
Deeplearning API that converts handwritten math equations to LaTeX
#Deeplearning #machinelearning
http://docs.mathpix.com/
ᅠᅠ
Team
@OpenArchiveBooks
@data_entusiasts
#Deeplearning #machinelearning
http://docs.mathpix.com/
ᅠᅠ
Team
@OpenArchiveBooks
@data_entusiasts
#ICYMI An Overview of #Python #DeepLearning Frameworks http://buff.ly/2mdtdY3
ᅠᅠ
Team
@OpenArchiveBooks
@data_entusiasts
ᅠᅠ
Team
@OpenArchiveBooks
@data_entusiasts
Real-World Super-Resolution of Face-Images from Surveillance Cameras
Most SR methods are trained on LR (low resolution) data, which is downsampled from HR (high resolution) data using bicubic interpolation, but real-life LR images are usually different, so models work worse on them. In this paper, the authors suggest using blur kernels, noise, and JPEG compression artifacts to generate LR images similar to the original ones.
Another suggested improvement is using ESRGAN and replacing VGG-loss with LPIPS-loss, as well as adding PatchGAN.
In addition, the authors show that NIMA metric better correlates with human perception (mean opinion rank) than traditional Image Quality Assessment methods.
Paper: https://arxiv.org/abs/2102.03113
#deeplearning #superresolution #gan #facesuperresolution
Team
@OpenArchiveBooks
@data_entusiasts
Most SR methods are trained on LR (low resolution) data, which is downsampled from HR (high resolution) data using bicubic interpolation, but real-life LR images are usually different, so models work worse on them. In this paper, the authors suggest using blur kernels, noise, and JPEG compression artifacts to generate LR images similar to the original ones.
Another suggested improvement is using ESRGAN and replacing VGG-loss with LPIPS-loss, as well as adding PatchGAN.
In addition, the authors show that NIMA metric better correlates with human perception (mean opinion rank) than traditional Image Quality Assessment methods.
Paper: https://arxiv.org/abs/2102.03113
#deeplearning #superresolution #gan #facesuperresolution
Team
@OpenArchiveBooks
@data_entusiasts
Contrastive Semi-supervised Learning for ASR
Nowadays, pseudo-labeling is the most common method for pre-training automatic speech recognition (ASR) models, but in the case of low-resource setups and domain transfer, it suffers from a supervised teacher model’s degrading quality. The authors of this paper suggest using contrastive learning to overcome this problem.
CSL approach (Contrastive Semi-supervised Learning) uses teacher-generated predictions to select positive and negative examples instead of using pseudo-labels directly.
Experiments show that CSL has lower WER not only in comparison with standard CE-PL (Cross-Entropy pseudo-labeling) but also under low-resource and out-of-domain conditions.
To demonstrate its resilience to pseudo-labeling noise, the authors apply CSL pre-training in a low-resource setup with only 10hr of labeled data, where it reduces WER by 8% compared to the standard cross-entropy pseudo-labeling (CE-PL). This WER reduction increase to 19% with a teacher trained only on 1hr of labels and 17% for out-of-domain conditions.
Paper: https://arxiv.org/abs/2103.05149
#deeplearning #asr #contrastivelearning #semisupervised
Team
@OpenArchiveBooks
@data_entusiasts
Nowadays, pseudo-labeling is the most common method for pre-training automatic speech recognition (ASR) models, but in the case of low-resource setups and domain transfer, it suffers from a supervised teacher model’s degrading quality. The authors of this paper suggest using contrastive learning to overcome this problem.
CSL approach (Contrastive Semi-supervised Learning) uses teacher-generated predictions to select positive and negative examples instead of using pseudo-labels directly.
Experiments show that CSL has lower WER not only in comparison with standard CE-PL (Cross-Entropy pseudo-labeling) but also under low-resource and out-of-domain conditions.
