Королёв про всё остальное (ex UX Research) pinned «Всем привет. Канал в задуманном виде не работает - я понял, что писать только про исследования мне не интересно, поэтому я чуть расширяю и меняю тему. Про что теперь будет: - про исследовательские методы и про UX исследования в контексте бизнеса (как сейчас)…»
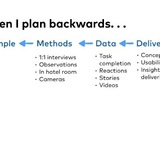
Я иногда мысленно возвращаюсь к исследованию Experience Sampling в Google (https://t.me/uxread/47), и, кажется, сформулировал для себя, что именно мне так нравится.
Обычно при исследовании подразумевается вопрос "как мы можем лучше решать текущую проблему нашего пользователя", это вопрос про небольшие итеративные улучшения существующего опыта, и мне, как исследователю, он приходит в голову первым.
Но они подразумевают другой вопрос: "какие проблемы нашего клиента мы ещё не решаем, хотя легко могли бы? Кто мог бы использовать наш продукт, но пока не использует?". Этот вопрос чуть больше связан с маркетингом и долгосрочным развитием продукта, я меньше привык его задавать, и он кажется свежим и неожиданным.
Зато теперь понятней, как перенести его на текущие проекты.
Обычно при исследовании подразумевается вопрос "как мы можем лучше решать текущую проблему нашего пользователя", это вопрос про небольшие итеративные улучшения существующего опыта, и мне, как исследователю, он приходит в голову первым.
Но они подразумевают другой вопрос: "какие проблемы нашего клиента мы ещё не решаем, хотя легко могли бы? Кто мог бы использовать наш продукт, но пока не использует?". Этот вопрос чуть больше связан с маркетингом и долгосрочным развитием продукта, я меньше привык его задавать, и он кажется свежим и неожиданным.
Зато теперь понятней, как перенести его на текущие проекты.
Telegram
UX Research
Google в 2011 сделали experience sampling, чтобы понять, чего добавить в поиск (и это опять был Tomer Sharon)
Так, у меня есть запрос на маленький нишевый инструмент для исследований, а ещё у меня для вас опрос, но начнём мы с кейса How Google Plans to Find…
Так, у меня есть запрос на маленький нишевый инструмент для исследований, а ещё у меня для вас опрос, но начнём мы с кейса How Google Plans to Find…
Ну и ещё, как и обещал, про VR стартапчики для психотерапии и mental health в целом. Я чуть раньше писал про limbix, которые делают VR для терапии фобий. Есть похожий стартап Psious, они делают VR окружения попроще, зато работающие на смартфонах, и они прислали мне парочку демо видео.
Тут надо сказать, как это вообще работает - в CBT (cognitive-behavoral therapy) психотерапии считается, что бесстрашие это что-то вроде навыка, который можно приобрести через опыт. Чтобы не травмироваться, опыт надо градуировать. Например, если вы боитесь полётов, то вам стоит сначала посмотреть на аэропорты издалека и привыкнуть, потом посидеть в терминале и привыкнуть, потом посмотреть, как люди заходят в самолёт и привыкнуть, потом посмотреть как взлетают, и привыкнуть, потом посидеть в самолёте и привыкнуть - что-то вроде растяжки. Каждый раз вы видите, что ничего плохого не происходит, страх притупляется, вам всё легче. Метаисследования показывают, что модель верна, и CBT помогает от тревожных расстройств и фобий очень-очень хорошо.
Так вот, иногда сразу идти в реальную ситуацию страшно, а воображаемых ситуаций недостаточно, и тогда хорошо работает VR, в котором эта ситуация смоделирована. Сейчас есть несколько стартапов, которые такие VR окружения делают, и Psious - один из.
Вот их видео, как вы едете в маленьком тесном лифте (для клаустрофобии) https://goo.gl/DC1pyB
А вот вы выстпаете перед здоровой аудиторией https://goo.gl/Gu85YT
В идеале, конечно, смотреть в VR коробке для смартфона, но и так норм.
Ну и у них есть ещё десяток, для страха полётов (как раз по тем сценариям, что я описал), для вождения, для ситуации экзамена итд.
Psious всё это объединяют с биофидбек датчиком, который замеряет, насколько вы сейчас боитесь, чтобы показывать более тревожное видео только после того, как предыдущее перестанет вас пугать.
Во-первых всё это классно само по себе, а во-вторых забавно, если лет через 5 появятся VR окружения для более экологичных тестирований, как сейчас браузерные рамки для прототипов. "Вань, сделай в прототипе пожалуйста, как будто клиент с этим приложением работает в метро, вставь его в VR с вагоном, у нас, кажется, была нужная библиотека в фигме". Вот это будет норм (надо было как-то привязать пост к исследованиям, сами понимаете).
Тут надо сказать, как это вообще работает - в CBT (cognitive-behavoral therapy) психотерапии считается, что бесстрашие это что-то вроде навыка, который можно приобрести через опыт. Чтобы не травмироваться, опыт надо градуировать. Например, если вы боитесь полётов, то вам стоит сначала посмотреть на аэропорты издалека и привыкнуть, потом посидеть в терминале и привыкнуть, потом посмотреть, как люди заходят в самолёт и привыкнуть, потом посмотреть как взлетают, и привыкнуть, потом посидеть в самолёте и привыкнуть - что-то вроде растяжки. Каждый раз вы видите, что ничего плохого не происходит, страх притупляется, вам всё легче. Метаисследования показывают, что модель верна, и CBT помогает от тревожных расстройств и фобий очень-очень хорошо.
Так вот, иногда сразу идти в реальную ситуацию страшно, а воображаемых ситуаций недостаточно, и тогда хорошо работает VR, в котором эта ситуация смоделирована. Сейчас есть несколько стартапов, которые такие VR окружения делают, и Psious - один из.
Вот их видео, как вы едете в маленьком тесном лифте (для клаустрофобии) https://goo.gl/DC1pyB
А вот вы выстпаете перед здоровой аудиторией https://goo.gl/Gu85YT
В идеале, конечно, смотреть в VR коробке для смартфона, но и так норм.
Ну и у них есть ещё десяток, для страха полётов (как раз по тем сценариям, что я описал), для вождения, для ситуации экзамена итд.
Psious всё это объединяют с биофидбек датчиком, который замеряет, насколько вы сейчас боитесь, чтобы показывать более тревожное видео только после того, как предыдущее перестанет вас пугать.
Во-первых всё это классно само по себе, а во-вторых забавно, если лет через 5 появятся VR окружения для более экологичных тестирований, как сейчас браузерные рамки для прототипов. "Вань, сделай в прототипе пожалуйста, как будто клиент с этим приложением работает в метро, вставь его в VR с вагоном, у нас, кажется, была нужная библиотека в фигме". Вот это будет норм (надо было как-то привязать пост к исследованиям, сами понимаете).
Nocode
Мне кажется, появляется новый навык - прототипирование сервисов.
Для исследования и оценки дизайна до разработки используют прототип - в минимальном виде - набор связанных ссылками картинок, в максимальном - интерактивные конструкции с анимацией и логикой, которые всё равно собираются быстрее, чем реальный продукт. Прототипы позволяют найти проблемы в дизайне, но не помогают оценить бизнес-гипотезы, например, достоверно оценить спрос.
