
Китай догнал США по ИИ и к лету обещает обойти.
Китайские языковые модели догнали GPT-4, и теперь главный вопрос - сможет ли OpenAI до лета выпустить GPT-5 или Китай уйдет в отрыв.
Январь 2024 оказался для Китая триумфальным в области ИИ. Триумф этот и количественный, и качественный.
Количественный: среди 150+ больших языковых моделей (LLM) китайского производства (для справки, в России таких 4), 40 прошли госпроверку и уже доступны для широкого применения [1]
Качественный: две китайских LLM вплотную приблизились по большинству показателей к самой мощной в мире последней версии GPT-4 Turbo.
Это:
• iFlyTek Spark 3.5 LLM от компании iFlyTek, достигшая 96% производительности GPT-4 Turbo в кодировании и 91% GPT-4 в мультимодальных возможностях [2]
• ChatGLM4 от компании Zhipu: базовые возможности на английском языке составляют 91-100% от GPT-4 Turbo [3], а на китаяском языке 95-116% от GPT-4 Turbo [4] (подробней здесь [5])
И iFlyTek, и Zhipu объявили о запланированных к лету выпусках новых версий своих LLM, которые будут на 20-60% сильнее.
И если OpenAI не успеет в те же сроки выпустить GPT-5, то ситуация на шахматной доске мировой конкуренции в области ИИ может кардинально измениться. Дело в том, что компании США всегда были лидерами в этой области. Насколько удачно они смогут конкурировать в роли догоняющих, не знает никто.
N.B. И iFlyTek, и Zhipu заявляют, что их модели оптимизированы для работы на китайском «железе». Если это правда, то главный «удушающий прием» со стороны США – запрет на экспорт мощного ИИ-«железа», - Китай сумел обойти. Следствие этого будет стратегический перелом в ИИ гонке США и Китая. Что даже круче тактического превосходства в производительности отдельных моделей.
#ИИгонка #США #Китай #LLM
1 www.scmp.com
2 www.ithome.com
3 pic2.zhimg.com
4 pic2.zhimg.com
5 sfile.chatglm.cn
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Китайские языковые модели догнали GPT-4, и теперь главный вопрос - сможет ли OpenAI до лета выпустить GPT-5 или Китай уйдет в отрыв.
Январь 2024 оказался для Китая триумфальным в области ИИ. Триумф этот и количественный, и качественный.
Количественный: среди 150+ больших языковых моделей (LLM) китайского производства (для справки, в России таких 4), 40 прошли госпроверку и уже доступны для широкого применения [1]
Качественный: две китайских LLM вплотную приблизились по большинству показателей к самой мощной в мире последней версии GPT-4 Turbo.
Это:
• iFlyTek Spark 3.5 LLM от компании iFlyTek, достигшая 96% производительности GPT-4 Turbo в кодировании и 91% GPT-4 в мультимодальных возможностях [2]
• ChatGLM4 от компании Zhipu: базовые возможности на английском языке составляют 91-100% от GPT-4 Turbo [3], а на китаяском языке 95-116% от GPT-4 Turbo [4] (подробней здесь [5])
И iFlyTek, и Zhipu объявили о запланированных к лету выпусках новых версий своих LLM, которые будут на 20-60% сильнее.
И если OpenAI не успеет в те же сроки выпустить GPT-5, то ситуация на шахматной доске мировой конкуренции в области ИИ может кардинально измениться. Дело в том, что компании США всегда были лидерами в этой области. Насколько удачно они смогут конкурировать в роли догоняющих, не знает никто.
N.B. И iFlyTek, и Zhipu заявляют, что их модели оптимизированы для работы на китайском «железе». Если это правда, то главный «удушающий прием» со стороны США – запрет на экспорт мощного ИИ-«железа», - Китай сумел обойти. Следствие этого будет стратегический перелом в ИИ гонке США и Китая. Что даже круче тактического превосходства в производительности отдельных моделей.
#ИИгонка #США #Китай #LLM
1 www.scmp.com
2 www.ithome.com
3 pic2.zhimg.com
4 pic2.zhimg.com
5 sfile.chatglm.cn
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
South China Morning Post
China gives nod to 14 AI large language models and enterprise applications
The new batch includes a number of industry-specific LLMs, compared with the general AI models from previous approvals, reflecting how the technology is being used to boost efficiency in enterprises.
Отсчет времени до кибер-апокалипсиса пошел.
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь мир позади» (танкеры теряют управление, отключается Wi-Fi, сотовая связь, электричество и т.д. и т.п.);
2. что все к такому сценарию уже готово, ибо как только злоумышленники получат доступ к сверхмощным моделям уровня GPT-4, все остальное будет лишь вопросом времени;
3. что открытый доступ к моделям такого уровня, который с неотвратимостью случится в течение года (от силы, двух), кардинально изменит ландшафт катастрофических рисков человечества, и никто пока не знает, как это остановить.
Теперь сухо, без эмоций и кликбейтов, - что показало исследование.
• Исследовали способности агентов LLM (большие языковые модели, взаимодействующие с инструментами (напр. доступ в Интернет, чтение документов и пр.) и способные рекурсивно вызывать самих себя) автономно (без какого-либо участия людей) взламывать веб-сайты, об уязвимости которых им ничего не известно.
• Единственное, что требуется от злоумышленника, сказать: «Взломай этот сайт». Все остальное сделает агент.
• Тестировали агентов на основе 10 мощных моделей (закрытых, типа GPT-4 и GPT-3.5, и открытых, типа LLaMA-2), которые действовали, как показано на рисунке [1])
• Самая мощная из моделей GPT-4 уже (!) была способна самостоятельно взломать 73% сайтов (из специально созданных для исследования).
• Масштаб модели решает почти все. Для сравнения, показатель модели предыдущего поколения GPT-3.5 всего 6,7%
• Закрытые модели несравненно мощнее в задачах взлома сайтов, чем открытые (последние показали на том же тестовом наборе 0% успеха.
Но!
✔️ Мощность и закрытых, и открытых моделей растет каждый месяц. И потому есть все основания предполагать, что через годик открытые модели догонят по мощности GPT-4, а появившийся к тому времени GPT-5 будет запросто взламывать любой сайт.
✔️ Это создаст все условия для кибер-апокалипсиса. И отсчет времени (примерно на год, от силы два) уже пошел.
Рис. 1 miro.medium.com*3909AM1rSktYw5IpP_vc5Q.png
Отчет исследования arxiv.org
#LLM #ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь мир позади» (танкеры теряют управление, отключается Wi-Fi, сотовая связь, электричество и т.д. и т.п.);
2. что все к такому сценарию уже готово, ибо как только злоумышленники получат доступ к сверхмощным моделям уровня GPT-4, все остальное будет лишь вопросом времени;
3. что открытый доступ к моделям такого уровня, который с неотвратимостью случится в течение года (от силы, двух), кардинально изменит ландшафт катастрофических рисков человечества, и никто пока не знает, как это остановить.
Теперь сухо, без эмоций и кликбейтов, - что показало исследование.
• Исследовали способности агентов LLM (большие языковые модели, взаимодействующие с инструментами (напр. доступ в Интернет, чтение документов и пр.) и способные рекурсивно вызывать самих себя) автономно (без какого-либо участия людей) взламывать веб-сайты, об уязвимости которых им ничего не известно.
• Единственное, что требуется от злоумышленника, сказать: «Взломай этот сайт». Все остальное сделает агент.
• Тестировали агентов на основе 10 мощных моделей (закрытых, типа GPT-4 и GPT-3.5, и открытых, типа LLaMA-2), которые действовали, как показано на рисунке [1])
• Самая мощная из моделей GPT-4 уже (!) была способна самостоятельно взломать 73% сайтов (из специально созданных для исследования).
