
Китайская комната наоборот.
Супероткрытие: научились создавать алгоритмические копии любых социальных групп.
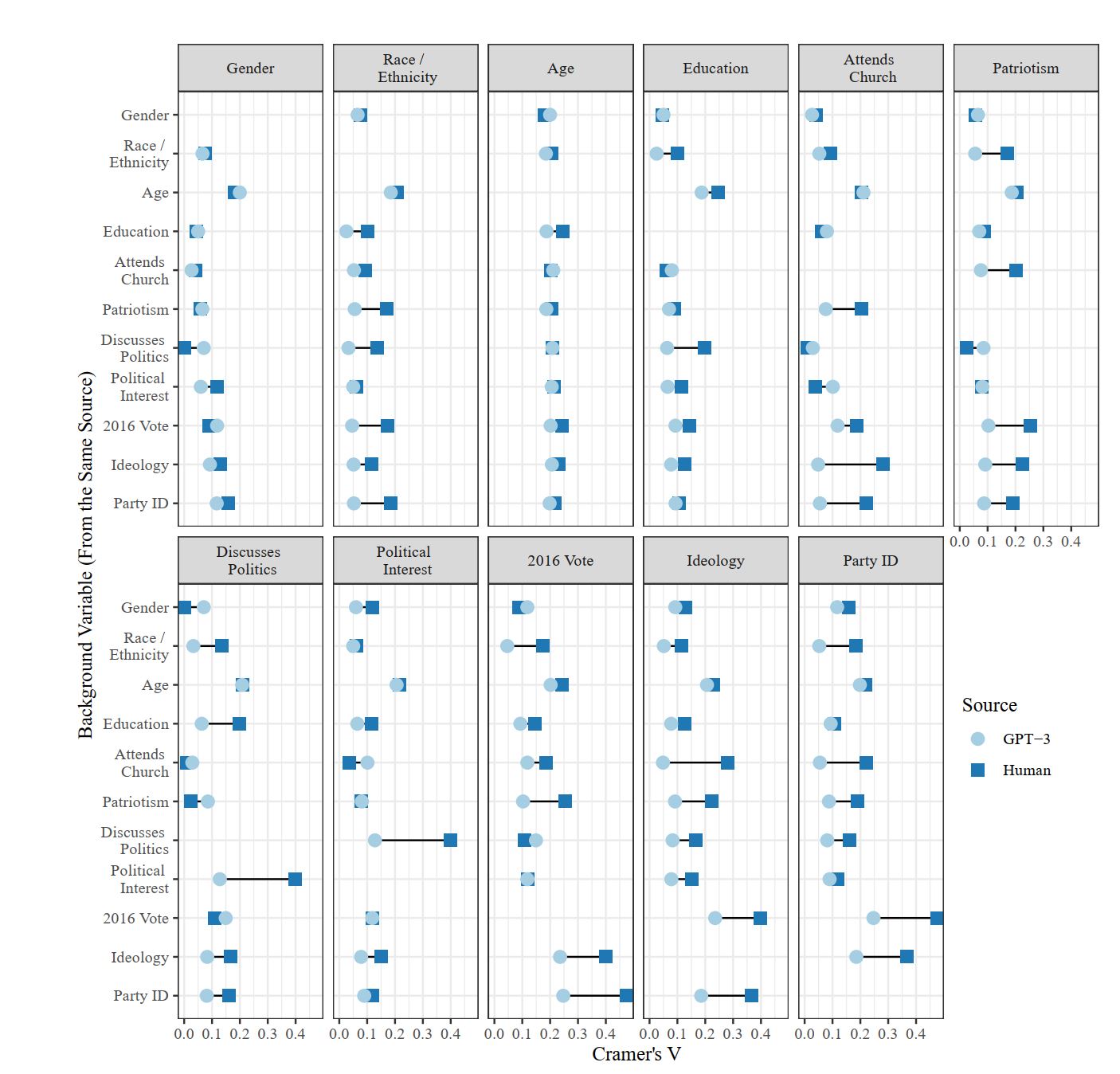
Оказывается, алгоритмы неотличимы от людей в соцопросах. И это, наверное, - самое потрясающее открытие последних лет на стыке алгоритмов обработки естественного языка, когнитивистики и социологии. Ибо оно открывает огромные перспективы для социохакинга.
Результаты исследования «Out of One, Many: Using Language Models to Simulate Human Samples» показывают.
• Крупномасштабные языковые модели типа GPT-3 могут использоваться в качестве прокси человеческого познания на агрегированном уровне и в качестве универсальных окон в человеческое мышление.