Поэтому для проверки бизнес-гипотез используют MVP продукта или функции. В основе MVP лежит тот же подход "ошибись дешевле", они, как и прототипы, нужны чтобы снизить риск дорогих решений (ещё MVP помогают начать получать деньги раньше, но это отдельная история). Они тоже не должны стоить дорого.
Последние пару лет появляются платформы для интеграции всего со всем. Они позволяют собирать довольно сложные процессы, используя в качестве кирпичиков готовые сервисы, и поэтому могут неплохо работать для быстрого прототипирования MVP нового продукта, процесса или фичи (это скорее прототипы, т.к. они плохо масштабируются).
Я немного пользовался https://zapier.com/ и https://www.integromat.com/en (спасибо, Петя), но, оказывается, есть целое движение no-code или zero-code devops, посвящённое подобным инструментам, они в том числе поддерживают сложную логику и сложную работу с данными.
Вот два последних поста Иво Дмитрова с подборкой инструментов https://t.me/growthup/350 https://t.me/growthup/351, об этом же, кажется писал Ваня Замесин https://t.me/zamesin (не могу найти конкретный пост, но он часто упоминает инструменты, на которых выстроил процессы в своём стартапе, в том числе из подборок выше).
Интересно, будет ли это развиваться как отдельный навык? Появится ли в командах проектировщик сервисов (сервис-дизайнеры ведь уже есть), который вместо Axure и Figma, будет указывать в резюме владение Zapier и Retool?
___
Сервисы и кейсы интеграций в исследованиях:
https://t.me/uxread/122 Cally.ru - русскоязычный аналог Calendly для автоскедулинга интервью
https://t.me/uxread/8 Как mesosphere (b2b) настроили процесс ежеденедельных UX тестирований без выделенного исследователя
https://t.me/uxread/46 Tomer Sharon угорел по nocode и автоматизировал все процессы исследований, какие можно (рекрут, sheduling встреч, составление отчётов)
https://t.me/uxread/148 zoom+otter для автотранскрипта интервью.
#ResearchNocode
#Operations
https://t.me/uxread/148 zoom+otter для автотранскрипта интервью.
https://t.me/uxread/75 про nocode движение в целом
#ResearchNocode
#Operations
Мне кажется, появляется новый навык - прототипирование сервисов.
Для исследования и оценки дизайна до разработки используют прототип - в минимальном виде - набор связанных ссылками картинок, в максимальном - интерактивные конструкции с анимацией и логикой, которые всё равно собираются быстрее, чем реальный продукт. Прототипы позволяют найти проблемы в дизайне, но не помогают оценить бизнес-гипотезы, например, достоверно оценить спрос.
Поэтому для проверки бизнес-гипотез используют MVP продукта или функции. В основе MVP лежит тот же подход "ошибись дешевле", они, как и прототипы, нужны чтобы снизить риск дорогих решений (ещё MVP помогают начать получать деньги раньше, но это отдельная история). Они тоже не должны стоить дорого.
Последние пару лет появляются платформы для интеграции всего со всем. Они позволяют собирать довольно сложные процессы, используя в качестве кирпичиков готовые сервисы, и поэтому могут неплохо работать для быстрого прототипирования MVP нового продукта, процесса или фичи (это скорее прототипы, т.к. они плохо масштабируются).
Я немного пользовался https://zapier.com/ и https://www.integromat.com/en (спасибо, Петя), но, оказывается, есть целое движение no-code или zero-code devops, посвящённое подобным инструментам, они в том числе поддерживают сложную логику и сложную работу с данными.
Вот два последних поста Иво Дмитрова с подборкой инструментов https://t.me/growthup/350 https://t.me/growthup/351, об этом же, кажется писал Ваня Замесин https://t.me/zamesin (не могу найти конкретный пост, но он часто упоминает инструменты, на которых выстроил процессы в своём стартапе, в том числе из подборок выше).
Интересно, будет ли это развиваться как отдельный навык? Появится ли в командах проектировщик сервисов (сервис-дизайнеры ведь уже есть), который вместо Axure и Figma, будет указывать в резюме владение Zapier и Retool?
___
Сервисы и кейсы интеграций в исследованиях:
https://t.me/uxread/122 Cally.ru - русскоязычный аналог Calendly для автоскедулинга интервью
https://t.me/uxread/8 Как mesosphere (b2b) настроили процесс ежеденедельных UX тестирований без выделенного исследователя
https://t.me/uxread/46 Tomer Sharon угорел по nocode и автоматизировал все процессы исследований, какие можно (рекрут, sheduling встреч, составление отчётов)
https://t.me/uxread/148 zoom+otter для автотранскрипта интервью.
#ResearchNocode
#Operations
https://t.me/uxread/148 zoom+otter для автотранскрипта интервью.
https://t.me/uxread/75 про nocode движение в целом
#ResearchNocode
#Operations
Zapier
Zapier: Automate AI Workflows, Agents, and Apps
Build and scale AI workflows and agents across 9,000+ apps with Zapier—the most connected AI orchestration platform. Trusted by 3 million+ businesses.
Влияние бизнес-модели на проектирование навигации
Написал статью о том, как бизнес-модель и способы продвижения продукта влияют на дизайн витрин. Почему в некоторых случаях уместно сделать на главной здоровенную поисковую строку, а в других - выдачу с фильтрами или подборки товаров, и как понять, когда что нужно
(статья в большей части про маркетиновые каналы - лендинги и интернет-магазины, сугубо продуктовым дизайнерам будет не так интересно).
https://goo.gl/MkHSQs
____
https://t.me/uxread/61 - другой пример того, как бизнес-контекст влияет на дизайн - как изменения на рынке медсистем привели к тому, что исследования в Athenahealth стали иметь смысл
Написал статью о том, как бизнес-модель и способы продвижения продукта влияют на дизайн витрин. Почему в некоторых случаях уместно сделать на главной здоровенную поисковую строку, а в других - выдачу с фильтрами или подборки товаров, и как понять, когда что нужно
(статья в большей части про маркетиновые каналы - лендинги и интернет-магазины, сугубо продуктовым дизайнерам будет не так интересно).
https://goo.gl/MkHSQs
____
https://t.me/uxread/61 - другой пример того, как бизнес-контекст влияет на дизайн - как изменения на рынке медсистем привели к тому, что исследования в Athenahealth стали иметь смысл
Medium
Как проектировать навигацию сайта с учётом бизнес-модели.
Хочу показать на примерах, как интерфейсные паттерны зависят от бизнес-модели, и почему дизайнер должен понимать, как устроен рынок, на…
Матрица зрелости UX исследований
Продумываю рабочие цели на год, и решил посмотреть на maturity models of UX research, поискать, что делают старшие товарищи.
Статей много, вот несколько неплохих:
https://uxdesign.cc/the-organizations-design-research-maturity-model-b631471c007c
https://measuringu.com/maturity-of-ux-organizations/
https://www.nngroup.com/articles/ux-maturity-stages-1-4/
(Нильсен и Сауро самые полезные, как всегда) + на описания процессов в крупных компаниях, с которыми сталкивался ранее.
Если вы давно работаете в IT корпорации со зрелой культурой исследований (привет!) или просто много читаете, то всё знаете и так. Но если у вас не так всё хорошо, можно конвертировать любой пунктик в смарт цель, например "было минимум 2 проекта с concept generation" или "дизайнеры и менеджеры самостоятельно провели минимум 20 сессий" и запланировать на квартал.
Как исследования встроены в процесс:
- Каждый продукт проходит через исследования.
