
#FTS #Go
Let's build a Full-Text Search engine in Go
Full-Text Search (FTS) is a technique for searching text in a collection of documents. A document can refer to a web page, a newspaper article, an email message, or any structured text.
Today we are going to build our own FTS engine. By the end of this post, we'll be able to search across millions of documents in less than a millisecond. We'll start with simple search queries like "give me all documents that contain the word cat" and we'll extend the engine to support more sophisticated boolean queries.
https://artem.krylysov.com/blog/2020/07/28/lets-build-a-full-text-search-engine/
Let's build a Full-Text Search engine in Go
Full-Text Search (FTS) is a technique for searching text in a collection of documents. A document can refer to a web page, a newspaper article, an email message, or any structured text.
Today we are going to build our own FTS engine. By the end of this post, we'll be able to search across millions of documents in less than a millisecond. We'll start with simple search queries like "give me all documents that contain the word cat" and we'll extend the engine to support more sophisticated boolean queries.
https://artem.krylysov.com/blog/2020/07/28/lets-build-a-full-text-search-engine/
Forwarded from Deleted Account
Если вы думаете о зарубежной магистратуре, то почему бы не рассмотреть теплую южную страну? Например Италию. Ловите подборку англоязычных ИТ программ в этой прекрасной стране.
Politecnico di Milano:
📌MSc in CS and Engineering
📌MSc in Geoinformatics Engineering
Politecnico di Torino:
📌MSc in Data Science and Engineering
📌MSc in Computer Engineering
Sapienza Università di Roma:
📌MSc in Artificial Intelligence and Robotics
📌MSc in Computer Science
📌MSc in Cybersecurity
📌MSc in Data Science
📌MSc in Engineering in CS
University of Bologna:
📌MSc in AI
📌MSc in bioinformatics
University of Trento:
📌MSc in AI systems
📌MSc in human-computer interaction
📌MSc in Computer Science
University of Padua:
📌MSc in cybersecurity
📌MSc in Data Science
📌MSc in Physics of data
Free University of Bozen-Bolzano
📌MSc in Computational Data Science
📌MSc in Software Engineering
Politecnico di Milano:
📌MSc in CS and Engineering
📌MSc in Geoinformatics Engineering
Politecnico di Torino:
📌MSc in Data Science and Engineering
📌MSc in Computer Engineering
Sapienza Università di Roma:
📌MSc in Artificial Intelligence and Robotics
📌MSc in Computer Science
📌MSc in Cybersecurity
📌MSc in Data Science
📌MSc in Engineering in CS
University of Bologna:
📌MSc in AI
📌MSc in bioinformatics
University of Trento:
📌MSc in AI systems
📌MSc in human-computer interaction
📌MSc in Computer Science
University of Padua:
📌MSc in cybersecurity
📌MSc in Data Science
📌MSc in Physics of data
Free University of Bozen-Bolzano
📌MSc in Computational Data Science
📌MSc in Software Engineering
Plone site
homepage
The programme degree aims to form Artificial Intelligence expert able to deal with design, development, integration and maintenance of innovative and complex computer systems.
#DL
A really cool specialisation on deep learning from amazing instructors
If you want to master it and have a portfolio by the end then you should for for it.
The price is quite affordable. You'll pay it back very soon, I believe
Deep Learning
https://www.coursera.org/specializations/deep-learning
A really cool specialisation on deep learning from amazing instructors
If you want to master it and have a portfolio by the end then you should for for it.
The price is quite affordable. You'll pay it back very soon, I believe
Deep Learning
https://www.coursera.org/specializations/deep-learning
Coursera
Deep Learning
Offered by DeepLearning.AI. Become a Machine Learning ... Enroll for free.
Recently, I've been looking for resources on DL/ML and production. Here's a good resource that addresses the full cycle starting from setting/formulation of a problem to deployment
https://course.fullstackdeeplearning.com/
https://course.fullstackdeeplearning.com/
Fullstackdeeplearning
Full Stack Deep Learning | Full Stack Deep Learning
Full Stack Deep Learning helps you bridge the gap from training machine learning models to deploying AI systems in the real world.
Forwarded from Tech Crunch
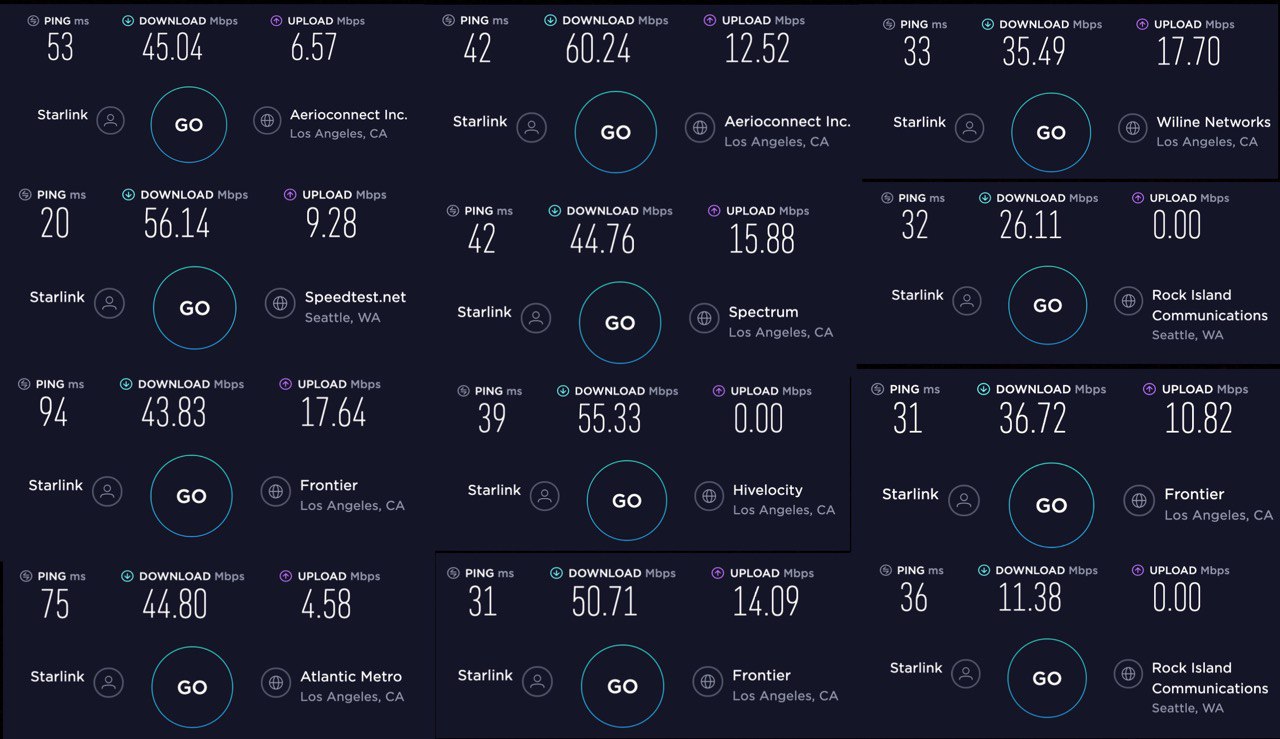
В США протестировали сеть спутникового интернета от SpaceX
Микроспутники Starlink от компании SpaceX Илона Маска раздают интернет со скоростью до 60 мегабит. Исследование спутникового проекта показало, что для потребительских целей средние показатели достаточно высокие.
Пока компания ведет работу над запуском на орбиту новых спутников для раздачи интернета, возник вопрос о том, какова будет скорости связи в реальности. Пробные замеры показали, что 11—60 мегабит. Средняя скорость — чуть несколько больше 40 мегабит.
Значительно ниже скорость для выгрузки данных – 4-17 мегабит. Замеры делались в Лос-Анджелесе, Сиэтле и Вашингтоне.
Таким образом скорость загрузки и выгрузки ниже желаемой руководством SpaceX — 1 гигабит. Хотя для пользователей достаточно и 15 мегабит, поскольку стандартная скорость «земного» широкополосного интернета в США такая же, а в сельской местности и того ниже.
Сейчас сеть спутников Starlink еще тестируется и, не исключено, что в конце концов скорость соединения приблизится к желанной для SpaceX. В настоящее время на орбите находятся примерно 600 спутников. Их количество планируется расширить до несколько тысяч, чтобы обеспечить глобальное покрытие.
Микроспутники Starlink от компании SpaceX Илона Маска раздают интернет со скоростью до 60 мегабит. Исследование спутникового проекта показало, что для потребительских целей средние показатели достаточно высокие.
Пока компания ведет работу над запуском на орбиту новых спутников для раздачи интернета, возник вопрос о том, какова будет скорости связи в реальности. Пробные замеры показали, что 11—60 мегабит. Средняя скорость — чуть несколько больше 40 мегабит.
Значительно ниже скорость для выгрузки данных – 4-17 мегабит. Замеры делались в Лос-Анджелесе, Сиэтле и Вашингтоне.
Таким образом скорость загрузки и выгрузки ниже желаемой руководством SpaceX — 1 гигабит. Хотя для пользователей достаточно и 15 мегабит, поскольку стандартная скорость «земного» широкополосного интернета в США такая же, а в сельской местности и того ниже.
Сейчас сеть спутников Starlink еще тестируется и, не исключено, что в конце концов скорость соединения приблизится к желанной для SpaceX. В настоящее время на орбите находятся примерно 600 спутников. Их количество планируется расширить до несколько тысяч, чтобы обеспечить глобальное покрытие.
{kind=link}
Для тех кто изучает МЛ и хочет лучше понять что такое AUC, ROC
https://dyakonov.org/2017/07/28/auc-roc-%D0%BF%D0%BB%D0%BE%D1%89%D0%B0%D0%B4%D1%8C-%D0%BF%D0%BE%D0%B4-%D0%BA%D1%80%D0%B8%D0%B2%D0%BE%D0%B9-%D0%BE%D1%88%D0%B8%D0%B1%D0%BE%D0%BA/
https://dyakonov.org/2017/07/28/auc-roc-%D0%BF%D0%BB%D0%BE%D1%89%D0%B0%D0%B4%D1%8C-%D0%BF%D0%BE%D0%B4-%D0%BA%D1%80%D0%B8%D0%B2%D0%BE%D0%B9-%D0%BE%D1%88%D0%B8%D0%B1%D0%BE%D0%BA/
Анализ малых данных
AUC ROC (площадь под кривой ошибок)
Площадь под ROC-кривой – один из самых популярных функционалов качества в задачах бинарной классификации. На мой взгляд, простых и полных источников информации «что же это такое» нет. Как правило, …
#ML, #softmax
I've asked my self why Softmax uses exponent. Here's a good response:
- Monotonically increasing — To ensure that larger inputs are mapped to larger outputs.
- Non-negative outputs — Because probability values must be non-negative.
- The outputs should sum to one — This can be achieved by simply dividing each element of the output by the sum of all elements of the output.
https://www.quora.com/Why-is-exponential-function-used-in-softmax-function-in-machine-learning
I've asked my self why Softmax uses exponent. Here's a good response:
- Monotonically increasing — To ensure that larger inputs are mapped to larger outputs.
- Non-negative outputs — Because probability values must be non-negative.
- The outputs should sum to one — This can be achieved by simply dividing each element of the output by the sum of all elements of the output.
https://www.quora.com/Why-is-exponential-function-used-in-softmax-function-in-machine-learning
Quora
Why is exponential function used in softmax function in machine learning?
Answer (1 of 2): A2A.
The goal of softmax function is to take a vector of arbitrary real numbers, such as [-1, 3, 2], and generate a probability distribution with the same number of elements (three in the example) such that larger elements get higher probabilities…
The goal of softmax function is to take a vector of arbitrary real numbers, such as [-1, 3, 2], and generate a probability distribution with the same number of elements (three in the example) such that larger elements get higher probabilities…
Here's another good question, that Daniil you may ask shortly: Why logit is slower than relu
https://www.coursera.org/learn/neural-networks-deep-learning/discussions/weeks/1/threads/OC2Bh8ahEeetfwrt7EZTMA
We've been discussing it with Agerke last week.
https://www.coursera.org/learn/neural-networks-deep-learning/discussions/weeks/1/threads/OC2Bh8ahEeetfwrt7EZTMA
We've been discussing it with Agerke last week.
Coursera
Coursera | Online Courses & Credentials From Top Educators. Join for Free | Coursera
Learn online and earn valuable credentials from top universities like Yale, Michigan, Stanford, and leading companies like Google and IBM. Join Coursera for free and transform your career with degrees, certificates, Specializations, & MOOCs in data science…
#ML #Sigmoid #Gradient Decent
Сижу читаю, про gradient decent сигмоидной фунцкции. Как мне нравится когда реализация может быть супер простой/эллегантной.
Зная/выведя формулу, в питоне, имплементация просто: dw = X.dot(H - Y).T / m
#. Кому интересно, докозательство формулы доступно по: https://medium.com/analytics-vidhya/derivative-of-log-loss-function-for-logistic-regression-9b832f025c2d
#. Имплементация алгоритма Логистической Регресси: https://ml-cheatsheet.readthedocs.io/en/latest/logistic_regression.html
Сижу читаю, про gradient decent сигмоидной фунцкции. Как мне нравится когда реализация может быть супер простой/эллегантной.
Зная/выведя формулу, в питоне, имплементация просто: dw = X.dot(H - Y).T / m
#. Кому интересно, докозательство формулы доступно по: https://medium.com/analytics-vidhya/derivative-of-log-loss-function-for-logistic-regression-9b832f025c2d
#. Имплементация алгоритма Логистической Регресси: https://ml-cheatsheet.readthedocs.io/en/latest/logistic_regression.html
Medium
The Derivative of Cost Function for Logistic Regression
Linear regression uses Least Squared Error as loss function that gives a convex loss function and then we can complete the optimization by…
#gradient #decent #DL
Хорошая статья на тему разбора различных типов Gradient Decent for logistics regression and cross entropy
“Gradient Descent — Demystified” by Avinash Kadimisetty https://link.medium.com/5exHc0Y8a9
Хорошая статья на тему разбора различных типов Gradient Decent for logistics regression and cross entropy
“Gradient Descent — Demystified” by Avinash Kadimisetty https://link.medium.com/5exHc0Y8a9
Medium
Gradient Descent — Demystified
In this article, I am going to discuss Gradient Descent in detail, explaining the different algorithms for optimisation apart from the…
#ML #System #Design
This booklet covers four main steps of designing a machine learning system:
Project setup
Data pipeline
Modeling: selecting, training, and debugging
Serving: testing, deploying, and maintaining
https://github.com/chiphuyen/machine-learning-systems-design
This booklet covers four main steps of designing a machine learning system:
Project setup
Data pipeline
Modeling: selecting, training, and debugging
Serving: testing, deploying, and maintaining
https://github.com/chiphuyen/machine-learning-systems-design
GitHub
GitHub - chiphuyen/machine-learning-systems-design: A booklet on machine learning systems design with exercises. NOT the repo for…
A booklet on machine learning systems design with exercises. NOT the repo for the book "Designing Machine Learning Systems", which is `dmls-book` - chiphuyen/machine-learning-systems-design
#ML #System #Design
"We can characterize the challenges for integrating machine learning within our systems as the three Ds. Decomposition, Data and Deployment."
"The first two components decomposition and data are interlinked, but we will first outline the decomposition challenge. Below we will mainly focus on supervised learning because this is arguably the technology that is best understood within machine learning."
http://inverseprobability.com/talks/notes/the-three-ds-of-machine-learning.html
"We can characterize the challenges for integrating machine learning within our systems as the three Ds. Decomposition, Data and Deployment."
"The first two components decomposition and data are interlinked, but we will first outline the decomposition challenge. Below we will mainly focus on supervised learning because this is arguably the technology that is best understood within machine learning."
http://inverseprobability.com/talks/notes/the-three-ds-of-machine-learning.html
Neil Lawrence’s Talks
Machine Learning Systems Design
Machine learning solutions, in particular those based on deep learning methods, form an underpinning of the current revolution in “artificial intelligence” t...
“TensorFlow vs PyTorch for Deep Learning” by Andreas Stöffelbauer https://link.medium.com/OV7ZUmUcl9
Medium
TensorFlow vs PyTorch for Deep Learning
Here’s what coding Deep Neural Networks in TensorFlow and PyTorch looks like
Forwarded from vc.ru
Ночью Илон Маск показал компактный беспроводной нейроинтерфейс Link, вживляемый под кожу черепа, и продемонстрировал его работу на свиньях, которым имплантировали чип для считывания мозговой активности.
С помощью Link можно будет лечить болезни — например, паралич, депрессию и болезнь Альцгеймера, играть в игры и управлять устройствами. Маск пообещал поддержку Tesla и StarCraft.
Главное из презентации Neuralink: vc.ru/future/154015
С помощью Link можно будет лечить болезни — например, паралич, депрессию и болезнь Альцгеймера, играть в игры и управлять устройствами. Маск пообещал поддержку Tesla и StarCraft.
Главное из презентации Neuralink: vc.ru/future/154015
Forwarded from DataEng
Mastering a data pipeline with Python / Robson Luis Monteiro Junior (Microsoft)
https://youtu.be/25fUlUsmg38
https://youtu.be/25fUlUsmg38
YouTube
Mastering a data pipeline with Python / Robson Luis Monteiro Junior (Microsoft)
Python Conf++ 2020 Online
Тезисы и презентация:
https://conf.python.ru/moscow/2020/abstracts/6316
Building data pipelines are a consolidated task, there are a vast number of tools that automate and help developers to create data pipelines with few clicks…
Тезисы и презентация:
https://conf.python.ru/moscow/2020/abstracts/6316
Building data pipelines are a consolidated task, there are a vast number of tools that automate and help developers to create data pipelines with few clicks…
Вкратце, хочу поделиться своим опытом прохождения на курсе по Глубокому Обучению.
Пока прошел первый модуль. Ушло примерно 2-3 недели, в основным по выходным. Если в часах, то около 20 часов. Доволен на 100% без преувеличений!
Из плюсов (минусов вообще пока не заметил):
1. Отлично продуманная программа: постепенно от логистической регресси, через однослойную сетку, к глубокой. Все сопровождается блестящим и подробным объяснением что-зачем-и-почему. Я, по-крайней мере, получил ответы на больинство своих вопросов, а на несколько тех, что не понял, смог добить самостоятельно в Гугле.
2. Супер профессиональный инструктор (сейчас именно об умении обучать, а не о его статусности в МЛ): Andrew Ng расставляет нужные акценты там где нужно, говорит о чем волноваться, а о чем не нужно. Дает понять где на математику нужно надавить, а где можно не сильно переживать. В моем случае это очень нужно, так как меня постоянно сопровождает Синдром Самозванца и я постоянно сомневаюсь, в своих способностях :)) И тот факт, что я в Амазоне, не всегда служит оправданием :))
3. Достаточно много практики. Задания в ноутбуках, среда разработки настроена - на лишнее отвлекаться не нужно. За первый модуль, пришлось несколько раз реализовать forward feed и back propagation, что сильно повысило мою уверенность в понимании как это устроено изнутри. Раньше я понимал, что используется chain rule и думал, что идет какая-то нереально навороченная реализация. На деле оказалось все куда проще: в зависимости от cost function и активационных функций, выбирается нужный метод, который знает как брать производную функции.
В общем, за первый модуль, я прокачал свой взгляд на сети и теперь уже могу осознано выбирать нужные гипер-параметры. Второй модуль как раз таки о практической части тренировки сетей и тюнинг параметров. Не могу не отметить профессионально упорядоченный материал и задания, отвечающие на вопрос "Почему?".
Все кому интересен Deep Learning и начинаете с нуля, рекомендую этот курс!
Чуть позже напишу свой отзыв о втором модуле.
https://www.coursera.org/specializations/deep-learning
Пока прошел первый модуль. Ушло примерно 2-3 недели, в основным по выходным. Если в часах, то около 20 часов. Доволен на 100% без преувеличений!
Из плюсов (минусов вообще пока не заметил):
1. Отлично продуманная программа: постепенно от логистической регресси, через однослойную сетку, к глубокой. Все сопровождается блестящим и подробным объяснением что-зачем-и-почему. Я, по-крайней мере, получил ответы на больинство своих вопросов, а на несколько тех, что не понял, смог добить самостоятельно в Гугле.
2. Супер профессиональный инструктор (сейчас именно об умении обучать, а не о его статусности в МЛ): Andrew Ng расставляет нужные акценты там где нужно, говорит о чем волноваться, а о чем не нужно. Дает понять где на математику нужно надавить, а где можно не сильно переживать. В моем случае это очень нужно, так как меня постоянно сопровождает Синдром Самозванца и я постоянно сомневаюсь, в своих способностях :)) И тот факт, что я в Амазоне, не всегда служит оправданием :))
3. Достаточно много практики. Задания в ноутбуках, среда разработки настроена - на лишнее отвлекаться не нужно. За первый модуль, пришлось несколько раз реализовать forward feed и back propagation, что сильно повысило мою уверенность в понимании как это устроено изнутри. Раньше я понимал, что используется chain rule и думал, что идет какая-то нереально навороченная реализация. На деле оказалось все куда проще: в зависимости от cost function и активационных функций, выбирается нужный метод, который знает как брать производную функции.
В общем, за первый модуль, я прокачал свой взгляд на сети и теперь уже могу осознано выбирать нужные гипер-параметры. Второй модуль как раз таки о практической части тренировки сетей и тюнинг параметров. Не могу не отметить профессионально упорядоченный материал и задания, отвечающие на вопрос "Почему?".
Все кому интересен Deep Learning и начинаете с нуля, рекомендую этот курс!
Чуть позже напишу свой отзыв о втором модуле.
https://www.coursera.org/specializations/deep-learning
Coursera
Deep Learning
Offered by DeepLearning.AI. Become a Machine Learning ... Enroll for free.