
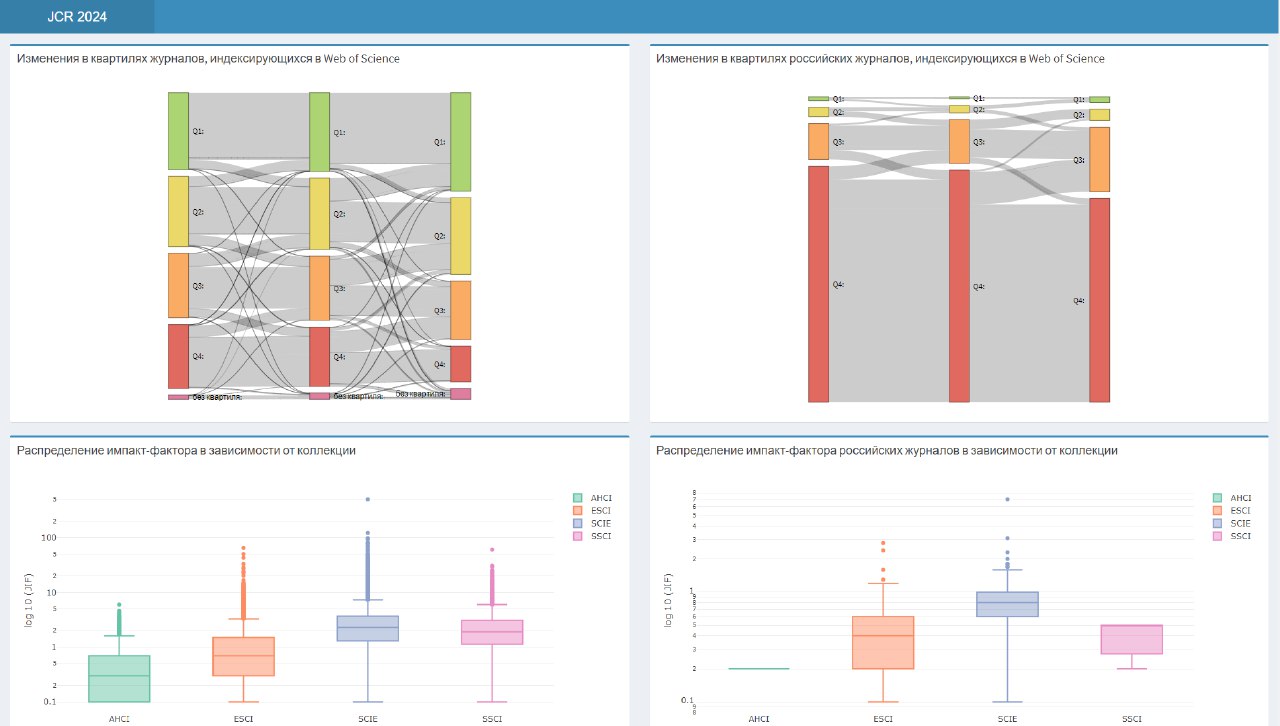
Обновление квартилей JCR
20 июня, как уже заметили некоторые наши коллеги, обновился список Journal Citation Reports (JCR) от Clarivate, в котором приводится распределение по квартилям для всех журналов, индексирующихся в Web of Science. А мы традиционно проанализировали «миграцию» журналов «классических» коллекций (SCIE и SSCI) между квартилями, добавив к sankey-диаграмме квартили за 2023 год (на диаграмме 2021, 2022 и 2023 годы приведены слева направо). Кроме того, мы дополнили приложение квартилями для российских журналов. Внизу же демонстрируются различия в распределении самого импакт-фактора для разных коллекций (AHCI, ESCI, SCIE и SSCI). Для журналов из коллекций Arts and Humanities Citation Index (AHCI) и Emerging Sources Citation Index (ESCI), как вы, наверное, помните, импакт-факторы опубликованы впервые в прошлом году, это — второй выпуск.
20 июня, как уже заметили некоторые наши коллеги, обновился список Journal Citation Reports (JCR) от Clarivate, в котором приводится распределение по квартилям для всех журналов, индексирующихся в Web of Science. А мы традиционно проанализировали «миграцию» журналов «классических» коллекций (SCIE и SSCI) между квартилями, добавив к sankey-диаграмме квартили за 2023 год (на диаграмме 2021, 2022 и 2023 годы приведены слева направо). Кроме того, мы дополнили приложение квартилями для российских журналов. Внизу же демонстрируются различия в распределении самого импакт-фактора для разных коллекций (AHCI, ESCI, SCIE и SSCI). Для журналов из коллекций Arts and Humanities Citation Index (AHCI) и Emerging Sources Citation Index (ESCI), как вы, наверное, помните, импакт-факторы опубликованы впервые в прошлом году, это — второй выпуск.
{kind=link}
Мы продолжаем нашу рубрику, посвященную истории развития наукометрии. Сегодня мы обратимся к истории одной из самых известных журнальных метрик — Journal Impact Factor (JIF). Посмотреть пост вы можете по ссылке.
#историянаукометрии
#историянаукометрии
Telegraph
Импакт-фактор
Ю. Гарфилд. «Агония и экстаз — история и значение импакт-фактора журнала» Импакт фактор или Journal Impact Factor (JIF) — это метрика, которая отображает среднее число цитирований статей, опубликованных в данном журнале за определённый период времени. Предтечей…
Дайджест: июнь 2024
Первый летний месяц в мире науки традиционно тихий. Тем не менее, за июнь произошел ряд интересных событий, и мы представляем свежий дайджест.
Научные публикации
- Подошла к концу история с амилоидной гипотезой возникновения болезни Альцгеймера (мы писали о ней ранее). Карен Эш, соавтор-корреспондент и коллега Сильвена Лесне, согласилась с необходимостью ретракции статьи 2006 года, и 24 июня статья была отозвана.
- На конференции FAccT’2024 была представлена работа А. Лизенфельда и М. Дингеманса, в которой анализируется, насколько генеративные ИИ с открытым исходным кодом действительно открыты (на самом деле не очень).
Редакторская политика
- На конференции Clarivate Ignite 2024, проходившей в Сан-Диего, США, представили IP Collaboration Hub. Новое решение позволит управлять всем процессом подачи и рассмотрения заявок на патенты и товарные знаки за рубежом с помощью единого механизма учета заявок.
- Кроме того, Web of Science запустили систему Research Horizon Navigator — новый модуль с поддержкой ИИ в InCites Benchmarking & Analytics. Он призван помогать быстро находить новые темы, возникающие в научном сообществе в области интересов конкретного исследователя или института.
- Система Problematic Paper Screener (PPS), используемая для обнаружения признаков плагиата в научных публикациях, теперь может распознавать так называемые «искаженные аббревиатуры» — довольно явный признак того, что статья была написана при помощи ИИ.
Базы данных
- В Scientometrics вышла статья о разработке и применении нового библиометрического пакета для R — biblioverlap. Сам пакет доступен в репозитории CRAN. Предлагаем читателям пробовать и делиться своими впечатлениями (мы тоже скоро планируем).
- Появился список Altmetrics 500. Туда входят статьи, которые привлекли наибольшее внимание в Интернете в 2023 году: в новостях, цитатах, Википедии и X/Twitter.
Университетские рейтинги
- 30 мая вышел новый выпуск международного рейтинга университетов RUR. Всего в этом году в рейтинге 131 российский вуз, но в первую сотню попал только МГУ.
- 19 июня на XII ежегодном форуме ведущих вузов «Будущее высшей школы» был представлен рейтинг лучших российских вузов RAEX-100. В топ-3 — МГУ, Бауманка и МФТИ.
- 25 июня был опубликован свежий рейтинг USNews, в котором рассматривается 2250 вузов из более чем 100 стран. Из России в рейтинге 42 вуза, на первом месте по стране — Южно-Уральский государственный университет.
Наука в мире
- Планируемые изменения в системе Research Excellence Framework (Великобритания) вызывают у научных администаторов опасения: если учитывать в REF результаты работы сотрудников, работающих всего на 0,2 ставки (FTE), то университеты могут начать фиктивно нанимать сильных ученых для повышения своих показателей.
Наука в России
- ТюмГУ вслед за САФУ и МГПУ утвердил право студентов использовать генеративный ИИ при написании ВКР.
- Федеральная антимонопольная служба оштрафовала Яндекс за распостранение рекламы сервиса по написанию рефератов, курсовых и дипломных работ.
- Опубликован список победителей в конкурсе на “президентскую мегастипендию для аспирантов” в размере 75 тыс. рублей. Мы поздравляем победителей!
- Указом Президента РФ от 18.06.24 были утверждены обновленные а) приоритетные направления научно-тенхологического развития и б) перечень важнейших наукоемких технологий.
И бонусная новость: фармацевтическая компания «Ланцет» подала иск с требованием прекратить правовую охрану товарного знака The Lancet (и не только). Дело зарегистрировано под номером №СИП-589/2024, к участию привлекли и Роспатент. Пока что суд вынес определение об оставлении искового заявления без движения, но мы будем с интересом наблюдать за развитием событий.
#дайджест #новости #редакторскаяполитика #базыданных #наукавроссии #искуственныйинтеллект #рейтинги
Первый летний месяц в мире науки традиционно тихий. Тем не менее, за июнь произошел ряд интересных событий, и мы представляем свежий дайджест.
Научные публикации
- Подошла к концу история с амилоидной гипотезой возникновения болезни Альцгеймера (мы писали о ней ранее). Карен Эш, соавтор-корреспондент и коллега Сильвена Лесне, согласилась с необходимостью ретракции статьи 2006 года, и 24 июня статья была отозвана.
- На конференции FAccT’2024 была представлена работа А. Лизенфельда и М. Дингеманса, в которой анализируется, насколько генеративные ИИ с открытым исходным кодом действительно открыты (на самом деле не очень).
Редакторская политика
- На конференции Clarivate Ignite 2024, проходившей в Сан-Диего, США, представили IP Collaboration Hub. Новое решение позволит управлять всем процессом подачи и рассмотрения заявок на патенты и товарные знаки за рубежом с помощью единого механизма учета заявок.
- Кроме того, Web of Science запустили систему Research Horizon Navigator — новый модуль с поддержкой ИИ в InCites Benchmarking & Analytics. Он призван помогать быстро находить новые темы, возникающие в научном сообществе в области интересов конкретного исследователя или института.
- Система Problematic Paper Screener (PPS), используемая для обнаружения признаков плагиата в научных публикациях, теперь может распознавать так называемые «искаженные аббревиатуры» — довольно явный признак того, что статья была написана при помощи ИИ.
Базы данных
- В Scientometrics вышла статья о разработке и применении нового библиометрического пакета для R — biblioverlap. Сам пакет доступен в репозитории CRAN. Предлагаем читателям пробовать и делиться своими впечатлениями (мы тоже скоро планируем).
- Появился список Altmetrics 500. Туда входят статьи, которые привлекли наибольшее внимание в Интернете в 2023 году: в новостях, цитатах, Википедии и X/Twitter.
Университетские рейтинги
- 30 мая вышел новый выпуск международного рейтинга университетов RUR. Всего в этом году в рейтинге 131 российский вуз, но в первую сотню попал только МГУ.
- 19 июня на XII ежегодном форуме ведущих вузов «Будущее высшей школы» был представлен рейтинг лучших российских вузов RAEX-100. В топ-3 — МГУ, Бауманка и МФТИ.
- 25 июня был опубликован свежий рейтинг USNews, в котором рассматривается 2250 вузов из более чем 100 стран. Из России в рейтинге 42 вуза, на первом месте по стране — Южно-Уральский государственный университет.
Наука в мире
- Планируемые изменения в системе Research Excellence Framework (Великобритания) вызывают у научных администаторов опасения: если учитывать в REF результаты работы сотрудников, работающих всего на 0,2 ставки (FTE), то университеты могут начать фиктивно нанимать сильных ученых для повышения своих показателей.
