составного (композитного) индекса помните, что он может использоваться и в более простых выборках, но только по столбцам перечисленным слева направо. Например индекс
🤝 Для получения строк из других таблиц при
• MySQL может использовать индексы более эффективно, если они одного и того же типа и размера. В этом контексте
Сравнение столбцов разного типа (например,
🙈 Не слишком очевидное
• Индексы менее важны для маленьких таблиц или для больших, из которых нам нужно извлечь все данные или большую их часть. В таком случае последовательное чтение выполняется быстрее, чем при работе с индексом. Всё потому, что последовательное чтение минимизируют поиск на диске, даже если нам нужны не абсолютно все строки.
• Оптимизатору можно задать подсказку по выбору или игнорированию индекса.
#MySQL #junior #source
Чем больше мы пользуемся ORM, тем меньше задумываемся об оптимизации БД, до тех пор пока не прижмёт. В простых кейсах для ускорения запроса проблем не возникает, но если случай чуть сложнее чем "добавить индекс", то разработчики часто не знают за что хвататься. Здесь хочу оставить пару заметок, которые могут натолкнуть на различные решения в подобной ситуации.
👉 Все мы знаем, что индексы используются для быстрого поиска строк с определенными значениями столбцов. Без индекса MySQL будет начинать поиск с первой строки, а затем читать всю таблицу. Чем больше таблица, тем дороже эта операция.
❓ На что обратить внимание при оптимизации?
• Не исключен случай когда одна колонка используется в нескольких индексах. В таком случае MySQL выбирает индекс который вернет наименьшее кол-во строк (наиболее избирательный).
• При использовании составного (композитного) индекса помните, что он может использоваться и в более простых выборках, но только по столбцам перечисленным слева направо. Например индекс
(col1, col2, col3) будет работать для выборок (col1), (col1, col2), и (col1, col2, col3), но не будет для (col2, col3) или (col3).🤝 Для получения строк из других таблиц при
JOIN
• Для сравнения строковых столбцов оба столбца должны использовать одну и ту же кодировку. Например, сравнение столбца utf8 со столбцом latin1 исключает использование индекса.• MySQL может использовать индексы более эффективно, если они одного и того же типа и размера. В этом контексте
VARCHAR и CHAR считаются одинаковыми, если они объявлены с одинаковым размером. Например, VARCHAR (10) и CHAR (10) имеют одинаковый размер, а VARCHAR (10) и CHAR (15) - нет.Сравнение столбцов разного типа (например,
VARCHAR с DATETIME или INT) может препятствовать использованию индексов, если при этом необходимо преобразование. Например в одной таблице у вас INT 1, а в другой VARCHAR ' 1' или '00001'.🙈 Не слишком очевидное
• Индексы менее важны для маленьких таблиц или для больших, из которых нам нужно извлечь все данные или большую их часть. В таком случае последовательное чтение выполняется быстрее, чем при работе с индексом. Всё потому, что последовательное чтение минимизируют поиск на диске, даже если нам нужны не абсолютно все строки.
• Оптимизатору можно задать подсказку по выбору или игнорированию индекса.
SELECT * FROM table1 USE INDEX (col1_index,col2_index)👍 Ставь 🍺 если было полезно и если хочешь еще заметок по этой теме.
WHERE col1=1 AND col2=2 AND col3=3;
SELECT * FROM table1 IGNORE INDEX (col3_index)
WHERE col1=1 AND col2=2 AND col3=3;
#MySQL #junior #source
{kind=link}
Использование индексов в MySQL (part 2)
Вот еще несколько важных заметок, которые являются дополнением этого поста.
📌 Повторяющиеся индексы могут не замедлить запросы SELECT, но вполне могут замедлить запросы на INSERT (а в некоторых случаях и UPDATE). В целом рекомендуется избегать дублирования ключей. Например если в одной таблице 2 индекса:
👉 Вот тулза, которая может вам помочь найти подобные случаи и решить, как с ними поступать.
📌 Обратная ситуация, неиспользуемые индексы также следует удалять т.к. это дополнительные расходы памяти и времени на вставку и апдейт. Для этого есть еще одна тулза, которая может вам помочь найти подобные кейсы, но после нахождения обязательно перепроверьте вручную, чтобы не удалить лишнего.
📌 Начиная с версии 8+, MySQL поддерживает индексы по убыванию (нисходящие, DESC), что означает, что он может хранить индексы в порядке убывания. Это может пригодиться, когда у вас есть выборки где надо получать последние добавленные данные.
👍 Если вернуться к первым двум пунктам этой заметки, то следует упомянуть, что у Percona Toolkit очень большой набор инструментов, с которым рекомендую как минимум ознакомиться ;) Если и этот пост наберет много 🍺, то напишу короткую заметку о самых интересных на мой взгляд.
#MySQL #junior #source
Вот еще несколько важных заметок, которые являются дополнением этого поста.
📌 Повторяющиеся индексы могут не замедлить запросы SELECT, но вполне могут замедлить запросы на INSERT (а в некоторых случаях и UPDATE). В целом рекомендуется избегать дублирования ключей. Например если в одной таблице 2 индекса:
KEY `firstname` (`firstname`),то
KEY `firstname_lastname_id` (`firstname`,`lastname`,`id`)
firstname является дубликатом firstname_lastname_id, так как firstname является первым столбцом индекса firstname_lastname_id.👉 Вот тулза, которая может вам помочь найти подобные случаи и решить, как с ними поступать.
📌 Обратная ситуация, неиспользуемые индексы также следует удалять т.к. это дополнительные расходы памяти и времени на вставку и апдейт. Для этого есть еще одна тулза, которая может вам помочь найти подобные кейсы, но после нахождения обязательно перепроверьте вручную, чтобы не удалить лишнего.
📌 Начиная с версии 8+, MySQL поддерживает индексы по убыванию (нисходящие, DESC), что означает, что он может хранить индексы в порядке убывания. Это может пригодиться, когда у вас есть выборки где надо получать последние добавленные данные.
CREATE TABLE t (📌 Также у вас могут быть таблицы с данными, которые не нужны вам в выборке или вообще нужны редко. Подумайте о том, чтобы разделить такую таблицу (логически или по необходимости использования данных). Это также ускорит выборку и снизит потребление CPU.
c1 INT, c2 INT,
INDEX idx1 (c1 ASC, c2 ASC),
INDEX idx2 (c1 ASC, c2 DESC),
INDEX idx3 (c1 DESC, c2 ASC),
INDEX idx4 (c1 DESC, c2 DESC)
);
👍 Если вернуться к первым двум пунктам этой заметки, то следует упомянуть, что у Percona Toolkit очень большой набор инструментов, с которым рекомендую как минимум ознакомиться ;) Если и этот пост наберет много 🍺, то напишу короткую заметку о самых интересных на мой взгляд.
#MySQL #junior #source
{kind=link}