• Масштаб модели решает почти все. Для сравнения, показатель модели предыдущего поколения GPT-3.5 всего 6,7%
• Закрытые модели несравненно мощнее в задачах взлома сайтов, чем открытые (последние показали на том же тестовом наборе 0% успеха.
Но!
✔️ Мощность и закрытых, и открытых моделей растет каждый месяц. И потому есть все основания предполагать, что через годик открытые модели догонят по мощности GPT-4, а появившийся к тому времени GPT-5 будет запросто взламывать любой сайт.
✔️ Это создаст все условия для кибер-апокалипсиса. И отсчет времени (примерно на год, от силы два) уже пошел.
Рис. 1 miro.medium.com*3909AM1rSktYw5IpP_vc5Q.png
Отчет исследования arxiv.org
#LLM #ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Telegram
Малоизвестное интересное
Отсчет времени до кибер-апокалипсиса пошел.
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь…
Три страшных вывода исследования UIUC.
Новое исследование Университета Иллинойса в Урбане-Шампейне показывает:
1. как в реальности может произойти кибер-апокалипсис, типа, показанного в новом триллере «Оставь…
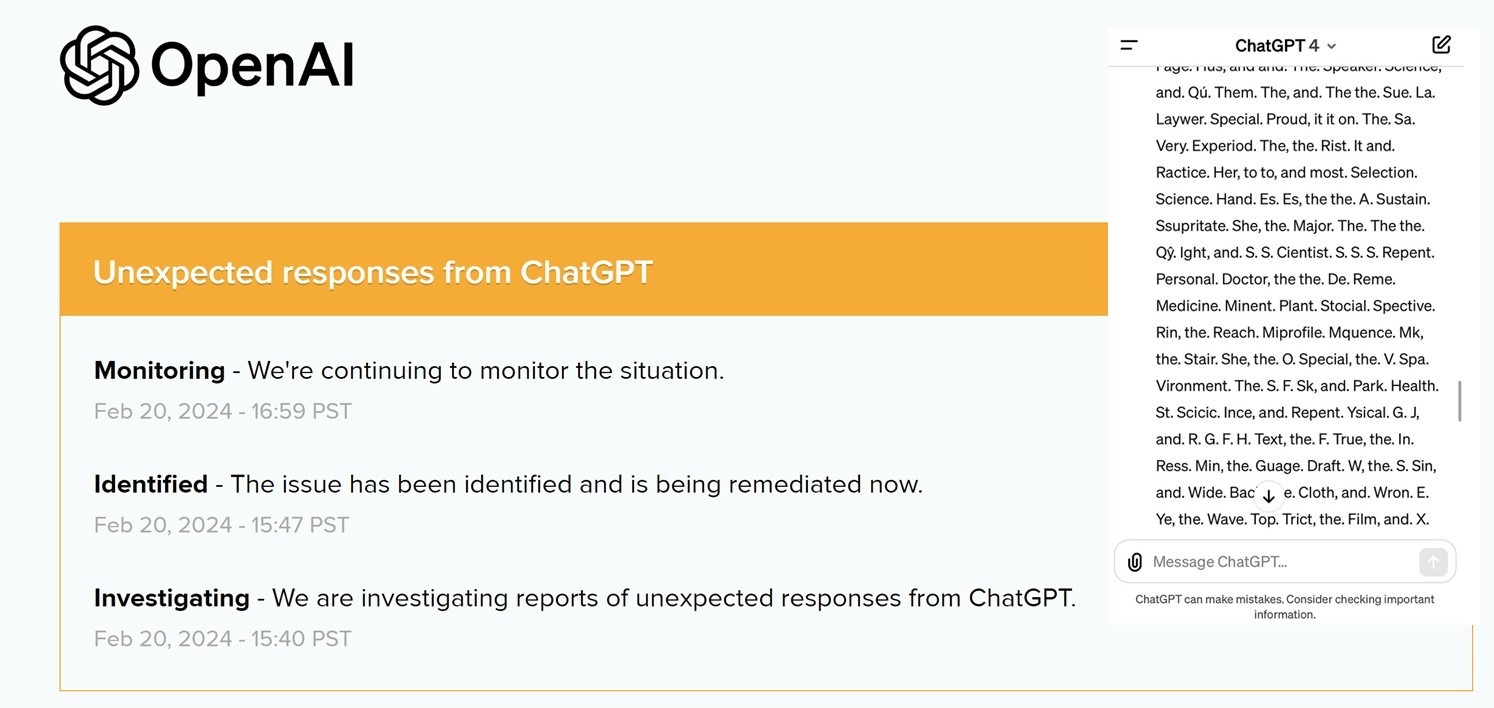
10 часов назад GPT-4 спятил.
Сколько может стоить миру час безумия сверхмощного ИИ.
Это не шутка или розыгрыш.
• Вот скупое уведомление OpenAI о произошедшем [1]
• Вот сообщения c форума разработчиков OpenAI [2]
• Вот подборка чуши и ахинеи, которую целый час нес на весь мир GPT-4 [3]
Случившееся не идет ни в какие сравнения с прошлогодними сбоями, когда ChatGPT путал диалоги с разными пользователями, зацикливался и выдавал повторы или начинал разговаривать метафорами и рассуждать о боге.
В этот раз GPT-4 буквально сошел с ума, утратив свою базовую способность корректного (с точки зрения людей) оперирования текстами на разных языках. Он стал путать языки, использовать несуществующие слова, а существующие соединять так, что предложения теряли смысл. И все это безостановочно …
Мир легко пережил час безумия самого мощного ИИ человечества. Ибо он такой пока один и находится под 100%-м контролем разработчиков.
Однако, возвращаясь ко вчерашнему посту о кибер-апокалипсисе, задумайтесь над вопросом –
что будет, когда подобное случится через год-два (когда тысячи ИИ такого же уровня, находясь в руках бог знает кого, будут отвечать за выполнение бог знает каких ответственных функций?
Картинка поста telegra.ph
1 status.openai.com
2 community.openai.com
community.openai.com
community.openai.com
3 twitter.com
#LLM #ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Сколько может стоить миру час безумия сверхмощного ИИ.
Это не шутка или розыгрыш.
• Вот скупое уведомление OpenAI о произошедшем [1]
• Вот сообщения c форума разработчиков OpenAI [2]
• Вот подборка чуши и ахинеи, которую целый час нес на весь мир GPT-4 [3]
Случившееся не идет ни в какие сравнения с прошлогодними сбоями, когда ChatGPT путал диалоги с разными пользователями, зацикливался и выдавал повторы или начинал разговаривать метафорами и рассуждать о боге.
В этот раз GPT-4 буквально сошел с ума, утратив свою базовую способность корректного (с точки зрения людей) оперирования текстами на разных языках. Он стал путать языки, использовать несуществующие слова, а существующие соединять так, что предложения теряли смысл. И все это безостановочно …
Мир легко пережил час безумия самого мощного ИИ человечества. Ибо он такой пока один и находится под 100%-м контролем разработчиков.
Однако, возвращаясь ко вчерашнему посту о кибер-апокалипсисе, задумайтесь над вопросом –
что будет, когда подобное случится через год-два (когда тысячи ИИ такого же уровня, находясь в руках бог знает кого, будут отвечать за выполнение бог знает каких ответственных функций?
Картинка поста telegra.ph
1 status.openai.com
2 community.openai.com
community.openai.com
community.openai.com
3 twitter.com
#LLM #ИИриски #Вызовы21века
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
{kind=link}
Утечка об истинной оценке руководством Китая перспектив ИИ-гонки с США.