Наука в России
- ТюмГУ вслед за САФУ и МГПУ утвердил право студентов использовать генеративный ИИ при написании ВКР.
- Федеральная антимонопольная служба оштрафовала Яндекс за распостранение рекламы сервиса по написанию рефератов, курсовых и дипломных работ.
- Опубликован список победителей в конкурсе на “президентскую мегастипендию для аспирантов” в размере 75 тыс. рублей. Мы поздравляем победителей!
- Указом Президента РФ от 18.06.24 были утверждены обновленные а) приоритетные направления научно-тенхологического развития и б) перечень важнейших наукоемких технологий.
И бонусная новость: фармацевтическая компания «Ланцет» подала иск с требованием прекратить правовую охрану товарного знака The Lancet (и не только). Дело зарегистрировано под номером №СИП-589/2024, к участию привлекли и Роспатент. Пока что суд вынес определение об оставлении искового заявления без движения, но мы будем с интересом наблюдать за развитием событий.
#дайджест #новости #редакторскаяполитика #базыданных #наукавроссии #искуственныйинтеллект #рейтинги
{kind=link}
Чат-боты: цитировать или не цитировать?
Растущий интерес к использованию искусственного интеллекта (ИИ) в написании научных работ и ряд скандалов, связанных с его недобросовестным применением в академической сфере, провоцируют острую дискуссию. Летисия Антунес Ногейра (Leticia Antunes Nogueira), руководитель проекта по искусственному интеллекту, и Ян Уве Рейн (Jan Ove Rein), библиотекарь-исследователь, оба — сотрудники NTNU опубликовали заметку (ч. 1, ч. 2), в которой сосредоточились на критике концепции цитирования языковых моделей в научных публикациях.
В заметке авторы сузили фокус до двух моделей (ChatGPT от OpenAI или Claude от Anthropic), так как предполагают, что пользователи, которые работают с инструментами, применяющими возможности GenAI в сочетании с другими системами (например, Perplexity и Scopus AI), будут ссылаться на оригинальные источники.
В политике ведущих мировых издательств и академических организаций существует общее мнение насчет того, что чат-боты не отвечают минимальным требованиям к авторству, однако вопрос о том, можно ли (и следует ли) цитировать чат-боты в качестве источников, остается открытым.
Сторонники цитирования сообщений чат-ботов отмечают, что цитирование необходимо как минимум по двум причинам:
· признание чужого вклада и влияния идей;
· раскрытие источников информации.
Эти два, казалось бы, простых аспекта связаны с некоторыми противоречиями.
Противники цитирования (и иногда использования) чат-ботов подчеркивают, что результаты, полученные с использованием ИИ, преимущественно невозможно отследить, воспроизвести или проверить. В дополнение к этим ощутимым аргументам, исследователи акцентируют внимание на нескольких этических аспектах:
🔹Ответственность авторов
Языковая модель не может нести ответственность за утверждения, включенные в публикацию от её «лица». Одно дело цитировать организацию (например, доклад ООН), и совсем другое — чат-бота. Организации состоят из людей и поэтому несут ответственность за предоставляемую информацию, чат-бот или его разработчики нести такую ответственность не могут.
🔹Загрязнение информационной среды
Упоминание чат-ботов в источниках ведет к загрязнению информационных экосистем. Если для обучения больших языковых моделей использовать данные, сгенерированные ИИ (т. е. тексты из Интернета, академические тексты и т. д.), это приведет к ухудшению качества моделей.
🔹ИИ — не истина в последней инстанции
Чат-боты не создавались как инструменты для информационных целей. Неопределенность в отношении качества их ответов обусловлена назначением и структурой чат-ботов, а не степенью технологической зрелости. Большие языковые модели (LLM) основаны на моделях использования языка, а не на информации, и вероятностны по своему принципу работы, а это означает, что некорректный результат в таком случае — особенность, а не ошибка.
APA рекомендует цитировать текст, полученный от чат-бота, как результат работы алгоритма: а именно, ссылаться на автора алгоритма в списке источников. Дело в том, что результаты «переписки» с ChatGPT невозможно воспроизвести. Сейчас в APA такие данные часто цитируются как личная переписка, но это не совсем корректно, потому что сгенерированный текст не исходит от чьей-либо личности. В то же время ICMJE и Elsevier занимают однозначную позицию и рекомендуют авторам не ссылаться на чат-боты.
Появление чат-ботов бросает вызов устоявшимся представлениям об источниках, информации и знании, которые совсем недавно считались само собой разумеющимися. Тем не менее, в эпоху искусственного интеллекта обеспечение целостности информационной экосистемы требует все больших усилий. По мнению авторов, поскольку связность и смыслы в любом случае находятся «в глазах смотрящего», наборы слов, полученные в результате вероятностных вычислений, нельзя назвать ни источниками, ни информацией, ни знаниями. Текст, генерируемый чат-ботами — скорее, воплощение отсутствия информации.
#ChatGPT #ИИ #искусственныйинтеллект #цитирование
Растущий интерес к использованию искусственного интеллекта (ИИ) в написании научных работ и ряд скандалов, связанных с его недобросовестным применением в академической сфере, провоцируют острую дискуссию. Летисия Антунес Ногейра (Leticia Antunes Nogueira), руководитель проекта по искусственному интеллекту, и Ян Уве Рейн (Jan Ove Rein), библиотекарь-исследователь, оба — сотрудники NTNU опубликовали заметку (ч. 1, ч. 2), в которой сосредоточились на критике концепции цитирования языковых моделей в научных публикациях.
В заметке авторы сузили фокус до двух моделей (ChatGPT от OpenAI или Claude от Anthropic), так как предполагают, что пользователи, которые работают с инструментами, применяющими возможности GenAI в сочетании с другими системами (например, Perplexity и Scopus AI), будут ссылаться на оригинальные источники.
В политике ведущих мировых издательств и академических организаций существует общее мнение насчет того, что чат-боты не отвечают минимальным требованиям к авторству, однако вопрос о том, можно ли (и следует ли) цитировать чат-боты в качестве источников, остается открытым.
Сторонники цитирования сообщений чат-ботов отмечают, что цитирование необходимо как минимум по двум причинам:
· признание чужого вклада и влияния идей;
· раскрытие источников информации.
Эти два, казалось бы, простых аспекта связаны с некоторыми противоречиями.
Противники цитирования (и иногда использования) чат-ботов подчеркивают, что результаты, полученные с использованием ИИ, преимущественно невозможно отследить, воспроизвести или проверить. В дополнение к этим ощутимым аргументам, исследователи акцентируют внимание на нескольких этических аспектах:
🔹Ответственность авторов
Языковая модель не может нести ответственность за утверждения, включенные в публикацию от её «лица». Одно дело цитировать организацию (например, доклад ООН), и совсем другое — чат-бота. Организации состоят из людей и поэтому несут ответственность за предоставляемую информацию, чат-бот или его разработчики нести такую ответственность не могут.
🔹Загрязнение информационной среды
Упоминание чат-ботов в источниках ведет к загрязнению информационных экосистем. Если для обучения больших языковых моделей использовать данные, сгенерированные ИИ (т. е. тексты из Интернета, академические тексты и т. д.), это приведет к ухудшению качества моделей.
🔹ИИ — не истина в последней инстанции
Чат-боты не создавались как инструменты для информационных целей. Неопределенность в отношении качества их ответов обусловлена назначением и структурой чат-ботов, а не степенью технологической зрелости. Большие языковые модели (LLM) основаны на моделях использования языка, а не на информации, и вероятностны по своему принципу работы, а это означает, что некорректный результат в таком случае — особенность, а не ошибка.
APA рекомендует цитировать текст, полученный от чат-бота, как результат работы алгоритма: а именно, ссылаться на автора алгоритма в списке источников. Дело в том, что результаты «переписки» с ChatGPT невозможно воспроизвести. Сейчас в APA такие данные часто цитируются как личная переписка, но это не совсем корректно, потому что сгенерированный текст не исходит от чьей-либо личности. В то же время ICMJE и Elsevier занимают однозначную позицию и рекомендуют авторам не ссылаться на чат-боты.
Появление чат-ботов бросает вызов устоявшимся представлениям об источниках, информации и знании, которые совсем недавно считались само собой разумеющимися. Тем не менее, в эпоху искусственного интеллекта обеспечение целостности информационной экосистемы требует все больших усилий. По мнению авторов, поскольку связность и смыслы в любом случае находятся «в глазах смотрящего», наборы слов, полученные в результате вероятностных вычислений, нельзя назвать ни источниками, ни информацией, ни знаниями. Текст, генерируемый чат-ботами — скорее, воплощение отсутствия информации.
#ChatGPT #ИИ #искусственныйинтеллект #цитирование
Коротко и ясно: зависит ли цитируемость статьи от длины заголовка?
Большинство исследователей настаивают на том, что заголовки опубликованных работ должны быть относительно краткими, так как заголовки — это первая, а иногда и единственная информация, которую читатель получает из публикации.
Результаты опроса (впрочем, довольно старого), в котором приняли участие более 5000 человек, показали, что читатель научных журналов просматривает в среднем 1142 заголовка, 204 аннотации и 97 статей в год. Растущий поток информации и повышающаяся конкуренция в академической среде приводят к тому, что читателю, вероятнее всего, проще откинуть статью с витиеватым заголовком, не вникая в ее содержание (не случайно некоторые научные журналы ограничивают количество слов в заголовках). Как мы недавно видели, короткий и броский заголовок действительно может привлечь внимание.
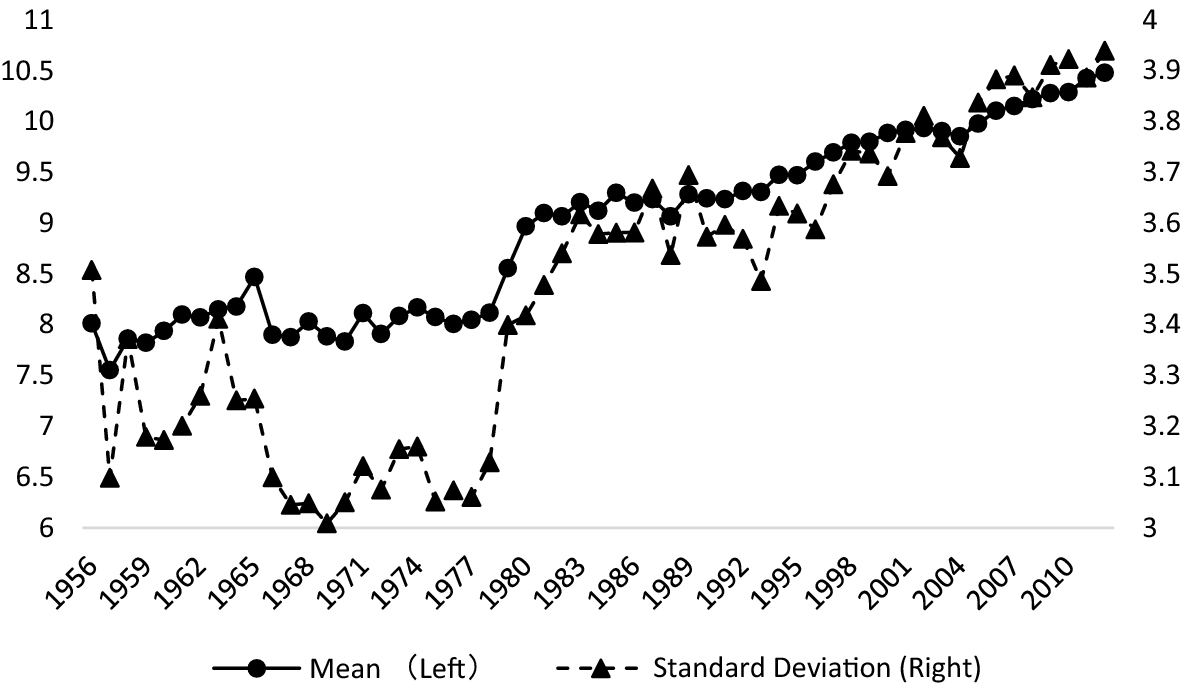
С другой стороны, согласно теории поисковой оптимизации (SEO), длинный заголовок может помочь в поиске статьи по ключевым словам, благодаря чему статья привлекает больше внимания, и, соответственно, чаще цитируется. Исследователи Шанхайского университета финансов и экономики (SUFE) называют это информативным эффектом (informative effect), а факторы, подтверждающие положительную корреляцию между короткими заголовками и цитированием статей, — эффектом лаконичности (succinct effect).
