
Цитирования и качество исследований: есть ли взаимосвязь?
Мы уже писали про анализ использования импакт-фактора в оценке исследований от британских коллег (там же мы кратко рассказали о программе UK Research Excellence Framework). Авторы того исследования обнаружили очень слабую положительную корреляцию между экспертными оценками статей и импакт-факторами журналов. Статья, о которой мы расскажем сегодня, является ответвлением исследования, проведенного в 2021 году в рамках подготовки к REF2028, и посвящена анализу взаимосвязи цитирований и качества исследований.
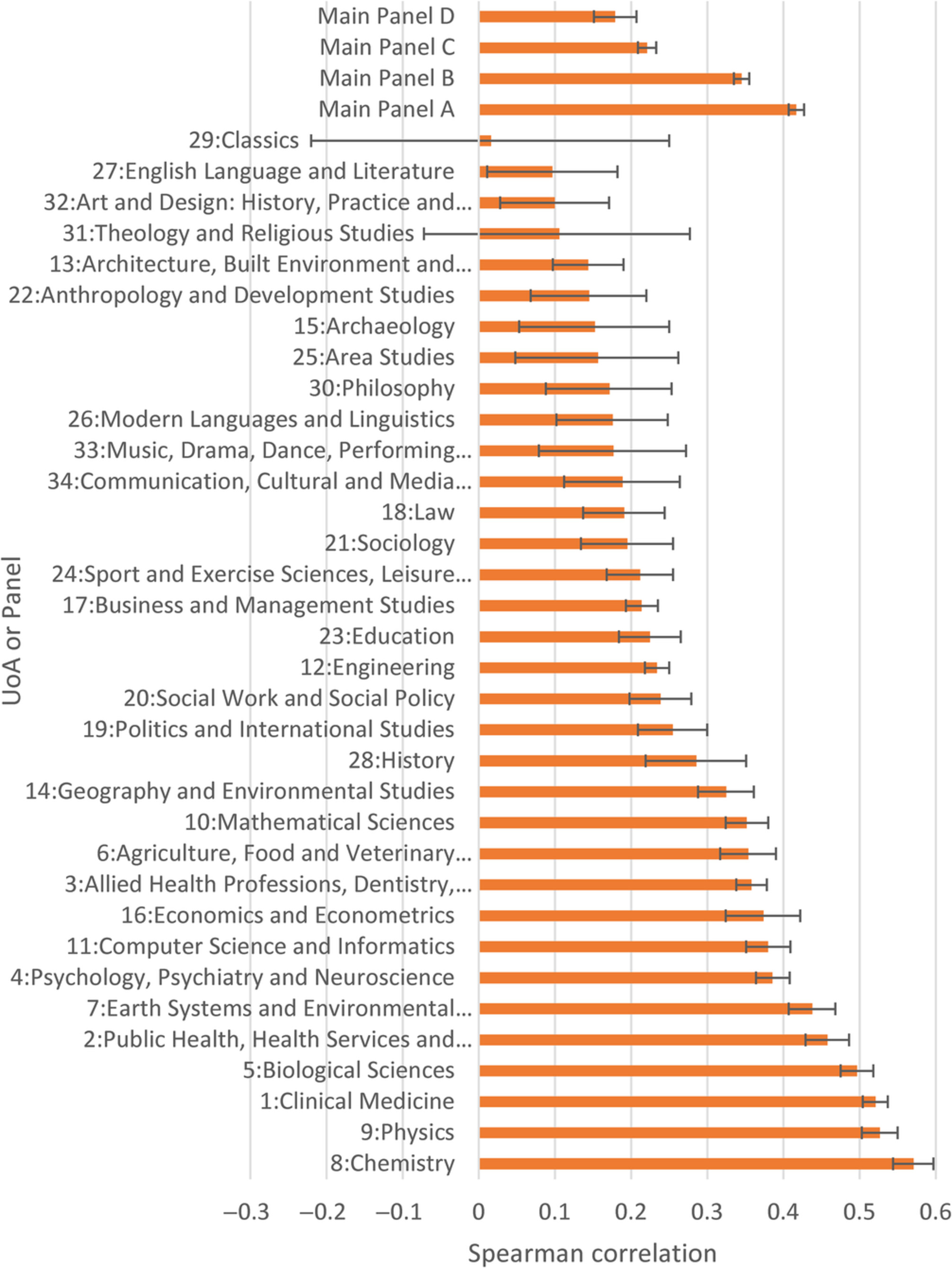
Ценность цитирований для оценки качества исследований нередко становится предметом научных споров. Безусловно, не всегда ясно, что именно подразумевают под качеством исследований, но обычно его рассматривают с точки зрения методологической строгости, новизны/оригинальности и влияния на науку или общество. Авторы называют свою статью первой крупномасштабной общенаучной академической оценкой взаимосвязи качества исследований и цитирований, сопоставляя данные для 87739 журнальных статей по 34 укрупненным предметным группам (UoA). Эти два показателя положительно коррелируют во всех академических областях, отражая в целом линейные отношения во всех областях.
Основные выводы, к которым авторы приходят:
• Статьи с большим количеством цитирований, как правило, более высокого качества во всех областях науки. Положительные корреляции наблюдаются даже в большинстве областей искусства и гуманитарных наук (включая Music, Drama, Dance, and Performing Arts; Studies in Creative Arts and Writing; Arts and Humanities), хотя сила этих связей значительно варьируется (см. скриншот).
• Высокое цитирование не гарантирует однозначное высокое качество исследований в какой-либо области.
• Положительная связь между исследованиями качества и цитируемости относительно универсальны.
К ограничениям данного исследования можно отнести тот факт, что все отобранные журнальные статьи публиковались сотрудниками британских университетов, и взаимосвязь между цитированием и качеством может быть иной в других странах. К тому же нормализация поля ограничена схемами Scopus и Dimensions, а сами статьи выбираются авторами самостоятельно и в большинстве случаев представляют лучшие по их мнению работы.
Таким образом, несмотря на то, что цитирование, нормализованное по соответствующим областям, положительно коррелирует с качеством исследований во всех областях, оно никогда не отражает значимость исследования в полной мере, даже при переходе к высокоцитируемым публикациям.
#обзор #цитирование #журналы #экспертнаяоценка
Мы уже писали про анализ использования импакт-фактора в оценке исследований от британских коллег (там же мы кратко рассказали о программе UK Research Excellence Framework). Авторы того исследования обнаружили очень слабую положительную корреляцию между экспертными оценками статей и импакт-факторами журналов. Статья, о которой мы расскажем сегодня, является ответвлением исследования, проведенного в 2021 году в рамках подготовки к REF2028, и посвящена анализу взаимосвязи цитирований и качества исследований.
Ценность цитирований для оценки качества исследований нередко становится предметом научных споров. Безусловно, не всегда ясно, что именно подразумевают под качеством исследований, но обычно его рассматривают с точки зрения методологической строгости, новизны/оригинальности и влияния на науку или общество. Авторы называют свою статью первой крупномасштабной общенаучной академической оценкой взаимосвязи качества исследований и цитирований, сопоставляя данные для 87739 журнальных статей по 34 укрупненным предметным группам (UoA). Эти два показателя положительно коррелируют во всех академических областях, отражая в целом линейные отношения во всех областях.
Основные выводы, к которым авторы приходят:
• Статьи с большим количеством цитирований, как правило, более высокого качества во всех областях науки. Положительные корреляции наблюдаются даже в большинстве областей искусства и гуманитарных наук (включая Music, Drama, Dance, and Performing Arts; Studies in Creative Arts and Writing; Arts and Humanities), хотя сила этих связей значительно варьируется (см. скриншот).
• Высокое цитирование не гарантирует однозначное высокое качество исследований в какой-либо области.
• Положительная связь между исследованиями качества и цитируемости относительно универсальны.
К ограничениям данного исследования можно отнести тот факт, что все отобранные журнальные статьи публиковались сотрудниками британских университетов, и взаимосвязь между цитированием и качеством может быть иной в других странах. К тому же нормализация поля ограничена схемами Scopus и Dimensions, а сами статьи выбираются авторами самостоятельно и в большинстве случаев представляют лучшие по их мнению работы.
Таким образом, несмотря на то, что цитирование, нормализованное по соответствующим областям, положительно коррелирует с качеством исследований во всех областях, оно никогда не отражает значимость исследования в полной мере, даже при переходе к высокоцитируемым публикациям.
#обзор #цитирование #журналы #экспертнаяоценка
{kind=link}
День русского языка: Пушкин в научных статьях
Сегодня, в День русского языка, в Вышке будут объявлены победители Конкурса лучших русскоязычных научных и научно-популярных работ работников НИУ ВШЭ. В этом году конкурс проводится уже в третий раз, в нем представлено 259 работ по двум номинациям: научной и научно-популярной.
Учреждение Дня русского языка приурочено ко дню рождения великого русского поэта Александра Сергеевича Пушкина, отмечаемого ежегодного 6 июня. Чтобы проследить влияние поэта на исследователей и их работы, мы проанализировали статьи из базы данных OpenAlex, у которых в заголовке присутствует слово «Пушкин». Всего таких статей было 1806. Из аннотаций к ним, переведенным на русский язык, составили облако слов. Самыми часто встречающимися словами были названия его произведений: Евгений Онегин, Борис Годунов, Медный всадник, а также другие русские писатели и поэты, на многих из которых творчество Александра Сергеевича оказало непосредственное влияние, — Анна Ахматова, Борис Пастернак, Владимир Набоков, Иосиф Бродский. Конечно, встречается и профессиональная лексика таких областей, как культурология и филология: культурный код, интертекстуальный анализ, критический прием. Интересно, что среди слов-ассоциаций выделяются также дополненная реальность и итальянское кино.
#вышка #инфографика #открытыйдоступ #OpenAlex #Пушкин
Сегодня, в День русского языка, в Вышке будут объявлены победители Конкурса лучших русскоязычных научных и научно-популярных работ работников НИУ ВШЭ. В этом году конкурс проводится уже в третий раз, в нем представлено 259 работ по двум номинациям: научной и научно-популярной.
Учреждение Дня русского языка приурочено ко дню рождения великого русского поэта Александра Сергеевича Пушкина, отмечаемого ежегодного 6 июня. Чтобы проследить влияние поэта на исследователей и их работы, мы проанализировали статьи из базы данных OpenAlex, у которых в заголовке присутствует слово «Пушкин». Всего таких статей было 1806. Из аннотаций к ним, переведенным на русский язык, составили облако слов. Самыми часто встречающимися словами были названия его произведений: Евгений Онегин, Борис Годунов, Медный всадник, а также другие русские писатели и поэты, на многих из которых творчество Александра Сергеевича оказало непосредственное влияние, — Анна Ахматова, Борис Пастернак, Владимир Набоков, Иосиф Бродский. Конечно, встречается и профессиональная лексика таких областей, как культурология и филология: культурный код, интертекстуальный анализ, критический прием. Интересно, что среди слов-ассоциаций выделяются также дополненная реальность и итальянское кино.
#вышка #инфографика #открытыйдоступ #OpenAlex #Пушкин
Сегодня международный день архивов, значит, самое время рассказать о базе публикаций от команды, возможно, главного из них — Internet Archive.
