
Предшественники наукометрии
Мы продолжаем нашу рубрику, посвященную истории развития «науки о науке».
В прошлый раз мы рассказывали о возникновении самого понятия. Сегодня мы хотим затронуть тему влияния предшествовавших научных проектов и течений на формирование наукометрии как отдельной научной области.
Второй пост можно найти по ссылке: https://telegra.ph/Predshestvenniki-naukometrii-03-06
#историянаукометрии #обзор
Мы продолжаем нашу рубрику, посвященную истории развития «науки о науке».
В прошлый раз мы рассказывали о возникновении самого понятия. Сегодня мы хотим затронуть тему влияния предшествовавших научных проектов и течений на формирование наукометрии как отдельной научной области.
Второй пост можно найти по ссылке: https://telegra.ph/Predshestvenniki-naukometrii-03-06
#историянаукометрии #обзор
Telegraph
Предшественники наукометрии
Мы продолжаем нашу рубрику #историянаукометрии. В прошлый раз мы рассказывали об истории самого понятия. Сегодня мы хотим затронуть тему влияния предшествовавших научных проектов и течений на формирование наукометрии как отдельной научной области. Де Кандоль…
“Я бы хотел публиковаться в Q1, но где же его найти”
В Journal of Infometrics вышла статья наших коллег Д.В. Косякова и В.В. Пислякова, посвященная проблеме неравенства дисциплин при распределении журналов по квартилям. Исследование показывает, что традиционное деление на квартили может давать привилегии одним дисциплинарным категориям и ущемлять другие.
Так, авторы отмечают, что дисциплинарные категории в Web of Science, используемые при классификации журналов в рамках Journal Citation Reports, а также ряд других классификаторов несбалансированы по числу статей в разных квартилях журналов, что объясняется тремя факторами:
- распределением по квартилям общего числа журналов, которое к тому же не всегда делится на 4;
- разным объемом журналов по количеству статей;
- выбором самого высокого квартиля, когда журналы классифицируются по нескольким дисциплинам.
Так, более чем в 80 предметных областях по WoS доля публикаций в журналах Q1 превышает 50% от общего числа всех публикаций (с максимумом в 87%! в категории «Инженерная защита окружающей среды (Engineering, Environmental)»).
Более того, в узких областях исследований (например, выделенных на основе тематических кластеров из SciVal), журналы Q1 могут отсутствовать полностью.
Результаты исследования дают дополнительные аргументы противникам использования квартильных показателей при формировании научной политики и оценке эффективности научных исследований. По мнению авторов, они также могут заинтересовать издателей при выборе тем для запуска новых изданий.
#обзор #квартили
В Journal of Infometrics вышла статья наших коллег Д.В. Косякова и В.В. Пислякова, посвященная проблеме неравенства дисциплин при распределении журналов по квартилям. Исследование показывает, что традиционное деление на квартили может давать привилегии одним дисциплинарным категориям и ущемлять другие.
Так, авторы отмечают, что дисциплинарные категории в Web of Science, используемые при классификации журналов в рамках Journal Citation Reports, а также ряд других классификаторов несбалансированы по числу статей в разных квартилях журналов, что объясняется тремя факторами:
- распределением по квартилям общего числа журналов, которое к тому же не всегда делится на 4;
- разным объемом журналов по количеству статей;
- выбором самого высокого квартиля, когда журналы классифицируются по нескольким дисциплинам.
Так, более чем в 80 предметных областях по WoS доля публикаций в журналах Q1 превышает 50% от общего числа всех публикаций (с максимумом в 87%! в категории «Инженерная защита окружающей среды (Engineering, Environmental)»).
Более того, в узких областях исследований (например, выделенных на основе тематических кластеров из SciVal), журналы Q1 могут отсутствовать полностью.
Результаты исследования дают дополнительные аргументы противникам использования квартильных показателей при формировании научной политики и оценке эффективности научных исследований. По мнению авторов, они также могут заинтересовать издателей при выборе тем для запуска новых изданий.
#обзор #квартили
Бизнес-модели открытого доступа: еще один подход к классификации
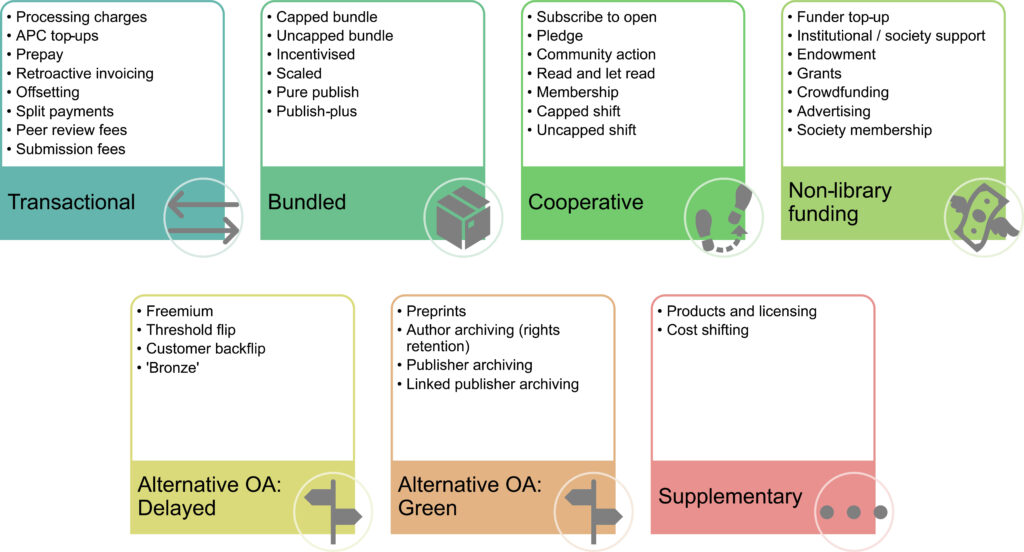
В рамках работы по оказанию помощи некоммерческим издателям в переходе на открытый доступ (ОА) Таша Меллинз-Коэн (Tasha Mellins-Cohen), исполнительный директор COUNTER и основательница Mellins-Cohen Consulting, классифицировала категории бизнес-моделей открытого доступа. В период с 2020 г. по 2024 г. она проанализировала возникающие бизнес-модели открытого доступа и выделила четыре крупные и несколько альтернативных категорий (на рисунке изображено распределение моделей, используемых на рынке).
1. Transactional (Gold OA)
В транзакционных моделях затраты на публикации переложены на авторов исследований. Такие модели широко распространены, но связаны с двумя этическими вопросами: первый — вопрос равенства и справедливости, так как не все исследователи могут позволить оплату публикаций, и второй — вопрос влияния платы за публикацию на редакционную политику издательств и соблазн их превращения в хищнические.
2. Bundled (Read-and-Publish)
Издатели, работающие как по подписке, так и с полностью открытым доступом, предлагают учреждениям возможность оплачивать «пакет услуг». Модель основана на уже существующих платежах за подписку, при этом библиотеки или консорциумы платят за поддержание доступа по подписке к спискам журналов или книг. На оплату за чтение накладывается отдельно рассчитываемая плата за открытый доступ, обычно основанная на стандартной плате за обработку статей.
3. Cooperative
Модель, которая основана на сотрудничестве между учреждениями. Учреждения оформляют подписку традиционным способом, и когда собран доход, запланированный издателем, журнал публикуется в открытом доступе. Если финансовые затраты на выпуск журнала не покрываются, контент остается доступным по подписке.
4. Non-library funding (Diamond/Platinum OA)
Модель строится на институциональном или общественном финансировании, грантах или пожертвованиях, что позволяет издателям предлагать бесплатный открытый доступ авторам с уверенностью, что их производственные расходы будут покрыты.
Platinum/Diamond OA часто предлагается университетскими издательствами, где расходы на публикацию включены в существующие бюджеты и являются частью миссии университета.
5 и 6. Delayed (Bronze OA) and Green OA
Открытый доступ Bronze OA подразумевает предоставление доступа к контенту после истечения срока действия эмбарго. При этом издатель может прекратить доступ к статьям в любое время. Кроме того, авторы не сохраняют авторские права на свои статьи. В результате статьи открытого доступа Bronze OA обычно недоступны для загрузки или распространения.
Green OA — оригинальный путь к открытому доступу, примером которого является arXiv. Депонирование препринтов (или постпринтов) позволяет авторам делать версии своей работы до или после рецензирования доступными для публичного изучения и использования. Green OA обеспечивается несколькими способами: исследования могут быть доступны в институциональных или дисциплинарных репозиториях, а также могут быть размещены на личном сайте автора.
Примечательно, что автор выделяет отдельную категорию Pseudo-models и относит к ней проект SPA-OPS, реализуемый в рамках Plan S. SPA-OPS расширяет подход к открытому доступу (трансформирует различные возможности продуктов и лицензирования, а также системы перераспределения затрат, такие как консорциальные публикации).
Модель открытого доступа, в которой автор оплачивает публикацию и обработку статьи (APC) широко распространена среди издательств, но всё же она не является универсальным решением, и не только из-за того, что устраняет одни неравенства и множит другие. В ряде случаев издательству выгоднее применять другие бизнес-модели, опираясь на географическое разнообразие авторов, существующие институциональные и спонсорские отношения, источники финансирования, а также типы публикуемых материалов.
#открытыйдоступ #обзор
В рамках работы по оказанию помощи некоммерческим издателям в переходе на открытый доступ (ОА) Таша Меллинз-Коэн (Tasha Mellins-Cohen), исполнительный директор COUNTER и основательница Mellins-Cohen Consulting, классифицировала категории бизнес-моделей открытого доступа. В период с 2020 г. по 2024 г. она проанализировала возникающие бизнес-модели открытого доступа и выделила четыре крупные и несколько альтернативных категорий (на рисунке изображено распределение моделей, используемых на рынке).
1. Transactional (Gold OA)
В транзакционных моделях затраты на публикации переложены на авторов исследований. Такие модели широко распространены, но связаны с двумя этическими вопросами: первый — вопрос равенства и справедливости, так как не все исследователи могут позволить оплату публикаций, и второй — вопрос влияния платы за публикацию на редакционную политику издательств и соблазн их превращения в хищнические.
2. Bundled (Read-and-Publish)
Издатели, работающие как по подписке, так и с полностью открытым доступом, предлагают учреждениям возможность оплачивать «пакет услуг». Модель основана на уже существующих платежах за подписку, при этом библиотеки или консорциумы платят за поддержание доступа по подписке к спискам журналов или книг. На оплату за чтение накладывается отдельно рассчитываемая плата за открытый доступ, обычно основанная на стандартной плате за обработку статей.
3. Cooperative
Модель, которая основана на сотрудничестве между учреждениями. Учреждения оформляют подписку традиционным способом, и когда собран доход, запланированный издателем, журнал публикуется в открытом доступе. Если финансовые затраты на выпуск журнала не покрываются, контент остается доступным по подписке.
4. Non-library funding (Diamond/Platinum OA)
Модель строится на институциональном или общественном финансировании, грантах или пожертвованиях, что позволяет издателям предлагать бесплатный открытый доступ авторам с уверенностью, что их производственные расходы будут покрыты.
Platinum/Diamond OA часто предлагается университетскими издательствами, где расходы на публикацию включены в существующие бюджеты и являются частью миссии университета.
5 и 6. Delayed (Bronze OA) and Green OA
Открытый доступ Bronze OA подразумевает предоставление доступа к контенту после истечения срока действия эмбарго. При этом издатель может прекратить доступ к статьям в любое время. Кроме того, авторы не сохраняют авторские права на свои статьи. В результате статьи открытого доступа Bronze OA обычно недоступны для загрузки или распространения.
Green OA — оригинальный путь к открытому доступу, примером которого является arXiv. Депонирование препринтов (или постпринтов) позволяет авторам делать версии своей работы до или после рецензирования доступными для публичного изучения и использования. Green OA обеспечивается несколькими способами: исследования могут быть доступны в институциональных или дисциплинарных репозиториях, а также могут быть размещены на личном сайте автора.
Примечательно, что автор выделяет отдельную категорию Pseudo-models и относит к ней проект SPA-OPS, реализуемый в рамках Plan S. SPA-OPS расширяет подход к открытому доступу (трансформирует различные возможности продуктов и лицензирования, а также системы перераспределения затрат, такие как консорциальные публикации).
Модель открытого доступа, в которой автор оплачивает публикацию и обработку статьи (APC) широко распространена среди издательств, но всё же она не является универсальным решением, и не только из-за того, что устраняет одни неравенства и множит другие. В ряде случаев издательству выгоднее применять другие бизнес-модели, опираясь на географическое разнообразие авторов, существующие институциональные и спонсорские отношения, источники финансирования, а также типы публикуемых материалов.
#открытыйдоступ #обзор
{kind=link}
Академический угон: обзор публикаций о hijacked журналах
В апрельском выпуске Journal of the Association for Information Science and Technology вышла статья Анны Абалкиной, посвященная проблемам, связанным с похищенными журналами (hijacked journals) в Scopus. Ранее мы затрагивали эту тему в контексте paper mills.
По мнению исследовательницы, уязвимость библиометрических баз данных Web of Science и Scopus, индексация в которых является показателями качества, приводит к распространению мошеннического контента. Издатели-мошенники активно используют в своих целях ошибки в системах безопасности баз данных и упущения в издательской политике редакции.