На основе выборки из более чем 300 000 статей SSCI по экономике с 1956 по 2012 год они определили, что статьи с короткими названиями лучше цитировались в период, когда поиск литературы не был так тесно связан с цифровыми технологиями (1956–2000 годы), а уже с 2001 года наблюдается рост цитируемости статей с длинными заголовками.
Здесь необходимо отметить несколько аспектов. Во-первых, сами авторы стали использовать больше слов в заголовке (см. график). В частности, в 2010–2012 годах в заголовке в среднем было 10,4 слова, что на 33% больше, чем 7,8 слов в 1956–1958 годах.
Согласно исследованию, в XXI веке количество цитирований статьи должно возрастать на 0,60% с каждым дополнительным словом, добавленным в название статьи. Следует отметить, что, помимо длины заголовка, в исследовании были учтены другие факторы, которые могут влиять на количество цитирований:
💠 Количество страниц в статье. Статьи тоже стали длиннее, а такие статьи, согласно некоторым исследованиям, чаще цитируют.
💠 Число соавторов. Было обнаружено, что чем больше соавторов, тем больше цитирований, так как статья привлекает больше внимания.
💠 Количество ссылок в работе. Чем больше в статье ссылок на предыдущие работы, тем больше доверия она вызывает. Также обширный список источников связан с формой взаимного альтруизма — «Я цитирую вас, а вы цитируете меня».
💠 Алфавитный порядок авторов. Первого автора из списка чаще цитируют и упоминают.
💠 Порядок статьи в выпуске. Первые статьи в выпуске, как правило, больше скачивают и цитируют.
На данном этапе развития науки почти весь поиск литературы осуществляется в онлайн-базах данных, причем многие поиски ограничиваются ключевыми словами. По мнению авторов исследования, статьи с краткими названиями были более привлекательны в предыдущие десятилетия, но с развитием интернета информативный эффект начал превосходить эффект лаконичности. Исследователям не стоит жалеть время на выбор заголовка публикации, так как число статей и журналов, к которым можно получить онлайн-доступ, постоянно растет. А мы планируем вскоре вернуться к этой теме со своим исследованием, чтобы слегка освежить данные, полученные в оригинальной статье.
#цитирование #SSCI #обзор
Большинство исследователей настаивают на том, что заголовки опубликованных работ должны быть относительно краткими, так как заголовки — это первая, а иногда и единственная информация, которую читатель получает из публикации.
Результаты опроса (впрочем, довольно старого), в котором приняли участие более 5000 человек, показали, что читатель научных журналов просматривает в среднем 1142 заголовка, 204 аннотации и 97 статей в год. Растущий поток информации и повышающаяся конкуренция в академической среде приводят к тому, что читателю, вероятнее всего, проще откинуть статью с витиеватым заголовком, не вникая в ее содержание (не случайно некоторые научные журналы ограничивают количество слов в заголовках). Как мы недавно видели, короткий и броский заголовок действительно может привлечь внимание.
С другой стороны, согласно теории поисковой оптимизации (SEO), длинный заголовок может помочь в поиске статьи по ключевым словам, благодаря чему статья привлекает больше внимания, и, соответственно, чаще цитируется. Исследователи Шанхайского университета финансов и экономики (SUFE) называют это информативным эффектом (informative effect), а факторы, подтверждающие положительную корреляцию между короткими заголовками и цитированием статей, — эффектом лаконичности (succinct effect).
На основе выборки из более чем 300 000 статей SSCI по экономике с 1956 по 2012 год они определили, что статьи с короткими названиями лучше цитировались в период, когда поиск литературы не был так тесно связан с цифровыми технологиями (1956–2000 годы), а уже с 2001 года наблюдается рост цитируемости статей с длинными заголовками.
Здесь необходимо отметить несколько аспектов. Во-первых, сами авторы стали использовать больше слов в заголовке (см. график). В частности, в 2010–2012 годах в заголовке в среднем было 10,4 слова, что на 33% больше, чем 7,8 слов в 1956–1958 годах.
Согласно исследованию, в XXI веке количество цитирований статьи должно возрастать на 0,60% с каждым дополнительным словом, добавленным в название статьи. Следует отметить, что, помимо длины заголовка, в исследовании были учтены другие факторы, которые могут влиять на количество цитирований:
💠 Количество страниц в статье. Статьи тоже стали длиннее, а такие статьи, согласно некоторым исследованиям, чаще цитируют.
💠 Число соавторов. Было обнаружено, что чем больше соавторов, тем больше цитирований, так как статья привлекает больше внимания.
💠 Количество ссылок в работе. Чем больше в статье ссылок на предыдущие работы, тем больше доверия она вызывает. Также обширный список источников связан с формой взаимного альтруизма — «Я цитирую вас, а вы цитируете меня».
💠 Алфавитный порядок авторов. Первого автора из списка чаще цитируют и упоминают.
💠 Порядок статьи в выпуске. Первые статьи в выпуске, как правило, больше скачивают и цитируют.
На данном этапе развития науки почти весь поиск литературы осуществляется в онлайн-базах данных, причем многие поиски ограничиваются ключевыми словами. По мнению авторов исследования, статьи с краткими названиями были более привлекательны в предыдущие десятилетия, но с развитием интернета информативный эффект начал превосходить эффект лаконичности. Исследователям не стоит жалеть время на выбор заголовка публикации, так как число статей и журналов, к которым можно получить онлайн-доступ, постоянно растет. А мы планируем вскоре вернуться к этой теме со своим исследованием, чтобы слегка освежить данные, полученные в оригинальной статье.
#цитирование #SSCI #обзор
{kind=link}
«Стоковые» члены редколлегии в хищнических журналах
Как мы упоминали ранее, хищнические издательства часто пользуются без авторизации личными данными ученых и включают их в редакционные коллегии своих журналов (если эти редколлегии, конечно, вообще есть).
В июльском выпуске Learned Publishing вышла статья, посвященная описанию «стоковых» персонажей (stock characters) хищнических редколлегий, под которыми автор подразумевает ученых, которые одновременно входят в редколлегии 20 и более недобросовестных журналов.
В период с 2017 по 2023 год Майк Даунс (Mike Downes) тщательно изучал тысячи редакционных коллегий журналов, издатели которых входят в Список Билла (Beall's List). Им были обнаружены 96 исследователей, каждый из которых состоит в редколлегиях от 20 до 503 журналов (по состоянию на 2023 год).
В выборку вошли только хищнические журналы, редакционная политика которых допускает три этических нарушения:
🔹 фабрикация дат рецензирования статей;
🔹 кража личных данных;
🔹 заполнение архивов фальшивыми статьями.
По мнению автора, «стоковые» персонажи встречались настолько часто, что можно уверенно воспринимать их присутствие или отсутствие в качестве полноценного критерия, отличающего честного издателя от недобросовестного.
Такие персонажи, как правило, обращают на себя внимание за счет следующих «красных флагов»:
🔹 невозможность обнаружить профиль ученого на сайте вуза, в котором он якобы работает;
🔹 членство в редколлегиях журналов по двум и более несвязанным темам;
🔹 такой ученый практически никогда не встречается в редколлегии влиятельного журнала.
Конечно, информация о членах редколлегии может быть украдена полностью или частично, т.е. в некоторых случаях ученые не знают, что выступают в такой роли, но иногда исследователи добровольно вступают в такие редколлегии (в таких случаях они там же публикуют свои работы). Очевидно, что членство в совете редколлегии хищнического журнала, которое указано в разделе «Достижения» или в каком-либо схожем разделе биографии исследователя, нельзя назвать кражей личных данных.
Опасность заключается в том, что если имя ученого упоминается в хищнических редколлегиях сначала один, два, а потом несколько раз, и исследователь не замечает этого (или не хочет замечать), такое лицо легко становится типичной жертвой кражи личных данных.
Майк Даунс отмечает, что после его переписки с рядом «стоковых» персонажей, нескольким авторам, внесенным в редколлегии без их согласия, удалось немного исправить ситуацию. Например, один исследователь, который когда-то входил в 361 редколлегии, на данный момент состоит в 118. Однако существуют и мертвые «стоковые» персонажи, которые не могут за себя постоять (так, например, один профессор уже четвертый год после смерти продолжает занимать должность главного редактора журнала).
«Стоковые» персонажи включают в редакционные коллегии, чтобы создать впечатление, что журнал соответствует академическим стандартам. Согласно опросу автора, «стоковых» персонажей и многих других ученых, появлявшихся в редакционных коллегиях хищнических издательств, часто объединяет смутное воспоминание о том, что они согласились стать членом редакционной коллегии много лет назад и с тех пор больше ничего об этом не слышали. Внимательность в таких вопросах может помочь вовремя заметить кражу личных данных исследователя и принять соответствующие меры.
#predatoryjournals #хищническиежурналы #редколлегия #обзор
Как мы упоминали ранее, хищнические издательства часто пользуются без авторизации личными данными ученых и включают их в редакционные коллегии своих журналов (если эти редколлегии, конечно, вообще есть).
В июльском выпуске Learned Publishing вышла статья, посвященная описанию «стоковых» персонажей (stock characters) хищнических редколлегий, под которыми автор подразумевает ученых, которые одновременно входят в редколлегии 20 и более недобросовестных журналов.
В период с 2017 по 2023 год Майк Даунс (Mike Downes) тщательно изучал тысячи редакционных коллегий журналов, издатели которых входят в Список Билла (Beall's List). Им были обнаружены 96 исследователей, каждый из которых состоит в редколлегиях от 20 до 503 журналов (по состоянию на 2023 год).
В выборку вошли только хищнические журналы, редакционная политика которых допускает три этических нарушения:
🔹 фабрикация дат рецензирования статей;
🔹 кража личных данных;
🔹 заполнение архивов фальшивыми статьями.
По мнению автора, «стоковые» персонажи встречались настолько часто, что можно уверенно воспринимать их присутствие или отсутствие в качестве полноценного критерия, отличающего честного издателя от недобросовестного.
Такие персонажи, как правило, обращают на себя внимание за счет следующих «красных флагов»:
🔹 невозможность обнаружить профиль ученого на сайте вуза, в котором он якобы работает;
🔹 членство в редколлегиях журналов по двум и более несвязанным темам;
🔹 такой ученый практически никогда не встречается в редколлегии влиятельного журнала.
Конечно, информация о членах редколлегии может быть украдена полностью или частично, т.е. в некоторых случаях ученые не знают, что выступают в такой роли, но иногда исследователи добровольно вступают в такие редколлегии (в таких случаях они там же публикуют свои работы). Очевидно, что членство в совете редколлегии хищнического журнала, которое указано в разделе «Достижения» или в каком-либо схожем разделе биографии исследователя, нельзя назвать кражей личных данных.
Опасность заключается в том, что если имя ученого упоминается в хищнических редколлегиях сначала один, два, а потом несколько раз, и исследователь не замечает этого (или не хочет замечать), такое лицо легко становится типичной жертвой кражи личных данных.