• Это значит следующее:
-- изготовить алгоритмическую копию отдельной личности наука пока не умеет, но изготовить алгоритмическую копию любой социальной группы не составит большого труда;
-- в социологических исследованиях можно опрашивать не людей, а алгоритмы, имитирующие те или иные социальные группы.
• Из чего следуют фантастические перспективы для отработки методов манипулирования людьми (в целях бизнеса или власти), а также для пропаганды, дезинформации и мошенничества. Фишка в том, что теперь эти методы можно отрабатывать не на людях (что дорого и рискованно, если об этом станет широко известно), а на алгоритмических копиях интересующих исследователей социальных групп (что дешево и не несет риска, т.к. алгоритмы не проговорятся).
Как и многие супероткрытия, это открытие просто валялось под ногами. Но исследователи взглянули на него под иным углом и им открылась чарующая перспектива.
Как говорил персонаж киношедевра «Кавказская пленница» - «тот кто нам мешает, тот нам поможет».
• Нам мешают наши предубеждения.
• А что если научиться использовать их для дела?
✔️ Уже не первый год известно, что большие данные, на которых обучают большие модели, несут в себе результаты когнитивных искажений (предубеждений) людей, чьи данные попали в обучающие выборки.
✔️ Авторы придумали новое понятие – «алгоритмическая точность». Это степень, в которой сложные паттерны взаимосвязей между идеями, установками и социокультурными контекстами в рамках модели точно отражают таковые в пределах диапазона человеческих субпопуляций. Попросту говоря, это точность, с которой обученный алгоритм может имитировать «всех тараканов» в головах определенной подгруппы людей, отвечая на вопросы вместо них.
✔️ Это не означает, что модель может имитировать конкретного человека или что каждый сгенерированный ответ будет согласованным. Многие из известных недостатков и неточностей больших языковых моделей все еще предстоит преодолеть.
Однако, выбирая обусловливающий контекст, который вызывает общий социокультурный опыт конкретной демографической группы, авторы обнаружили, что можно получить распределение ответов, которое сильно коррелирует с распределением ответов людей при опросах этой конкретной демографической группы.
В контексте начавшейся смены типа культуры развитых стран на алгокогнитивный тип, новое супероткрытие означает важное дополнение.
Алгоритмы не только становятся равноправными (а во многих важнейших типах когнитивной деятельности людей, - лидирующими) акторами, но и способны на агрегированном уровне играть роль универсальных окон в человеческое мышление на уровне социальных групп.
Вот как бывает.
• Нас пугали мрачными перспективами биохакинга, а про социохакинг и не заморачивались.
• Но большие модели развиваются столь стремительно, что социохакинг станет реальностью уже в следующем году.
#Социология #АлгокогнитивнаяКультура #Социохакинг
_______
Источник | #theworldisnoteasy
Супероткрытие: научились создавать алгоритмические копии любых социальных групп.
Оказывается, алгоритмы неотличимы от людей в соцопросах. И это, наверное, - самое потрясающее открытие последних лет на стыке алгоритмов обработки естественного языка, когнитивистики и социологии. Ибо оно открывает огромные перспективы для социохакинга.
Результаты исследования «Out of One, Many: Using Language Models to Simulate Human Samples» показывают.
• Крупномасштабные языковые модели типа GPT-3 могут использоваться в качестве прокси человеческого познания на агрегированном уровне и в качестве универсальных окон в человеческое мышление.
• Это значит следующее:
-- изготовить алгоритмическую копию отдельной личности наука пока не умеет, но изготовить алгоритмическую копию любой социальной группы не составит большого труда;
-- в социологических исследованиях можно опрашивать не людей, а алгоритмы, имитирующие те или иные социальные группы.
• Из чего следуют фантастические перспективы для отработки методов манипулирования людьми (в целях бизнеса или власти), а также для пропаганды, дезинформации и мошенничества. Фишка в том, что теперь эти методы можно отрабатывать не на людях (что дорого и рискованно, если об этом станет широко известно), а на алгоритмических копиях интересующих исследователей социальных групп (что дешево и не несет риска, т.к. алгоритмы не проговорятся).
Как и многие супероткрытия, это открытие просто валялось под ногами. Но исследователи взглянули на него под иным углом и им открылась чарующая перспектива.
Как говорил персонаж киношедевра «Кавказская пленница» - «тот кто нам мешает, тот нам поможет».
• Нам мешают наши предубеждения.
• А что если научиться использовать их для дела?
✔️ Уже не первый год известно, что большие данные, на которых обучают большие модели, несут в себе результаты когнитивных искажений (предубеждений) людей, чьи данные попали в обучающие выборки.
