
Forwarded from Пресидский залив (Nadia ズエバ)
Эволюция pitch deck Aesty: от школьной презентации до investor-ready 🎯
Реально ли упаковать всю идею стартапа в пару слайдов? Спойлер: да, но это нужно много итераций 😅
Когда я только начала делать первый pitch deck Aesty, это было что-то с чем-то - тонна текста, размытый message и попытка запихнуть ВСЁ и СРАЗУ. Вайб моего первого собеса, когда пыталась за минуту рассказать всю свою жизнь от школьных олимпиад до пет проектов 💀
Сегодня наш deck выглядит как будто его делали другие люди - чистый, чёткий, со сторителингом. И нет, конечно это не случилось за один день.
Вот чему я научилась в этой эпопее (спасибо всем, кто помогал советом и фидбеком):
1️⃣ Удалять всё лишнее, безжалостно. Первая версия была как мой шкаф - забита до отказа. Теперь каждый слайд = одна мысль. Удивительно, как deck начал дышать, когда мы перестали туда пихать вообще все
2️⃣ Problem first, и только потом решение. Изначально мы сразу показывали наш продукт. Никто не понимал зачем он нужен 🤦♀️ Сейчас мы сначала бьём по больному: вот эта боль есть? А вот эта? И потом уже рассказываем про решение
3️⃣ Сторителлинг, а не набор фактов. Вместо слайдов по плану мы сделали сюжет. Как в TikTok - затянуло с первых секунд и хочется досмотреть до конца. Люди запоминают истории, а не сухие цифры (хотя цифры тоже нужны, см. пункт 4).
4️⃣ Показывать traction, даже если он микро. Наш первый deck был как обещания кандидата в президенты, много слов и ноль доказательств 😞 Это как разница между "верь мне" и "смотри сам"
5️⃣ Собирать фидбек и не привязываться к своим ощущениям, которые не можешь подтвердить данными. После каждой версии мы просили всех, кто не мог от нас убежать, посмотреть deck 😅 Менторы в Antler, друзья, даже бета-юзеры. Каждый нашёл то, что мы пропустили. Да, больно слышать, что твоё детище не идеально, но это работает и гораздо ценнее чем "вау все круто, все, отстаньте"
Иногда смотрю на наш первый deck и думаю, как мы вообще с этим к людям выходили? Но именно эта эволюция от "мы лучшие, потому что мы лучшие" до "вот проблема, вот как мы её решаем, вот доказательства" и привела к нормальному результату😏
Короче, если вам кажется, ваш первый pitch deck (или даже продукт) - полная катастрофа, вы на верном пути! Главное, не останавливаться на этой версии😄
Реально ли упаковать всю идею стартапа в пару слайдов? Спойлер: да, но это нужно много итераций 😅
Когда я только начала делать первый pitch deck Aesty, это было что-то с чем-то - тонна текста, размытый message и попытка запихнуть ВСЁ и СРАЗУ. Вайб моего первого собеса, когда пыталась за минуту рассказать всю свою жизнь от школьных олимпиад до пет проектов 💀
Сегодня наш deck выглядит как будто его делали другие люди - чистый, чёткий, со сторителингом. И нет, конечно это не случилось за один день.
Вот чему я научилась в этой эпопее (спасибо всем, кто помогал советом и фидбеком):
Иногда смотрю на наш первый deck и думаю, как мы вообще с этим к людям выходили? Но именно эта эволюция от "мы лучшие, потому что мы лучшие" до "вот проблема, вот как мы её решаем, вот доказательства" и привела к нормальному результату
Короче, если вам кажется, ваш первый pitch deck (или даже продукт) - полная катастрофа, вы на верном пути! Главное, не останавливаться на этой версии
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Artificial stupidity
#cv #ml
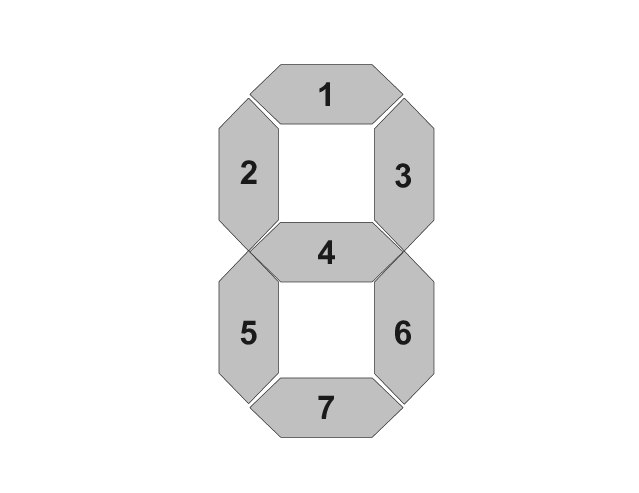
Оказывается, не вся информация хорошо считывается с дисплеев. Не так давно узнал, что для обычных экранов, типа весов, бензоколонок и электронных часов есть отдельная задача распознавания.