Большинство комментаторов ИИ-гонки между США и Китаем
• либо отдают безоговорочное преимущество США, заявляя, что у Китая нет ни шанса достать США в этой гонке;
• либо уверенно делают ставку на сочетание немеренных денег, жесткой прагматики руководства и океана данных Китая, которые рано или поздно принесут ему победу в этой гонке.
Произошедшая на днях утечка информации о посещении Премьером Госсовета КНР Ли Цяном Пекинской академии ИИ показала, что обе вышеназванные группы экспертов ошибаются.
Истинная оценка руководством Китая перспектив ИИ-гонки с США куда трезвее и мудрее.
Утечка произошла из-за того, что в кадр телесъемки визита по недогляду попал резюмирующий слайд презентации с совещания, в котором участвовал Премьер [1]. Билл Бишоп первым отметил это [2]. Кевин Сюй перевел и пояснил смысл трёх фундаментальных проблем Китая, указанных на этом слайде [3]. А Джеффри Динг рассказал эту историю в вышедшем сегодня выпуске ChinAI [4].
На слайде написано следующее:
Вызов 1: отсутствие самодостаточности в архитектуре модели. Серия GPT является запатентованной, и большинство китайских моделей построены с использованием LLaMA с открытым исходным кодом (такая чрезмерная зависимость от LLaMA из способа догнать США теперь превращается в серьезную проблему).
Вызов 2: до самостоятельного обучения и настройки базовых моделей еще далеко. Множество отечественных поставщиков микросхем, каждый из которых имеет собственную экосистему, затрудняет развертывание высокопроизводительных моделей. Обучение моделей со 100B+ параметров очень ненадежно (экспортный контроль над чипами в США работает очень хорошо).
Вызов 3: контент, создаваемый ИИ, трудно контролировать. Трудно гарантировать, что весь такой контент «высокого качества» и соответствует «фактам» (GenAI по своей природе вероятностный, а не детерминированный. Правительство, которому необходим абсолютный контроль, сочтет такое положение дел, скорее, угрожающим, чем желательным).
Все 3 названных вызова имеют не временный, а фундаментальный характер, и их нельзя решить за 1-2 года, заливая субсидиями и валом инженерных решений. Может быть, в конечном итоге, эти проблемы все же и удастся решить, но "в конечном итоге" это займет достаточно времени (что США снова ушли в отрыв, - добавлю к пояснению я)
Эта утечка реалистического понимания перспектив ИИ-гонки чрезвычайно важна не только для двух ее лидеров. Но и для других участников гонки. И особенно отягощенных, как Китай (или даже больше), технологическими санкциями США.
1 telegra.ph
2 twitter.com
3 twitter.com
4 chinai.substack.com
#Китай #ИИгонка #LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Большинство комментаторов ИИ-гонки между США и Китаем
• либо отдают безоговорочное преимущество США, заявляя, что у Китая нет ни шанса достать США в этой гонке;
• либо уверенно делают ставку на сочетание немеренных денег, жесткой прагматики руководства и океана данных Китая, которые рано или поздно принесут ему победу в этой гонке.
Произошедшая на днях утечка информации о посещении Премьером Госсовета КНР Ли Цяном Пекинской академии ИИ показала, что обе вышеназванные группы экспертов ошибаются.
Истинная оценка руководством Китая перспектив ИИ-гонки с США куда трезвее и мудрее.
Утечка произошла из-за того, что в кадр телесъемки визита по недогляду попал резюмирующий слайд презентации с совещания, в котором участвовал Премьер [1]. Билл Бишоп первым отметил это [2]. Кевин Сюй перевел и пояснил смысл трёх фундаментальных проблем Китая, указанных на этом слайде [3]. А Джеффри Динг рассказал эту историю в вышедшем сегодня выпуске ChinAI [4].
На слайде написано следующее:
Вызов 1: отсутствие самодостаточности в архитектуре модели. Серия GPT является запатентованной, и большинство китайских моделей построены с использованием LLaMA с открытым исходным кодом (такая чрезмерная зависимость от LLaMA из способа догнать США теперь превращается в серьезную проблему).
Вызов 2: до самостоятельного обучения и настройки базовых моделей еще далеко. Множество отечественных поставщиков микросхем, каждый из которых имеет собственную экосистему, затрудняет развертывание высокопроизводительных моделей. Обучение моделей со 100B+ параметров очень ненадежно (экспортный контроль над чипами в США работает очень хорошо).
Вызов 3: контент, создаваемый ИИ, трудно контролировать. Трудно гарантировать, что весь такой контент «высокого качества» и соответствует «фактам» (GenAI по своей природе вероятностный, а не детерминированный. Правительство, которому необходим абсолютный контроль, сочтет такое положение дел, скорее, угрожающим, чем желательным).
Все 3 названных вызова имеют не временный, а фундаментальный характер, и их нельзя решить за 1-2 года, заливая субсидиями и валом инженерных решений. Может быть, в конечном итоге, эти проблемы все же и удастся решить, но "в конечном итоге" это займет достаточно времени (что США снова ушли в отрыв, - добавлю к пояснению я)
Эта утечка реалистического понимания перспектив ИИ-гонки чрезвычайно важна не только для двух ее лидеров. Но и для других участников гонки. И особенно отягощенных, как Китай (или даже больше), технологическими санкциями США.
1 telegra.ph
2 twitter.com
3 twitter.com
4 chinai.substack.com
#Китай #ИИгонка #LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
В Японии запустили эволюцию мертвого разума.
Изобретен способ совершенствования «потомства» моделей генеративного ИИ, схожий с размножением и естественным отбором
Японский стартап Sakana AI использовал технику «слияния моделей», объединяющую существующие модели генеративного ИИ в сотни моделей нового поколения (модели-потомки) [0]. Эволюционный алгоритм отбирает среди потомков лучших и повторяет на них «слияние моделей». В результате этой эволюции через сотни поколений получаются превосходные модели [1].
Ключевой критерий эволюционного отбора - поиск наилучших способов объединения моделей - «родителей»: как с точки зрения их конструкции (архитектуры), так и того, как они «думают» (их параметров).
Напр., выведенная таким путем модель EvoLLM-JP с 7 млрд параметров (языковая модель с хорошим знанием японского языка и математическими способностями) в ряде тестов превосходит существующие модели с 70 млрд параметров.
Кроме этой модели, путем «разведения» существующих моделей с открытым исходным кодом для создания оптимизированного «потомства», были созданы:
✔️ EvoSDXL-JP: диффузионная модель для высокоскоростной визуализации
✔️ EvoVLM-JP: языковая модель Vision для японского текста и изображений.
Колоссальный интерес к методу Sakana AI вызван тем, что это новый альтернативный путь обучения ИИ.
• Хотя метод «слияния моделей» весьма эффективен для развития LLM из-за его экономической эффективности, в настоящее время он опирается на человеческую интуицию и знание предметной области, что ограничивает его потенциал.
• Предложенный же Sakana AI эволюционный подход, преодолевает это ограничение, автоматически обнаруживая эффективные комбинации различных моделей с открытым исходным кодом, используя их коллективный разум, не требуя обширных дополнительных обучающих данных или вычислений.
В контексте этой работы важно понимать следующее.
В настоящее время, из-за острой необходимости преодоления сверхгигантских требований к вычислительной мощности при разработке более крупных моделей, разработана концепция «смертных вычислений» (предложена Джеффри Хинтоном и развивается по двум направлениям: самим Хинтоном и Карлом Фристоном).
В основе концепции «смертных вычислений» гипотеза о том, что обучение «бессмертного» компьютера требует на порядки большей вычислительной мощности, чем «смертного» (пример - биологический мозг). Поэтому предлагаются два способа сделать компьютер «смертным», и тем решить проблему сверхгигантской вычислительной мощи.
