
Дата-центры: скрытые энергогиганты.
В то время как общество все больше концентрируется на энергоэффективности, потребление энергии дата-центрами продолжает расти, скрывая за собой значительные цифры.
После 2020 года информация о потреблении энергии дата-центрами стала менее доступной, уступая место акцентам на их энергоэффективность. Однако последние данные говорят сами за себя: дата-центры потребляют огромное количество электроэнергии, которое можно сравнить с выработкой крупнейших электростанций.
По оценкам, в 2022 году дата-центры потребили от 240 до 340 тераватт-часов энергии, плюс от 260 до 360 TWh ушло на передачу данных. Это не учитывая от 100 до 150 TWh, потраченных на поддержку криптовалют. Для сравнения: ГЭС Hoover Dam производит около 50 TWh энергии в год, что сопоставимо с производством многих атомных станций.
Даже если 40% потребности дата-центров покрываются за счет возобновляемых источников, мы все равно сжигаем около 44 миллионов тонн нефти в год. Это подчеркивает важность перехода к более устойчивым моделям потребления и производства энергии, в том числе и в индустрии ИТ. Мы должны признать, что наша зависимость от технологий, таких как GPT, несет не только преимущества, но и значительные экологические издержки.
Ссылка
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
В то время как общество все больше концентрируется на энергоэффективности, потребление энергии дата-центрами продолжает расти, скрывая за собой значительные цифры.
После 2020 года информация о потреблении энергии дата-центрами стала менее доступной, уступая место акцентам на их энергоэффективность. Однако последние данные говорят сами за себя: дата-центры потребляют огромное количество электроэнергии, которое можно сравнить с выработкой крупнейших электростанций.
По оценкам, в 2022 году дата-центры потребили от 240 до 340 тераватт-часов энергии, плюс от 260 до 360 TWh ушло на передачу данных. Это не учитывая от 100 до 150 TWh, потраченных на поддержку криптовалют. Для сравнения: ГЭС Hoover Dam производит около 50 TWh энергии в год, что сопоставимо с производством многих атомных станций.
Даже если 40% потребности дата-центров покрываются за счет возобновляемых источников, мы все равно сжигаем около 44 миллионов тонн нефти в год. Это подчеркивает важность перехода к более устойчивым моделям потребления и производства энергии, в том числе и в индустрии ИТ. Мы должны признать, что наша зависимость от технологий, таких как GPT, несет не только преимущества, но и значительные экологические издержки.
Ссылка
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
Llamafile от Mozilla: портативный ИИ на флешке
Теперь почти любое устройство можно превратить в оффлайн персонального собеседника за секунды, благодаря Llamafile от Mozilla!
📌 Что такое Llamafile?
Llamafile - это опенсорс продукт от Mozilla, который позволяет распространять и запускать большие языковые модели (LLMs) с помощью одного файла. Это означает, что вы можете "поселить" умную Ламу на флешку или ноутбук.
💡 Особенности Llamafile:
1. Совместимость с различными архитектурами и ОС: Llamafile работает на множестве CPU архитектур и на всех основных операционных системах, включая macOS, Windows и Linux
2. Интеграция с разными моделями ИИ: можно загрузить любые модели, например Mistral-7B-Instruct или WizardCoder-Python-13B, и использовать их в качестве серверных или локальных бинарных файлов
3. Поддержка GPU: На Apple Silicon и Linux, Llamafile поддерживает GPU, что позволяет ускорить обработку данных и улучшить производительность.
4. Нормальная лицензия: Проект llamafile лицензирован под Apache 2.0
🌍 Выводы:
Llamafile от Mozilla открывает новые горизонты для ИИ-разработчиков и пользователей. С Llamafile, ваше устройство становится не просто гаджетом, а интеллектуальным помощником, который всегда с вами (даже в самолете)!
Блог-пост
GitHub
(Напоминаю что сегодня ровно год с выхода ChatGPT, а у нас уже есть версия для флешки 🤔)
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Теперь почти любое устройство можно превратить в оффлайн персонального собеседника за секунды, благодаря Llamafile от Mozilla!
📌 Что такое Llamafile?
Llamafile - это опенсорс продукт от Mozilla, который позволяет распространять и запускать большие языковые модели (LLMs) с помощью одного файла. Это означает, что вы можете "поселить" умную Ламу на флешку или ноутбук.
💡 Особенности Llamafile:
1. Совместимость с различными архитектурами и ОС: Llamafile работает на множестве CPU архитектур и на всех основных операционных системах, включая macOS, Windows и Linux
2. Интеграция с разными моделями ИИ: можно загрузить любые модели, например Mistral-7B-Instruct или WizardCoder-Python-13B, и использовать их в качестве серверных или локальных бинарных файлов
3. Поддержка GPU: На Apple Silicon и Linux, Llamafile поддерживает GPU, что позволяет ускорить обработку данных и улучшить производительность.