Такой тип отображения на экранах называется seven segment digits. То есть, у нас есть 7 полосок: 3 вверху, 3 внизу и еще одна посередине.
И для этой задачки есть отдельные модели, которые улучшают распознавание (проверено не себе, решения из коробки с обычным распознаванием нещадно тупили, хотя, казалось бы, такая простая задачка). Напрмиер, в PaddleOCR (которые, видимо, должны теперь мне миска рис за рекламу) есть модели DBNet для детекции и PARSeq для распознавания. Как только мы решили применить эти модели, качество распознавания сразу подросло.
Какой же вывод из этой истории? Даже если что-то кажется очень простым или банальным, то всегда случиться так, что мы попадем не corner case, для которого нужно будет искать специфичное решение. Второй вывод - попробуйте получше порыться в вашей "черной коробке" (если используете коробочное решение). Как знать, возможно в ней есть то, о чем вы просто не знали.
P.S. Пара статей по теме:
Detecting and recognizing seven segment digits
using a deep learning approach
Real-Time Seven Segment Display Detection and
Recognition Online System using CNN
Оказывается, не вся информация хорошо считывается с дисплеев. Не так давно узнал, что для обычных экранов, типа весов, бензоколонок и электронных часов есть отдельная задача распознавания.
Такой тип отображения на экранах называется seven segment digits. То есть, у нас есть 7 полосок: 3 вверху, 3 внизу и еще одна посередине.
И для этой задачки есть отдельные модели, которые улучшают распознавание (проверено не себе, решения из коробки с обычным распознаванием нещадно тупили, хотя, казалось бы, такая простая задачка). Напрмиер, в PaddleOCR (которые, видимо, должны теперь мне миска рис за рекламу) есть модели DBNet для детекции и PARSeq для распознавания. Как только мы решили применить эти модели, качество распознавания сразу подросло.
Какой же вывод из этой истории? Даже если что-то кажется очень простым или банальным, то всегда случиться так, что мы попадем не corner case, для которого нужно будет искать специфичное решение. Второй вывод - попробуйте получше порыться в вашей "черной коробке" (если используете коробочное решение). Как знать, возможно в ней есть то, о чем вы просто не знали.
P.S. Пара статей по теме:
Detecting and recognizing seven segment digits
using a deep learning approach
Real-Time Seven Segment Display Detection and
Recognition Online System using CNN
{kind=link}
Forwarded from Кодим на Коленке | Уроки по программированию
Алгоритмические задачи
Подборка интересных задач с LeetCode и их решение на языке Java
🗝 Курс живет здесь
Кодим на Коленке | #Java
Подборка интересных задач с LeetCode и их решение на языке Java
🗝 Курс живет здесь
Кодим на Коленке | #Java
Forwarded from Love. Death. Transformers.
Неделя открытого кода от deepseek
День1 - Flash MLA
Cобственно есть разные варианты attn head, есть MHA, GQA, MQA и прочее. Для них есть кернелы(вставки в код на c++ которые позволяют ускорять операции на GPU) ну DeepSeek используют свой вариант - MLA, для него релизнули кернелы. Теперь это затащат в vllm/sglang и прочее и жить станет веселее.
День2 - DeepEP
Обучениe MoE из коробки довольно не эффективная штука если вы случайно не гений. Нужно писать умные стратегии паралелизма, раскладывать экспертов по нодам и вообще оптимизировать коммуникации всеми возможными способами.
Собственно DeepSeek релизит свой expert paralelesim. Код чистый советую потыкатся и поигратся.
