многие уже слышали про Zhipu AI (智谱 - с китайского можно перевести как "композиция мудрости" ), это еще один китайский ИИ-стартап, который выпускает свои базовые модели; в частности на прошлой неделе они выпустили модель GLM-Image для генерации картинок (примеры работы на первых двух картинках)
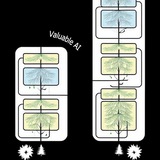
на третьей картинке изображен пайплайн работы их модели - сначала они авторегрессионно генерируют изображение более низкого качества, а потом улучшают его с помощью диффузии; интересно, что они используют отдельные токены для того, чтобы закодировать текст, который должен быть на изображении (4 картинка)
но привлекла мое внимание не сама модель, а тот факт, что эта модель - первая модель для генерации изображений, обученная на Huawei Ascend; DeepSeek в свое время заявлял сначала инференс на них, а потом и обучение - хотя были сомнения; а теперь - еще одна независимая компания
в общем, Huawei можно поздравить с достижением статуса "китайской Nvidia", а нас всех - с развитием рынка генеративных моделей
@valuableai
на третьей картинке изображен пайплайн работы их модели - сначала они авторегрессионно генерируют изображение более низкого качества, а потом улучшают его с помощью диффузии; интересно, что они используют отдельные токены для того, чтобы закодировать текст, который должен быть на изображении (4 картинка)
но привлекла мое внимание не сама модель, а тот факт, что эта модель - первая модель для генерации изображений, обученная на Huawei Ascend; DeepSeek в свое время заявлял сначала инференс на них, а потом и обучение - хотя были сомнения; а теперь - еще одна независимая компания
в общем, Huawei можно поздравить с достижением статуса "китайской Nvidia", а нас всех - с развитием рынка генеративных моделей
@valuableai
🔥17💘5
на прошлой неделе довольно широко прозвучала статья Engram от DeepSeek; суть статьи показана на первой картинке - перед вниманием добавляется новый блок памяти, который позволяет подмешивать к векторному представлению входов векторное представление n-грам из памяти; пример работы показан на второй картинке
интересно, что прибавку к качеству это дает в целом копеечную, если учесть затраченную память - в экспериментах такая фиксированная память это +20% к размеру модели при прибавке в разных тестах от сотых долей до первых процентов
в качестве контрастной новости: недавно вышла другая работа, где показали, что LLM (без внешней памяти) могут воспроизвести 96% текста Гарри Поттера, например; третья и четвертая картинка показывают, как этого можно достичь; на пятой картинке - результаты
в заключение хочется отметить, что так или иначе мы недалеко ушли от по-настоящему больших языковых моделей
@valuableai
интересно, что прибавку к качеству это дает в целом копеечную, если учесть затраченную память - в экспериментах такая фиксированная память это +20% к размеру модели при прибавке в разных тестах от сотых долей до первых процентов
в качестве контрастной новости: недавно вышла другая работа, где показали, что LLM (без внешней памяти) могут воспроизвести 96% текста Гарри Поттера, например; третья и четвертая картинка показывают, как этого можно достичь; на пятой картинке - результаты
в заключение хочется отметить, что так или иначе мы недалеко ушли от по-настоящему больших языковых моделей
@valuableai
👍3🔥2
Sakana AI предложили очередное простое улучшение: вместо того, чтобы делать сложные функции близости для позиционных векторов в трасформерах (как классические Positional Encoding или RoPE) или просто их выучивать, как было, например, в GPT2), они предложили простую идею - давайте предсказывать позицию для каждого токена (первая картинка)
это приводит к тому, что близость токенов определяется их семантической близостью, а из этого уже следует возможность для модели лучше работать с шумным текстом (например, с выходом ASR) или просто с длинным текстом (вторая картинка)
в целом, могу только поаплодировать коллегам, идея что называется витала в воздухе, а они ее ухватили и доказали ее полезность
P.S. напоминаю, что Sakana сейчас делают одни из самых интересных вещей в индустрии, уже не раз обозревал их работы (1, 2, 3)
@valuableai
это приводит к тому, что близость токенов определяется их семантической близостью, а из этого уже следует возможность для модели лучше работать с шумным текстом (например, с выходом ASR) или просто с длинным текстом (вторая картинка)
в целом, могу только поаплодировать коллегам, идея что называется витала в воздухе, а они ее ухватили и доказали ее полезность
P.S. напоминаю, что Sakana сейчас делают одни из самых интересных вещей в индустрии, уже не раз обозревал их работы (1, 2, 3)
@valuableai
❤9🔥4
тут по сети пошел гулять какой-то нейрошлак - якобы выдержки из письма Ильи Суцкевера совету директоров OpenAI; я отобрал те картинки, на которых что-то вменяемое
согласно им для сильного ИИ нужно минимум 3 ГВт электроэнергии непрерывно; из этого делается вывод, что практически сильный ИИ недостижим
в этой связи интересно, что некий британский физик(я все-таки надеюсь, что он больше ученый, чем британский) в конце прошлого года отправил, а буквально в первые минуты текущего года опубликовал гипотезу, которая призвана объяснить интеллект (в том числе ИИ) с физической точки зрения; в основе ее лежит как раз второй закон термодинамики и закон сохранения энергии, как и в "письме Суцкевера"
тут еще стоит вспомнить про книжку The Age of Em, про которую уже несколько раз упоминал, там базовым условием существования этих самых em (то есть копий человеческого мозга) является так называемое термодинамическое аппаратное обеспечение, которое использует для вычислений флуктуации внутри самого "железа"
@valuableai
согласно им для сильного ИИ нужно минимум 3 ГВт электроэнергии непрерывно; из этого делается вывод, что практически сильный ИИ недостижим
в этой связи интересно, что некий британский физик
тут еще стоит вспомнить про книжку The Age of Em, про которую уже несколько раз упоминал, там базовым условием существования этих самых em (то есть копий человеческого мозга) является так называемое термодинамическое аппаратное обеспечение, которое использует для вычислений флуктуации внутри самого "железа"
@valuableai
😁4⚡1
GPTZero продолжают свой анализ статей на конференциях, в этот раз в объектив их микроскопа попал NeurIPS
они проверили 4841 работу и в 51 нашли сгаллюцинированные цитаты, я бы сказал, что это - очень по-божески, чуть больше 1%; топ галлюцинаций по институциям на картинке;интересно, что коллеги из MBZUAI и в него попали
авторы исследования объясняют наличие галлюцинаций тем, что NeurIPS - сверхпопулярен, за 5 лет количество поданных работ почти утроилось и достигло 21 тысячи поданных статей; как следствие этого возникает необходимость в настоящей армии рецензентов, которой надо руководить
к чему я все это? я уже высказывался на тему реформы процесса рецензирования, а в следующую среду буду выступать на семинаре AIRI, представлю свое предложение на суд общественности, кому интересно - приходите или подключайтесь онлайн, регистрация здесь
@valuableai
они проверили 4841 работу и в 51 нашли сгаллюцинированные цитаты, я бы сказал, что это - очень по-божески, чуть больше 1%; топ галлюцинаций по институциям на картинке;
авторы исследования объясняют наличие галлюцинаций тем, что NeurIPS - сверхпопулярен, за 5 лет количество поданных работ почти утроилось и достигло 21 тысячи поданных статей; как следствие этого возникает необходимость в настоящей армии рецензентов, которой надо руководить
к чему я все это? я уже высказывался на тему реформы процесса рецензирования, а в следующую среду буду выступать на семинаре AIRI, представлю свое предложение на суд общественности, кому интересно - приходите или подключайтесь онлайн, регистрация здесь
@valuableai
👍5😢1