Проект FATCAT в полной мере отражает суть архивной деятельности — сохранение знания на все времена, в данном случае — знания о публикациях. Для нас с вами важен еще и второй принцип Internet Archive, распространяющийся на FATCAT — сделать все знания человечества доступными всем жителям Земли, разумеется, бесплатно.
FATCAT — открытая база метаданных научных публикаций наподобие OpenAlex, но с важными отличиями: каждая публикация (work) представлена всеми версиями, которые называются релизами (release). Остальные сущности — container (например, журнал или сервер препринтов), creator (автор, редактор, переводчик), file set (датасеты и сопроводительные материалы) и т.д., организаций, издателей, грантов среди них нет. Также система хранит в Internet Archive полные тексты публикаций, где это позволяется лицензией, и призывает всех пользователей указывать ссылки на полные тексты/данные для вечного хранения.
Вот как это выглядит на примере статьи одного из авторов нашего канала.
Конечно, система пока не может обеспечить качество авторских профилей, сопоставимое с коммерческими базами, учет цитирований там тоже в стадии становления, но совокупный объем данных, уже сохраненных в проекте, огромен: 131 миллион works, из которых 38 миллионов доступны в полном тексте, данные о 195 тысячах журналов и других изданий и многое другое. Все это собирается и обогащается из CrossRef, PubMed Central, CORE, Wikidata, ORCID, DOAJ, Норвежского списка журналов и других компонентов глобальной инфраструктуры открытой науки.
FATCAT имеет руководство и полноценный общедоступный API, отметим, порог входа там повыше, чем у CrossRef и OpenAlex, но сам доступ совершенно открыт, поэтому система активно используется множеством сторонних проектов. Идентификаторы FATCAT интегрированы во множество проектов в рамках открытой науки, в том числе в белый список журналов Российского центра научной информации.
Несмотря на скудные возможности некоммерческой команды, проект быстро развивается. Так, на его основе появился сервис, который многим будет интереснее, чем API и метаданные:
Internet Archive Scholar, реализующий полнотекстовой (sic!) поиск по 25 миллионам публикаций начиная с XVIII века.
#архив #открытыйдоступ
Проект FATCAT в полной мере отражает суть архивной деятельности — сохранение знания на все времена, в данном случае — знания о публикациях. Для нас с вами важен еще и второй принцип Internet Archive, распространяющийся на FATCAT — сделать все знания человечества доступными всем жителям Земли, разумеется, бесплатно.
FATCAT — открытая база метаданных научных публикаций наподобие OpenAlex, но с важными отличиями: каждая публикация (work) представлена всеми версиями, которые называются релизами (release). Остальные сущности — container (например, журнал или сервер препринтов), creator (автор, редактор, переводчик), file set (датасеты и сопроводительные материалы) и т.д., организаций, издателей, грантов среди них нет. Также система хранит в Internet Archive полные тексты публикаций, где это позволяется лицензией, и призывает всех пользователей указывать ссылки на полные тексты/данные для вечного хранения.
Вот как это выглядит на примере статьи одного из авторов нашего канала.
Конечно, система пока не может обеспечить качество авторских профилей, сопоставимое с коммерческими базами, учет цитирований там тоже в стадии становления, но совокупный объем данных, уже сохраненных в проекте, огромен: 131 миллион works, из которых 38 миллионов доступны в полном тексте, данные о 195 тысячах журналов и других изданий и многое другое. Все это собирается и обогащается из CrossRef, PubMed Central, CORE, Wikidata, ORCID, DOAJ, Норвежского списка журналов и других компонентов глобальной инфраструктуры открытой науки.
FATCAT имеет руководство и полноценный общедоступный API, отметим, порог входа там повыше, чем у CrossRef и OpenAlex, но сам доступ совершенно открыт, поэтому система активно используется множеством сторонних проектов. Идентификаторы FATCAT интегрированы во множество проектов в рамках открытой науки, в том числе в белый список журналов Российского центра научной информации.
Несмотря на скудные возможности некоммерческой команды, проект быстро развивается. Так, на его основе появился сервис, который многим будет интереснее, чем API и метаданные:
Internet Archive Scholar, реализующий полнотекстовой (sic!) поиск по 25 миллионам публикаций начиная с XVIII века.
#архив #открытыйдоступ
Сегодняшний пост посвящен тому, как выделять тематические кластеры методами, не основанными на цитированиях самих публикаций. Эти подходы тестируются на массиве 13817 публикаций НИУ ВШЭ в Scopus за 2019-2023 годы.
В качестве кластеров можно использовать:
1️⃣ Авторские ключевые слова. Хорошо описывают содержание и хорошо работают как лейблы кластеров, но есть не у всех публикаций и требуют внешние метрики качества. Кластеризация через совместную встречаемость.
2️⃣ Журналы. Узкоспециализированные журналы «ловят» тематики гораздо лучше AI, но чем шире тематика издания, тем ниже ценность метода. Можно кластеризовать журналы в группы наукометрическими (ссылки и пересечения в списках литературы) и лингвистическими (совпадение ключевых слов, схожесть аннотаций и названий) методами. Важное достоинство — журнал с репутацией/цитируемостью позволяет оценить средний уровень свежих работ.
3️⃣ Автоматически выделенные ключевые слова и прочие методы, основанные на программном анализе текстов (аннотаций и названий). Сложны для интерпретации и фильтрации по релевантности. Важно, что есть открытый набор из ~60 тысяч тематик/кластеров/ключевых слов, выделенный алгоритмически в OpenAlex/Wikidata, что позволяет сравнивать полученные кластеры с общемировыми трендами.
Для измерения и сопоставления кластеров можно использовать:
• журналы (уровни в экспертных списках и метрики),
• цитирования (требуют нормализации по тематике, году и типу публикации, лаг накопления),
• средние годы выпуска для оценки роста/затухания,
• международное соавторство (рекомендуется нормализация по тематикам).
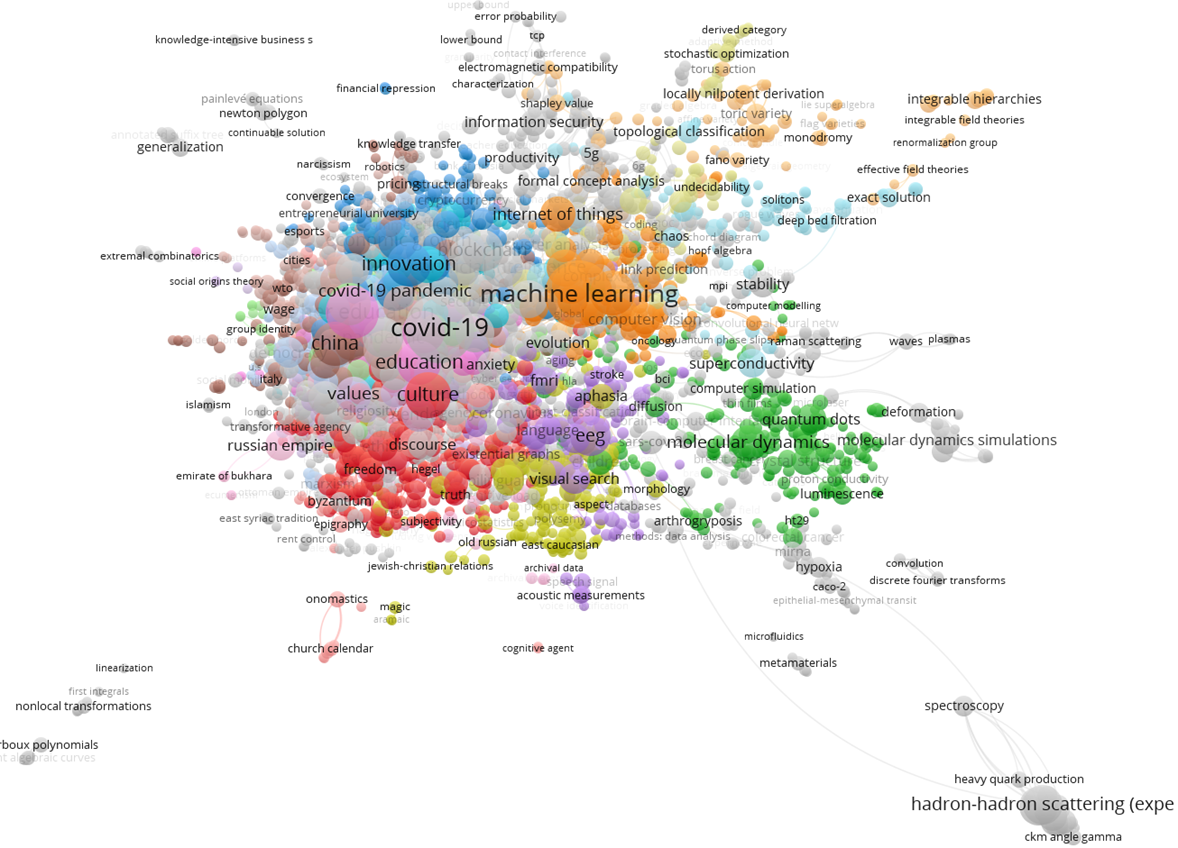
Самые часто встречающиеся ключевые слова для НИУ ВШЭ: covid-19, machine learning, higher education, culture, deep learning, china, education, innovation, subjective well-being, human capital, blockchain.
На графике представлена визуализация авторских ключевых слов, кластеризация на основе совместной встречаемости. Если сравнивать первые 50 кластеров, которые встречаются по наиболее частому ключевому слову, то по среднему возрасту они практически не отличаются, зато отличаются по среднему уровню журналов.
#инструменты #университеты #scopus #вышка
В качестве кластеров можно использовать:
1️⃣ Авторские ключевые слова. Хорошо описывают содержание и хорошо работают как лейблы кластеров, но есть не у всех публикаций и требуют внешние метрики качества. Кластеризация через совместную встречаемость.
2️⃣ Журналы. Узкоспециализированные журналы «ловят» тематики гораздо лучше AI, но чем шире тематика издания, тем ниже ценность метода. Можно кластеризовать журналы в группы наукометрическими (ссылки и пересечения в списках литературы) и лингвистическими (совпадение ключевых слов, схожесть аннотаций и названий) методами. Важное достоинство — журнал с репутацией/цитируемостью позволяет оценить средний уровень свежих работ.
3️⃣ Автоматически выделенные ключевые слова и прочие методы, основанные на программном анализе текстов (аннотаций и названий). Сложны для интерпретации и фильтрации по релевантности. Важно, что есть открытый набор из ~60 тысяч тематик/кластеров/ключевых слов, выделенный алгоритмически в OpenAlex/Wikidata, что позволяет сравнивать полученные кластеры с общемировыми трендами.
Для измерения и сопоставления кластеров можно использовать:
• журналы (уровни в экспертных списках и метрики),
• цитирования (требуют нормализации по тематике, году и типу публикации, лаг накопления),
• средние годы выпуска для оценки роста/затухания,
• международное соавторство (рекомендуется нормализация по тематикам).
Самые часто встречающиеся ключевые слова для НИУ ВШЭ: covid-19, machine learning, higher education, culture, deep learning, china, education, innovation, subjective well-being, human capital, blockchain.
На графике представлена визуализация авторских ключевых слов, кластеризация на основе совместной встречаемости. Если сравнивать первые 50 кластеров, которые встречаются по наиболее частому ключевому слову, то по среднему возрасту они практически не отличаются, зато отличаются по среднему уровню журналов.