Ярким примером эксплуатации такого рода ошибок являются “похищенные” журналы. Издатели-мошенники создают копии сайтов научных журналов, которые тяжело отличить от официальных страниц. Как правило, они копируют название журнала и его ISSN, заполняют страницу настоящими данными о членах редакционной коллегии или придумывают свою, включая в неё имена настоящих и/или выдуманных ученых. Злоумышленники создают архив, чтобы убедить потенциальных авторов в том, что журнал публикуется постоянно. Архив наполняется статьями из оригинального журнала или некачественным контентом.
Как правило, жертвами “похищений” становятся определенные типы журналов:
• выпускаемые исключительно в печатном виде (где сайт-клон может служить единственным сайтом для журнала);
• узкоспециализированные или университетские журналы (кражи журналов крупных и авторитетных издателей легче отследить).
Казалось бы, потенциальные авторы могут проверить профиль журнала в библиометрических базах данных, поскольку в них размещают всю необходимую информацию, включая ссылку на домашнюю страницу, однако у мошенников есть несколько стратегий, позволяющих ввести потенциальных авторов в заблуждение:
- похищение журналов без ссылок или с неактивными ссылками на домашнюю страницу в профиле в индексируемых базах данных;
- регистрация домена журнала с истекшим сроком действия (способ позволяет мошенникам не менять ссылку на домашнюю страницу в библиографических базах данных);
- взлом официального сайта журнала;
- подделка ссылки на домашнюю страницу журнала в его профиле в библиографических базах данных (indexjacking);
- «вторая жизнь» для журналов, которые прекратили выпускаться.
Методы, с помощью которых похищенные журналы действительно проникают в библиографические базы данных и, тем более, индексируют неутвержденный контент в этих базах данных, малоизучены. По данным Elsevier в Scopus это происходит, когда «журналы обновляют URL-адреса или другие каналы контента», по мнению других исследователей, основной причиной является несвоевременная оплата домена.
К сожалению, даже крупнейшие базы данных не ведут учет случаев удаления контента, опубликованного и проиндексированного во взломанных журналах. Известно, что Scopus хранит и обновляет список журналов и изданий, индексация которых прекращена (с указанием причин), однако информация о прекращении индексации взломанных журналов отдельно не фиксируется.
Отсутствие такого списка является проблемой для академического сообщества, так как материалы из похищенных журналов потенциально не рецензируется должным образом. Исследования показывают, что на такие статьи могут ссылаться авторитетные издания. Более того, отсутствие прозрачности в учете похищенных журналов позволяет обманывать ученых даже после удаления неутвержденного контента.
Несмотря на удаление материалов из Scopus и истечения срока действия доменов похищенных журналов, статьи всё ещё можно найти в различных базах данных (ORCID, eLibrary), а также в различных онлайн-репозиториях (ResearchGate, Academia.edu) или на сайтах университетов. Кроме того, неутвержденный контент по-прежнему присутствует в Scopus за все годы с 2013 по 2023 (по состоянию на сентябрь 2023 года). В таких случаях прозрачная документация могла бы помочь преодолеть асимметрию информации и сохранить научную честность.
#обзор #hijackedjournals #scopus
В апрельском выпуске Journal of the Association for Information Science and Technology вышла статья Анны Абалкиной, посвященная проблемам, связанным с похищенными журналами (hijacked journals) в Scopus. Ранее мы затрагивали эту тему в контексте paper mills.
По мнению исследовательницы, уязвимость библиометрических баз данных Web of Science и Scopus, индексация в которых является показателями качества, приводит к распространению мошеннического контента. Издатели-мошенники активно используют в своих целях ошибки в системах безопасности баз данных и упущения в издательской политике редакции.
Ярким примером эксплуатации такого рода ошибок являются “похищенные” журналы. Издатели-мошенники создают копии сайтов научных журналов, которые тяжело отличить от официальных страниц. Как правило, они копируют название журнала и его ISSN, заполняют страницу настоящими данными о членах редакционной коллегии или придумывают свою, включая в неё имена настоящих и/или выдуманных ученых. Злоумышленники создают архив, чтобы убедить потенциальных авторов в том, что журнал публикуется постоянно. Архив наполняется статьями из оригинального журнала или некачественным контентом.
Как правило, жертвами “похищений” становятся определенные типы журналов:
• выпускаемые исключительно в печатном виде (где сайт-клон может служить единственным сайтом для журнала);
• узкоспециализированные или университетские журналы (кражи журналов крупных и авторитетных издателей легче отследить).
Казалось бы, потенциальные авторы могут проверить профиль журнала в библиометрических базах данных, поскольку в них размещают всю необходимую информацию, включая ссылку на домашнюю страницу, однако у мошенников есть несколько стратегий, позволяющих ввести потенциальных авторов в заблуждение:
- похищение журналов без ссылок или с неактивными ссылками на домашнюю страницу в профиле в индексируемых базах данных;
- регистрация домена журнала с истекшим сроком действия (способ позволяет мошенникам не менять ссылку на домашнюю страницу в библиографических базах данных);
- взлом официального сайта журнала;
- подделка ссылки на домашнюю страницу журнала в его профиле в библиографических базах данных (indexjacking);
- «вторая жизнь» для журналов, которые прекратили выпускаться.
Методы, с помощью которых похищенные журналы действительно проникают в библиографические базы данных и, тем более, индексируют неутвержденный контент в этих базах данных, малоизучены. По данным Elsevier в Scopus это происходит, когда «журналы обновляют URL-адреса или другие каналы контента», по мнению других исследователей, основной причиной является несвоевременная оплата домена.
К сожалению, даже крупнейшие базы данных не ведут учет случаев удаления контента, опубликованного и проиндексированного во взломанных журналах. Известно, что Scopus хранит и обновляет список журналов и изданий, индексация которых прекращена (с указанием причин), однако информация о прекращении индексации взломанных журналов отдельно не фиксируется.
Отсутствие такого списка является проблемой для академического сообщества, так как материалы из похищенных журналов потенциально не рецензируется должным образом. Исследования показывают, что на такие статьи могут ссылаться авторитетные издания. Более того, отсутствие прозрачности в учете похищенных журналов позволяет обманывать ученых даже после удаления неутвержденного контента.
Несмотря на удаление материалов из Scopus и истечения срока действия доменов похищенных журналов, статьи всё ещё можно найти в различных базах данных (ORCID, eLibrary), а также в различных онлайн-репозиториях (ResearchGate, Academia.edu) или на сайтах университетов. Кроме того, неутвержденный контент по-прежнему присутствует в Scopus за все годы с 2013 по 2023 (по состоянию на сентябрь 2023 года). В таких случаях прозрачная документация могла бы помочь преодолеть асимметрию информации и сохранить научную честность.
#обзор #hijackedjournals #scopus
Сравнение методов расчета высокоцитируемых публикаций
Подсчет статей, которые выделяются за счет аномально высокого количества полученных цитирований, являются объектом изучения экспертов, занимающимися количественным анализом науки.
Очевидная необъективность и отсутствие точных методов, которые используются для составления «рейтингов» высокоцитируемых публикаций, заставляют исследователей искать новые подходы для их усовершенствования. Наиболее распространенным из различных критериев такой оценки является определение высокоцитируемых статей как статей, находящихся в первом процентиле (верхний 1%) числа цитирований, с чем связано два неразрешенных вопроса:
· как составить список наиболее цитируемых статей, ранжированных в порядке убывания (или возрастания), в зависимости от метода?
· как преобразовать это порядковое распределение в процентили, пригодные для сравнения публикаций в разных предметных областях?
Используемые для решения этих вопросов методы на данный момент имеют определенные недостатки. Но всё же общее мнение исследователей сводится к тому, что независимо от того, как рассчитывается рейтинг, необходимо учитывать практику публикаций и цитирования каждой научной специальности, чтобы уменьшить влияние асимметрии науки. Недавнее введение в Web of Science процентиля предметных категорий для журналов, перечисленных в Journal Citation Reports (JCR), является подтверждением такого консенсуса.
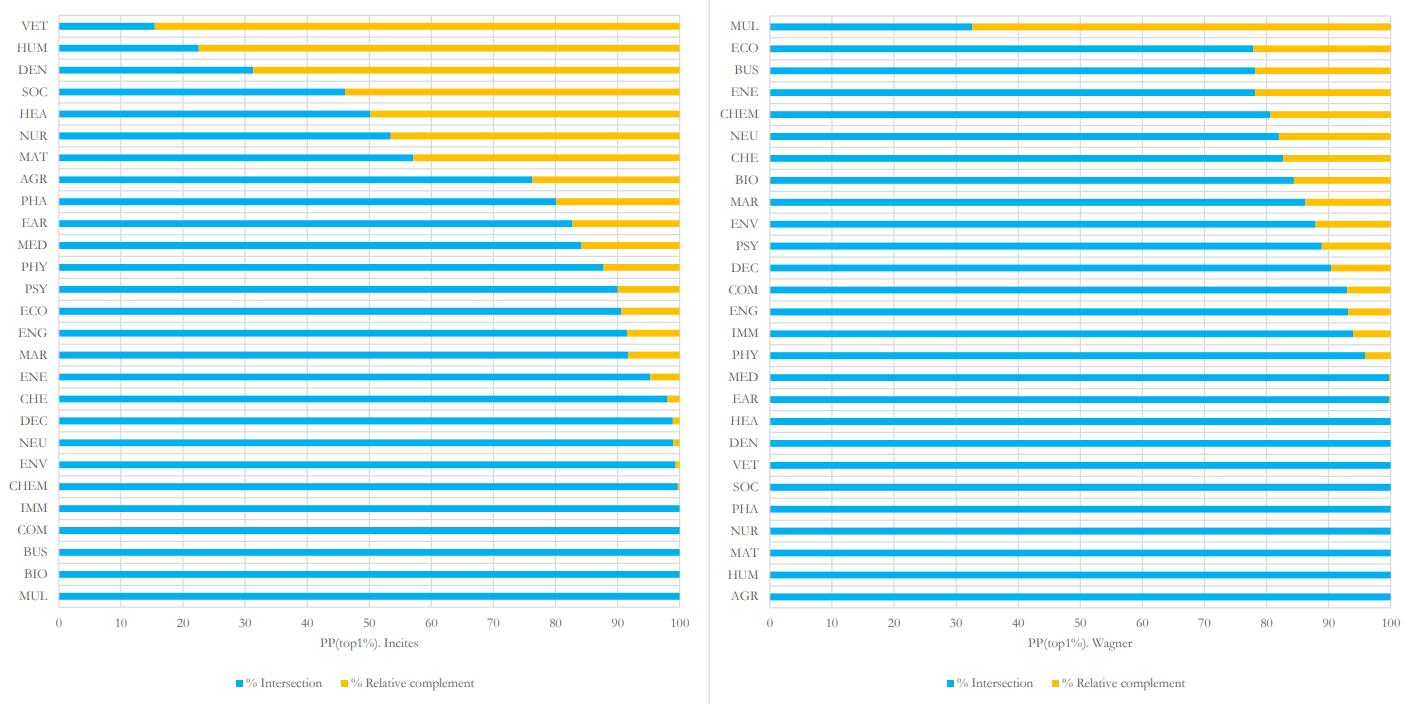
В 2022 году был предложен новый подход — метод Вагнер, который, в отличие от распространенных, не учитывает год выхода и тип публикации, а также направленность журнала. В апрельской статье Quantative Science Studies авторы проанализировали эффективность предложенного подхода путем его сопоставления с более привычным (в основе которого лежит метод InCites, схожий с методами Лейденского рейтинга и SCImago Journal Rank).
Исследование показало, что при использовании метода Вагнер статистическое предпочтение отдается публикациям из Китая, Японии, Южной Кореи и Сингапура, а также Саудовской Аравии и Швейцарии. В отличие от InCites, он отводит меньшую долю другим странам и регионам, таким как Австралия, Канада, Европейский союз, Великобритания, Бразилия и Южная Африка.
Анализ по дисциплинам (см. график) объясняет этот перекос: страны, в которых более развиты инженерные науки, более широко представлены в новом подходе. С другой стороны, страны со значительной долей публикаций фундаментальных исследований, исследований в области социальных и гуманитарных наук представлены недостаточно по сравнению с данными, полученными при помощи метода InCites.
Согласно результатам исследования, выбор метода расчета перцентилей влияет на долю представленности стран и дисциплин: по мнению авторов, метод Вагнер существенно искажает результаты, а «верность традиционным методам», применяемым для составления рейтинга высокоцитируемых статей, абсолютно оправдана.
#обзор #HCP #webofscience #рейтинги
Подсчет статей, которые выделяются за счет аномально высокого количества полученных цитирований, являются объектом изучения экспертов, занимающимися количественным анализом науки.
Очевидная необъективность и отсутствие точных методов, которые используются для составления «рейтингов» высокоцитируемых публикаций, заставляют исследователей искать новые подходы для их усовершенствования. Наиболее распространенным из различных критериев такой оценки является определение высокоцитируемых статей как статей, находящихся в первом процентиле (верхний 1%) числа цитирований, с чем связано два неразрешенных вопроса:
· как составить список наиболее цитируемых статей, ранжированных в порядке убывания (или возрастания), в зависимости от метода?
· как преобразовать это порядковое распределение в процентили, пригодные для сравнения публикаций в разных предметных областях?
