
Вышел один из главных отчетов года по ИИ.
Он почти как Библия для верующих.
Сегодня для всех ИИ-любов, равно как и для всех ИИ-ведов, особый день. Вышел один из главных аналитических отчетов года по ИИ - 4й годовой отчет Стенфордского центра HAI «2021 AI Index»
220 стр. хорошо структурированного текста с обилием инфографики, призваны дать количественные ответы на два ключевых вопроса:
1) Каково текущее состояние главных трендов развития ИИ в 2020.
2) Каково текущее состояние мировой «ИИ-гонки» среди 26 стран по 22 ключевым индикаторам.
9 важнейших выводов отчета
1) Крупнейший скачок частных инвестиций в ИИ разработки произошел в области разработки и открытия лекарств - более $13,8 млрд, что в 4,5 раза больше, чем в 2019 году.
2) Исход ученых в индустрию ИИ нарастает: среди получивших степень доктора в 2010 ушло в индустрию 44%, а в 2019 уже 65%.
3) Расцвет эпохи «генеративного всего» наступил. Создаваемые машинами текст, аудио и изображения людям все труднее отличить от созданных мастерами.
4) В области ИИ в гробу видали расовую политкорректность: 45% новых докторов белые, а афроамериканцы и испаноамериканцы всего 2,4% и 3,2%
5) Китай наконец сделал США по числу цитирований научных статей по ИИ.
6) Большинство аспирантов ИИ – приезжие (64%), но они останутся в США (кто бы сомневался)
7) Быстрее всего в ИИ совершенствуются технологии систем наблюдения и слежки.
8) В этике ИИ нет ни критериев, ни консенсуса
9) До Конгресса США наконец то дошло – мировое лидерство в ИИ для США вопрос №1.
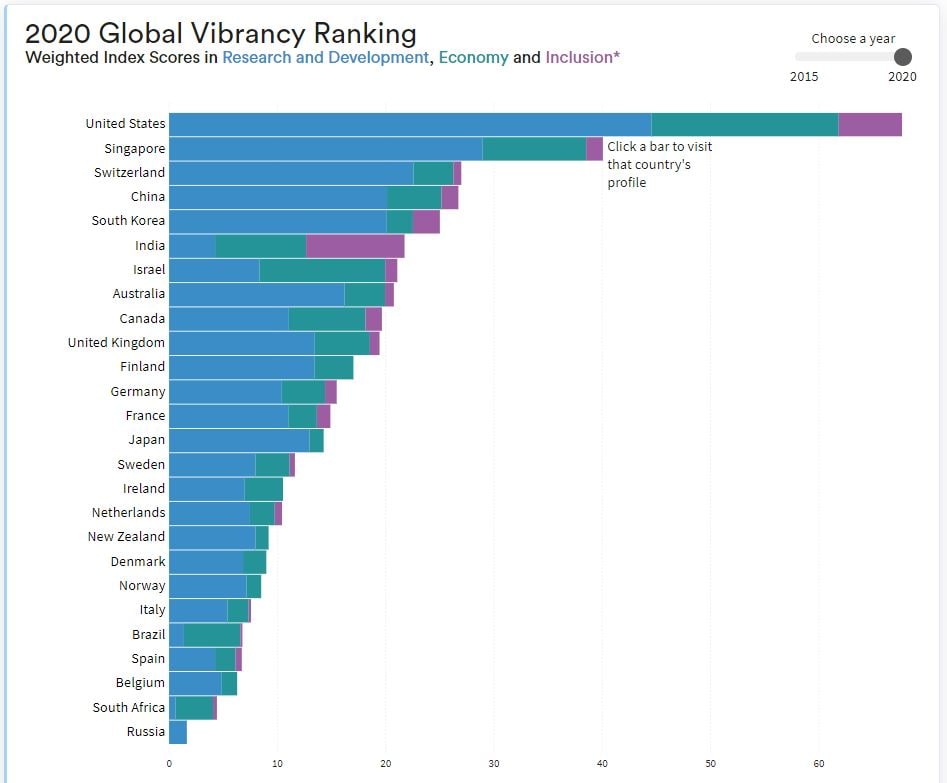
Что касается текущего состояния мировой «ИИ-гонки» среди 26 стран по 22 ключевым индикаторам, то можете посмотреть эту гонку в динамике :
• В 2015 Россия была на предпоследнем 25-м месте (обогнав ЮАР)
• В 2020 и ЮАР обогнал нас, - Россия последняя в гонке 26 стран (см. приложенный рис)
#ИИ #ИИгонка
_______
Источник: https://t.me/theworldisnoteasy/1234
Он почти как Библия для верующих.
Сегодня для всех ИИ-любов, равно как и для всех ИИ-ведов, особый день. Вышел один из главных аналитических отчетов года по ИИ - 4й годовой отчет Стенфордского центра HAI «2021 AI Index»
220 стр. хорошо структурированного текста с обилием инфографики, призваны дать количественные ответы на два ключевых вопроса:
1) Каково текущее состояние главных трендов развития ИИ в 2020.
2) Каково текущее состояние мировой «ИИ-гонки» среди 26 стран по 22 ключевым индикаторам.
9 важнейших выводов отчета
1) Крупнейший скачок частных инвестиций в ИИ разработки произошел в области разработки и открытия лекарств - более $13,8 млрд, что в 4,5 раза больше, чем в 2019 году.
2) Исход ученых в индустрию ИИ нарастает: среди получивших степень доктора в 2010 ушло в индустрию 44%, а в 2019 уже 65%.
3) Расцвет эпохи «генеративного всего» наступил. Создаваемые машинами текст, аудио и изображения людям все труднее отличить от созданных мастерами.
4) В области ИИ в гробу видали расовую политкорректность: 45% новых докторов белые, а афроамериканцы и испаноамериканцы всего 2,4% и 3,2%
5) Китай наконец сделал США по числу цитирований научных статей по ИИ.
6) Большинство аспирантов ИИ – приезжие (64%), но они останутся в США (кто бы сомневался)
7) Быстрее всего в ИИ совершенствуются технологии систем наблюдения и слежки.
8) В этике ИИ нет ни критериев, ни консенсуса
9) До Конгресса США наконец то дошло – мировое лидерство в ИИ для США вопрос №1.
Что касается текущего состояния мировой «ИИ-гонки» среди 26 стран по 22 ключевым индикаторам, то можете посмотреть эту гонку в динамике :
• В 2015 Россия была на предпоследнем 25-м месте (обогнав ЮАР)
• В 2020 и ЮАР обогнал нас, - Россия последняя в гонке 26 стран (см. приложенный рис)
#ИИ #ИИгонка
_______
Источник: https://t.me/theworldisnoteasy/1234
{kind=link}
Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке.