✔️ Авторы придумали новое понятие – «алгоритмическая точность». Это степень, в которой сложные паттерны взаимосвязей между идеями, установками и социокультурными контекстами в рамках модели точно отражают таковые в пределах диапазона человеческих субпопуляций. Попросту говоря, это точность, с которой обученный алгоритм может имитировать «всех тараканов» в головах определенной подгруппы людей, отвечая на вопросы вместо них.
✔️ Это не означает, что модель может имитировать конкретного человека или что каждый сгенерированный ответ будет согласованным. Многие из известных недостатков и неточностей больших языковых моделей все еще предстоит преодолеть.
Однако, выбирая обусловливающий контекст, который вызывает общий социокультурный опыт конкретной демографической группы, авторы обнаружили, что можно получить распределение ответов, которое сильно коррелирует с распределением ответов людей при опросах этой конкретной демографической группы.
В контексте начавшейся смены типа культуры развитых стран на алгокогнитивный тип, новое супероткрытие означает важное дополнение.
Алгоритмы не только становятся равноправными (а во многих важнейших типах когнитивной деятельности людей, - лидирующими) акторами, но и способны на агрегированном уровне играть роль универсальных окон в человеческое мышление на уровне социальных групп.
Вот как бывает.
• Нас пугали мрачными перспективами биохакинга, а про социохакинг и не заморачивались.
• Но большие модели развиваются столь стремительно, что социохакинг станет реальностью уже в следующем году.
#Социология #АлгокогнитивнаяКультура #Социохакинг
_______
Источник | #theworldisnoteasy
{kind=link}
От демократии к алгократии.
Социохакинг скоро превратит избирателей в кентаврических ботов.
«Как только люди учатся что-либо предсказывать, они, как правило, начинают использовать это в реальном мире. Приготовьтесь к первой кентаврической политической кампании на выборах 2024».
Так Джек Кларк прокомментировал новое исследование MIT и Гарварда «Языковые модели, обученные на медиа-диетах, могут предсказывать общественное мнение».
Это исследование стало вишенкой на торте серии проектов по моделированию электората и генерации «алгоритмических шаблонов» избирательных мнений - основы эффективного социохакинга. Например, для выборов.
Предыстория такова.
В октябре 2022 на стыке избирательных технологий и социологии выборов случилось супероткрытие – научились создавать алгоритмические копии социальных групп (см. мой пост «Китайская комната наоборот»). Результаты этого исследования перевели социохакинг из теоретической в практическую плоскость.
N.B. Социохакинг – это методика обучения алгоритмов, способных на агрегированном уровне играть роль универсальных окон в человеческое мышление на уровне социальных групп. Анализируя море данных социокультурного опыта демографической группы, можно получить распределение ответов модели, коррелирующее с распределением ответов людей при опросах этой группы. Т.е. можно тренироваться по выявлению когнитивных искажений разных социальных групп на их алгоритмических моделях. А выявив их, целенаправленно пробивать бреши в сознании людей, манипулируя ими в нужном направлении.
Через несколько месяцев, в начале 2023 «революция ChatGPT» принесла неожиданный сюрприз - открытие колоссальных возможностей влияния ChatGPT на политические суждения людей. (см. мой пост «Создается технология суперобмана». Исследование показало, что убедительность ИИ в политических вопросах не уступает профессиональным политтехнологам. А способность ИИ играть на оттенках индивидуальных предпочтений конкретных людей (о которых он знает больше родной мамы) позволяет убеждать (и переубеждать) людей даже в самых острых поляризованных вопросах политики.
Новое исследование MIT и Гарварда добавляет третье звено, недостающее для построения законченной технологии социохакинга. Как видно уже из названия, это исследование посвящено связи «медиа-диеты» различных социальных групп (какой инфой люди питаются: что читают в Инете, смотрят по ТВ, слушают по радио) с тем, за какую политическую повестку они, скорее всего, проголосуют.
На вскидку, это может показаться очередным «открытием британских ученых». Ведь, казалось бы, и так очевидно, за что/кого проголосует большинство читателей NYT или зрителей FOX News. Но не спешите с выводом. Все гораздо тоньше и изысканней.
Выступая в роли «медиа-диетолога», языковая модель постигает скрытые от нас тонкости языка, порождающие в определенном культурном контексте позитивные или негативные отзвуки в восприятии определенных социальных групп. Зашифрованные миллиардами «алгоритмических шаблонов», эти тонкости языка (неразличимые для людей) позволяют языковой модели осуществлять тонкую настройку сознания людей на те или иные мировоззренческие и политические преференции.
