
Нецитируемые статьи и их влияние на концентрацию цитирования
В продолжение поста про нецитируемые публикации в структуре научной коммуникации сегодня расскажем об исследовании влияния нецитируемых статей на концентрацию цитирования. Анализ коллег основан на метаданных о публикациях, извлеченных из основной коллекции WoS, охватывающей публикации с 1980 по 2020 год.
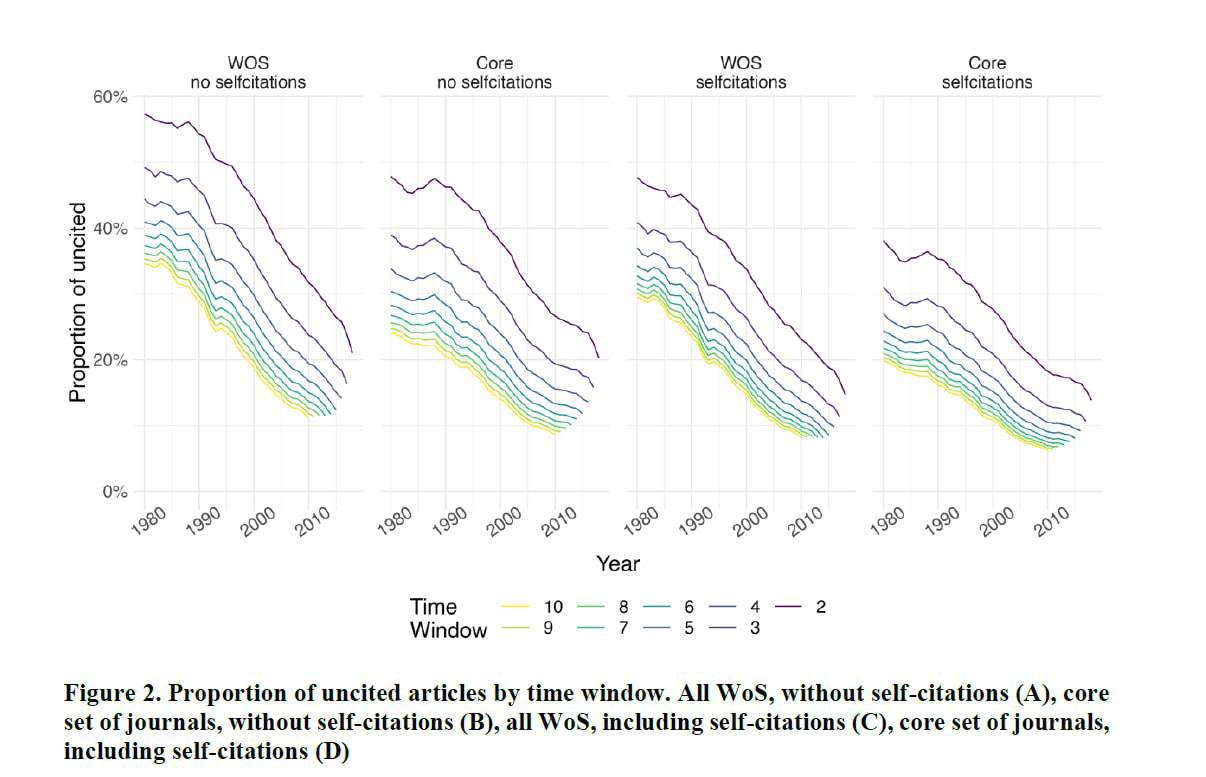
Для составления показателей концентрации коллеги используют два подхода: подход на основе цитирования и подход на основе ссылок. Подходы на основе цитирования и на основе ссылок различаются в отношении к статьям без ссылок. В подходе, основанном на цитировании, статьи без ссылок естественно включаются, поскольку процесс поиска данных начинается со всех статей, опубликованных в данном году. И наоборот, подход, основанный на ссылках, естественно исключает статьи без цитирования, поскольку анализ фокусируется на ссылках, сделанных в данном году. Кроме того, важно отметить, что количество нецитируемых статей имеет тенденцию к снижению с течением времени. Например, если рассматривать десятилетний период цитирования, то доля статей без ссылок снизилась с 34% в 1980 году до 11% в 2010 году среди всех статей в базе данных WoS, исключая самоцитирование.
Анализ показал, что наиболее надежным методом для анализа концентрации цитирования во времени является подход, основанный на цитировании, с учетом нецитируемых статей, с нормализацией по полю и году, а также с фиксированным временным окном. Необходимо также учитывать расширение библиометрических баз данных и эволюцию самоцитирования. Результаты этого метода показывают последовательное снижение концентрации цитирования.