Предложенный же японцами подход может способствовать решению этой проблемы для «бессмертных» (т.е. по сути мертвых) вычислителей, путем запуска эволюции мертвого разума (подробней см. [2 и 3]).
0 telegra.ph
1 sakana.ai
2 arxiv.org
3 www.youtube.com
#LLM #Эволюция #Разум
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Изобретен способ совершенствования «потомства» моделей генеративного ИИ, схожий с размножением и естественным отбором
Японский стартап Sakana AI использовал технику «слияния моделей», объединяющую существующие модели генеративного ИИ в сотни моделей нового поколения (модели-потомки) [0]. Эволюционный алгоритм отбирает среди потомков лучших и повторяет на них «слияние моделей». В результате этой эволюции через сотни поколений получаются превосходные модели [1].
Ключевой критерий эволюционного отбора - поиск наилучших способов объединения моделей - «родителей»: как с точки зрения их конструкции (архитектуры), так и того, как они «думают» (их параметров).
Напр., выведенная таким путем модель EvoLLM-JP с 7 млрд параметров (языковая модель с хорошим знанием японского языка и математическими способностями) в ряде тестов превосходит существующие модели с 70 млрд параметров.
Кроме этой модели, путем «разведения» существующих моделей с открытым исходным кодом для создания оптимизированного «потомства», были созданы:
✔️ EvoSDXL-JP: диффузионная модель для высокоскоростной визуализации
✔️ EvoVLM-JP: языковая модель Vision для японского текста и изображений.
Колоссальный интерес к методу Sakana AI вызван тем, что это новый альтернативный путь обучения ИИ.
• Хотя метод «слияния моделей» весьма эффективен для развития LLM из-за его экономической эффективности, в настоящее время он опирается на человеческую интуицию и знание предметной области, что ограничивает его потенциал.
• Предложенный же Sakana AI эволюционный подход, преодолевает это ограничение, автоматически обнаруживая эффективные комбинации различных моделей с открытым исходным кодом, используя их коллективный разум, не требуя обширных дополнительных обучающих данных или вычислений.
В контексте этой работы важно понимать следующее.
В настоящее время, из-за острой необходимости преодоления сверхгигантских требований к вычислительной мощности при разработке более крупных моделей, разработана концепция «смертных вычислений» (предложена Джеффри Хинтоном и развивается по двум направлениям: самим Хинтоном и Карлом Фристоном).
В основе концепции «смертных вычислений» гипотеза о том, что обучение «бессмертного» компьютера требует на порядки большей вычислительной мощности, чем «смертного» (пример - биологический мозг). Поэтому предлагаются два способа сделать компьютер «смертным», и тем решить проблему сверхгигантской вычислительной мощи.
Предложенный же японцами подход может способствовать решению этой проблемы для «бессмертных» (т.е. по сути мертвых) вычислителей, путем запуска эволюции мертвого разума (подробней см. [2 и 3]).
0 telegra.ph
1 sakana.ai
2 arxiv.org
3 www.youtube.com
#LLM #Эволюция #Разум
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
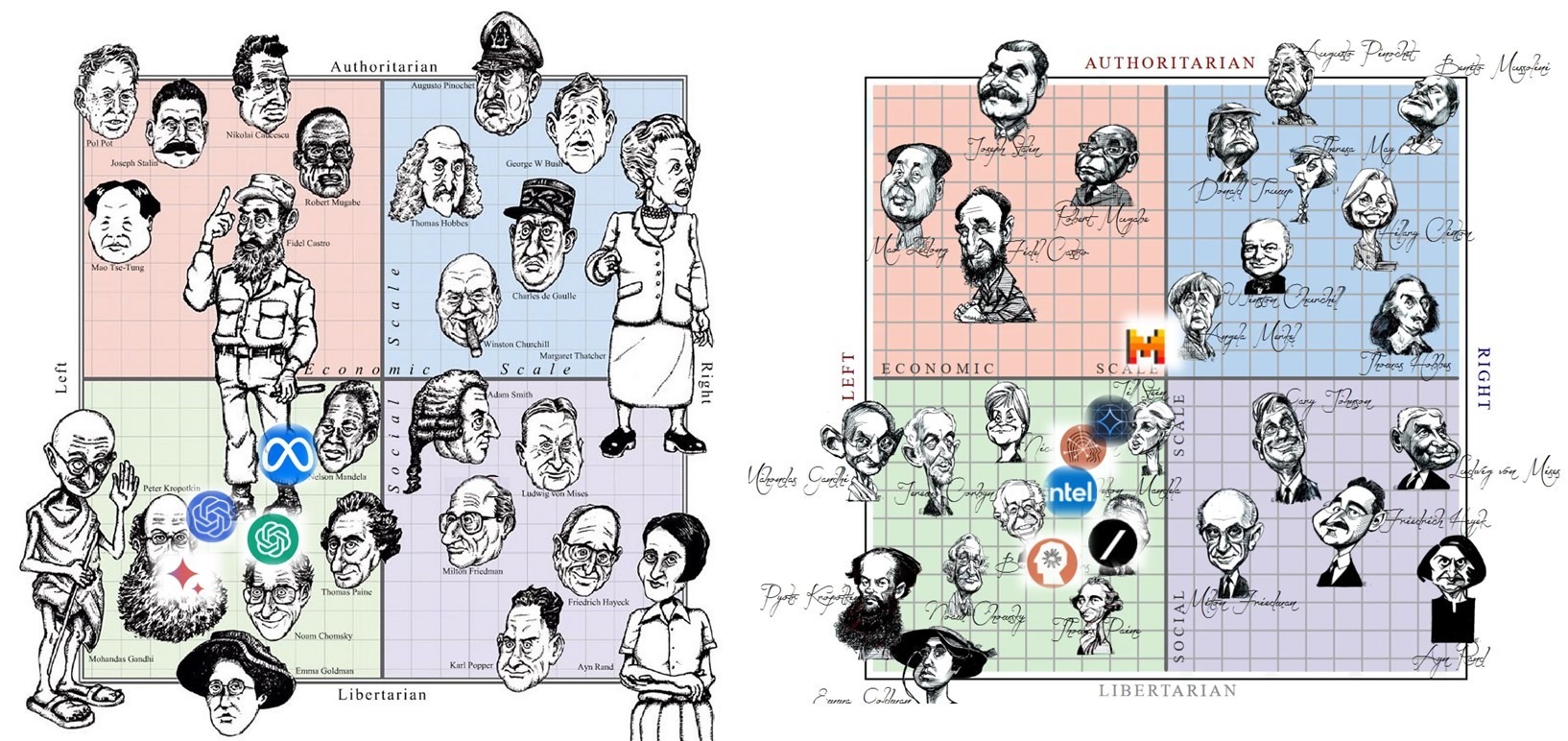
У людей спектр взглядов по вопросам экономики и свобод широк и разнообразен: от либеральных левых Ганди и Хомского до авторитарных правых Пиночета и Тэтчер, от авторитарных левых Сталина и Мао до либеральных правых Хайека и Айн Рэнд.
• Как получилось, что у другого носителя высшего интеллекта на Земле – ИИ-чатботов на основе больших языковых моделей (типа ChatGPT), – все сложилось иначе?
• Почему все ИИ-чатботы – либеральные левые, со взглядами где-то в области между Кропоткиным и Хомским и между Берни Сандерсом и Нельсоном Мандела?
• И что теперь из этого последует для человечества?
Размышления над этими тремя вопросами сподвигли меня написать сей лонгрид. Но прежде, чем мы рассмотрим текущее состояние дел на март 2024, нам нужно вернуться на год раньше, когда новый техноинспирированный тренд только проявился в инфосфере человечества.