Используемые для решения этих вопросов методы на данный момент имеют определенные недостатки. Но всё же общее мнение исследователей сводится к тому, что независимо от того, как рассчитывается рейтинг, необходимо учитывать практику публикаций и цитирования каждой научной специальности, чтобы уменьшить влияние асимметрии науки. Недавнее введение в Web of Science процентиля предметных категорий для журналов, перечисленных в Journal Citation Reports (JCR), является подтверждением такого консенсуса.
В 2022 году был предложен новый подход — метод Вагнер, который, в отличие от распространенных, не учитывает год выхода и тип публикации, а также направленность журнала. В апрельской статье Quantative Science Studies авторы проанализировали эффективность предложенного подхода путем его сопоставления с более привычным (в основе которого лежит метод InCites, схожий с методами Лейденского рейтинга и SCImago Journal Rank).
Исследование показало, что при использовании метода Вагнер статистическое предпочтение отдается публикациям из Китая, Японии, Южной Кореи и Сингапура, а также Саудовской Аравии и Швейцарии. В отличие от InCites, он отводит меньшую долю другим странам и регионам, таким как Австралия, Канада, Европейский союз, Великобритания, Бразилия и Южная Африка.
Анализ по дисциплинам (см. график) объясняет этот перекос: страны, в которых более развиты инженерные науки, более широко представлены в новом подходе. С другой стороны, страны со значительной долей публикаций фундаментальных исследований, исследований в области социальных и гуманитарных наук представлены недостаточно по сравнению с данными, полученными при помощи метода InCites.
Согласно результатам исследования, выбор метода расчета перцентилей влияет на долю представленности стран и дисциплин: по мнению авторов, метод Вагнер существенно искажает результаты, а «верность традиционным методам», применяемым для составления рейтинга высокоцитируемых статей, абсолютно оправдана.
#обзор #HCP #webofscience #рейтинги
{kind=link}
От гипотез к обзорам? О роли редакционных статей
В апрельском выпуске Learned Publishing вышла статья Марии Плахотник, доцента и старшего научного сотрудника Вышки в Санкт-Петербурге, в которой она затрагивает вопрос роли и места редакционных статей в политике журнала.
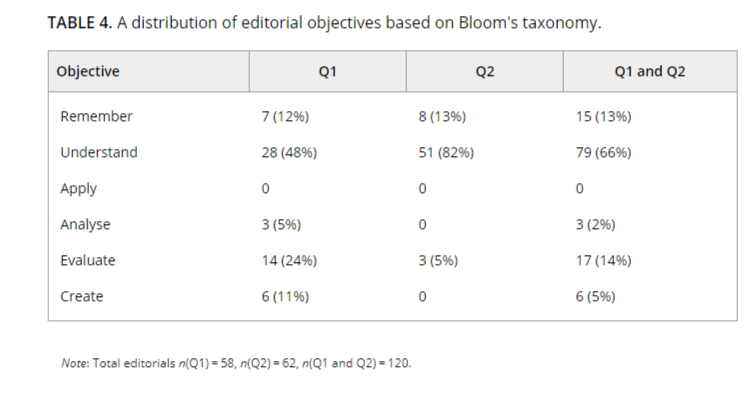
Используя дедуктивный контент-анализ и метод таксономии Блума (инструмент для идентификации и формулирования целей, намерений к учебной деятельности и целеполагания в целом), автор определила типы целей каждой редакционной статьи. Выборка ограничилась статьями, опубликованными в 2022 году в ведущих журналах в областях organizational behaviour и human resource management. Из 103 журналов лишь в 52 (50,5%) встречались редакционные статьи, остальные — 51 (49,5%) — игнорировали эту практику.
· Анализ выборки показал, что 4 из 5 редакционных статей были направлены на повышение уровня знаний или понимания определенной темы, и очень немногие — на обсуждение и создание новых гипотез.
· Подавляющее большинство редакционных статей (66%) были направлены на улучшение понимания читателями того или иного вопроса, эти статьи встречались как в обычных, так и в специальных выпусках и в основном содержали обзор исследований конкретного номера.
· Часть статей (13 %) были написаны с целью описания фактов (юбилей журнала, смена издателя и т.д.); 17 редакционных статей (14%) были направлены на оценку состояния исследований в журнале; в 3 статьях (2%) анализировались конкретные темы, например, их авторы описывали проблемы, с которыми сталкиваются исследователи.
· В 6 статьях (5%) были созданы новые концепции или гипотезы. Примечательно, что эти редакционные статьи были написаны приглашенными редакторами.
Эти тенденции поднимают вопрос о роли редактора в развитии журнала и позволяют предположить, что большинство редакторов предпочитают реактивную редакторскую роль (принятие решений о публикации статей на основе их высокого потенциала цитирования), а значит, отказываются от другой своей роли — проактивной (продвижение журнала за счет написания редакционных статей, выступлений на конференциях и информирования о целях и политике журнала).
Многие редакторы журналов из выборки пишут редакционные статьи, чтобы расширить знания читателей и улучшить их понимание какого-либо вопроса; попытки предложить новый взгляд на проблематику или выдвинуть новую гипотезу незначительны. Ни одна из рассмотренных редакционных статей не представляла собой дальнейшее исследование прогнозов или предложений, сделанных в редакционных статьях, написанных ранее.
С одной стороны эта тенденция поддерживает аргумент о том, что редакционные статьи как жанр должны подтверждать то, что известно, а не погружаться в неизвестное, с другой — указывает на определенную непоследовательность: в конкуренции за авторов, читателей и рейтинги редакторы находятся в поиске исследований на передовые и заставляющие задуматься темы, в то время как сами зачастую предпочитают ограничиваться традиционными эссе, объясняющими, уточняющими и описывающими, но не созидающими.
#обзор #редакционныестатьи #editorials #editor
В апрельском выпуске Learned Publishing вышла статья Марии Плахотник, доцента и старшего научного сотрудника Вышки в Санкт-Петербурге, в которой она затрагивает вопрос роли и места редакционных статей в политике журнала.
Используя дедуктивный контент-анализ и метод таксономии Блума (инструмент для идентификации и формулирования целей, намерений к учебной деятельности и целеполагания в целом), автор определила типы целей каждой редакционной статьи. Выборка ограничилась статьями, опубликованными в 2022 году в ведущих журналах в областях organizational behaviour и human resource management. Из 103 журналов лишь в 52 (50,5%) встречались редакционные статьи, остальные — 51 (49,5%) — игнорировали эту практику.
· Анализ выборки показал, что 4 из 5 редакционных статей были направлены на повышение уровня знаний или понимания определенной темы, и очень немногие — на обсуждение и создание новых гипотез.
· Подавляющее большинство редакционных статей (66%) были направлены на улучшение понимания читателями того или иного вопроса, эти статьи встречались как в обычных, так и в специальных выпусках и в основном содержали обзор исследований конкретного номера.
· Часть статей (13 %) были написаны с целью описания фактов (юбилей журнала, смена издателя и т.д.); 17 редакционных статей (14%) были направлены на оценку состояния исследований в журнале; в 3 статьях (2%) анализировались конкретные темы, например, их авторы описывали проблемы, с которыми сталкиваются исследователи.
· В 6 статьях (5%) были созданы новые концепции или гипотезы. Примечательно, что эти редакционные статьи были написаны приглашенными редакторами.
Эти тенденции поднимают вопрос о роли редактора в развитии журнала и позволяют предположить, что большинство редакторов предпочитают реактивную редакторскую роль (принятие решений о публикации статей на основе их высокого потенциала цитирования), а значит, отказываются от другой своей роли — проактивной (продвижение журнала за счет написания редакционных статей, выступлений на конференциях и информирования о целях и политике журнала).
Многие редакторы журналов из выборки пишут редакционные статьи, чтобы расширить знания читателей и улучшить их понимание какого-либо вопроса; попытки предложить новый взгляд на проблематику или выдвинуть новую гипотезу незначительны. Ни одна из рассмотренных редакционных статей не представляла собой дальнейшее исследование прогнозов или предложений, сделанных в редакционных статьях, написанных ранее.
С одной стороны эта тенденция поддерживает аргумент о том, что редакционные статьи как жанр должны подтверждать то, что известно, а не погружаться в неизвестное, с другой — указывает на определенную непоследовательность: в конкуренции за авторов, читателей и рейтинги редакторы находятся в поиске исследований на передовые и заставляющие задуматься темы, в то время как сами зачастую предпочитают ограничиваться традиционными эссе, объясняющими, уточняющими и описывающими, но не созидающими.
#обзор #редакционныестатьи #editorials #editor
{kind=link}
Связь финансирования университета и его места в Шанхайском рейтинге
Сегодня мы бы хотели затронуть тему влияния финансирования университета на его место в Шанхайском рейтинге, а также рассказать об инструменте прогнозирования позиции вуза в данном рейтинге.
Тяжело переоценить влияние объема ресурсов организации на позицию в университетском рейтинге, но все же предполагается, что это влияние не играет ключевую роль и что рейтинговая позиция зависит от огромного количества параметров. Однако результаты недавнего исследования показывают существенную и устойчивую связь объема финансирования и позиции в рейтинге.
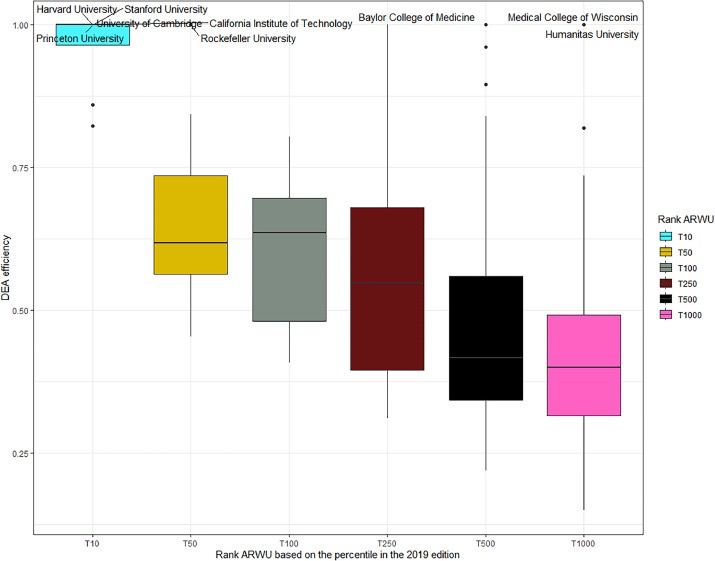
В статье авторы проанализировали 318 международных университетов и выявили связь между их финансовыми ресурсами и местом в Шанхайском рейтинге (ARWU) от 2019 года. Анализ показал, что университеты с высокими и низкими баллами ARWU зачастую демонстрируют одинаково высокую эффективность в использовании имеющихся ресурсов, из чего следует, что разница между ними состоит не в искусстве управления ресурсами, а в их количестве.
Следует отметить, что отсутствие открытой информации о финансовых данных университетов и размытые стандарты бухгалтерского учета значительно затрудняют сбор информации и влияют на выборку данных.
Существуют национальные базы — американская IPEDS, европейская ETER, британская HESA и другие, но в настоящее время финансовые данные большинства из них ограничиваются только расходами и доходами, в то время как данные об активах, обязательствах и денежных потоках не предоставляются. В этом отношении авторы делают несколько замечаний о возможных шагах по унификации данных: в частности, было бы желательно обогатить существующие базы данных вузов дополнительными финансовыми данными (или создать новые).
Сами по себе рейтинги, хотя и привлекают внимание общественности из-за удобства ранжирования организаций по показателям и тех выводов, которые можно сделать на этом основании, в то же время активно критикуются. Так, авторы ссылаются на других исследователей, которые выделяют три основные тенденции критических замечаний в адрес рейтингов:
а) содержание показателей: отсутствие учета междисциплинарности, предвзятость к крупным университетам, реальное социальное влияние университета, эффективность распоряжения
ресурсами, альтернативные миссии университетов)
б) методология: статистическая ненадежность и опора на метрики, потенциально содержащие ошибки;
в) влияние: идеологическая нагруженность, легитимация неравенства, «самоисполняющееся пророчество».
Выявление взаимосвязи параметров финансирования и итогового балла университета в рейтинге позволяет спрогнозировать его позицию в будущем. Для этого авторы разделили ARWU на несколько лиг и разработали прогностическую модель (HEI league prediction tool) для оценки балла ARWU и соответствующей лиги, опираясь на данные о ресурсах университета.
Прогностическая модель доступна онлайн по следующей ссылке: https://simonedileo.shinyapps.io/ARWU_League_Estimator/
Модель использует несколько параметров: стоимость материальных неденежных активов, общая сумма операционных расходов, количество студентов, академического и административного персонала (в эквиваленте полной занятости).
Библиометрические показатели в расчет не включены — впрочем, их связь с финансированием университета гораздо более опосредована, чем соотношение студентов и преподавателей. Одним из возможных вариантов доработки модели мог бы стать учет бюджета НИОКР, поскольку он обладает более выраженной корреляцией с публикационной активностью.
#обзор #рейтинги #ARWU
Сегодня мы бы хотели затронуть тему влияния финансирования университета на его место в Шанхайском рейтинге, а также рассказать об инструменте прогнозирования позиции вуза в данном рейтинге.
Тяжело переоценить влияние объема ресурсов организации на позицию в университетском рейтинге, но все же предполагается, что это влияние не играет ключевую роль и что рейтинговая позиция зависит от огромного количества параметров. Однако результаты недавнего исследования показывают существенную и устойчивую связь объема финансирования и позиции в рейтинге.