#инструменты #университеты #scopus #вышка
{kind=link}
Предметные рейтинги вузов: кейс норвежского списка журналов
Ранее мы обращали внимание на экспертные списки, используемые в мире в качестве инструментов оценки науки. Сегодня подготовили небольшой срез по публикациям 2019-2023 гг. крупнейших российских вузов в журналах, входящих в 1-ый и 2-ой уровни норвежского списка. Напомним, что ко второму уровню относятся ведущие журналы, а к первому — те, которые известны специалистам в своих областях и обеспечивают приемлемый уровень публикаций. Сводный балл, который лежит в основе сравнений, формировался исходя из принципа: 1 статья в ведущем журнале (2-го уровня; NPI2) = 3 статьи в обычном журнале (1-го уровня; NPI1). С результатами анализа можно ознакомиться по ссылке. Для удобства сравнений приводим аналитику в разрезе областей и организаций.
P.S. Заметим, что норвежская система оценки ориентируется также на долевой подсчет, поэтому результаты по некоторым областям могут быть смещены из-за мегаколлабораций.
#экспертныесписки #журналы #национальнаясистема
Ранее мы обращали внимание на экспертные списки, используемые в мире в качестве инструментов оценки науки. Сегодня подготовили небольшой срез по публикациям 2019-2023 гг. крупнейших российских вузов в журналах, входящих в 1-ый и 2-ой уровни норвежского списка. Напомним, что ко второму уровню относятся ведущие журналы, а к первому — те, которые известны специалистам в своих областях и обеспечивают приемлемый уровень публикаций. Сводный балл, который лежит в основе сравнений, формировался исходя из принципа: 1 статья в ведущем журнале (2-го уровня; NPI2) = 3 статьи в обычном журнале (1-го уровня; NPI1). С результатами анализа можно ознакомиться по ссылке. Для удобства сравнений приводим аналитику в разрезе областей и организаций.
P.S. Заметим, что норвежская система оценки ориентируется также на долевой подсчет, поэтому результаты по некоторым областям могут быть смещены из-за мегаколлабораций.
#экспертныесписки #журналы #национальнаясистема
Нецитируемые статьи в структуре научной коммуникации
В майском выпуске Journal of Informetrics вышла статья наших коллег из Вышки о нецитируемых статьях. В рамках исследования они выдвинули тезис о том, что нецитируемые публикации являются основой для построения особой формы научной коммуникации. Коллеги утверждают, что списки ссылок нецитируемых статей образуют динамическую систему, частично ответственную за перераспределение научного потенциала других публикаций в области.
В рамках исследования авторы обращались к базе данных INSPIRE, содержащей информацию о более чем 1,4 миллионах публикаций по физике высоких энергий. Окончательная выборка охватывает 729515 статей, опубликованных с 1970 по 2015 год.
Нецитируемые публикации обычно включают документы, которые по ряду причин не вписываются в стандарты современных баз данных. Часто к ним относятся статьи из журналов на иностранных языках, отличных от английского, книги и краткие сообщения, редакционные статьи. Сравнительное исследование языковых областей двух ведущих библиометрических баз данных показало, что 92,64% публикаций Scopus были на английском языке, а соответствующая доля в Web of Science составила 95,37%.
Кроме того, импакт-фактор журнала значительно коррелирует с коэффициентом нецитируемости. Например, в журналах первого квартиля (JCR Q1) коэффициент нецитируемости статей и обзоров составляет 1,7%, тогда как в журналах четвертого квартиля (JCR Q4) этот показатель уже равен 27,4%.
Сохраняются различия в нецитируемости и между дисциплинами. Как правило, самый высокий коэффициент нецитируемости наблюдается в гуманитарных науках.
Нужно учитывать и тот факт, что на некоторые открытия ссылаются без явного цитирования. В библиометрии это явление называется «вытеснение путем инкорпорации» (OBI — obliteration by incorporation): превращение определенных идей в универсально разделяемые без последующего цитирования. Такой тип цитирования не может быть извлечен из списков цитируемых ссылок. Для его обнаружения требуется полнотекстовый анализ. Вся эти схемы цитирования порождают нецитируемость.
Данные, полученные в ходе исследования, доказывают также, что высокоцитируемые статьи не являются прямыми противоположностями нецитируемых. Нецитируемые работы — это не ошибка исторического развития науки, а естественный результат непоследовательности и перекоса распределения вкладов в науку.
#обзор #вышка #цитирование
В майском выпуске Journal of Informetrics вышла статья наших коллег из Вышки о нецитируемых статьях. В рамках исследования они выдвинули тезис о том, что нецитируемые публикации являются основой для построения особой формы научной коммуникации. Коллеги утверждают, что списки ссылок нецитируемых статей образуют динамическую систему, частично ответственную за перераспределение научного потенциала других публикаций в области.
В рамках исследования авторы обращались к базе данных INSPIRE, содержащей информацию о более чем 1,4 миллионах публикаций по физике высоких энергий. Окончательная выборка охватывает 729515 статей, опубликованных с 1970 по 2015 год.
Нецитируемые публикации обычно включают документы, которые по ряду причин не вписываются в стандарты современных баз данных. Часто к ним относятся статьи из журналов на иностранных языках, отличных от английского, книги и краткие сообщения, редакционные статьи. Сравнительное исследование языковых областей двух ведущих библиометрических баз данных показало, что 92,64% публикаций Scopus были на английском языке, а соответствующая доля в Web of Science составила 95,37%.
Кроме того, импакт-фактор журнала значительно коррелирует с коэффициентом нецитируемости. Например, в журналах первого квартиля (JCR Q1) коэффициент нецитируемости статей и обзоров составляет 1,7%, тогда как в журналах четвертого квартиля (JCR Q4) этот показатель уже равен 27,4%.
Сохраняются различия в нецитируемости и между дисциплинами. Как правило, самый высокий коэффициент нецитируемости наблюдается в гуманитарных науках.
Нужно учитывать и тот факт, что на некоторые открытия ссылаются без явного цитирования. В библиометрии это явление называется «вытеснение путем инкорпорации» (OBI — obliteration by incorporation): превращение определенных идей в универсально разделяемые без последующего цитирования. Такой тип цитирования не может быть извлечен из списков цитируемых ссылок. Для его обнаружения требуется полнотекстовый анализ. Вся эти схемы цитирования порождают нецитируемость.
Данные, полученные в ходе исследования, доказывают также, что высокоцитируемые статьи не являются прямыми противоположностями нецитируемых. Нецитируемые работы — это не ошибка исторического развития науки, а естественный результат непоследовательности и перекоса распределения вкладов в науку.
#обзор #вышка #цитирование
Нецитируемые статьи и их влияние на концентрацию цитирования
В продолжение поста про нецитируемые публикации в структуре научной коммуникации сегодня расскажем об исследовании влияния нецитируемых статей на концентрацию цитирования. Анализ коллег основан на метаданных о публикациях, извлеченных из основной коллекции WoS, охватывающей публикации с 1980 по 2020 год.
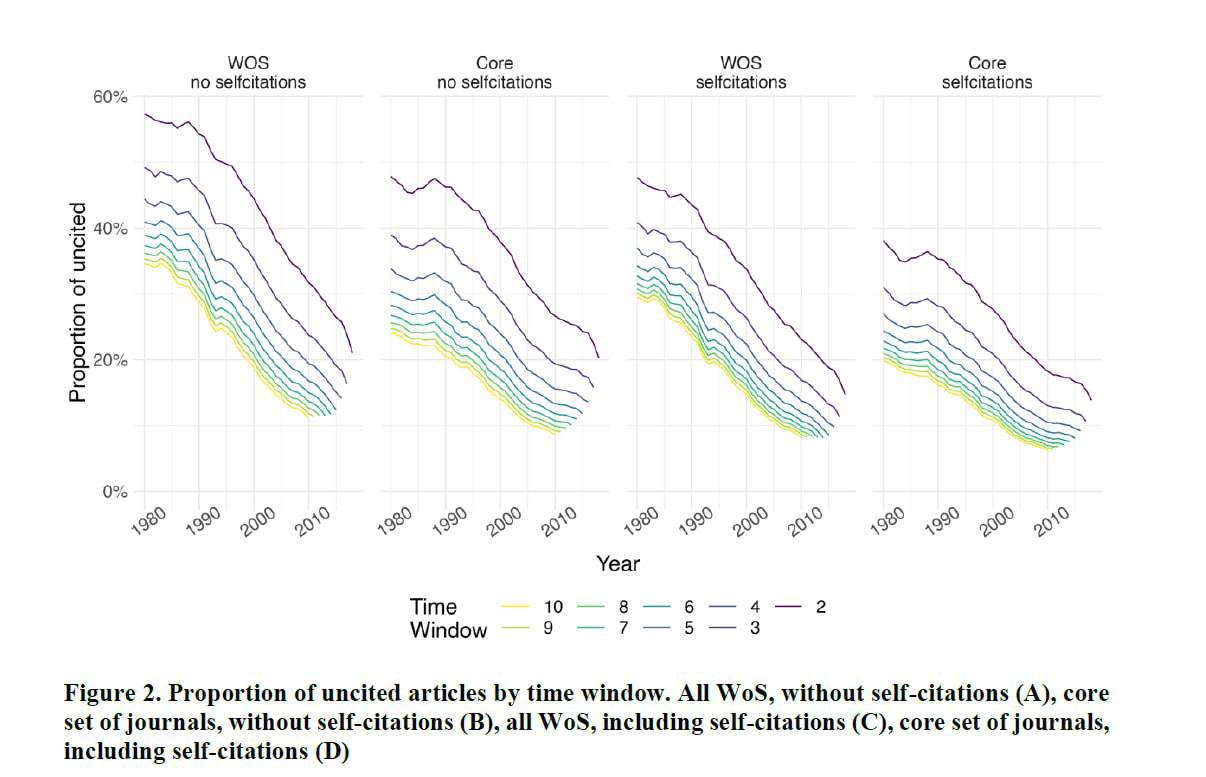
Для составления показателей концентрации коллеги используют два подхода: подход на основе цитирования и подход на основе ссылок. Подходы на основе цитирования и на основе ссылок различаются в отношении к статьям без ссылок. В подходе, основанном на цитировании, статьи без ссылок естественно включаются, поскольку процесс поиска данных начинается со всех статей, опубликованных в данном году. И наоборот, подход, основанный на ссылках, естественно исключает статьи без цитирования, поскольку анализ фокусируется на ссылках, сделанных в данном году. Кроме того, важно отметить, что количество нецитируемых статей имеет тенденцию к снижению с течением времени. Например, если рассматривать десятилетний период цитирования, то доля статей без ссылок снизилась с 34% в 1980 году до 11% в 2010 году среди всех статей в базе данных WoS, исключая самоцитирование.
Анализ показал, что наиболее надежным методом для анализа концентрации цитирования во времени является подход, основанный на цитировании, с учетом нецитируемых статей, с нормализацией по полю и году, а также с фиксированным временным окном. Необходимо также учитывать расширение библиометрических баз данных и эволюцию самоцитирования. Результаты этого метода показывают последовательное снижение концентрации цитирования.