В 2020-х расклад сил в технологическом соревновании стало предельно просто оценивать. Революция «Глубокого обучения Больших моделей на Больших данных» превратила вычислительную мощность в ключевой фактор прогресса практически всех интеллектуально емких индустрий: от разработки новых лекарств до новых видов вооружений. А там, где задействован ИИ (а он уже почти всюду) вычислительная мощность, вообще, решает все.
Формула превосходства стала предельно проста:
• собери как можно больше данных;
• создай как можно более сложную (по числу параметров) модель;
• обучи модель как можно быстрее.
Тот, у кого будет «больше-больше-быстрее» имеет максимально высокие шансы выиграть в технологической гонке. А здесь все упирается в вычислительную мощность «железа» (HW) и алгоритмов (SW).
И при всем уважении к алгоритмам, но в этой паре их роль №2. Ибо алгоритм изобрести, скопировать или даже украсть все же проще, чем HW. «Железо» либо есть, либо его нет.
Это мы проходили еще в СССР. Это же стало даже более критическим фактором в эпоху «Глубокого обучения Больших моделей на Больших данных».
Вот два самых свежих примера.
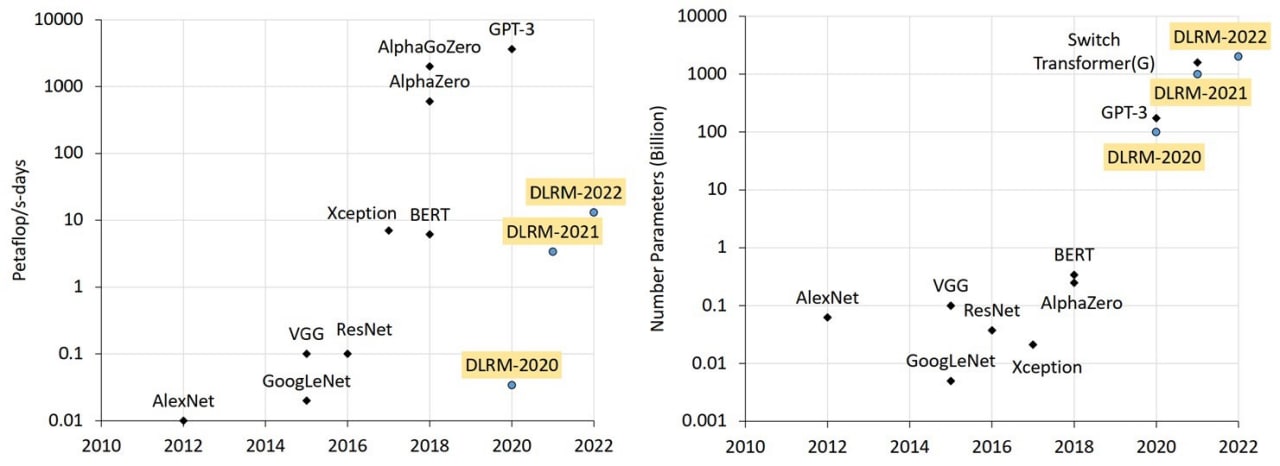
1) Facebook раскрыл свою систему рекомендаций. Она построена на модели рекомендаций глубокого обучения (DLRM). Содержит эта модель 12 триллионов параметров и требует суммарного объема вычислений более 10 Petaflop/s-days.
2) Microsoft скоро продемонстрирует модель для ИИ с 1 триллионом параметров. Она работает на системе вычислительной производительности 502 Petaflop/s на 3072 графических процессорах.
Для сравнения, языковая модель GPT-2, разработанная OpenAI 2 года назад, поразила мир тем, что у нее было 1,5 миллиарда параметров. А GPT-3, вышедшая в 2020 имела уже 175 млрд. параметров.
Как видите, модели с триллионами параметров – уже данность. И чтобы их учить не годами, а днями, нужно «железо» сумасшедшей вычислительной мощности.
Т.е. сами видите, - есть «железо» - участвуй в гонке, нет «железа» - кури в сторонке.
На приложенной картинке свежие данные о размерах моделей и требуемой для них вычислительной мощности.
#HPC #ИИгонка
_______
Источник | #theworldisnoteasy
В 2020-х расклад сил в технологическом соревновании стало предельно просто оценивать. Революция «Глубокого обучения Больших моделей на Больших данных» превратила вычислительную мощность в ключевой фактор прогресса практически всех интеллектуально емких индустрий: от разработки новых лекарств до новых видов вооружений. А там, где задействован ИИ (а он уже почти всюду) вычислительная мощность, вообще, решает все.
Формула превосходства стала предельно проста:
• собери как можно больше данных;
• создай как можно более сложную (по числу параметров) модель;
• обучи модель как можно быстрее.
Тот, у кого будет «больше-больше-быстрее» имеет максимально высокие шансы выиграть в технологической гонке. А здесь все упирается в вычислительную мощность «железа» (HW) и алгоритмов (SW).
И при всем уважении к алгоритмам, но в этой паре их роль №2. Ибо алгоритм изобрести, скопировать или даже украсть все же проще, чем HW. «Железо» либо есть, либо его нет.
Это мы проходили еще в СССР. Это же стало даже более критическим фактором в эпоху «Глубокого обучения Больших моделей на Больших данных».
Вот два самых свежих примера.
1) Facebook раскрыл свою систему рекомендаций. Она построена на модели рекомендаций глубокого обучения (DLRM). Содержит эта модель 12 триллионов параметров и требует суммарного объема вычислений более 10 Petaflop/s-days.
2) Microsoft скоро продемонстрирует модель для ИИ с 1 триллионом параметров. Она работает на системе вычислительной производительности 502 Petaflop/s на 3072 графических процессорах.
Для сравнения, языковая модель GPT-2, разработанная OpenAI 2 года назад, поразила мир тем, что у нее было 1,5 миллиарда параметров. А GPT-3, вышедшая в 2020 имела уже 175 млрд. параметров.
Как видите, модели с триллионами параметров – уже данность. И чтобы их учить не годами, а днями, нужно «железо» сумасшедшей вычислительной мощности.
Т.е. сами видите, - есть «железо» - участвуй в гонке, нет «железа» - кури в сторонке.
На приложенной картинке свежие данные о размерах моделей и требуемой для них вычислительной мощности.
#HPC #ИИгонка
_______
Источник | #theworldisnoteasy
{kind=link}
Броня и снаряды наши, а мозги китайские.
Отчет о состоянии и перспективах военного ИИ и автономного оружия России.
Несомненные успехи расследований Bellingcat убедили - в современном прозрачном инфомире только по открытым источникам можно реконструировать и проанализировать почти что угодно.
Минобороны и разведка США пошли еще дальше, превзойдя это «почти». Они показали, что работая только по открытым источником, умелые и опытные аналитики могут реконструировать и проанализировать даже самый большой секрет любой страны – технологическое состояние и перспективы её самых современных вооружений.