День3 - DeepGemm
Учат DeepSeekи на Hopper, поэтому им актуально иметь FP8 совместимые kernel для перемножения матриц(и численно не взрывается и ускорение ощутимое)
День4 - DualPipe
Вариант Pipeline паралелизма ускорения пузырька в коммуникациях, за счет чего ожидание степа меньше, быстрее учимся и тд. Я не претреню довольно давно мне сложно оценить полезность.
День5 - 3fs
Если вы хотите обрабатывать 100тб данных вам надо уметь очень быстро пересылать данные между S3<—>training nodes и прочим. Ну и уметь быстро это читать.
День6 - IntoTheInfra
Балансируем нагрузку, перекидываем ноды с инференс в трейн и обратно и прочие интересные трюки. Из любопытного - за сутки обрабатывают 608б токенов на вход и генерят 170б. Думаю у ребят за месяц скопится где то пара ТРИЛЛИОНОВ токенов синты.
День1 - Flash MLA
Cобственно есть разные варианты attn head, есть MHA, GQA, MQA и прочее. Для них есть кернелы(вставки в код на c++ которые позволяют ускорять операции на GPU) ну DeepSeek используют свой вариант - MLA, для него релизнули кернелы. Теперь это затащат в vllm/sglang и прочее и жить станет веселее.
День2 - DeepEP
Обучениe MoE из коробки довольно не эффективная штука если вы случайно не гений. Нужно писать умные стратегии паралелизма, раскладывать экспертов по нодам и вообще оптимизировать коммуникации всеми возможными способами.
Собственно DeepSeek релизит свой expert paralelesim. Код чистый советую потыкатся и поигратся.
День3 - DeepGemm
Учат DeepSeekи на Hopper, поэтому им актуально иметь FP8 совместимые kernel для перемножения матриц(и численно не взрывается и ускорение ощутимое)
День4 - DualPipe
Вариант Pipeline паралелизма ускорения пузырька в коммуникациях, за счет чего ожидание степа меньше, быстрее учимся и тд. Я не претреню довольно давно мне сложно оценить полезность.
День5 - 3fs
Если вы хотите обрабатывать 100тб данных вам надо уметь очень быстро пересылать данные между S3<—>training nodes и прочим. Ну и уметь быстро это читать.
День6 - IntoTheInfra
Балансируем нагрузку, перекидываем ноды с инференс в трейн и обратно и прочие интересные трюки. Из любопытного - за сутки обрабатывают 608б токенов на вход и генерят 170б. Думаю у ребят за месяц скопится где то пара ТРИЛЛИОНОВ токенов синты.
Forwarded from Эра Эрика (:
Привет, друг! 🤟
Не секрет, что в современном мире необходимо постоянно изучать новое. Кому-то обучение дается легко, кому-то сложно, а у кого-то даже сама мысль об этом вызывает ужас. Я занимаюсь созданием образовательных систем и преподаванием более шести лет. За это время я собрал простые хаки, которые помогают в обучении.
Ладно, ладно, уже рассказываю.
1. Понять, зачем. Как показывает практика, образование ради образования ни к чему не приводит. Поэтому это первое, с чего нужно начать. Мотивация может быть разной — от рабочей необходимости до простого любопытства.
2. Регулярность. Заниматься по часу в день будет куда эффективнее, чем целый день раз в неделю. Регулярность позволяет проще усваивать новое. Это такая "магия" мозга.
3. Режим. Обучение в одно и то же время позволяет выработать привычку, сделав этот процесс нормой жизни.
4. Постепенное увеличение сложности. Еще одна хитрость мозга: он часто воспринимает всё сложное и непонятное как что-то скучное. Начав с простого и постепенно увеличивая сложность, можно уменьшить вероятность попадания в эту ловушку.
5. Практика. Любая теория должна быть закреплена на практике, это также позволяет ускорить усвоение нового.
6. Эксперименты. Экспериментируй и не бойся что-то сломать — так ты сможешь быстрее добраться до сути вещей.
7. Комфорт. Создай себе комфортные условия, чтобы тебя ничего не отвлекало во время обучения: комфортное кресло, стол, освещение. И конечно, поставь телефон на беззвучный режим.
8. Отдых. Обучение проще дается, если есть силы на него. Поэтому обращай внимание на свою общую загруженность и, по возможности, разгрузи себя, чтобы было больше ресурсов для обучения.
Есть ещё практики, но это, пожалуй, самые важные и простые. Позже поговорим о продвинутом уровне.