Также было обнаружено, что различные регионы играют разную роль в своем вкладе в нецитируемость. Снижение относительной цитируемости статей Северной Америки и увеличение участия Европы и Азии влияет на структуру цитирования. В то время как Северная Америка по-прежнему составляет большую часть 1% самых цитируемых статей и производит много ссылок, которые получают эти статьи, ее роль среди статей, цитируемых только один раз, значительно ниже.
Выводы, сделанные в этой статье, подчеркивают важность учета нецитируемых статей и их потенциальное влияние на концентрацию цитирования.
#обзор #цитирование #wos
В продолжение поста про нецитируемые публикации в структуре научной коммуникации сегодня расскажем об исследовании влияния нецитируемых статей на концентрацию цитирования. Анализ коллег основан на метаданных о публикациях, извлеченных из основной коллекции WoS, охватывающей публикации с 1980 по 2020 год.
Для составления показателей концентрации коллеги используют два подхода: подход на основе цитирования и подход на основе ссылок. Подходы на основе цитирования и на основе ссылок различаются в отношении к статьям без ссылок. В подходе, основанном на цитировании, статьи без ссылок естественно включаются, поскольку процесс поиска данных начинается со всех статей, опубликованных в данном году. И наоборот, подход, основанный на ссылках, естественно исключает статьи без цитирования, поскольку анализ фокусируется на ссылках, сделанных в данном году. Кроме того, важно отметить, что количество нецитируемых статей имеет тенденцию к снижению с течением времени. Например, если рассматривать десятилетний период цитирования, то доля статей без ссылок снизилась с 34% в 1980 году до 11% в 2010 году среди всех статей в базе данных WoS, исключая самоцитирование.
Анализ показал, что наиболее надежным методом для анализа концентрации цитирования во времени является подход, основанный на цитировании, с учетом нецитируемых статей, с нормализацией по полю и году, а также с фиксированным временным окном. Необходимо также учитывать расширение библиометрических баз данных и эволюцию самоцитирования. Результаты этого метода показывают последовательное снижение концентрации цитирования.
Также было обнаружено, что различные регионы играют разную роль в своем вкладе в нецитируемость. Снижение относительной цитируемости статей Северной Америки и увеличение участия Европы и Азии влияет на структуру цитирования. В то время как Северная Америка по-прежнему составляет большую часть 1% самых цитируемых статей и производит много ссылок, которые получают эти статьи, ее роль среди статей, цитируемых только один раз, значительно ниже.
Выводы, сделанные в этой статье, подчеркивают важность учета нецитируемых статей и их потенциальное влияние на концентрацию цитирования.
#обзор #цитирование #wos
{kind=link}
Изменения в квартилях журналов WoS
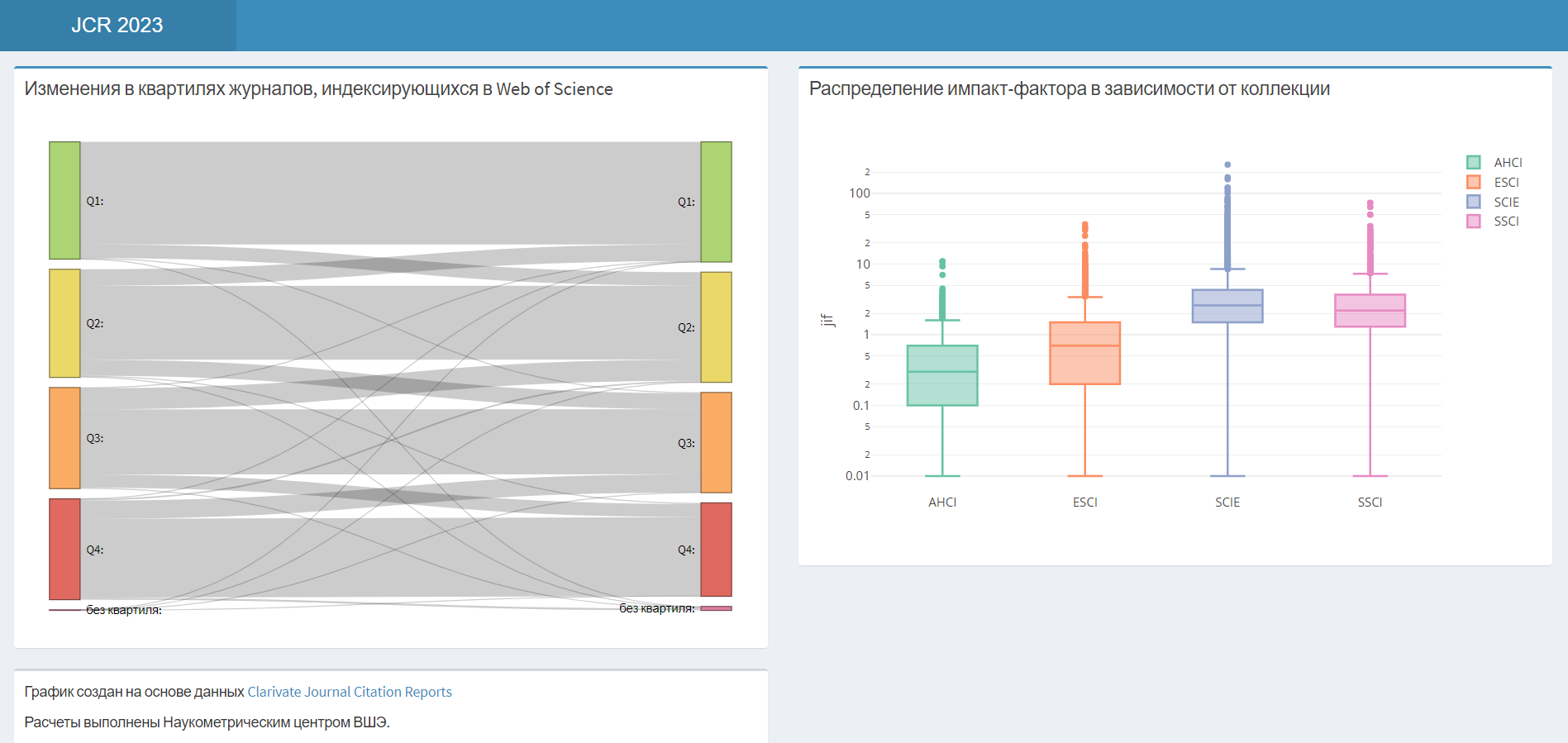
28 июня компания Clarivate опубликовала очередной список Journal Citation Reports (JCR), в котором приводится распределение по квартилям для всех журналов, индексирующихся в Web of Science.
Как и в случае с квартилями SJR, мы проанализировали «миграцию» журналов между квартилями. Кроме того, приведены диаграммы, показывающие различия в распределении самого импакт-фактора для разных коллекций (AHCI, ESCI, SCIE и SSCI). Нужно отметить, что для журналов из коллекций Arts and Humanities Citation Index (AHCI) и Emerging Sources Citation Index (ESCI) импакт-факторы опубликованы впервые.
#wos #журналы #инфографика #квартили
28 июня компания Clarivate опубликовала очередной список Journal Citation Reports (JCR), в котором приводится распределение по квартилям для всех журналов, индексирующихся в Web of Science.
Как и в случае с квартилями SJR, мы проанализировали «миграцию» журналов между квартилями. Кроме того, приведены диаграммы, показывающие различия в распределении самого импакт-фактора для разных коллекций (AHCI, ESCI, SCIE и SSCI). Нужно отметить, что для журналов из коллекций Arts and Humanities Citation Index (AHCI) и Emerging Sources Citation Index (ESCI) импакт-факторы опубликованы впервые.
#wos #журналы #инфографика #квартили
{kind=link}
И снова про Twitter: если вашу работу твитнули, какова вероятность, что ее процитируют?
В статье анализируется открытая база данных ученых в Twitter, о которой мы уже рассказывали ранее, а также отдельные твиты, содержащие ссылки на научные работы (Crossref Event Data 2023). Примерно 6,4 миллиона твитов, сделанных исследователями в этом наборе данных за 2017-2019 годы, были связаны с чуть более чем 1 миллионом отдельных DOI, найденных в таблице работ OpenAlex. Из 5 307 769 твитов, содержащих ссылки на журнальные статьи, 768 710 соответствовали ссылкам на работы, авторами которых был тот же пользователь Twitter, что составляет 14,5%.
Пользователи Twitter чаще цитируют :
• работы, связанные с их учебным заведением,
• работы, соавторами которых они являются,
• работы, имеющие непосредственное отношение к их собственным исследованиям,
• работы, опубликованные в журналах, в которых они тоже публиковались.
Из интересного:
• по мере развития карьеры и увеличения количества публикаций исследователи реже цитируют свои твиты,
• тематическое сходство твита с собственным исследованием и областью изучения оказывает большое влияние на связь между твитом и его последующим цитированием,
• чем больше работ исследователи публикуют в Twitter, тем меньше вероятность их цитирования,
• ученые, цитирующие свои собственные работы, могут показать, как Twitter может использоваться в качестве платформы для повышения узнаваемости собственной научной деятельности, утверждения себя в качестве эксперта в какой-либо области или расширения своего социального капитала .
#обзор #цитирование #twitter
В статье анализируется открытая база данных ученых в Twitter, о которой мы уже рассказывали ранее, а также отдельные твиты, содержащие ссылки на научные работы (Crossref Event Data 2023). Примерно 6,4 миллиона твитов, сделанных исследователями в этом наборе данных за 2017-2019 годы, были связаны с чуть более чем 1 миллионом отдельных DOI, найденных в таблице работ OpenAlex. Из 5 307 769 твитов, содержащих ссылки на журнальные статьи, 768 710 соответствовали ссылкам на работы, авторами которых был тот же пользователь Twitter, что составляет 14,5%.
Пользователи Twitter чаще цитируют :
• работы, связанные с их учебным заведением,
• работы, соавторами которых они являются,
• работы, имеющие непосредственное отношение к их собственным исследованиям,
• работы, опубликованные в журналах, в которых они тоже публиковались.
Из интересного:
• по мере развития карьеры и увеличения количества публикаций исследователи реже цитируют свои твиты,
• тематическое сходство твита с собственным исследованием и областью изучения оказывает большое влияние на связь между твитом и его последующим цитированием,
• чем больше работ исследователи публикуют в Twitter, тем меньше вероятность их цитирования,
• ученые, цитирующие свои собственные работы, могут показать, как Twitter может использоваться в качестве платформы для повышения узнаваемости собственной научной деятельности, утверждения себя в качестве эксперта в какой-либо области или расширения своего социального капитала .
#обзор #цитирование #twitter
Факторы, влияющие на публикацию в открытом доступе: на примере Springer Nature
Мы уже писали о проблеме перехода к открытому доступу (OA) и связанной с ним плате за обработку статей (APC). Многие авторы не могут позволить себе оплатить эти взносы. Таким образом ОА может скорее усугублять существующее неравенство в системе публикаций, чем преодолевать его. Коллеги провели исследование и изучили 522 411 статей, опубликованных в издательстве Springer Nature, чтобы выявить взаимосвязь между авторами, принадлежащими к странам с разным уровнем дохода, их выбором модели публикации и влиянием их статей на цитируемость. Была обнаружена сильная корреляция между уровнем журнала и моделью публикации в золотых ОА-журналах, в то время как в гибридных журналах ОА-вариант в основном отсутствует. Также положительная корреляция между цитированием и публикацией в открытом доступе в 1,3 раза слабее в странах с высоким уровнем дохода, чем в других странах.