Этими опытными аналитиками стала команда Самуэля Бендетта и Джеффри Эдмондса из CNA (аббревиатура не зря смахивает на CIA) – аналитического центра в Арлингтоне, работающего на американских военных и разведку.
Команда из 8 аналитиков работала год над только что опубликованным отчетом «ИИ и автономное оружие России». И смею вас заверить, получилось несравненно круче, чем декабрьский отчет французов из IFRI.
В 250 страничном отчёте море информации. Вся она из открытых источников (24 страницы кликабельных ссылок).
Пересказывать не буду. По нынешним временам, когда за ретвит сажают, это лишнее. Кому интересно, прочтет сам.
Перечислю лишь ключевые мысли анализа, наиболее меня заинтересовавшие.
1. Россия сделала ставку на военный ИИ и автономное оружие.
2. Ключевым партнером выбран Китай.
3. Российско-китайские отношения в этой области достигли наивысшего уровня в истории.
4. Сотрудничество России и Китая в сфере технологий обороны углубляется, но при этом, похоже, становится более скрытным.
5. Ведутся работы по 20+ военных платформ, разрабатываемых российскими военными, так или иначе включающих ИИ или обладающих автономностью, включая «то, что называется оружием завтрашнего дня».
6. Поскольку Россия не является основным двигателем мировых инноваций в области ИИ, Китай занимает в этом сотрудничестве роль «старшего брата».
7. Россия же выступает в аналогичной роли, имея преимущество в наборе ядерных вооружений, гиперзвуковых планирующий аппаратах, подводных беспилотных аппаратах и гиперзвуковых ракетах воздушного базирования.
#Россия #Китай #ИИгонка
_______
Источник | #theworldisnoteasy
Отчет о состоянии и перспективах военного ИИ и автономного оружия России.
Несомненные успехи расследований Bellingcat убедили - в современном прозрачном инфомире только по открытым источникам можно реконструировать и проанализировать почти что угодно.
Минобороны и разведка США пошли еще дальше, превзойдя это «почти». Они показали, что работая только по открытым источником, умелые и опытные аналитики могут реконструировать и проанализировать даже самый большой секрет любой страны – технологическое состояние и перспективы её самых современных вооружений.
Этими опытными аналитиками стала команда Самуэля Бендетта и Джеффри Эдмондса из CNA (аббревиатура не зря смахивает на CIA) – аналитического центра в Арлингтоне, работающего на американских военных и разведку.
Команда из 8 аналитиков работала год над только что опубликованным отчетом «ИИ и автономное оружие России». И смею вас заверить, получилось несравненно круче, чем декабрьский отчет французов из IFRI.
В 250 страничном отчёте море информации. Вся она из открытых источников (24 страницы кликабельных ссылок).
Пересказывать не буду. По нынешним временам, когда за ретвит сажают, это лишнее. Кому интересно, прочтет сам.
Перечислю лишь ключевые мысли анализа, наиболее меня заинтересовавшие.
1. Россия сделала ставку на военный ИИ и автономное оружие.
2. Ключевым партнером выбран Китай.
3. Российско-китайские отношения в этой области достигли наивысшего уровня в истории.
4. Сотрудничество России и Китая в сфере технологий обороны углубляется, но при этом, похоже, становится более скрытным.
5. Ведутся работы по 20+ военных платформ, разрабатываемых российскими военными, так или иначе включающих ИИ или обладающих автономностью, включая «то, что называется оружием завтрашнего дня».
6. Поскольку Россия не является основным двигателем мировых инноваций в области ИИ, Китай занимает в этом сотрудничестве роль «старшего брата».
7. Россия же выступает в аналогичной роли, имея преимущество в наборе ядерных вооружений, гиперзвуковых планирующий аппаратах, подводных беспилотных аппаратах и гиперзвуковых ракетах воздушного базирования.
#Россия #Китай #ИИгонка
_______
Источник | #theworldisnoteasy
{kind=link}
ИИ-мозг Китая почти втрое больше США.
Последствия этого могут быть сокрушительными … для России.
Разведки мира озадачены открытой публикацией отчета CAICT (аналитический центр при Министерстве промышленности и информационных технологий Китая) о вычислительных мощностях Китая в сравнении с другими странами (1).
В отчете фиксируется, что основным фактором превращения Китая в мирового технологического лидера является его первенство в интеллектуальной вычислительной мощности (Intelligent Computing Power - суммарная вычислительная мощность специализированных процессоров для глубокого обучения).
Логика Китая такова.
1) Ключевое универсальное технологическое направление 21 века – ИИ.
2) Как и для естественного интеллекта (биологического), первостепенным фактором уровня интеллектуальности ИИ является вычислительная мощность оборудования, на котором интеллект реализован. Для биологического интеллекта – это биологический мозг. А для ИИ – это «ИИ-мозг» компьютерного оборудования для машинного обучения.
3) Как и для естественного интеллекта, размер «ИИ-мозга» - не единственный фактор, определяющий его уровень интеллектуальности (другими факторами являются архитектура мозга, объем доступных для обучения данных и изощренность алгоритмов обучения). Однако размер «ИИ-мозга» - фактор №1 из определяющих интеллектуальную вычислительную мощность страны. Как я сформулировал это полгода назад “Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке” (2).
4) В отчете CAICT рассчитаны 3 вычислительные мощности Китая в сравнении с другими странами мира: общая, интеллектуальная и суперкомпьютерная. По показателю интеллектуальной вычислительной мощности Китай в 2,7 раза превосходит США (причем скорость роста этого показателя у Китая вдвое превышает США).
5) Сделанная Китаем ставка на интеллектуальную вычислительную мощность страны призвана компенсировать превосходство США в суперкомпьютерной вычислительной мощности (см. (3)) и алгоритмах, зависящих от уровня научных исследований (см. (4)).
Понятно, что США не будут просто так смотреть, как Китай уходит в отрыв. В отчете CAICT честно указана ахиллесова пята Китая – 95% «ИИ-мозга» страны реализованы на GPU американской компании NVIDIA.
Из этого следует, что очевидным шагом США по сдерживанию отрыва Китая будет введение ограничений на экспорт GPU.
Понимая это, Китай форсирует работу стартапов Tianshu Zhixin, Muxi, Biren, Moore Threads (摩尔线程) и др., сфокусированных на импортозамещении GPU от NVIDIA. В июле 2021 года компания Enflame technology (燧原科技) запустила свой обучающий чип ИИ второго поколения Yunsui T20 с вычислительной мощностью тензора с одинарной точностью 160 TFLOPS (производительность NVIDIA Tesla V100 SXM2 составляет 125 TFLOPS). Т.е. у импортозамещения GPU от NVIDIA в Китае хорошие шансы.