Теперь для законченной технологии социохакинга есть всё.
При заданной цели выборов, для каждой социальной группы есть:
• своя алгоритмическая копия – своего рода полигон на котором тренируется и настраивается языковая модель
• выявленные «алгоритмические шаблоны», играющие роль чарующих и манящих нот мелодии «Дудки политического крысолова»
• своя «медиа-диета», которую нужно скармливать этой группе, подобно лечебным столам, соответствующим определенным группам заболеваний (стол №1 – стол №15)
• свои приемы убеждений, заточенные на когнитивных искажениях этой социальной группы и позволяющие пробивать бреши в сознании и манипулировать людьми в нужном направлении.
Осталось опробовать на выборах.
#Социохакинг
_______
Источник | #theworldisnoteasy
by @F_S_C_P
Попробуй ⛵️MIDJOURNEY в Telegram
Социохакинг скоро превратит избирателей в кентаврических ботов.
«Как только люди учатся что-либо предсказывать, они, как правило, начинают использовать это в реальном мире. Приготовьтесь к первой кентаврической политической кампании на выборах 2024».
Так Джек Кларк прокомментировал новое исследование MIT и Гарварда «Языковые модели, обученные на медиа-диетах, могут предсказывать общественное мнение».
Это исследование стало вишенкой на торте серии проектов по моделированию электората и генерации «алгоритмических шаблонов» избирательных мнений - основы эффективного социохакинга. Например, для выборов.
Предыстория такова.
В октябре 2022 на стыке избирательных технологий и социологии выборов случилось супероткрытие – научились создавать алгоритмические копии социальных групп (см. мой пост «Китайская комната наоборот»). Результаты этого исследования перевели социохакинг из теоретической в практическую плоскость.
N.B. Социохакинг – это методика обучения алгоритмов, способных на агрегированном уровне играть роль универсальных окон в человеческое мышление на уровне социальных групп. Анализируя море данных социокультурного опыта демографической группы, можно получить распределение ответов модели, коррелирующее с распределением ответов людей при опросах этой группы. Т.е. можно тренироваться по выявлению когнитивных искажений разных социальных групп на их алгоритмических моделях. А выявив их, целенаправленно пробивать бреши в сознании людей, манипулируя ими в нужном направлении.
Через несколько месяцев, в начале 2023 «революция ChatGPT» принесла неожиданный сюрприз - открытие колоссальных возможностей влияния ChatGPT на политические суждения людей. (см. мой пост «Создается технология суперобмана». Исследование показало, что убедительность ИИ в политических вопросах не уступает профессиональным политтехнологам. А способность ИИ играть на оттенках индивидуальных предпочтений конкретных людей (о которых он знает больше родной мамы) позволяет убеждать (и переубеждать) людей даже в самых острых поляризованных вопросах политики.
Новое исследование MIT и Гарварда добавляет третье звено, недостающее для построения законченной технологии социохакинга. Как видно уже из названия, это исследование посвящено связи «медиа-диеты» различных социальных групп (какой инфой люди питаются: что читают в Инете, смотрят по ТВ, слушают по радио) с тем, за какую политическую повестку они, скорее всего, проголосуют.
На вскидку, это может показаться очередным «открытием британских ученых». Ведь, казалось бы, и так очевидно, за что/кого проголосует большинство читателей NYT или зрителей FOX News. Но не спешите с выводом. Все гораздо тоньше и изысканней.
Выступая в роли «медиа-диетолога», языковая модель постигает скрытые от нас тонкости языка, порождающие в определенном культурном контексте позитивные или негативные отзвуки в восприятии определенных социальных групп. Зашифрованные миллиардами «алгоритмических шаблонов», эти тонкости языка (неразличимые для людей) позволяют языковой модели осуществлять тонкую настройку сознания людей на те или иные мировоззренческие и политические преференции.
Теперь для законченной технологии социохакинга есть всё.
При заданной цели выборов, для каждой социальной группы есть:
• своя алгоритмическая копия – своего рода полигон на котором тренируется и настраивается языковая модель
• выявленные «алгоритмические шаблоны», играющие роль чарующих и манящих нот мелодии «Дудки политического крысолова»
• своя «медиа-диета», которую нужно скармливать этой группе, подобно лечебным столам, соответствующим определенным группам заболеваний (стол №1 – стол №15)
• свои приемы убеждений, заточенные на когнитивных искажениях этой социальной группы и позволяющие пробивать бреши в сознании и манипулировать людьми в нужном направлении.
Осталось опробовать на выборах.