Результаты исследования показывают, что:
• авторы, имеющие право на освобождение от платы за обработку статей (APC), публикуются в золотых ОА-журналах чаще, чем другие,
• авторы, имеющие право на скидку APC, имеют наименьший коэффициент публикаций в ОА-журналах (что позволяет предположить, что данная скидка недостаточно мотивирует авторов публиковаться в золотых ОА-журналах),
• наиболее значимыми факторами при выборе модели OA являются уровень дохода в стране, трудовой стаж и опыт OA-публикаций, пол автора оказывает наименьшее влияние.
#обзор #открытыйдоступ #apc #scopus
Мы уже писали о проблеме перехода к открытому доступу (OA) и связанной с ним плате за обработку статей (APC). Многие авторы не могут позволить себе оплатить эти взносы. Таким образом ОА может скорее усугублять существующее неравенство в системе публикаций, чем преодолевать его. Коллеги провели исследование и изучили 522 411 статей, опубликованных в издательстве Springer Nature, чтобы выявить взаимосвязь между авторами, принадлежащими к странам с разным уровнем дохода, их выбором модели публикации и влиянием их статей на цитируемость. Была обнаружена сильная корреляция между уровнем журнала и моделью публикации в золотых ОА-журналах, в то время как в гибридных журналах ОА-вариант в основном отсутствует. Также положительная корреляция между цитированием и публикацией в открытом доступе в 1,3 раза слабее в странах с высоким уровнем дохода, чем в других странах.
Результаты исследования показывают, что:
• авторы, имеющие право на освобождение от платы за обработку статей (APC), публикуются в золотых ОА-журналах чаще, чем другие,
• авторы, имеющие право на скидку APC, имеют наименьший коэффициент публикаций в ОА-журналах (что позволяет предположить, что данная скидка недостаточно мотивирует авторов публиковаться в золотых ОА-журналах),
• наиболее значимыми факторами при выборе модели OA являются уровень дохода в стране, трудовой стаж и опыт OA-публикаций, пол автора оказывает наименьшее влияние.
#обзор #открытыйдоступ #apc #scopus
О туризме в наукометрическом разрезе
Пока многие читатели "Выше квартилей" находятся в отпуске или готовятся к нему, мы решили поинтересоваться, как тема отдыха и путешествий освещается в научном мире.
Исследовались статьи базы OpenAlex, для которых указана тема "tourism" в 2018-2023 гг.
Вот некоторые результаты нашего анализа:
• В абсолютных значениях лидером оказались Индонезия и Китай, за ними следуют США и Великобритания.
• В относительных же величинах несмотря на общее небольшое количество публикаций лидируют небольшие курортные страны: Фиджи, Аруба, Багамы, Барбадос. У этих стран более 3% публикаций посвящено сфере туризма и гостеприимства. Более 2% - у Гайаны, Андорры, Маврикия, Французской Полинезии, Мальдив, Черногории, а у Ямайки и Кипра - более 1,5%.
• Нужно отметить, что эти величины тесно связаны с доходами стран от туризма (согласно данным UNWTO).
P.S. Картинка ученого-наукометриста в летнем отпуске сгенерирована Kandinsky 2.2 by Sber AI
#OpenAlex #открытыйдоступ #инфографика
Пока многие читатели "Выше квартилей" находятся в отпуске или готовятся к нему, мы решили поинтересоваться, как тема отдыха и путешествий освещается в научном мире.
Исследовались статьи базы OpenAlex, для которых указана тема "tourism" в 2018-2023 гг.
Вот некоторые результаты нашего анализа:
• В абсолютных значениях лидером оказались Индонезия и Китай, за ними следуют США и Великобритания.
• В относительных же величинах несмотря на общее небольшое количество публикаций лидируют небольшие курортные страны: Фиджи, Аруба, Багамы, Барбадос. У этих стран более 3% публикаций посвящено сфере туризма и гостеприимства. Более 2% - у Гайаны, Андорры, Маврикия, Французской Полинезии, Мальдив, Черногории, а у Ямайки и Кипра - более 1,5%.
• Нужно отметить, что эти величины тесно связаны с доходами стран от туризма (согласно данным UNWTO).
P.S. Картинка ученого-наукометриста в летнем отпуске сгенерирована Kandinsky 2.2 by Sber AI
#OpenAlex #открытыйдоступ #инфографика
Scientometrio в День эсперанто
Сегодня отмечается День эсперанто. В этот день в 1887 году Людвиг Заменгоф опубликовал учебник по одному из наиболее известных в мире искусственных международных языков, на активное развитие и использование которого возлагал большие надежды (название языка «эсперанто» отсылает к слову «надежда» и использовался самим Заменгофом в качестве псевдонима).
В основе эсперанто — романо-германские корни, есть заимствования из славянских языков, при этом грамматика максимально упрощена. За счет этого эсперанто значительно облегчает изучение других языков.
Сейчас языком эсперанто владеет по разным оценкам от ста тысяч до двух миллионов человек. Всеобщая ассоциация эсперанто насчитывает порядка 14 тысяч членов.
С точки зрения наукометрии эсперанто вряд ли можно считать объектом пристального изучения в мире: в базе OpenAlex индексируется всего лишь порядка тысячи статей и около 600 книг. Тем не менее публикации и книги выходят каждый год, и даже несмотря на повышение охвата нельзя не отметить, что со временем число публикаций постепенно увеличивается.
PS: В Scopus на данный момент индексируется 170 публикаций, для которых указан язык эсперанто, однако большинство из них на самом деле написаны на других языках — латышском и испанском. Судя по всему, в ряде случаев алгоритмы Scopus ошибочно определяют эти языки из-за максимального сходства с эсперанто.
#OpenAlex #открытыйдоступ #языки #эсперанто
https://i.ibb.co/BPQQTSd/Untitled.png
Сегодня отмечается День эсперанто. В этот день в 1887 году Людвиг Заменгоф опубликовал учебник по одному из наиболее известных в мире искусственных международных языков, на активное развитие и использование которого возлагал большие надежды (название языка «эсперанто» отсылает к слову «надежда» и использовался самим Заменгофом в качестве псевдонима).
В основе эсперанто — романо-германские корни, есть заимствования из славянских языков, при этом грамматика максимально упрощена. За счет этого эсперанто значительно облегчает изучение других языков.
Сейчас языком эсперанто владеет по разным оценкам от ста тысяч до двух миллионов человек. Всеобщая ассоциация эсперанто насчитывает порядка 14 тысяч членов.
С точки зрения наукометрии эсперанто вряд ли можно считать объектом пристального изучения в мире: в базе OpenAlex индексируется всего лишь порядка тысячи статей и около 600 книг. Тем не менее публикации и книги выходят каждый год, и даже несмотря на повышение охвата нельзя не отметить, что со временем число публикаций постепенно увеличивается.
PS: В Scopus на данный момент индексируется 170 публикаций, для которых указан язык эсперанто, однако большинство из них на самом деле написаны на других языках — латышском и испанском. Судя по всему, в ряде случаев алгоритмы Scopus ошибочно определяют эти языки из-за максимального сходства с эсперанто.
#OpenAlex #открытыйдоступ #языки #эсперанто
https://i.ibb.co/BPQQTSd/Untitled.png
{kind=link}
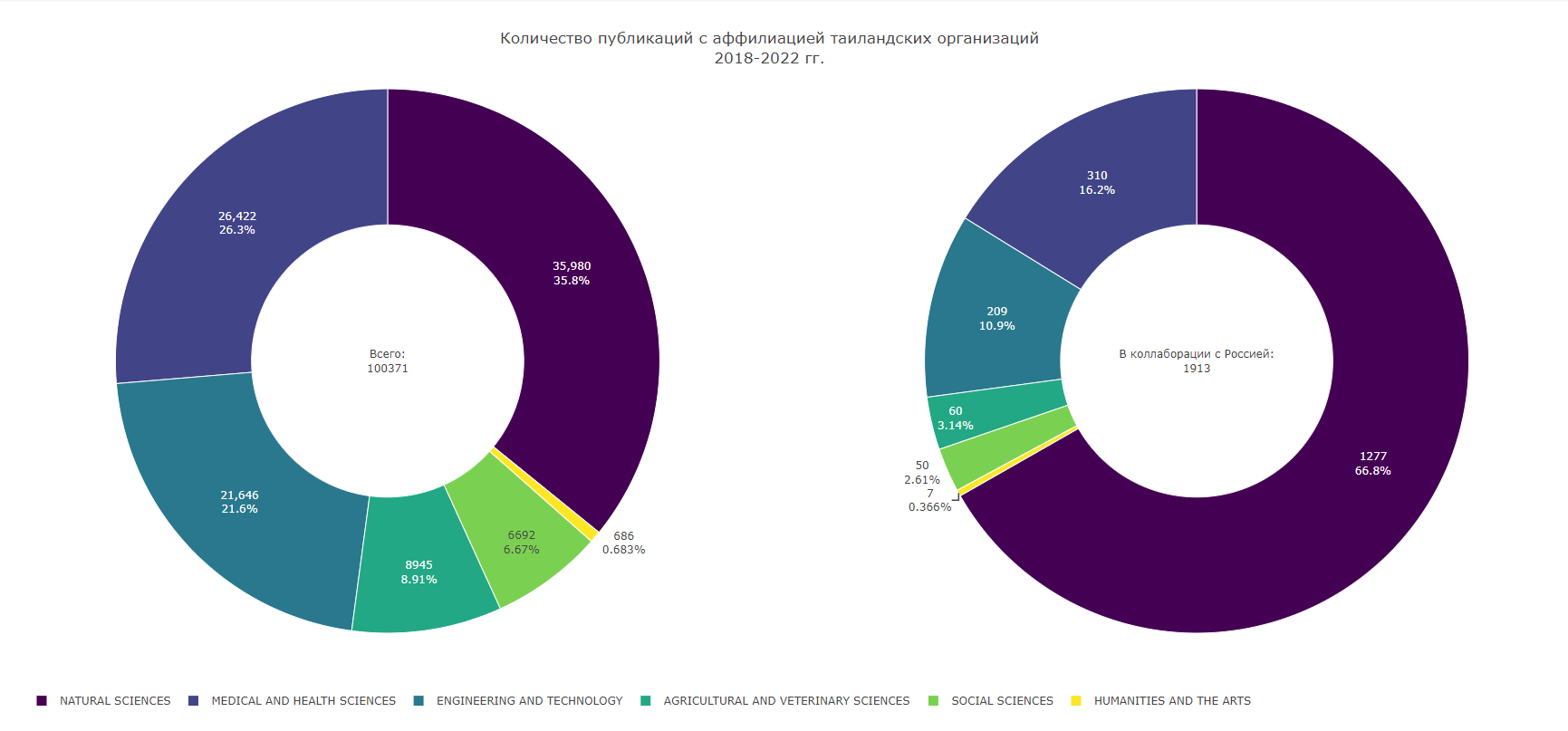
День науки в Таиланде
18 августа в Таиланде отмечается Национальный день науки. История этого праздника насчитывает 155 лет — он приурочен к солнечному затмению 1868 года, которое с исключительной точностью предсказал король Монгкут, правитель Сиама (ныне — Таиланд).
