
HSE SciBot — бот по поиску журналов в Списках Вышки
Наша команда поздравляет подписчиков с Днем знаний! К этому дню мы решили приурочить официальный анонс нашего нового продукта, созданного в сотрудничестве со студентами Вышки.
Встречайте — HSE SciBot (@hse_scibot). Бот предназначен для поиска научных журналов, включенных в Списки НИУ ВШЭ. С помощью него можно проверить актуальную информацию по изданиям, а также сформировать выборку подходящих журналов при выборе места публикации. Для каждого издания приводится его название, ISSN, указание на вхождение в список НИУ ВШЭ, а также предметные области и ссылки.
Помимо стандартного функционала, в бот интегрирован inline-режим для поиска журналов с автоматическими подсказками. Чтобы воспользоваться им, введите в текстовое поле внутри бота @hse_scibot и пробел, а затем начинайте вводить название издания или его часть. Сценарии использования бота мы приводим ниже.
Список журналов в боте соответствует актуальным спискам Вышки и регулярно обновляется. Будем рады обратной связи (команда /feedback в боте).
#новости #анонс #бот #hse_scibot #спискивышки
Наша команда поздравляет подписчиков с Днем знаний! К этому дню мы решили приурочить официальный анонс нашего нового продукта, созданного в сотрудничестве со студентами Вышки.
Встречайте — HSE SciBot (@hse_scibot). Бот предназначен для поиска научных журналов, включенных в Списки НИУ ВШЭ. С помощью него можно проверить актуальную информацию по изданиям, а также сформировать выборку подходящих журналов при выборе места публикации. Для каждого издания приводится его название, ISSN, указание на вхождение в список НИУ ВШЭ, а также предметные области и ссылки.
Помимо стандартного функционала, в бот интегрирован inline-режим для поиска журналов с автоматическими подсказками. Чтобы воспользоваться им, введите в текстовое поле внутри бота @hse_scibot и пробел, а затем начинайте вводить название издания или его часть. Сценарии использования бота мы приводим ниже.
Список журналов в боте соответствует актуальным спискам Вышки и регулярно обновляется. Будем рады обратной связи (команда /feedback в боте).
#новости #анонс #бот #hse_scibot #спискивышки
Об индексе Хирша на среднем цитировании: новая метрика – старые проблемы?
В последние годы h-индекс остается одним из наиболее широко используемых и одновременно обсуждаемых наукометрических показателей (в том числе и в нашем руководстве). Так, совсем недавно мы рассказывали о рейтинговании изданий в Google Scholar на основе журнального индекса Хирша, отметив при этом определенные недостатки используемого подхода. Критики зачастую подчеркивают, что h-индекс недооценивает молодых ученых, к тому же с его помощью оказывается довольно сложно сравнивать различные дисциплинарные области, обладающие своими особенностями цитирования. Попытки скорректировать методологию подсчета предпринимались неоднократно, в том числе и самим Х. Хиршем.
Новое прочтение показателя предложено в недавней работе бельгийского ученого И. Фассина. В ней автор развивает представленную ранее идею о ha-индексе – наибольшем числе публикаций, которые получили не менее ha цитат в среднем по годам. Такая нормализация, по мнению автора, позволяет уравнивать ученых, начавших свою карьеру относительно недавно и добившихся определенных успехов в науке, и признанных исследователей, у которых со временем ha-индекс остается относительно стабильным (пример сравнения динамики показателей приведен на картинке по данным статьи). Еще более значимое различие выявляется на журнальных подборках статей: хотя для рассмотренных в статье изданий показатель ha-индекса не уменьшается с течением времени, он значительно быстрее фиксирует достижение плато уровня цитируемости, чем индекс Хирша, отражающий накопительный эффект.
Между тем набор ограничений по использованию полученного индекса, упоминаемых И. Фассином в заключении, сводится к стандартным для h-индекса проблемам: невозможности выявления особенностей цитирования в отдельных науках и отсутствию учета эффекта мегаколлабораций при оценке публикационной активности авторов. Эти и другие недостатки h-подобных индексов служат хорошим напоминанием о том, что к любым подобным количественным показателям следует относиться с особой осторожностью и тем более слепо не полагаться на них при оценке публикационной активности.
#hиндекс #руководство #исследования
В последние годы h-индекс остается одним из наиболее широко используемых и одновременно обсуждаемых наукометрических показателей (в том числе и в нашем руководстве). Так, совсем недавно мы рассказывали о рейтинговании изданий в Google Scholar на основе журнального индекса Хирша, отметив при этом определенные недостатки используемого подхода. Критики зачастую подчеркивают, что h-индекс недооценивает молодых ученых, к тому же с его помощью оказывается довольно сложно сравнивать различные дисциплинарные области, обладающие своими особенностями цитирования. Попытки скорректировать методологию подсчета предпринимались неоднократно, в том числе и самим Х. Хиршем.
Новое прочтение показателя предложено в недавней работе бельгийского ученого И. Фассина. В ней автор развивает представленную ранее идею о ha-индексе – наибольшем числе публикаций, которые получили не менее ha цитат в среднем по годам. Такая нормализация, по мнению автора, позволяет уравнивать ученых, начавших свою карьеру относительно недавно и добившихся определенных успехов в науке, и признанных исследователей, у которых со временем ha-индекс остается относительно стабильным (пример сравнения динамики показателей приведен на картинке по данным статьи). Еще более значимое различие выявляется на журнальных подборках статей: хотя для рассмотренных в статье изданий показатель ha-индекса не уменьшается с течением времени, он значительно быстрее фиксирует достижение плато уровня цитируемости, чем индекс Хирша, отражающий накопительный эффект.
Между тем набор ограничений по использованию полученного индекса, упоминаемых И. Фассином в заключении, сводится к стандартным для h-индекса проблемам: невозможности выявления особенностей цитирования в отдельных науках и отсутствию учета эффекта мегаколлабораций при оценке публикационной активности авторов. Эти и другие недостатки h-подобных индексов служат хорошим напоминанием о том, что к любым подобным количественным показателям следует относиться с особой осторожностью и тем более слепо не полагаться на них при оценке публикационной активности.
#hиндекс #руководство #исследования
{kind=link}
Кто контролирует научные журналы мира?
Китай уверенно обгоняет США и страны Европы по числу публикаций в журналах мирового уровня, динамика по Индии в последние годы также демонстрирует космический прирост. Заметный прогресс показывает Южная Корея и многие другие страны региона. Исходя из этих тенденций легко отметить, что научный мир стремительно становится более азиатским.
Как это соотносится со страновым распределением журналов? Давно известно, что оно крайне смещено, но насколько сегодня сохраняется это все более демонстративное неравенство?