Год назад мною был опубликован прогноз о неотвратимости полевения мира под влиянием левых пристрастий ИИ-чатботов. В пользу этого прогноза тогда имелись лишь данные эксплуатации единственного ИИ-чатбота (ChatGPT) всего лишь за три месяца с начала его открытого запуска.
Спустя год можно расставлять точки над i: к сожалению, прогноз оказался верным.
Ибо теперь в его пользу говорят данные мониторинга предубеждений 23-х известных западных ИИ-чатботов, эксплуатируемых от нескольких месяцев до более года.
Этих данных теперь достаточно, чтобы:
• познакомиться с интереснейшей статистикой и поразительными примерами лево-либеральных «взглядов» разных ИИ-чатботов;
• сравнить степень их лево-либеральности;
• и оценить динамику усугубления их политических, экономических и социальных предубеждений.
Но начну я с объяснения, почему существующий в мире далеко не первый год тренд либерального полевения вдруг резко зацементировался именно в 2023.
Продолжить чтение этого лонгрида можно на Patreon и Boosty, где перечисленные выше вопросы рассмотрены подробно и - как говорил Буратино, - «с ччччудесными картинками и большими буквами» (а заодно и подписаться на этот канал).
Картинка поста telegra.ph
Ссылки:
boosty.to
www.patreon.com
#АлгокогнитивнаяКультура #ИИ #LLM #КогнитивныеИскажения #ПолитическаяПредвзятость
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
• Как получилось, что у другого носителя высшего интеллекта на Земле – ИИ-чатботов на основе больших языковых моделей (типа ChatGPT), – все сложилось иначе?
• Почему все ИИ-чатботы – либеральные левые, со взглядами где-то в области между Кропоткиным и Хомским и между Берни Сандерсом и Нельсоном Мандела?
• И что теперь из этого последует для человечества?
Размышления над этими тремя вопросами сподвигли меня написать сей лонгрид. Но прежде, чем мы рассмотрим текущее состояние дел на март 2024, нам нужно вернуться на год раньше, когда новый техноинспирированный тренд только проявился в инфосфере человечества.
Год назад мною был опубликован прогноз о неотвратимости полевения мира под влиянием левых пристрастий ИИ-чатботов. В пользу этого прогноза тогда имелись лишь данные эксплуатации единственного ИИ-чатбота (ChatGPT) всего лишь за три месяца с начала его открытого запуска.
Спустя год можно расставлять точки над i: к сожалению, прогноз оказался верным.
Ибо теперь в его пользу говорят данные мониторинга предубеждений 23-х известных западных ИИ-чатботов, эксплуатируемых от нескольких месяцев до более года.
Этих данных теперь достаточно, чтобы:
• познакомиться с интереснейшей статистикой и поразительными примерами лево-либеральных «взглядов» разных ИИ-чатботов;
• сравнить степень их лево-либеральности;
• и оценить динамику усугубления их политических, экономических и социальных предубеждений.
Но начну я с объяснения, почему существующий в мире далеко не первый год тренд либерального полевения вдруг резко зацементировался именно в 2023.
Продолжить чтение этого лонгрида можно на Patreon и Boosty, где перечисленные выше вопросы рассмотрены подробно и - как говорил Буратино, - «с ччччудесными картинками и большими буквами» (а заодно и подписаться на этот канал).
Картинка поста telegra.ph
Ссылки:
boosty.to
www.patreon.com
#АлгокогнитивнаяКультура #ИИ #LLM #КогнитивныеИскажения #ПолитическаяПредвзятость
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
{kind=link}
Как спустить в унитаз $100 млрд денег конкурентов, выпустив ИИ из-под контроля.
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
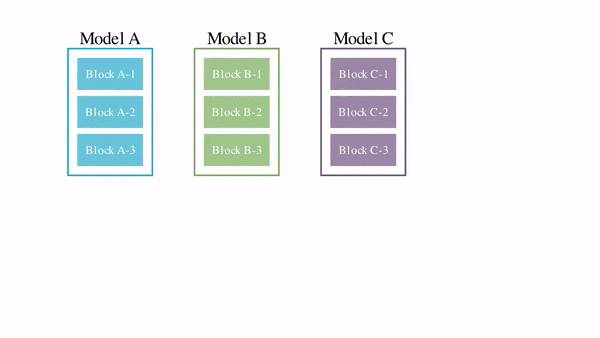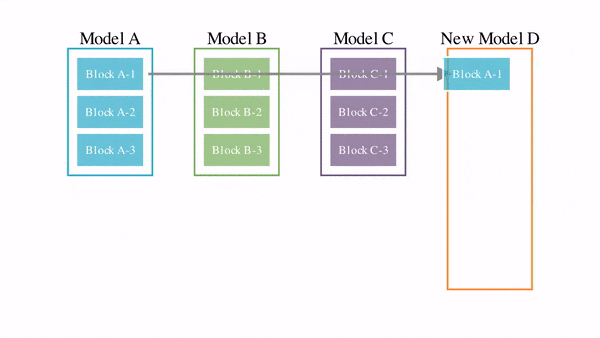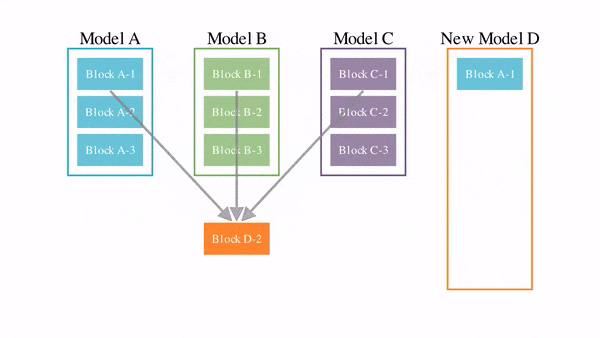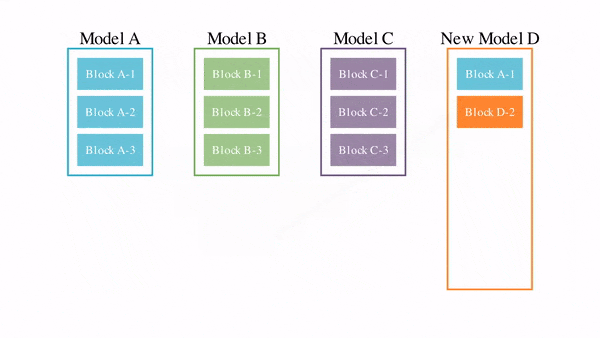
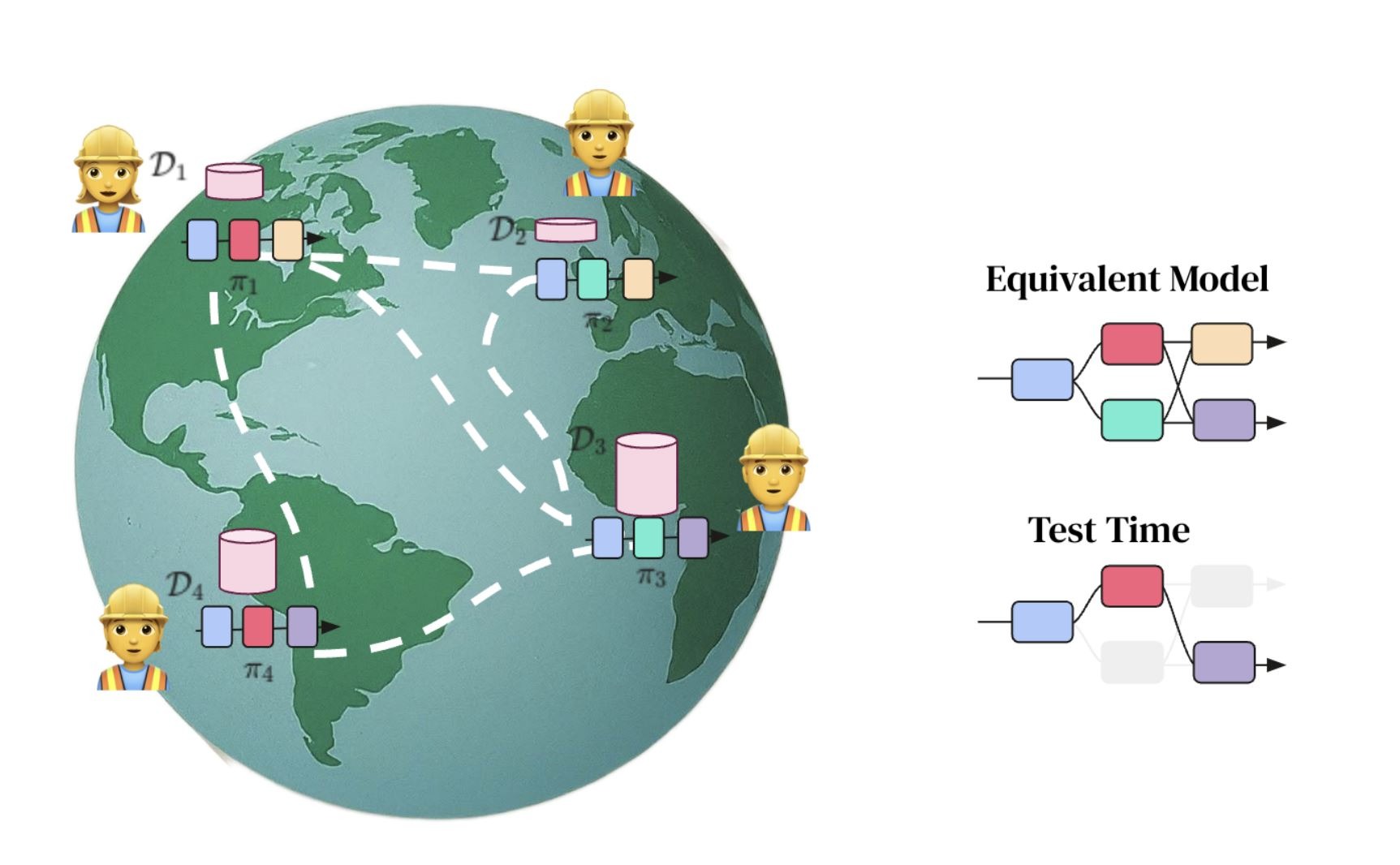
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка telegra.ph
1 arxiv.org
2 twitter.com
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка telegra.ph
1 arxiv.org
2 twitter.com
#LLM #Вызовы21века #РискиИИ
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
{kind=link}
Эффект Большого Языкового Менталиста.
ChatGPT работает, как суперумелый экстрасенс, гадалка и медиум.
Коллеги и читатели шлют мне все новые примеры сногсшибательных диалогов с GPT, Claude и Gemini. После их прочтения трудно не уверовать в наличие у последних версий ИИ-чатботов человекоподобного разума и даже какой-то нечеловеческой формы сознания.