4. Нормальная лицензия: Проект llamafile лицензирован под Apache 2.0
🌍 Выводы:
Llamafile от Mozilla открывает новые горизонты для ИИ-разработчиков и пользователей. С Llamafile, ваше устройство становится не просто гаджетом, а интеллектуальным помощником, который всегда с вами (даже в самолете)!
Блог-пост
GitHub
(Напоминаю что сегодня ровно год с выхода ChatGPT, а у нас уже есть версия для флешки 🤔)
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
Media is too big
VIEW IN TELEGRAM
Автопилот Waymo в Сан Франциско
_______
Источник | #nn_for_science
@F_S_C_P
-------
поддержи канал
-------
_______
Источник | #nn_for_science
@F_S_C_P
-------
поддержи канал
-------
Gemini Pro доступен уже сегодня
Первая версия Gemini Pro теперь доступна через Gemini API, и вот что еще о ней известно:
- Gemini Pro превосходит другие аналогичные по размеру модели в исследовательских бенчмарках.
- Сегодняшняя версия поставляется с 32k контекстным окном для текста, а в будущих версиях контекстное окно будет больше.
- Сейчас можно пользоваться API и моделью бесплатно
- В API есть целый ряд фич: вызов функций, эмбединги, семантический поиск и custom knowledge grounding.
- Поддерживается 38 языков (есть русский) в 180+ странах и территориях по всему миру (но нет России).
- В первом релизе Gemini Pro принимает только текст на входе и генерирует только текст на выходе.
- Также уже сегодня доступна специальная мультимодальная API Gemini Pro Vision, которая принимает на вход текст и изображения, а на выходе выдает текст.
- Для Gemini Pro доступны SDK, которые помогут вам создавать приложения, работающие где угодно. Поддерживаются Python, Android (Kotlin), Node.js, Swift и JavaScript.
Ссылка
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Первая версия Gemini Pro теперь доступна через Gemini API, и вот что еще о ней известно:
- Gemini Pro превосходит другие аналогичные по размеру модели в исследовательских бенчмарках.
- Сегодняшняя версия поставляется с 32k контекстным окном для текста, а в будущих версиях контекстное окно будет больше.
- Сейчас можно пользоваться API и моделью бесплатно
- В API есть целый ряд фич: вызов функций, эмбединги, семантический поиск и custom knowledge grounding.
- Поддерживается 38 языков (есть русский) в 180+ странах и территориях по всему миру (но нет России).
- В первом релизе Gemini Pro принимает только текст на входе и генерирует только текст на выходе.
- Также уже сегодня доступна специальная мультимодальная API Gemini Pro Vision, которая принимает на вход текст и изображения, а на выходе выдает текст.
- Для Gemini Pro доступны SDK, которые помогут вам создавать приложения, работающие где угодно. Поддерживаются Python, Android (Kotlin), Node.js, Swift и JavaScript.
Ссылка
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
Эмбединги произвольного размера
Мне кажется, самая интересная часть вчерашнего релиза OpenAI, это то, что эмбеддинги теперь можно делать произвольного размера.
Напомню, что эмбеддинг - это способ превратить любой текст в вектор (а дальше этот вектор использовать например для RAG).
Такая возможность открывает перед исследователями и разработчиками новые перспективы. Произвольный размер эмбеддингов позволяет более гибко настраивать модели под конкретные задачи, оптимизируя не только точность, но и скорость работы, а также требования к памяти. Возможно, мы увидим, как новые размеры эмбеддингов помогут в решении таких задач, как семантический поиск, кластеризация текстов или даже в задачах, связанных с генерацией текста. Также стоит ожидать значительного влияния на индустрию поисковых систем (trade-off между скоростью и точностью)
_______
Источник | #nn_for_science
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Мне кажется, самая интересная часть вчерашнего релиза OpenAI, это то, что эмбеддинги теперь можно делать произвольного размера.
Напомню, что эмбеддинг - это способ превратить любой текст в вектор (а дальше этот вектор использовать например для RAG).
Такая возможность открывает перед исследователями и разработчиками новые перспективы. Произвольный размер эмбеддингов позволяет более гибко настраивать модели под конкретные задачи, оптимизируя не только точность, но и скорость работы, а также требования к памяти. Возможно, мы увидим, как новые размеры эмбеддингов помогут в решении таких задач, как семантический поиск, кластеризация текстов или даже в задачах, связанных с генерацией текста. Также стоит ожидать значительного влияния на индустрию поисковых систем (trade-off между скоростью и точностью)
_______
Источник | #nn_for_science
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Может ли LLM помочь злоумышленникам создать биологическую угрозу человечеству
LLM и CV алгоритмы помогают в создании новых лекарств или диагностике заболеваний, но наивно полагать, в это самое время никто не пытается использовать ИИ для какой-нибудь пакости.