- Исследования проводятся регулярно, на них заложено при планировании проекта.
- Нормально проводить итеративные исследования (по несколько на запуск фичи или продукта)
Какие решения принимаются но основе исследований:
- Решения об изменении дизайна/принципа работы отдельных функций (исследования ориентированы на дизайнеров и продактов)
- Решения об изменении продуктовой стратегии, маркетинговой стратегии, запуске новых продуктов (исследования ориентированы на CMO и CPO).
- На основании исследования может быть принято (и иногда принимается) решение о переносе запуска/отмене запуска фичи/продукта/рекламной компании.
Какие методы используются:
- Есть исследования на прототипах до разработки (в идеале по большинству продуктов)
- Хотя бы часть продуктов исследуется на этапе идеи, до макетов
- Есть сессии кодизайна и concept generation с пользователями.
- Есть полноценные программы беты и пилотного запуска
- Исследования проводятся не только с текущими клиентами, но и с нетипичными клиентами, потенциальной аудиторией, экстремальными пользователями и т.д.
- Зрелые команды в среднем используют больше разных методов (т.е., вероятно, более изобретательны, или у них просто есть бюджет на айтрекер и нейромаркетинг).
Бюджет и ресурсы:
- На исследования и рекрут есть выделенный бюджет
- Есть отдельные люди, которые занимаются исследованиями большую часть времени.
- Экспертиза по исследованиям распределена - дизайнеры и продакты тоже могут проводить, есть лаборатория и оборудование, которое может использовать каждый
Как хранятся результаты:
- Результаты рассылают по почте в виде отчётов.
- Все знают, где лежат результаты, их можно легко посмотреть, есть доступная база (в airtable или ещё где-то)
- База не только есть, ей пользуются, все привыкли опираться на данные при принятии решений (это про культуру, и я пока не знаю, как это перевести в измеримую цель. Количество посещений портала, на котором лежат результаты?).
____
Как устроены процессы исследований в компаниях
Mesosphere https://t.me/uxread/8,
Atlassian https://t.me/uxread/39,
LinkedIn https://t.me/uxread/121,
Spotify https://t.me/uxread/104,
Facebook, https://t.me/uxread/71,
Ableton https://t.me/uxread/123,
Lyft https://t.me/uxread/11,
#Processes
Продумываю рабочие цели на год, и решил посмотреть на maturity models of UX research, поискать, что делают старшие товарищи.
Статей много, вот несколько неплохих:
https://uxdesign.cc/the-organizations-design-research-maturity-model-b631471c007c
https://measuringu.com/maturity-of-ux-organizations/
https://www.nngroup.com/articles/ux-maturity-stages-1-4/
(Нильсен и Сауро самые полезные, как всегда) + на описания процессов в крупных компаниях, с которыми сталкивался ранее.
Если вы давно работаете в IT корпорации со зрелой культурой исследований (привет!) или просто много читаете, то всё знаете и так. Но если у вас не так всё хорошо, можно конвертировать любой пунктик в смарт цель, например "было минимум 2 проекта с concept generation" или "дизайнеры и менеджеры самостоятельно провели минимум 20 сессий" и запланировать на квартал.
Как исследования встроены в процесс:
- Каждый продукт проходит через исследования.
- Исследования проводятся регулярно, на них заложено при планировании проекта.
- Нормально проводить итеративные исследования (по несколько на запуск фичи или продукта)
Какие решения принимаются но основе исследований:
- Решения об изменении дизайна/принципа работы отдельных функций (исследования ориентированы на дизайнеров и продактов)
- Решения об изменении продуктовой стратегии, маркетинговой стратегии, запуске новых продуктов (исследования ориентированы на CMO и CPO).
- На основании исследования может быть принято (и иногда принимается) решение о переносе запуска/отмене запуска фичи/продукта/рекламной компании.
Какие методы используются:
- Есть исследования на прототипах до разработки (в идеале по большинству продуктов)
- Хотя бы часть продуктов исследуется на этапе идеи, до макетов
- Есть сессии кодизайна и concept generation с пользователями.
- Есть полноценные программы беты и пилотного запуска
- Исследования проводятся не только с текущими клиентами, но и с нетипичными клиентами, потенциальной аудиторией, экстремальными пользователями и т.д.
- Зрелые команды в среднем используют больше разных методов (т.е., вероятно, более изобретательны, или у них просто есть бюджет на айтрекер и нейромаркетинг).
Бюджет и ресурсы:
- На исследования и рекрут есть выделенный бюджет
- Есть отдельные люди, которые занимаются исследованиями большую часть времени.
- Экспертиза по исследованиям распределена - дизайнеры и продакты тоже могут проводить, есть лаборатория и оборудование, которое может использовать каждый
Как хранятся результаты:
- Результаты рассылают по почте в виде отчётов.
- Все знают, где лежат результаты, их можно легко посмотреть, есть доступная база (в airtable или ещё где-то)
- База не только есть, ей пользуются, все привыкли опираться на данные при принятии решений (это про культуру, и я пока не знаю, как это перевести в измеримую цель. Количество посещений портала, на котором лежат результаты?).
____
Как устроены процессы исследований в компаниях
Mesosphere https://t.me/uxread/8,
Atlassian https://t.me/uxread/39,
LinkedIn https://t.me/uxread/121,
Spotify https://t.me/uxread/104,
Facebook, https://t.me/uxread/71,
Ableton https://t.me/uxread/123,
Lyft https://t.me/uxread/11,
#Processes
Medium
The organization’s design research maturity model
Maturity models, often a business-school student and management consultant’s trusted ally, help us understand where we stand relative to…
Пока, правда, не понимаю, как замерять влияние на продукты.
Понятно, что в самих интервью и тестированиях пользы не особо много, важно, как они влияют на продукт, насколько получается их донести до команды. Но не понятно, как это замерять или отслеживать.
Количество изменений по результатам исследований? Кривовато и легко накручивается.
Сколько денег (пунктов NPS, счастливых комментариев) принесли продуктовые изменения, сделанные по результатам исследований? Очень сложно отслеживать и честно считать.
Количество дизайнеров/продактов, которые лично побывали на сессии или провели её? Это вроде бы тоже про влияние, но не всегда прямо связано с влиянием на продукт.
Не знаю, короче. Если видели хорошие примеры, напишите мне.
Понятно, что в самих интервью и тестированиях пользы не особо много, важно, как они влияют на продукт, насколько получается их донести до команды. Но не понятно, как это замерять или отслеживать.
Количество изменений по результатам исследований? Кривовато и легко накручивается.
Сколько денег (пунктов NPS, счастливых комментариев) принесли продуктовые изменения, сделанные по результатам исследований? Очень сложно отслеживать и честно считать.
Количество дизайнеров/продактов, которые лично побывали на сессии или провели её? Это вроде бы тоже про влияние, но не всегда прямо связано с влиянием на продукт.
Не знаю, короче. Если видели хорошие примеры, напишите мне.
Инди Янг про хейт спичи на исследованиях и разные виды эмпатии
Инди Янг (соосновательница adaptive path, не абы кто) о том, что делать, when hate speech enters a research session, когда участник интервью начинает ясно выражать расистские или сексистские взгляды, или явно выражать неприязнь к исследователю.
https://indiyoung.com/when-hate-enters-a-research-session/
1) Одна из популярных реакций исследователя - стыд за то, что он не справился, не проконтролировал ситуацию и допустил такое на своём исследовании (неплохая статья о чувстве стыда в работе исследователя https://t.me/uxread/22). Отсюда стремление включить эмпатию на полную, простить и понять участника, а на деле вернуть себе чувство контроля и ощущение, что вы молодец.