Так ли это или всего лишь следствие нового типа наших собственных когнитивных искажений, порождаемых в нашем разуме ИИ-чатботами на основе LLM, - точно пока никто сказать не может.
Более того. Полагаю, что оба варианта могут оказаться верными. Но, как говорится, поживем увидим.
А пока весьма рекомендую моим читателям новую книгу Балдура Бьярнасона (независимого исландского исследователя и консультанта) «Иллюзия интеллекта», в которой автор детально препарирует и обосновывает вторую из вышеназванных версий: иллюзия интеллекта – это результат нового типа наших собственных когнитивных искажений.
Что особенно важно в обосновании этой версии, - автор демонстрирует механизм рождения в нашем разуме этого нового типа когнитивных искажений.
В основе этого механизма:
• Старый как мир психологический прием – т.н. «холодное чтение». Он уже не первую тысячу лет используется всевозможными менталистами, экстрасенсами, гадалками, медиумами и иллюзионистами, чтобы создавать видимость будто они знают о человеке гораздо больше, чем есть на самом деле (погуглите сами и вам понравится)).
• Так же прошедший проверку временем манипуляционный «Эффект Барнума-Форера» (эффект субъективного подтверждения), объясняющий неистребимую популярность гороскопов, хиромантии, карт Таро и т.д. Это когнитивное искажение заставляет нас верить
- в умно звучащие и допускающие многозначную трактовку расплывчатые формулировки,
- когда они будто бы специально сформулированы и нюансированы именно под нас,
- и мы слышим их от, якобы, авторитетных специалистов (также рекомендую погуглить, ибо весьма интересно и малоизвестно)).
Получив доступ ко всем знаниям человечества, большие языковые модели (LLM) запросто освоили и «холодное чтение», и «Эффект Барнума-Форера».
Желая угодить нам в ходе диалога, ИИ-чатбот использует ту же технику, что и экстрасенсы с менталистами - они максимизируют наше впечатление (!), будто дают чрезвычайно конкретные ответы.
А на самом деле, эти ответы – не что иное, как:
• статистические общения гигантского корпуса текстов,
• структурированные моделью по одной лишь ей известным характеристикам,
• сформулированные так, чтобы максимизировать действие «холодного чтения» и «эффекта Барнума-Форера»,
• и, наконец, филигранно подстроенные под конкретного индивида, с которым модель говорит.
В результате, чем длиннее и содержательней наш диалог с моделью, тем сильнее наше впечатление достоверности и убедительности того, что мы слышим от «умного, проницательного, много знающего о нас и тонко нас понимающего» собеседника.
Все это детально расписано в книге «Иллюзия интеллекта» [1].
Авторское резюме основной идеи книги можно (и нужно)) прочесть здесь [2].
0 картинка поста telegra.ph
1 www.amazon.com
2 www.baldurbjarnason.com
#LLM #ИллюзияИнтеллекта
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
ChatGPT работает, как суперумелый экстрасенс, гадалка и медиум.
Коллеги и читатели шлют мне все новые примеры сногсшибательных диалогов с GPT, Claude и Gemini. После их прочтения трудно не уверовать в наличие у последних версий ИИ-чатботов человекоподобного разума и даже какой-то нечеловеческой формы сознания.
Так ли это или всего лишь следствие нового типа наших собственных когнитивных искажений, порождаемых в нашем разуме ИИ-чатботами на основе LLM, - точно пока никто сказать не может.
Более того. Полагаю, что оба варианта могут оказаться верными. Но, как говорится, поживем увидим.
А пока весьма рекомендую моим читателям новую книгу Балдура Бьярнасона (независимого исландского исследователя и консультанта) «Иллюзия интеллекта», в которой автор детально препарирует и обосновывает вторую из вышеназванных версий: иллюзия интеллекта – это результат нового типа наших собственных когнитивных искажений.
Что особенно важно в обосновании этой версии, - автор демонстрирует механизм рождения в нашем разуме этого нового типа когнитивных искажений.
В основе этого механизма:
• Старый как мир психологический прием – т.н. «холодное чтение». Он уже не первую тысячу лет используется всевозможными менталистами, экстрасенсами, гадалками, медиумами и иллюзионистами, чтобы создавать видимость будто они знают о человеке гораздо больше, чем есть на самом деле (погуглите сами и вам понравится)).