Майк Даунс отмечает, что после его переписки с рядом «стоковых» персонажей, нескольким авторам, внесенным в редколлегии без их согласия, удалось немного исправить ситуацию. Например, один исследователь, который когда-то входил в 361 редколлегии, на данный момент состоит в 118. Однако существуют и мертвые «стоковые» персонажи, которые не могут за себя постоять (так, например, один профессор уже четвертый год после смерти продолжает занимать должность главного редактора журнала).
«Стоковые» персонажи включают в редакционные коллегии, чтобы создать впечатление, что журнал соответствует академическим стандартам. Согласно опросу автора, «стоковых» персонажей и многих других ученых, появлявшихся в редакционных коллегиях хищнических издательств, часто объединяет смутное воспоминание о том, что они согласились стать членом редакционной коллегии много лет назад и с тех пор больше ничего об этом не слышали. Внимательность в таких вопросах может помочь вовремя заметить кражу личных данных исследователя и принять соответствующие меры.
#predatoryjournals #хищническиежурналы #редколлегия #обзор
Выше квартилей pinned ««Стоковые» члены редколлегии в хищнических журналах Как мы упоминали ранее, хищнические издательства часто пользуются без авторизации личными данными ученых и включают их в редакционные коллегии своих журналов (если эти редколлегии, конечно, вообще есть).…»
Что с сайтами журналов в Elibrary?
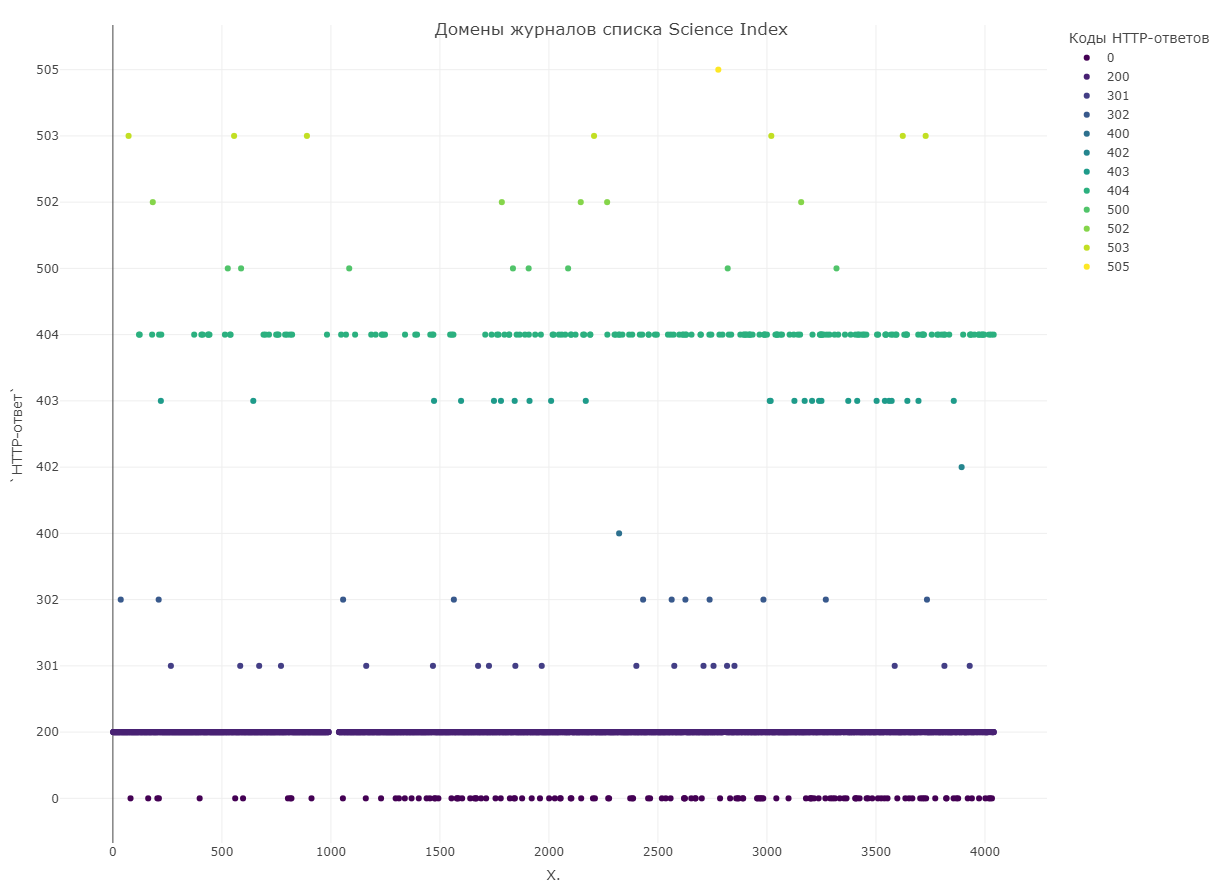
В нашем канале мы уже неоднократно упоминали о феномене «похищенных» (hijacked) журналов (некоторые мошеннические издательства создают копии сайтов научных журналов, которые тяжело отличить от официальных страниц). В комментариях к апрельскому посту наш коллега отметил неактуальность некоторых доменов университетов из 1-Мониторинга, что навело нас на мысль: сколько неактуальных сайтов журналов сейчас присутствует в российском сегменте?
Для исследования мы выбрали рейтинг Science Index 2022, размещенный на Elibrary. В него входят 4044 журнала, в том числе 3058 журналов из списка ВАК. В Elibrary домашняя страница указана у 3786 (93,6%) из них. Для проверки ответов сервера мы использовали сервис https://coolakov.ru/tools/ping/, позволяющий отследить редиректы и получить итоговый адрес страницы (или 404, если страница не найдена).
Полученные данные мы разместили на диаграмме. По оси X указывается место журнала в рейтинге, а на оси Y — код ответа сервера. Распределение по ответам серверов следующее:
3397 журналов — код 2ХХ (успешная обработка запроса)
30 журналов — коды 3ХХ (редирект и после этого успешная обработка запроса)
209 журналов — коды 4ХХ (ошибка на стороне клиента — нет доступа или ошибочный адрес сайта)
21 журнал — коды 5ХХ (ошибка на стороне сервера — например, сайт временно недоступен)
129 журналов — код 0 (такой код сервис возвращал, если сайта просто не существует).
Итак, для 359 журналов (почти 9%) журналов из Science Index указаны некорректные адреса веб-страниц (при этом редиректов на подозрительные ресурсы мы не обнаружили). 209 журналов, сайты которых возвращают коды 4XX, как правило, поменяли адрес или архитектуру сайта — нужно только обновить данные. А вот 129 журналов с несуществующими сайтами вызывают больше беспокойства.
#аналитика #Elibrary #сайты
В нашем канале мы уже неоднократно упоминали о феномене «похищенных» (hijacked) журналов (некоторые мошеннические издательства создают копии сайтов научных журналов, которые тяжело отличить от официальных страниц). В комментариях к апрельскому посту наш коллега отметил неактуальность некоторых доменов университетов из 1-Мониторинга, что навело нас на мысль: сколько неактуальных сайтов журналов сейчас присутствует в российском сегменте?
Для исследования мы выбрали рейтинг Science Index 2022, размещенный на Elibrary. В него входят 4044 журнала, в том числе 3058 журналов из списка ВАК. В Elibrary домашняя страница указана у 3786 (93,6%) из них. Для проверки ответов сервера мы использовали сервис https://coolakov.ru/tools/ping/, позволяющий отследить редиректы и получить итоговый адрес страницы (или 404, если страница не найдена).
Полученные данные мы разместили на диаграмме. По оси X указывается место журнала в рейтинге, а на оси Y — код ответа сервера. Распределение по ответам серверов следующее:
3397 журналов — код 2ХХ (успешная обработка запроса)
30 журналов — коды 3ХХ (редирект и после этого успешная обработка запроса)
209 журналов — коды 4ХХ (ошибка на стороне клиента — нет доступа или ошибочный адрес сайта)
21 журнал — коды 5ХХ (ошибка на стороне сервера — например, сайт временно недоступен)
129 журналов — код 0 (такой код сервис возвращал, если сайта просто не существует).
Итак, для 359 журналов (почти 9%) журналов из Science Index указаны некорректные адреса веб-страниц (при этом редиректов на подозрительные ресурсы мы не обнаружили). 209 журналов, сайты которых возвращают коды 4XX, как правило, поменяли адрес или архитектуру сайта — нужно только обновить данные. А вот 129 журналов с несуществующими сайтами вызывают больше беспокойства.
#аналитика #Elibrary #сайты
{kind=link}
История библиометрических баз данных и их разновидностей. Часть 1
Научные базы данных обеспечивают доступность и систематизацию растущего потока статей, материалов конференций, патентов и других исследований. Сегодня обращение к Web of Science, Scopus или другим базам данных для поиска статей — рутина любого исследователя. Мы используем базы данных, не придавая большого значения их различиям и не задумываясь об истории их появления. В сегодняшнем посте, посвященном истории наукометрии, мы посмотрим, как происходило становление баз данных, окружающих нас сегодня.
#историянаукометрии #Scopus #WoS #MAG #OpenAlex
Научные базы данных обеспечивают доступность и систематизацию растущего потока статей, материалов конференций, патентов и других исследований. Сегодня обращение к Web of Science, Scopus или другим базам данных для поиска статей — рутина любого исследователя. Мы используем базы данных, не придавая большого значения их различиям и не задумываясь об истории их появления. В сегодняшнем посте, посвященном истории наукометрии, мы посмотрим, как происходило становление баз данных, окружающих нас сегодня.
#историянаукометрии #Scopus #WoS #MAG #OpenAlex
Telegraph
История библиометрических баз данных и их разновидностей. Часть 1
Использование обширных цифровых баз данных стало неотъемлемым элементом академической деятельности. Они позволяют не только искать материалы в отдельных областях, но и отслеживать публикационную активность, а также проводить сложные аналитические исследования…
Некоммерческое издание публикаций не снижает их стоимости
Современная научная публикационная деятельность сталкивается с серьезными финансовыми вызовами. Растущая стоимость публикационного процесса увеличивает потребность в некоммерческих моделях публикаций. Однако существует вероятность того, что популярность таких моделей может ограничить рост издательств, но так и не привести к удешевлению процесса публикации. В сегодняшнем обзоре мы рассмотрим посвященное этой теме недавнее исследование Роба Джонсона, главы компании Research Consulting в области исследовательской политики.
Инициатива ЕС по снижению стоимости публикации
В мае 2023 года Совет ЕС назвал текущие расходы на публикации неприемлемыми:
«Расходы на платный доступ к статьям и их публикацию становятся непосильными, а каналы публикаций для исследователей часто находятся в руках частных компаний, которые зачастую контролируют интеллектуальную собственность на статьи».
Совет призвал Комиссию и EC поддержать политику, направленную на создание некоммерческой, открытой и многоформатной модели научных изданий, не влекущей за собой никаких расходов для авторов и читателей.
В своем исследовании Р. Джонсон указывает, что существующие издательства уменьшают расходы на процесс публикации путем использования государственных субсидий или масштабирования объема выпускаемых публикаций. Это же наблюдение подтверждает отчет Массачусетского технологического института «Доступ к науке и стипендиям: ключевые вопросы о будущем публикации научных работ», в котором предлагается два способа увеличения прибыли коммерческих изданий: увеличение количества публикаций и снижение расходов.
О состоянии коммерческих изданий свидетельствуют данные инициативы OpenAPC при библиотеке Билефельдского университета, которая публикует наборы данных о сборах, выплачиваемых университетами и исследовательскими институтами за статьи в журналах открытого доступа.