2) Ок, давайте посмотрим, что такое эмпатия, и поможет ли она тут, пишет Инди Янг.
3) Есть эмоциональная эмпатия - понимание и разделение эмоций другого, готовность выслушать, поддержать и справиться с эмоцией. Эмоциональную эмпатию дают друзья и психотерапевт, модератору исследования она помогает установить контакт с респондентом и помочь ему расслабиться. Эмоциональная эмпатия в ответ на ненависть требует больших эмоциональных усилий, и редко "окупается" в ситуации исследования.
4) Также есть когнитивная эмпатия - понимание того, почему человек ведёт себя определённым образом. Она возникает в ходе длительного интервью или listening session, а не рождается спонтанно от большой душевности. В случае problem space research потратить время на выработку когнитивной эмпатии может быть важно, потому что нам важно понять систему убеждений человека. В случае юзабилити-тестирований задача - протестировать интерфейс, исследовать систему убеждений обычно не нужно.
5) Вместо того, чтобы эмпатировать и прощать, Инди Янг советует воспринимать исследование, как ситуацию, в которой вы, как исследователь, нанимаете респондента для решения определённой задачи. В случае юзабилити-тестирования вы нанимаете респондента, чтобы лучше понять его ментальную модель и найти проблемы в интерфейсе. Если он вместо этого переключается на хейт спич, вы можете давать явную обратную связь, что это неуместно, и можете прекратить исследование, вместо того, чтобы страдать.
Ещё у Инди Янг есть книга Practical Empathy (не читал, но собираюсь) https://rosenfeldmedia.com/books/practical-empathy/
А узнал я о ней из канала https://t.me/uxresearch, очень рекомендую всем (не реклама, канал правда хорош).
Инди Янг (соосновательница adaptive path, не абы кто) о том, что делать, when hate speech enters a research session, когда участник интервью начинает ясно выражать расистские или сексистские взгляды, или явно выражать неприязнь к исследователю.
https://indiyoung.com/when-hate-enters-a-research-session/
1) Одна из популярных реакций исследователя - стыд за то, что он не справился, не проконтролировал ситуацию и допустил такое на своём исследовании (неплохая статья о чувстве стыда в работе исследователя https://t.me/uxread/22). Отсюда стремление включить эмпатию на полную, простить и понять участника, а на деле вернуть себе чувство контроля и ощущение, что вы молодец.
2) Ок, давайте посмотрим, что такое эмпатия, и поможет ли она тут, пишет Инди Янг.
3) Есть эмоциональная эмпатия - понимание и разделение эмоций другого, готовность выслушать, поддержать и справиться с эмоцией. Эмоциональную эмпатию дают друзья и психотерапевт, модератору исследования она помогает установить контакт с респондентом и помочь ему расслабиться. Эмоциональная эмпатия в ответ на ненависть требует больших эмоциональных усилий, и редко "окупается" в ситуации исследования.
4) Также есть когнитивная эмпатия - понимание того, почему человек ведёт себя определённым образом. Она возникает в ходе длительного интервью или listening session, а не рождается спонтанно от большой душевности. В случае problem space research потратить время на выработку когнитивной эмпатии может быть важно, потому что нам важно понять систему убеждений человека. В случае юзабилити-тестирований задача - протестировать интерфейс, исследовать систему убеждений обычно не нужно.
5) Вместо того, чтобы эмпатировать и прощать, Инди Янг советует воспринимать исследование, как ситуацию, в которой вы, как исследователь, нанимаете респондента для решения определённой задачи. В случае юзабилити-тестирования вы нанимаете респондента, чтобы лучше понять его ментальную модель и найти проблемы в интерфейсе. Если он вместо этого переключается на хейт спич, вы можете давать явную обратную связь, что это неуместно, и можете прекратить исследование, вместо того, чтобы страдать.
Ещё у Инди Янг есть книга Practical Empathy (не читал, но собираюсь) https://rosenfeldmedia.com/books/practical-empathy/
А узнал я о ней из канала https://t.me/uxresearch, очень рекомендую всем (не реклама, канал правда хорош).
Telegram
UX Research
Роль стыда и заботы о себе в работе UX исследователя
Все говорят, что soft skills и для менеджеров, и для исследований важнее всего, с другой стороны, конкретных статей на эту тему мало, всё больше расплывчатые рассуждения о том, что эмпатия - это очень важно.…
Все говорят, что soft skills и для менеджеров, и для исследований важнее всего, с другой стороны, конкретных статей на эту тему мало, всё больше расплывчатые рассуждения о том, что эмпатия - это очень важно.…
Наконец-то написал статью о том, почему айтрекер и CJM не нужны (немного кликбейта, да) https://goo.gl/ByDLPV
Medium
Cjm и айтрекер — инструменты коммуникации, а не исследований (и, скорее всего, вам не нужны)
Если вы хотите улучшать продукт на основе исследований клиентов и аналитики, вам нужно настроить два процесса:
Как headspace повышали вовлечённость и улучшали онбординг в приложении по habit formation loop (по пути проведя опрос и дневники)
Весьма элегантный кейс о том как Headspace (приложение для медитаций) с помощью дневников, опросов и интуиции улучшали онбординг и повышали ретеншн новых пользователей. И ещё это хороший пример, как формировать у пользователей привычку регулярно работать с продуктом с помощью habit formation loop.
У них была задача: увеличить % пользователей, которые продолжали заходить в приложение и медитировать спустя 2 недели после первого входа, т.к. такие пользователи с большой вероятностью покупали подписку.
1) Сначала попробовали вслепую: улучшили онборинг, вместо тяжёлых видео сделали лёгкие гифки, стали скачивать первую сессию в ходе скачивания приложения (чтобы пользователю не нужно было закачивать её отдельно после установки приложения). Всё это немного увеличило количество людей, которые доходили до медитации в первую сессию, но ко второй неделе процесс спадал, главная метрика не росла.
2) Потом прошли через исследования. У них была гипотеза, что дело не в интерфейсе, а в том, что людям долгосрочно не хватает мотивации для создания новой привычки.
- Провели опрос новых клиентов “What are you hoping to experience in the short-term / long-term through using Headspace?” и вытащили их цели и ожидания. Что узнали: несколько высокочастотных целей/проблем, которые люди пытаются решить с помощью медитации, и инсайт - часть пользователей в принципе не очень понимали зачем скачали приложение и чего ждут.
- Попутно получили ещё один инсайт - участники опроса сказали, что сам вопрос помог им лучше понять, чего они хотят и ожидают от медитации.
- Сделали дневниковые исследования - попросили группу новых клиентов на протяжении двух недель оценивать, как им медитировалось, какие были барьеры, почему забивали на практику. Что узнали: как и в опросе, выяснилось, что у людей часто нет сформированных ожиданий относительно медитации, в процессе практики они не чувствуют прогресса в достижении цели (потому что цели часто нет), и ещё не всегда понятно, как встроить практику в свою жизнь (когда медитировать, как часто, итд).
Весьма элегантный кейс о том как Headspace (приложение для медитаций) с помощью дневников, опросов и интуиции улучшали онбординг и повышали ретеншн новых пользователей. И ещё это хороший пример, как формировать у пользователей привычку регулярно работать с продуктом с помощью habit formation loop.
У них была задача: увеличить % пользователей, которые продолжали заходить в приложение и медитировать спустя 2 недели после первого входа, т.к. такие пользователи с большой вероятностью покупали подписку.
1) Сначала попробовали вслепую: улучшили онборинг, вместо тяжёлых видео сделали лёгкие гифки, стали скачивать первую сессию в ходе скачивания приложения (чтобы пользователю не нужно было закачивать её отдельно после установки приложения). Всё это немного увеличило количество людей, которые доходили до медитации в первую сессию, но ко второй неделе процесс спадал, главная метрика не росла.
2) Потом прошли через исследования. У них была гипотеза, что дело не в интерфейсе, а в том, что людям долгосрочно не хватает мотивации для создания новой привычки.
- Провели опрос новых клиентов “What are you hoping to experience in the short-term / long-term through using Headspace?” и вытащили их цели и ожидания. Что узнали: несколько высокочастотных целей/проблем, которые люди пытаются решить с помощью медитации, и инсайт - часть пользователей в принципе не очень понимали зачем скачали приложение и чего ждут.
- Попутно получили ещё один инсайт - участники опроса сказали, что сам вопрос помог им лучше понять, чего они хотят и ожидают от медитации.
- Сделали дневниковые исследования - попросили группу новых клиентов на протяжении двух недель оценивать, как им медитировалось, какие были барьеры, почему забивали на практику. Что узнали: как и в опросе, выяснилось, что у людей часто нет сформированных ожиданий относительно медитации, в процессе практики они не чувствуют прогресса в достижении цели (потому что цели часто нет), и ещё не всегда понятно, как встроить практику в свою жизнь (когда медитировать, как часто, итд).
А дальше круто - они не просто взяли CJM и стали ковырять барьеры, а наложили клиентский путь на habit formation loop (она норм описана в книге про формирование привычек), что позволило им систематизировать работу.
Немного про петлю формирования привычек: она состоит из четырёх частей - trigger, action, reward, investment (ниже скрин, он иллюстрирует). Т.е привычка в этой модели возникает так:
- есть триггер (напоминалка, будильник, контекст), который приводит к
- действию (чистить зубы, листать ленту в инстаграме, медитировать), которое приводит к
- награде (ощущение чистоты, чувство интереса, спокойствие), и которое можно закрепить
- инвестицией, укрепляющей привычку (покупкой новой щёточки, подпиской на новых людей в инстаграме, ведения дневника самочувствия после медитации).
Всё идёт по кругу, привычка закрепляется.
Что сделали хедспейс.
- Триггеры - тут нет проблем, пуши, напоминалки, ок.
- Действие - поняли, что тут есть барьер, люди не знают, как встроить медитацию в повседневную практику. Во сколько начинать? Сколько раз в неделю практиковать? Добавили подсказки/варианты времени. И ещё, помогли привязать медитацию к другим повседневным действиям (можно выбрать, хочешь ли ты медитировать сразу как проснёшься, после душа, после завтрака, или привязать медитацию к какому-то ещё регулярному событию).
- Вознаграждение. Они, поняли, что наградой может быть достижение цели, которую пользователь придумал сам, и что важно создать реалистичные ожидания относительно цели, и при этом дать ощущение, что человек двигается к ней. Стали в первую же сессию давать цели на выбор, формировать ожидания + сделали goal section, куда добавляли медитации, связанные с целью (направленные именно на снижение стресса, или хороший сон)
- Инвестиции - кусочек с инвестициями они почему-то не дожали, и даже в статье про это идей нет.
Там есть ещё большая часть про интуицию, и про то, что часть вещей они интуитивно выкинули, но она кажется более тривиальной, про это не пишу. На выходе получили 10% прироста к ретеншну второй недели, класс! Процент платящих пользователей тоже в итоге вырос.
___
Другие кейсы:
https://t.me/uxread/47 Как Google в 2011 делали experience sampling, чтобы понять, чего добавить в поиск (и это опять был Tomer Sharon)
https://t.me/uxread/57 Как Superhuman научились оценивать достижение product-market fit опросником
https://t.me/uxread/16 - Интерком про точечные интервью с пользователями, совершившим определенное действие на сайте
https://t.me/uxread/36 как gov.uk тестируют понятность текстов с помощью highligther testing (маркерных тестов) (хайлайтер тестинг)
Другие кейсы: #Cases
Другие методы: #Methods
Немного про петлю формирования привычек: она состоит из четырёх частей - trigger, action, reward, investment (ниже скрин, он иллюстрирует). Т.е привычка в этой модели возникает так:
- есть триггер (напоминалка, будильник, контекст), который приводит к
- действию (чистить зубы, листать ленту в инстаграме, медитировать), которое приводит к
- награде (ощущение чистоты, чувство интереса, спокойствие), и которое можно закрепить
- инвестицией, укрепляющей привычку (покупкой новой щёточки, подпиской на новых людей в инстаграме, ведения дневника самочувствия после медитации).
Всё идёт по кругу, привычка закрепляется.
Что сделали хедспейс.
- Триггеры - тут нет проблем, пуши, напоминалки, ок.
- Действие - поняли, что тут есть барьер, люди не знают, как встроить медитацию в повседневную практику. Во сколько начинать? Сколько раз в неделю практиковать? Добавили подсказки/варианты времени. И ещё, помогли привязать медитацию к другим повседневным действиям (можно выбрать, хочешь ли ты медитировать сразу как проснёшься, после душа, после завтрака, или привязать медитацию к какому-то ещё регулярному событию).
- Вознаграждение. Они, поняли, что наградой может быть достижение цели, которую пользователь придумал сам, и что важно создать реалистичные ожидания относительно цели, и при этом дать ощущение, что человек двигается к ней. Стали в первую же сессию давать цели на выбор, формировать ожидания + сделали goal section, куда добавляли медитации, связанные с целью (направленные именно на снижение стресса, или хороший сон)
- Инвестиции - кусочек с инвестициями они почему-то не дожали, и даже в статье про это идей нет.
Там есть ещё большая часть про интуицию, и про то, что часть вещей они интуитивно выкинули, но она кажется более тривиальной, про это не пишу. На выходе получили 10% прироста к ретеншну второй недели, класс! Процент платящих пользователей тоже в итоге вырос.
___
Другие кейсы:
https://t.me/uxread/47 Как Google в 2011 делали experience sampling, чтобы понять, чего добавить в поиск (и это опять был Tomer Sharon)
https://t.me/uxread/57 Как Superhuman научились оценивать достижение product-market fit опросником
https://t.me/uxread/16 - Интерком про точечные интервью с пользователями, совершившим определенное действие на сайте
https://t.me/uxread/36 как gov.uk тестируют понятность текстов с помощью highligther testing (маркерных тестов) (хайлайтер тестинг)
Другие кейсы: #Cases
Другие методы: #Methods
Telegram
UX Research
Google в 2011 сделали experience sampling, чтобы понять, чего добавить в поиск (и это опять был Tomer Sharon)
Так, у меня есть запрос на маленький нишевый инструмент для исследований, а ещё у меня для вас опрос, но начнём мы с кейса How Google Plans to Find…
Так, у меня есть запрос на маленький нишевый инструмент для исследований, а ещё у меня для вас опрос, но начнём мы с кейса How Google Plans to Find…
👍1
Наткнулся на воркшоп по Feature Canvas, как указано в анонсе "инструмент, который поможет вам начать работу над функцией или идеей, помня о пользователях, проблемах и контексте." (это не реклама, мне понравился инструмент)
Feature Canvas это фреймфорк, в котором прописано, о чём нам стоит знать, прежде чем делать новую функцию в продукте. Скачать его можно здесь http://bit.ly/2WfgmtD, и он классный - ничего особо нового, но структурировано, на мой взгляд, хорошо.
А сюда об этом пишу, потому что в нём отдельно выделены блоки про пользователей, их проблемы и контекст, и для каждого блока прописаны вопросы. Это готовый хороший шаблон для problem research интервью для новой фичи. Для быстрого погружения в исследования он подходит, как мне кажется, лучше, чем "спроси маму"
И вот ссылка на сам воркшоп, он в субботу http://bit.ly/2QbcYdU
____
Другие фреймворки для мышления:
https://t.me/uxread/145 ликбез по продуктовой аналитике
https://t.me/uxread/102 как структурированно продумывать исследовательские задачи, вопросы и гипотезы
#Frameworks
Feature Canvas это фреймфорк, в котором прописано, о чём нам стоит знать, прежде чем делать новую функцию в продукте. Скачать его можно здесь http://bit.ly/2WfgmtD, и он классный - ничего особо нового, но структурировано, на мой взгляд, хорошо.
А сюда об этом пишу, потому что в нём отдельно выделены блоки про пользователей, их проблемы и контекст, и для каждого блока прописаны вопросы. Это готовый хороший шаблон для problem research интервью для новой фичи. Для быстрого погружения в исследования он подходит, как мне кажется, лучше, чем "спроси маму"
И вот ссылка на сам воркшоп, он в субботу http://bit.ly/2QbcYdU
____
Другие фреймворки для мышления:
https://t.me/uxread/145 ликбез по продуктовой аналитике
https://t.me/uxread/102 как структурированно продумывать исследовательские задачи, вопросы и гипотезы
#Frameworks
Как проводить Кано
Недавно первый раз провёл опрос по модели Кано. Ниже смесь ссылок на толковые статьи по теме и личных наблюдений
Сам метод помогает приоритезировать баклог и решить, какие фичи нужно сделать в первую очередь, а какие можно отложить (а для маркетинга - на чём сфокусироваться при продвижении). Вот короткое объяснение, если не сталкивались раньше http://bit.ly/2WZNLpw
Теперь детали:
1) Вот самая простая, и одновременно подробная инструкция, которую я нашёл http://bit.ly/2JyqUhG (иногда открывается только под впн, не понимаю, почему). Там же есть ссылка на калькулятор в гугл таблицах, который позволяет быстро обработать сырые данные. Весьма удачно, что калькулятор принимает данные в том же формате, в котором их выдаёт surveygizmo. Есть ещё такой, http://bit.ly/2HxSFVz, он чуть длиннее, и в нём подробней объясняется матчасть (и классные детали вроде объяснения того, почему оценка сдвинута относительно нуля).
2) По рекруту - Сауро советует брать 50-300 человек, что обеспечивает погрешность в пределах 5-9%. К слову, в калькуляторе из первого гайда выше стандартные отклонения и доверительный интервал считаются автоматически.
3) IBM пишут http://bit.ly/30yYeKV, что один человек за раз может оценить до 15 фич, по моему опыту это так и работает. Исследовать за раз можно и больше, чем рандомизированно показывать каждому по 15 фич, тогда надо подкрутить выборку.
4) Самый большой подвох в том, как объяснить фичи понятно, не продавая. Я серьёзно, тут кроется самый простой и вероятный способ запороть результаты, и это занимает кучу времени, так что начните с этого. Лучше всего для сложных фич сделать прототип для наглядности, ну или хотя бы протестируйте понятность описания перед тем, как запускать опрос.
5) Классический график с гиперболами и стрелочками никто не понимает, для себя нашёл удобную формулу объяснения результатов - чем фича правее на графике, тем обидней, если её не будет, чем выше, тем приятней, если будет. Так, вроде, всем понятно (и на базе этого уже можно объяснять про базовые, восхищающие и т.д.)
6) Предсказания людей о том, какая функция их обрадует, могут не коррелировать с реальностью. Для валидации лучше включить в опрос несколько уже запущенных фич, и потом сравнить результаты по Кано с реальными данными по ним же.
7) И напоследок классная заметка Ани Булдаковой о том, что с любым методом приоритезации баклога (в том числе с Кано) надо поосторожней. Стратегию нельзя заменить голосовалочками и весами, и иногда твёрдая рука кормчего-визионера (постирония? Или нет?) и хороший анализ рынка важнее http://bit.ly/2M5XBVK
____
Ещё забавные кейсы:
https://t.me/uxread/153 - другой метод приоритезировать фичи - Technology Acсeptace Model. Про саму модель и про то, как её используют для скоринга фич в Athenahealth
https://t.me/uxread/57 Как Superhuman научились оценивать достижение product-market fit опросником
https://t.me/uxread/82 Как headspace повышали вовлечённость и улучшали онбординг в приложении по habit formation loop (по пути проведя опрос и дневники)
Другие кейсы: #Cases
Другие методы: #Methods
Недавно первый раз провёл опрос по модели Кано. Ниже смесь ссылок на толковые статьи по теме и личных наблюдений
Сам метод помогает приоритезировать баклог и решить, какие фичи нужно сделать в первую очередь, а какие можно отложить (а для маркетинга - на чём сфокусироваться при продвижении). Вот короткое объяснение, если не сталкивались раньше http://bit.ly/2WZNLpw
Теперь детали:
1) Вот самая простая, и одновременно подробная инструкция, которую я нашёл http://bit.ly/2JyqUhG (иногда открывается только под впн, не понимаю, почему). Там же есть ссылка на калькулятор в гугл таблицах, который позволяет быстро обработать сырые данные. Весьма удачно, что калькулятор принимает данные в том же формате, в котором их выдаёт surveygizmo. Есть ещё такой, http://bit.ly/2HxSFVz, он чуть длиннее, и в нём подробней объясняется матчасть (и классные детали вроде объяснения того, почему оценка сдвинута относительно нуля).
2) По рекруту - Сауро советует брать 50-300 человек, что обеспечивает погрешность в пределах 5-9%. К слову, в калькуляторе из первого гайда выше стандартные отклонения и доверительный интервал считаются автоматически.
3) IBM пишут http://bit.ly/30yYeKV, что один человек за раз может оценить до 15 фич, по моему опыту это так и работает. Исследовать за раз можно и больше, чем рандомизированно показывать каждому по 15 фич, тогда надо подкрутить выборку.
4) Самый большой подвох в том, как объяснить фичи понятно, не продавая. Я серьёзно, тут кроется самый простой и вероятный способ запороть результаты, и это занимает кучу времени, так что начните с этого. Лучше всего для сложных фич сделать прототип для наглядности, ну или хотя бы протестируйте понятность описания перед тем, как запускать опрос.
5) Классический график с гиперболами и стрелочками никто не понимает, для себя нашёл удобную формулу объяснения результатов - чем фича правее на графике, тем обидней, если её не будет, чем выше, тем приятней, если будет. Так, вроде, всем понятно (и на базе этого уже можно объяснять про базовые, восхищающие и т.д.)