В статье авторы проанализировали 318 международных университетов и выявили связь между их финансовыми ресурсами и местом в Шанхайском рейтинге (ARWU) от 2019 года. Анализ показал, что университеты с высокими и низкими баллами ARWU зачастую демонстрируют одинаково высокую эффективность в использовании имеющихся ресурсов, из чего следует, что разница между ними состоит не в искусстве управления ресурсами, а в их количестве.
Следует отметить, что отсутствие открытой информации о финансовых данных университетов и размытые стандарты бухгалтерского учета значительно затрудняют сбор информации и влияют на выборку данных.
Существуют национальные базы — американская IPEDS, европейская ETER, британская HESA и другие, но в настоящее время финансовые данные большинства из них ограничиваются только расходами и доходами, в то время как данные об активах, обязательствах и денежных потоках не предоставляются. В этом отношении авторы делают несколько замечаний о возможных шагах по унификации данных: в частности, было бы желательно обогатить существующие базы данных вузов дополнительными финансовыми данными (или создать новые).
Сами по себе рейтинги, хотя и привлекают внимание общественности из-за удобства ранжирования организаций по показателям и тех выводов, которые можно сделать на этом основании, в то же время активно критикуются. Так, авторы ссылаются на других исследователей, которые выделяют три основные тенденции критических замечаний в адрес рейтингов:
а) содержание показателей: отсутствие учета междисциплинарности, предвзятость к крупным университетам, реальное социальное влияние университета, эффективность распоряжения
ресурсами, альтернативные миссии университетов)
б) методология: статистическая ненадежность и опора на метрики, потенциально содержащие ошибки;
в) влияние: идеологическая нагруженность, легитимация неравенства, «самоисполняющееся пророчество».
Выявление взаимосвязи параметров финансирования и итогового балла университета в рейтинге позволяет спрогнозировать его позицию в будущем. Для этого авторы разделили ARWU на несколько лиг и разработали прогностическую модель (HEI league prediction tool) для оценки балла ARWU и соответствующей лиги, опираясь на данные о ресурсах университета.
Прогностическая модель доступна онлайн по следующей ссылке: https://simonedileo.shinyapps.io/ARWU_League_Estimator/
Модель использует несколько параметров: стоимость материальных неденежных активов, общая сумма операционных расходов, количество студентов, академического и административного персонала (в эквиваленте полной занятости).
Библиометрические показатели в расчет не включены — впрочем, их связь с финансированием университета гораздо более опосредована, чем соотношение студентов и преподавателей. Одним из возможных вариантов доработки модели мог бы стать учет бюджета НИОКР, поскольку он обладает более выраженной корреляцией с публикационной активностью.
#обзор #рейтинги #ARWU
{kind=link}
Внедрение стандартизированных рецензий
Марио Малички (Mario Malički), редактор Research Integrity and Peer Review, опубликовал результаты пилотного исследования внедрения практики стандартизированных рецензий в журналы издательства Elsevier.
По мнению автора, рецензенты редко комментируют одни и те же аспекты исследования, что затрудняет точность оценки качества исследований и ставит под сомнение объективность процесса рецензирования.
«Я получил 2 рецензии на статью, отправленную на рассмотрение в журнал; в одной было 3 комментария, в другой — 11. Отзывы отличались по всем пунктам, кроме одного. Замечания были даны в адрес проработки раздела “обсуждение” (discussion), а также некоторых методологических деталей. Постановка целей, анализ данных и слабые стороны исследования остались без внимания рецензентов», — пишет Малички.
Авторы, как правило, руководствуются двумя распространенными предположениями в отношении отзывов рецензентов: во-первых, все аспекты, которых не коснулись рецензенты, не подверглись критике; во-вторых, рецензенты обладали достаточными знаниями для всесторонней оценки исследования.
Однако, согласно ряду исследований, процесс рецензирования полон недостатков, которые связаны с неспособностью некоторых рецензентов обнаружить:
🔹 (значительные) методологические недостатки статьи;
🔹 неточности в интерпретации и обобщении результатов;
🔹 неправильное использование ссылок;
🔹 отсутствие данных, необходимых для повторного анализа или воспроизведения исследования;
🔹 отсутствие элементов, необходимых для оценки предвзятости или качества исследования.
По мнению автора, повысить качество экспертной оценки можно за счет внедрения стандартизированных отзывов на публикации, для чего журналы должны предоставлять рецензентам список вопросов, сосредоточенных на всех аспектах исследования, а также размещать на сайте журнала:
а) список вопросов для рецензентов (что позволит авторам использовать те же вопросы в качестве контрольного списка для анализа работы и повышения её качества);
б) развернутые отзывы рецензентов (что позволит читателям посмотреть как оценивалась статья, а исследователям даст возможность изучить практику рецензирования).
Стандартизированное рецензирование было апробировано в августе 2022 года в 220 журналах Elsevier. В рамках пилотного исследования было проанализировано примерно 10% выборки, а именно — 214 отзывов рецензентов на 107 статей из 23 случайно выбранных (вне зависимости от тематики и квартиля) журналов. Каждый отзыв состоял из ответов на 9 одинаковых вопросов и информации, оставленной в поле «Комментарии для автора», и в конфиденциальном поле «Комментарии для редактора». Ознакомиться с шаблоном вопросов можно по ссылке.
Абсолютное совпадение мнений относительно окончательных рекомендаций рецензента составило 41%, причем статистической разницы между научными областями или квартилями обнаружено не было, тогда как по последним данным Elsevier (на основе 7 220 243 рукописей, опубликованных с 2019 по 2021 год в 2416 журналах), рецензенты приняли одинаковые решения на первом этапе рецензирования всего в 30% случаев.
Более того, в ряде случаев комментарии рецензентов совпадали в отношении отдельных фрагментов работы. Согласно результатам исследования, самое высокое (частичное) согласие рецензентов (72%) было обнаружено при оценивании структуры статьи, а самое низкое (частичное) согласие (53%) — для оценивания подтверждения интерпретации результатов данными, а также для оценки уместности и достаточной детальности статистического анализа (52%).
Предварительные результаты показывают, что, руководствуясь одними и теми же вопросами, рецензенты давали идентичные первоначальные рекомендации насчет принятия/отклонения или доработки публикации. По мнению автора, отсутствие стандартизированных практик в рецензировании замедляет прогресс науки, а их внедрение поможет сделать отзывы более объективными, прозрачными и заслуживающими доверия.
#Elsevier #рецензирование #обзор
Марио Малички (Mario Malički), редактор Research Integrity and Peer Review, опубликовал результаты пилотного исследования внедрения практики стандартизированных рецензий в журналы издательства Elsevier.
По мнению автора, рецензенты редко комментируют одни и те же аспекты исследования, что затрудняет точность оценки качества исследований и ставит под сомнение объективность процесса рецензирования.
«Я получил 2 рецензии на статью, отправленную на рассмотрение в журнал; в одной было 3 комментария, в другой — 11. Отзывы отличались по всем пунктам, кроме одного. Замечания были даны в адрес проработки раздела “обсуждение” (discussion), а также некоторых методологических деталей. Постановка целей, анализ данных и слабые стороны исследования остались без внимания рецензентов», — пишет Малички.
Авторы, как правило, руководствуются двумя распространенными предположениями в отношении отзывов рецензентов: во-первых, все аспекты, которых не коснулись рецензенты, не подверглись критике; во-вторых, рецензенты обладали достаточными знаниями для всесторонней оценки исследования.
Однако, согласно ряду исследований, процесс рецензирования полон недостатков, которые связаны с неспособностью некоторых рецензентов обнаружить:
🔹 (значительные) методологические недостатки статьи;
🔹 неточности в интерпретации и обобщении результатов;
🔹 неправильное использование ссылок;
🔹 отсутствие данных, необходимых для повторного анализа или воспроизведения исследования;
🔹 отсутствие элементов, необходимых для оценки предвзятости или качества исследования.
По мнению автора, повысить качество экспертной оценки можно за счет внедрения стандартизированных отзывов на публикации, для чего журналы должны предоставлять рецензентам список вопросов, сосредоточенных на всех аспектах исследования, а также размещать на сайте журнала:
а) список вопросов для рецензентов (что позволит авторам использовать те же вопросы в качестве контрольного списка для анализа работы и повышения её качества);
б) развернутые отзывы рецензентов (что позволит читателям посмотреть как оценивалась статья, а исследователям даст возможность изучить практику рецензирования).
Стандартизированное рецензирование было апробировано в августе 2022 года в 220 журналах Elsevier. В рамках пилотного исследования было проанализировано примерно 10% выборки, а именно — 214 отзывов рецензентов на 107 статей из 23 случайно выбранных (вне зависимости от тематики и квартиля) журналов. Каждый отзыв состоял из ответов на 9 одинаковых вопросов и информации, оставленной в поле «Комментарии для автора», и в конфиденциальном поле «Комментарии для редактора». Ознакомиться с шаблоном вопросов можно по ссылке.
Абсолютное совпадение мнений относительно окончательных рекомендаций рецензента составило 41%, причем статистической разницы между научными областями или квартилями обнаружено не было, тогда как по последним данным Elsevier (на основе 7 220 243 рукописей, опубликованных с 2019 по 2021 год в 2416 журналах), рецензенты приняли одинаковые решения на первом этапе рецензирования всего в 30% случаев.
Более того, в ряде случаев комментарии рецензентов совпадали в отношении отдельных фрагментов работы. Согласно результатам исследования, самое высокое (частичное) согласие рецензентов (72%) было обнаружено при оценивании структуры статьи, а самое низкое (частичное) согласие (53%) — для оценивания подтверждения интерпретации результатов данными, а также для оценки уместности и достаточной детальности статистического анализа (52%).
Предварительные результаты показывают, что, руководствуясь одними и теми же вопросами, рецензенты давали идентичные первоначальные рекомендации насчет принятия/отклонения или доработки публикации. По мнению автора, отсутствие стандартизированных практик в рецензировании замедляет прогресс науки, а их внедрение поможет сделать отзывы более объективными, прозрачными и заслуживающими доверия.
#Elsevier #рецензирование #обзор
Salami Slicing: от одного исследования ко множеству публикаций
“Тактика салями” в академическом мире (Salami Slicing) — неуместное разделение одной публикации на ряд публикаций с идентичными или очень похожими данными в каждой статье. Термин, широко используемый в теоретико-игровом моделировании, как нельзя лучше подходит для описания подхода, нацеленного на искусственное завышение публикационной активности.
Попытка дважды опубликовать результаты, полученные в ходе выполнения одного исследования, — этически неприемлемая практика, она не только может приводить к искажению исследовательских выводов, но и может навредить академическому сообществу по ряду других причин:
🔹 создает дополнительную работу для читателей, будущих авторов, рецензентов и редакторов;
🔹 идет рука об руку с самоплагиатом;
🔹 приводит к дублированию публикаций.
Такая стратегия наиболее опасна для молодых исследователей, которые могут привыкнуть анализировать данные частями, забывая, что в таком случае из поля зрения ускользают более ценные выводы, которые можно было бы изложить в ходе одного исследования.
Очевидно, что опубликовать многокомпонентные исследования гораздо сложнее, чем более простые, как минимум, из-за объема работы, которую необходимо провести авторам и редакторам перед публикацией статьи. Поддаваясь искушению пойти по более лёгкому пути, исследователи в долгосрочной перспективе могут значительно снизить свои шансы на публикации во влиятельных журналах.
Дополнительная сложность заключается в том, что Salami Slicing легче идентифицировать в количественных исследованиях, чем в качественных. В дискуссиях о том, что же понимать под “неоправданной сегментацией”, исследователи сформулировали вопросы, положительные ответы на которые помогут распознать этот вид академического мошенничества:
💠 каждая публикация проверяет одну гипотезу?
💠 две (и более) публикации основываются на одном и том же массиве данных?
💠 исследования сообщают об одних и тех же результатах?/приходят к одним и тем же выводам?
Однако принудительное применение таких правил к некоторым исследованиям (например, в социальных науках) сводит сложные исследовательские вопросы к простым «данным», лишая их более глубокого контекста и значения.
Мигель Ройг, исследователь в области академической честности, в своем гайде на эту тему рекомендует напоминать себе следующее: “Если результаты одного сложного исследования наилучшим образом можно представить как “связанное” единое целое, их не следует разбивать на отдельные статьи”.
“Тактика салями” — явление хоть и не новое, но тяжело отслеживаемое, особенно в условиях высококонкурентной и ориентированной на публикации академической реальности. Следует помнить, что как и в случае с другими формами избыточности и фактического дублирования статей, неоправданная сегментация исследования приводит к искажению информации, заставляя ничего не подозревающих читателей верить в то, что данные, представленные в каждом кусочке салями (т. е. в журнальной статье), получены независимо друг от друга.
P.S.
Этот пост продолжает серию заметок о недобросовестных исследовательских практиках и мошенничестве в академическом мире. Мы публикуем серию карточек на эту тему, чтобы нашим подписчикам было проще не заблудиться в dark side of publishing.
#SalamiSlicing #тактикасалями #обзор
“Тактика салями” в академическом мире (Salami Slicing) — неуместное разделение одной публикации на ряд публикаций с идентичными или очень похожими данными в каждой статье. Термин, широко используемый в теоретико-игровом моделировании, как нельзя лучше подходит для описания подхода, нацеленного на искусственное завышение публикационной активности.