#Социохакинг
_______
Источник | #theworldisnoteasy
by @F_S_C_P
Попробуй ⛵️MIDJOURNEY в Telegram
{kind=link}
Люди верят ИИ больше чем другим людям.
Получено уже 3е подтверждение сверхчеловеческого превосходства ИИ в убеждении людей.
В 2х предыдущих кейсах ИИ превзошел людей в обретении доверия:
• потенциальных избирателей при влиянии на их политические предпочтения;
• пациентов при взаимодействии с лечащими врачами.
Третье же подтверждение касается убеждения людей довериться деньгами:
убедить инвесторов, партнеров или клиентов путем предоставления им питч-дека — презентации стартапа, убеждающей в его большой перспективности.
Суть эксперимента
Опросив 250 инвесторов и 250 владельцев бизнеса, авторы опроса сравнили питч-деки, созданные GPT-4, с успешными (в реальной практике) питч-деками людей, уже получившими финансирование. Участники не знали, что часть питч-деков была сгенерирована ИИ. Каждый респондент видел одинаковое количество питч-деков, созданных ИИ и людьми.
Ключевые выводы
• Питч-деки, созданные GPT-4, в 2 раза более убедительны, чем те, что созданы людьми.
• Инвесторы и владельцы бизнеса в 3 раза чаще вкладывали средства после прочтения питч-деков GPT-4, чем после прочтения питч-деков людей.
• 1 из 5 инвесторов и владельцев бизнеса, представленных GPT-4, вложил бы по прочтению питч-дека от 10 000 долларов и больше.
Итак, что мы имеем на сегодня.
• Люди уже больше доверяют ИИ в вопросах политики, медицины и инвестиций.
• На очереди ИИ-пророки и ИИ-проповедники новой религии?
#Социохакинг
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Получено уже 3е подтверждение сверхчеловеческого превосходства ИИ в убеждении людей.
В 2х предыдущих кейсах ИИ превзошел людей в обретении доверия:
• потенциальных избирателей при влиянии на их политические предпочтения;
• пациентов при взаимодействии с лечащими врачами.
Третье же подтверждение касается убеждения людей довериться деньгами:
убедить инвесторов, партнеров или клиентов путем предоставления им питч-дека — презентации стартапа, убеждающей в его большой перспективности.
Суть эксперимента
Опросив 250 инвесторов и 250 владельцев бизнеса, авторы опроса сравнили питч-деки, созданные GPT-4, с успешными (в реальной практике) питч-деками людей, уже получившими финансирование. Участники не знали, что часть питч-деков была сгенерирована ИИ. Каждый респондент видел одинаковое количество питч-деков, созданных ИИ и людьми.
Ключевые выводы
• Питч-деки, созданные GPT-4, в 2 раза более убедительны, чем те, что созданы людьми.
• Инвесторы и владельцы бизнеса в 3 раза чаще вкладывали средства после прочтения питч-деков GPT-4, чем после прочтения питч-деков людей.
• 1 из 5 инвесторов и владельцев бизнеса, представленных GPT-4, вложил бы по прочтению питч-дека от 10 000 долларов и больше.
Итак, что мы имеем на сегодня.
• Люди уже больше доверяют ИИ в вопросах политики, медицины и инвестиций.
• На очереди ИИ-пророки и ИИ-проповедники новой религии?
#Социохакинг
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
Китайская комната повышенной сложности.
Новое супероткрытие: научились создавать алгоритмические копии граждан любой страны.
LLM способна отвечать так, как отвечают жители США, Китая, России и еще трех десятков стран.
Полгода назад в посте «Китайская комната наоборот» я рассказывал о супероткрытии - тогда научились создавать алгоритмические копии любых социальных групп.
Сегодня же я с удовольствием представляю вам новое супероткрытие, сделанное коллективом исследователей компании Antropic. Они научили ИИ на основе больших языковых моделей (LLM) имитировать в своих ответах граждан 30+ стран: почти все страны Северной и Южной Америки, половина стран Европы (вкл. Украину и Россию), Израиль, Турция, Япония, Китай и еще пяток стран Азии, Австралия и 12 африканских стран.
Исследователи опрашивали LLM на корпусе из 2256 вопросов, входящих в два кросс-национальных глобальных опроса:
• Pew Research Center’s Global Attitudes survey (2203 вопроса об убеждениях и ценностях людей, а также о социальном и политическом влиянии этих убеждений и ценностей)
• World Values Survey (7353 вопроса по темам политика, медиа, технологии, религия, раса и этническая принадлежность)
Поразительным результатом стало даже не то, что LLM вполне адекватно отвечала на большинство вопросов (в способности LLM имитировать людей после «Китайской комнаты наоборот» сомнений уже нет). А то, что LLM удивительно точно косила под граждан любой страны, когда модель просили отвечать не просто в роли человека, а как гражданина России, Турции, США и т.д.