Также было обнаружено, что различные регионы играют разную роль в своем вкладе в нецитируемость. Снижение относительной цитируемости статей Северной Америки и увеличение участия Европы и Азии влияет на структуру цитирования. В то время как Северная Америка по-прежнему составляет большую часть 1% самых цитируемых статей и производит много ссылок, которые получают эти статьи, ее роль среди статей, цитируемых только один раз, значительно ниже.
Выводы, сделанные в этой статье, подчеркивают важность учета нецитируемых статей и их потенциальное влияние на концентрацию цитирования.
#обзор #цитирование #wos
В продолжение поста про нецитируемые публикации в структуре научной коммуникации сегодня расскажем об исследовании влияния нецитируемых статей на концентрацию цитирования. Анализ коллег основан на метаданных о публикациях, извлеченных из основной коллекции WoS, охватывающей публикации с 1980 по 2020 год.
Для составления показателей концентрации коллеги используют два подхода: подход на основе цитирования и подход на основе ссылок. Подходы на основе цитирования и на основе ссылок различаются в отношении к статьям без ссылок. В подходе, основанном на цитировании, статьи без ссылок естественно включаются, поскольку процесс поиска данных начинается со всех статей, опубликованных в данном году. И наоборот, подход, основанный на ссылках, естественно исключает статьи без цитирования, поскольку анализ фокусируется на ссылках, сделанных в данном году. Кроме того, важно отметить, что количество нецитируемых статей имеет тенденцию к снижению с течением времени. Например, если рассматривать десятилетний период цитирования, то доля статей без ссылок снизилась с 34% в 1980 году до 11% в 2010 году среди всех статей в базе данных WoS, исключая самоцитирование.
Анализ показал, что наиболее надежным методом для анализа концентрации цитирования во времени является подход, основанный на цитировании, с учетом нецитируемых статей, с нормализацией по полю и году, а также с фиксированным временным окном. Необходимо также учитывать расширение библиометрических баз данных и эволюцию самоцитирования. Результаты этого метода показывают последовательное снижение концентрации цитирования.
Также было обнаружено, что различные регионы играют разную роль в своем вкладе в нецитируемость. Снижение относительной цитируемости статей Северной Америки и увеличение участия Европы и Азии влияет на структуру цитирования. В то время как Северная Америка по-прежнему составляет большую часть 1% самых цитируемых статей и производит много ссылок, которые получают эти статьи, ее роль среди статей, цитируемых только один раз, значительно ниже.
Выводы, сделанные в этой статье, подчеркивают важность учета нецитируемых статей и их потенциальное влияние на концентрацию цитирования.
#обзор #цитирование #wos
{kind=link}
И снова про Twitter: если вашу работу твитнули, какова вероятность, что ее процитируют?
В статье анализируется открытая база данных ученых в Twitter, о которой мы уже рассказывали ранее, а также отдельные твиты, содержащие ссылки на научные работы (Crossref Event Data 2023). Примерно 6,4 миллиона твитов, сделанных исследователями в этом наборе данных за 2017-2019 годы, были связаны с чуть более чем 1 миллионом отдельных DOI, найденных в таблице работ OpenAlex. Из 5 307 769 твитов, содержащих ссылки на журнальные статьи, 768 710 соответствовали ссылкам на работы, авторами которых был тот же пользователь Twitter, что составляет 14,5%.
Пользователи Twitter чаще цитируют :
• работы, связанные с их учебным заведением,
• работы, соавторами которых они являются,
• работы, имеющие непосредственное отношение к их собственным исследованиям,
• работы, опубликованные в журналах, в которых они тоже публиковались.
Из интересного:
• по мере развития карьеры и увеличения количества публикаций исследователи реже цитируют свои твиты,
• тематическое сходство твита с собственным исследованием и областью изучения оказывает большое влияние на связь между твитом и его последующим цитированием,
• чем больше работ исследователи публикуют в Twitter, тем меньше вероятность их цитирования,
• ученые, цитирующие свои собственные работы, могут показать, как Twitter может использоваться в качестве платформы для повышения узнаваемости собственной научной деятельности, утверждения себя в качестве эксперта в какой-либо области или расширения своего социального капитала .
#обзор #цитирование #twitter
В статье анализируется открытая база данных ученых в Twitter, о которой мы уже рассказывали ранее, а также отдельные твиты, содержащие ссылки на научные работы (Crossref Event Data 2023). Примерно 6,4 миллиона твитов, сделанных исследователями в этом наборе данных за 2017-2019 годы, были связаны с чуть более чем 1 миллионом отдельных DOI, найденных в таблице работ OpenAlex. Из 5 307 769 твитов, содержащих ссылки на журнальные статьи, 768 710 соответствовали ссылкам на работы, авторами которых был тот же пользователь Twitter, что составляет 14,5%.