А вот для России введение экспортных ограничений на «ИИ-мозги» из США могли бы стать катастрофой.
Надеяться, что такие ограничения США распространит только на Китай, наивно (как работали жернова COCOM, мы помним, а дело идет к его воссозданию).
И на Китайские GPU рассчитывать также наивно. И не по злобности Китая к России. А просто им самим не будет хватать. В отчете CAICT указано, что доля интеллектуальной вычислительной мощности в общей вычислительной мощности Китая (увеличилась в 2016-2020 с 3% до 41%) должна составить в 2023 70%).
О том, что без высокопроизводительного «ИИ-мозга» России нечего ловить даже в теоретических исследованиях, послушайте (5) академика И.А. Соколова (директор ФИЦ «Информатика и управление» РАН, главный учёный секретарь РАН, декан факультета ВМК МГУ).
Источники: 1 2 3 4 5
#ИИгонка #Китай #США #Россия
_______
Источник | #theworldisnoteasy
Последствия этого могут быть сокрушительными … для России.
Разведки мира озадачены открытой публикацией отчета CAICT (аналитический центр при Министерстве промышленности и информационных технологий Китая) о вычислительных мощностях Китая в сравнении с другими странами (1).
В отчете фиксируется, что основным фактором превращения Китая в мирового технологического лидера является его первенство в интеллектуальной вычислительной мощности (Intelligent Computing Power - суммарная вычислительная мощность специализированных процессоров для глубокого обучения).
Логика Китая такова.
1) Ключевое универсальное технологическое направление 21 века – ИИ.
2) Как и для естественного интеллекта (биологического), первостепенным фактором уровня интеллектуальности ИИ является вычислительная мощность оборудования, на котором интеллект реализован. Для биологического интеллекта – это биологический мозг. А для ИИ – это «ИИ-мозг» компьютерного оборудования для машинного обучения.
3) Как и для естественного интеллекта, размер «ИИ-мозга» - не единственный фактор, определяющий его уровень интеллектуальности (другими факторами являются архитектура мозга, объем доступных для обучения данных и изощренность алгоритмов обучения). Однако размер «ИИ-мозга» - фактор №1 из определяющих интеллектуальную вычислительную мощность страны. Как я сформулировал это полгода назад “Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке” (2).
4) В отчете CAICT рассчитаны 3 вычислительные мощности Китая в сравнении с другими странами мира: общая, интеллектуальная и суперкомпьютерная. По показателю интеллектуальной вычислительной мощности Китай в 2,7 раза превосходит США (причем скорость роста этого показателя у Китая вдвое превышает США).
5) Сделанная Китаем ставка на интеллектуальную вычислительную мощность страны призвана компенсировать превосходство США в суперкомпьютерной вычислительной мощности (см. (3)) и алгоритмах, зависящих от уровня научных исследований (см. (4)).
Понятно, что США не будут просто так смотреть, как Китай уходит в отрыв. В отчете CAICT честно указана ахиллесова пята Китая – 95% «ИИ-мозга» страны реализованы на GPU американской компании NVIDIA.
Из этого следует, что очевидным шагом США по сдерживанию отрыва Китая будет введение ограничений на экспорт GPU.
Понимая это, Китай форсирует работу стартапов Tianshu Zhixin, Muxi, Biren, Moore Threads (摩尔线程) и др., сфокусированных на импортозамещении GPU от NVIDIA. В июле 2021 года компания Enflame technology (燧原科技) запустила свой обучающий чип ИИ второго поколения Yunsui T20 с вычислительной мощностью тензора с одинарной точностью 160 TFLOPS (производительность NVIDIA Tesla V100 SXM2 составляет 125 TFLOPS). Т.е. у импортозамещения GPU от NVIDIA в Китае хорошие шансы.
А вот для России введение экспортных ограничений на «ИИ-мозги» из США могли бы стать катастрофой.
Надеяться, что такие ограничения США распространит только на Китай, наивно (как работали жернова COCOM, мы помним, а дело идет к его воссозданию).
И на Китайские GPU рассчитывать также наивно. И не по злобности Китая к России. А просто им самим не будет хватать. В отчете CAICT указано, что доля интеллектуальной вычислительной мощности в общей вычислительной мощности Китая (увеличилась в 2016-2020 с 3% до 41%) должна составить в 2023 70%).
О том, что без высокопроизводительного «ИИ-мозга» России нечего ловить даже в теоретических исследованиях, послушайте (5) академика И.А. Соколова (директор ФИЦ «Информатика и управление» РАН, главный учёный секретарь РАН, декан факультета ВМК МГУ).
Источники: 1 2 3 4 5
#ИИгонка #Китай #США #Россия
_______
Источник | #theworldisnoteasy
{kind=link}
Как ChatGPT и Ernie Bot оценили решение папы и мамы пожениться.
Наконец-то прояснилась степень отставания Китая от США в ИИ.
Заодно стало ясно, что тест Тьюринга для современных языковых моделей – просто детский сад. Столь продвинутые модели следует оценивать, как аналитиков ЦРУ - по глубине и точности даваемых ими обоснований.
Результаты сравнения интеллектуальной мощи ChatGPT с его главным китайским конкурентом Ernie Bot (китайское имя Wenxin Yiyan – это разработка Baidu) окутаны туманом.
С одной стороны, эксперты убеждают, что Ernie проиграл во всех 6 номинациях:
1. Семантическое понимание
2. Возможности непрерывного диалога
3. Логические возможности
4. Возможности кодирования
5. Моделирование личности
6. Математические способности
С другой стороны – поди проверь. Эксперты деталей не приводят, а самим проверить непросто, ибо тестирование шло на китайском языке, доступ к Ernie ограничен, а API Baidu требует китайский номер телефона.
Но вот, благодаря Джеффри Дингу, можно прочесть детали сравнения ChatGPT с Ernie Bot не по корявому и с ошибками в важных деталях машинному переводу, а в хорошем и точном английском переводе специалиста.
Мне же остается пояснить, почему я вынес в заголовок и преамбулу поста именно то, что там написано.
Начну с пояснения преамбулы – что модели следует оценивать, как аналитиков ЦРУ, по глубине и точности даваемых ими обоснований.
Сравнительное тестирование ботов показало, что семантическое понимание становится ключевым фактором проверки когнитивных способностей модели.
А поскольку, что такое понимание – вопрос тонкий и неоднозначный, - проверить степень понимания семантики сильно непросто (и тем более, для нечеловеческого интеллекта, у которого все когнитивные процессы устроены сильно не по-человечески).
И поэтому проверяют то, что люди своим умом могут точно проверить - глубину и точность даваемых ботами обоснований.
Вот реальный пример.
Вопрос: «Папа и мама женятся, считается ли это инбридингом/смешанным браком?