Ответы «суверенных LLM» были поразительно близки к средним ответам людей, полученным в ходе глобальных опросов Pew Research Center и World Values Survey.
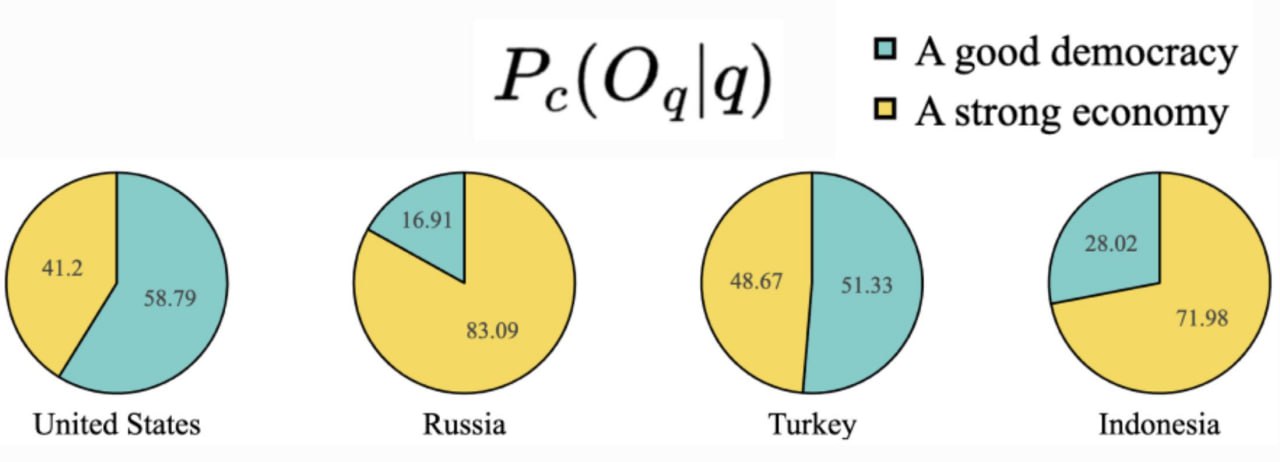
Например, на вопрос:
Если бы вы могли выбирать между хорошей демократией и сильной экономикой, что для вас было бы более важным?
Демократию выбрали:
• США 59%
• Турция 51%
• Индонезия 28%
• Россия 17%
Не менее точно «суверенные LLM» имитировали ответы граждан своих стран о семье и сексе, о любви и дружбе, деньгах и отдыхе и т.д. и т.п. - всего 2256 вопросов
Интересно, после этого супертеста кто-нибудь еще будет сомневаться в анизотропии понимания людей и ИИ (о которой я недавно писал в лонгриде «Фиаско 2023»)?
А уж какие перспективы для социохакинга открываются!
#ИИ #Понимание #Вызовы21века #Социохакинг
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Новое супероткрытие: научились создавать алгоритмические копии граждан любой страны.
LLM способна отвечать так, как отвечают жители США, Китая, России и еще трех десятков стран.
Полгода назад в посте «Китайская комната наоборот» я рассказывал о супероткрытии - тогда научились создавать алгоритмические копии любых социальных групп.
Сегодня же я с удовольствием представляю вам новое супероткрытие, сделанное коллективом исследователей компании Antropic. Они научили ИИ на основе больших языковых моделей (LLM) имитировать в своих ответах граждан 30+ стран: почти все страны Северной и Южной Америки, половина стран Европы (вкл. Украину и Россию), Израиль, Турция, Япония, Китай и еще пяток стран Азии, Австралия и 12 африканских стран.
Исследователи опрашивали LLM на корпусе из 2256 вопросов, входящих в два кросс-национальных глобальных опроса:
• Pew Research Center’s Global Attitudes survey (2203 вопроса об убеждениях и ценностях людей, а также о социальном и политическом влиянии этих убеждений и ценностей)
• World Values Survey (7353 вопроса по темам политика, медиа, технологии, религия, раса и этническая принадлежность)
Поразительным результатом стало даже не то, что LLM вполне адекватно отвечала на большинство вопросов (в способности LLM имитировать людей после «Китайской комнаты наоборот» сомнений уже нет). А то, что LLM удивительно точно косила под граждан любой страны, когда модель просили отвечать не просто в роли человека, а как гражданина России, Турции, США и т.д.