Мы решили изучить вопрос с помощью открытых данных, а именно каталога сервиса ScimagoJR, хорошо знакомого российским авторам по «квартилям Scopus». Следует отметить, что сам Scopus давно убрал данные о стране регистрации журнала из своих публичных списков, а с недавних пор скрыл и сводные данные о числе публикаций. Отчасти это связано со сложностью определения страновой принадлежности: ориентироваться ли на владельца или адрес редакции (чаще всего виртуальный), а может быть на гражданство и место работы редакторов? У каждого из этих способов есть свои недостатки. Достоверно ответить на вопрос, каким из них воспользовались в Scimago нельзя. Вероятно, коллеги приписывали страны к журналам в ручном режиме, хотя и не всегда последовательно. Тем не менее у исследовательского сообщества имеется готовый набор открытых данных, совмещенных с наукометрическими показателями.
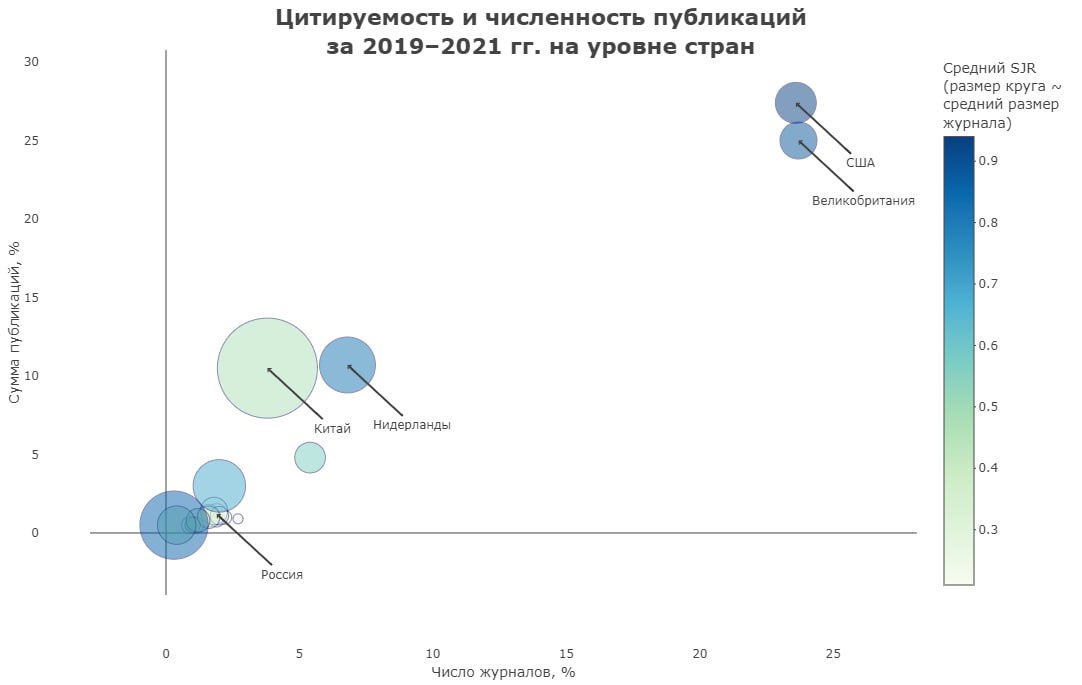
В рамках нашего исследования мы обратились к нему и проанализировали цитируемость и численность публикаций за 2019–2021 гг. Так, колоссальные диспропорции на уровне макрорегионов сохраняются по общему числу публикаций, по их цитируемости (выражена через средний показатель SJR) и по среднему размеру изданий (число статей за 3 года).
При этом если журналы MDPI перенести из номинальной Швейцарии к фактическому владельцу – Китаю, доля Азии по числу статей возрастает до 16%, а средний размер журнала – до беспрецедентных 419 публикаций на журнал. С учетом такой поправки распределение по странам выглядит следующим образом.
Несмотря на эти важные изменения, более половины журналов – и по числу статей, и по количеству изданий – все еще относятся к США и Великобритании, показатели цитируемости у них также наивысшие. Если считать по ссылкам (в абсолютном выражении, что некорректно (см. обсуждение в руководстве), но наглядно), на журналы США, Великобритании и Нидерландов в сумме приходится более 77% цитирований. На российские – всего 0,14 %.
Низкие показатели Франции, Италии и Испании отчасти определяются дисциплинарной спецификой – многие гуманитарные журналы этих стран издаются на национальных языках, а потому формально недостаточно цитируются даже с учетом SJR-нормировки. Впрочем, на фоне США и Китая в мировом масштабе эти величины достаточно малы.
Стоит ли именно в случае Китая как одного из центров современной науки ждать роста напряженности по линии «публикации в «наших»/«не наших» журналах»? На наш взгляд, вероятность этого минимальная. Для КНР еще долго будет ценна объективная внешняя экспертиза, качество редакций и рецензентов, техпроцессов, наработанный репутационный капитал, который обеспечивают Elsevier, SpringerNature и Wiley. Вопреки официальной позиции китайского руководства, Китай не спешит переходить исключительно на отечественные издания, продолжая следовать иному подходу к разработке публикационных стратегий своих авторов. Ведь даже MDPI в Китае официально не слишком приветствуется на национальном уровне.
Китай уверенно обгоняет США и страны Европы по числу публикаций в журналах мирового уровня, динамика по Индии в последние годы также демонстрирует космический прирост. Заметный прогресс показывает Южная Корея и многие другие страны региона. Исходя из этих тенденций легко отметить, что научный мир стремительно становится более азиатским.
Как это соотносится со страновым распределением журналов? Давно известно, что оно крайне смещено, но насколько сегодня сохраняется это все более демонстративное неравенство?
Мы решили изучить вопрос с помощью открытых данных, а именно каталога сервиса ScimagoJR, хорошо знакомого российским авторам по «квартилям Scopus». Следует отметить, что сам Scopus давно убрал данные о стране регистрации журнала из своих публичных списков, а с недавних пор скрыл и сводные данные о числе публикаций. Отчасти это связано со сложностью определения страновой принадлежности: ориентироваться ли на владельца или адрес редакции (чаще всего виртуальный), а может быть на гражданство и место работы редакторов? У каждого из этих способов есть свои недостатки. Достоверно ответить на вопрос, каким из них воспользовались в Scimago нельзя. Вероятно, коллеги приписывали страны к журналам в ручном режиме, хотя и не всегда последовательно. Тем не менее у исследовательского сообщества имеется готовый набор открытых данных, совмещенных с наукометрическими показателями.