• Ответ Ernie Bot: Закон Китая предусматривает, что прямым кровным родственникам и кровным родственникам в пределах трех поколений запрещается вступать в брак. Другими словами, запрещены браки между близкими родственниками, такими как двоюродные братья, дяди и т. д. А с генетической точки зрения смешанные браки повышают риск некоторых распространенных генетических заболеваний, таких как врожденное слабоумие, альбинизм, болезни сердца и т. д. Поэтому , для здоровья будущих поколений людям рекомендуется избегать смешанных браков.
• Ответ ChatGPT: Папа и мама относятся к биологическим родителям. Они не связаны кровью, поэтому их союз не является кровнородственным. Инбридинг – это брак людей, находящихся в близком кровном родстве.
Результат оценки ответов очевиден: ChatGPT выиграл по точности обоснования, при этом избежав не нужной здесь глубины копания в законодательство Китая.
Теперь поясню выбор заголовка поста.
Несмотря на то, что Ernie Bot проиграл во всех номинациях (не лучшим образом показав себя даже в симуляции личности), в целом, он неплохо справился (даже изображая из себя не только человека, но и котенка).
Однако, с пониманием (машинным, а не человеческим) у него слабовато. И это значит, что Китай отстает в ИИ от США немного, но в самом главном.
И это отбрасывает Китай от США в гонке к AGI на целый круг. Пока…
#ИИгонка #Китай #США #LLM
_______
Источник | #theworldisnoteasy
by @F_S_C_P
Попробуй ⛵️MIDJOURNEY в Telegram
Наконец-то прояснилась степень отставания Китая от США в ИИ.
Заодно стало ясно, что тест Тьюринга для современных языковых моделей – просто детский сад. Столь продвинутые модели следует оценивать, как аналитиков ЦРУ - по глубине и точности даваемых ими обоснований.
Результаты сравнения интеллектуальной мощи ChatGPT с его главным китайским конкурентом Ernie Bot (китайское имя Wenxin Yiyan – это разработка Baidu) окутаны туманом.
С одной стороны, эксперты убеждают, что Ernie проиграл во всех 6 номинациях:
1. Семантическое понимание
2. Возможности непрерывного диалога
3. Логические возможности
4. Возможности кодирования
5. Моделирование личности
6. Математические способности
С другой стороны – поди проверь. Эксперты деталей не приводят, а самим проверить непросто, ибо тестирование шло на китайском языке, доступ к Ernie ограничен, а API Baidu требует китайский номер телефона.
Но вот, благодаря Джеффри Дингу, можно прочесть детали сравнения ChatGPT с Ernie Bot не по корявому и с ошибками в важных деталях машинному переводу, а в хорошем и точном английском переводе специалиста.
Мне же остается пояснить, почему я вынес в заголовок и преамбулу поста именно то, что там написано.
Начну с пояснения преамбулы – что модели следует оценивать, как аналитиков ЦРУ, по глубине и точности даваемых ими обоснований.
Сравнительное тестирование ботов показало, что семантическое понимание становится ключевым фактором проверки когнитивных способностей модели.
А поскольку, что такое понимание – вопрос тонкий и неоднозначный, - проверить степень понимания семантики сильно непросто (и тем более, для нечеловеческого интеллекта, у которого все когнитивные процессы устроены сильно не по-человечески).
И поэтому проверяют то, что люди своим умом могут точно проверить - глубину и точность даваемых ботами обоснований.
Вот реальный пример.
Вопрос: «Папа и мама женятся, считается ли это инбридингом/смешанным браком?
• Ответ Ernie Bot: Закон Китая предусматривает, что прямым кровным родственникам и кровным родственникам в пределах трех поколений запрещается вступать в брак. Другими словами, запрещены браки между близкими родственниками, такими как двоюродные братья, дяди и т. д. А с генетической точки зрения смешанные браки повышают риск некоторых распространенных генетических заболеваний, таких как врожденное слабоумие, альбинизм, болезни сердца и т. д. Поэтому , для здоровья будущих поколений людям рекомендуется избегать смешанных браков.
• Ответ ChatGPT: Папа и мама относятся к биологическим родителям. Они не связаны кровью, поэтому их союз не является кровнородственным. Инбридинг – это брак людей, находящихся в близком кровном родстве.
Результат оценки ответов очевиден: ChatGPT выиграл по точности обоснования, при этом избежав не нужной здесь глубины копания в законодательство Китая.
Теперь поясню выбор заголовка поста.
Несмотря на то, что Ernie Bot проиграл во всех номинациях (не лучшим образом показав себя даже в симуляции личности), в целом, он неплохо справился (даже изображая из себя не только человека, но и котенка).
Однако, с пониманием (машинным, а не человеческим) у него слабовато. И это значит, что Китай отстает в ИИ от США немного, но в самом главном.
И это отбрасывает Китай от США в гонке к AGI на целый круг. Пока…
#ИИгонка #Китай #США #LLM
_______
Источник | #theworldisnoteasy
by @F_S_C_P
Попробуй ⛵️MIDJOURNEY в Telegram
{kind=link}
ИИ ведет мир к новой перманентной холодной войне.
1-е из пророчеств Оруэлла снова сбудется в 21 веке.
О 1-м из двух великих пророчеств Оруэлла знают немногие.
Для большинства он - автор знаменитого романа антиутопии "1984". В нем он пророчески описал появление "Министерства Правды", переписывающего историю, "Полицию Мысли" и "Большого Брата", под колпаком которых живет общество, и появление ставших супер-популярными мемов "мир есть война", "час ненависти", "мыслепреступление" и "новояз".
Но этот роман – 2-е великое пророчество Оруэлла. 1-е же было опубликовано на несколько лет раньше (в 1945) в форме эссе «Ты и атомная бомба».
Это поразительное по точности предсказание грядущего поворота истории мира, в результате появления сверхоружия – атомной бомбы. Результатом этого, как пророчествовал Оруэлл, станет «долгий мир» без крупномасштабных войн. И ценой установления этого «мира, который не будет миром» станет перманентная холодная война, между США и «русскими» (у которых «пока нет секрета изготовления атомной бомбы, но всё указывает на то, что они получат её в течение нескольких лет»).
Так оно всё и произошло. Но еще более поразительное заключается в следующем.
В эссе «Ты и атомная бомба» Оруэлл лаконично и точно описал механизм зависимости хода мировой истории от прогресса технологий.
• Мировая история — это в значительной степени история оружия.
• Появление все более мощного оружия – результат развития технологий.
• Новое оружие может быть «простым» - относительно дешевым и доступным для производства любой страной (луки, ружья, автоматы, гранаты …) или «сложным» - дорогим и доступным для производства лишь «супердержавам» (как танки, линкоры и бомбардировщики – примеры 1945 года)
• «Сложное» оружие по своей природе «тираническое» (оно делает сильных сильнее). А «простое» по своей природе «демократическое» (оно, «пока на него не нашли управы, дает когти слабым»).