Пользователи Twitter чаще цитируют :
• работы, связанные с их учебным заведением,
• работы, соавторами которых они являются,
• работы, имеющие непосредственное отношение к их собственным исследованиям,
• работы, опубликованные в журналах, в которых они тоже публиковались.
Из интересного:
• по мере развития карьеры и увеличения количества публикаций исследователи реже цитируют свои твиты,
• тематическое сходство твита с собственным исследованием и областью изучения оказывает большое влияние на связь между твитом и его последующим цитированием,
• чем больше работ исследователи публикуют в Twitter, тем меньше вероятность их цитирования,
• ученые, цитирующие свои собственные работы, могут показать, как Twitter может использоваться в качестве платформы для повышения узнаваемости собственной научной деятельности, утверждения себя в качестве эксперта в какой-либо области или расширения своего социального капитала .
#обзор #цитирование #twitter
«Призрак бродит по… журналам»: о последствиях использования GPT-моделей в качестве академического инструмента
ChatGPT от OpenAI, запущенный в конце ноября 2022, в последнее время находит всё больше применений в академической среде, о чем мы уже писали ранее. Он способен автоматизировать повторяющиеся задачи: например, генерировать код (правда не всегда актуальный для текущих версий пакетов), обобщать данные из нескольких научных статей, неплохо справляться с переводом текстов и даже перефразировать целые абзацы для большего соответствия академическому стилю. Однако у всего этого есть обратная сторона: во-первых, чат-боты, стремясь понравиться, зачастую выдают ложные факты за действительные, а во-вторых — могут недобросовестно использоваться самими авторами.
В недавней заметке в Scientometrics описывается одно из обнаруженных ограничений ChatGPT — склонность генерировать «призрачные» научные ссылки. Когда у чат-бота запрашивают библиографические ссылки по конкретной теме, он предоставляет правдоподобные результаты — это могут быть реальные названия статей, а в качестве источника публикации указываются названия ведущих журналов. Однако на практике выясняется, что таких статей никогда не существовало. Такие ссылки, сгенерированные при участии недобросовестных авторов, могут в конечном итоге попадать в научные публикации, особенно в тех издательствах, где процессы рецензирования слабы или вообще отсутствуют. Реальные же ссылки от GPT-моделей, вероятнее всего, усиливают эффект Матфея, о котором мы упоминали в одном из наших предыдущих постов.
Выявление таких «призрачных» ссылок — настоящий вызов для научного сообщества. Безусловно, полностью сгенерированная библиография вызовет вопросы у любого профессионала в области, однако отдельные аргументы, написанные при помощи GPT-моделей и ссылающиеся на несуществующие работы, могут с некоторой вероятностью тиражироваться в других исследованиях.
Мы же решили проверить описанный эффект сразу на трех моделях — ChatGPT, YandexGPT2 и GigaChat. Результаты вы можете видеть на скриншотах. Как и ожидалось, наиболее правдоподобные цитаты выдает ChatGPT. YandexGPT2 оказывается не менее изобретателен в создании новых публикаций: забывает о страницах, но упоминает реальных людей в качестве соавторов. А вот от GigaChat удается получить только библиографические сведения о журнале, без имен авторов и названия статей (вероятно, в данном случае использовались другие источники данных для обучения моделей).
#обзор #цитирование #искусственныйинтеллект #GPT
ChatGPT от OpenAI, запущенный в конце ноября 2022, в последнее время находит всё больше применений в академической среде, о чем мы уже писали ранее. Он способен автоматизировать повторяющиеся задачи: например, генерировать код (правда не всегда актуальный для текущих версий пакетов), обобщать данные из нескольких научных статей, неплохо справляться с переводом текстов и даже перефразировать целые абзацы для большего соответствия академическому стилю. Однако у всего этого есть обратная сторона: во-первых, чат-боты, стремясь понравиться, зачастую выдают ложные факты за действительные, а во-вторых — могут недобросовестно использоваться самими авторами.
В недавней заметке в Scientometrics описывается одно из обнаруженных ограничений ChatGPT — склонность генерировать «призрачные» научные ссылки. Когда у чат-бота запрашивают библиографические ссылки по конкретной теме, он предоставляет правдоподобные результаты — это могут быть реальные названия статей, а в качестве источника публикации указываются названия ведущих журналов. Однако на практике выясняется, что таких статей никогда не существовало. Такие ссылки, сгенерированные при участии недобросовестных авторов, могут в конечном итоге попадать в научные публикации, особенно в тех издательствах, где процессы рецензирования слабы или вообще отсутствуют. Реальные же ссылки от GPT-моделей, вероятнее всего, усиливают эффект Матфея, о котором мы упоминали в одном из наших предыдущих постов.