В рамках нашего исследования мы обратились к нему и проанализировали цитируемость и численность публикаций за 2019–2021 гг. Так, колоссальные диспропорции на уровне макрорегионов сохраняются по общему числу публикаций, по их цитируемости (выражена через средний показатель SJR) и по среднему размеру изданий (число статей за 3 года).
При этом если журналы MDPI перенести из номинальной Швейцарии к фактическому владельцу – Китаю, доля Азии по числу статей возрастает до 16%, а средний размер журнала – до беспрецедентных 419 публикаций на журнал. С учетом такой поправки распределение по странам выглядит следующим образом.
Несмотря на эти важные изменения, более половины журналов – и по числу статей, и по количеству изданий – все еще относятся к США и Великобритании, показатели цитируемости у них также наивысшие. Если считать по ссылкам (в абсолютном выражении, что некорректно (см. обсуждение в руководстве), но наглядно), на журналы США, Великобритании и Нидерландов в сумме приходится более 77% цитирований. На российские – всего 0,14 %.
Низкие показатели Франции, Италии и Испании отчасти определяются дисциплинарной спецификой – многие гуманитарные журналы этих стран издаются на национальных языках, а потому формально недостаточно цитируются даже с учетом SJR-нормировки. Впрочем, на фоне США и Китая в мировом масштабе эти величины достаточно малы.
Стоит ли именно в случае Китая как одного из центров современной науки ждать роста напряженности по линии «публикации в «наших»/«не наших» журналах»? На наш взгляд, вероятность этого минимальная. Для КНР еще долго будет ценна объективная внешняя экспертиза, качество редакций и рецензентов, техпроцессов, наработанный репутационный капитал, который обеспечивают Elsevier, SpringerNature и Wiley. Вопреки официальной позиции китайского руководства, Китай не спешит переходить исключительно на отечественные издания, продолжая следовать иному подходу к разработке публикационных стратегий своих авторов. Ведь даже MDPI в Китае официально не слишком приветствуется на национальном уровне.
{kind=link}
День программиста: в России и наукометрии
Сегодня, в 256-й день года, в России отмечается День программиста. Этот профессиональный праздник, установленный Указом Президента, отмечается с 2009 года.
Программирование и IT-разработки являются неотъемлемой составляющей современной жизни, и с каждым годом ценность и востребованность IT-сферы только возрастает. Наукометрию (наравне с другими научными областями) отмеченные тренды также не обходят стороной. Сегодня уже сложно представить себе ученого, всерьез занимающегося научными разработками, без базовых навыков работы с данными и программными средствами.
Так, практически все крупные наукометрические базы данных сегодня имеют API, для работы с которым официальными держателями и энтузиастами разрабатываются пакеты и библиотеки на языках программирования. Мы собрали подборку ссылок на библиотеки наиболее распространенных баз и языков, для некоторых из которых приводятся также примеры кода. Предлагаем ознакомиться со страницей на Google Colab, а ниже приводим общий список библиотек. Описание основных функций и ссылки на скачивание пакетов можно найти на соответствующих страницах.
Python:
- pyalex, diophila, OpenAlexAPI - официальные библиотеки для доступа к API OpenAlex. OpenAlex отличается очень понятным и подробно описанным API, на самом сайте приведены примеры кода для работы с базой как раз на языке Python.
- crossrefapi и habanero - две наиболее актуальные библиотеки для работы с API CrossRef. Оба пакета регулярно обновляются, а разработчики доступны на GitHub и откликаются на обратную связь. Существует также официальная библиотека crossref_commons_py от CrossRef, однако за последний год она не обновлялась, и, вероятно, разработка временно приостановлена.
- fatcat-openapi-client - библиотека для доступа к Fatcat, автоматически сгенерированная OpenAPI Generator. Fatcat - дочерний проект Internet Archive, позволяющий осуществлять поиск библиографической информации по данным The Wayback Machine, среди общих материалов из коллекций archive.org и не только. Fatcat изначально ориентирован на работу через API.
- pyBibX - новая библиотека, ориентированная на работу с 3 базами (Scopus, Web of Science и PubMed). Позволяет проводить базовый разведывательный анализ набора публикаций. Пакет отличают широкие встроенные возможности визуализации (в нашем коде приводим только некоторые примеры).
- pySciSci - еще одна новая библиотека, в основе которой принцип построения "науки о науке" (Science of Science). Позволяет работать с большими датасетами (включая дампы Microsoft Academic Graph), рассчитывать метрики и проводить сетевой анализ. Уже в скором времени может стать одним из ключевых инструментов в области, в особенности если верить амбициозным планам разработчиков, с которыми можно ознакомиться в недавней статье.
R:
- openalexR - классический и наиболее простой в освоении пакет для работы с API OpenAlex в R. Имеет важную функцию oa_snowball, которая позволяет искать литературу методом “снежного кома”.
- rcrossref - пакет для работы с API CrossRef. Как и openalexR, входит в экосистему rOpenSci - большого проекта по обеспечению свободного и удобного доступа к научным данным в самых разнообразных областях.
- bibliometrix - пакет для работы с уже загруженными датасетами из Scopus, WoS, Dimensions, PubMed и Cochrane. Позволяет легко преобразовать json/xml в привычный формат датафрейма в R.
Отдельно стоит упомянуть более редкие пакеты для работы с Crossref - crossref (Javascript), serrano (Ruby), crossref-rs (rust) и pitaya (Julia).
P.S. Мы намеренно не упомянули широко известные библиотеки для работы с API Scopus, WoS и Dimensions, поскольку доступ к базам на данный момент затруднен. Готового решения нет и для eLibrary: API продолжает оставаться закрытым, а разработка библиотеки (на Python) приостановлена. Что же касается Google Scholar, то он не имеет официального API, а единственный автоматизированный путь получения данных - парсинг, сопряженный с рисками блокировки.
#API #GitHub #OpenAlex #CrossRef #FatCat #Python #R
Сегодня, в 256-й день года, в России отмечается День программиста. Этот профессиональный праздник, установленный Указом Президента, отмечается с 2009 года.
Программирование и IT-разработки являются неотъемлемой составляющей современной жизни, и с каждым годом ценность и востребованность IT-сферы только возрастает. Наукометрию (наравне с другими научными областями) отмеченные тренды также не обходят стороной. Сегодня уже сложно представить себе ученого, всерьез занимающегося научными разработками, без базовых навыков работы с данными и программными средствами.
Так, практически все крупные наукометрические базы данных сегодня имеют API, для работы с которым официальными держателями и энтузиастами разрабатываются пакеты и библиотеки на языках программирования. Мы собрали подборку ссылок на библиотеки наиболее распространенных баз и языков, для некоторых из которых приводятся также примеры кода. Предлагаем ознакомиться со страницей на Google Colab, а ниже приводим общий список библиотек. Описание основных функций и ссылки на скачивание пакетов можно найти на соответствующих страницах.