To demonstrate its resilience to pseudo-labeling noise, the authors apply CSL pre-training in a low-resource setup with only 10hr of labeled data, where it reduces WER by 8% compared to the standard cross-entropy pseudo-labeling (CE-PL). This WER reduction increase to 19% with a teacher trained only on 1hr of labels and 17% for out-of-domain conditions.
Paper: https://arxiv.org/abs/2103.05149
#deeplearning #asr #contrastivelearning #semisupervised
Team
@OpenArchiveBooks
@data_entusiasts
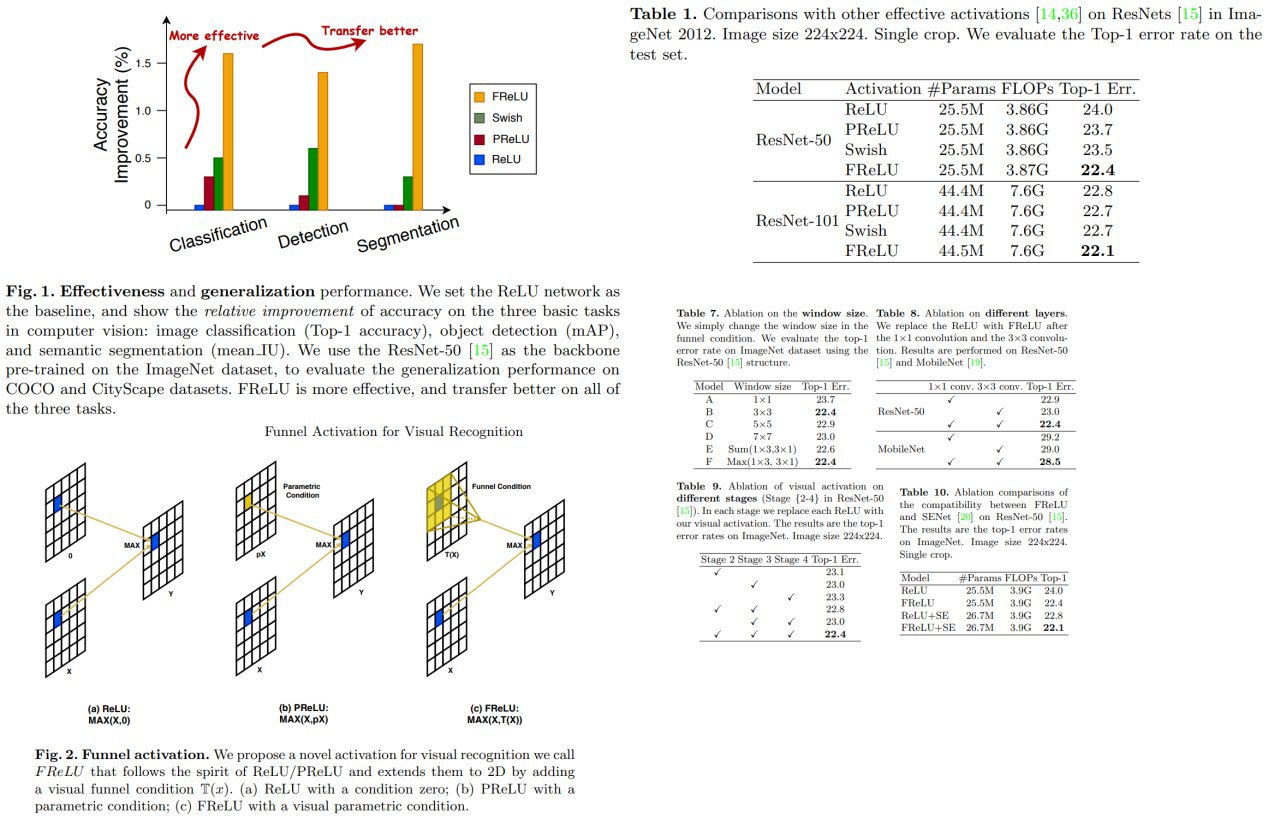
Funnel Activation for Visual Recognition
Authors offer a new activation function for image recognition tasks, called Funnel activation (FReLU), that extends ReLU and PReLU to a 2D activation by adding a negligible overhead of spatial condition.
Extensive experiments on COCO, ImageNet and CityScape show significant improvement and robustness.
Paper: https://arxiv.org/abs/2007.11824
Code: https://github.com/megvii-model/FunnelAct
#deeplearning #activationfunction #computervision #pytorch
Team
@OpenArchiveBooks
@data_entusiasts
Authors offer a new activation function for image recognition tasks, called Funnel activation (FReLU), that extends ReLU and PReLU to a 2D activation by adding a negligible overhead of spatial condition.
Extensive experiments on COCO, ImageNet and CityScape show significant improvement and robustness.
Paper: https://arxiv.org/abs/2007.11824
Code: https://github.com/megvii-model/FunnelAct
#deeplearning #activationfunction #computervision #pytorch
Team
@OpenArchiveBooks
@data_entusiasts
{kind=link}
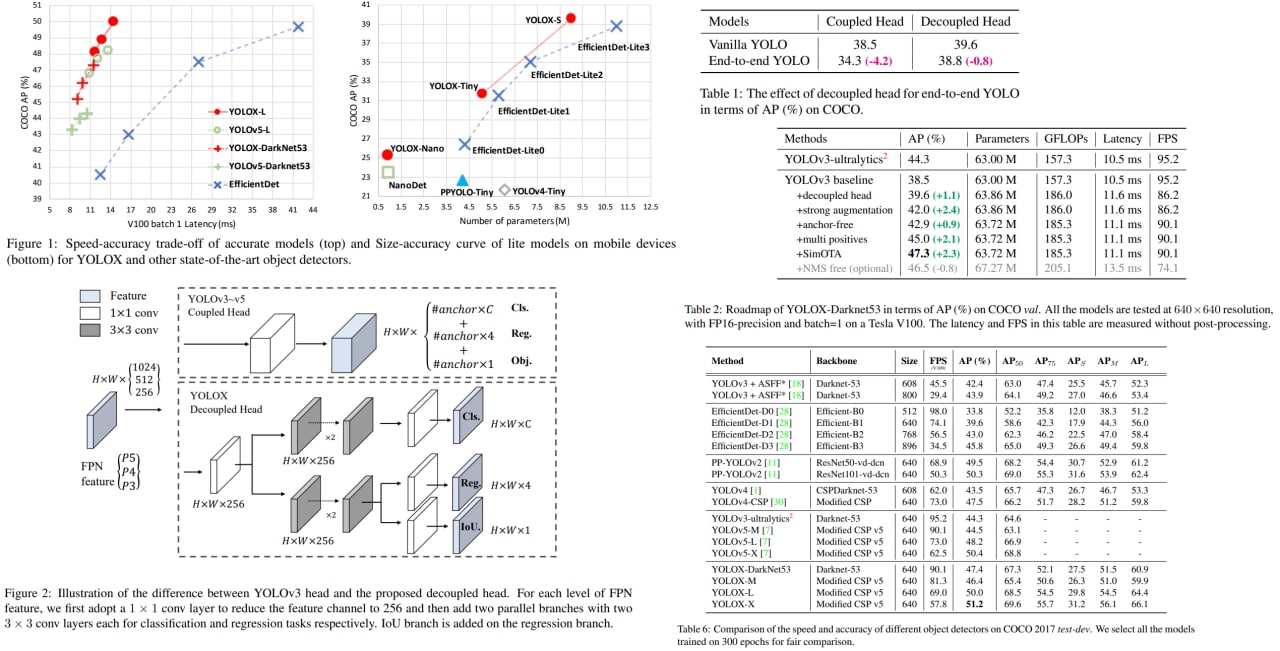
YOLOX: Exceeding YOLO Series in 2021
This paper presents a new high-performance variation of YOLO - YOLOX. Now it has an anchor-free detector, a decoupled head, and uses the leading label assignment strategy SimOTA.
Thanks to these changes, it reaches state-of-the-art results across a large scale range of models. For example, YOLOX-Nano gets 25.3% AP on COCO (+1.8% to NanoDet), YOLOX-L achieves 50.0% AP on COCO (+1.8 to YOLOv5-L).
For YOLOv3, one of the most widely used detectors in industry, they boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP.
The authors won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
They also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported.
Paper: https://arxiv.org/abs/2107.08430
Code: https://github.com/Megvii-BaseDetection/YOLOX
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-yolox
#deeplearning #cv #objectdetection #endtoend #anchorfree
Team
@OpenArchiveBooks
@data_entusiasts
This paper presents a new high-performance variation of YOLO - YOLOX. Now it has an anchor-free detector, a decoupled head, and uses the leading label assignment strategy SimOTA.
Thanks to these changes, it reaches state-of-the-art results across a large scale range of models. For example, YOLOX-Nano gets 25.3% AP on COCO (+1.8% to NanoDet), YOLOX-L achieves 50.0% AP on COCO (+1.8 to YOLOv5-L).
For YOLOv3, one of the most widely used detectors in industry, they boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP.
The authors won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
They also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported.
Paper: https://arxiv.org/abs/2107.08430
Code: https://github.com/Megvii-BaseDetection/YOLOX
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-yolox
#deeplearning #cv #objectdetection #endtoend #anchorfree
Team
@OpenArchiveBooks
@data_entusiasts
{kind=link}
End-to-End Object Detection with Transformers
Authors present a new method that views object detection as a direct set prediction problem.
This approach simplifies the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task.
The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture
DETR demonstrates accuracy and run-time performance on par with the well-established and highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily generalized to produce panoptic segmentation in a unified manner
Paper: https://arxiv.org/abs/2005.12872
Code: https://github.com/facebookresearch/detr
#deeplearning #objectdetection #transformer #coco
ᅠᅠ
Team
@OpenArchiveBooks
@data_entusiasts
Authors present a new method that views object detection as a direct set prediction problem.
This approach simplifies the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task.
The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture
DETR demonstrates accuracy and run-time performance on par with the well-established and highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily generalized to produce panoptic segmentation in a unified manner
Paper: https://arxiv.org/abs/2005.12872
Code: https://github.com/facebookresearch/detr
#deeplearning #objectdetection #transformer #coco
ᅠᅠ
Team
@OpenArchiveBooks
@data_entusiasts
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
This paper presents a new participatory Python-based natural language augmentation framework that supports the creation of transformations (modifications to the data) and filters (data splits according to specific features).
The current version of the framework contains 117 transformations and 23 filters for a variety of natural language tasks.
The authors demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models.
Paper: https://arxiv.org/abs/2112.02721
Code: https://github.com/GEM-benchmark/NL-Augmenter
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nlaugmenter
#deeplearning #nlp #augmentation #robustness
Team
@data_enthusiasts
@OpenArchiveBooks
This paper presents a new participatory Python-based natural language augmentation framework that supports the creation of transformations (modifications to the data) and filters (data splits according to specific features).
The current version of the framework contains 117 transformations and 23 filters for a variety of natural language tasks.
The authors demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models.
Paper: https://arxiv.org/abs/2112.02721
Code: https://github.com/GEM-benchmark/NL-Augmenter
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nlaugmenter
#deeplearning #nlp #augmentation #robustness
Team
@data_enthusiasts
@OpenArchiveBooks
{kind=link}
MIT's introductory course on deep learning methods with applications in game play, and more!
(Starting March 11th 2022)
http://introtodeeplearning.com/
#deeplearning
For previous years videos you can check their youtube channel:
https://www.youtube.com/playlist?list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI
Team
@data_enthusiasts
@OpenArchiveBooks
(Starting March 11th 2022)
http://introtodeeplearning.com/
#deeplearning
For previous years videos you can check their youtube channel:
https://www.youtube.com/playlist?list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI
Team
@data_enthusiasts
@OpenArchiveBooks