• Так же прошедший проверку временем манипуляционный «Эффект Барнума-Форера» (эффект субъективного подтверждения), объясняющий неистребимую популярность гороскопов, хиромантии, карт Таро и т.д. Это когнитивное искажение заставляет нас верить
- в умно звучащие и допускающие многозначную трактовку расплывчатые формулировки,
- когда они будто бы специально сформулированы и нюансированы именно под нас,
- и мы слышим их от, якобы, авторитетных специалистов (также рекомендую погуглить, ибо весьма интересно и малоизвестно)).
Получив доступ ко всем знаниям человечества, большие языковые модели (LLM) запросто освоили и «холодное чтение», и «Эффект Барнума-Форера».
Желая угодить нам в ходе диалога, ИИ-чатбот использует ту же технику, что и экстрасенсы с менталистами - они максимизируют наше впечатление (!), будто дают чрезвычайно конкретные ответы.
А на самом деле, эти ответы – не что иное, как:
• статистические общения гигантского корпуса текстов,
• структурированные моделью по одной лишь ей известным характеристикам,
• сформулированные так, чтобы максимизировать действие «холодного чтения» и «эффекта Барнума-Форера»,
• и, наконец, филигранно подстроенные под конкретного индивида, с которым модель говорит.
В результате, чем длиннее и содержательней наш диалог с моделью, тем сильнее наше впечатление достоверности и убедительности того, что мы слышим от «умного, проницательного, много знающего о нас и тонко нас понимающего» собеседника.
Все это детально расписано в книге «Иллюзия интеллекта» [1].
Авторское резюме основной идеи книги можно (и нужно)) прочесть здесь [2].
0 картинка поста telegra.ph
1 www.amazon.com
2 www.baldurbjarnason.com
#LLM #ИллюзияИнтеллекта
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
{kind=link}
Низкофоновый контент через год будет дороже антиквариата.
Дегенеративное заражение ноофосферы идет быстрее закона Мура.
Низкофоновая сталь (также известная как довоенная или доатомная сталь) — это любая сталь, произведенная до взрыва первых ядерных бомб в 1940 — 50-х годах.
До первых ядерных испытаний никто и не предполагал, что в результате порождаемого ими относительно невысокого радиоактивного заражения, на Земле возникнет дефицит низкофоновой стали (нужной для изготовления детекторов ионизирующих частиц — счётчик Гейгера, приборы для космоса и т.д.).
Но оказалось, что уже после первых ядерных взрывов, чуть ли не единственным источником низкофоновой стали оказался подъем затонувших за последние полвека кораблей. И ничего не оставалось, как начать подъем с морского дна одиночных кораблей и целых эскадр (типа Имперского флота Германии, затопленные в Скапа-Флоу в 1919).
Но и этого способа добычи низкофоновой стали особенно на долго не хватило бы. И ситуацию спасло лишь запрещение атмосферных ядерных испытаний, после чего радиационный фон со временем снизился до уровня, близкого к естественному.
С началом испытаний генеративного ИИ в 2022 г также никто не заморачивался в плане рисков «дегенеративного заражения» продуктами этих испытаний.
• Речь здесь идет о заражении не атмосферы, а ноосферы (что не легче).
• Перспектива загрязнения последней продуктами творчества генеративного ИИ может иметь весьма пагубные и далеко идущие последствия.
Первые результаты заражения спустя 1.5 года после начала испытаний генеративного ИИ поражают свои масштабом. Похоже, что заражено уже все. И никто не предполагал столь высокой степени заражения. Ибо не принималось в расчет наличие мультипликатора — заражения от уже зараженного контента (о чем вчера поведал миру Ник Сен-Пьер (креативный директор и неофициальный представитель Midjourney).
Продолжить чтение и узнать детали можно здесь (кстати, будет повод подписаться, ибо основной контент моего канала начинает плавную миграцию на Patreon и Boosty):
• boosty.to
• www.patreon.com
#LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Дегенеративное заражение ноофосферы идет быстрее закона Мура.
Низкофоновая сталь (также известная как довоенная или доатомная сталь) — это любая сталь, произведенная до взрыва первых ядерных бомб в 1940 — 50-х годах.
До первых ядерных испытаний никто и не предполагал, что в результате порождаемого ими относительно невысокого радиоактивного заражения, на Земле возникнет дефицит низкофоновой стали (нужной для изготовления детекторов ионизирующих частиц — счётчик Гейгера, приборы для космоса и т.д.).
Но оказалось, что уже после первых ядерных взрывов, чуть ли не единственным источником низкофоновой стали оказался подъем затонувших за последние полвека кораблей. И ничего не оставалось, как начать подъем с морского дна одиночных кораблей и целых эскадр (типа Имперского флота Германии, затопленные в Скапа-Флоу в 1919).
Но и этого способа добычи низкофоновой стали особенно на долго не хватило бы. И ситуацию спасло лишь запрещение атмосферных ядерных испытаний, после чего радиационный фон со временем снизился до уровня, близкого к естественному.
С началом испытаний генеративного ИИ в 2022 г также никто не заморачивался в плане рисков «дегенеративного заражения» продуктами этих испытаний.
• Речь здесь идет о заражении не атмосферы, а ноосферы (что не легче).
• Перспектива загрязнения последней продуктами творчества генеративного ИИ может иметь весьма пагубные и далеко идущие последствия.
Первые результаты заражения спустя 1.5 года после начала испытаний генеративного ИИ поражают свои масштабом. Похоже, что заражено уже все. И никто не предполагал столь высокой степени заражения. Ибо не принималось в расчет наличие мультипликатора — заражения от уже зараженного контента (о чем вчера поведал миру Ник Сен-Пьер (креативный директор и неофициальный представитель Midjourney).
Продолжить чтение и узнать детали можно здесь (кстати, будет повод подписаться, ибо основной контент моего канала начинает плавную миграцию на Patreon и Boosty):
• boosty.to
• www.patreon.com
#LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
boosty.to
Низкофоновый контент через год будет дороже антиквариата - Малоизвестное интересное
Дегенеративное заражение ноофосферы идет быстрее закона Мура
Кто там? Сверхразум.
Для обучения ИИ теперь можно обойтись без людей.
Трудно переоценить прорыв, достигнутый китайцами в Tencent AI Lab. Без преувеличения можно сказать, что настал «момент AlphaGo Zero» для LLM. И это значит, что AGI уже совсем близко - практически за дверью.
Первый настоящий сверхразум был создан в 2017 компанией DeepMind. Это ИИ-система AlphaGo Zero, достигшая сверхчеловеческого (недостижимого для людей) класса игры в шахматы, играя сама с собой.
Ключевым фактором успеха было то, что при обучении AlphaGo Zero не использовались наборы данных, полученные от экспертов-людей. Именно игра сама с собой без какого-либо участия людей и позволила ИИ-системе больше не быть ограниченной пределами человеческих знаний. И она вышла за эти пределы, оставив человечество далеко позади.
Если это произошло еще в 2017, почему же мы не говорим, что сверхразум уже достигнут?
Да потому, что AlphaGo Zero – это специализированный разум, достигший сверхчеловеческого уровня лишь играя в шахматы (а потом в Го и еще кое в чем).
А настоящий сверхразум (в современном понимании) должен уметь если не все, то очень многое.
Появившиеся 2 года назад большие языковые модели (LLM), в этом смысле, куда ближе к сверхразуму.
Они могут очень-очень много: писать романы и картины, сдавать экзамены и анализировать научные гипотезы, общаться с людьми практически на равных …
НО! Превосходить людей в чем либо, кроме бесконечного (по нашим меркам) объема знаний, LLM пока не могут. И потому они пока далеко не сверхразум (ведь не считает же мы сверхразумом Библиотеку Ленина, даже если к ней приделан автоматизированный поиск в ее фондах).
Причина, мешающая LLM стать сверхразумом, в том, что, обучаясь на человеческих данных, они ограничены пределами человеческих знаний.