Выявление таких «призрачных» ссылок — настоящий вызов для научного сообщества. Безусловно, полностью сгенерированная библиография вызовет вопросы у любого профессионала в области, однако отдельные аргументы, написанные при помощи GPT-моделей и ссылающиеся на несуществующие работы, могут с некоторой вероятностью тиражироваться в других исследованиях.
Мы же решили проверить описанный эффект сразу на трех моделях — ChatGPT, YandexGPT2 и GigaChat. Результаты вы можете видеть на скриншотах. Как и ожидалось, наиболее правдоподобные цитаты выдает ChatGPT. YandexGPT2 оказывается не менее изобретателен в создании новых публикаций: забывает о страницах, но упоминает реальных людей в качестве соавторов. А вот от GigaChat удается получить только библиографические сведения о журнале, без имен авторов и названия статей (вероятно, в данном случае использовались другие источники данных для обучения моделей).
#обзор #цитирование #искусственныйинтеллект #GPT
Telegram
Выше квартилей
Что пишут о ChatGPT в Scopus и Web of Science
Из-за популярности чат-ботов и ChatGPT растет количество исследований, посвященных им. Одно из них представляет собой анализ литературы по чат-ботам и комплексный обзор научных документов по ChatGPT и фокусируется…
Из-за популярности чат-ботов и ChatGPT растет количество исследований, посвященных им. Одно из них представляет собой анализ литературы по чат-ботам и комплексный обзор научных документов по ChatGPT и фокусируется…
Проблемное цитирование — непреднамеренная ошибка или лень?
В декабре вышла статья о последствиях преднамеренной лени в отношении цитирования. Авторы рассмотрели кейс с цитатой, приведенной известным поведенческим экономистом Джорджем Левенштейном. Он неправильно указал авторство цитаты, что оставило большой «радиоактивный след»: с легкой руки авторитетного ученого неверное авторство цитаты закрепилось и периодически возобновлялось в последующих работах его читателей. Кроме того, исследования показывают, что авторам свойственно ссылаться на высокоцитируемые статьи, даже если они подверглись серьезной и обоснованной критике.
Это лишь частный эпизод, который иллюстрирует проявление более общего феномена, который принято называть «problematic citation behavior».
Проблемное цитирование может быть двух видов:
а) Неточное цитирование (ошибки возникают из-за небрежного указания выходных данных цитируемой статьи),
б) Заимствованное цитирование (некритичное копирование цитат из вторичных источников).
Если неточное цитирование является результатом простой оплошности, то заимствованное цитирование отличается преднамеренным уклонением от добросовестной работы с источниками и производит ложное впечатление о том, что автор действительно ознакомился с цитируемой работой: известно, что высокое количество цитирований создает у читателя ощущение глубокого погружения автора в изучаемый вопрос.
Причины проблемного цитирования могут быть самыми разными. Например, нехватка времени в условиях “publish-or-perish”, излишнее доверие вторичным источникам, отсутствие доступа к требуемой публикации и, наконец, самые банальные — лень или недобросовестность ученого.
Заметим, что неточные ссылки затрудняют читательский поиск и доступ к работам и нарушают связь между оригинальной работой и исследованиями, которые на нее ссылаются, в результате чего автоматизированные индексы цитирования и базы данных, включая Scopus и Web of Science, пропускают или неправильно классифицируют ссылки на свои индексируемые публикации.
Мы рекомендуем всем читателям внимательно перепроверять цитаты из вторичных источников и ответственно относиться к оформлению собственных работ.
#обзор #цитирование #научнаяэтика
В декабре вышла статья о последствиях преднамеренной лени в отношении цитирования. Авторы рассмотрели кейс с цитатой, приведенной известным поведенческим экономистом Джорджем Левенштейном. Он неправильно указал авторство цитаты, что оставило большой «радиоактивный след»: с легкой руки авторитетного ученого неверное авторство цитаты закрепилось и периодически возобновлялось в последующих работах его читателей. Кроме того, исследования показывают, что авторам свойственно ссылаться на высокоцитируемые статьи, даже если они подверглись серьезной и обоснованной критике.
Это лишь частный эпизод, который иллюстрирует проявление более общего феномена, который принято называть «problematic citation behavior».
Проблемное цитирование может быть двух видов:
а) Неточное цитирование (ошибки возникают из-за небрежного указания выходных данных цитируемой статьи),
б) Заимствованное цитирование (некритичное копирование цитат из вторичных источников).