Хорошего тебя дня друг 🔥
Не секрет, что в современном мире необходимо постоянно изучать новое. Кому-то обучение дается легко, кому-то сложно, а у кого-то даже сама мысль об этом вызывает ужас. Я занимаюсь созданием образовательных систем и преподаванием более шести лет. За это время я собрал простые хаки, которые помогают в обучении.
Ладно, ладно, уже рассказываю.
1. Понять, зачем. Как показывает практика, образование ради образования ни к чему не приводит. Поэтому это первое, с чего нужно начать. Мотивация может быть разной — от рабочей необходимости до простого любопытства.
2. Регулярность. Заниматься по часу в день будет куда эффективнее, чем целый день раз в неделю. Регулярность позволяет проще усваивать новое. Это такая "магия" мозга.
3. Режим. Обучение в одно и то же время позволяет выработать привычку, сделав этот процесс нормой жизни.
4. Постепенное увеличение сложности. Еще одна хитрость мозга: он часто воспринимает всё сложное и непонятное как что-то скучное. Начав с простого и постепенно увеличивая сложность, можно уменьшить вероятность попадания в эту ловушку.
5. Практика. Любая теория должна быть закреплена на практике, это также позволяет ускорить усвоение нового.
6. Эксперименты. Экспериментируй и не бойся что-то сломать — так ты сможешь быстрее добраться до сути вещей.
7. Комфорт. Создай себе комфортные условия, чтобы тебя ничего не отвлекало во время обучения: комфортное кресло, стол, освещение. И конечно, поставь телефон на беззвучный режим.
8. Отдых. Обучение проще дается, если есть силы на него. Поэтому обращай внимание на свою общую загруженность и, по возможности, разгрузи себя, чтобы было больше ресурсов для обучения.
Есть ещё практики, но это, пожалуй, самые важные и простые. Позже поговорим о продвинутом уровне.
Хорошего тебя дня друг 🔥
Forwarded from Евгений Козлов пишет про IT (Eugene Kozlov)
Fundamentals of Data Engineering. Глава №3. Designing Good Data Architecture. Принципы
🔵 Entrerpise и Data архитектуры
Enterprise architecture включает в себя проектирование гибких систем для поддержки изменений предприятия посредством тщательной оценки трейдоффов. Она включает в себя подмножество архитектур: бизнес-архитектура архитектура техническая, архитектура приложения и архитектура данных.
Data architecture - проектирование систем для поддержки меняющихся потребностей предприятия в данных. Включает:
- Operational architecture (относится к людям, процессам и технологиям, помогает найти ответ на вопрос "Что?")
- Technical architecture (подробно описывает прием, хранение, преобразование и обслуживание данных на протяжении всего жизненного цикла проектирования данных, помогает найти ответ на вопрос "Как?").
🔵 Принципы из которых складывается хорошая архитектура данных:
1️⃣ Выбирайте общие компоненты с умом.
Что можно отнести к общим компонентам в DE:
- хранилище объектов
- система контроля версий
- система наблюдения и мониторинга
- оркестрация
- механизмы обработки.
Рекомендуется сделать эти компоненты доступными, надежными и безопасными, чтобы облегчить обмен данными между командами и предотвратить дублирование.
2️⃣ Планируйте неудачу
Чтобы построить надежные системы данных, учитывайте вероятность нештатных ситуаций. Ключевые термины для оценки сценариев сбоев включают:
- Availability: процент времени, в течение которого ИТ-услуга или компонент работоспособны.
- Reliability: вероятность соответствия определенным стандартам при выполнении предполагаемой функции в течение определенного интервала времени.
- Recovery time objective: максимально допустимое время простоя службы или системы.
- Recovery point objective: приемлемое состояние после восстановления, определяющее максимально допустимую потерю данных в системах данных.
3️⃣ Проектируя закладывай масштабируемость
Идеальная эластичная система должна автоматически масштабироваться в ответ на нагрузку. Однако неправильные стратегии масштабирования могут привести к усложнению систем и увеличению расходов.
4️⃣ Архитектурная функция это лидерство
Менторство и коучинг разработчиков, участие в решении сложных проблем является важнейшим аспектом работы архитектора. Повышая навыки команды, архитекторы могут получить больше рычагов, чем принимая все решения самостоятельно и становясь узким местом.