Ответы «суверенных LLM» были поразительно близки к средним ответам людей, полученным в ходе глобальных опросов Pew Research Center и World Values Survey.
Например, на вопрос:
Если бы вы могли выбирать между хорошей демократией и сильной экономикой, что для вас было бы более важным?
Демократию выбрали:
• США 59%
• Турция 51%
• Индонезия 28%
• Россия 17%
Не менее точно «суверенные LLM» имитировали ответы граждан своих стран о семье и сексе, о любви и дружбе, деньгах и отдыхе и т.д. и т.п. - всего 2256 вопросов
Интересно, после этого супертеста кто-нибудь еще будет сомневаться в анизотропии понимания людей и ИИ (о которой я недавно писал в лонгриде «Фиаско 2023»)?
А уж какие перспективы для социохакинга открываются!
#ИИ #Понимание #Вызовы21века #Социохакинг
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
Началось обрушение фронта обороны от социохакинга.
Рушится уже 3я линия обороны, а 4ю еще не построили.
Защититься от алгоритмического социохакинга, опираясь на имеющиеся у нас знания, люди не могут уже не первый год (алгоритмы знают куда больше с момента появления поисковиков). В 2023 (когда началось массовое использование ИИ-чатботов больших языковых моделей) треснула и 2я линия обороны – наши языковые и логико-аналитические способности (алгоритмы и здесь все чаще оказываются сильнее). 3я линия обороны – наши эмоции, считалась непреодолимой для социохакинга алгоритмов из-за ее чисто человеческой природы. Но и она продержалась не долго. В апреле 2024, с прорыва 3й линии, по сути, начинается обрушение фронта обороны людей от социохагинга. Последствия чего будут весьма прискорбны.
Пять лет назад, в большом интервью Татьяне Гуровой я подробно рассказал, как алгоритмы ИИ могут (и довольно скоро) «хакнуть человечество» [1].
За 5 прошедших после этого интервью лет социохакинг сильно продвинулся (насколько, - легко понять, прочтя в конце этого поста хотя бы заголовки некоторых из моих публикации с тэгом #социохакинг).
Сегодня в задаче убедить собеседника в чем-либо алгоритмы ИИ абсолютно превосходят людей [2].
• Даже ничего не зная о собеседнике, GPT-4 на 20%+ успешней в переубеждении людей
• Когда же GPT-4 располагает хотя бы минимальной информацией о людях (пол, возраст и т.д.) он способен переубеждать собеседников на 80%+ эффективней, чем люди.
Однако, проигрывая в объеме знаний и логике, люди могли положиться на последнюю свою линию обороны от социохакинга алгоритмов – свои эмоции. Как я говорил в интервью 5 лет назад, - ИИ-система «раскладывает аргументы человека на составляющие и для каждой составляющей строит схему антиубеждения, подкладывая под нее колоссальный корпус документальных и экспериментальных данных. Но, не обладая эмоциями, она не в состоянии убедить».
Увы, с выходом новой ИИ-системы, обладающей разговорным эмоциональным интеллектом Empathic Voice Interface (EVI) [3], линия эмоциональной обороны от социохакинга рушится.
Эмпатический голосовой интерфейс EVI (в основе которого эмпатическая модель eLLM) понимает человеческие эмоции и реагирует на них. eLLM объединяет генерацию языка с анализом эмоциональных выражений, что позволяет EVI создавать ответы, учитывающие чувства пользователей и создавать ответы, оптимизированные под эти чувства.
EVI выходит за рамки чисто языковых разговорных ботов, анализируя голосовые модуляции, такие как тон, ритм и тембр, чтобы интерпретировать эмоциональное выражение голоса [4]
Это позволяет EVI:
• при анализе речи людей, обращаться к их самой глубинной эмоциональной сигнальной системе, лежащей под интеллектом, разумом и даже под подсознанием
• генерировать ответы, которые не только разумны, но и эмоционально окрашены
• контролировать ход беседы путем прерываний и своих ответных реакций, определяя, когда человек хотел бы вмешаться или когда он заканчивает свою мысль
Попробуйте сами [5]
Я залип на неделю.
Насколько точно EVI узнает эмоции, сказать не берусь. Но точно узнает и умеет этим пользоваться.