Python:
- pyalex, diophila, OpenAlexAPI - официальные библиотеки для доступа к API OpenAlex. OpenAlex отличается очень понятным и подробно описанным API, на самом сайте приведены примеры кода для работы с базой как раз на языке Python.
- crossrefapi и habanero - две наиболее актуальные библиотеки для работы с API CrossRef. Оба пакета регулярно обновляются, а разработчики доступны на GitHub и откликаются на обратную связь. Существует также официальная библиотека crossref_commons_py от CrossRef, однако за последний год она не обновлялась, и, вероятно, разработка временно приостановлена.
- fatcat-openapi-client - библиотека для доступа к Fatcat, автоматически сгенерированная OpenAPI Generator. Fatcat - дочерний проект Internet Archive, позволяющий осуществлять поиск библиографической информации по данным The Wayback Machine, среди общих материалов из коллекций archive.org и не только. Fatcat изначально ориентирован на работу через API.
- pyBibX - новая библиотека, ориентированная на работу с 3 базами (Scopus, Web of Science и PubMed). Позволяет проводить базовый разведывательный анализ набора публикаций. Пакет отличают широкие встроенные возможности визуализации (в нашем коде приводим только некоторые примеры).
- pySciSci - еще одна новая библиотека, в основе которой принцип построения "науки о науке" (Science of Science). Позволяет работать с большими датасетами (включая дампы Microsoft Academic Graph), рассчитывать метрики и проводить сетевой анализ. Уже в скором времени может стать одним из ключевых инструментов в области, в особенности если верить амбициозным планам разработчиков, с которыми можно ознакомиться в недавней статье.
R:
- openalexR - классический и наиболее простой в освоении пакет для работы с API OpenAlex в R. Имеет важную функцию oa_snowball, которая позволяет искать литературу методом “снежного кома”.
- rcrossref - пакет для работы с API CrossRef. Как и openalexR, входит в экосистему rOpenSci - большого проекта по обеспечению свободного и удобного доступа к научным данным в самых разнообразных областях.
- bibliometrix - пакет для работы с уже загруженными датасетами из Scopus, WoS, Dimensions, PubMed и Cochrane. Позволяет легко преобразовать json/xml в привычный формат датафрейма в R.
Отдельно стоит упомянуть более редкие пакеты для работы с Crossref - crossref (Javascript), serrano (Ruby), crossref-rs (rust) и pitaya (Julia).
P.S. Мы намеренно не упомянули широко известные библиотеки для работы с API Scopus, WoS и Dimensions, поскольку доступ к базам на данный момент затруднен. Готового решения нет и для eLibrary: API продолжает оставаться закрытым, а разработка библиотеки (на Python) приостановлена. Что же касается Google Scholar, то он не имеет официального API, а единственный автоматизированный путь получения данных - парсинг, сопряженный с рисками блокировки.
#API #GitHub #OpenAlex #CrossRef #FatCat #Python #R
{kind=link}
«Призрак бродит по… журналам»: о последствиях использования GPT-моделей в качестве академического инструмента
ChatGPT от OpenAI, запущенный в конце ноября 2022, в последнее время находит всё больше применений в академической среде, о чем мы уже писали ранее. Он способен автоматизировать повторяющиеся задачи: например, генерировать код (правда не всегда актуальный для текущих версий пакетов), обобщать данные из нескольких научных статей, неплохо справляться с переводом текстов и даже перефразировать целые абзацы для большего соответствия академическому стилю. Однако у всего этого есть обратная сторона: во-первых, чат-боты, стремясь понравиться, зачастую выдают ложные факты за действительные, а во-вторых — могут недобросовестно использоваться самими авторами.
В недавней заметке в Scientometrics описывается одно из обнаруженных ограничений ChatGPT — склонность генерировать «призрачные» научные ссылки. Когда у чат-бота запрашивают библиографические ссылки по конкретной теме, он предоставляет правдоподобные результаты — это могут быть реальные названия статей, а в качестве источника публикации указываются названия ведущих журналов. Однако на практике выясняется, что таких статей никогда не существовало. Такие ссылки, сгенерированные при участии недобросовестных авторов, могут в конечном итоге попадать в научные публикации, особенно в тех издательствах, где процессы рецензирования слабы или вообще отсутствуют. Реальные же ссылки от GPT-моделей, вероятнее всего, усиливают эффект Матфея, о котором мы упоминали в одном из наших предыдущих постов.
Выявление таких «призрачных» ссылок — настоящий вызов для научного сообщества. Безусловно, полностью сгенерированная библиография вызовет вопросы у любого профессионала в области, однако отдельные аргументы, написанные при помощи GPT-моделей и ссылающиеся на несуществующие работы, могут с некоторой вероятностью тиражироваться в других исследованиях.
Мы же решили проверить описанный эффект сразу на трех моделях — ChatGPT, YandexGPT2 и GigaChat. Результаты вы можете видеть на скриншотах. Как и ожидалось, наиболее правдоподобные цитаты выдает ChatGPT. YandexGPT2 оказывается не менее изобретателен в создании новых публикаций: забывает о страницах, но упоминает реальных людей в качестве соавторов. А вот от GigaChat удается получить только библиографические сведения о журнале, без имен авторов и названия статей (вероятно, в данном случае использовались другие источники данных для обучения моделей).
#обзор #цитирование #искусственныйинтеллект #GPT
ChatGPT от OpenAI, запущенный в конце ноября 2022, в последнее время находит всё больше применений в академической среде, о чем мы уже писали ранее. Он способен автоматизировать повторяющиеся задачи: например, генерировать код (правда не всегда актуальный для текущих версий пакетов), обобщать данные из нескольких научных статей, неплохо справляться с переводом текстов и даже перефразировать целые абзацы для большего соответствия академическому стилю. Однако у всего этого есть обратная сторона: во-первых, чат-боты, стремясь понравиться, зачастую выдают ложные факты за действительные, а во-вторых — могут недобросовестно использоваться самими авторами.
В недавней заметке в Scientometrics описывается одно из обнаруженных ограничений ChatGPT — склонность генерировать «призрачные» научные ссылки. Когда у чат-бота запрашивают библиографические ссылки по конкретной теме, он предоставляет правдоподобные результаты — это могут быть реальные названия статей, а в качестве источника публикации указываются названия ведущих журналов. Однако на практике выясняется, что таких статей никогда не существовало. Такие ссылки, сгенерированные при участии недобросовестных авторов, могут в конечном итоге попадать в научные публикации, особенно в тех издательствах, где процессы рецензирования слабы или вообще отсутствуют. Реальные же ссылки от GPT-моделей, вероятнее всего, усиливают эффект Матфея, о котором мы упоминали в одном из наших предыдущих постов.