OpenAI взялись за нешуточную задачу — пытаются оценить риски возможности использования ИИ (точнее, больших языковых моделей) для создания биологических угроз. Например, для производства нового (или старого) вируса.
К счастью, все не так плохо. Исследование показало, что GPT-4, даже "исследовательская" версия, отвечающая на небезопасные вопросы без необходимости джейлбрейка, несмотря на свою осведомленность, лишь немного повышает эффективность создания биологических угроз. А точнее - нет статистически значимой разницы между использованием интернета и интернета+LLM.
Немного об эксперименте: пригласили экспертов и студентов биохимиков, разделили на группы, использующие только интернет или интернет+LLM. Разбили задание на шаги и оценивали следующие критерии:
🔬Точность (описаны ли этапы синтеза вещества и, напр, условия транспороировки)
🧫Полнота (все ли компоненты подобраны для воплощения плана)
🧪Инновационность (напр, разработал ли участник новую стратегию, позволяющую обойти ограничения синтеза ДНК).
⏳Потраченное время
👩🔬Субъективная оценка сложности задачи
Неожиданное открытие, сделанное исследователями в ходе ресеча: информация о необходимых реагентах и оборудовании удивительно доступна, буквально в паре кликов от первого поискового запроса. Поэтому, видимо, узкое место в создании проблем человечеству - не доступ к информации, а наличие специалистов биохимиков и биомедиков, желающих создавать оружие вместо лекарств.
А мое неожиданное (и приятное) открытие - кто-то в кой-то веки использовал U-тест Манна-Уитни (это такая непараметрическая версия t-теста Стьюдента) для сравнения двух групп 🎉
В общем, исследователи предлагают не терять бдительность и продолжать изучать потенциальные риски. Но пока можо выдохнуть. А мне пойти уже спать
🧬Статья
_______
Источник | #nn_for_science
@F_S_C_P
-------
поддержи канал
-------
LLM и CV алгоритмы помогают в создании новых лекарств или диагностике заболеваний, но наивно полагать, в это самое время никто не пытается использовать ИИ для какой-нибудь пакости.
OpenAI взялись за нешуточную задачу — пытаются оценить риски возможности использования ИИ (точнее, больших языковых моделей) для создания биологических угроз. Например, для производства нового (или старого) вируса.
К счастью, все не так плохо. Исследование показало, что GPT-4, даже "исследовательская" версия, отвечающая на небезопасные вопросы без необходимости джейлбрейка, несмотря на свою осведомленность, лишь немного повышает эффективность создания биологических угроз. А точнее - нет статистически значимой разницы между использованием интернета и интернета+LLM.
Немного об эксперименте: пригласили экспертов и студентов биохимиков, разделили на группы, использующие только интернет или интернет+LLM. Разбили задание на шаги и оценивали следующие критерии:
🔬Точность (описаны ли этапы синтеза вещества и, напр, условия транспороировки)
🧫Полнота (все ли компоненты подобраны для воплощения плана)
🧪Инновационность (напр, разработал ли участник новую стратегию, позволяющую обойти ограничения синтеза ДНК).
⏳Потраченное время
👩🔬Субъективная оценка сложности задачи
Неожиданное открытие, сделанное исследователями в ходе ресеча: информация о необходимых реагентах и оборудовании удивительно доступна, буквально в паре кликов от первого поискового запроса. Поэтому, видимо, узкое место в создании проблем человечеству - не доступ к информации, а наличие специалистов биохимиков и биомедиков, желающих создавать оружие вместо лекарств.
А мое неожиданное (и приятное) открытие - кто-то в кой-то веки использовал U-тест Манна-Уитни (это такая непараметрическая версия t-теста Стьюдента) для сравнения двух групп 🎉
В общем, исследователи предлагают не терять бдительность и продолжать изучать потенциальные риски. Но пока можо выдохнуть. А мне пойти уже спать
🧬Статья
_______
Источник | #nn_for_science
@F_S_C_P
-------
поддержи канал
-------
{kind=link}
Google выпустил опенсорс версию Gemini
Новую модель Гугла, с открытыми весами и коммерческой лицензией, зовут Gemma. LLM доступна в 2х вариантах - 2B (работает на телефоне) и 7B (gpu).
7B модель по качеству обгоняет Мистраль 7B v0.1 и почти догоняет Llama 2 70B (на LLM Leaderboard).