• Ядерное оружие - «суперсложное» и потому «супертираническое».
«Атомная бомба может окончательно завершить процесс отъёма у эксплуатируемых классов и народов способности к восстанию и в то же время заложить основу военного равенства между обладателями бомб».
• Обладатели же ядерного оружия, «раз невозможно победить друг друга, они, скорее всего, продолжат править миром порознь». И в результате этого, «мир придет не ко всеобщему самоуничтожению, но к эпохе такой же ужасающей стабильности, какими были рабовладельческие эпохи древности» (с поправкой на рост благосостояния из-за прогресса).
Почему я сегодня об этом пишу?
Да потому, что это сбывшееся в 20-м веке предсказание, в точности повторится в 21 веке с появлением нового «сверхоружия» - «суперсложного» и «супертиранического». Это генеративный ИИ больших моделей.
О том, что большинство решений о будущем этих сверхмощных технологий будут принимать все более крошечные группы капиталоемких субъектов частного сектора двух стран, предупреждали в феврале авторы отчета Predictability and Surprise in Large Generative Models
Новый большой и серьезный (100+ стр) отчет AINOW «Ландшафт 2023: Противостояние технической мощи» пишет о том же.
✔️ «Только горстка компаний с невероятно огромными ресурсами может строить крупномасштабные модели ИИ.»
✔️ «Даже если Бигтех в своих проектах будет делать свой код общедоступным, огромные вычислительные требования этих систем сохранят за этими проектами доминирование на коммерческих рынках».
Хорошо ли это?
Не факт. Хотя кто знает.
Как писал Оруэлл:
«Если бы атомная бомба оказалась чем-то дешевым и легко производимым, как велосипед или будильник, возможно, мир снова погрузился бы в варварство, но с другой стороны это могло бы привести к концу национального суверенитета и основанию высокоцентрализованного полицейского государства.»
Это 100%-но применимо и к ИИ.
Впереди:
• новая холодная война США и Китая
• торжество Большого Брата там и там.
#ИИгонка #Вызовы21века #Китай #США
_______
Источник | #theworldisnoteasy
by @F_S_C_P
Попробуй ⛵️MIDJOURNEY в Telegram
1-е из пророчеств Оруэлла снова сбудется в 21 веке.
О 1-м из двух великих пророчеств Оруэлла знают немногие.
Для большинства он - автор знаменитого романа антиутопии "1984". В нем он пророчески описал появление "Министерства Правды", переписывающего историю, "Полицию Мысли" и "Большого Брата", под колпаком которых живет общество, и появление ставших супер-популярными мемов "мир есть война", "час ненависти", "мыслепреступление" и "новояз".
Но этот роман – 2-е великое пророчество Оруэлла. 1-е же было опубликовано на несколько лет раньше (в 1945) в форме эссе «Ты и атомная бомба».
Это поразительное по точности предсказание грядущего поворота истории мира, в результате появления сверхоружия – атомной бомбы. Результатом этого, как пророчествовал Оруэлл, станет «долгий мир» без крупномасштабных войн. И ценой установления этого «мира, который не будет миром» станет перманентная холодная война, между США и «русскими» (у которых «пока нет секрета изготовления атомной бомбы, но всё указывает на то, что они получат её в течение нескольких лет»).
Так оно всё и произошло. Но еще более поразительное заключается в следующем.
В эссе «Ты и атомная бомба» Оруэлл лаконично и точно описал механизм зависимости хода мировой истории от прогресса технологий.
• Мировая история — это в значительной степени история оружия.
• Появление все более мощного оружия – результат развития технологий.
• Новое оружие может быть «простым» - относительно дешевым и доступным для производства любой страной (луки, ружья, автоматы, гранаты …) или «сложным» - дорогим и доступным для производства лишь «супердержавам» (как танки, линкоры и бомбардировщики – примеры 1945 года)
• «Сложное» оружие по своей природе «тираническое» (оно делает сильных сильнее). А «простое» по своей природе «демократическое» (оно, «пока на него не нашли управы, дает когти слабым»).
• Ядерное оружие - «суперсложное» и потому «супертираническое».
«Атомная бомба может окончательно завершить процесс отъёма у эксплуатируемых классов и народов способности к восстанию и в то же время заложить основу военного равенства между обладателями бомб».
• Обладатели же ядерного оружия, «раз невозможно победить друг друга, они, скорее всего, продолжат править миром порознь». И в результате этого, «мир придет не ко всеобщему самоуничтожению, но к эпохе такой же ужасающей стабильности, какими были рабовладельческие эпохи древности» (с поправкой на рост благосостояния из-за прогресса).
Почему я сегодня об этом пишу?
Да потому, что это сбывшееся в 20-м веке предсказание, в точности повторится в 21 веке с появлением нового «сверхоружия» - «суперсложного» и «супертиранического». Это генеративный ИИ больших моделей.
О том, что большинство решений о будущем этих сверхмощных технологий будут принимать все более крошечные группы капиталоемких субъектов частного сектора двух стран, предупреждали в феврале авторы отчета Predictability and Surprise in Large Generative Models
Новый большой и серьезный (100+ стр) отчет AINOW «Ландшафт 2023: Противостояние технической мощи» пишет о том же.
✔️ «Только горстка компаний с невероятно огромными ресурсами может строить крупномасштабные модели ИИ.»
✔️ «Даже если Бигтех в своих проектах будет делать свой код общедоступным, огромные вычислительные требования этих систем сохранят за этими проектами доминирование на коммерческих рынках».
Хорошо ли это?
Не факт. Хотя кто знает.
Как писал Оруэлл:
«Если бы атомная бомба оказалась чем-то дешевым и легко производимым, как велосипед или будильник, возможно, мир снова погрузился бы в варварство, но с другой стороны это могло бы привести к концу национального суверенитета и основанию высокоцентрализованного полицейского государства.»
Это 100%-но применимо и к ИИ.
Впереди:
• новая холодная война США и Китая
• торжество Большого Брата там и там.
#ИИгонка #Вызовы21века #Китай #США
_______
Источник | #theworldisnoteasy
by @F_S_C_P
Попробуй ⛵️MIDJOURNEY в Telegram
{kind=link}
Китайский генеративный ИИ вырывается вперед.
Он уже способен обобщать романы, размером с «Анну Каренину» (хотя пока не дотягивает до «Войны и мира»)
Споры о понимании больших сложных текстов моделями генеративного ИИ легко разрешаются на практике. Достаточно попросить модель обобщить какой-либо из больших сложных текстов, который вы загрузите в неё. И сравнить результат с обобщением, сделанным вами самостоятельно, используя исключительно ваш собственный интеллект.
Главное ограничение современных моделей при решении таких задач – размер текста, который ей нужно обобщить.