Создание Open Research Europe и сценарии развития
Сложившуюся ситуацию, как описано в инициативе ЕС, предлагается решить при помощи создания ORE — издательской платформы открытого доступа на некоммерческой основе. Предполагается, что эта платформа будет работать как независимое юридическое лицо, что позволит оценить полную стоимость публикационного цикла. Большинство услуг, связанных с производством публикаций, таких как редакционные, производственные или технологические функции, будут выполняться сторонними поставщиками, но допускается возможность реализации платформы на базе уже существующей академической или международной организации. Однако, насколько создание ORE решит проблему роста стоимости публикаций?
В 2023 году Р. Джонсон представил отчет о потенциале создания ORE. В нем рассматриваются вероятные внутренние и внешние факторы, потенциально способные повлиять на рост опубликованных материалов, а также предполагаемый рост расходов в период с 2026 по 2030 годы.
Р. Джонсон смоделировал несколько сценариев возможного роста публикаций под эгидой ORE. Им были выделены пять основных категорий предполагаемых затрат:
а) расходы на производство статей,
б) маркетинг и вовлечение сообщества,
в) разработка и обслуживание платформы,
г) зарплаты и оклады,
д) административные накладные расходы.
В результате расчеты автора показывают, что даже при самом оптимистичном сценарии маловероятно, что стоимость одной публикации будет значительно ниже текущих коммерческих расценок.
В целом исследование показывает, что, с учетом всех категорий расходов, некоммерческие модели издания слабо способствуют уменьшению стоимости публикационного процесса. Р. Джонсон указывает, что политика развития издательств открытого доступа предполагает две крайние стратегии: сохранение качества ценой потери доли влияния и доходности, либо наращивание объемов издаваемых материалов, рискуя потерять доверие читателей к качеству.
#обзор #OpenResearchEurope #коммерциализация
Современная научная публикационная деятельность сталкивается с серьезными финансовыми вызовами. Растущая стоимость публикационного процесса увеличивает потребность в некоммерческих моделях публикаций. Однако существует вероятность того, что популярность таких моделей может ограничить рост издательств, но так и не привести к удешевлению процесса публикации. В сегодняшнем обзоре мы рассмотрим посвященное этой теме недавнее исследование Роба Джонсона, главы компании Research Consulting в области исследовательской политики.
Инициатива ЕС по снижению стоимости публикации
В мае 2023 года Совет ЕС назвал текущие расходы на публикации неприемлемыми:
«Расходы на платный доступ к статьям и их публикацию становятся непосильными, а каналы публикаций для исследователей часто находятся в руках частных компаний, которые зачастую контролируют интеллектуальную собственность на статьи».
Совет призвал Комиссию и EC поддержать политику, направленную на создание некоммерческой, открытой и многоформатной модели научных изданий, не влекущей за собой никаких расходов для авторов и читателей.
В своем исследовании Р. Джонсон указывает, что существующие издательства уменьшают расходы на процесс публикации путем использования государственных субсидий или масштабирования объема выпускаемых публикаций. Это же наблюдение подтверждает отчет Массачусетского технологического института «Доступ к науке и стипендиям: ключевые вопросы о будущем публикации научных работ», в котором предлагается два способа увеличения прибыли коммерческих изданий: увеличение количества публикаций и снижение расходов.
О состоянии коммерческих изданий свидетельствуют данные инициативы OpenAPC при библиотеке Билефельдского университета, которая публикует наборы данных о сборах, выплачиваемых университетами и исследовательскими институтами за статьи в журналах открытого доступа.
Создание Open Research Europe и сценарии развития
Сложившуюся ситуацию, как описано в инициативе ЕС, предлагается решить при помощи создания ORE — издательской платформы открытого доступа на некоммерческой основе. Предполагается, что эта платформа будет работать как независимое юридическое лицо, что позволит оценить полную стоимость публикационного цикла. Большинство услуг, связанных с производством публикаций, таких как редакционные, производственные или технологические функции, будут выполняться сторонними поставщиками, но допускается возможность реализации платформы на базе уже существующей академической или международной организации. Однако, насколько создание ORE решит проблему роста стоимости публикаций?
В 2023 году Р. Джонсон представил отчет о потенциале создания ORE. В нем рассматриваются вероятные внутренние и внешние факторы, потенциально способные повлиять на рост опубликованных материалов, а также предполагаемый рост расходов в период с 2026 по 2030 годы.
Р. Джонсон смоделировал несколько сценариев возможного роста публикаций под эгидой ORE. Им были выделены пять основных категорий предполагаемых затрат:
а) расходы на производство статей,
б) маркетинг и вовлечение сообщества,
в) разработка и обслуживание платформы,
г) зарплаты и оклады,
д) административные накладные расходы.
В результате расчеты автора показывают, что даже при самом оптимистичном сценарии маловероятно, что стоимость одной публикации будет значительно ниже текущих коммерческих расценок.
В целом исследование показывает, что, с учетом всех категорий расходов, некоммерческие модели издания слабо способствуют уменьшению стоимости публикационного процесса. Р. Джонсон указывает, что политика развития издательств открытого доступа предполагает две крайние стратегии: сохранение качества ценой потери доли влияния и доходности, либо наращивание объемов издаваемых материалов, рискуя потерять доверие читателей к качеству.
#обзор #OpenResearchEurope #коммерциализация
{kind=link}
Дайджест: июль 2024
Представляем свежий дайджест научных событий за последний месяц.
Научные статьи
В Scientometrics вышло исследование классики библиометрического цитирования — какие старые публикации в этой области по-прежнему высоко цитируются.
Китайские ученые проанализировали, насколько оценки рецензентов соответствуют последующим цитированиям статей. Выяснилось, что корреляция невелика.
Journal of Informetrics опубликовал статью, посвященную новому подходу к вычислению расстояний между исследовательскими дисциплинами. Подход основан на изучении исследовательских коллабораций и измерении схожести публикаций.
В Quantitative Science Studies предлагается новый способ подсчета импакт-фактора для более точной оценки влияния и видимости научных журналов и публикаций.
Редакторская политика
Национальная организация по информационным стандартам (NISO) выпустила рекомендации по информированию об отзывах статей и публикации «выражений обеспокоенности» в связи (например) с сомнительной методологией.
А ODI (Open Discovery Initiative), основанная NISO, опубликовала лучшие практики внедрения предварительно индексированных поисковых инструментов. Вендоры отреагировали в основном положительно.
На Scholarly Kitchen вышло интервью с Ричардом Джефферсоном, основателем библиометрической платформы The Lens. Интересный рассказ о том, как была задумана и реализована The Lens, и какие вызовы стоят перед ней сейчас.
Одна из самых интересных новостей, на наш взгляд, касается Informa, материнской компании академического издательства Taylor & Francis. Она заключила с Microsoft соглашение о доступе к данным для обучения искусственного интеллекта. Многие исследователи, публикующиеся в издательстве, считают это сомнительным решением — во-первых, потому, что авторов об этом никто не предупреждал, а во-вторых, потому, что это создает тревожный прецедент и подчеркивает и без того «хищническую» природу академических публикаций.
Базы данных
Ежегодный отчет также выпустил Springer Nature. Помимо прочего, он показывает рост числа исследований в открытом доступе.
Издательство De Gruyter Brill объявило, что в 2025 году сделает 37 дополнительных журналов доступными бесплатно через свою модель Subscribe to Open (S2O).
ОЭСР переводит материалы и сервисы своей электронной библиотеки в открытый доступ.
Наука в мире
Исследователи MIT представили GenSQL, генеративный ИИ для баз данных на основе SQL, который может делать прогнозы, обнаруживать аномалии, угадывать пропущенные значения, исправлять ошибки или генерировать синтетические данные.
1-3 июля в Вашингтоне состоялась ежегодная конференция ICSSI (International Conference on Science and Innovation). К сожалению, архивов прошлых конференций на сайте нет, но мы будем надеяться на публикацию материалов конференции в будущих сборниках.
Наука в России
Альянс в сфере искусственного интеллекта выпустил новый рейтинг вузов России, готовящих специалистов по ИИ. Всего в рейтинг входит 207 университетов из 69 регионов страны.
В соответствии с приказом МинОбра, с 26 июля вносятся изменения в правилах формирования перечня рецензируемых научных изданий ВАК.
Академик Хохлов пишет об РЦНИ: на платформе начали появляться первые (январские) выпуски некоторых журналов РАН за 2024 год.
В НИУ ВШЭ разрабатывают технологию идентификации текстов, сгенерированных ИИ любого типа.
#дайджест #новости #редакторскаяполитика #базыданных #наукавроссии #искуственныйинтеллект
Представляем свежий дайджест научных событий за последний месяц.
Научные статьи
В Scientometrics вышло исследование классики библиометрического цитирования — какие старые публикации в этой области по-прежнему высоко цитируются.
Китайские ученые проанализировали, насколько оценки рецензентов соответствуют последующим цитированиям статей. Выяснилось, что корреляция невелика.
Journal of Informetrics опубликовал статью, посвященную новому подходу к вычислению расстояний между исследовательскими дисциплинами. Подход основан на изучении исследовательских коллабораций и измерении схожести публикаций.
В Quantitative Science Studies предлагается новый способ подсчета импакт-фактора для более точной оценки влияния и видимости научных журналов и публикаций.
Редакторская политика
Национальная организация по информационным стандартам (NISO) выпустила рекомендации по информированию об отзывах статей и публикации «выражений обеспокоенности» в связи (например) с сомнительной методологией.
А ODI (Open Discovery Initiative), основанная NISO, опубликовала лучшие практики внедрения предварительно индексированных поисковых инструментов. Вендоры отреагировали в основном положительно.
На Scholarly Kitchen вышло интервью с Ричардом Джефферсоном, основателем библиометрической платформы The Lens. Интересный рассказ о том, как была задумана и реализована The Lens, и какие вызовы стоят перед ней сейчас.
Одна из самых интересных новостей, на наш взгляд, касается Informa, материнской компании академического издательства Taylor & Francis. Она заключила с Microsoft соглашение о доступе к данным для обучения искусственного интеллекта. Многие исследователи, публикующиеся в издательстве, считают это сомнительным решением — во-первых, потому, что авторов об этом никто не предупреждал, а во-вторых, потому, что это создает тревожный прецедент и подчеркивает и без того «хищническую» природу академических публикаций.
Базы данных
Ежегодный отчет также выпустил Springer Nature. Помимо прочего, он показывает рост числа исследований в открытом доступе.
Издательство De Gruyter Brill объявило, что в 2025 году сделает 37 дополнительных журналов доступными бесплатно через свою модель Subscribe to Open (S2O).
ОЭСР переводит материалы и сервисы своей электронной библиотеки в открытый доступ.
Наука в мире
Исследователи MIT представили GenSQL, генеративный ИИ для баз данных на основе SQL, который может делать прогнозы, обнаруживать аномалии, угадывать пропущенные значения, исправлять ошибки или генерировать синтетические данные.
1-3 июля в Вашингтоне состоялась ежегодная конференция ICSSI (International Conference on Science and Innovation). К сожалению, архивов прошлых конференций на сайте нет, но мы будем надеяться на публикацию материалов конференции в будущих сборниках.
Наука в России
Альянс в сфере искусственного интеллекта выпустил новый рейтинг вузов России, готовящих специалистов по ИИ. Всего в рейтинг входит 207 университетов из 69 регионов страны.
В соответствии с приказом МинОбра, с 26 июля вносятся изменения в правилах формирования перечня рецензируемых научных изданий ВАК.
Академик Хохлов пишет об РЦНИ: на платформе начали появляться первые (январские) выпуски некоторых журналов РАН за 2024 год.
В НИУ ВШЭ разрабатывают технологию идентификации текстов, сгенерированных ИИ любого типа.