Если неточное цитирование является результатом простой оплошности, то заимствованное цитирование отличается преднамеренным уклонением от добросовестной работы с источниками и производит ложное впечатление о том, что автор действительно ознакомился с цитируемой работой: известно, что высокое количество цитирований создает у читателя ощущение глубокого погружения автора в изучаемый вопрос.
Причины проблемного цитирования могут быть самыми разными. Например, нехватка времени в условиях “publish-or-perish”, излишнее доверие вторичным источникам, отсутствие доступа к требуемой публикации и, наконец, самые банальные — лень или недобросовестность ученого.
Заметим, что неточные ссылки затрудняют читательский поиск и доступ к работам и нарушают связь между оригинальной работой и исследованиями, которые на нее ссылаются, в результате чего автоматизированные индексы цитирования и базы данных, включая Scopus и Web of Science, пропускают или неправильно классифицируют ссылки на свои индексируемые публикации.
Мы рекомендуем всем читателям внимательно перепроверять цитаты из вторичных источников и ответственно относиться к оформлению собственных работ.
#обзор #цитирование #научнаяэтика
Чат-боты: цитировать или не цитировать?
Растущий интерес к использованию искусственного интеллекта (ИИ) в написании научных работ и ряд скандалов, связанных с его недобросовестным применением в академической сфере, провоцируют острую дискуссию. Летисия Антунес Ногейра (Leticia Antunes Nogueira), руководитель проекта по искусственному интеллекту, и Ян Уве Рейн (Jan Ove Rein), библиотекарь-исследователь, оба — сотрудники NTNU опубликовали заметку (ч. 1, ч. 2), в которой сосредоточились на критике концепции цитирования языковых моделей в научных публикациях.
В заметке авторы сузили фокус до двух моделей (ChatGPT от OpenAI или Claude от Anthropic), так как предполагают, что пользователи, которые работают с инструментами, применяющими возможности GenAI в сочетании с другими системами (например, Perplexity и Scopus AI), будут ссылаться на оригинальные источники.
В политике ведущих мировых издательств и академических организаций существует общее мнение насчет того, что чат-боты не отвечают минимальным требованиям к авторству, однако вопрос о том, можно ли (и следует ли) цитировать чат-боты в качестве источников, остается открытым.
Сторонники цитирования сообщений чат-ботов отмечают, что цитирование необходимо как минимум по двум причинам:
· признание чужого вклада и влияния идей;
· раскрытие источников информации.
Эти два, казалось бы, простых аспекта связаны с некоторыми противоречиями.
Противники цитирования (и иногда использования) чат-ботов подчеркивают, что результаты, полученные с использованием ИИ, преимущественно невозможно отследить, воспроизвести или проверить. В дополнение к этим ощутимым аргументам, исследователи акцентируют внимание на нескольких этических аспектах:
🔹Ответственность авторов
Языковая модель не может нести ответственность за утверждения, включенные в публикацию от её «лица». Одно дело цитировать организацию (например, доклад ООН), и совсем другое — чат-бота. Организации состоят из людей и поэтому несут ответственность за предоставляемую информацию, чат-бот или его разработчики нести такую ответственность не могут.
🔹Загрязнение информационной среды
Упоминание чат-ботов в источниках ведет к загрязнению информационных экосистем. Если для обучения больших языковых моделей использовать данные, сгенерированные ИИ (т. е. тексты из Интернета, академические тексты и т. д.), это приведет к ухудшению качества моделей.
🔹ИИ — не истина в последней инстанции
Чат-боты не создавались как инструменты для информационных целей. Неопределенность в отношении качества их ответов обусловлена назначением и структурой чат-ботов, а не степенью технологической зрелости. Большие языковые модели (LLM) основаны на моделях использования языка, а не на информации, и вероятностны по своему принципу работы, а это означает, что некорректный результат в таком случае — особенность, а не ошибка.
APA рекомендует цитировать текст, полученный от чат-бота, как результат работы алгоритма: а именно, ссылаться на автора алгоритма в списке источников. Дело в том, что результаты «переписки» с ChatGPT невозможно воспроизвести. Сейчас в APA такие данные часто цитируются как личная переписка, но это не совсем корректно, потому что сгенерированный текст не исходит от чьей-либо личности. В то же время ICMJE и Elsevier занимают однозначную позицию и рекомендуют авторам не ссылаться на чат-боты.