Выявление таких «призрачных» ссылок — настоящий вызов для научного сообщества. Безусловно, полностью сгенерированная библиография вызовет вопросы у любого профессионала в области, однако отдельные аргументы, написанные при помощи GPT-моделей и ссылающиеся на несуществующие работы, могут с некоторой вероятностью тиражироваться в других исследованиях.
Мы же решили проверить описанный эффект сразу на трех моделях — ChatGPT, YandexGPT2 и GigaChat. Результаты вы можете видеть на скриншотах. Как и ожидалось, наиболее правдоподобные цитаты выдает ChatGPT. YandexGPT2 оказывается не менее изобретателен в создании новых публикаций: забывает о страницах, но упоминает реальных людей в качестве соавторов. А вот от GigaChat удается получить только библиографические сведения о журнале, без имен авторов и названия статей (вероятно, в данном случае использовались другие источники данных для обучения моделей).
#обзор #цитирование #искусственныйинтеллект #GPT
Telegram
Выше квартилей
Что пишут о ChatGPT в Scopus и Web of Science
Из-за популярности чат-ботов и ChatGPT растет количество исследований, посвященных им. Одно из них представляет собой анализ литературы по чат-ботам и комплексный обзор научных документов по ChatGPT и фокусируется…
Из-за популярности чат-ботов и ChatGPT растет количество исследований, посвященных им. Одно из них представляет собой анализ литературы по чат-ботам и комплексный обзор научных документов по ChatGPT и фокусируется…
О гендерном балансе: эксперимент в рамках конкурса грантового финансирования
В нашем канале мы не раз обращались к проблеме представленности женщин в академии: отмечали гендерный дисбаланс в различных дисциплинах (в том числе и в России), а также фиксируемый разрыв в цитировании работ. Продолжая цикл постов в рамках данной темы, сегодня планируем поговорить о соблюдении гендерного баланса при принятии решений о грантовой поддержке научных исследований.
В недавней работе испанских авторов широко освещается вопрос гендерной предвзятости в контексте привлечения грантового финансирования. Исследователи обращают внимание, что результаты предыдущих работ в этой области дают весьма противоречивые результаты. Стремясь внести ясность, авторы прибегают к проведению полевого эксперимента на базе экспертной системы университетов Галисии (Galician University System). В его рамках их интересовали 2 ключевых вопроса:
1. Есть ли различия в оценках проектов, где руководителями выступали мужчины или же, напротив, женщины?
2. Предвзяты ли рецензенты в отношении заявок, где ключевыми исследователями выступают авторы одного с ними пола?
В ходе эксперимента рецензенты оценивали схожий по характеристикам набор заявок, при этом сведения о ключевом исполнителе проекта выступали вмешательством.
Полученные эмпирические результаты свидетельствуют скорее о том, что обе гипотезы об отсутствии гендерной предвзятости на имеющемся эмпирическом материале не отвергаются. Авторы лишь обращают внимание на определенные (и статистически незначимые) различия в оценке женщинами заявок, где ключевыми исследователями выступают мужчины-руководители при отсутствии схожего паттерна поведения у рецензентов мужского пола.
Исследовательские выводы дают надежду на то, что хотя бы в отдельных аспектах соблюдение гендерного баланса в академической сфере не должно быть существенной проблемой. Между тем как отмечают сами авторы исследования, результаты эксперимента довольно сложно обобщить на другие кейсы грантовых систем и потенциально на другие страны. Кроме того, отмеченный гендерный дисбаланс рассматривался именно с позиции преференций при оценке непосредственных заявок: женщин-руководителей грантовых заявок все еще несравнимо меньше, чем мужчин.
#обзор #рецензирование #гранты #женщины
В нашем канале мы не раз обращались к проблеме представленности женщин в академии: отмечали гендерный дисбаланс в различных дисциплинах (в том числе и в России), а также фиксируемый разрыв в цитировании работ. Продолжая цикл постов в рамках данной темы, сегодня планируем поговорить о соблюдении гендерного баланса при принятии решений о грантовой поддержке научных исследований.
В недавней работе испанских авторов широко освещается вопрос гендерной предвзятости в контексте привлечения грантового финансирования. Исследователи обращают внимание, что результаты предыдущих работ в этой области дают весьма противоречивые результаты. Стремясь внести ясность, авторы прибегают к проведению полевого эксперимента на базе экспертной системы университетов Галисии (Galician University System). В его рамках их интересовали 2 ключевых вопроса:
1. Есть ли различия в оценках проектов, где руководителями выступали мужчины или же, напротив, женщины?
2. Предвзяты ли рецензенты в отношении заявок, где ключевыми исследователями выступают авторы одного с ними пола?
В ходе эксперимента рецензенты оценивали схожий по характеристикам набор заявок, при этом сведения о ключевом исполнителе проекта выступали вмешательством.
Полученные эмпирические результаты свидетельствуют скорее о том, что обе гипотезы об отсутствии гендерной предвзятости на имеющемся эмпирическом материале не отвергаются. Авторы лишь обращают внимание на определенные (и статистически незначимые) различия в оценке женщинами заявок, где ключевыми исследователями выступают мужчины-руководители при отсутствии схожего паттерна поведения у рецензентов мужского пола.
Исследовательские выводы дают надежду на то, что хотя бы в отдельных аспектах соблюдение гендерного баланса в академической сфере не должно быть существенной проблемой. Между тем как отмечают сами авторы исследования, результаты эксперимента довольно сложно обобщить на другие кейсы грантовых систем и потенциально на другие страны. Кроме того, отмеченный гендерный дисбаланс рассматривался именно с позиции преференций при оценке непосредственных заявок: женщин-руководителей грантовых заявок все еще несравнимо меньше, чем мужчин.
#обзор #рецензирование #гранты #женщины
{kind=link}
Международный день распространения информации о болезни Альцгеймера
21 сентября во всем мире отмечается Международный день распространения информации о болезни Альцгеймера. Это нейродегенеративное заболевание является наиболее распространенным вариантом деменции (на его долю приходится около 60% случаев). Сейчас в мире насчитывается более 55 млн пациентов с этим диагнозом, и согласно прогнозу ВОЗ это число будет удваиваться каждые 20 лет.