5️⃣Всегда рефлексируй по поводу архитектуры
Все настолько быстро меняется (технологии, инструменты и бизнес модели) и для того чтобы своевременно реагировать на эти изменения важно целиться не в что-то идеальное а скорее проектировать так чтобы была возможность изменять. Гибкость в нашем agile мире важнее всего.
6️⃣ Создавайте слабосвязанные системы
Слабосвязанная система обладает следующими свойствами:
- Небольшие компоненты.
- Взаимодействие посредством абстракций а не реализаций.
- Изменения в одном компоненте не влияют на другие.
- Каждый компонент обновляется отдельно.
7️⃣ Принимайте обратимые решения
Чтобы идти в ногу с быстро меняющимся технологическим ландшафтом и модульной архитектурой данных, следует выбирать самое лучшее из того что есть сейчас. Но при этом закладывать в систему возможность переезда на другие рельсы через время.
8️⃣ Безопасность
- Используйте модели безопасности с нулевым доверием.
- Выстройте модель совместной ответственности при вычислениях в облаке.
- Поощряйте инженеров по обработке данных выступать в роли инженеров по безопасности.
9️⃣FinOps
FinOps - дисциплина финансового управления и культурная практика в облаке, способствующая сотрудничеству между инженерными, финансовыми и бизнес специалистами для принятия решений о расходах на основе данных, с целью достичь максимального соотношения доходов к расходам.
———
На этом всё, в следующем посте рассмотрим архитектурные показатели.😊
🔵 Entrerpise и Data архитектуры
Enterprise architecture включает в себя проектирование гибких систем для поддержки изменений предприятия посредством тщательной оценки трейдоффов. Она включает в себя подмножество архитектур: бизнес-архитектура архитектура техническая, архитектура приложения и архитектура данных.
Data architecture - проектирование систем для поддержки меняющихся потребностей предприятия в данных. Включает:
- Operational architecture (относится к людям, процессам и технологиям, помогает найти ответ на вопрос "Что?")
- Technical architecture (подробно описывает прием, хранение, преобразование и обслуживание данных на протяжении всего жизненного цикла проектирования данных, помогает найти ответ на вопрос "Как?").
🔵 Принципы из которых складывается хорошая архитектура данных:
1️⃣ Выбирайте общие компоненты с умом.
Что можно отнести к общим компонентам в DE:
- хранилище объектов
- система контроля версий
- система наблюдения и мониторинга
- оркестрация
- механизмы обработки.
Рекомендуется сделать эти компоненты доступными, надежными и безопасными, чтобы облегчить обмен данными между командами и предотвратить дублирование.
2️⃣ Планируйте неудачу
Чтобы построить надежные системы данных, учитывайте вероятность нештатных ситуаций. Ключевые термины для оценки сценариев сбоев включают:
- Availability: процент времени, в течение которого ИТ-услуга или компонент работоспособны.
- Reliability: вероятность соответствия определенным стандартам при выполнении предполагаемой функции в течение определенного интервала времени.
- Recovery time objective: максимально допустимое время простоя службы или системы.
- Recovery point objective: приемлемое состояние после восстановления, определяющее максимально допустимую потерю данных в системах данных.
3️⃣ Проектируя закладывай масштабируемость
Идеальная эластичная система должна автоматически масштабироваться в ответ на нагрузку. Однако неправильные стратегии масштабирования могут привести к усложнению систем и увеличению расходов.
4️⃣ Архитектурная функция это лидерство
Менторство и коучинг разработчиков, участие в решении сложных проблем является важнейшим аспектом работы архитектора. Повышая навыки команды, архитекторы могут получить больше рычагов, чем принимая все решения самостоятельно и становясь узким местом.
5️⃣Всегда рефлексируй по поводу архитектуры
Все настолько быстро меняется (технологии, инструменты и бизнес модели) и для того чтобы своевременно реагировать на эти изменения важно целиться не в что-то идеальное а скорее проектировать так чтобы была возможность изменять. Гибкость в нашем agile мире важнее всего.
6️⃣ Создавайте слабосвязанные системы
Слабосвязанная система обладает следующими свойствами:
- Небольшие компоненты.
- Взаимодействие посредством абстракций а не реализаций.
- Изменения в одном компоненте не влияют на другие.
- Каждый компонент обновляется отдельно.
7️⃣ Принимайте обратимые решения
Чтобы идти в ногу с быстро меняющимся технологическим ландшафтом и модульной архитектурой данных, следует выбирать самое лучшее из того что есть сейчас. Но при этом закладывать в систему возможность переезда на другие рельсы через время.