Появление чат-ботов бросает вызов устоявшимся представлениям об источниках, информации и знании, которые совсем недавно считались само собой разумеющимися. Тем не менее, в эпоху искусственного интеллекта обеспечение целостности информационной экосистемы требует все больших усилий. По мнению авторов, поскольку связность и смыслы в любом случае находятся «в глазах смотрящего», наборы слов, полученные в результате вероятностных вычислений, нельзя назвать ни источниками, ни информацией, ни знаниями. Текст, генерируемый чат-ботами — скорее, воплощение отсутствия информации.
#ChatGPT #ИИ #искусственныйинтеллект #цитирование
Растущий интерес к использованию искусственного интеллекта (ИИ) в написании научных работ и ряд скандалов, связанных с его недобросовестным применением в академической сфере, провоцируют острую дискуссию. Летисия Антунес Ногейра (Leticia Antunes Nogueira), руководитель проекта по искусственному интеллекту, и Ян Уве Рейн (Jan Ove Rein), библиотекарь-исследователь, оба — сотрудники NTNU опубликовали заметку (ч. 1, ч. 2), в которой сосредоточились на критике концепции цитирования языковых моделей в научных публикациях.
В заметке авторы сузили фокус до двух моделей (ChatGPT от OpenAI или Claude от Anthropic), так как предполагают, что пользователи, которые работают с инструментами, применяющими возможности GenAI в сочетании с другими системами (например, Perplexity и Scopus AI), будут ссылаться на оригинальные источники.
В политике ведущих мировых издательств и академических организаций существует общее мнение насчет того, что чат-боты не отвечают минимальным требованиям к авторству, однако вопрос о том, можно ли (и следует ли) цитировать чат-боты в качестве источников, остается открытым.
Сторонники цитирования сообщений чат-ботов отмечают, что цитирование необходимо как минимум по двум причинам:
· признание чужого вклада и влияния идей;
· раскрытие источников информации.
Эти два, казалось бы, простых аспекта связаны с некоторыми противоречиями.
Противники цитирования (и иногда использования) чат-ботов подчеркивают, что результаты, полученные с использованием ИИ, преимущественно невозможно отследить, воспроизвести или проверить. В дополнение к этим ощутимым аргументам, исследователи акцентируют внимание на нескольких этических аспектах:
🔹Ответственность авторов
Языковая модель не может нести ответственность за утверждения, включенные в публикацию от её «лица». Одно дело цитировать организацию (например, доклад ООН), и совсем другое — чат-бота. Организации состоят из людей и поэтому несут ответственность за предоставляемую информацию, чат-бот или его разработчики нести такую ответственность не могут.
🔹Загрязнение информационной среды
Упоминание чат-ботов в источниках ведет к загрязнению информационных экосистем. Если для обучения больших языковых моделей использовать данные, сгенерированные ИИ (т. е. тексты из Интернета, академические тексты и т. д.), это приведет к ухудшению качества моделей.
🔹ИИ — не истина в последней инстанции
Чат-боты не создавались как инструменты для информационных целей. Неопределенность в отношении качества их ответов обусловлена назначением и структурой чат-ботов, а не степенью технологической зрелости. Большие языковые модели (LLM) основаны на моделях использования языка, а не на информации, и вероятностны по своему принципу работы, а это означает, что некорректный результат в таком случае — особенность, а не ошибка.
APA рекомендует цитировать текст, полученный от чат-бота, как результат работы алгоритма: а именно, ссылаться на автора алгоритма в списке источников. Дело в том, что результаты «переписки» с ChatGPT невозможно воспроизвести. Сейчас в APA такие данные часто цитируются как личная переписка, но это не совсем корректно, потому что сгенерированный текст не исходит от чьей-либо личности. В то же время ICMJE и Elsevier занимают однозначную позицию и рекомендуют авторам не ссылаться на чат-боты.
Появление чат-ботов бросает вызов устоявшимся представлениям об источниках, информации и знании, которые совсем недавно считались само собой разумеющимися. Тем не менее, в эпоху искусственного интеллекта обеспечение целостности информационной экосистемы требует все больших усилий. По мнению авторов, поскольку связность и смыслы в любом случае находятся «в глазах смотрящего», наборы слов, полученные в результате вероятностных вычислений, нельзя назвать ни источниками, ни информацией, ни знаниями. Текст, генерируемый чат-ботами — скорее, воплощение отсутствия информации.
#ChatGPT #ИИ #искусственныйинтеллект #цитирование
Коротко и ясно: зависит ли цитируемость статьи от длины заголовка?
Большинство исследователей настаивают на том, что заголовки опубликованных работ должны быть относительно краткими, так как заголовки — это первая, а иногда и единственная информация, которую читатель получает из публикации.