Попытка дважды опубликовать результаты, полученные в ходе выполнения одного исследования, — этически неприемлемая практика, она не только может приводить к искажению исследовательских выводов, но и может навредить академическому сообществу по ряду других причин:
🔹 создает дополнительную работу для читателей, будущих авторов, рецензентов и редакторов;
🔹 идет рука об руку с самоплагиатом;
🔹 приводит к дублированию публикаций.
Такая стратегия наиболее опасна для молодых исследователей, которые могут привыкнуть анализировать данные частями, забывая, что в таком случае из поля зрения ускользают более ценные выводы, которые можно было бы изложить в ходе одного исследования.
Очевидно, что опубликовать многокомпонентные исследования гораздо сложнее, чем более простые, как минимум, из-за объема работы, которую необходимо провести авторам и редакторам перед публикацией статьи. Поддаваясь искушению пойти по более лёгкому пути, исследователи в долгосрочной перспективе могут значительно снизить свои шансы на публикации во влиятельных журналах.
Дополнительная сложность заключается в том, что Salami Slicing легче идентифицировать в количественных исследованиях, чем в качественных. В дискуссиях о том, что же понимать под “неоправданной сегментацией”, исследователи сформулировали вопросы, положительные ответы на которые помогут распознать этот вид академического мошенничества:
💠 каждая публикация проверяет одну гипотезу?
💠 две (и более) публикации основываются на одном и том же массиве данных?
💠 исследования сообщают об одних и тех же результатах?/приходят к одним и тем же выводам?
Однако принудительное применение таких правил к некоторым исследованиям (например, в социальных науках) сводит сложные исследовательские вопросы к простым «данным», лишая их более глубокого контекста и значения.
Мигель Ройг, исследователь в области академической честности, в своем гайде на эту тему рекомендует напоминать себе следующее: “Если результаты одного сложного исследования наилучшим образом можно представить как “связанное” единое целое, их не следует разбивать на отдельные статьи”.
“Тактика салями” — явление хоть и не новое, но тяжело отслеживаемое, особенно в условиях высококонкурентной и ориентированной на публикации академической реальности. Следует помнить, что как и в случае с другими формами избыточности и фактического дублирования статей, неоправданная сегментация исследования приводит к искажению информации, заставляя ничего не подозревающих читателей верить в то, что данные, представленные в каждом кусочке салями (т. е. в журнальной статье), получены независимо друг от друга.
P.S.
Этот пост продолжает серию заметок о недобросовестных исследовательских практиках и мошенничестве в академическом мире. Мы публикуем серию карточек на эту тему, чтобы нашим подписчикам было проще не заблудиться в dark side of publishing.
#SalamiSlicing #тактикасалями #обзор
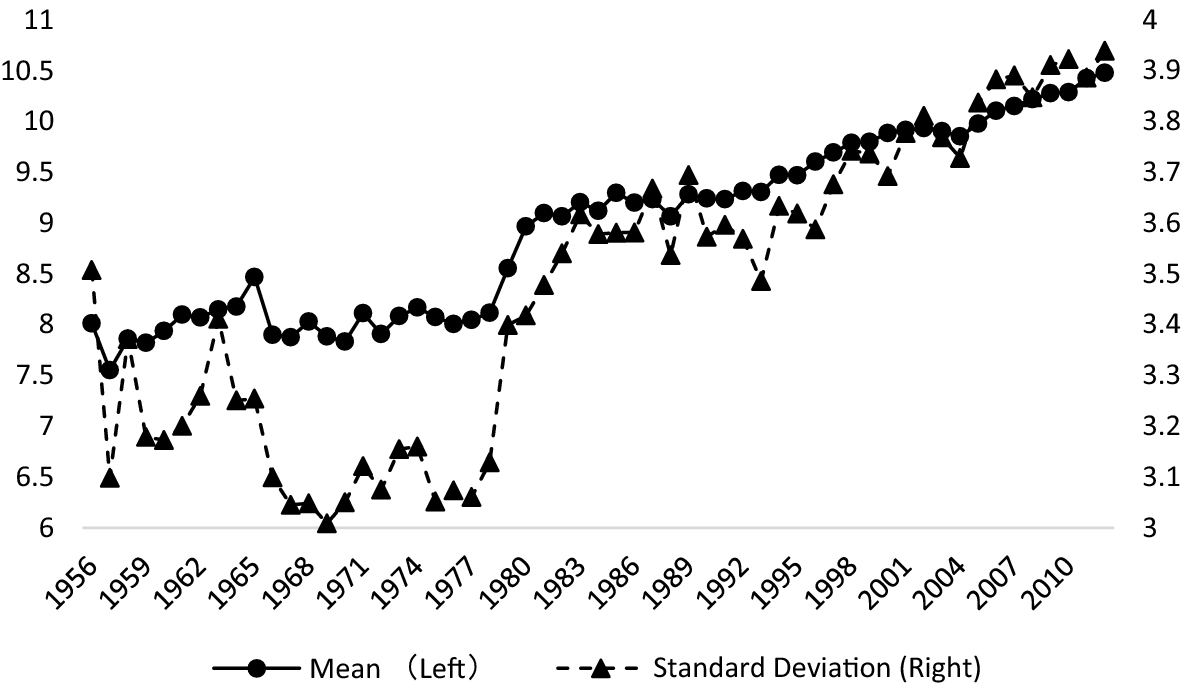
Коротко и ясно: зависит ли цитируемость статьи от длины заголовка?
Большинство исследователей настаивают на том, что заголовки опубликованных работ должны быть относительно краткими, так как заголовки — это первая, а иногда и единственная информация, которую читатель получает из публикации.
Результаты опроса (впрочем, довольно старого), в котором приняли участие более 5000 человек, показали, что читатель научных журналов просматривает в среднем 1142 заголовка, 204 аннотации и 97 статей в год. Растущий поток информации и повышающаяся конкуренция в академической среде приводят к тому, что читателю, вероятнее всего, проще откинуть статью с витиеватым заголовком, не вникая в ее содержание (не случайно некоторые научные журналы ограничивают количество слов в заголовках). Как мы недавно видели, короткий и броский заголовок действительно может привлечь внимание.
С другой стороны, согласно теории поисковой оптимизации (SEO), длинный заголовок может помочь в поиске статьи по ключевым словам, благодаря чему статья привлекает больше внимания, и, соответственно, чаще цитируется. Исследователи Шанхайского университета финансов и экономики (SUFE) называют это информативным эффектом (informative effect), а факторы, подтверждающие положительную корреляцию между короткими заголовками и цитированием статей, — эффектом лаконичности (succinct effect).
На основе выборки из более чем 300 000 статей SSCI по экономике с 1956 по 2012 год они определили, что статьи с короткими названиями лучше цитировались в период, когда поиск литературы не был так тесно связан с цифровыми технологиями (1956–2000 годы), а уже с 2001 года наблюдается рост цитируемости статей с длинными заголовками.
Здесь необходимо отметить несколько аспектов. Во-первых, сами авторы стали использовать больше слов в заголовке (см. график). В частности, в 2010–2012 годах в заголовке в среднем было 10,4 слова, что на 33% больше, чем 7,8 слов в 1956–1958 годах.
Согласно исследованию, в XXI веке количество цитирований статьи должно возрастать на 0,60% с каждым дополнительным словом, добавленным в название статьи. Следует отметить, что, помимо длины заголовка, в исследовании были учтены другие факторы, которые могут влиять на количество цитирований:
💠 Количество страниц в статье. Статьи тоже стали длиннее, а такие статьи, согласно некоторым исследованиям, чаще цитируют.
💠 Число соавторов. Было обнаружено, что чем больше соавторов, тем больше цитирований, так как статья привлекает больше внимания.
💠 Количество ссылок в работе. Чем больше в статье ссылок на предыдущие работы, тем больше доверия она вызывает. Также обширный список источников связан с формой взаимного альтруизма — «Я цитирую вас, а вы цитируете меня».
💠 Алфавитный порядок авторов. Первого автора из списка чаще цитируют и упоминают.
💠 Порядок статьи в выпуске. Первые статьи в выпуске, как правило, больше скачивают и цитируют.
На данном этапе развития науки почти весь поиск литературы осуществляется в онлайн-базах данных, причем многие поиски ограничиваются ключевыми словами. По мнению авторов исследования, статьи с краткими названиями были более привлекательны в предыдущие десятилетия, но с развитием интернета информативный эффект начал превосходить эффект лаконичности. Исследователям не стоит жалеть время на выбор заголовка публикации, так как число статей и журналов, к которым можно получить онлайн-доступ, постоянно растет. А мы планируем вскоре вернуться к этой теме со своим исследованием, чтобы слегка освежить данные, полученные в оригинальной статье.
#цитирование #SSCI #обзор
Большинство исследователей настаивают на том, что заголовки опубликованных работ должны быть относительно краткими, так как заголовки — это первая, а иногда и единственная информация, которую читатель получает из публикации.
Результаты опроса (впрочем, довольно старого), в котором приняли участие более 5000 человек, показали, что читатель научных журналов просматривает в среднем 1142 заголовка, 204 аннотации и 97 статей в год. Растущий поток информации и повышающаяся конкуренция в академической среде приводят к тому, что читателю, вероятнее всего, проще откинуть статью с витиеватым заголовком, не вникая в ее содержание (не случайно некоторые научные журналы ограничивают количество слов в заголовках). Как мы недавно видели, короткий и броский заголовок действительно может привлечь внимание.
С другой стороны, согласно теории поисковой оптимизации (SEO), длинный заголовок может помочь в поиске статьи по ключевым словам, благодаря чему статья привлекает больше внимания, и, соответственно, чаще цитируется. Исследователи Шанхайского университета финансов и экономики (SUFE) называют это информативным эффектом (informative effect), а факторы, подтверждающие положительную корреляцию между короткими заголовками и цитированием статей, — эффектом лаконичности (succinct effect).
На основе выборки из более чем 300 000 статей SSCI по экономике с 1956 по 2012 год они определили, что статьи с короткими названиями лучше цитировались в период, когда поиск литературы не был так тесно связан с цифровыми технологиями (1956–2000 годы), а уже с 2001 года наблюдается рост цитируемости статей с длинными заголовками.
Здесь необходимо отметить несколько аспектов. Во-первых, сами авторы стали использовать больше слов в заголовке (см. график). В частности, в 2010–2012 годах в заголовке в среднем было 10,4 слова, что на 33% больше, чем 7,8 слов в 1956–1958 годах.
Согласно исследованию, в XXI веке количество цитирований статьи должно возрастать на 0,60% с каждым дополнительным словом, добавленным в название статьи. Следует отметить, что, помимо длины заголовка, в исследовании были учтены другие факторы, которые могут влиять на количество цитирований:
💠 Количество страниц в статье. Статьи тоже стали длиннее, а такие статьи, согласно некоторым исследованиям, чаще цитируют.
💠 Число соавторов. Было обнаружено, что чем больше соавторов, тем больше цитирований, так как статья привлекает больше внимания.
💠 Количество ссылок в работе. Чем больше в статье ссылок на предыдущие работы, тем больше доверия она вызывает. Также обширный список источников связан с формой взаимного альтруизма — «Я цитирую вас, а вы цитируете меня».
💠 Алфавитный порядок авторов. Первого автора из списка чаще цитируют и упоминают.
💠 Порядок статьи в выпуске. Первые статьи в выпуске, как правило, больше скачивают и цитируют.
На данном этапе развития науки почти весь поиск литературы осуществляется в онлайн-базах данных, причем многие поиски ограничиваются ключевыми словами. По мнению авторов исследования, статьи с краткими названиями были более привлекательны в предыдущие десятилетия, но с развитием интернета информативный эффект начал превосходить эффект лаконичности. Исследователям не стоит жалеть время на выбор заголовка публикации, так как число статей и журналов, к которым можно получить онлайн-доступ, постоянно растет. А мы планируем вскоре вернуться к этой теме со своим исследованием, чтобы слегка освежить данные, полученные в оригинальной статье.
#цитирование #SSCI #обзор
{kind=link}
«Стоковые» члены редколлегии в хищнических журналах
Как мы упоминали ранее, хищнические издательства часто пользуются без авторизации личными данными ученых и включают их в редакционные коллегии своих журналов (если эти редколлегии, конечно, вообще есть).
В июльском выпуске Learned Publishing вышла статья, посвященная описанию «стоковых» персонажей (stock characters) хищнических редколлегий, под которыми автор подразумевает ученых, которые одновременно входят в редколлегии 20 и более недобросовестных журналов.
В период с 2017 по 2023 год Майк Даунс (Mike Downes) тщательно изучал тысячи редакционных коллегий журналов, издатели которых входят в Список Билла (Beall's List). Им были обнаружены 96 исследователей, каждый из которых состоит в редколлегиях от 20 до 503 журналов (по состоянию на 2023 год).
В выборку вошли только хищнические журналы, редакционная политика которых допускает три этических нарушения:
🔹 фабрикация дат рецензирования статей;
🔹 кража личных данных;
🔹 заполнение архивов фальшивыми статьями.
По мнению автора, «стоковые» персонажи встречались настолько часто, что можно уверенно воспринимать их присутствие или отсутствие в качестве полноценного критерия, отличающего честного издателя от недобросовестного.
Такие персонажи, как правило, обращают на себя внимание за счет следующих «красных флагов»:
🔹 невозможность обнаружить профиль ученого на сайте вуза, в котором он якобы работает;
🔹 членство в редколлегиях журналов по двум и более несвязанным темам;
🔹 такой ученый практически никогда не встречается в редколлегии влиятельного журнала.