#дайджест #новости #редакторскаяполитика #базыданных #наукавроссии #искуственныйинтеллект
{kind=link}
Использование ИИ в технологическом трансфере
Месяц назад в Nature вышла заметка основателя “Научного центра науки и инноваций Северо-Западного университета” Дашунь Вана (Dashun Wang), посвященная использованию алгоритмов ИИ для выявления ученых, нуждающихся в поддержке их научных результатов для практического приложения.
Во время пилотного проекта исследовательской группы Вана обнаружилось, что одна исследовательница в области биологии не знала о влиянии своих научных работ на рынок, но в результате знакомства с подразделением технологического трансфера она узнала, что частные компании широко цитируют ее исследования в своих патентах, и подала заявку на регистрацию своего изобретения. Этот пример сподвигнул Вана задаться вытекающими из этого кейса вопросами: можно ли выявить исследователей с невостребованным инновационным потенциалом и каким образом?
В течение нескольких лет исследовательский коллектив Вана работал с различными университетами США, пытаясь найти оптимальные способы максимизировать результаты научной деятельности.
В ходе исследования обнаружились некоторые потворяющиеся паттерны, например:
- женщины реже патентуют свои работы, чем мужчины (причем разница — от двух до десяти раз в зависимости от области), при одинаковом (судя по цитируемости) уровне работы;
- преподаватели с постоянным контрактом подают заявки чаще, чем те, кто трудоустроен по временному контракту.
Кроме того, выяснилось, что существует довольно много ученых, которые не стремятся к трансферу технологий, не взаимодействуют с соответствующим департаментом (а такие есть почти во всех университетах), не подают заявки на патенты.
Ван и его коллеги полагают, что публикующиеся ежегодно наборы данных о миллионах статей, препринтов и грантовых заявок можно анализировать при помощи ИИ, чтобы выявить пробелы и узкие места, которые мешают технологическим прорывам.
Одним из главных хайлайтов статьи является утверждение Вана о дихотомии между фундаментальными и прикладными исследованиями и условиями современности: сложно спрогнозировать какие исследования найдут непосредственное технологическое применение.
Вывод Вана состоит в том, что исследования были бы намного влиятельней, если бы университеты использовали инструменты ИИ с целью поиска научных результатов своих сотрудников, к которым применим технологический трансфер.
#обзор #искусственныйинтеллект #патенты
Месяц назад в Nature вышла заметка основателя “Научного центра науки и инноваций Северо-Западного университета” Дашунь Вана (Dashun Wang), посвященная использованию алгоритмов ИИ для выявления ученых, нуждающихся в поддержке их научных результатов для практического приложения.
Во время пилотного проекта исследовательской группы Вана обнаружилось, что одна исследовательница в области биологии не знала о влиянии своих научных работ на рынок, но в результате знакомства с подразделением технологического трансфера она узнала, что частные компании широко цитируют ее исследования в своих патентах, и подала заявку на регистрацию своего изобретения. Этот пример сподвигнул Вана задаться вытекающими из этого кейса вопросами: можно ли выявить исследователей с невостребованным инновационным потенциалом и каким образом?
В течение нескольких лет исследовательский коллектив Вана работал с различными университетами США, пытаясь найти оптимальные способы максимизировать результаты научной деятельности.
В ходе исследования обнаружились некоторые потворяющиеся паттерны, например:
- женщины реже патентуют свои работы, чем мужчины (причем разница — от двух до десяти раз в зависимости от области), при одинаковом (судя по цитируемости) уровне работы;
- преподаватели с постоянным контрактом подают заявки чаще, чем те, кто трудоустроен по временному контракту.
Кроме того, выяснилось, что существует довольно много ученых, которые не стремятся к трансферу технологий, не взаимодействуют с соответствующим департаментом (а такие есть почти во всех университетах), не подают заявки на патенты.
Ван и его коллеги полагают, что публикующиеся ежегодно наборы данных о миллионах статей, препринтов и грантовых заявок можно анализировать при помощи ИИ, чтобы выявить пробелы и узкие места, которые мешают технологическим прорывам.
Одним из главных хайлайтов статьи является утверждение Вана о дихотомии между фундаментальными и прикладными исследованиями и условиями современности: сложно спрогнозировать какие исследования найдут непосредственное технологическое применение.
Вывод Вана состоит в том, что исследования были бы намного влиятельней, если бы университеты использовали инструменты ИИ с целью поиска научных результатов своих сотрудников, к которым применим технологический трансфер.
#обзор #искусственныйинтеллект #патенты
Взаимодействовали ли вы с центром технологического трансфера в своем институте?
Да, успешно - 5
👍👍 6%
Да, но без успешного результата - 4
👍👍 5%
Нет, но знаю, что у нас есть такой отдел - 23
👍👍👍👍👍 29%
У нас нет центра технологического трансфера - 38
👍👍👍👍👍👍👍👍 48%
В моей области это неприменимо - 10
👍👍👍 13%
👥 80 человек уже проголосовало.
Да, успешно - 5
👍👍 6%
Да, но без успешного результата - 4
👍👍 5%
Нет, но знаю, что у нас есть такой отдел - 23
👍👍👍👍👍 29%
У нас нет центра технологического трансфера - 38
👍👍👍👍👍👍👍👍 48%
В моей области это неприменимо - 10
👍👍👍 13%
👥 80 человек уже проголосовало.
Самоцитирования журналов: тематический, страновой и квартильный разрезы
Постепенно возвращаясь к академическому ритму после летних каникул, мы решили обратить внимание наших подписчиков на динамику самоцитирований журналов, индексирующихся в Web of Science.
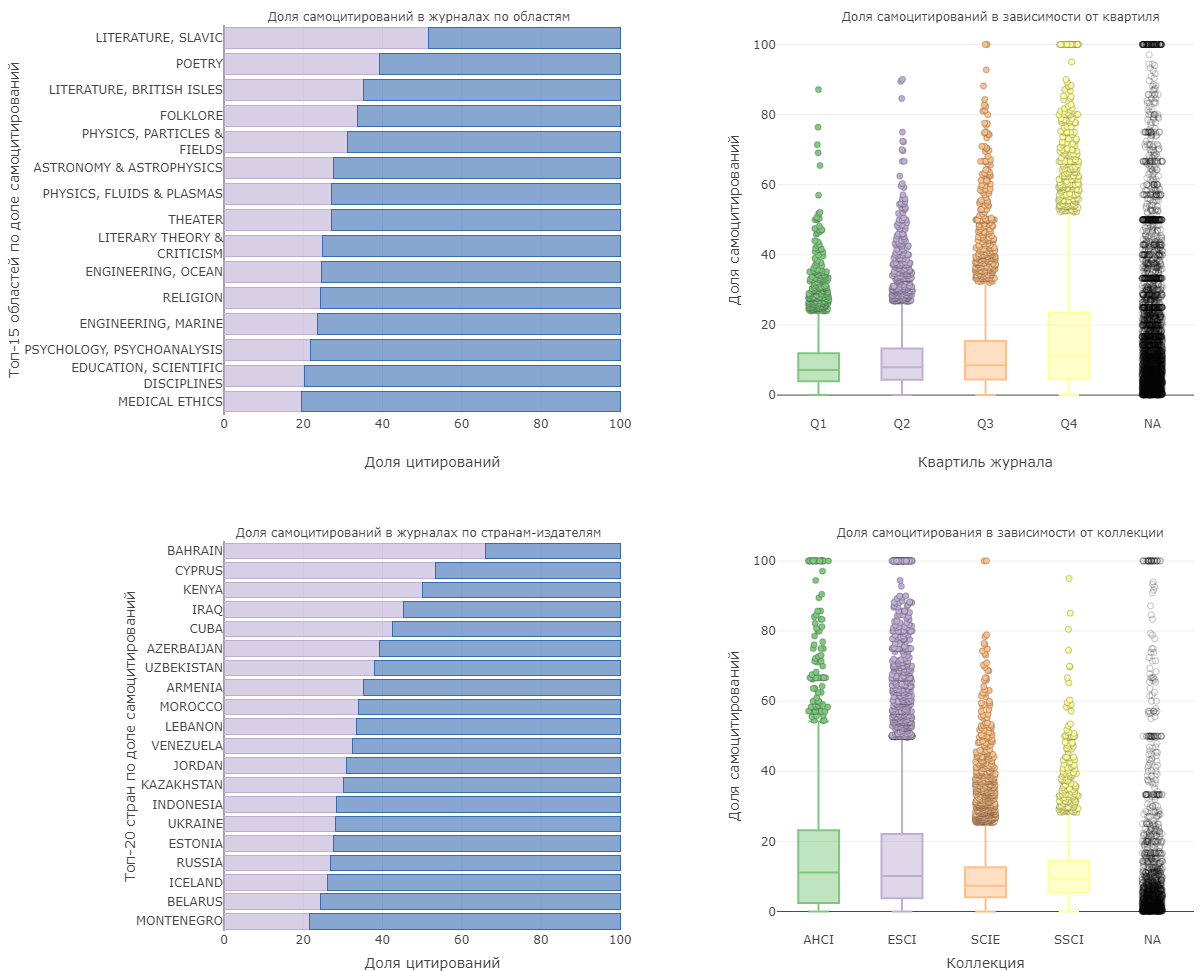
В онлайн-руководстве вопрос самоцитирований рассматривается как с точки зрения отдельного автора, так и с позиции журнального самоцитирования. Основная проблема самоцитирований в последнем случае — это искажение информации об истинной видимости журнальных статей академическим сообществом, что снижает надежность метрик, рассчитываемых на основе цитируемости (в том числе и широко используемых квартилей, являющихся побочным продуктом статистического подхода). Последние работы в области наукометрии (Bennett H., Singh B. & Slattery F.: 2024; Fiorillo. L.: 2024) показывают, что интерес к оценке самоцитирований не только сохраняется, но и является драйвером для описания тех изменений, которые претерпевают отдельные научные области.
Наша сегодняшняя аналитика продолжает заданное направление и построена на данных по источникам WoS за 2021-2023 гг. На диаграмме можно увидеть области, в которых наиболее часто встречается самоцитирование: в основном это узкие специфические области литературы (в частности, славянская литература — в среднем более 50% самоцитирований) и физики (физика полей и частиц, астрофизика, физика плазмы — 25-30%) Если говорить о странах-издателях журналов, то наибольшее количество самоцитирований встречается в журналах стран Африки и СНГ.
С квартилем журнала доля самоцитирований коррелирует слабо, но устойчиво — медианное значение составляет от 7,2% в журналах Q1 до 11,3% в Q4. Наблюдается и зависимость от коллекции, в которую входит журнал: меньше всего прибегают к самоцитированию авторы журналов из коллекции SCIE (Science Citation Index Expanded, 7,3%), за ней следует SSCI (Social Sciences Citation Index, 9,3%). У коллекций ESCI (Emerging Sources Citation Index) и AHCI (Arts & Humanities Citation Index) показатели самоцитирования выше — 10,2% и 11,1% соответственно.
#аналитика #самоцитирование #webofscience #руководство
Постепенно возвращаясь к академическому ритму после летних каникул, мы решили обратить внимание наших подписчиков на динамику самоцитирований журналов, индексирующихся в Web of Science.
В онлайн-руководстве вопрос самоцитирований рассматривается как с точки зрения отдельного автора, так и с позиции журнального самоцитирования. Основная проблема самоцитирований в последнем случае — это искажение информации об истинной видимости журнальных статей академическим сообществом, что снижает надежность метрик, рассчитываемых на основе цитируемости (в том числе и широко используемых квартилей, являющихся побочным продуктом статистического подхода). Последние работы в области наукометрии (Bennett H., Singh B. & Slattery F.: 2024; Fiorillo. L.: 2024) показывают, что интерес к оценке самоцитирований не только сохраняется, но и является драйвером для описания тех изменений, которые претерпевают отдельные научные области.