Результаты опроса (впрочем, довольно старого), в котором приняли участие более 5000 человек, показали, что читатель научных журналов просматривает в среднем 1142 заголовка, 204 аннотации и 97 статей в год. Растущий поток информации и повышающаяся конкуренция в академической среде приводят к тому, что читателю, вероятнее всего, проще откинуть статью с витиеватым заголовком, не вникая в ее содержание (не случайно некоторые научные журналы ограничивают количество слов в заголовках). Как мы недавно видели, короткий и броский заголовок действительно может привлечь внимание.
С другой стороны, согласно теории поисковой оптимизации (SEO), длинный заголовок может помочь в поиске статьи по ключевым словам, благодаря чему статья привлекает больше внимания, и, соответственно, чаще цитируется. Исследователи Шанхайского университета финансов и экономики (SUFE) называют это информативным эффектом (informative effect), а факторы, подтверждающие положительную корреляцию между короткими заголовками и цитированием статей, — эффектом лаконичности (succinct effect).
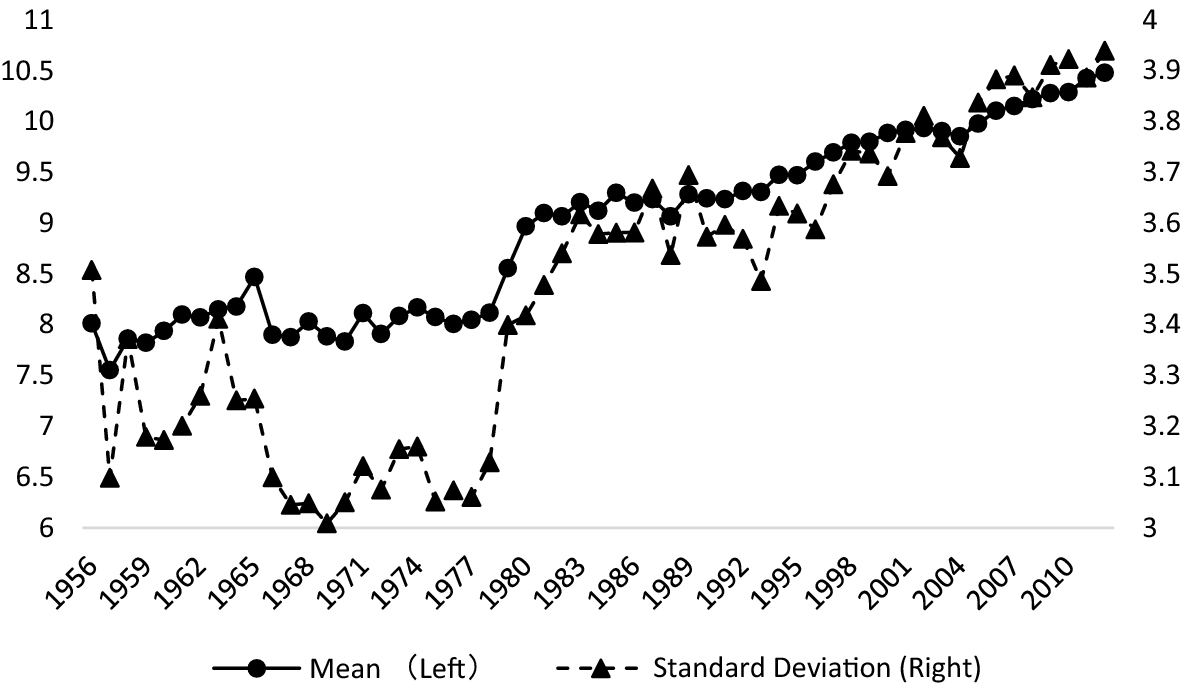
На основе выборки из более чем 300 000 статей SSCI по экономике с 1956 по 2012 год они определили, что статьи с короткими названиями лучше цитировались в период, когда поиск литературы не был так тесно связан с цифровыми технологиями (1956–2000 годы), а уже с 2001 года наблюдается рост цитируемости статей с длинными заголовками.
Здесь необходимо отметить несколько аспектов. Во-первых, сами авторы стали использовать больше слов в заголовке (см. график). В частности, в 2010–2012 годах в заголовке в среднем было 10,4 слова, что на 33% больше, чем 7,8 слов в 1956–1958 годах.
Согласно исследованию, в XXI веке количество цитирований статьи должно возрастать на 0,60% с каждым дополнительным словом, добавленным в название статьи. Следует отметить, что, помимо длины заголовка, в исследовании были учтены другие факторы, которые могут влиять на количество цитирований:
💠 Количество страниц в статье. Статьи тоже стали длиннее, а такие статьи, согласно некоторым исследованиям, чаще цитируют.