Конечно, информация о членах редколлегии может быть украдена полностью или частично, т.е. в некоторых случаях ученые не знают, что выступают в такой роли, но иногда исследователи добровольно вступают в такие редколлегии (в таких случаях они там же публикуют свои работы). Очевидно, что членство в совете редколлегии хищнического журнала, которое указано в разделе «Достижения» или в каком-либо схожем разделе биографии исследователя, нельзя назвать кражей личных данных.
Опасность заключается в том, что если имя ученого упоминается в хищнических редколлегиях сначала один, два, а потом несколько раз, и исследователь не замечает этого (или не хочет замечать), такое лицо легко становится типичной жертвой кражи личных данных.
Майк Даунс отмечает, что после его переписки с рядом «стоковых» персонажей, нескольким авторам, внесенным в редколлегии без их согласия, удалось немного исправить ситуацию. Например, один исследователь, который когда-то входил в 361 редколлегии, на данный момент состоит в 118. Однако существуют и мертвые «стоковые» персонажи, которые не могут за себя постоять (так, например, один профессор уже четвертый год после смерти продолжает занимать должность главного редактора журнала).
«Стоковые» персонажи включают в редакционные коллегии, чтобы создать впечатление, что журнал соответствует академическим стандартам. Согласно опросу автора, «стоковых» персонажей и многих других ученых, появлявшихся в редакционных коллегиях хищнических издательств, часто объединяет смутное воспоминание о том, что они согласились стать членом редакционной коллегии много лет назад и с тех пор больше ничего об этом не слышали. Внимательность в таких вопросах может помочь вовремя заметить кражу личных данных исследователя и принять соответствующие меры.
#predatoryjournals #хищническиежурналы #редколлегия #обзор
Как мы упоминали ранее, хищнические издательства часто пользуются без авторизации личными данными ученых и включают их в редакционные коллегии своих журналов (если эти редколлегии, конечно, вообще есть).
В июльском выпуске Learned Publishing вышла статья, посвященная описанию «стоковых» персонажей (stock characters) хищнических редколлегий, под которыми автор подразумевает ученых, которые одновременно входят в редколлегии 20 и более недобросовестных журналов.
В период с 2017 по 2023 год Майк Даунс (Mike Downes) тщательно изучал тысячи редакционных коллегий журналов, издатели которых входят в Список Билла (Beall's List). Им были обнаружены 96 исследователей, каждый из которых состоит в редколлегиях от 20 до 503 журналов (по состоянию на 2023 год).
В выборку вошли только хищнические журналы, редакционная политика которых допускает три этических нарушения:
🔹 фабрикация дат рецензирования статей;
🔹 кража личных данных;
🔹 заполнение архивов фальшивыми статьями.
По мнению автора, «стоковые» персонажи встречались настолько часто, что можно уверенно воспринимать их присутствие или отсутствие в качестве полноценного критерия, отличающего честного издателя от недобросовестного.
Такие персонажи, как правило, обращают на себя внимание за счет следующих «красных флагов»:
🔹 невозможность обнаружить профиль ученого на сайте вуза, в котором он якобы работает;
🔹 членство в редколлегиях журналов по двум и более несвязанным темам;
🔹 такой ученый практически никогда не встречается в редколлегии влиятельного журнала.
Конечно, информация о членах редколлегии может быть украдена полностью или частично, т.е. в некоторых случаях ученые не знают, что выступают в такой роли, но иногда исследователи добровольно вступают в такие редколлегии (в таких случаях они там же публикуют свои работы). Очевидно, что членство в совете редколлегии хищнического журнала, которое указано в разделе «Достижения» или в каком-либо схожем разделе биографии исследователя, нельзя назвать кражей личных данных.
Опасность заключается в том, что если имя ученого упоминается в хищнических редколлегиях сначала один, два, а потом несколько раз, и исследователь не замечает этого (или не хочет замечать), такое лицо легко становится типичной жертвой кражи личных данных.
Майк Даунс отмечает, что после его переписки с рядом «стоковых» персонажей, нескольким авторам, внесенным в редколлегии без их согласия, удалось немного исправить ситуацию. Например, один исследователь, который когда-то входил в 361 редколлегии, на данный момент состоит в 118. Однако существуют и мертвые «стоковые» персонажи, которые не могут за себя постоять (так, например, один профессор уже четвертый год после смерти продолжает занимать должность главного редактора журнала).
«Стоковые» персонажи включают в редакционные коллегии, чтобы создать впечатление, что журнал соответствует академическим стандартам. Согласно опросу автора, «стоковых» персонажей и многих других ученых, появлявшихся в редакционных коллегиях хищнических издательств, часто объединяет смутное воспоминание о том, что они согласились стать членом редакционной коллегии много лет назад и с тех пор больше ничего об этом не слышали. Внимательность в таких вопросах может помочь вовремя заметить кражу личных данных исследователя и принять соответствующие меры.
#predatoryjournals #хищническиежурналы #редколлегия #обзор
Некоммерческое издание публикаций не снижает их стоимости
Современная научная публикационная деятельность сталкивается с серьезными финансовыми вызовами. Растущая стоимость публикационного процесса увеличивает потребность в некоммерческих моделях публикаций. Однако существует вероятность того, что популярность таких моделей может ограничить рост издательств, но так и не привести к удешевлению процесса публикации. В сегодняшнем обзоре мы рассмотрим посвященное этой теме недавнее исследование Роба Джонсона, главы компании Research Consulting в области исследовательской политики.
Инициатива ЕС по снижению стоимости публикации
В мае 2023 года Совет ЕС назвал текущие расходы на публикации неприемлемыми:
«Расходы на платный доступ к статьям и их публикацию становятся непосильными, а каналы публикаций для исследователей часто находятся в руках частных компаний, которые зачастую контролируют интеллектуальную собственность на статьи».
Совет призвал Комиссию и EC поддержать политику, направленную на создание некоммерческой, открытой и многоформатной модели научных изданий, не влекущей за собой никаких расходов для авторов и читателей.
В своем исследовании Р. Джонсон указывает, что существующие издательства уменьшают расходы на процесс публикации путем использования государственных субсидий или масштабирования объема выпускаемых публикаций. Это же наблюдение подтверждает отчет Массачусетского технологического института «Доступ к науке и стипендиям: ключевые вопросы о будущем публикации научных работ», в котором предлагается два способа увеличения прибыли коммерческих изданий: увеличение количества публикаций и снижение расходов.
О состоянии коммерческих изданий свидетельствуют данные инициативы OpenAPC при библиотеке Билефельдского университета, которая публикует наборы данных о сборах, выплачиваемых университетами и исследовательскими институтами за статьи в журналах открытого доступа.
Создание Open Research Europe и сценарии развития
Сложившуюся ситуацию, как описано в инициативе ЕС, предлагается решить при помощи создания ORE — издательской платформы открытого доступа на некоммерческой основе. Предполагается, что эта платформа будет работать как независимое юридическое лицо, что позволит оценить полную стоимость публикационного цикла. Большинство услуг, связанных с производством публикаций, таких как редакционные, производственные или технологические функции, будут выполняться сторонними поставщиками, но допускается возможность реализации платформы на базе уже существующей академической или международной организации. Однако, насколько создание ORE решит проблему роста стоимости публикаций?
В 2023 году Р. Джонсон представил отчет о потенциале создания ORE. В нем рассматриваются вероятные внутренние и внешние факторы, потенциально способные повлиять на рост опубликованных материалов, а также предполагаемый рост расходов в период с 2026 по 2030 годы.
Р. Джонсон смоделировал несколько сценариев возможного роста публикаций под эгидой ORE. Им были выделены пять основных категорий предполагаемых затрат:
а) расходы на производство статей,
б) маркетинг и вовлечение сообщества,
в) разработка и обслуживание платформы,
г) зарплаты и оклады,
д) административные накладные расходы.
В результате расчеты автора показывают, что даже при самом оптимистичном сценарии маловероятно, что стоимость одной публикации будет значительно ниже текущих коммерческих расценок.
В целом исследование показывает, что, с учетом всех категорий расходов, некоммерческие модели издания слабо способствуют уменьшению стоимости публикационного процесса. Р. Джонсон указывает, что политика развития издательств открытого доступа предполагает две крайние стратегии: сохранение качества ценой потери доли влияния и доходности, либо наращивание объемов издаваемых материалов, рискуя потерять доверие читателей к качеству.
#обзор #OpenResearchEurope #коммерциализация
Современная научная публикационная деятельность сталкивается с серьезными финансовыми вызовами. Растущая стоимость публикационного процесса увеличивает потребность в некоммерческих моделях публикаций. Однако существует вероятность того, что популярность таких моделей может ограничить рост издательств, но так и не привести к удешевлению процесса публикации. В сегодняшнем обзоре мы рассмотрим посвященное этой теме недавнее исследование Роба Джонсона, главы компании Research Consulting в области исследовательской политики.
Инициатива ЕС по снижению стоимости публикации
В мае 2023 года Совет ЕС назвал текущие расходы на публикации неприемлемыми:
«Расходы на платный доступ к статьям и их публикацию становятся непосильными, а каналы публикаций для исследователей часто находятся в руках частных компаний, которые зачастую контролируют интеллектуальную собственность на статьи».
Совет призвал Комиссию и EC поддержать политику, направленную на создание некоммерческой, открытой и многоформатной модели научных изданий, не влекущей за собой никаких расходов для авторов и читателей.
В своем исследовании Р. Джонсон указывает, что существующие издательства уменьшают расходы на процесс публикации путем использования государственных субсидий или масштабирования объема выпускаемых публикаций. Это же наблюдение подтверждает отчет Массачусетского технологического института «Доступ к науке и стипендиям: ключевые вопросы о будущем публикации научных работ», в котором предлагается два способа увеличения прибыли коммерческих изданий: увеличение количества публикаций и снижение расходов.
О состоянии коммерческих изданий свидетельствуют данные инициативы OpenAPC при библиотеке Билефельдского университета, которая публикует наборы данных о сборах, выплачиваемых университетами и исследовательскими институтами за статьи в журналах открытого доступа.
Создание Open Research Europe и сценарии развития
Сложившуюся ситуацию, как описано в инициативе ЕС, предлагается решить при помощи создания ORE — издательской платформы открытого доступа на некоммерческой основе. Предполагается, что эта платформа будет работать как независимое юридическое лицо, что позволит оценить полную стоимость публикационного цикла. Большинство услуг, связанных с производством публикаций, таких как редакционные, производственные или технологические функции, будут выполняться сторонними поставщиками, но допускается возможность реализации платформы на базе уже существующей академической или международной организации. Однако, насколько создание ORE решит проблему роста стоимости публикаций?
В 2023 году Р. Джонсон представил отчет о потенциале создания ORE. В нем рассматриваются вероятные внутренние и внешние факторы, потенциально способные повлиять на рост опубликованных материалов, а также предполагаемый рост расходов в период с 2026 по 2030 годы.
Р. Джонсон смоделировал несколько сценариев возможного роста публикаций под эгидой ORE. Им были выделены пять основных категорий предполагаемых затрат:
а) расходы на производство статей,
б) маркетинг и вовлечение сообщества,
в) разработка и обслуживание платформы,
г) зарплаты и оклады,
д) административные накладные расходы.
В результате расчеты автора показывают, что даже при самом оптимистичном сценарии маловероятно, что стоимость одной публикации будет значительно ниже текущих коммерческих расценок.
В целом исследование показывает, что, с учетом всех категорий расходов, некоммерческие модели издания слабо способствуют уменьшению стоимости публикационного процесса. Р. Джонсон указывает, что политика развития издательств открытого доступа предполагает две крайние стратегии: сохранение качества ценой потери доли влияния и доходности, либо наращивание объемов издаваемых материалов, рискуя потерять доверие читателей к качеству.
#обзор #OpenResearchEurope #коммерциализация
{kind=link}
Использование ИИ в технологическом трансфере
Месяц назад в Nature вышла заметка основателя “Научного центра науки и инноваций Северо-Западного университета” Дашунь Вана (Dashun Wang), посвященная использованию алгоритмов ИИ для выявления ученых, нуждающихся в поддержке их научных результатов для практического приложения.
Во время пилотного проекта исследовательской группы Вана обнаружилось, что одна исследовательница в области биологии не знала о влиянии своих научных работ на рынок, но в результате знакомства с подразделением технологического трансфера она узнала, что частные компании широко цитируют ее исследования в своих патентах, и подала заявку на регистрацию своего изобретения. Этот пример сподвигнул Вана задаться вытекающими из этого кейса вопросами: можно ли выявить исследователей с невостребованным инновационным потенциалом и каким образом?
В течение нескольких лет исследовательский коллектив Вана работал с различными университетами США, пытаясь найти оптимальные способы максимизировать результаты научной деятельности.
В ходе исследования обнаружились некоторые потворяющиеся паттерны, например:
- женщины реже патентуют свои работы, чем мужчины (причем разница — от двух до десяти раз в зависимости от области), при одинаковом (судя по цитируемости) уровне работы;
- преподаватели с постоянным контрактом подают заявки чаще, чем те, кто трудоустроен по временному контракту.
Кроме того, выяснилось, что существует довольно много ученых, которые не стремятся к трансферу технологий, не взаимодействуют с соответствующим департаментом (а такие есть почти во всех университетах), не подают заявки на патенты.
Ван и его коллеги полагают, что публикующиеся ежегодно наборы данных о миллионах статей, препринтов и грантовых заявок можно анализировать при помощи ИИ, чтобы выявить пробелы и узкие места, которые мешают технологическим прорывам.