В современном Таиланде король Монгкут является весьма почитаемой фигурой. Его называют «Отцом науки и техники»: он принимал западные инновации и активно проводил модернизацию в Сиаме, а кроме того, занимался астрономией. Впоследствии солнечное затмение, к годовщине которого приурочен праздник, было названо в его честь.
На данный момент в Web of Science имеются профили 112 таиландских организаций, в том числе 88 университетов и 8 НИИ, и более чем 66 тысяч исследователей. По общему числу цитирований научных публикаций Таиланд занимает 44 место в мире и 14 в Азии. Распределение публикаций по тематикам представлено в нашей сегодняшней визуализации.
#WoS #национальныепраздники #деньнауки #Таиланд
18 августа в Таиланде отмечается Национальный день науки. История этого праздника насчитывает 155 лет — он приурочен к солнечному затмению 1868 года, которое с исключительной точностью предсказал король Монгкут, правитель Сиама (ныне — Таиланд).
В современном Таиланде король Монгкут является весьма почитаемой фигурой. Его называют «Отцом науки и техники»: он принимал западные инновации и активно проводил модернизацию в Сиаме, а кроме того, занимался астрономией. Впоследствии солнечное затмение, к годовщине которого приурочен праздник, было названо в его честь.
На данный момент в Web of Science имеются профили 112 таиландских организаций, в том числе 88 университетов и 8 НИИ, и более чем 66 тысяч исследователей. По общему числу цитирований научных публикаций Таиланд занимает 44 место в мире и 14 в Азии. Распределение публикаций по тематикам представлено в нашей сегодняшней визуализации.
#WoS #национальныепраздники #деньнауки #Таиланд
{kind=link}
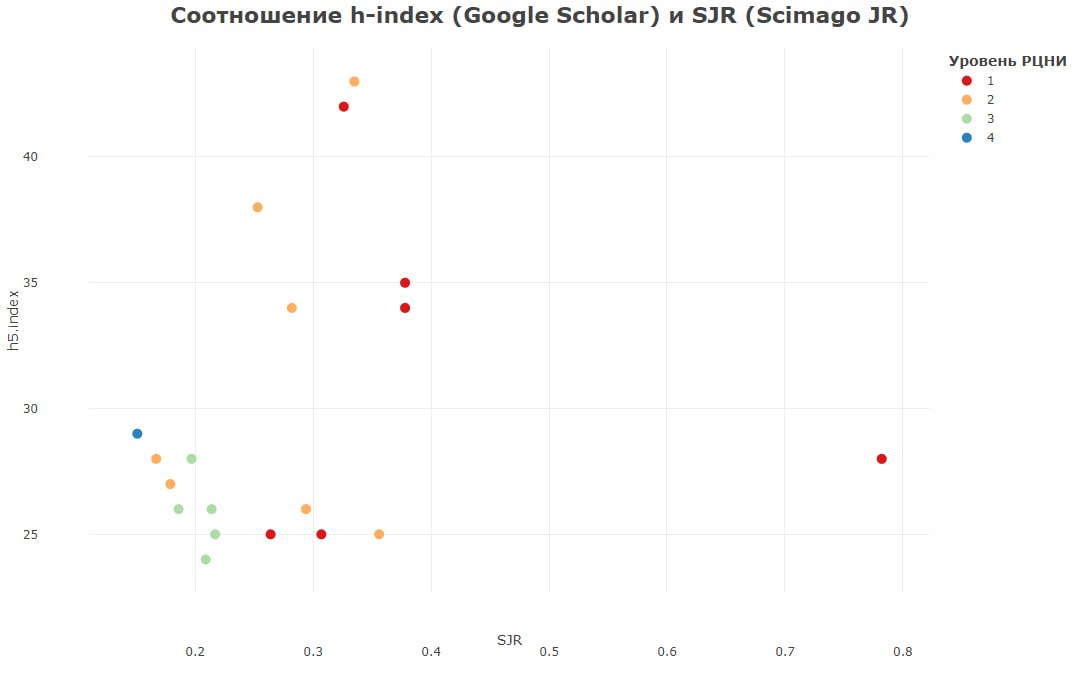
Метрики изданий в Google Scholar
В июле Google Scholar опубликовал обновленные данные по метрикам научных журналов, включая сборники материалов некоторых инженерных и IT-конференций. Из списка были исключены издания, в которых было размещено менее 100 публикаций за период с 2018 по 2022 г., а также те, у которых не было ни одной цитируемой статьи, вышедшей в данный пятилетний период. Дополнительно были опубликованы списки из 100 наиболее высоко оцененных журналов на 11 языках, включая русский.
Мы сравнили список российских журналов в Google Scholar, «белый» национальный список, размещенный на сайте РЦНИ, и метрики изданий в недавно опубликованном Scimago Journal Report. Из 100 журналов в русскоязычном списке Google Scholar в список РЦНИ входят 29, а в SJR — 19. Поскольку Google Scholar работает по поисковым алгоритмам, его охват намного выше, чем у многих других наукометрических баз, но он не предусматривает оценки качества источников, которые являются наиболее значимыми для отдельных наук. Поэтому в топ-100 входит достаточно много журналов, которые редко попадают в экспертные списки в связи с особенностями редакционной политики.
Google Scholar включает в себя большое количество перекрестных ссылок на цитируемые источники. Он достаточно удобен, если нужно быстро найти ссылку на оригинальную публикацию в конкретном журнале или проанализировать источники определенной статьи. Тем не менее широкий охват служит и определенным препятствием для адекватной оценки уровня и значимости отдельных изданий, так как селективность исходной выборки играет немаловажную роль в построении надежных показателей. Поэтому мы советуем с крайней осторожностью подходить к выбору места публикации лишь на основании представленных данных и обращаться к другим источникам, включая экспертные списки.
#GoogleScholar #рейтинги #hиндекс
В июле Google Scholar опубликовал обновленные данные по метрикам научных журналов, включая сборники материалов некоторых инженерных и IT-конференций. Из списка были исключены издания, в которых было размещено менее 100 публикаций за период с 2018 по 2022 г., а также те, у которых не было ни одной цитируемой статьи, вышедшей в данный пятилетний период. Дополнительно были опубликованы списки из 100 наиболее высоко оцененных журналов на 11 языках, включая русский.
Мы сравнили список российских журналов в Google Scholar, «белый» национальный список, размещенный на сайте РЦНИ, и метрики изданий в недавно опубликованном Scimago Journal Report. Из 100 журналов в русскоязычном списке Google Scholar в список РЦНИ входят 29, а в SJR — 19. Поскольку Google Scholar работает по поисковым алгоритмам, его охват намного выше, чем у многих других наукометрических баз, но он не предусматривает оценки качества источников, которые являются наиболее значимыми для отдельных наук. Поэтому в топ-100 входит достаточно много журналов, которые редко попадают в экспертные списки в связи с особенностями редакционной политики.
Google Scholar включает в себя большое количество перекрестных ссылок на цитируемые источники. Он достаточно удобен, если нужно быстро найти ссылку на оригинальную публикацию в конкретном журнале или проанализировать источники определенной статьи. Тем не менее широкий охват служит и определенным препятствием для адекватной оценки уровня и значимости отдельных изданий, так как селективность исходной выборки играет немаловажную роль в построении надежных показателей. Поэтому мы советуем с крайней осторожностью подходить к выбору места публикации лишь на основании представленных данных и обращаться к другим источникам, включая экспертные списки.
#GoogleScholar #рейтинги #hиндекс
{kind=link}
31 августа: День блога
В последний день лета отмечается День блога — дата, которую команда нашего небольшого наукометрического канала не могла обойти стороной. Впервые идея праздника возникла в 2005 году в Живом Журнале. Выбор 31.08 в качестве даты празднования неслучаен: цифры “3108” близки к англоязычному написанию слова “BLOG”. Форма блогов постоянно эволюционирует — от текстовых записей до аудио- и видео-подкастов, и блогосфера по-прежнему остается самым быстрорастущим сегментом Интернета. На начало 2022 года во Всемирной сети насчитывалось около 1,5 млрд блогов, а каждый месяц публикуется более 850 миллионов новых постов в блогах, то есть около 10 миллиардов постов в год.
В День блога принято писать короткие рецензии на 5 разных блогов и 31 августа публиковать эти записи у себя со ссылками на авторские страницы. Сегодня мы сделали небольшую подборку каналов, за которыми сами с интересом следим:
@national_subscription – активно развивающийся канал Российского центра научной информации (РЦНИ). Публикует официальную информацию о доступе к электронным ресурсам в рамках централизованной подписки, а также анонсы вебинаров и периодов тестового доступа к ресурсам различных издательств. Кроме того, здесь можно найти информацию о «Белом списке» научных журналов.
@lib_os – канал платформы "Библиотека для открытой науки" ГПНТБ СО РАН. Публикует большое количество актуальных новостей открытой науки.
@scientometrics_and_Research_Eval – канал наших коллег, в котором освещаются актуальные вопросы наукометрии и research evaluation.
@khokhlovAR – блог известного физика, академика Алексея Ремовича Хохлова. Интересный взгляд на науку “изнутри”, достаточно много постов о публикационной активности российских ученых и журналов, а также анализ и сравнение их показателей в различных наукометрических базах.
@begtin – канал Ивана Бегтина про открытые данные. Тематика канала будет интересна всем, кто интересуется данными в науке и не только.
#блоги #наукометрия
В последний день лета отмечается День блога — дата, которую команда нашего небольшого наукометрического канала не могла обойти стороной. Впервые идея праздника возникла в 2005 году в Живом Журнале. Выбор 31.08 в качестве даты празднования неслучаен: цифры “3108” близки к англоязычному написанию слова “BLOG”. Форма блогов постоянно эволюционирует — от текстовых записей до аудио- и видео-подкастов, и блогосфера по-прежнему остается самым быстрорастущим сегментом Интернета. На начало 2022 года во Всемирной сети насчитывалось около 1,5 млрд блогов, а каждый месяц публикуется более 850 миллионов новых постов в блогах, то есть около 10 миллиардов постов в год.
В День блога принято писать короткие рецензии на 5 разных блогов и 31 августа публиковать эти записи у себя со ссылками на авторские страницы. Сегодня мы сделали небольшую подборку каналов, за которыми сами с интересом следим:
@national_subscription – активно развивающийся канал Российского центра научной информации (РЦНИ). Публикует официальную информацию о доступе к электронным ресурсам в рамках централизованной подписки, а также анонсы вебинаров и периодов тестового доступа к ресурсам различных издательств. Кроме того, здесь можно найти информацию о «Белом списке» научных журналов.
@lib_os – канал платформы "Библиотека для открытой науки" ГПНТБ СО РАН. Публикует большое количество актуальных новостей открытой науки.
@scientometrics_and_Research_Eval – канал наших коллег, в котором освещаются актуальные вопросы наукометрии и research evaluation.
@khokhlovAR – блог известного физика, академика Алексея Ремовича Хохлова. Интересный взгляд на науку “изнутри”, достаточно много постов о публикационной активности российских ученых и журналов, а также анализ и сравнение их показателей в различных наукометрических базах.
@begtin – канал Ивана Бегтина про открытые данные. Тематика канала будет интересна всем, кто интересуется данными в науке и не только.
#блоги #наукометрия
HSE SciBot — бот по поиску журналов в Списках Вышки
Наша команда поздравляет подписчиков с Днем знаний! К этому дню мы решили приурочить официальный анонс нашего нового продукта, созданного в сотрудничестве со студентами Вышки.