💠 Число соавторов. Было обнаружено, что чем больше соавторов, тем больше цитирований, так как статья привлекает больше внимания.
💠 Количество ссылок в работе. Чем больше в статье ссылок на предыдущие работы, тем больше доверия она вызывает. Также обширный список источников связан с формой взаимного альтруизма — «Я цитирую вас, а вы цитируете меня».
💠 Алфавитный порядок авторов. Первого автора из списка чаще цитируют и упоминают.
💠 Порядок статьи в выпуске. Первые статьи в выпуске, как правило, больше скачивают и цитируют.
На данном этапе развития науки почти весь поиск литературы осуществляется в онлайн-базах данных, причем многие поиски ограничиваются ключевыми словами. По мнению авторов исследования, статьи с краткими названиями были более привлекательны в предыдущие десятилетия, но с развитием интернета информативный эффект начал превосходить эффект лаконичности. Исследователям не стоит жалеть время на выбор заголовка публикации, так как число статей и журналов, к которым можно получить онлайн-доступ, постоянно растет. А мы планируем вскоре вернуться к этой теме со своим исследованием, чтобы слегка освежить данные, полученные в оригинальной статье.
#цитирование #SSCI #обзор
Большинство исследователей настаивают на том, что заголовки опубликованных работ должны быть относительно краткими, так как заголовки — это первая, а иногда и единственная информация, которую читатель получает из публикации.
Результаты опроса (впрочем, довольно старого), в котором приняли участие более 5000 человек, показали, что читатель научных журналов просматривает в среднем 1142 заголовка, 204 аннотации и 97 статей в год. Растущий поток информации и повышающаяся конкуренция в академической среде приводят к тому, что читателю, вероятнее всего, проще откинуть статью с витиеватым заголовком, не вникая в ее содержание (не случайно некоторые научные журналы ограничивают количество слов в заголовках). Как мы недавно видели, короткий и броский заголовок действительно может привлечь внимание.
С другой стороны, согласно теории поисковой оптимизации (SEO), длинный заголовок может помочь в поиске статьи по ключевым словам, благодаря чему статья привлекает больше внимания, и, соответственно, чаще цитируется. Исследователи Шанхайского университета финансов и экономики (SUFE) называют это информативным эффектом (informative effect), а факторы, подтверждающие положительную корреляцию между короткими заголовками и цитированием статей, — эффектом лаконичности (succinct effect).
На основе выборки из более чем 300 000 статей SSCI по экономике с 1956 по 2012 год они определили, что статьи с короткими названиями лучше цитировались в период, когда поиск литературы не был так тесно связан с цифровыми технологиями (1956–2000 годы), а уже с 2001 года наблюдается рост цитируемости статей с длинными заголовками.
Здесь необходимо отметить несколько аспектов. Во-первых, сами авторы стали использовать больше слов в заголовке (см. график). В частности, в 2010–2012 годах в заголовке в среднем было 10,4 слова, что на 33% больше, чем 7,8 слов в 1956–1958 годах.
Согласно исследованию, в XXI веке количество цитирований статьи должно возрастать на 0,60% с каждым дополнительным словом, добавленным в название статьи. Следует отметить, что, помимо длины заголовка, в исследовании были учтены другие факторы, которые могут влиять на количество цитирований:
💠 Количество страниц в статье. Статьи тоже стали длиннее, а такие статьи, согласно некоторым исследованиям, чаще цитируют.
💠 Число соавторов. Было обнаружено, что чем больше соавторов, тем больше цитирований, так как статья привлекает больше внимания.
💠 Количество ссылок в работе. Чем больше в статье ссылок на предыдущие работы, тем больше доверия она вызывает. Также обширный список источников связан с формой взаимного альтруизма — «Я цитирую вас, а вы цитируете меня».
💠 Алфавитный порядок авторов. Первого автора из списка чаще цитируют и упоминают.
💠 Порядок статьи в выпуске. Первые статьи в выпуске, как правило, больше скачивают и цитируют.
На данном этапе развития науки почти весь поиск литературы осуществляется в онлайн-базах данных, причем многие поиски ограничиваются ключевыми словами. По мнению авторов исследования, статьи с краткими названиями были более привлекательны в предыдущие десятилетия, но с развитием интернета информативный эффект начал превосходить эффект лаконичности. Исследователям не стоит жалеть время на выбор заголовка публикации, так как число статей и журналов, к которым можно получить онлайн-доступ, постоянно растет. А мы планируем вскоре вернуться к этой теме со своим исследованием, чтобы слегка освежить данные, полученные в оригинальной статье.
#цитирование #SSCI #обзор
{kind=link}