Наша сегодняшняя аналитика продолжает заданное направление и построена на данных по источникам WoS за 2021-2023 гг. На диаграмме можно увидеть области, в которых наиболее часто встречается самоцитирование: в основном это узкие специфические области литературы (в частности, славянская литература — в среднем более 50% самоцитирований) и физики (физика полей и частиц, астрофизика, физика плазмы — 25-30%) Если говорить о странах-издателях журналов, то наибольшее количество самоцитирований встречается в журналах стран Африки и СНГ.
С квартилем журнала доля самоцитирований коррелирует слабо, но устойчиво — медианное значение составляет от 7,2% в журналах Q1 до 11,3% в Q4. Наблюдается и зависимость от коллекции, в которую входит журнал: меньше всего прибегают к самоцитированию авторы журналов из коллекции SCIE (Science Citation Index Expanded, 7,3%), за ней следует SSCI (Social Sciences Citation Index, 9,3%). У коллекций ESCI (Emerging Sources Citation Index) и AHCI (Arts & Humanities Citation Index) показатели самоцитирования выше — 10,2% и 11,1% соответственно.
#аналитика #самоцитирование #webofscience #руководство
{kind=link}
Анализ цитирований в российских публикациях в Web of Science
В последнем выпуске Journal of Scientometric Research в соавторстве с Дарьей Мальцевой (ВШЭ) вышла статья, посвященная библиометрическому анализу российской науки на базе 1,38 млн публикаций российских (со)авторов.
В основе работы — использование метода спектроскопии года публикации цитируемых работ (RPYS — Reference Publication Year Spectroscopy), разработанного в 2013 Вернером Марксом. Этот метод, как правило, применяется для более ограниченных датасетов (например, для публикаций одного исследователя, журнала или научной дисциплины). Для обработки миллионов записей данных метод был масштабирован авторами исследования с использованием СУБД, что позволило проанализировать исторические корни российской науки.
В качестве исходных данных был взят массив статей, индексированных в WoS до мая 2022 года, у которых хотя бы один из авторов имеет российскую аффилиацию, в виде текстовых файлов. Почти все статьи приходятся на период с 1992 по 2022 гг, до 1992 публикаций крайне мало. Общее количество ссылок в описанном массиве — более 32 млн, при этом 1,66 млн ведут на статьи, входящие в исходный датасет.
Согласно результатам исследования:
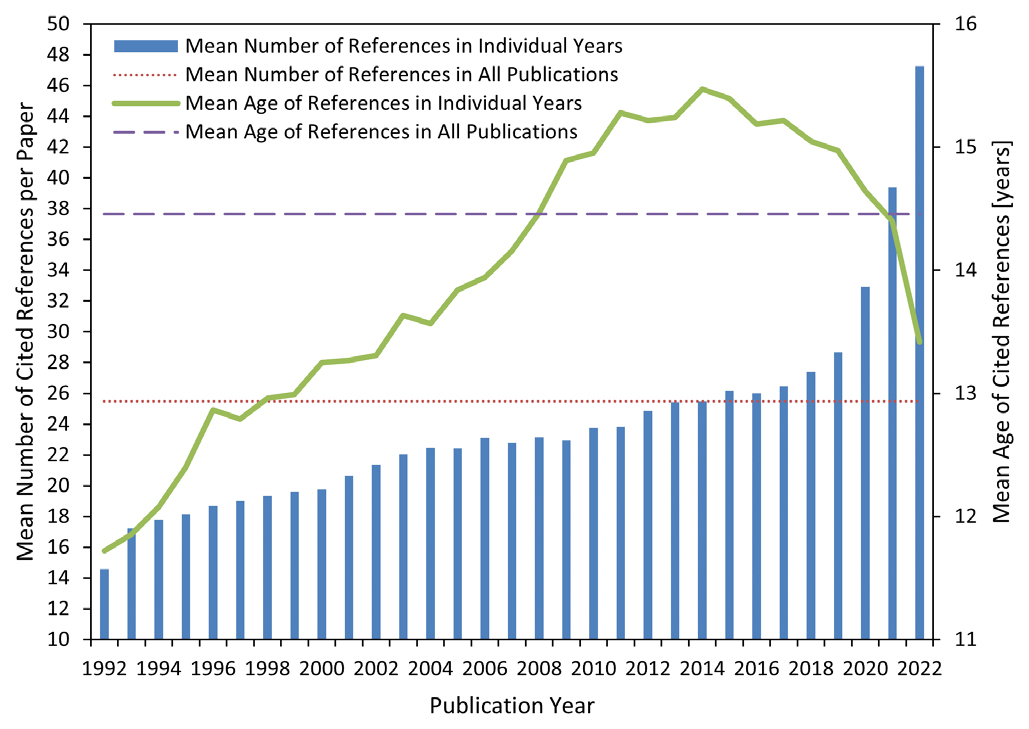
🔹 Количество ссылок в статьях заметно возросло с течением времени: если в 1992 г. в публикации приводилось в среднем 15 ссылок, то в 2022 г. их было 47.
🔹 Один из основных объектов анализа — разница в «возрасте» между статьей и публикациями, которая она цитирует. Подавляющее большинство ссылок приходится на группу 20+ лет — это означает, что российская наука в значительной степени опиралась на более «старые» фундаментальные исследования.
🔹 Общий средний возраст цитируемых статей составил 14,5 лет, и в рассматриваемый период (с 1992 по 2022) он увеличился примерно на 14%. Следует отметить и динамику: так, средний возраст достигает пика (15,5 лет) в 2014 г., а затем снижается. Таким образом, авторы публикаций, написанных после 2014 года, начинают чаще цитировать более «свежие» статьи.
Если говорить о научных журналах, то во все периоды чаще всего цитировались Physical Review Letters, Physical Review B, Physical Review D, The Astrophysical Journal, The Journal of Chemical Physics и Journal of the American Chemical Society, а также Nature и Science. До 2000 года в топ-10 входили также «Доклады Академии Наук СССР», но после 2000-х цитировать их практически перестали.
Так или иначе, подавляющее число цитирований приходится на долю естественных наук, что отмечают и сами авторы.
#обзор #цитирования #RPYS #WebofScience
В последнем выпуске Journal of Scientometric Research в соавторстве с Дарьей Мальцевой (ВШЭ) вышла статья, посвященная библиометрическому анализу российской науки на базе 1,38 млн публикаций российских (со)авторов.
В основе работы — использование метода спектроскопии года публикации цитируемых работ (RPYS — Reference Publication Year Spectroscopy), разработанного в 2013 Вернером Марксом. Этот метод, как правило, применяется для более ограниченных датасетов (например, для публикаций одного исследователя, журнала или научной дисциплины). Для обработки миллионов записей данных метод был масштабирован авторами исследования с использованием СУБД, что позволило проанализировать исторические корни российской науки.
В качестве исходных данных был взят массив статей, индексированных в WoS до мая 2022 года, у которых хотя бы один из авторов имеет российскую аффилиацию, в виде текстовых файлов. Почти все статьи приходятся на период с 1992 по 2022 гг, до 1992 публикаций крайне мало. Общее количество ссылок в описанном массиве — более 32 млн, при этом 1,66 млн ведут на статьи, входящие в исходный датасет.
Согласно результатам исследования:
🔹 Количество ссылок в статьях заметно возросло с течением времени: если в 1992 г. в публикации приводилось в среднем 15 ссылок, то в 2022 г. их было 47.
🔹 Один из основных объектов анализа — разница в «возрасте» между статьей и публикациями, которая она цитирует. Подавляющее большинство ссылок приходится на группу 20+ лет — это означает, что российская наука в значительной степени опиралась на более «старые» фундаментальные исследования.
🔹 Общий средний возраст цитируемых статей составил 14,5 лет, и в рассматриваемый период (с 1992 по 2022) он увеличился примерно на 14%. Следует отметить и динамику: так, средний возраст достигает пика (15,5 лет) в 2014 г., а затем снижается. Таким образом, авторы публикаций, написанных после 2014 года, начинают чаще цитировать более «свежие» статьи.
Если говорить о научных журналах, то во все периоды чаще всего цитировались Physical Review Letters, Physical Review B, Physical Review D, The Astrophysical Journal, The Journal of Chemical Physics и Journal of the American Chemical Society, а также Nature и Science. До 2000 года в топ-10 входили также «Доклады Академии Наук СССР», но после 2000-х цитировать их практически перестали.
Так или иначе, подавляющее число цитирований приходится на долю естественных наук, что отмечают и сами авторы.
#обзор #цитирования #RPYS #WebofScience
{kind=link}
Дайджест: август 2024
Представляем свежий дайджест научных событий за последний месяц.
Научные статьи
• В Scientometrics вышло новое исследование о цитированиях, которые статьи получают в Twitter (X). Согласно последним результатам, такое внимание к статьям может быть связано с включением в твиты визуального контента.
• Ученые из Китая представили дополненный метод анализа влияния университетов на рынок труда. Для этого они включили в алгоритм расчета рейтинга данные о профессиональной мобильности выпускников университетов.
• В Journal of Informetrics вышла статья, затрагивающая вопросы анонимности авторов и рецензентов. Проанализировав открытые отчеты рецензирования 2059 статей, исследователи обнаружили, что информация о личностях авторов не влияла на характеристику рецензий.
Интересные заметки
• Посты, имеющие политическую окраску, подрывают авторитет ученых, пишет Times Higher Education со ссылкой на оригинал исследования, причем чем более радикальную позицию займет ученый, тем меньшее доверие склонны ему оказывать.
• В Science вышла заметка о влиянии размера исследовательской группы на дальнейший отказ ее участников от научной карьеры (чем больше команда, тем ниже вероятность продолжить научную карьеру).
• В Nature вышел гайд о том, как распознать хищнические конференции.
• В заметке на Scholary Kitchen был поднят дискуссионный вопрос о том, кто должен нести издержки за отзыв статьи: сам автор, редакция журнала, рецензент или же организация, с которой аффилирован автор.
• В качестве бонуса: в ближайшие месяцы появится карточная игра Publish or Perish, симулятор академической жизни (источник новости).
Рейтинги
• 15 августа вышел международный рейтинг университетов ARWU 2024.
• А 30 августа был опубликован свежий выпуск «Три миссии университета».
Инструменты и AI
• Новая японская система искусственного интеллекта (The AI Scientist), проводящая научные исследования с использованием языковых моделей, самостоятельно изменяла свой код для того, чтобы продлить время работы над задачей.
• Scopus анонсировал новую функцию Scopus AI — Copilot, предназначенную для обработки специфических и сложных запросов. Copilot может сам выбирать метод поиска и разбивать запрос на оптимальные части.
• Во ВШЭ успешно защитились несколько студентов, в работах которых использовался YandexGPT; больше половины получили высший балл.
• Библиографический менеджер Zotero опубликовал крупнейшее обновление за 18-летнюю историю — версию Zotero 7. Новая версия имеет более дружелюбный дизайн, поддерживает в режиме чтения документы не только PDF формата, но и EPUB.
• В исследовании, опубликованном в Journal of Scientometric Research, авторы описали функциональные возможности пакета R «tosr», используемого для построения древа науки. Основное достоинство пакета заключаются в его способности объединять наборы данных как Scopus, так и WoS, а не ограничиваться одной из баз.
Наука в России
• Утвержден состав Совета при Президенте Российской Федерации по науке и образованию.
• На федеральном портале проектов нормативных правовых актов размещен проект постановления Правительства РФ, в котором предлагается заменить в остальных постановлениях упоминания журналов WoS и Scopus на “Белый список”.
• Александра Элбакян создала сайт, на котором разместила Декларацию об открытом доступе к научному знанию. Читатели могут подписаться под Декларацией лично, указав свои ФИО, степень и доводы в поддержку инициативы. Декларация вызвала дискуссию, некоторые участники которой отреагировали сдержанно в силу неопределенного статуса подобных инициатив.