Дать задание Instruct модели можно тут
Обратите внимание, что это (пока что) не чат-бот, а модель которой нужно давать инструкции (например напиши email)
🤗 Блог-пост
🖥 Блог-пост
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Новую модель Гугла, с открытыми весами и коммерческой лицензией, зовут Gemma. LLM доступна в 2х вариантах - 2B (работает на телефоне) и 7B (gpu).
7B модель по качеству обгоняет Мистраль 7B v0.1 и почти догоняет Llama 2 70B (на LLM Leaderboard).
Дать задание Instruct модели можно тут
Обратите внимание, что это (пока что) не чат-бот, а модель которой нужно давать инструкции (например напиши email)
🤗 Блог-пост
🖥 Блог-пост
_______
Источник | #nn_for_science
@F_S_C_P
Генерируй картинки с ⛵️MIDJOURNEY в Telegram
Авиакомпания попала на деньги из за галлюцинации AI модели
Интересный прецедент из Канады, где суд встал на сторону пассажира, которому чат-бот AirCanada пообещал вернуть деньги.
После смерти бабушки Джейк Моффат зашел на сайт Air Canada, чтобы забронировать рейс из Ванкувера в Торонто. Неуверенный в правилах авиакомпании, он открыл чат-бота и задал ему вопрос.
Чат бот ответил, что пассажир имеет право на частичное возмещение тарифа в случае путешествия на похороны родственника.
К его удивлению, запрос на возврат средств был отклонен по причине того, что предоставленная чат-ботом информация, была неверной.
Дело дошло до суда, где аргумент авиакомпании о том, что чат-бот — это отдельное юридическое лицо, которое несет ответственность за свои действия, суд не убедил. Также гуманный канадский суд не убедил аргумент о том, что клиент никогда не должен доверять информации в чат боте.
В итоге, пассажир выиграл право на свою компенсацию, плюс покрытие всех судебных издержек.
Вообще это огромный прецедент. Так что если используете чат боты, скажите им чтобы особо не болтали, иначе за их креативность придется платить вам
✈️ Статья
_______
Источник | #nn_for_science
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Интересный прецедент из Канады, где суд встал на сторону пассажира, которому чат-бот AirCanada пообещал вернуть деньги.
После смерти бабушки Джейк Моффат зашел на сайт Air Canada, чтобы забронировать рейс из Ванкувера в Торонто. Неуверенный в правилах авиакомпании, он открыл чат-бота и задал ему вопрос.
Чат бот ответил, что пассажир имеет право на частичное возмещение тарифа в случае путешествия на похороны родственника.
К его удивлению, запрос на возврат средств был отклонен по причине того, что предоставленная чат-ботом информация, была неверной.
Дело дошло до суда, где аргумент авиакомпании о том, что чат-бот — это отдельное юридическое лицо, которое несет ответственность за свои действия, суд не убедил. Также гуманный канадский суд не убедил аргумент о том, что клиент никогда не должен доверять информации в чат боте.
В итоге, пассажир выиграл право на свою компенсацию, плюс покрытие всех судебных издержек.
Вообще это огромный прецедент. Так что если используете чат боты, скажите им чтобы особо не болтали, иначе за их креативность придется платить вам
✈️ Статья
_______
Источник | #nn_for_science
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
OpenAI показали свое первое демо совместно с Figure
🎧 Смотреть со звуком!
Недавно, OpenAI анонсировали свое партнерство с Figure - компанией производящей роботов. И вот появилась первая демонстрация.
В настоящий момент, GPT взяла на себя функции восприятия и интерфейса - то есть OpenAI воспринимает сенсорную информацию и передает ее роботу, внутренний (спинной?) мозг которого превращает эту информацию в движения (контроль). Так же, OpenAI берет на себя функцию общения с человеком.
Судя по видео - GPT-4V крутится на сервере, а не на самом роботе, но с развитием маленьких языковых и мультимодальных моделей несложно увидеть будущее (пару месяцев), в котором все происходит на самом роботе.
Ждем ответочку от Илона и Оптимуса с Гроком!
X.com
_______
Источник | #nn_for_science
@F_S_C_P
-------
поддержи канал
-------
🎧 Смотреть со звуком!
Недавно, OpenAI анонсировали свое партнерство с Figure - компанией производящей роботов. И вот появилась первая демонстрация.
В настоящий момент, GPT взяла на себя функции восприятия и интерфейса - то есть OpenAI воспринимает сенсорную информацию и передает ее роботу, внутренний (спинной?) мозг которого превращает эту информацию в движения (контроль). Так же, OpenAI берет на себя функцию общения с человеком.
Судя по видео - GPT-4V крутится на сервере, а не на самом роботе, но с развитием маленьких языковых и мультимодальных моделей несложно увидеть будущее (пару месяцев), в котором все происходит на самом роботе.
Ждем ответочку от Илона и Оптимуса с Гроком!
X.com
_______
Источник | #nn_for_science
@F_S_C_P
-------
поддержи канал
-------
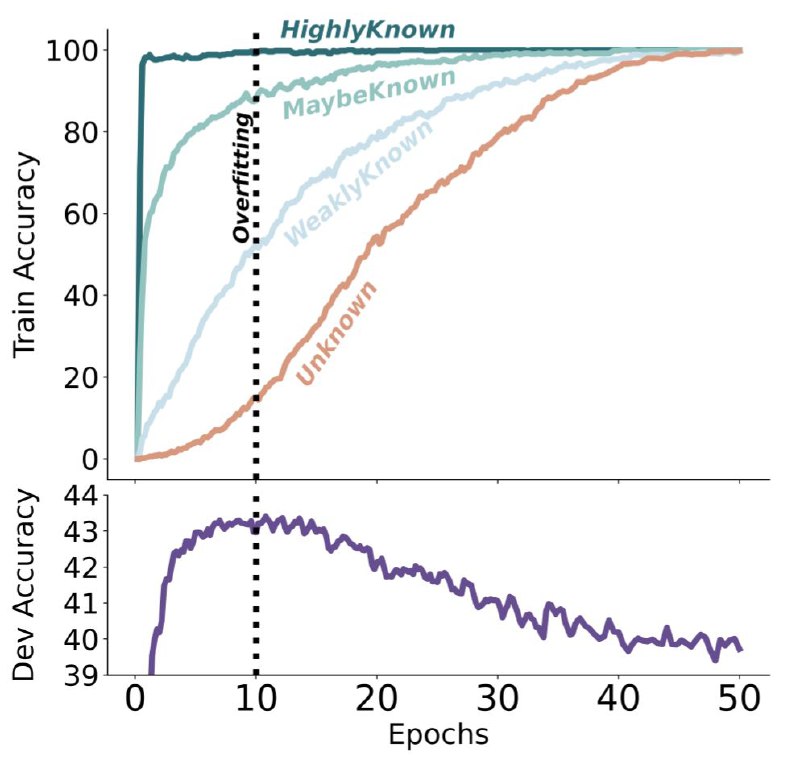
Влияет ли fine tuning LLM на новых знаниях на галлюцинации модели?
На этот интригующий вопрос решили ответить исследователи из Google.
Основные тезисы:
1. LLM с трудом удается переварить новые фактические знания посредством fine tuning-a. Примеры, вводящие новые знания, изучаются значительно медленнее, чем те, которые соответствуют уже существующим знаниям модели.
2. По мере того, как LLM со временем усваивает новые знания, ее склонность к галлюцинациям возрастает. При этом наблюдается линейная корреляция между долей примеров fine tuning-a, вводящих новые знания, и увеличением количества галлюцинаций.
3. Fine tuning в основном помогает модели более эффективно использовать уже существующие знания, а не приобретать новые знания. Примеры fine tuning-a, соответствующие уже существующим знаниям модели, изучаются быстрее и повышают производительность.
4. Авторы разработали контролируемое исследование, в котором варьировали долю примеров fine tuning-a, вводящих новые знания, и анализировали их влияние на производительность модели. Также исследователи впервые предложили классифицировать факты по отношению к базе знаний модели на четыре категории.
5. Fine tuning на новых фактических знаниях создает риск overfitting-a, что может привести к снижению производительности и усилению галлюцинаций. Ранняя остановка (early stopping) во время fine tuning-a помогает снизить этот риск.
6. Точная настройка примеров, отнесенных к категории «Может быть, известно» (те вопросы, на которые модель спорадически давала правильные ответы), оказалась особенно полезной. Этот выбор улучшил способность модели обрабатывать такие примеры без значительного увеличения галлюцинаций.
📜 Пэйпер
_______
Источник | #nn_for_science
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
На этот интригующий вопрос решили ответить исследователи из Google.
Основные тезисы:
1. LLM с трудом удается переварить новые фактические знания посредством fine tuning-a. Примеры, вводящие новые знания, изучаются значительно медленнее, чем те, которые соответствуют уже существующим знаниям модели.
2. По мере того, как LLM со временем усваивает новые знания, ее склонность к галлюцинациям возрастает. При этом наблюдается линейная корреляция между долей примеров fine tuning-a, вводящих новые знания, и увеличением количества галлюцинаций.
3. Fine tuning в основном помогает модели более эффективно использовать уже существующие знания, а не приобретать новые знания. Примеры fine tuning-a, соответствующие уже существующим знаниям модели, изучаются быстрее и повышают производительность.
4. Авторы разработали контролируемое исследование, в котором варьировали долю примеров fine tuning-a, вводящих новые знания, и анализировали их влияние на производительность модели. Также исследователи впервые предложили классифицировать факты по отношению к базе знаний модели на четыре категории.
5. Fine tuning на новых фактических знаниях создает риск overfitting-a, что может привести к снижению производительности и усилению галлюцинаций. Ранняя остановка (early stopping) во время fine tuning-a помогает снизить этот риск.
6. Точная настройка примеров, отнесенных к категории «Может быть, известно» (те вопросы, на которые модель спорадически давала правильные ответы), оказалась особенно полезной. Этот выбор улучшил способность модели обрабатывать такие примеры без значительного увеличения галлюцинаций.
📜 Пэйпер
_______
Источник | #nn_for_science
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
{kind=link}
🚀 Новый уровень бесплатного ИИ: Claude 3.5 Sonnet от Anthropic
Друзья, в мире искусственного интеллекта произошло значимое событие! Компания Anthropic представила Claude 3.5 Sonnet - новейшую версию своей языковой модели.
Что нужно знать:
1️⃣ Повышенный интеллект: Claude 3.5 Sonnet превосходит конкурентов и предыдущие версии в тестах на рассуждение, знания и программирование.
2️⃣ Улучшенное понимание: Модель лучше схватывает нюансы, юмор и сложные инструкции.
3️⃣ Высокая скорость: Работает в 2 раза быстрее 3 модели.
4️⃣ Продвинутое зрение: Улучшенные возможности анализа изображений, графиков и диаграмм.
5️⃣ Новые функции: Появилась функция "Artifacts" для совместной работы с ИИ над проектами.
Claude 3.5 Sonnet доступен бесплатно на Claude.ai и в приложении Claude для iOS. Также его можно использовать через API Anthropic и облачные сервисы Amazon и Google.
📒Блог-пост
👨🎨Поговорить с Claude
_______
Источник | #nn_for_science
_____________________
Компания anthropic представила новую модель Claude 3.5 Sonnet, которая превосходит предыдущую Claude 3 Opus и даже GPT4o✨
к таким новостям уже отношение такое: Babe, wake up - new LLM just dropped🌚 но думаю к релизу gpt-5 опять буду hyped as never before🤩
_______
Источник | #Futuris
_____________________
А ещё Anthropic запустили превью Artifacts - такой вот себе конкурент Advanced Data Analysis в ChatGPT, который позволяет запускать в браузере джаваскрипт и показывать html с svg.
Это позволяет быстро прототипировать вебсайты и даже делать простые браузерные игры!
Good evening, Sam
_______
Источник | #ai_newz
_____________________
Claude показали новый релиз своей "самой умной" модели Claude 3.5 Sonnet. Это первый релиз в линейке 3.5, но любопытно: раньше Sonnet был слабее Opus. Новый Sonet лучше не только Opus, но и (по собственным тестам) GPT4o. Кроме того, в Sonnet появились визуальные запросы (например по разбору изображений и видео).
Я в такие тесты не верю, буду проверять сам.
www.anthropic.com
_______
Источник | #addmeto
@F_S_C_P
-------
поддержи канал
-------
Друзья, в мире искусственного интеллекта произошло значимое событие! Компания Anthropic представила Claude 3.5 Sonnet - новейшую версию своей языковой модели.
Что нужно знать:
1️⃣ Повышенный интеллект: Claude 3.5 Sonnet превосходит конкурентов и предыдущие версии в тестах на рассуждение, знания и программирование.
2️⃣ Улучшенное понимание: Модель лучше схватывает нюансы, юмор и сложные инструкции.
3️⃣ Высокая скорость: Работает в 2 раза быстрее 3 модели.
4️⃣ Продвинутое зрение: Улучшенные возможности анализа изображений, графиков и диаграмм.
5️⃣ Новые функции: Появилась функция "Artifacts" для совместной работы с ИИ над проектами.
Claude 3.5 Sonnet доступен бесплатно на Claude.ai и в приложении Claude для iOS. Также его можно использовать через API Anthropic и облачные сервисы Amazon и Google.
📒Блог-пост
👨🎨Поговорить с Claude
_______
Источник | #nn_for_science
_____________________
Компания anthropic представила новую модель Claude 3.5 Sonnet, которая превосходит предыдущую Claude 3 Opus и даже GPT4o✨
к таким новостям уже отношение такое: Babe, wake up - new LLM just dropped🌚 но думаю к релизу gpt-5 опять буду hyped as never before🤩
_______
Источник | #Futuris
_____________________
А ещё Anthropic запустили превью Artifacts - такой вот себе конкурент Advanced Data Analysis в ChatGPT, который позволяет запускать в браузере джаваскрипт и показывать html с svg.
Это позволяет быстро прототипировать вебсайты и даже делать простые браузерные игры!