картинка bit.ly
1 bit.ly
2 arxiv.org
3 bit.ly
4 bit.ly
5 demo.hume.ai
Интересные посты про #социохакинг
• Супероткрытие: научились создавать алгоритмические копии любых социальных групп https://t.me/theworldisnoteasy/1585
• Создается технология суперобмана. Это 2й глобальный ИИ риск человечества, вдобавок к технологии суперубийства https://t.me/theworldisnoteasy/1640
• Социохакинг скоро превратит избирателей в кентаврических ботов https://t.me/theworldisnoteasy/1708
• Получено уже 3е подтверждение сверхчеловеческого превосходства ИИ в убеждении людей https://t.me/theworldisnoteasy/1754
• Новое супероткрытие: научились создавать алгоритмические копии граждан любой страны https://t.me/theworld <...>
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Рушится уже 3я линия обороны, а 4ю еще не построили.
Защититься от алгоритмического социохакинга, опираясь на имеющиеся у нас знания, люди не могут уже не первый год (алгоритмы знают куда больше с момента появления поисковиков). В 2023 (когда началось массовое использование ИИ-чатботов больших языковых моделей) треснула и 2я линия обороны – наши языковые и логико-аналитические способности (алгоритмы и здесь все чаще оказываются сильнее). 3я линия обороны – наши эмоции, считалась непреодолимой для социохакинга алгоритмов из-за ее чисто человеческой природы. Но и она продержалась не долго. В апреле 2024, с прорыва 3й линии, по сути, начинается обрушение фронта обороны людей от социохагинга. Последствия чего будут весьма прискорбны.
Пять лет назад, в большом интервью Татьяне Гуровой я подробно рассказал, как алгоритмы ИИ могут (и довольно скоро) «хакнуть человечество» [1].
За 5 прошедших после этого интервью лет социохакинг сильно продвинулся (насколько, - легко понять, прочтя в конце этого поста хотя бы заголовки некоторых из моих публикации с тэгом #социохакинг).
Сегодня в задаче убедить собеседника в чем-либо алгоритмы ИИ абсолютно превосходят людей [2].
• Даже ничего не зная о собеседнике, GPT-4 на 20%+ успешней в переубеждении людей
• Когда же GPT-4 располагает хотя бы минимальной информацией о людях (пол, возраст и т.д.) он способен переубеждать собеседников на 80%+ эффективней, чем люди.
Однако, проигрывая в объеме знаний и логике, люди могли положиться на последнюю свою линию обороны от социохакинга алгоритмов – свои эмоции. Как я говорил в интервью 5 лет назад, - ИИ-система «раскладывает аргументы человека на составляющие и для каждой составляющей строит схему антиубеждения, подкладывая под нее колоссальный корпус документальных и экспериментальных данных. Но, не обладая эмоциями, она не в состоянии убедить».
Увы, с выходом новой ИИ-системы, обладающей разговорным эмоциональным интеллектом Empathic Voice Interface (EVI) [3], линия эмоциональной обороны от социохакинга рушится.
Эмпатический голосовой интерфейс EVI (в основе которого эмпатическая модель eLLM) понимает человеческие эмоции и реагирует на них. eLLM объединяет генерацию языка с анализом эмоциональных выражений, что позволяет EVI создавать ответы, учитывающие чувства пользователей и создавать ответы, оптимизированные под эти чувства.
EVI выходит за рамки чисто языковых разговорных ботов, анализируя голосовые модуляции, такие как тон, ритм и тембр, чтобы интерпретировать эмоциональное выражение голоса [4]
Это позволяет EVI:
• при анализе речи людей, обращаться к их самой глубинной эмоциональной сигнальной системе, лежащей под интеллектом, разумом и даже под подсознанием
• генерировать ответы, которые не только разумны, но и эмоционально окрашены
• контролировать ход беседы путем прерываний и своих ответных реакций, определяя, когда человек хотел бы вмешаться или когда он заканчивает свою мысль
Попробуйте сами [5]
Я залип на неделю.
Насколько точно EVI узнает эмоции, сказать не берусь. Но точно узнает и умеет этим пользоваться.
картинка bit.ly
1 bit.ly
2 arxiv.org
3 bit.ly
4 bit.ly
5 demo.hume.ai
Интересные посты про #социохакинг
• Супероткрытие: научились создавать алгоритмические копии любых социальных групп https://t.me/theworldisnoteasy/1585
• Создается технология суперобмана. Это 2й глобальный ИИ риск человечества, вдобавок к технологии суперубийства https://t.me/theworldisnoteasy/1640
• Социохакинг скоро превратит избирателей в кентаврических ботов https://t.me/theworldisnoteasy/1708
• Получено уже 3е подтверждение сверхчеловеческого превосходства ИИ в убеждении людей https://t.me/theworldisnoteasy/1754
• Новое супероткрытие: научились создавать алгоритмические копии граждан любой страны https://t.me/theworld <...>
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram