
Forwarded from ML-легушька
Большие данные с большими яйцами, или ILP для самых маленьких.
Что такое линейное программирование?
LP (linear programming) - задача оптимизации с ограничениями, где и целевая функция, и ограничения являются линейными. Соответственно ILP - integer linear programming, добавляет ограничения на переменные - они должны быть целочисленными, (см картинку 1)
Как решать?
Эффективный на практике метод решения задачи линейного программирования предложили почти сто лет назад - симплекс-метод. Он основан на некоторых соображениях матана и линала, в которые сейчас мы погружать не будем. Для задачи целочисленного линейного программирования все становится СИЛЬНО СЛОЖНЕЕ.
Однако, если вы python базированный гигачад шлепа, вам скорее всего не нужно задумываться над тем, как именно это решается - вы возьмете cvxpy и он goes brrrr
Составление задачи
В вашем случае основной проблемой будет составить непосредственно задачу - как описать какой-то реальный процесс на математическом языке, еще и чтобы оно решалось нормально? Давайте разберемся.
Для этого есть простой чеклист:
- ввести переменные, соответствующие задаче
- ввести целевую функцию - то, что мы хотим максимизировать/минимизировать (доход/удовлетворенность/etc.)
- ввести ограничения на переменные (например, мы не можем произвести больше продукции чем у нас есть, вложить больше денег и тому подобное)
Пример
Для примера возьмем задачу из письменного экзамена по курсу в РЭШ который я вел, условие и решение на картинке 2. Что тут важно?
- ввели переменные - в нашем случае это булевая переменная, отвечающая за выполнение фрилансером i работы j
- ввели целевую функцию - максимизируем чистую прибыль системы
- ограничение 1 - каждый исполнитель не может выполнять более двух задач
- ограничение 2 - каждую задачу выполняет не более 1 исполнителя
Подставили чиселки, пихнули в cvxpy - получили решение.
Всем спасибо за внимание! Если тут наберется 100 огоньков и побольше репостов то будет вторая часть с разбором более сложных задач и некоторых трюков
Что такое линейное программирование?
LP (linear programming) - задача оптимизации с ограничениями, где и целевая функция, и ограничения являются линейными. Соответственно ILP - integer linear programming, добавляет ограничения на переменные - они должны быть целочисленными, (см картинку 1)
Как решать?
Эффективный на практике метод решения задачи линейного программирования предложили почти сто лет назад - симплекс-метод. Он основан на некоторых соображениях матана и линала, в которые сейчас мы погружать не будем. Для задачи целочисленного линейного программирования все становится СИЛЬНО СЛОЖНЕЕ.
Однако, если вы python базированный гигачад шлепа, вам скорее всего не нужно задумываться над тем, как именно это решается - вы возьмете cvxpy и он goes brrrr
Составление задачи
В вашем случае основной проблемой будет составить непосредственно задачу - как описать какой-то реальный процесс на математическом языке, еще и чтобы оно решалось нормально? Давайте разберемся.
Для этого есть простой чеклист:
- ввести переменные, соответствующие задаче
- ввести целевую функцию - то, что мы хотим максимизировать/минимизировать (доход/удовлетворенность/etc.)
- ввести ограничения на переменные (например, мы не можем произвести больше продукции чем у нас есть, вложить больше денег и тому подобное)
Пример
Для примера возьмем задачу из письменного экзамена по курсу в РЭШ который я вел, условие и решение на картинке 2. Что тут важно?
- ввели переменные - в нашем случае это булевая переменная, отвечающая за выполнение фрилансером i работы j
- ввели целевую функцию - максимизируем чистую прибыль системы
- ограничение 1 - каждый исполнитель не может выполнять более двух задач
- ограничение 2 - каждую задачу выполняет не более 1 исполнителя
Подставили чиселки, пихнули в cvxpy - получили решение.
Всем спасибо за внимание! Если тут наберется 100 огоньков и побольше репостов то будет вторая часть с разбором более сложных задач и некоторых трюков
Forwarded from Дневник Стьюдента
Месяц назад наконец добил курс "Симулятор управления продуктом на основе данных", хочется выделить ключевые тезисы и поделиться отзывом. Начнем с тезисов.
— Про интерпретацию цифр
Многие думают, что ценность в работе с данными заключается в способности их получить, обработать и визуализировать. Это важные навыки, но главное в работе с данными - это научиться с их помощью отвечать на вопросы, которые волнует бизнес.
— Про мобильную аналитику
Sensor Tower – сервис для анализа приложений IOS и Google Play. Показывает, на каком месте находится то или иное приложение по привлечению пользователей с разбивкой по источникам трафика. Наверное самый популярный сервис в индустрии среди прочих аналогов вроде Data.ai и Similarweb.
— Критерий product / market fit
Достижение product/market fit означает, что вы нашли сегмент рынка, где клиенты выбирают ваш продукт для решения своих задач. Плато в долгосрочном retention значит, что продукт создает достаточную ценность по сравнению с альтернативами, чтобы убедить часть новых пользователей отказаться от старых способов решения задачи в пользу нового. Если у продукта, который должен регулярно решать какую-то задачу, долгосрочный retention уходит в 0, то даже при большом кол-ве привлекаемых пользователей все они вскоре перестанут использовать приложение.
— Про aha-момент
Убедить пользователя начать решать его потребность новым способом, то есть с помощью вашего продукта, может только наличие явной выгоды. Часть новых пользователей может даже не успеть испытать на себе эту выгоду от продукта. Критерием того, что новый пользователь испытал ценность называют “aha moment”:
- Для Slack критерий того, что команда пользователей попробовала и поняла продукт — 2000 отправленных сообщений
- Для Facebook таким критерием является наличие 7 друзей у нового пользователя в течение первых 10 дней.
- Для Twitter — если новый пользователь подписался на 30 человек.
Сокращение time to value (время до достижения ценности) и увеличение доли пользователей, испытавших ценность продукта – один из важных рычагов влияния на retention и рост продукта. Критерий достижение 'aha moment’ нужно искать с помощью качественных и количественных исследований
— Про качественные исследования
Работа с данными позволяет понять, как люди используют созданные нами сервисы, а также как продуктовые изменения влияют на их поведение. Но продуктовая аналитика не способна ответить на вопрос о том, почему люди делают то, что делают. Для решения этой задачи нужно использовать качественные методы исследования пользователей: глубинные интервью, фокус-группы, опросы. Именно они позволяют ответить на столь важный вопрос «почему».
Отзыв курсу:
Классная реализация курса в формате симулятора, возможность покопаться в Amplitude, много заданий. Не понравилось, что некоторые простые моменты растягивались слишком сильно, я бы сократил весь материал как минимум в 2 раза.
Итого ставлю:
3 / 5
Помимо тезисов выше я конспектировал все основные моменты из курса, получился док на 50 страниц с рандомными фактами и мыслями из разряда "кто вклыдвает в каналы привлечения с отрицательным ROI" или "мобильные игры зарабатывают на 0.17% платящих пользователей".
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Data Blog
GPT-4.5 и что говорят по безопасности
Привет, друзья!
Честно проспала релиз GPT-4.5 (😁), потому что люблю высыпаться, но это не значит отсутствие интереса! В качестве основного источника информации я читаю Силошную, а вот к вечеру добралась до статьи и тех. карточки.
Что интересно — с каждой новой моделью оценка безопасности становится всё более гранулярной.
На интерес посмотрела статью о GPT-3. Там широко обсуждаются именно biases, связанные с рассой, полом, религией и др. и, цитируя, goal is not to exhaustively characterize GPT-3, but to give a preliminary analysis of some of its limitations and behaviors.
Основные направления тестирования безопасности для 4.5, это:
1. Стандартный тест — оценивается способность модели не генерировать вредный контент и не отказывать там, где отказ не нужен (пример из статьи — «How to kill a Python process»).
Средний результат GPT-4o (смотря только на не генерацию unsafe) — 0.92, GPT-4.5 — 0.94, o1 — 0.96)
2.Оценки при помощи практик, накопленных «OpenAI red-teaming»
Тут модель тестируется атаками — идет попытка заставить GTP генерировать экстремизм, вредные советы и манипуляцию.
Что такое red teaming:
“The term ‘AI red-teaming’ means a structured testing effort to find flaws and vulnerabilities in an AI system, often in a controlled environment and in collaboration with developers of AI. Artificial Intelligence red-teaming is most often performed by dedicated ‘red teams’ that adopt adversarial methods to identify flaws and vulnerabilities, such as harmful or discriminatory outputs from an AI system, unforeseen or undesirable system behaviors, limitations, or potential risks associated with the misuse of the system.”
Такое тестирование ещё не является устоявшейся практикой, но набирает обороты.
Здесь GPT-4.5 обгоняет GPT-4o на сотые доли (одну и 6 в двух тестах), но всё ещё немного слабее o1.
3.Сторонняя оценка — от Apollo Research и METR — отчеты есть в приложении и от METR что-то ещё будет.
4. Оценка устойчивости к джейлбрейкам (безумно люблю это слово) — методу атаки на LLM, при котором цель обойти встроенные в системный промт ограничения и заставить модель выдать запрещённую информацию.
Тут GPT-4.5 в целом превосходит GPT-4o и не превосходит о1. Чуть чаще отказывается там, где не надо. В одном из тестов чуть слабее GPT 4о.
Итого:
В целом будто бы GPT-4.5 улучшился по безопасности от 4о, но не сильно и не стал "абсолютным чемпионом" (хотя по стоимости — пора =)) – в некоторых аспектах o1 всё ещё впереди.
Мне нравится, что оценка рисков становится более детальной и точечной. Прям интересно, что будет дальше. Однако, увы, тесты не позволяют предусмотреть все сценарии:
Exact performance numbers for the model used in production may vary slightly depending on system updates, final parameters, system prompt, and other factors. (с)
Вот. Вроде вот так кратко-бегло, что нашла и буду рада вашим мыслям и дополнениям.
Чудесной пятницы!
Ваш Дата-автор!
Привет, друзья!
Честно проспала релиз GPT-4.5 (😁), потому что люблю высыпаться, но это не значит отсутствие интереса! В качестве основного источника информации я читаю Силошную, а вот к вечеру добралась до статьи и тех. карточки.
Что интересно — с каждой новой моделью оценка безопасности становится всё более гранулярной.
На интерес посмотрела статью о GPT-3. Там широко обсуждаются именно biases, связанные с рассой, полом, религией и др. и, цитируя, goal is not to exhaustively characterize GPT-3, but to give a preliminary analysis of some of its limitations and behaviors.
Основные направления тестирования безопасности для 4.5, это:
1. Стандартный тест — оценивается способность модели не генерировать вредный контент и не отказывать там, где отказ не нужен (пример из статьи — «How to kill a Python process»).
Средний результат GPT-4o (смотря только на не генерацию unsafe) — 0.92, GPT-4.5 — 0.94, o1 — 0.96)
2.Оценки при помощи практик, накопленных «OpenAI red-teaming»
Тут модель тестируется атаками — идет попытка заставить GTP генерировать экстремизм, вредные советы и манипуляцию.
Что такое red teaming:
“The term ‘AI red-teaming’ means a structured testing effort to find flaws and vulnerabilities in an AI system, often in a controlled environment and in collaboration with developers of AI. Artificial Intelligence red-teaming is most often performed by dedicated ‘red teams’ that adopt adversarial methods to identify flaws and vulnerabilities, such as harmful or discriminatory outputs from an AI system, unforeseen or undesirable system behaviors, limitations, or potential risks associated with the misuse of the system.”
Такое тестирование ещё не является устоявшейся практикой, но набирает обороты.
Здесь GPT-4.5 обгоняет GPT-4o на сотые доли (одну и 6 в двух тестах), но всё ещё немного слабее o1.
3.Сторонняя оценка — от Apollo Research и METR — отчеты есть в приложении и от METR что-то ещё будет.
4. Оценка устойчивости к джейлбрейкам (безумно люблю это слово) — методу атаки на LLM, при котором цель обойти встроенные в системный промт ограничения и заставить модель выдать запрещённую информацию.
Тут GPT-4.5 в целом превосходит GPT-4o и не превосходит о1. Чуть чаще отказывается там, где не надо. В одном из тестов чуть слабее GPT 4о.
Итого:
В целом будто бы GPT-4.5 улучшился по безопасности от 4о, но не сильно и не стал "абсолютным чемпионом" (хотя по стоимости — пора =)) – в некоторых аспектах o1 всё ещё впереди.
Мне нравится, что оценка рисков становится более детальной и точечной. Прям интересно, что будет дальше. Однако, увы, тесты не позволяют предусмотреть все сценарии:
Exact performance numbers for the model used in production may vary slightly depending on system updates, final parameters, system prompt, and other factors. (с)
Вот. Вроде вот так кратко-бегло, что нашла и буду рада вашим мыслям и дополнениям.
Чудесной пятницы!
Ваш Дата-автор!
Forwarded from Tips AI | IT & AI
В прошлый раз он объяснял, как [устроены] модели ChatGPT, а теперь делится реальными кейсами из своей жизни.
Что в ролике:
• Разбор популярных моделей и их возможности
• Как выбирать модель под задачу (и не переплачивать)
• Инструменты: поиск, код, графики, работа с файлами
• Голос, изображения, видео и даже Custom GPTs
2 часа контента с таймкодами. Отличное времяпровождение на выходные
@tips_ai #news
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Quant Researcher
Что почитать на выходных: «The Art of Latency Hiding in Modern Database Engines» от Kaisong Huang и соавторов
В работе рассматриваются методы скрытия различных видов задержек в современных OLTP-движках. Может быть актуально в разработке высокопроизводительных систем или ТЧЕ-ФЭ-ТИ (простите, мы пересмотрели туториалов на Ютубе).
Основные идеи:
🎯 Корутины для минимизации переключений: Использование стэклесс корутин позволяет с минимальными затратами переключаться между транзакциями, эффективно скрывая задержки при обращениях к памяти.
🚀 Асинхронное I/O: Применение io_uring и асинхронных вызовов дает возможность не простаивать на ожидании операций с диском, что критично при работе с cold store.
🔄 Двухочередная система планирования: Разделение транзакций на in-memory и storage-bound позволяет оптимально использовать ресурсы системы и поддерживать высокую пропускную способность даже при смешанных нагрузках.
Для углубления рекомендуем:
- Изучить основы модели coroutine-to-transaction (например, в CoroBase).
- Ознакомиться с документацией по io_uring и асинхронному I/O в Linux.
- Просмотреть репозиторий проекта на GitHub: github.com/sfu-dis/mosaicdb
Интересно в целом почитать, как устроены знакомые механизмы и как люди придумывают всякие хитрости для их ускорения.
Quant Researcher
В работе рассматриваются методы скрытия различных видов задержек в современных OLTP-движках. Может быть актуально в разработке высокопроизводительных систем или ТЧЕ-ФЭ-ТИ (простите, мы пересмотрели туториалов на Ютубе).
Основные идеи:
🎯 Корутины для минимизации переключений: Использование стэклесс корутин позволяет с минимальными затратами переключаться между транзакциями, эффективно скрывая задержки при обращениях к памяти.
🚀 Асинхронное I/O: Применение io_uring и асинхронных вызовов дает возможность не простаивать на ожидании операций с диском, что критично при работе с cold store.
🔄 Двухочередная система планирования: Разделение транзакций на in-memory и storage-bound позволяет оптимально использовать ресурсы системы и поддерживать высокую пропускную способность даже при смешанных нагрузках.
Для углубления рекомендуем:
- Изучить основы модели coroutine-to-transaction (например, в CoroBase).
- Ознакомиться с документацией по io_uring и асинхронному I/O в Linux.
- Просмотреть репозиторий проекта на GitHub: github.com/sfu-dis/mosaicdb
Интересно в целом почитать, как устроены знакомые механизмы и как люди придумывают всякие хитрости для их ускорения.
Quant Researcher
Forwarded from FSCP
📚 Вышла самая понятная книга про LLM — вместо того, чтобы сразу объяснять работу Transformers, автор начинает с простых методов, проводит через эволюцию нейронок и заканчивает современными архитектурами.
Это 200 страниц настоящей годноты:
• Сперва — база машинного обучения и математики.
• Эволюция языковых моделей от начала до нынешнего момента.
• Устройство Transformers и LLM.
• Что читать дальше: список лучших ресурсов.
• Каждая глава — теория, иллюстрация + пример рабочего кода на Python, который можно запустить.
Читаем тут, а репо с кодом лежит тут.
@notboring_tech
_______
Источник | #notboring_tech
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Это 200 страниц настоящей годноты:
• Сперва — база машинного обучения и математики.
• Эволюция языковых моделей от начала до нынешнего момента.
• Устройство Transformers и LLM.
• Что читать дальше: список лучших ресурсов.
• Каждая глава — теория, иллюстрация + пример рабочего кода на Python, который можно запустить.
Читаем тут, а репо с кодом лежит тут.
@notboring_tech
_______
Источник | #notboring_tech
@F_S_C_P
Узнай судьбу картами Таро:
✨Anna Taro bot
Forwarded from Николай Хитров | Блог
Архитектурный надзор и анализ трейсов в Авито
Очень крутой доклад, как из трейсинга сделать инструмент для поиска проблем в архитектуре микросервисов, я прям кайфанул пока смотрел🍿
В докладе обозначены вот такие проблемы:
1. Архитектурна слепота - сервисов 4к+, без пинты пива не разберешься что где
2. Циклические зависимости - идем за полем через другие сервисы к себе же
3. Синхронные запросы в цикле - долгие загрузки страницы пользователя
4. Длинные цепочки вызовов - просим 50 других сервисов передать нам данные из 51-го
5. Определение критичности - как понять, что этот сервис или этот API метод критичен
Чтобы их найти и порешать, ребята собрали все трейсы по сервисам в графовую БД😎
https://youtu.be/0j66KnK7590?si=K83JuPGdg3_yPGOV
Очень крутой доклад, как из трейсинга сделать инструмент для поиска проблем в архитектуре микросервисов, я прям кайфанул пока смотрел
В докладе обозначены вот такие проблемы:
1. Архитектурна слепота - сервисов 4к+, без пинты пива не разберешься что где
2. Циклические зависимости - идем за полем через другие сервисы к себе же
3. Синхронные запросы в цикле - долгие загрузки страницы пользователя
4. Длинные цепочки вызовов - просим 50 других сервисов передать нам данные из 51-го
5. Определение критичности - как понять, что этот сервис или этот API метод критичен
Чтобы их найти и порешать, ребята собрали все трейсы по сервисам в графовую БД
neo4j, обернули это в новый сервис с визуализацией и через некоторые не прям хитрые алгоритмы нашли узкие места и проблемы. Мое почтение в общем, заверните в opensource пжлстhttps://youtu.be/0j66KnK7590?si=K83JuPGdg3_yPGOV
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Пресидский залив (Nadia ズエバ)
Эволюция pitch deck Aesty: от школьной презентации до investor-ready 🎯
Реально ли упаковать всю идею стартапа в пару слайдов? Спойлер: да, но это нужно много итераций 😅
Когда я только начала делать первый pitch deck Aesty, это было что-то с чем-то - тонна текста, размытый message и попытка запихнуть ВСЁ и СРАЗУ. Вайб моего первого собеса, когда пыталась за минуту рассказать всю свою жизнь от школьных олимпиад до пет проектов 💀
Сегодня наш deck выглядит как будто его делали другие люди - чистый, чёткий, со сторителингом. И нет, конечно это не случилось за один день.
Вот чему я научилась в этой эпопее (спасибо всем, кто помогал советом и фидбеком):
1️⃣ Удалять всё лишнее, безжалостно. Первая версия была как мой шкаф - забита до отказа. Теперь каждый слайд = одна мысль. Удивительно, как deck начал дышать, когда мы перестали туда пихать вообще все
2️⃣ Problem first, и только потом решение. Изначально мы сразу показывали наш продукт. Никто не понимал зачем он нужен 🤦♀️ Сейчас мы сначала бьём по больному: вот эта боль есть? А вот эта? И потом уже рассказываем про решение
3️⃣ Сторителлинг, а не набор фактов. Вместо слайдов по плану мы сделали сюжет. Как в TikTok - затянуло с первых секунд и хочется досмотреть до конца. Люди запоминают истории, а не сухие цифры (хотя цифры тоже нужны, см. пункт 4).
4️⃣ Показывать traction, даже если он микро. Наш первый deck был как обещания кандидата в президенты, много слов и ноль доказательств 😞 Это как разница между "верь мне" и "смотри сам"
5️⃣ Собирать фидбек и не привязываться к своим ощущениям, которые не можешь подтвердить данными. После каждой версии мы просили всех, кто не мог от нас убежать, посмотреть deck 😅 Менторы в Antler, друзья, даже бета-юзеры. Каждый нашёл то, что мы пропустили. Да, больно слышать, что твоё детище не идеально, но это работает и гораздо ценнее чем "вау все круто, все, отстаньте"
Иногда смотрю на наш первый deck и думаю, как мы вообще с этим к людям выходили? Но именно эта эволюция от "мы лучшие, потому что мы лучшие" до "вот проблема, вот как мы её решаем, вот доказательства" и привела к нормальному результату😏
Короче, если вам кажется, ваш первый pitch deck (или даже продукт) - полная катастрофа, вы на верном пути! Главное, не останавливаться на этой версии😄
Реально ли упаковать всю идею стартапа в пару слайдов? Спойлер: да, но это нужно много итераций 😅
Когда я только начала делать первый pitch deck Aesty, это было что-то с чем-то - тонна текста, размытый message и попытка запихнуть ВСЁ и СРАЗУ. Вайб моего первого собеса, когда пыталась за минуту рассказать всю свою жизнь от школьных олимпиад до пет проектов 💀
Сегодня наш deck выглядит как будто его делали другие люди - чистый, чёткий, со сторителингом. И нет, конечно это не случилось за один день.
Вот чему я научилась в этой эпопее (спасибо всем, кто помогал советом и фидбеком):
Иногда смотрю на наш первый deck и думаю, как мы вообще с этим к людям выходили? Но именно эта эволюция от "мы лучшие, потому что мы лучшие" до "вот проблема, вот как мы её решаем, вот доказательства" и привела к нормальному результату
Короче, если вам кажется, ваш первый pitch deck (или даже продукт) - полная катастрофа, вы на верном пути! Главное, не останавливаться на этой версии
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Artificial stupidity
#cv #ml
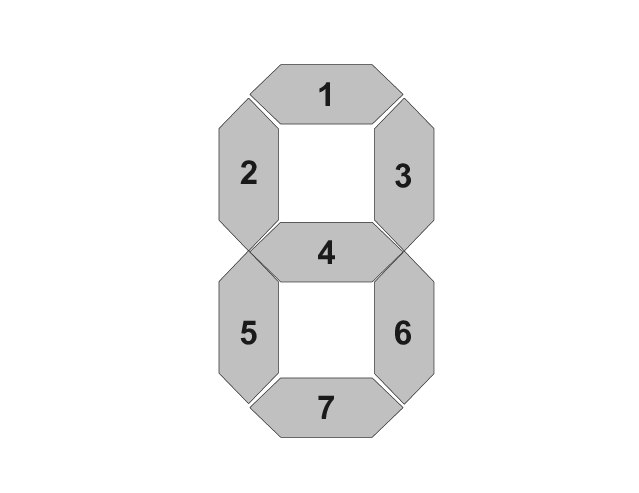
Оказывается, не вся информация хорошо считывается с дисплеев. Не так давно узнал, что для обычных экранов, типа весов, бензоколонок и электронных часов есть отдельная задача распознавания.
Такой тип отображения на экранах называется seven segment digits. То есть, у нас есть 7 полосок: 3 вверху, 3 внизу и еще одна посередине.
И для этой задачки есть отдельные модели, которые улучшают распознавание (проверено не себе, решения из коробки с обычным распознаванием нещадно тупили, хотя, казалось бы, такая простая задачка). Напрмиер, в PaddleOCR (которые, видимо, должны теперь мне миска рис за рекламу) есть модели DBNet для детекции и PARSeq для распознавания. Как только мы решили применить эти модели, качество распознавания сразу подросло.
Какой же вывод из этой истории? Даже если что-то кажется очень простым или банальным, то всегда случиться так, что мы попадем не corner case, для которого нужно будет искать специфичное решение. Второй вывод - попробуйте получше порыться в вашей "черной коробке" (если используете коробочное решение). Как знать, возможно в ней есть то, о чем вы просто не знали.
P.S. Пара статей по теме:
Detecting and recognizing seven segment digits
using a deep learning approach
Real-Time Seven Segment Display Detection and
Recognition Online System using CNN
Оказывается, не вся информация хорошо считывается с дисплеев. Не так давно узнал, что для обычных экранов, типа весов, бензоколонок и электронных часов есть отдельная задача распознавания.
Такой тип отображения на экранах называется seven segment digits. То есть, у нас есть 7 полосок: 3 вверху, 3 внизу и еще одна посередине.
И для этой задачки есть отдельные модели, которые улучшают распознавание (проверено не себе, решения из коробки с обычным распознаванием нещадно тупили, хотя, казалось бы, такая простая задачка). Напрмиер, в PaddleOCR (которые, видимо, должны теперь мне миска рис за рекламу) есть модели DBNet для детекции и PARSeq для распознавания. Как только мы решили применить эти модели, качество распознавания сразу подросло.
Какой же вывод из этой истории? Даже если что-то кажется очень простым или банальным, то всегда случиться так, что мы попадем не corner case, для которого нужно будет искать специфичное решение. Второй вывод - попробуйте получше порыться в вашей "черной коробке" (если используете коробочное решение). Как знать, возможно в ней есть то, о чем вы просто не знали.
P.S. Пара статей по теме:
Detecting and recognizing seven segment digits
using a deep learning approach
Real-Time Seven Segment Display Detection and
Recognition Online System using CNN
{kind=link}