Good evening, Sam
_______
Источник | #ai_newz
_____________________
Claude показали новый релиз своей "самой умной" модели Claude 3.5 Sonnet. Это первый релиз в линейке 3.5, но любопытно: раньше Sonnet был слабее Opus. Новый Sonet лучше не только Opus, но и (по собственным тестам) GPT4o. Кроме того, в Sonnet появились визуальные запросы (например по разбору изображений и видео).
Я в такие тесты не верю, буду проверять сам.
www.anthropic.com
_______
Источник | #addmeto
@F_S_C_P
-------
поддержи канал
-------
Anthropic
Introducing Claude 3.5 Sonnet
Introducing Claude 3.5 Sonnet—our most intelligent model yet. Sonnet now outperforms competitor models and Claude 3 Opus on key evaluations, at twice the speed.
Сложная система коммуникации слонов: МЛ помогает учёным обнаружить "имена" гигантов
Слоны одни из самых умных, социальных и эмоционально развитых существ на Земле. Они помнят сородичей, даже если долго не виделись, проявляют эмоции: радость, грусть и траур с случае утраты, они гармонично живут в матриархате, общаются широким спектром звуков, и, как показало недавнее исследование, кажется, называют друг друга по имени - используют уникальные акустические сигналы, обращаясь к знакомым слонам.
В отличие от дельфинов и попугаев, которые подражают звукам других особей, слоны создают совершенно уникальные звуки для обозначения своих сородичей.
Дело было так.
Исследователи записали звуки, издаваемые слонами в дикой природе при общении друг с другом и в одиночестве. Наблюдали за хорошо изученной семьёй слонов, членов которой люди научились хорошо различать (в т.ч. по уникальной форме ушей). Т.е для каждой записи был известен "владелец" звука, а иногда и адресат.
Затем удалили шумы, длительную тишину, нормировали громкость и немного нарезали.
Для анализа использовали кластеризацию (k-means, DBSCAN), группируя похожие звуки вместе и выделяя уникальные "имена"; сверточные нейросети (CNN) для идентификации уникальных паттернов в акустических данных для каждого слона (да, спектрограммы в мире науки - это "image"), рекуррентные нейросети (а именно - LTSM), чтобы учитывать контекст предыдущих звуковых событий.
В итоге алгоритмы не только идентифицировали уникальные звуки, но и классифицировали их, связывая определенные зовы с конкретными слонами: кто кого зовет (не оч точно, зато не случайно). Это позволило сделать гипотезу, что каждый слон имеет свой уникальный "зов", аналогичный человеческому имени.
Здорово, что люди прикладывают усилия, чтобы понять мир вокруг и сложные коммуникативные системы, будь то кашалоты, слоны или мы сами.
Статья в Nature
Данные
Код (R)
Кадр из Ashes and Snow
_______
Источник | #nn_for_science
@F_S_C_P
-------
поддержи канал
-------
Слоны одни из самых умных, социальных и эмоционально развитых существ на Земле. Они помнят сородичей, даже если долго не виделись, проявляют эмоции: радость, грусть и траур с случае утраты, они гармонично живут в матриархате, общаются широким спектром звуков, и, как показало недавнее исследование, кажется, называют друг друга по имени - используют уникальные акустические сигналы, обращаясь к знакомым слонам.
В отличие от дельфинов и попугаев, которые подражают звукам других особей, слоны создают совершенно уникальные звуки для обозначения своих сородичей.
Дело было так.
Исследователи записали звуки, издаваемые слонами в дикой природе при общении друг с другом и в одиночестве. Наблюдали за хорошо изученной семьёй слонов, членов которой люди научились хорошо различать (в т.ч. по уникальной форме ушей). Т.е для каждой записи был известен "владелец" звука, а иногда и адресат.
Затем удалили шумы, длительную тишину, нормировали громкость и немного нарезали.
Для анализа использовали кластеризацию (k-means, DBSCAN), группируя похожие звуки вместе и выделяя уникальные "имена"; сверточные нейросети (CNN) для идентификации уникальных паттернов в акустических данных для каждого слона (да, спектрограммы в мире науки - это "image"), рекуррентные нейросети (а именно - LTSM), чтобы учитывать контекст предыдущих звуковых событий.
В итоге алгоритмы не только идентифицировали уникальные звуки, но и классифицировали их, связывая определенные зовы с конкретными слонами: кто кого зовет (не оч точно, зато не случайно). Это позволило сделать гипотезу, что каждый слон имеет свой уникальный "зов", аналогичный человеческому имени.
Здорово, что люди прикладывают усилия, чтобы понять мир вокруг и сложные коммуникативные системы, будь то кашалоты, слоны или мы сами.