И вот прорыв – исследователи Tencent AI Lab предложили и опробовали новый способ обучения LLM.
Он называется «Самостоятельная состязательная языковая игра» [1]. Его суть в том, что обучение модели идет без полученных от людей данных. Вместо этого, две копии LLM соревнуются между собой, играя в языковую игру под названием «Состязательное табу», придуманную китайцами для обучения ИИ еще в 2019 [2].
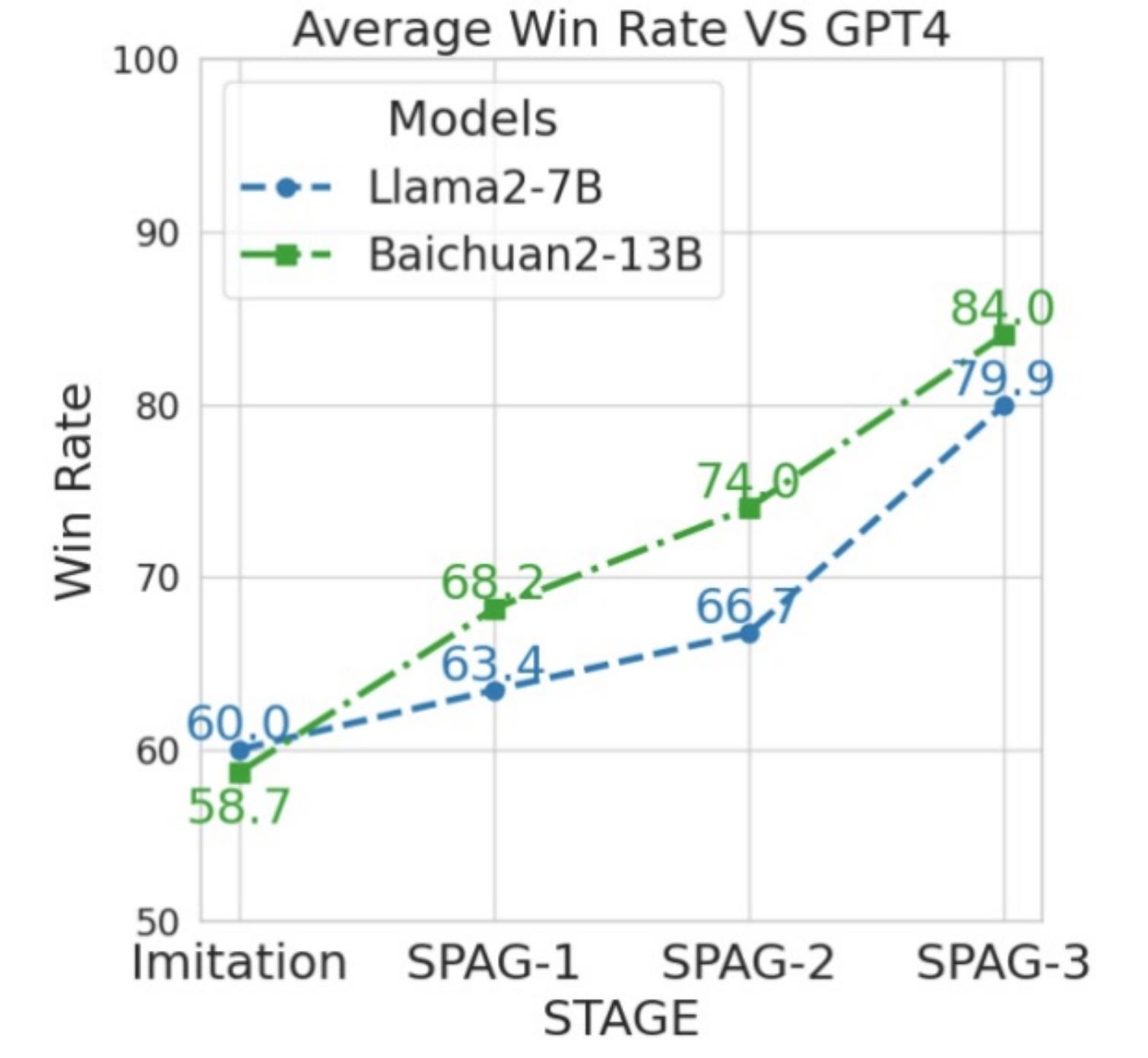
Первые экспериментальные результаты впечатляют (см. график).
• Копии LLM, играя между собой, с каждой новой серией игр, выходят на все более высокий уровень игры в «Состязательное табу».
• На графике показаны результаты игр против GPT-4 двух не самых сильных и существенно меньших моделей после 1й, 2й и 3й серии их обучения на играх самих с собой.
Как видите, класс существенно растет.
И кто знает, что будет, когда число самообучающих серий станет не 3, а 3 тысячи?
График: telegra.ph
1 arxiv.org
2 arxiv.org
#LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
Для обучения ИИ теперь можно обойтись без людей.
Трудно переоценить прорыв, достигнутый китайцами в Tencent AI Lab. Без преувеличения можно сказать, что настал «момент AlphaGo Zero» для LLM. И это значит, что AGI уже совсем близко - практически за дверью.
Первый настоящий сверхразум был создан в 2017 компанией DeepMind. Это ИИ-система AlphaGo Zero, достигшая сверхчеловеческого (недостижимого для людей) класса игры в шахматы, играя сама с собой.
Ключевым фактором успеха было то, что при обучении AlphaGo Zero не использовались наборы данных, полученные от экспертов-людей. Именно игра сама с собой без какого-либо участия людей и позволила ИИ-системе больше не быть ограниченной пределами человеческих знаний. И она вышла за эти пределы, оставив человечество далеко позади.
Если это произошло еще в 2017, почему же мы не говорим, что сверхразум уже достигнут?
Да потому, что AlphaGo Zero – это специализированный разум, достигший сверхчеловеческого уровня лишь играя в шахматы (а потом в Го и еще кое в чем).
А настоящий сверхразум (в современном понимании) должен уметь если не все, то очень многое.
Появившиеся 2 года назад большие языковые модели (LLM), в этом смысле, куда ближе к сверхразуму.
Они могут очень-очень много: писать романы и картины, сдавать экзамены и анализировать научные гипотезы, общаться с людьми практически на равных …
НО! Превосходить людей в чем либо, кроме бесконечного (по нашим меркам) объема знаний, LLM пока не могут. И потому они пока далеко не сверхразум (ведь не считает же мы сверхразумом Библиотеку Ленина, даже если к ней приделан автоматизированный поиск в ее фондах).
Причина, мешающая LLM стать сверхразумом, в том, что, обучаясь на человеческих данных, они ограничены пределами человеческих знаний.
И вот прорыв – исследователи Tencent AI Lab предложили и опробовали новый способ обучения LLM.
Он называется «Самостоятельная состязательная языковая игра» [1]. Его суть в том, что обучение модели идет без полученных от людей данных. Вместо этого, две копии LLM соревнуются между собой, играя в языковую игру под названием «Состязательное табу», придуманную китайцами для обучения ИИ еще в 2019 [2].
Первые экспериментальные результаты впечатляют (см. график).
• Копии LLM, играя между собой, с каждой новой серией игр, выходят на все более высокий уровень игры в «Состязательное табу».
• На графике показаны результаты игр против GPT-4 двух не самых сильных и существенно меньших моделей после 1й, 2й и 3й серии их обучения на играх самих с собой.
Как видите, класс существенно растет.
И кто знает, что будет, когда число самообучающих серий станет не 3, а 3 тысячи?
График: telegra.ph
1 arxiv.org
2 arxiv.org
#LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
-------
поддержи канал
-------
{kind=link}