6) Предсказания людей о том, какая функция их обрадует, могут не коррелировать с реальностью. Для валидации лучше включить в опрос несколько уже запущенных фич, и потом сравнить результаты по Кано с реальными данными по ним же.
7) И напоследок классная заметка Ани Булдаковой о том, что с любым методом приоритезации баклога (в том числе с Кано) надо поосторожней. Стратегию нельзя заменить голосовалочками и весами, и иногда твёрдая рука кормчего-визионера (постирония? Или нет?) и хороший анализ рынка важнее http://bit.ly/2M5XBVK
____
Ещё забавные кейсы:
https://t.me/uxread/153 - другой метод приоритезировать фичи - Technology Acсeptace Model. Про саму модель и про то, как её используют для скоринга фич в Athenahealth
https://t.me/uxread/57 Как Superhuman научились оценивать достижение product-market fit опросником
https://t.me/uxread/82 Как headspace повышали вовлечённость и улучшали онбординг в приложении по habit formation loop (по пути проведя опрос и дневники)
Другие кейсы: #Cases
Другие методы: #Methods
Хабр
User Experience и модель Кано
Впервые мне довелось столкнуться с моделью Кано при работе над улучшением системы регистрации пассажиров аэропорта Каструп в Копенгагене. Данная модель была разработана профессором Нориаки Кано в 80-х...
Я тут благородаря Саше (спасибо, Саша) задумался, как я вижу идеальную организацию UX research в компании.
Это ретроградная реакционная самотерапевтическая заметка, сори заранее.
Первое, что приходит в голову, когда думаешь про идеальную организацию исследований - посмотреть, как делают известные команды - Facebook, Airbnb, Lyft, Atlassian, кто ещё светится на рынке? Я немного писал об этом, и вот собрал всё в кучу https://bit.ly/2MraQjV (но сейчас не о ней).
Тренды понятны - ресёч опс, дизайн мышление и уход в сторону придумывания решений, обучение дизайнеров и распределение исследовательских компетенций, база инсайтов, совмещение quantitative и qualitative research, исследования в необычных контекстах/с экстремальными сегментами и т.д.
Но я думаю вот о чём, на ранних этапах развития исследований важно всё это выкинуть из головы. Забить на базы знаний в airtable, экспириенс семплинг, кано, гомс, и экстремальных пользователей. Проводить много-много юзабилити-тестирований и интервью, звать побольше людей в наблюдатели, и не заморачиваться.
Это кажется очевидной идеей, но я думаю, есть большая группа исследователей вроде меня, которым кажется, что просто проводить юзабилити-тестирования это не комильфо, не для того мы университеты кончали и работали в агенствах с дикими проектами. Надо всё время придумывать что-то заковыристое, изощрённое. Сложно свыкнуться с тем, что для 90% задач достаточно интервью (можно даже без слова "глубинное") и экселя.
Но это так.
Мне тут кажется уместной аналогия с примером Егора Данилова о машин лёрнинг для маленьких стартапов https://t.me/betternotworse/22. Сначала сделайте простую рабочую систему, а потом оптимизируйте её. (Знаю, многовато ссылок не по теме, но я только дочитал "Бесконечную шутку" и отыгрываюсь на вас).
В большинстве случаев простая рабочая система состоит из кучи интервью, юзабилити-тестирований и наблюдений.
А простая метрика для процесса исследований в начале - трафик исследований - количество участников команды (менеджеров, дизайнеров, разработчиков), которые побывали на сессиях и лично посмотрели на то, как люди работают с продуктом. Метрика набивается очень просто - нужно больше сессий и больше людей на каждой. Набьёте трафик, можно будет оптимизировать конверсию в продуктовые изменения, думать про хранение инсайтов, расширение методического репертуара и вот это всё. А пока забейте.
Это ретроградная реакционная самотерапевтическая заметка, сори заранее.
Первое, что приходит в голову, когда думаешь про идеальную организацию исследований - посмотреть, как делают известные команды - Facebook, Airbnb, Lyft, Atlassian, кто ещё светится на рынке? Я немного писал об этом, и вот собрал всё в кучу https://bit.ly/2MraQjV (но сейчас не о ней).
Тренды понятны - ресёч опс, дизайн мышление и уход в сторону придумывания решений, обучение дизайнеров и распределение исследовательских компетенций, база инсайтов, совмещение quantitative и qualitative research, исследования в необычных контекстах/с экстремальными сегментами и т.д.
Но я думаю вот о чём, на ранних этапах развития исследований важно всё это выкинуть из головы. Забить на базы знаний в airtable, экспириенс семплинг, кано, гомс, и экстремальных пользователей. Проводить много-много юзабилити-тестирований и интервью, звать побольше людей в наблюдатели, и не заморачиваться.
Это кажется очевидной идеей, но я думаю, есть большая группа исследователей вроде меня, которым кажется, что просто проводить юзабилити-тестирования это не комильфо, не для того мы университеты кончали и работали в агенствах с дикими проектами. Надо всё время придумывать что-то заковыристое, изощрённое. Сложно свыкнуться с тем, что для 90% задач достаточно интервью (можно даже без слова "глубинное") и экселя.
Но это так.
Мне тут кажется уместной аналогия с примером Егора Данилова о машин лёрнинг для маленьких стартапов https://t.me/betternotworse/22. Сначала сделайте простую рабочую систему, а потом оптимизируйте её. (Знаю, многовато ссылок не по теме, но я только дочитал "Бесконечную шутку" и отыгрываюсь на вас).
В большинстве случаев простая рабочая система состоит из кучи интервью, юзабилити-тестирований и наблюдений.
А простая метрика для процесса исследований в начале - трафик исследований - количество участников команды (менеджеров, дизайнеров, разработчиков), которые побывали на сессиях и лично посмотрели на то, как люди работают с продуктом. Метрика набивается очень просто - нужно больше сессий и больше людей на каждой. Набьёте трафик, можно будет оптимизировать конверсию в продуктовые изменения, думать про хранение инсайтов, расширение методического репертуара и вот это всё. А пока забейте.
Telegraph
UX исследования в разных компаниях
Вот как в Фейсбуке https://t.me/uxread/71 В Airbnb https://t.me/uxread/35 В Atlassian https://t.me/uxread/39 Ещё классное: У Airbnb выделеные research ops, survey sience и marketing research отделы. У Shopify 55 человек в research team. Есть система peer…
Я немного злюсь, когда обсуждают игру про страшную онлайн-форму, потому что с одной стороны да, наглядная иллюстрация UX проблем, а с другой, ну блин, давайте ещё пять раз проговорим, что правильная семантика элементов важна, что главный CTA надо выделять, что подписи к полям должны быть хорошо видны и лучше делать их снаружи, а потом ещё посмеёмся над сайтом федерации настольного тенниса Башкоторстана.
А злит меня это потому, что это опять топтание на базовом уровне форм и кнопок. Ну камон, ребята, ну хватит уже, для нормальной формы уже даже не нужны ни исследования, ни изобретательность, достаточно прочитать книжку по web form design, взять готовый движок с нормальными паттернами, и немного думать при проектировании. Да, есть жуткие примеры настоящих сайтов с лютыми паттернами, но обычно проблема там не в том, что все идиоты и не в курсе, как подписывать поля, а немного глубже (тех долг, организационные проблемы, просто всем плевать на канал, который не приносит денег ит.д.).