8️⃣ Безопасность
- Используйте модели безопасности с нулевым доверием.
- Выстройте модель совместной ответственности при вычислениях в облаке.
- Поощряйте инженеров по обработке данных выступать в роли инженеров по безопасности.
9️⃣FinOps
FinOps - дисциплина финансового управления и культурная практика в облаке, способствующая сотрудничеству между инженерными, финансовыми и бизнес специалистами для принятия решений о расходах на основе данных, с целью достичь максимального соотношения доходов к расходам.
———
На этом всё, в следующем посте рассмотрим архитектурные показатели.😊
Forwarded from Библиотека дата-сайентиста | Data Science, Machine learning, анализ данных, машинное обучение
This media is not supported in your browser
VIEW IN TELEGRAM
🔍 Топ-5 библиотек для объяснения ML моделей
🟢 SHAP (Shapley Additive Explanations)
Один из самых популярных методов объяснения модели на основе вкладов признаков.
🟢 LIME (Local Interpretable Model-agnostic Explanations)
Модель-агностичный подход, который обучает локальную интерпретируемую модель вокруг конкретного предсказания.
🟢 Eli5 (Explain Like I’m Five)
Упрощённое объяснение сложных ML-моделей, поддержка scikit-learn, Keras и других фреймворков.
🟢 AI Explainability 360 (AIX360)
Библиотека от IBM для объяснения моделей на различных типах данных: табличных, текстовых, изображениях и временных рядах.
🟢 InterpretML
Инструмент от Microsoft, который включает как интерпретируемые «прозрачные» модели, так и объяснители для «чёрных ящиков».
🟢 SHAP (Shapley Additive Explanations)
Один из самых популярных методов объяснения модели на основе вкладов признаков.
🟢 LIME (Local Interpretable Model-agnostic Explanations)
Модель-агностичный подход, который обучает локальную интерпретируемую модель вокруг конкретного предсказания.
🟢 Eli5 (Explain Like I’m Five)
Упрощённое объяснение сложных ML-моделей, поддержка scikit-learn, Keras и других фреймворков.
🟢 AI Explainability 360 (AIX360)
Библиотека от IBM для объяснения моделей на различных типах данных: табличных, текстовых, изображениях и временных рядах.
🟢 InterpretML
Инструмент от Microsoft, который включает как интерпретируемые «прозрачные» модели, так и объяснители для «чёрных ящиков».
Forwarded from Data Blog
Привет, друзья!
Как-то был запрос на методы объяснения для мультимодальных моделей (MM). Мой внутренний перфекционист не дал мне это сделать быстро, но жизнь подсунула обзорную статью с приятными картинками, которая сделала это просто прекрасно.
Смотреть: главы 4, 5.
✔️ Глава 4 касается методов, которые работают для LLM и могут быть обобщены для MM моделей. Краткий пересказ:
1. Описано Linear Probing (Линейное зондирование) — о котором я писала здесь.
Что делаем — извлекаем скрытые представления из модели и обучаем линейный классификатор.
2. Описан метод Logit Lens — метод, анализирующий, как выходные вероятности модели (логиты) изменяются на разных слоях.
Что делаем — на каждом слое скрытые представления проецируем в выходное пространство с помощью финального слоя модели.
3. Дальше Causal Tracing. Метод, подразумевающий внесение изменений в состояния сети, и анализа, как это повлияет на выход модели.
4. Потом Representation Decomposition — метод разбиения скрытых представлений модели на более понятные части. Очень схож с третьим и может задействовать зондирование, как инструмент анализа.
5. Предпоследнее — применение Sparse AutoEncoder — здесь мы при помощи автокодировщика, обучаемого на скрытых представлениях, вытаскиваем наиболее значимые фичи в «узкий слой» автоэнкодера.
6. Ну и классический Neuron-level Analysis — метод, изучающий индивидуальные нейроны в сети и их вклад в предсказания модели., при помощи анализа активаций отдельных нейронов при разных входных данных.
✔️ Теперь глава 5. Про методы, специфичные для мультимодальных моделей. Тут описано 5 штук:
1. Text-Explanations of Internal Embeddings — дословно, метод, назначающий текстовые описания внутренним представлениям модели.