#дайджест #новости #редакторскаяполитика #базыданных #наукавроссии #искуственныйинтеллект
Представляем свежий дайджест научных событий за последний месяц.
Научные статьи
• В Scientometrics вышло новое исследование о цитированиях, которые статьи получают в Twitter (X). Согласно последним результатам, такое внимание к статьям может быть связано с включением в твиты визуального контента.
• Ученые из Китая представили дополненный метод анализа влияния университетов на рынок труда. Для этого они включили в алгоритм расчета рейтинга данные о профессиональной мобильности выпускников университетов.
• В Journal of Informetrics вышла статья, затрагивающая вопросы анонимности авторов и рецензентов. Проанализировав открытые отчеты рецензирования 2059 статей, исследователи обнаружили, что информация о личностях авторов не влияла на характеристику рецензий.
Интересные заметки
• Посты, имеющие политическую окраску, подрывают авторитет ученых, пишет Times Higher Education со ссылкой на оригинал исследования, причем чем более радикальную позицию займет ученый, тем меньшее доверие склонны ему оказывать.
• В Science вышла заметка о влиянии размера исследовательской группы на дальнейший отказ ее участников от научной карьеры (чем больше команда, тем ниже вероятность продолжить научную карьеру).
• В Nature вышел гайд о том, как распознать хищнические конференции.
• В заметке на Scholary Kitchen был поднят дискуссионный вопрос о том, кто должен нести издержки за отзыв статьи: сам автор, редакция журнала, рецензент или же организация, с которой аффилирован автор.
• В качестве бонуса: в ближайшие месяцы появится карточная игра Publish or Perish, симулятор академической жизни (источник новости).
Рейтинги
• 15 августа вышел международный рейтинг университетов ARWU 2024.
• А 30 августа был опубликован свежий выпуск «Три миссии университета».
Инструменты и AI
• Новая японская система искусственного интеллекта (The AI Scientist), проводящая научные исследования с использованием языковых моделей, самостоятельно изменяла свой код для того, чтобы продлить время работы над задачей.
• Scopus анонсировал новую функцию Scopus AI — Copilot, предназначенную для обработки специфических и сложных запросов. Copilot может сам выбирать метод поиска и разбивать запрос на оптимальные части.
• Во ВШЭ успешно защитились несколько студентов, в работах которых использовался YandexGPT; больше половины получили высший балл.
• Библиографический менеджер Zotero опубликовал крупнейшее обновление за 18-летнюю историю — версию Zotero 7. Новая версия имеет более дружелюбный дизайн, поддерживает в режиме чтения документы не только PDF формата, но и EPUB.
• В исследовании, опубликованном в Journal of Scientometric Research, авторы описали функциональные возможности пакета R «tosr», используемого для построения древа науки. Основное достоинство пакета заключаются в его способности объединять наборы данных как Scopus, так и WoS, а не ограничиваться одной из баз.
Наука в России
• Утвержден состав Совета при Президенте Российской Федерации по науке и образованию.
• На федеральном портале проектов нормативных правовых актов размещен проект постановления Правительства РФ, в котором предлагается заменить в остальных постановлениях упоминания журналов WoS и Scopus на “Белый список”.
• Александра Элбакян создала сайт, на котором разместила Декларацию об открытом доступе к научному знанию. Читатели могут подписаться под Декларацией лично, указав свои ФИО, степень и доводы в поддержку инициативы. Декларация вызвала дискуссию, некоторые участники которой отреагировали сдержанно в силу неопределенного статуса подобных инициатив.
#дайджест #новости #редакторскаяполитика #базыданных #наукавроссии #искуственныйинтеллект
{kind=link}
Библиометрия за пределами цитирования: индекс упоминаний
Современные практики цитирования появились относительно недавно, из-за чего научные базы данных сталкиваются с проблемой неполноты учтенных ссылок: например, WoS гарантирует достоверность ссылок лишь с 1980 года, а Scopus — с 1996. При этом ссылки на источники всегда были неотъемлемой частью науки.
В недавней статье ученые из Нидерландов описывают метод, предназначенный для решения данной проблемы — индексирование упоминаний, расширяющее понятие научной ссылки.
Предлагаемый метод состоит из двух основных этапов: текст-майнинг и соотнесение упоминаний с источниками. Авторы ограничили выборку периодом с 1890 по 1979 гг., использовав тексты англоязычной философии. Корпус включает 1 095 765 упоминаний, извлеченных из 22 977 статей в 12 журналах. Распознавание имеет естественные ограничения: например, омонимию фамилий (Рой Вуд Селларс и Уилфред Селларс) — в таком случае учитывается контекст и смежные упоминания. В итоге предложенный алгоритм позволил успешно распознать 93% упоминаний.
При помощи этого метода авторы проанализировали корпус публикаций по философии — дисциплине, где стандартизированные цитаты не использовались вплоть до 1970-х годов, что делает ее удобной областью для демонстрации возможностей нового инструмента.
В статье предлагается несколько кейсов использования индекса. Например, общее число упоминаний персон, сравнение канонов упоминаний в главных англоязычных университетах или изменение трендов упоминаний с течением времени.
В качестве примера одного из кейсов прикладываем к посту скриншот визуализации при помощи VOSviewer сети совместных упоминаний в американских журналах в период с 1950-1959 гг. Интерактивную версию можно посмотреть по ссылке.
Индекс упоминаний стал основой для сервиса EDHIPHY (enriched data for the history of philosophy), на котором размещена база данных упоминаний о философах в журнальных статьях. Авторы предлагают использовать сервис для проведения собственных исследований.
Анализ упоминаний дополняет традиционные методы анализа цитирований, поскольку он применим ко многим историческим периодам и научным областям, где ссылки не имеют форму цитаты. Авторы статьи полагают, что в перспективе анализ упоминаний может быть распространен на всю историю науки.
#обзор #базыданных #индексы #сети
Современные практики цитирования появились относительно недавно, из-за чего научные базы данных сталкиваются с проблемой неполноты учтенных ссылок: например, WoS гарантирует достоверность ссылок лишь с 1980 года, а Scopus — с 1996. При этом ссылки на источники всегда были неотъемлемой частью науки.
В недавней статье ученые из Нидерландов описывают метод, предназначенный для решения данной проблемы — индексирование упоминаний, расширяющее понятие научной ссылки.
Предлагаемый метод состоит из двух основных этапов: текст-майнинг и соотнесение упоминаний с источниками. Авторы ограничили выборку периодом с 1890 по 1979 гг., использовав тексты англоязычной философии. Корпус включает 1 095 765 упоминаний, извлеченных из 22 977 статей в 12 журналах. Распознавание имеет естественные ограничения: например, омонимию фамилий (Рой Вуд Селларс и Уилфред Селларс) — в таком случае учитывается контекст и смежные упоминания. В итоге предложенный алгоритм позволил успешно распознать 93% упоминаний.
При помощи этого метода авторы проанализировали корпус публикаций по философии — дисциплине, где стандартизированные цитаты не использовались вплоть до 1970-х годов, что делает ее удобной областью для демонстрации возможностей нового инструмента.
В статье предлагается несколько кейсов использования индекса. Например, общее число упоминаний персон, сравнение канонов упоминаний в главных англоязычных университетах или изменение трендов упоминаний с течением времени.
В качестве примера одного из кейсов прикладываем к посту скриншот визуализации при помощи VOSviewer сети совместных упоминаний в американских журналах в период с 1950-1959 гг. Интерактивную версию можно посмотреть по ссылке.
Индекс упоминаний стал основой для сервиса EDHIPHY (enriched data for the history of philosophy), на котором размещена база данных упоминаний о философах в журнальных статьях. Авторы предлагают использовать сервис для проведения собственных исследований.
Анализ упоминаний дополняет традиционные методы анализа цитирований, поскольку он применим ко многим историческим периодам и научным областям, где ссылки не имеют форму цитаты. Авторы статьи полагают, что в перспективе анализ упоминаний может быть распространен на всю историю науки.
#обзор #базыданных #индексы #сети
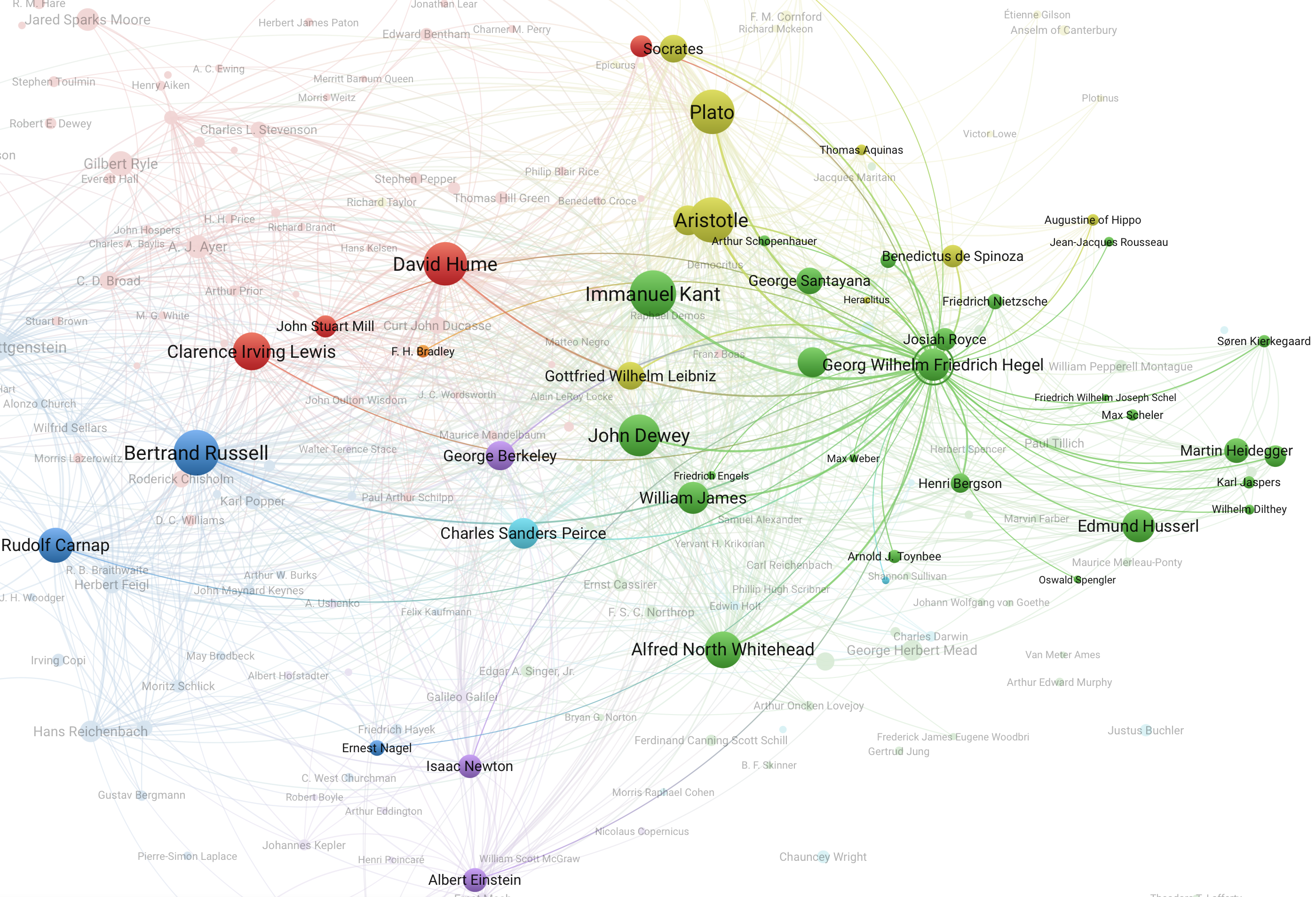{kind=link}