Но большая часть людей пройдут тест, подумают "вот это треш, боже, слава богу, у нас в 10 раз лучше" и пойдут дальше аккуратненько рисовать форму, которой вообще не должно быть, но которая существует, потому что процесс кривой и непродуманный. Или будут считать, что работа дизайнера и исследователя заключается в том, чтобы догадаться подчеркнуть ссылочку. Отсюда начинается моё любимое "у нас дизайн уже очень хороший, нам над смыслом надо поработать, над тем, как это устроено", под которым подразумевается "у нас хорошо работают маски в полях и в целом всё красивенько".
(я зануда, но как-то очень уж в лоб, ну правда)
А злит меня это потому, что это опять топтание на базовом уровне форм и кнопок. Ну камон, ребята, ну хватит уже, для нормальной формы уже даже не нужны ни исследования, ни изобретательность, достаточно прочитать книжку по web form design, взять готовый движок с нормальными паттернами, и немного думать при проектировании. Да, есть жуткие примеры настоящих сайтов с лютыми паттернами, но обычно проблема там не в том, что все идиоты и не в курсе, как подписывать поля, а немного глубже (тех долг, организационные проблемы, просто всем плевать на канал, который не приносит денег ит.д.).
Но большая часть людей пройдут тест, подумают "вот это треш, боже, слава богу, у нас в 10 раз лучше" и пойдут дальше аккуратненько рисовать форму, которой вообще не должно быть, но которая существует, потому что процесс кривой и непродуманный. Или будут считать, что работа дизайнера и исследователя заключается в том, чтобы догадаться подчеркнуть ссылочку. Отсюда начинается моё любимое "у нас дизайн уже очень хороший, нам над смыслом надо поработать, над тем, как это устроено", под которым подразумевается "у нас хорошо работают маски в полях и в целом всё красивенько".
(я зануда, но как-то очень уж в лоб, ну правда)
Канеман про работу памяти, дневниковые исследования и оптимальное время для опросов
Ну ладно, зато вот немного о том, как работа памяти влияет на дневниковые исследования, я почему-то не задумывался об этом раньше.
Часть данных из Канемана, часть отсюда https://academic.oup.com/iwc/article/23/5/473/660020 (Паша, спасибо за статью)
1) Опыт человека и воспоминания об этом опыте различаются. Люди обычно лучше всего запоминают пиковый момент и финал события (в нашем случае - взаимодействия с сервисом). Поэтому, если мы хотим в деталях узнать, как люди что-то делают, как часто у них возникает какая-то потребность и вообще получить подробное представление об их опыте, то лучше делать experience sampling и просить зафиксировать опыт по ходу, потом респонденты не вспомнят половину деталей.
2) Но тут самое интересное: выбор человека строится не на основе реального опыта, а на основе воспоминаний об этом опыте и о принятых ранее решениях. Условно, мы идём в Старбакс не потому что нам в прошлый раз там понравилось, а потому что помним, что в прошлый раз зашли (пример то ли из Канемана, то ли из Ариэли).
3) Более того, впечатления, которыми мы поделились с другими, влияют на наше будущее поведение больше, чем реальный опыт, потому что реальный опыт мы не очень-то помним. И поэтому ретроспективная оценка опыта предсказывает последующее поведение человека лучше, чем рейтинг сразу "на месте", мой рассказал о Старбаксе спустя пару дней предсказывает моё следующее посещение лучше, чем оценка НПС сразу выходе (НЕУЖЕЛИ НПС БУДЕТ ЛУЧШЕ ПРЕДСКАЗЫВАТЬ ОТТОК, ЕСЛИ ЗАМЕРЯТЬ ЕГО НА СЛЕДУЮЩИЙ ДЕНЬ? ШОК!).
4) То есть если нам нужно узнать больше о самом опыте, лучше просить людей давать самоотчёты сразу (эксприенс семплинг и дёргаем всех через приложение/мессенджер), а если мы хотим оценить возможный ретешн, то ретроспективно, спустя день/в конце недели (классический дневничок).
___
Ещё по теме:
https://t.me/uxread/68 Head of behavior science в Google
https://t.me/uxread/137 как имплицитное чувство вины за потребление мешает покупать красивые вещи (связка anticipatory guilt и hedonic consumption) (линк на там и атенахелз, потому что атенахелз становятся красивыми)
https://t.me/uxread/130 UX curve как опыт исследования опыт в динамике, дешёвая замена дневников
https://t.me/uxread/138 спекуляции на тему "как в разных культурах могут относиться к hedonic systems"
Больше "околонаучных" заметок по тегу
#Science
Ну ладно, зато вот немного о том, как работа памяти влияет на дневниковые исследования, я почему-то не задумывался об этом раньше.
Часть данных из Канемана, часть отсюда https://academic.oup.com/iwc/article/23/5/473/660020 (Паша, спасибо за статью)
1) Опыт человека и воспоминания об этом опыте различаются. Люди обычно лучше всего запоминают пиковый момент и финал события (в нашем случае - взаимодействия с сервисом). Поэтому, если мы хотим в деталях узнать, как люди что-то делают, как часто у них возникает какая-то потребность и вообще получить подробное представление об их опыте, то лучше делать experience sampling и просить зафиксировать опыт по ходу, потом респонденты не вспомнят половину деталей.
2) Но тут самое интересное: выбор человека строится не на основе реального опыта, а на основе воспоминаний об этом опыте и о принятых ранее решениях. Условно, мы идём в Старбакс не потому что нам в прошлый раз там понравилось, а потому что помним, что в прошлый раз зашли (пример то ли из Канемана, то ли из Ариэли).
3) Более того, впечатления, которыми мы поделились с другими, влияют на наше будущее поведение больше, чем реальный опыт, потому что реальный опыт мы не очень-то помним. И поэтому ретроспективная оценка опыта предсказывает последующее поведение человека лучше, чем рейтинг сразу "на месте", мой рассказал о Старбаксе спустя пару дней предсказывает моё следующее посещение лучше, чем оценка НПС сразу выходе (НЕУЖЕЛИ НПС БУДЕТ ЛУЧШЕ ПРЕДСКАЗЫВАТЬ ОТТОК, ЕСЛИ ЗАМЕРЯТЬ ЕГО НА СЛЕДУЮЩИЙ ДЕНЬ? ШОК!).
4) То есть если нам нужно узнать больше о самом опыте, лучше просить людей давать самоотчёты сразу (эксприенс семплинг и дёргаем всех через приложение/мессенджер), а если мы хотим оценить возможный ретешн, то ретроспективно, спустя день/в конце недели (классический дневничок).
___
Ещё по теме:
https://t.me/uxread/68 Head of behavior science в Google
https://t.me/uxread/137 как имплицитное чувство вины за потребление мешает покупать красивые вещи (связка anticipatory guilt и hedonic consumption) (линк на там и атенахелз, потому что атенахелз становятся красивыми)
https://t.me/uxread/130 UX curve как опыт исследования опыт в динамике, дешёвая замена дневников
https://t.me/uxread/138 спекуляции на тему "как в разных культурах могут относиться к hedonic systems"
Больше "околонаучных" заметок по тегу
#Science
OUP Academic
UX Curve: A method for evaluating long-term user experience Free
Abstract. The goal of user experience design in industry is to improve customer satisfaction and loyalty through the utility, ease of use, and pleasure pro