2. Network Dissection — метод, выявляющий нейроны, отвечающие за конкретные концепции. Офигенный метод (paper), красивый метод (визуализация), но очень плохо адаптирован для трансформеров.
3. Cross-attention Based Interpretability — анализ того, какие части текста и изображения наиболее связаны через кросс-аттеншены.
4. Training Data Attribution — методы, определяющие, какие обучающие примеры сильнее всего влияют на конкретные предсказания модели. Что делаем — сознательно и не очень меняем и подаем обучающие примеры.
5. В завершение классика — Feature Visualizations — методы, позволяющие визуализировать, какие части входных данных наиболее важны для модели. Как правило — градиетные методы.
✔️Вместо вывода:
За счет размера моделей, методы интерпретации мультимодальных моделей заимствуют подходы из LLM. Однако, они требуют доработок из-за сложности взаимодействий между модальностями. С одной стороны можно действовать грубо и просить на каждое внутреннее представление делать объяснение. Но это вычислительно не приятно и скорее относится к конструированию объяснимой модели, а не объяснению имеющейся.
Лично мне очень весь этот мультимодальный челлендж нравится. Думаю, как практически его потыкать (обязательно поделюсь результатом).
Чудесного воскресенья, друзья!
Сейчас в догонку кину картинки.
Ваш Дата-автор!
Как-то был запрос на методы объяснения для мультимодальных моделей (MM). Мой внутренний перфекционист не дал мне это сделать быстро, но жизнь подсунула обзорную статью с приятными картинками, которая сделала это просто прекрасно.
Смотреть: главы 4, 5.
✔️ Глава 4 касается методов, которые работают для LLM и могут быть обобщены для MM моделей. Краткий пересказ:
1. Описано Linear Probing (Линейное зондирование) — о котором я писала здесь.
Что делаем — извлекаем скрытые представления из модели и обучаем линейный классификатор.
2. Описан метод Logit Lens — метод, анализирующий, как выходные вероятности модели (логиты) изменяются на разных слоях.
Что делаем — на каждом слое скрытые представления проецируем в выходное пространство с помощью финального слоя модели.
3. Дальше Causal Tracing. Метод, подразумевающий внесение изменений в состояния сети, и анализа, как это повлияет на выход модели.
4. Потом Representation Decomposition — метод разбиения скрытых представлений модели на более понятные части. Очень схож с третьим и может задействовать зондирование, как инструмент анализа.
5. Предпоследнее — применение Sparse AutoEncoder — здесь мы при помощи автокодировщика, обучаемого на скрытых представлениях, вытаскиваем наиболее значимые фичи в «узкий слой» автоэнкодера.
6. Ну и классический Neuron-level Analysis — метод, изучающий индивидуальные нейроны в сети и их вклад в предсказания модели., при помощи анализа активаций отдельных нейронов при разных входных данных.
✔️ Теперь глава 5. Про методы, специфичные для мультимодальных моделей. Тут описано 5 штук:
1. Text-Explanations of Internal Embeddings — дословно, метод, назначающий текстовые описания внутренним представлениям модели.
2. Network Dissection — метод, выявляющий нейроны, отвечающие за конкретные концепции. Офигенный метод (paper), красивый метод (визуализация), но очень плохо адаптирован для трансформеров.
3. Cross-attention Based Interpretability — анализ того, какие части текста и изображения наиболее связаны через кросс-аттеншены.
4. Training Data Attribution — методы, определяющие, какие обучающие примеры сильнее всего влияют на конкретные предсказания модели. Что делаем — сознательно и не очень меняем и подаем обучающие примеры.
5. В завершение классика — Feature Visualizations — методы, позволяющие визуализировать, какие части входных данных наиболее важны для модели. Как правило — градиетные методы.
✔️Вместо вывода:
За счет размера моделей, методы интерпретации мультимодальных моделей заимствуют подходы из LLM. Однако, они требуют доработок из-за сложности взаимодействий между модальностями. С одной стороны можно действовать грубо и просить на каждое внутреннее представление делать объяснение. Но это вычислительно не приятно и скорее относится к конструированию объяснимой модели, а не объяснению имеющейся.
Лично мне очень весь этот мультимодальный челлендж нравится. Думаю, как практически его потыкать (обязательно поделюсь результатом).
Чудесного воскресенья, друзья!
Сейчас в догонку кину картинки.
Ваш Дата-автор!