Одним из главных хайлайтов статьи является утверждение Вана о дихотомии между фундаментальными и прикладными исследованиями и условиями современности: сложно спрогнозировать какие исследования найдут непосредственное технологическое применение.
Вывод Вана состоит в том, что исследования были бы намного влиятельней, если бы университеты использовали инструменты ИИ с целью поиска научных результатов своих сотрудников, к которым применим технологический трансфер.
#обзор #искусственныйинтеллект #патенты
Месяц назад в Nature вышла заметка основателя “Научного центра науки и инноваций Северо-Западного университета” Дашунь Вана (Dashun Wang), посвященная использованию алгоритмов ИИ для выявления ученых, нуждающихся в поддержке их научных результатов для практического приложения.
Во время пилотного проекта исследовательской группы Вана обнаружилось, что одна исследовательница в области биологии не знала о влиянии своих научных работ на рынок, но в результате знакомства с подразделением технологического трансфера она узнала, что частные компании широко цитируют ее исследования в своих патентах, и подала заявку на регистрацию своего изобретения. Этот пример сподвигнул Вана задаться вытекающими из этого кейса вопросами: можно ли выявить исследователей с невостребованным инновационным потенциалом и каким образом?
В течение нескольких лет исследовательский коллектив Вана работал с различными университетами США, пытаясь найти оптимальные способы максимизировать результаты научной деятельности.
В ходе исследования обнаружились некоторые потворяющиеся паттерны, например:
- женщины реже патентуют свои работы, чем мужчины (причем разница — от двух до десяти раз в зависимости от области), при одинаковом (судя по цитируемости) уровне работы;
- преподаватели с постоянным контрактом подают заявки чаще, чем те, кто трудоустроен по временному контракту.
Кроме того, выяснилось, что существует довольно много ученых, которые не стремятся к трансферу технологий, не взаимодействуют с соответствующим департаментом (а такие есть почти во всех университетах), не подают заявки на патенты.
Ван и его коллеги полагают, что публикующиеся ежегодно наборы данных о миллионах статей, препринтов и грантовых заявок можно анализировать при помощи ИИ, чтобы выявить пробелы и узкие места, которые мешают технологическим прорывам.
Одним из главных хайлайтов статьи является утверждение Вана о дихотомии между фундаментальными и прикладными исследованиями и условиями современности: сложно спрогнозировать какие исследования найдут непосредственное технологическое применение.
Вывод Вана состоит в том, что исследования были бы намного влиятельней, если бы университеты использовали инструменты ИИ с целью поиска научных результатов своих сотрудников, к которым применим технологический трансфер.
#обзор #искусственныйинтеллект #патенты
Анализ цитирований в российских публикациях в Web of Science
В последнем выпуске Journal of Scientometric Research в соавторстве с Дарьей Мальцевой (ВШЭ) вышла статья, посвященная библиометрическому анализу российской науки на базе 1,38 млн публикаций российских (со)авторов.
В основе работы — использование метода спектроскопии года публикации цитируемых работ (RPYS — Reference Publication Year Spectroscopy), разработанного в 2013 Вернером Марксом. Этот метод, как правило, применяется для более ограниченных датасетов (например, для публикаций одного исследователя, журнала или научной дисциплины). Для обработки миллионов записей данных метод был масштабирован авторами исследования с использованием СУБД, что позволило проанализировать исторические корни российской науки.
В качестве исходных данных был взят массив статей, индексированных в WoS до мая 2022 года, у которых хотя бы один из авторов имеет российскую аффилиацию, в виде текстовых файлов. Почти все статьи приходятся на период с 1992 по 2022 гг, до 1992 публикаций крайне мало. Общее количество ссылок в описанном массиве — более 32 млн, при этом 1,66 млн ведут на статьи, входящие в исходный датасет.
Согласно результатам исследования:
🔹 Количество ссылок в статьях заметно возросло с течением времени: если в 1992 г. в публикации приводилось в среднем 15 ссылок, то в 2022 г. их было 47.
🔹 Один из основных объектов анализа — разница в «возрасте» между статьей и публикациями, которая она цитирует. Подавляющее большинство ссылок приходится на группу 20+ лет — это означает, что российская наука в значительной степени опиралась на более «старые» фундаментальные исследования.
🔹 Общий средний возраст цитируемых статей составил 14,5 лет, и в рассматриваемый период (с 1992 по 2022) он увеличился примерно на 14%. Следует отметить и динамику: так, средний возраст достигает пика (15,5 лет) в 2014 г., а затем снижается. Таким образом, авторы публикаций, написанных после 2014 года, начинают чаще цитировать более «свежие» статьи.
Если говорить о научных журналах, то во все периоды чаще всего цитировались Physical Review Letters, Physical Review B, Physical Review D, The Astrophysical Journal, The Journal of Chemical Physics и Journal of the American Chemical Society, а также Nature и Science. До 2000 года в топ-10 входили также «Доклады Академии Наук СССР», но после 2000-х цитировать их практически перестали.
Так или иначе, подавляющее число цитирований приходится на долю естественных наук, что отмечают и сами авторы.
#обзор #цитирования #RPYS #WebofScience
В последнем выпуске Journal of Scientometric Research в соавторстве с Дарьей Мальцевой (ВШЭ) вышла статья, посвященная библиометрическому анализу российской науки на базе 1,38 млн публикаций российских (со)авторов.
В основе работы — использование метода спектроскопии года публикации цитируемых работ (RPYS — Reference Publication Year Spectroscopy), разработанного в 2013 Вернером Марксом. Этот метод, как правило, применяется для более ограниченных датасетов (например, для публикаций одного исследователя, журнала или научной дисциплины). Для обработки миллионов записей данных метод был масштабирован авторами исследования с использованием СУБД, что позволило проанализировать исторические корни российской науки.
В качестве исходных данных был взят массив статей, индексированных в WoS до мая 2022 года, у которых хотя бы один из авторов имеет российскую аффилиацию, в виде текстовых файлов. Почти все статьи приходятся на период с 1992 по 2022 гг, до 1992 публикаций крайне мало. Общее количество ссылок в описанном массиве — более 32 млн, при этом 1,66 млн ведут на статьи, входящие в исходный датасет.
Согласно результатам исследования:
🔹 Количество ссылок в статьях заметно возросло с течением времени: если в 1992 г. в публикации приводилось в среднем 15 ссылок, то в 2022 г. их было 47.
🔹 Один из основных объектов анализа — разница в «возрасте» между статьей и публикациями, которая она цитирует. Подавляющее большинство ссылок приходится на группу 20+ лет — это означает, что российская наука в значительной степени опиралась на более «старые» фундаментальные исследования.
🔹 Общий средний возраст цитируемых статей составил 14,5 лет, и в рассматриваемый период (с 1992 по 2022) он увеличился примерно на 14%. Следует отметить и динамику: так, средний возраст достигает пика (15,5 лет) в 2014 г., а затем снижается. Таким образом, авторы публикаций, написанных после 2014 года, начинают чаще цитировать более «свежие» статьи.
Если говорить о научных журналах, то во все периоды чаще всего цитировались Physical Review Letters, Physical Review B, Physical Review D, The Astrophysical Journal, The Journal of Chemical Physics и Journal of the American Chemical Society, а также Nature и Science. До 2000 года в топ-10 входили также «Доклады Академии Наук СССР», но после 2000-х цитировать их практически перестали.
Так или иначе, подавляющее число цитирований приходится на долю естественных наук, что отмечают и сами авторы.
#обзор #цитирования #RPYS #WebofScience
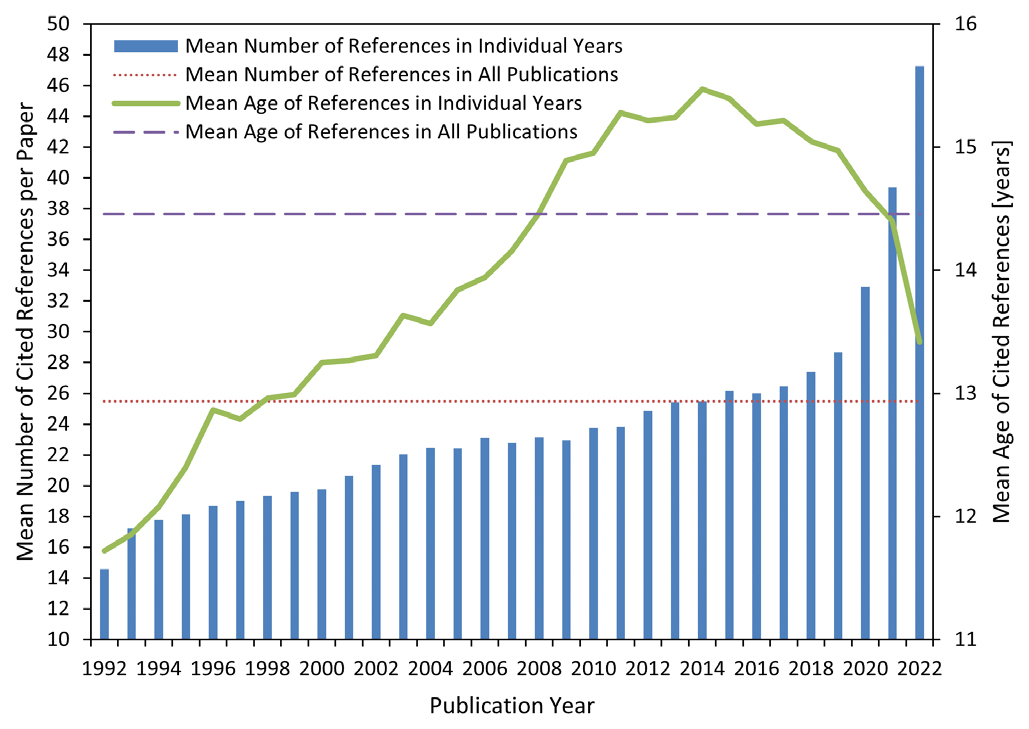{kind=link}
Библиометрия за пределами цитирования: индекс упоминаний
Современные практики цитирования появились относительно недавно, из-за чего научные базы данных сталкиваются с проблемой неполноты учтенных ссылок: например, WoS гарантирует достоверность ссылок лишь с 1980 года, а Scopus — с 1996. При этом ссылки на источники всегда были неотъемлемой частью науки.
В недавней статье ученые из Нидерландов описывают метод, предназначенный для решения данной проблемы — индексирование упоминаний, расширяющее понятие научной ссылки.
Предлагаемый метод состоит из двух основных этапов: текст-майнинг и соотнесение упоминаний с источниками. Авторы ограничили выборку периодом с 1890 по 1979 гг., использовав тексты англоязычной философии. Корпус включает 1 095 765 упоминаний, извлеченных из 22 977 статей в 12 журналах. Распознавание имеет естественные ограничения: например, омонимию фамилий (Рой Вуд Селларс и Уилфред Селларс) — в таком случае учитывается контекст и смежные упоминания. В итоге предложенный алгоритм позволил успешно распознать 93% упоминаний.
При помощи этого метода авторы проанализировали корпус публикаций по философии — дисциплине, где стандартизированные цитаты не использовались вплоть до 1970-х годов, что делает ее удобной областью для демонстрации возможностей нового инструмента.
В статье предлагается несколько кейсов использования индекса. Например, общее число упоминаний персон, сравнение канонов упоминаний в главных англоязычных университетах или изменение трендов упоминаний с течением времени.
В качестве примера одного из кейсов прикладываем к посту скриншот визуализации при помощи VOSviewer сети совместных упоминаний в американских журналах в период с 1950-1959 гг. Интерактивную версию можно посмотреть по ссылке.
Индекс упоминаний стал основой для сервиса EDHIPHY (enriched data for the history of philosophy), на котором размещена база данных упоминаний о философах в журнальных статьях. Авторы предлагают использовать сервис для проведения собственных исследований.
Анализ упоминаний дополняет традиционные методы анализа цитирований, поскольку он применим ко многим историческим периодам и научным областям, где ссылки не имеют форму цитаты. Авторы статьи полагают, что в перспективе анализ упоминаний может быть распространен на всю историю науки.
#обзор #базыданных #индексы #сети
Современные практики цитирования появились относительно недавно, из-за чего научные базы данных сталкиваются с проблемой неполноты учтенных ссылок: например, WoS гарантирует достоверность ссылок лишь с 1980 года, а Scopus — с 1996. При этом ссылки на источники всегда были неотъемлемой частью науки.
В недавней статье ученые из Нидерландов описывают метод, предназначенный для решения данной проблемы — индексирование упоминаний, расширяющее понятие научной ссылки.
Предлагаемый метод состоит из двух основных этапов: текст-майнинг и соотнесение упоминаний с источниками. Авторы ограничили выборку периодом с 1890 по 1979 гг., использовав тексты англоязычной философии. Корпус включает 1 095 765 упоминаний, извлеченных из 22 977 статей в 12 журналах. Распознавание имеет естественные ограничения: например, омонимию фамилий (Рой Вуд Селларс и Уилфред Селларс) — в таком случае учитывается контекст и смежные упоминания. В итоге предложенный алгоритм позволил успешно распознать 93% упоминаний.
При помощи этого метода авторы проанализировали корпус публикаций по философии — дисциплине, где стандартизированные цитаты не использовались вплоть до 1970-х годов, что делает ее удобной областью для демонстрации возможностей нового инструмента.