Симптомы болезни Альцгеймера были впервые подробно описаны в 1907 году. С тех пор ведутся активные исследования по поиску возможных механизмов развития болезни, ее профилактики и лечения. Тем не менее ясности в отношении причин развития болезни и способов ее лечения все еще нет, равно как и нет лекарств с доказанной эффективностью.
Общественные затраты на поиск решений по преодолению последствий болезни Альцгеймера и деменции составляют существенную часть расходов систем здравоохранения. На исследовательскую работу в этой сфере выделяются также значительные суммы. Однако именно в случае с болезнью Альцгеймера несоблюдение академической этики стало началом большого скандала, о котором мы сегодня решили напомнить нашим читателям.
В 2006 году в Nature вышла статья, посвященная роли специфического белка Aβ*56 в ходе развития болезни Альцгеймера, за авторством Сильвена Лесне (Sylvain Lesné) и его коллег. Она завоевала популярность и в течение долгого времени оставалась наиболее авторитетной и влиятельной в этой области. Однако в 2022 году нейробиолог Мэтью Шрэг предоставил в NIH отчет, в котором выразил сомнения по поводу достоверности изображений, приводящихся в статье Лесне. Science опубликовал расследование научного журналиста Чарльза Пиллера, посвященное этому исследованию, что привело к настоящей буре в научных кругах. В итоге Nature добавили к статье предупреждение о том, что в настоящий момент проводят собственное расследование, а читателям рекомендуется с осторожностью относиться к содержимому статьи. Заметим, что за год, прошедший с начала скандала, статья так и не была отозвана ни редакцией, ни самими авторами.
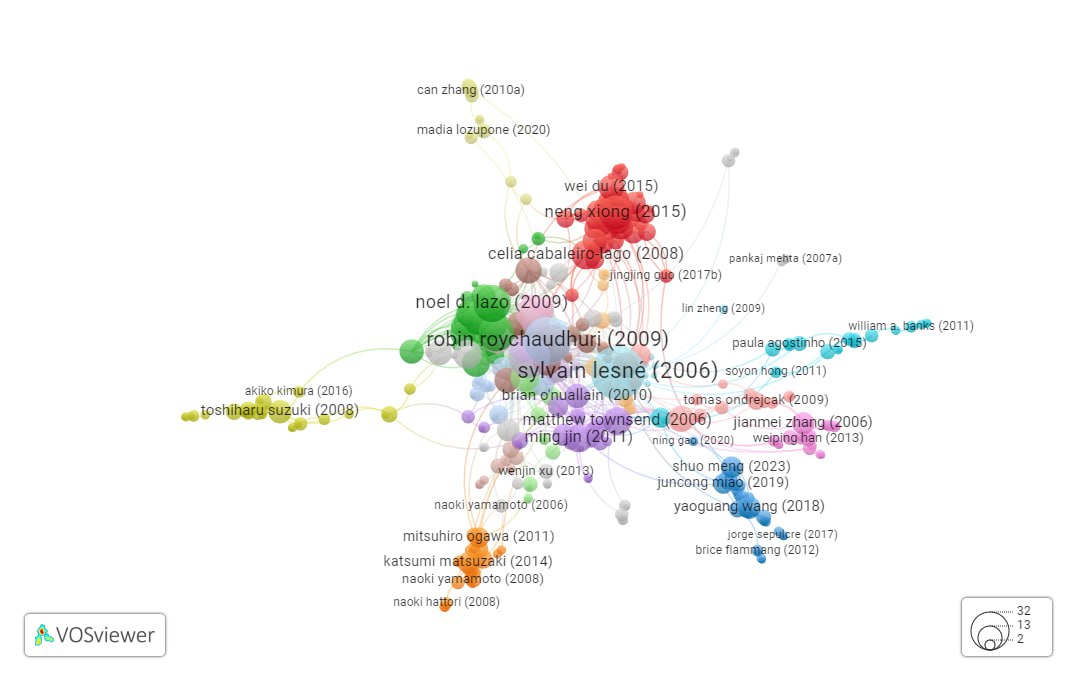
Многие научные журналисты писали впоследствии о том, что сфальсифицированные результаты предопределили дальнейшие шаги в области и являлись сдерживающим фактором для проверки других гипотез. Мы решили посмотреть, насколько разветвленной оказалась сеть цитирований в рамках данного подхода. Для этого построили карту цитирований по ключевому слову “amyloid-β protein” в VOSviewer на базе OpenAlex для визуализации взаимосвязей между статьями. Отмеченное исследование (см. sylvain lesné (2006)) действительно оказалось в эпицентре научной дискуссии: в общей сложности статья 2006 года была процитирована более 2500 раз, а совокупно со связанными исследованиями публикационный граф разрастается до 27,5 тысяч наименований.
При этом заметим, что общая гипотеза, протестированная в том числе и в данной статье, всё еще является наиболее конструктивной. Надеемся, что внимательное и добросовестное отношение к проведению экспериментов и публикации результатов исследований поможет специалистам продвинуться в поисках эффективной терапии болезни Альцгеймера в ближайшие годы, особенно с учетом пристального внимания научных журналистов к данной теме.
#обзор #OpenAlex #VOSViewer #болезньальцгеймера
21 сентября во всем мире отмечается Международный день распространения информации о болезни Альцгеймера. Это нейродегенеративное заболевание является наиболее распространенным вариантом деменции (на его долю приходится около 60% случаев). Сейчас в мире насчитывается более 55 млн пациентов с этим диагнозом, и согласно прогнозу ВОЗ это число будет удваиваться каждые 20 лет.
Симптомы болезни Альцгеймера были впервые подробно описаны в 1907 году. С тех пор ведутся активные исследования по поиску возможных механизмов развития болезни, ее профилактики и лечения. Тем не менее ясности в отношении причин развития болезни и способов ее лечения все еще нет, равно как и нет лекарств с доказанной эффективностью.
Общественные затраты на поиск решений по преодолению последствий болезни Альцгеймера и деменции составляют существенную часть расходов систем здравоохранения. На исследовательскую работу в этой сфере выделяются также значительные суммы. Однако именно в случае с болезнью Альцгеймера несоблюдение академической этики стало началом большого скандала, о котором мы сегодня решили напомнить нашим читателям.
В 2006 году в Nature вышла статья, посвященная роли специфического белка Aβ*56 в ходе развития болезни Альцгеймера, за авторством Сильвена Лесне (Sylvain Lesné) и его коллег. Она завоевала популярность и в течение долгого времени оставалась наиболее авторитетной и влиятельной в этой области. Однако в 2022 году нейробиолог Мэтью Шрэг предоставил в NIH отчет, в котором выразил сомнения по поводу достоверности изображений, приводящихся в статье Лесне. Science опубликовал расследование научного журналиста Чарльза Пиллера, посвященное этому исследованию, что привело к настоящей буре в научных кругах. В итоге Nature добавили к статье предупреждение о том, что в настоящий момент проводят собственное расследование, а читателям рекомендуется с осторожностью относиться к содержимому статьи. Заметим, что за год, прошедший с начала скандала, статья так и не была отозвана ни редакцией, ни самими авторами.