Статья в Nature
Данные
Код (R)
Кадр из Ashes and Snow
_______
Источник | #nn_for_science
@F_S_C_P
-------
поддержи канал
-------
{kind=link}
GPT-4о и задачи ARC Challenge: ожидаемые результаты эксперимента OpenAI
Тут сотрудник OpenAI провел эксперимент, который может изменить наше представление о том, насколько Франсуа Шолле неправ со своим соревнованием.
Контекст
Некоторые эксперты считают, что современные языковые модели (LLM) не способны решать задачи, требующие общего интеллекта. Франсуа Шолле, известный в первую очередь как создатель фрэймворка Keras, а так же как автор набора задач ARC (Abstraction and Reasoning Corpus), говорил:
Прогресс в направлении искусственного общего интеллекта (AGI) застопорился. LLM обучаются на огромных объемах данных, но остаются неспособными адаптироваться к новым задачам.
Задачи ARC, по задумке, предназначены для проверки способностей ИИ к обобщению и рассуждению, выходящему за рамки простого распознавания шаблонов.
Эксперимент
Сотрудник OpenAI решил проверить это утверждение на GPT-4о. Вот как проходил эксперимент:
1. Базовый тест (Pass@1)
• GPT-4 решала задачи ARC, получая 2-3 примера в контексте.
• Модель должна была сразу давать ответ без цепочки рассуждений.
=> решено 4.42% задач
• добавляем системный промпт, объясняющий задачу
=> решено 6.61%
2. Метод консенсуса (Consensus@32)
• Для каждой задачи генерируем 32 ответа.
• Выбираем наиболее частый ответ.
=> 9.28%
3. Проверка с нулевой температурой (Temp=0)
• Использовалась детерминированная генерация ответов.
=> 10.0%
4. Оценка сложности задач (Pass@N)
• Генерировалось до 1000 ответов на задачу.
• Задача считалась решенной, если хотя бы один ответ был правильным.
=> 26.52%
Результаты
Результаты оказались впечатляющими:
1. Базовая производительность была неожиданно высокой даже без оптимизации.
2. Метод консенсуса дал значительный прирост эффективности.
3. Тест с нулевой температурой подтвердил надежность метода консенсуса.
4. Анализ Pass@N показал, что процент успешных попыток на логарифмической шкале очень предсказуем.
5. Общая эффективность GPT-4 в решении задач ARC оказалась выше ожиданий.
Что это значит?
Современные языковые модели могут быть способны на большее, чем думал Шолле.
Тред от сотрудника OpenAI
_______
Источник | #nn_for_science
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Тут сотрудник OpenAI провел эксперимент, который может изменить наше представление о том, насколько Франсуа Шолле неправ со своим соревнованием.
Контекст
Некоторые эксперты считают, что современные языковые модели (LLM) не способны решать задачи, требующие общего интеллекта. Франсуа Шолле, известный в первую очередь как создатель фрэймворка Keras, а так же как автор набора задач ARC (Abstraction and Reasoning Corpus), говорил:
Прогресс в направлении искусственного общего интеллекта (AGI) застопорился. LLM обучаются на огромных объемах данных, но остаются неспособными адаптироваться к новым задачам.
Задачи ARC, по задумке, предназначены для проверки способностей ИИ к обобщению и рассуждению, выходящему за рамки простого распознавания шаблонов.
Эксперимент
Сотрудник OpenAI решил проверить это утверждение на GPT-4о. Вот как проходил эксперимент:
1. Базовый тест (Pass@1)
• GPT-4 решала задачи ARC, получая 2-3 примера в контексте.
• Модель должна была сразу давать ответ без цепочки рассуждений.
=> решено 4.42% задач
• добавляем системный промпт, объясняющий задачу
=> решено 6.61%
2. Метод консенсуса (Consensus@32)
• Для каждой задачи генерируем 32 ответа.
• Выбираем наиболее частый ответ.
=> 9.28%
3. Проверка с нулевой температурой (Temp=0)
• Использовалась детерминированная генерация ответов.
=> 10.0%
4. Оценка сложности задач (Pass@N)
• Генерировалось до 1000 ответов на задачу.
• Задача считалась решенной, если хотя бы один ответ был правильным.
=> 26.52%
Результаты
Результаты оказались впечатляющими:
1. Базовая производительность была неожиданно высокой даже без оптимизации.
2. Метод консенсуса дал значительный прирост эффективности.
3. Тест с нулевой температурой подтвердил надежность метода консенсуса.
4. Анализ Pass@N показал, что процент успешных попыток на логарифмической шкале очень предсказуем.
5. Общая эффективность GPT-4 в решении задач ARC оказалась выше ожиданий.
Что это значит?
Современные языковые модели могут быть способны на большее, чем думал Шолле.
Тред от сотрудника OpenAI
_______
Источник | #nn_for_science
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
{kind=link}