Встречайте — HSE SciBot (@hse_scibot). Бот предназначен для поиска научных журналов, включенных в Списки НИУ ВШЭ. С помощью него можно проверить актуальную информацию по изданиям, а также сформировать выборку подходящих журналов при выборе места публикации. Для каждого издания приводится его название, ISSN, указание на вхождение в список НИУ ВШЭ, а также предметные области и ссылки.
Помимо стандартного функционала, в бот интегрирован inline-режим для поиска журналов с автоматическими подсказками. Чтобы воспользоваться им, введите в текстовое поле внутри бота @hse_scibot и пробел, а затем начинайте вводить название издания или его часть. Сценарии использования бота мы приводим ниже.
Список журналов в боте соответствует актуальным спискам Вышки и регулярно обновляется. Будем рады обратной связи (команда /feedback в боте).
#новости #анонс #бот #hse_scibot #спискивышки
Наша команда поздравляет подписчиков с Днем знаний! К этому дню мы решили приурочить официальный анонс нашего нового продукта, созданного в сотрудничестве со студентами Вышки.
Встречайте — HSE SciBot (@hse_scibot). Бот предназначен для поиска научных журналов, включенных в Списки НИУ ВШЭ. С помощью него можно проверить актуальную информацию по изданиям, а также сформировать выборку подходящих журналов при выборе места публикации. Для каждого издания приводится его название, ISSN, указание на вхождение в список НИУ ВШЭ, а также предметные области и ссылки.
Помимо стандартного функционала, в бот интегрирован inline-режим для поиска журналов с автоматическими подсказками. Чтобы воспользоваться им, введите в текстовое поле внутри бота @hse_scibot и пробел, а затем начинайте вводить название издания или его часть. Сценарии использования бота мы приводим ниже.
Список журналов в боте соответствует актуальным спискам Вышки и регулярно обновляется. Будем рады обратной связи (команда /feedback в боте).
#новости #анонс #бот #hse_scibot #спискивышки
Об индексе Хирша на среднем цитировании: новая метрика – старые проблемы?
В последние годы h-индекс остается одним из наиболее широко используемых и одновременно обсуждаемых наукометрических показателей (в том числе и в нашем руководстве). Так, совсем недавно мы рассказывали о рейтинговании изданий в Google Scholar на основе журнального индекса Хирша, отметив при этом определенные недостатки используемого подхода. Критики зачастую подчеркивают, что h-индекс недооценивает молодых ученых, к тому же с его помощью оказывается довольно сложно сравнивать различные дисциплинарные области, обладающие своими особенностями цитирования. Попытки скорректировать методологию подсчета предпринимались неоднократно, в том числе и самим Х. Хиршем.
Новое прочтение показателя предложено в недавней работе бельгийского ученого И. Фассина. В ней автор развивает представленную ранее идею о ha-индексе – наибольшем числе публикаций, которые получили не менее ha цитат в среднем по годам. Такая нормализация, по мнению автора, позволяет уравнивать ученых, начавших свою карьеру относительно недавно и добившихся определенных успехов в науке, и признанных исследователей, у которых со временем ha-индекс остается относительно стабильным (пример сравнения динамики показателей приведен на картинке по данным статьи). Еще более значимое различие выявляется на журнальных подборках статей: хотя для рассмотренных в статье изданий показатель ha-индекса не уменьшается с течением времени, он значительно быстрее фиксирует достижение плато уровня цитируемости, чем индекс Хирша, отражающий накопительный эффект.
Между тем набор ограничений по использованию полученного индекса, упоминаемых И. Фассином в заключении, сводится к стандартным для h-индекса проблемам: невозможности выявления особенностей цитирования в отдельных науках и отсутствию учета эффекта мегаколлабораций при оценке публикационной активности авторов. Эти и другие недостатки h-подобных индексов служат хорошим напоминанием о том, что к любым подобным количественным показателям следует относиться с особой осторожностью и тем более слепо не полагаться на них при оценке публикационной активности.
#hиндекс #руководство #исследования
В последние годы h-индекс остается одним из наиболее широко используемых и одновременно обсуждаемых наукометрических показателей (в том числе и в нашем руководстве). Так, совсем недавно мы рассказывали о рейтинговании изданий в Google Scholar на основе журнального индекса Хирша, отметив при этом определенные недостатки используемого подхода. Критики зачастую подчеркивают, что h-индекс недооценивает молодых ученых, к тому же с его помощью оказывается довольно сложно сравнивать различные дисциплинарные области, обладающие своими особенностями цитирования. Попытки скорректировать методологию подсчета предпринимались неоднократно, в том числе и самим Х. Хиршем.
Новое прочтение показателя предложено в недавней работе бельгийского ученого И. Фассина. В ней автор развивает представленную ранее идею о ha-индексе – наибольшем числе публикаций, которые получили не менее ha цитат в среднем по годам. Такая нормализация, по мнению автора, позволяет уравнивать ученых, начавших свою карьеру относительно недавно и добившихся определенных успехов в науке, и признанных исследователей, у которых со временем ha-индекс остается относительно стабильным (пример сравнения динамики показателей приведен на картинке по данным статьи). Еще более значимое различие выявляется на журнальных подборках статей: хотя для рассмотренных в статье изданий показатель ha-индекса не уменьшается с течением времени, он значительно быстрее фиксирует достижение плато уровня цитируемости, чем индекс Хирша, отражающий накопительный эффект.
Между тем набор ограничений по использованию полученного индекса, упоминаемых И. Фассином в заключении, сводится к стандартным для h-индекса проблемам: невозможности выявления особенностей цитирования в отдельных науках и отсутствию учета эффекта мегаколлабораций при оценке публикационной активности авторов. Эти и другие недостатки h-подобных индексов служат хорошим напоминанием о том, что к любым подобным количественным показателям следует относиться с особой осторожностью и тем более слепо не полагаться на них при оценке публикационной активности.
#hиндекс #руководство #исследования
{kind=link}
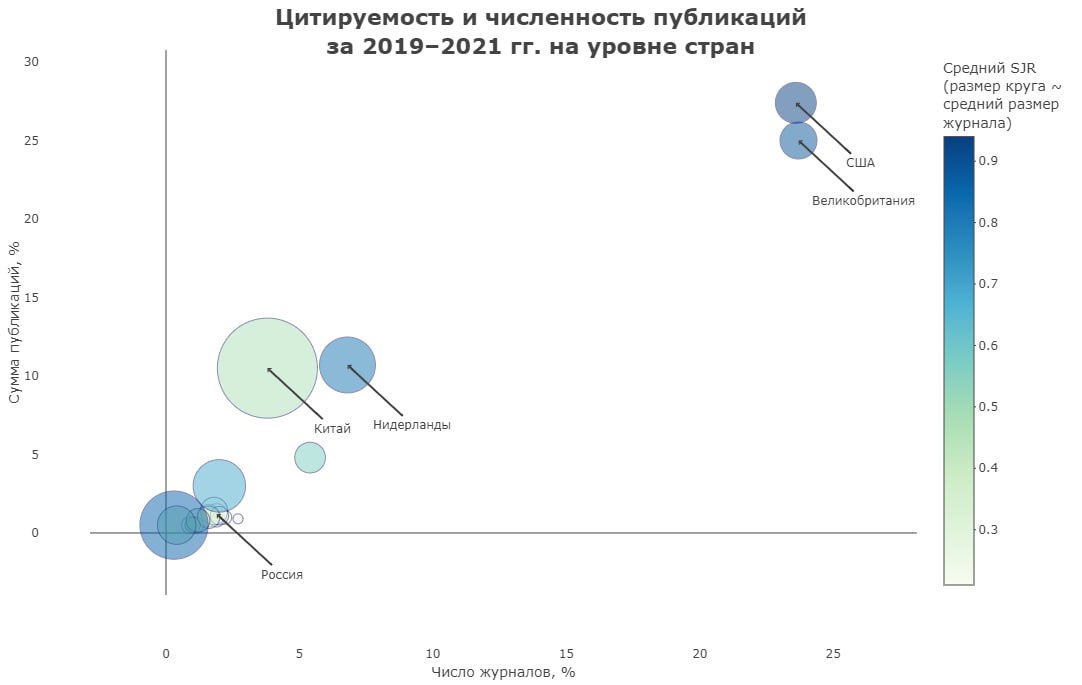
Кто контролирует научные журналы мира?
Китай уверенно обгоняет США и страны Европы по числу публикаций в журналах мирового уровня, динамика по Индии в последние годы также демонстрирует космический прирост. Заметный прогресс показывает Южная Корея и многие другие страны региона. Исходя из этих тенденций легко отметить, что научный мир стремительно становится более азиатским.
Как это соотносится со страновым распределением журналов? Давно известно, что оно крайне смещено, но насколько сегодня сохраняется это все более демонстративное неравенство?
Мы решили изучить вопрос с помощью открытых данных, а именно каталога сервиса ScimagoJR, хорошо знакомого российским авторам по «квартилям Scopus». Следует отметить, что сам Scopus давно убрал данные о стране регистрации журнала из своих публичных списков, а с недавних пор скрыл и сводные данные о числе публикаций. Отчасти это связано со сложностью определения страновой принадлежности: ориентироваться ли на владельца или адрес редакции (чаще всего виртуальный), а может быть на гражданство и место работы редакторов? У каждого из этих способов есть свои недостатки. Достоверно ответить на вопрос, каким из них воспользовались в Scimago нельзя. Вероятно, коллеги приписывали страны к журналам в ручном режиме, хотя и не всегда последовательно. Тем не менее у исследовательского сообщества имеется готовый набор открытых данных, совмещенных с наукометрическими показателями.
В рамках нашего исследования мы обратились к нему и проанализировали цитируемость и численность публикаций за 2019–2021 гг. Так, колоссальные диспропорции на уровне макрорегионов сохраняются по общему числу публикаций, по их цитируемости (выражена через средний показатель SJR) и по среднему размеру изданий (число статей за 3 года).
При этом если журналы MDPI перенести из номинальной Швейцарии к фактическому владельцу – Китаю, доля Азии по числу статей возрастает до 16%, а средний размер журнала – до беспрецедентных 419 публикаций на журнал. С учетом такой поправки распределение по странам выглядит следующим образом.
Несмотря на эти важные изменения, более половины журналов – и по числу статей, и по количеству изданий – все еще относятся к США и Великобритании, показатели цитируемости у них также наивысшие. Если считать по ссылкам (в абсолютном выражении, что некорректно (см. обсуждение в руководстве), но наглядно), на журналы США, Великобритании и Нидерландов в сумме приходится более 77% цитирований. На российские – всего 0,14 %.
Низкие показатели Франции, Италии и Испании отчасти определяются дисциплинарной спецификой – многие гуманитарные журналы этих стран издаются на национальных языках, а потому формально недостаточно цитируются даже с учетом SJR-нормировки. Впрочем, на фоне США и Китая в мировом масштабе эти величины достаточно малы.