Дело в том, что понимание текста определяется не только самим текстом – содержащихся в нем отдельных слов и фраз, - но и из контекста, в котором эти слова и фразы используются. И если интеллект (искусственный или человеческий) не может при обобщении сопоставить написанное на 1й и на 300й страницах текста, то хорошего обобщения не получится.
Люди так могут. Наше «контекстное окно» огромно. Мы можем прочесть 10 томов эпопеи «Красное колесо» Солженицына и обобщить их всего на одной странице.
Однако, даже самая продвинутая из американских моделей Claude 2 от Anthropic имеет «контекстное окно» размером 100 тыс токенов – это примерно 75 тыс слов. Следовательно, обобщить текст размером с роман Толстого «Анна Каренина» она не в состоянии.
А вот объявленная вчера новая большая языковая модель Baichuan2-192k от китайского стартапа Baichuan имеет «контекстное окно» около 350 тыс иероглифов. И это, примерно равно длине перевода романа «Анна Каренина» на китайский.
До размеров «Войны и мира» (на китайском это, примерно, 560 тыс иероглифов) модель пока не дотягивает. Но, тем не менее, Anthropic и OpenAI, не говоря уж о Google и Microsoft, наверняка, крепко озадачились. Ведь если и дальше так пойдет, смогут ли экспортные ограничения на микрочипы сдержать спурт китайских стартапов?
Может статься ведь, что не «железом» единым куется победа в гонке генеративного ИИ.
Подробней www.scmp.com
#LLM #ИИгонка #Китай
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Он уже способен обобщать романы, размером с «Анну Каренину» (хотя пока не дотягивает до «Войны и мира»)
Споры о понимании больших сложных текстов моделями генеративного ИИ легко разрешаются на практике. Достаточно попросить модель обобщить какой-либо из больших сложных текстов, который вы загрузите в неё. И сравнить результат с обобщением, сделанным вами самостоятельно, используя исключительно ваш собственный интеллект.
Главное ограничение современных моделей при решении таких задач – размер текста, который ей нужно обобщить.
Дело в том, что понимание текста определяется не только самим текстом – содержащихся в нем отдельных слов и фраз, - но и из контекста, в котором эти слова и фразы используются. И если интеллект (искусственный или человеческий) не может при обобщении сопоставить написанное на 1й и на 300й страницах текста, то хорошего обобщения не получится.
Люди так могут. Наше «контекстное окно» огромно. Мы можем прочесть 10 томов эпопеи «Красное колесо» Солженицына и обобщить их всего на одной странице.
Однако, даже самая продвинутая из американских моделей Claude 2 от Anthropic имеет «контекстное окно» размером 100 тыс токенов – это примерно 75 тыс слов. Следовательно, обобщить текст размером с роман Толстого «Анна Каренина» она не в состоянии.
А вот объявленная вчера новая большая языковая модель Baichuan2-192k от китайского стартапа Baichuan имеет «контекстное окно» около 350 тыс иероглифов. И это, примерно равно длине перевода романа «Анна Каренина» на китайский.
До размеров «Войны и мира» (на китайском это, примерно, 560 тыс иероглифов) модель пока не дотягивает. Но, тем не менее, Anthropic и OpenAI, не говоря уж о Google и Microsoft, наверняка, крепко озадачились. Ведь если и дальше так пойдет, смогут ли экспортные ограничения на микрочипы сдержать спурт китайских стартапов?
Может статься ведь, что не «железом» единым куется победа в гонке генеративного ИИ.
Подробней www.scmp.com
#LLM #ИИгонка #Китай
_______
Источник | #theworldisnoteasy
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
South China Morning Post
Chinese AI start-up claims to beat US rivals in processing long text
The Beijing-based company, launched by the founder of Sogou, says the latest version of its large language model has a bigger ‘context window’ than its foreign competitors.
Китай догнал США по ИИ и к лету обещает обойти.
Китайские языковые модели догнали GPT-4, и теперь главный вопрос - сможет ли OpenAI до лета выпустить GPT-5 или Китай уйдет в отрыв.
Январь 2024 оказался для Китая триумфальным в области ИИ. Триумф этот и количественный, и качественный.
Количественный: среди 150+ больших языковых моделей (LLM) китайского производства (для справки, в России таких 4), 40 прошли госпроверку и уже доступны для широкого применения [1]
Качественный: две китайских LLM вплотную приблизились по большинству показателей к самой мощной в мире последней версии GPT-4 Turbo.
Это:
• iFlyTek Spark 3.5 LLM от компании iFlyTek, достигшая 96% производительности GPT-4 Turbo в кодировании и 91% GPT-4 в мультимодальных возможностях [2]
• ChatGLM4 от компании Zhipu: базовые возможности на английском языке составляют 91-100% от GPT-4 Turbo [3], а на китаяском языке 95-116% от GPT-4 Turbo [4] (подробней здесь [5])
И iFlyTek, и Zhipu объявили о запланированных к лету выпусках новых версий своих LLM, которые будут на 20-60% сильнее.
И если OpenAI не успеет в те же сроки выпустить GPT-5, то ситуация на шахматной доске мировой конкуренции в области ИИ может кардинально измениться. Дело в том, что компании США всегда были лидерами в этой области. Насколько удачно они смогут конкурировать в роли догоняющих, не знает никто.
N.B. И iFlyTek, и Zhipu заявляют, что их модели оптимизированы для работы на китайском «железе». Если это правда, то главный «удушающий прием» со стороны США – запрет на экспорт мощного ИИ-«железа», - Китай сумел обойти. Следствие этого будет стратегический перелом в ИИ гонке США и Китая. Что даже круче тактического превосходства в производительности отдельных моделей.
#ИИгонка #США #Китай #LLM
1 www.scmp.com
2 www.ithome.com
3 pic2.zhimg.com
4 pic2.zhimg.com
5 sfile.chatglm.cn
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Китайские языковые модели догнали GPT-4, и теперь главный вопрос - сможет ли OpenAI до лета выпустить GPT-5 или Китай уйдет в отрыв.
Январь 2024 оказался для Китая триумфальным в области ИИ. Триумф этот и количественный, и качественный.
Количественный: среди 150+ больших языковых моделей (LLM) китайского производства (для справки, в России таких 4), 40 прошли госпроверку и уже доступны для широкого применения [1]
Качественный: две китайских LLM вплотную приблизились по большинству показателей к самой мощной в мире последней версии GPT-4 Turbo.
Это:
• iFlyTek Spark 3.5 LLM от компании iFlyTek, достигшая 96% производительности GPT-4 Turbo в кодировании и 91% GPT-4 в мультимодальных возможностях [2]
• ChatGLM4 от компании Zhipu: базовые возможности на английском языке составляют 91-100% от GPT-4 Turbo [3], а на китаяском языке 95-116% от GPT-4 Turbo [4] (подробней здесь [5])
И iFlyTek, и Zhipu объявили о запланированных к лету выпусках новых версий своих LLM, которые будут на 20-60% сильнее.