Многие научные журналисты писали впоследствии о том, что сфальсифицированные результаты предопределили дальнейшие шаги в области и являлись сдерживающим фактором для проверки других гипотез. Мы решили посмотреть, насколько разветвленной оказалась сеть цитирований в рамках данного подхода. Для этого построили карту цитирований по ключевому слову “amyloid-β protein” в VOSviewer на базе OpenAlex для визуализации взаимосвязей между статьями. Отмеченное исследование (см. sylvain lesné (2006)) действительно оказалось в эпицентре научной дискуссии: в общей сложности статья 2006 года была процитирована более 2500 раз, а совокупно со связанными исследованиями публикационный граф разрастается до 27,5 тысяч наименований.
При этом заметим, что общая гипотеза, протестированная в том числе и в данной статье, всё еще является наиболее конструктивной. Надеемся, что внимательное и добросовестное отношение к проведению экспериментов и публикации результатов исследований поможет специалистам продвинуться в поисках эффективной терапии болезни Альцгеймера в ближайшие годы, особенно с учетом пристального внимания научных журналистов к данной теме.
#обзор #OpenAlex #VOSViewer #болезньальцгеймера
{kind=link}
Постколониализм в науке: Индия и Великобритания
2023 год ознаменовался ростом влияния Индии и усилением ее соперничества не только с Китаем, но и с бывшей метрополией – Великобританией, а заодно и с другими бывшими частями Британской империи. Год назад Индия сместила Великобританию с пятого места по номинальному размеру экономики и, судя по динамике, вернуть утраченное будет очень сложно.
В науке, на первый взгляд, ситуация похожая: по итогам 2022 г. Индия впервые обогнала Соединенное Королевство по числу публикаций в Scopus, выйдя на третье место в мире (Германию Индия опередила еще в 2019 г.), причем без учета конференционных материалов, с которыми у Индии проблем не меньше, чем у России. При этом в 2022 г. наблюдается существенный скачок.
Сотрудничество Индии с Великобританией все эти годы скорее развивалось, но оставалось на достаточно низком уровне: на совместные публикации приходится порядка 3,5%, а на исключительно двусторонние работы без аффилиаций третьих стран – 1%.
Распределение выглядит иначе, если вместо общего списка Scopus взять набор ведущих мировых журналов, например, Nature Index (140+ наиболее авторитетных изданий по естественным наукам и медицине, отобранных экспертами компании Nature Publishing Group со штабом в Лондоне). Здесь пока ни о каком опережении говорить не приходится, но разрыв быстро сокращается: в 2014 г. на одну статью Индии в топовых журналах приходилось 6 статей UK, в 2023 г. – уже 3,7.
Соавторство в таких работах предсказуемо гораздо выше: примерно в каждой шестой работе Индии в Nature Index есть и ученые из Великобритании. Наука становится все более международной, и без интернационального партнерства сложно оставаться в высшей лиге. При этом число исключительно двусторонних работ с Соединенным Королевством снижается, а по предварительным данным за этот год резко упало с 1,8% до 1,1%: это отражает не только тренд на усложнение конфигурации международного соавторства, но и рост самостоятельности Индии как новой ведущей силы мировой науки. Впрочем, в глобальном масштабе нового тут мало: в конце концов, даже сами цифры, которыми мы пользуемся, когда-то изобрели именно там, а львы с индийского герба в пару раз древнее британских аналогов.
2023 год ознаменовался ростом влияния Индии и усилением ее соперничества не только с Китаем, но и с бывшей метрополией – Великобританией, а заодно и с другими бывшими частями Британской империи. Год назад Индия сместила Великобританию с пятого места по номинальному размеру экономики и, судя по динамике, вернуть утраченное будет очень сложно.
В науке, на первый взгляд, ситуация похожая: по итогам 2022 г. Индия впервые обогнала Соединенное Королевство по числу публикаций в Scopus, выйдя на третье место в мире (Германию Индия опередила еще в 2019 г.), причем без учета конференционных материалов, с которыми у Индии проблем не меньше, чем у России. При этом в 2022 г. наблюдается существенный скачок.
Сотрудничество Индии с Великобританией все эти годы скорее развивалось, но оставалось на достаточно низком уровне: на совместные публикации приходится порядка 3,5%, а на исключительно двусторонние работы без аффилиаций третьих стран – 1%.
Распределение выглядит иначе, если вместо общего списка Scopus взять набор ведущих мировых журналов, например, Nature Index (140+ наиболее авторитетных изданий по естественным наукам и медицине, отобранных экспертами компании Nature Publishing Group со штабом в Лондоне). Здесь пока ни о каком опережении говорить не приходится, но разрыв быстро сокращается: в 2014 г. на одну статью Индии в топовых журналах приходилось 6 статей UK, в 2023 г. – уже 3,7.
Соавторство в таких работах предсказуемо гораздо выше: примерно в каждой шестой работе Индии в Nature Index есть и ученые из Великобритании. Наука становится все более международной, и без интернационального партнерства сложно оставаться в высшей лиге. При этом число исключительно двусторонних работ с Соединенным Королевством снижается, а по предварительным данным за этот год резко упало с 1,8% до 1,1%: это отражает не только тренд на усложнение конфигурации международного соавторства, но и рост самостоятельности Индии как новой ведущей силы мировой науки. Впрочем, в глобальном масштабе нового тут мало: в конце концов, даже сами цифры, которыми мы пользуемся, когда-то изобрели именно там, а львы с индийского герба в пару раз древнее британских аналогов.
Bloomberg.com
UK Slips Behind India to Become World’s Sixth Biggest Economy
Britain has dropped behind India to become the world’s sixth largest economy, delivering a further blow to the government in London as it grapples with a brutal cost-of-living shock.
Международный день всеобщего доступа к информации
Доступность данных и информации — один из ключевых приоритетов повышения качества жизни, создающий очевидные преимущества для созидательного развития всего человечества. Этот принцип четко фиксируется в 19 статье Всеобщей декларации прав человека: человек обладает свободой искать, получать и распространять информацию. Ежегодным напоминанием значимости приведенного тезиса является учрежденный по инициативе ЮНЕСКО Международный день всеобщего доступа к информации, отмечаемый сегодня, 28 сентября.