Стоит ли именно в случае Китая как одного из центров современной науки ждать роста напряженности по линии «публикации в «наших»/«не наших» журналах»? На наш взгляд, вероятность этого минимальная. Для КНР еще долго будет ценна объективная внешняя экспертиза, качество редакций и рецензентов, техпроцессов, наработанный репутационный капитал, который обеспечивают Elsevier, SpringerNature и Wiley. Вопреки официальной позиции китайского руководства, Китай не спешит переходить исключительно на отечественные издания, продолжая следовать иному подходу к разработке публикационных стратегий своих авторов. Ведь даже MDPI в Китае официально не слишком приветствуется на национальном уровне.
Китай уверенно обгоняет США и страны Европы по числу публикаций в журналах мирового уровня, динамика по Индии в последние годы также демонстрирует космический прирост. Заметный прогресс показывает Южная Корея и многие другие страны региона. Исходя из этих тенденций легко отметить, что научный мир стремительно становится более азиатским.
Как это соотносится со страновым распределением журналов? Давно известно, что оно крайне смещено, но насколько сегодня сохраняется это все более демонстративное неравенство?
Мы решили изучить вопрос с помощью открытых данных, а именно каталога сервиса ScimagoJR, хорошо знакомого российским авторам по «квартилям Scopus». Следует отметить, что сам Scopus давно убрал данные о стране регистрации журнала из своих публичных списков, а с недавних пор скрыл и сводные данные о числе публикаций. Отчасти это связано со сложностью определения страновой принадлежности: ориентироваться ли на владельца или адрес редакции (чаще всего виртуальный), а может быть на гражданство и место работы редакторов? У каждого из этих способов есть свои недостатки. Достоверно ответить на вопрос, каким из них воспользовались в Scimago нельзя. Вероятно, коллеги приписывали страны к журналам в ручном режиме, хотя и не всегда последовательно. Тем не менее у исследовательского сообщества имеется готовый набор открытых данных, совмещенных с наукометрическими показателями.
В рамках нашего исследования мы обратились к нему и проанализировали цитируемость и численность публикаций за 2019–2021 гг. Так, колоссальные диспропорции на уровне макрорегионов сохраняются по общему числу публикаций, по их цитируемости (выражена через средний показатель SJR) и по среднему размеру изданий (число статей за 3 года).
При этом если журналы MDPI перенести из номинальной Швейцарии к фактическому владельцу – Китаю, доля Азии по числу статей возрастает до 16%, а средний размер журнала – до беспрецедентных 419 публикаций на журнал. С учетом такой поправки распределение по странам выглядит следующим образом.
Несмотря на эти важные изменения, более половины журналов – и по числу статей, и по количеству изданий – все еще относятся к США и Великобритании, показатели цитируемости у них также наивысшие. Если считать по ссылкам (в абсолютном выражении, что некорректно (см. обсуждение в руководстве), но наглядно), на журналы США, Великобритании и Нидерландов в сумме приходится более 77% цитирований. На российские – всего 0,14 %.
Низкие показатели Франции, Италии и Испании отчасти определяются дисциплинарной спецификой – многие гуманитарные журналы этих стран издаются на национальных языках, а потому формально недостаточно цитируются даже с учетом SJR-нормировки. Впрочем, на фоне США и Китая в мировом масштабе эти величины достаточно малы.
Стоит ли именно в случае Китая как одного из центров современной науки ждать роста напряженности по линии «публикации в «наших»/«не наших» журналах»? На наш взгляд, вероятность этого минимальная. Для КНР еще долго будет ценна объективная внешняя экспертиза, качество редакций и рецензентов, техпроцессов, наработанный репутационный капитал, который обеспечивают Elsevier, SpringerNature и Wiley. Вопреки официальной позиции китайского руководства, Китай не спешит переходить исключительно на отечественные издания, продолжая следовать иному подходу к разработке публикационных стратегий своих авторов. Ведь даже MDPI в Китае официально не слишком приветствуется на национальном уровне.
{kind=link}
День программиста: в России и наукометрии
Сегодня, в 256-й день года, в России отмечается День программиста. Этот профессиональный праздник, установленный Указом Президента, отмечается с 2009 года.
Программирование и IT-разработки являются неотъемлемой составляющей современной жизни, и с каждым годом ценность и востребованность IT-сферы только возрастает. Наукометрию (наравне с другими научными областями) отмеченные тренды также не обходят стороной. Сегодня уже сложно представить себе ученого, всерьез занимающегося научными разработками, без базовых навыков работы с данными и программными средствами.
Так, практически все крупные наукометрические базы данных сегодня имеют API, для работы с которым официальными держателями и энтузиастами разрабатываются пакеты и библиотеки на языках программирования. Мы собрали подборку ссылок на библиотеки наиболее распространенных баз и языков, для некоторых из которых приводятся также примеры кода. Предлагаем ознакомиться со страницей на Google Colab, а ниже приводим общий список библиотек. Описание основных функций и ссылки на скачивание пакетов можно найти на соответствующих страницах.
Python:
- pyalex, diophila, OpenAlexAPI - официальные библиотеки для доступа к API OpenAlex. OpenAlex отличается очень понятным и подробно описанным API, на самом сайте приведены примеры кода для работы с базой как раз на языке Python.
- crossrefapi и habanero - две наиболее актуальные библиотеки для работы с API CrossRef. Оба пакета регулярно обновляются, а разработчики доступны на GitHub и откликаются на обратную связь. Существует также официальная библиотека crossref_commons_py от CrossRef, однако за последний год она не обновлялась, и, вероятно, разработка временно приостановлена.
- fatcat-openapi-client - библиотека для доступа к Fatcat, автоматически сгенерированная OpenAPI Generator. Fatcat - дочерний проект Internet Archive, позволяющий осуществлять поиск библиографической информации по данным The Wayback Machine, среди общих материалов из коллекций archive.org и не только. Fatcat изначально ориентирован на работу через API.
- pyBibX - новая библиотека, ориентированная на работу с 3 базами (Scopus, Web of Science и PubMed). Позволяет проводить базовый разведывательный анализ набора публикаций. Пакет отличают широкие встроенные возможности визуализации (в нашем коде приводим только некоторые примеры).
- pySciSci - еще одна новая библиотека, в основе которой принцип построения "науки о науке" (Science of Science). Позволяет работать с большими датасетами (включая дампы Microsoft Academic Graph), рассчитывать метрики и проводить сетевой анализ. Уже в скором времени может стать одним из ключевых инструментов в области, в особенности если верить амбициозным планам разработчиков, с которыми можно ознакомиться в недавней статье.
R:
- openalexR - классический и наиболее простой в освоении пакет для работы с API OpenAlex в R. Имеет важную функцию oa_snowball, которая позволяет искать литературу методом “снежного кома”.
- rcrossref - пакет для работы с API CrossRef. Как и openalexR, входит в экосистему rOpenSci - большого проекта по обеспечению свободного и удобного доступа к научным данным в самых разнообразных областях.
- bibliometrix - пакет для работы с уже загруженными датасетами из Scopus, WoS, Dimensions, PubMed и Cochrane. Позволяет легко преобразовать json/xml в привычный формат датафрейма в R.
Отдельно стоит упомянуть более редкие пакеты для работы с Crossref - crossref (Javascript), serrano (Ruby), crossref-rs (rust) и pitaya (Julia).
P.S. Мы намеренно не упомянули широко известные библиотеки для работы с API Scopus, WoS и Dimensions, поскольку доступ к базам на данный момент затруднен. Готового решения нет и для eLibrary: API продолжает оставаться закрытым, а разработка библиотеки (на Python) приостановлена. Что же касается Google Scholar, то он не имеет официального API, а единственный автоматизированный путь получения данных - парсинг, сопряженный с рисками блокировки.
#API #GitHub #OpenAlex #CrossRef #FatCat #Python #R
Сегодня, в 256-й день года, в России отмечается День программиста. Этот профессиональный праздник, установленный Указом Президента, отмечается с 2009 года.
Программирование и IT-разработки являются неотъемлемой составляющей современной жизни, и с каждым годом ценность и востребованность IT-сферы только возрастает. Наукометрию (наравне с другими научными областями) отмеченные тренды также не обходят стороной. Сегодня уже сложно представить себе ученого, всерьез занимающегося научными разработками, без базовых навыков работы с данными и программными средствами.
Так, практически все крупные наукометрические базы данных сегодня имеют API, для работы с которым официальными держателями и энтузиастами разрабатываются пакеты и библиотеки на языках программирования. Мы собрали подборку ссылок на библиотеки наиболее распространенных баз и языков, для некоторых из которых приводятся также примеры кода. Предлагаем ознакомиться со страницей на Google Colab, а ниже приводим общий список библиотек. Описание основных функций и ссылки на скачивание пакетов можно найти на соответствующих страницах.
Python:
- pyalex, diophila, OpenAlexAPI - официальные библиотеки для доступа к API OpenAlex. OpenAlex отличается очень понятным и подробно описанным API, на самом сайте приведены примеры кода для работы с базой как раз на языке Python.
- crossrefapi и habanero - две наиболее актуальные библиотеки для работы с API CrossRef. Оба пакета регулярно обновляются, а разработчики доступны на GitHub и откликаются на обратную связь. Существует также официальная библиотека crossref_commons_py от CrossRef, однако за последний год она не обновлялась, и, вероятно, разработка временно приостановлена.
- fatcat-openapi-client - библиотека для доступа к Fatcat, автоматически сгенерированная OpenAPI Generator. Fatcat - дочерний проект Internet Archive, позволяющий осуществлять поиск библиографической информации по данным The Wayback Machine, среди общих материалов из коллекций archive.org и не только. Fatcat изначально ориентирован на работу через API.
- pyBibX - новая библиотека, ориентированная на работу с 3 базами (Scopus, Web of Science и PubMed). Позволяет проводить базовый разведывательный анализ набора публикаций. Пакет отличают широкие встроенные возможности визуализации (в нашем коде приводим только некоторые примеры).
- pySciSci - еще одна новая библиотека, в основе которой принцип построения "науки о науке" (Science of Science). Позволяет работать с большими датасетами (включая дампы Microsoft Academic Graph), рассчитывать метрики и проводить сетевой анализ. Уже в скором времени может стать одним из ключевых инструментов в области, в особенности если верить амбициозным планам разработчиков, с которыми можно ознакомиться в недавней статье.
R:
- openalexR - классический и наиболее простой в освоении пакет для работы с API OpenAlex в R. Имеет важную функцию oa_snowball, которая позволяет искать литературу методом “снежного кома”.
- rcrossref - пакет для работы с API CrossRef. Как и openalexR, входит в экосистему rOpenSci - большого проекта по обеспечению свободного и удобного доступа к научным данным в самых разнообразных областях.
- bibliometrix - пакет для работы с уже загруженными датасетами из Scopus, WoS, Dimensions, PubMed и Cochrane. Позволяет легко преобразовать json/xml в привычный формат датафрейма в R.
Отдельно стоит упомянуть более редкие пакеты для работы с Crossref - crossref (Javascript), serrano (Ruby), crossref-rs (rust) и pitaya (Julia).
P.S. Мы намеренно не упомянули широко известные библиотеки для работы с API Scopus, WoS и Dimensions, поскольку доступ к базам на данный момент затруднен. Готового решения нет и для eLibrary: API продолжает оставаться закрытым, а разработка библиотеки (на Python) приостановлена. Что же касается Google Scholar, то он не имеет официального API, а единственный автоматизированный путь получения данных - парсинг, сопряженный с рисками блокировки.
#API #GitHub #OpenAlex #CrossRef #FatCat #Python #R
{kind=link}