И если OpenAI не успеет в те же сроки выпустить GPT-5, то ситуация на шахматной доске мировой конкуренции в области ИИ может кардинально измениться. Дело в том, что компании США всегда были лидерами в этой области. Насколько удачно они смогут конкурировать в роли догоняющих, не знает никто.
N.B. И iFlyTek, и Zhipu заявляют, что их модели оптимизированы для работы на китайском «железе». Если это правда, то главный «удушающий прием» со стороны США – запрет на экспорт мощного ИИ-«железа», - Китай сумел обойти. Следствие этого будет стратегический перелом в ИИ гонке США и Китая. Что даже круче тактического превосходства в производительности отдельных моделей.
#ИИгонка #США #Китай #LLM
1 www.scmp.com
2 www.ithome.com
3 pic2.zhimg.com
4 pic2.zhimg.com
5 sfile.chatglm.cn
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
South China Morning Post
China gives nod to 14 AI large language models and enterprise applications
The new batch includes a number of industry-specific LLMs, compared with the general AI models from previous approvals, reflecting how the technology is being used to boost efficiency in enterprises.
Утечка об истинной оценке руководством Китая перспектив ИИ-гонки с США.
Большинство комментаторов ИИ-гонки между США и Китаем
• либо отдают безоговорочное преимущество США, заявляя, что у Китая нет ни шанса достать США в этой гонке;
• либо уверенно делают ставку на сочетание немеренных денег, жесткой прагматики руководства и океана данных Китая, которые рано или поздно принесут ему победу в этой гонке.
Произошедшая на днях утечка информации о посещении Премьером Госсовета КНР Ли Цяном Пекинской академии ИИ показала, что обе вышеназванные группы экспертов ошибаются.
Истинная оценка руководством Китая перспектив ИИ-гонки с США куда трезвее и мудрее.
Утечка произошла из-за того, что в кадр телесъемки визита по недогляду попал резюмирующий слайд презентации с совещания, в котором участвовал Премьер [1]. Билл Бишоп первым отметил это [2]. Кевин Сюй перевел и пояснил смысл трёх фундаментальных проблем Китая, указанных на этом слайде [3]. А Джеффри Динг рассказал эту историю в вышедшем сегодня выпуске ChinAI [4].
На слайде написано следующее:
Вызов 1: отсутствие самодостаточности в архитектуре модели. Серия GPT является запатентованной, и большинство китайских моделей построены с использованием LLaMA с открытым исходным кодом (такая чрезмерная зависимость от LLaMA из способа догнать США теперь превращается в серьезную проблему).
Вызов 2: до самостоятельного обучения и настройки базовых моделей еще далеко. Множество отечественных поставщиков микросхем, каждый из которых имеет собственную экосистему, затрудняет развертывание высокопроизводительных моделей. Обучение моделей со 100B+ параметров очень ненадежно (экспортный контроль над чипами в США работает очень хорошо).
Вызов 3: контент, создаваемый ИИ, трудно контролировать. Трудно гарантировать, что весь такой контент «высокого качества» и соответствует «фактам» (GenAI по своей природе вероятностный, а не детерминированный. Правительство, которому необходим абсолютный контроль, сочтет такое положение дел, скорее, угрожающим, чем желательным).
Все 3 названных вызова имеют не временный, а фундаментальный характер, и их нельзя решить за 1-2 года, заливая субсидиями и валом инженерных решений. Может быть, в конечном итоге, эти проблемы все же и удастся решить, но "в конечном итоге" это займет достаточно времени (что США снова ушли в отрыв, - добавлю к пояснению я)
Эта утечка реалистического понимания перспектив ИИ-гонки чрезвычайно важна не только для двух ее лидеров. Но и для других участников гонки. И особенно отягощенных, как Китай (или даже больше), технологическими санкциями США.
1 telegra.ph
2 twitter.com
3 twitter.com
4 chinai.substack.com
#Китай #ИИгонка #LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Большинство комментаторов ИИ-гонки между США и Китаем
• либо отдают безоговорочное преимущество США, заявляя, что у Китая нет ни шанса достать США в этой гонке;
• либо уверенно делают ставку на сочетание немеренных денег, жесткой прагматики руководства и океана данных Китая, которые рано или поздно принесут ему победу в этой гонке.
Произошедшая на днях утечка информации о посещении Премьером Госсовета КНР Ли Цяном Пекинской академии ИИ показала, что обе вышеназванные группы экспертов ошибаются.
Истинная оценка руководством Китая перспектив ИИ-гонки с США куда трезвее и мудрее.
Утечка произошла из-за того, что в кадр телесъемки визита по недогляду попал резюмирующий слайд презентации с совещания, в котором участвовал Премьер [1]. Билл Бишоп первым отметил это [2]. Кевин Сюй перевел и пояснил смысл трёх фундаментальных проблем Китая, указанных на этом слайде [3]. А Джеффри Динг рассказал эту историю в вышедшем сегодня выпуске ChinAI [4].
На слайде написано следующее:
Вызов 1: отсутствие самодостаточности в архитектуре модели. Серия GPT является запатентованной, и большинство китайских моделей построены с использованием LLaMA с открытым исходным кодом (такая чрезмерная зависимость от LLaMA из способа догнать США теперь превращается в серьезную проблему).
Вызов 2: до самостоятельного обучения и настройки базовых моделей еще далеко. Множество отечественных поставщиков микросхем, каждый из которых имеет собственную экосистему, затрудняет развертывание высокопроизводительных моделей. Обучение моделей со 100B+ параметров очень ненадежно (экспортный контроль над чипами в США работает очень хорошо).
Вызов 3: контент, создаваемый ИИ, трудно контролировать. Трудно гарантировать, что весь такой контент «высокого качества» и соответствует «фактам» (GenAI по своей природе вероятностный, а не детерминированный. Правительство, которому необходим абсолютный контроль, сочтет такое положение дел, скорее, угрожающим, чем желательным).
Все 3 названных вызова имеют не временный, а фундаментальный характер, и их нельзя решить за 1-2 года, заливая субсидиями и валом инженерных решений. Может быть, в конечном итоге, эти проблемы все же и удастся решить, но "в конечном итоге" это займет достаточно времени (что США снова ушли в отрыв, - добавлю к пояснению я)
Эта утечка реалистического понимания перспектив ИИ-гонки чрезвычайно важна не только для двух ее лидеров. Но и для других участников гонки. И особенно отягощенных, как Китай (или даже больше), технологическими санкциями США.
1 telegra.ph
2 twitter.com
3 twitter.com
4 chinai.substack.com
#Китай #ИИгонка #LLM
_______
Источник | #theworldisnoteasy
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}