Сегодня датасеты (наборы данных) стали неотъемлемой составляющей нашей жизни, в том числе и научной. Научные датасеты создаются как отдельными исследователями, так и целыми научными коллективами, а иногда источником служат данные коммерческих компаний. Набор собираемых данных поистине широк: начиная от результатов социологических опросов и заканчивая наборами последовательности генов.
В недавнем исследовании на основе данных OpenAlex канадские ученые решили проверить, насколько ценными для проведения повторных исследований оказываются собираемые в ходе исследований данные. Они выяснили, что 90% датасетов в дальнейшем не цитируются, а среди оставшихся большинство цитируется только один раз (чаще всего — самими создателями набора данных). Тем не менее существуют распространенные датасеты, использующиеся для работ, которые тематически могут быть не связаны друг с другом: так, около 130 датасетов цитировались более 100 раз.
Вот еще несколько авторских выводов:
• Наиболее активно датасеты распространяются в медицинской среде — 43% от общего количества проанализированных датасетов посвящены Health Science, а среднее количество цитат — 11,0 (при общем среднем 7,71).
• Больше всего датасетов создают ученые США, Великобритании и Германии — в общей сложности почти 70% от общего числа, причем более 50% приходится на долю США.
• Используют же готовые датасеты чаще всего в Великобритании, Германии и Австралии, причем Австралия ненамного, но все же опережает США по количеству цитат без учета самоцитирований.
На приведенной схеме отображено межинституциональное взаимодействие по повторному использованию готовых данных.
От себя заметим, что в исследовании не упоминается, какое количество статей, датасеты которых цитируются, сами при этом находится в открытом доступе. Мы решили проанализировать это по авторским материалам. Оказалось, что в 91% случаев источники по данным OpenAlex имеют статус «Closed» (можно предположить, что в данном случае процент некорректных метаданных может вносить значимый вклад в полученный результат, а отдельные статьи могут все же находиться в статусе “Open Access”), в 3% случаев источники имеют «гибридный» статус, и только оставшиеся 6% случаев — примеры, когда публикации источников находятся в открытом доступе. Повышение прозрачности в данном аспекте является немаловажным шагом для повышения открытости, видимости собранных данных и их повторного использования для тестирования нового набора гипотез.
P.S. Также хотим напомнить, что в руководстве есть подробный раздел с открытыми наборами данных, которые представляют интерес для всех, кто интересуется наукометрией.
#датасеты #открытыеданные #OpenAlex
Доступность данных и информации — один из ключевых приоритетов повышения качества жизни, создающий очевидные преимущества для созидательного развития всего человечества. Этот принцип четко фиксируется в 19 статье Всеобщей декларации прав человека: человек обладает свободой искать, получать и распространять информацию. Ежегодным напоминанием значимости приведенного тезиса является учрежденный по инициативе ЮНЕСКО Международный день всеобщего доступа к информации, отмечаемый сегодня, 28 сентября.
Сегодня датасеты (наборы данных) стали неотъемлемой составляющей нашей жизни, в том числе и научной. Научные датасеты создаются как отдельными исследователями, так и целыми научными коллективами, а иногда источником служат данные коммерческих компаний. Набор собираемых данных поистине широк: начиная от результатов социологических опросов и заканчивая наборами последовательности генов.
В недавнем исследовании на основе данных OpenAlex канадские ученые решили проверить, насколько ценными для проведения повторных исследований оказываются собираемые в ходе исследований данные. Они выяснили, что 90% датасетов в дальнейшем не цитируются, а среди оставшихся большинство цитируется только один раз (чаще всего — самими создателями набора данных). Тем не менее существуют распространенные датасеты, использующиеся для работ, которые тематически могут быть не связаны друг с другом: так, около 130 датасетов цитировались более 100 раз.
Вот еще несколько авторских выводов:
• Наиболее активно датасеты распространяются в медицинской среде — 43% от общего количества проанализированных датасетов посвящены Health Science, а среднее количество цитат — 11,0 (при общем среднем 7,71).
• Больше всего датасетов создают ученые США, Великобритании и Германии — в общей сложности почти 70% от общего числа, причем более 50% приходится на долю США.
• Используют же готовые датасеты чаще всего в Великобритании, Германии и Австралии, причем Австралия ненамного, но все же опережает США по количеству цитат без учета самоцитирований.
На приведенной схеме отображено межинституциональное взаимодействие по повторному использованию готовых данных.
От себя заметим, что в исследовании не упоминается, какое количество статей, датасеты которых цитируются, сами при этом находится в открытом доступе. Мы решили проанализировать это по авторским материалам. Оказалось, что в 91% случаев источники по данным OpenAlex имеют статус «Closed» (можно предположить, что в данном случае процент некорректных метаданных может вносить значимый вклад в полученный результат, а отдельные статьи могут все же находиться в статусе “Open Access”), в 3% случаев источники имеют «гибридный» статус, и только оставшиеся 6% случаев — примеры, когда публикации источников находятся в открытом доступе. Повышение прозрачности в данном аспекте является немаловажным шагом для повышения открытости, видимости собранных данных и их повторного использования для тестирования нового набора гипотез.
P.S. Также хотим напомнить, что в руководстве есть подробный раздел с открытыми наборами данных, которые представляют интерес для всех, кто интересуется наукометрией.
#датасеты #открытыеданные #OpenAlex
Zenodo
Dataset Citation and Re-use Data
This dataset includes processed citation data for datasets recorded in OpenAlex as of May 2022. It identifies self-citations to these datasets at the individual, institutional, and country level, and includes domain classifications of the citing works using…
Победителя (или победителей) объявят уже через полтора часа. Предлагаем всем нашим подписчикам сделать собственное предсказание. Итак, кто победит?
• Карл Джун, Стивен Розенберг и Мишель Садлен (CAR-T) - 24
👍👍👍👍👍👍👍👍 45%
• Роб Найт (Микробиом человека) - 10
👍👍👍👍 19%
• Эммануэль Миньо, Клиффорд Сейпер и Масаси Янагисава (гипокретин/орексин) - 7
👍👍👍 13%
• Другой ученый (ваш вариант в комментариях) - 12
👍👍👍👍👍 23%
👥 53 человека уже проголосовало.
• Карл Джун, Стивен Розенберг и Мишель Садлен (CAR-T) - 24
👍👍👍👍👍👍👍👍 45%
• Роб Найт (Микробиом человека) - 10
👍👍👍👍 19%
• Эммануэль Миньо, Клиффорд Сейпер и Масаси Янагисава (гипокретин/орексин) - 7
👍👍👍 13%
• Другой ученый (ваш вариант в комментариях) - 12
👍👍👍👍👍 23%
👥 53 человека уже проголосовало.