В статье предлагается несколько кейсов использования индекса. Например, общее число упоминаний персон, сравнение канонов упоминаний в главных англоязычных университетах или изменение трендов упоминаний с течением времени.
В качестве примера одного из кейсов прикладываем к посту скриншот визуализации при помощи VOSviewer сети совместных упоминаний в американских журналах в период с 1950-1959 гг. Интерактивную версию можно посмотреть по ссылке.
Индекс упоминаний стал основой для сервиса EDHIPHY (enriched data for the history of philosophy), на котором размещена база данных упоминаний о философах в журнальных статьях. Авторы предлагают использовать сервис для проведения собственных исследований.
Анализ упоминаний дополняет традиционные методы анализа цитирований, поскольку он применим ко многим историческим периодам и научным областям, где ссылки не имеют форму цитаты. Авторы статьи полагают, что в перспективе анализ упоминаний может быть распространен на всю историю науки.
#обзор #базыданных #индексы #сети
{kind=link}
Качество исследования vs влияние: дискуссия о подходе к оценке публикаций
Зачастую ценность результатов научных исследований определяется не только их качеством. Важную роль могут играть также ненаучные факторы, не относящиеся напрямую к научному содержанию: объем публикации, особенности издания, упоминаемые аффилиации, репутация авторов и т.п.
В недавней статье исследователи, входящие в число рецензентов журнала Scientometrics, ставят вопрос о том, что должно быть ориентиром в оценке публикации: достаточно ли оценивать качество работы или следует руководствоваться более широким понятием научного влияния?
С одной стороны, в большинстве стран и институтов научная политика ориентирована на эффективное распределение средств для увеличения пользы от научных работ и максимизации их социального влияния.
С другой стороны, авторы указывают, что существующие во многих странах системы оценки научных исследований — например, британская программа REF 2021 — ориентированы в основном именно на оценку качества публикации (оригинальность, значимость, логичность), используя в качестве метода преимущественно экспертное рецензирование. Хотя в британской программе социальный импакт тоже учитывается, но имеет меньший вес по сравнению с оценкой качества (60% против 25%).
В последние годы эта проблема обсуждается довольно активно. Так, в 2022 году в рамках инициативы Coalition for Advancing Research Assessment (CoARA) было сформулировано «Соглашение о реформировании оценки научных исследований», что привело к очередному витку наукометрической дискуссии: стоит ли оценивать исследования на основе качества ограниченного числа работ или на основе влияния неограниченного числа только индексируемых публикаций.
В статье авторы предполагают, что выбор подхода, ориентированного на оценку влияния публикации, может быть оправдан потенциальной ролью ненаучных факторов. Чтобы оценить их значимость, авторы использовали, с одной стороны, экспертные оценки, которые рецензенты присвоили 6 446 публикациям в рамках первой итальянской процедуры по оценке публикаций (Research Assessment Exercise) за период 2001-2003 гг., а с другой – показатели научного влияния, которое измерялось через цитируемость публикаций согласно данным Web of Science с нормировкой на области и окна цитирования. На основе этих данных были построены 3 прогностические модели со случайными эффектами, включающие:
1. только ненаучные факторы;
2. ненаучные факторы и экспертную оценку, присвоенную рецензентами;
3. ненаучные факторы и краткосрочный импакт, измеряемый ранним цитированием.
Сравнение моделей показало, что прогностическая точность первой регрессионной модели с точки зрения коэффициента детерминации схожа со второй. Таким образом, дорогостоящая качественная экспертная оценка несущественно отличалась в точности предсказаний от количественной оценки, основанной на ненаучных параметрах.
Выяснилось, что для положительного долгосрочного влияния важны следующие факторы: наличие иностранных соавторов, их репутация, длина публикации и импакт-фактор журнала; процент самоцитирований и «возраст» цитируемых статей, напротив, имеют отрицательное влияние. Общее количество авторов и наличие открытого доступа оказались практически незначимыми факторами.
Хотя качественное рецензирование остается важной частью оценки исследований, включение и учет ненаучных факторов, описываемых количественными методами, могут дать более полное представление о влиянии публикаций. В то же время, оглядываясь на отечественный опыт проведения процедуры оценки, Д. Косяков и А. Гуськов еще в 2019 году подчеркивали, что он тяготеет скорее к обратной крайности: качественная оценка по большей части исключалась в пользу формальных количественных метрик.
Нахождение баланса представляется важной задачей в рамках совершенствования государственной политики в области оценки научных организаций и исследовательских коллективов.
#обзор #рецензирование #экспертныеоценки
Зачастую ценность результатов научных исследований определяется не только их качеством. Важную роль могут играть также ненаучные факторы, не относящиеся напрямую к научному содержанию: объем публикации, особенности издания, упоминаемые аффилиации, репутация авторов и т.п.
В недавней статье исследователи, входящие в число рецензентов журнала Scientometrics, ставят вопрос о том, что должно быть ориентиром в оценке публикации: достаточно ли оценивать качество работы или следует руководствоваться более широким понятием научного влияния?
С одной стороны, в большинстве стран и институтов научная политика ориентирована на эффективное распределение средств для увеличения пользы от научных работ и максимизации их социального влияния.
С другой стороны, авторы указывают, что существующие во многих странах системы оценки научных исследований — например, британская программа REF 2021 — ориентированы в основном именно на оценку качества публикации (оригинальность, значимость, логичность), используя в качестве метода преимущественно экспертное рецензирование. Хотя в британской программе социальный импакт тоже учитывается, но имеет меньший вес по сравнению с оценкой качества (60% против 25%).
В последние годы эта проблема обсуждается довольно активно. Так, в 2022 году в рамках инициативы Coalition for Advancing Research Assessment (CoARA) было сформулировано «Соглашение о реформировании оценки научных исследований», что привело к очередному витку наукометрической дискуссии: стоит ли оценивать исследования на основе качества ограниченного числа работ или на основе влияния неограниченного числа только индексируемых публикаций.
В статье авторы предполагают, что выбор подхода, ориентированного на оценку влияния публикации, может быть оправдан потенциальной ролью ненаучных факторов. Чтобы оценить их значимость, авторы использовали, с одной стороны, экспертные оценки, которые рецензенты присвоили 6 446 публикациям в рамках первой итальянской процедуры по оценке публикаций (Research Assessment Exercise) за период 2001-2003 гг., а с другой – показатели научного влияния, которое измерялось через цитируемость публикаций согласно данным Web of Science с нормировкой на области и окна цитирования. На основе этих данных были построены 3 прогностические модели со случайными эффектами, включающие:
1. только ненаучные факторы;
2. ненаучные факторы и экспертную оценку, присвоенную рецензентами;
3. ненаучные факторы и краткосрочный импакт, измеряемый ранним цитированием.
Сравнение моделей показало, что прогностическая точность первой регрессионной модели с точки зрения коэффициента детерминации схожа со второй. Таким образом, дорогостоящая качественная экспертная оценка несущественно отличалась в точности предсказаний от количественной оценки, основанной на ненаучных параметрах.
Выяснилось, что для положительного долгосрочного влияния важны следующие факторы: наличие иностранных соавторов, их репутация, длина публикации и импакт-фактор журнала; процент самоцитирований и «возраст» цитируемых статей, напротив, имеют отрицательное влияние. Общее количество авторов и наличие открытого доступа оказались практически незначимыми факторами.
Хотя качественное рецензирование остается важной частью оценки исследований, включение и учет ненаучных факторов, описываемых количественными методами, могут дать более полное представление о влиянии публикаций. В то же время, оглядываясь на отечественный опыт проведения процедуры оценки, Д. Косяков и А. Гуськов еще в 2019 году подчеркивали, что он тяготеет скорее к обратной крайности: качественная оценка по большей части исключалась в пользу формальных количественных метрик.
Нахождение баланса представляется важной задачей в рамках совершенствования государственной политики в области оценки научных организаций и исследовательских коллективов.
#обзор #рецензирование #экспертныеоценки
Большие языковые модели в наукометрии, или зачем нам SciBERT
Не все научные публикации одинаковы с точки зрения их влияния на социальную реальность. Нередко показатель цитируемости и импакт-фактор журнала дают нам некоторое представление о том, насколько серьезная работа перед нами, однако даже недавний пример с сетью взаимосвязей между первыми работами, которые цитируют статью Хопфилда о нейронных сетях, показывает, что одной только высокой цитируемости недостаточно: например, работы уже второго «поколения» цитирований получали в разы больше внимания, чем изначальный труд. Кроме того, не секрет, что в отдельных областях большее внимание привлекают обзоры по научным областям: обычно они цитируются довольно активно, поскольку обобщают информацию по какой-либо тематике, но в то же время не каждый обзор представляет из себя что-то большее, чем простое фиксирование текущего положения дел.
В сентябре Scientometrics опубликовали статью китайских исследователей, в которой описывается метод интеллектуального распознавания высококачественных научных работ на основе метасемантических сетей, задействующих deep learning и LLM-технологии. Раньше это было практически нереализуемой задачей: методы оценки научных статей ограничивались качественным (на основе рецензирования) и количественным (на основе библиометрических показателей) подходами. Недостатки этих методов хорошо изучены — в первом случае это проблемы с воспроизводимостью, неполнота знаний у рецензентов и возможный конфликт интересов, а во втором — временной лаг и разная чувствительность показателей, которая неизбежно влияет на финальную оценку.
Авторы предлагают новый подход к определению качества научной статьи как взвешенной суммы импакт-фактора журнала и средневзвешенной цитируемости статьи, где веса определяются методом информационной энтропии, а потом для «высококачественных» и «низкокачественных» работ строится упомянутая метасемантическая сеть на основе известной языковой модели SciBERT (одна из вариаций еще более широко известной модели BERT от Google). Таким образом, в перспективе это позволит измерять качество статей напрямую по их содержанию, без временного лага.
Кстати, еще одну вариацию BERT (SPS-BERT) уже другой исследовательский коллектив использовал для прогнозирования появления прорывных технологий. Согласно их результатам, этот метод позволяет предсказать индекс прорыва (о котором мы писали ранее) точнее, чем все прочие существующие методы. По крайней мере, на наборах данных DBLP и PubMed.
LLM вообще приобретают всё большую популярность в нашей среде. Тот же Scientometrics в сентябре опубликовал call for papers по теме «искусственный интеллект в наукометрии» (подача заявок до 28 февраля 2025 года).
Оставляя в стороне многократно обсуждаемые вопросы этичности использования инструментов ИИ в различных сферах, мы можем сказать, что перспективы их использования в сфере наукометрии скорее радуют. Языковые модели открывают широкий простор для совершенно новых исследований и выводов, а кроме того, предлагают принципиально иные подходы к оценке научных исследований.
#LLM #обзор #SciBERT
Не все научные публикации одинаковы с точки зрения их влияния на социальную реальность. Нередко показатель цитируемости и импакт-фактор журнала дают нам некоторое представление о том, насколько серьезная работа перед нами, однако даже недавний пример с сетью взаимосвязей между первыми работами, которые цитируют статью Хопфилда о нейронных сетях, показывает, что одной только высокой цитируемости недостаточно: например, работы уже второго «поколения» цитирований получали в разы больше внимания, чем изначальный труд. Кроме того, не секрет, что в отдельных областях большее внимание привлекают обзоры по научным областям: обычно они цитируются довольно активно, поскольку обобщают информацию по какой-либо тематике, но в то же время не каждый обзор представляет из себя что-то большее, чем простое фиксирование текущего положения дел.
В сентябре Scientometrics опубликовали статью китайских исследователей, в которой описывается метод интеллектуального распознавания высококачественных научных работ на основе метасемантических сетей, задействующих deep learning и LLM-технологии. Раньше это было практически нереализуемой задачей: методы оценки научных статей ограничивались качественным (на основе рецензирования) и количественным (на основе библиометрических показателей) подходами. Недостатки этих методов хорошо изучены — в первом случае это проблемы с воспроизводимостью, неполнота знаний у рецензентов и возможный конфликт интересов, а во втором — временной лаг и разная чувствительность показателей, которая неизбежно влияет на финальную оценку.
Авторы предлагают новый подход к определению качества научной статьи как взвешенной суммы импакт-фактора журнала и средневзвешенной цитируемости статьи, где веса определяются методом информационной энтропии, а потом для «высококачественных» и «низкокачественных» работ строится упомянутая метасемантическая сеть на основе известной языковой модели SciBERT (одна из вариаций еще более широко известной модели BERT от Google). Таким образом, в перспективе это позволит измерять качество статей напрямую по их содержанию, без временного лага.
Кстати, еще одну вариацию BERT (SPS-BERT) уже другой исследовательский коллектив использовал для прогнозирования появления прорывных технологий. Согласно их результатам, этот метод позволяет предсказать индекс прорыва (о котором мы писали ранее) точнее, чем все прочие существующие методы. По крайней мере, на наборах данных DBLP и PubMed.
LLM вообще приобретают всё большую популярность в нашей среде. Тот же Scientometrics в сентябре опубликовал call for papers по теме «искусственный интеллект в наукометрии» (подача заявок до 28 февраля 2025 года).
Оставляя в стороне многократно обсуждаемые вопросы этичности использования инструментов ИИ в различных сферах, мы можем сказать, что перспективы их использования в сфере наукометрии скорее радуют. Языковые модели открывают широкий простор для совершенно новых исследований и выводов, а кроме того, предлагают принципиально иные подходы к оценке научных исследований.
#LLM #обзор #SciBERT
{kind=link}